基于用户投票的六大排名算法研究讲解
推荐系统的常用算法

推荐系统的常⽤算法参考回答:推荐算法:基于⼈⼝学的推荐、基于内容的推荐、基于⽤户的协同过滤推荐、基于项⽬的协同过滤推荐、基于模型的协同过滤推荐、基于关联规则的推荐FM:LR:逻辑回归本质上是线性回归,只是在特征到结果的映射中加⼊了⼀层逻辑函数g(z),即先把特征线性求和,然后使⽤函数g(z)作为假设函数来预测。
g(z)可以将连续值映射到0 和1。
g(z)为sigmoid function.则sigmoid function 的导数如下:逻辑回归⽤来分类0/1 问题,也就是预测结果属于0 或者1 的⼆值分类问题。
这⾥假设了⼆值满⾜伯努利分布,也就是其也可以写成如下的形式:对于训练数据集,特征数据x={x1, x2, … , xm}和对应的分类标签y={y1, y2, … , ym},假设m个样本是相互独⽴的,那么,极⼤似然函数为:log似然为:如何使其最⼤呢?与线性回归类似,我们使⽤梯度上升的⽅法(求最⼩使⽤梯度下降),那么。
如果只⽤⼀个训练样例(x,y),采⽤随机梯度上升规则,那么随机梯度上升更新规则为:Embedding:Embedding在数学上表⽰⼀个maping:,也就是⼀个function。
其中该函数满⾜两个性质:1)injective (单射的):就是我们所说的单射函数,每个Y只有唯⼀的X对应;2)structure-preserving(结构保存):⽐如在X所属的空间上,那么映射后在Y所属空间上同理。
那么对于word embedding,就是找到⼀个映射(函数)将单词(word)映射到另外⼀个空间(其中这个映射具有injective和structure-preserving的特点),⽣成在⼀个新的空间上的表达,该表达就是word representation。
●协同过滤的itemCF,userCF区别适⽤场景参考回答:Item CF 和 User CF两个⽅法都能很好的给出推荐,并可以达到不错的效果。
百度排名算法到底有什么原理
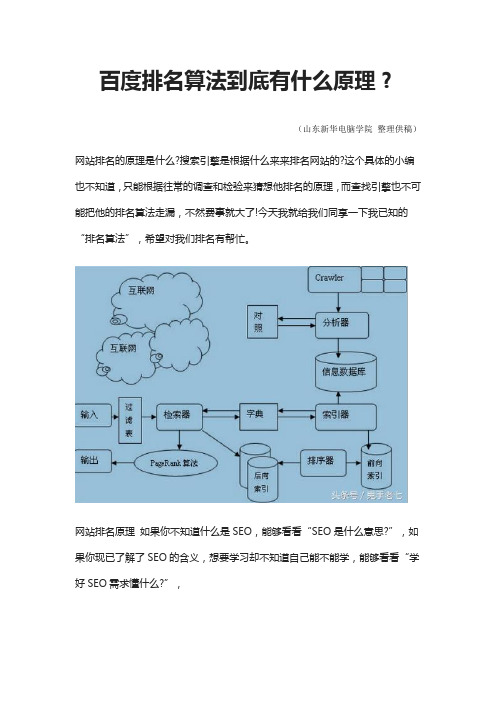
百度排名算法到底有什么原理?(山东新华电脑学院整理供稿)网站排名的原理是什么?搜索引擎是根据什么来来排名网站的?这个具体的小编也不知道,只能根据往常的调查和检验来猜想他排名的原理,而查找引擎也不可能把他的排名算法走漏,不然费事就大了!今天我就给我们同享一下我已知的“排名算法”,希望对我们排名有帮忙。
网站排名原理如果你不知道什么是SEO,能够看看“SEO是什么意思?”,如果你现已了解了SEO的含义,想要学习却不知道自己能不能学,能够看看“学好SEO需求懂什么?”,下面进入正题:在讲排名规则之前,我们先要了解什么是网站排名,排名的方针是什么?网站排名:就是访客在查找引擎文本框输入关键词,而查找引擎通过关键词检索查找引擎数据库,并根据匹配相似度来摆放,这也就有了网站排名的先后。
排名的方针:一个页面我们称之为网页,而多个页面组合在一同我们称之为网站,而我们优化、排名的方针其实是单独的网页。
所以我们往常经常说:网站排名、网站优化,专业正确的说法应该是网页优化、网页排名。
那么百度根据什么来摆放这些网页呢?排名规则一:超链接,外链查找引擎知道我们的网站有两个方法,一个是我们主动提交;另一个就是查找引擎程序通过其他网站找到了我们的网站;而第二种就是所谓的超链接也就是外链。
虽然现在许多SEOER一贯再说外链效果几乎没有了,查找引擎也一贯再说降低了外链的效果,但不得不说外链仍然是一个很重要的排名要素。
通过分析链接网站的数量来评价其被链接的网站的质量怎样,这样的效果就是,保证了用户在运用查找引擎时,质量越高、越受欢迎的页面越靠前。
简略来讲,判定某个页面是否优异或许声威,其它的页面的“定见”是非常重要的。
即便一个网页并不那么优异,但是只需其他网页对它的“信任投票”(反向链接)超过了其它页面,那么它的排名也会靠前,甚至排名第一。
外链虽然重要,但它并不仅仅是仅有的排名要素。
排名规则二:关联度,相关性不论是外链仍是站内,相关性都是非常重要的,访客查找一个词,如果他查找的词与我们网站本身设定的关键词相关联,那么我们的网站就可能参与排名。
关键词排名规则(古怪科技)

规则一、用户投票我们知道用户投票算法是百度在2004年时候提出的,之前是匹配算法。
其实大家每个人都有自己的搜索引擎,就像站内搜索一样,这就是匹配算法,把标题、内容与用户搜索的关键词进行匹配,把结构反馈给用户。
那么百度为什么会提出投票算法,因为投票算法就是他人对你网站的评价,当你发现一个好的东西你会把它分享给你的朋友,分享传播就会产生链接,投票算法的价值在于投票推荐。
那么投票是不是越多越好呢?其实不一定,关键还要看用户是不是真心实意的帮你推荐,链接的质量度还要高。
百度绿萝算法1.0与2.0就是打击作弊投票算法的。
有些站长在网页源代码里加了nofollow,告诉搜索引擎不要传递权重。
操作注意点:投递链接不能只发一个链接;不要在同一个平台发布;链接的价值在于被用户点击;规则二、关键词匹配A、你要做的关键词需要出现在网站标题上面,网站标题一般会告诉用户网站的主题内容,是做什么;B、你要做的关键词需要出现在网站的内容里面,没有必要特点增加,自然一点就可以,不能挂羊头卖狗肉;C、在做链接的锚文本也要出现关键词,用户投票推荐;规则三、内容相关网站要怎么更新,更新多少合适,为什么发的网站没有被百度收录,原创文章真的高质量吗?其实不一定。
发布的文章要与网站主题相关,不能发与网站主题无关的文章,不然不会被收录,而且对降低网站的综合得分。
规则四、用户体验用户体验算法是用户的对你网站的满意度,如果一个用户看到你的网站他没有去点击,或者点击了之后没有去点击其他页面,没有页面停留时间,访问轨迹,跳出率等等。
那么百度用户体验到底应该怎么做?规则五、SEO作弊我们知道搜索引擎有二个名单,白名单与黑名单,黑名单通过人工判断放入作弊的SEO网站,通过白名单与黑名单数据,工程师写算法告诉搜索引擎黑名单的网站都有哪些特征,比如:外链暴涨,在文章里加内链,内容全部复制被人的。
如果网站被降权的可以去看下网站降权的原因分析及解决办法。
基于用户预测的推荐算法研究

基于用户预测 的推荐 算法研 究
于奕 L ( 1 . 湘潭大学 ,长沙 4 1 1 1 0 5;2 . 湖南生物机电职业技术学 院 长沙 4 1 1 1 0 5 ) 摘 要 :B 2 C只是一个过渡性的商业模式 ,未来 电子 商务真正模式是 C 2 B 。推荐 系统是在 电子商务 平台上常见的一
是什 么新鲜 事 ,网购 以其便 捷性 、丰富性 等优 点深 入人 心 。 然 而 . 目前 的 网购 是 建 立 在 传 统 的 生 产 零 售 体 系 之 上 的 . 电 子 商务 只是 用 互 联 网 的手 段 把 零 售 的效 率 提 升 了 。 目前 电 子 商 务 主 流 都 是 B 2 C f B u s i n e s s t o C u s t o me r企 业 对 客 户) 。C 2 B( 即C u s t o m e r t o B u s i n e s s 客 户 对 企 业 )模 式 最 早 是 阿 里 巴 巴集 团 总 参 谋 长 曾 鸣 提 出 来 的 。 在 C 2 B模 式 中 .消 费 者 的需 求 是 提 前 确 定 的 ,这 样 就 能 精 确 生 产 , 提 高 供 应 链 效 率 ,减 少 库 存 。 实 现 C 2 B模 式 最 大 的难 点 是 确 定 消 费 者 的 需 求 。 目前 ,市 面 上 最 普 遍 的做 法 是 先 列 出 多 款 产 品 请 消 费 者 根 据 喜 好 进 行 投 票 ,最 后 选 出 得 票 高 的 产 品进 行 生 产 。 而 提 出根 据 推 荐 算 法 得 出 客 户 的需 求 ,将 可 能 是 一 个 新 的 方 式 来
Ke y wo r d s :El e c t on r i c c o mme c e; r Re c o mme n dபைடு நூலகம்a t i o n s y s t e m; p r e d i c t i o n Us e r N e e d; P e r s o n li a z e d; C o l l a b o r a t i o n p l a f t o r m
客户需求优先级排定的八个维度!(马上收藏)

客户需求优先级排定的八个维度!(马上收藏)因为工作需要,我查阅了网络上常规的几种需求优先级排序方法结合实际工作经验,选取了比较重要的8个维度。
理论上8个维度已经非常充足,真实使用中不必完全使用。
可以选取重要的维度进行判断,通过新的权重分配,得到最后的优先级评估结果。
以下所有评估默认五分制进行,在通过加权求得最后的需求优先级评估值。
评估值越大,优先级越高。
为了降低模型的主观因素,建议每个维度由多人进行打分,取平均分会有更好的效果。
最后,由于模型是线性的,仅起到参考作用,还是需要产品经理做出最终决策。
1. 目标契合度(20%)目标对需求优先级的影响非常关键,因为目标体现了需求实现的最终价值。
我们需要结合产品当前阶段和Roadmap,进行需求契合程度的判断。
2. 需求价值(10%)需求价值分为用户价值,公司价值两块来分析,使用四象限法进行分数指标的确定。
在不同的产品类型侧重的价值方向不同,所以究竟是用户价值更重要还是公司价值更重要是需要通过自己判断的。
但如果两者都体现了很好的价值,那么评分自然可以较高。
3. Kano模型(10%)Kano模型是非常经典的判断模型,包含基本型需求>期望型需求>兴奋型需求实际运用中需要根据现有需求的分布情况进行综合判断,有时期望形的需求可以比必须需求更重要。
因为必须需求也要看用户群范围,如果必须需求的用户群并不大,或者现有产品阶段的必须需求覆盖面已经较广时,期望需求评分可以更高。
4. 重要紧急程度(10%)重要紧急程度的分析可以运用在众多领域,包含重要且紧急>重要不紧急>紧急不重要>不重要也不紧急。
比较简单,不做赘述。
5. ROI投入产出比(20%)投入产出建议将投入分两部分进行分析,投入包含产品设计和产品实现两个阶段,这两个阶段有时并不会等价。
产出也需要进行细致分析,因为通常而言,产出和时间的关系非常大,有些产品的长尾效应非常严重。
6. 需求来源(10%)需求来源也是一个参考维度,因为谁提的需求可以用来判断需求的真实场景和缘由。
投票计分算法

投票计分算法通常用于评估投票者的满意度或支持度,以便对结果进行排名或分类。
下面是一个简单的投票计分算法的示例,以800字进行描述:假设我们有一个投票系统,用户可以对自己喜欢的选项进行投票。
我们希望根据用户投票的次数和积极程度来给用户分配积分。
算法如下:1. 初始化积分池为100分,每个用户初始积分相同。
2. 对于每个投票,将该投票对应的积分从积分池中扣除,并增加对应用户的积分。
3. 对于每个投票,根据投票的积极程度(如是否为连续投票、是否为高票数投票等),给予额外的积分奖励。
例如,连续投票可以获得额外积分奖励,高票数投票可以获得更多的积分奖励。
4. 累计用户积分,将积分高的用户进行排名并展示结果。
这个算法的主要目的是通过用户的投票行为和积极程度来奖励用户,以激励更多的用户参与投票,同时也保证排名结果能够反映出用户的支持程度。
算法的优缺点分析:优点:1. 简单易实现:该算法简单易懂,不需要复杂的计算和数据结构,适合于小型系统的实现。
2. 公平性:该算法不考虑用户的其他属性(如性别、年龄等),只根据投票行为和积极程度来分配积分,保证了公平性。
3. 可扩展性:该算法可以通过增加额外的奖励机制来适应不同的场景,如针对不同投票内容的奖励等。
缺点:1. 缺乏多样性:该算法只考虑了投票次数和积极程度两个因素,对于其他因素(如专业性、经验等)的考虑较少,可能影响结果的全面性和准确性。
2. 难以处理极端情况:如果某个用户拥有大量机器人账号进行刷票,该算法可能无法准确反映其真实支持度。
在实际应用中,可以根据具体场景和需求对算法进行调整和优化,例如增加其他奖励机制、考虑用户的其他属性等。
同时,也需要考虑算法的安全性和可靠性,防止恶意刷票和作弊行为的发生。
基于用户行为的改进PageRank影响力算法

基于用户行为的改进PageRank影响力算法王鹏;汪振;李松江;赵建平【摘要】In the calculation of user influence,the PageRank algorithm considers only the following relation among users,which leads to the low accuracy of the calculation results.Therefore,a URank algorithm combining user behavior factors with PageRank algorithm is proposed.By using the factors such as forwarding rate,comment rate and authentication,the user's quality can be obtained by combining the quality of users and the quality of followers.Experimental results show that based on the SIR propagation model,URank algorithm is superior to PageRank algorithm in computational accuracy.%PageRank算法在计算用户影响力方面只考虑用户间的跟随关系,导致计算结果准确性低下.为此,提出一种将用户行为因素与PageRank 算法相结合的URank算法.利用网络中用户发布信息的转发率、评论率以及是否认证等行为因素,综合用户自身质量与追随者质量,得到用户影响力.基于SIR传播模型的实验结果表明,URank算法在计算准确性方面优于PageRank算法.【期刊名称】《计算机工程》【年(卷),期】2017(043)012【总页数】5页(P155-159)【关键词】社交网络;用户影响力;PageRank算法;用户行为;传播模型【作者】王鹏;汪振;李松江;赵建平【作者单位】长春理工大学计算机科学技术学院,长春130022;长春理工大学计算机科学技术学院,长春130022;长春理工大学计算机科学技术学院,长春130022;长春理工大学计算机科学技术学院,长春130022【正文语种】中文【中图分类】TP391当前,根据国内外学者的研究情况可以将用户影响力评定方法总结为根据用户行为计算用户影响力,研究用户行为与用户影响力之间的关系。
大数据经典算法PageRank 讲解

如果按这个公式迭代算下去,会发现自连接点的问题解决了,从而每个页面 都拥有一个合理的pagerank。
分块式Pagerank算法:
火龙果整理
单击此处添加段落文字内容
原来的算法存在的问题:
1.时间开销大。每次迭代就算时间开销为
2.因特网中数据大部分是分布式的,计算过程需要多次传递数据,网 络负担太大。
火龙果整理
PageRank算法
基本PageRank 面向主题PageRank Link Spam与反作弊 导航页与权威页
一小组:王高翔,李渠,刘晴,柳永康,刘昊骋 二小组: 王飞,李天照,赵俊杰,陈超,陈瑾翊
一.Pagerank定义及终点,自连接点的概念
早期搜索引擎的弊端
火龙果整理
火龙果整理
TrustRank
TrustRank的思想很直观:如果一个页面的普通rank远高 于可信网页的topic rank,则很可能这个页面被spam了。 设一个页面普通rank为P,TrustRank为T,则定义网页的 Spam Mass为:(P – T)/P。 Spam Mass越大,说明此页面为spam目标页的可能性越 大。
为了克服这种问题,需要对PageRank 计算方法进行一个平滑处理,具体做 单击添加 法是加入“跳转因子(teleporting)”。所谓跳转因子,就是我们认为在任 何一个页面浏览的用户都有可能以一个极小的概率瞬间转移到另外一个随机 页面。当然,这两个页面可能不存在超链接,因此不可能真的直接转移过去, 跳转因子只是为了算法需要而强加的一种纯数学意义的概率数字。
3.n维矩阵式一个稀疏矩阵,无论计算还是存储都很浪费资源。
能否考虑先算出局部的Pagerank值??
分块式Pagerank算法:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于用户投票的六大排名算法研究收藏到:0时间:2013-12-28 文章来源:马海祥博客访问次数:281随着互联网的发展,网站的数量也在随着成倍的增加着,就中国的互联网来说,根据中国互联网信息中心的数据显示,目前中国的网站数量每半年都会以接近10%的数量增长。
这些大量的网站涌现,也就意味着我们已进入了“信息大爆炸”的时代。
而如今用户担心的已不再是信息太少,而是信息太多。
如何从大量信息之中,快速有效地找出最重要的内容,成了互联网的一大核心问题。
所以各种各样的排名算法,已成为目前过滤信息的主要手段之一,尤其是搜索引擎的排名。
在对信息进行排名的同时,也就意味着将信息按照重要性依次排列,并且及时进行更新。
排列的依据,可以基于信息本身的特征,也可以基于用户的投票,即让用户决定,什么样的信息可以排在第一位。
下面,我将借助马海祥博客的平台整理和分析一些基于用户投票的排名算法,跟大家共同分享一下:一、Delicious和Hacker News排名算法1、Delicious排名算法Delicious是提供了一种简单共享网页的方法,它为无数互联网用户提供共享及分类他们喜欢的网页书签。
对于最初的信息排名来说,最直觉、最简单的算法,莫过于按照单位时间内用户的投票数进行排名。
得票最多的项目,自然就排在第一位。
旧版的Delicious,有一个“热门书签排行榜”,就是这样统计出来的,如下图所示:它按照“过去60分钟内被收藏的次数”进行排名。
每过60分钟,就统计一次。
Delicious算法的优点是:比较简单、容易部署、内容更新相当快;Delicious算法的缺点是:一方面,排名变化不够平滑,前一个小时还排名靠前的内容,往往第二个小时就一落千丈,另一方面,缺乏自动淘汰旧项目的机制,某些热门内容可能会长期占据排行榜前列。
2、Hacker News排名算法Hacker News是一个网络社区,可以张贴链接,或者讨论某个主题,如下图所示:每个帖子前面有一个向上的三角形,如果你觉得这个内容很好,就点击一下,投上一票。
根据得票数,系统自动统计出热门文章排行榜。
但是,并非得票最多的文章排在第一位,还要考虑时间因素,新文章应该比旧文章更容易得到好的排名。
Hacker News使用Paul Graham开发的Arc语言编写。
它的排名算法的实现的方法如下图所示:将上面的代码还原为数学公式就是:P表示帖子的得票数,减去1是为了忽略发帖人的投票。
T表示距离发帖的时间(单位为小时),加上2是为了防止最新的帖子导致分母过小(之所以选择2,可能是因为从原始文章出现在其他网站,到转贴至Hacker News,平均需要两个小时)。
G表示"重力因子"(gravityth power),即将帖子排名往下拉的力量,默认值为1.8,后文会详细讨论这个值。
从这个公式来看,决定帖子排名有三个因素:第一个因素是得票数P在其他条件不变的情况下,得票越多,排名越高,如下图所示:从上图可以看到,有三个同时发表的帖子,得票分别为200票、60票和30票(减1后为199、59和29),分别以黄色、紫色和蓝色表示。
在任一个时间点上,都是黄色曲线在最上方,蓝色曲线在最下方。
如果你不想让“高票帖子”与“低票帖子”的差距过大,可以在得票数上加一个小于1的指数,比如(P-1)^0.8。
第二个因素是距离发帖的时间T在其他条件不变的情况下,越是新发表的帖子,排名越高。
或者说,一个帖子的排名,会随着时间不断下降。
从前一张图可以看到,经过24小时之后,所有帖子的得分基本上都小于1,这意味着它们都将跌到排行榜的末尾,保证了排名前列的都将是较新的内容。
第三个因素是重力因子G它的数值大小决定了排名随时间下降的速度。
从上图可以看到,三根曲线的其他参数都一样,G的值分别为1.5、1.8和2.0。
G值越大,曲线越陡峭,排名下降得越快,意味着排行榜的更新速度越快。
马海祥博客点评:知道了Delicious和Hacker News是算法构成,就可以调整参数的值,以适用你自己的应用程序。
二、Reddit算法排名对于Hacker News的排名算法,它的特点是用户只能投赞成票,但是很多网站还允许用户投反对票。
就是说,除了好评以外,你还可以给某篇文章差评。
如下图的Reddit社区所示:Reddit是美国最大的网上社区,它的每个帖子前面都有向上和向下的箭头,分别表示“赞成”和“反对”。
用户点击进行投票,Reddit根据投票结果,计算出最新的“热点文章排行榜”。
那么怎样才能将赞成票和反对票结合起来,计算出一段时间内最受欢迎的文章呢?如果文章A有100张赞成票、5张反对票,文章B有1000张赞成票、950张反对票,谁应该排在前面呢?这就需要我们来仔细的分析一下Reddit排名算法的工作原理了。
Reddit的程序是开源的,使用Python语言编写。
排名算法的代码大致如下图所示:这段代码考虑了这样几个因素:(1)、帖子的新旧程度tt = 发贴时间- 2005年12月8日7:50:50t的单位为秒,用unix时间戳计算。
不难看出,一旦帖子发表,t就是固定值,不会随时间改变,而且帖子越新,t值越大。
至于2005年12月8日,应该是Reddit成立的时间。
(2)、赞成票与反对票的差xx = 赞成票- 反对票(3)、投票方向yy是一个符号变量,表示对文章的总体看法。
如果赞成票居多,y就是+1;如果反对票居多,y就是-1;如果赞成票和反对票相等,y就是0。
(4)、帖子的受肯定(否定)的程度zz表示赞成票与反对票之间差额的绝对值。
如果对某个帖子的评价,越是一边倒,z就越大。
如果赞成票等于反对票,z就等于1。
结合以上的几个变量,我们可以得出Reddit的最终得分计算公式如下:对于这个公式马海祥觉得又可以分成两个部分来讨论:1、这个部分表示,赞成票与反对票的差额z越大,得分越高。
需要注意的是,这里用的是以10为底的对数,意味着z=10可以得到1分,z=100可以得到2分。
也就是说,前10个投票人与后90个投票人(乃至再后面900个投票人)的权重是一样的,即如果一个帖子特别受到欢迎,那么越到后面投赞成票,对得分越不会产生影响。
当赞成票等于反对票,z=1,因此这个部分等于0,也就是不产生得分。
2、这个部分表示,t越大,得分越高,即新帖子的得分会高于老帖子。
它起到自动将老帖子的排名往下拉的作用。
分母的45000秒,等于12.5个小时,也就是说,后一天的帖子会比前一天的帖子多得2分。
结合前一部分,可以得到结论,如果前一天的帖子在第二天还想保持原先的排名,在这一天里面,它的z值必须增加100倍(净赞成票增加100倍)。
y的作用是产生加分或减分。
当赞成票超过反对票时,这一部分为正,起到加分作用;当赞成票少于反对票时,这一部分为负,起到减分作用;当两者相等,这一部分为0。
这就保证了得到大量净赞成票的文章,会排在前列;赞成票与反对票接近或相等的文章,会排在后面;得到净反对票的文章,会排在最后(因为得分是负值)。
马海祥博客点评:这种算法的一个问题是,对于那些有争议的文章(赞成票和反对票非常接近),它们不可能排到前列。
假定同一时间有两个帖子发表,文章A有1张赞成票(发帖人投的)、0张反对票,文章B有1000张赞成票、1000张反对票,那么A的排名会高于B,这显然不合理。
结论就是,Reddit的排名,基本上由发帖时间决定,超级受欢迎的文章会排在最前面,一般性受欢迎的文章、有争议的文章都不会很靠前。
这决定了Reddit是一个符合大众口味的社区,不是一个很激进、可以展示少数派想法的地方。
三、Stack Overflow排名算法对于Reddit的排名算法,它的特点是用户可以投赞成票,也可以投反对票。
也就是说,除了时间因素以外,只要考虑两个变量就够了。
但是,还有一些特定用途的网站,必须考虑更多的因素。
而程序员问答社区Stack Overflow,就是这样一个网站。
你在上面提出各种关于编程的问题,等待别人回答。
访问者可以对你的问题进行投票(赞成票或反对票),表示这个问题是不是有价值。
如下图所示:一旦有人回答了你的问题,其他人也可以对这个回答投票(赞成票或反对票)。
排名算法的作用是,找出某段时间内的热点问题,即哪些问题最被关注、得到了最多的讨论。
在Stack Overflow的页面上,每个问题前面有三个数字,分别表示问题的得分、回答的数目和该问题的浏览次数。
以这些变量为基础,就可以设计算法了。
其创始人之一的Jeff Atwood,曾经在几年前,公布过排名得分的计算公式如下:写成php代码,就是下面这样:各个算法变量的含义如下:1、Qviews(问题的浏览次数)某个问题的浏览次数越多,就代表越受关注,得分也就越高。
这里使用了以10为底的对数,用意是当访问量越来越大,它对得分的影响将不断变小。
2、Qscore(问题得分)和Qanswers(回答的数量)首先,Qscore(问题得分)= 赞成票-反对票。
如果某个问题越受到好评,排名自然应该越靠前。
Qanswers表示回答的数量,代表有多少人参与这个问题。
这个值越大,得分将成倍放大。
这里需要注意的是,如果无人回答,Qanswers就等于0,这时Qscore再高也没用,意味着再好的问题,也必须有人回答,否则进不了热点问题排行榜。
3、Ascores(回答得分)一般来说,“回答”比“问题”更有意义。
这一项的得分越高,就代表回答的质量越高。
但是马海祥感觉,简单加总的设计还不够全面。
这里有两个问题。
首先,一个正确的回答胜过一百个无用的回答,但是,简单加总会导致,1个得分为100的回答与100个得分为1的回答,总得分相同。
其次,由于得分会出现负值,因此那些特别差的回答,会拉低正确回答的得分。
4、Qage(距离问题发表的时间)和Qupdated(距离最后一个回答的时间)改写一下,可以看得更清楚:Qage和Qupdated的单位都是秒。
如果一个问题的存在时间越久,或者距离上一次回答的时间越久,Qage和Qupdated的值就相应增大。
也就是说,随着时间流逝,这两个值都会越变越大,导致分母增大,因此总得分会越来越小。
马海祥博客点评:Stack Overflow热点问题的排名,与参与度(Qviews和Qanswers)和质量(Qscore和Ascores)成正比,与时间(Qage和Qupdated)成反比。
四、牛顿冷却定律牛顿冷却定律原是用于物理学的,本意是指温度高于周围环境的物体向周围媒质传递热量逐渐冷却时所遵循的规律。
当物体表面与周围存在温度差时,单位时间从单位面积散失的热量与温度差成正比,比例系数称为热传递系数。
但伴随着互联网信息的日益增多,这种定律也四、适用于最新文章的展示排名情况。