分布式锁服务算法

分布式锁服务--debby设计与实现
单栋栋,赵东升,樊楷,苏飞
摘要:
我们实现了一个分布式锁服务系统,并能提供可靠的存储服务。系统的接口非常简单,类似普通文件的接口。我们设计的重点在于系统的可靠性与可用性,而系统的性能放在次要位置。同时我们也实现paxos协议,并用它为整个系统提供可靠容错的系统日志。
1.背景介绍
随着计算机网络技术的飞速发展,出现了越来越多的分布式系统,我们利用这些系统已提高现有系统的性能,可用性和稳定性。尽管分布式系统的设计已日趋成熟,但要在分布式系统中进行协调和信息交流仍然不是一件容易的,特别在松耦合的分布式系统中,所有的信息传递只能通过网络来完成,必须面临网络丢包、延迟甚至瘫痪等等复杂的问题。要在这样的系统中都实现可靠的一致性协议来进行信息的交流,对于系统设计而言是非常困难的,而且有一些是在应用中没有办法实现的。因此,我们希望提供一种非侵入式的服务来帮助分布式系统各个成员间的动作协调和信息交流,通过使用这一服务,各个分布式系统的成员可以非常简单的达成同步,而不需要在系统内部加入复杂的协调机制。因此,我们设计并实现了debby分布式锁服务系统,这是一个类似于提供全文件读写的分布式文件系统的结构,它设计的目标并非提供海量数据的存储,而是用于提供具有高可靠性和高可用性的锁服务,同时可以方便高效的信息发布机制。为了保证debby系统的可靠性,我们的系统设定了5个服务器来组成一个debby实例,只有一个服务器用来向外提供服务,而其它服务器都作为备份服务,用来在主服务器崩溃时继续提供服务。为了在5个服务器之间提供一致性保证,我们还在底层实现了Paxos协议,只要有半数以上的debby服务器能够正常运行,就可以提供服务。
利用debby系统,现在分布式系统可以非常便捷的进行同步协调和信息发布。比如当多台服务器提供同一服务时,往往需要选择其中一台服务器来作为主服务器,把其他服务器作为备份服务器,而且当主服务器崩溃时,又要能及时选出新的主服务器来提供服务。如果没有debby系统,在分布式系统内部实现这样的备份机制非常困难,唯一的办法或许就是通过Paxos协议来达到一致性,而有的时候甚至Paxos协议也无法派上用场,比如当只有一个备份服务器的时候。然而利用的debby,实现上述功能变得非常简单,只需要所有的服务器都到debby系统中去获取一个互斥锁,然后获得锁的服务器就自动成为主服务器。只要所有的服务器都遵守这一约定,就保证了系统中只会有一个主服务器。debby提供了非常简单易用的信息发布机制,在获取到互斥锁后,服务器可以通过debby提供的分布式文件服务,在文件写入自己的地址,其他服务器以及客户就可以非常容易的通过读取debby文件内容来得到服务器的地址。如果主服务器崩溃,debby系统会自动释放互斥锁,并且通过事件机制来通知其它服务器来重新选择主服务器。
Google公司已经实现了类似的分布式锁服务系统Chubby,并广泛的应用于内部系统中,他们的经验表明这样的系统具有非常好的可用性和可靠性,能够给其他分布式应用的构建带来非常大的帮助。
2.系统设计
2.1整体设计
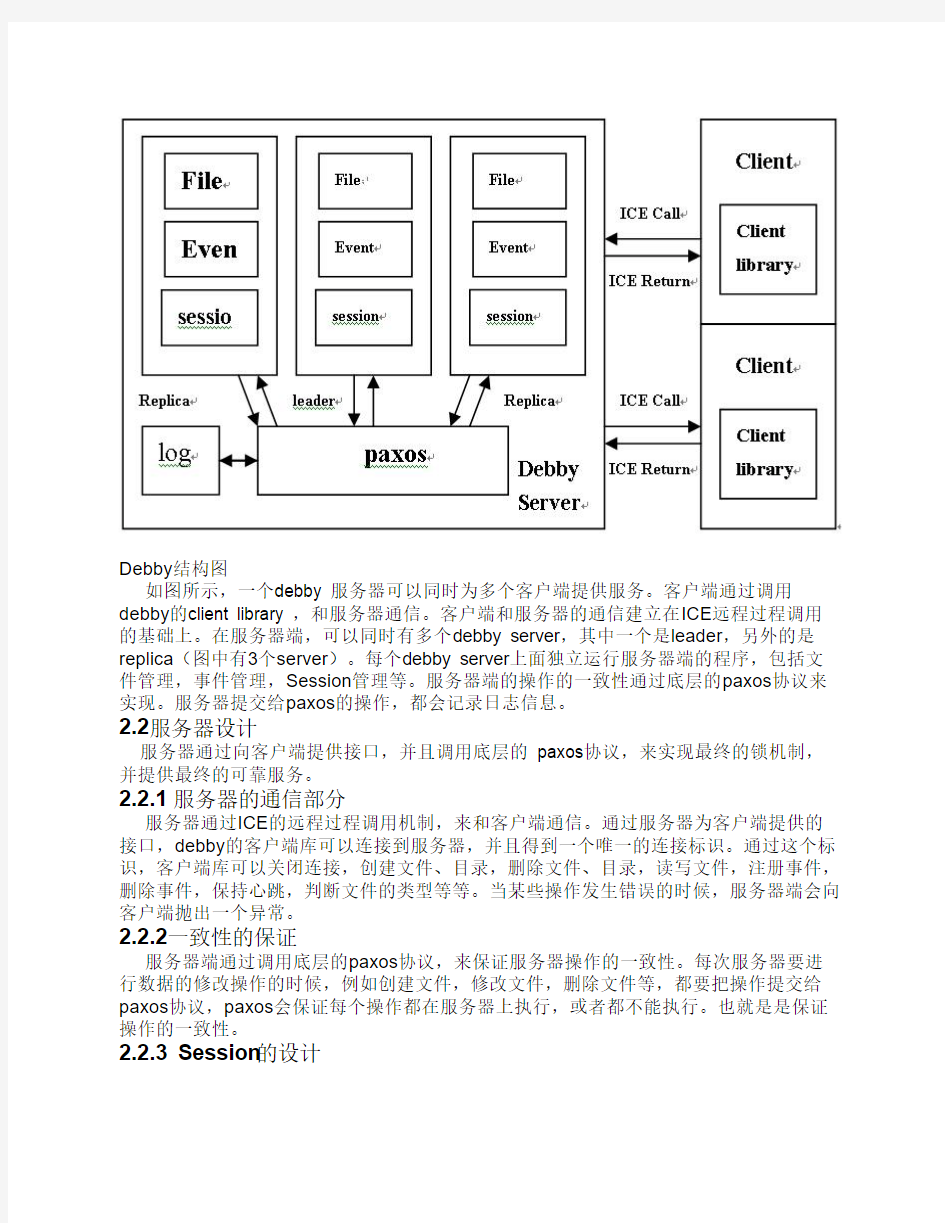
Debby结构图
如图所示,一个debby 服务器可以同时为多个客户端提供服务。客户端通过调用debby的client library ,和服务器通信。客户端和服务器的通信建立在ICE远程过程调用的基础上。在服务器端,可以同时有多个debby server,其中一个是leader,另外的是replica(图中有3个server)。每个debby server上面独立运行服务器端的程序,包括文件管理,事件管理,Session管理等。服务器端的操作的一致性通过底层的paxos协议来实现。服务器提交给paxos的操作,都会记录日志信息。
2.2服务器设计
服务器通过向客户端提供接口,并且调用底层的 paxos协议,来实现最终的锁机制,并提供最终的可靠服务。
2.2.1 服务器的通信部分
服务器通过ICE的远程过程调用机制,来和客户端通信。通过服务器为客户端提供的接口,debby的客户端库可以连接到服务器,并且得到一个唯一的连接标识。通过这个标识,客户端库可以关闭连接,创建文件、目录,删除文件、目录,读写文件,注册事件,删除事件,保持心跳,判断文件的类型等等。当某些操作发生错误的时候,服务器端会向客户端抛出一个异常。
2.2.2一致性的保证
服务器端通过调用底层的paxos协议,来保证服务器操作的一致性。每次服务器要进行数据的修改操作的时候,例如创建文件,修改文件,删除文件等,都要把操作提交给paxos协议,paxos会保证每个操作都在服务器上执行,或者都不能执行。也就是是保证操作的一致性。
2.2.3 Session的设计
每个Session是一个客户端和一个debby服务的关系。通过心跳机制,客户端和服务器保持联系。在每个心跳到来的时候,服务器会把发生的事件返回给客户端。
2.2.4文件、目录的设计
对于每个Session,debby提供一个简单的文件系统接口,文件和路径的格式类似于UNIX,例如/ls/foo/dir/file。文件系统向外提供通常的文件系统服务,例如文件、目录的创建,文件、目录的修改、删除等。debby应该向客户端提供对临时文件进行操作的服务。临时文件被客户端创建,在Session失效的时候,临时文件应该被删除。
为了方便,以及提高性能,debby的文件和目录都放在内存中,定期进行snapshot,将文件系统的内容flush到磁盘。在系统恢复的时候,会根据磁盘的内容恢复文件系统。
2.2.5事件机制的设计
对于每个Session, debby提供一个事件管理器,事件管理器会记录客户端已经注册的事件、和已经发生的事件。对于已经发生的事件,服务器会在每个keepAlive的远程过程调用的时候,将客户订阅的事件捎带返回,同时在服务器端删除这些已经发生的事件。2.3客户端设计
利用服务器端提供的接口,我们通过客户端来最终实现锁机制,并向外提供服务。我们希望客户端向外提供尽量易于理解的接口,从而可以让用户可以方便的使用debby系统的服务。
客户端通过ICE库来和服务器进行远程调用,并且通过定期的keepAlive信息保持和服务器的会话。每次客户端与服务器建立会话后,都得到一个独一无二的句柄,并且以后所有的操作都通过这一句柄来完成,从而可以在每次操作时判断用户的身份。尽管在应用程序中,可以有多个对象使用同一个客户端的服务,但在服务器看来,一个客户端只对应唯一的用户。
客户端向外提供的API可以分为两个部分,一部分是实现类似于普通文件系统的目录操作,另外一部分则用来提供全文读写、锁服务以及事件注册。
在提供目录操作的部分,我们的接口与普通文件系统非常类似,具体的操作包括create(),remove(),mkdir(),exist(),isdir(),list()。通过这些操作,用户可以修改系统目录结构,创建和删除文件和目录。与普通的文件系统不同的是,我们在create接口中提供了是否创建临时文件的选项,如果创建的是临时文件,那么当这个客户端与服务器失去连接后,debby服务器会自动删除临时文件。这可以作为一种信息发布的方式,也是我们实现锁机制利用的底层特性。
我们提供了read()和write()操作来进行全文读写,即一次读或者写整个文件的内容。之所以这样设计,是因为debby中的文件其主要作用是为了提供一种信息发布的机制,而不是作为大规模数据的存储。为了防止用户的误用来对debby的整体服务性能造成影响,比如存储非常大的文件,我们对文件的大小进行了限制,目前暂定为1M。这样规模的文件,我们可以很方便的只提供全读和全写的操作,由用户自己来确定文件内容的格式。我们提供了lock()和release()操作来提供锁服务,当多个用户想要获取某个资源时,应当首先获取对那个资源的锁,才可以安全的使用资源。当完成对资源的使用时,用户应当调用release()操作来是释放操作,从而使得其它用户可以使用资源。因为Chubby的使用数据表明几乎所有用户使用的都是互斥锁而非共享锁,因此目前我们只提供互斥锁服务。
我们还提供了事件机制,通过事件机制,用户只需要在某个事件上注册好回调,当事件发生时,就会自动调用用户注册的回调函数。通过这一机制,用户不需要通过轮询来获得信息,大大减轻了服务器的负担,使其具有更好的可扩展性。目前我们提供的事件包括EventCreated, EventRemoved, EventChanged, EventLockChanged, EventArbitrary五种。前三个事件分别代表目录或文件的创建、删除和改变,这里目录的内容改变指的是目
录内文件的创建或删除。第四个事件是指在某个路径上的锁发生改变,包括锁被获取或释放。第五个事件则是指在一个路径上的所有事件,包括创建、删除、改变以及锁的改变。
2.4 snapshot机制设计
Debby的paxos框架保证了各个replica存放数据的一致性。也支持备份在crush掉之后恢复。到目前为止,所有的故障恢复均基于log,log存放在稳定存储器(硬盘)中。但由此引发了新问题:随着系统运行,日志将会越来越多。这有两方面问题:log的存储需要无限量的磁盘空间,并且更糟的是,这也可能会导致恢复时间越来越长。
这里介绍的snapshot(快照)机制想法很简单。就是要将文件系统的数据结构直接序列化到磁盘上,这样之前的日志就不再需要了。于是可通知paxos部分将log删除。当然,paxos部分并不知道任何有关的数据结构,因此,application进程必须负责snapshot的执行。
debby提供了snapshot机制,允许客户端应用程序通知文件系统执行snpsoht操作。用户应用程序可在任何时间发起snapshot命令。当snapshot操作完成,snapshot部分应通知paxos部分以删除其过时的snapshot存储和log。当某台服务器crush掉之后恢复时,snapshot类将负责为其从磁盘中导入最新的文件数据结构,然后重放截断日志,以重建服务器的服务环境。
当然snapshot机制也增加了一些复杂性:在实现snapshot机制之前,crush掉的服务器在恢复时只需从其他机器获得最近的log即可进行更新。而实现snapshot机制之后,如需保持状态的一致性,得包括进最近的log和snapshot复本。
2.5容错日志设计
Debby系统的主要设计目标是高可靠性与高可用性,这主要依靠多台服务器一起运行来实现。一台机器坏悼都有备份机接替工作,但如果保证系统中的机器数据的一致性是一个非常大的问题。我们主要用paxos一致性协议[][],它保证每一时刻,系统中的大部分机器的状态都是一致的,状态不一致的机器可以通过一定方法恢复到一致的状态。
paxos保证系统的一致性主要靠容错日志,系统的每次操作paxos都会把这个操作记录在日志中,通过这个日志就能过从错误中恢复。我们的系统中,要写入日志的值就可要对数据库进行操作的值。
基本的paxos主要分为三个步骤[4]:
一.有多少机器中通过一些算法选出一个leader
二.选出的leader可以提交决议到系统中,leader发送消息给其它机器,其它机器回复leader
三.当leader收至半数以上的应答,就发消息给其它机器,表明可以记日志。
基础的paxos协议没有对那个状态不一致的系统进行处理,在我们的容错日志设计中,有第一与第二步中间加了一步准备阶段。当leader被选出来已后,向其它机器发一个消息,表明自己是leader,并把当前的系统状态发给大家。其它机器根据leader发过的状态信息,判断自己的信息是不是最新,返回给leader自己的状态,leader根据这些信息来决定自己是否需要进行catch up操作,其它机器可以与leader通信,更新状态。
在基本的paxos中,如果每台机器都给其它机器返回信息,第三步可以省略。基本的paxos做每一次决议都要选leader,比较费时,我们通过给leader一个租约时间,在这个时间中,其它机器保证不会同意选出新的leader。leader在租约时间内可经续租约,从而保证leader长间的成为leader。下图是我们使用paxos对容错日志系统的设计[]。
3.系统实现
3.1服务器端实现
在服务器端实现了向客户端提供的接口,并且调用底层的 paxos协议的接口,来实现最终的锁机制,并提供最终的可靠服务。debby的服务器实现了Session管理,心跳机制,文件、目录的管理,事件管理,以及和客户端、paxos协议的通信。
3.1.1Session机制的实现
对于客户端和服务器建立的每一个连接,服务器都会保存一个
3.1.2文件、目录的实现
考虑到实现的方便和高效,debby的文件和目录是放在内存中的。debby的文件系统分为常规的文件系统,和临时的文件系统。常规文件系统和临时文件系统是分开实现的,他们的命名空间也是相互独立的。
在常规文件目录中,对于文件和目录的管理,提供了通常意义下的操作,包括文件、目录的创建,文件、目录的修改、删除等。系统实现了两个版本的文件、目录系统。第一个是用STL的map实现,整个文件系统只有一个map,map的每一个元素是<路径,debby文件>的pair。这个实现版本效率比较差,并且操作起来非常不方便,实现起来比较麻烦。考虑到文件系统的组织结构,debby提供了文件系统的第二个实现版本,用树来实现。在开源的tree.hh基础上,debby用模板实现了通用的内存目录MemDir。通过MemDir,用户可以定义自己的inode类型,在inode中,用户应该提供相应的方法,这些方法在MemDir 中被调用。
对于临时文件系统,系统维护了一个从handle到路径名称的map,当一个Session失效的时候,系统会释放一个handle所对应的文件。
3.1.3事件机制的实现
debby维护了一个事件管理器,事件管理器会记录客户端已经注册的事件、和已经发生的事件。对于已注册的事件,系统维护一个事件到handle列表的map,如果某一个事件发生了,则会通知列表里面记录的每一个连接。
3.2客户端实现
当用户启动客户端时,就会启动一个心跳线程,专门用于向debby服务器发送keepAlive 信息以维持会话。在客户端的大部分操作都通过服务器提供的远程调用服务来实现,比如文件和目录的创建、删除等操作。
对于互斥锁的获取和释放操作,debby并不提供直接的支持,而是通过客户端通过创建和删除临时文件来完成。比如当客户获取"/ls/printer"的互斥锁,客户端就会试图创建"/ls/ printer.lck~"文件,如果这个文件已经存在,说明互斥锁已经被其他用户获得,服务器向客户端抛出异常,客户端获取异常后返回失败。如果成功了创建了那个文件,就表明客户成功获取了该互斥锁。当用户要释放锁时,客户端就会删除"/ls/printer.lck~"文件,来表明用户已经释放锁。为了防止这样的文件和用户的普通文件重名,我们规定用户不能创建以"~"结尾的文件名。对于锁服务,我们最需要处理的问题是当客户端崩溃时,需要自动的释放锁,临时文件的机制使得我们可以实现这个功能,因为如果客户端和服务器失去连接,服务器就会删除用于所服务的临时文件,也就是释放了该用户拥有的所有锁。
在实现事件机制时,尽管客户可以在事件上注册回调,但服务器并不需要管理回调函数,只是通知客户端事件的发生,对回调的管理有客户端完成。用户可以在一个路径的一个事件上注册多个回调,只有在注册第一个回调是需要由客户端向服务器注册,后续的操
作就完全由客户端来完成。当客户端收到一个事件时,它会调用注册到这个事件的所有回调。用户也可以取消在一个路径上注册的所有回调。
回调的实现,我们通过一个类Callback来实现,这个类有一个纯虚函数run(),用户要定义自己的回调时,需要首先创建一个Callback的子类,并实现其run()函数作为回调函数。当客户端要收到事件时,对于每一个注册的Callback,都会创建一个线程来调用其run()函数。在用户的子类中,可以把任何用户的回调函数需要的数据作为其Callback子类的成员,从而使得其回调函数可以实现几乎任意强大的功能。
客户端另外一个需要处理的问题是当debby服务器发生改变时如何能转换到适当的服务器,并且能够处理由于改变服务器导致的一段时间内服务失效问题。我们通过ICE的多终端功能和重试功能来解决这个问题。当ICE进行初始化的时候,我们会把debby的5个服务器地址都传给ICE,这样ICE会自动尝试所有5个服务器,只要有一个服务器提供服务,就可以建立其连接并进行远程调用。因此我们只要保证debby服务器端同一时间内只有一个服务器在提供服务,就能够保证debby客户端能够找到master。但在改变服务器期间,回出现没有任何一个服务器提供服务的情况,此时我们需要利用ICE的重试机制,即我们可以给ICE提供一个重试时间的序列,比如(1 3 5)表示如果ICE客户端无法与服务器建立连接,会在接下来的第1秒,第3秒和第5秒进行重试,只要在重试中能连上服务器就可正常工作,否则认为连接失效抛出异常。我们也给我们的客户端ICE提供了重试时间序列,为(10 30 60),这样只要服务器端能够在60秒内恢复,我们就可以向用户提供连续的服务。
3.3snapshot机制实现
对于Google公司的Chubby,其文件系统以数据库的形式采用Berkeley DB实现。Berkeley DB采用B-树结构,可以提供高效率的Key-value查找。在我们的版本里进一步做了简化。文件系统采用自定义的tree实现,于是在序列化时只需对 MemDir中的文件树做遍历,记下相应节点(INode)的信息和其父节点即可。由于Debby系统采用C++编写,standard library中未提供序列化功能,只能自己编码完成(考虑过用boost库实现,由于使用起来不方便而作罢)。
Snapshot类主要实现两个函数:
public static void serialize(MemDir& md);
public MemDir& void Unserialize();
其中,属性DIR_PATH为序列化后的文件系统数据结构的存放路径; Serialize方法将传入的文件系统数据结构MemDir序列化后存入路径为DIR_PATH的文件中, Unserialize 方法在服务器恢复时调用,其从路径为DIR_PATH的文件中恢复数据结构MemDir并返回之。
3.4容错日志实现
我们主要实现了一个paxos框架,用paxos框架来产生容错日志。对2.5小节的设计,我们的机器共有三种角色,LOOKING表示当前机器正在寻找leader。LEADERG表示当前机器为leader。FOLLOWER表示当前机器为非leader。paxos过程如下:
1.通过leader选举算法,得到一个leader。每台机器要参与leader的选举,必须提交一个veiw号,这个号要保证是递增的。在我们的实现中,每台机器即可以推举自己当leader,也可以推举别的机器当leader。所以在我们的实现中,每台机器都有自己的编号例如0~N-1,当前被达成一致的view对应的leader就是view%N对应的机器[5],如果该机器没有起启动,则再次选leader,如何得到leader没有启动,可以通过心跳机制来保证。在我们的实现中,当一台机器被选成leader,马上就得给其它机器发心跳,而leader也是通过心跳来续约租约时间的。这里所涉及到的消息包括viewchange消息,与heartbeat消息
2.当一台机器被选为leader后,向大家发送一个准备信息,包括当前的view与系统的状态,向大家来同步。其它机器对这个消息进行应答并通过自己的状态信息。leader汇总这些信息,判断自己的状态是否为最新,如果不是最新,刚向收到回复消息的机器中选择一个状态最新的机器,向那台机器请求数据,以恢复来最新状态。系统中必定有一台机器的状态是最新的,这个可以由paxos的性质来保证。其它服务器如果状态不是最近,可以向leader发请求来恢复最新状态。这里所涉及到的消息包括prepare消息,prepareok消息,catch up消息
3.当第2步完成时,leader状态是最新的,并且系统中的大部分机器的状态都是最新的,即一半以上的机器状态一致。leader就可以响应其它程序向paxos系统提交决议,其它机器收到决议并向leader与其它机器应答消息,当应答的消息过半时,表示协议已经达成,每台机器把这协议记录在本地的日志中。如果协议没有达成,leader可以自动重新提交协议,直到达成协议,也可直接返回协议没有答成给调用者,由调用都重新提交协议,在paxos系统中,这次提交的协议号与上次失败的协议号是相同的。这里涉及到的消息包括proposal消息,accept消息
在系统的运行过程中,如果有一台宕掉的机器起来,它首先通过一定时间侦听当前leader发送的心跳消息,如果没有收到心跳消息,由进入选leader状态。如果收到消息,向leader更新自己的状态信息到最新。在一个已有leader的系统中,如果有别的新的机器发选leader的消息,大家都会把它拒绝,当新的机器收到心跳消息时,自动转变角色。4.实验
4.1paxos实验
我们的实验环境主要是在单台机器下(PM1.5GHz 512MB),通过多个终端来模拟多台机器对paxos的系统测试实验。在针对paxos系统的一致性进行测试实验,我们主要采用同步提交的方法,即下一次提交的协议必需等上一次提交后并且已经得到结果了才能提交。这些实验我们都默认系统已经把leader选出,所有的决议都leader提交。在实验中leader提交的策略如下:如果一次提交,再1秒钟内paxos系统还没有对该协议达成一致,则返回提交失败而paxos系统对本次操作不记日志,否则则提交成功,paxos对这次操作记下日志。paxos记日志的方式是把提交的内容与协议号写入磁盘。系统中的通过主要用多播实现,系统之间的catch up通过单点tcp连接进行通讯。
我们总共做了四组实验,在这四组实验中也可以分成两组,一组用3个终端,另一组用5个终端完成。3个终端表示我们paxos系统中有3台机器中,我们模拟系统中只剩2台机器,与3台机器都存在的情况。5个终端的实验中模拟了3台机器与5台机器的情况。表一,是3台机器的模拟结果,表二,是5台机器的模拟结果。
在实验的结果中,我们可以看出,系统中机器数比较少时,达成协议的速度比较快。在同一个系统中,也就是系统中的机器数量一定时,宕掉的机器越多出现提交失败的比例也越高,而整个系统特别在有许多机器的,其运行速度也越慢。
表一 3个终端模拟1台机器宕机与没有机器宕机的情况
表二 5个终端模拟2台机器宕机与没有机器宕机的情况
5.总结
在本文中,我们实现了类似于chubby系统的分布式锁服务系统Debby。此锁服务系统采用C++实现,由多台服务器共同维护一个类似文件系统的数据结构,并保证此数据结构在多个服务器进程之间的一致性。整个系统具有容错性能(fault tolerance),能够保证在复杂的网络情况中(丢包、传送延迟,机器瘫痪等)稳定运行。多个进程通过paxos算法保持各自维护的数据间的一致性。系统的运行日志(log)和快照(snapshot)将被备份到硬盘上,服务器在宕机后可依此自动恢复。客户端与服务器之间的通信采用ICE远端过程调用。Debby系统可用于分布式环境中的leader选举,名字服务(name service)以及共享资源的并发控制等。
通过这次课程项目,我们深入了解了分布式系统如何保持各个备份间的一致性和容错性,并亲自开发了一个真实的分布式系统,加深了对课程内容的理解,也锻炼了动手能力,在此感谢老师给我们提供的机会,也感谢助教师兄的工作。
参考文献
基于SpringCloud微服务系统设计方案
微服务系统设计方案 1.微服务本质 微服务架构从本质上说其实就是分布式架构,与其说是一种新架构,不如说是一种微服务架构风格。 简单来说,微服务架构风格是要开发一种由多个小服务组成的应用。每个服务运行于独立的进程,并且采用轻量级交互。多数情况下是一个HTTP的资源API。这些服务具备独立业务能力并可以通过自动化部署方式独立部署。这种风格使最小化集中管理,从而可以使用多种不同的编程语言和数据存储技术。 对于微服务架构系统,由于其服务粒度小,模块化清晰,因此首先要做的是对系统整体进行功能、服务规划,优先考虑如何在交付过程中,从工程实践出发,组织好代码结构、配置、测试、部署、运维、监控的整个过程,从而有效体现微服务的独立性与可部署性。 本文将从微服务系统的设计阶段、开发阶段、测试阶段、部署阶段进行综合阐述。 理解微服务架构和理念是核心。 2.系统环境
3.微服务架构的挑战 可靠性: 由于采用远程调用的方式,任何一个节点、网络出现问题,都将使得服务调用失败, 随着微服务数量的增多,潜在故障点也将增多。 也就是没有充分的保障机制,则单点故障会大量增加。 运维要求高: 系统监控、高可用性、自动化技术 分布式复杂性: 网络延迟、系统容错、分布式事务 部署依赖性强: 服务依赖、多版本问题 性能(服务间通讯成本高): 无状态性、进程间调用、跨网络调用 数据一致性: 分布式事务管理需要跨越多个节点来保证数据的瞬时一致性,因此比起传统的单体架构的事务,成本要高得多。另外,在分布式系统中,通常会考虑通过数据的最终一致性来解决数据瞬时一致带来的系统不可用。 重复开发: 微服务理念崇尚每个微服务作为一个产品看待,有自己的团队开发,甚至可以有自己完全不同的技术、框架,那么与其他微服务团队的技术共享就产生了矛盾,重复开发的工作即产生了。
系统概要设计文档
系统概要设计文档
1 / 18
目录
系统概要设计文档 ....................................................................................................... 1b5E2RGbCAP 目录 ................................................................................................................................2p1EanqFDPw 1 引言 .............................................................................................................................. 3DXDiTa9E3d 1.1 编写目的及阅读建议 ...................................................................................... 3RTCrpUDGiT 1.2 系统概述 ......................................................................................................... 35PCzVD7HxA 1.3 文档概述 ............................................................................................................. 3jLBHrnAILg 1.4 设计原则与设计要求 ......................................................................................3xHAQX74J0X 2 引用文件 ...................................................................................................................... 3LDAYtRyKfE 3 设计概述 ....................................................................................................................... 4Zzz6ZB2Ltk 3.1 功能需求规定 .................................................................................................... 4dvzfvkwMI1 3.2 运行环境 ........................................................................................................... 4rqyn14ZNXI 4 系统体系结构设计 ..................................................................................................... 4EmxvxOtOco 4.1 系统总体设计 ................................................................................................... 4SixE2yXPq5 4.1.1 概述 ........................................................................................................ 46ewMyirQFL 4.1.2 设计思想 ............................................................................................... 5kavU42VRUs 4.1.3 基本处理流程 ........................................................................................ 6y6v3ALoS89 4.1.4 系统数据结构设计 ............................................................................... 9M2ub6vSTnP 4.4 接口设计 ........................................................................................................ 100YujCfmUCw 4.4.1 用户接口 ............................................................................................. 10eUts8ZQVRd 4.4.2 外部接口 ............................................................................................ 10sQsAEJkW5T 4.4.3 内部接口 ............................................................................................. 11GMsIasNXkA 5 运行设计 ..................................................................................................................... 11TIrRGchYzg 5.1 系统初始化 ................................................................................................... 117EqZcWLZNX 5.2 运行控制 ........................................................................................................... 11lzq7IGf02E 5.3 运行结束 .......................................................................................................... 11zvpgeqJ1hk 6 系统出错处理设计 ..................................................................................................... 11NrpoJac3v1 6.1 出错信息 ..........................................................................................................111nowfTG4KI 6.2 补救措施 .......................................................................................................... 12fjnFLDa5Zo 7 系统维护设计 ............................................................................................................. 12tfnNhnE6e5 附录 ............................................................................................................................. 12HbmVN777sL
2 / 18
计算机算法设计与分析期末考试复习题
1、二分搜索算法是利用( A )实现的算法。 A、分治策略 B、动态规划法 C、贪心法 D、回溯法 2、下列不是动态规划算法基本步骤的是( A )。 A、找出最优解的性质 B、构造最优解 C、算出最优解 D、定义最优解 3、最大效益优先是( A )的一搜索方式。 A、分支界限法 B、动态规划法 C、贪心法 D、回溯法 4、最长公共子序列算法利用的算法是( B )。 A、分支界限法 B、动态规划法 C、贪心法 D、回溯法 5. 回溯法解TSP问题时的解空间树是( A )。 A、子集树 B、排列树 C、深度优先生成树 D、广度优先生成树6.下列算法中通常以自底向上的方式求解最优解的是( B )。 A、备忘录法 B、动态规划法 C、贪心法 D、回溯法 7、衡量一个算法好坏的标准是(C )。 A 运行速度快 B 占用空间少 C 时间复杂度低 D 代码短 8、以下不可以使用分治法求解的是(D )。 A 棋盘覆盖问题 B 选择问题 C 归并排序 D 0/1背包问题 9. 实现循环赛日程表利用的算法是( A )。 A、分治策略 B、动态规划法 C、贪心法 D、回溯法 10、实现最长公共子序列利用的算法是( B )。 A、分治策略 B、动态规划法 C、贪心法 D、回溯法11.下面不是分支界限法搜索方式的是( D )。 A、广度优先 B、最小耗费优先 C、最大效益优先 D、深度优先 12.下列算法中通常以深度优先方式系统搜索问题解的是( D )。 A、备忘录法 B、动态规划法 C、贪心法 D、回溯法 13. 一个问题可用动态规划算法或贪心算法求解的关键特征是问题的( B )。 A、重叠子问题 B、最优子结构性质 C、贪心选择性质 D、定义最优解14.广度优先是( A )的一搜索方式。 A、分支界限法 B、动态规划法 C、贪心法 D、回溯法 15.背包问题的贪心算法所需的计算时间为( B )。
图论在网络拓扑发现算法中的应用
小 型 微 型 计 算 机 系 统 Journal of Chinese Computer Systems
2008 年 月 第 期 Vol.28 No. 2008
?
图论在网络拓扑发现算法中的应用
路连兵 1+,胡吉明 2,姜 岩 1
1,2
,2
(河海大学 计算机及信息工程学院,江苏 南京
210098)
E-mail :famioo@https://www.360docs.net/doc/d111136897.html,
摘
要:网络拓扑发现技术已经广泛地应用在各种项目软件中。然而,随着网络结构复杂度升级,这给拓扑发现带来了
挑战。所以我们越来越需要一种高效,准确的网络拓扑算法自动发现网络拓扑结构。目前的拓扑算法主要集中在:(1)路 由层的发现。这个层面的发现算法在技术上比较简单,只需要寻找路由与路由之间,或路由端口与子网之间的连接关系, 利用路由器的自身特性,很容易实现。(2)链路层的发现。直到目前为止,已有的厂商工具很难准确发现网络拓扑,已发 表的理论文献知识也只是理论上阐述,实际应用难度比较大。本论文,提出一种基于图论的骨架树数据存储结构算法,可 以高效推断网络的拓扑关系。 关键词:骨架树;子网;地址转发表;图论;信任节点
Topology Discovery in Networks Based on Graph Theory*
LU Lian-Bing1+, HU Ji-Ming2,Jiang Yan1,2
1,2
(School of Computer Science and Information, Hohai University, Nanjing Jiangsu 210098, China)
Abstract: Topology discovery systems are starting to be introduced in the form of easily and widely deployed software. However, Today's IP network is complex and dynamic. Keeping track of topology information efficiently is a difficult task. So, we need effective algorithms for automatically discovering physical network topology. Earlier work has typically focused on: (1) Layer-3 (network layer) topology, which can only router-to-router interconnections and router interface-to-subnet relationships. This work is relatively easy and has lots of systems can do it. (2)Layer-2(link layer), till now, no tools can discovery the network topology exactly because of bad algorithm. In this paper, Skeleton-tree based on Graph theory is proposed to infer the connections between network nodes. Key words: Skeleton-tree; subnets; Address Forwarding Table; Graph Theory;Trust Node
作者简介: 路连兵(1979-),男,江苏泗洪人,硕士。 主要研究网络自拓扑,软件项目管理,Perl 研究;胡吉明(1967-),男,硕导,副教授,主要研究 领域为计算机应用技术,网络安全,数据挖掘,Z 语言; 姜岩(1979-),男,硕士研究生,主要研究方向,网络应用,中间件
基于微服务架构的基础设施设计
基于微服务架构的基础设施设计 摘要:本文首先分析传统的单体架构进而解释微服务架构以及分布式环境下四层架构,详细分析了迁移需解决的关键问题如服务间通信机制、数据最终一致性等;然后分析了分布式系统核心问题和DevOps基本原则,以此为设计依据提出微服务架构基础设施总体设计,并且对其关键组件如服务注册与发现、持续交付平台、服务网关的实施提出具体方案;最后针对微服务架构基础设施在运维管理中的应用场景进行了探讨,说明了微服务架构设计思想优于单体架构设计思想。 关键词:软件工程;微服务;服务注册与发现;持续交付 中图分类号:TP311.5 文献标识码:A DOI: 10.3969/j.issn.1003 6970.2016.05.023 本文著录格式:蒋勇.基于微服务架构的基础设施设计卟软件,2016,37(5):93-97 0.引言 理论上任何业务系统如果长期存在的话,随着此系统业务变更、功能增加必然会不断演变,在一个更大的分布式环境中,这种改变尤其明显,那么就需要架构分析设计时更多的考虑系统所处的生态环境建设,这样才能使得整个系统不
断进化。随着虚拟化技术的发展以及docker容器实践逐渐完善,微服务架构的设计思想逐渐浮出水面,形成分布式环境下新的最重要的设计思想。文献对分布式环境下资源及应用平台进行了研究,但对于应用自身依赖的基础设施建设没有讨论。本文将详细探讨如何基于微服务架构进行基础设施建设的设计与分析。 1.从分布式单体架构到微服务架构迁移 1.1分布式单体架构 分布式单体架构指的是在分布式环境下直接部署运行 一个整体开发的应用,由整体应用来提供系统所需的服务,它在技术上通常采用分层实现,大致分为表现层、应用层、数据层,它有天然的优势:它是模块独立无关的,各层之间是技术分离的;它有统一的技术栈和开发标准;它通常在一个进程中运行,模块相互之间协同消耗极小。 但是,在分布式环境下,随着系统功能的增加,系统越来越复杂,单体架构存在一些必然的缺陷:首先,由于整个系统是一个完整整体,必须重复部署多个才能提高系统性能,而往往系统瓶颈仅仅由于其中某一个或几个功能过载产生,这就极大浪费了运行环境资源;其次,由于系统功能的变更和演变,某一个功能的变化可能影响其它功能的正常结果,也带来重新部署和运维管理的复杂性,持续集成变得极为困难;最后,由于整个系统采用统一的技术栈和开发标准,必
OpenJudge算法设计与分析习题解答
1、硬币面值组合 描述 使用1角、2角、5角硬币组成n 角钱。 设1角、2角、5角的硬币各用了a、b、c个,列出所有可能的a, b, c组合。 输出顺序为:先按c的值从小到大,若c相同则按b的值从小到大。 输入 一个整数n(1 <= n <= 100),代表需要组成的钱的角数。 输出 输出有若干行,每行的形式为: i a b c 第1列i代表当前行数(行数从001开始,固定3个字符宽度,宽度不足3的用0填充),后面3列a, b, c分别代表1角、2角、5角硬币的个数(每个数字固定12个字符宽度,宽度不足的在左边填充空格)。
源代码: #include
} 2、比赛排名 描述 5名运动员参加100米赛跑,各自对比赛结果进行了预测: A说:E是第1名。 B说:我是第2名。 C说:A肯定垫底。 D说:C肯定拿不了第1名。 E说:D应该是第1名。 比赛结束后发现,只有获第1名和第2名的选手猜对了,E不是第2名和第3名,没有出现名次并列的情况。 请编程判断5位选手各是第几名。 输入 无 输出 输出要求:按ABCDE的顺序输出5行,其中第1行是A的名次,第2行是B的名次, 第3行是C的名次,第4行是D的名次,第5行是E的名次。 样例输入
微服务架构设计V1
微服务架构设计
目录 一、微服务架构介绍 (3) 二、微服务出现和发展 (3) 三、传统开发模式和微服务的区别 (4) 四、微服务的具体特征 (7) 五、SOA和微服务的区别 (9) 六、怎么具体实践微服务 (11) 七、常见的设计模式和应用 (17) 八、优点和缺点 (23) 九、思考:意识的转变 (26)
一、微服务架构介绍 微服务架构(Microservice Architecture)是一种架构概念,旨在通过将功能分解到各个离散的服务中以实现对解决方案的解耦。你可以将其看作是在架构层次而非获取服务的 类上应用很多SOLID原则。微服务架构是个很有趣的概念,它的主要作用是将功能分解到离散的各个服务当中,从而降低系统的耦合性,并提供更加灵活的服务支持。 概念:把一个大型的单个应用程序和服务拆分为数个甚至数十个的支持微服务,它可扩展单个组件而不是整个的应用程序堆栈,从而满足服务等级协议。 定义:围绕业务领域组件来创建应用,这些应用可独立地进行开发、管理和迭代。在分散的组件中使用云架构和平台式部署、管理和服务功能,使产品交付变得更加简单。 本质:用一些功能比较明确、业务比较精练的服务去解决更大、更实际的问题。 二、微服务出现和发展 微服务(Microservice)这个概念是2012年出现的,作为加快Web和移动应用程序开发进程的一种方法,2014年开始受到各方的关注,而2015年,可以说是微服务的元年; 越来越多的论坛、社区、blog以及互联网行业巨头开始对微服务进行讨论、实践,可以说这样更近一步推动了微服务的发展和创新。而微服务的流行,Martin Fowler功不可没。 这老头是个奇人,特别擅长抽象归纳和制造概念。特别是微服务这种新生的名词,都有一个特点:一解释就懂,一问就不知,一讨论就打架。
算法设计与分析详细设计说明书
高校医务收费管理系统研究项目详细设计 第一部分、引言 1.1编写目的 本说明在概要设计的基础上,对高校医务收费管理系统研究项目的各模块、程序、子系统分别进行了实现层面上的要求和说明。根据概要设计说明书中的设计内容,编写详细设计说明书,为开发过程提供系统处理过程的详细说明,使系统开发各类技术人员对整个系统所需实现的功能以及系统的功能模块的划分、实现和数据库的表结构清楚的认识,为整个系统的开发、测试、评定和移交的提供基础,本报告一旦确认后将成为系统开发各类技术人员共同遵守的准则,并为以后的编程工作提供依据。 软件开发小组的产品实现成员应该阅读和参考本说明进行代码的编写、测试。 1.2背景 说明: A、软件系统的名称:高校医务收费管理系统研究项目 B、任务提出者:高校医务人员 开发者:医务收费系统开发小组 实现完成的系统将在高校医务收费的诊断室、门诊、住院部使用,所应用的网络系统是该系统的内部局域网。 C、本系统将是独立的系统,目前不与高校医务收费的财务系统和其他资料系统提供接口, 所产生的输出都是独立的。 本系统将使用SQL Server 2000作为数据库存储系统,SQL Server 2000企业版将由高校医务收费自行购买。
1.3定义 IPO图——输入/处理/输出图,一般用来描述一个程序的功能和机制; VB语言:1991年,美国微软公司推出了Visual Basic(可简称VB),目前的最新版本是VB 2005(VB8)中文版。Visual 意即可视的、可见的,指的是开发像windows操作系统的图形用户界面(Graphic User Interface,GUI)的方法,它不需要编写大量代码去描述界面元素的外观和位置,只要把预先建立好的对象拖放到屏幕上相应的位置即可。SQL全称是“结构化查询语言(Structu red Query Language)”,最早的是IBM的圣约瑟研究实验室为其关系数据库管理系统SYSTEM R开发的一种查询语言,它的前身是SQUARE语言。SQL 语言结构简洁,功能强大,简单易学,所以自从IBM公司1981年推出以来,SQL语言,得到了广泛的应用。医务收费系统:医务收费是帮助医务人员、医务工作人员对医务收费管理软件。 1.4参考资料 相关的文件包括: A、《高校医务收费高校医务收费管理系统研究项目可行性研究报告》; B、《高校医务收费高校医务收费管理系统研究项目概要设计》; 参考资料: ①杨晶《VB程序设计教程与实训》北京-科学出版社2006 ②张海潘《软件工程》北京清华大学出版版社2003 ③李昭原《数据库原理与应用》科学出版社2002 ④徐兰芳, 彭冰《数据库设计与实现》上海-上海交通大学出版社2006 ⑤(美)Wendy Boggs 《UML与Rational Rose 2002从入门到精通》邱仲潘等译北京-电子工业出版社2002 ⑥《金华市发达装配厂库存管理系统KCGL》的可行性分析 ⑦《中华人民共和国国家标准UDC 681.3》 ⑧《计算机软件产品开发文件编制指南GB 8567-88》 第二部分、程序系统的结构 2.1系统结构
《算法分析与设计》期末试题及参考答案
《算法分析与设计》期末试题及参考答案 一、简要回答下列问题: 1.算法重要特性是什么? 1.确定性、可行性、输入、输出、有穷性 2. 2.算法分析的目的是什么? 2.分析算法占用计算机资源的情况,对算法做出比较和评价,设计出额更好的算法。 3. 3.算法的时间复杂性与问题的什么因素相关? 3. 算法的时间复杂性与问题的规模相关,是问题大小n的函数。 4.算法的渐进时间复杂性的含义? 4.当问题的规模n趋向无穷大时,影响算法效率的重要因素是T(n)的数量级,而其他因素仅是使时间复杂度相差常数倍,因此可以用T(n)的数量级(阶)评价算法。时间复杂度T(n)的数量级(阶)称为渐进时间复杂性。 5.最坏情况下的时间复杂性和平均时间复杂性有什么不同? 5. 最坏情况下的时间复杂性和平均时间复杂性考察的是n固定时,不同输入实例下的 算法所耗时间。最坏情况下的时间复杂性取的输入实例中最大的时间复杂度: W(n) = max{ T(n,I) } , I∈Dn 平均时间复杂性是所有输入实例的处理时间与各自概率的乘积和: A(n) =∑P(I)T(n,I) I∈Dn 6.简述二分检索(折半查找)算法的基本过程。 6. 设输入是一个按非降次序排列的元素表A[i:j] 和x,选取A[(i+j)/2]与x比较, 如果A[(i+j)/2]=x,则返回(i+j)/2,如果A[(i+j)/2] 概要设计 打招呼并判断用户是否使用该程序 1)获取数据确认用户使用该程序时提醒用户输入数据 判断用户输入数据的合法性并将合法数据存入数组 循环体1:控制第一个运算符 2)运算部分循环体2:控制第二个运算符 循环体3:控制第三个运算符 比较运算部分的结果与24:采用3个循环结构 3)输出结果打印出第一个可能的结果,终止程序 输出 没有结果时输出提示信息,终止程序 详细设计 先来分析输入部分的设计原理,作为程序的设计者,和用户的沟通是很重要的。所以开头设计了一个打招呼函数,在该函数中向用户说明程序的功能并征求用户是否开始该程序。这样的设计思路更加人性化。不仅如此,在输入数据时,设计一个循环结构,用来检测用户输入的数据是否合法,如果超出取值范围会提醒用户重新输入。这样就能够比较顺利地完成数据的获取任务。 基于穷举和简化算法结构两个出发点,该程序主体采用的是循环结构。 首先,考虑到四个数之间只能有三个运算符,每种运算符都有四种可能(加、减、乘、 除)。所以总共有4*4*4种可能的组合方式(暂不考虑家括号下的运算顺序),所以我设计了三重循环。分别以i,j,k作为计数变量,先固定i、j保持不变,k从0变到3,分别表示按照加、减、乘、除的方式依次循环,然后再让i保持不变,让k由0变到1,再将k循环从0到3循环一次,以此往复就可以把运算符所有可能的组合穷尽。 当然这是算法实现的基本过程,而在将运算方式(加、减、乘、除)与计数变量联系起来的桥梁就是函数。函数可以对两个整数进行处理,要使其根据计数变量的不同进行不同的类型的运算,就叫引入一个新的变量,在执行函数功能时让它作为开关(在该程序中,0代表加,1代表减,2代表乘,3代表除)就可以了。 最后一部分即输出部分给出了运算结果,先采用循环结构比较结果值与24是否相等(由于计算机本身精度的原因,其实只要当结果和24的差值足够小时就可以确定这种可能是可以得出24的),如果判断成立,马上输出结果并停止进一步的循环检测(减少运算量,提高效率);如果没有可能,就输出“NO SOLUTION!”提醒用户所输入的四个数无法组合形成24。在这一步就会发掘出运算部分的四维数组的优势,中括号中的数字组合刚好对应一定的运算方式,在打印过程中就有章可循了。 总的设计思路还是按照解决问题的一般逻辑问题进行的,其中不乏很多以前没有实践过的思路和方法,而且也会涉及到一些其他方面的知识,比如电脑本身的数据结构、精度等等。所以一个完整的程序需要合乎逻辑的算法,以及多方面的考虑和技术的支持。 一、选择题 1.一个.java文件中可以有()个public类。 A.一个B.两个C.多个D.零个 2.一个算法应该是() A.程序B.问题求解步骤的描述 C.要满足五个基本特性D.A和C 3.用计算机无法解决“打印所有素数”的问题,其原因是解决该问题的算法违背了算法特征中的()A.唯一性B.有穷性C.有0个或多个输入D.有输出 4.某校有6位学生参加学生会主席竞选,得票数依次为130,20,98,15,67,3。若采用冒泡排序算法对其进行排序,则完成第二遍时的结果是() A.3,15,130,20,98,67B.3,15,20,130,98,67 C.3,15,20,67,130,98 D.3,15,20,67,98,130 5.下列关于算法的描述,正确的是() A.一个算法的执行步骤可以是无限的B.一个完整的算法必须有输出 C.算法只能用流程图表示D.一个完整的算法至少有一个输入 6.Java Application源程序的主类是指包含有()方法的类。 A、main方法 B、toString方法 C、init方法 D、actionPerfromed方法 7.找出满足各位数字之和等于5的所有三位数可采用的算法思路是() A.分治法B.减治法C.蛮力法D.变治法 8.在编写Java Application程序时,若需要使用到标准输入输出语句,必须在程序的开头写上( )语句。 A、import java.awt.* ; B、import java.applet.Applet ; C、import java.io.* ; D、import java.awt.Graphics ; 9.计算某球队平均年龄的部分算法流程图如图所示,其中:c用来记录已输入球员的人数,sum用来计算有效数据之和,d用来存储从键盘输入的球员年龄值,输入0时表示输入结束。 车联网(VANET)是移动自组织网络在道路上的应用,其具有移动自组织网络(MANET)的各种特点,故此,我们先介绍MANET的环境下的服务协同研究,可发现一些具有实用价值的思想和方案对V ANET环境下的研究具有积极的借鉴意义。 由于MANET通信环境恶劣,移动性强的特点,传统的服务组合方法多是面向有线网络,集中式体系结构,不适用于目前自主移动网络,而目前MANET环境下典型的服务组合系统有以下三种。 1)基于代理的分布式服务组合,BDSCP 该系统框架分为四层:网络层、服务发现层、网络组合与管理层以及应用层。其系统框架分层图如下图1所示。其基本工作流程如图2所示。 图1.BDSCP系统框分层图 图2.系统服务组合基本工作流程图 BDSCP协议作为一个专门面向MANET环境的服务组合框架,采用分布式的动态服务管理者选择机制,避免的了单点失效,并设计了一种基于服务分组的服务发现方法,有效提高服务发现效率;同时还为发现的服务提供了基于分组的服务路由机制,但是也存在一定的问题 (1)代理寻找过程和频繁的发现过程不仅浪费大量的宽带资源还延长了协议响应时间。(2)提出的GSD服务发现协议需要节点周期的向邻居节点广播服务信息,容易造成广播包冗余;同时重复的服务查询包和单播方式的转发引起的服务查询包冗余现象也比较突出。(3)BDSCP没有涉及出现多个候选服务的时候如何进行选择。 (4)没有对网络中服务的QoS进行考虑,尤其是当出现多个候选服务的时候。 2)失败容忍的上下文感知服务组合协议,FTCASCP 该设计以设计出具有分布式的、容错性、上下文感知的服务组合系统为出发点,其采用在一个服务会话中寻找组合服务的所有原子服务的策略来提高服务组合的效率,其体系结构如图3所示,工作的主要流程阶段如图4所示。 xxxx信息系统V2.0 【模块名称】 概要设计说明书 版本号 xxx信息化建设项目组2018年05月01日 修正历史表 文档信息 目录 1.引言 (7) 1.1编写目的 (7) 1.2阅读对象 (7) 1.3术语定义 (7) 1.4参考资料 (7) 1.5图例 (7) 1.6其他 (7) 2.总体设计 (7) 2.1系统目标 (7) 2.2需求规定 (7) 2.2.1系统功能 (7) 2.2.2系统性能 (7) 2.2.3输入输出要求 (7) 2.2.4数据管理能力要求 (7) 2.2.5故障处理要求 (8) 2.2.6其他专门要求 (8) 2.3设计原则 (8) 2.5用户类及特征要求 (8) 2.6功能模块清单 (8) 2.7人工处理过程 (8) 2.8尚未解决的问题 (8) 2.9限制与约束 (8) 3.接口设计 (8) 3.1用户接口 (8) 3.2外部接口 (8) 3.3内部接口 (8) 4.全局数据结构设计 (8) 4.1数据库表名清单 (9) 4.2数据库表之间关系 (9) 4.3数据库表的详细清单 (9) 4.4视图的设计 (9) 4.5数据结构和程序的关系 (9) 4.6主要算法设计 (9) 4.7其他数据结构设计 (9) 5.系统功能说明 (9) 5.1系统功能概述 (9) 5.2系统数据流图 (9) 5.3系统外部接口 (9) 6.用户界面设计 (9) 6.1用户界面设计基本原则 (9) 6.1.1用户界面设计原则 (10) 6.1.2一般交互原则 (10) 6.1.3信息显示原则 (10) 6.1.4数据输入原则 (10) 6.2设计规范 (10) 6.2.1界面规范的总体规定 (10) 6.2.2界面一致性规范 (10) 6.2.3系统响应时间规范 (10) 6.2.4用户帮助设施规范 (10) 6.2.5出错信息和警告规范 (10) 7.运行设计 (10) 7.1运行模块设计 (10) 7.2运行控制 (10) 7.3运行时间 (10) 8.系统出错处理设计 (11) 8.1出错信息 (11) 8.2补救措施 (11) 9.安全性设计 (11) 9.1身份证认证 (11) IP网络拓扑自动发现 自从20世纪90年代以来,越来越多的企业及个人在加入Internet网,使网络规模持续扩大。为了适应越来越多的流量,新节点、新链路不断的被引进到网络上,从而使手工维护很难跟上网络的变化,给网络管理带来困难。 网络由一起工作的大量实体构成,向用户提供某种服务。这些实体功能由硬件和软件执行,一些出现在真实网络中实体的例子有路由器、服务器、普通主机、链路等,所有这些都影响着网络运行的方式及提供给最终用户的服务质量。例如,如果一个应用服务器(Web Server)出现宕机而从网络上剥离下来,那么用户将得不到他们所期望的服务(浏览网页)。提到拓扑发现,一般是指发现完成最终用户服务所涉及到的所有实体,不仅要发现实体,而且要发现实体在网络中所起的作用及实体间互相连接的方式。 网络拓扑对网络管理、网络规划非常有用。例如,网络故障、流量瓶颈等重要信息能直接显示在网络拓扑上,这样网络管理员对当前的网络状况就有一个清楚的认识,对哪里发生了故障一目了然。如果网络拓扑上显示一条链路总处于满负荷传输状态,那么扩大该条链路的容量对提高网络性能将有很大帮助。此外,网络拓扑对网络仿真也十分重要,要仿真能否在现有网络上新开放一种应用,必须首先有正确的网络拓扑。 获得网络拓扑的最简单的方法莫过于让管理员根据实际网络手工绘出其拓扑,但现在网络越来越复杂,越来越庞大,并一直在膨胀,而且实体在网络中担负的功能也越来越复杂,要跟踪这样一个网络需要花费很多时间或精力,而且网络一旦有所改变所有工作必须重做。网络拓扑自动发现正是基于这个原因发展起来的,本文对能用于拓扑发现的一些常用的工具和技术作了简要的介绍,并基于笔者的实践提供了一个简单的算法实现,该算法主要针对同一个管理机构下的IP网络的拓扑自动发现,更复杂的拓扑发现算法可在此基础上进一步扩展。 一、用于拓扑发现的工具 1. Ping 算法概要设计文档 引言 编写目的 本文档为“基于改进实数的遗传算法求解高维问题”算法设计的概要设计说明书,为算法的改进详细的设计的主要依据。读者为项目组成员,使得项目组内成员对整个算法的主要功能以及其概要的实现手段有一个宏观的把握,是算法的一个雏形,同时也是最基本的引导性文档。 编写背景 ①算法名称:基于改进实数的遗传算法求解高维问题 ②算法负责人:周振永 ③参与人员:周振永,杨耀峰,刘俊 ④指导教师:魏静萱 术语及说明 a.遗传算法:是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计 算模型,是一种通过模拟自然进化过程搜索最优解的方法 b.交叉:来自两个不同个体的基因的重新组合 c.变异:在一定情况下基因发生变化 d.适度值:个体适应环境能力的大小 参考资料 1)函数全局优化的改进实数遗传算法,金芬、徐小平 2)实数遗传算法的改进研究,王福林、王吉权、吴昌友、吴秋峰 总体设计 需求设计 在求解连续参数优化问题时,基本的遗传算法(SGA)存在全局优化能力不强、易于陷入局部最优,从而导致求解效率低和求解精度不高等缺陷。与基本遗传算法相比,实数编码的遗传算法不仅收敛速度快,而且精度高,因此基于实数编码的遗传算法得到越来越多的国内外学者的重视和研究,但基本的实数遗传算法不能有效地求解多峰函数的优化问题,在优化问题的维数较高时问题更加突出。为此很多文献提出了改进 运行环境 本算法是在win7 64位系统,4G内存, CPU PC电脑上的VS2012平台下进行测试 基本算法的操作流程 步骤1 初始化种群,在一定范围内,随机产生popsize个个体作为初始种群 步骤2计算种群的目标函数值,排序后并按照选择度选择最低的那一段个体作为之后的变异能够达到最优的主力军,并存储起来 步骤3从种群按一定的交叉比率随机选择m(m是3的倍数)个个体,然后按照交叉算法,以及变异算法进而得到新的m个个体 步骤4将原种群与新生成的这m个个体进行排序并选择按目标值排序得到的最优的按选择度得到的最优的几个个体 步骤5然后将在步骤2中得到的那最低的一段与步骤4种得到的一段进行合并,然后就组成了新的一代 步骤6判断是否满足收敛条件,若满足则输出最优解,否则转向步骤2 西南交通大学2015-2016学年第(一)学期考试试卷 课程代码 3244152 课程名称 算法分析与设计 考试时间 120 分钟 阅卷教师签字: 一、 填空题(每空1分,共15分) 1、 程序是 (1) 用某种程序设计语言的具体实现。 2、 矩阵连乘问题的算法可由 (2) 设计实现。 3、 从分治法的一般设计模式可以看出,用它设计出的程序一般是 (3) 。 4、 大整数乘积算法是用 (4) 来设计的。 5、 贪心算法总是做出在当前看来 (5) 的选择。也就是说贪心算法并不从整体最优考虑,它所做出的选择只是在某种意义上的 (6) 。 6、 回溯法是一种既带有 (7) 又带有 (8) 的搜索算法。 7、 平衡二叉树对于查找算法而言是一种变治策略,属于变治思想中的 (9) 类型。 8、 在忽略常数因子的情况下,O 、Ω和Θ三个符号中, (10) 提供了算法运行时间的一个上界。 9、 算法的“确定性”指的是组成算法的每条 (11) 是清晰的,无歧义的。 10、 问题的 (12) 是该问题可用动态规划算法或贪心算法求解的关键特征。 11、 算法就是一组有穷 (13) ,它们规定了解决某一特定类型问题的 (14) 。 12、 变治思想有三种主要的类型:实例化简,改变表现, (15) 。 二、 选择题(每题2分,共20分) 1、 二分搜索算法是利用( )实现的算法。 A 、分治策略 B 、动态规划法 C 、贪心法 D 、回溯法 2、 衡量一个算法好坏的标准是( )。 A 、运行速度快 B 、占用空间少 C 、 时间复杂度低 D 、代码短 3、 能采用贪心算法求最优解的问题,一般具有的重要性质为:( ) A. 最优子结构性质与贪心选择性质 B .重叠子问题性质与贪心选择性质 C .最优子结构性质与重叠子问题性质 D. 预排序与递归调用 4、 常见的两种分支限界法为( ) 班 级 学 号 姓 名 密封装订线 密封装订线 密封装订线概要设计及详细设计
《算法分析与设计》期末复习题
服务发现与组合相关研究(2)
最全面的概要设计说明书
IP网络拓扑自动发现------------------------------------------------------算法比较经典---已读
算法概要设计文档
算法分析与设计期末考试试卷b卷