Kettle开发使用手册
kettle技术手册

Kettle 技术手册Etl 介绍ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于金融IT 来说,经常会遇到大数据量的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少。
Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
kettle 部署运行将kettle2.5.1文件夹拷贝到本地路径,例如D 盘根目录。
双击运行kettle文件夹下的spoon.bat文件,出现kettle欢迎界面:稍等几秒选择没有资源库,打开kettle主界面创建transformation,job点击页面左上角的创建一个新的transformation,点击保存到本地路径,例如保存到D:/etltest下,保存文件名为EtltestTrans,kettle默认transformation文件保存后后缀名为ktr点击页面左上角的创建一个新的job,点击保存到本地路径,例如保存到D:/etltest下,保存文件名为EtltestJob,kettle默认job文件保存后后缀名为kjb 创建数据库连接在transformation页面下,点击左边的【Main Tree】,双击【DB连接】,进行数据库连接配置。
connection name自命名连接名称Connection type选择需要连接的数据库Method of access选择连接类型Server host name写入数据库服务器的ip地址Database name写入数据库名Port number写入端口号Username写入用户名Password写入密码例如如下配置:点击【test】,如果出现如下提示则说明配置成功点击关闭,再点击确定保存数据库连接。
kettle使用手册

kettle使用手册Kettle使用手册一、Kettle简介1.1 Kettle概述Kettle(也被称为Pentaho Data Integration)是一款开源的ETL(Extract, Transform, Load)工具,它能够从各种数据源中提取数据,并进行各种转换和加工,最后将数据加载到指定的目的地中。
Kettle具有强大的数据处理功能和友好的图形化界面,使得数据集成和转换变得简单而高效。
1.2 功能特点- 数据抽取:从多种数据源中提取数据,包括关系型数据库、文件、Web服务等。
- 数据转换:支持多种数据转换操作,如字段映射、类型转换、数据清洗等。
- 数据加载:将转换后的数据加载到不同的目的地,如数据库表、文件、Web服务等。
- 调度管理:支持定时调度和监控,可自动执行数据集成任务。
二、安装与配置2.1 系统要求在安装Kettle之前,请确保满足以下系统要求: - 操作系统:Windows、Linux、Unix等。
- Java版本:JDK 1.8及以上。
- 内存:建议至少4GB的可用内存。
2.2 安装Kettle最新版本的Kettle安装包,并按照安装向导进行安装。
根据系统要求和个人需求进行相应的配置选项,完成安装过程。
2.3 配置Kettle在安装完成后,需要进行一些配置以确保Kettle正常运行。
具体配置步骤如下:- 打开Kettle安装目录下的kettle.properties文件。
- 根据实际需要修改配置项,如数据库连接、日志路径、内存分配等。
- 保存修改并重启Kettle。
三、Kettle基础操作3.1 数据抽取3.1.1 创建数据源连接打开Kettle,左上角的“新建连接”按钮,在弹出的窗口中选择待抽取的数据源类型(如MySQL、Oracle等),填写相关参数并测试连接。
3.1.2 设计数据抽取作业- 打开Kettle中的“转换”视图。
- 从左侧的工具栏中选择适当的输入组件(如“表输入”或“文件输入”),将其拖拽到设计区域中。
kettle使用手册
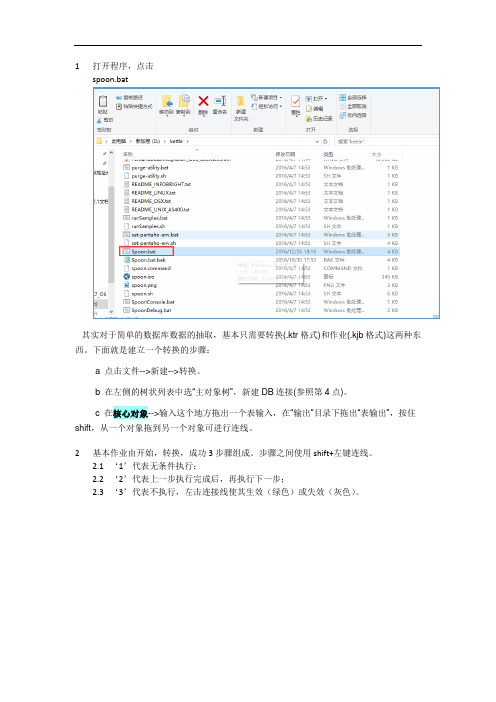
1打开程序,点击spoon.bat其实对于简单的数据库数据的抽取,基本只需要转换(.ktr格式)和作业(.kjb格式)这两种东西。
下面就是建立一个转换的步骤:a 点击文件-->新建-->转换。
b 在左侧的树状列表中选“主对象树”,新建DB连接(参照第4点)。
c 在核心对象-->输入这个地方拖出一个表输入,在“输出”目录下拖出“表输出”,按住shift,从一个对象拖到另一个对象可进行连线。
2基本作业由开始,转换,成功3步骤组成。
步骤之间使用shift+左键连线。
2.1‘1’代表无条件执行;2.2‘2’代表上一步执行完成后,再执行下一步;2.3‘3’代表不执行,左击连接线使其生效(绿色)或失效(灰色)。
3打开具体步骤中的转换流程,点击‘Transformation’跳转至相应具体转换流程,编辑此转换具体路径,双击转换,弹出窗口,‘1’为相对路径,点击‘2’选择具体Visit.ktr 转换,为绝对路径。
4建立数据库连接,输入相应信息测试,成功即可图45转换具体设置,如图4,‘表输出’至‘文本文件输出’流程跳接线为错误处理步骤,当输出格式不能满足表输出的目的表结构类型时,将会将记录输出到‘文本文件输出’中的记录中。
5.1双击‘表输入’,输入相应的SSQL语句,选择配置数据库连接,或新增,预览查询生成的结果(如果数据库配置中使用变量获取,此处预览生成错误)。
5.2双击‘表输出’,选择数据库连接,‘浏览’选择相应目标表,(此处‘使用批量插入’勾选去除,目的是在错误处理步骤中无法使用批量处理,可能是插件兼容问题)6表输出插件定义a) Target Schema:目标模式。
要写数据的表的Schema的名称。
允许表明中包含“。
”对数据源来说是很重要的b) 目标表:要写数据的表名。
c) 提交记录数量:在数据表中用事物插入行。
如果n比0大,每n行提交一次连接。
否则不使用事务,速度会慢一些。
d) 裁剪表:在第一行数据插入之前裁剪表。
Kettle开发使用手册

Kettle开发使用手册Kettle开发使用手册4月版本历史说明1.Kettle介绍1.1.什么是KettleKettle是纯Java编写的、免费开源的ETL工具,主要用于抽取(Extraction)、转换(Transformation)、和装载(Loading)数据。
Kettle中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
在这种思想的设计下,Kettle广泛用于不同数据库之间的数据抽取,例如Mysql 数据库的数据传到Oracle,Oracle数据库的数据传到Greenplum数据库。
1.2.Kettle的安装Kettle工具是不需要安装的,直接网上下载解压就能够运行了。
不过它依赖于Java,需要本地有JDK环境,如果是安装4.2或5.4版本,JDK需要1.5以上的版本,推荐1.6或1.7的JDK。
运行Kettle直接双击里面的批处理文件spoon.bat就行了,如图 1.1所示:图1.12.Kettle脚本开发2.1.建立资源库(repository仓库)Repository仓库是用来存储所有kettle文件的文件系统,由于数据交换平台服务器管理kettle文件也是用Repository仓库,因此我们这边本地的kettle开发环境也是要用到该资源库。
建立资源库的方式是工具 --> 资源库- -> 连接资源库,这时候弹出一个窗口,我们点击右上角的“+”号,跟着点击下面的kettle file repository选项,按确定,如图2.1所示:图2.1跟着在右上角选择一个目录,建议在kettle路径下新建repository文件夹,再选择这个文件夹作为根目录,名称和描述能够任意写,如图2.2所示:。
kettle操作手册

1.什么Kettle?Kettle是一个开源的ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)项目,项目名很有意思,水壶。
按项目负责人Matt的说法:把各种数据放到一个壶里,然后呢,以一种你希望的格式流出。
Kettle包括三大块:Spoon——转换/工作(transform/job)设计工具(GUI方式)Kitchen——工作(job)执行器(命令行方式)Span——转换(trasform)执行器(命令行方式)Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
2.Kettle简单例子2.1下载及安装Kettle下载地址:/projects/pentaho/files现在最新的版本是 3.6,为了统一版本,建议下载 3.2,即下载这个文件pdi-ce-3.2.0-stable.zip。
解压下载下来的文件,把它放在D:\下面。
在D:\data-integration文件夹里,我们就可以看到Kettle的启动文件Kettle.exe或Spoon.bat。
2.2 启动Kettle点击D:\data-integration\下面的Kettle.exe或Spoon.bat,过一会儿,就会出现Kettle的欢迎界面:稍等几秒,就会出现Kettle的主界面:2.3 创建kettle后台管理点击【新建】,新建资源库信息这里我们选择KETTLE 后台管理数据库的类型,以及配置JDBC设置完成后,点击【创建或更新】,将会在指定的数据库里面新建KETTLE的后台管理数据表。
再设置【名称】,点击【确定】。
回到登陆界面,选择新建的【资源库】,输入用户账号密码(默认账号:admin,密码:admin)进入KTETTLE 的开发界面2.4 kettle说明主对象树:转换(任务),作业(JOB)核心对象:主对象中可用的组件2.5 值映射组件使用的字段名:源字段目标字段名:目标字段源值:源数据的值目标值:替换的值注:最好先将源值去空格,再进行替换2.6 增加常量组件名称:映射字段类型:字段类型格式:数据格式长度:值:常量的值2.7计算器组件新字段:映射字段计算:计算类型字段A,B,C:需计算的字段值类型:数据的类型2.8获取系统信息组件名称:显示的名称类型:显示的类型(系统时间,IP,指令等等)2.9增加序列组件值的名称:映射值的名称起始值:序列的初始值增加值:设置增加的值最大值:设置最大值2.10 表输出组件数据库连接:设置数据库目标表:设置目标的表提交记录数量:设置提交数量忽略插入错误:跳过错误,继续执行指定库字段:数据库字段:选择插入的字段2.11 多路选择(Switch/Case) 组件更多路选择的字段:设置Switch的字段分支值的数据类型:设置值的类型分支值:值:设置case的值目标步骤:跳过的操作步骤缺省的目标步骤:未通过的操作步骤2.12 Null if... 组件名称:选择替换的字段需要转换成NULL的值:需要转换成NULL的值2.12 执行SQL脚本组件数据库连接:选择数据库SQL script :输入要执行的SQL语句参数:设置要替换的参数字段2.13 Modified Java Script Value 组件Java Script:脚本的输入:输入字段:输出字段字段名称:定义的字段名改成为:新的字段名类型:字段类型Replace Value:是否替换的值2.14 合并记录组件旧数据源:输入数据源新数据源:输入数据源匹配关键字段:匹配关键字段数据字段:数据字段2.15 记录关联(笛卡尔输出) 组件条件:输入关联的条件2.16 Merge Join 组件第一个步骤:第一个操作的步骤第二个步骤:第二个操作的步骤步骤选择的字段:步骤关联的字段2.17 行转列组件关键字:选择表的关键字分组字段:分组的字段目标字段:选择目标在字段VALUE:值字段名称关键字值:关键字值类型:数据类型2.18 生成随机值组件名称:新生成字段名类型:随机数的类型2.19 去除重复行组件字段名称:关键字的字段忽略大小写:是否忽略大小写注意:去掉重复行需先排序2.20 插入/ 更新组件数据库连接:选择数据库目标表:选择目标表不执行任何更新:是否执行更新操作查询的关键字:关键字更新字段:选择要插入更新的字段2.21 表输入组件数据库连接:选择数据库SQL:输入SQL语句预览:数据预览获得SQL查询语句:获得SQL查询语句2.22 排序记录组件字段名称:选择排序的字段名称升序:是否升序大小写敏感:是否区分大小写2.23 XML输出组件文件名称:输出文件的名称跟路径扩展:扩展名2.24 文本文件输出组件文件名称:输出文件的名称跟路径扩展:扩展名2.25 Write to log 组件日志级别:选择日志级别字段:选择打印的字段2.26 过滤记录组件条件:输入条件发送True给的步骤:返回True的步骤发送false给的步骤:返回false的步骤2.27 JOB定时组件重复:是否重复类型:选择类型2.28 转换组件转换文件名:选择执行转换的文件指定日志文件:输出日志文件2.5 命令行运行ktr和kjb在上面的过程中,我们都是在IDE工具中,直接点击按钮进行运行文件的,但在实际中,我们需要脱离IDE,进行单独的运行,这时就必须用到命令行来运行文件了。
Kettle的使用说明

KETTLE使用说明简介Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle可以在/网站下载到。
注:ETL,是英文Extract-Transform-Load 的缩写,用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程。
ETL 一词较常用在数据仓库,但其对象并不限于数据仓库。
下载和安装首先,需要下载开源免费的pdi-ce软件压缩包,当前最新版本为5.20.0。
下载网址:/projects/pentaho/files/Data%20Integration/然后,解压下载的软件压缩包:pdi-ce-5.2.0.0-209.zip,解压后会在当前目录下上传一个目录,名为data-integration。
由于Kettle是使用Java开发的,所以系统环境需要安装并且配置好JDK。
žKettle可以在/网站下载ž 下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可。
运行Kettle进入到Kettle目录,如果Kettle部署在windows环境下,双击运行spoon.bat 或Kettle.exe文件。
Linux用户需要运行spoon.sh文件,进入到Shell提示行窗口,进入到解压目录中执行下面的命令:# chmod +x spoon.sh# nohup ./spoon.sh & 后台运行脚本这样就可以打开配置Kettle脚本的UI界面。
Kettle配置使用说明

Kettle配置使用说明Kettle配置使用说明1.文件结构1.1 kettle4.0.1该文件夹存放的是kettle4.0.1的桌面应用程序,/kettle4.0.1/Spoon.bat是运行软件的一个批处理文件,双击运行。
1.2 workspace该文件夹存放的是以各个警种总队全拼命名的分别存放.ktr文件和.job文件的文件夹。
Start.job是一个启动总纲。
1.3 script该文件夹是存放的数据库建库脚本,目前是oracle10g版本1.4 model存放的是powerDesign的cdm概念模型文件用于根据需要生成pdm和script。
2.文件路径配置本系统使用的都是系统所在路径的相对路径,不管处于什么目录下都请将kettle4.0.1和workspace的文件夹放在同一目录之下。
当然你可以随意改变文件夹的名称。
3.运行环境配置先运行一次/kettle4.0.1/Spoon.bat,Linux就不说了,如果你用的是windows系统,那么你可以在/${userhome}/.kettle下找到一个.kettle的文件夹主要说下:Response.xml-记录资源库信息(自己去勾)Kettle.property-这是好东西,可以让你在软件中任何可以使用到环境变量的地方使用到里面的配置信息(键-值对配置),类似全局变量。
当然是有利有弊,配置点什么数据库连接和一些常用的东西之外别把那里当仓库,想下全局变量定义的多了会给系统带来什么风险。
A_fileInput=file:///E:/Test_Server/srcFile/A_fileOutput=file:///E:/Test_Server/errFile/这2个属性是配置读取的Excel文件和输出错误的Excel文件用到的路径配置。
由于文件名命名的差异和存放位置的不同需要使用者自行配置。
有在系统内修改文件路径的风险,当然这是没有办法避免的,只能在项目初期和用户有这方面的约定俗成。
Kettle用户操作手册1

Kettle用户操作手册1.kettle介绍1.1 什么是kettleKettle是“Kettle E.T.T.L. Envirnonment”只取首字母的缩写,这意味着它被设计用来帮助你实现你的ETTL 需要:抽取、转换、装入和加载数据;它的名字起源正如该项目的主程序员MATT所说:希望把各种数据放到一个壶里然后以一种指定的格式流出。
Spoon是一个图形用户界面,它允许你运行转换或者任务。
1.2 Kettle 的安装要运行此工具你必须安装 Sun 公司的JAVA 运行环境1.4 或者更高版本,相关资源你可以到网络上搜索JDK 进行下载,Kettle 的下载可以到取得最新版本。
1.3 运行SPOON下面是在不同的平台上运行Spoon 所支持的脚本:Spoon.bat: 在windows 平台运行Spoon。
Spoon.sh: 在Linux、Apple OSX、Solaris 平台运行Spoon。
1.4 资源库一个Kettle资源库可以包含那些转换信息,这意味着为了从数据库资源中加载一个转换就必须连接相应的资源库。
在启动SPOON的时候,可以在资源库中定义一个数据库连接,利用启动spoon时弹出的资源库对话框来定义,如图所示:单击加号便可新增;关于资源库的信息存储在文件“reposityries.xml”中,它位于你的缺省home 目录的隐藏目录“.kettle”中。
如果是windows 系统,这个路径就是c:\Documents and Settings\<username>\.kettle。
如果你不想每次在Spoon 启动的时候都显示这个对话框,你可以在“编辑/选项”菜单下面禁用它。
admin 用户的缺省密码也是admin。
如果你创建了资源库,你可以在“资源库/编辑用户”菜单下面修改缺省密码。
1.5 定义1.5.1 转换主要用来完成数据的转换处理。
转换步骤,可以理解为将一个或者多个不同的数据源组装成一条数据流水线。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Kettle开发使用手册2017年4月版本历史说明1.Kettle介绍1.1.什么是KettleKettle是纯Java编写的、免费开源的ETL工具,主要用于抽取(Extraction)、转换(Transformation)、和装载(Loading)数据。
Kettle中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
在这种思想的设计下,Kettle广泛用于不同数据库之间的数据抽取,例如Mysql数据库的数据传到Oracle,Oracle数据库的数据传到Greenplum数据库。
1.2.Kettle的安装Kettle工具是不需要安装的,直接网上下载解压就可以运行了。
不过它依赖于Java,需要本地有JDK环境,如果是安装4.2或5.4版本,JDK需要1.5以上的版本,推荐1.6或1.7的JDK。
运行Kettle直接双击里面的批处理文件spoon.bat就行了,如图1.1所示:图1.12.Kettle脚本开发2.1.建立资源库(repository仓库)Repository仓库是用来存储所有kettle文件的文件系统,由于数据交换平台服务器管理kettle文件也是用Repository仓库,因此我们这边本地的kettle开发环境也是要用到该资源库。
建立资源库的方式是工具 --> 资源库- -> 连接资源库,这时候弹出一个窗口,我们点击右上角的“+”号,跟着点击下面的kettle file repository选项,按确定,如图2.1所示:图2.1跟着在右上角选择一个目录,建议在kettle路径下新建repository文件夹,再选择这个文件夹作为根目录,名称和描述可以任意写,如图2.2所示:图2.2建完后会kettle工具会自动连接到repository资源库,每次打开kettle 也会弹出一个窗口让你先连接到资源库。
在连接到资源库的情况下打开文件就是资源库所在目录了,如图2.3所示。
注意你在资源库建的目录结构要跟数据交换平台的目录结构一致,这样写好kettle脚本,保存后放的路径能跟交换平台的目录结构一致了。
图2.32.2.在目标数据库里新建表在做数据迁移的时候我们需要先在目标数据库建立与源数据库类似的表结构,才能在这两张表之间做数据迁移,以oracle数据库到gp数据库,T_SF_DWJFDJXX_TEST表做数据迁移为例,我们先建类似的表结构,首先先把表结构的代码拷出来:create table T_SF_DWJFDJXX_TEST(NSRNBM NUMBER(10) not null,DWSBH VARCHAR2(18) not null,JFDWNBM NUMBER(10) not null,HYFL_DM CHAR(1) not null,JFDWLX_DM CHAR(3) not null,SBJC_DM CHAR(2) not null,SBGLJG_DM VARCHAR2(11) not null,SWGLJG_DM VARCHAR2(11) not null,SBDJ_ZT CHAR(2) not null,DJSLRY_DM VARCHAR2(11),DJSL_RQ DATE,LRRY_DM VARCHAR2(11),XGRY_DM VARCHAR2(11),DJ_RQ DATE,DJJG_DM VARCHAR2(11),LR_SJ TIMESTAMP(6),XG_SJ TIMESTAMP(6),ZDFY_BJ CHAR(1),XMMC VARCHAR2(100),KNQYBZ_DM CHAR(1),ZDYCKJN_BJ CHAR(1),SJJHPT_SJ TIMESTAMP(6),SJJHPT_DZ NUMBER(14));跟着在这个表结构的基础上,在目标数据库创建新表。
需要注意的是,gp数据库的数据类型有些跟oracle的一样,有些不同。
相同的就不用改了,不同的就改下。
以上面的数据类型为例,相同的有char、date、timestamp,不同的是varchar2和number,因此,varchar2(n)要改成varchar(n),number(n)要改成integer(注意不带数字长度n)。
建完之后,我们就可以在这不同数据库的两张表之间进行数据迁移或数据定时传输。
2.3.源数据库和目标数据库的jndi设置Jndi是kettle连接数据库的配置文件,相当于oracle的tns。
Jndi设置的目录是在kettle目录下的simple-jndi文件夹里,打开后编辑jdbc.properties 来设置jndi,下面附上公司揭阳涉税项目oracle 到gp数据库的jndi设置,分别是源端oracle数据库和目标端gp数据库。
配置信息的斜杠左边是jndi名,这里jndi的命名规则是数据库名_用户名,注意本地的jndi名要跟交换平台的jndi名一致。
配置信息的斜杠右边分别是数据库类型、驱动、数据库地址、用户名和密码。
注意,相同数据库配置写法相同,不同数据库的配置写法略有不同,像下面的oracle和gp数据库的driver和url地址写法就不一样。
oracle_db_mhpt/type=javax.sql.DataSourceoracle_db_mhpt/driver=oracle.jdbc.driver.OracleDriveroracle_db_mhpt/url=jdbc:oracle:thin:@172.16.11.91:1521:zrmhdboracle_db_mhpt/user=db_mhptoracle_db_mhpt/password=DB_MHPTgp_public/type=javax.sql.DataSourcegp_public/driver=org.postgresql.Drivergp_public/url=jdbc:postgresql://172.16.11.165:5432/postgresgp_public/database=8gp_public/user=gpadmingp_public/password=gpadmin2.4.写kettle脚本Kettle脚本有两种,ktr脚本跟kjb脚本,其中ktr负责执行,具体要做什么由ktr来负责;kjb负责调度,调用一个或多个ktr。
Ktr和kjb的关系类似于像员工和领导之间,员工负责具体的事务操作,领导负责计划安排工作。
新建ktr脚本可以点击左上角的文件 --> 新建 --> 转换,新建kjb脚本就文件 --> 新建 --> 作业。
我们这里传输数据只要用到kjb脚本,一张表的数据传输要有1个脚本。
首先先新建一个ktr文件,如图2.4所示,跟着我们按照主界面的提示拖动主键来操作。
拖动组件在核心对象的组件库里。
图2.4跟着我们需要4个组件,分别是获取变量、表输入、字符串操作、插入/更新,先从组件库里找到这些组件然后拖动到右边面板上,查找组件可以用组件名称来在组建的搜索框里搜索。
拖动后如图2.5所示。
图2.5然后给他们组件之间建立连接,用拉箭头来连接即可,如图2.6所示:图2.6组件之间连接完之后,跟着双击组件一个个编辑。
第一步是获取变量,在获取变量前首先要设置入参用来获取变量,设置变量先双击主对象树的ktr名(转换1是未保存文件到本地的默认名),跟着设置命名参数。
如图2.7跟2.8所示。
其中start_timestamp和end_timestamp这两个是数据交换平台服务器上默认的用于增量抽取数据的两个入参,分别表示数据开始时间跟数据结束时间。
这里填上了默认值方便测试。
图2.7 图2.8设置入参后再编辑获取变量的组件,这里名称跟入参一样,kettle变量名的写法是${Variables},类型我们选择string,因为服务器上交换平台传进来的start_timestamp和end_timestamp参数也是string类型的,我们这里跟它一致。
也如图2.9所示:图2.9第二步是表输入,首先要先连接数据库,之前我们在本地文件上配置了jndi,这里jndi就用得上。
新建或编辑数据库连接,选择好连接的数据库,还有jndi 连接方式,再填上jndi名称和连接名称,设置完了就点击左下角的测试来测试本地能不能连上数据库。
连上了我们才做其他的步骤。
图2.10连通好后,写好sql语句。
这里sql语句用到变量,kettle变量的写法是${variables},而使用变量要在左右两端再加上单引号,变成’${variables}’。
注意数据库后台的日期类型是date,而变量是字符串类型,因此需要做个变量的类型转换。
因为有使用变量,所以需要勾上“替换sql语句里的变量”单选框。
设置好后可以预览下数据看下。
图2.11第三步是字段去除左右空格,编辑“字符串操作”,点get fields获取从上个步骤表表输入获取的字段名,然后把trim type全部选择both,意思是去除字段左右两端的空格。
如果get fields得到的字段有start_timestamp和end_timestamp这两个,这两个多余的,就删去。
如下图所示:图2.12第四步是插入数据到目标端的新表,首先是要先连通目标端的数据库。
设置好后再点击“测试”连通到目标端的数据库。
图2.13跟着是设置目标表(目标模式可以不填),点击浏览选择模式/用户下的数据库表。
然后设置每插入多少条数据提交的提交记录数量,用来查询的关键字选择主键的字段,而更新字段是全部,点击获取字段即可。
他这里操作的原理是:如果目标表有符合该查询的条件的记录时,那么更新此条数据;不符合时,那么将源表的此条数据插入到目标表。
图2.14这四个步骤编辑完成后最后就是执行这四个步骤了,点击左上角的运行图标,设置时间参数或者时间参数按照默认值,运行后,如果全部组件都有绿色勾勾的标志的话说明全部运行成功,如下图所示。
如果某一个步骤失败的话就是红色勾勾的标志,这时候就要看日志或者步骤度量来分析了。
从下面的步骤度量看表输入有1条数据输入进来,插入/更新步骤有1条数据写进去了。
图2.153.在数据交换平台设置定时任务以公司这边的数据交换平台为例(http://172.16.11.17:9001/WebContentadmin/admin),如果交换平台的jndi设置没有设置的话,那么要首先设置这样跑kettle脚本的话才能连到数据库,注意本地kettle的jndi名要跟交换平台的jndi名一致,需要统一命名。
图3.1跟着将脚本放上服务器,可以在页面上上传文件到服务器。
图3.2上传好后,需要先跑一回脚本跑成功才能设置定时调度,所以我们先运行一次。