在sourceinsight中查看单个函数圈复杂度的方法
方法一、集成SourceMonitor工具,查看单个函数圈复杂度
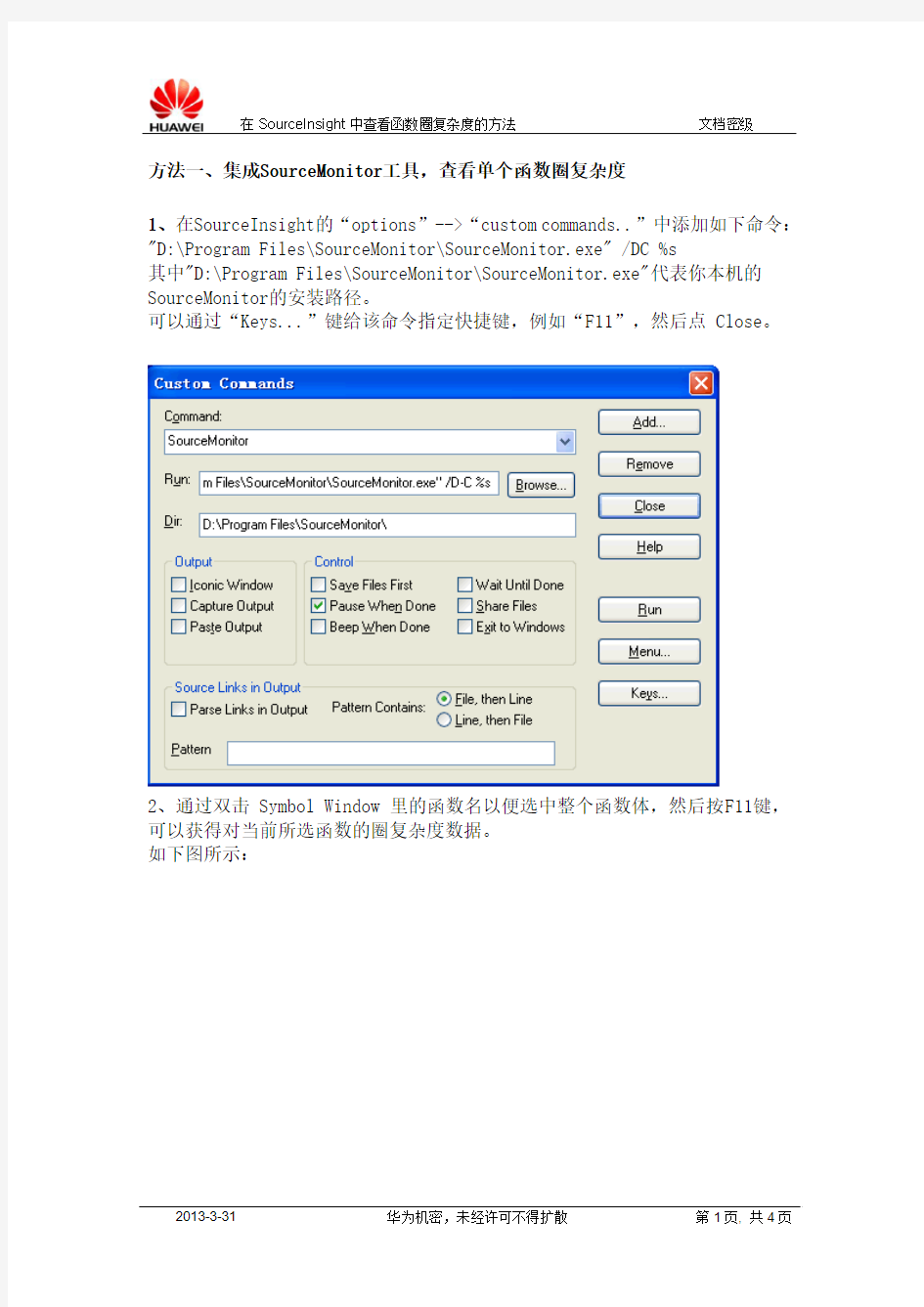
1、在SourceInsight的“options”-->“custom commands..”中添加如下命令:"D:\Program Files\SourceMonitor\SourceMonitor.exe" /DC %s
其中"D:\Program Files\SourceMonitor\SourceMonitor.exe"代表你本机的SourceMonitor的安装路径。
可以通过“Keys...”键给该命令指定快捷键,例如“F11”,然后点 Close。
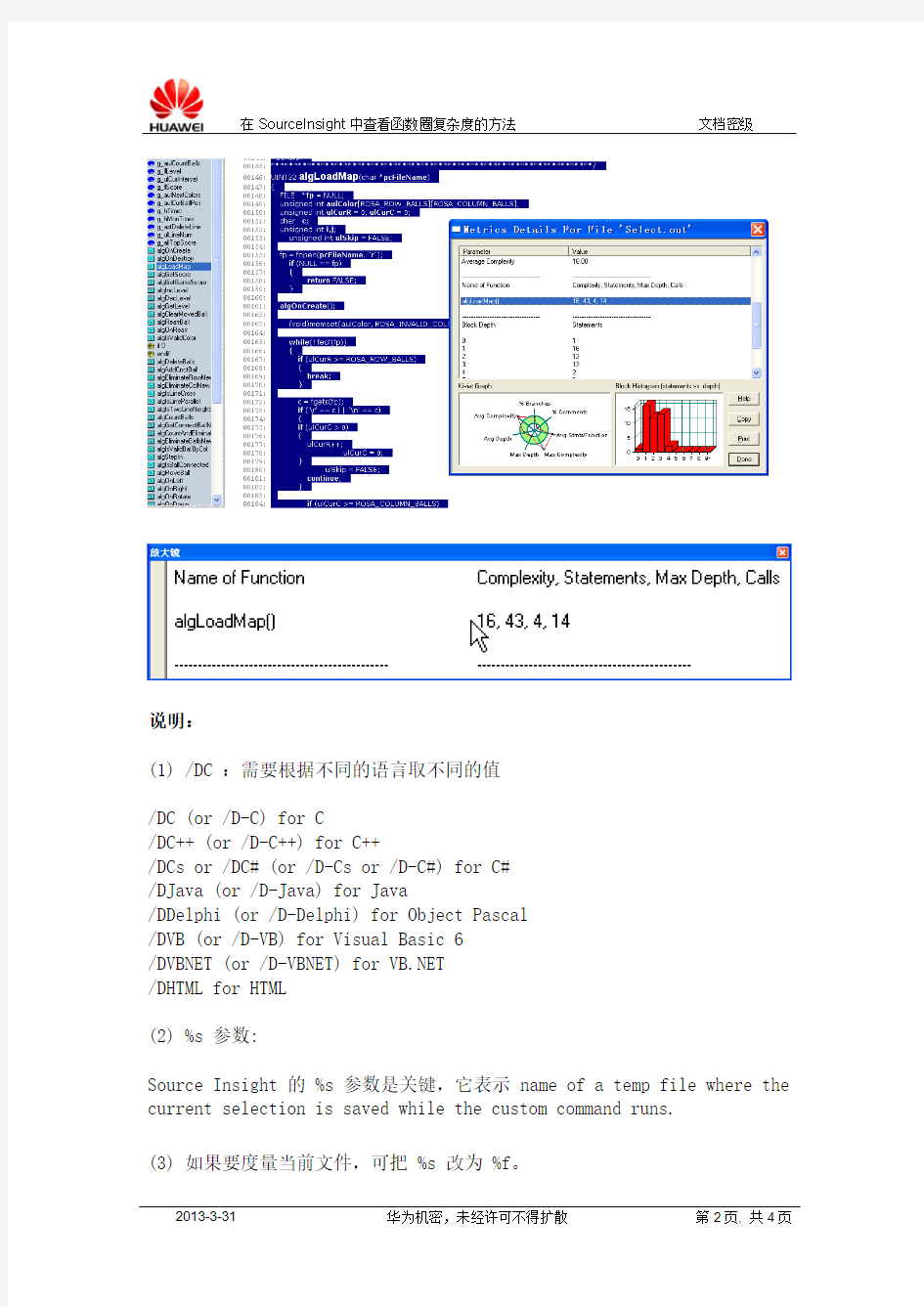
2、通过双击 Symbol Window 里的函数名以便选中整个函数体,然后按F11键,可以获得对当前所选函数的圈复杂度数据。
如下图所示:
说明:
(1) /DC :需要根据不同的语言取不同的值
/DC (or /D-C) for C
/DC++ (or /D-C++) for C++
/DCs or /DC# (or /D-Cs or /D-C#) for C#
/DJava (or /D-Java) for Java
/DDelphi (or /D-Delphi) for Object Pascal
/DVB (or /D-VB) for Visual Basic 6
/DVBNET (or /D-VBNET) for https://www.360docs.net/doc/d4628878.html,
/DHTML for HTML
(2) %s 参数:
Source Insight 的 %s 参数是关键,它表示 name of a temp file where the current selection is saved while the custom command runs.
(3) 如果要度量当前文件,可把 %s 改为 %f。
方法二、利用SoureceInsight自身的度量功能(不准确,仅供参考)
1、设置项目的代码度量项:
Project属性->code metrics,选中decision count(但SI的decision count计算方法和圈复杂度还不完全一样,仅供参考)
2、双击函数名,即可在右边的symbol list中看到函数的对应度量值:
SourceInsight和UltraEdit技巧
Source Insight使用技巧 默认情况下,SI已经定义了很多非常实用的快捷键: F5 指定行号,实现行跳转,在遇到编译错误的时候,能特别方便的找到出错行。Shift+F8 高亮显示指定标识,快速浏览标识的使用情况。 Ctrl+鼠标点击标识 直接跳转至标识定义处。 Ctrl+F 本文件内查找。 F3 本文件查找结果的上一个。 F4 本文件查找结果的下一个。 F7 打开Browse Project Symbols窗口,快速浏览工程内标识定义。 Ctrl+M Source Insight设置 1、背景色选择 要改变背景色Options->preference->windows background->color设置背景色2、解决字符等宽对齐问题。 SIS默认字体是VERDANA,很漂亮。这网页上应该也是用的VERDANA 字体。但由于美观的缘故,VERDANA字体是不等宽的。比如下面两行llllllllll MMMMMMMMMM 同样10个字符,长度差多了.用VERDANA来看程序,有些本应该对齐的就歪了。解放方法是使用等宽的字体,但肯定比较丑。比较推荐的是用Courier New。 3、解决TAB键缩进问题 Options-> Document Options里面的右下角Editing Options栏里,把Expand tabs勾起来,然后确定。OK,现在TAB键的缩进和四个空格的缩进在SIS里面看起来就对齐咯 4、SI中的自动对齐设置: 在C程序里, 如果遇到行末没有分号的语句,如IF, WHILE, SWITCH等, 写到该行末按回车,则新行自动相对上一行缩进两列。 Option->Document option下的Auto Indient中Auto Indient Type有三种类型None,Simple,Smart。个人推荐选用Simple类型。 5、向项目中添加文件时,只添加特定类型的文件(文件类型过滤器) 编辑汇编代码时,在SIS里建立PROJECT并ADD TREE的时候,根据默认设置并不会把该TREE里面所有汇编文件都包含进来
算法时间复杂度的计算
算法时间复杂度的计算 [整理] 基本的计算步骤 时间复杂度的定义 一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n))为算法的渐进时间复杂度(O是数量级的符号 ),简称时间复杂度。 根据定义,可以归纳出基本的计算步骤 1. 计算出基本操作的执行次数T(n) 基本操作即算法中的每条语句(以;号作为分割),语句的执行次数也叫做语句的频度。在做算法分析时,一般默认为考虑最坏的情况。 2. 计算出T(n)的数量级 求T(n)的数量级,只要将T(n)进行如下一些操作: 忽略常量、低次幂和最高次幂的系数 令f(n)=T(n)的数量级。 3. 用大O来表示时间复杂度 当n趋近于无穷大时,如果lim(T(n)/f(n))的值为不等于0的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n))。 一个示例: (1) int num1, num2; (2) for(int i=0; i 算法的时间复杂度和空间复杂度-总结通常,对于一个给定的算法,我们要做两项分析。第一是从数学上证明算法的正确性,这一步主要用到形式化证明的方法及相关推理模式,如循环不变式、数学归纳法等。而在证明算法是正确的基础上,第二部就是分析算法的时间复杂度。算法的时间复杂度反映了程序执行时间随输入规模增长而增长的量级,在很大程度上能很好反映出算法的优劣与否。因此,作为程序员,掌握基本的算法时间复杂度分析方法是很有必要的。 算法执行时间需通过依据该算法编制的程序在计算机上运行时所消耗的时间来度量。而度量一个程序的执行时间通常有两种方法。 一、事后统计的方法 这种方法可行,但不是一个好的方法。该方法有两个缺陷:一是要想对设计的算法的运行性能进行评测,必须先依据算法编制相应的程序并实际运行;二是所得时间的统计量依赖于计算机的硬件、软件等环境因素,有时容易掩盖算法本身的优势。 二、事前分析估算的方法 因事后统计方法更多的依赖于计算机的硬件、软件等环境因素,有时容易掩盖算法本身的优劣。因此人们常常采用事前分析估算的方法。 在编写程序前,依据统计方法对算法进行估算。一个用高级语言编写的程序在计算机上运行时所消耗的时间取决于下列因素: (1). 算法采用的策略、方法;(2). 编译产生的代码质量;(3). 问题的输入规模;(4). 机器执行指令的速度。 一个算法是由控制结构(顺序、分支和循环3种)和原操作(指固有数据类型的操作)构成的,则算法时间取决于两者的综合效果。为了便于比较同一个问题的不同算法,通常的做法是,从算法中选取一种对于所研究的问题(或算法类型)来说是基本操作的原操作,以该基本操作的重复执行的次数作为算法的时间量度。 1、时间复杂度 (1)时间频度一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。 (2)时间复杂度在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n))为算法的渐进时间复杂度,简称时间复杂度。 Source Insight实质上是一个支持多种开发语言(java,c ,c 等等) 的编辑器,只不过由于其查找、定位、彩色显示等功能的强大,常被我 们当成源代码阅读工具使用。 作为一个开放源代码的操作系统,Linux附带的源代码库使得广大爱好者有了一个广泛学习、深入钻研的机会,特别是Linux内核的组织极为复杂,同时,又不能像windows平台的程序一样,可以使用集成开发环境通过察看变量和函数,甚至设置断点、单步运行、调试等手段来弄清楚整个程序的组织结构,使得Linux内核源代码的阅读变得尤为困难。 当然Linux下的vim和emacs编辑程序并不是没有提供变量、函数搜索,彩色显示程序语句等功能。它们的功能是非常强大的。比如,vim和emacs就各自内嵌了一个标记程序,分别叫做ctag和etag,通过配置这两个程序,也可以实现功能强大的函数变量搜索功能,但是由于其配置复杂,linux附带的有关资料也不是很详细,而且,即使建立好标记库,要实现代码彩色显示功能,仍然需要进一步的配置(在另一片文章,我将会讲述如何配置这些功能),同时,对于大多数爱好者来说,可能还不能熟练使用vim和emacs那些功能比较强大的命令和快捷键。 为了方便的学习Linux源程序,我们不妨回到我们熟悉的window环境下,也算是“师以长夷以制夷”吧。但是在Window平台上,使用一些常见的集成开发环境,效果也不是很理想,比如难以将所有的文件加进去,查找速度缓慢,对于非Windows平台的函数不能彩色显示。于是笔者通过在互联网上搜索,终于找到了一个强大的源代码编辑器,它的卓越性能使得学习Linux内核源代码的难度大大降低,这便是Source Insight3.0,它是一个Windows平台下的共享软件,可以从https://www.360docs.net/doc/d4628878.html,/上边下载30天试用版本。由于Source Insight是一个Windows平台的应用软件,所以首先要通过相应手段把Linux系统上的程序源代码弄到Windows平台下,这一点可以通过在linux平台上将 /usr/src目录下的文件拷贝到Windows平台的分区上,或者从网上光盘直接拷贝文件到Windows平台的分区来实现。 下面主要讲解如何使用Source Insight,考虑到阅读源程序的爱好者都有相当的软件使用水平,本文对于一些琐碎、人所共知的细节略过不提,仅介绍一些主要内容,以便大家能够很快熟练使用本软件,减少摸索的过程。 安装Source Insight并启动程序,可以进入图1界面。在工具条上有几个值得注意的地方,如图所示,图中内凹左边的是工程按钮,用于显示工程窗口的情况;右边的那个按钮按下去将会显示一个窗口,里边提供光标所在的函数体内对其他函数的调用图,通过点击该窗体里那些函数就可以进入该函数所在的地方。 算法的时间复杂度计算 定义:如果一个问题的规模是n,解这一问题的某一算法所需要的时间为T(n),它是n的某一函数 T(n)称为这一算法的“时间复杂性”。 当输入量n逐渐加大时,时间复杂性的极限情形称为算法的“渐近时间复杂性”。 我们常用大O表示法表示时间复杂性,注意它是某一个算法的时间复杂性。大O表示只是说有上界,由定义如果f(n)=O(n),那显然成立f(n)=O(n^2),它给你一个上界,但并不是上确界,但人们在表示的时候一般都习惯表示前者。 此外,一个问题本身也有它的复杂性,如果某个算法的复杂性到达了这个问题复杂性的下界,那就称这样的算法是最佳算法。 “大O记法”:在这种描述中使用的基本参数是 n,即问题实例的规模,把复杂性或运行时间表达为n的函数。这里的“O”表示量级 (order),比如说“二分检索是 O(logn)的”,也就是说它需要“通过logn量级的步骤去检索一个规模为n的数组”记法 O ( f(n) )表示当 n增大时,运行时间至多将以正比于 f(n)的速度增长。 这种渐进估计对算法的理论分析和大致比较是非常有价值的,但在实践中细节也可能造成差异。例如,一个低附加代价的O(n2)算法在n较小的情况下可能比一个高附加代价的 O(nlogn)算法运行得更快。当然,随着n足够大以后,具有较慢上升函数的算法必然工作得更快。 O(1) Temp=i;i=j;j=temp; 以上三条单个语句的频度均为1,该程序段的执行时间是一个与问题规模n无关的常数。算法的时间复杂度为常数阶,记作T(n)=O(1)。如果算法的执行时间不随着问题规模n的增加而增长,即使算法中有上千条语句,其执行时间也不过是一个较大的常数。此类算法的时间复杂度是O(1)。 O(n^2) 2.1. 交换i和j的内容 sum=0;(一次) for(i=1;i<=n;i++) (n次) for(j=1;j<=n;j++) (n^2次) sum++;(n^2次) 解:T(n)=2n^2+n+1 =O(n^2) 2.2. for (i=1;i 排序法最差时间分析平均时间复杂度稳定度空间复杂度 冒泡排序()() 稳定() 快速排序()(*) 不稳定()() 选择排序()() 稳定() 二叉树排序()(*) 不一顶() 插入排序()() 稳定() 堆排序(*) (*) 不稳定() 希尔排序不稳定() 、时间复杂度 ()时间频度一个算法执行所耗费地时间,从理论上是不能算出来地,必须上机运行测试才能知道.但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费地时间多,哪个算法花费地时间少就可以了.并且一个算法花费地时间与算法中语句地执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多.一个算法中地语句执行次数称为语句频度或时间频度.记为(). ()时间复杂度在刚才提到地时间频度中,称为问题地规模,当不断变化时,时间频度()也会不断变化.但有时我们想知道它变化时呈现什么规律.为此,我们引入时间复杂度概念. 一般情况下,算法中基本操作重复执行地次数是问题规模地某个函数,用()表示,若有某个辅助函数(),使得当趋近于无穷大时,()()地极限值为不等于零地常数,则称()是()地同数量级函数.记作()O(()),称O(()) 为算法地渐进时间复杂度,简称时间复杂度. 在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为(),另外,在时间频度不相同时,时间复杂度有可能相同,如()与()它们地频度不同,但时间复杂度相同,都为(). 按数量级递增排列,常见地时间复杂度有:常数阶(),对数阶(),线性阶(), 线性对数阶(),平方阶(),立方阶(),...,次方阶(),指数阶().随着问题规模地不断增大,上述时间复杂度不断增大,算法地执行效率越低. 、空间复杂度与时间复杂度类似,空间复杂度是指算法在计算机内执行时所需存储空间地度量.记作: ()(()) 我们一般所讨论地是除正常占用内存开销外地辅助存储单元规模.讨论方法与时间复杂度类似,不再赘述. ()渐进时间复杂度评价算法时间性能主要用算法时间复杂度地数量级(即算法地渐近时间复杂度)评价一个算法地时间性能. 、类似于时间复杂度地讨论,一个算法地空间复杂度( )()定义为该算法所耗费地存储空间,它也是问题规模地函数.渐近空间复杂度也常常简称为空间复杂度. 空间复杂度( )是对一个算法在运行过程中临时占用存储空间大小地量度.一个算法在计算机存储器上所占用地存储空间,包括存储算法本身所占用地存储空间,算法地输入输出数据所占用地存储空间和算法在运行过程中临时占用地存储空间这三个方面.算法地输入输出数据所占用地存储空间是由要解决地问题决定地,是通过参数表由调用函数传递而来地,它不随本算法地不同而改变.存储算法本身所占用地存储空间与算法书写地长短成正比,要压缩这方面地存储空间,就必须编写出较短地算法.算法在运行过程中临时占用地存储空间随算法地不同而异,有地算法只需要占用少量地临时工作单元,而且不随问题规模地大小而改变,我们称这种算法是“就地"进行地,是节省存储地算法,如这一节介绍过地几个算法都是如此;有地算法需要占用地临时工作单元数与解决问题地规模有关,它随着地增大而增大,当较大时,将占用较多地存储单元,例如将在第九章介绍地快速排序和归并排序算法就属于这种情况.文档收集自网络,仅用于个人学习 如当一个算法地空间复杂度为一个常量,即不随被处理数据量地大小而改变时,可表示为();当一个算法地空间复杂度与以为底地地对数成正比时,可表示为();当一个算法地空司复杂度与成线性比例关系时,可表示为().若形参为数组,则只需要为它分配一个存储由实参传送 昆明理工大学信息工程与自动化学院学生实验报告 ( 2011 —2012 学年第 1 学期) 一、上机目的及内容 1.上机内容 求两个自然数m和n的最大公约数。 2.上机目的 (1)复习数据结构课程的相关知识,实现课程间的平滑过渡; (2)掌握并应用算法的数学分析和后验分析方法; (3)理解这样一个观点:不同的算法能够解决相同的问题,这些算法的解题思路不同,复杂程度不同,解题效率也不同。 二、实验原理及基本技术路线图(方框原理图或程序流程图) (1)至少设计出三个版本的求最大公约数算法; (2)对所设计的算法采用大O符号进行时间复杂性分析; (3)上机实现算法,并用计数法和计时法分别测算算法的运行时间; (4)通过分析对比,得出自己的结论。 三、所用仪器、材料(设备名称、型号、规格等或使用软件) 1台PC及VISUAL C++软件 四、实验方法、步骤(或:程序代码或操作过程) 实验采用三种方法求最大公约数 1、连续整数检测法。 2、欧几里得算法 3、分解质因数算法 根据实现提示写代码并分析代码的时间复杂度: 方法一: int f1(int m,int n) { int t; if(m>n)t=n; else t=m; while(t) { if(m%t==0&&n%t==0)break; else t=t-1; } return t; } 根据代码考虑最坏情况他们的最大公约数是1,循环做了t-1次,最好情况是只做了1次,可以得出O(n)=n/2; 方法二:int f2(int m,int n) { r=m%n; while(r!=0) { m=n; n=r; r=m%n; } return n; } 根据代码辗转相除得到欧几里得的O(n)= log n 方法三: int f3(int m,int n) { int i=2,j=0,h=0; int a[N],b[N],c[N]; while(i 一、选择题 (1)算法的空间复杂度是指 A)算法程序的长度 B)算法程序中的指令条数 C)算法程序所占的存储空间 D)执行过程中所需要的存储空间 正确答案: D (2)用链表表示线性表的优点是 A)便于随机存取 B)花费的存储空间较顺序存储少 C)便于插入和删除操作 D)数据元素的物理顺序与逻辑顺序相同 正确答案: C (3)数据结构中,与所使用的计算机无关的是数据的 A)存储结构 B)物理结构 C)逻辑结构 D)物理和存储结构 正确答案: C (4)结构化程序设计主要强调的是 A)程序的规模 B)程序的效率 C)程序设计语言的先进性 D)程序易读性 正确答案: D (5)软件设计包括软件的结构、数据接口和过程设计,其中软件的过程设计是指A)模块间的关系 B)系统结构部件转换成软件的过程描述 C)软件层次结构 D)软件开发过程 正确答案: B (6)检查软件产品是否符合需求定义的过程称为 A)确认测试 B)集成测试 C)验证测试 D)验收测试 正确答案: A (7)数据流图用于抽象描述一个软件的逻辑模型,数据流图由一些特定的图符构成。下列图符名标识的图符不属于数据流图合法图符的是 A)控制流 B)加工 C)数据存储 D)源和潭 正确答案: A (8)应用数据库的主要目的是 A)解决数据保密问题 B)解决数据完整性问题 C)解决数据共享问题 D)解决数据量大的问题 正确答案: C (9)在数据库设计中,将E-R图转换成关系数据模型的过程属于 A)需求分析阶段 B)逻辑设计阶段 C)概念设计阶段 D)物理设计阶段 正确答案: B (10)在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。其中数据独立性最高的阶段是 A)数据库系统 B)文件系统 C)人工管理 D)数据项管理 正确答案: A (11)下列说法错误的是 A)关系中每一个属性对应一个值域 B)关系中不同的属性可对应同一值域 C)对应同一值域的属性为不同的属性 D)DOM(A)表示属性A的取值范围 正确答案: C [NextPage] (12)对关系S和R进行集合运算,产生的元组属于S中的元组,但不属于R中的元组,这种集合运算称为 for(i=1;i<=n;i++) for(j=1;j<=i;j++) for(k=1;k<=j;k++) x++; 它的时间复杂度是多少? 自己计算了一下,数学公式忘得差不多了,郁闷; (1)时间复杂性是什么? 时间复杂性就是原子操作数,最里面的循环每次执行j次,中间循环每次执行 a[i]=1+2+3+...+i=i*(i+1)/2次,所以总的时间复杂性=a[1]+...+a[i]+..+a[n]; a[1]+...+a[i]+..+a[n] =1+(1+2)+(1+2+3)+...+(1+2+3+...+n) =1*n+2*(n-1)+3*(n-2)+...+n*(n-(n-1)) =n+2n+3n+...+n*n-(2*1+3*2+4*3+...+n*(n-1)) =n(1+2+...+n)-(2*(2-1)+3*(3-1)+4*(4-1)+...+n*(n-1)) =n(n(n+1))/2-[(2*2+3*3+...+n*n)-(2+3+4+...+n)] =n(n(n+1))/2-[(1*1+2*2+3*3+...+n*n)-(1+2+3+4+...+n)] =n(n(n+1))/2-n(n+1)(2n+1)/6+n(n+1)/2 所以最后结果是O(n^3)。 【转】时间复杂度的计算 算法复杂度是在《数据结构》这门课程的第一章里出现的,因为它稍微涉及到一些数学问题,所以很多同学感觉很难,加上这个概念也不是那么具体,更让许多同学复习起来无从下手, 下面我们就这个问题给各位考生进行分析。 首先了解一下几个概念。一个是时间复杂度,一个是渐近时间复杂度。前者是某个算法的时间耗费,它是该算法所求解问题规模n的函数,而后者是指当问题规模趋向无穷大时,该算法时间复杂度的数量级。 当我们评价一个算法的时间性能时,主要标准就是算法的渐近时间复杂度,因此,在算法分析时,往往对两者不予区分,经常是将渐近时间复杂度T(n)=O(f(n))简称为时间复杂度,其中的f(n)一般是算法中频度最大的语句频度。 此外,算法中语句的频度不仅与问题规模有关,还与输入实例中各元素的取值相关。但是我们总是考虑在最坏的情况下的时间复杂度。以保证算法的运行时间不会比它更长。 常见的时间复杂度,按数量级递增排列依次为:常数阶O(1)、对数阶O(log2n)、线性阶O(n)、线性对数阶O(nlog2n)、平方阶O(n^2)、立方阶O(n^3)、k次方阶O(n^k)、指数阶O(2^n)。 下面我们通过例子加以说明,让大家碰到问题时知道如何去解决。 1、设三个函数f,g,h分别为f(n)=100n^3+n^2+1000 , g(n)=25n^3+5000n^2 , h(n)=n^1.5+5000nlgn 请判断下列关系是否成立: (1)f(n)=O(g(n)) (2)g(n)=O(f(n)) (3)h(n)=O(n^1.5) (4)h(n)=O(nlgn) 这里我们复习一下渐近时间复杂度的表示法T(n)=O(f(n)),这里的"O"是数学符号,它的严格定义是"若T(n)和f(n)是定义在正整数集合上的两个函数,则T(n)=O(f(n))表示存在正的常数C和n0 ,使得当n≥n0时都满足0≤T(n)≤C?f(n)。"用容易理解的话说就是这两个函数当整型自变量n趋向于无穷大时,两者的比值是一个不等于0的常数。这么一来,就好计算了吧。 ◆(1)成立。题中由于两个函数的最高次项都是n^3,因此当n→∞时,两个函数的比值是一个常数,所以这个关系式是成立的。 ◆(2)成立。与上同理。 ◆(3)成立。与上同理。 ◆(4)不成立。由于当n→∞时n^1.5比nlgn递增的快,所以h(n)与nlgn的比值不是常数, (1) 算法的复杂度主要包括______复杂度和空间复杂 度。 (1) 算法的空间复杂度是指______。(D) A. 算法程序的长度 B. 算法程序中的指令条数 C. 算法程序所占的存储空间 D. 算法执行过程中所需要的存储空间 (2) 下列关于栈的叙述中正确的是______。(D) A. 在栈中只能插入数据 B. 在栈中只能删除数据 C. 栈是先进先出的线性表 D. 栈是先进后出的线性表 (3) 在深度为5的满二叉树中,叶子结点的个数为______。(C) A. 32 B. 31 C. 16 D. 15 (4) 对建立良好的程序设计风格,下面描述正确的是______。(A) A. 程序应简单、清晰、可读性好 B. 符号名的命名要符合语法 C. 充分考虑程序的执行效率 D. 程序的注释可有可无 (5) 下面对对象概念描述错误的是______。(A) A. 任何对象都必须有继承性 B. 对象是属性和方法的封装体 C. 对象间的通讯靠消息传递 D. 操作是对象的动态性属性 (6) 下面不属于软件工程的3个要素的是______。(D) A. 工具 B. 过程 C. 方法 D. 环境 (7) 程序流程图(PFD)中的箭头代表的是______。(B) A. 数据流 B. 控制流 C. 调用关系 D. 组成关系 (8) 在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。其中数据独立性的阶段是______。(A) A. 数据库系统 B. 文件系统 C. 人工管理 D. 数据项管理 (9) 用树形结构来表示实体之间联系的模型称为______。(B) A. 关系模型 B. 层次模型 C. 网状模型 D. 数据模型 (10) 关系数据库管理系统能实现的专门关系运算包括______。(B) A. 排序、索引、统计 B. 选择、投影、连接 C. 关联、更新、排序 D. 显示、打印、制表 文档类型开发文档 保密级别公开 技术报告 名称:SourceInsight3.5软件安装流程 编号: 版本号:V1.0.0 负责人:董磊 成员: 日期:2016年06月01日 目录 目录 (1) 版本 (2) 1文档目的 (3) 2安装SourceInsight3.5 (3) 3配置SourceInsight3.5 (9) 4使用SourceInsight3.5新建工程 (11) 图表目录 (16) 版本 1文档目的 Source Insight是一个面向项目开发的程序编辑器和代码浏览器,它拥有内置的对C/C++,C#和Java等程序的分析。能分析源代码并在工作的同时动态维护它自己的符号数据库,并自动显示有用的上下文信息。Source Insight不仅仅是一个强大的程序编辑器,它还能显示reference trees,class inheritance diagrams和call trees。Source Insight提供了最快速的对源代码的导航和任何程序编辑器的源信息。Source Insight提供了快速和革新的访问源代码和源信息的能力。与众多其它编辑器产品不同。 本文档详细介绍了SourceInsight3.5软件的安装流程、配置以及使用方法。2安装SourceInsight3.5 解压SourceInsight3.5压缩包并打开此文件夹,运行“InsightSetup”,当弹出如下图所示界面时,点击“Agree”,表示同意条款。 图2-1 当弹出如下图所示界面时,点击“Next”。 图2-2 当弹出如下图所示界面时,点击“Next”。 图2-3 当弹出如下图所示界面时,保持默认的安装路径,点击“Next”。 算法时间复杂度计算示 例 Company number:【WTUT-WT88Y-W8BBGB-BWYTT-19998】 基本计算步骤? 示例一:? (1) int num1, num2; (2) for(int i=0; i 几种常见算法的介绍及复杂度分析 1.基本概念 1.1 稳定排序(stable sort)和非稳定排序 稳定排序是所有相等的数经过某种排序方法后,仍能保持它们在排序之前的相对次序,。反之,就是非稳定的排序。比如:一组数排序前是a1,a2,a3,a4,a5,其中a2=a4,经过某种排序后为a1,a2,a4,a3,a5,则我们说这种排序是稳定的,因为a2排序前在a4的前面,排序后它还是在a4的前面。假如变成a1,a4,a2,a3,a5就不是稳定的了。 1.2 内排序( internal sorting )和外排序( external sorting) 在排序过程中,所有需要排序的数都在内存,并在内存中调整它们的存储顺序,称为内排序;在排序过程中,只有部分数被调入内存,并借助内存调整数在外存中的存放顺序排序方法称为外排序。 1.3 算法的时间复杂度和空间复杂度 所谓算法的时间复杂度,是指执行算法所需要的计算工作量。一个算法的空间复杂度,一般是指执行这个算法所需要的内存空间。 2.几种常见算法 2.1 冒泡排序(Bubble Sort) 冒泡排序方法是最简单的排序方法。这种方法的基本思想是,将待排序的元素看作是竖着排列的―气泡‖,较小的元素比较轻,从而要往上浮。在冒泡排序算法中我们要对这个―气泡‖序列处理若干遍。所谓一遍处理,就是自底向上检查一遍这个序列,并时刻注意两个相邻的元素的顺序是否正确。如果发现两个相邻元素的顺序不对,即―轻‖的元素在下面,就交换它们的位置。显然,处理一遍之后,―最轻‖的元素就浮到了最高位置;处理二遍之后,―次轻‖的元素就浮到了次高位置。在作第二遍处理时,由于最高位置上的元素已是―最轻‖元素,所以不必检查。一般地,第i遍处理时,不必检查第i高位置以上的元素,因为经过前面i-1遍的处理,它们已正确地排好序。 冒泡排序是稳定的,算法时间复杂度是O(n ^2)。 2.2 选择排序(Selection Sort) 选择排序的基本思想是对待排序的记录序列进行n-1遍的处理,第i遍处理是将L[i..n]中最小者与L[i]交换位置。这样,经过i遍处理之后,前i个记录的位置已经是正确的了。 选择排序是不稳定的,算法复杂度是O(n ^2 )。 2.3 插入排序(Insertion Sort) 插入排序的基本思想是,经过i-1遍处理后,L[1..i-1]己排好序。第i遍处理仅将L[i]插入L[1..i-1]的适当位置,使得L[1..i] 又是排好序的序列。要达到这个目的,我们可以用顺序比较的方法。首先比较L[i]和L[i-1],如果L[i-1]≤ L[i],则L[1..i]已排好序,第i遍处理就结束了;否则交换L[i]与L[i-1]的位置,继续比较L[i-1]和L[i-2],直到找到某一个位置j(1≤j≤i-1),使得L[j] ≤L[j+1]时为止。图1演示了对4个元素进行插入排序的过程,共需要(a),(b),(c)三次插入。直接插入排序是稳定的,算法时间复杂度是O(n ^2) 。 2.4 堆排序 堆排序是一种树形选择排序,在排序过程中,将A[n]看成是完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系来选择最小的元素。 堆排序是不稳定的,算法时间复杂度O(nlog n)。 2.5 归并排序 设有两个有序(升序)序列存储在同一数组中相邻的位置上,不妨设为A[l..m],A[m+1..h],将它们归并为一个有序数列,并存储在A[l..h]。 其时间复杂度无论是在最好情况下还是在最坏情况下均是O(nlog2n)。 SourceInsight 快捷方式大全 完成语法: Ctrl+E 复制一行: Ctrl+K 恰好复制该位置右边的该行的字符: Ctrl+Shift+K 复制到剪贴板: Ctrl+Del 剪切一行: Ctrl+U 剪切该位置右边的该行的字符: Ctrl+; 剪切到剪贴板: Ctrl+Shift+X 剪切一个字: Ctrl+, 左边缩进: F9 右边缩进: F10 插入一行: Ctrl+I 插入新行: Ctrl+Enter 加入一行: Ctrl+J 从剪切板粘贴: Ctrl+Ins 粘贴一行: Ctrl+P 重复上一个动作: Ctrl+Y 重新编号: Ctrl+R 重复输入: Ctrl+\ 替换: Ctrl+H 智能重命名: Ctrl+' 关闭文件: Ctrl+W 关闭所有文件: Ctrl+Shift+W 新建: Ctrl+N 转到下一个文件: Ctrl+Shift+N 打开: Ctrl+O 重新装载文件: Ctrl+Shift+O 另存为: Ctrl+Shift+S 显示文件状态: Shift+F10 激活语法窗口: Alt+L 回到该行的开始: Home 回到选择的开始: Ctrl+Alt+[ 到块的下面: Ctrl+Shift+] 到块的上面: Ctrl+Shift+[ 书签: Ctrl+M 到文件底部: Ctrl+End, Ctrl+(KeyPad) End 到窗口底部: (KeyPad) End (小键盘的END) 到一行的尾部: End 到选择部分的尾部: Ctrl+Alt+] 后退: Alt+,, Thumb 1 Click 后退到索引: Alt+M 向前: Alt+., Thumb 2 Click 转到行: F5, Ctrl+G 理工大学信息工程与自动化学院学生实验报告 (2011 —2012 学年第 1 学期) 课程名称:算法设计与分析开课实验室:信自楼机房444 2011 年10月 12日 一、上机目的及容 1.上机容 求两个自然数m和n的最大公约数。 2.上机目的 (1)复习数据结构课程的相关知识,实现课程间的平滑过渡; (2)掌握并应用算法的数学分析和后验分析方法; (3)理解这样一个观点:不同的算法能够解决相同的问题,这些算法的解题思路不同,复杂程度不同,解题效率也不同。 二、实验原理及基本技术路线图(方框原理图或程序流程图) (1)至少设计出三个版本的求最大公约数算法; (2)对所设计的算法采用大O符号进行时间复杂性分析; (3)上机实现算法,并用计数法和计时法分别测算算法的运行时间; (4)通过分析对比,得出自己的结论。 三、所用仪器、材料(设备名称、型号、规格等或使用软件) 1台PC及VISUAL C++6.0软件 四、实验方法、步骤(或:程序代码或操作过程) 实验采用三种方法求最大公约数 1、连续整数检测法。 根据实现提示写代码并分析代码的时间复杂度: 方法一: int f1(int m,int n) { int t; if(m>n)t=n; else t=m; while(t) { if(m%t==0&&n%t==0)break; else t=t-1; } return t; } 根据代码考虑最坏情况他们的最大公约数是1,循环做了t-1次,最好情况是只做了1次,可以得出O(n)=n/2; 方法二:int f2(int m,int n) { int r; r=m%n; while(r!=0) { m=n; n=r; r=m%n; } return n; } 根据代码辗转相除得到欧几里得的O(n)= log n 方法三: int f3(int m,int n) { int i=2,j=0,h=0; int a[N],b[N],c[N]; while(i 算法的时间复杂度 Prepared on 22 November 2020 时间复杂度:如果一个问题的规模是n,解这一问题的某一算法所需要的时间为T(n),它是n的某一函数,T(n)称为这一算法的“时间复杂度”。渐近时间复杂度:当输入量n逐渐加大时,时间复杂性的极限情形称为算法的“渐近时间复杂度”。 当我们评价一个算法的时间性能时,主要标准就是算法的渐近时间复杂度,因此,在算法分析时,往往对两者不予区分,经常是将渐近时间复杂度T(n)=O(f(n))简称为时间复杂度,其中的f(n)一般是算法中频度最大的语句频度。 此外,算法中语句的频度不仅与问题规模有关,还与输入实例中各元素的取值相关。但是我们总是考虑在最坏的情况下的时间复杂度。以保证算法的运行时间不会比它更长。 常见的时间复杂度,按数量级递增排列依次为:常数阶O(1)、对数阶 O(log2n)、线性阶O(n)、线性对数阶O(nlog2n)、平方阶O(n^2)、立方阶O(n^3)、k次方阶O(n^k)、指数阶O(2^n)。 下面我们通过例子加以说明,让大家碰到问题时知道如何去解决。 1、设三个函数f,g,h分别为 f(n)=100n^3+n^2+1000 , g(n)=25n^3+5000n^2 , h(n)=n^+5000nlgn 请判断下列关系是否成立: (1) f(n)=O(g(n)) (2) g(n)=O(f(n)) (3) h(n)=O(n^ (4) h(n)=O(nlgn) 这里我们复习一下渐近时间复杂度的表示法T(n)=O(f(n)),这里的"O"是数学符号,它的严格定义是"若T(n)和f(n)是定义在正整数集合上的两个函数,则T(n)=O(f(n))表示存在正的常数C和n0 ,使得当n≥n0时都满足0≤T(n)≤Cf(n)。"用容易理解的话说就是这两个函数当整型自变量n趋向于无穷大时,两者的比值是一个不等于0的常数。这么一来,就好计算了吧。 ◆ (1)成立。题中由于两个函数的最高次项都是n^3,因此当n→∞时,两个函数的比值是一个常数,所以这个关系式是成立的。 ◆(2)成立。与上同理。 ◆(3)成立。与上同理。 ◆(4)不成立。由于当n→∞时n^比nlgn递增的快,所以h(n)与nlgn的比值不是常数,故不成立。 2、设n为正整数,利用大"O"记号,将下列程序段的执行时间表示为n的函数。 (1) i=1; k=0 while(i 数据结构时间复杂度的计算 for(i=1;i<=n;i++) for(j=1;j<=i;j++) for(k=1;k<=j;k++) x++; 它的时间复杂度是多少? 自己计算了一下,数学公式忘得差不多了,郁闷; (1)时间复杂性是什么? 时间复杂性就是原子操作数,最里面的循环每次执行j次,中间循环每次执行 a[i]=1+2+3+...+i=i*(i+1)/2次,所以总的时间复杂性=a[1]+...+a[i]+..+a[n]; a[1]+...+a[i]+..+a[n] =1+(1+2)+(1+2+3)+...+(1+2+3+...+n) =1*n+2*(n-1)+3*(n-2)+...+n*(n-(n-1)) =n+2n+3n+...+n*n-(2*1+3*2+4*3+...+n*(n-1)) =n(1+2+...+n)-(2*(2-1)+3*(3-1)+4*(4-1)+...+n*(n-1)) =n(n(n+1))/2-[(2*2+3*3+...+n*n)-(2+3+4+...+n)] =n(n(n+1))/2-[(1*1+2*2+3*3+...+n*n)-(1+2+3+4+...+n)] =n(n(n+1))/2-n(n+1)(2n+1)/6+n(n+1)/2 所以最后结果是O(n^3)。 【转】时间复杂度的计算 算法复杂度是在《数据结构》这门课程的第一章里出现的,因为它稍微涉及到一些数学问题,所以很多同学感觉很难,加上这个概念也不是那么具体,更让许多同学复习起来无从下手,下面我们就这个问 题给各位考生进行分析。 首先了解一下几个概念。一个是时间复杂度,一个是渐近时间复杂度。前者是某个算法的时间耗费,它是该算法所求解问题规模n的函数,而后者是指当问题规模趋向无穷大时,该算法时间复杂度的数量级。 当我们评价一个算法的时间性能时,主要标准就是算法的渐近时间复杂度,因此,在算法分析时,往往对两者不予区分,经常是将渐近时间复杂度T(n)=O(f(n))简称为时间复杂度,其中的f(n)一般是算法中 频度最大的语句频度。 Source Insight使用简单说明 Source Insight是一个功能十分强大、使用也很方便的程序编辑器。它内置对C/C++、Java 甚至x86汇编语言程序的解析,在你编程时提供有用的函数、宏、参数等提示,因而,Source Insight正在国际、国内众多的IT公司使用。 Source Insight功能强大,它的窗口、菜单初一看来似乎很多,所以刚刚开始使用Source Insight的朋友往往觉得很麻烦。这里本人结合自己的使用经验,简单说说Source Insight的使用。(本文以McuSystem为例,Source Insight 以3.0版本为例。其他版本的Source Insight 大同小异) 和众多程序编辑环境一样,Source Insight中也有Project。 建立工程的方法很简单: 1.打开Source Insight,选择Project菜单->New Project; 2.在出现的对话框中选择并选择存放工程文件的文件夹,输入工程名(比如 McuSystem),点击“保存”; 3.又出现一个对话框,在Configuration部分可以选择这个工程使用全局配置文件还 是自己单独的配置文件,这个无所谓,(不过最好选择单独的配置文件),再点击 “OK”; 4.再次出现一个对话框,这是选择文件添加到Project中,通过左边的树状图找到你 想添加的文件,点击Add就可以了(如图1)。你可以将不通路径下的文件添加到 同一个工程中,而不用拷贝源文件。选择完后点击Close; 图1 这样工程就建立好了,文件列表就出现在Project Window中(如果Project Window被关闭了,可以选中View菜单->Project Window)。点击Project Window中任意一个文件,文件的内容出现在中央的编辑区了。(如图2)算法的时间复杂度和空间复杂度-总结
Source Insight用法精细
算法的时间复杂性
常用的排序算法的时间复杂度和空间复杂度
最大公约数的三种算法复杂度分析时间计算
(1)算法的空间复杂度是指
算法的时间复杂度计算
(1)算法的复杂度主要包括______复杂度和空间复杂度。
SourceInsight3.5软件安装流程.V1.0.0
算法时间复杂度计算示例
几种常见算法的介绍及复杂度分析
sourceinsight 快捷键 大全
最大公约数的三种算法复杂度分析时间计算
算法的时间复杂度
数据结构时间复杂度的计算
[完整版]Source_Insight教程及技巧