Masslynx数据处理

Masslynx数据处理SOP
1、首先有原始数据和Sample list(拔完UPLC-Q-TOF就拷下来的)
2、先打开Masslynx-File-Project wizard- 新建一个project 命名,选择
project的保存位置,project建成后,自动生成以下文件夹:
其中最后一项为配置设置-总文件
3、将原始数据导入(复制、粘贴)至Project下的Data文件夹,将Sample list
放入Sample DB文件夹中
4、因为Sample list比较混乱,含有空白及QC样本并且血样和尿液数据混合
在一起,所以要整理Sample list。
5、Open-Sample list-选中原始Sample list-删除空白(必须删除空白),删除
QC,分别将尿液中的血液数据剔除,将血液中的尿液数据剔除。
6、得到的尿液数据Sample list另存为LN-Urine-N,保存于Sample DB
得到的血液数据Sample list另存为LN-Blood-N,保存于Sample DB
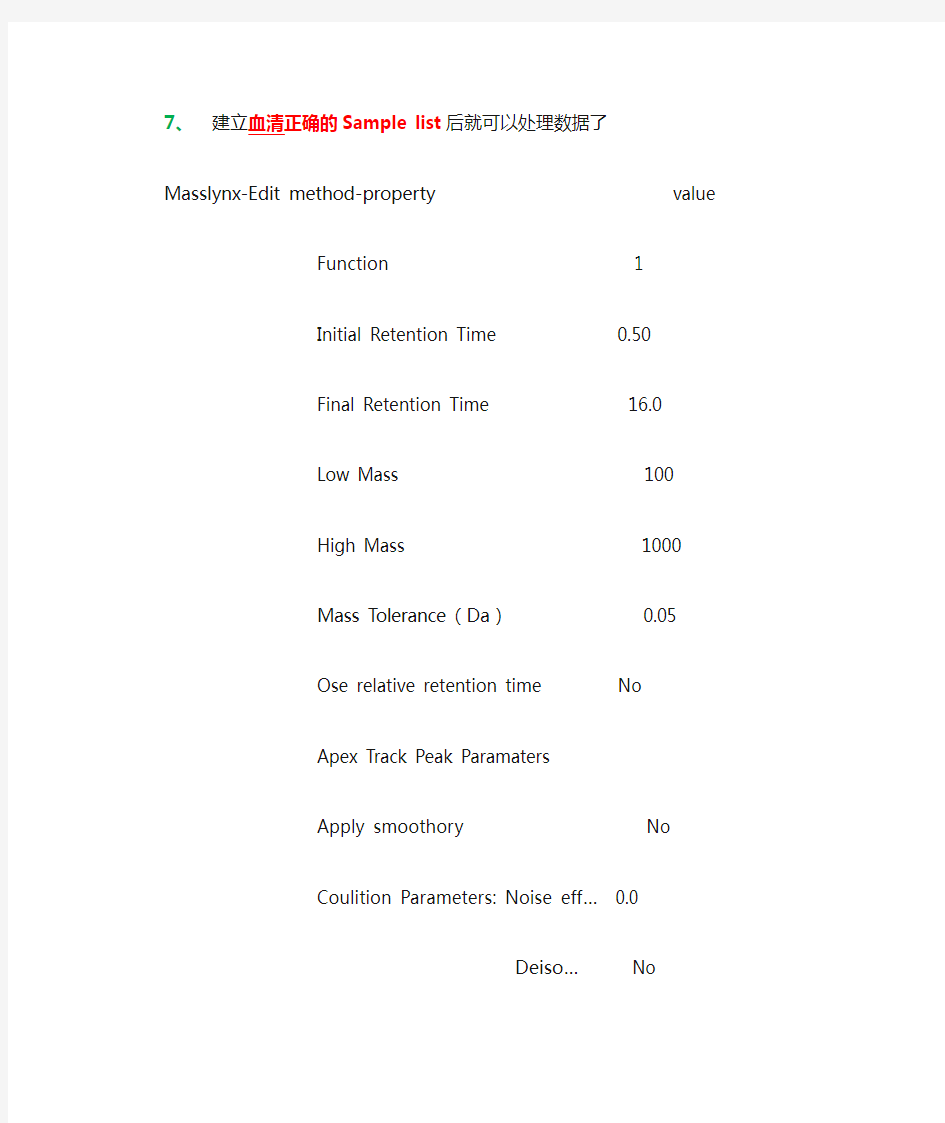
7、建立血清正确的Sample list后就可以处理数据了
Masslynx-Edit method-property value
Function 1
Initial Retention Time 0.50
Final Retention Time 16.0
Low Mass 100
High Mass 1000
Mass Tolerance(Da) 0.05
Ose relative retention time No
Apex Track Peak Paramaters
Apply smoothory No
Coulition Parameters: Noise eff… 0.0
Deiso… No
!处理尿样时:其他参数与blood保持一致,仅以下改变:
Final Retention Time 12
High Mass 1500
8、将设置好参数的method 另存为“blood(或其它)”存放在“METHOD”文件
9、Masslynx-Process Samples-选择
“project”-选中已经建立的
“Sample list”-选中所需处理的样品编号
“Method”编号对应于Sample list中的编号
Processing options 选中?Detect Peaks
?Collect Markers
?PCA
点击OK,即开始处理数据
数据处理过程包括:
数据处理、色谱峰自动识别、峰对齐及归一化等
这一系列过程都是自动完成的
10、自动完成后可以得到
Trend View
Loadings View
Scores View
Chromatogram View
四种形式的视图
11、将Markerlynx Date set 保存为Markerlynx blood
12、另存导出markers,对象名称为csv,将csv格式的文件导入SIMCA-P进行PCA、PLS-DA分析。
数据录入及处理SOP
编号:HX-DS-001-2016/01 机密 XXXX 的SOP 版本号:2012/01页数:页(包括封面)颁布日期:2016-12-01起效日期:2016-12-01起草人: 2016年 11 月 16 日审核人: 2016 年 11月 16 日批准人:李梅华 2016 年 11 月 16 日版本更新记录版本号起效日期失效日期制(修)订理由简报2012/012016-012-01原始版审查记录审查日期签名审查日期签名 15 263748通过管线敷设技术不仅可以解决吊顶层配置不规范高中资料试卷问题,而且可保障各类管路习题到位。在管路敷设过程中,要加强看护关于管路高中资料试卷连接管口处理高对全部高中资验;通电检查所有设备高中资料试卷相互作用与相互关系,根据生产工艺高中资料试卷要求,对电气设备进行空载与带负荷下高中资料试卷调控试验;对设备进行调整使其在正常工况下与过度工作下都可以正常工作;对于继电保护进行整电力保护装置调试技术,电力保护高中资料试卷配置技术是指机组在进行继电保护高中资料试卷总体配置时,需要在最大限度内来确保机组高中资料试卷安全,并且尽可能地缩小故障高中资料试卷破坏范围
文件编号:HX-DS-001-2016/01昆明市第一人民医院药物临床试验机构文 件 类 别:标准操作规程版 次:2016/01文 件 名 称:药物临床试验方案设计规范页 码:第1页共6页1目的:为了规范呼吸专业组药物临床试验方案的设计,按照药物管理法、药物注册管理办法、GCP 及其相关规定的要求,特制订本规程。2范围:本规程适用于呼吸专业组各类临床试验方案设计。3职责:呼吸专业组研究人员对本规程实施负责。4修订(制订)理由:原始版。5依据:《GCP》。6定义:7程序内容: 试验数据记录SOP 目的:保证原始资料记录真实、可靠、提高药品研究的质量。 范围:适用于所有药物临床试验。 内容:对临床试验中试验数据记录进行统一规定,保证数据真实可靠。 药物临床试验中的各种数据是科学、客观评价药物有效性和安全性的重要原始文件。应按照国家有关规定妥善保存,并随时备查。 一、 试验数据的质量控制与记录 1. 承担药物临床试验的实验室检测和其他检查的辅助科室必须制定各检测项目质量控制的标准操作规程,保证数据(含图谱)真实、准确、可靠。 2. 各检测项目应有明确、清晰的实验操作步骤,实验条件(含温度湿度)及结果应使用编制的专用科研记录本或实验报告本记录,并由实验者签名、注明实验日期。 3. 人体药代动力学及生物利用度研究中生物样品的测定图谱和积分参数,应在专用计算机上按课题分类记录,所打印的相关数据、图谱必须分类装订成册。 4. 生物样品药物浓度测定需有随行质控记录;其他实验检测项目(包括血常规、生化检查及其他特殊检测指标)应有室内质控记录和定期的全国室间质控考评结果记录。 二、 准确、真实、完整记录试验数据的保证措施 1. 实验室及辅助部门检测人员发出各种检测报告前应检查数据准确无误。 2. 研究者应保证将数据真实、准确、完整、及时、合法地载入病历和记录于病例报告表中。在正常范围内的数据也应具体记录,对显著偏离或在临床可接受范围以外的数据必须加以核实。各检测项目均须注明所采用的计量单位。 、管路敷设技术通过管线敷设技术不仅可以解决吊顶层配置不规范高中资料试卷问题,而且可保障各类管路习题到位。在管路敷设过程中,要加强看护关于管路高中资料试卷连接管口处理高中资料试卷弯扁度固定盒位置保护层防腐跨接地线弯曲半径标高等,要求技术交底。管线敷设技术中包含线槽、管架等多项方式,为解决高中语文电气课件中管壁薄、接口不严等问题,合理利用管线敷设技术。线缆敷设原则:在分线盒处,当不同电压回路交叉时,应采用金属隔板进行隔开处理;同一线槽内,强电回路须同时切断习题电源,线缆敷设完毕,要进行检查和检测处理。、电气课件中调试对全部高中资料试卷电气设备,在安装过程中以及安装结束后进行高中资料试卷调整试验;通电检查所有设备高中资料试卷相互作用与相互关系,根据生产工艺高中资料试卷要求,对电气设备进行空载与带负荷下高中资料试卷调控试验;对设备进行调整使其在正常工况下与过度工作下都可以正常工作;对于继电保护进行整核对定值,审核与校对图纸,编写复杂设备与装置高中资料试卷调试方案,编写重要设备高中资料试卷试验方案以及系统启动方案;对整套启动过程中高中资料试卷电气设备进行调试工作并且进行过关运行高中资料试卷技术指导。对于调试过程中高中资料试卷技术问题,作为调试人员,需要在事前掌握图纸资料、设备制造厂家出具高中资料试卷试验报告与相关技术资料,并且了解现场设备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规定,制定设备调试高中资料试卷方案。、电气设备调试高中资料试卷技术电力保护装置调试技术,电力保护高中资料试卷配置技术是指机组在进行继电保护高中资料试卷总体配置时,需要在最大限度内来确保机组高中资料试卷安全,并且尽可能地缩小故障高中资料试卷破坏范围,或者对某些异常高中资料试卷工况进行自动处理,尤其要避免错误高中资料试卷保护装置动作,并且拒绝动作,来避免不必要高中资料试卷突然停机。因此,电力高中资料试卷保护装置调试技术,要求电力保护装置做到准确灵活。对于差动保护装置高中资料试卷调试技术是指发电机一变压器组在发生内部故障时,需要进行外部电源高中资料试卷切除从而采用高中资料试卷主要保护装置。
大数据处理技术的总结与分析
数据分析处理需求分类 1 事务型处理 在我们实际生活中,事务型数据处理需求非常常见,例如:淘宝网站交易系统、12306网站火车票交易系统、超市POS系统等都属于事务型数据处理系统。这类系统数据处理特点包括以下几点: 一就是事务处理型操作都就是细粒度操作,每次事务处理涉及数据量都很小。 二就是计算相对简单,一般只有少数几步操作组成,比如修改某行得某列; 三就是事务型处理操作涉及数据得增、删、改、查,对事务完整性与数据一致性要求非常高。 四就是事务性操作都就是实时交互式操作,至少能在几秒内执行完成; 五就是基于以上特点,索引就是支撑事务型处理一个非常重要得技术. 在数据量与并发交易量不大情况下,一般依托单机版关系型数据库,例如ORACLE、MYSQL、SQLSERVER,再加数据复制(DataGurad、RMAN、MySQL数据复制等)等高可用措施即可满足业务需求。 在数据量与并发交易量增加情况下,一般可以采用ORALCERAC集群方式或者就是通过硬件升级(采用小型机、大型机等,如银行系统、运营商计费系统、证卷系统)来支撑. 事务型操作在淘宝、12306等互联网企业中,由于数据量大、访问并发量高,必然采用分布式技术来应对,这样就带来了分布式事务处理问题,而分布式事务处理很难做到高效,因此一般采用根据业务应用特点来开发专用得系统来解决本问题。
2数据统计分析 数据统计主要就是被各类企业通过分析自己得销售记录等企业日常得运营数据,以辅助企业管理层来进行运营决策。典型得使用场景有:周报表、月报表等固定时间提供给领导得各类统计报表;市场营销部门,通过各种维度组合进行统计分析,以制定相应得营销策略等. 数据统计分析特点包括以下几点: 一就是数据统计一般涉及大量数据得聚合运算,每次统计涉及数据量会比较大。二就是数据统计分析计算相对复杂,例如会涉及大量goupby、子查询、嵌套查询、窗口函数、聚合函数、排序等;有些复杂统计可能需要编写SQL脚本才能实现. 三就是数据统计分析实时性相对没有事务型操作要求高。但除固定报表外,目前越来越多得用户希望能做做到交互式实时统计; 传统得数据统计分析主要采用基于MPP并行数据库得数据仓库技术.主要采用维度模型,通过预计算等方法,把数据整理成适合统计分析得结构来实现高性能得数据统计分析,以支持可以通过下钻与上卷操作,实现各种维度组合以及各种粒度得统计分析。 另外目前在数据统计分析领域,为了满足交互式统计分析需求,基于内存计算得数据库仓库系统也成为一个发展趋势,例如SAP得HANA平台。 3 数据挖掘 数据挖掘主要就是根据商业目标,采用数据挖掘算法自动从海量数据中发现隐含在海量数据中得规律与知识。
RULE规则
RULE规则 一、rule description 命令功能 rule description 命令用来配置某条规则的描述信息。 undo rule description命令用来删除某条规则的描述信息。 缺省情况下,各规则没有描述信息。 命令格式 rule rule-id description undo rule rule-id description 参数说明 视图 基本ACL视图、高级ACL视图、二层ACL视图、 UCL视图、基本ACL6视图、高级ACL6视图 缺省级别
2:配置级 使用指南 使用场景 当前规则的标识方式主要是使用rule-id,一个数字很难很好地表达该规则的含义、用途等信息,不便于用户标记,一定长度字符串的标记方式就可以解决这个问题。 前置条件 在使用rule rule-id description进行描述信息配置的时候,必须保证该rule-id的规则已经存在,否则系统提示错误信息: Warning: The acl subitem number does not exist. 该rule-id的规则的配置可以在使用不同视图下的rule命令来配置,分别为:rule(高级ACL6视图)、rule(高级ACL视图)、rule(基本ACL6视图)、rule (基本ACL视图)、rule(二层ACL视图)、rule(UCL视图)。 配置影响 该命令是覆盖式命令,配置结果可以使用display acl和display acl ipv6查询。 使用实例 #假设ACL 2001的规则5是允许源地址是192.168.32.1的报文,配置增加规则5的描述信息。
数据处理的基本方法
第六节数据处理的基本方法 前面我们已经讨论了测量与误差的基本概念,测量结果的最佳值、误差和不确定度的计算。然而,我们进行实验的最终目的是为了通过数据的获得和处理,从中揭示出有关物理量的关系,或找出事物的内在规律性,或验证某种理论的正确性,或为以后的实验准备依据。因而,需要对所获得的数据进行正确的处理,数据处理贯穿于从获得原始数据到得出结论的整个实验过程。包括数据记录、整理、计算、作图、分析等方面涉及数据运算的处理方法。常用的数据处理方法有:列表法、图示法、图解法、逐差法和最小二乘线性拟合法等,下面分别予以简单讨论。 列表法是将实验所获得的数据用表格的形式进行排列的数据处理方法。列表法的作用有两种:一是记录实验数据,二是能显示出物理量间的对应关系。其优点是,能对大量的杂乱无章的数据进行归纳整理,使之既有条不紊,又简明醒目;既有助于表现物理量之间的关系,又便于及时地检查和发现实验数据是否合理,减少或避免测量错误;同时,也为作图法等处理数据奠定了基础。 用列表的方法记录和处理数据是一种良好的科学工作习惯,要设 计出一个栏目清楚、行列分明的表格,也需要在实验中不断训练,逐步掌握、熟练,并形成习惯。 一般来讲,在用列表法处理数据时,应遵从如下原则:
(1) 栏目条理清楚,简单明了,便于显示有关物理量的关系。 (2) 在栏目中,应给出有关物理量的符号,并标明单位(一般不重复写在每个数据的后面)。 (3) 填入表中的数字应是有效数字。 (4) 必要时需要加以注释说明。 例如,用螺旋测微计测量钢球直径的实验数据列表处理如下。 用螺旋测微计测量钢球直径的数据记录表 从表中,可计算出 D i D = n = 5.9967 ( mm)
1 Locus 数据处理软件简介
GPS数据解算实验 上机报告 专业测绘工程 班级测绘06-2班 学生姓名张剑华 学号 0604070224 指导教师隋心
一.概述 1. Locus 数据处理软件简介 Locus processor是一个崭新的自动后处理软件包。它的介面友好,操作简便,对新老用户一样都会感到应用自如。本软件包的功能有: ●选星计划 ●接收机设置 ●数据传输 ●基线向量处理 ●网平差 ●质量分析 ●坐标转换 ●报表生成 ●结果输出 ●Rinex格式转换 Locus processor集快速后处理引擎与优异的粗差探测工具于一体,确保处理无误。一旦启动处理引擎,Locus processor便连续刷新网图显示,最后提供外业实测GPS网图。 1.1获取Locus processor资料的出处 ●Locus processor处理软件 ●Locus接收机及手持控制器(选件)——《Locus 系统操作手册》 ●教学范例——本手册 ●在线帮助 1.2软件对环境的要求: ●PC机的CPU——Pentium 90MHz及以上。 ●操作系统——Windows 95/98/NT。 ●硬盘——安装至少需35 MB。 ●RAM——最小35 MB。 ●具有CD ROM、串口、鼠标等。 1.3 软件安装 1.启动Windows,如果Windows已在运行中,应关闭其他应用运行项目。 2.将CD插入CD ROM驱动器。 3.随即,在大多数电脑中便自行启动安装。 4.如果不能自动安装,便由“开始”菜单中选“运行”菜单项。 5.打入X : \ SETUP并回车(此处X是CD ROM的盘符)。Locus processor在得到认可之后,即便自动安装。
Stata软件基本操作和大数据分析报告入门
Stata软件基本操作和数据分析入门 第一讲 Stata操作入门 张文彤赵耐青 第一节概况 Stata最初由美国计算机资源中心(Computer Resource Center)研制,现在为Stata公司的产品,其最新版本为7.0版。它操作灵活、简单、易学易用,是一个非常有特色的统计分析软件,现在已越来越受到人们的重视和欢迎,并且和SAS、SPSS一起,被称为新的三大权威统计软件。 Stata最为突出的特点是短小精悍、功能强大,其最新的7.0版整个系统只有10M左右,但已经包含了全部的统计分析、数据管理和绘图等功能,尤其是他的统计分析功能极为全面,比起1G以上大小的SAS系统也毫不逊色。另外,由于Stata在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此运算速度极快。 由于Stata的用户群始终定位于专业统计分析人员,因此他的操作方式也别具一格,在Windows席卷天下的时代,他一直坚持使用命令行/程序操作方式,拒不推出菜单操作系统。但是,Stata的命令语句极为简洁明快,而且在统计分析命令的设置上又非常有条理,它将相同类型的统计模型均归在同一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。更为令人叹服的是,Stata语句在简洁的同时又拥有着极高的灵活性,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。
除了操作方式简洁外,Stata的用户接口在其他方面也做得非常简洁,数据格式简单,分析结果输出简洁明快,易于阅读,这一切都使得Stata成为非常适合于进行统计教学的统计软件。 Stata的另一个特点是他的许多高级统计模块均是编程人员用其宏语言写成的程序文件(ADO文件),这些文件可以自行修改、添加和下载。用户可随时到Stata网站寻找并下载最新的升级文件。事实上,Stata的这一特点使得他始终处于统计分析方法发展的最前沿,用户几乎总是能很快找到最新统计算法的Stata程序版本,而这也使得Stata自身成了几大统计软件中升级最多、最频繁的一个。 由于以上特点,Stata已经在科研、教育领域得到了广泛应用,WHO的研究人员现在也把Stata作为主要的统计分析工作软件。 第二节 Stata操作入门 一、Stata的界面 图1即为Stata 7.0启动后的界面,除了Windows版本的软件都有的菜单栏、工具栏,状态栏等外,Stata的界面主要是由四个窗口构成,分述如下: 1.结果窗口:位于界面右上部,软件运行中的所有信息,如所执行的命令、执行结果和出错信息等均在这里列出。窗口中会使用不同的颜色区分不同的文本,如白色表示命令,红色表示错误信息。 2.命令窗口:位于结果窗口下方,相当于DOS软件中的命令行,此处用于键入需要执行的命令,回车后即开始执行,相应的结果则会在结果窗口中显示出来。
大学物理实验数据处理基本方法
实验数据处理基本方法 实验必须采集大量数据,数据处理是指从获得数据开始到得出最后结 论的整个加工过程,它包括数据记录、整理、计算与分析等,从而寻找出 测量对象的内在规律,正确地给出实验结果。因此,数据处理是实验工作 不可缺少的一部分。数据处理涉及的内容很多,这里只介绍常用的四种方 法。 1列表法 对一个物理量进行多次测量,或者测量几个量之间的函数关系,往往 借助于列表法把实验数据列成表格。其优点是,使大量数据表达清晰醒目, 条理化,易于检查数据和发现问题,避免差错,同时有助于反映出物理量 之间的对应关系。所以,设计一个简明醒目、合理美观的数据表格,是每 一个同学都要掌握的基本技能。 列表没有统一的格式,但所设计的表格要能充分反映上述优点,应注意以下几点:1.各栏目均应注明所记录的物理量的名称(符号 )和单位; 2.栏目的顺序应充分注意数据间的联系和计算顺序,力求简明、齐全、有条理; 3.表中的原始测量数据应正确反映有效数字,数据不应随便涂改,确实要修改数据时, 应将原来数据画条杠以备随时查验; 4.对于函数关系的数据表格,应按自变量由小到大或由大到小的顺序排列,以便于判 断和处理。 2图解法 图线能够明显地表示出实验数据间的关系,并且通过它可以找出两个 量之间的数学关系,因此图解法是实验数据处理的重要方法之一。图解法 处理数据,首先要画出合乎规范的图线,其要点如下: 1.选择图纸作图纸有直角坐标纸 ( 即毫米方格纸 ) 、对数坐标纸和 极坐标纸等,根据 作图需要选择。在物理实验中比较常用的是毫米方格纸,其规格多为17 25 cm 。 2.曲线改直由于直线最易描绘 , 且直线方程的两个参数 ( 斜率和截距 ) 也较易算得。所以对于两个变量之间的函数关系是非线性的情形,在用图解法时 应尽可能通过变量代换 将非线性的函数曲线转变为线性函数的直线。下面为几种常用的变换方法。 ( 1) xy c ( c 为常数 ) 。 令 z 1,则 y cz,即 y 与 z 为线性关系。 x ( 2) x c y ( c 为常x2,y 1 z ,即 y 与为线性关系。
HGO软件处理数据 上
测绘工程专业选修课程<控制网平差与程序设计> 软件应用-HGO GNSS数据处理软件 辽宁科技大学土木工程学院测绘工程教研室
一、软件简介 中海达GNSS数据处理软件由卫星预报、野外动静态数据采集、数据传输、项目管理、静态基线处理、动态路线处理、闭合差搜索、网平差、成果输出、坐标系管理及坐标转换等模块组成。 HGO(Hi-Target Geomatics Office)软件全名“HGO数据处理软件包”,是中海达在十多年的后处理软件运用与用户体验改进的基础上继HDS2003软件后推出的第二代静态解算软件。该软件用于高精度测量用户的基线数据处理,网平差,坐标转换。 软件的功能及特点包括: 1.该软件设计支持GPS、Glonass、Compass多系统解算,支持静态,动态(走走停停,后处理RTK)等多种作业模式。 2.全新第二代基线处理引擎,能够解算超长时间的静态数据,并能智能剔除粗差数据,用户的基线处理变得前所未有的简单。 3.全新的网平差模块,能进行WGS84系统下约束平差、当地约束平差等工作。 4.全新的用户界面设计,与国际软件接轨。 5.配套完整的解决软件工具,包括全新的Rinex转换软件ConvertRinex、坐标转换软件CoordTool、精密星历下载软件SP3Gate等。 二、软件静态数据处理流程
创建工程项目 导入野外观测数据 GNSS 基线处理 对整网进行平差 检查和打印成果 三、典型算例 1.数据来源 数据为辽宁科技大学测绘工程专业09级《空间定位技术及应用》实验数据,于2011年11 月7日采用中海达V30采集2个时段数据,数据格式为*.ZHD。 点名 仪器高 2.建立一个新的项目 HGO数据处理软件是面向项目进行管理的。因此,不管是进行单点定位,还是进行静态基 线处理、动态路线处理,或者是进行网平差。首先需要建立一个新的项目,或者打开一个
大数据处理分析的六大最好工具
大数据处理分析的六大最好工具 来自传感器、购买交易记录、网络日志等的大量数据,通常是万亿或EB的大小,如此庞大的数据,寻找一个合适处理工具非常必要,今天我们为大家分享在大数据处理分析过程中六大最好用的工具。 【编者按】我们的数据来自各个方面,在面对庞大而复杂的大数据,选择一个合适的处理工具显得很有必要,工欲善其事,必须利其器,一个好的工具不仅可以使我们的工作事半功倍,也可以让我们在竞争日益激烈的云计算时代,挖掘大数据价值,及时调整战略方向。本文转载自中国大数据网。 CSDN推荐:欢迎免费订阅《Hadoop与大数据周刊》获取更多Hadoop技术文献、大数据技术分析、企业实战经验,生态圈发展趋势。 以下为原文: 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设计的硬件和软件工具进行处理。该数据集通常是万亿或EB的大小。这些数据集收集自各种各样的来源:传感器、气候信息、公开的信息、如杂志、报纸、文章。大数据产生的其他例子包括购买交易记录、网络日志、病历、事监控、视频和图像档案、及大型电子商务。大数据分析是在研究大量的数据的过程中寻找模式,相关性和其他有用的信息,可以帮助企业更好地适应变化,并做出更明智的决策。 Hadoop Hadoop 是一个能够对大量数据进行分布式处理的软件框架。但是Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理PB 级数据。此外,Hadoop 依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
软件版本定义规则
软件版本定义规则 1引言 1.1编写目的 本文档作为本公司开发部测试部各项目组在进行软件设计、开发、测试时进行版本定义的指导性规则。 1.2定义和限制 软件版本号为形如A.B.C.D的由”.”所间隔开的4段字符组成。其中A、B、C段为从0开始的整数,D段为从0开始的整数或者整数加英文字符的形式。 2定义规则 在任何项目中,符合以下条件的模块需要独立维护版本: ?客户端和服务器端程序需要分开进行版本维护; ?可以独立运行并完成主要设计功能的模块; ?完成某些特定功能的接口程序或模块; ?其他必要的模块 2.1何时更改 在项目进行到以下进程时,需要更改软件版本号: ?测试中FIX了部分缺陷需要提交测试时; ?公开发布或者需要提交给用户时; ?增加或更改了系统需求,软件重新进行开发时; ?更改了系统的设计框架、重新进行开发时; 2.2如何更改 ?普通项目的所有模块初始软件版本号为0.0.0.1,如是从原有系统上升级或其他特殊原因可更改为其他初始版本号。 ?在每次提交测试时,需要更改软件版本号的D段,从1开始递增,特殊情况时可在D段整数后面增加英文字符作为标识。 ?每次公开发布或者提交给用户时,需要更改软件版本号的C段,从0开始递增; 同时将D段归0。因此所有D段为0的版本应该都是公开发布版本。 ?在原有总体设计上增加部分系统需求时,需要更改软件版本号的B段,从0开始递增,同时将C、D段归0。
?总体设计上有更改或者主要的功能模块设计上有变化,则可以更改软件版本号的A 段,从0开始递增,同时将B、C、D段归0。 规则表如下: 示例: ?假设原有版本为1.3.1.6, ?在下次提交新的测试版本时,版本号应升级为1.3.1.7; ? 1.3.1.7测试通过后需要对用户发布,则应该将版本升级为1.3.2.0; ?此时又修改了部分测试中发现的缺陷,并重新提交测试时,版本号应该升级为1.3.2.1; ?再次重新提交测试的版本号应该为1.3.2.2; ?如果用户经过试用,提交了部分新的需求,经过我们的重新修改部分编码,再次提交测 试,则测试时的版本号应该升级为1.4.0.1; ?测试通过后提交给用户的版本号应该为1.4.1.0; ?如果由于设计上的缺陷,系统需要重新设计和编码,进行了比较大的改动,并提交测试, 则测试时的版本号应该升级为2.0.0.1。
数据基础知识及数据处理
数据处理 (从小数据到大数据) 一、小数据 1、信息的度量 在计算机中: 最小数据单位:位(bit) Bit: 0 或1 (由电的状态产生:有电1,无电0)基本数据单位:字节(Byte, B) 1B=8bit 1KB=1024B 1MB=1024KB 1GB=1024MB 1TB=1024GB。 …… 2、不同数制的表示方法 十进制(Decimal notation),如120, (120) 10,120D 二进制(Binary notation) ,如(1010)2 , 1010B 八进制(Octal notation) ,如(175)8 , 175O 十六进制数(Hexdecimal notation) ,如(2BF)16 , 2BF03H
3、不同数制之间的转换方法 (1)任意其他进制(二、八、十六)转换成十进制,可“利用按权展开式展开”。 例如: 10110.101B =1×24+0×23+1×22+1×21+0×20+1×2-1+0×2-2+1×2-3 =22.625D 347.6O =3×82+4×81+7×80+6×8-1 =231.75D
D5.6H =D×161+5×160+6×16-1 =213.375D (2)十进制转换成任意其他进制(二、八、十六),整数部分的转换可按“除基取余,倒序排列”的方法,小数部分的转换可按“乘基取整,顺序排列”的方法。(除倒取,乘正取) 例,十进制数59转换为二进制数111011B
例:十进制数0.8125转换为二进制数0.1101B 同理:317 D= 100111101B = 475O = 13DH 0.4375D = 0.0111B = 0.34O = 0.7H (3)八进制数转换成二进制数,可按“逐位转换,一位拆三位”的方法。(8421法) 例如:3107.46O = 3 1 0 7 . 4 6 O =011 001 000 111 . 100 110 B =11001000111.10011B (4)十六进制数转换成二进制数,可按“逐位转换,一位拆四位”的方法。(8421法)
数据处理软件介绍.
Chapter4 Introduction to Analysis-of-Variance Procedures Chapter T able of Contents 52Chapter4.Introduction to Analysis-of-Variance Procedures SAS OnlineDoc?:Version8 Chapter4 Introduction to Analysis-of-Variance Procedures 54Chapter4.Introduction to Analysis-of-Variance Procedures The following section presents an overview of some of the fundamental features of analysis of variance.Subsequent sections describe how this analysis is performed with procedures in SAS/STAT software.For more detail,see the chapters for the individual procedures.Additional sources are described in the“References”section on page61. De?nitions Analysis of variance(ANOV Ais a technique for analyzing experimental data in which one or more response(or dependent or simply Yvariables are measured un-der various conditions identi?ed by one or more classi?cation variables.The com-binations of levels for the classi?cation variables form the cells of the experimental design for the data.For example,an experiment may measure weight change(the dependent variablefor men and women who participated in three different weight-loss programs.The six cells of the design are formed by the six combinations of sex (men,womenand program(A,B,C.
客户投诉定义及基本判定规则
客户投诉定义及基本判定规则第一章总则 第一条为规范客户投诉的处理,维护客户正当权益,促进业务健康发展,特制定本规则。 第二章客户投诉相关定义 第二条客户投诉
客户对本公司的产品或其服务过程不满意的表示,其中明确或隐含地期望得到回应或解决。 第三条投诉件基本构成要素 投诉人、投诉对象、投诉内容和投诉诉求。 第四条投诉人 投诉人即与本公司直接发生投诉行为的人员,包括: (一)客户:与本公司发生直接、有效、
合法业务的投保人、被保人、受益人等;以及由以上人员进行书面授权委托的代理人。 (二)准客户:从未拥有过本公司任何产品,但主动表示或经本公司分析存在购买意愿或能力的终端个人或客户。 (三)第三者:指本公司业务条款和约定中规定的,因保险的意外事故遭受人身、财产损害的需要本公司进行业务处理的第 3 三人。 第五条投诉对象
投诉对象即投诉具体针对的主体,包括: (一)本公司组织体和本公司正式聘用人员、试用期工作人员和实习期工作人员。 (二)本公司书面授权委托进行相关业务的代理人、服务商、运营商等,包括组织体及其正式聘用的人员。 (三)国家法律法规规定的有关主体。第六条投诉内容
投诉内容是指投诉人对投诉事件过程的描述,以及相关的证 明。 第七条投诉诉求 投诉诉求是指投诉人期望得到的处理结果或需求。 第八条如客户举报涉及保险诈骗、公司员工利用职务之便弄虚作假、谋取私利行为,不作为客户投诉范畴管理,由
对应的管理部门进行后续处理。 第三章抱怨件及投诉件的区分 第九条投诉受理后,按后续处理要求分为抱怨件、投诉件。 (一)抱怨件:投诉人仅为发泄不满情绪,明确无后续处理 要求的事件;(现阶段投诉系统暂时未对抱怨件进行统计分析,后 4
数据处理基础知识 word
检测数据处理基础知识 误差及相关概念→真实值与标准值 误差是测量值与真实结果之间的差异,要想知道误差的大小,必须知道真实的结果,这个真实的值,我们称之“真值”。 1.真实值 从理论上说,样品中某一组分的含量必然有一个客观存在的真实数值,称之 为“真实值”或“真值”。用“μ”表示。但实际上,对于客观存在的真值,人 们不可能精确的知道,只能随着测量技术的不断进步而逐渐接近真值。实际工作中,往往用“标准值”代替“真值”。 2.标准值 采用多种可靠的分析方法、由具有丰富经验的分析人员经过反复多次测定得 出的结果平均值,是一个比较准确的结果。 实际工作中一般用标准值代替真值。例如原子量、物理化学常数:阿佛伽得 罗常数为6.02×10等。 与我们实验相关的是将纯物质中元素的理论含量作为真实值。 1.准确度 准确度是测定值与真实值接近的程度。 为了获得可靠的结果,在实际工作中人们总是在相同条件下,多测定几次,然后求平均值,作为测定值。一般把这几次在相同条件下的测定叫平行测定。如 果这几个数据相互比较接近,就说明分析的精密度高。 2.精密度 精密度是几次平行测定结果相互接近的程度。 3.精密度和准确度的关系 (1)精密度是保证准确度的先决条件。 (2)高精密度不一定保证高准确度。 1.误差 (1)定义:个别测定结果X、X …X与真实值μ之差称为个别测定的误差,简称误差。 (2)表示:各次测定结果误差分别表示为X -μ、X -μ……X -μ。 (3)计算方法: 绝对误差 相对误差 对于绝对误差——测定值大于真值,误差为正值;测定值小于真值,误差为 负值。 对于相对误差——反映误差在测定结果中所占百分率,更具实际意义。 2.偏差 偏差是衡量精密度的大小。 误差的分类→系统误差 1.定义 由某种固定的原因造成的误差,若能找出原因,设法加以测定,就可以消除,所以也叫可测误差。 2.特点
CSS规则定义英汉对照表
CSS规则定义英汉对照表 一、类型 Font-family字体 font-size字体大小 font-weight 字体浓淡 font-style 字体风格如:斜体、正常等 font-variant 字体变量(用来设定字体是正常显示,还是以小型大写 字母显示) line-height 行高(用来设定字行间距) text-transform文本转换(用来设定字体的大小写转换) text-decoration(字体装饰):underline下划线overline上划线line-through线-穿过blink闪光none无 二、背景 background-color(C) 背景颜色 background-image(l) 背景图片 background-repeat(R) 背景重复 background-attachment(T)背景附着(用来设定背景图片是否随文档滚 background-position(X) 背景位置X
background-position(Y) 背景位置Y 三、区块 word-spacing 词|、司距 letter-spacing 字符间距 vertical-align 垂直对齐 text-aline 水平对齐 text-indent 文本缩进 white-space 空白 dispaly 显示 四、方框 width 宽度 height 高度 float 漂浮 clear 规定元素的哪一侧不允许出现其他浮动元素padding 间隙(设定间隙的宽度) margin 边距(用来设定边距的宽度)
五、边框 style 样式(如:虚线等等) width 宽度 color 颜色 六、列表 list-style-type 列表样式类型(用来设定列表项标记(list-item marker)的类型) list-style-image 列表样式图片(用来设定列表样式图片标记的地址) list-style-position列表样式位置(用来设定列表样式标记的位置) 七、定位 position 位置 width 宽度 height 高度 visibility 规定元素是否可见(即使不可见,但仍占用空间,建议使用display来创建不占
规则的概念与写法
规则的概念与写法 (一)规则的概念、特点 规则和守则、制度都是由国家的领导机关和职能部门根据宪法和其它有关法律、法规的精神制定的、具有一定约束力的规范性公文。其中,规则是国家机关、人民团体、企事业单位为了进行管理或开展某项公务活动而制定的、要求有关人员共同遵守的规范性公文。 规则适用于对一定范围内的某一具体管理工作进行程序规范和行为规范,以保证该项工作的正常进行。如《游泳规则》,是为加强游泳池管理工作而制定的,凡游泳者都必须遵守有关规定。又如《交通规则》,是为加强交通管理,保证交通安全而面向社会制定的,行人、车辆行驶要遵守这些规则,管理人员要以这些规则为依据进行交通管理。 规则具有以下特点: 1.针对性。规则的制发具有很强的针对性。它是依据有关法律、法规的规定,针对某项管理工作或某项公务活动而制定的操作规定,其内容必须合法,不能有任何随意性。 2.可操作性。规则的规范事项必须周密、精细、具体,可以直接付诸实施,不需要再订出实施细则来保证其贯彻执行。 (二)规则的结构、内容和写法
规则由首部、正文和尾部三部分组成。 首部 一般仅有标题项目。如果制发机关级别规格较高,还需要写明制发的时间和依据等项内容。 (1)标题:由事由和文种构成,如《城市公共交通车船乘坐规则》、《计算机房安全管理规则》等。有的则由制发机关、事由和文种构成,如《××市工人运动会参赛规则》等。 (2)制发的时间、依据:写在标题之下,有的用括号注明规则通过的年、月、日期与会议名称;有的注明批准、公布的年、月、日期和机关,有的写明公布的年、月、日期和机关。 正文 规则的正文内容由总则、分则、附则组成。总则是关于制定规则的指导思想、缘由、依据等项内容。分则是规范项目,它是规则的实质性内容,要求执行的依据。 规则正文的结构形式主要有两种:这种形式有二种表述方法:一是条款式,全文按序列条;二是章条式,全文分若干章,第一章为总则,最后一章为附则,中间为公则。
数据处理的基本方法
数据处理的基本方法 由实验测得的数据,必须经过科学的分析和处理,才能提示出各物理量之间的关系。我们把从获得原始数据起到结论为止的加工过程称为数据处理。物理实验中常用的数据处理方法有列表法、作图法、逐差法和最小二乘法等。 1、列表法 列表法是记录和处理实验数据的基本方法,也是其它实验数据处理方法的基础。将实验数据列成适当的表格,可以清楚地反映出有关物理量之间的一一对应关系,既有助于及时发现和检查实验中存在的问题,判断测量结果的合理性;又有助于分析实验结果,找出有关物理量之间存在的规律性。一个好的数据表可以提高数据处理的效率,减少或避免错误,所以一定要养成列表记录和处理数据的习惯。 第一页前一个下一页最后一页检索文本 2、作图法 利用实验数据,将实验中物理量之间的函数关系用几何图线表示出来,这种方法称为作图法。作图法是一种被广泛用来处理实验数据的方法,它不仅能简明、直观、形象地显示物理量之间的关系,而且有助于我人研究物理量之间的变化规律,找出定量的函数关系或得到所求的参量。同时,所作的图线对测量数据起到取平均的作用,从而减小随机误差的影响。此外,还可以作出仪器的校正曲线,帮助发现实验中的某些测量错误等。因此,作图法不仅是一个数据处理方法,而且是实验方法中不可分割的部分。
第一页前一个下一页最后一页检索文本 第一页前一个下一页最后一页检索文本 共 32 张,第 31 张 3、逐差法
逐差法是物理实验中处理数据常用的一种方法。凡是自变量作等量变化,而引起应变量也作等量变化时,便可采用逐差法求出应变量的平均变化值。逐差法计算简便,特别是在检查数据时,可随测随检,及时发现差错和数据规律。更重要的是可充分地利用已测到的所有数据,并具有对数据取平均的效果。还可绕过一些具有定值的求知量,而求出所需要的实验结果,可减小系统误差和扩大测量范围。 4、最小二乘法 把实验的结果画成图表固然可以表示出物理规律,但是图表的表示往往不如用函数表示来得明确和方便,所以我们希望从实验的数据求经验方程,也称为方程的回归问题,变量之间的相关函数关系称为回归方程。 第一节有效数字及其计算 一、有效数字 对物理量进行测量,其结果总是要有数字表示出来的.正确而有效地表示出测量结果的数字称为有效数字.它是由测量结果中可靠的几位数字加上可疑的一位数字构成.有效数字中的最后一位虽然是有可疑的,即有误差,但读出来总比不读要精确.它在一定程度上反映了客观实际,因此它也是有效的.例如,用具有最小刻度为毫米的普通米尺测量某物体长度时,其毫米的以上部分是可以从刻度上准确地读出来的.我们称为准确数字.而毫米以下的部分,只能估读一下它是最小刻度的十分之几,其准确性是值得怀疑的.因此,我们称它为 可疑数字,若测量长度L=15.2mm,“15”这两位是准确的,而最后一位“2”是可疑的,但它也是有效的,因此,对测量结果15.2mm来说,这三位都是有效的,称为三位有效数字. 为了正确有效地表示测量结果,使计算方便,对有效数字做如下的规定: 1.物理实验中,任何物理量的数值均应写成有效数字的形式. 2.误差的有效数字一般只取一位,最多不超过两位. 3.任何测量数据中,其数值的最后一位在数值上应与误差最后一位对齐(相同单位、相同10次幂情况下).如L=(1.00±0.02)mm,是正确的,I=(360±0.25) A或g=(980.125±0.03)cm/S2都是错误的. 4.常数2,1/2,21 2,π及C等有效数字位数是无限的. 5.当0不起定位作用,而是在数字中间或数字后面时,和其它数据具有相同的地位,都算有效数字,不能随意省略.如31.01、2.0、2.00中的0,均为有效数字.6.有效数字的位数与单位变换无关,即与小数点位置无关.如L=11.3mm=1.13cm=0.0113m=0.0000113Km均为三位有效数字.由此,也可以看出:用以表示小数点位置的“0”不是有效数字,或者说,从第一位非零数字算起的数字才是有效数字.7.在记录较大或较小的测量量时,常用一位整数加上若干位小数再乘以10的幂的形式表示,称为有效数字的科学记数法.例测得光速为2.99×108m/s,有效数字为三位.电子质量为9.11×10-31Kg有效数字也是三位. 二、有效数字的运算法则 由于测量结果的有效数字最终取决于误差的大小,所以先计算误差,就可以准确知道任何一种运算结果所应保留的有效数字,这应该作为有效数字运算的总法则.此外,当数字运算时参加运算的分量可能很多,各分量的有效数字也多少不一,而且在运算中,数字愈来愈多,除不尽时,位数也越写越多,很是繁杂,我们掌握了误差及有效数字的基本知识后,就可以找到数字计算规则,使得计算尽量简单化,减少徒劳的计算.同时也不会影响结果的精确度.
如何零基础入门数据分析
如何零基础入门数据分析 随着数据分析相关领域变得火爆,最近越来越多的被问到:数据分析如何从头学起?其中很多提问者都是商科背景,之前没有相关经验和基础。 我在读Buisness Analytics硕士之前是商科背景,由于个人兴趣爱好,从大三开始到现在即将硕士毕业,始终没有停下自学的脚步。Coursera和EDX等平台上大概上过20多门网课,Datacamp上100多门课里,刷过70多门。这篇文章是想谈一谈个人的数据分析学习经验,希望对想要入门这个领域的各位有帮助。 1. 基本工具 学习数据分析的第一步,是了解相关工具 Excel excel至是最基础的数据分析工具,至今还是非常有效的,原因是它便于使用,受众范围极广,且分析结果清晰可见。 相信大多数人都有使用excel的基本经验,不需要根据教材去学习了。重点掌握:基本操作的快捷键;函数:计算函数、if类、字符串函数、查找类(vlookup 和match),一定要熟悉函数功能的绝对和相对引用;数据透视表功能等。另外,excel可以导入一些模块来使用,典型的包括数据分析模块,作假设检验常用;规划求解,作线性规划和决策等问题非常有效。利用这些模块可以获得很不错的分析报告,简单且高效。 SQL 数据分析的绝对核心!大部分数据分析工作都是对数据框进行的,在这个过程中,需要不断的根据已有变量生成新变量、过滤掉一些样本还有转换level。
SQL的设计就是为了解决这些问题。其他常用的数据操作工具,包括R语言的数据框、Python里的pandas,基本都是借鉴了SQL的思想,一通百通。 SQL入门容易,它的语法极其简单,基本可以说上过一门相关的课或看过一本相关的书就可以了解大概,但融会贯通并能够进行各种逻辑复杂的操作,就需要长时间的锤炼了。 SQL的学习建议,随便找一本书或者网课就好,因为主流的课程基本都是一个思路:先讲SELECT、WHERE、GROUP BY(配合简单的聚合函数)、ORDER BY这类单表操作,之后讲JOIN进行多表连接。除此之外,必会的基本技能还应该包括WINDOW FUNCTION和CASE WHEN等等。学了基本的内容之后,就是找项目多练,不断提升。 R/Python 熟练SQL之后,对数据操作方面的内容就得心应手了。接下来更复杂的问题,如搜索和建模,则需要使用编程语言。 R vs Python 目前最主流的数据分析编程语言就是R和Python,网上遍是关于这两者的争论,有兴趣的可以简单看一下,但不用陷入过度的纠结。我个人的经验来看,熟练两者其中的任何一个都可以胜任数据分析中的大部分工作,不存在某一个语言有明显缺陷的情况。 这里不想大篇幅的比较两者,但是想简单的说一下两者的侧重点: R语言是为了解决统计问题而设计的,因此它有一个很人性化的地方:最大程度的简化语言,从而让分析人员忽略编程内容,直面数据分析。也因为是统计语言,很多基本的统计分析内容在R里都是内置函数,调用十分便捷。此外,R