计量经济学习题第三章
计量经济学(第四版)第三章练习题及答案
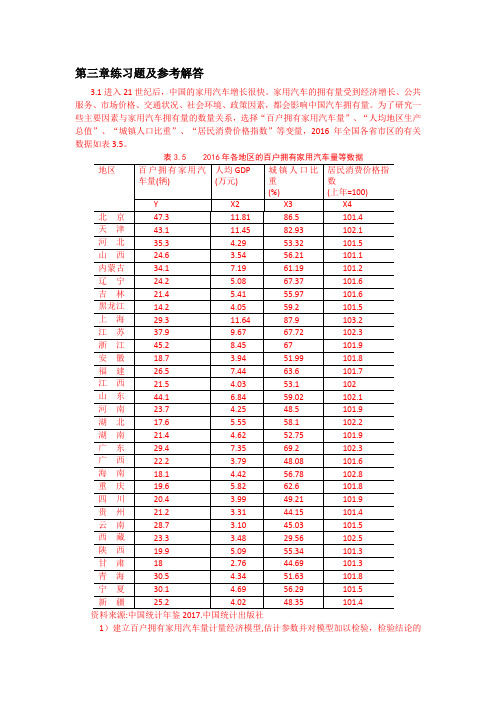
第三章练习题及参考解答3.1进入21世纪后,中国的家用汽车增长很快。
家用汽车的拥有量受到经济增长、公共服务、市场价格、交通状况、社会环境、政策因素,都会影响中国汽车拥有量。
为了研究一些主要因素与家用汽车拥有量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量,2016年全国各省市区的有关数据如表3.5。
表3.5 2016年各地区的百户拥有家用汽车量等数据资料来源:中国统计年鉴2017.中国统计出版社1)建立百户拥有家用汽车量计量经济模型,估计参数并对模型加以检验,检验结论的依据是什么?。
2)分析模型参数估计结果的经济意义,你如何解读模型估计检验的结果? 3) 你认为模型还可以如何改进?【练习题3.1 参考解答】:1)建立线性回归模型: 1223344t t t t t Y X X X u ββββ=++++ 回归结果如下:由F 统计量为14.69998, P 值为0.000007,可判断模型整体上显著, “人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量联合起来对百户拥有家用汽车量有显著影响。
解释变量参数的t 统计量的绝对值均大于临界值0.025(27) 2.052t =,或P 值均明显小于0.05α=,表明在其他变量不变的情况下,“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”分别对百户拥有家用汽车量都有显著影响。
2)X2的参数估计值为4.8117,表明随着经济的增长,人均地区生产总值每增加1万元,平均说来百户拥有家用汽车量将增加近5辆。
由于城镇公共交通的大力发展,有减少家用汽车的必要性,X3的参数估计值为-0.4449,表明随着城镇化的推进,“城镇人口比重”每增加1%,平均说来百户拥有家用汽车量将减少0.4449辆。
汽车价格和使用费用的提高将抑制家用汽车的使用, X4的参数估计值为-5.7685,表明随着家用汽车使用成本的提高, “居民消费价格指数”每增加1个百分点,平均说来百户拥有家用汽车量将减少5.7685辆。
计量经济学章节练习题(第三章 多元线性回归模型)已改

第三章 多元线性回归模型一、单项选择题1、决定系数2R 是指【 】A 剩余平方和占总离差平方和的比重B 总离差平方和占回归平方和的比重C 回归平方和占总离差平方和的比重D 回归平方和占剩余平方和的比重2、在由n=30的一组样本估计的、包含3个解释变量的线性回归模型中,计算的多重决定系数为0.8500,则调整后的决定系数为【 】A 0.8603B 0.8389C 0.8 655D 0.83273、设k 为模型中的参数个数,则回归平方和是指【 】 A 21)(Y Yn i i -∑= B 21)ˆ(in i i Y Y -∑= C 21)ˆ(Y Y n i i-∑= D )1/()(21--∑=k Y Y n i i4、下列样本模型中,哪一个模型通常是无效的【 】A i C (消费)=500+0.8i I (收入)B d i Q (商品需求)=10+0.8i I (收入)+0.9i P (价格)C s i Q (商品供给)=20+0.75i P (价格)D i Y (产出量)=0.656.0i L (劳动)4.0iK (资本) 5、对于iki k i i i e X X X Y +++++=ββββˆˆˆˆ22110 ,统计量∑∑----)1/()ˆ(/)ˆ(22k n Y Y k Y Y i i i 服从【 】 A t(n-k) B t(n-k-1) C F(k-1,n-k) D F(k,n-k-1)6、对于iki k i i i e X X X Y +++++=ββββˆˆˆˆ22110 ,检验H 0:0=i β),,1,0(k i =时,所用的统计量)ˆvar(ˆi it ββ=服从【 】A t(n-k-1)B t(n-k-2)C t(n-k+1)D t(n-k+2)7、调整的判定系数 与多重判定系数 之间有如下关系【 】A 1122---=k n n R RB 11122----=k n n R R C 11)1(122---+-=k n n R R D 11)1(122-----=k n n R R 8、用一组有30 个观测值的样本估计模型i i i i u X X Y +++=22110βββ后,在0.05的显著性水平下对的显著性作t 检验,则1β显著地不等于零的条件是其统计量t 大于【 】 A 05.0t (30) B 025.0t (28) C (27) D 025.0F (1,28)9、如果两个经济变量X 与Y 间的关系近似地表现为当X 发生一个绝对量变动(∆X )时,Y 有一个固定地相对量(∆Y/Y )变动,则适宜配合的回归模型是【 】A i i i u X Y ++=10ββB ln i i i u X Y ++=10ββC i ii u X Y ++=110ββ D ln i i i u X Y ++=ln 10ββ 10、对于iki k i i i e X X X Y +++++=ββββˆˆˆˆ22110 ,如果原模型满足线性模型的基本假设,则在零假设j β=0下,统计量)ˆ(/ˆjj s ββ(其中s(j β)是j β的标准误差)服从【 】 A t (n-k ) B t (n-k-1) C F (k-1,n-k ) D F (k ,n-k-1)11、下列哪个模型为常数弹性模型【 】A ln i i i u X Y ++=ln ln 10ββB ln i i i u X Y ++=10ln ββC i i i u X Y ++=ln 10ββD i ii u X Y ++=110ββ 12、模型i i i u X Y ++=ln 10ββ中,Y 关于X 的弹性为【 】1β025.0tA iX 1β B i X 1β C i Y 1β D i Y 1β 13、模型ln i i i u X Y ++=ln ln 10ββ中,的实际含义是【 】A X 关于Y 的弹性B Y 关于X 的弹性C X 关于Y 的边际倾向D Y 关于X 的边际倾向14、关于经济计量模型进行预测出现误差的原因,正确的说法是【 】A.只有随机因素B.只有系统因素C.既有随机因素,又有系统因素D.A 、B 、C 都不对15、在多元线性回归模型中对样本容量的基本要求是(k 为解释变量个数):【 】A n ≥k+1B n<k+1C n ≥30或n ≥3(k+1)D n ≥3016、用一组有30个观测值的样本估计模型i i i i u X X Y +++=22110βββi ,并在0.05的显著性水平下对总体显著性作F 检验,则检验拒绝零假设的条件是统计量F 大于【 】A F 0.05(3,30)B F 0.025(3,30)C F 0.05(2,27)D F 0.025(2,27)17、对小样本回归系数进行检验时,所用统计量是( )A 正态统计量B t 统计量C χ2统计量D F 统计量18、在多元回归中,调整后的判定系数2R 与判定系数2R 的关系有【 】A 2R <2RB 2R >2RC 2R =2RD 2R 与2R 的关系不能确定 19、根据判定系数2R 与F 统计量的关系可知,当2R =1时有【 】A F =-1B F =0C F =1D F =∞20、回归分析中,用来说明拟合优度的统计量为【 】A 相关系数B 判定系数C 回归系数D 标准差21、对于二元线性回归模型的总体显著性检验的F 统计量,正确的是【 】。
新《计量经济学》第3章 计量练习题

《计量经济学》第3章习题一、单项选择题1.多元线性回归模型的“线性”是指对( )而言是线性的。
A .解释变量B .被解释变量C .回归参数D .剩余项 2.多元线性回归模型参数向量β最小二乘估计式的矩阵表达式为( )A .'1'ˆ()XX X Y β-= B .'1'ˆ()X X X Y β-= C .'1ˆ()XX XY β-= D .'1'ˆ()XX XY β-= 3.ˆβ的方差-协方差矩阵ˆ()Var Cov β-为( ) A .2'1()X X σ- B . 2'1()XX σ- C .'12()XX σ- D . '12()X X σ- 4.修正可决系数与未经修正的多重可决系数之间的关系为( )A .2211(1)n R R n k -=--- B .221(1)1n kR R n -=--- C .2211n k R R n -=-- D .2211n R R n k-=--5.多重可决系数R 2是指( )A .残差平方和占总离差平方和的比重B .总离差平方和占回归平方和的比重C .回归平方和占总离差平方和的比重D .回归平方和占残差平方和的比重 二、多项选择题1.多元线性回归模型的古典假定有( )A .零均值假定B .同方差和无自相关假定C .随机扰动项与解释变量不相关假定D .无多重共线性假定E .正态性假定2.对模型01122i i i i Y X X u βββ=+++进行总体显著性检验,如果检验结果总体线性关系显著,则可能有( )A .1β=2β=0B .1β≠0,2β=0C .1β≠0,2β≠0D .1β=0,2β≠0E .1β=2β≠0 3.残差平方和是指( )A .被解释变量观测值与估计值之间的变差B .被解释变量回归估计值总变差的大小C .被解释变量观测值总变差的大小D .被解释变量观测值总变差中未被列入模型的解释变量解释的那部分变差E.被解释变量观测值总变差中由多个解释变量作出解释的那部分变差4.关于多重可决系数,说法正确的有()A.多重可决系数越大,表示回归方程与样本拟合得越好B.多重可决系数与模型中解释变量的数目有关,一般而言,解释变量越多,多重可决系数就越大C.实际应用中,使用修正的可决系数判断依据。
计量经济学第三章练习题及参考全部解答

第三章练习题及参考解答3.1为研究中国各地区入境旅游状况,建立了各省市旅游外汇收入(Y,百万美元)、旅行社职工人数(X1,人)、国际旅游人数(X2,万人次)的模型,用某年31个省市的截面数据估计结果如下:Y = -151.0263 0.1179X1i1.5452X2it=(-3.066806)(6.652983)(3.378064)2 2R2=0.934331 R 0.92964 F=191.1894 n=311)从经济意义上考察估计模型的合理性。
2)在5%显著性水平上,分别检验参数M, :2的显著性。
3)在5%显著性水平上,检验模型的整体显著性。
练习题3.1参考解答:(1)由模型估计结果可看出:从经济意义上说明,旅行社职工人数和国际旅游人数均与旅游外汇收入正相关。
平均说来,旅行社职工人数增加1人,旅游外汇收入将增加0.1179百万美元;国际旅游人数增加1万人次,旅游外汇收入增加 1.5452百万美元。
这与经济理论及经验符合,是合理的。
矚慫润厲钐瘗睞枥庑赖。
(2)取。
=0.05,查表得t0.025(31 — 3) = 2.048因为3个参数t统计量的绝对值均大于t0.025(31 — 3) =2.048,说明经t检验3个参数均显著不为0,即旅行社职工人数和国际旅游人数分别对旅游外汇收入都有显著影响。
聞創沟燴鐺險爱氇谴净。
(3)取G =0.05,查表得F0.O5(2,28) =3.34,由于F =199.1894 a F0.05(2,28^ 3.34,说明旅行社职工人数和国际旅游人数联合起来对旅游外汇收入有显著影响,线性回归方程显著成立。
残骛楼諍锩瀨濟溆塹籟。
3.2表3.6给出了有两个解释变量X2和.X3的回归模型方差分析的部分结果:n=14+1=15因为TSS=RSS+ESS 残差平方和RSS=TSS-ESS=66042-65965=77回归平方和的自由度为:k-仁3-仁2残差平方和RSS的自由度为:n-k=15-3=12(2)可决系数为:R2=65965 =0£98834TSS 660422 n -1 ' e215 -1 77修正的可决系数:R 1 "2=1 0.9986n —k送y, 15—3 66042(3)这说明两个解释变量X2和.X3联合起来对被解释变量有很显著的影响,但是还不能确定两个解释变量X2和.X3各自对Y 都有显著影响。
计量经济学第三章课后习题

(1)估计回归方程的参数及随机干扰项的方差∧2σ,计算2R及2R。
(2)对方程进行F检验,对参数进行t检验,并构造参数95%的置信区间。
(3)如果商品单价变为35元,则某一月收入为20000元的家庭消费支出估计是多少?构造该估计值的95%的置信区间。
(个值与均值)R代码与输出结果:x1=c(23.56,24.44,32.07,32.46,31.15,34.14,35.3,38.7,39.63,46.68)x2=c(7620,9120,10670,11160,11900,12920,14340,15960,18000,19300)y=c(591.9,654.5,623.6,647,674,644.4,680,724,757.1,706.8)nx1=length(x1)nx2=length(x2)ny=length(y)nx1;nx2;nylm.1=lm(y~x1+x2)summary(lm.1)Call:lm(formula = y ~ x1 + x2)Residuals:Min 1Q Median 3Q Max-22.014 -14.084 4.591 10.502 19.640Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) 626.509285 40.130100 15.612 1.07e-06 ***x1 -9.790570 3.197843 -3.062 0.01828 *x2 0.028618 0.005838 4.902 0.00175 **---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘’1Residual standard error: 17.39 on 7 degrees of freedomMultiple R-squared: 0.9022, Adjusted R-squared: 0.8743F-statistic: 32.29 on 2 and 7 DF, p-value: 0.0002923由输出结果显示,两个解释变量的估计值为-9.79057、0.028618。
计量经济学第三版庞浩第三章习题

计量经济学第三版庞浩第三章习题第三章习题3.1(1)2021年各地区的百户拥有家用汽车量及影响因素数据图形可以看出,2021年各地区的百户拥有家用汽车量及影响因素的差异明显,其变动的方向基本相同,相互间可能具有一定的相关性,因而将其模型设定为线性回归模型形式:Y=β1+β2X2+β3X3+β4X4① R2是0.*****,修正的R2为0.*****,说明模型对样本拟合较好② F检验,分别针对H0:βj=0(j=1,2,3,4),给定显著性水平α=0.05,在F分布表中查出自由度为k-1=3,n-k=27的临界值Fα(3,27)=3.65,由表可知,F=17.*****Fα(3,27)=3.65,应拒绝原假设,回归方程显著。
③ t检验,分别针对H0:βj=0(j=1,2,3,4),给定显著性水平α=0.05,查t分布表得自由度为n-k=27临界值t=2.0518,所以这些系数都是显著的。
(2)人均GDP增加1万元,百户拥有家用汽车增加5.*****辆,城镇人口比重增加1个百分点,百户拥有家用汽车减少0.*****辆,交通工具消费价格指数每上升1,百户拥有家用汽车减少2.*****辆。
0.052(n-k)=2.0518。
对应的t统计量分别为4.*****,4.*****,-2.*****,-4.*****,其绝对值均大于t(27)(3)将其模型设定为Y=β1+β2X2+β3LnX3+β4LnX4Y=1148.758+5.*****X2-22.*****LnX3-230.8481LnX4改进后的R2为0.*****原R2为0.*****,拟合程度得到了提高3.2(1)估计参数Y = - *****.58+0.*****X2 + 18.*****X3 模型检验R2是0.*****,修正的R2是0.*****,说明模型对样本拟合较好F检验,分别针对H0;βj=0(j=1,2,3),给定显著性水平α=0.05,在F分布表中查出自由度为k-1=2,n-k=15的临界值Fα(2,15)=4.77,由表可知,F=522.0976F(2,15)=4.77,应拒绝原假设,回归方程显著。
计量经济学第3章参考答案
(3) = TSS
RSS 480 = = 750 2 1− R 1 − 0.36
7. 答: (1) cov( = x, y )
1 2 2 ( xt − x )( y = r σx σ y = 0.9 × 16 ×10 =11.38 ∑ t − y) n −1
∑ ( x − x )( y − y )=
即表明截距项也显著不为 0,通过了显著性检验。 (3)Yf=2.17+0.2023×45=11.2735
2 1 (x f − x ) 1 (45 − 29.3) 2 ˆ 1+ + = × × + = 4.823 t0.025 (8) × σ 1.8595 2.2336 1+ n ∑ ( x −x ) 2 10 992.1
3
2
五、综合题 1. 答: (1)建立深圳地方预算内财政收入对 GDP 的回归模型,建立 EViews 文件,利用地方预 算内财政收入(Y)和 GDP 的数据表,作散点图
可看出地方预算内财政收入(Y)和 GDP 的关系近似直线关系,可建立线性回归模型:
Yt = β1 + β 2 GDPt + u t
第 3 章参考答案
一、名词解释 1. 高斯-马尔可夫定理:在古典假定条件下,OLS 估计量是模型参数的最佳线性无偏估计 量,这一结论即是高斯-马尔可夫定理。 2. 总变差(总离差平方和) :在回归模型中,被解释变量的观测值与其均值的离差平方和。 3. 回归变差(回归平方和) :在回归模型中,因变量的估计值与其均值的离差平方和,也就 是由解释变量解释的变差。 4. 剩余变差(残差平方和) :在回归模型中,因变量的观测值与估计值之差的平方和,是不 能由解释变量所解释的部分变差。 5. 估计标准误差:在回归模型中,随机误差项方差的估计量的平方根。 6. 样本决定系数:回归平方和在总变差中所占的比重。 7. 拟合优度:样本回归直线与样本观测数据之间的拟合程度。 8. 估计量的标准差:度量一个变量变化大小的测量值。 9. 协方差:用 Cov(X,Y)表示,度量 X,Y 两个变量关联程度的统计量。 10. 显著性检验:利用样本结果,来证实一个虚拟假设的真伪的一种检验程序。 11. 拟合优度检验:检验模型对样本观测值的拟合程度,用 R 2 表示,该值越接近 1,模型 对样本观测值拟合得越好。 12. t 检验:是针对每个解释变量进行的显著性检验,即构造一个 t 统计量,如果该统计量 的值落在置信区间外,就拒绝原假设。 13. 点预测:给定自变量的某一个值时,利用样本回归方程求出相应的样本拟合值,以此作 为因变量实际值均值的估计值。
计量经济学第三章13题
2
F0.05 (2, 21) 3.47 ,该回归分析的统计量 F 87.07231 显著大于3.47,因此 ln Y 与 lnK 、 lnL 有显著
3 的 关 系 ; 再 看 t 分 布 , 因 为 t0.05 (21) 1.721 , 其 常 数 项 0 2 , 4 1 0 2 5 1 .、 7 2 lnK 1 的系数
解: ⑴ 最小线性二乘估计的检验结果和回归方程为:
⑵ 异方差检验 X与Y散点图,从下图可以看出方差基本一致。
怀特检验结果:(这个表有些项看不懂,故也不知道怎么分析)
G-Q检验: 两个样本的估计结果为:
于是得到如下的F统计量: F 设,即不是异方差的。
RSS1 / 4 295354.3 4.09883268 F0.05 (4, 4) 6.39 ,故接受原假 RSS2 / 4 72058.15
通过Eviews 软件进行回归分析得到如下结果:92388 和修正的可决系数 R 0.882139 都是接近于1的, 故该回归方程的 模 拟 情 况 还 是 比 较 好 的 。 在 5% 的 显 著 性 水 平 下 , 自 由 度 为 (2, 21) 的 F 分 布 的 临 界 值 为
说明这两项已经通过检验,但是 1 5 . 6 9 2 1 7 0 1 . 7 21 lnL 的回归系数没有通过检验。
⑵ 这个题不知道怎么做,只能根据答案提示做出结果,具体不知道怎么分析。
第四章 8题 下表列出了某年中国部分省市城镇居民家庭平均每个全年可支配收入(X)与消费性
支出(Y)的统计数据。 地区 北 京 天 津 河 北 山 西 内蒙古 辽 宁 吉 林 黑龙江 上 海 江 苏 可支配 收入(X) 10349.69 8140.5 5661.16 4724.11 5129.05 5357.79 4810 4912.88 11718.01 6800.23 消费性 支出 (Y) 8493.49 6121.04 4348.47 3941.87 3927.75 4356.06 4020.87 3824.44 8868.19 5323.18 地区 浙 山 河 湖 湖 广 陕 甘 青 新 江 东 南 北 南 东 西 肃 海 疆 可支配 收入 (X) 9279.16 6489.97 4766.26 5524.54 6218.73 9761.57 5124.24 4916.25 5169.96 5644.86 消费性 支出 (Y ) 7020.22 5022 3830.71 4644.5 5218.79 8016.91 4276.67 4126.47 4185.73 4422.93
计量经济学习题第三章
第三章、经典单方程计量经济学模型:多元线性回归模型一、内容提要本章将一元回归模型拓展到了多元回归模型,其基本的建模思想与建模方法与一元的情形相同。
主要内容仍然包括模型的基本假定、模型的估计、模型的检验以及模型在预测方面的应用等方面。
只不过为了多元建模的需要,在基本假设方面以及检验方面有所扩充。
本章仍重点介绍了多元线性回归模型的基本假设、估计方法以及检验程序。
与一元回归分析相比,多元回归分析的基本假设中引入了多个解释变量间不存在(完全)多重共线性这一假设;在检验部分,一方面引入了修正的可决系数,另一方面引入了对多个解释变量是否对被解释变量有显著线性影响关系的联合性F检验,并讨论了F检验与拟合优度检验的内在联系。
本章的另一个重点是将线性回归模型拓展到非线性回归模型,主要学习非线性模型如何转化为线性回归模型的常见类型与方法。
这里需要注意各回归参数的具体经济含义。
本章第三个学习重点是关于模型的约束性检验问题,包括参数的线性约束与非线性约束检验。
参数的线性约束检验包括对参数线性约束的检验、对模型增加或减少解释变量的检验以及参数的稳定性检验三方面的内容,其中参数稳定性检验又包括邹氏参数稳定性检验与邹氏预测检验两种类型的检验。
检验都是以F检验为主要检验工具,以受约束模型与无约束模型是否有显著差异为检验基点。
参数的非线性约束检验主要包括最大似然比检验、沃尔德检验与拉格朗日乘数检验。
它们仍以估计无约束模型与受约束模型为基础,但以最大似然χ分布为检验统计原理进行估计,且都适用于大样本情形,都以约束条件个数为自由度的2量的分布特征。
非线性约束检验中的拉格朗日乘数检验在后面的章节中多次使用。
二、典型例题分析例1.某地区通过一个样本容量为722的调查数据得到劳动力受教育的一个回归方程为36.0.+=-10+094medufedu.0sibsedu210131.0R2=0.214式中,edu为劳动力受教育年数,sibs为该劳动力家庭中兄弟姐妹的个数,medu与fedu分别为母亲与父亲受到教育的年数。
计量经济学第三章习题及答案
一、单项选择题1.多元线性回归分析中(回归模型中的参数个数为k),调整后的可决系数与可决系数之间的关系()A. B. ≥C. D.2.已知五元线性回归模型估计的残差平方和为,样本容量为46,则随机误差项的方差估计量为( )A. 33.33B. 40C. 38.09D. 203.多元线性回归分析中的 RSS反映了()A.因变量观测值总变差的大小B.因变量回归估计值总变差的大小C.因变量观测值与估计值之间的总变差D.Y关于X的边际变化4.在古典假设成立的条件下用OLS方法估计线性回归模型参数,则参数估计量具有()的统计性质。
A.有偏特性 B. 非线性特性C.最小方差特性 D. 非一致性特性5.关于可决系数,以下说法中错误的是()A.可决系数的定义为被回归方程已经解释的变差与总变差之比B.C.可决系数反映了样本回归线对样本观测值拟合优劣程度的一种描述D.可决系数的大小不受到回归模型中所包含的解释变量个数的影响二、多项选择题1.调整后的判定系数与判定系数之间的关系叙述正确的有()A.与均非负B.有可能大于C.判断多元回归模型拟合优度时,使用D.模型中包含的解释变量个数越多,与就相差越大E.只要模型中包括截距项在内的参数的个数大于1,则2.对多元线性回归方程(有k个参数)的显著性检验,所用的F统计量可表示为()A. B.C. D.E.三、判断题1.在对参数进行最小二乘估计之前,没有必要对模型提出古典假定。
2.一元线性回归模型与多元线性回归模型的基本假定是相同的。
3.拟合优度检验和F检验是没有区别的。
参考答案:一、单项选择题1.A2.D3.C4.C5.D二、多项选择题1.CDE 2.BE三、判断题1.答:错误。
在古典假定条件下,OLS估计得到的参数估计量是该参数的最佳线性无偏估计(具有线性、无偏性、有效性)。
总之,提出古典假定是为了使所作出的估计量具有较好的统计性质以便进行统计推断。
2.答:错误。
在多元线性回归模型里除了对随机误差项提出假定外,还对解释变量之间提出无多重共线性的假定。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第三章、经典单方程计量经济学模型:多元线性回归模型一、内容提要本章将一元回归模型拓展到了多元回归模型,其基本的建模思想与建模方法与一元的情形相同。
主要内容仍然包括模型的基本假定、模型的估计、模型的检验以及模型在预测方面的应用等方面。
只不过为了多元建模的需要,在基本假设方面以及检验方面有所扩充。
本章仍重点介绍了多元线性回归模型的基本假设、估计方法以及检验程序。
与一元回归分析相比,多元回归分析的基本假设中引入了多个解释变量间不存在(完全)多重共线性这一假设;在检验部分,一方面引入了修正的可决系数,另一方面引入了对多个解释变量是否对被解释变量有显著线性影响关系的联合性F检验,并讨论了F检验与拟合优度检验的内在联系。
本章的另一个重点是将线性回归模型拓展到非线性回归模型,主要学习非线性模型如何转化为线性回归模型的常见类型与方法。
这里需要注意各回归参数的具体经济含义。
本章第三个学习重点是关于模型的约束性检验问题,包括参数的线性约束与非线性约束检验。
参数的线性约束检验包括对参数线性约束的检验、对模型增加或减少解释变量的检验以及参数的稳定性检验三方面的内容,其中参数稳定性检验又包括邹氏参数稳定性检验与邹氏预测检验两种类型的检验。
检验都是以F检验为主要检验工具,以受约束模型与无约束模型是否有显著差异为检验基点。
参数的非线性约束检验主要包括最大似然比检验、沃尔德检验与拉格朗日乘数检验。
它们仍以估计无约束模型与受约束模型为基础,但以最大似然χ分布为检验统计原理进行估计,且都适用于大样本情形,都以约束条件个数为自由度的2量的分布特征。
非线性约束检验中的拉格朗日乘数检验在后面的章节中多次使用。
二、典型例题分析例1.某地区通过一个样本容量为722的调查数据得到劳动力受教育的一个回归方程为36.0.+=-10+094medufedu.0sibsedu210131.0R2=0.214式中,edu为劳动力受教育年数,sibs为该劳动力家庭中兄弟姐妹的个数,medu与fedu分别为母亲与父亲受到教育的年数。
问(1)sibs 是否具有预期的影响?为什么?若medu 与fedu 保持不变,为了使预测的受教育水平减少一年,需要sibs 增加多少?(2)请对medu 的系数给予适当的解释。
(3)如果两个劳动力都没有兄弟姐妹,但其中一个的父母受教育的年数为12年,另一个的父母受教育的年数为16年,则两人受教育的年数预期相差多少? 解答:(1)预期sibs 对劳动者受教育的年数有影响。
因此在收入及支出预算约束一定的条件下,子女越多的家庭,每个孩子接受教育的时间会越短。
根据多元回归模型偏回归系数的含义,sibs 前的参数估计值-0.094表明,在其他条件不变的情况下,每增加1个兄弟姐妹,受教育年数会减少0.094年,因此,要减少1年受教育的时间,兄弟姐妹需增加1/0.094=10.6个。
(2)medu 的系数表示当兄弟姐妹数与父亲受教育的年数保持不变时,母亲每增加1年受教育的机会,其子女作为劳动者就会预期增加0.131年的教育机会。
(3)首先计算两人受教育的年数分别为 10.36+0.131⨯12+0.210⨯12=14.452 10.36+0.131⨯16+0.210⨯16=15.816因此,两人的受教育年限的差别为15.816-14.452=1.364例2.以企业研发支出(R&D )占销售额的比重为被解释变量(Y ),以企业销售额(X1)与利润占销售额的比重(X2)为解释变量,一个有32容量的样本企业的估计结果如下:099.0)046.0()22.0()37.1(05.0)log(32.0472.0221=++=R X X Y其中括号中为系数估计值的标准差。
(1)解释log(X1)的系数。
如果X1增加10%,估计Y 会变化多少个百分点?这在经济上是一个很大的影响吗?(2)针对R&D 强度随销售额的增加而提高这一备择假设,检验它不虽X1而变化的假设。
分别在5%和10%的显著性水平上进行这个检验。
(3)利润占销售额的比重X2对R&D 强度Y 是否在统计上有显著的影响? 解答:(1)log(x1)的系数表明在其他条件不变时,log(x1)变化1个单位,Y 变化的单位数,即∆Y=0.32∆log(X1)≈0.32(∆X1/X1)=0.32⨯100%,换言之,当企业销售X1增长100%时,企业研发支出占销售额的比重Y 会增加0.32个百分点。
由此,如果X1增加10%,Y 会增加0.032个百分点。
这在经济上不是一个较大的影响。
(2)针对备择假设H1:01>β,检验原假设H0:01=β。
易知计算的t 统计量的值为t=0.32/0.22=1.468。
在5%的显著性水平下,自由度为32-3=29的t 分布的临界值为1.699(单侧),计算的t 值小于该临界值,所以不拒绝原假设。
意味着R&D 强度不随销售额的增加而变化。
在10%的显著性水平下,t 分布的临界值为1.311,计算的t 值小于该值,拒绝原假设,意味着R&D 强度随销售额的增加而增加。
(3)对X2,参数估计值的t 统计值为0.05/0.46=1.087,它比在10%的显著性水平下的临界值还小,因此可以认为它对Y 在统计上没有显著的影响。
例3.下表为有关经批准的私人住房单位及其决定因素的4个模型的估计量和相关统计值(括号内为p-值)(如果某项为空,则意味着模型中没有此变量)。
数据为美国40个城市的数据。
模型如下:μββββββββ++++++++=statetax localtax unemp popchangincome value density g hou 76543210sin式中housing ——实际颁发的建筑许可证数量,density ——每平方英里的人口密度,value ——自由房屋的均值(单位:百美元),income ——平均家庭的收入(单位:千美元),popchang ——1980~1992年的人口增长百分比,unemp ——失业率,localtax ——人均交纳的地方税,statetax ——人均缴纳的州税(1)检验模型A 中的每一个回归系数在10%水平下是否为零(括号中的值为双边备择p-值)。
根据检验结果,你认为应该把变量保留在模型中还是去掉? (2)在模型A 中,在10%水平下检验联合假设H 0:βi =0(i=1,5,6,7)。
说明被择假设,计算检验统计值,说明其在零假设条件下的分布,拒绝或接受零假设的标准。
说明你的结论。
(3)哪个模型是“最优的”?解释你的选择标准。
(4)说明最优模型中有哪些系数的符号是“错误的”。
说明你的预期符号并解释原因。
确认其是否为正确符号。
解答:(1)直接给出了P-值,所以没有必要计算t-统计值以及查t 分布表。
根据题意,如果p-值<0.10,则我们拒绝参数为零的原假设。
由于表中所有参数的p-值都超过了10%,所以没有系数是显著不为零的。
但由此去掉所有解释变量,则会得到非常奇怪的结果。
其实正如我们所知道的,多元回去归中在省略变量时一定要谨慎,要有所选择。
本例中,value 、income 、popchang 的p-值仅比0.1稍大一点,在略掉unemp 、localtax 、statetax 的模型C 中,这些变量的系数都是显著的。
(2)针对联合假设H 0:βi =0(i=1,5,6,7)的备择假设为H1:βi =0(i=1,5,6,7) 中至少有一个不为零。
检验假设H0,实际上就是参数的约束性检验,非约束模型为模型A ,约束模型为模型D ,检验统计值为462.0)840/()7763.4()37/()7763.47038.5()1/()/()(=-+-+-+=----=e e e k n RSS k k RSS RSS F U U R U U R显然,在H0假设下,上述统计量满足F 分布,在10%的显著性水平下,自由度为(4,32)的F 分布的临界值位于2.09和2.14之间。
显然,计算的F 值小于临界值,我们不能拒绝H0,所以βi (i=1,5,6,7)是联合不显著的。
(3)模型D 中的3个解释变量全部通过显著性检验。
尽管R2与残差平方和较大,但相对来说其AIC 值最低,所以我们选择该模型为最优的模型。
(4)随着收入的增加,我们预期住房需要会随之增加。
所以可以预期β3>0,事实上其估计值确是大于零的。
同样地,随着人口的增加,住房需求也会随之增加,所以我们预期β4>0,事实其估计值也是如此。
随着房屋价格的上升,我们预期对住房的需求人数减少,即我们预期β3估计值的符号为负,回归结果与直觉相符。
出乎预料的是,地方税与州税为不显著的。
由于税收的增加将使可支配收入降低,所以我们预期住房的需求将下降。
虽然模型A 是这种情况,但它们的影响却非常微弱。
4、在经典线性模型基本假定下,对含有三个自变量的多元回归模型:μββββ++++=3322110X X X Y你想检验的虚拟假设是H0:1221=-ββ。
(1)用21ˆ,ˆββ的方差及其协方差求出)ˆ2ˆ(21ββ-Var 。
(2)写出检验H0:1221=-ββ的t 统计量。
(3)如果定义θββ=-212,写出一个涉及β0、θ、β2和β3的回归方程,以便能直接得到θ估计值θˆ及其标准误。
解答:(1)由数理统计学知识易知)ˆ(4)ˆ,ˆ(4)ˆ()ˆ2ˆ(221121ββββββVar Cov Var Var +-=- (2)由数理统计学知识易知)ˆ2ˆ(1ˆ2ˆ2121ββββ---=se t ,其中)ˆ2ˆ(21ββ-se 为)ˆ2ˆ(21ββ-的标准差。
(3)由θββ=-212知212βθβ+=,代入原模型得μββθβμβββθβ+++++=+++++=33212103322120)2()2(X X X X X X X Y这就是所需的模型,其中θ估计值θˆ及其标准误都能通过对该模型进行估计得到。
三、习题(一)基本知识类题型 3-1.解释下列概念:1) 多元线性回归 2) 虚变量 3) 正规方程组 4) 无偏性 5) 一致性6) 参数估计量的置信区间 7) 被解释变量预测值的置信区间 8) 受约束回归 9) 无约束回归 10) 参数稳定性检验3-2.观察下列方程并判断其变量是否呈线性?系数是否呈线性?或都是?或都不是?1) i i i X Y εββ++=310 2) i i i X Y εββ++=log 10 3)i i i X Y εββ++=log log 104) i i i X Y εβββ++=)(210 5) i ii X Y εββ+=106) i i i X Y εββ+-+=)1(1107) i i i i X X Y εβββ+++=10221103-3.多元线性回归模型与一元线性回归模型有哪些区别?3-4.为什么说最小二乘估计量是最优的线性无偏估计量?多元线性回归最小二乘估计的正规方程组,能解出唯一的参数估计的条件是什么?3-5.多元线性回归模型的基本假设是什么?试说明在证明最小二乘估计量的无偏性和有效性的过程中,哪些基本假设起了作用? 3-6.请说明区间估计的含义。