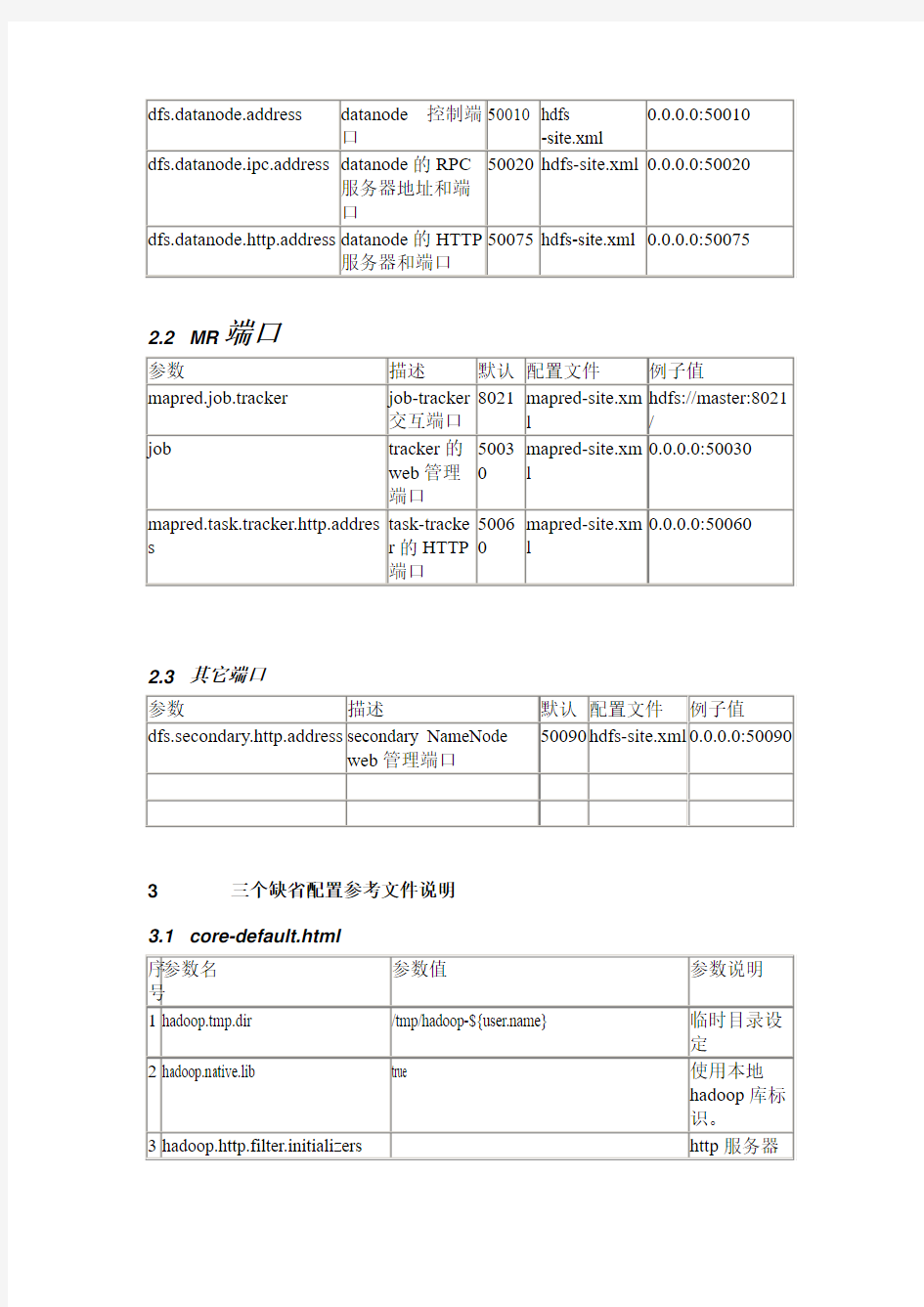
hadoop三个配置文件的参数含义说明

Hadoop集群MYSQL的安装指南
前言 本篇主要介绍在大数据应用中比较常用的一款软件Mysql,我相信这款软件不紧紧在大数据分析的时候会用到,现在作为开源系统中的比较优秀的一款关系型开源数据库已经被很多互联网公司所使用,而且现在正慢慢的壮大中。 在大数据分析的系统中作为离线分析计算中比较普遍的两种处理思路就是:1、写程序利用 mapper-Reducer的算法平台进行分析;2、利用Hive组件进行书写Hive SQL进行分析。 第二种方法用到的Hive组件存储元数据最常用的关系型数据库最常用的就是开源的MySQL了,这也是本篇最主要讲解的。 技术准备 VMware虚拟机、CentOS 6.8 64 bit、SecureCRT、VSFTP、Notepad++ 软件下载 我们需要从Mysql官网上选择相应版本的安装介质,官网地址如下: MySQL下载地址:https://www.360docs.net/doc/f210164460.html,/downloads/
默认进入的页面是企业版,这个是要收费的,这里一般建议选择社区开源版本,土豪公司除外。
然后选择相应的版本,这里我们选择通用的Server版本,点击Download下载按钮,将安装包下载到本地。 下载完成,上传至我们要安装的系统目录。 这里,需要提示下,一般在Linux系统中大型公用的软件安装在/opt目录中,比如上图我已经安装了Sql Server On linux,默认就安装在这个目录中,这里我手动创建了mysql目录。 将我们下载的MySQL安装介质,上传至该目录下。
安装流程 1、首先解压当前压缩包,进入目录 cd /opt/mysql/ tar -xf mysql-5.7.16-1.el7.x86_64.rpm-bundle.tar 这样,我们就完成了这个安装包的解压。 2、创建MySql超级管理用户 这里我们需要单独创建一个mySQL的用户,作为MySQL的超级管理员用户,这里也方便我们以后的管理。 groupaddmysql 添加用户组 useradd -g mysqlmysql 添加用户 id mysql 查看用户信息。
Hadoop全分布式安装配置
Hadoop全分布式安装配置 一实验目的: 1、了解Hadoop的体系结构、组成; 2、熟练掌握Hadoop的配置、安装方法; 3、通过安装Hadoop了解Hadoop的原理; 二实验内容: 集群包含三个安装了Linux操作系统的节点。将其中的一个节点作为NameNode,另外两个节点作为DataNode,安装之前先利用ping命令,确认三个节点之间的网络互通,即可以互相ping通。假设三个节点IP地址如下,实际的集群节点IP地址可以不同。 NameNode:192.168.198.2 主机名:master DataNode1:192.168.198.3 主机名:slaver1 DataNode2:192.168.198.4 主机名:slaver2 三实验环境: 在申请的虚拟服务器上安装了VMWare Workstation虚拟3个Ubuntu14.04系统。 四安装配置过程: 1、安装Vmware WorkStation软件 下载安装Vmware WorkStation12.0软件。 2、在虚拟机上安装linux操作系统 在Vmware WorkStation12.0中创建一个Ubuntu14.04系统。拷贝镜像文件复制出三个系统。分别为master、slaver1、slaver2。 3、配置hosts、hostname文件
在三台机器上配置相同的hosts文件 (1)修改hosts sudo gedit /etc/hosts 192.168.198.200 master 192.168.198.199 slave1 192.168.198.198 slave2 (2)修改hostname sudo gedit /etc/hostname 4、配置ip地址 配置ip:sudo gedit /etc/network/interfaces slave2 auto eth0 iface eth0 inet static address 192.168.198.198 gateway 192.168.198.107 netmask 255.255.255.0 slave1 auto eth0 iface eth0 inet static address 192.168.198.199 gateway 192.168.198.107 netmask 255.255.255.0 master auto eth0 iface eth0 inet static address 192.168.198.200 gateway 192.168.198.107 netmask 255.255.255.0
hadoop集群完整配置过程详细笔记
本文为笔者安装配置过程中详细记录的笔记 1.下载hadoop hadoop-2.7.1.tar.gz hadoop-2.7.1-src.tar.gz 64位linux需要重新编译本地库 2.准备环境 Centos6.4 64位,3台 hadoop0 192.168.1.151namenode hadoop1 192.168.1.152 datanode1 Hadoop2 192.168.1.153 datanode2 1)安装虚拟机: vmware WorkStation 10,创建三台虚拟机,创建时,直接建立用户ha,密码111111.同时为root密码。网卡使用桥接方式。 安装盘 、 2). 配置IP.创建完成后,设置IP,可以直接进入桌面,在如下菜单下配置IP,配置好后,PING 确认好用。 3)更改三台机器主机名 切换到root用户,更改主机名。 [ha@hadoop0 ~]$ su - root Password: [root@hadoop0 ~]# hostname hadoop0 [root@hadoop0 ~]# vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=hadoop0 以上两步后重启服务器。三台机器都需要修改。 4)创建hadoop用户 由于在创建虚拟机时,已自动创建,可以省略。否则用命令创建。
5)修改hosts文件 [root@hadoop0 ~]# vi /etc/hosts 127.0.0.1 localhostlocalhost.localdomain localhost4 localhost4.localdomain4 ::1localhostlocalhost.localdomain localhost6 localhost6.localdomain6 192.168.1.151 hadoop0 192.168.1.152 hadoop1 192.168.1.153 hadoop2 此步骤需要三台机器都修改。 3.建立三台机器间,无密码SSH登录。 1)三台机器生成密钥,使用hadoop用户操作 [root@hadoop0 ~]# su– ha [ha@hadoop0 ~]$ ssh -keygen -t rsa 所有选项直接回车,完成。 以上步骤三台机器上都做。 2)在namenode机器上,导入公钥到本机认证文件 [ha@hadoop0 ~]$ cat ~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys 3)将hadoop1和hadoop2打开/home/ha/.ssh/ id_rsa.pub文件中的内容都拷贝到hadoop0的/home/ha /.ssh/authorized_keys文件中。如下: 4)将namenode上的/home/ha /.ssh/authorized_keys文件拷贝到hadoop1和hadoop2的/home/ha/.ssh文件夹下。同时在三台机器上将authorized_keys授予600权限。 [ha@hadoop1 .ssh]$ chmod 600 authorized_keys 5)验证任意两台机器是否可以无密码登录,如下状态说明成功,第一次访问时需要输入密码。此后即不再需要。 [ha@hadoop0 ~]$ ssh hadoop1 Last login: Tue Aug 11 00:58:10 2015 from hadoop2 4.安装JDK1.7 1)下载JDK(32或64位),解压 [ha@hadoop0 tools]$ tar -zxvf jdk-7u67-linux-x64.tar.gz 2)设置环境变量(修改/etx/profile文件), export JAVA_HOME=/usr/jdk1.7.0_67 export CLASSPATH=:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin 3)使环境变量生效,然后验证JDK是否安装成功。
hadoop3安装和配置
hadoop3.0.0安装和配置1.安装环境 硬件:虚拟机 操作系统:Centos 7 64位 IP:192.168.0.101 主机名:dbp JDK:jdk-8u144-linux-x64.tar.gz Hadoop:hadoop-3.0.0-beta1.tar.gz 2.关闭防火墙并配置主机名 [root@dbp]#systemctl stop firewalld #临时关闭防火墙 [root@dbp]#systemctl disable firewalld #关闭防火墙开机自启动 [root@dbp]#hostnamectl set-hostname dbp 同时修改/etc/hosts和/etc/sysconfig/network配置信息 3.配置SSH无密码登陆 [root@dbp]# ssh-keygen -t rsa #直接回车 [root@dbp]# ll ~/.ssh [root@dbp .ssh]# cp id_rsa.pub authorized_keys [root@dbp .ssh]# ssh localhost #验证不需要输入密码即可登录
4.安装JDK 1、准备jdk到指定目录 2、解压 [root@dbp software]# tar–xzvf jdk-8u144-linux-x64.tar.gz [root@dbp software]# mv jdk1.8.0_144/usr/local/jdk #重命名4、设置环境变量 [root@dbp software]# vim ~/.bash_profile 5、使环境变量生效并验证 5.安装Hadoop3.0.0 1、准备hadoop到指定目录 2、解压
hadoop安装简要过程和相关配置文件
Hadoop安装简要过程及配置文件 1、机器准备 ①、Linux版操作系统centos 6.x ②、修改主机名,方便配置过程中记忆。修改文件为: /etc/sysconfig/network 修改其中的HOSTNAME即可 ③、配置局域网内,主机名与对应ip,并且其中集群中所有的机器的文件相同,修改文件为 /etc/hosts 格式为: 10.1.20.241 namenode 10.1.20.242 datanode1 10.1.20.243 datanode2 2、环境准备 ①、配置ssh免密码登陆,将集群中master节点生成ssh密码文件。具体方法: 1)、ssh-keygen -t rsa 一直回车即可,将会生成一份 ~/.ssh/ 文件夹,其中id_rsa为私钥文件 id_rsa.pub公钥文件。 2)、将公钥文件追加到authorized_keys中然后再上传到其他slave节点上 追加文件: cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 上传文件: scp ~/.ssh/authorized_keys root@dananode:~/.ssh/ 3)、测试是否可以免密码登陆:ssh 主机名或局域网ip ②、配置JDK ③、创建hadoop用户 groupadd hadoop useradd hadoop -g hadoop 4)、同步时间 ntpdate https://www.360docs.net/doc/f210164460.html, 5)、关闭防火墙 service iptables stop 3、安装cdh5 进入目录/data/tools/ (个人习惯的软件存储目录,你可以自己随便选择); wget "https://www.360docs.net/doc/f210164460.html,/cdh5/one-click-install/redhat/ 6/x86_64/cloudera-cdh-5-0.x86_64.rpm" yum --nogpgcheck localinstall cloudera-cdh-5-0.x86_64.rpm 添加cloudera仓库验证: rpm --importhttps://www.360docs.net/doc/f210164460.html,/cdh5/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera
Hadoop的安装与配置及示例wordcount的运行
Hadoop的安装与配置及示例程序 wordcount的运行 目录 前言 (1) 1 机器配置说明 (2) 2 查看机器间是否能相互通信(使用ping命令) (2) 3 ssh设置及关闭防火墙 (2) 1)fedora装好后默认启动sshd服务,如果不确定的话可以查一下[garon@hzau01 ~]$ service sshd status (3) 2)关闭防火墙(NameNode和DataNode都必须关闭) (3) 4 安装jdk1.6(集群中机子都一样) (3) 5 安装hadoop(集群中机子都一样) (4) 6 配置hadoop (4) 1)配置JA V A环境 (4) 2)配置conf/core-site.xml、conf/hdfs-site.xml、conf/mapred-site.xml文件 (5) 3)将NameNode上完整的hadoop拷贝到DataNode上,可先将其进行压缩后直接scp 过去或是用盘拷贝过去 (7) 4)配置NameNode上的conf/masters和conf/slaves (7) 7 运行hadoop (7) 1)格式化文件系统 (7) 2)启动hadoop (7) 3)用jps命令查看进程,NameNode上的结果如下: (8) 4)查看集群状态 (8) 8 运行Wordcount.java程序 (8) 1)先在本地磁盘上建立两个文件f1和f2 (8) 2)在hdfs上建立一个input目录 (9) 3)将f1和f2拷贝到hdfs的input目录下 (9) 4)查看hdfs上有没有f1,f2 (9) 5)执行wordcount(确保hdfs上没有output目录) (9) 6)运行完成,查看结果 (9) 前言 最近在学习Hadoop,文章只是记录我的学习过程,难免有不足甚至是错误之处,请大家谅解并指正!Hadoop版本是最新发布的Hadoop-0.21.0版本,其中一些Hadoop命令已发生变化,为方便以后学习,这里均采用最新命令。具体安装及配置过程如下:
Hadoop安装手册_Hadoop2.0-v1.6
Hadoop2.0安装手册目录 第1章安装VMWare Workstation 10 (4) 第2章VMware 10安装CentOS 6 (10) 2.1 CentOS系统安装 (10) 2.2 安装中的关键问题 (13) 2.3 克隆HadoopSlave (17) 2.4 windows中安装SSH Secure Shell Client传输软件 (19) 第3章CentOS 6安装Hadoop (23) 3.1 启动两台虚拟客户机 (23) 3.2 Linux系统配置 (24) 3.2.1软件包和数据包说明 (25) 3.2.2配置时钟同步 (25) 3.2.3配置主机名 (26) 3.2.5使用setup 命令配置网络环境 (27) 3.2.6关闭防火墙 (29) 3.2.7配置hosts列表 (30) 3.2.8安装JDK (31) 3.2.9免密钥登录配置 (32) 3.3 Hadoop配置部署 (34) 3.3.1 Hadoop安装包解压 (34) 3.3.2配置环境变量hadoop-env.sh (34) 3.3.3配置环境变量yarn-env.sh (35) 3.3.4配置核心组件core-site.xml (35) 3.3.5配置文件系统hdfs-site.xml (35) 3.3.6配置文件系统yarn-site.xml (36) 3.3.7配置计算框架mapred-site.xml (37) 3.3.8 在master节点配置slaves文件 (37) 3.3.9 复制到从节点 (37) 3.4 启动Hadoop集群 (37) 3.4.1 配置Hadoop启动的系统环境变量 (38) 3.4.2 创建数据目录 (38) 3.4.3启动Hadoop集群 (38) 第4章安装部署Hive (44) 4.1 解压并安装Hive (44) 4.2 安装配置MySQL (45) 4.3 配置Hive (45) 4.4 启动并验证Hive安装 (46) 第5章安装部署HBase (49) 5.1 解压并安装HBase (49) 5.2 配置HBase (50) 5.2.1 修改环境变量hbase-env.sh (50) 5.2.2 修改配置文件hbase-site.xml (50) 5.2.3 设置regionservers (51)
Hadoop安装部署手册
1安装环境介绍1.1软件环境 1)CentOS6.5x64 2)Jdk1.7x64 3)Hadoop2.6.2x64 4)Hbase-0.98.9 5)Zookeeper-3.4.6 1.2集群环境 集群中包括3个节点:1个Master,2个Slave 2安装前的准备 2.1下载JDK 2.2下载Hadoop 2.3下载Zookeeper 2.4下载Hbase 3开始安装 3.1CentOS安装配置 1)安装3台CentOS6.5x64(使用BasicServer模式,其他使用默认配置,安装过程略) 2)Master.Hadoop配置 a) 配置网络
保存,退出(esc+:wq+enter),使配置生效 b) 配置主机名 修改为: c) 配置hosts 修改为: 修改为: 在最后增加如下内容 以上调整,需要重启系统才能生效 g) 配置用户 新建hadoop用户和组,设置hadoop用户密码
id_rsa 和id_rsa.pub ,默认存储在 "/home/hadoop/.ssh"目录下。 a) 把id_rsa.pub 追加到授权的key 里面去 b) 修改 .ssh 目录的权限以及 authorized_keys 的权限 c) 用root 用户登录服务器修改SSH 配置文件"/etc/ssh/sshd_config" 的下列内容 3) Slave1.Hadoop 、Slave1.Hadoop 配置 相同的方式配置Slave1和Slave2的IP 地址,主机名和hosts 文件,新建hadoop 用户和组及用户密码等等操作 3.2 无密码登陆配置 1) 配置Master 无密码登录所有Slave a) 使用hadoop 用户登陆Master.Hadoop b) 把公钥复制所有的Slave 机器上。使用下面的命令格式进行复制公钥 2) 配置Slave 无密码登录Master a) 使用hadoop 用户登陆Slave b) 把公钥复制Master 机器上。使用下面的命令格式进行复制公钥
Hadoop系统操作安装手册
基于网络音乐云Hadoop系统及MapReduce模型管理平台 V1.0 操作手册 北京华康嘉合科技有限公司
目录 一、服务器基础配置 (2) 二、实现Linux的ssh无密码验证配置 (2) 三、修改Linux机器名 (2) 四、安装JDK,并配置环境变量 (3) 五、安装Hadoop,并修改文件的配置 (3) 六、创建Hadoop备份的目录 (5) 七、将Hadoop的bin加入环境变量 (6) 八、修改部分运行文件的权限 (6) 九、格式化Hadoop,启动Hadoop (6) 十、新加datanode的安装步骤 (7)
一、服务器基础配置 首先,需要将服务器IP进行固定。 本文采用主机IP:10.0.0.30,分机:10.0.0.31; 主机名称:namenode,分机名称:datanode; 本文红色字体为终端命令或需修改添加部分。 二、实现Linux的ssh无密码验证配置 1.生成密钥:在namenode(主机)上,使用终端输入ssh-keygen –t rsa,一直回车,生成密钥; 2.在namenode上使用命令cd /root/.ssh进入文件夹,使用ls可查 看两个文件:id_rsa.pub,id_rsa; 3.然后执行cp id_rsa.pub authorized_keys;使用ssh localhost验证是 否成功,第一次需要输入登录密码,以后就不需要输入密码; 4.拷贝密钥: [root@namenode .ssh] #scp authorized_keys 10.0.0.31:/root/.ssh 这是拷贝命令,将namenode上的authorized_keys 拷贝到datanode的/root/.ssh 上; 5.验证是否成功,在namenode上输入ssh 10.0.0.31,第一次连接需 要输入yes,就可以连接到datanode上了,无需使用密码即为成功;此时,系统已登录至datanode下,不在namenode上了,可输入命令exit返回至namenode; 三、修改Linux机器名 1.查看主机名: 在命令行输入:hostname [root@namenode ~]# hostname namenode//这是你的主机名。 2.修改机器名 执行cd /etc/sysconfig ,进如sysconfig目录下 执行vi network,修改network文件(文件修改方法,键盘点击Insert键进入输入模式,修改好文件后,按Esc键退出输入模式,直接输入:w进行文件保存,:q退出编辑模式;也可在文件夹内选择需修改文件直接打开进行文件修改) NETWORKING=yes HOSTNAME=namenode(修改成你需要的)
Hadoop详细安装配置过程
1.下载并安装安装ssh sudo apt-get install openssh-server openssh-client 3.搭建vsftpd #sudo apt-get update #sudo apt-get install vsftpd 配置参考的开始、关闭和重启 $sudo /etc/vsftpd start #开始 $sudo /etc/vsftpd stop #关闭 $sudo /etc/vsftpd restart #重启 4.安装 sudo chown -R hadoop:hadoop /opt cp /soft/ /opt sudo vi /etc/profile alias untar='tar -zxvf' sudo source /etc/profile source /etc/profile untar jdk* 环境变量配置 # vi /etc/profile ●在profile文件最后加上 # set java environment export JAVA_HOME=/opt/ export CLASSPATH=.:$JAVA_HOME/lib/:$JAVA_HOME/lib/ export PATH=$JAVA_HOME/bin:$PATH 配置完成后,保存退出。 ●不重启,更新命令 #source /etc/profile ●测试是否安装成功 # Java –version 其他问题: 出现unable to resolve host 解决方法 参考 开机时停在Starting sendmail 不动了的解决方案 参考安装软件时出现E: Unable to locate package vsftpd 参考vi/vim 使用方法讲解 参考分类: Hadoop
hadoop环境配置入门教程
ubuntu 下安装配置hadoop 1.0.4 第一次搞hadoop,折腾我2天,功夫不负有心人,终于搞好了,现在来分享下, 我的环境 操作系统:wmv虚拟机中的ubuntu12.04 hadoop版本:hadoop-1.0.4(听说是稳定版就下了) eclipse版本:eclipse-jee-indigo-SR2-win32 1.先安装好jdk,然后配置好jdk的环境变量,在这里我就不累赘了!网上多的是 2.安装ssh这个也不用说了 2.把hadoop-1.0.4.tar.gz拖到虚拟机中,解压,比如: /home/wys/Documents/hadoop-1.0.4/ (有的还单独建了个用户,为了舍去不必要的麻烦我都是用root用户来操作的) 3.修改hadoop-1.0.4/conf 下面的core-site.xml文件,如下:
192.168.116.128这个是虚拟机中ubuntu的ip,听说用localhost,127.0.0.1都不行,我没试过,直接写上ip地址了 tmp是预先创建的一个目录 4.修改hadoop-env.sh 把export JAVA_HOME=xxxxxx 这行的#号去掉,写上jdk的目录路径 5.修改hdfs-site.xml如下:
Hadoop安装配置超详细步骤
Hadoop的安装 1、实现linux的ssh无密码验证配置. 2、修改linux的机器名,并配置/etc/hosts 3、在linux下安装jdk,并配好环境变量 4、在windows下载hadoop 1.0.1,并修改hadoop-env.sh,core-site.xml, hdfs-site.xml, mapred-site.xml,masters,slaves文件的配置 5、创建一个给hadoop备份的文件。 6、把hadoop的bin加入到环境变量 7、修改部分运行文件的权限 8、格式化hadoop,启动hadoop 注意:这个顺序并不是一个写死的顺序,就得按照这个来。如果你知道原理,可以打乱顺序来操作,比如1、2、3,先哪个后哪个,都没问题,但是有些步骤还是得依靠一些操作完成了才能进行,新手建议按照顺序来。
一、实现linux的ssh无密码验证配置 (1)配置理由和原理 Hadoop需要使用SSH协议,namenode将使用SSH协议启动namenode和datanode进程,(datanode向namenode传递心跳信息可能也是使用SSH协议,这是我认为的,还没有做深入了解)。大概意思是,namenode 和datanode之间发命令是靠ssh来发的,发命令肯定是在运行的时候发,发的时候肯定不希望发一次就弹出个框说:有一台机器连接我,让他连吗。所以就要求后台namenode和datanode 无障碍的进行通信。 以namenode到datanode为例子:namenode作为客户端,要实现无密码公钥认证,连接到服务端datanode上时,需要在namenode上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到datanode上。当namenode通过ssh连接datanode时,datanode就会生成一个随机数并用namenode的公钥对随机数进行加密,并发送给namenode。namenode收到加密数之后再用私钥进行解密,并将解密数回传给datanode,datanode确认解密数无误之后就允许namenode 进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端namenode公钥复制到datanode上。
ubuntu下hadoop配置指南
ubuntu下hadoop配置指南 目录 1.实验目的 2.实验内容(hadoop伪分布式与分布式集群环境配置) 3.运行wordcount词频统计程序 一 . 实验目的 通过学习和使用开源的Apache Hadoop工具,亲身实践云计算环境下对海量数据的处理,理解并掌握分布式的编程模式MapReduce,并能够运用MapReduce编程模式完成特定的分布式应用程序设计,用于处理实际的海量数据问题。 二 . 实验内容 1.实验环境搭建 1.1. 前期准备 操作系统:Linux Ubuntu 10.04 Java开发环境:需要JDK 6及以上,Ubuntu 10.04默认安装的OpenJDK可直接使用。不过我使用的是sun的jdk,从官方网站上下载,具体可以参考博客:ubuntu下安装JDK 并配置java环境 Hadoop开发包:试过了hadoop的各种版本,包括0.20.1,0.20.203.0和0.21.0,三个版本都可以配置成功,但是只有0.20.1这个版本的eclipse插件是可用的,其他版本的eclipse插件都出现各种问题,因此当前使用版本为hadoop-0.20.1 Eclipse:与hadoop-0.20.1的eclipse插件兼容的只有一些低版本的eclipse,这里使用eclipse-3.5.2。 1.2. 在单节点(伪分布式)环境下运行Hadoop (1)添加hadoop用户并赋予sudo权限(可选)
为hadoop应用添加一个单独的用户,这样可以把安装过程和同一台机器上的其他软件分离开来,使得逻辑更加清晰。可以参考博客:Ubuntu-10.10如何给用户添加sudo 权限。 (2)配置SSH 无论是在单机环境还是多机环境中,Hadoop均采用SSH来访问各个节点的信息。在单机环境中,需要配置SSH 来使用户hadoop 能够访问localhost 的信息。首先需要安装openssh-server。 [sql]view plaincopyprint? 1. s udo apt-get install openssh-server 其次是配置SSH使得Hadoop应用能够实现无密码登录: [sql]view plaincopyprint? 1. s u - hadoop 2. s sh-keygen -trsa -P "" 3. c p ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys 第一条命令将当前用户切换为hadoop(如果当前用户就是hadoop,则无需输入),第二条命令将生成一个公钥和私钥对(即id_dsa和id_dsa.pub两个文件,位于~/.ssh文件夹下),第三条命令使得hadoop用户能够无需输入密码通过SSH访问localhost。这时可通过以下命令来验证安装是否成功(如果没有提示输入密码直接登录成功,则说明安装成功): [sql]view plaincopyprint? 1. s sh localhost (3)配置Hadoop Hadoop的配置文件都放在/hadoop/conf这个文件夹下面,主要是四个配置文件,分别是core-site.xml,hadoop-env.sh,hdsf-site.xml和mapred-site.xml。 修改conf/hadoop-‐env.sh,设置JAVA_HOME,在该文件中找到如下行,去掉前面的注释。
云计算实验Hadoop安装与配置
实验一:Hadoop安装与配置 实验目的: 熟悉Hadoop的安装与配置方法,能够检查hadoop的运行状态与日志内容,运行简单的wordcount实例。设置eclipse开发环境。 实验要求: 独立完成实验过程,记录实验的过程、结果以及遇到的问题及解决方法(截图等),以便完成实验检查工作。 实验过程: 1.在windows系统建立root账号,分配管理员权限,切换到root账号 2.打开virtualbox虚拟机:master与slave 3.修改windows的hosts文件(C:\WINDOWS\system32\drivers\etc),并进行连通性测 试。 4.分别添加hadoop配置文件 5.启动Hadoop 6.查看hadoop的日志 7.检查WEB管理界面 8.运行wordcount实例(操作HDFS文件系统,建立文件夹,添加文件) 9.设置eclipse开发环境,在其中运行wordcount实例 扩展练习: 修改master与slave的ip地址。将master地址设为192.168.56.X,其中X为桌号,slave地址设为192.168.56.X+1 参考资料: 1.Hadoop集群_第5期_Hadoop安装配置 2.Hadoop集群_第6期_WordCount运行详解 3.Hadoop集群_第7期_Eclipse开发环境设置 配置说明: 1利用xshell登录hadoop.master,利用xftp进行文件传输 2 将hosts文件拷贝到/etc/hosts 3 将core-site.xml,hdfs-site.xml,mapred-site.xml,masters和slaves拷贝到/usr/hadoop/conf 4 利用xshell登录slave.master,利用xftp进行上述文件传输
hadoop安装配置指南
Hadoop安装、配置指南 一、环境 1、软件版本 Hadoop:hadoop-0.20.2. Hive:hive-0.5.0 JDK:jdk1.6以上版本 2、配置的机器: 主机[服务器master]:192.168.10.121 hadoop13 从机[服务器slaves]:192.168.10.68 hadoop4 在本文中,在命令或 二、先决条件 1、配置host: 打开/etc/host文件,添加如下映射 192.168.10.121 hadoop13 hadoop13 192.168.10.68 hadoop4 hadoop4 2、配置SSH自动登陆 1)以ROOT用户,登陆到[服务器master]上执行,如下操作: ssh-keygen -t rsa //一路回车 cd ~/.ssh cat id_rsa.pub >> authorized_keys scp -r ~/.ssh [服务器slaves]:~/ 2)以ROOT用户,登陆到[服务器slaves]上执行,如下操作: scp -r ~/.ssh [服务器master]:~/ 3)测试SSH是否配置成功 在主服务器中执行如下命令:ssh [服务器master] ssh 192.168.10.68 成功显示结果: Last login: Thu Aug 26 14:11:27 2010 from https://www.360docs.net/doc/f210164460.html, 在从服务器中执行如下命令:ssh [服务器slaves] ssh 192.168.10.121 成功显示结果 Last login: Thu Aug 26 18:23:58 2010 from https://www.360docs.net/doc/f210164460.html, 三、安装hadoop
hadoop安装配置笔记
Hadoop安装配置教程 一、安装JDK1.8.0_40 1.网上下载好压缩包jdk-8u40-linux-x64.gz后,手动安装JDK1.8.0_40 sudo mkdir /usr/lib/jvm sudo tar zxvf jdk-8u40-linux-x64.gz -C /usr/lib/jvm 2.配准环境变量 sudo gedit /etc/profile 在profile文件最下面输入: #set Java Evironment export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_40 export CLASSPATH=".:$JAVA_HOME/lib:$CLASSPATH" export PATH="$JAVA_HOME/bin:$PATH" 3.验证JDK是否安装成功 java –version 如果验证成功,会出现如下信息: 1
否则会出现如下信息: 依次输入如下命令: sudo update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk1.8.0_40/bin/java 300 sudo update-alternatives --install /usr/bin/javac javac /usr/lib/jvm/jdk1.8.0_40/bin/javac 300 sudo update-alternatives --config java 此时再输入命令java –version即可看到所安装的JDK版本信息了。 二、配置SSH免密码登陆 假设电脑的当前目录是/home/hadoop,其中hadoop是用户名,主机名字是master,从机名字是slave1和slave2 1.确认已经连接网络,输入如下命令安装SSH: sudo apt-get install ssh 2.三台电脑下输入如下命令: 2
hadoop安装步骤
jdk-8u101-Linux-x64.gz (Java) hadoop-2.7.3.tar.gz (Hadoop 包)
1.安装虚拟机 在VM上安装下载好的Ubuntu的系统,具体过程自行百度。可以安装完一个以后克隆,但是本人安装过程中遇到很多问题,经常需要删除虚拟机,重新安装,而被克隆的虚拟机不能删除,所以本人就用了很长时候,一个一个安装。 一共3台虚拟机:分配情况和IP地址如下: (注:查看ip地址的指令 ifconfig) 安装虚拟机时可以设置静态IP,因为过程中常常遇到网络连接问 题,ifconfig找不到IPV4地址。当然,也可以不设,默认分配。 参 考https://www.360docs.net/doc/f210164460.html,/wolf_soul/article/details/46409323 192.168.159.132 master 192.168.159.134 node1
如下图所示: 同样地,在node1和node2机器上做相似的操作,分别更改主机名为node1和node2,然后把hosts文件更改和master一样。
3. 给hadoop用户添加权限,打开/etc/sudoers文件 sudo gedit /etc/sudoers 分别在各个主机上执行上述指令,看是否能与其他主机连通。出现下图代表能够连通:
如果都成功ping通,进行下面的操作。 5.安装jdk和配置环境变量 分别在每台主机上安装jdk,并配置环境变量。(嫌麻烦的前面可以安装完jdk后再克隆) 1)下载jdk安装包(自行百度),并将安装包拖入到虚拟机当中 2)通过cd命令进入到安装包的当前目录,利用如下命令进行解压缩。 3)利用如下命令将解压后的文件夹移到/usr目录下 4)配置环境变量 在末尾加上四行: [plain]view plain copy print? 1.#java 2.export JAVA_HOME=/usr/java 3.export JRE_HOME=/usr/java/jre
Centos7安装和配置hadoop2.7.3的流程和总结
CentOS7安装完整流程及总结 一、前言 配置一台master服务器,两台(或多台)slave服务器,master 可以无密码SSH登录到slave。卸载centos7自带的openjdk,通过SecureCRT的rz命令上传文件到服务器,解压安装JDK,解压安装Hadoop,配置hadoop的、、、文件。配置好之后启动hadoope服务,用jps命令查看状态。再运行hadoop自带的wordcount程序做一个Hello World实例。 二、准备工作 我的系统: windows 10 家庭普通中文版 cpu:intel i5 内存:8G 64位操作系统 需要准备的软件和文件(全部是64位安装包) 1.虚拟机:VMware 12 Pro 官网下载:选择DVD ISO(标准版) 及 以上,官网下载:下载地址:
version 三、安装过程 提示:先创建一台虚拟机,安装好centos7系统,使用VMware 的克隆功能,克隆另外两台虚拟机。这样可以节省时间。 虚拟机设置 (根当三台虚拟机安装好之后,获得它们的IP地址,并设置主机名,据实际IP地址和主机名)修改/etc/hosts文件内容为: 1、vi /etc/hosts命令修改,然后保存(vi的相关命令见引用来 源16)
2、more /etc/hosts查看 3、重启后,hosts生效。命令: reboot now SSH免密码登录 提示:我全程用的都是root用户,没有另外创建用户。每台服务器都生成公钥,再合并到authorized_keys。 1)CentOS默认没有启动ssh无密登录,去掉/etc/ssh/sshd_config 其中2行的注释,每台服务器都要设置, 2)#RSAAuthentication yes 3)#PubkeyAuthentication yes 4)输入命令,ssh-keygen -t rsa,生成key,都不输入密码,一直 回车,/root就会生成.ssh文件夹,每台服务器都要设置, 5)合并公钥到authorized_keys文件,在master服务器,进入
linux安装+hadoop配置
多机环境下的hadoop平台搭建过程说明 目录 一、引言 (1) 二、部署过程说明 (2) 2.1、部署阶段 (2) 2.1.1、安装ubuntu-14.04.2-desktop-amd64 (3) 2.1.2、安装jdk 第一步:在usr下面新建一个文件夹Java, 然后将jdk复制 过来 (13) 2.1.3、安装hadoop (14) 2.1.4、配置JAVA环境变量 (15) 2.1.5、创建ssh-key (16) 2.2、多机环境下的配置阶段 (18) 2.2.1、/etc/hosts文件的配置修改 (18) 2.2.2、多机的ssh-key配置 (19) 2.2.3、JAVA_HOME环境变量的配置 (19) 2.2.4、master和slaves文件的配置修改 (20) 2.2.5、core-site、mapred-site和hdfs-site文件的配置修改 (20) 2.2.6、复制master的配置文件到各个slaves (21) 2.3、启动运行阶段 (22) 2.3.1、格式化namenode (首次运行必需) (22) 2.3.2、启动hadoop (22) 三、参考资源 (24)
一、引言 多机环境下的hadoop平台搭建是通过在每台机器上部署 hadoop来构成一个hadoop的集群运行环境。 本文的环境搭建是在每台机器上安装双系统(windows和linux)或者单linux系统。本文hadoop部署之前下载了如下的程序:ubuntu-14.04.2-desktop-amd64、hadoop 2.7.0、jdk1.7.0 for linux。这些程序均可以从网上下载,其中jdk1.7.0 for linux (此处下载的是64位的)是直接从官网上下载。 本文的环境搭建选择了三台机器,其中一台机器要作为master,而另外两台机器要作为slaves。 二、部署过程说明 参考网上相关资源,本文所采取的部署过程分为三个阶段:单 机部署阶段、多机环境下的配置阶段、和启动运行阶段。单机部署 阶段主要是在每台机器上安装和配置unbuntu、JDK 和hadoop程序;第二阶段主要是进一步配置每台机器,以构成hadoop集群环境;第 三个阶段主要是启动hadoop。 各个阶段的详细操作步骤如下。 2.1、部署阶段 单机部署阶段主要是对集群环境中的每台机器,进行ubuntu、JDK和hadoop的安装与配置。该阶段要做的工作与单机版的hadoop 平台搭建类似。