编译原理1
编译原理 实验1 有穷自动机的构造与实现

}
char digitprocess(char buffer, FILE* fp)
{
int i=-1;
while((IsDigit(buffer)))
{
digittp[++i]=buffer;
buffer=fgetc(fp);
}
digittp[i+1]=\0';
return(buffer);
buffer=fgetc(fp);
}
alphatp[i+1]='\0';
return(buffer);
}
int main(int argc, char* argv[])
{
FILE *fp;//文件指针,指向要分析的源程序
char cbuffer;//保存最新读入的字符
if((fp=fopen(sourceFile,"r"))==NULL)//判断源文件是否存在
}
int main(int argc, char* argv[])
{
FILE *fp;//文件指针,指向要分析的源程序
char cbuffer;//保存最新读入的字符
if((fp=fopen(sourceFile,"r"))==NULL)//判断源文件是否存在
printf("文件%s不存在", sourceFile);
(2)无符号整型数,要求长度不超过20。
四、实验结果
1.识别标识符(以字母开始由字母和数字构成的字符串,要求长度不超过10)。
#include <stdio.h>
#include <string.h>
bit 编译原理(一)

bit 编译原理(一)Bit 编译原理解析什么是 Bit 编译定义Bit 编译是一种将代码分割成独立的模块,并对这些模块进行单独管理和编译的技术。
它可以将大型应用程序划分为更小、更容易维护和共享的部分,同时还能提供模块化的性能优化。
原理Bit 编译的原理是将应用程序拆分成独立的模块。
每个模块都可以单独开发、测试和部署,并且可以通过 Bit 管理库进行共享和复用。
Bit 编译使用一种称为“编译器”的工具将模块编译为可执行的代码。
编译器将源代码转换成计算机可以理解和执行的指令集。
Bit 编译的核心原理是将应用程序拆分为多个模块,这些模块可以被独立编译,并且可以在编译时或运行时进行动态链接。
这样可以有效地减小编译和链接的开销,并提供更好的可维护性和可扩展性。
Bit 编译的优势模块化开发Bit 编译将应用程序划分为多个独立的模块,每个模块都可以独立进行开发、测试和部署。
这样可以提高开发效率,同时也减小了维护的负担。
代码复用通过将模块以 Bit 包的形式进行共享,可以实现代码的复用。
这样可以避免重复编写相同或相似的代码,提高代码的可维护性和可扩展性。
性能优化Bit 编译将模块独立编译,并在编译时或运行时进行动态链接。
这种方式可以减小编译和链接的开销,提高应用程序的性能。
Bit 编译的应用场景大型应用程序开发Bit 编译适用于大型应用程序的开发,它可以将应用程序拆分为多个独立的模块,提高开发效率和代码的可维护性。
组件库开发对于组件库的开发来说,Bit 编译可以将组件拆分为独立的模块,并通过 Bit 管理库进行共享和复用。
微服务架构在微服务架构中,每个微服务可以作为一个独立的模块进行开发、测试和部署。
Bit 编译可以帮助管理和编译这些独立的模块。
结语Bit 编译是一种将应用程序拆分为独立模块并进行单独管理和编译的技术。
它可以提高开发效率、代码的可维护性和可扩展性。
在大型应用程序开发、组件库开发和微服务架构中,Bit 编译都有着广泛的应用前景。
编译原理实验一词法分析

编译原理实验⼀词法分析实验⼀词法分析【实验⽬的】 (1)熟悉词法分析器的基本功能和设计⽅法; (2)掌握状态转换图及其实现; (3)掌握编写简单的词法分析器⽅法。
【实验内容】 对⼀个简单语⾔的⼦集编制⼀个⼀遍扫描的词法分析程序。
【实验要求】 (1)待分析的简单语⾔的词法 1) 关键字 begin if then while do end 2) 运算符和界符 := + - * / < <= <> > >= = ; ( ) # 3) 其他单词是标识符(ID)和整形常数(NUM),通过以下正规式定义: ID=letter(letter|digit)* NUM=digitdigit* 4) 空格由空⽩、制表符和换⾏符组成。
空格⼀般⽤来分隔 ID、NUM、运算符、界符和关键字,词法分析阶段通常被忽略。
(2)各种单词符号对应的种别编码 (3)词法分析程序的功能 输⼊:所给⽂法的源程序字符串 输出:⼆元组(syn,token 或 sum)构成的序列。
syn 为单词种别码; token 为存放的单词⾃⾝字符串; sum 为整形常数。
【实验代码】1 #include<iostream>2 #include<string.h>3 #include<conio.h>4 #include<ctype.h>5using namespace std;6int sum,syn,p,m,n;7char ch,chs[8],s[100];8char *tab[6]={"begin","if","then","while","do","end"};910int scanner(){11for(n=0;n<8;n++) chs[n]='\0';12 m=0;13 n=0;14 ch=s[p++];15while(ch=='') ch=s[p++];16if(isalpha(ch)){17while(isalpha(ch)||isdigit(ch)){18//isalpha(ch)函数:判断字符ch是否为英⽂字母,⼩写字母为2,⼤写字母为1,若不是字母019//isdigit(ch)函数:判断字符ch是否为数字,是返回1,不是返回020 chs[m++]=ch;21 ch=s[p++];22 }23 syn=10;24for(n=0;n<6;n++)25if(strcmp(chs,tab[n])==0) syn=n+1;26 p--;27 }else if(isdigit(ch)){28 sum=0;29while(isdigit(ch)){30 sum=sum*10+(ch-'0');31 ch=s[p++];32 }33 syn=11;34 p--;35 }else if(ch==':'){36 syn=17;37 chs[m++]=ch;38 ch=s[p++];39if(ch=='='){ syn=18;chs[m]=ch;p++;}40 p--;41 }else if(ch=='<'){42 syn=20;43 chs[m++]=ch;44 ch=s[p++];45if(ch=='>') { syn=21;chs[m]=ch;p++;}46if(ch=='=') { syn=22;chs[m]=ch;p++;}47 p--;48 }else if(ch=='>'){49 syn=23;50 chs[m++]=ch;51 ch=s[p++];52if(ch=='=') { syn=24;chs[m]=ch;p++;}53 p--;54 }else switch(ch){55case'+':syn=13;chs[m]=ch;break;56case'-':syn=14;chs[m]=ch;break;57case'*':syn=15;chs[m]=ch;break;58case'/':syn=16;chs[m]=ch;break;59case'=':syn=25;chs[m]=ch;break;60case';':syn=26;chs[m]=ch;break;61case'(':syn=27;chs[m]=ch;break;62case')':syn=28;chs[m]=ch;break;63case'#':syn=0;chs[m]=ch;break;64default:syn=-1;65 }66return0;67 }68int main(){69 p=0;70 cout<<"Please input code and end with character '#':"<<endl;71do{72//cin>>ch;不识别空格73 ch=getchar();74 s[p++]=ch;75 }while(ch!='#');76 p=0;77do{78 scanner();79switch(syn){80case11:cout<<'('<<syn<<','<<sum<<')'<<endl;break;81case -1:cout<<'('<<syn<<','<<"error"<<')'<<endl;break;82default:cout<<'('<<syn<<','<<chs<<')'<<endl;83 }84 }while(syn!=0);85//getch():是⼀个不回显函数,当⽤户按下某个字符时,函数⾃动读取,⽆需按回车,所在头⽂件是conio.h。
编译原理-陈火旺版-第一章

编译器的作用与重要性
01
编译器是将高级语言程序翻译成机器语言程序的软件工具,是 软件开发的基础设施之一。
02
编译器可以提高程序的执行效率,使得程序能够在各种计算机
上运行。
编译器还可以对程序进行优化,提程简介
01
02
03
词法分析
将输入的源程序分解成一 个个的单词符号,即词法 单元。
词法分析器的构造
构造原理
根据词法规则构造出识别相应单 词符号的有限自动机,然后将有 限自动机转换为对应的程序代码
构造方法
手工构造法、自动生成法
注意事项
处理好单词符号的二义性问题; 识别出源程序中的错误并进行适 当的处理。
04
语法分析
语法分析概述
语法分析的任务
根据语言的语法规则,对输 入的符号序列进行合法性检 查,并构造出相应的语法结
中间代码的形式
常见的中间代码形式有三地址码、四元式、树形表示等。
中间代码生成算法
根据源程序的语法结构和语义规则,生成相应的中间代码序列。
符号表管理
符号表的作用
符号表用于记录源程序中各种标识符的属性信息,如类型、作用域 和存储地址等。
符号表的组织方式
常见的符号表组织方式有线性表、散列表和树形结构等。
循环优化
通过循环展开、循环合并、循环交换等技术来改进循环的性能。
目标代码生成方法
机器无关代码生成
机器相关代码生成
生成与特定机器无关的中间代码,然后在 运行时将其转换为特定机器上的目标代码 。
直接生成特定机器上的目标代码,这需要 考虑机器的指令集、寄存器分配、内存访 问等因素。
汇编语言代码生成
高级语言虚拟机代码生成
龙书 编译原理(一)

龙书编译原理(一)编译原理简介什么是编译编译是指将人类编写的高级程序代码转换成机器能够理解的底层语言的过程。
编译器是负责完成这种转换的程序。
编译器的工作过程编译器大致可以分为以下几个步骤:1.分词2.语法分析3.语义分析4.中间代码生成5.代码优化6.目标代码生成分词分词阶段将源代码拆分成一个个单词。
单词是指代码中的标识符、关键字、运算符等不可拆分的最小单元。
例如,针对以下代码:int main(){printf("Hello, World!\n");return0;}分词后会得到这样的结果:intmain(){printf("Hello, World!");return;}语法分析语法分析阶段将单词组成的序列转化成语法分析树,也叫做抽象语法树。
语法分析树采用树状结构表示程序的语法结构。
例如,对于以下代码:int main(){printf("Hello, World!\n");return0;}语法分析树大致如下:Program│└─── Main Function│├─── Declare int│├─── Function Body│ ││ ├─── Call printf│ │ ││ │ ├─── String "Hello, World!"│ │ ││ │ └─── End of Arg uments│ ││ └─── Return 0│└─── End of Main Function语义分析语义分析阶段检查程序的语义错误和类型错误。
例如,一个整数类型的变量不能被赋值给一个字符串类型的变量。
中间代码生成中间代码生成阶段将语法分析树转化成一种中间代码,以便在后面的优化和目标代码生成阶段使用。
中间代码通常是一种抽象的栈式或寄存器式指令集。
例如,以下代码:int main(){int a =1+2;printf("%d\n", a);return0;}中间代码大致如下:1: t1 = 12: t2 = 23: t3 = t1 + t24: a = t35: printf("%d\n", a)6: return 0代码优化代码优化阶段根据中间代码尽量优化程序性能,以及压缩代码。
编译原理LL(1)文法分析器实验(java)

编译原理LL(1)文法分析器实验本程序是基于已构建好的某一个语法的预测分析表来对用户的输入字符串进行分析,判断输入的字符串是否属于该文法的句子。
基本实现思想:接收用户输入的字符串(字符串以“#”表示结束)后,对用做分析栈的一维数组和存放分析表的二维数组进行初始化。
然后取出分析栈的栈顶字符,判断是否为终结符,若为终结符则判断是否为“#”且与当前输入符号一样,若是则语法分析结束,输入的字符串为文法的一个句子,否则出错若不为“#”且与当前输入符号一样则将栈顶符号出栈,当前输入符号从输入字符串中除去,进入下一个字符的分析。
若不为“#”且不与当前输入符号一样,则出错。
若栈顶符号为非终结符时,查看预测分析表,看栈顶符号和当前输入符号是否构成产生式,若产生式的右部为ε,则将栈顶符号出栈,取出栈顶符号进入下一个字符的分析。
若不为ε,将产生式的右部逆序的入栈,取出栈顶符号进入下一步分析。
程序流程图:本程序中使用以下文法作对用户输入的字符串进行分析:E→TE’E’→+TE’|εT→FT’T’→*FT’|εF→i|(E)该文法的预测分析表为:1、显示预测分析表,提示用户输入字符串2、输入的字符串为正确的句子:3、输入的字符串中包含了不属于终结符集的字符4、输入的字符串不是该文法能推导出来的句子程序代码:package ;import java.io.*;public class LL {String Vn[] = { "E", "E'", "T", "T'", "F" }; // 非终结符集String Vt[] = { "i", "+", "*", "(", ")", "#" }; // 终结符集String P[][] = new String[5][6]; // 预测分析表String fenxi[] ; // 分析栈int count = 1; // 步骤int count1 = 1;//’分析栈指针int count2 = 0, count3 = 0;//预测分析表指针String inputString = ""; // 输入的字符串boolean flag;public void setCount(int count, int count1, int count2, int count3){this.count = count;this.count1 = count1;this.count2 = count2;this.count3 = count3;flag = false;}public void setFenxi() { // 初始化分析栈fenxi = new String[20];fenxi[0] = "#";fenxi[1] = "E";}public void setP() { // 初始化预测分析表for (int i = 0; i < 5; i++) {for (int j = 0; j < 6; j++) {P[i][j] = "error";}}P[0][0] = "->TE'";P[0][3] = "->TE'";P[1][1] = "->+TE'";P[1][4] = "->ε";P[1][5] = "->ε";P[2][0] = "->FT'";P[2][3] = "->FT'";P[3][1] = "->ε";P[3][2] = "->*FT'";P[3][4] = "->ε";P[3][5] = "->ε";P[4][0] = "->i";P[4][3] = "->(E)";// 打印出预测分析表System.out.println(" 已构建好的预测分析表");System.out.println("----------------------------------------------------------------------");for (int i=0; i<6; i++) {System.out.print(" "+Vt[i]);}System.out.println();System.out.println("----------------------------------------------------------------------");for (int i=0; i<5; i++) {System.out.print(" "+Vn[i]+" ");for (int j=0; j<6; j++) {int l = 0;if (j>0) {l = 10-P[i][j-1].length();}for (int k=0; k<l; k++) {System.out.print(" ");}System.out.print(P[i][j]+" ");}System.out.println();}System.out.println("----------------------------------------------------------------------"); }public void setInputString(String input) {inputString = input;}public boolean judge() {String inputChar = inputString.substring(0, 1); // 当前输入字符boolean flage = false;if (count1 >= 0) {for (int i=0; i<6; i++) {if (fenxi[count1].equals(Vt[i])) { // 判断分析栈栈顶的字符是否为终结符flage = true;break;}}}if (flage) {// 为终结符时if (fenxi[count1].equals(inputChar)) {if (fenxi[count1].equals("#")&&inputString.length()==1) { // 栈顶符号为结束标志时// System.out.println("最后一个");String fenxizhan = "";for (int i=0; i<=P.length; i++) { // 拿到分析栈里的全部内容(滤去null)if (fenxi[i] == null) {break;} else {fenxizhan = fenxizhan + fenxi[i];}}// 输出当前分析栈情况,输入字符串,所用产生式或匹配System.out.print(" " + count);String countToString = Integer.toString(count);int farWay = 14 - countToString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(fenxizhan);farWay = 20 - fenxizhan.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(inputString);farWay = 25 - inputString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.println("接受");flag = true;return true;} else {// 分析栈栈顶符号不为结束标志符号时String fenxizhan = "";for (int i=0; i<=P.length; i++) { // 拿到分析栈里的全部内容(滤去null)if (fenxi[i] == null) {break;} else {fenxizhan = fenxizhan + fenxi[i];}}// 输出当前分析栈情况,输入字符串,所用产生式或匹配System.out.print(" "+count);String countToString = Integer.toString(count);int farWay = 14 - countToString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(fenxizhan);farWay = 20 - fenxizhan.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(inputString);farWay = 25 - inputString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.println("\"" + inputChar + "\"" + "匹配");// 将栈顶符号出栈,栈顶指针减一fenxi[count1] = null;count1 -= 1;if (inputString.length() > 1) { // 当当前输入字符串的长度大于1时,将当前输入字符从输入字符串中除去inputString = inputString.substring(1, inputString.length());} else { // 当前输入串长度为1时inputChar = inputString;}// System.out.println(" "+count+" "+fenxizhan+"// "+inputString +" "+P[count3][count2]);// System.out.println(count + inputChar + "匹配");count++;judge();}}else { // 判断与与输入符号是否一样为结束标志System.out.println(" 分析到第" + count + "步时出错!");flag = false;return false;}} else {// 非终结符时boolean fla = false;for (int i=0; i<6; i++) { // 查询当前输入符号位于终结符集的位置if (inputChar.equals(Vt[i])) {fla = true;count2 = i;break;}}if(!fla){System.out.println(" 分析到第" + count + "步时出错!");flag = false;return false;}for (int i=0; i<5; i++) { // 查询栈顶的符号位于非终结符集的位置if (fenxi[count1].equals(Vn[i])) {count3 = i;break;}}if (P[count3][count2] != "error") { // 栈顶的非终结符与输入的终结符存在产生式时String p = P[count3][count2];String s1 = p.substring(2, p.length()); // 获取对应的产生式if (s1.equals("ε")) { // 产生式推出“ε”时String fenxizhan = "";for (int i=0; i<=P.length; i++) {if (fenxi[i] == null) {break;} else {fenxizhan = fenxizhan + fenxi[i];}}// 输出当前分析栈情况,输入字符串,所用产生式或匹配System.out.print(" " + count);String countToString = Integer.toString(count);int farWay = 14 - countToString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(fenxizhan);farWay = 20 - fenxizhan.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(inputString);farWay = 25 - inputString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.println(fenxi[count1] + P[count3][count2]);// 将栈顶符号出栈,栈顶指针指向下一个元素fenxi[count1] = null;count1 -= 1;count++;judge();} else { // 产生式不推出“ε”时int k = s1.length();String fenxizhan = "";for (int i=0; i<=P.length; i++) {if (fenxi[i] == null) {break;} else {fenxizhan = fenxizhan + fenxi[i];}}// 输出当前分析栈情况,输入字符串,所用产生式或匹配System.out.print(" "+count);String countToString = Integer.toString(count);int farWay = 14 - countToString.length();for (int o=0; o<farWay; o++) {System.out.print(" ");}System.out.print(fenxizhan);farWay = 20 - fenxizhan.length();for (int o=0; o<farWay; o++) {System.out.print(" ");}System.out.print(inputString);farWay = 25 - inputString.length();for (int o=0; o<farWay; o++) {System.out.print(" ");}System.out.println(fenxi[count1] + P[count3][count2]);for (int i=1; i<=k; i++) { // 将产生式右部的各个符号入栈String s2 = s1.substring(s1.length() - 1, s1.length());s1 = s1.substring(0, s1.length() - 1);if (s2.equals("'")) {s2 = s1.substring(s1.length() - 1, s1.length())+ s2;i++;s1 = s1.substring(0, s1.length() - 1);}fenxi[count1] = s2;if (i < k)count1++;// System.out.println("count1=" + count1);}// System.out.println(" "+count+" "+fenxizhan+"// "+inputString +" "+P[count3][count2]);count++;// System.out.println(count);judge();}} else {System.out.println(" 分析到第" + count + "步时出错!");flag = false;return false;}}return flag;}public static void main(String args[]) {LL l = new LL();l.setP();String input = "";boolean flag = true;while (flag) {try {InputStreamReader isr = new InputStreamReader(System.in);BufferedReader br = new BufferedReader(isr);System.out.println();System.out.print("请输入字符串(输入exit退出):");input = br.readLine();} catch (Exception e) {e.printStackTrace();}if(input.equals("exit")){flag = false;}else{l.setInputString(input);l.setCount(1, 1, 0, 0);l.setFenxi();System.out.println();System.out.println("分析过程");System.out.println("----------------------------------------------------------------------");System.out.println(" 步骤| 分析栈| 剩余输入串| 所用产生式");System.out.println("----------------------------------------------------------------------");boolean b = l.judge();System.out.println("----------------------------------------------------------------------");if(b){System.out.println("您输入的字符串"+input+"是该文发的一个句子");}else{System.out.println("您输入的字符串"+input+"有词法错误!");}}}}}。
编译原理第一章练习和答案
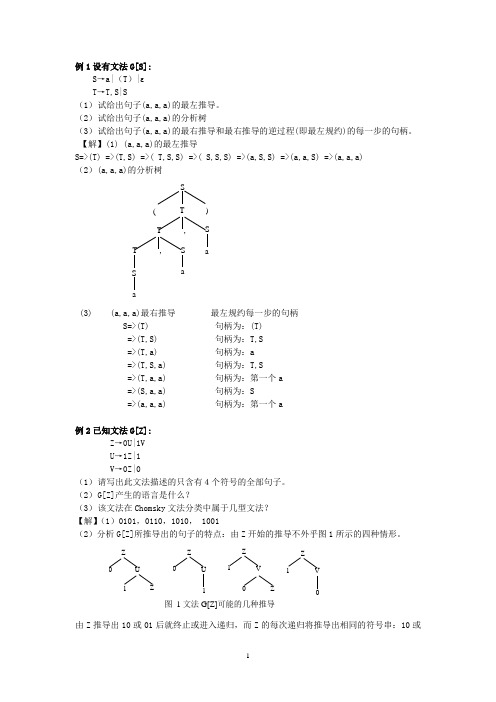
例1设有文法G[S]:S →a|(T )| T →T,S|S (1) 试给出句子(a,a,a)的最左推导。
(2) 试给出句子(a,a,a)的分析树 (3) 试给出句子(a,a,a)的最右推导和最右推导的逆过程(即最左规约)的每一步的句柄。
【解】(1) (a,a,a)的最左推导S=>(T) =>(T,S) =>( T,S,S) =>( S,S,S) =>(a,S,S) =>(a,a,S) =>(a,a,a) (2)(a,a,a)的分析树S( T ) T , S S T ,S aa(3) (a,a,a)最右推导 最左规约每一步的句柄S=>(T) 句柄为:(T) =>(T,S) 句柄为:T,S =>(T,a) 句柄为:a =>(T,S,a) 句柄为:T,S =>(T,a,a) 句柄为:第一个a =>(S,a,a) 句柄为:S=>(a,a,a) 句柄为:第一个a例2已知文法G[Z]:Z →0U|1V U →1Z|1 V →0Z|0(1) 请写出此文法描述的只含有4个符号的全部句子。
(2) G [Z]产生的语言是什么? (3) 该文法在Chomsky 文法分类中属于几型文法? 【解】(1)0101,0110,1010, 1001(2)分析G[Z]所推导出的句子的特点:由Z 开始的推导不外乎图1所示的四种情形。
图 1文法G[Z]可能的几种推导Z1U Z UZ1Z1Z1V由Z 推导出10或01后就终止或进入递归,而Z 的每次递归将推导出相同的符号串:10或01。
所以G[Z]产生的语言L(G[Z])={x|x∈(10|01)+ }(3)该文法属于3型文法。
例3 已知文法G=({A,B,C},{a,b,c},P,A), P由以下产生式组成:A→abcA→aBbcBb→bBBc→CbccbC→CbaC→aaBaC→aa此文法所表示的语言是什么?【解】分析文法的规则:每使用一次Bc→Cbcc,b、c的个数各增加一个;每使用一次aC→aaB或aC→aa, a的个数就增加一个;产生式Bb→bB、 bC→Cb起连接转换作用。
编译原理实验一╲t 词法分析

实验一词法分析一、实验目的:编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
二、实验内容:如源程序为C语言。
输入如下一段:main(){int a=-5,b=4,j;if(a>=b)j=a-b;else j=b-a;}要求输出如图:(2,”main”)(5,”(”)(5,”)”)(5,”{”)(1,”int”)(2,”a”)(4,”=”)(3,”-5”)(5,”,”)(2,”b”)(4,”=”)(3,”4”)(5,”,”)(2,”j”)(5,”;”)(1,”if”)(5,”(”)(2,”a”)(4,”>=”)(2,”b”)(5,”)”)(2,”j”)(4,”=”)(2,”a”)(4,”-”)(2,”b”)(5,”;”)(1,”else”)(2,”j”)(4,”=”)(2,”b”)(4,”-”)(2,”a”)(5,”;”)(5,”}”)在示例程序的基础上,增加对自加、自减、正负号的判断。
三、源程序:#include<iostream>using namespace std;FILE *fp;char cbuffer;char *key[8]={"if","else","for","while","do","return","break","continue"};int atype,id=4;int search(char searchchar[ ],int wordtype) /*判断单词是保留字还是标识符*/{int i=0;int p;switch (wordtype){case 1:for (i=0;i<=7;i++){if (strcmp(key[i],searchchar)==0){ p=i+1; break; } /*是保留字则p为非0且不重复的整数*/ else p=0; /*不是保留字则用于返回的p=0*/}return(p);}}char alphaprocess(char buffer){ int atype; /*保留字数组中的位置*/int i=-1;char alphatp[20];while ((isalpha(buffer))||(isdigit(buffer))||buffer=='_'){alphatp[++i]=buffer;buffer=fgetc(fp);} /*读一个完整的单词放入alphatp数组中*/alphatp[i+1]='\0';atype=search(alphatp,1);/*对此单词调用search函数判断类型*/if(atype!=0){ printf("%s, (1,%d)\n",alphatp,atype-1); id=1; }else{ printf("(%s ,2)\n",alphatp); id=2; }return buffer;}char digitprocess(char buffer){int i=-1;char digittp[20];while ((isdigit(buffer))){digittp[++i]=buffer;buffer=fgetc(fp);}digittp[i+1]='\0';printf("(%s ,3)\n",digittp);id=3;return(buffer); }char otherprocess(char buffer){char ch[20];ch[0]=buffer;ch[1]='\0';if(ch[0]==','||ch[0]==';'||ch[0]=='{'||ch[0]=='}'||ch[0]=='('||ch[0]==')') { printf("(%s ,5)\n",ch);buffer=fgetc(fp);id=4;return(buffer);}if(ch[0]=='*'||ch[0]=='/'){ printf("(%s ,4)\n",ch);buffer=fgetc(fp);id=4;return(buffer);}if(ch[0]=='='||ch[0]=='!'||ch[0]=='<'||ch[0]=='>'){ buffer=fgetc(fp);if(buffer=='='){ ch[1]=buffer;ch[2]='\0';printf("(%s ,4)\n",ch);}else {printf("(%s ,4)\n",ch);id=4;return(buffer);}buffer=fgetc(fp);id=4;return(buffer);}if(ch[0]=='+'||ch[0]=='-'){if(id==4){ /*在当前符号以前是运算符,则此时为正负号*/ int i=1;buffer=fgetc(fp);ch[1]=buffer;ch[2]='\0';if(ch[0] == ch[1]){printf("(%s,3)\n",ch);buffer=fgetc(fp);return buffer;}while(isdigit(ch[i])){ch[++i] = fgetc(fp);}ch[i] = '\0';id=3;printf("(%s ,3)\n",ch);return(buffer);}buffer=fgetc(fp);ch[1]=buffer;if(ch[0] == ch[1]){ch[2]='\0';printf("(%s,3)\n",ch);buffer=fgetc(fp);return buffer;}ch[1]='\0';printf("(%s ,4)\n",ch);buffer=fgetc(fp);id=4;return(buffer);}}void main(){if ((fp=fopen("example.c","r"))==NULL) /*只读方式打开一个文件*/ printf("error");else{cbuffer = fgetc(fp); /*fgetc( )函数:从磁盘文件读取一个字符*/while (cbuffer!=EOF){if(cbuffer==' '||cbuffer=='\n') /*掠过空格和回车符*/cbuffer=fgetc(fp);elseif(isalpha(cbuffer))cbuffer=alphaprocess(cbuffer);elseif (isdigit(cbuffer))cbuffer=digitprocess(cbuffer);else cbuffer=otherprocess(cbuffer);}}system("pause");}四、实验运行结果:五、实验心得:通过这次实验,更加深了我对编译中的词法分析过程的理解,我将老师所给的示例加以修改,添加了++,--,以及正负号的判断,虽然还有很多实际问题没有考虑进去,例如程序中若有‘//’或者‘/*..*/’时则无法判断出解释语句。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、大题:
1.正规式转换为NFA P57例4.7 连画图
2.判断LL(1)文法,构造LL(1)语法分析表P97例97 的第一题
3.SLR(1)文法的判定P137
4.代码的优化(参照书本)P249
5.目标代码生成(表达式—>中间代码—>目标代码)P277
P248第6题
复习题:
第一章
1.编译有哪6个阶段,哪个阶段是可检类型?
答:词法分析->语法分析->语义分析->中间代码生成->代码优化->目标代码生成
2.语义。
语法。
词法分析。
答:词法分析:从左到右一个字符一个字符地读入源程序,对构成源程序的字符流进行扫描和分解,从而识别出一个个单词。
语法分析:在词法分析的基础上将单词序列分解成各类语法短语。
语义分析:审查源程序有无语义错误,为代码生成阶段收集类型信息。
3.语言处理工具P7(估计不会考)
第三章
1.判断文法类型P38
2.给出一个具体文法,确定语法类别P38
3.给出一个式子写出句子,句柄,直接短语P44
4.正规语言和正规文法的关系(判断)P53
5.规范推导定义?给出一个句子,给出其规范推导过程(应用)。
6.句子语法树是唯一的吗?给一句子画出语法树(应用)。
答:不是的,语法树看P41
7.正规文法是否可以用上下文无关文法描述?
正规文法是上下文无关文法的特例,可以用正规文法描述的语言,其正规文法描述的形式也是上下文无关文法的描述形式,即可以用上下文无关文法描述
8.语法树,句柄,NFA定义,O形文法?
9.状态转换族。
给一个文法画出。
10.短语树,短语规则的规约过程
第四章
1、词法分析器的输入输出是什么?
答:输入源程序,输出单词符号。
2、扫描器的作用P2
3、有穷自动机等价是什么P61
4、给出一个文法。
消除左递归(应用
5、求正规式的等价NFA
如S=((ba)*|a)*Cb
第五章
1、常用2种语法分析是什么:自顶向下、自底向上。
2、技术first,follow集合,判断分析L(1)
画出语法分析表
如:
S—>eB
B—>SDa|E
D—>eA|A
A—>b|E
(通过select判断)
第七章
1、区别LR(0),SLR(1)文法
2、LR(k),当k=0,1时分别表示什么意义
3、LR(0)项目有哪几种?
答:移进项目、待约项目、归约项目、接受项目
如:给出项目:E—>d
E—>@.a&分别是什么项目?
4、LR(k)文法是否都有二义性(判):lr(0)有二义性,lr(1)不一定5、给LR文法判断是否是SLR(1)文法?(大题)
如:
S—>S×id
S—>id
6、给出项目集;求closure(I
如:I={S—>a,A}
解:
A—>a
A—>bB
A—>Ba
B—>
和
A—>a
A—>bB
A—>Ba
第八章
1、布尔表达式逆波兰式表达式
如:¬(b∨c)∧(¬a∧c)
a+b/c =>abc/+ 前后缀表
2、BC翻译
3、语法制导翻
4、文法符号有哪2种属性?(综合、继承两种属性)(判
5、算术表达式的三元式,逆波兰
6、语句翻译
第十章
1、数组元素地址计算与存储方式是否有关:是有关的
2、常用2种动态存储分配:栈式动态存储分配、堆式动态存储分配
3、小程序:其传值与传地址分别是什么(应用)
第十一章
1、块有几个入口、出口语句:1个入口,1-n个出口
2、给出流程图优化其
代码外提(值不变)->强度削弱(乘变加,除变减)->删除归纳变量
第十二章
1、代码生成要考虑寄存器使用
2、表达式的四元式,最优代码。