ALOS-1 PALSAR FBD数据预处理-2015.06.18
ALOS-1 PALSAR FBD数据预处理文档参考说明参考ALOS-1 PALSAR PLR数据预处理-2015.06.18.docx文档的说明。
备注:以读取ALOS-1 PALSAR Level 1.1 ALPSRP083230570-L1.1数据为例1. 提取感兴趣区域——PolSARPro
1)环境设置
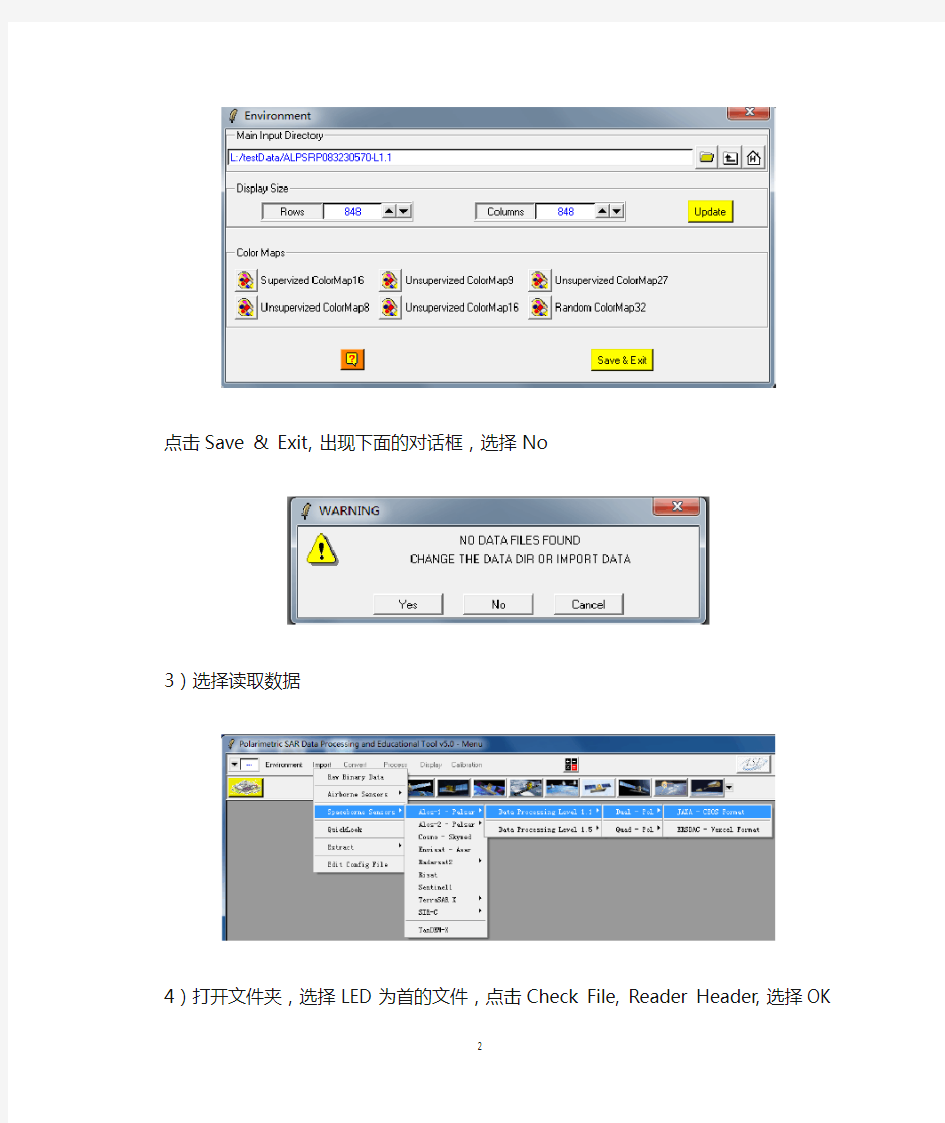
2)选择Environment,设置欲读取文件的目录
点击Save & Exit,出现下面的对话框,选择No
3)选择读取数据
4)打开文件夹,选择LED为首的文件,点击Check File, Reader Header,选择OK
5)Import->QuickLook生成快视图
6)Import->Extract->Sub Area
但是在已知选定的区域范围时,不用执行步骤5),直接执行下面的操作即可。Import->Extract->Full Resolution
点击Run,出现对话框,点击Yes
至此为止,数据已经读取,并已经以相干矩阵[T]的形式存在2. Fefined Lee滤波——PolSARPro
Process->Polarimetric Speckle Filter->Lee Refined Filter
输入输出目录保持不变,Window Size Row设置为3,点击Run,出现对话框,点击Yes 2. Cloude分解参数提取——PolSARPro
Process->H/A/Alpha Decomposition->Decomposition Parameters
选择分解参数,设置窗口大小,点击Run
备注:Window Size Row和Window Size Col都设置为3
3. NEST读取数据
双击NEST图标。选择File->Import Raster Data->ALOS PALSAR CEOS
数据读进去后,打开Bands下的Intensity_HH。
4. 图像切割
选择Utilities->Spatial Subset from View
注意选择的区域范围与前面PolSARPro软件处理的范围必须保持一致。点击OK
5. 将PolSARPro处理结果导入到NEST软件
选择File->Import Raster Data->PolSARPro
6.元数据替换
选择Utilities->Metadata->Replace Metadata
备注:将该元数据添加到C2特征参数集中7. 特征参数列表
总共7个特征参数
8.数据保存为Tiff格式
选择File->Export Raster Data->GeoTIFF,出现提示对话框,选择Yes
9. 保存数据说明
保存后的数据文件为:C2.tiff
其中数据包含7个波段,分别对应步骤7中的特征参数
Band1,Cloude分解参数之一散射角Alpha
Band2,[C]矩阵元素C11
Band3,[C]矩阵元素C12虚部
Band4,[C]矩阵元素C12实部
Band5,[C]矩阵元素C22
Band6,Cloude分解参数之一极化熵H
Band7,掩膜数据,无用
数据采集与处理讲解
1数据的采集与处理 1.1数据的采集 施工监控中需对影响施工及控制精度的数据进行收集,主要包括环境参数和结构参数,前者又主要是指风速风向数据;后者主要指结构容重、弹模等数据。施工监控需进行收集的数据如表1-1所示。 1.1.2数据采集方法 基于港珠澳大桥特殊的地理位置,采用远程数据采集系统,与传统的数据采集系统相比,具有不受地理环境、气候、时间的影响等优势。而借助无线传输手段的远程数据采集系统,更具有工程造价和人力资源成本低,传输数据不受地域的影响,可靠性高,免维护等优点。远程无线数据采集系统的整体结构如图1-2所示。 1-2 远程无线数据采集系统组成结构图
1.2数据的处理与评估 在数据分析之前, 数据处理要能有效地从监测数据中寻找出异常值, 必须对监测数据进行可靠性检验, 剔除粗差的影响, 以保证监测数据的准确、可靠。我们拟采用的是最常用的μ检验法来判别系统误差; 用“3σ准则”剔除粗差; 采用了“五点二次中心平滑”法对观测数据进行平滑修正。同时, 在数据处理之后, 采用关联分析技术寻找某一测点的最佳关联点, (为保证系统评判的可靠性, 某一测点的关联点宜选用2 个以上)。我们选用3 个关联测点, 如果异常测值的关联测点有2 个以上发生异常, 且异常方向一致, 则认为测值异常是由结构变化引起, 否则, 认为异常是由监测系统异常引起。出现异常时, 经过判定, 自动提醒用户检查监测系统或者相应的结构(根据测点所在位置), 及时查明情况, 并采取一些必要的应急措施, 同时对测值做标注, 形成报表, 进行评估。 1.2.1系统误差的判别 判别原则: 异常值检验方法是建立在随机样本观测值遵从正态分布和小概率原理的基础之上的。根据观测值的正态分布特征性, 出现大偏差观测值的概率是很小的。当测值较少时, 在正常情况下, 根据小概率原理, 它们是不会出现的, 一旦出现则表明有异常值。依统计学原理: 偏差处于2 倍标准差或3 倍标准差范围内的数据为正常值, 之外的则判定为异常。事实上标准差σ多数情况下是求知的, 通常用样本值计算的标准差S 来替代。桥梁健康监测资料的数据量特别大, 一般都为大样本, 所以我们用μ检验。在分析中, 我们将所得的数据分成两组Y1 、Y2,并设()1211,1Y N u δ, ()2222,2Y N u δ择统计量为 : 'y y U -= (1) 式中12y y 、—两组样本的平均值: 21n 、n —两组样本的子样数: 21S S 、 —两组样本的方差。若 '2 a U U ≥ (2) 则存在系统误差。否则, 不存在系统误差。 1.2.2 粗差点的剔除 在观测次数充分多的前提下, 其测值的跳动特征描述如下式: ()112j j j j d y y y +-=-+ (3) 式中j y (j=1,2,3,4,……,n- 1)是一系列观测值。
数据挖掘算法综述
数据挖掘方法综述 [摘要]数据挖掘(DM,DataMining)又被称为数据库知识发现(KDD,Knowledge Discovery in Databases),它的主要挖掘方法有分类、聚类、关联规则挖掘和序列模式挖掘等。 [关键词]数据挖掘分类聚类关联规则序列模式 1、数据挖掘的基本概念 数据挖掘从技术上说是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在的有用的信息和知识的过程。这个定义包括好几层含义: 数据源必须是真实的、大量的、含噪声的、发现的是用户感兴趣的知识, 发现的知识要可接受、可理解、可运用, 并不要求发现放之四海皆准的知识, 仅支持特定的发现问题, 数据挖掘技术能从中自动分析数据进行归纳性推理从中发掘出潜在的数据模式或进行预测, 建立新的业务模型帮助决策者调整策略做出正确的决策。数据挖掘是是运用统计学、人工智能、机器学习、数据库技术等方法发现数据的模型和结构、发现有价值的关系或知识的一门交叉学科。数据挖掘的主要方法有分类、聚类和关联规则挖掘等 2、分类 分类(Classification)又称监督学习(Supervised Learning)。监
督学习的定义是:给出一个数据集D,监督学习的目标是产生一个联系属性值集合A和类标(一个类属性值称为一个类标)集合C的分类/预测函数,这个函数可以用于预测新的属性集合(数据实例)的类标。这个函数就被称为分类模型(Classification Model),或者是分类器(Classifier)。分类的主要算法有:决策树算法、规则推理、朴素贝叶斯分类、支持向量机等算法。 决策树算法的核心是Divide-and-Conquer的策略,即采用自顶向下的递归方式构造决策树。在每一步中,决策树评估所有的属性然后选择一个属性把数据分为m个不相交的子集,其中m是被选中的属性的不同值的数目。一棵决策树可以被转化成一个规则集,规则集用来分类。 规则推理算法则直接产生规则集合,规则推理算法的核心是Separate-and-Conquer的策略,它评估所有的属性-值对(条件),然后选择一个。因此,在一步中,Divide-and-Conquer策略产生m条规则,而Separate-and-Conquer策略只产生1条规则,效率比决策树要高得多,但就基本的思想而言,两者是相同的。 朴素贝叶斯分类的基本思想是:分类的任务可以被看作是给定一个测试样例d后估计它的后验概率,即Pr(C=c j︱d),然后我们考察哪个类c j对应概率最大,便将那个类别赋予样例d。构造朴素贝叶斯分类器所需要的概率值可以经过一次扫描数据得到,所以算法相对训练样本的数量是线性的,效率很高,就分类的准确性而言,尽管算法做出了很强的条件独立假设,但经过实际检验证明,分类的效果还是
分布式数据库管理系统简介
分布式数据库管理系统简介 一、什么是分布式数据库: 分布式数据库系统是在集中式数据库系统的基础上发展来的。是数据库技术与网络技术结合的产物。 分布式数据库系统有两种:一种是物理上分布的,但逻辑上却是集中的。这种分布式数据库只适宜用途比较单一的、不大的单位或部门。另一种分布式数据库系统在物理上和逻辑上都是分布的,也就是所谓联邦式分布数据库系统。由于组成联邦的各个子数据库系统是相对“自治”的,这种系统可以容纳多种不同用途的、差异较大的数据库,比较适宜于大范围内数据库的集成。 分布式数据库系统(DDBS)包含分布式数据库管理系统(DDBMS和分布式数据库(DDB)。 在分布式数据库系统中,一个应用程序可以对数据库进行透明操作,数据库中的数据分别在不同的局部数据库中存储、由不同的DBMS进行管理、在不同的机器上运行、由不同的 操作系统支持、被不同的通信网络连接在一起。 一个分布式数据库在逻辑上是一个统一的整体:即在用户面前为单个逻辑数据库,在物理上则是分别存储在不同的物理节点上。一个应用程序通过网络的连接可以访问分布在不同地理位置的数据库。它的分布性表现在数据库中的数据不是存储在同一场地。更确切地讲,不存储在同一计算机的存储设备上。这就是与集中式数据库的区别。从用户的角度看,一个分布式数据库系统在逻辑上和集中式数据库系统一样,用户可以在任何一个场地执行全局应用。就好那些数据是存储在同一台计算机上,有单个数据库管理系统(DBMS)管理一样,用 户并没有什么感觉不一样。 分布式数据库中每一个数据库服务器合作地维护全局数据库的一致性。 分布式数据库系统是一个客户/ 服务器体系结构。 在系统中的每一台计算机称为结点。如果一结点具有管理数据库软件,该结点称为数据库服务器。如果一个结点为请求服务器的信息的一应用,该结点称为客户。在ORACL客户, 执行数据库应用,可存取数据信息和与用户交互。在服务器,执行ORACL软件,处理对ORACLE 数据库并发、共享数据存取。ORACL允许上述两部分在同一台计算机上,但当客户部分和 服务器部分是由网连接的不同计算机上时,更有效。 分布处理是由多台处理机分担单个任务的处理。在ORACL数据库系统中分布处理的例 子如: 客户和服务器是位于网络连接的不同计算机上。 单台计算机上有多个处理器,不同处理器分别执行客户应用。 参与分布式数据库的每一服务器是分别地独立地管理数据库,好像每一数据库不是网络化的数据库。每一个数据库独立地被管理,称为场地自治性。场地自治性有下列好处: ?系统的结点可反映公司的逻辑组织。
大数据处理流程的主要环节
大数据处理流程的主要环节 大数据处理流程主要包括数据收集、数据预处理、数据存储、数据处理与分析、数据展示/数据可视化、数据应用等环节,其中数据质量贯穿于整个大数据流程,每一个数据处理环节都会对大数据质量产生影响作用。通常,一个好的大数据产品要有大量的数据规模、快速的数据处理、精确的数据分析与预测、优秀的可视化图表以及简练易懂的结果解释,本节将基于以上环节分别分析不同阶段对大数据质量的影响及其关键影响因素。 一、数据收集 在数据收集过程中,数据源会影响大数据质量的真实性、完整性数据收集、一致性、准确性和安全性。对于Web数据,多采用网络爬虫方式进行收集,这需要对爬虫软件进行时间设置以保障收集到的数据时效性质量。比如可以利用八爪鱼爬虫软件的增值API设置,灵活控制采集任务的启动和停止。 二、数据预处理 大数据采集过程中通常有一个或多个数据源,这些数据源包括同构或异构的数据库、文件系统、服务接口等,易受到噪声数据、数据值缺失、数据冲突等影响,因此需首先对收集到的大数据集合进行预处理,以保证大数据分析与预测结果的准确性与价值性。
大数据的预处理环节主要包括数据清理、数据集成、数据归约与数据转换等内容,可以大大提高大数据的总体质量,是大数据过程质量的体现。数据清理技术包括对数据的不一致检测、噪声数据的识别、数据过滤与修正等方面,有利于提高大数据的一致性、准确性、真实性和可用性等方面的质量; 数据集成则是将多个数据源的数据进行集成,从而形成集中、统一的数据库、数据立方体等,这一过程有利于提高大数据的完整性、一致性、安全性和可用性等方面质量; 数据归约是在不损害分析结果准确性的前提下降低数据集规模,使之简化,包括维归约、数据归约、数据抽样等技术,这一过程有利于提高大数据的价值密度,即提高大数据存储的价值性。 数据转换处理包括基于规则或元数据的转换、基于模型与学习的转换等技术,可通过转换实现数据统一,这一过程有利于提高大数据的一致性和可用性。 总之,数据预处理环节有利于提高大数据的一致性、准确性、真实性、可用性、完整性、安全性和价值性等方面质量,而大数据预处理中的相关技术是影响大数据过程质量的关键因素 三、数据处理与分析 1、数据处理 大数据的分布式处理技术与存储形式、业务数据类型等相关,针对大数据处理的主要计算模型有MapReduce分布式计算框架、分布式内存计算系统、分布式流计算系统等。
分布式数据库系统复习题
一、何为分布式数据库系统?一个分布式数据库系统有哪些特点? 答案:分布式数据库系统通俗地说,是物理上分散而逻辑上集中的数据库系统。分布式数据库系统使用计算机网络将地理位置分散而管理和控制又需要不同程度集中的多个逻辑单位连接起来,共同组成一个统一的数据库系统。因此,分布式数据库系统可以看成是计算机网络与数据库系统的有机结合。一个分布式数据库系统具有如下特点: 物理分布性,即分布式数据库系统中的数据不是存储在一个站点上,而是分散存储在由计算机网络连接起来的多个站点上,而且这种分散存储对用户来说是感觉不到的。 逻辑整体性,分布式数据库系统中的数据物理上是分散在各个站点中,但这些分散的数据逻辑上却构成一个整体,它们被分布式数据库系统的所有用户共享,并由一个分布式数据库管理系统统一管理,它使得“分布”对用户来说是透明的。 站点自治性,也称为场地自治性,各站点上的数据由本地的DBMS管理,具有自治处理能力,完成本站点的应用,这是分布式数据库系统与多处理机系统的区别。 另外,由以上三个分布式数据库系统的基本特点还可以导出它的其它特点,即:数据分布透明性、集中与自治相结合的控制机制、存在适当的数据冗余度、事务管理的分布性。 二、简述分布式数据库的模式结构和各层模式的概念。 分布式数据库是多层的,国内分为四层: 全局外层:全局外模式,是全局应用的用户视图,所以也称全局试图。它为全局概念模式的子集,表示全局应用所涉及的数据库部分。 全局概念层:全局概念模式、分片模式和分配模式 全局概念模式描述分布式数据库中全局数据的逻辑结构和数据特性,与集中式数据库中的概念模式是集中式数据库的概念视图一样,全局概念模式是分布式数据库的全局概念视图。分片模式用于说明如何放置数据库的分片部分。分布式数据库可划分为许多逻辑片,定义片段、片段与概念模式之间的映射关系。分配模式是根据选定的数据分布策略,定义各片段的物理存放站点。 局部概念层:局部概念模式是全局概念模式的子集。局部内层:局部内模式 局部内模式是分布式数据库中关于物理数据库的描述,类同集中式数据库中的内模式,但其描述的内容不仅包含只局部于本站点的数据的存储描述,还包括全局数据在本站点的存储描述。 三、简述分布式数据库系统中的分布透明性,举例说明分布式数据库简单查询的 各级分布透明性问题。 分布式数据库中的分布透明性即分布独立性,指用户或用户程序使用分布式数据库如同使用集中式数据库那样,不必关心全局数据的分布情况,包括全局数据的逻辑分片情况、逻辑片段的站点位置分配情况,以及各站点上数据库的数据模型等。即全局数据的逻辑分片、片段的物理位置分配,各站点数据库的数据模型等情况对用户和用户程序透明。
数据采集与预处理-课程标准_教学大纲
《数据采集与预处理》课程标准 1. 概述 1.1课程的性质 本课程是大数据技术与应用专业、云计算技术与应用专业、软件技术专业的专业核心课程,是校企融合系列化课程,该课程教学内容以任务驱动为主线,围绕企业级应用进行项目任务设计。 1.2课程设计理念 本课程遵循应用型本科和高等职业教育规律,以大数据技术与应用实际工作岗位需求为导向选取课程内容,完成了数据采集和预处理平台搭建、网络爬虫实践、日志数据采集实践和数据预处理实践等完整的数据采集与预处理应用案例,课程目标是培养学生具备“大数据分析”应用项目所需数据采集与预处理的综合职业能力;坚持开放性设计原则,吸收企业专家参与,构建以“工作任务”为载体的“项目化”课程结构;课程教学实施教、学、做一体,坚持理论为实践服务的教学原则,通过模拟企业大数据采集与预处理应用业务进行组织,锻炼学生的实践操作能力。 1.3课程开发思路 通过岗位技能的项目化以及大数据采集与预处理任务的序列化,对内容体系结构进行了适当调 整与重构,以适应教学课程安排。以项目案例及其任务实现为驱动,凭借翔实的操作步骤和准确的 说明,帮助学生迅速掌握大数据采集与预处理的相关知识与技能,并且充分考虑学习操作时可能发 生的问题,并提供了详细的解决方案,突出岗位技能训练。 2.课程目标 本课程的培养目标是使学生以大数据分析岗位需求为依托,以实际工作任务为导向,理清大数据采集与预处理中常用工具的作用及应用,培养学生大数据采集与预处理的实际操作技能。 2.1知识目标 本课程本书以任务驱动为主线,围绕企业级应用进行项目任务设计,完成了数据采集和预处理平台搭建、网络爬虫实践、日志数据采集实践和数据预处理实践等完整的数据采集与预处理应用案例,要求学生系统掌握scrapy、Flume、pig、kettle、Pandas、openrefine和urllib、selenium基本库 1
数据挖掘分类算法介绍
数据挖掘分类算法介绍 ----------------------------------------------------------------------------------------------------------------------------- 分类是用于识别什么样的事务属于哪一类的方法,可用于分类的算法有决策树、bayes分类、神经网络、支持向量机等等。 决策树 例1 一个自行车厂商想要通过广告宣传来吸引顾客。他们从各地的超市获得超市会员的信息,计划将广告册和礼品投递给这些会员。 但是投递广告册是需要成本的,不可能投递给所有的超市会员。而这些会员中有的人会响应广告宣传,有的人就算得到广告册不会购买。 所以最好是将广告投递给那些对广告册感兴趣从而购买自行车的会员。分类模型的作用就是识别出什么样的会员可能购买自行车。 自行车厂商首先从所有会员中抽取了1000个会员,向这些会员投递广告册,然后记录这些收到广告册的会员是否购买了自行车。 数据如下:
在分类模型中,每个会员作为一个事例,居民的婚姻状况、性别、年龄等特征作为输入列,所需预测的分类是客户是否购买了自行车。 使用1000个会员事例训练模型后得到的决策树分类如下:
※图中矩形表示一个拆分节点,矩形中文字是拆分条件。 ※矩形颜色深浅代表此节点包含事例的数量,颜色越深包含的事例越多,如全部节点包含所有的1000个事例,颜色最深。经过第一次基于年龄的拆分后,年龄大于67岁的包含36个事例,年龄小于32岁的133个事例,年龄在39和67岁之间的602个事例,年龄32和39岁之间的229个事例。所以第一次拆分后,年龄在39和67岁的节点颜色最深,年龄大于67岁的节点颜色最浅。 ※节点中的条包含两种颜色,红色和蓝色,分别表示此节点中的事例购买和不购买自行车的比例。如节点“年龄>=67”节点中,包含36个事例,其中28个没有购买自行车,8个购买了自行车,所以蓝色的条比红色的要长。表示年龄大于67的会员有74.62%的概率不购买自行车,有23.01%的概率购买自行车。 在图中,可以找出几个有用的节点: 1. 年龄小于32岁,居住在太平洋地区的会员有7 2.75%的概率购买自行车; 2. 年龄在32和39岁之间的会员有68.42%的概率购买自行车; 3. 年龄在39和67岁之间,上班距离不大于10公里,只有1辆汽车的会员有66.08%的概率购买自行车;
Matlab学习系列012.大数据预处理1剔除异常值及平滑处理
012. 数据预处理(1)——剔除异常值及平滑处理 测量数据在其采集与传输过程中,由于环境干扰或人为因素有可能造成个别数据不切合实际或丢失,这种数据称为异常值。为了恢复数据的客观真实性以便将来得到更好的分析结果,有必要先对原始数据(1)剔除异常值; 另外,无论是人工观测的数据还是由数据采集系统获取的数据,都不可避免叠加上“噪声”干扰(反映在曲线图形上就是一些“毛刺和尖峰”)。为了提高数据的质量,必须对数据进行(2)平滑处理(去噪声干扰); (一)剔除异常值。 注:若是有空缺值,或导入Matlab数据显示为“NaN”(非数),需要①忽略整条空缺值数据,或者②填上空缺值。 填空缺值的方法,通常有两种:A. 使用样本平均值填充;B. 使用判定树或贝叶斯分类等方法推导最可能的值填充(略)。 一、基本思想: 规定一个置信水平,确定一个置信限度,凡是超过该限度的误差,
就认为它是异常值,从而予以剔除。 二、常用方法:拉依达方法、肖维勒方法、一阶差分法。 注意:这些方法都是假设数据依正态分布为前提的。 1. 拉依达方法(非等置信概率) 如果某测量值与平均值之差大于标准偏差的三倍,则予以剔除。 3x i x x S -> 其中,11 n i i x x n ==∑为样本均值,1 2 211()1n x i i S x x n =?? ??? =--∑为样本的标准偏差。 注:适合大样本数据,建议测量次数≥50次。 代码实例(略)。 2. 肖维勒方法(等置信概率) 在 n 次测量结果中,如果某误差可能出现的次数小于半次时,就予以剔除。 这实质上是规定了置信概率为1-1/2n ,根据这一置信概率,可计算出肖维勒系数,也可从表中查出,当要求不很严格时,还可按下
数据采集与处理技术
数据采集与处理技术 参考书目: 1.数据采集与处理技术马明建周长城西安交通大学出版社 2.数据采集技术沈兰荪中国科学技术大学出版社 3.高速数据采集系统的原理与应用沈兰荪人民邮电出版社 第一章绪论 数据采集技术(Data Acquisition)是信息科学的一个重要分支,它研究信息数据的采集、存贮、处理以及控制等作业。在智能仪器、信号处理以及工业自动控制等领域,都存在着数据的测量与控制问题。将外部世界存在的温度、压力、流量、位移以及角度等模拟量(Analog Signal)转换为数字信号(Digital Signal), 在收集到计算机并进一步予以显示、处理、传输与记录这一过程,即称为“数据采集”。相应的系统即为数据采集系统(Data Acquisition System,简称DAS)数据采集技术以在雷达、通信、水声、遥感、地质勘探、震动工程、无损检测、语声处理、智能仪器、工业自动控制以及生物医学工程等领域有着广泛的应用。 1.1 数据采集的意义和任务 数据采集是指将温度、压力、流量、位移等模拟量采集、转换为数字量后,再由计算机进行存储、处理、显示或打印的过程。相应的系统称为数据采集系统。 数据采集系统的任务:采集传感器输出的模拟信号并转换成计算机能识别的数字信号,然后送入计算机,根据不同的需要由计算机进行相应的计算和处理,得出所需的数据。与此同时,将计算得到的数据进行显示或打印,以便实现对某些物理量的监视,其中一部分数据还将被生产过程中的计算机控制系统用来控制某些物理量。 数据采集系统的好坏,主要取决于精度和速度。 1.2 数据采集系统的基本功能 1.数据采集:采样周期
大数据采集技术和预处理技术
现如今,很多人都听说过大数据,这是一个新兴的技术,渐渐地改变了我们的生活,正是由 于这个原因,越来越多的人都开始关注大数据。在这篇文章中我们将会为大家介绍两种大数 据技术,分别是大数据采集技术和大数据预处理技术,有兴趣的小伙伴快快学起来吧。 首先我们给大家介绍一下大数据的采集技术,一般来说,数据是指通过RFID射频数据、传 感器数据、社交网络交互数据及移动互联网数据等方式获得的各种类型的结构化、半结构化 及非结构化的海量数据,是大数据知识服务模型的根本。重点突破高速数据解析、转换与装 载等大数据整合技术设计质量评估模型,开发数据质量技术。当然,还需要突破分布式高速 高可靠数据爬取或采集、高速数据全映像等大数据收集技术。这就是大数据采集的来源。 通常来说,大数据的采集一般分为两种,第一就是大数据智能感知层,在这一层中,主要包 括数据传感体系、网络通信体系、传感适配体系、智能识别体系及软硬件资源接入系统,实 现对结构化、半结构化、非结构化的海量数据的智能化识别、定位、跟踪、接入、传输、信 号转换、监控、初步处理和管理等。必须着重攻克针对大数据源的智能识别、感知、适配、 传输、接入等技术。第二就是基础支撑层。在这一层中提供大数据服务平台所需的虚拟服务器,结构化、半结构化及非结构化数据的数据库及物联网络资源等基础支撑环境。重点攻克 分布式虚拟存储技术,大数据获取、存储、组织、分析和决策操作的可视化接口技术,大数 据的网络传输与压缩技术,大数据隐私保护技术等。 下面我们给大家介绍一下大数据预处理技术。大数据预处理技术就是完成对已接收数据的辨析、抽取、清洗等操作。其中抽取就是因获取的数据可能具有多种结构和类型,数据抽取过 程可以帮助我们将这些复杂的数据转化为单一的或者便于处理的构型,以达到快速分析处理 的目的。而清洗则是由于对于大数并不全是有价值的,有些数据并不是我们所关心的内容, 而另一些数据则是完全错误的干扰项,因此要对数据通过过滤去除噪声从而提取出有效数据。在这篇文章中我们给大家介绍了关于大数据的采集技术和预处理技术,相信大家看了这篇文 章以后已经知道了大数据的相关知识,希望这篇文章能够更好地帮助大家。
分布式数据库系统(1)
分布式数据库系统(1) 胡经国 本文作者的话 本文是根据有关文献和资料编写的《漫话云计算》系列文稿之一。以此作为云计算学习笔录,供云计算业外读者进一步学习和研究参考。希望能够得到大家的指教和喜欢! 下面是正文 一、分布式数据库系统概述 1、概述一 分布式数据库(Distributed Database,DDB)是指数据分散存储在计算机网络中的各台计算机上的数据库。 分布式数据库系统(Distributed Database System,DDBS)通常使用较小的计算机系统,每台计算机可单独放在一个地方;每台计算机中都可能有DBMS (数据库管理系统)的一份完整拷贝副本,或者部分拷贝副本,并具有自己局部的数据库;位于不同地点的许多计算机通过网络互相连接,共同组成一个完整的、全局的、逻辑上集中、物理上分布的大型数据库系统。 2、概述二 分布式数据库,是指利用高速计算机网络,将物理上分散的多个数据存储单元连接起来组成一个逻辑上统一的数据库。 分布式数据库的基本思想,是将原来集中式数据库中的数据分散存储到多个通过网络连接的数据存储节点上,以获取更大的存储容量和更高的并发访问量。 近年来,随着数据量的高速增长,分布式数据库技术也得到了快速的发展。传统的关系型数据库开始从集中式模型向分布式架构发展。基于关系型的分布式数据库,在保留传统数据库的数据模型和基本特征前提下,从集中式存储走向分布式存储,从集中式计算走向分布式计算。 另一方面,随着数据量越来越大,关系型数据库开始暴露出一些难以克服的缺点。以NoSQL为代表的、具有高可扩展性、高并发性等优势的非关系型数据库快速发展;一时间市场上出现了大量的key-value(键-值)存储系统、文档型数据库等NoSQL数据库产品。NoSQL类型数据库正日渐成为大数据时代下分布式数据库领域的主力。 这种按分布式组织数据库的方法克服了物理中心数据库组织的弱点。
大数据采集与处理技术考试卷
一、绪论 (一)、1、“数据采集”是指什么? 将温度、压力、流量、位移等模拟量经测量转换电路输出电量后再采集转换成数字量后,再由PC 机进行存储、处理、显示或打印的过程。 2、数据采集系统的组成? 由数据输入通道,数据存储与管理,数据处理,数据输出及显示这五个部分组成。 3、数据采集系统性能的好坏的参数? 取决于它的精度和速度。 4、数据采集系统具有的功能是什么? (1)、数据采集,(2)、信号调理,(3)、二次数据计算,(4)、屏幕显示,(5)、数据存储,(6)、打印输出,(7)、人机联系。 5、数据处理系统的分类? 分为预处理和二次处理两种;即为实时(在线)处理和事后(脱机)处理。 6、集散式控制系统的典型的三级结构? 一种是一般的微型计算机数据采集系统,一种是直接数字控制型计算机数据采集系统,还有一种是集散型数据采集系统。 7、控制网络与数据网络的结合的优点? 实现信号的远程传送与异地远程自动控制。 (二)、问答题: 1、数据采集的任务是什么? 数据采集系统的任务:就是传感器输出信号转换为数字信号,送入工业控制机机处理,得出所需的数据。同时显示、储存或打印,以便实现对某些物理量的监视,还将被生产过程中的PC机控制系统用来控制某些物理量。 2、微型计算机数据采集系统的特点是 (1)、系统结构简单;(2)、微型计算机对环境要求不高;(3)、微型计算机的价格低廉,降低了数据采集系统的成本;(4)、微型计算机数据采集系统可作为集散型数据采集系统的一个基本组成部分;(5)、微型计算机的各种I/O模板及软件齐全,易构成系统,便于使用和维修; 3、简述数据采集系统的基本结构形式,并比较其特点? (1)、一般微型计算机数据采集与处理系统是由传感器、模拟多路开关、程控放大器、采样/保持器、A/D转换器、计算机及外设等部分组成。 (2)、直接数字控制型数据采集与处理系统(DDC)是既可对生产过程中的各个参数进行巡回检测,还可根据检测结果,按照一定的算法,计算出执行器应该的状态(继电器的通断、阀门的位置、电机的转速等),完成自动控制的任务。系统的I/O通道除了AI和DI外,还有模拟量输出(AO)通道和开关量输出(FDO)通道。 (3)、集散式控制系统也称为分布式控制系统,总体思想是分散控制,集中管理,即用几台计算机分别控制若干个回路,再用监督控制计算机进行集中管理。 (三)、分析题: 1、如图所示,分析集散型数据采集与处理系统的组成原理,系统有那些特点?
振动信号的采集与预处理
振动信号的采集与预处理 几乎所有的物理现象都可看作是信号,但这里我们特指动态振动信号。 振动信号采集与一般性模拟信号采集虽有共同之处,但存在的差异更多,因此,在采集振动信号时应注意以下几点: 1. 振动信号采集模式取决于机组当时的工作状态,如稳态、瞬态等; 2. 变转速运行设备的振动信号采集在有条件时应采取同步整周期采集; 3. 所有工作状态下振动信号采集均应符合采样定理。 对信号预处理具有特定要求是振动信号本身的特性所致。信号预处理的功能在一定程度上说是影响后续信号分析的重要因素。预处理方法的选择也要注意以下条件: 1. 在涉及相位计算或显示时尽量不采用抗混滤波; 2. 在计算频谱时采用低通抗混滤波; 3. 在处理瞬态过程中1X矢量、2X矢量的快速处理时采用矢量滤波。 上述第3条是保障瞬态过程符合采样定理的基本条件。在瞬态振动信号采集时,机组转速变化率较高,若依靠采集动态信号(一般需要若干周期)通过后处理获得1X和2X矢量数据,除了效率低下以外,计算机(服务器)资源利用率也不高,且无法做到高分辨分析数据。机组瞬态特征(以波德图、极坐标图和三维频谱图等型式表示)是固有的,当组成这些图谱的数据间隔过大(分辨率过低)时,除许多微小的变化无法表达出来,也会得出误差很大的分析结论,影响故障诊断的准确度。一般来说,三维频谱图要求数据的组数(△rpm分辨率)较少,太多了反而影响对图形的正确识别;但对前面两种分析图谱,则要求较高的分辨率。目前公认的方式是每采集10组静态数据采集1组动态数据,可很好地解决不同图谱对数据分辨率的要求差异。 影响振动信号采集精度的因素包括采集方式、采样频率、量化精度三个因素,采样方式不同,采集信号的精度不同,其中以同步整周期采集为最佳方式;采样频率受制于信号最高频率;量化精度取决于A/D转换的位数,一般采用12位,部分系统采用16位甚至24位。 振动信号的采样过程,严格来说应包含几个方面: 1. 信号适调 由于目前采用的数据采集系统是一种数字化系统,所采用的A/D芯片对信号输入量程有严格限制,为了保证信号转换具有较高的信噪比,信号进入A/D以前,均需进行信号适调。适调包括大信号的衰减处理和弱信号的放大处理,或者对一些直流信号进行偏置处理,使其满足A/D输入量程要求。 2. A/D转换
数据挖掘中的文本挖掘的分类算法综述
数据挖掘中的文本挖掘的分类算法综述 摘要 随着Internet上文档信息的迅猛发展,文本分类成为处理和组织大量文档数据的关键技术。本文首先对数据挖掘进行了概述包括数据挖掘的常用方法、功能以及存在的主要问题;其次对数据挖掘领域较为活跃的文本挖掘的历史演化、研究现状、主要内容、相关技术以及热点难点问题进行了探讨;在第三章先分析了文本分类的现状和相关问题,随后详细介绍了常用的文本分类算法,包括KNN 文本分类算法、特征选择方法、支持向量机文本分类算法和朴素贝叶斯文本分类算法;;第四章对KNN文本分类算法进行深入的研究,包括基于统计和LSA降维的KNN文本分类算法;第五章对数据挖掘、文本挖掘和文本分类的在信息领域以及商业领域的应用做了详细的预测分析;最后对全文工作进行了总结和展望。 关键词:数据挖掘,文本挖掘,文本分类算法 ABSTRACT With the development of Web 2.0, the number of documents on the Internet increases exponentially. One important research focus on how to deal with these great capacity of online documents. Text classification is one crucial part of information management. In this paper we first introduce the basic information of data mining, including the methods, contents and the main existing problems in data mining fields; then we discussed the text mining, one active field of data mining, to provide a basic foundation for text classification. And several common algorithms are analyzed in Chapter 3. In chapter 4 thorough research of KNN text classification algorithms are illustrated including the statistical and dimension reduction based on LSA and in chapter 5 we make some predictions for data mining, text mining and text classification and finally we conclude our work. KEYWORDS: data mining, text mining, text classification algorithms,KNN 目录 摘要 (1) ABSTRACT (1) 目录 (1)
分布式数据库系统
分布式数据库系统 分布式数据库系统有两种:一种是物理上分布的,但逻辑上却是集中的。这种分布式数据库只适宜用途比较单一的、不大的单位或部门。另一种分布式数据库系统在物理上和逻辑上都是分布的,也就是所谓联邦式分布数据库系统。由于组成联邦的各个子数据库系统是相对“自治”的,这种系统可以容纳多种不同用途的、差异较大的数据库,比较适宜于大范围内数据库的集成。 ----- ---- 分布式数据库系统(DDBS)包含分布式数据库管理系统(DDBMS)和分布式数据库(DDB)。在分布式数据库系统中,一个应用程序可以对数据库进行透明操作,数据库中的数据分别在不同的局部数据库中存储、由不同的DBMS进行管理、在不同的机器上运行、由不同的操作系统支持、被不同的通信网络连接在一起。 一个分布式数据库在逻辑上是一个统一的整体,在物理上则是分别存储在不同的物理节点上。一个应用程序通过网络的连接可以访问分布在不同地理位置的数据库。它的分布性表现在数据库中的数据不是存储在同一场地。更确切地讲,不存储在同一计算机的存储设备上。这就是与集中式数据库的区别。从用户的角度看,一个分布式数据库系统在逻辑上和集中式数据库系统一样,用户可以在任何一个场地执行全局应用。就好那些数据是存储在同一台计算机上,有单个数据库管理系统(DBMS)管理一样,用户并没有什么感觉不一样。 分布式数据库系统是在集中式数据库系统的基础上发展起来的,是计算机技术和网络技术结合的产物。分布式数据库系统适合于单位分散的部门,允许各个部门将其常用的数据存储在本地,实施就地存放本地使用,从而提高响应速度,降低通信费用。分布式数据库系统与集中式数据库系统相比具有可扩展性,通过增加适当的数据冗余,提高系统的可靠性。在集中式数据库中,尽量减少冗余度是系统目标之一.其原因是,冗余数据浪费存储空间,而且容易造成各副本之间的不一致性.而为了保证数据的一致性,系统要付出一定的维护代价.减少冗余度的目标是用数据共享来达到的。而在分布式数据库中却希望增加冗余数据,在不同的场地存储同一数据的多个副本,其原因是:①.提高系统的可靠性、可用性当某一场地出现故障时,系统可以对另一场地上的相同副本进行操作,不会因一处故障而造成整个系统的瘫痪。②.提高系统性能系统可以根据距离选择离用户最近的数据副本进行操作,减少通信代价,改善整个系统的性能。 分布式数据库具有以下几个特点: (1)、数据独立性与位置透明性。数据独立性是数据库方法追求的主要目标之一,分布透明性指用户不必关心数据的逻辑分区,不必关心数据物理位置分布的细节,也不必关心重复副本(冗余数据)的一致性问题,同时也不必关心局部场地上数据库支持哪种数据模型.分布透明性的优点是很明显的.有了分布透明性,用户的应用程序书写起来就如同数据没有分布一样.当数据从一个场地移到另一个场地时不必改写应用程序.当增加某些数据的重复副本时也不必改写应用程序.数据分布的信息由系统存储在数据字典中.用户对非本地数据的访问请求由系统根据数据字典予以解释、转换、传送. (2)、集中和节点自治相结合。数据库是用户共享的资源.在集中式数据库中,为了保证数据库的安全性和完整性,对共享数据库的控制是集中的,并设有DBA负责监督和维护系统的正常运行.在分布式数据库中,数据的共享有两个层次:一是局部共享,即在局部数据库中存储局部场地上各用户的共享数据.这些数据是本场地用户常用的.二是全局共享,即在分布式数据库的各个场地也存储可供网中其它场地的用户共享的数据,支持系统中的全局应用.因此,相应的控制结构也具有两个层次:集中和自治.分布式数据库系统常常采用集中和自治相结合的控制结构,各局部的DBMS可以独立地管理局部数据库,具有自治的功能.同时,系统又设有集中控制机制,协调各局部DBMS 的工作,执行全局应用。当然,不同的系统集中和自治的程度不尽相同.有些系统高度自治,连全局
数据挖掘主要算法
朴素贝叶斯: 有以下几个地方需要注意: 1. 如果给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分类为例),比如说是句子单词的话,则长度为整个词汇量的长度,对应位置是该单词出现的次数。 2. 计算公式如下: 其中一项条件概率可以通过朴素贝叶斯条件独立展开。要注意一点就是的计算方法,而由朴素贝叶斯的前提假设可知, = ,因此一般有两种,一种是在类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本的总和;第二种方法是类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本中所有特征出现次数的总和。 3. 如果中的某一项为0,则其联合概率的乘积也可能为0,即2中公式的分子为0,为了避免这种现象出现,一般情况下会将这一项初始化为1,当然为了保证概率相等,分母应对应初始化为2(这里因为是2类,所以加2,如果是k类就需要加k,术语上叫做laplace 光滑, 分母加k的原因是使之满足全概率公式)。 朴素贝叶斯的优点: 对小规模的数据表现很好,适合多分类任务,适合增量式训练。 缺点: 对输入数据的表达形式很敏感。 决策树: 决策树中很重要的一点就是选择一个属性进行分枝,因此要注意一下信息增益的计算公式,并深入理解它。 信息熵的计算公式如下:
其中的n代表有n个分类类别(比如假设是2类问题,那么n=2)。分别计算这2类样本在总样本中出现的概率p1和p2,这样就可以计算出未选中属性分枝前的信息熵。 现在选中一个属性xi用来进行分枝,此时分枝规则是:如果xi=vx的话,将样本分到树的一个分支;如果不相等则进入另一个分支。很显然,分支中的样本很有可能包括2个类别,分别计算这2个分支的熵H1和H2,计算出分枝后的总信息熵H’=p1*H1+p2*H2.,则此时的信息增益ΔH=H-H’。以信息增益为原则,把所有的属性都测试一边,选择一个使增益最大的属性作为本次分枝属性。 决策树的优点: 计算量简单,可解释性强,比较适合处理有缺失属性值的样本,能够处理不相关的特征; 缺点: 容易过拟合(后续出现了随机森林,减小了过拟合现象); Logistic回归: Logistic是用来分类的,是一种线性分类器,需要注意的地方有: 1. logistic函数表达式为: 其导数形式为: 2. logsitc回归方法主要是用最大似然估计来学习的,所以单个样本的后验概率为: 到整个样本的后验概率:
数据挖掘决策树算法概述
决策树是分类应用中采用最广泛的模型之一。与神经网络和贝叶斯方法相比,决策树无须花费大量的时间和进行上千次的迭代来训练模型,适用于大规模数据集,除了训练数据中的信息外不再需要其他额外信息,表现了很好的分类精确度。其核心问题是测试属性选择的策略,以及对决策树进行剪枝。连续属性离散化和对高维大规模数据降维,也是扩展决策树算法应用范围的关键技术。本文以决策树为研究对象,主要研究内容有:首先介绍了数据挖掘的历史、现状、理论和过程,然后详细介绍了三种决策树算法,包括其概念、形式模型和优略性,并通过实例对其进行了分析研究 目录 一、引言 (1) 二、数据挖掘 (2) (一)概念 (2) (二)数据挖掘的起源 (2) (三)数据挖掘的对象 (3) (四)数据挖掘的任务 (3) (五)数据挖掘的过程 (3) (六)数据挖掘的常用方法 (3) (七)数据挖掘的应用 (5) 三、决策树算法介绍 (5) (一)归纳学习 (5) (二)分类算法概述 (5) (三)决策树学习算法 (6) 1、决策树描述 (7) 2、决策树的类型 (8) 3、递归方式 (8) 4、决策树的构造算法 (8) 5、决策树的简化方法 (9) 6、决策树算法的讨论 (10) 四、ID3、C4.5和CART算法介绍 (10) (一)ID3学习算法 (11) 1、基本原理 (11) 2、ID3算法的形式化模型 (13) (二)C4.5算法 (14) (三)CART算法 (17) 1、CART算法理论 (17) 2、CART树的分支过程 (17) (四)算法比较 (19) 五、结论 (24) 参考文献...................................................................................... 错误!未定义书签。 致谢.............................................................................................. 错误!未定义书签。
大数据分析和处理的方法步骤
大数据处理数据时代理念的三大转变:要全体不要抽样,要效率不要绝对精确,要相关不要因果。具体的大数据处理方法其实有很多,但是根据长时间的实践,天互数据总结了一个基本的大数据处理流程,并且这个流程应该能够对大家理顺大数据的处理有所帮助。整个处理流程可以概括为四步,分别是采集、导入和预处理、统计和分析,以及挖掘。 采集 大数据的采集是指利用多个数据库来接收发自客户端的数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。比如,电商会使用传统的关系型数据库MySQL和Oracle等来存储每一笔事务数据,除此之外,Redis和MongoDB 这样的NoSQL数据库也常用于数据的采集。 在大数据的采集过程中,其主要特点和挑战是并发数高,因为同时有可能会有成千上万的用户来进行访问和操作,比如火车票售票网站和淘宝,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑。并且如何在这些数据库之间进行负载均衡和分片的确是需要深入的思考和设计。 统计/分析 统计与分析主要利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求,在这方面,一些实时性需求会用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL 的列式存储Infobright等,而一些批处理,或者基于半结构化数据的需求可以使用Hadoop。统计与分析这部分的主要特点和挑战是分析涉及的数据量大,其对系统资源,特别是I/O会有极大的占用。 导入/预处理 虽然采集端本身会有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,并且可以在导入基础上做一些简单的清洗和预处理工作。也有一些用户会在导入时使用来自Twitter的Storm来对数据进行流式计算,来满足