正则表达式全部符号解释
常用正则表达式及特殊符号
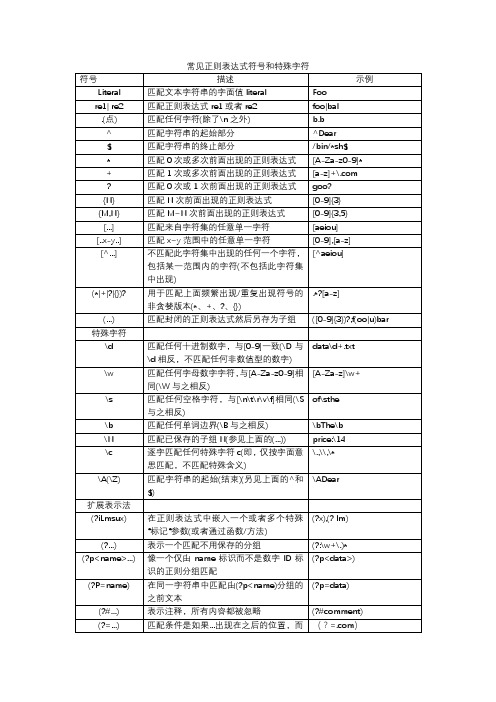
(?#...mment)
(?=...)
匹配条件是如果...出现在之后的位置,而不适用输入字符串;称作正向前视断言
(?=.com)
(?!...)
匹配条件是如果...不出现之后的位置,而不使用输入字符串;称作负向前视断言
(?!.net)
(?<=...)
[A-Za-z0-9]*
+
匹配1次或多次前面出现的正则表达式
[a-z]+\.com
?
匹配0次或1次前面出现的正则表达式
goo?
{N}
匹配N次前面出现的正则表达式
[0-9]{3}
{M,N}
匹配M~N次前面出现的正则表达式
[0-9]{3,5}
[...]
匹配来自字符集的任意单一字符
[aeiou]
[..x-y..]
匹配x~y范围中的任意单一字符
[0-9],[a-z]
[^...]
不匹配此字符集中出现的任何一个字符,包括某一范围内的字符(不包括此字符集中出现)
[^aeiou]
(*|+|?|{})?
用于匹配上面频繁出现/重复出现符号的非贪婪版本(*、+、?、{})
.*?[a-z]
(...)
匹配封闭的正则表达式然后另存为子组
([0-9]{3})?,f(oo|u)bar
特殊字符
\d
匹配任何十进制数字,与[0-9]一致(\D与\d相反,不匹配任何非数值型的数字)
data\d+.txt
\w
匹配任何字母数字字符,与[A-Za-z0-9]相同(\W与之相反)
[A-Za-z]\w+
\s
匹配任何空格字符,与[\n\t\r\v\f]相同(\S与之相反)
正则表达式中常见的基本符号

正则表达式中常见的基本符号一、元字符。
1. 点号(.)- 含义:匹配除换行符之外的任何单个字符。
- 原因:在正则表达式中,点号是一个非常通用的匹配单个字符的符号。
例如,在模式“a.c”中,它可以匹配“abc”“a c”“a!c”等,只要中间是一个除换行符以外的字符就可以匹配成功。
这在处理一些格式不太固定但有部分固定内容的文本时非常有用。
2. 星号(*)- 含义:匹配前面的元素零次或多次。
- 原因:它主要用于表示某个字符或字符组可以出现任意次数(包括零次)。
例如,“ab*”可以匹配“a”(因为b出现零次)、“ab”、“abb”、“abbb”等。
在处理像电话号码中可选的区号部分或者某个单词的复数形式(其中字母可能重复多次)等情况时会用到。
3. 加号(+)- 含义:匹配前面的元素一次或多次。
- 原因:与星号类似,但至少要求前面的元素出现一次。
例如,“ab+”可以匹配“ab”、“abb”、“abbb”等,但不能匹配“a”,因为这里的b必须至少出现一次。
在验证密码强度时,如果要求密码中必须包含至少一个数字,可以使用类似“[0 - 9]+”的模式。
4. 问号(?)- 含义:匹配前面的元素零次或一次。
- 原因:用于表示某个字符或字符组是可选的。
例如,“colou?r”可以匹配“color”和“colour”,因为u是可选的。
在处理不同的拼写变体或者可选的语法结构时很有用。
二、字符类相关符号。
1. 方括号([])- 含义:定义一个字符类,匹配方括号内的任意一个字符。
- 原因:这是一种指定多个可能字符的简洁方式。
例如,“[aeiou]”可以匹配任何一个元音字母。
可以在方括号内使用范围表示法,如“[a - z]”匹配任何小写字母,“[0 - 9]”匹配任何数字。
这种方式在验证输入是否为特定类型的字符(如字母、数字、特定符号等)时非常常见。
2. 脱字符(^)在字符类中的用法。
- 含义:当脱字符在字符类的开头时,表示否定该字符类,即匹配除了字符类中字符以外的任何字符。
中文符号正则表达式

中文符号正则表达式一、校验数字的表达式数字:^[0-9]*$n位的数字:^\d{n}$至少n位的数字:^\d{n,}$m-n位的数字:^\d{m,n}$零和非零开头的数字:^(0|[1-9][0-9]*)$非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$有两位小数的正实数:^[0-9]+(.[0-9]{2})?$有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$非零的正整数:^[1-9]\d*$ 或^([1-9][0-9]*){1,3}$ 或^\+?[1-9][0-9]*$非零的负整数:^\-[1-9][]0-9"*$ 或^-[1-9]\d*$非负整数:^\d+$ 或^[1-9]\d*|0$非正整数:^-[1-9]\d*|0$ 或^((-\d+)|(0+))$非负浮点数:^\d+(\.\d+)?$ 或^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[ 1-9][0-9]*))$负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9] *[1-9][0-9]*)))$浮点数:^(-?\d+)(\.\d+)?$ 或^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$二、校验字符的表达式汉字:^[\u4e00-\u9fa5]{0,}$英文和数字:^[A-Za-z0-9]+$ 或^[A-Za-z0-9]{4,40}$长度为3-20的所有字符:^.{3,20}$由26个英文字母组成的字符串:^[A-Za-z]+$由26个大写英文字母组成的字符串:^[A-Z]+$由26个小写英文字母组成的字符串:^[a-z]+$由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或^\w{3,20}中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+禁止输入含有~的字符[^~\x22]+其它:.*匹配除 \n 以外的任何字符。
正则表达式各字符含义

匹配或.例如,''能匹配""或"".'()'则匹配""或"".
*
匹配前面地子表达式零次或多次.例如,*能匹配""以及"".*等价于{,}.
匹配前面地子表达式一次或多次.例如,''能匹配""以及"",但不能匹配"".等价于{,}.
?
匹配前面地子表达式零次或一次.例如,"()?"可以匹配""或""中地"" .?等价于{}.
{}
是一个非负整数.匹配确定地次.例如,'{}'不能匹配""中地'',但是能匹配""中地两个.
{,}
是一个非负整数.至少匹配次.例如,'{,}'不能匹配""中地'',但能匹配""中地所有.'{,}'等价于''.'{,}'则等价于'*'.
{}
和均为非负整数,其中< .最少匹配次且最多匹配次.例如,"{}"将匹配""中地前三个.'{}'等价于'?'.请注意在逗号和两个数之间不能有空格.
正则表达式所有标点符号

正则表达式所有标点符号
在正则表达式中,标点符号不仅是用来分隔不同的字符和子表达式的,它们还有特定的含义和用法。
以下是正则表达式中所有标点符号的含义及用法:
1. ^:表示匹配字符串的开始位置,例如 ^a 表示以字母 a 开
始的字符串。
2. $:表示匹配字符串的结束位置,例如 a$ 表示以字母 a 结
尾的字符串。
3. .:匹配任意一个字符,例如 a.b 可以匹配 aab、acb、a1b 等。
4. *:匹配前面的字符出现任意多次,例如 ab*c 可以匹配 ac、abc、abbc、abbbc 等。
5. +:匹配前面的字符出现至少一次,例如 ab+c 可以匹配 abc、abbc、abbbc 等。
6. ?:匹配前面的字符出现零次或一次,例如 ab?c 可以匹配 ac、abc 等。
7. []:表示字符集合,可以匹配其中任意一个字符,例如 [abc] 可以匹配 a、b、c 中任何一个字符。
8. [^]:表示取反字符集合,可以匹配除了其中任何一个字符以外的字符,例如 [^abc] 可以匹配除了 a、b、c 以外的任意一个字符。
9. ():表示分组,可以对其中的字符进行分组提取,例如 (ab)+c 表示匹配一个或多个 ab 后面跟着字母 c。
10. {}:表示重复次数,可以匹配前面的字符重复出现的次数,例如 a{2,5}c 表示匹配两个到五个 a 后面跟着字母 c。
11. |:表示或者,可以匹配其中任意一个子表达式,例如 a|b|c 表示匹配 a、b、c 中任意一个字符。
以上是正则表达式中所有标点符号的含义及用法,熟练掌握它们可以帮助你更高效地编写正则表达式。
正则表达式中符号含义大全

\n 匹配 n,其中 n 是八进制换码值。八进制换码值必须是 1、2、或 3 位长。例如,"\11" 和 "\011" 都匹配制表字符。"\0011" 和 "\001" & "1" 是等效的。八进制换码值必须不超过 256。如果超过了,则只有前两位组成表达式。允许在正则表达式中使用 ASCII 码。
{n} 匹配 n 次。n 是非负整数
{n,} n 是一个非负整数。至少匹配 n 次。例如,"o{2,}" 和 "Bob" 中的 "o" 不匹配,但和 "foooood" 中的所有 o 匹配。"o{1,}" 与 "o+" 等效。"o{0,}" 和 "o*" 等效。
\v 匹配垂直制表符。
\w 匹配包括下划线在内的任何字字符。与 "[A-Za-z0-9_]" 等效。
\W 匹配任何非字字符。与 "[^A-Za-z0-9_]" 等效。
\num 匹配 num,其中 num 是一个正整数。返回记住的匹配的引用。例如,"(.)\1" 匹配两个连续的同一字符。
\xn 匹配 n,其中 n 是十六进制换码值。十六进制换
js正则表达式符号含义

js正则表达式符号含义\ 做为转意,即通常在"\"后⾯的字符不按原来意义解释,如/b/匹配字符"b",当b前⾯加了反斜杆后/\b/,转意为匹配⼀个单词的边界。
-或-对正则表达式功能字符的还原,如"*"匹配它前⾯元字符0次或多次,/a*/将匹配a,aa,aaa,加了"\"后,/a\*/将只匹配"a*"。
^ 匹配⼀个输⼊或⼀⾏的开头,/^a/匹配"an A",⽽不匹配"An a"$ 匹配⼀个输⼊或⼀⾏的结尾,/a$/匹配"An a",⽽不匹配"an A"* 匹配前⾯元字符0次或多次,/ba*/将匹配b,ba,baa,baaa+ 匹配前⾯元字符1次或多次,/ba*/将匹配ba,baa,baaa? 匹配前⾯元字符0次或1次,/ba*/将匹配b,ba(x) 匹配x保存x在名为$1...$9的变量中x|y 匹配x或y{n} 精确匹配n次{n,} 匹配n次以上{n,m} 匹配n-m次[xyz] 字符集(character set),匹配这个集合中的任⼀⼀个字符(或元字符)[^xyz] 不匹配这个集合中的任何⼀个字符[\b] 匹配⼀个退格符\b 匹配⼀个单词的边界\B 匹配⼀个单词的⾮边界\cX 这⼉,X是⼀个控制符,/\cM/匹配Ctrl-M\d 匹配⼀个字数字符,/\d/ = /[0-9]/\D 匹配⼀个⾮字数字符,/\D/ = /[^0-9]/\n 匹配⼀个换⾏符\r 匹配⼀个回车符\s 匹配⼀个空⽩字符,包括\n,\r,\f,\t,\v等\S 匹配⼀个⾮空⽩字符,等于/[^\n\f\r\t\v]/\t 匹配⼀个制表符\v 匹配⼀个重直制表符\w 匹配⼀个可以组成单词的字符(alphanumeric,这是我的意译,含数字),包括下划线,如[\w]匹配"$5.98"中的5,等于[a-zA-Z0-9] \W 匹配⼀个不可以组成单词的字符,如[\W]匹配"$5.98"中的$,等于[^a-zA-Z0-9]。
正则表达式全部符号解释

如果n为八进制数字(0-3),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。
\un
匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(?)。
$
匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配'\n'或'\r'之前的位置。
*
匹配前面的子表达式零次或多次。例如,zo*能匹配"z"以及"zoo"。*等价于{0,}。
+
匹配前面的子表达式一次或多次。例如,'zo+'能匹配"zo"以及"zoo",但不能匹配"z"。+等价于{1,}。
\B
匹配非单词边界。'er\B'能匹配"verb"中的'er',但不能匹配"never"中的'er'。
\cx
匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的'c'字符。
\d
匹配一个数字字符。等价于[0-9]。
\D
匹配一个非数字字符。等价于[^0-9]。
正则表达式全部符号解释
ห้องสมุดไป่ตู้字符
描述
\
将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,'n'匹配字符"n"。'\n'匹配一个换行符。序列'\\'匹配"\"而"\("则匹配"("。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(?=patter n)
正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供 以后使用。例如,'Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不
?
匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。
{n} n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。
{n,} {n,m}
正则表达式全部符号解释
字符
\
^ $ * +
描述 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,'n' 匹配字符 "n" 。'\n' 匹配一个换行符。序列 '\\' 匹配 "\" 而 "\(" 则匹配 "("。 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。
中使用
SubMatches
集合,
(?:patter 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组
n) 合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。
匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。
.
匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。
(pattern)
匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '\('
集合得到,在VBScript 或 '\)'。
?
n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。 'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o 。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少 的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配 单个 "o",而 'o+' 将匹配所有 'o'。
匹配一个非数字字符。等价于 [^0-9]。
\f 匹配一个换页符。等价于 \x0c 和 \cL。 \n 匹配一个换行符。等价于 \x0a 和 \cJ。 \r 匹配一个回车符。等价于 \x0d 和 \cM。 \s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 \S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 \t 匹配一个制表符。等价于 \x09 和 \cI。 \v 匹配一个垂直制表符。等价于 \x0b 和 \cK。
\w \W \xn \num \n
\nm
\nml \un
匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。
匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价 于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。. 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八 进制数字 (0-7),则 n 为一个八进制转义值。 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至 少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。
\cx
\d \D
负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。
字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符 。匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中 的 'er'。 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视 为一个原义的 'c' 字符。 匹配一如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。
[xyz] 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。
[^xyz] [a-z] [^a-z]
\b \B
(?!patter n)
负向预查,在任何不匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取 供以后使用。例如'Windows (?!95|98|NT|2000)' 能匹配 "Windows 3.1" 中的 "Windows",但不能匹配 "Windows 2000" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不