07 多维尺度分析方法

第七讲 多维尺度分析
多维尺度分析(MultiDimensional Scaling)是分析研究对象的相似性或差异性的一种多元统计分析方法。采用MDS可以创建多维空间感知图,图中的点(对象)的距离反应了它们的相似性或差异性(不相似性)。一般在两维空间,最多三维空间比较容易解释,可以揭示影响研究对象相似性或差异性的未知变量-因子-潜在维度。
在市场研究领域主要研究消费者的态度,衡量消费者的知觉及偏好。涉及的研究对象非常广泛,例如:汽车、洗头水、饮料、快餐食品、香烟和国家、企业品牌、政党候选人等。通过MDS分析能够为市场研究提供有关消费者的知觉和偏好信息。
MDS一般需要借助SPSS或SAS统计分析软件,输入有关消费者对事物的知觉或偏好数据,转换为一组对象或对象特征构成的多维空间知觉或偏好图——感知图。
应用MDS,收集的数据值大小必须能够反应两个研究对象的相似性或差异性程度。这种数据叫做邻近数据,所有研究对象的邻近数据可以用一个邻近矩阵表示。
反映邻近的测量方式:
z相似性-数值越大对应着研究对象越相似。
z差异性-数值越大对应着研究对象越不相似。
测量邻近性数据的类型:
z两个地点(位置)之间的实际距离。(测量差异性)
z两个产品之间相似性或差异性的消费者心理测量。(差异性或相似性)
z两个变量的相关性测量。(相关系数测量相似性)
z从一个对象过渡到另一个对象的转换概率。例如概率反应了消费者对品牌或产品偏好的变化。(测量相似性)
z反映两种事物在一起的程度。例如:用早餐时人们经常将哪两种食品搭配在一起。(测量相似性)z谁喜欢谁,谁是谁的领导,谁传递给谁信息,谁是谁的上游或下游等等社会网络数据等(测量相似性)
邻近数据即可以直接测量(距离),也可以通过计算得到(变量间的相关系数)。
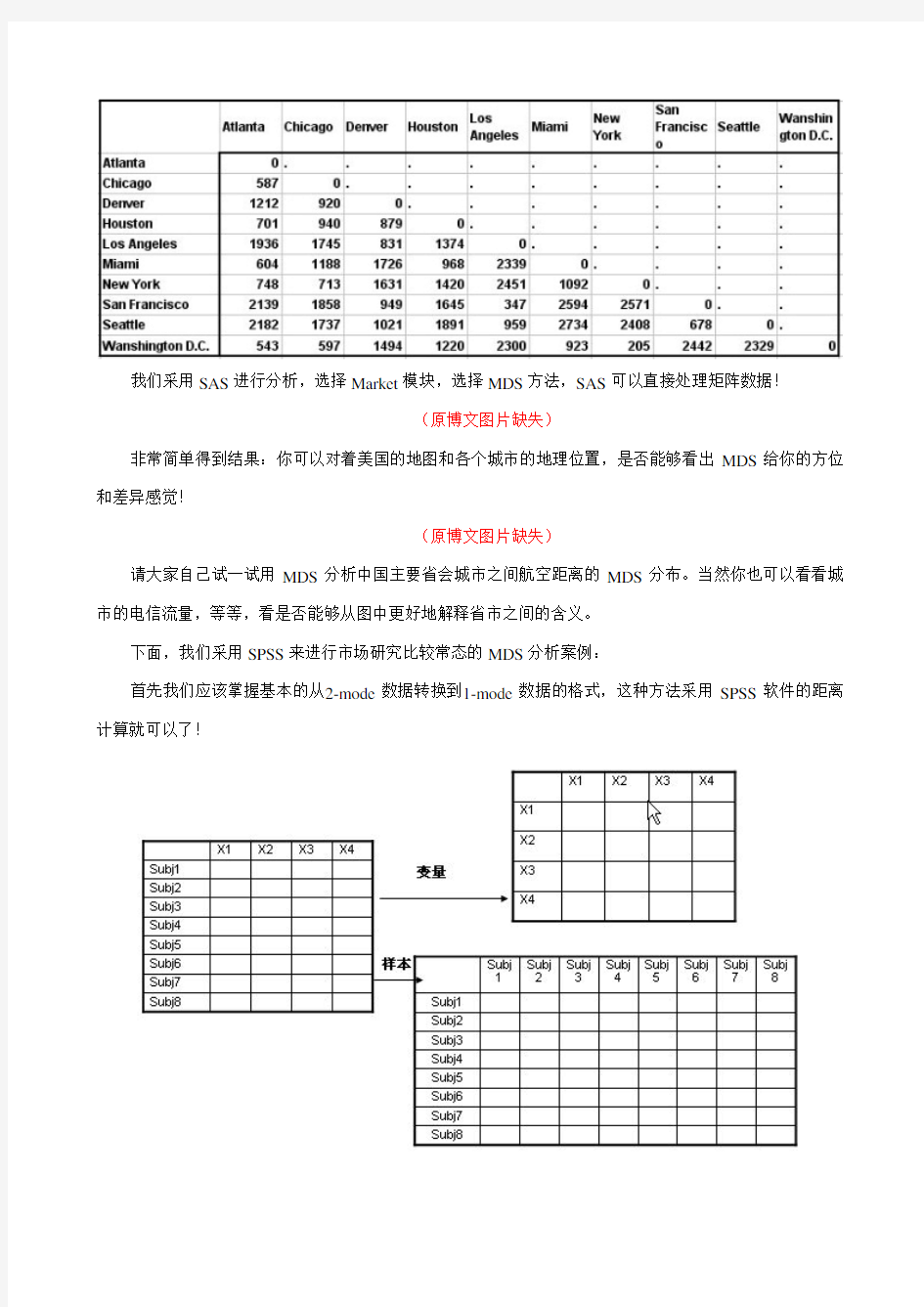
MDS最经典的案例就是用感知图表现美国主要城市的航空距离!
我们采用SAS进行分析,选择Market模块,选择MDS方法,SAS可以直接处理矩阵数据!
(原博文图片缺失)
非常简单得到结果:你可以对着美国的地图和各个城市的地理位置,是否能够看出MDS给你的方位和差异感觉!
(原博文图片缺失)
请大家自己试一试用MDS分析中国主要省会城市之间航空距离的MDS分布。当然你也可以看看城市的电信流量,等等,看是否能够从图中更好地解释省市之间的含义。
下面,我们采用SPSS来进行市场研究比较常态的MDS分析案例:
首先我们应该掌握基本的从2-mode数据转换到1-mode数据的格式,这种方法采用SPSS软件的距离计算就可以了!
我们通过上面的过程就可以得到所谓的相似矩阵或差异矩阵!
好在SPSS软件基本上不用这样操作,因为MDS分析已经把这个过程内置在分析中了,我们可以直接得到结果;
假设:我们调查人们对当前25个社会问题的关系程度,采用1-5的五级里克特量表
我们选择SPSS分析菜单下的度量模型下的多维尺度分析:
这时候大家要注意你选择的数据类型:是矩阵还是需要系统计算出来,我们选择从数据中创建距离!得到结果后,如果你满意,可以自己把结果采用散点图表示出来:
大家会解释MDS得到的感知图吗?
z应用一:MDS构造的感知图中,现由产品品牌点与理想点的竞争关系。如果理想点附近没有其他品牌,说明现有产品未能满足消费者的需求。新开发产品应按理想点附近产品品牌特征设计。同时可以了解消费者心目中不同品牌的竞争地位。根据感知图的关系指定新产品的市场营销策略。z应用二:MDS可以表示消费者心中理想品牌的形象感知图,感知图表现了企业的位置,可知道竞争地位(产品/品牌),位置接近,在消费者心中形象相似,当然竞争比较激烈,也可具体研究某种营销策略。
z应用三:广告本身应具有吸引力,容易记忆。理解竞争者广告间的相似程度和竞争地位。MDS感知图可以提供给广告策划人有关消费者知觉构层。可以判断消费者用以比较广告的标准,发现消费者诉求点。
z应用四:需要研究消费者转换品牌的原因,制定新的策略,留住消费者。MDS可以构造该品牌和其它品牌消费者的感知图。比较品牌竞争位置,理解消费者转换品牌的原因。指定相应的改变产品特征或新的广告策略。
当然如何得到数据的相似矩阵或差异矩阵,可以采用很多调查手段:语义差异法,配到比较法、描点
法等等;其实,MDS在当前的市场研究领域慢慢大家不喜欢用来,因为有更好的分析手段了,但是大家对MDS的理解可以帮助我们更透彻的看到数据的分析思想和找到相似或差异数据的手段!
MDS是市场研究的重要工具,但劣势明显。
z收集资料和计算比较困难。
z感知图的维度有时候解释和命名比较困难。
z当评价的品牌较多时,问卷比较长,设计比较困难。
z消费者评价容易产生烦躁情绪,而改变潜在的感知维度。
可以考虑其它几种产生感知图的市场研究技术。
z对应分析correspondence analysis CA
z判别分析discrimination analysis DA
z主成分分析principal component analysis PCA
z因子分析factor analysis FA
层次分析法模型
二、模型的假设 1、假设我们所统计和分析的数据,都是客观真实的; 2、在考虑影响毕业生就业的因素时,假设我们所选取的样本为简单随机抽样,具有典型性和普遍性,基本上能够集中反映毕业生就业实际情况; 3、在数据计算过程中,假设误差在合理范围之内,对数据结果的影响可以忽略. 三、符号说明
四、模型的分析与建立 1、问题背景的理解 随着我国改革开放的不断深入,经济转轨加速,社会转型加剧,受高校毕业生总量的增加,劳动用工管理与社会保障制度,劳动力市场的不尽完善,以及高校的毕业生部分择业期望过高等因素的影响,如今的毕业生就业形势较为严峻.为了更好地解决广大学生就业中的问题,就需要客观地、全面地分析和评价毕业生就业的若干主要因素,并将它们从主到次依秩排序. 针对不同专业的毕业生评价其就业情况,并给出某一专业的毕业生具体的就业策略. 2、方法模型的建立 (1)层次分析法 层次分析法介绍:层次分析法是一种定性与定量相结合的、系统化、层次化的分析方法,它用来帮助我们处理决策问题.特别是考虑的因素较多的决策问题,而且各个因素的重要性、影响力、或者优先程度难以量化的时候,层次分析法为我们提供了一种科学的决策方法. 通过相互比较确定各准则对于目标的权重,及各方案对于每一准则的权重.这些权重在人的思维过程中通常是定性的,而在层次分析法中则要给出得到权重的定量方法. 我们现在主要对各个因素分配合理的权重,而权重的计算一般用美国运筹学
家T.L.Saaty 教授提出的AHP 法. (2)具体计算权重的AHP 法 AHP 法是将各要素配对比较,根据各要素的相对重要程度进行判断,再根据计算成对比较矩阵的特征值获得权重向量k W . Step1. 构造成对比较矩阵 假设比较某一层k 个因素12,,,k C C C 对上一层因素ο的影响,每次两个因素i C 和j C ,用ij C 表示i C 和j C 对ο的影响之比,全部比较结果构成成对比较矩阵C ,也叫正互反矩阵. *()k k ij C C =, 0ij C >,1 ij ji C C =, 1ii C =. 若正互反矩阵C 元素成立等式:* ij jk ik C C C = ,则称C 一致性矩阵. 标度ij C 含义 1 i C 与j C 的影响相同 3 i C 比j C 的影响稍强 5 i C 比j C 的影响强 7 i C 比j C 的影响明显地强 9 i C 比j C 的影响绝对地强 2,4,6,8 i C 与j C 的影响之比在上述两个相邻等级之间 11 ,,29 i C 与j C 影响之比为上面ij a 的互反数 Step2. 计算该矩阵的权重 通过解正互反矩阵的特征值,可求得相应的特征向量,经归一化后即为权重向量 12 = [ , ,..., ]T k k k kk Q q q q ,其中的ik q 就是i C 对ο的相对权重.由特征方程 A-I=0λ,利用Mathematica 软件包可以求出最大的特征值 max λ 和相应的特征向 量. Step3. 一致性检验 1)为了度量判断的可靠程度,可计算此时的一致性度量指标CI :
层次分析法与模糊综合评价的区别
层次分析法与模糊综合判别的区别与联系 1、层次分析法 [ 参考文献:吋义成, 柯丽华, 黄德育. 系统综合评价技术及其应用[M]. 北京: 冶金工业出版社,2006] 人们在日常生活中经常要从一堆同样大小的物品中挑选出最重要的物品,如重量最大的物品,即至少要确定各物品的相对重量。这时,经验和常识告诉我们,可以利用两两比较的方法来达到目的。 若在没有称量仪器的条件下对一组物体的重量进行估计,则可以通过爱对比较这组物体相对重量的方法,得出每对物体相对重量比的判断,从而形成比较判断矩阵,再通过求解判断矩阵的最大特征根和它所对应的特征向量问题,就能计算出这组物体的相对重量。 将此方法应用到复杂的社会、经济和科学管理等领域中,就能确定各种方案、措施、政策等 相对于总目标的重要性排序情况,以供领导者决策。 一般的层次分析法模型由图5-1 所示,分为目标层、准则层、指标层、方案层组成。需要注意几点: (1)层次分析法的评价结构并非是上述部分一成不变的,其中的当指标层因素较少时准则层可以省去(图5-2 ),当某一准则对应的指标层元素过多时可以将其指标层细分为“子准则层和指标层”(图5-4 )。由于层次分析法是利用两两比较完成的,为了便于人的比较与判别,每层的元素个数在3~7 之间为佳,超过7 以后增加了比较判断的难度,因此当元素过多时,可以将其分类后分成两层或多层来判别。 (2)准则层与指标层之间的关系可以对比一下图5-1 和图5-4 ,即每个准则可能有独 用的指标体系,也可能是各准则之间共用某几个指标。 (3)层次分析法的特点是基于某个目标,对多个待评价方案进行评价,从而得到方案的重要性排序。具体到某个问题,其并无相应的数据。而模糊综合判别有相应的基础数据。两者可以结合一起用,比如常用的是模糊综合评判过程中,权重可以由层次分析法计算。 层次分析法的骤如下: 1)在作者建立评价模型后,根据经验对每层里的各个元素建立重要性判别矩阵,从判 别矩阵中可以得到某一层中各个指标的归一化权重(表5-1中的W B,W C1,W C2,W C3,W C4)。(表5-1和5-2 的数据为图5-1 模型的) 2)由层与层之间权重的传递可以得到最低层(具体指标层)的综合权重。如图5-1 所示的图中有得到各个C ij的综合权重W ij(表5-2第2列)。 3)最后,在指标层与方案层之间建立判别矩阵,针对每一个指标C ij 都需要建立一个各 方案A i的比较矩阵,判别A针对C j的重要性w A i (表5-2的每一行)。最后将指标C ij的综合权重W ij与W Ai进行乘法求和,从而得到方案A的最终综合权重刀(W ij心Ai),即为续表5-2的最后一行。
最新复杂系统决策模型与层次分析法
复杂系统决策模型与层次分析法
费用居住饮食交通例3?科研课题 科研课題 承徳 可行性 实用价值学 术 意 义 人 才 培 养 §3.4复杂系统决策模型与层次分析法 Analitic Hierachy Process (AHP) T. L. Saaty 1970* —种定性和定量相结合的、系统化、层次化的分析方法。—?问题举例 1.在海尔、新飞、容声和雪花四个牌号的电冰箱中选购一种。要考虑品牌的信誉、冰箱的功能、价格和耗电量。 2.在泰山、杭州和承德三处选择一个旅游点。要考虑景点的景色、居住的环境、饮食的特色、交通便利和旅游的费用。 3.在基础研究、应用研究和数学教育中选择一个领域申报科研课题。要考虑成果的贡献(实用价值、科学意义),可行性(难度、周期和经费)和人才培养。 -?模型和方法 1.层次结构模型的构造 步骤一:确定层次结构,将决策的目标、考虑的因素(决策准则)和决策对象按它们之间的相互关系分为最高层、中间层和最低层,绘出层次结构图。 最高层:决策的目的、要解决的问题。 最低层:决策时的备选方案。 中间层:考虑的因素、决策的准则。 对于相邻的两层,称高层为目标层,低层为因素层。 例1.选购冰箱迭购冰箱步骤二:通过相互比较,确定下一 层各因素对上一层目标的影响的权重,将定性的判断定量化,即构 造因素判断矩阵。 例2.
步骤三:由矩阵的特征值确定判别的一致性;由相应的特征向量表示各因素的影响 权重,计算权向量。 步骤四:通过综合计算给出最底层(各方案)对最高层(总目标)影响的权重, 权重最大的方案即为实现目标的最由选择。 2. 因素判断矩阵 比较n 个因素y 二(y“兀,…,yJ 对目标z 的影响. 采用两两成对比较,用弘表示因素y :与因素力对目标z 的影响程度之比。 通常用数字r 9及其倒数作为程度比较的标度,即九级标度法 Xi/Xj 相当 较重要 重要 很重要绝对重要 Si ; 1 3 5 7 9 2, 4, 6, 8 居于上述两个相邻判断之间。 当弘> 1时,对目标Z 来说Xi 比X :重要,其数值大小表示重要的程度。 同时必有3二1/氐<1,对目标Z 来说X :比血不重要,其数值大小表示不重 要的程度。 称矩阵A = ( aij )为因素判断矩阵。 因为>0且a.i =1/ 故称A 二(% )为正互反矩阵。 例.选择旅游景点Z :目标,选择景点 y :因素,决策准则 如果a £j a jk =a ik i, j, k=l, 2,n.则称正互反矩阵A 具有一致性.这表明对 各个因素所作的两两比较是可传递的。 —致性互正反矩阵A=(如)具有性质: A 的每一行例)均为任意指定行(列)的正数倍数,因此wnk (A )二1. A 有特征值九二n,其余特征值均为零. 记A 的对应特征值九二n 的特征向量为w 二(w : w 2,…,wj 贝IJ a £j 二w, w ;1 如果在目标Z 中n 个因素y= (yi, y 2,…,yj 所占比重分别为w 二(w 】w?,…,wj, 则 =1,且因素判断矩阵为A=(w i w ;1) o 因此,称一致性正互反矩阵A 相应于特征值n 的归一化特征向量为因素 y= (yi> y?,…,yJ 对目标z 的权向量 4. 一致性检验与因素排序 定理1: n 阶正互反矩阵A 是一致性的当且仅当其最大特征值为n. 定理2:正互反矩阵具有模最大的正实数特征值九,其重数为1,且相应特征向量 为正向量. 为刻画n 阶正互反矩阵A=(如)与一致性接近的程度,定义一致性指标(Consensus index): 1 2 7 5 5 1/2 1 4 3 3 4 = 1/7 1/4 1 1/2 1/3 1/5 1/3 I 1 J/5 1/3 3 1 1 yi 费用, 景色, ys 居住, 3.—致性与权向量 yi 饮食,ys 交通
模糊层次分析法的Matlab实现
一、引言 层析分析法是将定量与定性相结合的多目标决策法,是一种使用频率很高的方法,在经济管理、城市规划等许多领域得到了广泛应用。由于其结果受主观思维的影响较大,许多科研工作者对其进行了深入的研究,将模糊理论与层次分析法相结合,提出了模糊层次分析法。为克服层次分析法中判断矩阵的一致性与人类思维的一致性存在的显著差异,文献[1-2]引入了模糊一致矩阵。为解决解的精度及收敛问题,文献[3-4]引入幂法来求排序向量。运用模糊层次分析法研究实际问题时,常采用迭代法来得到精度更高的排序向量,这就要求选择合适的初始值并通过大量的计算,为此,文中利用三种方法计算了初始排序向量,并给出了算法的Matlab程序,最后通过实例说明。 二、模糊层次分析法 为解决AHP种所存在的问题,模糊层次分析法引入模糊一致矩阵,无需再进行一致性检验,同时使用幂法来计算排序向量,可以减少迭代齿数,提高收敛速度,满足计算精度的要求.具体步骤: 1.构造优先关系矩阵 采用0.1~0.9标度[2],建立优先判断矩阵 2.将优先关系矩阵转化为模糊一致矩阵 3.计算排序向量 (1)和行归一法: (2)方根法: (3)利用排序法: (4)利用幂法[5-6]求精度更高的排序向量: 否则,继续迭代。 三、模糊层次分析法的程序实现 给出模糊层次分析法的Matlab程序。 clear; clc; E=input('输入计算精度e:') Max=input('输入最大迭代次数Max:')
F=input('输入优先关系矩阵F:'); %计算模糊一致矩阵 N=size(F); r=sum(F'); for i=1:N(1) for j=1:N(2) R(i,j)=(r(i)-r(j))/(2*N(1))+0.5; end end E=R./R'; % 计算初始向量---------- % W=sum(R')./sum(sum(R)); % 和行归一法 %--------------------------------------------------------- for i=1:N(1) S(i)=R(i,1); for j=2:N(2) S(i)=S(i)*R(i,j); end end S=S^(1/N(1)); W = S./sum(S);%方根法%-------------------------------------------------------- % a=input('参数a=?'); %W=sum(R')/(N(1)*a)-1/(2*a)+1/N(1); %排序法 % 利用幂法计算排序向量----V(:,1)=W'/max(abs(W)); %归一化 for i=1:Max V(:,i+1)=E*V(:,i); V(:,i+1)=V(:,i+1)/max(abs(V(:,i+1))); if max(abs(V(:,i+1)-V(:,i)))k=i; A=V(:,i+1)./sum(V(:,i+1)); break Else End End 四、计算实例
人脸识别 多维尺度分析
基于等距算法模式识别的学习与研究
一、Isomap 算法实现的基本步骤 1.等距离映射(Isomap) 该算法是一种全局非线性优化算法。Isomap 算法以多维尺度变换( fmult mensional scaling ,简称MDS)为基础,利用数据点间的测地线距离来替代MDS 中的欧氏距离,力求保持数据的内在流形结构,最大限度的保持数据点问在低维空间中的欧氏距离误差最小,最终实现数据点的低维空间的表示。Isomap 算法的目的是将高维空间 n R 中的数据集合},,,{21N x x x X =映射到低维流形空间 )(D d R d <<中,得到低维嵌人数据集合: },,,{Y 21N y y y = 2.具体算法步骤如下: 步骤1:计算样本点i x 的邻域点集(取欧氏距离最近的个近邻点),构造邻域图。 步骤2:计算测地线距离。根据邻域图,使用计算样本点间的最短距离),(j i c x x d ,近似看作为两点间的测地线距离),(j i M x x d 。 步骤3:使用MDS 对最短距离矩阵c D 。重构d 维嵌入。, 2)()(N I I I D N I I I D T N N G T N N c ---=)(τ,令321λλλ≥≥≥ 是矩阵)(c D τ的前 d 个最大的特征值,d v νν,,,21 为对应的d 个特征向量,则d 维嵌入坐标为: N d N N d y y y Y ????? ??? ??? ? ?? ? ?=νλνλνλ111121],,,[ Isomap 算法作为常用的流形学习算法,在低维空间中可以有效保持高维空 间数据的非线性结构,但在小样本情况时,当每类样本数小于构造邻域图数值尼时,计算得出的各个点的最短距离就不能正确得出测地线距离了。本文使用Gabor’s 波对预处理后的图像进行5个中心频率、8个方向的滤波,输出40副滤波图像。但在增加了样本数量的同时,也对系统的硬件要求提出了更高的要求。为了进一步降低计算量,本文提出使用Gabor 特征融合方法,很好地解决了这一问题。将每个中心频率的不同方向滤波结果进行相加,得到一个该中心频率的滤波图像。图l 给出对ORL 数据库中的人脸经过Gabor~,波后相同中心频率的8个不同方向的滤波结果相加后的图像。通过实验结果的比较表明,使用该方法对一副图像计算得出的5副图像和将一副图像的40副Gabor 滤波图像作为Isomap
数学建模之层次分析法
第四讲层次分析法 在现实世界中,往往会遇到决策的问题,比如如何选择旅游景点的问题,选择升学志愿的问题等等。在决策者作出最后的决定以前,他必须考虑很多方面的因素或者判断准则,最终通过这些准则作出选择。 比如选择一个旅游景点时,你可以从宁波、普陀山、浙西大峡谷、雁荡山和楠溪江中选择一个作为自己的旅游目的地,在进行选择时,你所考虑的因素有旅游的费用、旅游地的景色、景点的居住条件和饮食状况以及交通状况等等。这些因素是相互制约、相互影响的。我们将这样的复杂系统称为一个决策系统。这些决策系统中很多因素之间的比较往往无法用定量的方式描述,此时需要将半定性、半定量的问题转化为定量计算问题。层次分析法是解决这类问题的行之有效的方法。层次分析法将复杂的决策系统层次化,通过逐层比较各种关联因素的重要性来为分析、决策提供定量的依据。 一、建立系统的递阶层次结构 首先要把问题条理化、层次化,构造出一个有层次的结构模型。一个决策系统大体可以分成三个层次: (1) 最高层(目标层):这一层次中只有一个元素,一般它是分析问题的预定目标或理想结果; (2) 中间层(准则层):这一层次中包含了为实现目标所涉及的中间环节,它可以由若干个层次组成,包括所需考虑的准则、子准则; (3) 最低层(方案层):这一层次包括了为实现目标可供选择的各种措施、决策方案等。 比如旅游景点问题,我们可以得到下面的决策系统: 目标层——选择一个旅游景点 准则层——旅游费用、景色、居住、饮食、交通 方案层——宁波、普陀山、浙西大峡谷、雁荡山、楠溪江 二、构造成对比较判断矩阵和正互反矩阵 在确定了比较准则以及备选的方案后,需要比较若干个因素对同一目标的影响,从额确定它们在目标中占的比重。如旅游问题中,五个准则对于不同决策者在进行决策是肯定会有不同的重要程度,而不同的方案在相同的准则上也有不同的适合程度表现。层次结构反映了因素之间的关系,但准则层中的各准则在目标衡量中所占的比重并不一定相同,在决策者的
数学建模算法--复杂系统决策模型与层次分析法
数学建模算法--复杂系统决策模型与层次分析法 §3.4 复杂系统决策模型与层次分析法 Analitic Hierachy Process (AHP) T.L.Saaty 1970’ 一种定性和定量相结合的、系统化、层次化的分析方法。 一. 问题举例 1. 在海尔、新飞、容声和雪花四个牌号的电冰箱中选购一种。要考虑品牌的信誉、冰箱的功能、价格和耗电量。 2. 在泰山、杭州和承德三处选择一个旅游点。要考虑景点的景色、居住的环境、饮食的特色、交通便利和旅游的费用。 3. 在基础研究、应用研究和数学教育中选择一个领域申报科研课题。要考虑成果的贡献(实用价值、科学意义),可行性(难度、周期和经费)和人才培养。 二. 模型和方法 1. 层次结构模型的构造 步骤一:确定层次结构,将决策的目标、考虑的因素(决策准则)和决策对象按它们之间的相互关系分为最高层、中间层和最低层,绘出层次结构图。 最高层:决策的目的、要解决的问题。 最低层:决策时的备选方案。 中间层:考虑的因素、决策的准则。 对于相邻的两层,称高层为目标层,低层为因素层。 例 1. 选购冰箱 例2. 旅游景点 例3. 选购冰箱 品牌 功能 价格 耗电 海尔 新飞 容声 雪花 旅游景点 居住 景色 费用 饮食 交通 泰山 杭州 承德 科研课题 贡献 可行性 实 用 价 值 学 术 意 义 人 才 培 养 难 度 周 期 经 费 基础 应用 教育
步骤二: 通过相互比较,确定下一层各因素对上一层目标的影响的权重,将定性的判断定量化,即构造因素判断矩阵。 步骤三:由矩阵的特征值确定判别的一致性;由相应的特征向量表示各因素的影响权重,计算权向量。 步骤四: 通过综合计算给出最底层(各方案)对最高层(总目标)影响的权重,权重最大的方案即为实现目标的最由选择。 2. 因素判断矩阵 比较n 个因素y=(y 1,y 2,…,y n )对目标 z 的影响. 采用两两成对比较,用a ij 表示因素 y i 与因素y j 对目标z 的影响程度之比。 通常用数字 1~ 9及其倒数作为程度比较的标度, 即九级标度法 x i /x j 相当 较重要 重要 很重要 绝对重要 a ij 1 3 5 7 9 2, 4, 6, 8 居于上述两个相邻判断之间。 当a ij > 1时,对目标 Z 来说 x i 比 x j 重要, 其数值大小表示重要的程度。 同时必有 a ji = 1/ a ij ≤1,对目标 Z 来说 x j 比 x i 不重要,其数值大小表示不重要的程度。 称矩阵 A = ( a ij )为因素判断矩阵。 因为 a ij >0 且 a ji =1/ a ij 故称A = (a ij )为正互反矩阵。 例. 选择旅游景点 Z :目标,选择景点 y :因素,决策准则 y 1 费用,y 2 景色,y 3 居住,y 4 饮食,y 5 交通 3. 一致性与权向量 如果 a ij a jk =a ik i, j, k=1,2,…,n, 则称正互反矩阵A 具有一致性. 这表明对各个因素所作的两两比较是可传递的。 一致性互正反矩阵A=( a ij )具有性质: A 的每一行(列)均为任意指定行(列)的正数倍数,因此 rank(A)=1. A 有特征值λ=n, 其余特征值均为零. 记A 的对应特征值λ=n 的特征向量为w=(w 1 w 2 ,…, w n ) 则 a ij =w i w j -1 如果在目标z 中n 个因素y=(y 1,y 2,…,y n )所占比重分别为w=(w 1 w 2 ,…, w n ), 则 ∑i w i =1, 且因素判断矩阵为 A=(w i w j -1) 。 因此,称一致性正互反矩阵A 相应于特征值n 的归一化特征向量为因素y=(y 1,y 2,…,y n )对目标z 的权向量 4. 一致性检验与因素排序 定理1: n 阶正互反矩阵A 是一致性的当且仅当其最大特征值为 n. 定理2: 正互反矩阵具有模最大的正实数特征值λ1, 其重数为1, 且相应特征向量为正向量. 为刻画n 阶正互反矩阵A=( a ij )与一致性接近的程度, 定义一致性指标(Consensus index) : CI=(λ1-n)/(n-1) CI = 0, A 有完全的一致性。CI 接近于 0, A 有满意的一致性 。 Saaty 又引入平均随机一致性指标RT n 1 2 3 4 5 6 7 8 9 RI 0 0 0.58 0.90 1.12 1.24 1.32 1.41 1.45 当CR = CI / RI < 0.1 时, 认为A 有满意的一致性。 ????????????????=1133/15/11123 /15/13/12/114/17/133412/155 721A
模糊层次分析法的程序实现
、模糊层次分析法的程序实现 给出模糊层次分析法的Matlab程序。 clear; clc; E=input('输入计算精度e:') Max=input('输入最大迭代次数Max:') F=input('输入优先关系矩阵F:'); %计算模糊一致矩阵 N=size(F); r=sum(F'); for i=1:N(1) for j=1:N(2) R(i,j)=(r(i)-r(j))/(2*N(1))+0.5; end end E=R./R'; % 计算初始向量---------- % W=sum(R')./sum(sum(R)); % 和行归一法 %--------------------------------------------------------- for i=1:N(1) S(i)=R(i,1); for j=2:N(2) S(i)=S(i)*R(i,j); end end S=S^(1/N(1)); W = S./sum(S);%方根法%-------------------------------------------------------- % a=input('参数a=?'); %W=sum(R')/(N(1)*a)-1/(2*a)+1/N(1); %排序法 % 利用幂法计算排序向量----V(:,1)=W'/max(abs(W)); %归一化 for i=1:Max V(:,i+1)=E*V(:,i); V(:,i+1)=V(:,i+1)/max(abs(V(:,i+1))); if max(abs(V(:,i+1)-V(:,i)))k=i; A=V(:,i+1)./sum(V(:,i+1)); break Else End End 四、计算实例 由优先关系矩阵得到模糊一致矩阵 利用三种方法计算排序向量分别为:
层次分析法模型
二、模型的假设 1、假设我们所统计与分析的数据,都就是客观真实的; 2、在考虑影响毕业生就业的因素时,假设我们所选取的样本为简单随机抽样,具有典型性与普遍性,基本上能够集中反映毕业生就业实际情况; 3、在数据计算过程中,假设误差在合理范围之内,对数据结果的影响可以忽略、 三、符号说明
四、模型的分析与建立 1、问题背景的理解 随着我国改革开放的不断深入,经济转轨加速,社会转型加剧,受高校毕业生总量的增加,劳动用工管理与社会保障制度,劳动力市场的不尽完善,以及高校的毕业生部分择业期望过高等因素的影响,如今的毕业生就业形势较为严峻、为了更好地解决广大学生就业中的问题,就需要客观地、全面地分析与评价毕业生就业的若干主要因素,并将它们从主到次依秩排序、 针对不同专业的毕业生评价其就业情况,并给出某一专业的毕业生具体的就业策略、 2、方法模型的建立 (1)层次分析法 层次分析法介绍:层次分析法就是一种定性与定量相结合的、系统化、层次化的分析方法,它用来帮助我们处理决策问题、特别就是考虑的因素较多的决策问题,而且各个因素的重要性、影响力、或者优先程度难以量化的时候,层次分析法为我们提供了一种科学的决策方法、 通过相互比较确定各准则对于目标的权重,及各方案对于每一准则的权重、这些权重在人的思维过程中通常就是定性的,而在层次分析法中则要给出得到权重的定量方法、 我们现在主要对各个因素分配合理的权重,而权重的计算一般用美国运筹学家T、L、Saaty教授提出的AHP法、 (2)具体计算权重的AHP 法 AHP法就是将各要素配对比较,根据各要素的相对重要程度进行判断,再根据 W、 计算成对比较矩阵的特征值获得权重向量 k
(完整版)基于层次分析法的模糊综合评价模型
2016江西财经大学数学建模竞赛 A题 城市交通模型分析 参赛队员: 黄汉秦、乐晨阳、金霞 参赛队编号:2016018 2016年5月20日~5月25日
承诺书 我们仔细阅读了江西财经大学数学建模竞赛的竞赛章程。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们将受到严肃处理。 我们参赛选择的题号是(从A/B/C中选择一项填写): A 我们的参赛队编号为2016018 参赛队员(打印并签名) : 队员1. 姓名专业班级计算机141 队员2. 姓名专业班级计算机141 队员3. 姓名专业班级计算机141 日期: 2016 年 5 月 25 日
编号和阅卷专用页 江西财经大学数学建模竞赛组委会 2016年5月15日制定
城市交通模型分析 摘要 随着国民经济的高速发展和城市化进程的加快,我国机动车保有量及道路交通流量急剧增加,交通出行结构发生了根本变化,城市道路交通拥挤堵塞问题已成为制约经济发展、降低人民生活质量、削弱经济活力的瓶颈之一。本篇论文针对道路拥挤的问题采用层次分析法进行数学建模分析,讨论拥堵的深层次问题及解决方案。 首先建立绩效评价指标的层次结构模型,确定了目标层,准则层(一级指标),子准则层(二级指标)。 其次,建立评价集V=(优,良,中,差)。对于目标层下每个一级评价指标下相对于第m 个评价等级的隶属程度由专家的百分数u 评判给出,即U =[0,100]应用模糊统计建立它们的隶属函数A(u), B(u), C(u) ,D(u),最后得出目标层的评价矩阵Ri ,(i=1,2,3,4,5)。利用A,B 两城相互比较法,根据实际数据建立二级指标对于相应一级指标的模糊判断矩阵P i (i=1,2,3,4,5) 然后,我们经过N 次试验调查,明确了各层元素相对于上层指标的重要性排序,构造模糊判断矩阵P ,利用公式 1 ,ij ij n kj k u u u == ∑ 1 ,n i ij j w u ==∑ 1 ,i i n j j w w w == ∑ []R W R W R W R W R W W R W O 5 5 4 4 3 3 2 2 1 1 ,,,,==计算出权重值,经过一致性检验公式 RI CI CR = 检验后,均有0.1CR <,由此得出各层次的权向量()12,,T n W W W W =K 。然后后, 给出建立绩效评价模型(其中O 是评价结果向量),应用模糊数学中最大隶属度原则,对被评价城市交通的绩效进行分级评价。 接着在改进方案中,我们具体以交叉口为中心建立模型,其中包括道路长度、宽度、车辆平均长度、车速等等考虑因素。通过车辆排队长度可以间接判断交通拥堵情况,不需要测量车速、时间等因素而浪费的人力物力和财力,有效的提高了工作成本和效率。为管理城市交通要道提供了良好的模型和依据。 【关键字】交通拥堵 层次分析法 模糊综合评判 绩效评价 隶属度
多维尺度与对应分析
多维尺度与对应分析 多维尺度与对应分析多维尺度分析(MDS),是基于研究对象之间的相似性或距离,将研究对象在一个低维(二维或三维)的空间形象地表示出来,进行聚类或维度分析的一种图示法。通过多维尺度分析所呈现的空间定位图,能简单明了地说明各研究对象之间的相对关系。 多维尺度分析常用于品牌形象评价,比较消费者对公司及其竞争对手的品牌认知差异,了解在消费者心目中,公司品牌与竞争对手相比处于什么样的位置。如,广州民众对市内各医院,从专业、服务、费用、方便等四个角度的感知评价,通过多维尺度分析所产生的空间定位图。广州民众对市内各医院的感知评价基本分为三类,中山医院、省人民医院、中医药大学医院、省中医院,及专科医院是民众心目中是专业性强、技术高的医院;市/区的中医院、人民医院及妇幼保健医院是费用比较合理的医院;红十字会医院、军区/部队医院的特点则不明显(注:由于样本数量限制,分院、同类型医院合并分析,差异性有所平均,结论仅供参考。) 对应分析的本质是将行和列变量的交叉表变换为一张散点图,从而将表格中包含的类别关联信息用各散点空间位置关系的形式表现出来。如上述数据用对应分析呈现如下:
似乎看起来,对应分析比多维尺度分析更直观、更简单易懂;而且在操作上,通过xlstat插件做对应分析非常方便,做一个多维尺度分析所花的时间可以做十个对应分析了。那么,能用对应分析来替代多元尺度分析吗? 通过分析两者所使用的原始数据表格,能容易区分两者的差异所在,并且知道在什么时候用多维尺度分析,什么时候用对应分析。 多维尺度分析,计算的是行变量之间的差异性或相似性,即表中“省人民医院、中山医院、省中医院 …”等各类医院之间的差异或相似性。 对应分析,计算的是行变量与列变量的相关性,如表中行变量中“省人民医院”与列变量“医院专 业水平、医院服务…”之间的相关性。 所以,在上述多维尺度空间图中,强调的是各类医院之间的相对位置;在上述对应分析图中,强调的是各类医院与专业、服务、费用、方便等之间的相关性,而不是各医院之间的相对关系。 那么,对应分析图中各医院的分布,同样能说明各医院之间的相对位置吗?我们用聚类分析来验证,同样用“专
层次分析法的计算步骤
8.3.2 层次分析法的计算步骤 一、建立层次结构模型 运用AHP进行系统分析,首先要将所包含的因素分组,每一组作为一个层次,把问题条理化、层次化,构造层次分析的结构模型。这些层次大体上可分为3类 1、最高层:在这一层次中只有一个元素,一般是分析问题的预定目标或理想结果,因此又称目标层; 2、中间层:这一层次包括了为实现目标所涉及的中间环节,它可由若干个层次组成,包括所需要考虑的准则,子准则,因此又称为准则层; 3、最底层:表示为实现目标可供选择的各种措施、决策、方案等,因此又称为措施层或方案层。 层次分析结构中各项称为此结构模型中的元素,这里要注意,层次之间的支配关系不一定是完全的,即可以有元素(非底层元素)并不支配下一层次的所有元素而只支配其中部分元素。这种自上而下的支配关系所形成的层次结构,我们称之为递阶层次结构。 递阶层次结构中的层次数与问题的复杂程度及分析的详尽程度有关,一般可不受限制。为了避免由于支配的元素过多而给两两比较判断带来困难,每层次中各元素所支配的元素一般地不要超过9个,若多于9个时,可将该层次再划分为若干子层。 例如,大学毕业的选择问题,毕业生需要从收入、社会地位及发展机会方面考虑是否留校工作、读研究生、到某公司或当公务员,这些关系可以将其划分为如图8.1所示的层次结构模型。 图8.1 再如,国家综合实力比较的层次结构模型如图6 .2: 图6 .2 图中,最高层表示解决问题的目的,即应用AHP所要达到的目标;中间层表示采用某种措施和政策来实现预定目标所涉及的中间环节,一般又分为策略层、约束层、准则层等;最低层表示解决问题的措施或政策(即方案)。 然后,用连线表明上一层因素与下一层的联系。如果某个因素与下一层所有因素均有联系,那么称这个因素与下一层存在完全层次关系。有时存在不完全层次关系,即某个因素只与下一层次的部分因素有联系。层次之间可以建立子层次。子层次从属于主层次的某个因素。它的因素与下一层次的因素有联系,但不形成独立层次,层次结构模型往往有结构模型表示。 二、构造判断矩阵 任何系统分析都以一定的信息为基础。AHP的信息基础主要是人们对每一层次各因素的相对重要性给出的判断,这些判断用数值表示出来,写成矩阵形式就是判断矩阵。判断矩阵是AHP工作的出发点,构造判断矩阵是AHP的关键一步。 当上、下层之间关系被确定之后,需确定与上层某元素(目标A或某个准则Z)相联系的下层各元素在上层元素Z之中所占的比重。 假定A层中因素Ak与下一层次中因素B1,B2,…,Bn有联系,则我们构造的判断矩阵如表8.16所示。 表8.16 判断距阵 Ak B1 B2 …Bn
基于.层次分析法的模糊综合评价
校园环境质量的模糊综合评价方法 信息与计算科学2003级马文彬 指导教师杜世平副教授 摘要:本文应用模糊数学理论,把模糊综合评价方法具体应用到校园环境质量综合评价研究中,结合校园的实际情况将环境评价系统根据需要分成若干个指标,建立了因子集、评价集、隶属函数和权重集,实现对校园环境的质量等级综合评判。采用层次分析法计算评价的权重集,并对取大取小算法和评价结果的最大隶属度原则进行了改进,取得较好的效果。实例表明:模糊综合评价方法可操作性强、效果较好,可在一般环境的质量评价中广泛应用。 关键词:校园环境质量,模糊综合评价,层次分析法,权重 Fuzzy Comprehensive Evaluation Method for the Environment Quality of university Campus MA Wen-bin Information and Computational Science , Grade 2003 Directed by Du Shi-ping (Associate Prof ) Abstract: In this paper,based on fuzzy mathematics theory, the fuzzy comprehensive evaluation is applied in the environment quality evaluation of university campus,combining the actual situation list to evaluate the general level of university campus by fuzzy comprehensive evaluation. By setting up the factor sets, the evaluation sets, subjection functions and the weighting sets. Implementation of the Campus Environment Quality Level comprehensive evaluation. The evaluation of the weighting sets are made by AHP. The choosing big or small algorithm and the maximal subjection degree of the evaluation result is improved, and the effect is very good.The applying example indicates: the researched method is feasible and effective, it can be used widely in the environment quality assessment. Keywords:Environment quality of university campus,Fuzzy Comprehensive Evaluation,Analytical Hierarchy Process,Weighting
模糊层次分析法
5.结论 由以上计算过程可以看出,模糊层次分析法同普通层次分析法相比具有以下优点:(1)检验一次性更方便。根据定理2.1或定理2.2可直接检验模糊矩阵是否具有一致性。(2)调整过程更简洁。通过调整模糊矩阵的元素可很快使模糊矩阵具有模糊一致性。(3)判断依据更合理。根据定理2.1或定理2.2作为检验一致性的标准更科学简便。 参考文献[1]张吉军.模糊层次分析法.模糊系统与数学,2000,14(2):80-88 [2]吕跃进.基于模糊一致矩阵的模糊层次分析法的排序.模糊系统与数学,2002,16(2):79-85 [3]JohnMGleason.Fuzzysetcomputationalprocessesinriskanalysis.IEEETransactionson EngineeringManagement,1991,38(2):177-178 4.3.2层次总排序 同理,可求得其他矩阵对应元素的权重,并得到C层次总排序如下: 4.3.5结论 球面网壳动力稳定临界力简化计算 王节1黄显民2 (1.黑龙江省林业设计研究院2.哈尔滨工业大学建筑设计研究院150008) 摘要:球面网壳动力稳定临界力简化估算公式是针对跨度30m ̄60m,矢跨比1/10 ̄1/6的单层球面网壳,对于其它类型的网壳结构要具体分析。 关键词:单层球面网壳动力稳定动力稳定临界力中图分类号:TB122文献标识码:A 网壳结构是杆件沿曲面有规律布置而组成的空间杆系结构。具有刚度大、自重轻、受力均匀、在水平、竖向及多维地震作用下的动内力分布均匀且较小,结构抗震性能良好。结构在罕遇地震作用下的动力失稳临界峰值较高,随着矢跨比增加,结构刚度增大,地震作用稳定性提高。而且造型丰富美观、综合技术指标好等特点,是大跨度、大空间结构的主要结构形式之一。目前世界上跨度最大的网壳结构是美国新奥尔良体育馆的超级穹顶,跨度213米。近年来,网壳结构在我国获得了迅速的发展,哈尔滨速滑馆,由筒壳及两个半球壳组成的组合网壳,网壳平面投影86.2m×191.2m,是已建成最大的网壳结构。 在我国,单层球面网壳多应用在跨度较小的结构中,主要原因是该类结构为缺陷敏感性结构,在大雪、强风和强烈地震作用下,杆件进入塑性,结构通过塑性变形吸收地震能量,随着地震输入能量的增加,结构产生很大的塑性变形甚至失稳倒塌破坏。目前关于球面网壳的研究主要集中在结构静力稳定性及静力后屈
多维标度分析
武夷学院实验报告 课程名称:多元统计分析项目名称:多维标度分析姓名:专业: 14信计班级:1班学号:同组成员:无
(一)操作步骤 (1)点击分析-度量--多维尺度 ,进入多维标度分析的主对话框,如下图。 (2变量为设定变量列表框,用于将要分析的表示距离的变量移入此处。本案例是将北京,合肥,长沙,杭州,南昌,南京,上海,武汉,广州,成都,福州,昆明放置于此框。 (3)单个矩阵表示如果数据文件中有多个受访者的距离阵时。就应当使用该选项选取代表不同受访者的变量。
(4)距离用于设置所使用距离的产生方式。 ①数据为距离数据表示如果所提供的数据为距离阵,可直接用于分析。单击"形状"有3个选项(图:正对称表示距离阵为完全对称形式,且行列表示相同的项目,要对角线上下三角中相应的数值对称相等,正对称表示距离阵为不完全对称结构且行列表示相同项目,上下三角中相应的数值不想等,矩形表示距离阵为距离完全不对称形式,并需要在行数框中输入行数,如下图。
②从数据中创建度量表示如果数据代表的不是距离,使用该选项可以根据数据生成距离阵。 单击"度量标准"打开数据测度方法对话框,如下图。其中,度量标准用于选择不相似性量度方法,转换值是选择进行标准化转化的方法,创建距离矩阵表示是根据变量还是根据样品创建距离阵(变量间计算成对变量之间的不相似性矩阵,个案间计算两两样品之间的不相似性距离矩阵)。 设置完成后,点击继续返回主对话框。 (5)在主对话框中点击模型,用于设置数据和模型的类型,如下图。
①度量水平用于指定测量尺度。其中,序数为有序数据,区间为定距数据,比率为比例数据,鉴于本例中的数据是距离,因此选择interval。 ②条件性用于进一步定义距离阵的情况。矩阵表示只有一个矩阵或者每个矩阵代表不同的个体时采用,它表示距离阵的数值意义相同,是可以相互比较的,行只在非对称或者距离阵时才使用。表示只对同一行间数据进行比较才有意义,无约束表示不受任何限制,资料中所有数值的比较都有意义。 ③维数用于指定多维尺度分析的维度。最小值输入最少维度,最大值输入最大维度,由于一般是计算二维解,均输入2。 ④度量模型用于选择距离测量模式。Euclidean 距离是欧几里得距离,个别差异Euclidean 距离加权欧几里距离。
层次分析法评价TOP方案的模型
层次分析法评价TOP方案的模型 一、建立模型 最高层。最高层也叫目标层,这一层次中只有一个元素,它一般是我们所要分析的预定目标或理想结果。 中间层。中间层也叫准则层,这一层次中包含了为实现最高层所涉及的中间环节,它可以由若干个层次组成,包括所需考虑的一些准则、子准则。 最低层。最低层也叫方案层,这一层次包括了为实现最高层而提供了选择的各种措施、决策方案等。 评估互动社区层次结构(如图): 二、构造判断矩阵 针对上一层次某一因素,下一层次中凡与该因素联系的全部因素进行两两比较。确定各准则对目标的权重,以及各个方案对每个准则的权重。按标度表赋值后,构成矩阵形式,就是判断矩阵。
表1 第一层判断矩阵 表2 第二层判断矩阵 表3 第二层判断矩阵 表4 第二层判断矩阵 A:选择合适的互动社区产品B1:系统功能B2:系统易用性B4:系统排名 注:bij即为比值,则当i=j时,bij=1。i不等于j时,bij=1/bij(i,j=1,2,3,4),bij 的确定应在广泛征求专家和诸多群众意见的基础上确定 三、单排序矩阵权数的计算(以第一层为例) 判断矩阵A=(bij)满足特征值问题:AW=nW,其中n为特征根,W为标准化特征向量。 当n=λmax(最大特征值)时,W=(W1,W2……Wn)T(T为矩阵转置的符号),即为接受判断的各因素对所联系因素指标的权数。 求解W按以下步骤: (1) 计算判断矩阵A各行各个元素幂的和
6 1W = 6 2W = …….. 6 6W = (2) 将A 的各行元素的和进行归一化 6 1 j Wi Wi Wj == ∑ 求出W 的分量Wi ; (3)最后按以下公式: 6 1 max ()/i BW i nWi λ==∑ ,求出λmax 。 四、相容性检验 当矩阵完全相容时,即任一bij=bik*bkj ,则λmax =n 。一般地,主观判断矩阵不可能完全相容,此时λ