ocfs2 oracle集群文件系统常见问题解决方案

Node 0:centos238
Ip:192.168.192.238
Node 1:xen241
Ip:192.168.192.241
Node 2:xen242
Ip:192.168.192.242
Problem 1、
Discription:
[root@xen241 init.d]# service o2cb configure
Configuring the O2CB driver.
This will configure the on-boot properties of the O2CB driver.
The following questions will determine whether the driver is loaded on boot. The current values will be shown in brackets ('[]'). Hitting
Load O2CB driver on boot (y/n) [n]: n
Cluster stack backing O2CB [o2cb]: o2cb
Cluster to start on boot (Enter "none" to clear) [ocfs2]: ocfs2
Specify heartbeat dead threshold (>=7) [301]: 301
Specify network idle timeout in ms (>=5000) [30000]: 30000
Specify network keepalive delay in ms (>=1000) [2000]: 2000
Specify network reconnect delay in ms (>=2000) [2000]: 2000
Writing O2CB configuration: OK
Stopping O2CB cluster ocfs2: OK
Unloading module "ocfs2": OK
Unmounting ocfs2_dlmfs filesystem: OK
Unloading module "ocfs2_dlmfs": OK
Unmounting configfs filesystem: OK
Unloading module "configfs": OK
[root@xen241 init.d]# mount.ocfs2 /dev/sdc1 /mnt/ocfs2/
mount.ocfs2: Unable to access cluster service while trying initialize cluster
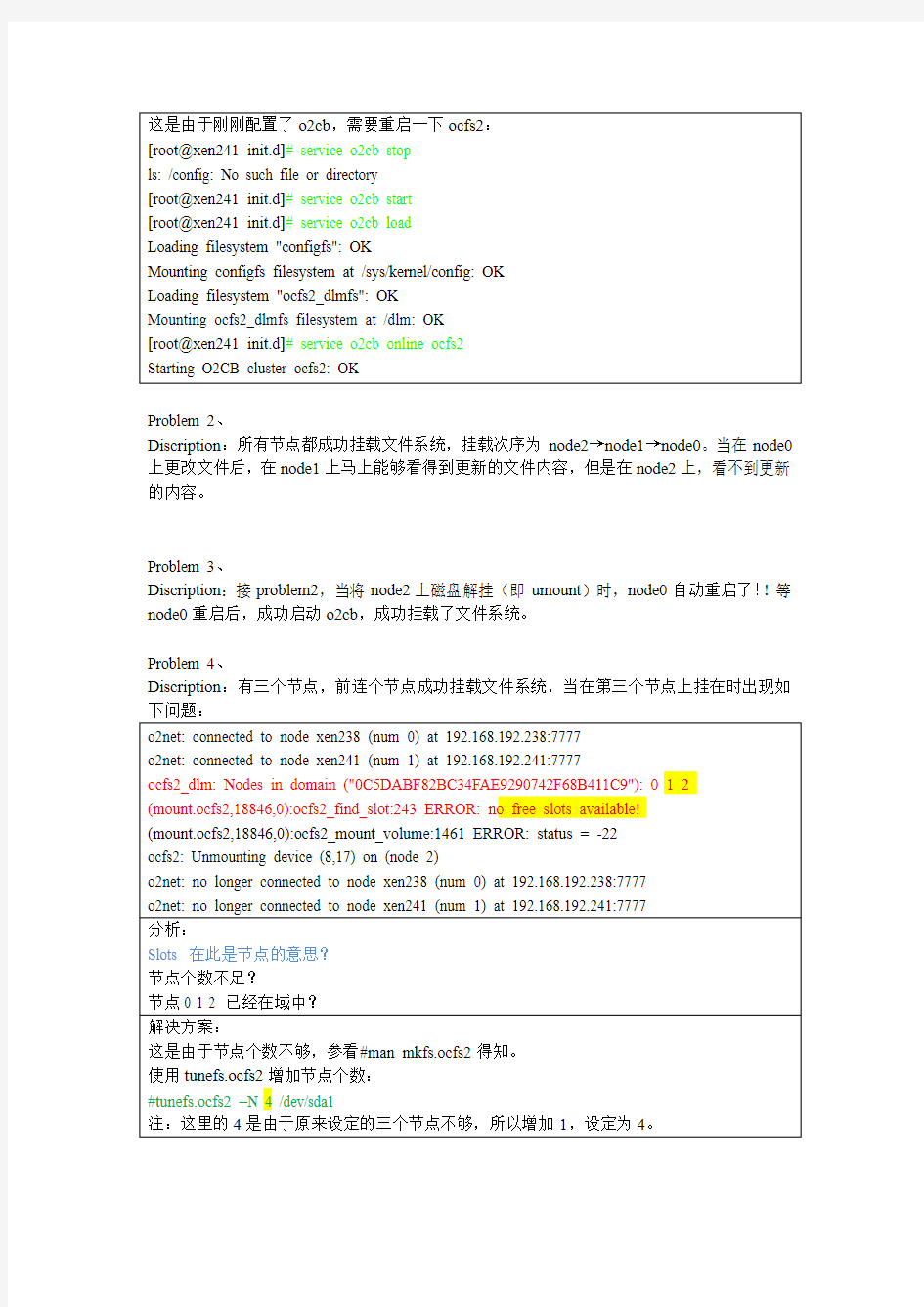
这是由于刚刚配置了o2cb,需要重启一下ocfs2:
[root@xen241 init.d]# service o2cb stop
ls: /config: No such file or directory
[root@xen241 init.d]# service o2cb start
[root@xen241 init.d]# service o2cb load
Loading filesystem "configfs": OK
Mounting configfs filesystem at /sys/kernel/config: OK
Loading filesystem "ocfs2_dlmfs": OK
Mounting ocfs2_dlmfs filesystem at /dlm: OK
[root@xen241 init.d]# service o2cb online ocfs2
Starting O2CB cluster ocfs2: OK
Problem 2、
Discription:所有节点都成功挂载文件系统,挂载次序为node2→node1→node0。当在node0上更改文件后,在node1上马上能够看得到更新的文件内容,但是在node2上,看不到更新的内容。
Problem 3、
Discription:接problem2,当将node2上磁盘解挂(即umount)时,node0自动重启了!!等node0重启后,成功启动o2cb,成功挂载了文件系统。
Problem 4、
Discription:有三个节点,前连个节点成功挂载文件系统,当在第三个节点上挂在时出现如下问题:
o2net: connected to node xen238 (num 0) at 192.168.192.238:7777
o2net: connected to node xen241 (num 1) at 192.168.192.241:7777
ocfs2_dlm: Nodes in domain ("0C5DABF82BC34FAE9290742F68B411C9"): 0 1 2
(mount.ocfs2,18846,0):ocfs2_find_slot:243 ERROR: no free slots available!
(mount.ocfs2,18846,0):ocfs2_mount_volume:1461 ERROR: status = -22
ocfs2: Unmounting device (8,17) on (node 2)
o2net: no longer connected to node xen238 (num 0) at 192.168.192.238:7777
o2net: no longer connected to node xen241 (num 1) at 192.168.192.241:7777
分析:
Slots 在此是节点的意思?
节点个数不足?
节点0 1 2 已经在域中?
解决方案:
这是由于节点个数不够,参看#man mkfs.ocfs2得知。
使用tunefs.ocfs2增加节点个数:
#tunefs.ocfs2 –N 4 /dev/sda1
注:这里的4是由于原来设定的三个节点不够,所以增加1,设定为4。
Problem 5、
Discription:当集群有多个节点时,能够成功挂载第一个节点的文件系统,但是在挂载第二个节点时出现错误,提示如下:
(4801,2):o2net_connect_expired:1583ERROR: no connection established with node 0 after 30.0 seconds, giving up and returning errors.
(5348,2):dlm_request_join:1019 ERROR: status = -107
(5348,2):dlm_try_to_join_domain:1194 ERROR: status = -107
(5348,2):dlm_join_domain:1467 ERROR: status = -107
(5348,2):dlm_register_domain:1702 ERROR: status = -107
(5348,2):ocfs2_dlm_init:2547 ERROR: status = -107
(5348,2):ocfs2_mount_volume:1253 ERROR: status = -107
ocfs2: Unmounting device (8,129) on (node 2)
分析:这里是由于防火墙的原因,关闭防火墙就能成功挂载了
解决方案:
1、关闭防火墙
马上生效:
#service iptables stop 停用防火墙
#service iptables start 启用防火墙
2、为ocfs2打开需要的端口(推荐)
在/etc/sysconfig/iptables里加入如下两行:(注意添加的位置)
-A INPUT -p tcp -m state --state NEW -m tcp --dport 7777 -j ACCEPT
-A OUTPUT -p tcp -m state --state NEW -m tcp --dport 7777 -j ACCEPT
Problem 6、
Discription:昨天晚上三个节点正常挂载上后,未做任何改变,上午也没出错,下午14:40来了发现节点0上满屏被刷成如下的错误,关机也不行,且提示不能卸载ocfs2文件系统。最后一直按着电源,强行关机!
end_request:I/O error, dev sda, sector 1855
(ksoftirqd/1,6,1):o2hb_bio_end_io:237 ERROR: IO Error -5
(o2hb-0C5DABFB2B,5734,1):o2hb_do_disk_heartbeat:768 ERROR: status = -5
分析:
开机后iscsi盘都未能自动挂载!手动挂载→ip通
问题解决:
Node0 的网线掉了。插上网线,登录iscsi设备,挂载ocfs2。没问题了!!
Problem 7、
Discription:改变卷标,使用tunefs.ocfs2 –L “label name” device 的命令来改变卷标,给出如下错误提示:
[root@xen241 ~]#tunefs.ocfs2 –L “forxen2” /dev/sda2
Tunefs.ocfs2: Trylock failed while opening device “/dev/sda2”
分析:
由lock想到是否要只能在一个卷上更改,于是,毅然将这个分区在其他节点上卸载了
(umount)。但是还是出现在样的问题,难道???
于是在将所有节点上的此分区都卸载,再更改,成功!
解决:
卷标不能在线更改,必须将这个分区所有挂载都umount掉才能更改!
Problem 8、
Discription:node1、2均已挂载,node0挂载出现如下问题:
[root@xen238 ~]# mount.ocfs2 /dev/sda1 /mnt/ocfs2-1
mount.ocfs2: Transport endpoint is not connected while mounting /dev/sda1 on /mnt/ocfs2-1. Check 'dmesg' for more information on this error.
[root@xen238 ~]# dmesg
(o2net,30122,0):o2net_connect_expired:1664 ERROR: no connection established with node 1 after 30.0 seconds, giving up and returning errors.
(o2net,30122,0):o2net_connect_expired:1664 ERROR: no connection established with node 2 after 30.0 seconds, giving up and returning errors.
(mount.ocfs2,31014,0):dlm_request_join:1036 ERROR: status = -107
(mount.ocfs2,31014,0):dlm_try_to_join_domain:1210 ERROR: status = -107
(mount.ocfs2,31014,0):dlm_join_domain:1488 ERROR: status = -107
(mount.ocfs2,31014,0):dlm_register_domain:1754 ERROR: status = -107
(mount.ocfs2,31014,0):ocfs2_dlm_init:2808 ERROR: status = -107
(mount.ocfs2,31014,0):ocfs2_mount_volume:1447 ERROR: status = -107
ocfs2: Unmounting device (8,1) on (node 0)
Problem 9、
Discription:node0、node2均已挂载成功两个分区,node1也开机自动挂载1个分区,但是令一个分区却不能自动挂载,手动挂在时提示如下错误:
[root@xen241 ISO]# mount /dev/sdb2 /mnt/ocfs2-2
mount.ocfs2: Unknown code B 0 while mounting /dev/sdb2 on /mnt/ocfs2-2. Check 'dmesg' for more information on this error.
[root@xen241 ISO]# dmesg
(mount.ocfs2,4420,0):dlm_join_domain:1468 Timed out joining dlm domain 8B0DD282CCE54ADBBD556D42D88B11ED after 91200 msecs
ocfs2: Unmounting device (8,18) on (node 1)
解决方案:
将不能挂载的分区在各个节点上卸载后重新挂载一次,解决了!
Problem 10、
Discription:在IBM服务器机群上安装ocfs2,两个节点,安装后启动时出现如下错误:[root@cnode036 ocfs2]# service o2cb online
Starting O2CB cluster ocfs2: Failed
Cluster ocfs2 created
Node cnode025 added
o2cb_ctl: Internal logic failure while adding node cnode036
Stopping O2CB cluster ocfs2: OK
[root@cnode036 ocfs2]#
仔细查看cluster.conf文件发现两个节点的number都是0。
解决方法:
当然是将后一个number改成1了。OK!
Problem 11、(没解决呢)
Discription:两个不同网段的电脑想要挂载同一块存储。
目前想到两个办法:
方法1(目前觉得行不通,继续测试中):
创建两个不同的集群,但是若使用了相同的集群name,会出现冲突问题,因为在你还没挂载分区前,使用mounted.ocfs2 –f命令查看到的是另一个集群上的节点的挂载情况。
所以想到是使用不同的集群名字。但是遇到了另一个问题(problem 12)。解决这个problem12之后,使用mounted.ocfs2 –f查看到的还是另一个集群上节点的挂载情况,因为这个新的集群根本就还没有开始挂载存储的!
方法2:公网、私网IP
方法3:木头在QQ上说的防火墙
查看NAT映射????
Problem 12、
Discription:为集群改另一个名字(非默认名),出现如下错误:
[root@cnode036 iscsi]# service o2cb configure
Configuring the O2CB driver.
This will configure the on-boot properties of the O2CB driver.
The following questions will determine whether the driver is loaded on
boot. The current values will be shown in brackets ('[]'). Hitting
will abort.
Load O2CB driver on boot (y/n) [n]: y
Cluster stack backing O2CB [o2cb]:
Cluster to start on boot (Enter "none" to clear) [ocfs2]: ocfs22
Specify heartbeat dead threshold (>=7) [301]:
Specify network idle timeout in ms (>=5000) [30000]:
Specify network keepalive delay in ms (>=1000) [2000]:
Specify network reconnect delay in ms (>=2000) [2000]:
Writing O2CB configuration: OK
Starting O2CB cluster ocfs22: Failed
o2cb_ctl: Memory allocation failed while setting cluster name
Stopping O2CB cluster ocfs22: OK
特殊字体为新的集群名字。
为集群命名!
解决办法:
Before you change a cluster name, you missed one important step, you
need to offline the cluster. So the right steps is:
1. /etc/init.d/o2cb offline
2. change /etc/ocfs2/cluster.conf
3. run /etc/init.d/o2cb configure and change the name.
Now, since you have already changed the configuration file(step 2 and
3), there are 2 different ways to get the right cluster up. One is
"umount the ocfs2 volume and reboot the box.", this is simple.
The other is that you can just renamed the cluster name(in cluster.conf
and o2cb configure) back to the name in your /config/cluster and then do
the steps I described above(1,2,3).
注意:这里需要注意cluster.conf文件中cluster项中的name和所有node项中的cluster必须一致!
Problem 13、
Discription:在IBM集群上挂载ocfs2存储
Vendor: IBM Model: 2145 Rev: 0000
Type: Direct-Access ANSI SCSI revision: 06
SCSI device sdc: 1048576000 512-byte hdwr sectors (536871 MB)
sdc: Write Protect is off
sdc: Mode Sense: 97 00 10 08
SCSI device sdc: drive cache: write through w/ FUA
SCSI device sdc: 1048576000 512-byte hdwr sectors (536871 MB)
sdc: Write Protect is off
sdc: Mode Sense: 97 00 10 08
SCSI device sdc: drive cache: write through w/ FUA
sdc: sdc1 sdc2 sdc3 sdc4 < sdc5 >
sd 16:0:0:0: Attached scsi disk sdc
sd 16:0:0:0: Attached scsi generic sg3 type 0
OCFS2 1.2.9 Mon May 19 11:42:54 PDT 2008 (build a693806cb619dd7f225004092b675ede)
(7553,0):ocfs2_initialize_super:1455 ERROR: couldn't mount because of unsupported optional features (50).
(7553,0):ocfs2_fill_super:578 ERROR: status = -22
ocfs2: Unmounting device (8,37) on (node 255)
对于第二个错,需要在格式化文件系统的时候添加其他的参数,所以这里重新执行格式化就行了。
[root@cnode025 sbin]# mkfs.ocfs2 -b 4K -C 32K -L forxen3 –N 3 /dev/sdc1 --fs-feature-level=max-compat
注意后面特殊字体部分,格式化文件系统完成后便可以挂载了!这里是因为安装的ocfs2的版本较低,需要使用这个参数。查看man mkfs.ocfs2 得到:
--fs-feature-level=feature-level
Choose from a set of pre-determined file-system features.
This option is designed to allow users to conveniently
choose a set of file system features which fits their
needs. There is no downside to trying a set of features
which your module might not support - if it won鈚mount the
new file system simply reformat at a lower level. Feature
levels can be fine-tuned via the --fs-features option. Cur-
rently, there are 3 types of feature levels:
max-compat
Chooses fewer features but ensures that the
file system can be mounted from older versions
of the OCFS2 module.
分布式文件系统Hadoop HDFS与传统文件系统Linux FS的比较与分析
6苏州大学学报(工科版)第30卷 图1I-IDFS架构 2HDFS与LinuxFS比较 HDFS的节点不管是DataNode还是NameNode都运行在Linux上,HDFS的每次读/写操作都要通过LinuxFS的读/写操作来完成,从这个角度来看,LinuxPS是HDFS的底层文件系统。 2.1目录树(DirectoryTree) 两种文件系统都选择“树”来组织文件,我们称之为目录树。文件存储在“树叶”,其余的节点都是目录。但两者细节结构存在区别,如图2与图3所示。 一二 Root \ 图2ItDFS目录树围3LinuxFS目录树 2.2数据块(Block) Block是LinuxFS读/写操作的最小单元,大小相等。典型的LinuxFSBlock大小为4MB,Block与DataN-ode之间的对应关系是固定的、天然存在的,不需要系统定义。 HDFS读/写操作的最小单元也称为Block,大小可以由用户定义,默认值是64MB。Block与DataNode的对应关系是动态的,需要系统进行描述、管理。整个集群来看,每个Block存在至少三个内容一样的备份,且一定存放在不同的计算机上。 2.3索引节点(INode) LinuxFS中的每个文件及目录都由一个INode代表,INode中定义一组外存上的Block。 HDPS中INode是目录树的单元,HDFS的目录树正是在INode的集合之上生成的。INode分为两类,一类INode代表文件,指向一组Block,没有子INode,是目录树的叶节点;另一类INode代表目录,没有Block,指向一组子INode,作为索引节点。在Hadoop0.16.0之前,只有一类INode,每个INode都指向Block和子IN-ode,比现有的INode占用更多的内存空间。 2.4目录项(Dentry) Dentry是LinuxFS的核心数据结构,通过指向父Den姆和子Dentry生成目录树,同时也记录了文件名并 指向INode,事实上是建立了<FileName,INode>,目录树中同一个INode可以有多个这样的映射,这正是连
【大数据软件】Gcluster集群的文件系统
1 理论知识 1.1 概念 1.1.1 全局统一命名空间的定义 全局统一命名空间将磁盘和内存资源集成一个单一的虚拟存储池,对上层用户屏蔽了底层的物理硬件。 1.1.2 GlusterFS的定义 GlusterFS是一套可扩展的开源群集文件系统,并能够轻松地为客户提供全局命名空间、分布式前端以及高达数百PB级别的扩展性。 1.1.3 元数据的定义 元数据,是用来描述一个给定的文件或是区块在分布式文件系统中所处的位置。注:元数据时网络附加存储解决方案在规模化方面的致命弱点,因其所有节点都必须不断与服务器(或集群组)保持联系以延续真个群集的元数据,故增加了额外的开销,致使硬件在等待响应元数据请求过程中而效率低下。 1.2 数据定位技术 Gluster通过其自有的弹性Hash算法可计算出文件在群集中每个节点的位置, 而无需联系群集内的其他节点,从而降低了追踪元数据的变化而带来额外的开销。 1.2.1 数据访问流程 - 根据输入的文件路径和文件名计算hash值 - 根据hash值在群集中选择子卷(存储服务器),进行文件定位 - 对所选择的子卷进行数据访问 1.2.2 Davies-Meyer算法 Gluster使用Davies-Meyer算法计算文件名的hash值,获得一个32位整数,算法特点如下: - 非常好的hash分布性
- 高效率的计算 1.3 Gluster的架构 1.3.1 存储服务器(Brick Server) - 存储服务器主要提供基本的数据存储功能 - 最终通过统一调度策略分布在不同的存储服务器上(通过Glusterfsd来处理数据服务请求) - 数据以原始格式直接存储于服务器本地文件系统(EXT3/EXT4/XFS/ZFS 等) 1.3.2 客户端和存储网关(NFS/Samba)
Tomcat集群与负载均衡
Tomcat集群与负载均衡(转载) 在单一的服务器上执行WEB应用程序有一些重大的问题,当网站成功建成并开始接受大量请求时,单一服务器终究无法满足需要处理的负荷量,所以就有点显得有点力不从心了。另外一个常见的问题是会产生单点故障,如果该服务器坏掉,那么网站就立刻无法运作了。不论是因为要有较佳的扩充性还是容错能力,我们都会想在一台以上的服务器计算机上执行WEB应用程序。所以,这时候我们就需要用到集群这一门技术了。 在进入集群系统架构探讨之前,先定义一些专门术语: 1. 集群(Cluster):是一组独立的计算机系统构成一个松耦合的多处理器系统,它们之间通过网络实现进程间的通信。应用程序可以通过网络共享内存进行消息传送,实现分布式计算机。 2. 负载均衡(Load Balance):先得从集群讲起,集群就是一组连在一起的计算机,从外部看它是一个系统,各节点可以是不同的操作系统或不同硬件构成的计算机。如一个提供Web服务的集群,对外界来看是一个大Web服务器。不过集群的节点也可以单独提供服务。 3. 特点:在现有网络结构之上,负载均衡提供了一种廉价有效的方法扩展服务器带宽和增加吞吐量,加强网络数据处理能力,提高网络的灵活性和可用性。集群系统(Cluster)主要解决下面几个问题: 高可靠性(HA):利用集群管理软件,当主服务器故障时,备份服务器能够自动接管主服务器的工作,并及时切换过去,以实现对用户的不间断服务。 高性能计算(HP):即充分利用集群中的每一台计算机的资源,实现复杂运算的并行处理,通常用于科学计算领域,比如基因分析,化学分析等。 负载平衡:即把负载压力根据某种算法合理分配到集群中的每一台计算机上,以减轻主服务器的压力,降低对主服务器的硬件和软件要求。 目前比较常用的负载均衡技术主要有: 1. 基于DNS的负载均衡 通过DNS服务中的随机名字解析来实现负载均衡,在DNS服务器中,可以为多个不同的地址配置同一个名字,而最终查询这个名字的客户机将在解析这个名字时得到其中一个地址。因此,对于同一个名字,不同的客户机会得到不同的地址,他们也就访问不同地址上的Web服务器,从而达到负载均衡的目的。 2. 反向代理负载均衡(如Apache+JK2+Tomcat这种组合) 使用代理服务器可以将请求转发给内部的Web服务器,让代理服务器将请求均匀地转发给多台内部Web服务器之一上,从而达到负载均衡的目的。这种代理方式与普通的代理方式有所不同,标准代理方式是客户使用代理访问多个外部Web服务器,而这种代理方式是多个客户使用它访问内部Web服务器,因此也被称为反向代理模式。 3. 基于NAT(Network Address Translation)的负载均衡技术(如Linux Virtual Server,简称LVS)
多媒体集群指挥调度系统
多媒体集群指挥调度系统公安系统解决方案 杭州溢远网络技术有限公司 2014年1月
目录
第一章概述 公安机关是政府维护社会稳定,保障人民生命财产安全的重要职能部门,承担了预防、制止犯罪、打击社会恶势力、反恐、管理交通、消防、危险物品等重要的职责。 公安人员在办理案件的过程中,由于犯罪分子都有一定的反侦查的手段和措施,目前主要的通讯手段还是模拟集群、固定视频监控和少量的单兵移动视频为主,由于技术的限制,这些系统都具有一定的使用局限性。 随着城市化进程的不断扩大,城区高楼大厦对信号的屏蔽作用日趋严重。同时,一些偏远乡镇在融入城市化进程中的同时并没有被已经建设的公安专网覆盖,因此在新兴城市的城区外围有很多分散的地方,传统集群覆盖的范围一般都在老城区范围以内,很难形成一套整体统一的指挥。 在一些重大安全保障和大案要案的调查取证中,一般都需要公安、海关、武警等多部门联合行动,执行一次联合执法任务都需要做大量的协助和前期准备工作。负责统一指挥的领导或首长都需要对现场情况有充分的了解和掌握,才能做出准确的判断和指挥,通常情况下现有的监控手段还无法满足这样对机动性要求很高,进行联动指挥和多警种信息共享的行动。另外现场实时视频情况及照片的及时保存,作为对犯罪分子定罪的依据也极为重要。
公安人员办理相关犯罪案件的时候,迫切需要一种能同时提供多种业务,无线信号覆盖范围广泛,使用时无地域限制,信号盲点少,分组容量大,终端保密性高,抗干扰能力强的系统设备来满足公安侦办案件时对通讯的保障和其他功能的需要。在功能方面,则希望能具备抓拍现场图片和视频片段的能力,以及动态视频采集的能力,为日后案件侦查、侦破、人员抓捕以及最终定罪提供可靠的法律证据,同时也希望能满足隐蔽拍摄和位置信息定位,让 指挥中心随时了解人员的位置及状态信息,使得指挥决策更加快捷、直观、有效。 目前,公安部门在道路交通、治安防范、巡访管控、维稳处突、信息导侦、大型安保、特警执勤等各方面,有同步化、三维化、可视化的迫切需求。通过本系统的建设将为用户建立一套“听得到、看得见、查的着”的融合通信指挥调度平台。 1.1应用场景 公安机关保卫国家安全与维护社会治安秩序的任务,主要是通过公安专业工作实现的,公安专业工作主要包括:刑事执法工作、治安行政管理工作、保卫工作、警卫工作。结合公安专业工作内容,系统主要有以下几个运用场景: 1.1.1日常公开执法 路面交巡警在公开执法过程中,利用系统平台和车载手持终端系
Hadoop分布式文件系统:架构和设计
Hadoop分布式文件系统:架构和设计 引言 (2) 一前提和设计目标 (2) 1 hadoop和云计算的关系 (2) 2 流式数据访问 (2) 3 大规模数据集 (2) 4 简单的一致性模型 (3) 5 异构软硬件平台间的可移植性 (3) 6 硬件错误 (3) 二HDFS重要名词解释 (3) 1 Namenode (4) 2 secondary Namenode (5) 3 Datanode (6) 4 jobTracker (6) 5 TaskTracker (6) 三HDFS数据存储 (7) 1 HDFS数据存储特点 (7) 2 心跳机制 (7) 3 副本存放 (7) 4 副本选择 (7) 5 安全模式 (8) 四HDFS数据健壮性 (8) 1 磁盘数据错误,心跳检测和重新复制 (8) 2 集群均衡 (8) 3 数据完整性 (8) 4 元数据磁盘错误 (8) 5 快照 (9)
引言 云计算(cloud computing),由位于网络上的一组服务器把其计算、存储、数据等资源以服务的形式提供给请求者以完成信息处理任务的方法和过程。在此过程中被服务者只是提供需求并获取服务结果,对于需求被服务的过程并不知情。同时服务者以最优利用的方式动态地把资源分配给众多的服务请求者,以求达到最大效益。 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS 能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。 一前提和设计目标 1 hadoop和云计算的关系 云计算由位于网络上的一组服务器把其计算、存储、数据等资源以服务的形式提供给请求者以完成信息处理任务的方法和过程。针对海量文本数据处理,为实现快速文本处理响应,缩短海量数据为辅助决策提供服务的时间,基于Hadoop云计算平台,建立HDFS分布式文件系统存储海量文本数据集,通过文本词频利用MapReduce原理建立分布式索引,以分布式数据库HBase 存储关键词索引,并提供实时检索,实现对海量文本数据的分布式并行处理.实验结果表 明,Hadoop框架为大规模数据的分布式并行处理提供了很好的解决方案。 2 流式数据访问 运行在HDFS上的应用和普通的应用不同,需要流式访问它们的数据集。HDFS的设计中更多的考虑到了数据批处理,而不是用户交互处理。比之数据访问的低延迟问题,更关键的在于数据访问的高吞吐量。 3 大规模数据集 运行在HDFS上的应用具有很大的数据集。HDFS上的一个典型文件大小一般都在G字节至T字节。因此,HDFS被调节以支持大文件存储。它应该能提供整体上高的数据传输带宽,能在一个集群里扩展到数百个节点。一个单一的HDFS实例应该能支撑数以千万计的文件。
RedHat GFS 集群文件系统入门和进阶 资源帖
https://www.360docs.net/doc/e76907448.html,/viewthread.php?tid=777867&extra=page %3D1%26filter%3Ddigest GFS = RedHat Global File System GFS 的入门必读 以下为入门必看 - GFS 的介绍 https://www.360docs.net/doc/e76907448.html,/solutions/gfs/ - RedHat杂志关于GFS的最佳实践https://www.360docs.net/doc/e76907448.html,/magazine/009jul05/features/gfs_practices/ - RedHat杂志关于GFS和以太网和SAN光纤存储网的介绍https://www.360docs.net/doc/e76907448.html,/magazine/008jun05/features/gfs/ - RedHat杂志关于企业如何用GFS来存储数据的介绍https://www.360docs.net/doc/e76907448.html,/magazine/009jul05/features/gfs_overview/ - RedHat杂志关于用GFS来做数据共享的介绍https://www.360docs.net/doc/e76907448.html,/magazine/006apr05/features/gfs/ - RedHat杂志关于RHCS集群的介绍https://www.360docs.net/doc/e76907448.html,/magazine/009jul05/features/cluster/ - RedHat 官方的GFS 概述文档https://www.360docs.net/doc/e76907448.html,/whitepapers/rha/gfs/GFS_INS0032US.pdf - RedHat 关于GFS扩展性的介绍 https://www.360docs.net/doc/e76907448.html,/solutions/scaleout/ - RedHat和HP提供的HP MC/SG + GFS的方案介绍https://www.360docs.net/doc/e76907448.html,/promo/hp_serviceguard/ (注意右侧的多个连接所指向的文档) - GFS 6.1U3版本的Release notes https://www.360docs.net/doc/e76907448.html,/docs/manua ... HEL4U3-relnotes.txt - GFS 6.1U2版本的Release notes https://www.360docs.net/doc/e76907448.html,/docs/manua ... HEL4U2-relnotes.txt - GFS 6.1的Release notes https://www.360docs.net/doc/e76907448.html,/docs/manua ... FS_6_1-relnotes.txt - GFS 6.1的Admin Guide https://www.360docs.net/doc/e76907448.html,/docs/manuals/csgfs/browse/rh-gfs-en/ - 本版suran007 同学提供的"GFS6.1 ON RHAS4 U2安装文档" https://www.360docs.net/doc/e76907448.html,/viewthr ... &extra=page%3D1
数据库负载均衡解决方案
双节点数据库负载均衡解决方案 问题的提出? 在SQL Server数据库平台上,企业的数据库系统存在的形式主要有单机模式和集群模式(为了保证数据库的可用性或实现备份)如:失败转移集群(MSCS)、镜像(Mirror)、第三方的高可用(HA)集群或备份软件等。伴随着企业的发展,企业的数据量和访问量也会迅猛增加,此时数据库就会面临很大的负载和压力,意味着数据库会成为整个信息系统的瓶颈。这些“集群”技术能解决这类问题吗?SQL Server数据库上传统的集群技术 Microsoft Cluster Server(MSCS) 相对于单点来说Microsoft Cluster Server(MSCS)是一个可以提升可用性的技术,属于高可用集群,Microsoft称之为失败转移集群。 MSCS 从硬件连接上看,很像Oracle的RAC,两个节点,通过网络连接,共享磁盘;事实上SQL Server 数据库只运行在一个节点上,当出现故障时,另一个节点只是作为这个节点的备份; 因为始终只有一个节点在运行,在性能上也得不到提升,系统也就不具备扩展的能力。当现有的服务器不能满足应用的负载时只能更换更高配置的服务器。 Mirror 镜像是SQL Server 2005中的一个主要特点,目的是为了提高可用性,和MSCS相比,用户实现数据库的高可用更容易了,不需要共享磁盘柜,也不受地域的限制。共设了三个服务器,第一是工作数据库(Principal Datebase),第二个是镜像数据库(Mirror),第三个是监视服务器(Witness Server,在可用性方面有了一些保证,但仍然是单服务器工作;在扩展和性能的提升上依旧没有什么帮助。
XP不能访问Win7系统下共享文件的解决方法(图解)_百度文库
XP不能访问Win7系统下共享文件的解决方法 许多局域网用户发现,在安装了Windows7之后,网络中的文件夹相互共享会出现不少问题,经常会出现安装XP系统的电脑无法访问Windows7的共享文件夹,有些虽然能看到Windows7下的共享目录,但是一旦进入目录,就会提示没有访问权限。经过笔者近几天的苦心研究,终于发现只需要几步修改,就能让XP和Windows7之间进行互通,不再会出现共享文件夹无法访问的情况。 首先,进入到“网络和共享中心”进行设置,将Windows 的防火墙关闭。虽然这样做会有不安全的风险,但是为了能实现不同系统间的相互访问,也只能不得已而为之了。 在关闭了Windows防火墙后,下一步要进入到防火墙设置界面左边的“高级设置”中,对“入站规则”和“出站规则”进行修改。在这两个规则中,分别找到“文件和打印机共享”选项,并且将其全部选项设定成“Allow all connection”。 ●关闭Windows7自带的网络防火墙 在进行完以上设定后,要进入到“用户帐户”里,开启“Guest”帐户,并且在系统服务里,开启对应的共享功能。至此,共享的设定已经完成得差不多了。最后是对所对应的共享文件夹进行设置。如果熟悉XP共享设置的用户,基本上可以很方便的对以下设置进行操作,其Windows7设置共享的理念和XP几乎是相同的,有所区别的只是设置的路径有所不同。 第一步选择要共享的文件夹,单击右键选择“属性”,在“共享”的选项卡里选择“高级共享”,并且将“共享此文件夹”前的钩打上,随后在“权限”中依次点击“添加”——“高级”——“立即查找”。然后在查找的结果中选择“Everyone”以及“Guest”并确认即可。
WIN7和XP系统在局域网文件共享设置方法
WIN7/XP系统在局域网文件共享设置方法 现代家庭,多数都有2台以上电脑,我家就有两台笔记本,一台台式机。笔记本因为买得晚通常配置较高,一般装的是WIN7系统,而台式机配置因为买的早配置相对较低,一般装的是XP系统。有时候想把台式机中的文件移到笔记本上,亦或是把笔记本中的文件移到台式机上,如果文件小用个U盘也挺方便,如果是几个G或者几十个G的话你会不会觉得相当纠结?学习了本文的设置方法你就再也不需要纠结了。好了,废话少说,现在开始学习局域网中文件共享的设置方法。 Windows XP和Windows 7系统的计算机通过局域网互联时,经常出现安装Windows XP系统的计算机很难在网上邻居中找到安装Windows 7系统的计算机的情况,反之也一样。具体表现就是网上邻居中可以显示计算机名但无法访问,或者根本找不到对方的计算机。 问题分析 在访问权限方面,WIN7确实做了诸多限制,通过对WindowsXP 和Windows7操作系统的设置,可以实现Windows 7 和Windows XP系统的局域网互连互通以及文件共享。 设置前必须先要关闭系统的防火墙(Mcafee、诺顿等)。若必须使用防火墙功能,建议用户咨询一下杀毒软件公司具体的局域网的权限设置方法。
解决方案 一、WindowsXP系统的设置方法: 设置共享可能对你电脑中的资料安全有负面影响,自己要对保密、安全、共享之间作个平衡。为了提高安全性,建议使用NTFS 磁盘格式,并对隐私文件设置读写权限。 1、WIN7系统设置方法: 选择要共享的文件夹 电脑常识 右键点击文件夹属性
设置文件夹高级共享选项
分布式文件存储方案
1DFS系统 (DFS) 是AFS的一个版本,作为开放软件基金会(OSF)的分布 分布式文件系统 式计算环境(DCE)中的文件系统部分。 如果文件的访问仅限于一个用户,那么分布式文件系统就很容易实现。可惜的是,在许多网络环境中这种限制是不现实的,必须采取并发控制来实现文件的多用户访问,表现为如下几个形式: 只读共享任何客户机只能访问文件,而不能修改它,这实现起来很简单。 受控写操作采用这种方法,可有多个用户打开一个文件,但只有一个用户进行写修改。而该用户所作的修改并不一定出现在其它已打开此文件的用户的屏幕上。 并发写操作这种方法允许多个用户同时读写一个文件。但这需要操作系统作大量的监控工作以防止文件重写,并保证用户能够看到最新信息。这种方法即使实现得很好,许多环境中的处理要求和网络通信量也可能使它变得不可接受。 NFS和AFS的区别 NFS和AFS的区别在于对并发写操作的处理方法上。当一个客户机向服务器请求一个文件(或数据库记录),文件被放在客户工作站的高速缓存中,若另一个用户也请求同一文件,则它也会被放入那个客户工作站的高速缓存中。当两个客户都对文件进行修改时,从技术上而言就存在着该文件的三个版本(每个客户机一个,再加上服务器上的一个)。有两种方法可以在这些版本之间保持同步: 无状态系统在这个系统中,服务器并不保存其客户机正在缓存的文件的信息。因此,客户机必须协同服务器定期检查是否有其他客户改变了自己正在缓存的文件。这种方法在大的环境中会产生额外的LAN通信开销,但对小型LAN来说,这是一种令人满意的方法。NFS 就是个无状态系统。 回呼(Callback)系统在这种方法中,服务器记录它的那些客户机的所作所为,并保留它们正在缓存的文件信息。服务器在一个客户机改变了一个文件时使用一种叫回叫应答(callbackpromise)的技术通知其它客户机。这种方法减少了大量网络通信。AFS(及OSFDCE的DFS)就是回叫系统。客户机改变文件时,持有这些文件拷贝的其它客户机就被回叫并通知这些改变。 无状态操作在运行性能上有其长处,但AFS通过保证不会被回叫应答充斥也达到了这一点。方法是在一定时间后取消回叫。客户机检查回叫应答中的时间期限以保证回叫应答是当前有效的。回叫应答的另一个有趣的特征是向用户保证了文件的当前有效性。换句话说,若
集群的负载均衡技术综述
集群的负载均衡技术综述 摘要:当今世界,无论在机构内部的局域网还是在广域网如Internet上,信息处理量的增长都远远超出了过去最乐观的估计,即使按照当时最优配置建设的网络,也很快会感到吃不消。如何在完成同样功能的多个网络设备之间实现合理的业务量分配,使之不致于出现一台设备过忙、而别的设备却未充分发挥处理能力的情况,负载均衡机制因此应运而生。本组在课堂上讲解了《集群监控与调度》这一课题,本人在小组内负责负载均衡部分内容,以及PPT的制作。 关键词:负载均衡集群网络计算机 一、前言 负载均衡建立在现有网络结构之上,它提供了一种廉价有效的方法扩展服务器带宽和增加吞吐量,加强网络数据处理能力,提高网络的灵活性和可用性。它主要完成以下任务:解决网络拥塞问题,服务就近提供,实现地理位置无关性;为用户提供更好的访问质量;提高服务器响应速度;提高服务器及其他资源的利用效率;避免了网络关键部位出现单点失效。 其实,负载均衡并非传统意义上的“均衡”,一般来说,它只是把有可能拥塞于一个地方的负载交给多个地方分担。如果将其改称为“负载分担”,也许更好懂一些。说得通俗一点,负载均衡在网络中的作用就像轮流值日制度,把任务分给大家来完成,以免让一个人累死累活。不过,这种意义上的均衡一般是静态的,也就是事先确定的“轮值”策略。 与轮流值日制度不同的是,动态负载均衡通过一些工具实时地分析数据包,掌握网络中的数据流量状况,把任务合理分配出去。结构上分为本地负载均衡和地域负载均衡(全局负载均衡),前一种是指对本地的服务器集群做负载均衡,后一种是指对分别放置在不同的地理位置、在不同的网络及服务器群集之间作负载均衡。 服务器群集中每个服务结点运行一个所需服务器程序的独立拷贝,诸如Web、FTP、Telnet或e-mail服务器程序。对于某些服务(如运行在Web服务器上的那些服务)而言,程序的一个拷贝运行在群集内所有的主机上,而网络负载均衡则将工作负载在这些主机间进行分配。对于其他服务(例如e-mail),只有一台主机处理工作负载,针对这些服务,网络负载均衡允许网络通讯量流到一个主机上,并在该主机发生故障时将通讯量移至其他主机。 二、负载均衡技术实现结构 在现有网络结构之上,负载均衡提供了一种廉价有效的方法扩展服务器带宽和增加吞吐量,加强网络数据处理能力,提高网络的灵活性和可用性。它主要完成以下任务: 1.解决网络拥塞问题,服务就近提供,实现地理位置无关性 2.为用户提供更好的访问质量 3.提高服务器响应速度
负载均衡软件实现与硬件实现方案
该文档是word2003—word2007兼容版 软件、硬件负载均衡部署方案 目录 1、硬件负载均衡之F5部署方案 (2) 1.1网络拓扑结构 (2) 1.2反向代理部署方式 (3) 2软件负载均衡方案 (4) 2.1负载均衡软件实现方式之一- URL重定向方式 (4) 2.2负载均衡软件实现方式之二- 基于DNS (5) 2.3负载均衡软件实现方式之三- LVS (8) 2.4负载均衡软件实现方式之四- 专业负载均衡软件 (16) 总结: (16)
1、硬件负载均衡之F5部署方案 对于所有的对外服务的服务器,均可以在BIG-IP上配置Virtual Server实现负载均衡,同时BIG-IP可持续检查服务器的健康状态,一旦发现故障服务器,则将其从负载均衡组中摘除。 BIG-IP利用虚拟IP地址(VIP由IP地址和TCP/UDP应用的端口组成,它是一个地址)来为用户的一个或多个目标服务器(称为节点:目标服务器的IP地址和TCP/UDP应用的端口组成,它可以是internet的私网地址)提供服务。因此,它能够为大量的基于TCP/IP的网络应用提供服务器负载均衡服务。根据服务类型不同分别定义服务器群组,可以根据不同服务端口将流量导向到相应的服务器。BIG-IP连续地对目标服务器进行L4到L7合理性检查,当用户通过VIP请求目标服务器服务时,BIG-IP根椐目标服务器之间性能和网络健康情况,选择性能最佳的服务器响应用户的请求。如果能够充分利用所有的服务器资源,将所有流量均衡的分配到各个服务器,我们就可以有效地避免“不平衡”现象的发生。 利用UIE+iRules可以将TCP/UDP数据包打开,并搜索其中的特征数据,之后根据搜索到的特征数据作相应的规则处理。因此可以根据用户访问内容的不同将流量导向到相应的服务器,例如:根据用户访问请求的URL将流量导向到相应的服务器。 1.1网络拓扑结构 网络拓扑结构如图所示:
3种分布式文件系统
第一部分CEPH 1.1 特点 Ceph最大的特点是分布式的元数据服务器通过CRUSH,一种拟算法来分配文件的locaiton,其核心是 RADOS(resilient automatic distributed object storage),一个对象集群存储,本身提供对象的高可用,错误检测和修复功能。 1.2 组成 CEPH文件系统有三个主要模块: a)Client:每个Client实例向主机或进程提供一组类似于POSIX的接口。 b)OSD簇:用于存储所有的数据和元数据。 c)元数据服务簇:协调安全性、一致性与耦合性时,管理命名空间(文件名和 目录名) 1.3 架构原理 Client:用户 I/O:输入/输出 MDS:Metadata Cluster Server 元数据簇服务器 OSD:Object Storage Device 对象存储设备
Client通过与OSD的直接通讯实现I/O操作。这一过程有两种操作方式: 1. 直接通过Client实例连接到Client; 2. 通过一个文件系统连接到Client。 当一个进行打开一个文件时,Client向MDS簇发送一个请求。MDS通过文件系统层级结构把文件名翻译成文件节点(inode),并获得节点号、模式(mode)、大小与其他文件元数据。注意文件节点号与文件意义对应。如果文件存在并可以获得操作权,则MDS通过结构体返回节点号、文件长度与其他文件信息。MDS同时赋予Client操作权(如果该Client还没有的话)。目前操作权有四种,分别通过一个bit表示:读(read)、缓冲读(cache read)、写(write)、缓冲写(buffer write)。在未来,操作权会增加安全关键字,用于client向OSD证明它们可以对数据进行读写(目前的策略是全部client 都允许)。之后,包含在文件I/O中的MDS被用于限制管理能力,以保证文件的一致性与语义的合理性。 CEPH产生一组条目来进行文件数据到一系列对象的映射。为了避免任何为文件分配元数据的需要。对象名简单的把文件节点需要与条目号对应起来。对象复制品通过CRUSH(著名的映射函数)分配给OSD。例如,如果一个或多个Client打开同一个文件进行读操作,一个MDS会赋予他们读与缓存文件内容的能力。通过文件节点号、层级与文件大小,Client可以命名或分配所有包含该文件数据的对象,并直接从OSD簇中读取。任何不存在的对象或字节序列被定义为文件洞或0。同样的,如果Client打开文件进行写操作。它获得使用缓冲写的能力。任何位置上的数据都被写到合适的OSD上的合适的对象中。Client 关闭文件时,会自动放弃这种能力,并向MDS提供新的文件大小(写入时的最大偏移)。它重新定义了那些存在的并包含文件数据的对象的集合。 CEPH的设计思想有一些创新点主要有以下两个方面: 第一,数据的定位是通过CRUSH算法来实现的。
教你用局域网共享文件管理软件来管理服务器共享文件访问
教你用局域网共享文件管理软件来管理服务器共享文件访问 作者:大势至日期:2013.12.13 说到共享文件审计这一功能近几年用的越来越多,也是由于网络共享越来越广泛,从普通用户层面上来看现在各大运营商的”带宽“越来越”宽“,以至于不忍浪费这么好的资源,曾几何时我个人也想过将自己多年来收藏的资源拿来共享一下,做一个简单的服务器放在互联网中共享,但又害怕不安全; 从企业用户层面上来讲文件服务器的安全性也越来越重要,常常在服务器上共享一些重要的文件供局域网用户使用,极大地方便了企业内部资源、信息、文件的交换和使用。但是,由于缺乏对局域网用户访问共享文件的管理和控制,使得员工访问共享文件的各种操作行为,如读取、修改、删除、剪切和重命名等无法有效管理和记录,从而一旦员工私自拷贝和窃取公司的商业机密也无法进行有效的查证和防范,同时如果员工不小心或有意删除共享文件的行为也无法进行有效的预防和保护,从而容易给企业带来巨大风险和重大损失。而如果通过服务器配置不同用户,设定不同权限来限制员工访问共享文件的方式,由于操作极为复杂,在企业员工数量较多的情况下,工作量也极大,从而不利于有效管理共享文件、监控共享文件的使用,也无法有效保护单位的商业机密和信息安全。因此,企事业单位迫切需要一套专门的共享文件监控软件、局域网共享软件来记录局域网用户对共享文件的各种操作,同时有效防止员工有意或不小心删除共享文件而给企业带来的重大损失。 因此今天分享一款文件审计系统——大势至共享文件审计系统(百度搜索“大势至共享文件审计系统”下载吧),可能普通用户拿来做日常简单的安全防护来用、更多的是推荐给大中型企事业单位来用。 软件名称:大势至共享文件审计系统V3.1 软件语言:简体中文
san文件系统与集群文件系统
SAN文件系统与集群文件系统 及其应用发展趋势 张敬亮 摘要:本文主要介绍与分析传统网络存储方式与新的存储架构,以及国内自主研发的集群存储系统—蓝鲸集群存储系统与SAN文件系统的发展与应用情况。 关键字:SAN 集群文件系统、蓝鲸集群文件系统 1传统网络存储方式所面临的挑战 随着以NAS1和SAN2为代表的网络存储架构逐渐走向成熟,厂商对其理念进行的大量宣传与推广,以及网络存储系统对数据进行集中存储和管理所带来的优越性,网络存储已经逐渐被人们接受,其应用也迅速推广至各个行业。换言之,传统的NAS和SAN产品很好地解决了分散存储所面临的可用性、可管理性和可扩展性等大部分问题,但随着信息化技术的迅猛发展,诸如高性能计算、视频编辑、遥感信息处理等技术的大规模应用,对网络传存储系统提出了更高的要求: 1.需要支持更多的客户机进行高性能的文件共享,从而提高业务处理效率,减少因数据拷贝而造成的不必要的损失。 2.希望系统的性能和容量可在线扩展,无需停止业务。 然而,在目前主流的存储架构中,存在着如下问题: 1.由于SAN提供的是块级数据共享, 所以,要想实现多个平台的文件共享,还有很多障碍。 2.在SAN系统中,因为每个应用节点的逻辑卷之间无法实现容量共享,所以整个系统的存储利用率仍然比较低。而且,当系统中的逻辑卷容量不足时,无法实现 在不影响业务的情况下的在线扩容。 3.NAS产品可以实现文件共享,而且每个节点都可以同时共享整个系统的存储空间,利用率更高。但在传统的NAS产品中,所有数据都要经过单一I/O(输入/ 输出)节点,所以当客户节点增多或负载加大时,NAS产品的文件并发访问性能 不尽如人意,同时,一般的NAS产品都无法实现存储容量和性能的在线扩展。 4.虽然陆续出现了诸如NAS集群、NAS网关等改良的方案,但都因为架构的限制无法实现本质上的突破。 2新的存储架构应运而生 为解决上述问题产生了新型存储架构,即支持集群文件系统的集群存储架构和结合 1 Network Attached Storage,网络附连存储 2 Storage Area Storage,存储区域网
负载均衡软件实现方式
负载均衡软件实现方式之一- URL重定向方式 有一种用软件实现负载均衡的方式,是基于"URL重定向"的. 先看看什么是URL重定向: "简单的说,如果一个网站有正规的URL和别名URL,对别名URL进行重定向到正规URL,访问同一个网址,或者网站改换成了新的域名则把旧的域名重定向到新的域名,都叫URL 重定向" (https://www.360docs.net/doc/e76907448.html,/service/host_faq.php) "很多网络协议都支持“重定向”功能,例如在HTTP协议中支持Location指令,接收到这个指令的浏览器将自动重定向到Location指明的另一个URL上。" (https://www.360docs.net/doc/e76907448.html,/art/200604/25388.htm) 这种方式,对于简单的网站,如果网站是自己开发的,也在一定程度上可行.但是它存在着较多的问题: 1、“例如一台服务器如何能保证它重定向过的服务器是比较空闲的,并且不会再次发送Location指令,Location指令和浏览器都没有这方面的支持能力,这样很容易在浏览器上形成一种死循环。” 2、在哪里放LOCATION,也是一个问题。很有可能用户会访问系统的很多个不同URL,这个时候做起来会非常麻烦。并且,对URL的访问,有的时候是直接过来的,可以被重定向,有的时候是带着SESSION之类的,重定向就可能会出问题。并且,这种做法,将负载均衡这个系统级的问题放到了应用层,结果可能是麻烦多多。 3、这种方式一般只适用于HTTP方式,但是实际上有太多情况不仅仅是HTTP方式了,特别是用户如果在应用里面插一点流媒体之类的。 4、重定向的方式,效率远低于IP隧道。 5、这种方式,有的时候会伴以对服务器状态的检测,但往往也是在应用层面实现,从而实时性大打折扣。 实际上,这种方式是一种“对付”的解决方法,并不能真正用于企业级的负载均衡应用(这里企业级是指稍微复杂一点的应用系统) 可以看一下专业的负载均衡软件是如何来实现的: https://www.360docs.net/doc/e76907448.html,/pcl/pcl_sis_theory.htm 对比一下可以发现,专业的负载均衡软件要更适用于正规应用,而重定向方式则比较适用于
Hadoop分布式文件系统方案
Hadoop分布式文件系统:架构和设计要点 Hadoop分布式文件系统:架构和设计要点 原文:https://www.360docs.net/doc/e76907448.html,/core/docs/current/hdfs_design.html 一、前提和设计目标 1、硬件错误是常态,而非异常情况,HDFS可能是有成百上千的server组成,任何一个组件都有可能一直失效,因此错误检测和快速、自动的恢复是HDFS的核心架构目标。 2、跑在HDFS上的应用与一般的应用不同,它们主要是以流式读为主,做批量处理;比之关注数据访问的低延迟问题,更关键的在于数据访问的高吞吐量。 3、HDFS以支持大数据集合为目标,一个存储在上面的典型文件大小一般都在千兆至T字节,一个单一HDFS实例应该能支撑数以千万计的文件。 4、 HDFS应用对文件要求的是write-one-read-many访问模型。一个文件经过创建、写,关闭之后就不需要改变。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。典型的如MapReduce框架,或者一个web crawler应用都很适合这个模型。 5、移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效,这在数据达到海量级别的时候更是如此。将计算移动到数据附近,比之将数据移动到应用所在显然更好,HDFS提供给应用这样的接口。 6、在异构的软硬件平台间的可移植性。 二、Namenode和Datanode HDFS采用master/slave架构。一个HDFS集群是有一个Namenode和一定数目的Datanode 组成。Namenode是一个中心服务器,负责管理文件系统的namespace和客户端对文件的访问。Datanode在集群中一般是一个节点一个,负责管理节点上它们附带的存储。在部,一个文件其实分成一个或多个block,这些block存储在Datanode集合里。Namenode执行文件系统的namespace操作,例如打开、关闭、重命名文件和目录,同时决定block到具体Datanode节点的映射。Datanode在Namenode的指挥下进行block的创建、删除和复制。Namenode和Datanode 都是设计成可以跑在普通的廉价的运行linux的机器上。HDFS采用java语言开发,因此可以部署在很大围的机器上。一个典型的部署场景是一台机器跑一个单独的Namenode节点,集群中的其他机器各跑一个Datanode实例。这个架构并不排除一台机器上跑多个Datanode,不过这比较少见。
负载均衡系统构架
负载均衡系统构架 负载均衡系统构架 【摘要】随着计算机网络和Internet应用的飞速发展,信息共享日益广泛化,并深入到人们工作和生活的各个领域。人们对信息共享的依赖正逐渐增强。而作为提供信息载体的服务器的压力也越来越大,对于电子商务、信息共享平台急需合理分配访问流量来减少服务器的压力。 本文对目前的负载均衡技术进行简单的阐述,并对现有均衡算法进行简单的比较,分析其不足之处。并采用LVS(Linux虚拟服务器)实现负载均衡的架构。采用Keepalived技术实现负载均衡的高可用性。并对LVS不同策略上实现的均衡结果进行详细的比较。最终完成对负载均衡系统的构建同时提供了详细的系统搭建步骤,为研究该方向的人员提供可靠的参考资料。 【关键词】负载均衡、LVS、Keepalived、高并发 中图分类号:TN711 文献标识码:A 文章编号: 简介 1.1背景 目前随着网络技术的迅速崛起,网络信息共享数据越来越大,访问量和数据流量的快速增长,所需的处理能力和运算强度也越来越大,使得单一的服务器设备根本无法承担。在此情况下,如果花大量的资金进行硬件方面的升级,会造成大量的资源浪费。并且对于下一次升级来说,将会投入更大的成本,如何才能利用现有资源,在少量的投入下解决该问题? 针对此情况而衍生出来的一种廉价有效透明的方法来扩展现有网络设备和服务器的带宽、增加吞吐量、加强网络数 据处理能力、提高网络的灵活性和可用性的技术就是负载均 衡(Load Balance)。 1.2负载均衡技术概述 负载均衡(又称为负载分担),英文名称为Load Balance,其
文档共享管理系统解决方案doc
书生文档共享管理系统(SDP )是用于政府、企业等机构安全共享文档信息的整体解决方案,它依托书生TESDI 数字权限管理技术、SEP 数字文档技术,以集中管理的方式完整保存各单位日常产生的各类文档,提供最大程度的共享机制,使文档信息的价值得到最充分的利用,同时还能保证敏感文件不会被泄露, 即使是对合法阅读者也能进行拷贝、打印等权限的管理和控制,从而彻底解决机构用户的信息数字化率和信息使用率偏低的问题。 SDP 是一个文档集中存放,受限访问的平台。SDP 系统采用了书生SEPReader 作为文档阅读的终端,采用SEPWriter 作为文档转换的工具。SEP Writer 将不同格式不同应用程序生成的文档转换成统一的SEP 格式,再通过SDP 客户端将转换后的文件提交给给安全文档管理服务器(SDP Server ),保存到专门的安全文档数据库中。SDP 服务器统一控制每个文档针对每个操作人员的浏览、复制、打印、传播、摘录等权限,最大限度的保证电子文档安全,而且又不妨碍合法和正常的阅读以及操作。 SDP 系统集成了多种主流的用户身份机制,包括Windows 域和活动目录,Lotus 用户集成,LDAP 用户集成以及提供集成其他基于数据库的应用系统用户机制。可以和各种类型的应用系统无缝集成。SDP 提供14 种不同粒度的访问权限,可以充分满足复杂的管理需要。 传统的文档管理系统不同的是,SDP 文档管理系统真正防止了非受限的传播重要文档,比如传统的档案系统,虽然有多级的用户权限管理机制,但文档一旦被某个用户访问,用户就可以不受限的将该文档通过拷贝,邮寄等方式传播给他人。而SDP 采用的文档的终生机制,文档无论何时被访问,除非管理员特别指定,文档都受SDP 管理系统的控制。可以称作是全程安全的文档管理系统。 书生文档管理保护系统可以与书生Office 配合进行使用,会具有最佳的使用效果。用户在用Office 编辑定稿后轻松一键即可提交给文档服务器,便捷方便的操作最大程度地降低了使用者的负担,使文档集中共享的制度能得到最有效的贯彻执行。 信息化与电子文档管理的困境 ? 电子文档的易复制性、易传播性是文档管理的巨大挑战 ? 敏感信息被泄露往往会带来重大损失 ? 传统的文档权限管理能够防止未经授权的访问, 但一旦能看文档就拥有对该文档的全部权限, 特 别是可以随意外传, 使敏感信息的安全高度依赖于人的道德和忠诚, 一旦有权限阅读的人有私心, 信息的安全就缺乏保障 ? 要让能读能看某个文档的人不能传播该文档, 这是一个世界性难题 ? 上述问题不解决, 就不得不为保密的原因而放弃共享, 导致信息数字化率降低、工作效率下降TESDI 与其它DRM 技术的比较 ? 传统DRM 技术将电子文档与指定电脑绑定, 但无法限制电子文档被复制和传播, 只是该文档在其它电脑上无法打开。相当于保险柜可以随便抱走, 只是没钥匙打不开