遗传算法工具箱识别(GA)Bouc-Wen模型参数辨识_识别

Bouc-Wen模型因数字处理方便简单而得到较为广泛的应用,力可以表示为:
利用遗传算法工具箱(GA)对Bouc-Wen模型进行参数识别。
实验数据来源于对磁流变阻尼器(MR damper)进行性能测试,试验获得的数据包括力F,位移x,采用频率已知,速度和加速度可以由位移求导得出。
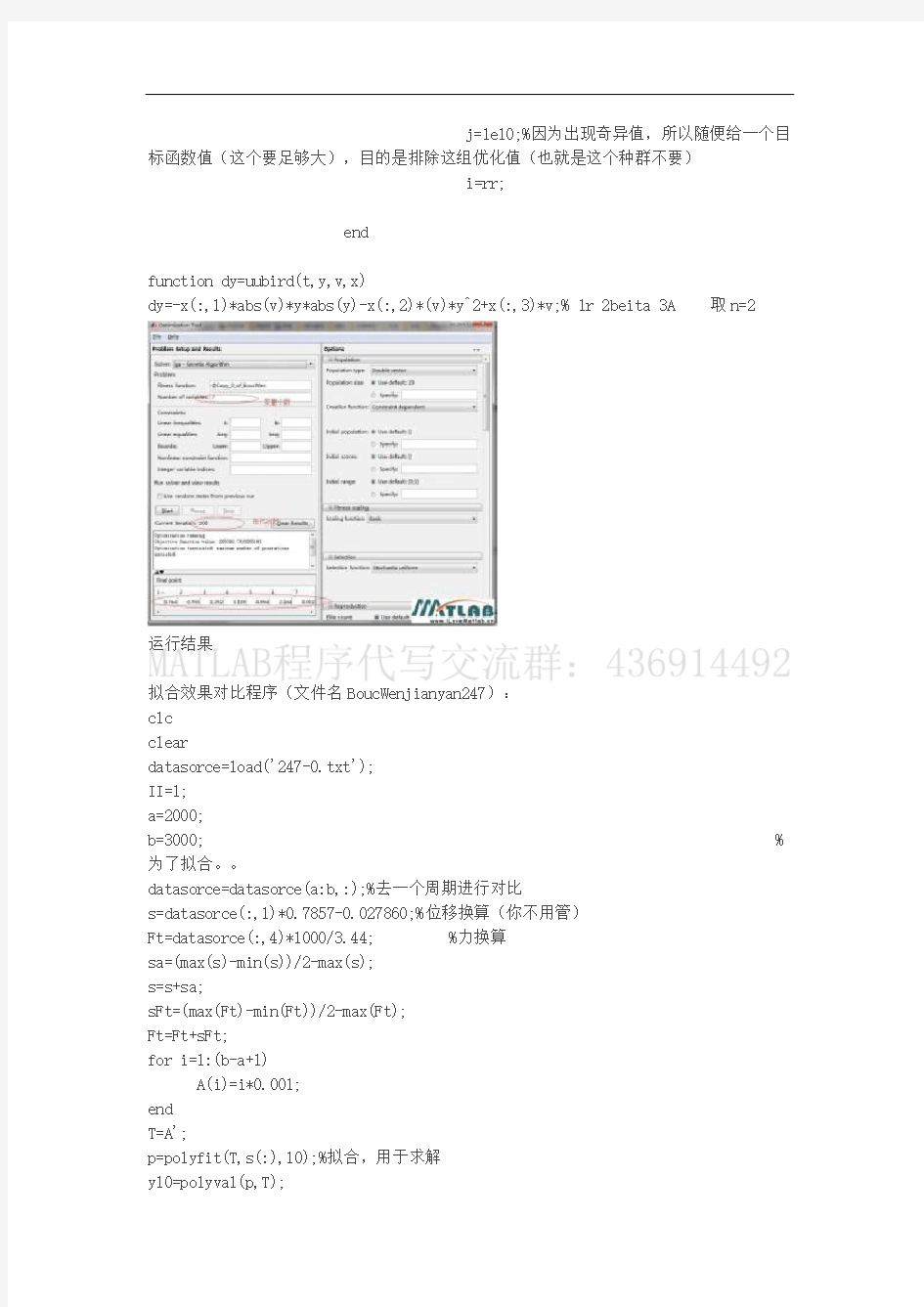
参数识别出现程序如下:(文件名:Copy_0_of_BoucWen)
function j=myfung(x)
y0=[0];
yy=y0;
tspan=[]';
s=[]';
v=[]';
Ft=[]';
rr=max(size(s));%计算数据个数
i=1;
while
(i
[t
y]=ode45(@uubird,[tspan(i),tspan(i+1)],y0,[],v(i),x);%参考论坛的
y0=y(end,:);
yy=[yy;y0];
i=i+1;
kk=max(size(y));
if kk>150 %微分方程计算,停止是有条件的(具体没去研究),这边设置150次,不管有没有收敛,都停止,不然整个程序运行的实际太久,你也可以改成其他的,慢慢研究
break;
end
end
if (i==rr)&(~isnan(yy(1,1)))==1%判断是否出现奇异点(就是NAN),如果没有出现,就是正常的
F=x(:,4)*yy(:,1)+x(:,5)*(s-ones(size(s)) *x(:,6))+x(:,7)*v;%x(:,4)代表alpha 5代表k0,6代表s0 7代表c0 位移s就是公式中的x
j=sum((F-Ft).*(F-Ft));
i=i+1;
else i<(rr-1)%出现奇异点(NAN)
j=1e10;%因为出现奇异值,所以随便给一个目标函数值(这个要足够大),目的是排除这组优化值(也就是这个种群不要)
i=rr;
end
function dy=uubird(t,y,v,x)
dy=-x(:,1)*abs(v)*y*abs(y)-x(:,2)*(v)*y^2+x(:,3)*v;% 1r 2beita 3A 取n=2
运行结果
拟合效果对比程序(文件名BoucWenjianyan247):
clc
clear
datasorce=load('247-0.txt');
II=1;
a=2000;
b=3000; %为了拟合。。
datasorce=datasorce(a:b,:);%去一个周期进行对比
s=datasorce(:,1)*0.7857-0.027860;%位移换算(你不用管)
Ft=datasorce(:,4)*1000/3.44; %力换算
sa=(max(s)-min(s))/2-max(s);
s=s+sa;
sFt=(max(Ft)-min(Ft))/2-max(Ft);
Ft=Ft+sFt;
for i=1:(b-a+1)
A(i)=i*0.001;
end
T=A';
p=polyfit(T,s(:),10);%拟合,用于求解
y10=polyval(p,T);
syms x
y= p(1)*x^10 + p(2)*x^9 +p(3)*x^8 + p(4)*x^7 + p(5)*x^6 + p(6)*x^5 + p(7)*x^4 + p(8)*x^3 +p(9)*x^2 + p(10)*x +p(11);
f=diff(y);
ac=diff(y,2);
for i=1:(b-a+1)
x=i*0.001;
v(i)=eval(f);
acc(i)=eval(ac);
vm(i)=(v(i)*v(i)-s(i)*acc(i))^0.5;
I(i)=0;
end
v=v';
T=T';
y0=[0];
yy=y0;
rr=max(size(s));
tspan=0:0.001:(rr-1)*0.001;
i=1;
x=[0.764 -0.7651 2.291 3.108
4.994 2.163925 3.002];%%参数识别出出来的结果
while (i [t y]=ode45(@uubird,[tspan(i),tspan(i+1)],y0,[],v(i),x); y0=y(end,:); yy=[yy;y0]; i=i+1; end F=x(:,4)*yy(:,1)+x(:,5)*(s-ones(size(s))*x(:,6))+x(:,7)*v;%4alpha 5k0 6x0 7c0 s=s(100:2:800,:); v=v(100:2:800,:); F=F(100:2:800,:); Ft=Ft(100:2:800,:); figure(1),plot(v,Ft,'k',v,F,'r--'),hold on figure(2),plot(s,Ft,'k',s,F,'r--'),hold on 实线是试验测得的结果。 [attach]188480[/attach][attach]188480[/attach][attach]188480[/attach] 如果觉得效果不够好,可以增加迭代次数。 遗传算法参数调整实验报告 算法设计: 编码方案:遍历序列 适应度函数:遍历路程 遗传算子设计: 选择算子:精英保留+轮盘赌 交叉算子:Pxover ,顺序交叉、双亲双子, 变异算子:Pmutation ,随机选择序列中一个染色体(城市)与其相邻染色体交换 首先,我们改编了我们的程序,将主函数嵌套在多层迭代之内,从外到内依此为: 过程中,我们的程序将记录每一次运行时种群逐代进化(收敛)的情况,并另外记录总体测试结果。 测试环境: AMD Athlon64 3000+ (Overclock to 2.4GHz) 目标:寻求最优Px 、Pm 组合 方式:popsize = 50 maxgen = 500 \ 10000 \ 15000 Px = 0.1~0.9(0.05) Pm = 0.01~0.1(0.01) count = 50 测试情况:运行近2万次,时间约30小时,产生数据文件总共5.8GB 测试结果:Px, Pm 对收敛结果的影响,用灰度表示结果适应度,黑色为适应度最低 结论:Px = 0.1 ,Pm = 0.01为最优,并刷新最优结果19912(之前以为是20310),但20000次测试中最优解只出现4次,程序需要改进。 Maxgen = 5000 Pm=0.01 Px = 0.1 Maxgen = 10000 0.1 0.9 Px = 0.1 0.9 0.1 目标:改进程序,再寻求最优参数 方式:1、改进变异函数,只保留积极变异; 2、扩大测试范围,增大参数步进 popsize = 100 \ 200 \ 400 \ 800 maxgen = 10000 Px = 0.1 \ 0.5 \ 0.9 Pm = 0.01 \ 0.04 \ 0.07 \ 0.1 count = 30 测试情况:运行1200次,时间8小时,产生数据文件600MB 测试结果: 结论:Px = 0.1,Pm = 0.01仍为最优,收敛情况大有改善,10000代基本收敛到22000附近,并多次达到最优解19912。变异函数的修改加快了整体收敛速度。 但是收敛情况对Pm并不敏感。另外,单个种群在遗传过程中收敛速度的统计,将是下一步的目标。 第四章 等效电路模型参数在线辨识 通过第三章函数拟合的方法可以确定钒电池等效电路模型中的参数,但是在实际运行过程中模型参数随着工作环境温度、充放电循环次数、SOC 等因素发生变化,根据离线试验数据计算得到的参数值估算电池SOC 可能会造成较大的估计误差。因此,在实际运行时,应对钒电池等效电路模型参数进行在线辨识,做出实时修正,提高基于模型估算SOC 的精度。 4.1 基于遗忘因子的最小二乘算法 参数辨识是根据被测系统的输入输出来,通过一定的算法,获得让模型输出值尽量接近系统实际输出值的模型参数估计值。根据能否实时辨识系统的模型参数,可以将常用的参数辨识方法分为离线和在线两类,离线辨识只能在数据采集完成后进行,不能对系统模型实时地在线调整参数,对于具有非线性特性的电池系统往往不能得到满意的辨识结果;在线辨识方法一般能够根据实时采集到的数据对系统模型进行辨识,在线调整系统模型参数。常用的辨识方法有最小二乘法、极大似然估计法和Kalman 滤波法等。因最小二乘法原理简明、收敛较快、容易理解和掌握、方便编程实现等特点,在进行电池模型参数辨识时采用了效果较好的含遗忘因子的递推最小二乘法。 4.1.1 批处理最小二乘法简介 假设被辨识的系统模型: 12121212()()()1n n n n b z b z b z y z G z u z a z a z a z ------+++==++++L L (4-1) 其相应的差分方程为: 1 1 ()()()n n i i i i y k a y k i b u k i ===--+-∑∑(4-2) 若考虑被辨识系统或观测信息中含有噪声,则被辨识模型式(4-2)可改写为: 1 1 ()()()()n n i i i i z k a y k i b u k i v k ===--+-+∑∑(4-3) 式中, ()z k 为系统输出量的第k 次观测值;()y k 为系统输出量的第k 次真值,()y k i -为系统输出量的第k i -次真值;()u k 为系统的第k 个输入值,()u k i -为 系统的第k i -个输入值;()v k 为均值为0的随机噪声。 遗传算法解决简单问题 %主程序:用遗传算法求解y=200*exp(-0.05*x).*sin(x)在区间[-2,2]上的最大值clc; clear all; close all; global BitLength global boundsbegin global boundsend bounds=[-2,2]; precision=0.0001; boundsbegin=bounds(:,1); boundsend=bounds(:,2); %计算如果满足求解精度至少需要多长的染色体 BitLength=ceil(log2((boundsend-boundsbegin)'./precision)); popsize=50; %初始种群大小 Generationmax=12; %最大代数 pcrossover=0.90; %交配概率 pmutation=0.09; %变异概率 %产生初始种群 population=round(rand(popsize,BitLength)); %计算适应度,返回适应度Fitvalue和累计概率cumsump [Fitvalue,cumsump]=fitnessfun(population); Generation=1; while Generation 一需求分析 1.本程序演示的是用简单遗传算法随机一个种群,然后根据所给的交叉率,变异率,世代数计算最大适应度所在的代数 2.演示程序以用户和计算机的对话方式执行,即在计算机终端上显示“提示信息”之后,由用户在键盘上输入演示程序中规定的命令;相应的输入数据和运算结果显示在其后。3.测试数据 输入初始变量后用y=100*(x1*x1-x2)*(x1*x2-x2)+(1-x1)*(1-x1)其中-2.048<=x1,x2<=2.048作适应度函数求最大适应度即为函数的最大值 二概要设计 1.程序流程图 2.类型定义 int popsize; //种群大小 int maxgeneration; //最大世代数 double pc; //交叉率 double pm; //变异率 struct individual { char chrom[chromlength+1]; double value; double fitness; //适应度 }; int generation; //世代数 int best_index; int worst_index; struct individual bestindividual; //最佳个体 struct individual worstindividual; //最差个体 struct individual currentbest; struct individual population[POPSIZE]; 3.函数声明 void generateinitialpopulation(); void generatenextpopulation(); void evaluatepopulation(); long decodechromosome(char *,int,int); void calculateobjectvalue(); void calculatefitnessvalue(); void findbestandworstindividual(); void performevolution(); void selectoperator(); void crossoveroperator(); void mutationoperator(); void input(); void outputtextreport(); 4.程序的各函数的简单算法说明如下: (1).void generateinitialpopulation ()和void input ()初始化种群和遗传算法参数。 input() 函数输入种群大小,染色体长度,最大世代数,交叉率,变异率等参数。 (2)void calculateobjectvalue();计算适应度函数值。 根据给定的变量用适应度函数计算然后返回适度值。 (3)选择函数selectoperator() 在函数selectoperator()中首先用rand ()函数产生0~1间的选择算子,当适度累计值不为零时,比较各个体所占总的适应度百分比的累计和与选择算子,直到达到选择算子的值那个个体就被选出,即适应度为fi的个体以fi/∑fk的概率继续存在; 显然,个体适应度愈高,被选中的概率愈大。但是,适应度小的个体也有可能被选中,以便增加下一代群体的多样性。 (4)染色体交叉函数crossoveroperator() 这是遗传算法中的最重要的函数之一,它是对个体两个变量所合成的染色体进行交叉,而不是变量染色体的交叉,这要搞清楚。首先用rand ()函数产生随机概率,若小于交叉概率,则进行染色体交叉,同时交叉次数加1。这时又要用rand()函数随机产生一位交叉位,把染色 浅析电力系统模型参数辨识 (贵哥提供) 一、现状分析 随着我国电力事业的迅猛发展, 超高压输电线路和大容量机组的相继投入, 对电力系统稳定计算、以及其安全性、经济性和电能质量提出了更高的要求。现代控制理论、计算机技术、现代应用数学等新理论、新方法在电力系统的应用,正在促使电力工业这一传统产业迅速走向高科技化。 我国大区域电网的互联使网络结构更复杂,对电力系统安全稳定分析提出了更高的要求,在线、实时、精确的辨识电力系统模型参数变得更加紧迫。由于电力系统模型的基础性、重要性,国外早在上世纪三十年代就开始了这方面的分析研究,[1,2]国内外的电力工作者在模型参数辨识方面做了大量的研究工作。[3]随后IEEE相继公布了有关四大参数的数学模型。1990年全国电网会议上的调查确定了模型参数的地位,促进了模型参数辨识的进一步发展,并提出了研究发电机、励磁、调速系统、负荷等元件的动态特性和理论模型,以及元件在极端运行环境下的动态特性和参数辨识的要求。但传统的测量手段,限制了在线实时辨识方法的实现。 同步相量测量技术的出现和WAMS系统的研究与应用,使实现在线实时的电力系统模型参数辨识成为可能。同步相量是以标准时间信号GPS作为同步的基准,通过对采样数据计算而得的相量。相量测量装置是进行同步相量测量和输出以及动态记录的装置。PMU的核心特征包括基于标准时钟信号的同步相量测量、失去标准时钟信号的授时能力、PMU与主站之间能够实时通信并遵循有关通信协议。 自1988年Virginia Tech研制出首个PMU装置以来,[4]PMU技术取得了长足发展,并在国内外得到了广泛应用。截至2006年底,在我国范围内,已有300多台P MU装置投入运行,并且可预计,在不久的将来PMU装置会遍布电力系统的各个主要电厂和变电站。这为基于PMU的各种应用提供了良好的条件。 二、系统辨识的概念 系统模型是实际系统本质的简化描述。[5]模型可分为物理模型和数学模型两大类。物理模型是根据相似原理构成的一种物理模拟,通过模型试验来研究系统的 GATBX遗传算法工具箱函数及实例讲解 基本原理: 遗传算法是一种典型的启发式算法,属于非数值算法范畴。它是模拟达尔文的自然选择学说和自然界的生物进化过程的一种计算模型。它是采用简单的编码技术来表示各种复杂的结构,并通过对一组编码表示进行简单的遗传操作和优胜劣汰的自然选择来指导学习和确定搜索的方向。遗传算法的操作对象是一群二进制串(称为染色体、个体),即种群,每一个染色体都对应问题的一个解。从初始种群出发,采用基于适应度函数的选择策略在当前种群中选择个体,使用杂交和变异来产生下一代种群。如此模仿生命的进化进行不断演化,直到满足期望的终止条件。 运算流程: Step 1:对遗传算法的运行参数进行赋值。参数包括种群规模、变量个数、交叉概率、变异概 率以及遗传运算的终止进化代数。 Step 2:建立区域描述器。根据轨道交通与常规公交运营协调模型的求解变量的约束条件,设置变量的取值范围。 Step 3:在Step 2的变量取值范围内,随机产生初始群体,代入适应度函数计算其适应度值。 Step 4:执行比例选择算子进行选择操作。 Step 5:按交叉概率对交叉算子执行交叉操作。 Step 6:按变异概率执行离散变异操作。 Step 7:计算Step 6得到局部最优解中每个个体的适应值,并执行最优个体保存策略。 Step 8:判断是否满足遗传运算的终止进化代数,不满足则返回Step 4,满足则输出运算结果。 运用遗传算法工具箱: 运用基于Matlab的遗传算法工具箱非常方便,遗传算法工具箱里包括了我们需要的各种函数库。目前,基于Matlab的遗传算法工具箱也很多,比较流行的有英国设菲尔德大学开发的遗传算法工具箱GATBX、GAOT以及Math Works公司推出的GADS。实际上,GADS就是大家所看到的Matlab中自带的工具箱。我在网上看到有问为什么遗传算法函数不能调用的问题,其实,主要就是因为用的工具箱不同。因为,有些人用的是GATBX带有的函数,但MATLAB自带的遗传算法工具箱是GADS,GADS当然没有GATBX里的函数,因此运行程序时会报错,当你用MATLAB来编写遗传算法代码时,要根据你所安装的工具箱来编写代码。 以GATBX为例,运用GATBX时,要将GATBX解压到Matlab下的toolbox文件夹里,同时,set path将GATBX文件夹加入到路径当中。 这块内容主要包括两方面工作:1、将模型用程序写出来(.M文件),即目标函数,若目标函数非负,即可直接将目标函数作为适应度函数。2、设置遗传算法的运行参数。包括:种群规模、变量个数、区域描述器、交叉概率、变异概率以及遗传运算的终止进化代数等等。 基于遗传算法的PID控制器参数整定报告 一、遗传算法。 遗传算法(GAs)是基于自然界生物进化机制的搜索寻优技术。用遗传算法来整定PID参数,可以提高优化性能,对控制系统有良好的控制精度、动态性能和鲁棒性。 一般的,Gas包括三个基本要素:复制、交叉和突变。 二、PID Optimal-Tuning PID控制:对偏差信号e(t)进行比例、积分和微分运算变换后形成的一种控制规律。 (1) 可调参数:比例度δ(P)、积分时间Ti(I)、微分时间Td(D)。 通常,PID控制准则可以写成下面传递函数的形式: ) 1( ) (s T T s K s G d i p + + =(2) Kp、Ti和Td分别是比例放大率、积分时间常量和微分时间常量。 1)比例控制(P):是一种最简单的控制方式。其控制器的输出与输入误差信号成比例关系。当仅有比例控制时系统输出存在稳态误 差(Steady state error),比例度减小,稳态误差减小; 2)积分(I)控制:在积分控制中,控制器的输出与输入误差信号的积分成正比关系。 3)微分(D)控制:在微分控制中,控制器的输出与输入误差信号()()()()? ? ? ? ? ? + + =?t e dt d T d e T t e K t u d t i p0 1 τ τ 的微分(即误差的变化率)成正比关系。 文中,性能指标是误差平方的时间加权积分,表示为: ),,1,0(,0 2n k dt e t J i t k ==? (3) 其中n 是非负整数,i t 是积分周期。此外,其他标准项如超调量、上升时间和稳定时间也被一个合成性能指标选择: ))(1(s s r r c t c t c os J ++= (4) s r os t t 、、分别代表超调量、上升时间和稳定时间。s r c 、c 两个系数有用户定义或决定。预期的性能指标的最下化可以认为是小的超调量、短的上升时间和稳定时间。 三个PID 参数的编码方式如下: 10101011:S 1010100011100111 p K i K d K p K 、i K 和d K 都是八位二进制字符格式。 自适应函数的选择关系到性能指标,如: 101)(J J F F == (5) 实际上,)(J F 可以是任何一个能切实表达F 和J 关系的非线性函数。 遗传操作是模拟生物基因遗传的操作,从优化搜索的角度而言,遗传操作可使问题的解一代一代地优化,并逼近最优解,主要包括三个遗传算子:选择、交叉和变异。关于他们的具体方法这里不在赘述。 三、 计算机实现 作者编程使用的事TURBO C 。程序包括两个部分:一个是仿真PID 控制系统的闭环阶跃响应;另一个是实施对一代所有成员的遗传算法的仿真,这里遗传算法将一代作为一个整体。在第一代生物的二进制代码随机产生之后,这个过程重复直至迭代次数达到预选的次数。 步长、PID 参数X 围、性能指标、自适应函数和方法得时间延迟都是从一个文件中读取。而遗传算法的的参数,诸如世代数、交叉概率、变异概率、选择概率等通过菜单选择。 整个闭环系统仿真的完成可以用四阶龙格库塔法或直接时域计算。在程序中,复制的实现是通过轮盘赌博法的线性搜索,面积加权于上一代成员的适应值。交叉发生在每一对复制产生的成员。 交叉操作是将一个随机产生的一个在0到1之间数与交叉概率比较决定是否需要交叉。如果需要交叉,则在1到47之间随机产生一个交叉位置代码。变异,对新一代所有成员都随机产生一个0到1之间的数与变异概率比较,然后再决定是否改变代码的一位。同理,反转也是这样判定和操作的。另一需要说明的事,两个反转位置代码是在1~48之间随机选择的。同样, 实验六 遗传算法与优化设计 一、实验目的 1. 了解遗传算法的基本原理和基本操作(选择、交叉、变异); 2. 学习使用Matlab 中的遗传算法工具箱(gatool)来解决优化设计问题; 二、实验原理及遗传算法工具箱介绍 1. 一个优化设计例子 图1所示是用于传输微波信号的微带线(电极)的横截面结构示意图,上下两根黑条分别 代表上电极和下电极,一般下电极接地,上电极接输入信号,电极之间是介质(如空气,陶瓷等)。微带电极的结构参数如图所示,W 、t 分别是上电极的宽度和厚度,D 是上下电极间距。当微波信号在微带线中传输时,由于趋肤效应,微带线中的电流集中在电极的表面,会产生较大的欧姆损耗。根据微带传输线理论,高频工作状态下(假定信号频率1GHz ),电极的欧姆损耗可以写成(简单起见,不考虑电极厚度造成电极宽度的增加): 图1 微带线横截面结构以及场分布示意图 {} 28.6821ln 5020.942ln 20.942S W R W D D D t D W D D W W t D W W D e D D παπππ=+++-+++?????? ? ??? ??????????? ??????? (1) 其中πρμ0=S R 为金属的表面电阻率,为电阻率。可见电极的结构参数影响着电极损 耗,通过合理设计这些参数可以使电极的欧姆损耗做到最小,这就是所谓的最优化问题或者称为规划设计问题。此处设计变量有3个:W 、D 、t ,它们组成决策向量[W, D ,t ] T ,待优化函数(,,)W D t α称为目标函数。 上述优化设计问题可以抽象为数学描述: ()()min .. 0,1,2,...,j f X s t g X j p ????≤=? (2) 其中()T n x x x X ,...,,21=是决策向量,x 1,…,x n 为n 个设计变量。这是一个单目标的数学规划问题:在一组针对决策变量的约束条件()0,1,...,j g X j p ≤=下,使目标函数最小化(有时 也可能是最大化,此时在目标函数()X f 前添个负号即可)。满足约束条件的解X 称为可行解,所有满足条件的X 组成问题的可行解空间。 2. 遗传算法基本原理和基本操作 遗传算法(Genetic Algorithm, GA)是一种非常实用、高效、鲁棒性强的优化技术,广 泛应用于工程技术的各个领域(如函数优化、机器学习、图像处理、生产调度等)。遗传算法是模拟生物在自然环境中的遗传和进化过程而形成的一种自适应全局优化算法。按照达尔文的进化论,生物在进化过程中“物竞天择”,对自然环境适应度高的物种被保留下来,适应度差的物种而被淘汰。物种通过遗传将这些好的性状复制给下一代,同时也通过种间的交配(交叉)和变异不断产生新的物种以适应环境的变化。从总体水平上看,生物在进化过程中子代总要比其父代优良,因此生物的进化过程其实就是一个不断产生优良物种的过程,这和优化设计问题具有惊人的相似性,从而使得生物的遗传和进化能够被用于实际的优化设计问题。 按照生物学知识,遗传信息基因(Gene)的载体是染色体(Chromosome),染色体中 一定数量的基因按照一定的规律排列(即编码),遗传基因在染色体中的排列位置称为基因 最新最全的遗传算法工具箱Gaot_v5及说明 Gaot_v5下载地址:https://www.360docs.net/doc/f32216246.html,/mirage/GAToolBox/gaot/gaotv5.zip 添加遗传算法路径: 1、 matlab的file下面的set path把它加上,把路径加进去后在 2、 file→Preferences→General的Toolbox Path Caching里点击update Toolbox Path Cache更新一下,就OK了 遗传算法工具箱Gaot_v5包括许多实用的函数,各种算子函数,各种类型的选择方式,交叉、变异方式。这些函数按照功能可以分成以下几类: 主程序 ga.m提供了 GAOT 与外部的接口。它的函数格式如下: [x endPop bPop traceInfo]=ga(bounds,evalFN,evalOps,startPop,opts,termFN,termOps, selectFn,selectOps,xOverFNs,xOverOps,mutFNs,mutOps) 输出参数及其定义如表 1 所示。输入参数及其定义如表 2 所示。 表1 ga.m的输出参数 输出参数 定义 x 求得的最好的解,包括染色体和适应度 endPop 最后一代染色体(可选择的) bPop 最好染色体的轨迹(可选择的) traceInfo 每一代染色体中最好的个体和平均适应度(可选择的) 表2 ga.m的输入参数 表3 GAOT核心函数及其它函数 核心函数: (1)function [pop]=initializega(num,bounds,eevalFN,eevalOps,options)--初始种群的生成函数 【输出参数】 pop--生成的初始种群 【输入参数】 num--种群中的个体数目 bounds--代表变量的上下界的矩阵 eevalFN--适应度函数 eevalOps--传递给适应度函数的参数 options--选择编码形式(浮点编码或是二进制编码)[precision F_or_B],如 precision--变量进行二进制编码时指定的精度 F_or_B--为1时选择浮点编码,否则为二进制编码,由precision指定精度) (2)function [x,endPop,bPop,traceInfo] = ga(bounds,evalFN,evalOps,startPop,opts,... termFN,termOps,selectFN,selectOps,xOverFNs,xOverOps,mutFNs,mutOps)--遗传算法函数 【输出参数】 x--求得的最优解 endPop--最终得到的种群 bPop--最优种群的一个搜索轨迹 【输入参数】 文章编号:1006-1576(2005)06-0115-02 Matlab遗传算法工具箱的应用 曾日波 (江西财经大学电子学院,江西南昌 330013) 摘要:Matlab遗传算法(GA)优化工具箱是基于基本操作及终止条件、二进制和十进制相互转换等操作的综合函数库。其实现步骤包括:通过输入及输出函数求出遗传算法主函数、初始种群的生成函数,采用选择、交叉、变异操作求得基本遗传操作函数。以函数仿真为例,对该函数优化和GA改进,只需改写函数m文件形式即可。 关键词:遗传算法;Matlab;遗传算法工具箱;仿真 中图分类号:TP391.9 文献标识码:A Application of Genetic Algorithm Toolbox Based on Matlab ZENG Ri-bo (College of Finance and Economics Electronics, Jiangxi University, Nanchang 330013, China) Abstract: The optimization toolbox of Matlab genetic algorithm (GA) is a excellent generalized function library is to bases on basic operation and terminate term, the inter-conversion between binary system and ten system the system etc. Its step includes: the main function of GA and the creation functions of initial population was calculated through inputting and outputting functions, and the basic functions of genetic operation was computed by choosing, interlacing, and aberrance functions to realize the system. Take the function simulation as an example, the optimization of function and improvement of GA were achieved by modification the file format of m function. Keywords: Genetic algorithm; Matlab; Optimization toolbox; Simulation 1 引言 遗传算法(GA:Genetic Algorithm)是对生物进化过程进行的数学方式仿真。将Matlab引入遗传算法,在Matlab平台上开发遗传算法的优化工具箱(GAOT:Genetic Algorithm for Optimization Toolbox),可更好地认识GA,改进GA。 2 基于Matlab的优化工具箱 遗传算法的优化工具箱(GAOT)是从遗传算法的基本结构出发,考虑到基本操作及终止条件、二进制和十进制的相互转换等操作的综合函数库。 2.1遗传算法主函数 function[x,endPop,bPop,traceInfo]= ga(bounds,evalFN,evalOps,startPop,opts,termFN,termOps, selectFN,selectOps,xOverFNs,xOverOps,mutFNs,mutOps) 输出参数:x-最优解,endPop-最终种群,bPop-最优种群的搜索轨迹。 输入参数:bounds-变量上下界的矩阵,evalFN-适应度函数,evalOps-传递给适应度函数的参数,startPop-初始种群,termFN-终止函数的名称,termOps-传递个终止函数的参数,selectFN -选择函数的名称,selectOps-传递个选择函数的参数,xOverFNs-交叉函数名称表,以空格分开,xOverOps-传递给交叉函数的参数表,mutFNs-变异函数表,mutOps-传递给交叉函数的参数表。 2.2 初始种群的生成函数 function[pop]=initializega (num,bounds,eevalFN,eevalOps,options) 输出参数:pop-生成的初始种群。 输入参数:num-种群中的个体数目,bounds -代表变量的上下界的矩阵,eevalFN-适应度函数,eevalOps-传递给适应度函数的参数,options -选择编码形式(浮点编码或是二进制编码)[precision F_or_B],precision-变量进行二进制编码时指定的精度,F_or_B-为1时选择浮点编码,否则为二进制编码,由precision指定精度)。 2.3 基本遗传操作函数 (1) 选择 function[newPop] = Select(oldPop,options) 参数说明:newPop-由父代种群选出的新的种群,oldPop-当前的种群(即父代种群),options -选择概率。 (2) 交叉 function [c1,c2]=crossover(p1,p2,bounds,ops) 参数说明:p1-第一个父代个体,p2-第二个父代个体,bounds-可行域的边界矩阵,c1、c2-产生的两个新的子代。 (3) 变异 function [child] = Mutation(par,bounds,genInfo,Ops) 变异操作是由一个父代产生单个子代。 3 仿真实例与分析 收稿日期:2005-06-15;修回日期:2005-08-07 作者简介:曾日波(1964-),男,江西人,2000年获华中科技大学工程硕士学位,从事嵌入式系统的应用研究。 ·115· matlab遗传算法工具箱函数及实例讲解 最近研究了一下遗传算法,因为要用遗传算法来求解多元非线性模型。还好用遗传算法的工箱予以实现了,期间也遇到了许多问题。借此与大家分享一下。 首先,我们要熟悉遗传算法的基本原理与运算流程。 基本原理:遗传算法是一种典型的启发式算法,属于非数值算法范畴。它是模拟达尔文的自然选择学说和自然界的生物进化过程的一种计算模型。它是采用简单的编码技术来表示各种复杂的结构,并通过对一组编码表示进行简单的遗传操作和优胜劣汰的自然选择来指导学习和确定搜索的方向。遗传算法的操作对象是一群二进制串(称为染色体、个体),即种群,每一个染色体都对应问题的一个解。从初始种群出发,采用基于适应度函数的选择策略在当前种群中选择个体,使用杂交和变异来产生下一代种群。如此模仿生命的进化进行不断演化,直到满足期望的终止条件。 运算流程: Step 1:对遗传算法的运行参数进行赋值。参数包括种群规模、变量个数、交叉概率、变异概率以及遗传运算的终止进化代数。 Step 2:建立区域描述器。根据轨道交通与常规公交运营协调模型的求解变量的约束条件,设置变量的取值范围。 Step 3:在Step 2的变量取值范围内,随机产生初始群体,代入适应度函数计算其适应度值。 Step 4:执行比例选择算子进行选择操作。 Step 5:按交叉概率对交叉算子执行交叉操作。 Step 6:按变异概率执行离散变异操作。 Step 7:计算Step 6得到局部最优解中每个个体的适应值,并执行最优个体保存策略。 Step 8:判断是否满足遗传运算的终止进化代数,不满足则返回Step 4,满足则输出运算结果。 其次,运用遗传算法工具箱。 运用基于Matlab的遗传算法工具箱非常方便,遗传算法工具箱里包括了我们需要的各种函数库。目前,基于Matlab的遗传算法工具箱也很多,比较流行的有英国设菲尔德大学开发的遗传算法工具箱GATBX、GAOT以及Math Works公司推出的GADS。实际上,GADS 就是大家所看到的Matlab中自带的工具箱。我在网上看到有问为什么遗传算法函数不能调用的问题,其实,主要就是因为用的工具箱不同。因为,有些人用的是GATBX带有的函数,但MATLAB自带的遗传算法工具箱是GADS,GADS当然没有GATBX里的函数,因此运行程序时会报错,当你用MATLAB来编写遗传算法代码时,要根据你所安装的工具箱来编写代码。 matlab遗传算法工具箱函数及实例讲解(转引) 核心函数:? (1)function [pop]=initializega(num,bounds,eevalFN,eevalOps,options)--初始种群的生成函数?【输出参数】? ?pop--生成的初始种群?【输入参数】? ?num--种群中的个体数目? ?bounds--代表变量的上下界的矩阵? ?eevalFN--适应度函数? ?eevalOps--传递给适应度函数的参数? ?options--选择编码形式(浮点编码或是二进制编码)[precision F_or_B],如? precision--变量进行二进制编码时指定的精度? F_or_B--为1时选择浮点编码,否则为二进制编码,由precision指定精度)? (2)function [x,endPop,bPop,traceInfo] = ga(bounds,evalFN,evalOps,startPop,opts.? ?termFN,termOps,selectFN,selectOps,xOverFNs,xOverOps,mutFNs ,mutOps)--遗传算法函数?【输出参数】? x--求得的最优解? endPop--最终得到的种群? bPop--最优种群的一个搜索轨迹?【输入参数】? bounds--代表变量上下界的矩阵? evalFN--适应度函数? evalOps--传递给适应度函数的参数? startPop-初始种群? opts[epsilon prob_ops display]--opts(1:2)等同于initializega 的options参数,第三个参数控制是否输出,一般为0。如[1e-6 termFN--终止函数的名称,如['maxGenTerm']? termOps--传递个终止函数的参数,如[100]? selectFN--选择函数的名称,如['normGeomSelect']? selectOps--传递个选择函数的参数,如[0.08]? xOverFNs--交叉函数名称表,以空格分开,如['arithXover heuristicXover simpleXover']? xOverOps--传递给交叉函数的参数表,如[2 0;2 3;2 0]? mutFNs--变异函数表,如['boundaryMutation multiNonUnifMutation nonUnifMutation unifMutation']? mutOps--传递给交叉函数的参数表,如[4 0 0;6 100 3;4 100 3;4 0 0]?注意】matlab工具箱函数必须放在工作目录下?【问题】求f(x)=x+10*sin(5x)+7*cos(4x)的最大值,其中0=x=9?【分析】选择二进制编码,种群中的个体数目为10,二进制编码长度为20,交叉概率为0.95,变异概率为0.08?【程序清单】? 基于最小二乘模型的Bayes 参数辨识方法 王晓侃1,冯冬青2 1 郑州大学电气工程学院,郑州(450001) 2 郑州大学信息控制研究所,郑州(450001) E-mail :wxkbbg@https://www.360docs.net/doc/f32216246.html, 摘 要:从辨识定义出发,首先介绍了Bayes 基本原理及其两种常用的方法,接着重点介绍了基于最小二乘模型的Bayes 参数辨识,最后以实例用MATLAB 进行仿真,得出理想的辨识结果。 关键词:辨识定义;Bayes 基本原理;Bayes 参数辨识 中国图书分类号:TP273+.1 文献标识码:A 0 概述 系统辨识是建模的一种方法。不同的学科领域,对应着不同的数学模型,从某种意义上讲,不同学科的发展过程就是建立它的数学模型的过程。建立数学模型有两种方法:即解析法和系统辨识。L. A. Zadehll 于1962年曾对”辨识”给出定义[1]:系统辨识是在对输入和输出观测的基础上,在指定的一类系统中,确定一个与被识别的系统等价的系统。一般系统输出y(n)通常用系统过去输出y(n-m)和现在输入u(n)及过去输入u(n-m)的函数描述 y(n)=f(y(n-1),y(n-2),...,y(n-m y ), u(n),u(n-1),... ,u(n-m u ))=f(x(n),n) x(n)=[y(n-1),y(n-2),...y(n-m y ), u(n),u(n-1),...,u(n-m u )]’ 这里f(,)为未知函数关系,一般情况为泛函数,可以是线性函数或非线性函数,分别对应于线性或非线性系统,通常这个函数未知,但是局部输入输出数据可以测出,系统辨识的任务就是根据这部分信息寻找确定函数或确定系统来逼近这个未知函数。但实际上我们不可能找到一个与实际系统完全等价的模型。从实用的角度来看,系统辨识就是从一组模型中选择一个模型,按照某种准则,使之能最好地拟合由系统的输入输出观测数据体现出的实际系统的动态或静态特性。接下来本文就以最小二乘法为基础的Bayes 辨识方法为例进行分析介绍并加以仿真[4]。 1 Bayes 基本原理 Bayes 辨识方法的基本思想是把所要估计的参数看做随机变量,然后设法通过观测与该参数有关联的其他变量,以此来推断这个参数。 设μ是描述某一动态系统的模型,θ是模型μ的参数,它会反映在该动态系统的输入输出观测值中。如果系统的输出变量z(k)在参数θ及其历史纪录(1) k D ?条件下的概率密度函 数是已知的,记作p(z(k)|θ,(1) k D ?),其中(1) k D ?表示(k-1)时刻以前的输入输出数据集 合,那么根据Bayes 的观点参数θ的估计问题可以看成是把参数θ当作具有某种先验概率密 度p (θ,(1) k D ?)的随机变量,如果输入u(k)是确定的变量,则利用Bayes 公式,把参数θ 的后验概率密度函数表示成[2] p (θ,k D )= p (θ|z (k ),u(k ), (1) k D ?)=p (θ|z (k ),(1) k D ?) = (k-1) (k-1) p(z(k)/,D )p(/D ) (k-1)(k-1)p(z(k)/,D )p(/D )d θθθθθ∞∫?∞ (1) 在式(1)中,参数θ的先验概率密度函数p(θ|(1) k D ?)及数据的条件概率密度函数p(z(k)|θ, 基于遗传算法的参数优化估算模型 【摘要】支持向量机中参数的设置是模型是否精确和稳定的关键。固定的参数设置往往不能满足优化模型的要求,同时使得学习算法过于死板,不能体现出来算法的智能化优点,因此利用遗传算法(Genetic Algorithm,简称GA)对估算模型的参数进行优化,使得估算模型灵活、智能,更加符合实际工程建模的需求。 【关键词】遗传算法;参数优化;估算模型 1.引言 随着支持向量机估算模型在工程应用的不断深入。研究发现,支持向量机算法(包括LS-SVM算法)存在着一些本身不可避免的缺陷,最为突出的是参数的选取和优化问题,以往在参数选取方面,一般依靠专家系统或者设定初始值盲目搜寻等等,在实际应用必然会影响模型的精准度,造成一定影响。如何选取合理的参数成为支持向量机算法应用过程中应用中关注的问题,同时也是目前应用研究的重点。而常用的交叉验证试算的方法,不仅耗时,且搜索目的不清,使得资源浪费,耗时耗力。不能有效的对参数进行优化。 针对参选取的问题,本文使用GA算法对模型中的参数设置进行优化。 2.遗传算法 2.1 遗传算法的实施过程 遗传算法的实施过程中包括了编码、产生群体、计算适应度、复制、交换、变异等操作。图1详细的描述了遗传算法的流程。 其中,变量GEN是当前进化代数;N是群体规模;M是算法执行的最大次数。 遗传算法在参数寻优过程中,基于生物遗传学的基本原理,模拟自然界生物种群的“物竞天则,适者生存”的自然规律。把自变量看作生物体,把它转化成由基因构成的染色体(个体),把寻优的目标函数定义为适应度,未知函数视为生存环境,通过基因操作(如复制、交换和变异等),最终求出全局最优解。 2.2 GA算法的基本步骤 遗传算法操作的实施过程就是对群体的个体按照自然进化原则(适应度评估)施加一定的操作,从而实现模型中数据的优胜劣汰,使得进化过程趋于完美。从优化搜索角度出发,遗传算法可使问题的解,一代一代地进行优化,并逼近最优解。 通常采用的遗传算法的工作流程和结果形式有Goldberg提出的,常用的GA 算法基本步骤如下: ①选择编码策略,把参数集合X和域转换为位串结构空间S。常用的编码方法有二进制编码和浮点数编码。 ②定义合适的适应度函数,保证适应度函数非负。 ③确定遗传策略,包括选择群体大小,选择、交叉、变异方法,以及确定交叉概率、变异概率等其它参数。 ④随机初始化生成群体N,常用的群体规模:N=20~200。 ⑤计算群体中个体位串解码后的适应值。 ⑥按照遗传策略,运用选择、交叉和变异算子作用于群体,形成下一代群体。 ⑦判断群体性能是否满足某一个指标,或者以完成预订迭代次数,若满足则 ISSN 1000-0054CN 11-2223/N 清华大学学报(自然科学版)J T singh ua Un iv (Sci &Tech ),1999年第39卷第3期 1999,V o l.39,N o.311/34 37~40 负荷建模和参数辨识的遗传进化算法* 朱守真, 沈善德, 郑宇辉, 李 力, 艾 芊, 曲祖义 清华大学电机工程与应用电子技术系,北京100084; 东北电力集团公司,沈阳110006 收稿日期:1998-06-23 第一作者:女,1950年生,副教授 *基金项目:国家攀登计划B(85-35) 文 摘 提出了一种用于电力系统负荷建模和参数辨识的遗传进化算法,该方法与传统的最小二乘法相比具有全局搜索优化特点,适用于非线性、不连续或微分不连续的各种负荷模型。该方法已成功用于工业负荷实测数据辨识及动态和静态负荷建模。在静态负荷建模上,辨识结果略优于传统的最小二乘法,且通用性更好,只需做极小的修改就可以用于各种形式的静态负荷模型。在动态负荷建模上算法不仅给出了更优秀的结果,而且表现出很好的稳健性。结果表明此方法在负荷建模中的优势。 关键词 遗传进化算法;负荷建模;参数辨识分类号 T M 761 电力负荷模型是电力系统分析、规划、运行和计算的基础,尤其在计算中对电力系统动态行为的模拟结果影响很大。不同的计算需要采用不同的负荷模型,常规采用以不同比例的恒定阻抗、恒定电流、恒定功率或考虑不同动静比例负荷模型的方式使计算结果相差很大,甚至会导致完全错误的结论[1,2]。研究表明建立符合实际的负荷模型是十分必要的。负荷特性具有时变、非线形、不确定等多种特点,且实际负荷的用电设备构成差别很大,尤其是当电压或电流变化时,负荷产生突变,这也增加了建模的难度和复杂性。参数辨识是负荷建模的核心,目前常用的有最小二乘法、辅助变量法、分段线性多项式等方法,其中传统的方法不能有效地克服负荷建模中的非线性和不连续性等问题,会产生多值性等误差。近年来ANN 方法在建模方面已取得成功,但该方法更侧重于模拟模型的动态过程,且形成的结果是非参数模型。 遗传进化算法是模拟自然界进化中优胜劣汰的 优化过程,原则上能以较大的概率找到全局的最优解,具有并行、通用、鲁棒性强,全局收敛性好等优 点。研究人员已在发电规划[3],发电调度[4],无功优化[5]中用算例证明了EP 方法比传统的梯度寻优技术更优越。 本文采用遗传进化算法对静态、动态负荷进行了实测建模。 1 电力负荷的数学模型 本文主要描述以负荷特性来分类的静态和动态模型的建模方法。1.1 静态负荷模型 静态负荷模型表示某一时刻负荷所吸收的有功功率和无功功率与同一时刻负荷母线电压和频率之间的函数关系。静态负荷模型一般以幂函数和多项式模型表示。 本文以幂函数模型为例进行计算,幂函数表示的静态负荷特性如下: P =P 0U a 1f a 2, Q =Q 0 U b 1 f b 2 . (1) 定义误差函数 E w = N i =1 [W m (i )-W c (i )] 2 N (2)式中:N 为测量点数,W m (i )分别表示第i 次有功或无功功率测量值,W c (i )表示利用第i 次采样U i ,f i 的值由式(1)得到的有功或无功计算值,X p 、X q 是待辨识参数的向量: X p =[P 0,a 1,a 2], X q =[Q 0,b 1,b 2]. (3) 辨识问题表述为极小值寻优问题,即搜索一组参数使误差E w 达到最小值。1.2 动态负荷的模型 动态负荷模型表示某一时刻负荷所吸收的有功遗传算法参数调整实验报告(精)
等效电路模型参数在线辨识
遗传算法MATLAB完整代码(不用工具箱)
遗传算法的流程图
浅析电力系统模型参数辨识
遗 传 算 法 详 解 ( 含 M A T L A B 代 码 )
遗传算法的参数整定报告
MATLAB实验遗传算法与优化设计
最新最全的遗传算法工具箱及说明
Matlab遗传算法工具箱的应用
matlab遗传算法工具箱函数及实例讲解
遗 传 算 法 详 解 ( 含 M A T L A B 代 码 )
基于最小二乘模型的Bayes参数辨识方法
基于遗传算法的参数优化估算模型
负荷建模和参数辨识的遗传进化算法