传智播客-培训课程(7)Hive_1
传智播客刘意老师JAVA全面学习笔记

第二十天
第 四 页
传智播客 JAVA 学习笔记
1:递归(理解)66 2:IO 流(掌握)66 3:自学字符流
第二十一天
1:字符流(掌握)69
第二十一天
1:字符流(掌握)69 2:IO 流小结(掌握)70 3:案例(理解 练习一遍)71
第二十二天
1:登录注册 IO 版本案例(掌握)72 2:数据操作流(操作基本类型数据的流)(理解)72 3:内存操作流(理解)72 4:打印流(掌握)72 5:标准输入输出流(理解)73 6:随机访问流(理解)73 7:合并流(理解)73 8:序列化流(理解)73 9:Properties(理解)74 10:NIO(了解)74
第八天
1:如何制作帮助文档(了解)28 2:通过 JDK 提供的 API 学习了 Math 类(掌握)28 3:代码块(理解)28 4:继承(掌握)28
第九天
1:final 关键字(掌握)30 2:多态(掌握)30 3:抽象类(掌握)32 4:接口(掌握)33
第十天
1:形式参数和返回值的问题(理解)35 2:包(理解)35 3:导包(掌握)35 4:权限修饰符(掌握)36 5:常见的修饰符(理解)36 6:内部类(理解)37
第 五 页
传智播客 JAVA 学习笔记
JAVA 学习总结
姓名:陈鑫
第一天
1:计算机概述(了解) (1)计算机 (2)计算机硬件 (3)计算机软件 系统软件:window,linux,mac 应用软件:qq,yy,飞秋 (4)软件开发(理解) 软件:是由数据和指令组成的。(计算器) 开发:就是把软件做出来。 如何实现软件开发呢? 就是使用开发工具和计算机语言做出东西来 (5)语言 自然语言:人与人交流沟通的 计算机语言:人与计算机交流沟通的 C,C++,C#,Java (6)人机交换 图形界面:操作方便只管 DOS 命令:需要记忆一些常见的命令 2:键盘功能键的认识和快捷键(掌握) (1)功能键的认识 tab shift ctrl alt windos 空格 上下左右 回车 截图 (2)快捷键 全选 Ctrl+A 复制 Ctrl+C 粘贴 Ctrl+V 剪切 Ctrl+X 撤销 Ctrl+Z 保存 Ctrl+S
Hadoop基础知识培训

存储+计算(HDFS2+Yarn)
集中存储和计算的主要瓶颈
Oracle IBM
EMC存储
scale-up(纵向扩展)
➢计算能力和机器数量成正比 ➢IO能力和机器数量成非正比
多,Intel,Cloudera,hortonworks,MapR • 硬件基于X86服务器,价格低,厂商多 • 可以自行维护,降低维护成本 • 在互联网有大规模成功案例(BAT)
总 结
• Hadoop平台在构建数据云(DAAS)平台有天 然的架构和成本的优势
成本投资估算:从存储要求计算所需硬件及系统软件资源(5000万用户 为例)
往HDFS中写入文件
• 首要的目标当然是数 据快速的并行处理。 为了实现这个目标, 我们需要竟可能多的 机器同时工作。
• Cient会和名称节点达 成协议(通常是TCP 协议)然后得到将要 拷贝数据的3个数据节 点列表。然后Client将 会把每块数据直接写 入数据节点中(通常 是TCP 协议)。名称 节点只负责提供数据 的位置和数据在族群 中的去处(文件系统 元数据)。
• 第二个和第三个数据 节点运输在同一个机 架中,这样他们之间 的传输就获得了高带 宽和低延时。只到这 个数据块被成功的写 入3个节点中,下一 个就才会开始。
• 如果名称节点死亡, 二级名称节点保留的 文件可用于恢复名称 节点。
• 每个数据节点既扮演者数据存储的角色又 冲当与他们主节点通信的守护进程。守护 进程隶属于Job Tracker,数据节点归属于 名称节点。
传智播客_Java培训_毕向东_Java基础[09-网络编程]
![传智播客_Java培训_毕向东_Java基础[09-网络编程]](https://img.taocdn.com/s3/m/20b96a31eefdc8d376ee32a5.png)
北京传智播客教育
—高级软件人才实作培训专家! 基本思路(服务端)
服务端需要明确它要处理的数据是从哪个 端口进入的。 当有客户端访问时,要明确是哪个客户 端,可通过accept()获取已连接的客户端 对象,并通过该对象与客户端通过IO流进 行数据传输。 当该客户端访问结束,关闭该客户端。
北京传智播客教育
—高级软件人才实作培训专家! 网络通讯要素
IP地址:InetAddress
• • •
网络中设备的标识 不易记忆,可用主机名 本地回环地址:127.0.0.1 主机名:localhost 用于标识进程的逻辑地址,不同进程的标识 有效端口:0~65535,其中0~1024系统使用或保留端口。 通讯的规则 常见协议:TCP,UDP
北京传智播客教育
—高级软件人才实作培训专家! 服务端
建立服务端需要监听一个端口
ServerSocket ss = new ServerSocket(9999); Socket s = ss.accept (); InputStream in = s.getInputStream(); byte[] buf = new byte[1024]; int num = in.read(buf); String str = new String(buf,0,num); System.out.println(s.getInetAddress().toString()+”:”+str); s.close(); ss.close();
北京传智播客教育
—高级软件人才实作培训专家! 接收端
在接收端,要指定监听的端口。
DatagramSocket ds = new DatagramSocket(10000); byte[] by = new byte[1024]; DatagramPacket dp = new DatagramPacket(by,by.length); ds.receive(dp); String str = new String(dp.getData(),0,dp.getLength()); System.out.println(str+"--"+dp.getAddress()); ds.close();
Hive教程(官方Tutorial)

浏览表和分区以上例⼦,通过⼀个userid 的哈希函数,表被分成32个桶。
在每个桶中的数据,是以viewTime 升序进⾏存储。
这样组织数据允许⽤户有效地在这n个桶上进⾏抽样。
合适的排序使得内部操作充分利⽤熟悉的数据结构来进⾏更加有效的查询。
在这个例⼦,CLUSTERED BY 指定列进⾏分桶,以及创建多少个桶。
⾏格式分隔符指定在hive表中,⾏如何存储。
在这种分隔符情况下,指定了字段是如何结束,集合项(数组和map)如何结束,以及map的key是如何结束的。
STORED AS SEQUENCE FILE 表⽰这个数据是以⼆进制格式进⾏存储数据在hdfs上。
对于以上例⼦的ROW FORMAT 的值和STORED AS 表⽰系统默认值。
表名和列名不区分⼤⼩写。
CREATE TABLE page_view(viewTime INT, userid BIGINT,page_url STRING, referrer_url STRING,ip STRING COMMENT 'IP Address of the User')COMMENT 'This is the page view table'PARTITIONED BY(dt STRING, country STRING)CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETSROW FORMAT DELIMITEDFIELDS TERMINATED BY '1'COLLECTION ITEMS TERMINATED BY '2'MAP KEYS TERMINATED BY '3'STORED AS SEQUENCEFILE;CREATE TABLE page_view(viewTime INT, userid BIGINT,page_url STRING, referrer_url STRING,friends ARRAY<BIGINT>, properties MAP<STRING, STRING>,ip STRING COMMENT 'IP Address of the User')COMMENT 'This is the page view table'PARTITIONED BY(dt STRING, country STRING)CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETSROW FORMAT DELIMITEDFIELDS TERMINATED BY '1'COLLECTION ITEMS TERMINATED BY '2'MAP KEYS TERMINATED BY '3'STORED AS SEQUENCEFILE;列出数据库⾥的所有的表,也可以这么浏览:这样将会列出以page 开头的表,模式遵循Java正则表达式语法。
大数据培训之hive学习

HIVE编程实战一HIVE基础1.1 什么是hive?Hadoop生态系统是为了处理大数据集而产生的一个合乎成本效益的解决方案。
Hadoop实现了一个特别的计算模型,即MapReduce,其可以将计算认为分割成多个处理单元然后分散到Hadoop集群中的家用或服务器级别的硬件机器上,从而降低成本并提供动态扩展的能力。
基于这个计算模型的下面是一个被称之为HDFS(Hadoop分布式文件系统)的分布式文件系统。
不过,仍然存在一个挑战,那就是用户如何从一个现有的数据基础架构转移到Hadoop 上,而这个基础架构是基于传统关系型数据库和结构化SQL语言的。
对于大量的关系型数据库的维护、实施、开发人员,这个问题将如何解决呢?这就是Hive出现的原因。
Hive提供了一个被称之为Hive查询语言,简称HQL的SQL方言(与MYSQL及其类似),用来查询存储在Hadoop集群中的数据。
Hive可以将大多数的查询转换为MapReduce的job任务,从而使得采用简单的SQL编程方式,来替换掉原有的MapReduce中的复杂java编程。
Hive最适合于数据仓库应用程序,使用该应用程序进行相关的静态数据分析,不需要快速响应给出结果,而且数据本身不会频繁变化。
Hive不是一个完整的数据库,其中最大的限制就是hive不支持记录级别的更新、插入或者删除,但是用户可以通过查询生成新表或者将查询结果导入到文件中。
同时,基于Mapreduce的hive查询延时比较严重,没有传统的RDBMS查询速度快,hive不支持事物。
因此,hive是最适合数据仓库应用程序的,其可以维护海量数据,而且可以对数据进行分析,然后形成统计结果以及报表等。
1.2 HIVE组成模块所有的命令和查询都会进入到Driver(驱动模块),通过该模块对输入进行解析编译,对需求的计算进行优化,然后按照指定的步骤执行。
当需要启动MapReduce任务时,Hive 本身是不会生成Java Mapreduce程序。
传智播客Hibernate课件

北京传智播客教育
—高级软件人才实作培训专家 ! Hibernate入门
9.通过id查询客户信息
北京传智播客教育
—高级软件人才实作培训专家 ! Hibernate入门
10. 查询所有的客户信息
北京传智播客教育
—高级软件人才实作培训专家 ! Hibernate入门
}
北京传智播客教育
—高级软件人才实作培训专家 ! Hibernate入门
3 创建对象-关系映射文件 Hibernate 采用 XML 格式的文件来指定对象和关系数据之间的映射. 在运行时 Hibernate 将根据这个映射文件来生成各种 SQL 语句 映射文件的扩展名为 .hbm.xml 这里Customer.hbm.xml文件
date
timestamp
BIRTHDAY
REGISTERED_TI ME
DATE
TIMESTAMP
汉语(java)
英语(hibernate)
北京传智播客教育
日语(sql)
—高级软件人才实作培训专家 ! Hibernate入门
北京传智播客教育
2 创建表和对应的javaBean文件(持久化类)
create table customer ( id int primary key, name varchar(12), age int, des text ) public class Customer { private private private private Integer id; String name; Integer age; String des;
char
boolean ng.String byte[]
character
Hive培训ppt课件
3*
HIVE基本操Байду номын сангаас实例
1、登录生产环境,ssh 。 [hadoop@hm-nn-ser-01 ~]$ hive
2、查看表 hive (default)> show tables;
4*
HIVE基本操作实例
1* 0
Hive RCFile性能测试数据
1* 1
生产上HIVE表说明
目前生产环境上表名和分区结构说明如下: 三张表:ip_rc、http_rc、pdp_rc 三个分区,根据日期、小时、采集节点进行分区: 日期---pt_date---20140103 小时---pt_hour---2014010312 采集节点---pt_data---1
hive和普通关系数据库的异同hive的数据存储hive没有专门的数据存储格式也没有为数据建立索引用户可以非常自由的组织hive中的表只需要在创建表的时候告诉hive数据中的列分隔符和行分隔符hive就可以解析数据
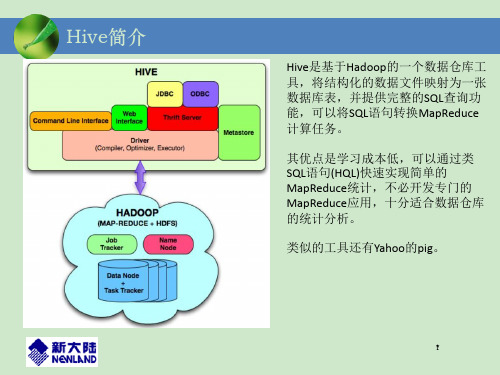
Hive简介
Hive是基于Hadoop的一个数据仓库工 具,将结构化的数据文件映射为一张 数据库表,并提供完整的SQL查询功 能,可以将SQL语句转换MapReduce 计算任务。
1* 2
HIVE语句规范和注意事项
1、Sql测试 由于集群计算资源比较宝贵,建议复杂一些的Sql语句需先在一个小时分区数据测 试,测试无误后生产数据上跑; 2、日期和小时分区 根据日期查找,pt_date条件注意放在where条件首位,在该分区下查找,防止全 表扫描。 3、字符集 Hadoop和Hive都是用UTF-8编码的,所有中文必须是UTF-8编码才能正常使用, 导出数据编码格式也是UTF-8。 4、String数据类型 只能用like进行模糊查询。 5、只有一个reduce的场景:
Java基础[07-集合]
![Java基础[07-集合]](https://img.taocdn.com/s3/m/f220371855270722192ef730.png)
—高级软件人才实作培训专家!
Map集合
通过查看API后,可以发现Map集合的特点 1:是一个双列集合 2:Map一次存一对元素,以键值对的形式存 在,键和值有对应关系 3:Map集合中必须要保证集合中键的唯一性 Map和Collection的区别?
北京传智播客教育
—高级软件人才实作培训专家!
List接口下的常用类
ArrayList:底层数据结构是数组结构。线程 不安全。所以它的出现替代了Vector。增删的 效率很慢,但是查询的效率很高。 Vector:底层数据结构是数组结构。线程安全 。无论增删还是查询都非常慢。 LinkedList:底层是链表数据结构。线程不安 全。对元素的增删的操作效率很高,查询的效 率低。
北京传智播客教Βιβλιοθήκη —高级软件人才实作培训专家!
Collection接口中的功能
存储:add,addAll 删除:remove,removeAll,clear 判断:contains, containsAll,isEmpty 取出:iterator 将集合变成数组:toArray 取两个集合的交集:retainAll 获取集合的长度:size
北京传智播客教育
—高级软件人才实作培训专家!
Map体系的案例
重点讲解Map的获取元素的两种方式 用学生对象做键,学生所在的归属地做值。同 姓名同年龄的学生视为同一个人。 "cbxzbvavdvgd"获取字符串中,每一个字母出 现次数:a(1)b(2)c(1)d(2)g(1)v(3)x(1)z(1) czbk:预热班,就业班 预热班:01 zhangsan;02 lisi 就业班:01 wangwu;02 zhaoliu
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
—高级软件人才实作培训专家! Hive的系统架构
1. 2. 3.
2.修改$HIVE_HOME/bin的hive-config.sh,增加以下三行 export JAVA_HOME=/usr/local/jdk export HIVE_HOME=/usr/local/hive export HADOOP_HOME=/usr/local/hadoop
—高级软件人才实作培训专家! Hive的安装
Hive的数据模型-数据库
类似传统数据库的DataBase 默认数据库"default" 使用#hive命令后,不使用hive>use <数据库名>,系统 默认的数据库。可以显式使用hive> use default;
创建一个新库 hive > create database test_dw;
—高级软件人才实作培训专家!
修改$HIVE_HOME/conf/hive-site.xml <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop0:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>admin</value> </property>
—高级软件人才实作培训专家!
Hive的安装
在Hadoop0上
把hive-0.9.0.tar.gz复制到/usr/local 解压hive-0.9.0.tar.gz与重命名 #cd /usr/local #tar -zxvf hive-0.9.0.tar.gz #mv hive-0.9.0 hive
—高级软件人才实作培训专家!
Hive的安装
cd $HIVE_HOME mv hive-env.sh.template hive-env.sh mv hive-default.xml.template hive-site.xml
1.修改hadoop的hadoop-env.sh(否则启动hive汇报找不到类的错误) export HADOOP_CLASSPATH=.:$CLASSPATH:$HADOOP_CLASSPATH: $HADOOP_HOME/bin
启动 #hive hive>show tables; hive>create table test(id int,name string); hive>quit;
观察:#hadoop fs -ls /user/hive 参数:hive.metastore.warehouse.dir
—高级软件人才实作培训专家!
—高级软件人才实作培训专家! Hive的数据模型-内部表
创建数据文件inner_table.dat 创建表 hive>create table inner_table (key string); 加载数据 hive>load data local inpath '/root/inner_table.dat' into table inner_table; 查看数据 select * from inner_table select count(*) from inner_table 删除表 drop table inner_table
修改/etc/profile文件。 #vi /etc/profile 增加 export HIVE_HOME=/usr/local/hive 修改 export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HIVE_HOME/bin 保存退出 #source /etc/profile
—高级软件人才实作培训专家! Hive的数据类型
基本数据类型 tinyint/smallint/int/bigint float/double boolean string • 复杂数据类型 Array/Map/Struct • 没有date/datetime
—高级软件人才实作培训专家!
Hive的数据存储
—高级软件人才实作培训专家! Hive与传统数据库
查询语言 数据存储位置 数据格式 HiveQL HDFS 用户定义 SQL Raw Device or 本地FS 系统决定
数据更新
索引 执行 执行延迟 可扩展性 数据规模
不支持
新版本有,但弱 MapReduce 高 高 大
支持
有 Executor 低 低 小
—高级软件人才实作培训专家!
Hive的数据模型-分区表
—高级软件人才实作培训专家! 什么是Hive(二)
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。 Hive的表其实就是HDFS的目录/文件,按表名把 文件夹分开。如果是分区表,则分区值是子文件 夹,可以直接在M/R Job里使用这些数据。
—高级软件人才实作培训专家! Hive的系统架构
—高级软件人才实作培训专家!
Hadoop深入浅出
讲师: 吴 超 博客: Q Q: 3774 Biblioteka 6624北京传智播客教育
—高级软件人才实作培训专家! 课程安排
Hive是什么?其体系结构简介* Hive的安装与管理* HiveQL数据类型,表以及表的操作* HiveQL查询数据*** Hive的Java客户端** ---------------------------加深拓展--------------------- Hive的自定义函数UDF*
Hive的metastore
metastore是hive元数据的集中存放地。metastore默 认使用内嵌的derby数据库作为存储引擎 Derby引擎的缺点:一次只能打开一个会话
使用Mysql作为外置存储引擎,多用户同时访问
—高级软件人才实作培训专家!
Hive的安装
—高级软件人才实作培训专家!
Hive的数据模型-分区表
Partition 对应于数据库的 Partition 列的密集索引 在 Hive 中,表中的一个 Partition 对应于表下的一 个目录,所有的 Partition 的数据都存储在对应的 目录中
例如:test表中包含 date 和 city 两个 Partition, 则对应于date=20130201, city = bj 的 HDFS 子目录为: /warehouse/test/date=20130201/city=bj 对应于date=20130202, city=sh 的HDFS 子目录为; /warehouse/test/date=20130202/city=sh
Hive的数据存储基于Hadoop HDFS Hive没有专门的数据存储格式 存储结构主要包括:数据库、文件、表、视图 Hive默认可以直接加载文本文件(TextFile),还支持
sequence file
创建表时,指定Hive数据的列分隔符与行分隔符, Hive即可解析数据
—高级软件人才实作培训专家!
配置MySQL的metastore
1.上传mysql-connector-java-5.1.10.jar到$HIVE_HOME/lib 2.登录MYSQL,创建数据库hive #mysql -uroot -padmin mysql>create database hive; mysql>GRANT all ON hive.* TO root@'%' IDENTIFIED BY 'admin'; mysql>flush privileges; mysql>set global binlog_format='MIXED'; 3.把mysql的数据库字符类型改为latin1
—高级软件人才实作培训专家!
什么是Hive(一)
Hive 是建立在 Hadoop 上的数据仓库基础构架。它 提供了一系列的工具,可以用来进行数据提取转化加 载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的 类 SQL 查询语言,称为 QL ,它允许熟悉 SQL 的用 户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完 成的复杂的分析工作。