SAS讲义 第十二课拼接和合并数据集
第十二课 拼接和合并数据集
数据集的连接是把两个或两个以上的数据集的观测连接成一个新的数据集。连接的方式有二种:拼接和合并。在SAS 数据步中用SET 语句可以拼接数据集,而用MERGE 语句可以合并数据集。例如我们有二个数据集A 和B ,要拼接和合并成新的数据集C ,二种不同方法
的程序和结果见示意图12-1 所示:
一. 数据集的拼接
数据集的拼接可分成三种主要的拼接情况:
1 相同变量的数据集拼接
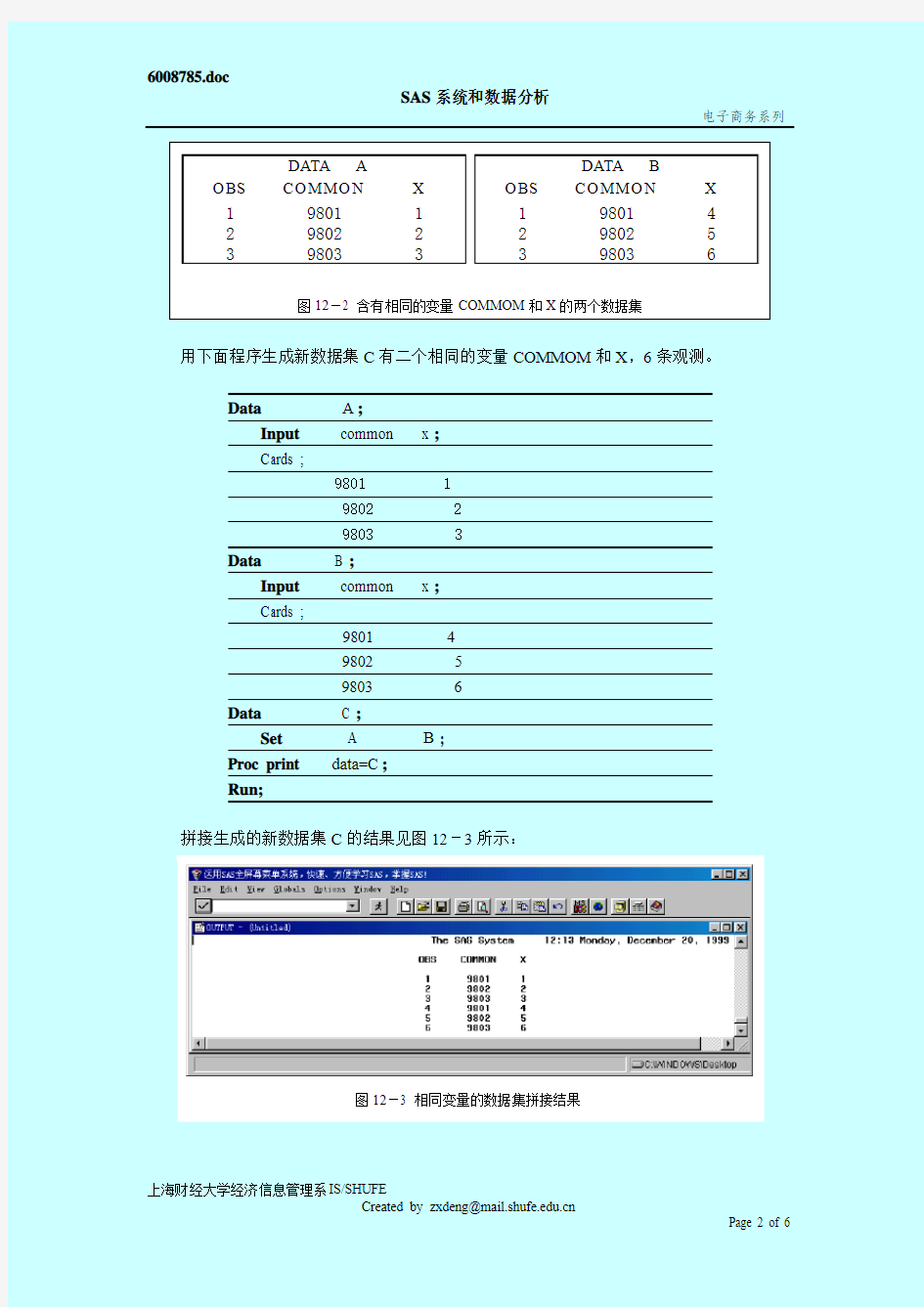
这是最简单的情况,在这种情况下,新生成的数据集就含有这些相同的变量,观测的数目是所有这些数据集的观测总和。例如数据集A 和B 都含有二个相同的变量COMMOM 和X ,且都有三条观测,见图12-2 所示:
A B
SAS 数据集的连接
D A T A C ; S ET A B ;R U N ;
D A T A C ;
M ER G E A B ;R U N ;
A B
A B
图12-1 数据集的两种连接方式:拼接和合并
DATA A DATA B O BS CO MMO N X O BS CO MMO N X 198011198014 298022298025 398033398036
图12-2 含有相同的变量COMMOM和X的两个数据集
用下面程序生成新数据集C有二个相同的变量COMMOM和X,6条观测。
Data A;
Input common x ;
Cards ;
9801 1
9802 2
98033
Data B ;
Input common x ;
Cards ;
98014
98025
98036
Data C ;
Set A B ;
Proc print data=C;
Run;
拼接生成的新数据集C的结果见图12-3所示:
图12-3 相同变量的数据集拼接结果
2不相同变量的数据集拼接
如果二个数据集A和B含有的变量不完全相同,如上例中数据集B含有的不是COMMON 和X变量而是COMMON和Y变量,见图12-4所示。用SET语句拼接A和B数据集后,新生成的数据集C就含有三个变量COMMON、X和Y,观测的数目仍然是所有这些数据集的观测总和,但原数据集中没有的变量在拼接后新数据集中为缺失值。
DATA A DATA B
O BS CO MMO N X O BS CO MMO N Y
198011198014
298022298025
398033398036
图12-4 含有不相同的变量X和Y的两个数据集
生成新数据集C的程序如下:
Data C;
Set A B ;
Proc print data=C ;
Run ;
拼接生成的新数据集C的结果见图12-5所示:
图12-5 不相同变量的数据集拼接结果
3按关键字排序后拼接数据集
如果要求新生成的数据集C按共同的关键字例如COMMON排序观测,那么预先要数据集A和B也已按COMMON关键字排序好了,可通过排序过程PROC SORT 和BY指明关键字。生成新数据集C的程序如下:
Proc sort data= A;
By Common ;
Proc sort data= B ;
By Common ;
Data C;
Set A B ;
By Common ;
Proc print data=C ;
Run ;
拼接生成的新数据集C的结果见图12-6所示:
图12-6 按关键字排序后拼接的数据集结果
无论哪一种拼接形式,用SET语句拼接生成的新数据集的观测总数为原各输入数据集观测数之和。
二.数据集的合并
数据集的合并是通过使用MERGE语句把两个或两个以上数据集中的两条观测或两条以上的观测合并为新生数据集中的一条观测。
数据集的合并可分成二种主要的合并情况:
●一对一合并(不带BY语句)
●匹配合并(带有BY语句)
1一对一合并(不带BY语句)
把一个数据集中的第一条观测同另外一个数据集中第一条观测合并,第二条观测同另外一个数据集中第二条观测合并,以此类推。新生成的数据集中的观测总数为这些数据集中观测个数的最大值。如果相对应的某个数据集已没有观测,则相应的变量值为缺省值。如果在几个数据集中有共同的变量,则在合并后新生成的数据集中只有一个变量,其值为列在
MERGE语句中最后一个含有该变量的数据集中的观测值。例如我们有二个数据集A和B,见图12-7所示:
DATA A DATA B
O BS CO MMO N X O BS CO MMO N Y
198011198014
298022298036
398033
图12-7 含有不相同的变量和相同变量不同值的两个数据集
生成新数据集C的程序如下:
Data C ;
Merge A B;
Proc print data=C ;
Run ;
合并的新数据集C的结果见图12-8所示:
图12-8 一对一合并(不带BY语句)后的结果
2匹配合并(带有BY语句)
DATA O RDERS DATA PRO DUCTS O BS P_ID Q uantity O BS P_ID P_N ame Price
198********Apple4
29803229803Banana6
398033
图12-9 定单数据集ORDERS和产品数据集PRODUCTS
如果想把两个或两个以上的数据集按照相同的关键字值合并,则在MERGE语句后面要用BY跟关键字语句。且每一个数据集必须预先按关键字排序好。如果两个数据集中观测的关键字值不匹配,输出所有这些观测,相应的新增变量的值为缺省值。如果两个数据集中观测的关键字值是多对多匹配,要注意新生成的数据集中相同关键字值的观测数为各数据集中这个关键字值的观测数的最大值,相同关键字值的观测按顺序一对一合并,无论哪一个数据集中这个相同关键字值的观测没有了,都取这个相同关键字值的最后一条观测继续合并。例如我们有一个定单数据集ORDERS和一个产品数据集PRODUCTS,见图12-9所示:
要合并生成一个新的定单销售数据集SALES的程序如下:
Proc sort data= ORDERS;
By P_ID ;
Proc sort data= PRODUCTS;
By P_ID ;
Data SALES;
Merge ORDERS PRODUCTS ;
By P_ID ;
Proc print data=SALES ;
Run ;
合并的新数据集SALES结果见图12-10所示:
SAS软件对数据集一些简单操作
SAS软件对数据集一些简单操作Libname AA 'd:\SAS'; Data AA.feng; Input a b c; cards; 3 4 56 64 43 34 累加 DATA A; INPUT X Y @@; S+X; CARDS; 3 5 7 9 20 21 ; PROC PRINT; RUN; ; run; DATA D1; INFILE ‘C:FIT.TXT' INPUT NUM $ 1-4 SEX $ 5 H 6-9 W 10-11; RUN; 建立数据集求均值 data a; input name$sex$math chinese@@; cards; 张三男82 96 刘四女81 98 王五男90 92 黄六女92 92 ; proc print data=a; proc means data=a mean; var math chinese; run; 保留列 data b; set a; keep name math; run; 丢弃列 data b; set b;
drop name; run; 条件选择 data c; set a; if math>90 and chinese>90; run; 把超过九十分改为90分data aa; set a; if chinese>90 then chinese=90; run; 筛选行 data aaa ; set a(firstobs=2 obs=3); run; 拆分男女 data a1 a2; set a; select(sex); when('男')output a1; when('女')output a2; otherwise put sex='wrong'; end; drop sex; run; 合并 data new; set a1(in=male) a2(in=female); if male=1 then sex=''; if female=1 then sex=''; run; 纵向合并Set 横向合并merge 重命名rename 改标志label 排序语句 proc sort data=a out=b; by sex;
《SAS数据分析范例》(SAS数据集)
《SAS数据分析范例》数据集 目录 表1 sas.bd1 (3) 表2 sas.bd3 (4) 表3 sas.bd4 (5) 表4 sas.belts (6) 表5 sas.c1d2 (7) 表6 sas.c7d31 (8) 表7 sas.dead0 (9) 表8 sas.dqgy (10) 表9 sas.dqjyjf (11) 表10 sas.dqnlmy3 (12) 表11 sas.dqnlmy (13) 表12 sas.dqrjsr (14) 表13 sas.dqrk (15) 表14 sas.gjxuexiao0 (16) 表15 sas.gnsczzgc (17) 表16 sas.gnsczzs (18) 表17 sas.gr08n01 (19) 表18 sas.iris (20) 表19 sas.jmcxck0 (21) 表20 sas.jmjt052 (22) 表21 sas.jmjt053 (23) 表22 sas.jmjt054 (24) 表23 sas.jmjt055 (25) 表24 sas.jmxfsps (26) 表25 sas.jmxfspzs0 (27) 表26 sas.jmxfzss (28) 表27 sas.jmxfzst (29) 表28 sas.kscj2 (30) 表29 sas.modeclu4 (31) 表30 sas.ms8d1 (32) 表31 sas.nlmyzzs (33) 表32 sas.plates (34) 表33 sas.poverty (35) 表34 sas.rjnycpcl0 (36) 表35 sas.rjsrs (37) 表36 sas.sanmao (38) 表37 sas.sczz1 (39) 表38 sas.sczz06s (40) 表39 sas.sczz (41) 表40 sas.sczzgc1 (42)
第三课SAS数据集
第三课SAS数据集 一.SAS数据集的结构 SAS数据集是关系型的,它通常分为两部分: ●描述部分——包含了一些关于数据属性的信息 ●数据部分——包括数据值 SAS的数据值被安排在一个矩阵式的表状结构中,见图3-1所示。 ●表的列称之为变量(Variable),变量类似于其它文件类型的域或字段(Field); ●表的行称之为观察(Observation),观察相当于记录(Record)。 变量1 变量2 变量3 变量4 Name Test1 Test2 Test3 观察1 Xiaoer 90 86 88 观察2 Zhangsan 100 98 89 观察3 Lisi 79 76 70 观察4 Wangwu 68 71 64 观察5 Zhaoliu 100 89 99 图3-1 一个SAS数据文件 二.SAS数据集形式 SAS系统中共有两种类型的数据集: ●SAS 数据文件(SAS data files) ●SAS 数据视窗(SAS data views) SAS 数据文件不仅包括描述部分,而且包括数据部分。SAS 数据视窗只有描述部分,没有数据部分,只包含了与其它数据文件或者其它软件数据的映射关系,能使SAS的所有过程可访问到,实际上并不包含SAS 数据视窗内的数据值。 自始自终,在SAS语言中,“SAS数据集”与这二种形式中之一有关。在下面的例子中,PRINT过程用相同方法处理数据集aaa.abc,而忽略它的形式: PROC PRINT DATA=aaa.abc 三.SAS数据集的名字 SAS数据集名字包括三个部分,格式如下: Libref.data-set-name.membertype ●Libref(库标记)──这是SAS数据库的逻辑名字 ●data-set-name(数据集名字)──这是SAS数据集的名字 ●membertype(成员类型)──SAS数据集名字的这一部分用户使用时不必给出。 SAS 数据文件的成员类型是DATA;SAS 数据视窗的成员类型是VIEW 例如上面例子中的aaa.abc这个SAS数据集名字,aaa是库标记,abc是数据集名字,成
SAS数据集操作
目录 SAS 数据集操作 2014年03月28日 1.合并 2.删选,修改 3.查询 PPT 模板下载:https://www.360docs.net/doc/d76049180.html,/moban/
1 数据集的合并: (1)纵向合并:添加或合并样本变量 (2)横向合并:添加或合并(指标)变量
(1)数据集纵向合并:可以添加或合并样本变量 形式: data 合并后数据名; set 数据名1 数据名2 ; run; 例:将名为male、female 的两个数据集纵向合并成一个名为total 的数据集data total; set male female; proc print data=total; run; /*若male 与female 变量名不同则total 的变量名为两者之并,数据值以缺失值形式出现*/
(2)数据集横向合并:添加或合并(指标)变量 形式: data 合并后数据名; merge 数据名1 数据名2 ; by 共有变量名; run; 例:将名为dataONE 和data TWO 的两个数据集按共有变量pid 横向合并成数据集total2 (以下程序以data total2 名义保存)
data one; input pid sex$ age; cards; 101 m 54 105 w 36 102 m 43 104 w 45 ; data two; input pid weight height; cards; 105 54 163 102 63 174 103 57 173 104 45 156 ;
proc sort data=one;/*必须先对共有变量(本例中pid)分别排序才能横向合并*/ by pid; /* 排序语句proc sort data=被排序变量所在数据集名; by 被排序变量名;排序时默认数值由小到大字母由先而后*/ proc sort data=two; /*必须先对共有变量(本例中pid)分别排序才能横向合并*/ by pid; /*以下为合并过程*/ data total2; /*合并后数据名*/ merge one two; /*形式: merge 被合并数据集名1 被合并数据集名2; */ 注意输出结果中的缺省值,输入数据时若有缺省分量一定要以. 表示,否则SAS 会将该行数据自行删除*/ by pid; proc print data=total2; run;
sas数据集例题
试 验目的本实验主要练习数据集的导入和导出,建立、删除和保留变量、数据集的合并与拆分,排序、转置等操作。 掌握从已有数据文件建立数据集以及在已有数据集的基础上建立、删除变量; 掌握sas的程序控制的三种基本控制流; 掌握数据数据修正、排序、转置和标准化的过程或语句。 实验内容完成下列各题 一.某班12 名学生3 门功课成绩如下: 用sas的data步建立数据集。 筛选出有一科不及格的学生。 计算每人平均成绩,并按五级制评定综合成绩。 二.教材P141的6,7题。 三.data2_1.sav和data2_2.sav是一组被试(编号1-47)分别做两个量表数据,请把它们合并起来,保存为“量表.sav”,data2_3.sav是另一组被试(编号48-65)做成量表的数据,请把这些数据加到“量表.sav”里,并保存。 1)a1、a5、a30、a43、a49和b2、b6、b19为反向计分,把他们转化为正向。 2)data2_1.sav和data2_2.sav是一组被试(编号1-47)分别做两个量表的 数据,请把它们合并起来,保存为“量表.sav”,data2_3.sa v是另一组被试(编号48-65)做成量表的数据,请把这些数据加到“量表.sav”里,并保存。 3)a1到a25为a量表的第一个维度,a26到a50为第二个维度,b量表只有 一个维度,分别求出三个维度的总分(即所有项目得分相加)。 4)把b量表总分按照从小到大的顺序排列,设置另外一个变量(group),b 量表得分前十名赋值“1”,标签为“高分组”,后十名赋值“3”,标签为“低分组”,其它赋值“2”,标签为“中间组”。 5)各维度总分中如果有缺失,请用该维度的平均分进行替换。
SAS介绍和SAS数据集
SAS系统
SAS系统介绍
SAS系统是用于数据分析与决策支持的大
邓 伟 2013.11 wdeng@https://www.360docs.net/doc/d76049180.html,
型集成式模块化软件包。 其早期的名称Statistical Analysis Software 统计分析软件→大型集成应用系统 商业智能(BI)和分析挖掘(DM)
1
2
SAS系统是用于决策支持 的大型集成信息系统
SAS系统主要完成以数据为中心的四大任务: 数据访问 数据管理 数据呈现 数据分析
SAS历史
SAS成立于1976年,是全球最大的私人软件公司(预 打包软件),全球十大独立软件供应商之一 1966年 美国北卡州立大学 Jim Barr and Jim
Goodnight
1972年 推出SAS72供大学使用 1976年 创立公司
SAS软件研究所(SAS Institute Inc.) 举办第一个SUGI (SAS Users Group International) 会议 Base SAS 软件上市 与IBM建立合作伙伴关系
3 4
SAS历史
1985 第一个PC DOS SAS System 版本(Base SAS 和SAS/RTERM 软件)取得成功 1986面向个人计算机的SAS/IML 和SAS/STAT 软 件上市 1992
决策支持功能扩展到以下领域:指导性数据分析、临床 试验分析和报告、财务电子表格和英语查询 SAS第一个垂直市场软件:制药行业的临床审查系统上 市
SAS历史
1995 SAS 成为真正的端到端数据仓库解决 方案唯一的供应商,推出Rapid Warehousing Program 1999 美国食品和药品管理局选择SAS开发的 技术,作为接收和归档电子数据的标准
5
6
1
SAS EG数据统计分析题库
《SAS EG数据统计分析题库》 单选题 1、分析教师和会计师之间收入的差异,选择什么分析方法最合适? A、卡方分析 B、方差分析 C、两样本T检验 D、相关系数 答案C 2、分析购买不同产品的频次时,使用以下哪个任务? A、列表数据 B、汇总表 C、汇总统计量 D、单因子频数 答案D 3、以下哪个语句可以将字符型数值date(示例:“2001-02-19”)转换为数值类型? A、INPUT(date,YYMMDD10.) B、PUT(date,YYMMDD10) C、INPUT(date,YYMMDD10.) D、PUT(date,YYMMDD10)
答案A 4、来自于总体的样本最主要的属性是什么? A、随机 B、有代表性 C、正态分布 D、连续分布 答案B 5、D—W统计量用于检验? A、异方差 B、自相关 C、解释变量线性相关 D、扰动项不服从正态分布 答案B 6、什么统计量用于检验解释变量之间线性相关 A、标准化的残差 B、D—W统计量
C、Cook's D D、膨胀系数 答案D 7、连续变量右偏的情况下,中位数在均值的? A、左边 B、右边 C、相等 D、无法判断 答案A 8、代表变量离散程度的指标是? A、均值 B、标准差 C、最大值 D、中位数 答案B 9、解释变量是多分类变量,被解释变量是连续变量,使用什么分析方法?
A、卡方分析 B、方差分析 C、两样本T检验 D、相关系数 答案B 10、如果在方差分析中有20个观察值,你要计算残差。那么以下哪个值会是残差和? A、-20 B、0 C、400 D、从已知信息中无法推断 答案B 11、要进行一项研究,比较男女月均信用卡支出。可能使用哪一种统计方法? A、单样本T检验 B、双样本T检验 C、单因素方差分析 D、双因素方差分析 答案、C
SAS例题及程序输出
地质勘探中,在A,B,C 三个地区采集了一些岩石,测量其部分化学成分,其 数据见表3.5。假定这三个地区掩饰的成分遵从()3,(1,2,3)(0.05)i i N i μα∑==() 。 (1)检验不全01231123:=:,,H H ∑=∑∑∑∑∑;不全等; (2)检验(1)(2)(1)(2)01::H H μμμμ=≠;; (3)检验(1)(2)(3)()()01::,i j H H i j μμμμμ==≠≠;存在使。 表3.5 岩石部分化学成分数据 解: (1)检验假设
01231123:=:,,H H ∑=∑∑∑∑∑;不全等, 在H 0成立时,取近似检验统计量为2()f χ 统计量: ()()*4=121ln d M d ξλ-=--。 由样本值计算三个总体的样本协方差阵: 1(1)(1)(1)(1) 11()() 11111110.243081=0.642649.2855240.014060.020520.00452n S A X X X X n n ααα='==----?? ?- ? ??? ∑()(), 1(2)(2)(2)(2) 23()() 12211116.30461= 4.756710.672230.05570.23880.006675n S A X X X X n n ααα='==----?? ?- ? ?-??∑()(), 1(3)(3)(3)(3) 33()()1 3311112.97141=0.63370.342140.00010.002950.001875n S A X X X X n n ααα='==----?? ? ? ?-?? ∑()()。 进一步计算可得 1231 0.0018318,0.0000942,0.0011851,0.0000417,10 S A S S S = ==== 24.52397,0.433333,12,M d f === (1)=13.896916d M ξ=-。 对给定显著性水平=0.05α,利用软件SAS9.3进行检验时,首先计算p 值: p =P {ξ≥13.896916}=0.3073394。 因为p 值=0.3073394>0.05,故接收0H ,即认为方差阵之间无显著性差异。 proc iml ; n1=5;n2=4;n3=4; n=n1+n2+n3;k=3;p=3; x1={47.22 5.06 0.1, 47.45 4.35 0.15,
sas习题大全带程序编码资料
P265 1 今有某种型号的电池三批,它们分别是A、B、C三个工厂所生产的,为评比其质量,各随机抽取5只电池为样品,经试验得其寿命(h)如下: A B C 4042 4845 38 2628 3432 30 39 50 40 50 43 试在显著性水平0.05下检验电池的平均寿命有无显著的差异,若差异是显著的, 试求均差μ A -μ B ,μ A -μ C 和μ B -μ C 的置信水平为95%的置信区间。 代码: data l1; do b=1to5; do a=1to3; input x@@; output; end; end; cards; 40 26 39 42 28 50 48 34 40 45 32 50 38 30 43 proc anova; class a; model x=a; run; 结果输出: The SAS System 19:15 Friday, April 9, 2012 5 The ANOVA Procedure Class Level Information Class Levels Values a 3 1 2 3 Number of observations 15 The SAS System 19:15 Friday, April 9, 2012 6 The ANOVA Procedure Dependent Variable: x
Sum of Source DF Squares Mean Square F Value Pr > F Model 2 615.6000000 307.8000000 17.07 0.0003 Error 12 216.4000000 18.0333333 Corrected Total 14 832.0000000 R-Square Coeff Var Root MSE x Mean 0.739904 10.88863 4.246567 39.00000 Source DF Anova SS Mean Square F Value Pr > F a 2 615.6000000 307.8000000 17.07 0.0003 结论:结论:在显著水平为0.05下0.0003<0.05,所以各个总体均值间有显著差异。 代码: data l1;p265 1 (ua-ub) input lei n; do rep= 1to n; input x@@; output;end; cards; 1 5 40 42 48 45 38 2 5 26 28 34 32 30 ; proc ttest; class lei; var x; run;
SAS系统和数据分析SAS数据集的编辑
第十一课SAS数据集的编辑 通常从外部数据源转换得到SAS数据集后,并不是所有的数据集都满足统计数据要求,可立即调用统计过程进行统计分析。需要对数据集进行满足统计数据要求的编辑或生成新的数据集。 一、增加数据集一个新变量 SAS系统可通过赋值语句把包含操作符的表达式赋值给数据集所要创建的新变量。SAS 的表达式中还可以包含SAS函数,如一些常用的SAS函数见下表: 函数分类常用函数功能 数学运算函数ABS( ) 取绝对值 SQRT( ) 求平方根 INT( ) 取整数部分 EXP( ) 计数e的次幂 LOG( ) 求e为底的自然对数SIN( ) 计算正弦 LAGn( ) 求给定变量滞后为n的值 统计计算函数MAX( ) 求最大值 MIN( ) 求最小值 MEAN( ) 求平均值 SUM( ) 求和 DIFn( ) 求给定变量X的第n阶差STD( ) 求标准差 PROBNORM( ) 标准正态分布函数 日期时间处理函数DA TE( )/TODAY()取当日的日期值DAY( ) 计算某月的那一日HOUR( ) 计算小时 TIME( ) 取当日的时间YEAR( ) 取年值 字符函数INDEX( ) 搜寻字符串的位置LEFT( ) 字符串表达式左对齐SUBSTR( ) 抽取子字符串TRIM( ) 移走尾部空格LENGTH( ) 给出字符变量的长度UPCASE( ) 转换为大写 财政金融函数COMPOUND( ) 计算复利 IRR( ) 计算内部赢利率 NPV( ) 计算净现值 SA VING( ) 计算定期储蓄的本金和利息
例如,有一个学生成绩数据集中的数据来源写在CARDS语句后,但我们还需产生新的变量平均分和总分,数据步的程序如下: Data class2 ; Input id test1-test5 ; average=mean(test1,test2,test3,test4,test5); total=test1+test2+test3+test4+test5; Cards ; 980801 100 100 100 100 100 980802 90 100 90 100 90 980803 81 82 83 84 85 Proc print data=class2 ; Run ; 在OUTPUT窗口中显示的运行结果见图11.1所示。 图11.1 用赋值表达式创建数据集的新变量 二、选择数据集的变量和观测 数据库的三种基本操作是选择、投影和连接,如果我们把数据库看成是一张表格,选择和投影操作相当于从一张大的数据库表格中挑选所需的行和列形成一张小的数据库表格。连接操作相当于把两张或两张以上的数据库表格按某种规则合并成一张数据库表格。原始数据库表格可以是外部数据文件(用INFILE语句输入),或在作业流中(用CARDS语句输入),或来自其他SAS数据集(用SET语句输入)。 1.选择变量(即选择列) 使用DATA语句的DROP=和KEEP=选项可以控制从原始数据库中读出的变量是否被写入将要创建的数据集。
SAS将proc步的输出导出为数据集
SAS将proc步的输出导出为数据集 sas的各种proc步,例如corr univariate,运行完之后都会在结果(result)与输出(output)中显示,下面的方法是将proc步的输出变成sas数据集。 需要用到ods语句 ods listing close;该语句的作用是使得proc步的输出不在output中显示 ods results off;该语句的作用是使得proc步的输出不在results中显示 proc univariate data=sashelp.class; var age; run; ods results on; proc步结束后重新打开results和listing ods listing;
ods output语句的功能是将输出窗口output的输出对象转化成sas数据集,使用如下: ods listing close; ods results off; ods output basicmeasure=bm; proc univariate data=sashelp.class; var age; run; ods results on; ods listing; 该程序的作用是将proc过程的基本测度对象basicmeasure 输出到数据集bm中。 可以通过ods trace语句知道输出管道的对象: ods listing close; ods results off;
ods trace on; proc univariate data=sashelp.class; var age; run; ods trace off; ods results on; ods listing;
SAS学习系列10. 合并数据集
10.合并数据集 一、用SET 语句拼接合并数据集 用SET语句可以把两个数据集拼接合并在一起,适用于两个数据集具有相同的变量。 基本形式为: data 新数据集名; set 旧数据集1 旧数据集2; 注:(1)按原来顺序合并成新数据集(数据集1在上,2在下); (2)若一个数据集包含了另一个数据集没有的变量,那么合并后,该变量下将会出现缺省值。 例1路径“C:\MyRawData\”下有关于娱乐公园南北门游客的数据South.dat 和North.dat,都包括变量Entrance、PassNumber、PartySize、Age,后者多了一列Lot(停车): 先分别读入数据存为数据集再合并成一个新数据集,并创建了新变量,AmountPaid.
代码: data southentrance; infile'c:\MyRawData\South.dat'; input Entrance $ PassNumber PartySize Age; proc print data = southentrance; title'South Entrance Data'; run; data northentrance; infile'c:\MyRawData\North.dat'; input Entrance $ PassNumber PartySize Age Lot; proc print data = northentrance; title'North Entrance Data'; run; data bothentrance; set southentrance northentrance; if Age =.then AmountPaid =.; else if Age < 3then AmountPaid = 0; else if Age < 65then AmountPaid = 35; else AmountPaid = 27; run; proc print data = bothentrance; title'Both Entrances'; run; 运行结果:
SAS学习系列05. 数据步创建数据集的过程
05. 数据步创建数据集的过程 数据步创建数据集的过程分为两个阶段: 1. 编译阶段:扫描语法错误,生成数据集的“描述信息”; 2. 执行阶段:逐条记录地读入并处理输入数据(循环执行若干次数据步)。 (一)编译阶段 将数据从外部文件读入“程序数据向量”(Program Data Vector)。 一、在输入缓冲区(内存)创建“程序数据向量” 注意:是读入外部数据时创建,而不是读入SAS数据集时创建。例1下面的数据步代码: infile'D:\我的文档\My SAS Files\9.3\invent.dat'; input Item $ 1-13 IDnum $ 15-19 InStock 21-22 BackOrd 24-25; Total=instock+backord; run; 将创建如下的“程序数据向量”:包括 _N_:记录数据步执行的次数,读入一条记录则+1; _ERROR_:用来指示错误,默认是0,遇到错误则变为1; 注意:_N_和_ERROR_是该处理过程自动生成的,将来也不会出现
在数据集的观测值中。 Item、IDnum、InStock、BackOrd:数据集自身的变量,其变量属性(长度、类型等)在第一次读到数据时确定; Total:数据步中赋值语句生成的变量。 二、检查语法错误 (1)关键词缺少或拼写错误; (2)无效的变量名; (3)标点符号缺失或拼写错误; (4)无效的可选参数。 三、生成数据集的“描述信息” 遇到数据步的run;语句时生成,包括: (1)数据集的名称; (2)数据集包含变量的个数; (3)数据集各变量的变量名和属性。 注意:此时,“程序数据向量”中还没有内容,数据集中也还没有观测值,观测值将在执行阶段从“程序数据向量”中逐条读取。 (二)执行阶段 逐条记录地从“程序数据向量”读入并处理输入数据(循环执行若干次数据步)。
SAS软件建立与管理SAS数据集
建立与管理SAS数据集 ●用窗口建立SAS数据集(VT 、INSIGHT) ●从SAS系统的文件菜单里使用IMPORT与EXPORT进行SAS数据集 与流行的数据库进行转换 ●用DATA步语句建立SAS数据集 1.DATA语句及其选项的使用(知识点) 1.1字符变量的录入与数值型变量在录入时的区别; 1.2日期型变量录入的规则; 1.3类似会计里的习惯表达方式的了解与掌握; 1.4掌握INFORMAT与FORMAT语句的使用; 1.5掌握LABEL语句的使用; 1.6掌握TITLE与FOOTNOTE语句的使用; 1.7如何除去观测号; 1.8如何定义列格式录入; 1.9缺失值的处理; 2.INPUT语句及其选项的使用(知识点) 2.1列格式的读取(数据中有空格); 2.2从其他文本文件中读取数据(INFILE语句的使用); 如:INFILE ‘E:\DATA-HW\DCW.TXT’;
?如何选择读入的数据(FIRSTOBS与OBS) ?INFILE 语句要位于INPUT语句前 2.3自由录入格式; 2.4 LENGTH语句的使用。如 LENGTH NAME $12; 如果变量值太长时使用。 2.5如何产生一个新的变量;并且给新变量赋值。 3.PRINT语句的使用 PROC PRINT DATA=SAS-data-set
金融数据库——SAS数据处理应用题
SAS数据处理应用题_2005 以下练习题选自《SAS数据处理综合练习》,解决这些题目原则上需要学完《SAS编程技术与金融数据》前18章内容。 1. 创建一包含10000个变量(X1-X10000),100个观测值的SAS数据集。分别用DATA 步,DA TA步数组语句和IML过程实现。 2. 创建包含日期变量DA TE的SAS数据集,日期值从1900年1月1日到2000年1月1日。 3. 多种方法创建包含变量X的10000个观测值的SAS数据集。 4. 利用随机数函数RANUNI对某数据集设计返回抽样方案? 5. 利用随机数函数RANUNI对某数据集设计不返回抽样方案? 6. 数据集A中日期变量DATE包含有缺失值,创建包含日期变量DATE的数据集B,并填充开始到结束日之间的所有日期值。 7. 创建组标识变量GROUP,将数据集A中的观测等分为10组,观测值不能整除10时,前余数组各多加一个观测值。 8. 数据集A有一个变量n,5个观测值1,2,3,4,5。数据A1由下面程序2产生,同样有一个变量n,5个观测值1,2,3,4,5。试分析下面两段程序中,PUT语句在Log窗口输出结果的差异,为什么? 程序1:Data a; Set a; Put n=; Run; 程序2: data a1; do n=1 to 5; output; end; put n=; run; 9. 假设数据集A中的变量logdate为如下形式的字符格式:1998-12-2 1999-8-6 1999-8-10 将其转换为日期格式变量date。 如果字符格式的数据为: 19981202 19990806
二、创建SAS数据集(学生)
二、创建SAS数据集 本课内容: 1.用编写SAS程序的方法建立数据集 2.用“菜单”工具导入SAS外部环境建立的数据(.dbf和excel ) 3.非编程方式建立SAS数据集 前面说过,SAS语言是一种专用的数据管理、分析语言,它提供了很强的数据操作能力。这些能力表现在它可以轻易地读入任意复杂格式的输入数据,并可以对输入的数据进行计算、子集选择、更新、合并、拆分等操作。另外,SAS 系统还提供了用来访问其它数据库系统的接口,访问各种微机用数据库文件(如dBase、FoxPro、Excel )的接口及向导等。但是对于SAS系统来说,无论何种类型的数据文件,都需要转换为SAS数据集的形式才能被系统使用,只有SAS数据集才能被系统识别和使用。用SAS 语言直接或间接产生数据集的方式很多,本课程只介绍以下几种常用的方法。 一、 用编写SAS程序的方法建立数据集 1.用INPUT 语句和CARDS语句在程序中输入数据 在数据步中输入原始数据,要使用INPUT 语句来指定输入的变量和格式,用CARDS 语句输入数据的值,数据输入完毕后要以一个分号结束,分号单独占一行(从CARDS到分号之间的行我们称为数据块)。 ①INPUT 语句的自由格式: 以每一个列作为每个观测的变量(系统默认),变量之间用空格分开。变量如果是字符型的需要在变量名后面加一个$符号。 产生数据集常用SAS语句: DATA [数据集名]; INPUT [变量名]; CARDS; 数据块 ; RUN
例2.1: data c9901; input code name$ sex$ math chinese; cards; 1 李明 男 9 2 98 2 张红艺 女 89 106 3 王思明 男 86 90 4 张聪 男 98 109 5 刘颍 女 80 110 ; proc print;run; 以上程序运行后生成的数据集有五个观测,五个变量,每行数据的各变量之间用空格分隔。为输入这些数据,INPUT 语句中依次列出了五个变量名,并在字符型变量NAME 和SEX 后加了$符。程序提交运行后生成一个名为c9901的SAS临时数据集。 如果要将生成的数据集放入永久逻辑库,可以使用SASUSER,也可使用预先设定的自定义逻辑库名,然后修改data语句中的数据集名,将其改为两水平命名,把数据集保存到指定的永久库中。 注意:在SAS工作中一旦要与逻辑库发生联系,无论是放置数据集还是从逻辑库中调用某个已经存在的数据集,数据集的名称要采用两水平命名(即逻辑库名+数据集名称)。例如:现在要将c9901放到sasuser库中,程序的data语句要写:data sasuser.c9901;运行后 c9901放入sasuser中,如果要将建立的数据集放入自定义永久库中时,逻辑库名替换为自定义符号。 使用自由格式输入数据有一些限制条件: 1)数据块中的每行为一个观测,各数据值之间用空格分隔; 2)无论是字符型还是数值型缺失数据都必须用小数点表示; 3)字符型数据长度不能超过8个字符,中间不允许有空白; 有特殊格式的数据需要用有格式输入,即在变量名后加格式名。其中最常见的是用来输入日期。数据中的日期输入方法经常是多种多样的,比如1998 年10 月9 日可以写成“1998-10-9”,“19981009”,“9/10/98”等等,为读入这样的日期数据就需要为它指定特殊的日期输入格式。另外,日期数据在SAS 中是按数值存储的,所以如果要显示日期值,也需要为它指定特殊的日期输出格式。
SAS编程题目 基础
SAS编程题目基础 设某班的学生分为三组,一次考试成绩如下(数学满分100,语文满分120) 姓名性别数学语文组别 李明男92 98 1 张红艺女89 106 1 王思明男86 90 1 姓名性别数学语文组别 张聪男95 92 2 刘颖女98 101 2 高红女91 92 2 姓名性别数学语文组别 赵强男93 99 3 李云芳女96 102 3 周山男88 98 3 (1)请把上述三个数据表输入为SAS数据集chengji1,chengji2,chengji3. (2)请合并(1)中的三个数据集得到整个班学生的成绩chengji0. (3)计算每个学生两门课的平均成绩(百分制),并按此由高到低排名(得到新数据集chengji)。 (4)找出该班数学成绩>90分的学生(得到新数据集math90)。 (5)在数据集chengji0中,找出该班每组平均成绩最低的人,得到新数据集last,并且要求数据集last中只包含学生姓名、组别和平均成绩。 (6)计算该班学生的数学总分,以及数学平均分。 (7)计算该班每个学生的数学成绩与该班数学平均分之差。 (8)随机抽三名学生,并创建包含这三名学生姓名、数学成绩、语文成绩的宏文本。(9)画出该班学生数学成绩、语文成绩关系的二维图。 (10)用宏编写程序:在包含学生信息的数据集x中,找出数学成绩大于y且小于z的学生。 (11)调用宏,在随机抽出的3名学生中找出数学成绩大于80小于90的学生。 (12)随机抽n名学生,并寻找其中平均成绩第一和最后一名的学生,同时将每次抽取、寻找的结果放在同一数据集中。 (13)随机抽取3名,4名,...,8名学生,即共抽取6次,并计算每次抽取后学生的平均成绩的标准差,同时将学生个数与标准差作图,以观察标准差有无随学生个数增加而减少的趋势。
SAS系统和数据分析SAS数据集
第三课SAS数据集 一、SAS数据集的结构 SAS数据集是关系型的,它通常分为两部分: ●描述部分——包含了一些关于数据属性的信息 ●数据部分——包括数据值 SAS的数据值被安排在一个矩阵式的表状结构中,如图3-1所示。 ●表的列称之为变量(Variable),变量类似于其他文件类型的域或字段(Field) ●表的行称之为观察(Observation),观察相当于记录(Record) 变量1 变量2 变量3 变量4 Name Test1 Test2 Test3 观察1 Xiaoer 90 86 88 观察2 Zhangsan 100 98 89 观察3 Lisi 79 76 70 观察4 Wangwu 68 71 64 观察5 Zhaoliu 100 89 99 图3.1 一个SAS数据文件 二、SAS数据集形式 SAS系统中共有两种类型的数据集: ●SAS 数据文件(SAS data files) ●SAS 数据视窗(SAS data views) SAS 数据文件不仅包括描述部分,而且包括数据部分。SAS 数据视窗只有描述部分,没有数据部分,只包含了与其他数据文件或者其他软件数据的映射关系,能使SAS的所有过程可访问到,实际上并不包含SAS 数据视窗内的数据值。 自始至终,在SAS语言中,“SAS数据集”与这两种形式中之一有关。在下面的例子中,PRINT过程用相同方法处理数据集aaa.abc,而忽略它的形式: PROC PRINT DATA=aaa.abc 三、SAS数据集的名字 SAS数据集名字包括三个部分,格式如下: Libref.data-set-name.membertype ●Libref(库标记)──这是SAS数据库的逻辑名字 ●data-set-name(数据集名字)──这是SAS数据集的名字 ●membertype(成员类型)──SAS数据集名字的这一部分用户使用时不必给出。 SAS 数据文件的成员类型是DATA;SAS数据视窗的成员类型是VIEW
第4章 用编程读入数据建立SAS数据集
第4章用编程读入数据建立sas数据集 §4.1 sas编程基本概念 §4.1 概述 sas语言程序由数据步和过程步组成。 sas语言的基本单位是语句,每个sas语句一般由一个关键字(如data,proc,input,cards,by)开头,包含sas名字、特殊字符、运算符等,以分号结束。 sas关键字是用于sas语句开头的特殊单词,sas语句除了赋值、累加、注释、空语句以外都以关键字开头。 sas名字在sas程序中标识各种sas成分,如变量、数据集、数据库,等等。 数据步和过程步 数据步用来生成数据集(从数据片中或外部数据文件中读取数据)、计算整理数据等。 语法: data 数据集名; .....; run; 过程步:面向SAS数据集,完成某个特定的计算、分析和呈现功能 语法: proc 过程名;
......; run; sas程序的书写规则 sas程序是由一至多个数据步骤(data step)和过程步(Procedure Step)互相交叉组合而形成。 根据各个数据步骤的属性或过程步的功能,来实现sas 数据文件的建立、进行统计分析等。 sas系统的编译方式是以数据步或过程步为一个区块来编译的,语法编译无误便开始执行该数据步或过程步,执行完整一个数据步或过程步区块后便继续处理下一个数据步或过程步。一个区块接一个区块地将所有程序代码编译及执行完后,便完成了该程序的执行。sas程序代码提交出去,便已将程序交由sas系统去完成。 用户必须确定sas系统在log窗口中是否有显示错误的程序代码,分析数据的属性是否正确。 sas的程序代码是自由格式的程序代码,每个语句由关键词开始,以“;”作为一个程序语法的结束; 一行可以含多个程序语句; 一个程序语句也可以分成多行,但必须以空格(只要有一个空格的地方,就可用任意多个空格来替代)为分隔。注:在命令框中键入num即可显示或取消行数。 指定逻辑库名与逻辑文件名
sas编程习题与实例应用
一、数据集整理与SAS基本编程 1、试用产生标准正态分布函数的随机函数normal(seed)产生均值为170,方差为64的正态随机数100个,并计算其常规统计量(均值、标准差、变异系数、偏度和峰度)。 data date1; mu=170; sigma=8; do i=1to100; y=mu+sigma*RANNOR(0); output ; end; run; proc means data=data1 mean std cv stderr skewness; var y; output out=result; run; 2、设已知数据集class中有5个变量:name, sex, age, height 和weight,请编写程序新建数据集class1,其中class1只包含name, sex, age三个变量,且把name重命名为id。 data class; input name$ sex$ age heigh weigh; cards; 小明男 15 160 50 ; run; data class1;
set class; keep name sex age; rename name=id ; run ; proc print data =class1; run ; 3、SAS 的逻辑库可分为永久库和临时库两种,请编写一段程序直接建立永久库sasuser 中的下例数据集,并按降序排序。 数据名tong :20 13 20 16 23 19 19 16 data Sasuser.tong; input x@@; cards ; 20 13 20 16 23 19 19 16 ; run ; proc sort data =Sasuser.tong; by descending x ; run ; proc print data =Sasuser.tong; run ; 4、设已知数据集data1和数据集data2 number province 1 Hebei 3 Zhejiang 5 Gansu 请编写程序串接data1和data2,且分组变量为number 。 data data1; input number province$; cards ; 1 Hebei 3 Zhejiang number city 2 Chengdu 4 Nanjing