应用统计学习题及答案
《应用统计学》练习试题及答案解析

《应用统计学》本科第一章导论一、单项选择题1.统计有三种涵义,其基础是( )。
(1)统计学 (2)统计话动 (3)统计方法 (4)统计资料2.一个统计总体( )。
(1)只能有个标志 (2)只能有一个指标 (3)可以有多个标志 (4)可以有多个指标3.若要了解某市工业生产设备情况,则总体单位是该市( )。
(1)每一个工业企业 (2)每一台设备 (3)每一台生产设备 (4)每一台工业生产设备4.某班学生数学考试成绩分刷为65分、71分、80分和87分,这四个数字是( )。
(1)指标 (2)标志 (3)变量 (4)标志值5.下列属于品质标志的是( )。
(1)工人年龄 (2)工人性别 (3)工人体重 (d)工人工资6.现要了解某机床厂的生产经营情况,该厂的产量和利润是( )。
(1)连续变量 (2)离散变量 ()3前者是连续变量,后者是离散变量 (4)前者是离散变量,后者是连续变量7.劳动生产率是( )。
(1)动态指标 (2)质量指标 (3)流量指标 (4)强度指标8.统计规律性主要是通过运用下述方法经整理、分析后得出的结论( )。
(1)统计分组法 (2)大量观察法 (3)练台指标法 (4)统计推断法9.( )是统计的基础功能。
(1)管理功能 (2)咨询功能 (3)信息功能 (4)监督功能10.( )是统计的根本准则,是统计的生命线。
(1)真实性 (2)及时件 (3)总体性 (4)连续性11.构成统计总体的必要条件是( )。
(1)差异性 (2)综合性 (3)社会性 (4)同质性12.数理统计学的奠基人是( )。
(1) 威廉·配第 (2)阿亭瓦尔 (3)凯特勒 (4)恩格尔13.统汁研究的数量必须是( )。
(1)抽象的量 (2)具体的量 (3)连续不断的量 (4)可直接相加量14.数量指标一般表现为( )。
(1)平均数 (2)相对数 (3)绝对数 (1)众数15.指标是说明总体特征的.标志则是说明总体单位特征的,所以( )。
应用统计学时间序列习题及答案

计算题:34323*22562584*22582603*22602502*2250254++++++++++=a = (人计算(1)第一季度该店平均每月商品销售额(2)第一季度平均销售员人数(3)第一季度平均每个销售员的销售额 (4)第一季度平均每月每个销售员的销售额 解:(1)商品销售额为时期总量指标时间序列,4月不属一季度,该数据无用3280350300++=a = (万元)(2) 销售员人数是时点总量指标时间序列,间断间隔相等,用首尾折半法,4月初人数相当于3月末人数,这个数据有用32424045240+++=b = (人) (3)32424045240280350300+++++==平均人数一季度销售额c = (万元/人) (4)3324240452403028350300c d =+++++==平均人数一季度月平均销售额 = (万元/人)要求:(1)根据表中资料 ,计算并填制表中空白栏指标(2)计算该地财政收入的这几年的年平均发展水平、年平均增长水平(水平法)和平均增长速度(几何平均法)(3)超过平均增长速度的年份有哪些年?解:注意平均时项数的确定,写计量单位,我以下省略了单位1430%02.193*430116430%02.193*4307%02.193*4304554301)26n 0010-=-=-='-=-=∆+++=+++=a a V V n a a n a a a a n n n ((3)填全表中各年的环比增长速度,和年平均增长速度进行比较即可4. 某地1980~1990年间(以1979年为基期:a0),地区生产总值以平均 每年25%的速度增长(平均增长速度),而1991~2000年间地区生产总值以平均每年30%的速度增长(平均增长速度),2001~2012年间地区生产总值以平均每年18%的速度增长,则1980~2012年间,该地区的生产总值平均每年的增长速度是多少?(重点:正确确定时间段长短)解:注意是以1979年为基期,经过33年发展到2012年,求这段时间的平均增长速度1%118*%130*%125133121011-=-='V V5. 某地1980年的人口是120万人,1981~2000年间人口平均增长率为1.2%,之后下降到1%,按此增长率到2008年人口会达到多少?如果要求到2012年人口控制在170万以内,则2008年以后人口的增长速度应控制在什么范围内? 解:1)2(%101*%2.101*)140812*******-='==V V V a a a a ((1)分别用最小平方法的普通法和简捷法配合直线方程,并预测2010年该企业产值 (2)比较两种方法得出的结果有无异同。
应用统计学课后习题参考答案

统计学课后习题答案+模拟题库2套选择题第一章统计学及其基本概念----(孙晨凯整理)一、单项选择题1. 推断统计学研究()。
(知识点:1.2 答案:D)A.统计数据收集的方法B.数据加工处理的方法C.统计数据显示的方法D.如何根据样本数据去推断总体数量特征的方法2. 在统计史上被认为有统计学之名而无统计学之实的学派是()。
(知识点:1.3 答案:D)A.数理统计学派B.政治算术学派C.社会统计学派D.国势学派3. 下列数据中哪个是定比尺度衡量的数据()。
(知识点:1.4 答案:B)A.性别B.年龄C.籍贯D.民族4. 统计对现象总体数量特征的认识是()。
(知识点:1.6 答案:C)A.从定性到定量B.从定量到定性C.从个体到总体D.从总体到个体5. 调查10个企业职工的工资水平情况,则统计总体是()。
(知识点:1.6 答案:C)A.10个企业B.10个企业职工的全部工资C.10个企业的全部职工D.10个企业每个职工的工资6. 从统计总体中抽取出来作为代表这一总体的、由部分个体组成的集合体是().(知识点:1.6 答案:A)A. 样本B. 总体单位C. 个体D. 全及总体7. 三名学生期末统计学考试成绩分别为80分、85分和92分,这三个数字是()。
(知识点:1.7 答案:D)A. 指标B. 标志C. 变量D. 标志值8. 以一、二、三等品来衡量产品质地的优劣,那么该产品等级是()。
(知识点:1.7 答案:A)A. 品质标志B. 数量标志C. 质量指标D. 数量指标9. ()表示事物的质的特征,是不能以数值表示的。
(知识点:1.7 答案:A)A. 品质标志B. 数量标志C. 质量指标D. 数量指标10. 在出勤率、废品量、劳动生产率、商品流通费用额和人均粮食生产量五个指标中,属于数量指标的有几个()。
(知识点:1.7 答案:B)A. 一个B. 二个C. 三个D. 四个二、多项选择题1.“统计”一词通常的涵义是指()。
应用统计学习题及答案
一、简答题(3*3=9分)1、试举例说明总体和总体单位之间的关系。
2、举例说明标志和指标之间的关系。
3、抽样调查、重点调查和典型调查这3种非全面调查的区别是什么4、季节变动的测定常用什么方法?简述其基本步骤。
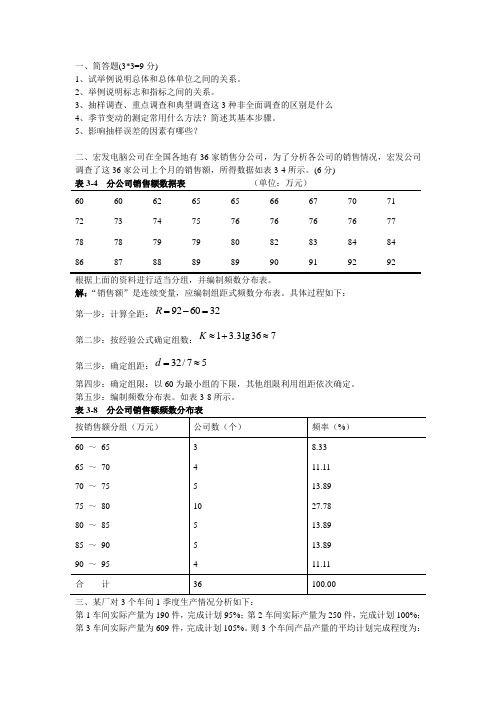
5、影响抽样误差的因素有哪些?二、宏发电脑公司在全国各地有36家销售分公司,为了分析各公司的销售情况,宏发公司调查了这36家公司上个月的销售额,所得数据如表3-4所示。
(6分)表3-4 分公司销售额数据表(单位:万元)60 60 62 65 65 66 67 70 7172 73 74 75 76 76 76 76 7778 78 79 79 80 82 83 84 8486 87 88 89 89 90 91 92 92根据上面的资料进行适当分组,并编制频数分布表。
解:“销售额”是连续变量,应编制组距式频数分布表。
具体过程如下:第一步:计算全距:926032R=-=第二步:按经验公式确定组数:1 3.3lg367 K≈+≈第三步:确定组距:32/75d=≈第四步:确定组限:以60为最小组的下限,其他组限利用组距依次确定。
第五步:编制频数分布表。
如表3-8所示。
三、某厂对3个车间1季度生产情况分析如下:第1车间实际产量为190件,完成计划95%;第2车间实际产量为250件,完成计划100%;第3车间实际产量为609件,完成计划105%。
则3个车间产品产量的平均计划完成程度为:95%100%105%100%3++=。
另外,1车间产品单位成本为18元/件,2车间产品单位成本为12元/件,3车间产品单位成本为15元/件,则3个车间平均单位成本为:181215153++=元/件。
以上平均指标的计算是否正确?如不正确请说明理由并改正。
(6分)答:两种计算均不正确。
平均计划完成程度的计算,因各车间计划产值不同,不能对其进行简单平均,这样也不符合计划完成程度指标的特定含义。
正确的计算方法是:平均计划完成程度190250609101.84%1902506090.95 1.0 1.05m x m x ++===++∑∑ 平均单位成本的计算也因各车间的产量不同,不能简单相加,产量的多少对平均单位成本有直接的影响。
《应用统计学》习题解答

参数估计与假设检验1、根据某大学100名学生的抽样调查,每月平均用于购买书籍的费用为4.5元,标准差为5元,求大学生每月用于购买书籍费用的区间估计(置信度为95%)。
(3.52,5.48)2、一种元件,要求其平均寿命不小于1000h,现在从一批这种元件中随机抽取25件,测得平均寿命为950 h,已知这种元件寿命服从σ=100 h 的正态分布,试在显著性水平α= 0.05 条件下确定这批元件是否合格.3、19世纪生物学家孟德尔按颜色与形状把豌豆分为四类:黄而圆的,青而圆的,黄而有角,青而有角的。
他根据遗传学的理论指出,这四类豌豆个数之比为9:3:3:1。
他在556颗豌豆中观察到这四类的个数分别为:315,108,101,32。
试在显著性水平α=0.05下,检验孟德尔理论的正确性。
解:用随机变量X表示杂交后的豌豆的类型,对可能的四种类型黄圆、黄皱、绿圆和绿皱,X的取值分别1, 2, 3和4.四种类型豌豆的数量分别记为fi (i = 1, 2, 3, 4)又记pi = P{X = i} (i = 1, 2, 3, 4)根据孟德尔的理论应有p1 = 9/16,p2 = 3/16,p3 = 3/16,p4 = 1/16要检验孟德尔理论的正确性,就是要检验上式就是X的分布律.于是提出假设H0:p1 = 9/16,p2 = 3/16,p3 = 3/16,p4 = 1/16由于n =556很大,可采用分布拟合χ2检验.检验统计量H0的拒绝域为)3(~)(41222∑=-=i iiinpnpfχχ{}{}81.7)3(2205.02≥=≥χχχ由于观察值χ2=0.470未落入拒绝域,所以在显著水平α = 0.05下不能拒绝原假设H0,即不能拒绝孟德尔的理论.方差分析:1、某企业准备用3种方法组装一种新的产品,为确定哪种方法每小时生产的产品数量最多,随机抽取了30名工人,并指定每个人使用其中的一种方法。
通过对每个工人生产的产品数进行方差分析得到下面的结果:方差分析表(1)完成上面的方差分析表。
应用统计学习题集及答案

统计学一、填空1.统计工作和统计资料之间是(统计过程与统计结果)的关系,统计学和统计工作之间是(统计理论与统计实践)的关系。
2.统计表中,宾词配置方式有(平行设置)和(层叠设置)两种。
3.总体参数估计有(点估计)和(区间估计)两种方法。
4.进行工业生产设备普查时,调查单位是(每台生产设备),报告单位是(工业企业)。
5.调查资料准确性的检查方法有(逻辑性检查)和(计算检查)。
6.根据分组标志的不同,分配数列可分为(品质分配数列)和(变量数列)。
7.总量指标按其反映时间状态不同分为(日期指标)和(时点指标)。
8.各年末商品库存量数列属于(时期)数列,各年的基建投资额数列属于(时点)数列。
9.统计研究运用大量观察法是由于研究对象的(大量性)和(复杂性)。
10.统计调查根据(被研究总体的范围)可分为全面调查和非全面调查,根据(调查登记时间是否)否可分为连续调查和不连续调查。
11任何一个统计分布都必须满足(多组频率大于0)和(各组频率之和等于100%)两个条件。
12.相关分析研究的是(相关)关系,它所使用的分析指标是(相关系)。
中楼阁13.根据时间间隔相等的时期数列计算序时平均数时应采用(简单算术平均)方法。
根据时间间隔相等的时点数列计算序时平均数时应采用(首末折半)方法。
14.某市城镇房屋普查中,统计总体是(城镇所属房屋)、总体单位是(每一座房屋)。
15.统计报表按填报单位不同可分为(基层报表)和(综合报表)。
16总量指标按其反映现象总体内容不同分为(总体单位总量)和(总体标志总量)。
17.销售利润率指标属于(结构)相对指标,成本利润率属于(强度)相对指标。
20.本期定基发展速度与前一期定期发展速度之比等于(环比发展速度),本期累计增长18.普查的对象主要是(时点)现象,因而要求统一规定调查资料所属的(标准时间)。
19.按照资料汇总特点不同,普查可分为(一般普查)和(快速普查)两种形式。
20.根据相关密切程度的判断标准,0.5<|V|<0.8时称为(显著相关),0.8<|V|<1时称为(高度相关)。
自-应用统计学习题答案(一二章)

《应用统计学》第一章 答案1.解:(1)1,2,5{(,)|01,1,,5}i x x x x i χ===或551151,2,5(,)(1),01,1,,5iii i x x i P x x x p p x i ==-∑∑=-==或(2)14,T T 是统计量,23,T T 不是统计量,因为含有未知参数p(3)51113(01101)555i i x x ===++++=∑,5222111133()()151510n i i i i s x x x n ===-=-=--∑∑ 2.解:因为~(30,4)X N ,所以4~(30,)X N n,因而(31)111X P X P >==-Φ=-Φ=-Φ当n=4时,(31)11(1)10.840.16P X >=-Φ=-Φ=-= 当n=9时,(31)11(1.5)10.930.07P X >=-Φ=-Φ=-= 当n=16时,(31)11(2)10.980.02P X >=-Φ=-Φ=-= 7.解:(1)~()X P λ,(),0,1,,!kP X k e k EX DX k λλλ-∴=====且联合分布列为111111(,,)(),1,,!!!niii k kn nn n n i i i i i n P X k X k P X k e e i n k k k λλλλ=--==∑=======∏∏(2)因为样本与总体同分布且独立,所以有11111()n n i i i i EX E X EX n n n n λλ=====⨯⨯=∑∑;2211111()n ni i i i DX D X DX n n n n n λλ=====⨯⨯=∑∑ (3)22221111()(())()11n n i i i i E S E X X EX nEX n n ===-=---∑∑ 因为i EX λ=,所以222222(),()i i i EX DX EX EX DX EX nλλλλ=+=+=+=+因此2221(()())1ES n n n nλλλλλ=⨯+-⨯+=- 8.解:(1)111,2,(,)(1),1,,nniii i x n x n P x x x p p i n ==-∑∑=-=(2)()EX E X p ==,2211111(1)()(1)n ni ii i p p DX D X DXn p p n n nn==-===⨯⨯⨯-=∑∑ (3)0,0(),011,1n x n m F x x n x <⎧⎪-⎪=≤<⎨⎪≥⎪⎩11.解:(1)~(,)X R a b ,1,()0,a x b f x b a ⎧<<⎪∴=-⎨⎪⎩其它,0,(),1,x a x a F x a x b b a x b ≤⎧⎪-⎪=<<⎨-⎪≥⎪⎩联合密度函数为1,2,11(,)()()nn i ni f x x x f x b a ===-∏(2)()n X 的密度函数为111(),()(())()0,n n n x a n a x b f x n F x f x b a b a---⎧⋅<<⎪==--⎨⎪⎩其它,所以有 11()111()()()()()()()[()()][||]11()()bbbn n n n naaan n b b n n b b a a n na ax a nEX xf x dx x n dx x a a x a dxb a b a b a n n x a a x a nb a x a dx a x a dx n n n b a b a --+--==⋅⋅=-+------+=-+-=+=++--⎰⎰⎰⎰⎰(`1)X 的密度函数为1111(),()(1())()0,n n b x n a x b f x n F x f x b a b a---⎧⋅<<⎪=-=--⎨⎪⎩其它,所以有 11(1)111111()()()()(1)(1)()()()()()(1)()()1()bbbn n naaan n bbn n n naan b n n nab x nEX xf x dx x n dx x b x dxb a b a b a nnx x b dx x b b x b dx b a b a n na b x b b x b dx n b a -------==⋅⋅=------=-=-+----+=-+-=+-⎰⎰⎰⎰⎰⎰15.证:222111~(,),~(,),~(0,)n n n X N X N X X N nn σμσμσ+++∴-~(0,1)X N 又因为222(1)~(1)n S n χσ--,且1n X X +-与2S 相互独立,所以有~(1)XT t n -16.解:1~(0,1),(,,)n X N X X 为取自总体的样本,且正态分布具有可加性3614~(0,3),~(0,3),i i i i X N X N ==∴∑∑36~(0,1),~(0,1)iiXXN N ξη∴=∑∑,且ξη与相互独立3622222141(()())~(2)3i i i i Y X X ξηχ==∴=+=+∑∑,所以取c=1/317.解:21~(0,),(,,)n X N X X σ为取自总体的样本,22~(0,1),()~(1)iiX X N χσσ∴(1)22121()~()nii X Y n χσσ==∑ (2)22221()~()nii X nY n χσσ==∑(3)222321~(0,~(0,1),~(1)nnii nii XX Y XN n N n σχσ=∴=∑∑∑(4)2242~(1)niXY χσ=∑由此可以导出1234,,,Y Y Y Y 的分布 27.证:(1)111,2,11(,;,)(;,)()()()nii nnx nn i i i i L x x x f x x e αλαλαλαλα=--==∑==Γ∏∏取1(,,)1n h x x =,1111((,,),,)()()()nii nx nn i i g T x x x e αλαλαλα=--=∑=Γ∏,所以由因子分解定理知11(,)(,)nni i i i x x αλ==∑∏是的充分统计量(2)当α已知时,111,2,11(,;,)(;,)()()()ni i nn xn n i i i i L x x x f x x eαλαλαλαλα=--==∑==Γ∏∏ 取1111(,,)()()()nnn i i h x x x αα-==Γ∏,11((,,),)nii x n n g T x x eλαλλ=-∑=所以由因子分解定理知1ni i x λ=∑是的充分统计量(3)当λ已知时,111,2,11(,;,)(;,)()()()nii nnx nn i i i i L x x x f x x e αλαλαλαλα=--==∑==Γ∏∏取11(,,)nii x n h x x eλ=-∑=,111((,,),)()()()nn n i i g T x x x ααλαα-==Γ∏所以由因子分解定理知1ni i x α=∏是的充分统计量29.证:(1)(1)(1)(1)1,2,121(,;)()nn n nn n ni i L x x x xxx x θθθθθθθθαθα-+-+-+-+===∏取1(,,)1n h x x =,(1)11((,,),)()nn n n i i g T x x x θθθθα-+==∏所以由因子分解定理知1ni i x θ=∏是的充分统计量32.解:(1)1111111(,,;)exp{ln }!!!!nii x nn n n n i i n n P X x X x e ex x x x x λλλλλ=--=∑====⋅⋅⋅∑取11111(),()ln ,(,,),(,,)!!nn n i n i n a eQ T x x x h x x x x λλλλ-=====∑,所以泊松分布族{():0}P λλ>是单参数分布族(2)2221111221111(,,;)()}}221}exp{}2n n n n n i i i i i i n n ni i i i L x x x x x e x x e μμλμμμ-===-==--=-+=-∑∑∑∑∑取22111111(),(),(,,),(,,)exp{}2(2)n nn n i n i ni i a eQ T x x x h x x x μμμμπ-======-∑∑ 所以正态分布族{(,1):}N μμ-∞<<+∞是单参数分布族 (3)21211(,,;)}2nn ii L x x xλσ==-∑取211211()(),(,,),(,,)12nn i n i a Q T x x x h x x σσσ=====∑所以正态分布族22{(0,):0}N σσ>是单参数分布族(4)011110(,,;)()()nii n n n xn i n i L x x x eαλαλλα=--=∑=Γ∏ 取00111110(),(),(,,),(,,)()()n nnn i n i ni i a Q n T x x x h x x x ααλλλλα-======Γ∑∏,所以G amma 分布族0{(,):0}Ga αλλ>是单参数分布族 (5)00111001111100()()(,,;)()(1)()exp{(1)ln(1)}()()()()n n n na a nb n n i i i i i i i i a b a b L x x b x x x b x a b a b ---====Γ+Γ+=-=--ΓΓΓΓ∑∏∏∏取01011110()()(),()(1),(,,)ln(1),(,,)()()()nnnn i n i i i a b a b Q b b T x x x h x x x a b α-==Γ+==-=-=ΓΓ∑∏,所以Beta 分布族0{(,):0}Be a b b >是单参数分布族 (6)11(,,;)nii x n n L x x eλλλ=-∑=,取11111(),(),(,,),(,,)!!nnn i n i n a Q T x x x h x x x x λλλλ===-==∑,所以指数分布族{():0}E λλ>是单参数分布族 34.证:11,2,(,;)(1)nii x nn L x x x θθθ=∑=-,取1(,,)1n h x x =,11((,,),)(1)nii x nn g T x x θθθ=∑=-所以由因子分解定理知1n i i x =∑是几何分布的充分统计量《应用统计学》第二章 答案1.解:(1)ˆ,X EX p pX ==∴=为p的矩估计; (2)设1,2,,n x x x 为样本的一组观测值,则111,2,()(,;)(1)nniii i x n x n L p L x x x p p p ==-∑∑==-11ln ()ln ()ln(1)nni i i i L p x p n x p ===+--∑∑,令11ln ()01nniii i xn x L p p pp==-∂=-=∂-∑∑所以ˆpX =为p 的极大似然估计 5.解:(;)(1)x xm x m f x p C p p -=-,设1,2,,n x x x 为样本的一组观测值,则似然函数为1111,2,(,;)(1)nniin i i x mn x x x n m m L x x x p C C p p ==-∑∑=-,取对数为11,2,11ln (,;)ln ln ()ln(1)nnnx x n mmi i i i L x x x p C C x p mn x p ===++--∑∑,令11ln ()01nniii i xmn x L p ppp==-∂=+=∂-∑∑,得ˆX pm =为p 的极大似然估计,1-ˆXpm=为q的极大似然估计 15.解:1,1(;)0,x f x θθθ<<+⎧=⎨⎩其它,0,(;),11,1x F x x x x θθθθθθ≤⎧⎪=-<<+⎨⎪≥+⎩(1)21211ˆ,222X X EX X θθ+-==∴==-为θ的矩估计 设1,2,,n x x x 为样本的一组观测值,则似然函数为1,2,(,;)1n L x x x θ=为常数所以符合条件的所有(1)()1,n X X θθ≤≤≤≤+即()(1)ˆ1n X X θ-≤≤都可以看作是θ的极大似然估计。
应用统计学:参数估计习题及答案

简答题1、矩估计的推断思路如何?有何优劣?2、极大似然估计的推断思路如何?有何优劣?3、什么是抽样误差?抽样误差的大小受哪些因素影响?4、简述点估计和区间估计的区别和特点。
5、确定重复抽样必要样本单位数应考虑哪些因素?计算题1、对于未知参数的泊松分布和正态分布分别使用矩法和极大似然法进行点估计,并考量估计结果符合什么标准2、某学校用不重复随机抽样方法选取100名高中学生,占学生总数的10%,学生平均体重为50公斤,标准差为48.36公斤。
要求在可靠程度为95%(t=1.96)的条件下,推断该校全部高中学生平均体重的范围是多少?3、某县拟对该县20000小麦进行简单随机抽样调查,推断平均亩产量。
根据过去抽样调查经验,平均亩产量的标准差为100公斤,抽样平均误差为40公斤。
现在要求可靠程度为95.45%(t=2)的条件下,这次抽样的亩数应至少为多少?4、某地区对小麦的单位面积产量进行抽样调查,随机抽选25公顷,计算得平均每公顷产量9000公斤,每公顷产量的标准差为1200公斤。
试估计每公顷产量在8520-9480公斤的概率是多少?(P(t=1)=0.6827, P(t=2)=0.9545, P(t=3)=0.9973)5、某厂有甲、乙两车间都生产同种电器产品,为调查该厂电器产品的电流强度情况,按产量等比例类型抽样方法抽取样本,资料如下:样本容量(个)平均电流强度(安培)电流强度标准差(安培)合格率(%)甲车间20 1.5 0.8 90乙车间40 1.6 0.6 95试推断:(1)在95.45%(t=2)的概率保证下推断该厂生产的全部该种电器产品的平均电流强度的可能范围(2)以同样条件推断其合格率的可能范围(3)比较两车间产品质量6、采用简单随机重复和不重复抽样的方法在2000件产品中抽查200件,其中合格品190件,要求:(1)计算样本合格品率及其抽样平均误差(2)以95.45%的概率保证程度对该批产品合格品率和合格品数量进行区间估计。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
个人收集整理资料, 仅供交流学习, 勿作商业用途 1 / 10 应用统计学习题及答案 简答题 1.简述普查和抽样调查的特点。 答: 普查是指为某一特定目的而专门组织的全面调查,它具有以下几个特点: <1)普查通常具有周期性。 <2)普查一般需要规定统一的标准调查时间,以避免调查数据的重复或遗漏,保证普查结果的准确性。 <3)普查的数据一般比较准确,规划程度也较高。 <4)普查的使用范围比较窄。 抽样调查指从调查对象的总体中随机抽取一部分单位作为样本进行调查,并根据样本调查结果来推断总体数量特征的一种数据收集方法。它具有以下几个特点:b5E2RGbCAP <1)经济性。这是抽样调查最显著的一个特点。 <2)时效性强。抽样调查可以迅速、及时地获得所需要的信息。 <3)适应面广。它适用于对各个领域、各种问题的调查。 <4)准确性高。 2.为什么要计算离散系数? 答: 离散系数是指一组数据的标准差与其相应得均值之比,也称为变异系数。 对于平均水平不同或计量单位不同的不同组别的变量值,是不能用方差和标准差比较离散程度的。为消除变量值水平高低和计量单位不同对离散程度测度值的影响,需要计算离散系数。离散系数的作用主要是用于比较不同总体或样本数据的离散程度。离散系数大的说明数据的离散程度也就大,离散系数小的说明数据的离散程度也就小。p1EanqFDPw 个人收集整理资料, 仅供交流学习, 勿作商业用途 2 / 10 3、加权算术平均数受哪几个因素的影响?若报告期与基期相比各组平均数没变,则总平均数的变动情况可能会怎样?请说明原因。DXDiTa9E3d 答: 加权算术平均数受各组平均数喝次数结构报告期与基期相比各组平均数没变,则总平均数的变动受次数结构<权数)变动的影响,可能不变、上升、下降。如果各组次数结构不变,则总平均数 ;如果组平均数高的组次数比例上升,组平均数低的组次数比例下降,则总平均数上升;如果组平均数低的组次数比例上升,组平均数高的组次数比例下降,则总平均数下降。RTCrpUDGiT 4.解释相关关系的含义,说明相关关系的特点。 答: 变量之间存在的不确定的数量关系为相关关系。 相关关系的特点:一个变量的取值不能由另一个变量唯一确定,当变量x取某个值时,变量y的取值可能有几个;变量之间的相关关系不能用函数关系进行描述,但也不是无任何规律可循。通常对大量数据的观察与研究,可以发现变量之间存在一定的客观规律。5PCzVD7HxA 5.解释抽样推断的含义。 答: 简单说,就是用样本中的信息来推断总体的信息。总体的信息通常无法获得或者没有必要获得,这时我们就通过抽取总体中的一部分单位进行调查,利用调查的结果来推断总体的数量特征。jLBHrnAILg 6.回归分析与相关分析的区别是什么? 答: <1)相关分析所研究的两个变量是对等关系,而回归分析所研究的两个变量不是对等关系;<2)对于两个变量X和Y来说,相关分析个人收集整理资料, 仅供交流学习, 勿作商业用途 3 / 10 只能计算出一个反映两个变量间相关密切程度的相关系数,而回归分析可分别建立两个不同的回归方程;<3)相关分析对资料的要求是,两个变量都必须是随机的,而回归分析对资料的要求是自变量是给定的,因变量是随机的。xHAQX74J0X 7.什么是方差分析? 答: 方差分析是通过对误差的分析,检验多个总体均值是否相等的一种统计方法。它分为单因素方差分析和双因素方差分析。LDAYtRyKfE 8.简述相关分析与回归分析的联系。 答: 相关分析是用于判断两个变量之间相关关系的密切程度,进而对这种判断的可靠程度加以检验的统计方法;而回归分析是分析研究变量之间相关关系的一种统计分析方法,考察一个变量随其余变量变化而变化的情况。相关分析是回归分析的基础和前提,回归分析是相关分析的深入和继续。Zzz6ZB2Ltk 计算题 1.下面是20个长途电话通话时间的频数分布,计算该数据的平均数 通话时间/分钟 频数 通话时间/分钟 频数
4-7 4 20-23 1 8-11 5 24-27 1 12-15 7 合计 20 16-19 2 答案: 由题意: 通话时间/分钟 通话时间/分钟
4-7 5.4 20-23 211 个人收集整理资料, 仅供交流学习, 勿作商业用途 4 / 10 5 .5 8-11 9.5 5 24-27 25.5 1
12-15 13.5 7 合计 20 16-19 17.5 2 平均数==12.3 2.拥有工商管理学位的大学毕业生每年年薪的标准差大约为2000美元,假定希望估计每年年薪底薪的95%置信区间,当边际误差分别500美元时,样本容量应该为多大?<)dvzfvkwMI1 答:
=61.47=62 3.某一汽车装配操作线完成时间的计划均值为2.2分钟。由于完成时间既受上一道装配操作线的影响,又影响到下一道装配操作线的生产,所以保持2.2分钟的标准是很重要的。一个随机样本由45项组成,其完成时间的样本均值为2.39分钟,样本标准差为0.20分钟。在0.05的显著性水平下检验操作线是否达到了2.2分钟的标准。rqyn14ZNXI 答案: 根据题意,此题为双侧假设检验问题 <1)原假设:;备择假设: <2)构造统计量:,得 <3)由于,则查表得: <4),,所以拒绝原假设,即在0.05的显著水平下没有达到2.2分钟的标准。 个人收集整理资料, 仅供交流学习, 勿作商业用途 5 / 10 4.下表中的数据是主修信息系统专业并获得企业管理学士学位的学生,毕业后的月薪示)的回归方程。EmxvxOtOco 总评分 月薪/美元 总评分 月薪/美元 2.6 2800 3.2 3000 3.4 3100 3.5 3400 3.6 3500 2.9 3100 解:
2.6 2800 6.76 7280 7840000 3.4 3100 11.56 10540 9610000 3.6 3500 12.96 12600 12250000 3.2 3000 10.24 9600 9000000 3.5 3400 12.25 11900 11560000 2.9 3100 8.41 8990 9610000 =19.2 =18900 =62.18 =60910 59870000
设 ==581.08 =18900/6-581.08*19.2/6=1290.54 于是 5.设总体X的概率密度函数为
其中为未知参数,是来自X的样本。 <1)试求的极大似然估计量; <2)实验证 是的无偏估计量。 解: <1)当>0时,似然函数为: 个人收集整理资料, 仅供交流学习, 勿作商业用途 6 / 10 令 ,即 解得: 是的单调函数,所以 的极大似然估计量 <2)因为
, 故是的无偏估计量。 6、某商店为解决居民对某种商品的需要,调查了100户住户,得出每月每户平均需要量为10千克,样本方差为9。若这个商店供应10000户,求最少需要准备多少这种商品,才能以95%的概率满足需要?SixE2yXPq5 解: 设每月每户至少准备
查表得, 若供应10000户,则需要准备104400kg。 7.糖果厂用自动包装机装糖,每包重量服从正态分布,某日开工后随机抽查10包的重量如下:494,495,503,506,492,493,498,507,502,490度为95%,试求:6ewMyirQFL <1)平均每包重量的置信区间,若总体标准差为5克; <2)平均每包重量的置信区间,若总体标准差未知; <); 解: n=10,为小样本 个人收集整理资料, 仅供交流学习, 勿作商业用途 7 / 10 (1) 方差已知,由±, =<494+495+503+506+492+493+498+507+502+490)/10,
计算可得平均每包重量的置信区间为<494.9,501.1) <2)方差未知,由± =<494+495+503+506+492+493+498+507+502+490)/10, s即样本方差,
计算可得,平均每包重量的置信区间为<493.63,502.37) 8.假定某化工原料在处理前和处理后取样得到的含脂率如下表: 处理前 0.140 0.138 0.143 0.142 0.144 0.137 处理后 0.135 0.140 0.142 0.136 0.138 0.140 假定处理前后含脂率都服从正态分布,问处理后与处理前含脂率均值有无显著差异。 解: 根据题中数据 可得: , 由于 <30,且 总体方差未知,所以先用F检验两总体方差是否存在差异。 (1) 设:; 则 F= 由,查F分布得,
接受,即处理前后两总体方差相同。 (2) 设, 则T=, T=1.26<=2.2281 接受,即处理前后含脂率无显著差异。