Baseline Evaluations On The CAS-PEAL-R1 Face Database

Baseline Evaluations on the CAS-PEAL-R1
Face Database
Bo Cao1,2, Shiguang Shan1, Xiaohua Zhang1, Wen Gao1,2
1ICT-ISVISION Joint Research&Development Laboratory for Face Recognition, Chinese Academy of Sciences, P.O.Box 2704, Beijing, China, 100080
{bcao, sgshan, wgao}@https://www.360docs.net/doc/dd7298397.html,
2Graduate School of the Chinese Academy of Sciences
Abstract. In this paper, three baseline face recognition algorithms are evaluated
on the CAS-PEAL-R1 face database which is publicly released from a
large-scale Chinese face database: CAS-PEAL. The main objectives of the
baseline evaluations are to 1) elementarily assess the difficulty of the database
for face recognition algorithms, 2) provide an example evaluation protocol on
the database, and 3) identify the strengths and weakness of some popular
algorithms. Particular description of the datasets used in the evaluations and the
underlying philosophy are given. The three baseline algorithms evaluated are
Principle Components Analysis (PCA), a combined Principle Component
Analysis and Linear Discriminant Analysis (PCA+LDA), and PCA+LDA
algorithm based on Gabor features (G PCA+LDA). Four face image
preprocessing methods are also tested to emphasize the influences of the
preprocessing methods on the performances of face recognition algorithms.
1 Introduction
Automatic Face Recognition (AFR) has become one of the most active research areas in pattern recognition, computer vision and psychology and much progress has been made in the past few years [1], [2]. However, AFR remains a research area far from mature and its application is still limited in controllable environments. Therefore, evaluating and comparing the potential AFR technologies exhaustively and objectively to discover the real choke points and the valuable future research topics, and developing algorithms robust to variations in pose, expression, accessories, lighting, etc. are becoming more and more significant.
Aiming at these goals, large-scale and diverse face databases are obviously one of the basic requirements. Internationally, FERET [3] and FRVT [4] have pioneered both evaluation protocols and database construction. Especially, the FERET database is widely used in the research field. Besides the significant FERET tests, its success can also be contributed to 1) the public availability of the database, 2) the large number of subjects and diverse images, and 3) the explicit and categorized partition of the gallery sets and probe sets. Actually, these sets are used by many different researchers to compare their algorithms and test the performances under different image variations, such as illumination, facial expression and aging variations.
Despite its success in the evaluations of face recognition algorithms, the FERET database has limitations in the relatively simple and unsystematically controlled variations of face images for research purposes. Considering these limitations, we design and construct a large-scale Chinese face database (the CAS-PEAL face database), which is now partly made available as a released subset named by CAS-PEAL-R1.
In the paper, the recommended partition of the images in the CAS-PEAL-R1 database is proposed to compose the training set, the gallery set and the probe sets which can be used to evaluate a specific face recognition algorithm. Also, the evaluation results of three baseline face recognition algorithms combining different preprocessing methods are provided. This paper can be an informative complement to the documents on the database itself.
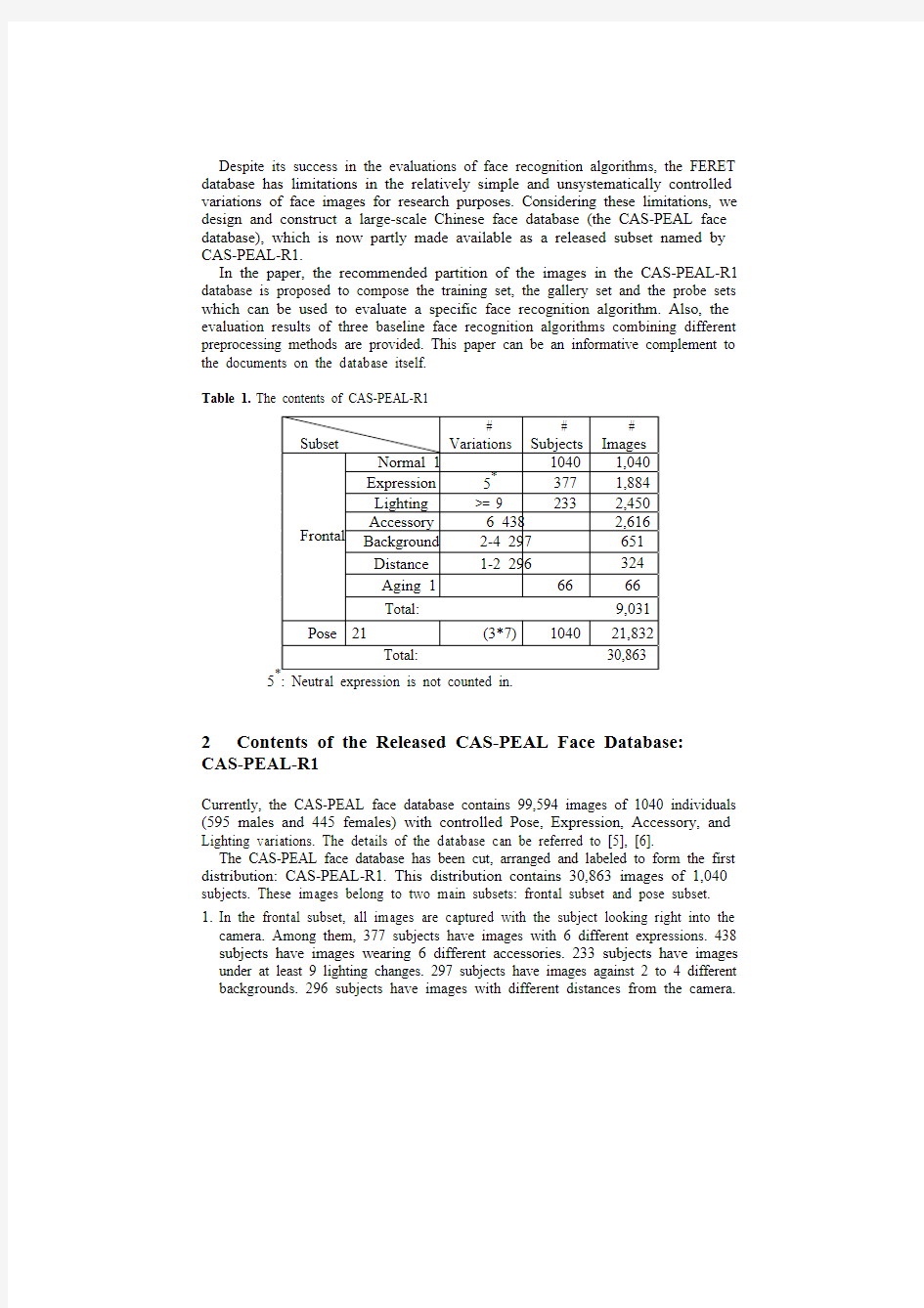
Table 1. The contents of CAS-PEAL-R1
5
2 Contents of the Released CAS-PEAL Face Database: CAS-PEAL-R1
Currently, the CAS-PEAL face database contains 99,594 images of 1040 individuals (595 males and 445 females) with controlled Pose, Expression, Accessory, and Lighting variations. The details of the database can be referred to [5], [6].
The CAS-PEAL face database has been cut, arranged and labeled to form the first distribution: CAS-PEAL-R1. This distribution contains 30,863 images of 1,040 subjects. These images belong to two main subsets: frontal subset and pose subset.
1.In the frontal subset, all images are captured with the subject looking right into the
camera. Among them, 377 subjects have images with 6 different expressions. 438 subjects have images wearing 6 different accessories. 233 subjects have images under at least 9 lighting changes. 297 subjects have images against 2 to 4 different backgrounds. 296 subjects have images with different distances from the camera.
Furthermore, 66 subjects have images recorded in two sessions at a 6-month interval.
2.In the pose subset, images of 1040 subjects across 21 different poses without any
other variations are included.
The content of CAS-PEAL-R1 is summarized in Table 1.
3 Datasets Used in the Evaluations
To compare different algorithms convincingly, two additional aspects should be considered: 1) the scale of the datasets which are used in the training and testing of a specific algorithm, 2) the statistical significance of the differences between different algorithms.
These two aspects are closely related. If the scale of the test sets is very small, the performance scores may be highly stochastic and become incomparable. Though some methods do exist to tackle this problem, such as the permutation methodology proposed in [7], a large-scale test set is still helpful. Also, the scale of the training set can influence the comparison of two algorithms. Martinez et al. [8] demonstrates that PCA can outperform LDA when the training data set is small, while LDA is normally considered superior than PCA in face recognition. Considering these problems, we compose the test sets and the training set from the CAS-PEAL-R1 database as large as possible. And the test sets are categorized to restrict the images in one probe set to undergo one main variation, which can be used to identify the strengths and weakness of a specific algorithm and to address the variations associated with changes in the probe sets.
In the evaluation, three kinds of datasets are composed from the CAS-PEAL-R1 database: a training set, a gallery set and several probe sets. Their definition and descriptions are as follows:
1.Training set. A training set is a collection of images which are used to generate a
generic representation of faces and/or to tune parameters of the classifier. In the evaluation, the training set contains 1,200 images (300 subjects randomly selected from the 1,040 subjects in the CAS-PEAL-R1 database and each subject contains four images randomly selected from the frontal subset of the CAS-PEAL-R1 database).
2.Gallery set. A gallery set is a collection of images of known individuals against
which testing images are matched. In the evaluation, the gallery set contains 1,040 images of 1,040 subjects (each subject has one image under normal condition).
Actually, the gallery set consists of all the normal images mentioned in Table 1. 3.Probe set. A probe set is a collection of probe images of unknown individuals to
be recognized. In the evaluation, nine probe sets are composed from the CAS-PEAL-R1 database. Among them, six probe sets correspond to the six subsets in the frontal subset: expression, lighting, accessory, background, distance and aging, as described in Table 1. The other three probe sets correspond to the images of subjects in the pose subset: looking upwards, looking right into the camera, and looking downwards. All the images that appear in the training set are excluded from these probe sets.
The datasets used in the evaluation are summarized in Table 2.
Table 2. The datasets used in the evaluation protocols
4 Baseline Face Recognition Algorithms
The three baseline algorithms evaluated are Principle Components Analysis (PCA)
[9], (also known as Eigenfaces), a combined Principle Component Analysis and Linear Discriminant Analysis (PCA+LDA, a variant of Fisherfaces) [10], and PCA+LDA algorithm based on Gabor features (G PCA+LDA). PCA and PCA+LDA based face recognition algorithms are both fundamental and well studied. Recently, 2D Gabor wavelets are extensively used for local feature representation and extraction, and demonstrate their success in face recognition [11], [12]. So, the PCA+LDA algorithm based on Gabor features is also used as a baseline algorithm to reflect this trend.
Instead of using the grey-scale images as the original features in the PCA and PCA+LDA algorithms, the representation of the original features in the third algorithm is based on the Gabor wavelet transform of the original images. Gabor wavelets are biologically motivated convolution kernels which are plane waves restricted by a Gaussian envelope function, and those kernels demonstrate spatial locality and orientation selectivity. In face recognition, Gabor wavelets exhibit robustness to moderate lighting changes, small deformations [11]. A family of Gabor wavelets (kernels, filters) can be defined as follows:
[]2/)2/||||||||(22,,2,222,||||)(σσσψ???=
e e e k z z k i z k v u v u v u v u r (1) where u i v v u e k k φ=,; v
f k v k max
= gives the frequency, and
),0[,8πφφπ∈=u u u gives the orientation, and ()y x z ,=.
u i v v u e k k φ=, (2) Probe sets (frontal) Datasets
Training set Gallery set expression lighting accessory background distance Aging Num. of
images
1,200 1,040 1,570 2,2432,285 553 275 66 Probe sets (pose)
looking upwards (PU)looking right into the camera (PM) looking downwards (PD) Num. of
images 4,998 4,993 4,998
where z k i v u e ,→
is the oscillatory wave function, whose real part and imaginary part are cosine function and sinusoid function respectively.
In this algorithm, we use the Gabor wavelets with the following parameters: five scales }4,3,2,1,0{∈v , eight orientations }7,6,5,4,3,2,1,0{∈u , πσ2=, π=max k , and 2=f . These parameters can be adjusted according to the size of the normalized faces.
At each image pixel, a set of convolution coefficients can be calculated using a family of Gabor kernels as defined by equation (1). The Gabor wavelet transform of an image is the collection of the coefficients of all the pixels. To reduce the dimensionality, the pixels are sampled and their convolution coefficients are concatenated to form the original features of the PCA+LDA algorithm. These concatenated coefficients are also called the augmented Gabor feature vector in [12]. In the experiments, the size of the normalized faces is 6464× and the pixels are sampled every four pixel both in row and in column, so the dimensionality of the features is 9000 (401515××). It should be noted that each feature is normalized to zero mean and unit variance to compensate for the scale variance of different Gabor kernels. 5 Preprocessing
In the evaluation, the preprocessing of the face images is divided into three steps: geometric normalization, masking, and illumination normalization. The first two steps are to provide features that are invariant to geometric transformations of the face images, such as the location, the rotation and the scale of the face in an image, and remove irrelevant information for the purpose of face recognition, such as the background and the hair of a subject. Illumination normalization is to decrease the variations of images of one face induced by lighting changes while still keeping distinguishing features, which is generally much more difficult than the first two steps. The details of the three steps are described as follows:
In geometric normalization step, each face image is scaled and rotated so that the eyes are positioned in line and the distance between them equals a predefined length. Then, the face image is cropped to include only the face region with little hair and background as Fig. 1(a) shows (the size of the cropped face image is 6464×). In masking step, a predefined mask is put on each cropped face image to further reduce the effect of different hair styles and backgrounds which are not the intrinsic characteristics, as Fig. 1(b) shows. Typically, the hair style of a specific subject and the background are constant in a face database, so better performance can be obtained with larger face regions. However, this bias should be avoided as much as possible by restricting the above cropping and masking procedures.
In illumination normalization step, four illumination normalization methods are evaluated: Histogram Equalization (HE), Gamma Intensity Correction (GIC), Region-based Histogram Equalization (RHE) and Region-based Gamma Intensity Correction (RGIC) [13], [14]. Fig. 2(b) illustrates the effect of these four methods on an example face image.
(a) (b)
Fig. 1. Example normalized face images in Step 1 and Step 2. (a) Geometrically normalized face images. (b) Masked face images
Original HE GIC RHE RGIC
(a) (b)
Fig. 2. Partition of face region and example images processed by different illumination normalization methods. (a) Partition of face region for region-based illumination normalization methods. (b) Images processed by different illumination normalization methods
Results
6 Evaluation
6.1 Frontal Face Images
The three baseline face recognition algorithms (PCA, PCA+LDA and G PCA+LDA) are trained on the training set, and evaluated on the six frontal probe sets as described in Section 3. Before training and testing, all the images are preprocessed as described in Section 5, using the four illumination normalization methods or no illumination normalization respectively. Table 3 and Fig. 3 show the performance of these algorithms on the frontal probe sets.
Table 3. Identification performance of the three baseline algorithms on the six frontal probe sets and the union (Total) set of these sets
Fig. 3. Identification performance on frontal images
6.2 Face Images under Different Poses
Two baseline face recognition algorithms (PCA+LDA and G PCA+LDA) are trained on the training set, and evaluated on the three pose probe sets as described in Section 3. Before training and testing, all the images are preprocessed as described in Section 5, using the RGIC illumination normalization method or no illumination normalization respectively. Table 4 and Fig. 4 show the performance of these algorithms on the pose probe sets.
7 Conclusion
In this paper, the evaluation results of three baseline algorithms with different preprocessing methods on the CAS-PEAL-R1 database are presented. Also, we describe the contents of the CAS-PEAL-R1 database which is a released version of the CAS-PEAL database, and the partition of the datasets used in the evaluation. From these results, the difficulty of the database, and the strengths and weakness of commonly used algorithms can be inferred, which may be some good references for the potential users of the database.
We believe that not only the characteristics of a face database itself, such as the scale, the diversity of the variations, the detailed ground-truth information and well organized structure, but also a standard evaluation protocol including the partition of training sets, gallery sets and probe sets, performance measures, etc. contributes to the success of the database. The paper sets an example of the evaluations on the CAS-PEAL-R1 database and provides baseline evaluation results to the research community.
Table 4. Identification performance of two baseline algorithms on the three pose probe sets and the union (Total) set of these sets
Fig. 4. Identification performance on images under poses
Acknowledgements
This research is partially sponsored by Natural Science Foundation of China under contract No.60332010, National Hi-Tech Program of China (No. 2001AA114190 and 2002AA118010), and ISVISION Technologies Co., Ltd.
References
1. W. Zhao, R. Chellappa, A. Rosenfeld and P. J. Phillips, “Face Recognition: A Literature
Survey,” Technical Report, CS-TR4167, University of Maryland, 2000. Revised 2002, CS-TR4167R.
2. R. Chellappa, C. Wilson, and S. Sirohey, “Human and Machine Recognition of Faces: A
Survey,” Proc. IEEE, vol. 83, no. 5, pp. 705-740, 1995.
3. P. J. Phillips, H. Moon, S. Rizvi, and P. Rauss, “The FERET Evaluation Methodology for
Face-Recognition Algorithms,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 22, No. 10, pp. 1090-1104, 2000.
4. P. J. Phillips, P. Grother, J. Ross, D. Blackburn, E. Tabassi, and M. Bone, “Face Recognition
Vendor Test 2002: Evaluation Report,” March 2003.
5. D. Zhou, X. Zhang, B. Liu, and W. Gao, “Introduction of the JDL Large-scale Facial
Database,” The 4th Chinese Conference on Biometrics Recognition (Sinobiometrics’03), pp.
118-121, 2003.
6. https://www.360docs.net/doc/dd7298397.html,/peal/index.html
7. J. R. Beveridge, K. She, B. A. Draper, and G. H. Givens, “A Nonparametric Statistical
Comparison of Principal Component and Linear Discriminant Subspaces for Face Recognition,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 535 – 542, December 2001.
8. A. M. Martinez and A. C. Kak, “PCA versus LDA,” IEEE Trans. Pattern Analysis and
Machine Intelligence, vol. 23, no. 2, pp. 228-233, 2001.
9. M. Turk and A. Pentland, “Face Recognition Using Eigenfaces,” IEEE Conference on
Computer Vision and Pattern Recognition, 1991.
10. P. N. Belhumeur, J. P. Hespanha, and D. J. Kriegman, “Eigenfaces vs. Fisherfaces:
Recognition using class specific linear projection,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 19, no. 7, pp. 711-720, 1997.
11. N. Kruger, C. Malsburg, L. Wiskott, and J. M. Fellous, “Face Recognition by Elastic Bunch
Graph Matching,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 19, no. 7, pp. 775-779, 1997.
12. C. Liu and H. Wechsler, “Gabor Feature Based Classification Using the Enhanced Fisher
Linear Dsicriminant Model for Face Recognition,” IEEE Trans. Image Processing, vol. 11, no. 4, pp. 467-476, 2002.
13. S. Shan, W. Gao, B. Cao, and D. Zhao, “Illumination Normalization for Robust Face
Recognition against Varying Lighting Conditions,” IEEE International Workshop on Analysis and Modeling of Faces and Gestures, pp. 157-164, Nice, France, 2003.
14. S. Shan, W. Gao, and L. Qing, “Generating Canonical Form Face Images for Illumination
Insensitive Face Recognition,” The 4th Chinese Conference on Biometrics Recognition (Sinobiometrics’03), pp. 29-35, 2003.
黄自艺术歌曲钢琴伴奏及艺术成就
【摘要】黄自先生是我国杰出的音乐家,他以艺术歌曲的创作最为代表。而黄自先生特别强调了钢琴伴奏对于艺术歌曲组成的重要性。本文是以黄自先生创作的具有爱国主义和人道主义的艺术歌曲《天伦歌》为研究对象,通过对作品分析,归纳钢琴伴奏的弹奏方法与特点,并总结黄自先生的艺术成就与贡献。 【关键词】艺术歌曲;和声;伴奏织体;弹奏技巧 一、黄自艺术歌曲《天伦歌》的分析 (一)《天伦歌》的人文及创作背景。黄自的艺术歌曲《天伦歌》是一首具有教育意义和人道主义精神的作品。同时,它也具有民族性的特点。这首作品是根据联华公司的影片《天伦》而创作的主题曲,也是我国近代音乐史上第一首为电影谱写的艺术歌曲。作品创作于我国政治动荡、经济不稳定的30年代,这个时期,这种文化思潮冲击着我国各个领域,连音乐艺术领域也未幸免――以《毛毛雨》为代表的黄色歌曲流传广泛,对人民大众,尤其是青少年的不良影响极其深刻,黄自为此担忧,创作了大量艺术修养和文化水平较高的艺术歌曲。《天伦歌》就是在这样的历史背景下创作的,作品以孤儿失去亲人的苦痛为起点,发展到人民的发愤图强,最后升华到博爱、奋起的民族志向,对青少年的爱国主义教育有着重要的影响。 (二)《天伦歌》曲式与和声。《天伦歌》是并列三部曲式,为a+b+c,最后扩充并达到全曲的高潮。作品中引子和coda所使用的音乐材料相同,前后呼应,合头合尾。这首艺术歌曲结构规整,乐句进行的较为清晰,所使用的节拍韵律符合歌词的特点,如三连音紧密连接,为突出歌词中号召的力量等。 和声上,充分体现了中西方作曲技法融合的创作特性。使用了很多七和弦。其中,一部分是西方的和声,一部分是将我国传统的五声调式中的五个音纵向的结合,构成五声性和弦。与前两首作品相比,《天伦歌》的民族性因素增强,这也与它本身的歌词内容和要弘扬的爱国主义精神相对应。 (三)《天伦歌》的伴奏织体分析。《天伦歌》的前奏使用了a段进唱的旋律发展而来的,具有五声调性特点,增添了民族性的色彩。在作品的第10小节转调入近关系调,调性的转换使歌曲增添抒情的情绪。这时的伴奏加强和弦力度,采用切分节奏,节拍重音突出,与a段形成强弱的明显对比,突出悲壮情绪。 c段的伴奏采用进行曲的风格,右手以和弦为主,表现铿锵有力的进行。右手为上行进行,把全曲推向最高潮。左手仍以柱式和弦为主,保持节奏稳定。在作品的扩展乐段,左手的节拍低音上行与右手的八度和弦与音程对应,推动音乐朝向宏伟、壮丽的方向进行。coda 处,与引子材料相同,首尾呼应。 二、《天伦歌》实践研究 《天伦歌》是具有很强民族性因素的作品。所谓民族性,体现在所使用的五声性和声、传统歌词韵律以及歌曲段落发展等方面上。 作品的整个发展过程可以用伤感――悲壮――兴奋――宏达四个过程来表述。在钢琴伴奏弹奏的时候,要以演唱者的歌唱状态为中心,选择合适的伴奏音量、音色和音质来配合,做到对演唱者的演唱同步,并起到连接、补充、修饰等辅助作用。 作品分为三段,即a+b+c+扩充段落。第一段以五声音阶的进行为主,表现儿童失去父母的悲伤和痛苦,前奏进入时要弹奏的使用稍凄楚的音色,左手低音重复进行,在弹奏完第一个低音后,要迅速的找到下一个跨音区的音符;右手弹奏的要有棱角,在前奏结束的时候第四小节的t方向的延音处,要给演唱者留有准备。演唱者进入后,左手整体的踏板使用的要连贯。随着作品发展,伴奏与旋律声部出现轮唱的形式,要弹奏的流动性强,稍突出一些。后以mf力度出现的具有转调性质的琶音奏法,要弹奏的如流水般连贯。在重复段落,即“小
我国艺术歌曲钢琴伴奏-精
我国艺术歌曲钢琴伴奏-精 2020-12-12 【关键字】传统、作风、整体、现代、快速、统一、发展、建立、了解、研究、特点、突出、关键、内涵、情绪、力量、地位、需要、氛围、重点、需求、特色、作用、结构、关系、增强、塑造、借鉴、把握、形成、丰富、满足、帮助、发挥、提高、内心 【摘要】艺术歌曲中,伴奏、旋律、诗歌三者是不可分割的重 要因素,它们三个共同构成一个统一体,伴奏声部与声乐演唱处于 同样的重要地位。形成了人声与器乐的巧妙的结合,即钢琴和歌唱 的二重奏。钢琴部分的音乐使歌曲紧密的联系起来,组成形象变化 丰富而且不中断的套曲,把音乐表达的淋漓尽致。 【关键词】艺术歌曲;钢琴伴奏;中国艺术歌曲 艺术歌曲中,钢琴伴奏不是简单、辅助的衬托,而是根据音乐 作品的内容为表现音乐形象的需要来进行创作的重要部分。准确了 解钢琴伴奏与艺术歌曲之间的关系,深层次地了解其钢琴伴奏的风 格特点,能帮助我们更为准确地把握钢琴伴奏在艺术歌曲中的作用 和地位,从而在演奏实践中为歌曲的演唱起到更好的烘托作用。 一、中国艺术歌曲与钢琴伴奏 “中西结合”是中国艺术歌曲中钢琴伴奏的主要特征之一,作 曲家们将西洋作曲技法同中国的传统文化相结合,从开始的借鉴古 典乐派和浪漫主义时期的创作风格,到尝试接近民族乐派及印象主 义乐派的风格,在融入中国风格的钢琴伴奏写作,都是对中国艺术 歌曲中钢琴写作技法的进一步尝试和提高。也为后来的艺术歌曲写 作提供了更多宝贵的经验,在长期发展中,我国艺术歌曲的钢琴伴 奏也逐渐呈现出多姿多彩的音乐风格和特色。中国艺术歌曲的钢琴
写作中,不可忽略的是钢琴伴奏织体的作用,因此作曲家们通常都以丰富的伴奏织体来烘托歌曲的意境,铺垫音乐背景,增强音乐感染力。和声织体,复调织体都在许多作品中使用,较为常见的是综合织体。这些不同的伴奏织体的歌曲,极大限度的发挥了钢琴的艺术表现力,起到了渲染歌曲氛围,揭示内心情感,塑造歌曲背景的重要作用。钢琴伴奏成为整体乐思不可缺少的部分。优秀的钢琴伴奏织体,对发掘歌曲内涵,表现音乐形象,构架诗词与音乐之间的桥梁等方面具有很大的意义。在不断发展和探索中,也将许多伴奏织体使用得非常娴熟精确。 二、青主艺术歌曲《我住长江头》中钢琴伴奏的特点 《我住长江头》原词模仿民歌风格,抒写一个女子怀念其爱人的深情。青主以清新悠远的音乐体现了原词的意境,而又别有寄寓。歌调悠长,但有别于民间的山歌小曲;句尾经常出现下行或向上的拖腔,听起来更接近于吟哦古诗的意味,却又比吟诗更具激情。钢琴伴奏以江水般流动的音型贯穿全曲,衬托着气息宽广的歌唱,象征着绵绵不断的情思。由于运用了自然调式的旋律与和声,显得自由舒畅,富于浪漫气息,并具有民族风味。最有新意的是,歌曲突破了“卜算子”词牌双调上、下两阕一般应取平行反复结构的惯例,而把下阕单独反复了三次,并且一次比一次激动,最后在全曲的高音区以ff结束。这样的处理突出了思念之情的真切和执著,并具有单纯的情歌所没有的昂奋力量。这是因为作者当年是大革命的参加者,正被反动派通缉,才不得不以破格的音乐处理,假借古代的