SAS分析法代码
生存分析的SAS编程操作

phreg过程
phreg过程针对生存数据执行基于Cox比例风 险模型(Cox proportional hazards model)的 回归分析; 可以检验有关回归参数的线性假设; 针对配对病例-对照研究执行条件logistic回归 分析过程; 创建包含有关统计量的输出数据集等.
phreg过程可包含的语句
sas回归系数置信区间

sas回归系数置信区间【引言】在统计学中,回归分析是一种常用的数据分析方法。
而SAS作为一种强大的统计分析软件,其回归分析功能也备受青睐。
在进行回归分析时,我们通常会关注回归系数的置信区间,以评估回归系数的显著性和可靠性。
本文将从SAS回归分析的角度,探讨回归系数置信区间的相关知识。
【回归系数的置信区间】回归系数的置信区间是指在一定置信水平下,回归系数的真实值有多大可能落在一个区间内。
通常我们使用95%的置信水平,即置信区间为95%。
在SAS中,我们可以通过PROC REG或PROC GLM来进行回归分析,并计算回归系数的置信区间。
以PROC REG为例,我们可以使用以下代码进行回归分析:```proc reg data=mydata;model y = x1 x2 x3;run;```其中,mydata为数据集名称,y为因变量,x1、x2、x3为自变量。
运行后,我们可以得到回归系数的估计值、标准误、t值和p值等信息。
其中,标准误是计算置信区间的关键指标之一。
在SAS中,我们可以使用以下代码计算回归系数的置信区间:```proc reg data=mydata;model y = x1 x2 x3;ods output ParameterEstimates=PE;run;proc sql;select Estimate, Estimate-1.96*StdErr as Lower, Estimate+1.96*StdErr as Upperfrom PEwhere Label like 'x%'order by Estimate;quit;```其中,ParameterEstimates=PE表示将回归系数的估计值、标准误等信息输出到PE数据集中。
然后,我们使用SQL语句从PE数据集中提取回归系数的估计值、下限和上限,并按估计值从小到大排序。
这样,我们就得到了回归系数的置信区间。
SAS软件应用之典型相关分析

SAS软件应用之典型相关分析典型相关分析(Canonical Correlation Analysis,CCA)是一种多变量统计分析方法,用于研究两组变量之间的关系以及它们之间的线性组合。
SAS软件提供了强大的工具和函数来执行典型相关分析,包括PROC CANCORR和CORRCAN。
PROCCANCORR是SAS中执行典型相关分析的主要过程。
它可以分析两组变量之间的关系,并计算它们之间的典型相关系数以及相关变量之间的线性组合得分。
以下是一个使用PROCCANCORR进行典型相关分析的示例代码:```/* 导入数据集data1和data2 */data data1;input var1 var2 var3;datalines;123456789;run;data data2;input var4 var5 var6;datalines;101112131415161718;run;/*运行PROCCANCORR进行典型相关分析*/proc cancorr data=data1 data=data2 out=results;var var1 var2 var3;with var4 var5 var6;run;/*输出典型相关系数和相关变量的得分*/proc print data=results;run;```在上述示例中,我们首先导入两个数据集`data1`和`data2`,其中`data1`包含三个自变量(`var1`,`var2`,`var3`),`data2`包含三个因变量(`var4`,`var5`,`var6`)。
然后,我们使用PROC CANCORR指定自变量和因变量,并将结果保存在名为`results`的输出数据集中。
最后,我们使用PROC PRINT打印结果数据集。
在输出结果中,我们可以查看典型相关系数以及自变量和因变量的得分。
典型相关系数表示两组变量之间的相关程度,取值范围为-1到1、得分表示原始变量的线性组合结果,可以用于分析变量之间的关系。
生存分析的SAS编程操作

指定一系列时间点,从而在结果中针对这些时间点显示相应的Kaplan-Meier估计值,该时间点在 输出结果中所在的列以“_TIME_”为标识。
指定生存时间四分位数间距可信区间的置信水平(须在0.0001~0.9999之间),默认设置为 “alpha=0.05”。
指定寿命表区间的个数,此选项可被“width=”和“intervals=”所覆盖。当设置“ninterval=”选项 时,lifetest过程将根据所设置的区间个数划分寿命表的区间,但区间端点将会作适当的调整,使 其以整数的形式出现。因此,最终划分的区间数不一定与设置的区间数完全相符。默认设置为 “ninterval=10”。
半参数法:Cox模型分析方法。
B
3
生存分析方法的SAS过程
非参数法:lifetest过程; 参数法:lifereg过程; 半参数法:phreg过程。
B
4
生存分析的非参数方法
B
5
非参数法生存分析示例1
45例乳腺癌患者中,免疫过氧化物酶检测结果 显示9例阳性、36例阴性,比较其生存时间分 布的SAS程序如下。
run;
B
19
phreg过程
phreg过程针对生存数据执行基于Cox比例风 险模型(Cox proportional hazards model)的 回归分析;
可以检验有关回归参数的线性假设; 针对配对病例-对照研究执行条件logistic回归
分析过程; 创建包含有关统计量的输出数据集等。
proc lifetest plots=(s); time time*censor(1); strata immuno;
sas使用手册

sas使用手册SAS(Statistical Analysis System)是一款广泛使用的统计分析软件,其使用手册对于使用者来说是不可或缺的指南。
以下是一个简短的SAS使用手册,以帮助您快速了解其基本功能和操作。
一、概述SAS是一个模块化、集成化的软件系统,主要用于数据管理、统计分析、预测建模和报告生成。
它支持多种编程语言,包括SAS语言、SAS宏语言和SAS SQL语言,使得用户可以根据自己的需求进行定制化操作。
二、安装与启动要使用SAS,您需要先将其安装到您的计算机上。
您可以从SAS官网下载适合您操作系统的安装程序,并按照屏幕提示进行安装。
安装完成后,您可以通过启动SAS Enterprise Guide或SAS Studio来使用SAS。
三、数据管理SAS提供了一系列数据管理工具,可以帮助您导入、清洗、合并和转换数据。
您可以使用DATA步来创建、修改和删除数据集,使用SQL语言进行更高级的数据查询和操作。
四、统计分析SAS提供了广泛的统计分析方法,包括描述性统计、方差分析、回归分析、聚类分析、主成分分析等。
您可以使用PROC步来调用相应的过程,并指定所需的参数和选项。
例如,要执行回归分析,您可以编写以下代码:PROC REG DATA=your_dataset; MODELdependent_variable = independent_variable / VIF; RUN;五、模型构建与预测SAS提供了多种预测模型,包括线性回归模型、逻辑回归模型、决策树模型、神经网络模型等。
您可以使用PROC步来构建和评估模型,例如:PROC SVM DATA=your_dataset; CLASS target_variable; MODEL dependent_variable = independent_variable; CROSSVALIDATE; RUN;六、报告生成SAS支持将分析结果导出为各种格式的报告,包括HTML、PDF、Word等。
sas常用代码

sas常用代码1、导入数据2、提取年份(在年份不为4位数时,需要这一步)Data 某表1;set某表;Year=year(date);Run;注:如果需要提取一般数据,则采用如下数据:Data 某表1,set某表;Year=year(date,2,4);表示从第二个字符起,取4个字符Run3、排序(按照代码和年对ROA里的数据进行排序)【这一步是在合并具有相同变量的表时必须要做的。
】PROCSORT DATA=ROA;BY CODE YEAR;RUN;4、合并Datahebing;Merge ROA1 ASSEST1;by code year;run;注:hebing中包含了所有的ROA1和ASSEST1数据(无if)有取舍合并Datahebing;mergeROA1 (in=a) ASSEST1 (in=b);by code year;if a=1 and b=1;Run;5、删除不需要的数据Data hebing1;sethebing;ifROA<0 then delete;run;Data hebing1;sethebing;if roa=.or roa=" " then delete;(删除缺失值)(if ros+roa+roe=. then delete;同时删除rosroa roe中的缺失值)run;6、取自然对数和删除变量Data hebing2;set hebing1;Inassest=log(assest);InROA=log(1+roa);Run;7、对连续变量的缩尾处理winsorize(消除极端值影响)只有连续变量才能消除极端值影响Data temp1;set hebing2; d=1;run;procmeansnoprint;varinassestinroa; by d;output out=tmp2(drop=_freq_ _type_) p1=x1-x2 p99=y1-y2;Data hebing3;merge temp1 tmp2; by d;array z{1:2} inassestinroa;array x{1:2} x1-x2; array y{1:2} y1-y2;do i=1 to 2;if z[i]if z[i]>y[i] then z[i]=y[i];end; drop i d x1-x2 y1-y2;run;8、年份和行业的控制data hebing3; set hebing2;if year=2001then year01=1; else year01=0;if year=2002then year02=1; else year02=0;if year=2003then year03=1; else year03=0;if year=2004then year04=1; else year04=0;if year=2005then year05=1; else year05=0;if year=2006then year06=1; else year06=0;if year=2007then year07=1; else year07=0;if year=2008then year08=1; else year08=0;if year=2009then year09=1; else year09=0;if year=2010then year10=1; else year10=0;if year=2011then year11=1; else year11=0;if year=2012then year12=1; else year12=0;if year=2013then year13=1; else year13=0;if indus="B"then induB=1; else induB=0;if indus="C"then induC=1; else induC=0;if indus="D"then induD=1; else induD=0;if indus="E"then induE=1; else induE=0;if indus="F"then induF=1; else induF=0;if indus="G"then induG=1; else induG=0;if indus="H"then induH=1; else induH=0;if indus="J"then induJ=1; else induJ=0;if indus="K"then induK=1; else induK=0;if indus="L"then induL=1; else induL=0;if indus="M"then induM=1; else induM=0;run;9、描述性统计(针对所有变量)procmeans data=hebing3 n(数量)mean(均值)std(标准偏差)minq1medianq3maxmaxdec=4(最多保留4位小数);var lnfeelnnum ;run;9、变量之间的相关性分析proccorr data=hebing3pearsonspearman; var lnfeelnnum ;run;10、回归procreg data=hebing3;model lnfee=lnnum;run;1、以e为底的自然对数是LOG(x);2、以2为底的对数是LOG2(x);3、以10为底的对数是LOG10(x)。
SAS数据分析常用操作指南

SAS数据分析常用操作指南在当今数据驱动的时代,数据分析成为了企业决策、科学研究等领域的重要手段。
SAS 作为一款功能强大的数据分析软件,被广泛应用于各个行业。
本文将为您介绍 SAS 数据分析中的一些常用操作,帮助您更好地处理和分析数据。
一、数据导入与导出数据是分析的基础,首先要将数据导入到 SAS 中。
SAS 支持多种数据格式的导入,如 CSV、Excel、TXT 等。
以下是常见的导入方法:1、通过`PROC IMPORT` 过程导入 CSV 文件```sasPROC IMPORT DATAFILE='your_filecsv'OUT=your_datasetDBMS=CSV REPLACE;RUN;```在上述代码中,将`'your_filecsv'`替换为实际的 CSV 文件路径,`your_dataset` 替换为要创建的数据集名称。
2、从 Excel 文件导入```sasPROC IMPORT DATAFILE='your_filexlsx'OUT=your_datasetDBMS=XLSX REPLACE;RUN;```导出数据同样重要,以便将分析结果分享给他人。
可以使用`PROC EXPORT` 过程将数据集导出为不同格式,例如:```sasPROC EXPORT DATA=your_datasetOUTFILE='your_filecsv'DBMS=CSV REPLACE;RUN;```二、数据清洗与预处理导入的数据往往存在缺失值、异常值等问题,需要进行清洗和预处理。
1、处理缺失值可以使用`PROC MEANS` 过程查看数据集中变量的缺失情况,然后根据具体情况选择合适的处理方法,如删除包含缺失值的观测、用均值或中位数填充等。
2、异常值检测通过绘制箱线图或计算统计量(如均值、标准差)来检测异常值。
对于异常值,可以选择删除或进行修正。
3、数据标准化/归一化为了消除不同变量量纲的影响,常常需要对数据进行标准化或归一化处理。
sas统计分析代码
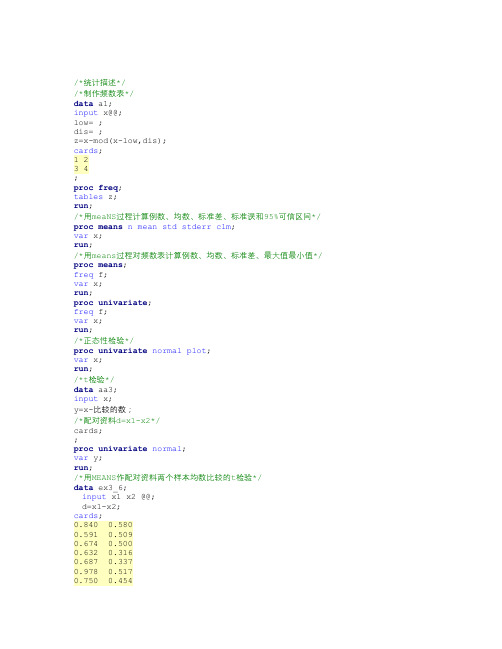
/*统计描述*//*制作频数表*/data a1;input x@@;low= ;dis= ;z=x-mod(x-low,dis);cards;1 23 4;proc freq;tables z;run;/*用meaNS过程计算例数、均数、标准差、标准误和95%可信区间*/ proc means n mean std stderr clm;var x;run;/*用means过程对频数表计算例数、均数、标准差、最大值最小值*/ proc means;freq f;var x;run;proc univariate;freq f;var x;run;/*正态性检验*/proc univariate normal plot;var x;run;/*t检验*/data aa3;input x;y=x-比较的数;/*配对资料d=x1-x2*/cards;;proc univariate normal;var y;run;/*用MEANS作配对资料两个样本均数比较的t检验*/data ex3_6;input x1 x2 @@;d=x1-x2;cards;0.840 0.5800.591 0.5090.674 0.5000.632 0.3160.687 0.3370.978 0.5170.750 0.4540.730 0.5121.200 0.9970.870 0.506;proc means t prt;var d;run;/*用UNIVARIATE过程作配对资料两样本均数比较的t检验*/proc univariate data=ex3_6;var d;run;proc ttest data=ex3_6;var d;run;data ex3_7;input x @@;if _n_<21then c=1;else c=2;cards;-0.70 -5.60 2.00 2.80 0.70 3.50 4.00 5.80 7.10 -0.502.50 -1.60 1.703.00 0.404.50 4.60 2.50 6.00 -1.403.70 6.50 5.00 5.20 0.80 0.20 0.60 3.40 6.60 -1.10 6.00 3.80 2.00 1.60 2.00 2.20 1.20 3.10 1.70 -2.00 ;proc ttest;var x;class c;run;/*方差分析*/DATA RANDOM;INPUT X GROUP @@;CARDS;3.53 14.59 14.34 12.66 13.59 13.13 12.64 12.56 13.50 13.25 13.30 14.04 13.53 13.56 13.85 14.07 13.52 13.93 14.19 12.96 11.37 13.93 12.98 1 4.00 13.55 1 2.96 14.30 1 4.16 1 2.59 12.42 23.36 24.32 2 2.34 2 2.68 2 2.95 2 1.56 2 3.11 2 1.81 2 1.77 21.98 22.63 2 2.86 2 2.93 2 2.17 2 2.72 2 2.65 2 2.22 2 2.90 2 2.97 2 2.36 2 2.56 2 2.52 2 2.27 22.98 23.72 22.80 23.57 24.02 2 2.31 2 2.86 3 2.28 3 2.39 3 2.28 3 2.48 32.28 33.21 3 2.23 3 2.32 3 2.68 3 2.66 3 2.32 32.61 33.64 32.58 33.65 32.66 33.68 3 2.65 33.48 32.42 32.41 32.66 33.29 32.70 33.04 32.81 31.97 31.68 30.89 41.06 41.08 41.27 41.63 41.89 41.19 42.17 42.28 41.72 41.98 41.74 42.16 43.37 42.97 41.69 40.94 42.11 42.81 42.52 41.31 42.51 41.88 41.41 43.19 41.92 42.47 41.02 42.10 43.71 4;RUN;/*正态性检验*/PROC UNIVARIATE NORMAL;CLASS GROUP;VAR X;RUN;PROC ANOVA;CLASS GROUP;MODEL X=GROUP;MEANS GROUP/HOVTEST SNK LSD DUNNETT; RUN;/*hovtest方差齐性检验*//*方差分析*/PROC GLM;CLASS GROUP;MODEL X=GROUP;MEANS GROUP/HOVTEST SNK LSD DUNNETT; RUN;DATA A;INPUT X TREAT BLOCK @@;CARDS;0.82 1 10.73 1 20.43 1 30.41 1 40.68 1 50.65 2 10.54 2 20.34 2 30.21 2 40.43 2 50.51 3 10.23 3 20.28 3 30.31 3 40.24 3 5;RUN;PROC PRINT;RUN;PROC ANOVA;CLASS TREAT BLOCK;MODEL X=TREAT BLOCK;MEANS TREAT/SNK ALPHA=0.05;MEANS TREAT;RUN;DATA BLOCK;INPUT BLOCK TREAT X@@;CARDS;1 1 0.82 1 2 0.65 13 0.512 1 0.73 2 2 0.54 2 3 0.233 1 0.43 3 2 0.34 3 3 0.284 1 0.41 4 2 0.21 4 3 0.315 1 0.68 5 2 0.43 5 3 0.24;PROC ANOVA;CLASS BLOCK TREAT;MODEL X=BLOCK TREAT;MEANS TREAT/HOVTEST SNK LSD DUNNETT; RUN;;PROC GLM;CLASS BLOCK TREAT;MODEL X=BLOCK TREAT;MEANS TREAT/HOVTEST SNK LSD DUNNETT; RUN;/*roc曲线分析*/data ex21;input group num;do i=1to num;input value@@;output; end;cards;1 256.5 13.5 12.8 6.2 13.9 14.7 9.5 9.0 6.9 16.813.3 10.8 12.2 14.9 13.7 12.8 5.3 11.8 12.47.6 13.3 11.9 11.2 12.3 12.70 208.5 6.4 4.6 1.7 9.7 5.3 4.9 5.7 3.8 6.56.3 5.4 3.3 4.7 8.6 6.3 5.9 4.8 4.5 5.2;run;proc logistic descending;model group=value/scale=none outroc=rocl;run;proc print;run ;proc gplot;plot _SENSIT_*_1MSPEC_;run;DATA CHISQGROUP;INPUT COL ROW X@@;CARDS;1 1 46 12 62 1 18 2 2 8;PROC FREQ;WEIGHT X;TABLE COL*ROW/CHISQ;RUN;DATA CHISQPAIRED;/*请注意配对结果中没有进行校正,所以对于需要校正的情况,需要手动计算。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
为区分过程名称的拼写,故意部分小写,以便识别和记忆。
基本SAS程序代码结构:---------PROC MODE data=Arndata.moddat; /* 命令的解释*/var yx1-x6; /* 命令的解释 */model y = x1-x6;run;------------------------------------------正态性检验PROC UNIvariate---------PROC UNIvariate data=Arndata.unidat;var x1;run;------------------------------------------相关分析和回归分析PROC REG 回归---------PROC REG data=Arndata.regdat;var y x1-x6;model y = x1-x6 / selection=stepwise; /* 加入逐步回归选项 */printcli;/* 加入输出预测结果部分,还可以输出acov,all,cli,clm,collin,collinoint,cookd,corrb,covb,dw(时序检验统计量),i,influence,p,partial,pcorr1,pcorr2,r,scorr1,scorr2,seqb,spec,ss1,ss2,stb,tol,vif(异方差检验统计量),xpx*/plot y*x2 /conf95; /* 做散点图 */run;---------------------------------------------------DATA Arndata.regdat;x2x2 = x2*x2;x1x2 = x1*x2;PROC REG data=Arndata.regdat;var y x1 x2 x2x2x1x2 ; /* 多项式回归,非线性回归 */model y = x1 x2 x2x2 x1x2 / selection=stepwise; /* 加入逐步回归选项 */print cli;plot y*x2 /conf95; /* 做散点图 */run;------------------------------------------PROC RSreg 二次响应面回归PROC ORTHOreg 病态数据回归PROC NLIN 非线性回归PROC TRANSreg 变换回归PROC CALIS 线性结构方程和路径分析PROC GLM 一般线性模型PROC GENmod 广义线性模型方差分析PROC ANOVA 单因素均衡数据和非均衡数据---------PROC ANOVA data=Arndata.anovadat; /* 命令的解释 */classtyp; / * 命令的解释 */model y =typ; /* 可以看出此处是单因素方差分析(分类型自变量对数值型自变量的影响) */run;------------------------------------------PROC GLM 多因素非均衡数据:---------PROC GLM data=Arndata.glmdat; /* 命令的解释*/class typeatypeb; /* 命令的解释 */model y = typeatypeb; /* 可以看出此处是不考虑交互作用的多因素方差分析(分类型自变量对数值型自变量的影响) */run;---------------------------------------------------PROC GLM data=Arndata.glmdat; /* 命令的解释*/class typeatypeb; /* 命令的解释 */model y = typea typebtypea*typeb; /* 可以看出此处是考虑交互作用的多因素方差分析(分类型自变量对数值型自变量的影响) */run;------------------------------------------主成分分析PROC PRINcomp---------PROC PRINcomp data=Arndata.pmdat n=4 out=w1outstat=w2 ;varx1-x6;PROC print data=w1;PROC plot data=w1vpct=80;/* 一句话,其实print就是plot输出图形的文字形式而已 */plot prin1*prin2 $ districts='*'/haxis=-3.5 to 3 by 0.5 HREF=-2,0,2vaxis=-3 to 4.5 by 1.5HREF=-2,0,2; /* 主成分的散点图,也就是载荷图 */run;------------------------------------------因子分析PROC FACTOR---------PROC FACTOR data=Arndata.factordat simplecorr ;var yx1-x6;title'18个财务指标的分析';title2'主成分解';run;PROC FACTOR data=Arndata.factordatn=4 ; /* 选择4个公共因子 */var y x1-x6;run;PROC FACTOR data=Arndata.factordat n=4rotate=VARImaxREorder;/* 因子旋转:方差最大因子法 */var y x1-x6;run;------------------------------------------PROC SCORE---------PROC FACTOR data=Arndata.factordat n=4rotate=VARImax REorder score out=score_Out; /* 输出因子得分矩阵 */run;PROC print data=score_Out;var districts factor1 factor2 factor3 factor4;run;PROC plot data=score_Out;plot factor1*factor2 $ districts='*' / href=0 Vref=0; /* 因子的散点图,也就是载荷图 */run;------------------------------------------典型相关分析PROC CANcorr基本SAS程序代码结构:---------DATAjt(TYPE=CORR);/* TYPE=CORR 表明数据类型为相关矩阵,而不是原始数据, type还可以是cov,ucov,factor,sscp,ucorr等*/input names$ 1-2(x1 x2 y1-y3)(6.); /* name $ 表示读取左侧的变量名,1-2表示变量名的字符落在第1,2列上 */cards;x1 1 0.8 ……x2 ……y1 ……y2 ……y3 ……;PROC CANcorr data=Arndata.cancorrdatedf=70redundancy; /* 误差自由度的参考值,默认值是n=1000; redundancy表示输出冗余度分析的结果*/var x1 x2;with y1 y2 y3;run;------------------------------------------对应分析 /* 交叉表分析的拓展,寻找行和列的关系,一般行指代各种cases,而列代表各种visions */PROC CORResp---------PROC CORResp data=Arndata.correspdatout=result;varx1-x6;id Type;run;options ps=40;proc plot data=result;plot dim2*dim1="*" $ Type / boxhaxis=-0.2 to 0.3 by 0.1Vaxis=-0.1 to 0.3 by 0.1Href=0 Vref=0;run;------------------------------------------聚类分析PROC CLUSTER---------PROC CLUSTER data=Arndata.clusdatmethod=ave outtree=clusdat_Out;var x1-x6;id datid;run;proc tree horizontal; /* 做聚类树*/run;------------------------------------------PROC FASTclus---------PROC FASTclus data=Arndata.clusdatmaxclusters=3 list out=clusdat_Out;var x1-x6;id datid;run;------------------------------------------PROC ACEclusPROC VARCLUS---------PROC VARclus data=Arndata.clusdat; /* 系统默认使用主成分法聚类 */var x1-x6;run;---------PROC VARclus hierarchy data=Arndata.clusdat; /* 保证分析过程中不同水平的谱系结构 */var x1-x6;run;---------PROC VARclus centroid data=Arndata.clusdatouttree=clusdat_out; /* 使用重心法聚类 */var x1-x6;run;------------------------------------------PROC TREE---------PROC TREE data=Arndata.clusdat horizontal; /* 使用TREE过程绘制聚类谱系图 */var x1-x6;run;------------------------------------------判别分析PROC DISCRIM---------PROC DISCRIM data=Arndata.discrimdatlistout=discrimdat_Out distance pool=yes;class Typ; /* 指定分类变量 */var x1-x6; /* 用于建立判别识别函数的变量 */id iddiscrim; /* 标注样本的变量 */run;---------第二种方法,将需要判别的新样本放在testdata里:---------PROC DISCRIM data=Arndata.discrimdat1testdata=Arndata.discrimdat2testlisttestout=discrimdat_Out; /* 将原来的几个选项加注test标示*/class Typ; /* 指定分类变量 */var x1-x6; /* 用于建立判别识别函数的变量 */id iddiscrim; /* 标注样本的变量 */run;------------------------------------------PROC STEPdisc:逐步判别分析过程---------PROC STEPdisc method=stepwise data=Arndata.discrimdatSLentry=0.10 SLstay=0.10; /* 设定引入和剔除的显著性水平 */class Typ; /* 指定分类变量 */var x1-x6; /* 用于建立判别识别函数的变量 */run;------------------------------------------PROC CANdisc:Fisher判别分析过程---------PROC CANdisc data=Arndata.discrimdat out=discrimdat_Outdistance simple;class Typ; /* 指定分类变量 */var x1-x6; /* 用于建立判别识别函数的变量 */run;proc print data=discrimdat_Out;run;------------------------------------------。