hadoop笔记

一.操作过程中的总结
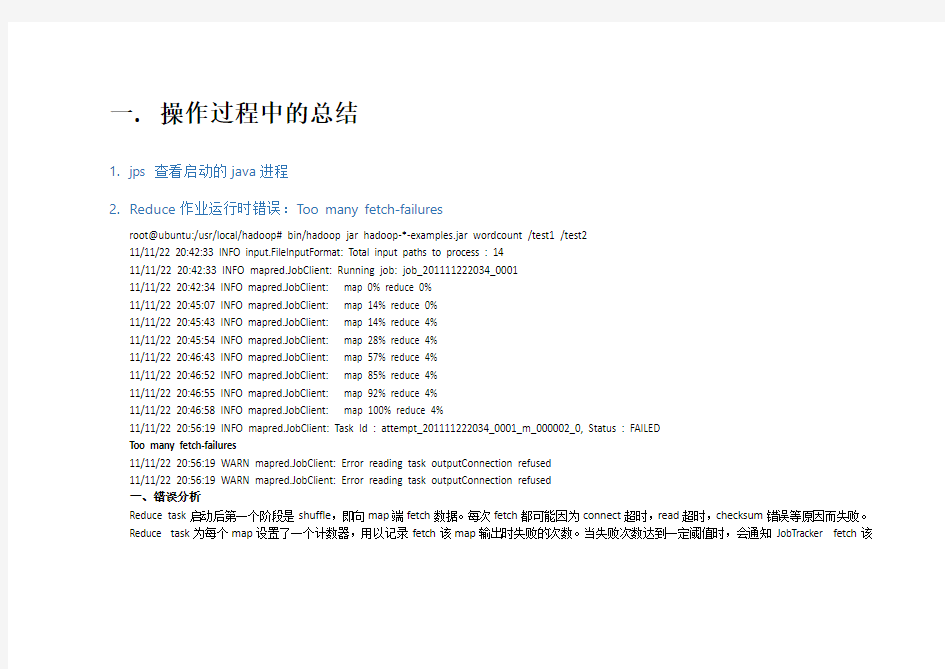
1.jps 查看启动的java进程
2.Reduce作业运行时错误:Too many fetch-failures
root@ubuntu:/usr/local/hadoop# bin/hadoop jar hadoop-*-examples.jar wordcount /test1 /test2
11/11/22 20:42:33 INFO input.FileInputFormat: Total input paths to process : 14
11/11/22 20:42:33 INFO mapred.JobClient: Running job: job_201111222034_0001
11/11/22 20:42:34 INFO mapred.JobClient: map 0% reduce 0%
11/11/22 20:45:07 INFO mapred.JobClient: map 14% reduce 0%
11/11/22 20:45:43 INFO mapred.JobClient: map 14% reduce 4%
11/11/22 20:45:54 INFO mapred.JobClient: map 28% reduce 4%
11/11/22 20:46:43 INFO mapred.JobClient: map 57% reduce 4%
11/11/22 20:46:52 INFO mapred.JobClient: map 85% reduce 4%
11/11/22 20:46:55 INFO mapred.JobClient: map 92% reduce 4%
11/11/22 20:46:58 INFO mapred.JobClient: map 100% reduce 4%
11/11/22 20:56:19 INFO mapred.JobClient: Task Id : attempt_201111222034_0001_m_000002_0, Status : FAILED
Too many fetch-failures
11/11/22 20:56:19 WARN mapred.JobClient: Error reading task outputConnection refused
11/11/22 20:56:19 WARN mapred.JobClient: Error reading task outputConnection refused
一、错误分析
Reduce task启动后第一个阶段是shuffle,即向map端fetch数据。每次fetch都可能因为connect超时,read超时,checksum错误等原因而失败。
Reduce task为每个map设置了一个计数器,用以记录fetch该map输出时失败的次数。当失败次数达到一定阈值时,会通知JobTracker fetch该
map输出操作失败次数太多了,并打印如下log:
Failed to fetch map-output from attempt_201105261254_102769_m_001802_0 even after MAX_FETCH_RETRIES_PER_MAP retries... reporting to the JobTracker
其中阈值计算方式为:
max(MIN_FETCH_RETRIES_PER_MAP,
getClosestPowerOf2((this.maxBackoff * 1000 / BACKOFF_INIT) + 1));
默认情况下MIN_FETCH_RETRIES_PER_MAP=2 maxBackoff=300 BACKOFF_INIT=4000,因此默认阈值为6,可通过修改mapred.reduce.copy.backoff参数来调整。
当达到阈值后,Reduce task通过umbilical协议告诉TaskTracker,TaskTracker在下一次heartbeat时,通知JobTracker。当JobTracker发现超过50%的Reduce汇报fetch某个map的输出多次失败后,JobTracker会failed掉该map并重新调度,打印如下log:
"Too many fetch-failures for output of task: attempt_201105261254_102769_m_001802_0 ... killing it"
二、出错原因及更正:
很可能是节点间的联通不够全面.
1) 检查、/etc/hosts
要求本机ip 对应服务器名
要求要包含所有的服务器ip + 服务器名
本人使用的是虚拟机OS为:ubuntu11.04 ,重启系统后出现该错误,最后发现ubuntu系统在每次启动时,会在/etc/hosts文件最前端添加如下信息:
127.0.0.1 localhost your_hostname
::1 localdata1 your_hostname
若将这两条信息注销掉,(或者把your_hostname删除掉)上述错误即可解决。
2) 检查.ssh/authorized_keys
要求包含所有服务器(包括其自身)的public key
尽管我们在安装hadoop之前已经配置了各节点的SSH无密码通信,假如有3个IP分别为192.168.128.131 192.168.128.132 192.168.133 ,对应的主机名为master 、slave1 、slave2 。从每个节点第一次执行命令$ ssh 主机名(master 、slave1 、slave2) 的时候,会出现一行关于密钥的yes or no ?的提示信息,Enter确认后再次连接就正常了。如果我们没有手动做这一步,如果恰好在hadoop/conf/core-site.xml 及mpred-site.xml
中相应的IP 用主机名代替了,则很可能出现该异常。
3.ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Incompatible namespaceID
问题的产生:
今天遇到了一个问题
我执行了./hadoop namenode -format 之后
启动hadoop: ./start-all.sh 的时候
运行jps发现datanode没有起来但是TaskTracker是正常启动的
然后我去datanode的错误日志里面发现的下面的问题:
2012-11-23 14:31:14,319 INFO org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2012-11-23 14:31:14,334 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source MetricsSystem,sub=Stats registered.
2012-11-23 14:31:14,335 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2012-11-23 14:31:14,335 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: DataNode metrics system started
2012-11-23 14:31:14,406 INFO org.apache.hadoop.metrics2.impl.MetricsSourceAdapter: MBean for source ugi registered.
2012-11-23 14:31:14,798 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Incompatible namespaceIDs in /data/hdfs/data: namenode namespaceID = 971169702; datanode namespaceID = 1507918015
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:232)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:147)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:385)
at org.apache.hadoop.hdfs.server.datanode.DataNode.
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:1582)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:1521)
at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:1539)
at org.apache.hadoop.hdfs.server.datanode.DataNode.secureMain(DataNode.java:1665)
at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:1682)
/data/hdfs/data
这个目录是我 hdfs-site.xml 配置文件里面dfs.data.dir 的值:
解决的办法:
1.进入每个datanode的dfs.data.dir 的current目录,修改里面的文件VERSION
#Fri Nov 23 15:00:17 CST 2012
namespaceID=246015542
storageID=DS-2085496284-192.168.1.244-50010-1353654017403
cTime=0
storageType=DATA_NODE
layoutVersion=-32
里面有个namespaceID 将其修改成为报错信息中的
namenode namespaceID = 971169702
相同的namespaceID .
然后重新启动datanode全部都能正常启动了。
2.由于是测试环境,于是产生的第一个想法是直接删除每个datanode 上面dfs.data.dir目录下所有的文件rm -rf *
删除之后
重新启动也是可以正常的启动所有的datanode
进到dfs.data.dir目录下所有的datanode又全部重新生成了。
4.ssh中“Host key verification failed.“的解决方案所有的节点都要配置
(注:这里为了简便,将knownhostfile设为/dev/null,就不保存在known_hosts中了)
二.配置hadoop
1.伪分布式模式
新建用户和组
addgroup hadoop
adduser --ingroup hadoop hadoop
注销root以hadoop用户登录
配置SSH
ssh-keygen -t rsa(密码为空,路径默认)
cp .ssh/id_rsa.pub .ssh/authorized_keys
准备HADOOP运行环境
wget https://https://www.360docs.net/doc/b111587014.html,/dist/hadoop/core/hadoop-1.1.2/hadoop-1.1.2.tar.gz tar -xzvf hadoop-1.1.2.tar.gz
在/home/hadoop/.bashrc 中追加:
export PATH=/home/hadoop/hadoop-1.1.2/bin:$PATH 重新登录就生效
ssh localhost
which hadoop
配置HADOOP运行参数
vi conf/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_11
vi conf/core-site.xml
vi conf/hdfs-site.xml
vi conf/mapred-site.xml
格式化名称节点并启动集群
hadoop namenode -format
启动集群并查看WEB管理界面
start-all.sh
访问http://localhost:50030 可以查看JobTracker 的运行状态
访问http://localhost:50060 可以查看TaskTracker 的运行状态
访问http://localhost:50070 可以查看NameNode 以及整个分布式文件系统的状态,浏览分布式文件系统中的文件以及log 等停止集群
stop-all.sh停止集群
2.多机完全分布式模式
三台机器
namenode(NameNode、SecondaryNameNode、JobTracker、DataNode、TaskTracker)
data1(DataNode、TaskTracker)
data2(DataNode、TaskTracker)
vi /etc/hostname(分别给每一台主机指定主机名,主机名必须唯一,如三台机器的主机名分别为namenode,data1,data2)
vi /etc/hosts(分别给每一台主机指定主机名到IP地址的映射)
新建用户和组
三台机器上面都要新建用户和组
addgroup hadoop
adduser --ingroup hadoop hadoop
gpasswd -a hadoop sudo
更改临时目录权限
chmod 777 /tmp
注销root以hadoop用户登录
配置SSH
在namenode上面执行
ssh-keygen -t rsa(密码为空,路径默认)
该命令会在用户主目录下创建.ssh 目录,并在其中创建两个文件:id_rsa 私钥文件,是基于RSA 算法创建,该私钥文件要妥善保管,不要泄漏。id_rsa.pub 公钥文件,和id_rsa 文件是一对儿,该文件作为公钥文件,可以公开
把公钥追加到其他主机的authorized_keys 文件中
ssh-copy-id -i .ssh/id_rsa.pub hadoop@namenode
ssh-copy-id -i .ssh/id_rsa.pub hadoop@data1
ssh-copy-id -i .ssh/id_rsa.pub hadoop@data2
可以在namenode上面通过ssh无密码登陆data1和data2
ssh namenode
ssh data1
ssh data2
同理在data1,data2,也执行相同的操作
准备HADOOP运行环境
wget https://https://www.360docs.net/doc/b111587014.html,/dist/hadoop/core/hadoop-1.1.2/hadoop-1.1.2.tar.gz tar -xzvf hadoop-1.1.2.tar.gz
在/home/hadoop/.bashrc 中追加:
export PATH=/home/hadoop/hadoop-1.1.2/bin:$PATH
source .bashrc
ssh localhost
which hadoop
配置HADOOP运行参数
vi conf/masters
把localhost替换为:namenode
vi conf/slaves
删除localhost,加入两行:
namenode
data1
data2
vi conf/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_11
vi conf/core-site.xml
vi conf/hdfs-site.xml
vi conf/mapred-site.xml
复制HADOOP文件到其他节点
scp -r /home/hadoop/hadoop-1.1.2 hadoop@data1:/home/hadoop/hadoop-1.1.2
scp -r /home/hadoop/hadoop-1.1.2 hadoop@data2:/home/hadoop/hadoop-1.1.2
格式化名称节点并启动集群
hadoop namenode -format
启动集群并查看WEB管理界面
start-all.sh
访问http://localhost:50030 可以查看JobTracker 的运行状态
访问http://localhost:50060 可以查看TaskTracker 的运行状态
访问http://localhost:50070 可以查看NameNode 以及整个分布式文件系统的状态,浏览分布式文件系统中的文件以及log 等停止集群
stop-all.sh停止集群
a.hadoop的第一个示例wordcount
运行步骤
2.2 新建输入文件内容
在当前目录新建一个文件夹叫input,在文件夹里新建三个文件f1.txt,f2.txt,f3.txt,并分别写入一些内容。
2.3 在运行的hadoop中创建文件夹
注意在操作之前,一定要保证这个时候hadoop已经正常运行,datanode、jodtracker、namenode等必要信息均显示正常。使用如下的命令创建文件夹
然后查看我们在hadoop中是否已经成功创建了该文件夹:
如果我们能看到类似drwr-xr-x ....../home/hadoop/input字样那表明我们这一步已经成功了。
然后查看文件是否在hadoop中,并查看文件内容是否和输入的一致:
注:我们可以通过10.1.151.168:50070/dfshealth.jsp来从浏览器中查看整个hdfs文件系统的目录,打开namenode的链接,点击其中的Browse the filesystem超级链接,就可以看到相应的目录结构了。
2.5 运行example例子
我们要运行的例子在hadoop的安装目录下,名称叫做hadoop-examples-1.2.1.jar。到了这一步,无疑是出错率最高的时候,运行命令如下:
其中,output是输出文件夹,必须不存在,它由程序自动创建,如果预先存在output文件夹,则会报错。
在操作之前,请务必多次检查如下内容:
1.自己的input目录是否已经存入输入内容;
2.output文件夹是否存在;
3.运行的hadoop用jps查看一下是否所有应该运行的进程都存在;
4.如果之前开过hadoop运行,这不是第一次开的话。可以试试先./stop-all.sh,然后把core-site.xml中的hadoop.tmp.dir的value
所在路径,即/home/hadoop/tmp/hadoop_tmp删除,然后重新建立一遍,如果你是新建的hadoop用户,最好用chown指令再把文件的所属更改一下。如上一样的操作对hdfs-site.xml中的dfs.data.dir的value路径做一遍。最好对所有datanode和namenode 也做一遍,保险起见。因为,我就是这些小细节上出了问题,由于之前运行导致这些本应该空的文件夹中存在文件,而频繁报错。
5.如果之前运行过wordcount报错记住还要用命令hadoop dfs -rmr output/*output为你的输出文件夹路径*/把output文件夹删除。
报错内容如下:
2.6 查看运行结果
我们可以查看output文件夹的内容来检查程序是否成功创建文件夹,通过查看output文件里面的part-r-00000文件的内容来检查程序执行结果:
正常显示结果会像如下样式一样:
hadoop 1
hello 3
jave 1
world 1
我们可以看到hadoop出现一次,hello出现3次,java出现一次,world出现一次,这跟预期是一样的,说明执行成功。
2.7 关闭hadoop进程
如果我们要关闭hadoop集群,则只需要运行stop-all.sh:
再次运行jps时,只有一个jps进程在运行,其它hadoop的进程都已经关闭了。
错误笔记
1. 启动时发现莫名其妙的datanode没有启动。
从logs日志中看到Incompatible namespaceIDs in /home/hadoop/tmp/hadoop_tmp,想起来这个文件夹是自己新建的,是不是伪分布式时在里面产生了垃圾?于是sudo rm -rf然后sudo mkdir重来了一次,想想不安全我再把其他的之前新建的文件夹全部重新按照这个方法操作了一次;最后-format然后./start-all.sh,搞定啦。Datanode、JobTracker、SecondaryNameNode、Jps、TaskTracker、NameNode 全部启动。
2. 遇到sudo重定向权限不够的问题。
众所周知,使用echo 并配合命令重定向是实现向文件中写入信息的快捷方式。比如要向test.asc 文件中随便写入点内容,可以:
hadoop基本操作指令
Hadoop基本操作指令 假设Hadoop的安装目录HADOOP_HOME为/home/admin/hadoop,默认认为Hadoop环境已经由运维人员配置好直接可以使用 启动与关闭 启动Hadoop 1. 进入HADOOP_HOME目录。 2. 执行sh bin/start-all.sh 关闭Hadoop 1. 进入HADOOP_HOME目录。 2. 执行sh bin/stop-all.sh 文件操作 Hadoop使用的是HDFS,能够实现的功能和我们使用的磁盘系统类似。并且支持通配符,如*。 查看文件列表 查看hdfs中/user/admin/aaron目录下的文件。 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -ls /user/admin/aaron 这样,我们就找到了hdfs中/user/admin/aaron目录下的文件了。 我们也可以列出hdfs中/user/admin/aaron目录下的所有文件(包括子目录下的文件)。 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -lsr /user/admin/aaron 创建文件目录 查看hdfs中/user/admin/aaron目录下再新建一个叫做newDir的新目录。 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -mkdir /user/admin/aaron/newDir 删除文件 删除hdfs中/user/admin/aaron目录下一个名叫needDelete的文件 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -rm /user/admin/aaron/needDelete 删除hdfs中/user/admin/aaron目录以及该目录下的所有文件
hadoop集群完整配置过程详细笔记
本文为笔者安装配置过程中详细记录的笔记 1.下载hadoop hadoop-2.7.1.tar.gz hadoop-2.7.1-src.tar.gz 64位linux需要重新编译本地库 2.准备环境 Centos6.4 64位,3台 hadoop0 192.168.1.151namenode hadoop1 192.168.1.152 datanode1 Hadoop2 192.168.1.153 datanode2 1)安装虚拟机: vmware WorkStation 10,创建三台虚拟机,创建时,直接建立用户ha,密码111111.同时为root密码。网卡使用桥接方式。 安装盘 、 2). 配置IP.创建完成后,设置IP,可以直接进入桌面,在如下菜单下配置IP,配置好后,PING 确认好用。 3)更改三台机器主机名 切换到root用户,更改主机名。 [ha@hadoop0 ~]$ su - root Password: [root@hadoop0 ~]# hostname hadoop0 [root@hadoop0 ~]# vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=hadoop0 以上两步后重启服务器。三台机器都需要修改。 4)创建hadoop用户 由于在创建虚拟机时,已自动创建,可以省略。否则用命令创建。
5)修改hosts文件 [root@hadoop0 ~]# vi /etc/hosts 127.0.0.1 localhostlocalhost.localdomain localhost4 localhost4.localdomain4 ::1localhostlocalhost.localdomain localhost6 localhost6.localdomain6 192.168.1.151 hadoop0 192.168.1.152 hadoop1 192.168.1.153 hadoop2 此步骤需要三台机器都修改。 3.建立三台机器间,无密码SSH登录。 1)三台机器生成密钥,使用hadoop用户操作 [root@hadoop0 ~]# su– ha [ha@hadoop0 ~]$ ssh -keygen -t rsa 所有选项直接回车,完成。 以上步骤三台机器上都做。 2)在namenode机器上,导入公钥到本机认证文件 [ha@hadoop0 ~]$ cat ~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys 3)将hadoop1和hadoop2打开/home/ha/.ssh/ id_rsa.pub文件中的内容都拷贝到hadoop0的/home/ha /.ssh/authorized_keys文件中。如下: 4)将namenode上的/home/ha /.ssh/authorized_keys文件拷贝到hadoop1和hadoop2的/home/ha/.ssh文件夹下。同时在三台机器上将authorized_keys授予600权限。 [ha@hadoop1 .ssh]$ chmod 600 authorized_keys 5)验证任意两台机器是否可以无密码登录,如下状态说明成功,第一次访问时需要输入密码。此后即不再需要。 [ha@hadoop0 ~]$ ssh hadoop1 Last login: Tue Aug 11 00:58:10 2015 from hadoop2 4.安装JDK1.7 1)下载JDK(32或64位),解压 [ha@hadoop0 tools]$ tar -zxvf jdk-7u67-linux-x64.tar.gz 2)设置环境变量(修改/etx/profile文件), export JAVA_HOME=/usr/jdk1.7.0_67 export CLASSPATH=:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin 3)使环境变量生效,然后验证JDK是否安装成功。
hadoop学习课程介绍
云凡教育Hadoop网络培训第二期 开课时间:2014年1月20日 授课方式:YY在线教育+课程视频+资料、笔记+辅导+推荐就业 YY教育平台:20483828 课程咨询:1441562932 大胃 云凡教育Hadoop交流群:306770165 费用: 第二期优惠特价:999元; 授课对象: 对大数据领域有求知欲,想成为其中一员的人员 想深入学习hadoop,而不只是只闻其名的人员 基础技能要求: 具有linux操作一般知识(因为hadoop在linux下跑) 有Java基础(因为hadoop是java写的并且编程也要用java语言) 课程特色 1,以企业实际应用为向导,进行知识点的深入浅出讲解; 2,从零起步,循序渐进,剖析每一个知识; 3,萃取出实际开发中最常用、最实用的内容并以深入浅出的方式把难点化于无形之中 学习安排: Hadoop的起源与生态系统介绍(了解什么是大数据;Google的三篇论文;围绕Hadoop形成的一系列的生态系统;各个子项目简要介绍)
1_Linux系统环境搭建和基本命令使用 针对很多同学对linux命令不熟悉,在课程的学习中,由于命令不熟悉导致很多错误产生,所以特意增加一节linux基础课程,讲解一些常用的命令,对接下来的学习中做好入门准备; 02_Hadoop本地(单机)模式和伪分布式模式安装 本节是最基本的课程,属于入门级别,主要对Hadoop 介绍,集中安装模式,如何在linux上面单机(本地)和伪分布模式安装Hadoop,对HDFS 和MapReduce进行测试和初步认识。 03_HDFS的体系结构、Shell操作、Java API使用和应用案例 本节是对hadoop核心之一——HDFS的讲解。HDFS是所有hadoop操作的基础,属于基本的内容。对本节内容的理解直接影响以后所有课程的学习。在本节学习中,我们会讲述hdfs的体系结构,以及使用shell、java不同方式对hdfs 的操作。在工作中,这两种方式都非常常用。学会了本节内容,就可以自己开发网盘应用了。在本节学习中,我们不仅对理论和操作进行讲解,也会讲解hdfs 的源代码,方便部分学员以后对hadoop源码进行修改。 04_MapReduce入门、框架原理、深入学习和相关MR面试题 本节开始对hadoop核心之一——mapreduce的讲解。mapreduce是hadoop 的核心,是以后各种框架运行的基础,这是必须掌握的。在本次讲解中,掌握mapreduce执行的详细过程,以单词计数为例,讲解mapreduce的详细执行过程。还讲解hadoop的序列化机制和数据类型,并使用自定义类型实现电信日志信息的统计。最后,还要讲解hadoop的RPC机制,这是hadoop运行的基础,通过该节学习,我们就可以明白hadoop是怎么明白的了,就不必糊涂了,本节内容特别重要。 05_Hadoop集群安装管理、NameNode安全模式和Hadoop 1.x串讲复习 hadoop就业主要是两个方向:hadoop工程师和hadoop集群管理员。我们课程主要培养工程师。本节内容是面向集群管理员的,主要讲述集群管理的知
hadoop基本命令_建表-删除-导数据
HADOOP表操作 1、hadoop简单说明 hadoop 数据库中的数据是以文件方式存存储。一个数据表即是一个数据文件。hadoop目前仅在LINUX 的环境下面运行。使用hadoop数据库的语法即hive语法。(可百度hive语法学习) 通过s_crt连接到主机。 使用SCRT连接到主机,输入hive命令,进行hadoop数据库操作。 2、使用hive 进行HADOOP数据库操作
3、hadoop数据库几个基本命令 show datebases; 查看数据库内容; 注意:hadoop用的hive语法用“;”结束,代表一个命令输入完成。 usezb_dim; show tables;
4、在hadoop数据库上面建表; a1: 了解hadoop的数据类型 int 整型; bigint 整型,与int 的区别是长度在于int; int,bigint 相当于oralce的number型,但是不带小数点。 doubble 相当于oracle的numbe型,可带小数点; string 相当于oralce的varchar2(),但是不用带长度; a2: 建表,由于hadoop的数据是以文件有形式存放,所以需要指定分隔符。 create table zb_dim.dim_bi_test_yu3(id bigint,test1 string,test2 string)
row format delimited fields terminated by '\t' stored as textfile; --这里指定'\t'为分隔符 a2.1 查看建表结构: describe A2.2 往表里面插入数据。 由于hadoop的数据是以文件存在,所以插入数据要先生成一个数据文件,然后使用SFTP将数据文件导入表中。
Hadoop 学习笔记
Hadoop 在Hadoop上运行MapReduce命令 实验jar:WordCount.jar 运行代码:root/……/hadoop/bin/hadoop jar jar包名称使用的包名称input(输入地址) output(输出地址) 生成测试文件:echo -e "aa\tbb \tcc\nbb\tcc\tdd" > ceshi.txt 输入地址:/data2/u_lx_data/qiandongjun/eclipse/crjworkspace/input 输出地址:/data2/u_lx_data/qiandongjun/eclipse/crjworkspace/output 将测试文件转入输入文件夹:Hadoop fs -put ceshi.txt /data2/u_lx_data/qiandongjun/eclipse/crjworkspace/input/ceshi.txt 运行如下代码:hadoop jar /data2/u_lx_data/qiandongjun/eclipse/crjworkspace/WordCount.jar WordCount /data2/u_lx_data/qiandongjun/eclipse/crjworkspace/input/ceshi.txt /data2/u_lx_data/qiandongjun/eclipse/crjworkspace/output Hadoop架构 1、HDFS架构 2、MapReduce架构 HDFS架构(采用了Master/Slave 架构) 1、Client --- 文件系统接口,给用户调用 2、NameNode --- 管理HDFS的目录树和相关的的文件元数据信息以及监控DataNode的状 态。信息以“fsimage”及“editlog”两个文件形势存放 3、DataNode --- 负责实际的数据存储,并将数据定期汇报给NameNode。每个节点上都 安装一个DataNode 4、Secondary NameNode --- 定期合并fsimage和edits日志,并传输给NameNode (存储基本单位为block) MapReduce架构(采用了Master/Slave 架构) 1、Client --- 提交MapReduce 程序并可查看作业运行状态 2、JobTracker --- 资源监控和作业调度 3、TaskTracker --- 向JobTracker汇报作业运行情况和资源使用情况(周期性),并同时接 收命令执行操作 4、Task --- (1)Map Task (2)Reduce Task ——均有TaskTracker启动 MapReduce处理单位为split,是一个逻辑概念 split的多少决定了Map Task的数目,每个split交由一个Map Task处理 Hadoop MapReduce作业流程及生命周期 一共5个步骤 1、作业提交及初始化。JobClient将作业相关上传到HDFS上,然后通过RPC通知JobTracker,
(完整版)hadoop例题
选择题 1、关于MapReduce的描述错误的是() A、MapReduce框架会先排序map任务的输出 B、通常,作业的输入输出都会被存储在文件系统中 C、通常计算节点和存储节点是同一节点 D、一个Task通常会把输入集切分成若干独立的数据块 2、关于基于Hadoop的MapReduce编程的环境配置,下面哪一步是不必要的() A、安装linux或者在Windows下安装Cgywin B、安装java C、安装MapReduce D、配置Hadoop参数 3、关于基于Hadoop的MapReduce编程的环境配置,下面哪一步是不必要的() A、配置java环境变量 B、配置Hadoop环境变量 C、配置Eclipse D、配置ssh 4、下列说法错误的是() A、MapReduce中maperconbiner reducer 缺一不可 B、在JobConf中InputFormat参数可以不设 C、在JobConf中MapperClass参数可以不设
D、在JobConf中OutputKeyComparator参数可以不设 5、下列关于mapreduce的key/value对的说法正确的是() A、输入键值对不需要和输出键值对类型一致 B、输入的key类型必须和输出的key类型一致 C、输入的value类型必须和输出的value类型一致 D、输入键值对只能映射成一个输出键值对 6、在mapreduce任务中,下列哪一项会由hadoop系统自动排序() A、keys of mapper's output B、values of mapper's output C、keys of reducer's output D、values of reducer's output 7、关于mapreduce框架中一个作业的reduce任务的数目,下列说法正确的是() A、由自定义的Partitioner来确定 B、是分块的总数目一半 C、可以由用户来自定义,通过JobConf.setNumReducetTask(int)来设定一个作业中reduce的任务数目 D、由MapReduce随机确定其数目 8、MapReduce框架中,在Map和Reduce之间的combiner的作用是() A、对Map的输出结果排序 B、对中间过程的输出进行本地的聚集
hadoop3安装和配置
hadoop3.0.0安装和配置1.安装环境 硬件:虚拟机 操作系统:Centos 7 64位 IP:192.168.0.101 主机名:dbp JDK:jdk-8u144-linux-x64.tar.gz Hadoop:hadoop-3.0.0-beta1.tar.gz 2.关闭防火墙并配置主机名 [root@dbp]#systemctl stop firewalld #临时关闭防火墙 [root@dbp]#systemctl disable firewalld #关闭防火墙开机自启动 [root@dbp]#hostnamectl set-hostname dbp 同时修改/etc/hosts和/etc/sysconfig/network配置信息 3.配置SSH无密码登陆 [root@dbp]# ssh-keygen -t rsa #直接回车 [root@dbp]# ll ~/.ssh [root@dbp .ssh]# cp id_rsa.pub authorized_keys [root@dbp .ssh]# ssh localhost #验证不需要输入密码即可登录
4.安装JDK 1、准备jdk到指定目录 2、解压 [root@dbp software]# tar–xzvf jdk-8u144-linux-x64.tar.gz [root@dbp software]# mv jdk1.8.0_144/usr/local/jdk #重命名4、设置环境变量 [root@dbp software]# vim ~/.bash_profile 5、使环境变量生效并验证 5.安装Hadoop3.0.0 1、准备hadoop到指定目录 2、解压
Hadoop快速入门
?项目 ?维基 ?Hadoop 0.18文档 Last Published: 07/01/2009 00:38:20 文档 概述 快速入门 集群搭建 HDFS构架设计 HDFS使用指南 HDFS权限指南 HDFS配额管理指南 命令手册 FS Shell使用指南 DistCp使用指南 Map-Reduce教程 Hadoop本地库 Streaming Hadoop Archives Hadoop On Demand API参考 API Changes 维基 常见问题 邮件列表 发行说明 变更日志 PDF Hadoop快速入门 ?目的 ?先决条件 o支持平台 o所需软件 o安装软件 ?下载 ?运行Hadoop集群的准备工作 ?单机模式的操作方法 ?伪分布式模式的操作方法
o配置 o免密码ssh设置 o执行 ?完全分布式模式的操作方法 目的 这篇文档的目的是帮助你快速完成单机上的Hadoop安装与使用以便你对Hadoop 分布式文件系统(HDFS)和Map-Reduce框架有所体会,比如在HDFS上运行示例程序或简单作业等。 先决条件 支持平台 ?GNU/Linux是产品开发和运行的平台。 Hadoop已在有2000个节点的GNU/Linux主机组成的集群系统上得到验证。 ?Win32平台是作为开发平台支持的。由于分布式操作尚未在Win32平台上充分测试,所以还不作为一个生产平台被支持。 所需软件 Linux和Windows所需软件包括: 1.Java TM1.5.x,必须安装,建议选择Sun公司发行的Java版本。 2.ssh必须安装并且保证sshd一直运行,以便用Hadoop 脚本管理远端 Hadoop守护进程。 Windows下的附加软件需求 1.Cygwin - 提供上述软件之外的shell支持。 安装软件 如果你的集群尚未安装所需软件,你得首先安装它们。 以Ubuntu Linux为例: $ sudo apt-get install ssh $ sudo apt-get install rsync
Hadoop 集群基本操作命令-王建雄-2016-08-22
Hadoop 集群基本操作命令 列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help (注:一般手动安装hadoop大数据平台,只需要创建一个用户即可,所有的操作命令就可以在这个用户下执行;现在是使用ambari安装的dadoop大数据平台,安装过程中会自动创建hadoop生态系统组件的用户,那么就可以到相应的用户下操作了,当然也可以在root用户下执行。下面的图就是执行的结果,只是hadoop shell 支持的所有命令,详细命令解说在下面,因为太多,我没有粘贴。) 显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name (注:可能有些命令,不知道什么意思,那么可以通过上面的命令查看该命令的详细使用信息。例子: 这里我用的是hdfs用户。) 注:上面的两个命令就可以帮助查找所有的haodoop命令和该命令的详细使用资料。
创建一个名为 /daxiong 的目录 $ bin/hadoop dfs -mkdir /daxiong 查看名为 /daxiong/myfile.txt 的文件内容$ bin/hadoop dfs -cat /hadoop dfs -cat /user/haha/part-m-00000 上图看到的是我上传上去的一张表,我只截了一部分图。 注:hadoop fs <..> 命令等同于hadoop dfs <..> 命令(hdfs fs/dfs)显示Datanode列表 $ bin/hadoop dfsadmin -report
$ bin/hadoop dfsadmin -help 命令能列出所有当前支持的命令。比如: -report:报告HDFS的基本统计信息。 注:有些信息也可以在NameNode Web服务首页看到 运行HDFS文件系统检查工具(fsck tools) 用法:hadoop fsck [GENERIC_OPTIONS]
hadoop常用命令
启动Hadoop ?进入HADOOP_HOME目录。 ?执行sh bin/start-all.sh 关闭Hadoop ?进入HADOOP_HOME目录。 ?执行sh bin/stop-all.sh 1、查看指定目录下内容 hadoopdfs –ls [文件目录] eg: hadoopdfs –ls /user/wangkai.pt 2、打开某个已存在文件 hadoopdfs –cat [file_path] eg:hadoopdfs -cat /user/wangkai.pt/data.txt 3、将本地文件存储至hadoop hadoopfs –put [本地地址] [hadoop目录] hadoopfs –put /home/t/file.txt /user/t (file.txt是文件名) 4、将本地文件夹存储至hadoop hadoopfs –put [本地目录] [hadoop目录] hadoopfs –put /home/t/dir_name /user/t (dir_name是文件夹名) 5、将hadoop上某个文件down至本地已有目录下hadoopfs -get [文件目录] [本地目录] hadoopfs –get /user/t/ok.txt /home/t 6、删除hadoop上指定文件 hadoopfs –rm [文件地址] hadoopfs –rm /user/t/ok.txt 7、删除hadoop上指定文件夹(包含子目录等)hadoopfs –rm [目录地址] hadoopfs –rmr /user/t
8、在hadoop指定目录内创建新目录 hadoopfs –mkdir /user/t 9、在hadoop指定目录下新建一个空文件 使用touchz命令: hadoop fs -touchz /user/new.txt 10、将hadoop上某个文件重命名 使用mv命令: hadoop fs –mv /user/test.txt /user/ok.txt (将test.txt重命名为ok.txt) 11、将hadoop指定目录下所有内容保存为一个文件,同时down至本地hadoopdfs –getmerge /user /home/t 12、将正在运行的hadoop作业kill掉 hadoop job –kill [job-id] 1、列出所有Hadoop Shell支持的命令 $ bin/hadoopfs -help 2、显示关于某个命令的详细信息 $ bin/hadoopfs -help command-name 3、用户可使用以下命令在指定路径下查看历史日志汇总 $ bin/hadoop job -history output-dir 这条命令会显示作业的细节信息,失败和终止的任务细节。 4、关于作业的更多细节,比如成功的任务,以及对每个任务的所做的尝试次数等可以用下面的命令查看 $ bin/hadoop job -history all output-dir 5、格式化一个新的分布式文件系统: $ bin/hadoopnamenode -format 6、在分配的NameNode上,运行下面的命令启动HDFS: $ bin/start-dfs.sh bin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。 7、在分配的JobTracker上,运行下面的命令启动Map/Reduce: $ bin/start-mapred.sh bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动TaskTracker守护进程。 8、在分配的NameNode上,执行下面的命令停止HDFS: $ bin/stop-dfs.sh
(完整word版)hadoop安装教程
1、VMware安装 我们使用Vmware 14的版本,傻瓜式安装即可。(只要) 双击 如过 2.安装xshell 双击 3.安装镜像: 解压centos6.5-empty解压 双击打开CentOS6.5.vmx 如果打不开,在cmd窗口中输入:netsh winsock reset 然后重启电脑。 进入登录界面,点击other 用户名:root 密码:root 然后右键open in terminal 输入ifconfig 回车 查看ip地址
打开xshell
点击链接 如果有提示,则接受 输入用户名:root 输入密码:root 4.xshell连接虚拟机 打开虚拟机,通过ifconfig查看ip
5.安装jkd 1.解压Linux版本的JDK压缩包 mkdir:创建目录的命令 rm -rf 目录/文件删除目录命令 cd 目录进入指定目录 rz 可以上传本地文件到当前的linux目录中(也可以直接将安装包拖到xshell窗口) ls 可以查看当前目录中的所有文件 tar 解压压缩包(Tab键可以自动补齐文件名)
pwd 可以查看当前路径 文档编辑命令: vim 文件编辑命令 i:进入编辑状态 Esc(左上角):退出编辑状态 :wq 保存并退出 :q! 不保存退出 mkdir /home/software #按习惯用户自己安装的软件存放到/home/software目录下 cd /home/software #进入刚刚创建的目录 rz 上传jdk tar包 #利用xshell的rz命令上传文件(如果rz命令不能用,先执行yum install lrzsz -y ,需要联网) tar -xvf jdk-7u51-linux-x64.tar.gz #解压压缩包 2.配置环境变量 1)vim /etc/profile 2)在尾行添加 #set java environment JAVA_HOME=/home/software/jdk1.8.0_65 JAVA_BIN=/home/software/jdk1.8.0_65/bin PATH=$JAVA_HOME/bin:$PATH CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME JAVA_BIN PATH CLASSPATH Esc 退出编辑状态 :wq #保存退出 注意JAVA_HOME要和自己系统中的jdk目录保持一致,如果是使用的rpm包安
hadoop入门学习资料大全
Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。 搜索了一些WatchStor存储论坛关于hadoop入门的一些资料分享给大家希望对大家有帮助 jackrabbit封装hadoop的设计与实现 https://www.360docs.net/doc/b111587014.html,/thread-60444-1-1.html 用Hadoop进行分布式数据处理 https://www.360docs.net/doc/b111587014.html,/thread-60447-1-1.html
Hadoop源代码eclipse编译教程 https://www.360docs.net/doc/b111587014.html,/thread-60448-1-2.html Hadoop技术讲解 https://www.360docs.net/doc/b111587014.html,/thread-60449-1-2.html Hadoop权威指南(原版) https://www.360docs.net/doc/b111587014.html,/thread-60450-1-2.html Hadoop源代码分析完整版 https://www.360docs.net/doc/b111587014.html,/thread-60451-1-2.html 基于Hadoop的Map_Reduce框架研究报告 https://www.360docs.net/doc/b111587014.html,/thread-60452-1-2.html Hadoop任务调度 https://www.360docs.net/doc/b111587014.html,/thread-60453-1-2.html Hadoop使用常见问题以及解决方法 https://www.360docs.net/doc/b111587014.html,/thread-60454-1-2.html HBase:权威指南
Hadoop命令大全
Hadoop命令大全 Hadoop配置: Hadoop配置文件core-site.xml应增加如下配置,否则可能重启后发生Hadoop 命名节点文件丢失问题:
1、列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help 2、显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name 3、用户可使用以下命令在指定路径下查看历史日志汇总 $ bin/hadoop job -history output-dir 这条命令会显示作业的细节信息,失败和终止的任务细节。 4、关于作业的更多细节,比如成功的任务,以及对每个任务的所做的尝试次数等可以用下面的命令查看 $ bin/hadoop job -history all output-dir 5、格式化一个新的分布式文件系统: $ bin/hadoop namenode -format 6、在分配的NameNode上,运行下面的命令启动HDFS: $ bin/start-dfs.sh bin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。 7、在分配的JobTracker上,运行下面的命令启动Map/Reduce: $ bin/start-mapred.sh bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves 文件的内容,在所有列出的slave上启动TaskTracker守护进程。 8、在分配的NameNode上,执行下面的命令停止HDFS: $ bin/stop-dfs.sh bin/stop-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止DataNode守护进程。 9、在分配的JobTracker上,运行下面的命令停止Map/Reduce: $ bin/stop-mapred.sh bin/stop-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止TaskTracker守护进程。 10、启动所有 $ bin/start-all.sh 11、关闭所有 $ bin/stop-all.sh DFSShell 10、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 11、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 12、查看名为 /foodir/myfile.txt 的文件内容 $ bin/hadoop dfs -cat /foodir/myfile.txt
hadoop提交作业分析
Hadoop提交作业流程分析 bin/hadoop jar mainclass args …… 这样的命令,各位玩Hadoop的估计已经调用过NN次了,每次写好一个Project或对Project做修改后,都必须打个Jar包,然后再用上面的命令提交到Hadoop Cluster上去运行,在开发阶段那是极其繁琐的。程序员是“最懒”的,既然麻烦肯定是要想些法子减少无谓的键盘敲击,顺带延长键盘寿命。比如有的人就写了些Shell脚本来自动编译、打包,然后提交到Hadoop。但还是稍显麻烦,目前比较方便的方法就是用Hadoop eclipse plugin,可以浏览管理HDFS,自动创建MR程序的模板文件,最爽的就是直接Run on hadoop了,但版本有点跟不上Hadoop的主版本了,目前的MR模板还是的。还有一款叫Hadoop Studio的软件,看上去貌似是蛮强大,但是没试过,这里不做评论。那么它们是怎么做到不用上面那个命令来提交作业的呢不知道没关系,开源的嘛,不懂得就直接看源码分析,这就是开源软件的最大利处。 我们首先从bin/hadoop这个Shell脚本开始分析,看这个脚本内部到底做了什么,如何来提交Hadoop作业的。 因为是Java程序,这个脚本最终都是要调用Java来运行的,所以这个脚本最重要的就是添加一些前置参数,如CLASSPATH等。所以,我们直接跳到这个脚本的最后一行,看它到底添加了那些参数,然后再
逐个分析(本文忽略了脚本中配置环境参数载入、Java查找、cygwin 处理等的分析)。 #run it exec "$JAVA"$JAVA_HEAP_MAX $HADOOP_OPTS -classpath "$CLASSPATH"$CLASS "$@" 从上面这行命令我们可以看到这个脚本最终添加了如下几个重要参数:JAVA_HEAP_MAX、HADOOP_OPTS、CLASSPATH、CLASS。下面我们来一个个的分析(本文基于Cloudera Hadoop 分析)。 首先是JAVA_HEAP_MAX,这个就比较简单了,主要涉及代码如下:JAVA_HEAP_MAX=-Xmx1000m # check envvars which might override default args if [ "$HADOOP_HEAPSIZE" !="" ];then #echo"run with heapsize $HADOOP_HEAPSIZE" JAVA_HEAP_MAX="-Xmx""$HADOOP_HEAPSIZE""m" #echo$JAVA_HEAP_MAX fi
hadoop安装简要过程和相关配置文件
Hadoop安装简要过程及配置文件 1、机器准备 ①、Linux版操作系统centos 6.x ②、修改主机名,方便配置过程中记忆。修改文件为: /etc/sysconfig/network 修改其中的HOSTNAME即可 ③、配置局域网内,主机名与对应ip,并且其中集群中所有的机器的文件相同,修改文件为 /etc/hosts 格式为: 10.1.20.241 namenode 10.1.20.242 datanode1 10.1.20.243 datanode2 2、环境准备 ①、配置ssh免密码登陆,将集群中master节点生成ssh密码文件。具体方法: 1)、ssh-keygen -t rsa 一直回车即可,将会生成一份 ~/.ssh/ 文件夹,其中id_rsa为私钥文件 id_rsa.pub公钥文件。 2)、将公钥文件追加到authorized_keys中然后再上传到其他slave节点上 追加文件: cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 上传文件: scp ~/.ssh/authorized_keys root@dananode:~/.ssh/ 3)、测试是否可以免密码登陆:ssh 主机名或局域网ip ②、配置JDK ③、创建hadoop用户 groupadd hadoop useradd hadoop -g hadoop 4)、同步时间 ntpdate https://www.360docs.net/doc/b111587014.html, 5)、关闭防火墙 service iptables stop 3、安装cdh5 进入目录/data/tools/ (个人习惯的软件存储目录,你可以自己随便选择); wget "https://www.360docs.net/doc/b111587014.html,/cdh5/one-click-install/redhat/ 6/x86_64/cloudera-cdh-5-0.x86_64.rpm" yum --nogpgcheck localinstall cloudera-cdh-5-0.x86_64.rpm 添加cloudera仓库验证: rpm --importhttps://www.360docs.net/doc/b111587014.html,/cdh5/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera
(完整版)hadoop常见笔试题答案
Hadoop测试题 一.填空题,1分(41空),2分(42空)共125分 1.(每空1分) datanode 负责HDFS数据存储。 2.(每空1分)HDFS中的block默认保存 3 份。 3.(每空1分)ResourceManager 程序通常与NameNode 在一个节点启动。 4.(每空1分)hadoop运行的模式有:单机模式、伪分布模式、完全分布式。 5.(每空1分)Hadoop集群搭建中常用的4个配置文件为:core-site.xml 、hdfs-site.xml 、mapred-site.xml 、yarn-site.xml 。 6.(每空2分)HDFS将要存储的大文件进行分割,分割后存放在既定的存储块 中,并通过预先设定的优化处理,模式对存储的数据进行预处理,从而解决了大文件储存与计算的需求。 7.(每空2分)一个HDFS集群包括两大部分,即namenode 与datanode 。一般来说,一 个集群中会有一个namenode 和多个datanode 共同工作。 8.(每空2分) namenode 是集群的主服务器,主要是用于对HDFS中所有的文件及内容 数据进行维护,并不断读取记录集群中datanode 主机情况与工作状态,并通过读取与写入镜像日志文件的方式进行存储。 9.(每空2分) datanode 在HDFS集群中担任任务具体执行角色,是集群的工作节点。文 件被分成若干个相同大小的数据块,分别存储在若干个datanode 上,datanode 会定期向集群内namenode 发送自己的运行状态与存储内容,并根据namnode 发送的指令进行工作。 10.(每空2分) namenode 负责接受客户端发送过来的信息,然后将文件存储位置信息发 送给client ,由client 直接与datanode 进行联系,从而进行部分文件的运算与操作。 11.(每空1分) block 是HDFS的基本存储单元,默认大小是128M 。 12.(每空1分)HDFS还可以对已经存储的Block进行多副本备份,将每个Block至少复制到 3 个相互独立的硬件上,这样可以快速恢复损坏的数据。 13.(每空2分)当客户端的读取操作发生错误的时候,客户端会向namenode 报告错误,并 请求namenode 排除错误的datanode 后,重新根据距离排序,从而获得一个新的的读取路径。如果所有的datanode 都报告读取失败,那么整个任务就读取失败。14.(每空2分)对于写出操作过程中出现的问题,FSDataOutputStream 并不会立即关闭。 客户端向Namenode报告错误信息,并直接向提供备份的datanode 中写入数据。备份datanode 被升级为首选datanode ,并在其余2个datanode 中备份复制数据。 NameNode对错误的DataNode进行标记以便后续对其进行处理。 15.(每空1分)格式化HDFS系统的命令为:hdfs namenode –format 。 16.(每空1分)启动hdfs的shell脚本为:start-dfs.sh 。 17.(每空1分)启动yarn的shell脚本为:start-yarn.sh 。 18.(每空1分)停止hdfs的shell脚本为:stop-dfs.sh 。 19.(每空1分)hadoop创建多级目录(如:/a/b/c)的命令为:hadoop fs –mkdir –p /a/b/c 。 20.(每空1分)hadoop显示根目录命令为:hadoop fs –lsr 。 21.(每空1分)hadoop包含的四大模块分别是:Hadoop common 、HDFS 、