R语言--列联表检验和相关性检验概述
R语言之相关性分析
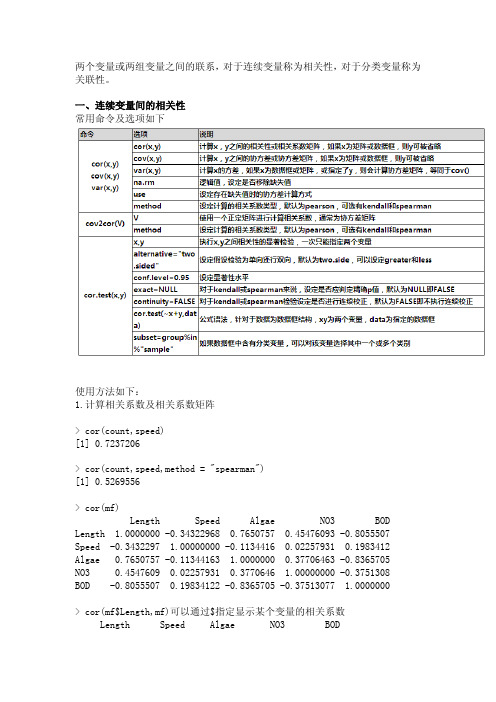
两个变量或两组变量之间的联系,对于连续变量称为相关性,对于分类变量称为关联性。
一、连续变量间的相关性常用命令及选项如下使用方法如下:1.计算相关系数及相关系数矩阵> cor(count,speed)[1] 0.7237206> cor(count,speed,method = "spearman")[1] 0.5269556> cor(mf)Length Speed Algae NO3 BOD Length 1.0000000 -0.34322968 0.7650757 0.45476093 -0.8055507 Speed -0.3432297 1.00000000 -0.1134416 0.02257931 0.1983412 Algae 0.7650757 -0.11344163 1.0000000 0.37706463 -0.8365705NO3 0.4547609 0.02257931 0.3770646 1.00000000 -0.3751308BOD -0.8055507 0.19834122 -0.8365705 -0.37513077 1.0000000> cor(mf$Length,mf)可以通过$指定显示某个变量的相关系数Length Speed Algae NO3 BOD[1,] 1 -0.3432297 0.7650757 0.4547609 -0.80555072.计算方差及协方差矩阵> cov(count,speed)[1] 123> var(count,speed)[1] 123> cov(mf)Length Speed Algae NO3 BOD Length 9.4900000 -4.95000000 45.858333 0.70683333 -111.55667 Speed -4.9500000 21.91666667 -10.333333 0.05333333 41.74167 Algae 45.8583333 -10.33333333 378.583333 3.70166667 -731.73333 NO3 0.7068333 0.05333333 3.701667 0.25456667 -8.50850 BOD -111.5566667 41.74166667 -731.733333 -8.50850000 2020.87333> cov2cor(cov(mf))Length Speed Algae NO3 BOD Length 1.0000000 -0.34322968 0.7650757 0.45476093 -0.8055507 Speed -0.3432297 1.00000000 -0.1134416 0.02257931 0.1983412Algae 0.7650757 -0.11344163 1.0000000 0.37706463 -0.8365705NO3 0.4547609 0.02257931 0.3770646 1.00000000 -0.3751308BOD -0.8055507 0.19834122 -0.8365705 -0.37513077 1.00000003.相关系数的显著性检验> cor.test(count,speed)Pearson's product-moment correlationdata: count and speedt = 2.5689, df = 6, p-value = 0.0424alternative hypothesis: true correlation is not equal to 095 percent confidence interval:0.03887166 0.94596455sample estimates:cor0.72372064.使用公式语法> cor.test(~count+speed,data=fw3,subset = cover%in%c("open","closed"))计算fw3数据框中cover分类变量的open和closed两个类别的相关系数检验。
R语言思维导图-简单高清脑图_知犀思维导图思维导图-简单高清脑图_知犀

R语言数据集标注标量标签值标签数据结构向量矩阵数据框列表因子数组数据的导入从键盘输入导入Excel数据导入XML数据从网页抓取导入SPSS数据导入SAS数据导入Stata数据导入netCDF数据导入HDF5数据访问数据库通过Stat/Transfer导入绘图图形参数符号线条颜色文本属性图形尺寸边界尺寸图形辅助标题坐标轴参考线图例文本标注常用图形条形图饼图直方图核密度图箱线图点图高级绘图数据管理基本数据管理变量创建重编码重命名缺失值重编码某些值为缺失值在分析中排除缺失值类型转换数据排序数据集的合并添加列添加行数据集选子集选入变量删除变量选入观测subset()函数随机抽样用SQL语句操作数据框高级数据管理数值与字符处理函数数学函数统计函数概率函数字符处理函数其他实用函数将函数应用于矩阵和数据框控制流循环语句条件语句用户自编函数整合与重构转置整合数据reshape包统计分析方法描述性统计分析相关函数summary()sapply()Hmisc包的describe()pastecs包的stat.desc()psych包的describe()分组计算描述性统计量分组计算描述性统计量分组计算概述统计量结果的可视化频数表和列联表生成频数表独立性检验相关性的度量结果的可视化将表转换为扁平格式相关相关的类型相关性的显著性检验相关关系的可视化t校验独立样本的t校验非独立样本的t校验多于两组的情况组间差异的非参数检验两组的比较多于两组的比较组间差异的可视化。
R语言--列联表检验和相关性检验

5.5 列联表检验
1. 概念 2. Pearsonχ2独立性检验 3. Fisher精确独立性检验 4. McNemar检验 5. 三维列联表的条件独立性检验
5.5 列联表检验
1. 概念:设两个随机变量X,Y均为离散型的,X取值于{a1, a2, …,aI}, Y取值
于{b1, b2, …,bJ}。设(X1,Y1),(X2,Y2), …,(Xn,Yn)为简单样 本,记nij为(X1,Y1),(X2,Y2), …,(Xn,Yn)中等于( ai, aj ) 的个数。在求解问题时,常把数据列为形如表5.9的形式,称为列
采用连续修正的情况下, 参数orrect默认为TRUE
5.5 列联表检验
3. Fisher精确独立性检验:
在样本数较小时,需要用Fisher精确检验来完成独立性实验。 使用函数fisher.test()作精确独力检验。
例5.28 某医师为研究乙肝免疫球蛋白预防胎儿宫内感染HBV的效果,将33例HBsAg阳性孕妇随机分为 预防注射组和对照组,结果如表5.12所示。问两组新生儿的HBV总体感染率有无差别。
假设检验简介
4. 两类错误:
第一类错误:否定了真实的原假设。 犯第一类错误的概率为:P {否定H0|H0为真|}
第二类错误:接受了错误的原假设。 犯第二类错误的概率为:P {接受H0|H0为假|}
5. P值:
犯第一类错误的概率,即:P 值=P {否定H0|H0为真}
当P值<α(如α=0.05),则拒绝原假设;否则,接受原假设。 使用P值的方法与使用拒绝域的方法是等价的。
表5.12 两组新生儿HBV感染情况的比较
乙法
合计
甲法
+
—
+
R语言绘图:相关性分析及绘图展示

相关性分析gaom在我们平时分析的时候,经常会遇到样品间的相关性检验分析,并以此判断对我们后续分析的影响。
今天主要跟大家讨论一下简单的相关性分析以及结果展示。
利用的测试数据还是之前我们在geo数据库中随便找的一份表达谱数据。
首先还是导入数据,进行简单分析,获取相关数值。
rm(list=ls())#先把我们的R清空一下data<-read.table(file = "C:\\Users\\gaom\\Desktop\\R语言绘图\\相关性分析\\test_data.txt", header = T,s =1,sep="\t")#读取数据cor(data,method = "pearson")#方法可选pearson、kendall、spearman。
## T01 T02 T03 T04 T05 T06 T07## T01 1.0000000 0.9626878 0.9820587 0.9775637 0.9672888 0.9664156 0.9752635## T02 0.9626878 1.0000000 0.9871793 0.9739935 0.9779155 0.9794141 0.9786400## T03 0.9820587 0.9871793 1.0000000 0.9823576 0.9819684 0.9808063 0.9833352## T04 0.9775637 0.9739935 0.9823576 1.0000000 0.9915693 0.9890907 0.9815730## T05 0.9672888 0.9779155 0.9819684 0.9915693 1.0000000 0.9943036 0.9805366## T06 0.9664156 0.9794141 0.9808063 0.9890907 0.9943036 1.0000000 0.9798487## T07 0.9752635 0.9786400 0.9833352 0.9815730 0.9805366 0.9798487 1.0000000## T08 0.9714801 0.9791369 0.9816482 0.9814655 0.9804464 0.9796599 0.9938647## T09 0.9746475 0.9802358 0.9845114 0.9814857 0.9800746 0.9794935 0.9947428## T10 0.9636498 0.9717902 0.9757652 0.9759936 0.9771073 0.9755922 0.9850377## T11 0.9739732 0.9677072 0.9775576 0.9796979 0.9778722 0.9760231 0.9876567## T12 0.9613186 0.9685109 0.9732389 0.9739145 0.9757272 0.9737234 0.9855969## T08 T09 T10 T11 T12## T01 0.9714801 0.9746475 0.9636498 0.9739732 0.9613186## T02 0.9791369 0.9802358 0.9717902 0.9677072 0.9685109## T03 0.9816482 0.9845114 0.9757652 0.9775576 0.9732389## T04 0.9814655 0.9814857 0.9759936 0.9796979 0.9739145## T05 0.9804464 0.9800746 0.9771073 0.9778722 0.9757272## T06 0.9796599 0.9794935 0.9755922 0.9760231 0.9737234## T07 0.9938647 0.9947428 0.9850377 0.9876567 0.9855969## T08 1.0000000 0.9942297 0.9858170 0.9849012 0.9837345## T09 0.9942297 1.0000000 0.9849167 0.9850892 0.9839299## T10 0.9858170 0.9849167 1.0000000 0.9867687 0.9878700## T11 0.9849012 0.9850892 0.9867687 1.0000000 0.9919710## T12 0.9837345 0.9839299 0.9878700 0.9919710 1.0000000获得每个样品之间的相关系数,下面让我们把这些结果可视化。
R语言第三章 相关性与相似性度量

第三章 相关性与相似性度量本章介绍数据属性的相关性、数据对象的相似性度量方法。
本章的主要内容是:数据对象相似性和数据属性相关性的概念;数据属性相关性的度量方法;数据对象相似性度量的方法;相关性和相似性的R 软件操作。
第一节 数据属性相关性度量一、 相关性与相似性数据对象通常由多个数据属性描述,一个数据集中的所有数据对象通常都具有相同的属性集;因此,每个数据对象可以看作多维空间中的点(向量),其中每个维代表对象的一个不同属性。
这样的数据集可以用一个n ×p 的数据矩阵表示,其中n 行表示n 个对象,p 列表示p 个属性,如图3-1所示。
⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=np n n p p x x x x x x x x x X 212222111211 图3-1 数据矩阵数据矩阵表示的数据集中,X ij 表示第i 个对象的第j 个属性值;向量X i =(X i1,X i2,…,X ip )表示对象X i (称为对象i ),每一个分量表示对象i 的不同属性取值;向量Y j =(Y 1j ,Y 2j ,…,Y nj )表示属性Y j (称为属性j ),每一个分量表示属性j 的不同对象取值。
在第二章,考察了数据的中心趋势、离散程度以及偏度和峰度等一维属性特征。
然而,在许多数据分析会涉及到数据对象的相似性和数据属性的相关性,如聚类分析、异常点检测、最邻近分类等。
数据属性的相关性和数据对象的相似性可以统一称为邻近性。
邻近性的度量常常包含许多主观上的考虑,如属性的性质(离散、连续以及二元性、稀疏性)、测量的尺度(定名的、定序的、定距的、定比的)和属性的重要性程度等。
数据属性的邻近性称为相关性,数据对象的邻近性称为相似性。
数据属性的相关性用相关系数来描述,数据对象的相似性通常由某种距离度量。
由于数据属性的类型不同,数据属性相关性度量的指标可以分为相合系数、等级相关系数、简单相关系数、夹角余弦和相关指数。
R语言的各种检验

R语言的各种检验R语言的各种检验1、W检验(Shapiro–Wilk (夏皮罗–威克尔) W统计量检验)检验数据是否符合正态分布,R函数:shapiro.test().结果含义:当p值小于某个显著性水平α(比如0.05)时,则认为样本不是来自正态分布的总体,否则则承认样本来自正态分布的总体。
2、K检验(经验分布的Kolmogorov-Smirnov检验)R函数:ks.test(),如果P值很小,说明拒绝原假设,表明数据不符合F(n,m)分布。
3、相关性检验:R函数:cor.test()cor.test(x, y, alternative = c("two.sided", "less", "greater"),method = c("pearson", "kendall", "spearman"),exact = NULL, conf.level = 0.95, ...) 结果含义:如果p值很小,则拒绝原假设,认为x,y是相关的。
否则认为是不相关的。
4、T检验用于正态总体均值假设检验,单样本,双样本都可以。
t.test()t.test(x, y = NULL, alternative = c("two.sided", "less", "greater"),mu = 0, paired = FALSE, var.equal = FALSE, conf.level = 0.95, ...)结果意义:P值小于显著性水平时拒绝原假设,否则,接受原假设。
具体的假设要看所选择的是双边假设还是单边假设(又分小于和大于)5、正态总体方差检验t.test(x, y = NULL, alternative = c("two.sided", "less", "greater"),mu = 0, paired = FALSE, var.equal = FALSE, conf.level = 0.95, ...)结果含义:P值小于显著性水平时拒绝原假设,否则,接受原假设。
R语言方法总结

计算描述性统计量:1、summary:例:summarymtcarsvarssummary函数提供了最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计;2、apply函数或sapply函数计算所选择的任意描述性统计量;mean、sd、var、min、max、median、length、range 和quantile;函数fivenum可返回图基五数总括Tukey’s five-number summary,即最小值、下四分位数、中位数、上四分位数和最大值;sapply例:mystats <- functionx, na.omit = FALSE {if na.omitx <- xis.naxm <- meanxn <- lengthxs <- sdxskew <- sumx - m^3/s^3/nkurt <- sumx - m^4/s^4/n - 3returncn = n, mean = m, stdev = s, skew = skew, kurtosis = kurt}sapplymtcarsvars, mystats3、describe:Hmisc包:返回变量和观测的数量、缺失值和唯一值的数目、平均值、分位数,以及五个最大的值和五个最小的值;例:libraryHmiscdescribemtcarsvars4、stat.desc:pastecs包若basic=TRUE默认值,则计算其中所有值、空值、缺失值的数量,以及最小值、最大值、值域,还有总和;若desc=TRUE同样也是默认值,则计算中位数、平均数、平均数的标准误、平均数置信度为95%的置信区间、方差、标准差以及变异系数;若norm=TRUE不是默认的,则返回正态分布统计量,包括偏度和峰度以及它们的统计显著程度和Shapiro–Wilk正态检验结果;这里使用了p值来计算平均数的置信区间默认置信度为0.95:例:librarypastecsstat.descmtcarsvars5、describe:psych包计算非缺失值的数量、平均数、标准差、中位数、截尾均值、绝对中位差、最小值、最大值、值域、偏度、峰度和平均值的标准误例:librarypsychdescribemtcarsvars分组计算描述性统计量1、aggregate:例:aggregatemtcarsvars, by = listam = mtcars$am, mean2、by:例:dstats <- functionxcmean=meanx, sd=sdxbymtcarsvars, mtcars$am, dstatsbymtcars,vars,mtcars$am,plyr::colwisdstats3、summaryBy:doBy包例librarydoBysummaryBympg + hp + wt ~ am, data = mtcars, FUN = mystats 4、describe.by:doBy包describe.by函数不允许指定任意函数, 例:librarypsychdescribe.bymtcarsvars, mtcars$am5、reshape包分组:重铸和融合例:libraryreshapedstats <- functionx cn = lengthx, mean = meanx,sd = sdxdfm <- meltmtcars, measure.vars = c"mpg", "hp","wt", id.vars = c"am", "cyl"castdfm, am + cyl + variable ~ ., dstats频数表和列联表1、table:生成简单的频数统计表mytable <- withArthritis, tableImprovedMytable2、prop.table:频数转化为比例值prop.tablemytable3、prop.table100:转化为百分比prop.tablemytable100二维列联表4、tableA,B/xtabs~A+b,data=mydata例:mytable <- xtabs~ Treatment+Improved, data=Arthritis5、margin.table和prop.table:函数分别生成边际频数和比例1:行,2:列行和与行比例margin.tablemytable, 1prop.tablemytable, 1列和与列比例margin.tablemytable, 2prop.tablemytable, 2prop.tablemytable6、addmargins:函数为这些表格添加边际和addmarginsmytableadmarginsprop.tablemytableaddmarginsprop.tablemytable, 1, 2addmarginsprop.tablemytable, 2, 17.crossTable:gmodels包例:librarygmodelsCrossTableArthritis$Treatment, Arthritis$Improved多维列联表1、table和xtabs:都可以基于三个或更多的类别型变量生成多维列联表;2、ftable:例:mytable <- xtabs~ Treatment+Sex+Improved, data=Arthritismytableftablemytablemargin.tablemytable, 1margin.tablemytable, 2margin.tablemytable, 3margin.tablemytable, c1,3ftableprop.tablemytable, c1, 2ftableaddmarginsprop.tablemytable, c1, 2, 3 gtableaddmarginsprop.tablemytable, c1, 2, 3 100独立检验1、卡方独立性检验:chisq.test例:libraryvcdmytable <- xtabs~Treatment+Improved, data=Arthritischisq.testmytablemytable <- xtabs~Improved+Sex, data=Arthritischisq.testmytable2、Fisher精确检验:fisher.test例:mytable <- xtabs~Treatment+Improved, data=Arthritis fisher.testmytable3、Cochran-Mantel—Haenszel检验:mantelhaen.test例:mytable <- xtabs~Treatment+Improved+Sex, data=Arthritis mantelhaen.testmytable相关性度量1、assocstats:例:libraryvcdmytable <- xtabs~Treatment+Improved, data=Arthritisassocstatsmytable2、cor:函数可以计算这三种相关系数,3、cov:函数可用来计算协方差例:states <- state.x77, 1:6covstatescorstatescorstates, method="spearman"x <- states, c"Population", "Income", "Illiteracy", "HS Grad"y <- states, c"Life Exp", "Murder"corx, y4、pcor:偏相关ggm包例:libraryggmpcorc1, 5, 2, 3, 6, covstates相关性的显著性检验1、cor.test其中的x和y为要检验相关性的变量, alternative则用来指定进行双侧检验或单侧检验取值为"two.side"、"less"或"greater" ,而method用以指定要计算的相关类型"pearson"、"kendall"或"spearman"当研究的假设为总体的相关系数小于0时,请使用alternative= "less";在研究的假设为总体的相关系数大于0时,应使用alternative="greater";在默认情况下,假设为alternative="two.side"总体相关系数不等于0;例:cor.teststates, 3, states, 52、corr.test:可以为Pearson、Spearman或Kendall相关计算相关矩阵和显著性水平;例:librarypsychcorr.teststates, use = "complete"3、pcor.test:psych包t 检验1、t.testy~x,data独立样本例:libraryMASSt.testProb ~ So, data=UScrime2、t.testy1,y2,paired=TRUE非独立例:libraryMASSsapplyUScrimec"U1", "U2", functionx cmean = meanx,sd = sdxwithUScrime, t.testU1, U2, paired = TRUE组间差异的非参数检验两组的比较:1、wilcox.testy~x,data :评估观测是否是从相同的概率分布中抽得例:withUScrime, byProb, So, medianwilcox.testProb ~ So, data=UScrime2、wilcox.testy1,y2,paried=TRUE:它适用于两组成对数据和无法保证正态性假设的情境;例:sapplyUScrimec"U1", "U2", medianwithUScrime, wilcox.testU1, U2, paired = TRUE多于两组的比较:1、kruskal.testy~A,data:各组独立例:states <- as.data.framecbindstate.region, state.x77kruskal.testIlliteracy ~ state.region, data=states2、friedman.testy~A|B,data:各组不独立非参数多组比较:1、npmc :npmc包例:class <- state.regionvar <- state.x77, c"Illiteracy"mydata <- as.data.framecbindclass, varrmclass,varlibrarynpmcsummarynpmcmydata, type = "BF"aggregatemydata, by = listmydata$class, median回归用一个或多个预测变量也称自变量或解释变量来预测响应变量也称因变量、效标变量或结果变量的方法;1、lm: 拟合回归模型lmy~x1+x2+x3,data简单线性回归1、lm: data是数据框例:fit <- lmweight ~ height, data = womensummaryfitwomen$weightfittedfitresidualsfitplotwomen$height, women$weight, main = "Women Age 30-39",xlab = "Height in inches", ylab = "Weight in pounds"多项式回归例:fit2 <- lmweight ~ height + Iheight^2, data = womensummaryfit2plotwomen$height, women$weight, main = "Women Age 30-39",xlab = "Height in inches", ylab = "Weight in lbs"lineswomen$height, fittedfit22、scatterplot:绘制二元关系图例:librarycarscatterplotweight ~ height, data = women, spread = FALSE,lty.smooth = 2, pch = 19, main = "Women Age 30-39", xlab = "Height inches",ylab = "Weight lbs."多元线性回归1、scatterplotMatrix:car包scatterplotMatrix函数默认在非对角线区域绘制变量间的散点图, 并添加平滑loess 和线性拟合曲线;对角线区域绘制每个变量的密度图和轴须图;例:fit <- lmMurder ~ Population + Illiteracy + Income +Frost, data = states有交互项的多元线性回归例:fit <- lmmpg ~ hp + wt + hp:wt, data = mtcarssummaryfit1、effect : effects包:展示交互项的结果term即模型要画的项, mod为通过lm拟合的模型, xlevels是一个列表,指定变量要设定的常量值, multiline=TRUE选项表示添加相应直线;例:libraryeffectsploteffect"hp:wt", fit,xlevels=listwt = c2.2, 3.2, 4.2,multiline = TRUE回归诊断1、confint:求模型参数的置信区间例:fit <- lmMurder ~ Population + Illiteracy + Income +Frost, data=statesconfintfit2、plot:生成评价模型拟合情况的图形例:fit <- lmweight ~ height, data = womenparmfrow = c2, 2plotfit3、lm :删除观测点例:newfit <- lmweight ~ height + Iheight^2, data = women-c13, 15,parmfrow = c2, 2plotnewfitparopargvlma包提供了对所有线性模型假设进行检验的方法检验正态性:4、Plot:car包:学生化残差studentized residual,也称学生化删除残差或折叠化残差例:librarycarfit <- lmMurder ~ Population + Illiteracy + Income + Frost, data = statesPlotfit, labels = sstates, id.method = "identify" ,simulate = TRUE, main ="Q-Q Plot"注:id.method = "identify"选项能够交互式绘图5、fitted:提取模型的拟合值例:fittedfit“Nevada”6、residuals:二项式回归模型的残差例:residualsfit“Nevada”7、residplot:生成学生化残差柱状图即直方图,并添加正态曲线、核密度曲线和轴须图;它不需要加载car包例:residplot <- functionfit, nbreaks=10 {z <- rstudentfithistz, breaks=nbreaks, freq=FALSE,xlab="Studentized Residual",main="Distribution of Errors"rugjitterz, col="brown"curvednormx, mean=meanz, sd=sdz,add=TRUE, col="blue", lwd=2linesdensityz$x, densityz$y,col="red", lwd=2, lty=2legend"topright",legend = c "Normal Curve", "Kernel Density Curve",lty=1:2, col=c"blue","red", cex=.7}residplotfit误差的独立性8、durbinWatsonTest :验证独立性例:durbinWatsonTestfit验证线性9、crPlots:car包成分残差图也称偏残差图例:crPlotsfit同方差性car包的两个函数10、ncvTest :生成一个计分检验,零假设为误差方差不变,备择假设为误差方差随着拟合值水平的变化而变化;若检验显著,则说明存在异方差性11、spreadLevelPlot:添加了最佳拟合曲线的散点图,展示标准化残差绝对值与拟合值的关系;例:librarycarncvTestfitspreadLevelPlotfit线性模型假设的综合验证1、gvlma :gvlma包:线性模型假设进行综合验证,同时还能做偏斜度、峰度和异方差性的评价例:librarygvlmagvmodel <- gvlmafitsummarygvmodel多重共线性1、vif :car包:函数提供VIF值, vif>2就表明存在多重共线性问题例:viffitsqrtviffit > 2异常观测值1、outlierTest :car包:求得最大标准化残差绝对值Bonferroni调整后的p值例:librarycaroutlierTestfit高杠杆值点1、hat.plot :观测点的帽子值大于帽子均值的2或3倍,即可以认定为高杠杆值点例:hat.plot <- functionfit{p <- lengthcoefficientsfitn <- lengthfittedfitplothatvaluesfit, main = "Index Plot of Hat Values"ablineh = c2, 3 p/n, col = "red", lty = 2identify1:n, hatvaluesfit, nameshatvaluesfit}hat.plotfit强影响点:Cook’s D值大于4/n-k -1,则表明它是强影响点,其中n 为样本量大小, k 是预测变量数目;例:cutoff <- 4/nrowstates - lengthfit$coefficients - 2plotfit, which = 4, cook.levels = cutoffablineh = cutoff, lty = 2, col = "red"1、influencePlot:car包:离群点、杠杆值和强影响点的信息整合到一幅图形中例:influencePlotfit, id.method = "identify", main = "Influence Plot",sub = "Circle size is proportial to Cook's Distance"纵坐标超过+2或小于2的州可被认为是离群点,水平轴超过0.2或0.3的州有高杠杆值通常为预测值的组合;圆圈大小与影响成比例,圆圈很大的点可能是对模型参数的估计造成的不成比例影响的强影响点变量变换1、powerTransform:car包:函数通过λ 的最大似然估计来正态化变量 x;例:librarycarsummarypowerTransformstates$Murder2、boxTidwell:car包:通过获得预测变量幂数的最大似然估计来改善线性关系例:librarycarboxTidwellMurder ~ Population + Illiteracy, data = states模型比较1、anova:基础包:比较两个嵌套模型的拟合优度例:fit1 <- lmMurder ~ Population + Illiteracy + Income +Frost, data = statesfit2 <- lmMurder ~ Population + Illiteracy, data = statesanovafit2, fit12、AIC:AIC值越小的模型可以不嵌套要优先选择,它说明模型用较少的参数获得了足够的拟合度;例:fit1 <- lmMurder ~ Population + Illiteracy + Income +Frost, data = statesfit2 <- lmMurder ~ Population + Illiteracy, data = statesAICfit1, fit2变量选择1、stepAIC:MASS包:逐步回归模型例:libraryMASSfit1 <- lmMurder ~ Population + Illiteracy + Income +Frost, data = statesstepAICfit, direction = "backward"2、regsubsets:leaps包:全子集回归例:libraryleapsleaps <- regsubsetsMurder ~ Population + Illiteracy +Income + Frost, data = states, nbest = 4plotleaps, scale = "adjr2"交叉验证1、crossval 函数:bootstrap 包:实现k 重交叉验证例:shrinkage <- functionfit, k = 10 {requirebootstrapdefine functionstheta.fit <- functionx, y {lsfitx, y}theta.predict <- functionfit, x {cbind1, x %% fit$coef}matrix of predictorsx <- fit$model, 2:ncolfit$modelvector of predicted valuesy <- fit$model, 1results <- crossvalx, y, theta.fit, theta.predict, ngroup = kr2 <- cory, fit$fitted.values^2r2cv <- cory, results$cv.fit^2cat"Original R-square =", r2, "\n"catk, "Fold Cross-Validated R-square =", r2cv, "\n"cat"Change =", r2 - r2cv, "\n"}2、shrinkage:交叉验证;R平方减少得越少,预测则越精确;例:fit <- lmMurder ~ Population + Income + Illiteracy +Frost, data = statesshrinkagefit相对重要性1、scale:将数据标准化为均值为0、标准差为1的数据集,这样用R回归即可获得标准化的回归系数;注意, scale函数返回的是一个矩阵,而lm函数要求一个数据框例:zstates <- as.data.framescalestateszfit <- lmMurder ~ Population + Income + Illiteracy +Frost, data = zstatescoefzfit2、relweights :相对权重例:relweights <- functionfit, ... {R <- corfit$modelnvar <- ncolRrxx <- R2:nvar, 2:nvarrxy <- R2:nvar, 1svd <- eigenrxxevec <- svd$vectorsev <- svd$valuesdelta <- diagsqrtevcorrelations between original predictors and new orthogonal variableslambda <- evec %% delta %% teveclambdasq <- lambda^2regression coefficients of Y on orthogonal variablesbeta <- solvelambda %% rxyrsquare <- colSumsbeta^2rawwgt <- lambdasq %% beta^2import <- rawwgt/rsquare 100lbls <- namesfit$model2:nvarrownamesimport <- lblscolnamesimport <- "Weights"plot resultsbarplottimport, names.arg = lbls, ylab = "% of R-Square",xlab = "Predictor Variables", main = "Relative Importance of Predictor Variables",sub = paste"R-Square = ", roundrsquare, digits = 3,...returnimport}using relweightsfit <- lmMurder ~ Population + Illiteracy + Income +Frost, data = statesrelweightsfit, col = "lightgrey"方差分析1、aov =lm单因素方差分析2、plotmeans:绘制带置信区间的图形例:librarymultcompattachcholesteroltabletrtaggregateresponse, by = listtrt, FUN = meanaggregateresponse, by = listtrt, FUN = sdfit <- aovresponse ~ trtsummaryfitlibrarygplotsplotmeansresponse ~ trt, xlab = "Treatment", ylab = "Response", main = "Mean Plot\nwith 95% CI"detachcholesterol多重比较1、TukeyHSD:对各组均值差异的成对检验例:TukeyHSDfitparlas = 2parmar = c5, 8, 4, 2plotTukeyHSDfitparopar2、glht:multcomp包:多重均值比较例:librarymultcompparmar = c5, 4, 6, 2tuk <- glhtfit, linfct = mcptrt = "Tukey"plotcldtuk, level = 0.05, col = "lightgrey"paropar评估检验的假设条件1、正态检验:librarycarPlotlmresponse ~ trt, data = cholesterol, simulate = TRUE,main = " Plot", labels = FALSE2、方差齐性检验:bartlett.testresponse ~ trt, data = cholesterol3、检测离群点:outlierTest car包librarycaroutlierTestfit单因素协方差分析例:datalitter, package = "multcomp"attachlittertabledoseaggregateweight, by = listdose, FUN = meanfit <- aovweight ~ gesttime + dosesummaryfit1、effects :effects包:计算调整的均值例:libraryeffectseffect"dose", fit2、ancova :HH包:绘制因变量、协变量和因子之间的关系图例:libraryHHancovaweight ~ gesttime + dose, data = litter3、interaction.plot:函数来展示双因素方差分析的交互效应例:interaction.plotdose, supp, len, type = "b", col = c"red", "blue", pch = c16, 18,main = "Interaction between Dose and Supplement Type"4、plotmeans:gplots包:展示交互效应例:librarygplotsplotmeanslen ~ interactionsupp, dose, sep = " ",connect = listc1, 3, 5, c2, 4, 6,col = c"red", "darkgreen",main = "Interaction Plot with 95% CIs",xlab = "Treatment and Dose Combination"5、interaction2wt:HH包:可视化结果例:libraryHHinteraction2wtlen ~ supp dose6、colMeans:计算每列的平均值7、nrow/ncol :计算数组额行数和列数8、mahalanobis:用协方差来计算两点之间距离的方法稳健多元方差分析Wilks.test :稳健单因素MANOV A。
R语言非参数检验

1. R语言卡方检验皮尔森拟合优度塔防检验。
假设H0:总体具有某分布F 备择假设H1:总体不具有该分布。
我们将数轴分成若干个区间,所抽取的样本会分布在这些区间中。
在原假设成立的条件下,我们便知道每个区间包含样本的个数的期望值。
用实际值Ni 与期望值Npi可以构造统计量K 。
皮尔森证明,n趋向于无穷时,k收敛于m-1的塔防分布。
m为我们分组的个数。
有了这个分布,我们就可以做假设检验。
#如果是均匀分布,则没有明显差异。
这里组其实已经分好了,直接用。
H0:人数服从均匀分布> x <- c(210,312,170,85,223)> n <- sum(x); m <- length(x)> p <- rep(1/m,m)> K <- sum((x-n*p)^2/(n*p)); K #计算出K值[1] 136.49> p <- 1-pchisq(K,m-1); p #计算出p值[1] 0 #拒绝原假设。
在R语言中chisq.test(),可以完成拟合优度检验。
默认就是检验是否为均匀分布,如果是其他分布,需要自己分组,并在参数p中指出。
上面题目的解法:chisq.test(x)Chi-squared test for given probabilitiesdata: xX-squared = 136.49, df = 4, p-value < 2.2e-16 #同样拒绝原假设。
例,用这个函数检验其他分布。
抽取31名学生的成绩,检验是否为正态分布。
> x <- c(25,45,50,54,55,61,64,68,72,75,75,78,79,81,83,84,84,84,85,86,86,86,87,89,89,89,90,91,91,92,100)> A <- table(cut(x,breaks=c(0,69,79,89,100))) #对样本数据进行分组。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
假设检验简介
3. 基本思想:反证法思想
为了检验一个“假设”是否成立,就先假定这个“假设”是成立的, 而看由此会产生的效果。如果导致一个不合理现象出现,就表明原先 的“假设”不成立,就拒绝这个“假设”;如果由此没有导致不合理 现象的发生,则不能拒绝原“假设”。
该方法又区别于纯数学中的反证法。这里所谓的“不合理”,并不是形式逻辑 中的绝对矛盾,而是基于人们实践中广泛采用的一个原则:小概率事件在一次 观察中可以认为基本上不会发生。
H0:X与Y独立,H1:X与Y不独立(相关). 用chisq.test()函数可完成列联表数据的Pearsonχ2 独立性检验,需将列联表写成矩阵形式。
P198,使用该函数计算 Pearson拟合优度χ2检验
5.5 列联表检验
例5.26 在一次社会调查中,以问卷方式共调查了901人的月收入及对工作的满意程度,其中有收入A分为:小于 3000元、3000~7500元、7500~12000元及超过12000元4档。对工作的满意程度B分为:很不满意、较不满意、基本 满意和很满意4档。调查表用4x4列联表表示,如表5.10所示。试分析工资收入与对工作的满意度是否有关。
后出生的儿童
88
76
64
96
65
80
81
72
60
总结
列联表检验
相关性检验
1. 2. 3. 4.
Pearsonχ2独立性检验 Fisher精确独立性检验 McNemar检验 三维列联表的条件独立性检验
cor.test()函数进行相关性系数的计算和检验
107
132
128
202
5.5 列联表检验
5. 三维列联表的条件独立性检验:
例5.30 表5.15是1976—1977年美国佛罗里达州的凶杀案件中,326名被告的肤色与 死刑判决情况表。试用这组数据分析,被判死刑是否与被告的肤色有关。
表5.15 被告肤色与死刑判决情况
被告
白种人 黑种人 合计
死刑 是 19 17 36 否 141 149 290
合计
160 166 326
用chisq.test()函数作χ2检验,再用prop.test()函数作比例检验。
5.5 列联表检验
例5.31 (继5.30)表5.16给出了带有被害人的数据。再分析被判死刑是否与被告的肤色有关。
表5.16 被告人与被害人肤色以及死刑判决情况 被告 被害人 白种人 白种人 黑种人 白种人 黑种人 黑种人 6 97 0 11 9 52 死刑 是 19 否 132
McNemar是用来比较两种检验,比如A和B,来看A和B是否有差异。
例5.29 某胸科医院同时用甲、乙两种方法测定202份痰标本中的抗酸杆菌,结果如 表5.14所示。问甲、乙两法的检出率有无显著差异?
表5.12 两组新生儿HBV感染情况的比较 乙 法 甲法 合计 — 25 74
+
49
+
—
合计
21
70
5.5 列联表检验
1. 概念 2. Pearsonχ2独立性检验 3. Fisher精确独立性检验
4. McNemar检验
5. 三维列联表的条件独立性检验
5.5 列联表检验
设两个随机变量X,Y均为离散型的,X取值于{a1, a2, …,aI}, Y取值 1. 概念: 于{b1, b2, …,bJ}。设(X1,Y1),(X2,Y2), …,(Xn,Yn)为简单样 本,记nij为(X1,Y1),(X2,Y2), …,(Xn,Yn)中等于( ai, aj ) 的个数。在求解问题时,常把数据列为形如表5.9的形式,称为 列联表;根据列联表数据做的检验称为列联表检验。
表5.10 列联表 工资收入 很不满意 较不满意 基本满意 很满意 合计
<3000
3000~7500 7500~12000 >12000 合计
20
22 13 7 62
24
38 28 18 108
80
104 81 54 319
82
125 113 92 412
206
289 235 171 901
5.5 列联表检验
假设检验简介
4. 两类错误:
第一类错误:否定了真实的原假设。 犯第一类错误的概率为:P {否定H0|H0为真|}
第二类错误:接受了错误的原假设。 犯第二类错误的概率为:P {接受H0|H0为假|}
5. P值:
犯第一类错误的概率,即:P 值=P {否定H0|H0为真}
当P值<α(如α=0.05),则拒绝原假设;否则,接受原假设。 使用P值的方法与使用拒绝域的方法是等价的。
采用连续修正的情况下, 参数orrect默认为TRUE
5.ቤተ መጻሕፍቲ ባይዱ 列联表检验
3. Fisher精确独立性检验:
在样本数较小时,需要用Fisher精确检验来完成独立性实验。 使用函数fisher.test()作精确独力检验。
例5.28 某医师为研究乙肝免疫球蛋白预防胎儿宫内感染HBV的效果,将33例HBsAg阳性孕妇随机分为
5.6 相关性检验
例5.33 一项有6个人参加表演的竞赛,有两人进行评定,评定结果如表5.18所示。试检验这两个评定员对 等级评定有无相关关系。 表5.18 两位评判者的评判成绩 甲的打分 乙的打分 1 6 2 5 3 4 4 3 5 2 6 1
例5.34 某幼儿园对9对双胞胎的智力进行检验,并按百分制打分。现有资料如5.19所示,使用Kendall相关 检验方法检验双胞胎的智力是否相关。 表5.19 9对双胞胎的得分情况 先出生的儿童 86 77 68 91 70 71 85 87 63
预防注射组和对照组,结果如表5.12所示。问两组新生儿的HBV总体感染率有无差别。
表5.12 两组新生儿HBV感染情况的比较 组别 预防注射组 对照组 合计 阳性 4 5 9 阴性 18 6 24 合计 22 11 33
用Fisher精确检验对吸烟数(据例5.27)作检验。
5.5 列联表检验
4. McNemar检验:
表5.9 列联表 b1 a1 a2 . . . aI 合计 n11 n21 . . . nI1 N·1 b2 n12 n22 . . . n2J N· 1 … … … bJ n1J n2J . . . nIJ N· 1 合计 n1· n2· . . . nI·
… …
5.5 列联表检验
2. Pearsonχ2独立性检验:
H0:ρXY=0,H0:ρXY≠0
5.6 相关性检验
例5.32 对于20个随机选取的黄麻个体植株,记录青植株重量Y与它们的干植株重量X。设 二元总体(X,Y)服从二维正态分布,其观测数据如表5.17所示。试分析青植株重量与干植 株重量是否有相关性。
表5.17 青植株与干植株的重量 X 1 2 3 4 5 6 7 68 63 70 6 65 9 10 Y 971 892 1125 82 931 112 162 8 9 10 11 12 13 14 X 12 20 30 33 27 21 5 Y 321 315 375 462 352 305 84 15 16 17 18 19 20 X 14 27 17 53 62 65 Y 229 332 185 703 872 740
R语言实用教程
第五章
假设检验
假设检验简介 5.5 列联表检验
5.6 相关性检验
总结
假设检验简介
1. 概念 2. 方法 3. 基本思想 4. 两类错误
5. P值
假设检验简介
1. 概念:假设检验是统计推断中的一个重要内容,它是利用样 本数据对某个事先做出的统计假设按照某种设计好的 方法进行检验,判断此假设是否正确。
例5.27 为了研究吸烟是否与患肺癌有关,对63位肺癌患者及43名非肺癌患者(对照组) 调查了其中的吸烟人数,得到2x2列联表,如表5.11所示。
表5.11 列联表 患肺癌 吸烟 不吸烟 合计 60 3 63 未患肺癌 32 11 43 合计 92 14 106
Chisq.test(x,correct=FALSE) 与 Chisq.test(x)
原假设/零假设(记为H0):作为检验的对象的假设。 备择假设(记为H1):与原假设对立的假设。
参数性假设检验:总体分布已知,通过样本检验 2. 方法
关于未知参数的某个检验。
用t.test()函数作 t 检验 用var.test()函数作 F 检验 用prop.text()函数作二项分布的近似检验
非参数性假设检验:总体分布未知时的检验问题。
用mantelhaen.test()函数完成Mantel-Haenszel检验。
5.6 相关性检验
cor.test()函数进行相关性系数的计算和检验:
函数功能:对成对数据进行相关性检验,有3中方法可供使用,分别是 Pearson检验、Kendall检验和Spearman检验。 函数的使用格式为: cor.test(x, y, alternative = c(“two.sided”, “less”, “greater”), method = c("pearson", "kendall", "spearman"),conf.level = 0.95) 其中x,y是供检验的样本;alternative指定是双侧检验还是单侧检验;method 为检验的方法;conf.level为检验的置信水平。