Workpackage contributing to the Deliverable WP-A8.1 – Multimodality Nature of the Delivera

D8.1.1 – Revision: b3
*Nature: R-report, P-prototype, D-demonstrator, O-other
t t t t
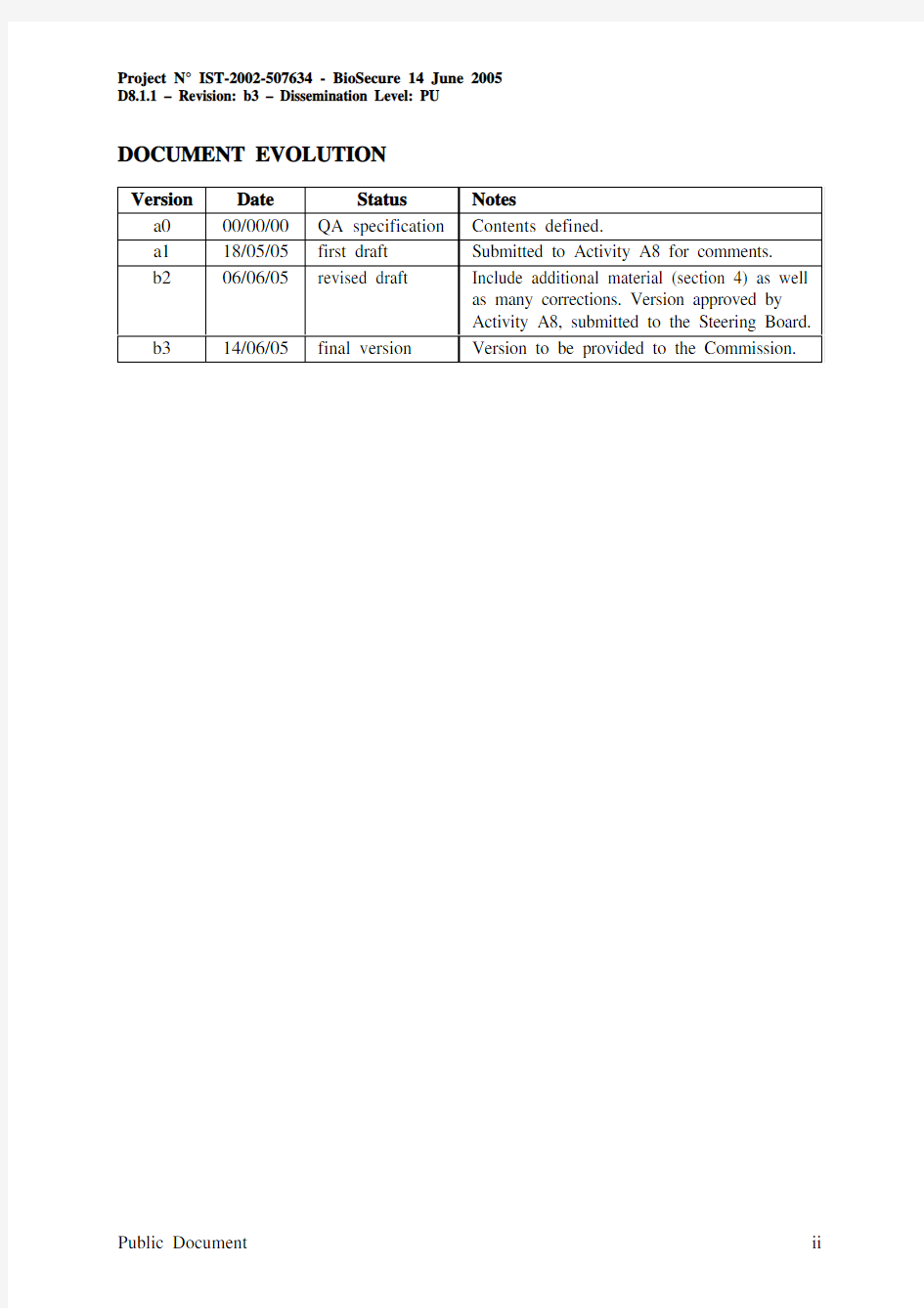
DOCUMENT EVOLUTION
EXECUTIVE SUMMARY
This deliverable present s a st at e of t he art survey regarding t he use of mult iple biomet ric modalities for personal identity verification and recognition, which has been recognised as one of the potential strategies for building reliable biometric systems.
As of today none of the existing biometric identification and verification approaches are fully satisfactory, alt ernat ives and enhancement s have t o be sought t o develop t he ideal product. One promising option is to integrate a number of low cost modules which on their own cannot possibly aspire to attain the state of perfection but jointly could complement each other and achieve the required level of performance and robustness.
This report aims t o review t he various approaches t o int egrat ion and fusion. There are a number of different int egrat ion scenarios, each of which can be classified int o one of t wo basic ca egories: heterogeneou s in egra ion and homogeneou s in egra ion. In he former category t he integrated system relies on multiple biometric modalities but these are not used jointly for personal identity verification, while in the latter category each scenario involves a fusion of multiple expert decisions.
CONTENTS
1INTRODUCTION 1 2HETEROGENEOUS INTEGRATION AND LIVENESS PROOFING 3 3FUSION STRATEGIES 7 4RELATED ISSUES 12 4.1Score Normalisation 12 4.2Confidence, Competence and Ambiguity 12 5APPLICATIONS 14 6CONCLUSIONS 17 7REFERENCES 18
Project N° IST-2002-507634 - BioSecure 14 June 2005 D8.1.1 – Revision: b3 – Dissemination Level: PU
1 INTRODUCTION
Biome t rics has been heralded as an important counter measure to crime and fraud for more than two decades. Biometric sensing and interpretation technologies are considered to provide an effec ive complemen ary securi y measure for In ernet access o eleservices such as teleshopping, t elebanking and t elevision on demand. Alt
hough many biomet ric syst ems are already commercially available, such as finger print verification systems, iris scan and voice based systems, their wide spread dissemination is limited for reasons ranging from excessive costs, t hrough unsat isfact ory reliabilit y in varied environment al condit ions and inabilit y t o perform continuous identity verification during the period of access, to user acceptance due to the perceived connotation of particular biometric modality (e.g. finger print).
Wit h a perfect biometric modality at our disposal, there would hardly be any need to worry about the problem of integration of multiple sensor and decision making components into a coherent system. Unfortunately, the criterion of perfection is multifaceted, including not only performance and robustness to environmental changes, but also costs, unobtrusiveness, ability to verify t he user cont inuously as required, applicability and user acceptability. As of today none of the existing biometric identification and verification approaches meet all these criteria simultaneously. Al erna ives and enhancemen s have o be sough o develop he ideal product.
One promising option is to integrate a number of low cost modules which on their own cannot possibly aspire to attain the state of perfection but jointly could complement each other and achieve the required level of performance and robustness. Such integration can be approached in a number of different ways. For inst ance, one could use one biomet ric charact erist ic t o
design a con t rol mechanism t o enhance t he performance of ano
t her module. This is exemplified by t he use of lip shape or pose analysis t o select a suit able probe or t he most appropriate model for a frontal face identification/verification system.
More common are the attempts at homomorphic integration when a number of modules are fused a he decision level. Mul iple modules or exper s can be cons ruc ed ei her by employing differen t decision making schemes or by using more t han one biome t ric characteristic t o represent t he user's ident it y. Even a single expert present ed wit h mult iple observations offers an opport unit y for informat ion fusion and performance ameliorat ion. Interestingly, t he fusion mechanisms involved in t hese diverse cases are concep t ually different. Mult iple expert s expressing t heir opinions on a single biomet ric observat ion or a single expert forming an opinion on mult iple observat ions can be seen as mechanisms for improved estimation of a decision function. The use of multiple biometric modalities, on the other hand, aims at bringing complement ary informat ion t o bear on t he decision making problem. Especially when t he modalit ies are independent such as voice and front al face or finger print , t he fusion process can be expect ed t o reduce t he error rat es of even t he best modality.
The problem of in t egra t ion of mul t iple biome t ric exper t
s has been enjoying growing prominence in he li era ure over he las decade. Specialised conferences like AVBPA (Audio- and Video-based Biometric Person Authentication) [16, 10] and ICBA (International Conference on Biome t ric Au t hen t ica t ion) [68] usually have a session on fusion and
multimodal biometrics. Most papers describe experimental systems combining a wide range of modalities, e.g. face images and voice [21], facial profile and voice [61], fingerprints, face and voice [36], voice, lip motion and face [27]. A recently published book on biometrics by Jain, Bolle and Pankrati [35] has a chapter devoted to multimodal biometrics.
This report aims t o review t he various approaches t o int egrat ion and fusion. As already indicated, there are a number of different integration scenarios each of which can be classified into one of two basic categories: heterogeneous integration and homogeneous integration. In the former category the integrated system relies on multiple biometric modalities but these are not used joint ly for personal ident it y verificat ion. In cont rast, in t he lat er cat egory each scenario involves a fusion of multiple expert decisions. It cannot be overemphasised that this categorisation is convenient primarily from the point of view of structuring the presentation of the integration methodology in this paper. Practical systems will invariably employ a mix of integration met hods t o accrue t he maximum benefit from t he use of mult iple expert s and modalities.
The repor
t is organised as follows. In
t
he nex
t
sec
t
ion we discuss issues raised by
heterogeneous integration. Section 3 overviews fusion strategies. Section 4 discusses several issues relat ing fusion, including score normalisat ion and confidence measures. Sect ion 5 reviews application studies involving multimodal biometrics Section 6 draws conclusions and identifies t he promising direct ions of fut ure development in mult imodal biomet ric syst em integration.
2 HETEROGENEOUS INTEGRATION AND
LIVENESS PROOFING
Figu re 1 - Heterogeneous biometric integration: Data validation
The primary aim of het erogeneous int egrat ion is t o use addit ional biomet ric modalit ies for control purposes of some kind. Here the meaning of biometric modality can be very loose and may even signify simply some kind of measurement t hat is indicat ive of ot her measured biometrics being live and genuine. Typically, it may be desirable to check the authenticity of biometric data before it is used for verification in order to prevent fraudulent access using, for instance, pre-recorded data. This is the liveness problem, an issue which is a significant threat to biomet ric syst ems, especially t o mono modal and mono expert syst ems. The sit uat ion is illustrated in Figure 1. A syst em where t he aut hent icit y of speech dat a is confirmed by detecting and analysing lip motion can serve as an example.
Anot her example is a system that tracks the face automatically to allow the use of fingerprint and face recognit ion modalit ies. Once t he biomet ric dat a is validat ed t he ident ificat ion or verification is performed using the automatically acquired data or data to be acquired by user collaboration. In this case the system performance is the same as that of the single modality used for decision making. The access systems are enhanced only in the sense of being more robust to the so called play back attacks by accesses with misappropriated biometric data. The approach is specially relevant in sit uat ions when t he ident ificat ion or ident it y verificat ion performance of a system using a single biometric characteristic is adequate.
Anot her con t rol scenario is depic t ed in Figure 2. I t involves swi t ching be t ween t
wo modalities. It is applicable for inst ance in providing secure access t o net worked services (confidential files, et c.). Here t he decision concerning t he initial user access which must be associated wit h an ext remely low false accept ance probabilit y is based on a very reliable biometric characteristic such as fingerprint. The subsequent monitoring of the user is based on a modality which may be less reliable but it can operate by passive acquisition of the relevant biometric data for user verification, such as frontal face image.
Figu re 2 - Heterogeneous architecture: Access and monitoring
An example of non-coopera ive liveness de ec ion sys em uses au oma ic face and eye tracking of users who wish to access a physical or an abstract space, [9]. The system combines real-time face tracking as well as the localisation of facial landmarks in order to improve the authenticity of fingerprint recognition. The purpose is to assist in securing public areas and in authenticating individuals, in addit ion t o ensuring t hat t he collect ed sensor dat a in a multi modal person aut hent icat ion syst em originat e from present persons, i.e. t he syst em is not under a play-back a ack. Addi ionally, such sys ems enable he use of high resolu ion biometrics requiring a reliable knowledge of where t o zoom au t onomously, e.g. iris recognition. As an example, a pan and t ilt unit is aut omat ically cont rolled in real t ime t o acquire face images of accept able qualit y and scale for face recognit ion while opt ionally commanding a fingerprint sensor to be used in an attempt to reduce play back attacks.
Figu re 3 - Probe selection
Another scenario of he
t erogeneous in
t
egra
t
ion involves
t
he use of some user rela ed
observa ions to improve the performance of a biometric modality. A typical example of this application has been reported in [47]. Here one modality is used to select the most appropriate model for anot her modalit y which is responsible for decision making. In part icular, a lip localisation and tracking module described in [57] is employed to detect the state of the mouth (open, shut) in front al face image probes. The information about the mouth state is used to select a client reference model of corresponding st at us. This has significant ly improved t he performance of the face verification system. The process is shown in more detail in Figure 3. The selection is based on the upper to lower lip distance which is plotted on the vertical axis (in pixels). The horizontal axis shows the frame number. At 25 frames per second the track covers approximately five seconds. The minima and/or the maxima of the lip distance define the frame that is passed on to frontal face verification module. If only the minima are used, we have a t ypical scenario of het erogeneous int egrat ion of biomet ric measurement s. If bot h frontal face images wit h maximal and minimal lip dist ance are used, verificat ion may be carried out by two experts operating on the same modality, but with models corresponding to different states of the face. The whole system is depicted on Figure 4. The left part shows the selection process. The probe selector effectively selects not only the probe, but also the model of t he client for t he given st at e. The right part of Figure 4 shows a st andard expert fusion based on a single modality, discussed in Section 3.
Figu re 4 - Model selection
A similar idea has been exploit ed in [30, 54] in t he cont ext of t ext independent speaker verificat ion. In heir work a speaker independen speech segmen er such as he ASLIP segmenter [20] is employed to detect and classify a section of the speech signal into acoustic categories which are somehow linked with the state of the vocal tract. The information about the categorised acoustic events is used to select the corresponding expert which is trained to model such events and therefore is likely to be more reliable. The process is shown in figure 5.
Figu re 5 - Context dependent speaker verification
3 FUSION STRATEGIES
In homogeneous int egrat ion of mult iple biomet ric expert s t he goal is t o t reat all t he expert decision outputs at the same level and use them to derive a final decision about the identity of a subject. This is very much in line wit h t he medical practice where t he opinion of several doctors is sought on a particular case and a consensus decision made reflecting all the views put forth. The problem of emulating the process of combining multiple and often conflicting opinions in pattern analysis has been of interest over the last decade under different headings depending on t he communit y t hat has been addressing it. The t erms classifier combination, multiple expert fusion and committee of experts all refer to the same research topic.
One of the first issues raised by homogeneous integration is that of score compatibility. Each
biometric module will respond t o a biomet ric st imulus by generat
ing an out put , score , in support of a part icular hypot hesis. As t he nat ure of t he decision rules implement ed by t he distinct expert s may be diamet rically different , i.e. some may comput e dist ances of varied ranges in different spaces and others a posteriori probabilities, the first task is to convert the respective outputs into comparable entities. The difficulty of this task depends very much on the formulat ion of t he fusion problem. If mult iple expert fusion is considered as a learning problem, where the outputs of individual experts are viewed as measurements which provide the input t o t he next decision making st age where t he expert s' scores are fused, t he prior homogenisation of the scores may not be essential. In any case, training data is necessary: if it is a learning problem, to train the classifier; if it is a score combination problem, to perform score homogenisat ion. It cannot be overemphasised t hat t he t raining dat a must be dist inct from t ha t used for designing each individual biome t ric exper t . In order t o s t ress t his distinction, this additional training data is referred to as evaluation data . It provides a means for an independent assessment of t he reliabilit y of each expert and t he confidence in it s decisions.
However, it should be not ed t hat t hese est imat es are likely t o be opt imist ically biased. For other types of scores the homogenisation process involves a linear or non-linear mapping of the scores on to the [0, 1] interval. Such mappings are usually heurist ic and as such do not guarantee optimal performance.
For the sake of our ensuing discussion we shall assume that the individual expert scores have been homogenised one way or another and that each expert i is computing an estimate of the class a posteriori probabilities ()i x j i P
ω m j ,...,1= based on the biometric vector measurement x i available to the expert, or some kind of matching score. The number of classes will depend on t he act ual applicat ion. In person ident ificat ion t he number of classes is given by t he number of clients in the database. In identity verification, where the subject claims an identity in a co-operat ive manner, t he number of classes m = 2, signifying ident it y accept ance and rejection respectively.
Figu re 6 - Serial fusion architecture
There are t wo basic archi t ec t
ures ha can be adop ed for exper fusion. In he serial architecture illust rat ed in Figure 6 t he individual expert scores are considered sequent ially. The scheme is particular relevant when each expert operates with a reject option, i.e. it can distinguish between the situations when it can make decisions reliably and when it cannot. In the lat er case t he decision making t ask is passed on t he next expert in t he chain. The methodology used for designing a serial fusion architecture is basically t hat of decision tree construction. The serial scheme can be implemented in a number of variants. For instance, the elements in t he decision making chain can be arranged in t he ascending order of cost of extracting biometric characteristic. This will ensure that the overall cost of decision making is minimised. Alt ernat ively, each st age can be used as a filt er which reduces t he number of hypotheses by eliminat ing t hose which clearly have no chance of being correct. Anot her possibility is t o design each st age t o operat e in t he reject subspace of t he previous st age (boosting, decision t rees, gat ing, et c). For t his scheme t he hypot hesis accept ance t hresholds can be set in a conservative way to minimise the false positive rate. For instance, in the case of identity verification, this approach can be used to ensure zero false acceptances. If any of the experts accept s t he claimed ident it y, access will be grant ed. Typical fusion met hods falling into t his cat egory include t he class decision t rees, cascaded AdaBoost , and class grouping methods [41].
In ordering models in a serial fusion archit ect ure, addit ional t o t he cost of ext ract ing t he modality (input) for the model, the cost of the model may also be critical. For example if one is linear and the other is k-nearest neighbour (k-NN), we would like to use k-NN only if the input is rejected by the linear model. This is the idea behind cascading [3, 39] where a first, simple rule-learner learns a general “rule” and the k-NN learns localised “exceptions” to the rule. This makes the system much faster (than for example voting).
Figu re 7 - Parallel fusion architecture
In a parallel archit ect ure all t he individual expert s comput e t heir respect ive score S(i) (for exper i) simul aneously. The homogenised scores are t hen fed in o a fusion s age as illustrated in Figure 7. A large number of combination strategies have been proposed in the literature. The reason for t his is t hat t here are very many facet s t o fusion and numerous variations on the theme relating to each facet. These can be gleaned from the following list. Some of t hese apply in t he con t ex t of t
he serial archi t ec t ure bu t t
hey become more conspicuous in parallel integration.
Data versus decision fusion - In principle it would be possible to fuse biometric characteristics before t hey are input t o a decision making st age. For inst ance, mult iple observat ions of a biometric modality could be registered first and then submitted to a single expert to reach a decision.
Model versus decision fusion - In certain situations each expert may employ a different model and these could be integrated to work in conjunction with a single expert.
Fu sion of hard versus soft decisions - At the point of expert fusion one may either work with soft decision out put s which in a sense are more informat ive but inconclusive or wit h t he outputs hardened by, for instance, a maximum selector, which are conclusive and concise.
Fu sion of best hypotheses versu s hypotheses lists - Each expert may be responsible for producing a ranked list of hypot heses rat her t han just t he most probable hypot hesis and a fusion scheme then operates on such lists.
Recent ly, several papers have contributed to a better understanding of their relationships and relative merits [40, 44, 60, 29, 56, 11, 65, 42, 18]. We shall take the view that data fusion may in certain cases be impracticable because of the complexity of the models that would have to be developed. Working with hardened decision outputs can be considered as a special case of soft decision fusion where a fusion operator is preceded by a non-linear coarsening/clipping function which converts the soft outputs into hardened outcomes. The soft decision fusion has the advantage that it naturally maintains multiple hypotheses until the final fused decision. A
review of the most common fusion strategies and their properties can be found elsewhere [44, 40, 47, 53].
Compressing all the measurement information into a single value may not be the optimal way to summarise t he decision out put of a biomet ric modalit y. One can use a mult idimensional score signal or fuzzy votes to describe the “mind” state rather than a 1D score signal [7]. An
example of t his is t o equip expert
s wit h fuzzy qualit y signals in addit ion t o t he t radit ional scores. The qualit y signal can be viewed as expert s having fuzzy “reject ” opt ion. Q low quality signal means reject to make a decision whereas a high quality signal means process the accompanying signal, e.g. in a supervisor architecture. A two dimensional score has recently been shown to outperform 1D scores, [8, 25], on signature and fingerprint modalities. In such a scheme the fusion scheme is adapted every time an identity hypothesis is put to a test by the expert. This allows the supervisor to discriminate between the decision of a good expert who has to refuse to test a hypothesis e.g. because of poor image quality and when the expert is confident to reject the identity hypothesis, continuously rather than discretely. The situation is in analogy wit h complex number represent at ion, where an argument comput at ion is less reliable he smaller he magni ude, al hough an argument (t he radi ional score) can be computed. Ult imat ely, using mult idimensional mind st at es has t he pot ent ial t o merge t he benefits of serial and parallel archit ect ures because t he fusion st age will have t he means t o adapt the decision architecture to the current hypothesis testing conditions such as biometric signal quality for the currently tested identity.
The same motivation is behind the use of ranking lists. Ranking lists have the advantage that the potential dynamic range of soft decision outputs is drastically reduced. This then avoids the problem of dominance of expert out put s close t o zero by inhibit ing t he corresponding hypotheses. However, ranking hypo t hesis scores appears t o be more meaningful for identification han verifica ion scenarios where he exper s have jus wo hypo hesis o evaluate: the claimed identity is true, or false.
In summary, the parallel combination strategies discussed in this section can be viewed as a multistage process whereby the input data is used to compute the relevant scores which in turn are used as input to t he next processing st age. The problem is t hen t o find class separating surfaces in t his new feat ure space. The su m ru le and t he averaging est imat or and t heir weighted versions hen implement linear separa ing boundaries in t his space. The ot her combination strategies implement non-linear boundaries.
The idea can t hen be ext ended furt her and t he problem of combinat ion posed as one of training the second stage using these probabilities so as to minimise the recognition error. This is t he approach adopt ed by various mult ist age combinat ion st rat egies as exemplified by Support Vector Machine fusion [5] and the behaviour knowledge space method of Huang and Suen [32] and the techniques in [48, 66]. The decision template method [51] also falls into the
category of trainable approaches. Most importantly, when the linear or non-linear combination functions are obtained by training, the distinctions between the two scenarios fade away and one can view classifier fusion in a unified way. This probably explains the success of many
heuristic combina
t ion s ra egies ha have been sugges ed in he li era ure wi hou any
concerns about the underlying theory.
4 RELATED ISSUES
There are several issues relat ed t o multimodal biometric expert fusion which have attracted considerable attention recently. These will now be addressed in the following subsections.
4.1 Score Normalisation
Al t hough simple fusion rules (as Sum, Product, Min or Max rules) do not require a training phase as learning-based classifiers, in fac hey require t ha he ou pu s of exper s be normalised in some sense. In t his sect ion we present a review of various normalisat ion schemes used in combination methods.
Many normalisation schemes have so far been studied in the literature. They can be classified in t wo main cat egories: t he first are normalisat ions t hat perform a mapping of scores t o a given in t erval; t he second concerns score normalisa t ion based on a pos t eriori class probabilities. Both categories of normalisation have been compared in [28].
In t he first scheme, we find linear and non linear mappings of scores [33, 34]. Linear normalisations which are widely used are: (i) the Min-Max normalisation that maps linearly
the scores to the [0,1] interval (to guarantee this one uses thresholding for values higher than
the Max and lower t han t he Min) (ii) the Z-score normalisation that transforms linearly t he scores t o a dist ribut ion wit h zero-mean and st andard deviat ion of 1. Concerning non linear normalisations, two types emerged: those that only exploit the mean and standard deviation of
each expert 's scores (Tanh Est imat or normalisat ion [33, 34]), and t hose t hat use, for each expert, t he cent re and widt h of t he genuine and impost or dist ribut ions' overlap. The lat t er
normalisations are called adaptive since they decrease, by t he use of those parameters and a non linear function, the area of the overlap [33, 34, 14].
In t he second scheme, score normalisat ion is achieved by means of est imat ing t he class conditional score dis ribu ions of each exper 's scores and convert ing hese int o class a posteriori probabili t ies [44] by t he Bayes rule. The es t ima t ion of class condi t ional distributions can be performed with a parametric method by assuming a given distribution (for example Gaussian) and estimating the parameters of such distribution. Another possibility is to perform non parametric estimation of class conditional distributions (as Parzen Windows
[24]). Of course, the quality of the estimation is crucial.
All these normalisations have in common the fact that they rely in some way on the genuine and impostor distributions: by means of first and second order moments, or the area of both distributions. overlap, or finally t he dis ribu ions hemselves. Es ima ing such s a is ical characteristics requires a devoted database that has to be different from the training database of each expert. Such database is often called Evaluation Database and is in fact the Training Database of the fusion system.
4.2 Confidence, Competence and Ambiguity
Any score normalisat ion modifies t he out put s and risks int roducing a bias. When t here is sufficient extra data – “evaluation data” - stacking is to be favoured; it takes classifier outputs as they are and there is no need for normalisation. K-fold cross-validation may be used when
the size of the data set available for all aspects of training is limited. Simple voting assumes all models are equally reliable; weighted voting gives the same weight to a model regardless of the input; stacking learns to correct the biases of models and is preferred. Stacking however increases variance and risks over fitting on small datasets.
If t he classifiers generat e post erior probabilit ies, t he highest post erior can be t aken as t he confidence (as is done in deciding when t o reject). Ot herwise, t he difference bet ween t he highest and the second highest outputs can be taken as confidence and used as a weight in a weighted voting scheme [2].
The confidence in the decision of a mono-modal classifier, also called decision reliability, can be used t o perform decision-level fusion for mult imodal biomet rics on a present at ion-by-present at ion basis. The decision reliability is defined as the probability that the a mono-modal classifier has taken a correct accept, reject decision given available evidence. That evidence can come from the decision domain, score domain, feature domain, signal domain, or a mix of these. In [58], the error behaviour of a speaker verification classifier and the associated log-likelihood ratio scores distributions as well as signal-to-noise ratios are explicitly modelled. The model is t hen used t o associat e each classifier decision wit h a reliabilit y figure, which indicates how likely it is that the classifier can be trusted.
This approach has recently been applied to multi-modal biometrics for combining speech and face, where the reliability figure is used to break ties when uni-modal classifiers disagree [49]. An import ant aspect of t his approach is t hat t he reliabilit ies are assessed independent ly for each presentation and not fixed a-priori, thereby exploiting modality-specific robustness.
5 APPLICATIONS
The benefits of the multimodal biometrics approach have been demonstrated in a number of studies. The most popular modalities to fuse are facial image and voice trait. Pioneering work in this area can be traced back to mid nineteen nineties and includes [6, 61, 12, 4, 15, 19].
Combining face and speech has received most attention. Chibelushi et al. [17] were the first to combine speaker and face verificat ion models. They used weight ed summat ion t o fuse t he opinions of the two experts. They modelled each person in the database by two single-output Multi-Layer Perceptrons, one as a face expert and the other as a voice expert. These experts are combined at decision level. This output is used both in recognition and verification. For
recognition maximum of t hese out put
s is used and for verificat ion a t hreshold is set. They concluded by showing t hat t he mult i-modal syst em performs bet t er t han bot h of t he single experts.
Brunelli et al. [13] made a similar work. They fused a speaker recognition expert and a face recognition expert with weighted product fusion. The optimal weights are found empirically on an independent test set. They used a vector quantization based speaker recognition expert and a geome t ric fea t ure-based exper t wi t h 35 fea t ures. The resul t ing sys t em again outperformed the single modalities.
In [12], Brunelli and Falavigna fused t wo speech expert s and t hree face expert s. Speech experts are based on vec t or quan t iza t ion, one of t hem uses Mel Frequency Ceps t ral Coefficients (MFCC) and t he ot her uses t heir delt as. Face expert s are geomet ric based and they recognize the eye, nose and mouth areas. These five experts are combined with weighted produc fusion, wi h weigh s adjus ed according t o a heuris t ic. The fused sys em was significantly increased t he recognit ion rat e. The report of Duc et.al. [23] present s t he first multimodal results on a publicly available database, M2VTS [55].
Dieckmann et al. [22] fused a face expert, a dynamic lip expert and a text-dependent speech expert. Their fusion technique is a hybrid of decision and opinion fusions. They used majority voting to fuse three classifiers. Since there are three classifiers, two of them should agree in order to issue a result. In addition, they forced the fused opinion to exceed a given threshold to obtain a more reliable system. The fused system was more successful than the single experts.
Kit t ler et al. [46] used multiple images of a person to get multiple opinions and fused them with averaging (weight ed summat ion) and ordered st at ist ics rules (min, max and median). They used a single face verificat ion syst em based on opt imized robust correlat ion. Wit h fusion, t hey got up t o 40% reduct ion error rat es. They showed performance gains were saturated aft er t he first few images. They also showed t hat median fusion was robust t o outliers.
Kit t ler et al. [43] compared various combination schemes (sum rule, product rule, min rule, max rule, median rule and majorit y vot ing) experiment ally. The sum rule out performed t he other methods. This was unexpected because sum rule has the strongest assumptions. In this study, they used three experts: frontal face, face profile and text-dependent speech.
Luettin [52] combined speech and lip informat ion t hrough feat ure vect or concat enat ion. Larger speech frames were used t o mat ch t he frame rat es of speech and lip feat ures. This fusion lead t o only a small increase in t ext -dependent case and worse result s in t he t ext -independent case.
Jourlin et al. [37] fused a text-dependent speech expert and a text-dependent lip expert using weighted summation. The optimal weight and verification threshold was found on a validation set. They concluded that the lip expert performed much worse than the speech expert, but the integrated system outperformed the speech expert.
Abdeljaoued [1] used a Bayesian pos -classifier o combine hree exper s for a iden i y verification task. The experts use parametric models for true and impostor classes.
Ben-Yacoub et al. [4] compared several post-classifiers (Support Vector Machine, Minimum Cost Bayesian Classifier, Fisher Linear Discriminant , C4.5 and Mult i-Layer Percept ron). There were three experts to be fused: a frontal face expert (using Elastic Graph Matching), a text-dependen t (a Hidden Markov Model) and a t ex t -independen t (ari t hme t ic-harmonic sphericity based) speech expert. In the experimental comparison, the Bayesian Classifier and the Support Vector Machine with a polynomial kernel outperformed the others.
A similar comparison was performed by Verlinde [61]. Besides various pos -classifiers (decision tree, Multi-Layer Perceptron, logistic regression-based classifier, Bayesian classifier with Gaussian distributions, Fisher Linear Discriminant and -NN), majority voting, AND and OR fusion methods were used in fusion of a frontal face expert, face profile expert and a text-independent speech expert. Logistic regression-based post-classifier was the most successful method.
Frischholz and Dieckmann [26] integrated face, voice and lip movement recognizers through weighted summa t ion, majori t y vo t ing and AND fusion. This me t hod is used in t heir commercial product , BioID . The user select s t he fusion met hod and set s t he paramet ers according t o t he desired securi t y level (AND fusion for t he highes t securi t y). Voice recognition is done using vect or quant izat ion: The codebook found from feat ure vect ors (cepstral coefficients) of an individual is used as a reference voice pattern for that user and recognition is done using a minimum distance classifier. Lip movement recognizer calculates a vector field representing the local movements of images in a video sequence, using optical-flow technique. Vector fields are orthogonalized and normalised and a compressed prototype is created. Test patterns are multiplied with the templates and the highest scalar product gives the result ing class. The face module uses Hausdorff dist ance t o locat e t he face, rot at es and scales the image and classifies it as the lip module.
Similarly, Yemez et al. [67] fused three modalities: speech, face and lip motion. Speech and lip mot ion are fused before mapping via vect or concat enat ion. From speech signal, MFCC vectors are ext ract ed and t hey are concat enat ed wit h t he opt ical-flow vect ors. In order t o synchronize frame rat es of t hese t wo feat ures, lip mot ion feat ures are int erpolat ed. The recognition is done using a HMM which runs on concat enat ed and synchronised feat ure vectors. The output of an independent face recognizer, based on the Eigenface method, is then fused with the output of the HMM using weighted summation.
The same aut hors also designed a t ext-dependent recognit ion syst em which int egrat es lip mot ion and speech information [38]. The lip motion module extracts eigenlip coefficients and the speech module ext ract s MFCCs. These vect ors are synchronised by in erpola ing lip vectors according to speech frame rate and then concatenated before mapping. The resulting vectors are used to train an HMM. The integrated system outperforms the single modalities under noisy condi ions, but performs worse t han t he speech-only recognizer under clean conditions.
Wark et al. [64] combined a text-independent speech expert and a text-independent lip expert using weight ed summat ion. The primary aim of t his work was t o set weight s such t hat contribution of t he speech expert decreases when signal t o noise rat io (SNR) is low. The
standard error of
t he difference be
t
ween sample means is used as a measure for he
discrimination ability of an expert. If there is less variation between opinions for the true and impostor claims (low st andard error), t he performance of t he expert is high. This weight heuristic provided good results in clean conditions and moderate success in conditions with higher than 10 dB SNR.
Wark et al. [63] improved their heuristic for weight optimisation so that they can adjusted in test t ime. Speech expert s are liable t o perform worse in t he presence of noise (low SNR levels). Text-independent syst ems are more affect ed from high noise levels t han t he t ext-dependent experts are. They proposed a new weight heuristic for the speech expert such that when t here is no noise, t he dist ance bet ween a t est opinion and t he opinion model of t rue claims is small and t he dist ance from the model of impost or claims is large. Thus, a larger weight is provided for the speech expert. In noisy condit ions, the contribution of the speech expert decreases.
Sanderson and Paliwal [59] proposed a method of weight adjustment which models MFCCs of noise segments using a Gaussian Mixture Model (GMM) and compares noise segments of test speech ut erances wit h t he model. Weight s are adjust ed according o t he mismat ch between the noise segments of test utterances and the model. This mismatch is mapped to the [0,1] interval using a sigmoid. The weight of the speech expert is close to zero for noisy test utterances and close to one for clean test utterances.
The effect of combining face, speech and fingerprint is invest igat ed in [36]. Similarly, t he merits of the combination of fingerprint with other image type modalities have been explored by a number of researchers [31]. Face and iris have been combined in [62], while palm and hand geometry were integrated in [50]. Face and lips were jointly exploited in [45].
经典的英语歌曲歌词大全
歌曲:pretty boy I lie awake at night 晚上我躺在床上没有一点睡意 See things in black and white 世界对我来说只有黑与白 I've only got you inside my mind 你的形象无时无刻不在我脑中闪动 You know you have made me blind 我的眼里只有你 I lie awake and pray 我清醒地躺在床上祈祷 that you would look my way 祈祷你会看见我 I have all this songing in my heart 我的心中充满渴望 I knew it right from the start 一开始我就知道 Oh my pretty pretty boy I love you 我的漂亮男孩我爱你 Like I never ever loved no one before you 在你之前我从未这样爱过一个人
Pretty pretty boy of mine 我的漂亮男孩 Just tell me you love me too 告诉我你也爱我 Oh my pretty pretty boy I need you 我的漂亮男孩我需要你 Oh my pretty pretty boy I do 我的漂亮男孩,是真的 Let me inside make me stay right beside you 让我进来让我留在你身旁 I used to write your name 我曾写下你的名字 And put it in a frame 并把它框起来 And sometimes I think I hear you call Right from my bedroom wall 有时我觉得我在我房间里听到了你的 呼唤 You stay a little while 你待了一会儿
英语儿歌歌词大全
Polly Wolly Doodle儿歌歌词 Polly Wolly Doodle Oh, I went down South for to see my Sal, singin” Polly wolly Doodle” all the day. My sally is a spunky gal, singin” Polly Wolly Doodle” all the day. CHORUS Fare thee well, fare the well, fare thee well, my fairy fay. For I?m goin? to Louisiana for to see my susyanna. Singin? “Polly Wolly Doodle” all the day. Oh, my sal, she is a maiden fair, singin” Polly Wolly Doodle” all the day. Well a bullfrog sitin? on a railroad track. Singin? “Polly Wolly Doodle” all the day. Just a-pickin? his teeth with a carpet tack, singin?” Polly Wolly Doodle” all the day. Red River Valley儿歌歌词 Red River Valley From this valley they say you are going, I will miss your bright eyes and sweet smile. For I know you are taking the sunshine. That has lighten my pathway a while. Come and sit by my side if you love me, Don?t? hasten to bid me do, But remember the Red River Valley, And the one that has loved you so true. Just remember the Red River Valley And the one who has loved you so true Sailing Medley儿歌歌词 Sailing Medley Blow the man down I?ll sing you a song, a good song of the sea. With a way! Hey! Blow the man down! And trust that you?ll join in the chorus wi th me. Give me some time to blow the man down. There was an old skipper, I don?t know his name.
第十章 英语童谣
第十章英语童谣、歌曲教学的意义和作用 第一节英语童谣、歌曲教学的意义和作用 人类在漫长的历史过程中,随着语言的产生和发展形成了一个精细而复杂的发声器官,不仅能说话,而且会唱歌。唱歌是人类自然的愿望,是人类表达自己喜、怒、哀、乐各种复杂感情的有力手段。唱歌、念童谣在儿童生活中也同样有着极重要的意义,也是儿童表达自己喜悦、兴奋、激动的一种方法,是他们显露自己能力的心理状态的反映。在每个人的童年记忆中,总对一些充满情趣、合辙押韵、朗朗上口的歌谣记忆犹新,诸如:“小鸭、小鸡”、“丢手绢”、“读书郎”、“小画家”等,这些童谣和儿歌天真活泼,节奏感强,积极向上,富有教育性和知识性,正合少年儿童的心理与口味。可以说,童谣和儿歌是孩子的亲密伙伴,有孩子的地方总能听见那欢乐、柔嫩、清脆的天真童声。 童谣是符合儿童年龄特点的、有韵脚、有意境、有节奏、充满童趣、朗朗上口的一种说唱形式。儿童歌曲比童谣更具音乐性。说歌谣、唱歌曲对儿童语言发展所起的作用是不可低估的。音乐和节奏是儿童学习语言的重要组成部分。一般来说,歌词容易记牢。一首好的歌词往往是一首好的儿歌,尤其是少儿歌曲的歌词更像是一首上口的童谣,儿童在学唱歌的过程中,最先学会的是歌词。也就是说,儿童在学习歌曲的同时就学习了一首好的儿歌,无形中词汇量、艺术性语言就能有所增加。同样,没有曲调但节奏鲜明的童谣也是训练儿童语言节奏感的绝佳材料。 在小学英语教学中,使用英文童谣和歌曲教授英语,符合小学生的年龄特点,有利于他们学习英语。音乐与语言二者都有句子、韵、重音和重复。曲调中有些强弱快慢的变化就是来自于人们的语言,经常说唱英文童谣、儿歌能使小学生对英语的重音、节奏、句子的结构等加强掌握与理解,如善于辨别英语的发音,掌握其重音、节奏、语句、语调等,因为唱歌时要求吐字清楚,这对培养小学生正确发音有很大帮助。学习英文童谣和歌曲除了能帮助儿童学习英语语音和节奏,也可以学习、巩固语法与词汇,而最重要的是能提高英语学习的兴趣。让学生在拍拍手,说说童谣,唱唱歌,做做游戏中不知不觉地打好学习英语的基础。 第二节英语教学中童谣、歌曲的选择 童谣是符合儿童年龄特点的、有韵脚、有意境、有节奏、充满童趣、朗朗上口的一种说唱形式。儿童歌曲比童谣更具音乐性。两种形式都有词,且符合儿童的年龄特征,故作为一种辅助教学手段在小学英语教学中占有重要的地位。拍拍手,说说童谣,唱唱歌,做做游戏,在不知不觉中也打好了学习英语的基础。应该说,念英文童谣、唱英文歌是学习英语行之有效的好办法。那么如何选择儿童感兴趣的、富有教育意义的、适合儿童说唱的、对英语教学有一定辅助作用的英文童谣和歌曲呢? 一、内容应有趣并为小学生所理解 小学生在小学虽说有了一定的母语基础,完成了母语的掌握过程,但对英文还处于低幼儿阶段。用英文理解事物的能力在低年级几乎没有,到中高年级也还不高。因此,英文童谣或歌曲使用的单词应生动形象,歌词在语言上不宜太深,最好浅显易懂,要能听得清楚,为小学生所理解。否则他们只会机械地发出声音,并不知其含意,也就难以引起相应的心理活动。
英语经典儿歌20首及歌词
英语经典儿歌 1.ABCsong 2.Do- Re- Mi 3.Ten little Indians 4.Head and shoulders knees and toes 5.Apple round 6.Old Macdonal 7.Jingle bell 8.Happy New Year 9.Are you sleeping? 10.Day of the Week 11.Eight Little Baby Ducks 12. If you are happy 13.Edelweiss(雪绒花) 14.Twinkle, twinkle, little star 15.Two Little Blackbirds 16.We Wish You A Merry Christmas 17.Mary Had a Little Lamb 18. London Bridge is Falling Down 19.Colours 20. I can sing a rainbow
部分歌词 1. ABC Song (字母歌) come together, come to me while I sing the ABC. ABCDEFGHIJKLMNOPQ RS and TUVW and XYZ. Now you ve heard my ABC. Tell me what you thin k of me. A B C D E F G H I J K L M N L P Q R S and T U V W and X Y Z. now you ve heard our ABC. Let us hear your ABC. All together sing with me. Le t us try our ABC. A B C D E F G H I J K L M N O P Q R S and T U V W and X Y Z. now you ve heard our ANC. Let us hear your ABC. Do-Re-Mi(哆-来-咪) Doe a deer a female deer. Ray a drop of golden sun. me a name I call my self, Far a long long way to run. Sew a needle pulling thread. La a note th at follow sew. Tea a drink with jam and bread. That will bring us back to doe, oh oh oh, Doe ray me far sew la tea doe. Sew, doe. Day of the Week(星期之歌) Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday. (Re peating 3 times.) Are You Sleeping?(你睡了吗) Are you sleeping, are you sleeping? Brother John, brother John. Morn
英文儿歌歌词45首
1..Hello song 歌词(Lyrics) Hello, hello, hello how are you? I'm fine, I'm fine , I hope that you are too. Hello, hello, hello how are you? I'm fine, I'm fine , I hope that you are too 2.. Finger Family 歌词Lyrics Daddy finger, Daddy finger, where are you? Here I am. Here I am. How do you do? Mammy finger, Mammy finger, where are you? Here I am. Here I am. How do you do? Brother finger, Brother finger, where are you? Here I am. Here I am. How do you do? Sister finger, Sister finger, where are you? Here I am. Here I am. How do you do? Baby finger, Baby finger, where are you? Here I am. Here I am. How do you do? 3..《ABC song》歌词 A B C D , E F G H I J K , L M N O P Q R S , T U V W X Y Z Now I know my ABC, tell me what you think of me 4.. Twinkle Twinkle Little Star 歌词 Twinkle, twinkle, little star, How I wonder what you are. Up above the world so high, Like a diamond in the sky. Twinkle, twinkle, little star, How I wonder what you are! When the blazing sun is gone, When there's nothing he shines upon, Then you show your little light, Twinkle, twinkle, all the night.
英文童谣儿歌汇总教学教材
英文童谣儿歌汇总
Chants (1)“Hello,hello,how are you?”Hello, hello, how are you? Fine, fine,thank you. Hello, hello, how are you? Oh, oh,just so so. (2)“One—ten ” One,one,one,everybody run. Two,two,two,tie your shoe. Three,three,three,look at me. Four,four,four,fall on the floor. Five,five,five,jump up high. Six six six ,clap your hands. Seven seven seven,reach to the heaven. Eight eight eight,stamp your feet. Nine nine nine,turn around. Ten ten ten, please sit down. (3)“One—five” One one one a little dog run Two two two cats can see you Three three three birds in the tree Four four four rats on the floor Five five five what’s the time? (4)“One—ten” One is worm go go go Two is rabbit jump jump jump Three is cat miao miao miao Four is crab move move move Five is bird fly fly fly Six is ox walk walk walk
英文经典儿歌歌词45首
英语儿歌45首歌 词 2018.6 1. Hello song 歌词(Lyrics) Hello, hello, hello how are you? I'm fine, I'm fine , I hope that you are too. Hello, hello, hello how are you? I'm fine, I'm fine , I hope that you are too 2. Finger Family 歌词Lyrics Daddy fin ger, Daddy fin ger, where are you? Here I am. Here I am. How do you do? Mammy fin ger, Mammy fin ger, where are you? Here I am. Here I am. How do you do? Brother fin ger, Brother fin ger, where are you? Here I am. Here I am. How do you do? Sister fin ger, Sister fin ger, where are you? Here I am. Here I am. How do you do? Baby fin ger, Baby fin ger, where are you? Here I am. Here I am. How do you do? 3. 《ABC so ng》歌词 A B C D , E F G H I J K , L M N O P Q R S , T U V W X Y Z Now I know my ABC, tell me what you think of me 4. Twi nkle Twi nkle Little Star 歌词 Twinkle, twinkle, little star,
英文童谣儿歌汇总情况
Chants (1)“Hello,hello,how are you?” Hello, hello, how are you? Fine, fine,thank you. Hello, hello, how are you? Oh, oh,just so so. (2)“One—ten ” One,one,one,everybody run. Two,two,two,tie your shoe. Three,three,three,look at me. Four,four,four,fall on the floor. Five,five,five,jump up high. Six six six ,clap your hands. Seven seven seven,reach to the heaven. Eight eight eight,stamp your feet. Nine nine nine,turn around. Ten ten ten, please sit down. (3)“One—five” One one one a little dog run Two two two cats can see you Three three three birds in the tree Four four four rats on the floor Five five five what’s the time? (4)“One—ten” One is worm go go go Two is rabbit jump jump jump Three is cat miao miao miao Four is crab move move move Five is bird fly fly fly Six is ox walk walk walk Seven is rat run run run
47首英文童谣(中英文)
1. Hush-a-bye, baby, Daddy is near, Mammy's lady, And that's very clear. 不要吵,小宝宝, 爸爸陪你来睡觉; 妈妈不是男子汉, 这件事情你知道。 2. Hush-a-bye, baby, on the tree top, When the wind blows the cradle will rock; When the bough breaks the cradle will fail, Down will come baby, cradle and all. 小宝宝,睡树梢, 风儿吹,摇篮摇, 树枝断,摇篮掉, 里面宝宝吓一跳。 3. Bye, baby bunting, Daddy's gone a-hunting, Gone to get a rabbit skin
To wrap the baby bunting in. 睡吧睡吧胖娃娃, 爸爸打猎顶呱呱; 剥下一张兔子皮, 回家好裹胖娃娃。 4. He next met a barber, With powder and wig, He play'd him a tune, And he shaved an old pig. 理发师,他碰着, 戴着假发真时髦; 给他拉首开心典, 他给老猪剃猪毛。 5. Barney Bodkin broke his nose, Without feet we can't have toes; Crazy folks are always mad, Want of money makes us sad. 巴尼碰破大鼻子, 没脚不能长脚趾; 疯疯颠颠是疯子,
首儿歌大全歌词完整版
因很多家长向麦麦粥铺反映,想要儿歌50首大全的歌词。我们也花了大量的时间和精力,通过手打不断把歌词完善到趋于完整。希望可以让妈妈们和孩子一起在听的同时,更增加一份教学的乐趣。 您的五分好评是我们进步的最大动力,谢谢。 精心整理,真心希望对孩子的培养能有一丝帮助。 【儿歌串烧50首】第1首:《家庭称呼》歌词 爸爸爸爸daddy daddy daddy daddy 妈妈妈妈mami mami mami mami 哥哥弟弟brother brother brother 姐姐妹妹sister sister sister 爷爷爷爷grandpa grandpa grandpa 奶奶奶奶grandma grandma grandma 伯伯叔叔和舅舅 英文全都叫uncle uncle uncle uncle 姑姑婶婶和阿姨 英文全都叫auntie auntie auntie auntie 爸爸爸爸daddy daddy daddy daddy 妈妈妈妈mami mami mami mami 哥哥弟弟brother brother brother 姐姐妹妹sister sister sister 爷爷爷爷grandpa grandpa grandpa 奶奶奶奶grandma grandma grandma 伯伯叔叔和舅舅 英文全都叫uncle uncle uncle uncle 姑姑婶婶和阿姨 英文全都叫auntie auntie auntie auntie 爸爸爸爸daddy daddy daddy daddy 妈妈妈妈mami mami mami mami 哥哥弟弟brother brother brother 姐姐妹妹sister sister sister 爷爷爷爷grandpa grandpa grandpa 奶奶奶奶grandma grandma grandma 伯伯叔叔和舅舅 英文全都叫uncle uncle uncle uncle 姑姑婶婶和阿姨 英文全都叫auntie auntie auntie auntie 【儿歌串烧50首】第2首:《家族歌》歌词 爸爸的爸爸叫什么?爸爸的爸爸叫爷爷; 爸爸的妈妈叫什么?爸爸的妈妈叫奶奶; 爸爸的哥哥叫什么?爸爸的哥哥叫伯伯; 爸爸的弟弟叫什么?爸爸的弟弟叫叔叔; 爸爸的姐妹叫什么?爸爸的姐妹叫姑姑。 妈妈的爸爸叫什么?妈妈的爸爸叫外公; 妈妈的妈妈叫什么?妈妈的妈妈叫外婆;
幼儿英语儿歌童谣
假期特载】英语儿歌集(汇编) ? ?关靖华 ?399位粉丝 ? 1楼 致小读者和家长们: 1990年左右,武汉外语学院编撰的初级英语教学录像带是一套非常好的寓教于 乐的教材。并且曾在杭州市电视台播放。其中都是含有不同语法现象的“儿歌”。现在是假期,从今天开始,利用这个帖子逐个介绍这些儿歌。 练习1:字母 a 的“名称音”以及“祈使句”的训练: 儿歌的标题————Rain!雨! —Rain! Rain! Go away! ———Come again another day! ————祈使句 —Little Johnny wants to play. “三单”现在 式 + s —Rain! Rain! Go away! ———Come again another day! —It's mother's washing day. 现在分词作形容词使用。 练习好 rain 的读音,则有利于发 train(火车)的读音。 ——声明:1. 请你们自己译成汉语;—————2. 家长可以用这些“儿歌”教你们的孩子。 ?2008-7-22 08:50 ?回复
? ?关靖华 ?399位粉丝 ? 2楼 练习 2 :字母 e 的“名称音”以及“现在进行 时态”的训练: ——One! Two! Three! ————I love coffee. ————Billy loves tea. (三单现在时 态 + s ) ——Jimmy is swimming in the sea! 这是“现 在进行时态”的句子。 另外,通过以下歌曲可以练习现在进行时 态的疑问句: ————Are you sleeping? Are you sleeping ? ——————Brother John! Brother John! ————Morning bells are ringing! ——————Morning bells are ringing! ————Ding-ding-dong! Ding-ding-dong! 按《两只老虎!两只老虎!》那个调子唱。 ?2008-7-22 08:53 ?回复 ? ?关靖华 ?399位粉丝 ? 3楼 练习 3:字母 i 的“名称音”以及“习惯用 语 So do I!”的训练: 第一首短诗 — Apple-pie! Apple-pie! —— Peter likes apple-pie.“三单”现在时 + s ——So do I! So do I! 第二首短诗 ——I see Dinah Price, (Dinah Price 人名) ————Skating on the ice. ——I think skating is nice. ————So does Dinah Price!(第三身单数,现在时态 + es ) ?2008-7-22 08:56
推荐5首最经典的英文儿歌(中英对照)
1、Twinkle, twinkle, little star 一闪一闪小星星 Twinkle twinkle little star 一闪一闪小星星 How I wonder what you are? 我想知道你是什么? Looking at your magic light 看着你闪着魔幻般的光芒 Watching over us tonight 在晚上注视着我们 Before my dreams take me away 在我的梦想带走我之前 I kneel beside my bed and pray 我在床旁边下跪并且为 For all the children in the dark 所有在黑暗中的孩子祈祷 Till tomorrow, twinkle little star.... 直到明天,闪光小星星…. Promise me you'll twinkle little star.... 请你许诺我,闪光小星星…. Cos everybody needs a little star. 因为大家需要一个小星星。 2、We Wish You A Merry Christmas 我们祝你圣诞快乐 We wish you a Merry Christmas.我们祝你圣诞快乐, We wish you a Merry Christmas.我们祝你圣诞快乐, We wish you a Merry Christmas and a Happy New Year.我们祝你圣诞快乐并新年快乐, Good tidings we bring to you and your kin.我们把佳音带给你及你的亲友, Good tidings for Christmas and a Happy New Year. 圣诞佳音并新年佳音。 3、Walking,walking 走啊走 Walking,walking,Walking,walking.走啊走啊走啊走, hop,hop,hop.跳,跳,跳, hop,hop,hop.跳,跳,跳, running,running,running.跑,跑,跑,
最新英文儿歌歌词大全
英文儿歌歌词大全 转载 1. Twinkle, Twinkle Little Star(—闪,一闪,小星星) Twi nkle. Twin kle Little Star, How I won der what you are! Up above the world so high, Like a diam ond in the sky. Twin kle, twi nkle little star, How I won der what you are! 2. ROW, ROW,ROW YOUR BOAT 划,戈U,划你的船 Row, Row, Row, Your Boat, Gently DownThe Stream. Merrily ,Merrily, Merrily, Merrily, life Is But A Dream. 3. ROUND THE VILLAGE 绕着村落 Go round and round the village, Go round and round the village, Go round and round the village, As we have done before. Go in and out the win dows. Go in and out the win dows. Go in and out the win dows. As we have done before. Now sta nd and play the part ner. Now sta nd and play the part ner. Now sta nd and play the part ner. And bow before you go. Now follow me to London. Now follow me to London. Now follow me to London. As we have done before. Nowshake his hand but leave him. Nowshake his hand but leave him. Now shake his hand but leave him. And bow before you go. 4. FLY, FLY, BUTTERFLY 飞,飞,蝴蝶 Fly, fly, fly , the butterfly. I n the meadow is flyi ng high. In
27英文童谣47首
英文童谣47首(英汉对照)English Nursery Rhyme Collections 1.Hush-a-bye, baby, Daddy is near, Mammy's lady, And that's very clear. 不要吵,小宝宝, 爸爸陪你来睡觉; 妈妈不是男子汉, 这件事情你知道。 2.Hush-a-bye, baby, on the tree top, When the wind blows the cradle will rock; When the bough breaks the cradle will fail, Down will come baby, cradle and all. 小宝宝,睡树梢, 风儿吹,摇篮摇, 树枝断,摇篮掉, 里面宝宝吓一跳。 3.Bye, baby bunting, Daddy's gone a-hunting, Gone to get a rabbit skin To wrap the baby bunting in. 睡吧睡吧胖娃娃, 爸爸打猎顶呱呱; 剥下一张兔子皮, 回家好裹胖娃娃。 4.He next met a barber, With powder and wig, He play'd him a tune, And he shaved an old pig. 理发师,他碰着,戴着假发真时髦; 给他拉首开心典, 他给老猪剃猪毛。 5.Barney Bodkin broke his nose, Without feet we can't have toes; Crazy folks are always mad, Want of money makes us sad. 巴尼碰破大鼻子, 没脚不能长脚趾; 疯疯颠颠是疯子, 没钱只能哭鼻子。 6.A Little Betty Blue Lost her holiday shoe, What can little Betty do? Give her another to match the other, And then she may walk out in two. 小贝蒂, 丢只鞋, 这个难题怎么解? 给只鞋, 配那只, 穿着鞋儿好上街。 7.Bbb, baaa, black sheep, Have you any wool? Yes, sir, yes, sir, Three bags full; One for the master, And one for the dame, And one for the little boy Who lives down the lane. 咩咩咩,黑绵羊, 多少羊毛身上长? 先生先生你来看, 三个口袋鼓囊囊; 一袋主人面前放, 一袋是为主妇装, 一袋送给小男孩, 住在前面小街巷。 8.As a little fat man of Bombay Was smoking one very hot day, A bird called a snipe Flew away with his pipe, Which vexed the fat man of Bombay. 孟买有个胖老头, 大热天里把烟抽; 一只鹬鸟飞过头, 抢走他的大烟斗, 惹得老头把气怄。 9.When I was a little boy I had but little wit; 'tis a long time ago, And I have no more yet; Nor ever, ever shall Until that I die, For the longer I live The more fool am I. 当我是个小男孩, 那时我就没脑袋; 现在我的头发白, 还是没有长脑袋;
经典英语儿歌歌词
雪绒花(Edelweiss)》、《Do-Re-Mi》、《you are my sunshine》这三首英文歌词很多人都认为是最好听的儿童英文歌曲,无论是歌词还是旋律都健康有意义,也很好听。 下面是这三首儿童英文歌曲的歌词 《雪绒花(Edelweiss)》 edelweiss, edelweiss every morning you greet me small and white, clean and bright you look happy to meet me blossom of snow may you bloom and grow bloom and grow forever edelweiss, edelweiss bless my homeland forever small and white, clean and bright you look happy to meet me blossom of snow may you bloom and grow bloom and grow forever edelweiss, edelweiss bless my homeland forever
《Do-Re-Mi》 doe a deer a female deer ray a drop of golden sun me a name i call myself far a long long way to run sew a needle pulling thread la a note to follow sew tea a drink with jam and bread that will bring us back to do doe a deer a female deer ray a drop of golden sun me a name i call myself far a long long way to run sew a needle pulling thread la a note to follow sew tea a drink with jam and bread that will bring us back to do do-re-mi-fa-so-la-te do-so-do 《you are my sunshine》 You make me happy when skies are grey You'll never know, dear, how much I love you
经典欧美英文儿歌歌词25首
. Twinkle Twinkle Little Star 1 Twinkle, twinkle, little star, How I wonder what you are. Up above the world so high, Like a diamond in the sky. Twinkle, twinkle, little star, How I wonder what you are! When the blazing sun is gone, When there's nothing he shines upon, Then you show your little light, Twinkle, twinkle, all the night. twinkle, little star, How I wonder what you are! Twinkle, twinkle, little star, How I wonder what you are! Finger Family 2 Daddy finger, Daddy finger, where are you? Here I am. Here I am. How do you do? Mammy finger, Mammy finger, where are you? Here I am. Here I am. How do you do? Brother finger, Brother finger, where are you? Here I am. Here I am. How do you do? Sister finger, Sister finger, where are you? Here I am. Here I am. How do you do? Baby finger, Baby finger, where are you? Here I am. Here I am. How do you do? 3 Ten Little Indian Boys One little, two little, three little Indians, four little, five little, six little Indians, seven little, eight little, nine little Indians, ten little Indian boys. Ten little, nine little, eight little Indians, seven little, six little, five little Indians, four little, three little, two little Indians, . .
幼儿英语儿歌歌词
语感启蒙一:1、little bee Little bee, little bee, Round, round, round, Little bee, little bee, Sound, sound, sound, Bzzzzzzzzzz. (重复一遍) & 语感启蒙一:2、peek-a-boo(躲猫猫) Peek, peek, peek-a-boo, Peek, peek, I see you. Peek, peek, peek-a-boo, Peek, peek, I see you. (peek: 偷看,窥视Peek-a-boo: 躲猫猫) 语感启蒙一:3、Eentsy weentsy spider ~ the eentsy weentsy spider went up the water spout 小小蜘蛛,爬上了水管 down came the rain ,and washed spider out 雨滴落下,冲走了蜘蛛 out came the sun and dried up all the rain 太阳出来,蒸发了水滴 and the eentsy weentsy spider went up the spout again 小小蜘蛛,再爬上水管 (重复一遍)(spout: 1.喷口;茶壶等的嘴2. 从喷口,壶嘴流出的水柱,水流3. 水落管) 语感启蒙一:4、the chimney Here is the chimney. 一个烟囱, Here is the top. 一个盖儿, · Open the lid, 揭开这个盖儿, out Santa will pop. 圣诞老人冒出来! 语感启蒙一:5、Jack and Jill Jack and Jill went up the hill 杰克和吉尔, to fetch a pail of water 上山去打水。
(完整word版)英文经典儿歌歌词45首
英语儿歌45首歌词 2018.6 1.Hello song 歌词(Lyrics) Hello, hello, hello how are you? I'm fine, I'm fine , I hope that you are too. Hello, hello, hello how are you? I'm fine, I'm fine , I hope that you are too 2.Finger Family 歌词Lyrics Daddy finger, Daddy finger, where are you? Here I am. Here I am. How do you do? Mammy finger, Mammy finger, where are you? Here I am. Here I am. How do you do? Brother finger, Brother finger, where are you? Here I am. Here I am. How do you do? Sister finger, Sister finger, where are you? Here I am. Here I am. How do you do? Baby finger, Baby finger, where are you? Here I am. Here I am. How do you do? 3. 《ABC song》歌词 A B C D , E F G H I J K , L M N O P Q R S , T U V W X Y Z Now I know my ABC, tell me what you think of me 4.Twinkle Twinkle Little Star 歌词 Twinkle, twinkle, little star, How I wonder what you are. Up above the world so high,