java生成word,html文件并将内容保存至数据库

java生成word,html文件并将内容保存至数据库
发布时间:2009-7-15 阅读:793
在最近的一个项目中需要将一段字符类型的文本存为word,html并要将word的内容保存在数据库中,于是就有了如下的一个工具类,希望能对碰到这样需求的朋友提供点帮助。
匆匆忙忙的就copy上来了,没有做一些删减,有一些多余的东西,有兴趣的朋友可以自行略去。我的注释相对比较清楚,可以按照自己的需求进行组合。
在操作word的地方使用了jacob(jacob_1.9),这个工具网上很容易找到,将jacob.dll放置系统Path中,直接放在system32下也可以,jacob.jar放置在classPath 中。
代码如下:WordBridge.java
/**
* WordBridge.java
*/
package com.kela.util;
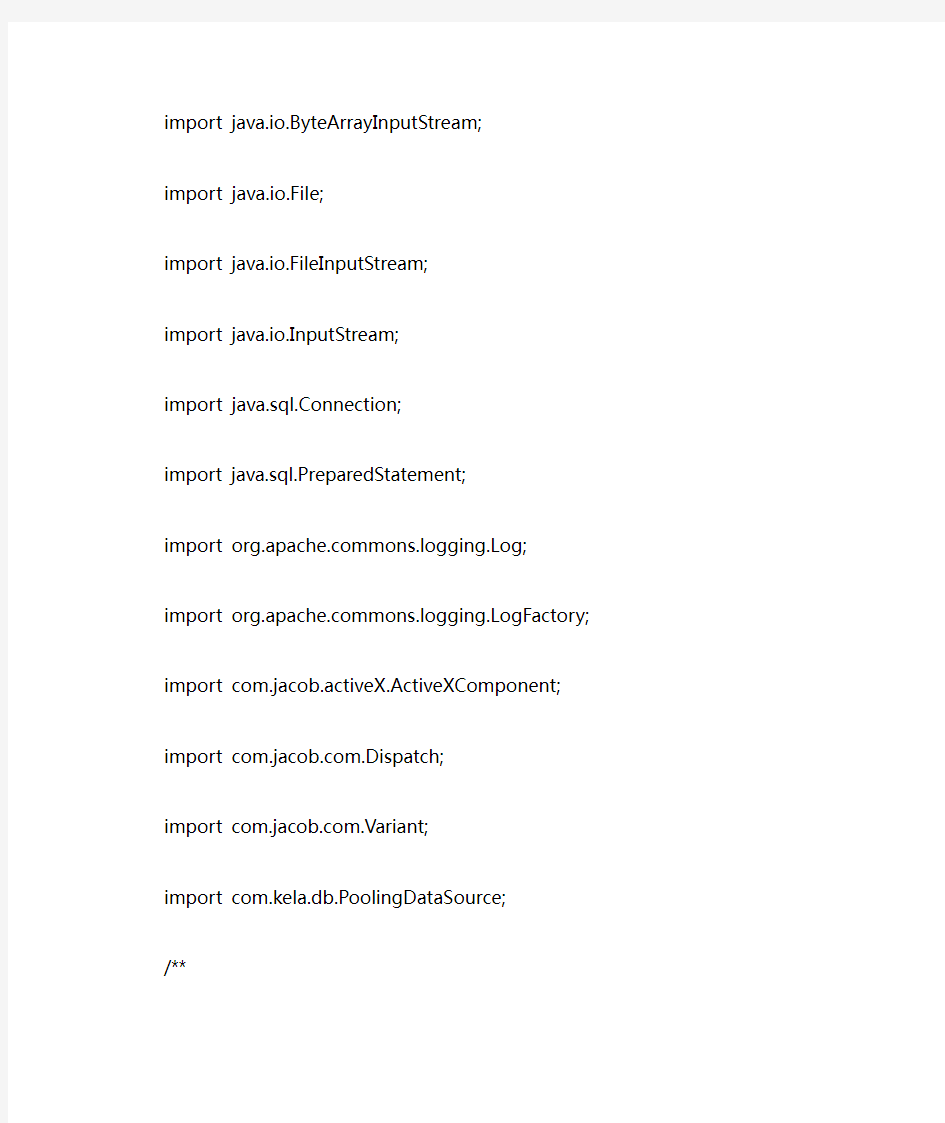
import java.io.ByteArrayInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.PreparedStatement;
import https://www.360docs.net/doc/fd7321093.html,mons.logging.Log;
import https://www.360docs.net/doc/fd7321093.html,mons.logging.LogFactory;
import com.jacob.activeX.ActiveXComponent;
import https://www.360docs.net/doc/fd7321093.html,.Dispatch;
import https://www.360docs.net/doc/fd7321093.html,.Variant;
import com.kela.db.PoolingDataSource;
/**
* 说明: 对word的操作
*
* @author kela.kf@https://www.360docs.net/doc/fd7321093.html,
*/
public class WordBridge {
Log log = LogFactory.getLog("WordBridgt");
private ActiveXComponent MsWordApp = null;
private Dispatch document = null;
/**
* 打开word
* @param makeVisible, true显示word, false不显示word
*/
public void openWord(boolean makeVisible) {
if (MsWordApp == null) {
MsWordApp = new ActiveXComponent("Word.Application");
}
Dispatch.put(MsWordApp, "Visible", new Variant(makeVisible));
}
/**
* 创建新的文档
*
*/
public void createNewDocument() {
Dispatch documents = Dispatch.get(MsWordApp, "Documents").toDispatch();
document = Dispatch.call(documents, "Add").toDispatch();
}
/**
* 关闭文档
*/
public void closeDocument() {
// 0 = wdDoNotSaveChanges
// -1 = wdSaveChanges
// -2 = wdPromptToSaveChanges
Dispatch.call(document, "Close", new Variant(0));
document = null;
}
/**
* 关闭word
*
*/
public void closeWord() {
Dispatch.call(MsWordApp, "Quit");
MsWordApp = null;
document = null;
}
/**
* 插入文本
* @param textToInsert 文本内容
*/
public void insertText(String textToInsert) {
Dispatch selection = Dispatch.get(MsWordApp, "Selection").toDispatch(); Dispatch.put(selection, "Text", textToInsert);
}
/**
* 保存文件
* @param filename
*/
public void saveFileAs(String filename) {
Dispatch.call(document, "SaveAs", filename);
}
/**
* 将word转换成html
* @param htmlFilePath
*/
public void wordToHtml(String htmlFilePath) {
Dispatch.invoke(document,"SaveAs", Dispatch.Method, new
Object[]{htmlFilePath,new Variant(8)}, new int[1]);
}
/**
* 保存word的同时,保存一个html
* @param text 需要保存的内容
* @param wordFilePath word的路径
* @param htmlFilePath html的路径
* @throws LTOAException
*/
public void wordAsDbOrToHtml(String text, String wordFilePath, String htmlFilePath) throws LTOAException {
try {
openWord(false);
createNewDocument();
insertText(text);
saveFileAs(wordFilePath);
wordToHtml(htmlFilePath);
} catch (Exception ex) {
log.error("错误- 对word的操作发生错误");
log.error("原因- " + ex.getMessage());
throw new LTOAException(LTOAException.ERR_UNKNOWN, "对word的操作发生错误("
+ this.getClass().getName() + ".wordAsDbOrToHtml())", ex);
} finally {
closeDocument();
closeWord();
}
}
/**
* 将word保存至数据库
* @param wordFilePath
* @param RecordID
* @throws LTOAException
*/
public void wordAsDatabase(String wordFilePath, String RecordID) throws LTOAException {
Connection conn = null;
PreparedStatement pstmt = null;
PoolingDataSource pool = null;
File file = null;
String sql = "";
try {
sql = " UPDATE Document_File SET FileBody = ? WHERE RecordID = ? ";
pool = new PoolingDataSource();
conn = pool.getConnection();
file = new File(wordFilePath);
InputStream is = new FileInputStream(file);
byte[] blobByte = new byte[is.available()];
is.read(blobByte);
is.close();
pstmt = conn.prepareStatement(sql);
pstmt.setBinaryStream(1,(new ByteArrayInputStream(blobByte)), blobByte.length);
pstmt.setString(2, RecordID);
pstmt.executeUpdate();
} catch (Exception ex) {
log.error("错误- 表Document_File 更新数据发生意外错误");
log.error("原因- " + ex.getMessage());
throw new LTOAException(LTOAException.ERR_UNKNOWN,
"表Document_File插入数据发生意外错误("
+ this.getClass().getName() + ".wordAsDatabase())", ex);
} finally {
pool.closePrepStmt(pstmt);
pool.closeConnection(conn);
}
}
/**
* 得到一个唯一的编号
* @return 编号
*/
public String getRecordID() {
String sRecordID = "";
java.util.Date dt=new java.util.Date();
long lg=dt.getTime();
Long ld=new Long(lg);
sRecordID =ld.toString();
return sRecordID;
}
/**
* 得到保存word和html需要的路径
* @param systemType 模块类型givInfo, sw, fw
* @param fileType 文件类型doc, html
* @param recID 文件编号
* @return 路径
*/
public String getWordFilePath(String systemType, String fileType, String recID) {
String filePath = "";
File file = new File(this.getClass().getResource("/").getPath());
filePath = file.getPath().substring(0, file.getPath().length() - 15);
if(systemType.equals IgnoreCase("govInfo")) {
if(fileType.equalsIgnoreCase("doc"))
filePath = filePath + "/uploadFiles/govInfo/document/" + recID + ".doc";
else if(fileType.equalsIgnoreCase("htm"))
filePath = filePath + "/HTML/govInfo/" + recID + ".htm";
} else if(systemType.equalsIgnoreCase("sw")){
if(fileType.equalsIgnoreCase("doc"))
filePath = filePath + "/uploadFiles/sw/document/" + recID + ".doc";
else if(fileType.equalsIgnoreCase("htm"))
filePath = filePath + "/HTML/sw/" + recID + ".htm";
} else if(systemType.equalsIgnoreCase("fw")) {
if(fileType.equals IgnoreCase("doc"))
filePath = filePath + "/uploadFiles/fw/document/" + recID + ".doc";
else if(fileType.equalsIgnoreCase("htm"))
filePath = filePath + "/HTML/fw/" + recID + ".htm";
}
return filePath;
}
}
如何能让Java生成复杂Word文档(1)
先用office2003或者2007编辑好word的样式,然后另存为xml,将xml翻译为FreeMarker 模板,最后用java来解析FreeMarker模板并输出Doc。经测试这样方式生成的word文档完全符合office标准,样式、内容控制非常便利,打印也不会变形,生成的文档和office中编辑文档完全一样。 AD:客户要求用程序生成标准的word文档,要能打印,而且不能变形,以前用过很多解决方案,都在客户严格要求下牺牲的无比惨烈。 POI读word文档还行,写文档实在不敢恭维,复杂的样式很难控制不提,想象一下一个20多页,嵌套很多表格和图像的word文档靠POI来写代码输出,对程序员来说比去山西挖煤还惨,况且文档格式还经常变化。 iText操作Excel还行。对于复杂的大量的word也是噩梦。 直接通过JSP输出样式基本不达标,而且要打印出来就更是惨不忍睹。 Word从2003开始支持XML格式,用XML还做就很简单了。 大致的思路是先用office2003或者2007编辑好word的样式,然后另存为xml,将xml 翻译为FreeMarker模板,最后用java来解析FreeMarker模板并输出Doc。经测试这样方式生成的word文档完全符合office标准,样式、内容控制非常便利,打印也不会变形,生成的文档和office中编辑文档完全一样。 看看实际效果 首先用office【版本要2003以上,以下的不支持xml格式】编辑文档的样式,图中红线的部分就是我要输出的部分:
将编辑好的文档另存为XML 再用Firstobject free XML editor将xml中我们需要填数据的地方打上FreeMarker标记
学习Java to Html
JavaToHtml 为了方便在blog中粘贴源代码,特意找了这方面的工具(本来琢磨自己写,可惜能力有限,再次受打击了~~~) JavaToHtml开源,Eclipse Plugin 大家都知道读源代码很累,读乱七八糟的源代码那就想吐了,所以格式化源代码还是很有必要的,不信看看下面的例子。 格式化后的漂亮效果: import java.util.Vector; public class Stack
} } 下面是原版的: import java.util.Vector; public class Stack
java解析FSN文件
package action; import java.util.ArrayList; import tools.FsnTools; import bean.FsnBody; import bean.FsnModel; public class FsnReaderAction { public final static int intstep=2; //Uint16字节长度 public final static int stringstep=4; //Uint32字节长度 public final static int fsnHeadLengh=32;//fsn文件头字节长度 public final static int fsnPerBodyNoImg=100; //fsn文件体每条记录,不包括图像信息的字节长度 public final static int fsnPerBodyImg=1644; //fsn文件体每条记录,包括图像信息的字节长度 public int filePos=0; //fsn文件字节流当前指针位置 public FsnModel fm; //本实例解析的FsnMedel对象 public String fsnFilePath ;//FSN文件的存储完整路径,包括文件名 public FsnReaderAction(String filePath){ this.fsnFilePath=filePath; } public FsnModel readFsnFile() throws Exception { // FsnModel ret=null; try{ this.fm=new FsnModel(this.fsnFilePath); //hzyimport 把文件转成字节流数组 byte[] fsnbytes =FsnTools.toByteArray(this.fsnFilePath); this.fm.setSize(fsnbytes.length); System.out.println("File Lengh: "+fsnbytes.length); // 读取头文件 setHead(fsnbytes); long counter = this.fm.getCounter(); // 冠字号信息条数// System.out.println("this.fm.getHeadString()[2]="+this.fm.getHeadStr ing()[2]); int size = this.fm.getHeadString()[2] != 0x2D ? fsnPerBodyImg: fsnPerBodyNoImg; // System.out.println("this.fm.getHeadString()[2] ="+this.fm.getHeadString()[2] ); // System.out.println("counter ="+counter); // System.out.println("size="+size); // System.out.println("counter =* size"+counter * size); // System.out.println("fsnHeadLengh="+fsnHeadLengh);
Java生产WORD并下载到本地
1.为你的项目导入freeMarker包 我的项目是依靠maven来维护依赖的,所以引入很方便,只需要在pom文件中加入下面这个依赖就好 [html]view plain copy 1.
5.将文件已utf-8编码保存,另存为为.ftl,找不到该格式直接改文件后缀名就行,这样得到test.ftl 6.前台触发事件 我的项目是基于SpringMVC的,所以前台触发只需要在view层的文件里加个按钮事件即可,直接上代码 [javascript]view plain copy 1.function generateMillCertificate(id) {//点击下载按钮触发的事件 2. window.location.href = '../deliveryOrder/exportMillCertificate?id=' + id; 3. } 7.后台生成文件,并返回给客户的浏览器 这里又分为两步 a.controller层接收请求,根据参数拼凑数据,放在map中 [java]view plain copy 1./*** 2. * 导出Word材质单 3. * 4. * @return 5. * @throws Exception 6. */ 7.@RequestMapping(value = "exportMillCertificate", method = RequestMethod. GET) 8.@ResponseBody 9.public void exportMillCertificate(HttpServletRequest request, 10. HttpServletResponse response) throws Exception { 11.//获得数据,系统相关,就不展示了 12. Map
将图片转成base64字符串并在JSP页面显示的Java代码
*本事例主要讲了如下几点: * 1:将图片转换为BASE64加密字符串. * 2:将图片流转换为BASE64加密字符串. * 3:将BASE64加密字符串转换为图片. * 4:在jsp文件中以引用的方式和BASE64加密字符串方式展示图片. 首先看工具类: import ; import ; import ; import ; import ; import ; import ; import ; import ; /** * @author IluckySi 1
* @since */ public class ImageUtil { private static BASE64Encoder encoder = new ; private static BASE64Decoder decoder = new ; /** * 将图片转换为BASE64加密字符串. * @param imagePath 图片路径. * @param format 图片格式. * @return */ public String convertImageToByte(String imagePath, String format) { File file = new File(imagePath); BufferedImage bi = null; ByteArrayOutputStream baos = null; String result = null;
try { bi = ImageIO.read(file); baos = new ByteArrayOutputStream(); ImageIO.write(bi, format == null ? "jpg" : format, baos); byte[] bytes = baos.toByteArray(); result = encoder.encodeBuffer(bytes).trim(); "将图片转换为BASE64加密字符串成功!"); } catch (IOException e) { "将图片转换为BASE64加密字符串失败: " + e); } finally { try { if(baos != null) { baos.close(); baos = null; } } catch (Exception e) { "关闭文件流发生异常: " + e); } 3
(完整word版)JAVA代码规范详细版
JAVA代码规范 本Java代码规范以SUN的标准Java代码规范为基础,为适应我们公司的实际需要,可能会做一些修改。本文档中没有说明的地方,请参看SUN Java标准代码规范。如果两边有冲突,以SUN Java标准为准。 1. 标识符命名规范 1.1 概述 标识符的命名力求做到统一、达意和简洁。 1.1.1 统一 统一是指,对于同一个概念,在程序中用同一种表示方法,比如对于供应商,既可以用supplier,也可以用provider,但是我们只能选定一个使用,至少在一个Java项目中保持统一。统一是作为重要的,如果对同一概念有不同的表示方法,会使代码混乱难以理解。即使不能取得好的名称,但是只要统一,阅读起来也不会太困难,因为阅读者只要理解一次。 1.1.2 达意 达意是指,标识符能准确的表达出它所代表的意义,比如:newSupplier, OrderPaymentGatewayService等;而supplier1, service2,idtts等则不是好的命名方式。准确有两成含义,一是正确,而是丰富。如果给一个代表供应商的变量起名是order,显然没有正确表达。同样的,supplier1, 远没有targetSupplier意义丰富。 1.1.3 简洁 简洁是指,在统一和达意的前提下,用尽量少的标识符。如果不能达意,宁愿不要简洁。比如:theOrderNameOfTheTargetSupplierWhichIsTransfered 太长,transferedTargetSupplierOrderName则较好,但是transTgtSplOrdNm就不好了。省略元音的缩写方式不要使用,我们的英语往往还没有好到看得懂奇怪的缩写。 1.1.4 骆驼法则 Java中,除了包名,静态常量等特殊情况,大部分情况下标识符使用骆驼法则,即单词之间不使用特殊符号分割,而是通过首字母大写来分割。比如: supplierName, addNewContract,而不是supplier_name, add_new_contract。
word域代码转换html丢失解决办法
. Word转html存在域代码丢失。 Aspose ,jacob,poi都无法解决 在使用jocob转换成html时域代码会被包裹 可以统一提取出来转换成latex ,latex转换成图片,解决word域代码丢失问题 private void processFormula(List