编译原理复习题目集答案
编译原理试题及答案

编译原理试题及答案一、选择题1. 编译器的主要功能是什么?A. 程序设计B. 程序翻译C. 程序调试D. 数据处理答案:B2. 下列哪一项不是编译器的前端处理过程?A. 词法分析B. 语法分析C. 语义分析D. 代码生成答案:D3. 在编译原理中,词法分析器的主要作用是什么?A. 识别程序中的关键字和标识符B. 将源代码转换为中间代码C. 检查程序的语法结构D. 确定程序的运行环境答案:A4. 语法分析通常采用哪种方法?A. 自顶向下分析B. 自底向上分析C. 正则表达式匹配D. 直接解释执行答案:B5. 语义分析的主要任务是什么?A. 检查程序的语法结构B. 检查程序的类型安全C. 识别程序中的变量和常量D. 将源代码转换为机器代码答案:B二、简答题1. 简述编译器的工作原理。
答案:编译器的工作原理主要包括以下几个步骤:词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。
词法分析器将源代码分解成一系列的词素;语法分析器根据语法规则检查词素序列是否合法;语义分析器检查程序的语义正确性;中间代码生成器将源代码转换为中间代码;代码优化器对中间代码进行优化;最后,目标代码生成器将优化后的中间代码转换为目标机器代码。
2. 什么是词法分析器,它在编译过程中的作用是什么?答案:词法分析器是编译器前端的一个组成部分,负责将源代码分解成一个个的词素(tokens),如关键字、标识符、常量、运算符等。
它在编译过程中的作用是为语法分析器提供输入,是编译过程的基础。
三、论述题1. 论述编译器中的代码优化技术及其重要性。
答案:代码优化是编译过程中的一个重要环节,它旨在提高程序的执行效率,减少资源消耗。
常见的代码优化技术包括:常量折叠、死代码消除、公共子表达式消除、循环不变代码外提、数组边界检查消除等。
代码优化的重要性在于,它可以显著提高程序的运行速度和性能,同时降低程序对内存和处理器资源的需求。
四、计算题1. 给定一个简单的四则运算表达式,请写出其对应的逆波兰表达式。
最新编译原理复习题及答案

编译原理复习题及答案一、选择题1.一个正规语言只能对应(B)A 一个正规文法B 一个最小有限状态自动机2.文法G[A]:A→εA→aB B→Ab B→a是(A)A 正规文法B 二型文法3.下面说法正确的是(A)A 一个SLR(1)文法一定也是LALR(1)文法B 一个LR(1)文法一定也是LALR(1)文法4.一个上下文无关文法消除了左递归,提取了左公共因子后是满足LL(1)文法的(A)A 必要条件B 充分必要条件5.下面说法正确的是(B)A 一个正规式只能对应一个确定的有限状态自动机B 一个正规语言可能对应多个正规文法6.算符优先分析与规范归约相比的优点是(A)A 归约速度快B 对文法限制少7.一个LR(1)文法合并同心集后若不是LALR(1)文法(B)A 则可能存在移进/归约冲突B 则可能存在归约/归约冲突C 则可能存在移进/归约冲突和归约/归约冲突8.下面说法正确的是(A)A Lex是一个词法分析器的生成器B Yacc是一个语法分析器9.下面说法正确的是(A)A 一个正规文法也一定是二型文法B 一个二型文法也一定能有一个等价的正规文法10.编译原理是对(C)。
A、机器语言的执行B、汇编语言的翻译C、高级语言的翻译D、高级语言程序的解释执行11.用高级语言编写的程序经编译后产生的程序叫(B)A.源程序 B.目标程序C.连接程序D.解释程序12.(C)不是编译程序的组成部分。
A.词法分析程序B.代码生成程序C.设备管理程序D.语法分析程序13.通常一个编译程序中,不仅包含词法分析,语法分析,语义分析,中间代码生成,代码优化,目标代码生成等六个部分,还应包括(C)。
A.模拟执行器B.解释器 C.表格处理和出错处理D.符号执行器14.源程序是句子的集合,(B)可以较好地反映句子的结构。
A. 线性表B. 树C. 完全图D. 堆栈15.词法分析器的输出结果是(D)。
A、单词自身值B、单词在符号表中的位置C、单词的种别编码D、单词的种别编码和自身值16.词法分析器不能(D)A. 识别出数值常量B. 过滤源程序中的注释C. 扫描源程序并识别记号D. 发现括号不匹配17.文法:G:S→xSx | y所识别的语言是(D)。
编译原理复习题有答案

编译原理复习题有答案编译原理复习题及答案一、选择题1. 编译器的主要功能是什么?A. 代码格式化B. 代码优化C. 将源代码转换为机器码D. 错误检测和修复答案:C2. 词法分析阶段的主要任务是什么?A. 语法分析B. 语义分析C. 识别源程序中的词法单元D. 代码生成答案:C3. 下列哪个不是编译原理中的常见数据结构?A. 栈B. 队列C. 哈希表D. 链表答案:D4. 语法分析通常采用哪种方法?A. 递归下降分析B. 动态规划C. 贪心算法D. 深度优先搜索答案:A5. 代码优化的目的是什么?A. 增加程序长度B. 减少程序运行时间C. 提高程序的可读性D. 增加程序的复杂性答案:B二、简答题1. 简述编译过程的主要阶段。
答案:编译过程主要分为四个阶段:词法分析、语法分析、语义分析和代码生成。
词法分析负责将源代码分解成词法单元;语法分析构建语法树,检查源代码的语法结构;语义分析检查程序的语义正确性;代码生成将源代码转换成目标代码或机器码。
2. 什么是自底向上的语法分析方法?答案:自底向上的语法分析方法是一种从叶子节点开始,逐步向上构建语法树的方法。
它通常使用移进-归约分析技术,通过将输入符号与栈顶符号进行匹配,不断地将它们归约成非终结符,直到整个输入被归约为起始符号。
3. 请解释什么是中间代码,并说明其作用。
答案:中间代码是一种介于源代码和目标代码之间的代码形式,通常用于代码优化和目标代码生成。
它具有高级语言的可读性,同时又能表达程序的控制流和数据流信息。
中间代码使得编译器可以在不同的阶段对程序进行优化,提高程序的执行效率。
三、论述题1. 论述编译原理中的错误处理机制。
答案:编译原理中的错误处理机制主要包括错误检测、错误恢复和错误报告。
错误检测是指在编译过程中识别出源代码中的语法或语义错误;错误恢复是指在检测到错误后,编译器采取的措施以继续编译过程,避免因单个错误而中断整个编译;错误报告则是向程序员提供错误信息,帮助其定位和修复错误。
编译原理习题及答案

( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( 10.× 22.√
) ) ) ) ) ) ) ) ) ) ) ) ) ) ) ) ) ) ) ) ) ) 11.
二、填空题: 2.编译过程可分为 ( 词法分析) , (语法分析) , (语义分析与中间代码生成 ) , (优化)和(目标 代码生成 )五个阶段。 3.如果一个文法存在某个句子对应两棵不同的语法树,则称这个文法是( 二义性的 4.从功能上说,程序语言的语句大体可分为( 5.语法分析器的输入是( 单词符号 6.扫描器的任务是从( 源程序中 执行性 )语句和(说明性 ) 。 ) 。 ) ,其输出是( 语法单位 )中识别出一个个( 单词符号 ) 。 )语句两大类。
因此,文法 G[为二义文法。
五.计算题(10 分) 已知文法 A->aAd|aAb| ε
判断该文法是否是 SLR(1) 文法,若是构造相应分析表,并对输入串 ab# 给出分析过程。 解:增加一个非终结符 S/后,产生原文法的增广文法有: S'->A A->aAd|aAb|ε 下 面 构 造 它 的 LR(0) 项 目 集 规 范 族 为 :
对输入串 ab#给出分析过程为:
一、是非题:
1.一个上下文无关文法的开始符,可以是终结符或非终结符。 2.一个句型的直接短语是唯一的。 3.已经证明文法的二义性是可判定的。 4.每个基本块可用一个 DAG 表示。 5.每个过程的活动记录的体积在编译时可静态确定。 6.2 型文法一定是 3 型文法。 7.一个句型一定句子。 8.算符优先分析法每次都是对句柄进行归约。 X 9.采用三元式实现三地址代码时,不利于对中间代码进行优化。 10.编译过程中,语法分析器的任务是分析单词是怎样构成的。 11.一个优先表一定存在相应的优先函数。 13.递归下降分析法是一种自下而上分析法。 14.并不是每个文法都能改写成 LL(1)文法。 15.每个基本块只有一个入口和一个出口。 16.一个 LL(1)文法一定是无二义的。 17.逆波兰法表示的表达试亦称前缀式。 18.目标代码生成时,应考虑如何充分利用计算机的寄存器的问题。 19.正规文法产生的语言都可以用上下文无关文法来描述。 20.一个优先表一定存在相应的优先函数。 21.3 型文法一定是 2 型文法。 22.如果一个文法存在某个句子对应两棵不同的语法树, 则文法是二义性的。 答案:1.× 12.√ 13.× 2.× 14.√ 3.× 15.√ 4.√ 16.√ 5.√ 17.× 6.× × 18.√ 19.√ 20.× 21.√ 7.× 8.× 9.√ X 12.目标代码生成时,应考虑如何充分利用计算机的寄存器的问题。
完整版编译原理复习题及答案

编译原理复习题及答案一、选择题1.一个正规语言只能对应( B )A 一个正规文法B 一个最小有限状态自动机2.文法G[A] :A→εA→aB B→Ab B→a是( A )A 正规文法B 二型文法3.下面说法正确的是( A ) A一个SLR(1)文法一定也是LALR (1)文法B一个LR (1)文法一定也是LALR (1)文法4.一个上下文无关文法消除了左递归,提取了左公共因子后是满足LL (1)文法的( A )A 必要条件B 充分必要条件5.下面说法正确的是( B )A 一个正规式只能对应一个确定的有限状态自动机B 一个正规语言可能对应多个正规文法6.算符优先分析与规范归约相比的优点是( A )A 归约速度快B 对文法限制少7.一个LR (1)文法合并同心集后若不是LALR (1)文法( B )A 则可能存在移进/归约冲突B 则可能存在归约/归约冲突C 则可能存在移进/归约冲突和归约/ 归约冲突8.下面说法正确的是( A )A Lex 是一个词法分析器的生成器B Yacc 是一个语法分析器9.下面说法正确的是( A )A一个正规文法也一定是二型文法B一个二型文法也一定能有一个等价的正规文法10.编译原理是对(C) 。
A 、机器语言的执行B、汇编语言的翻译C、高级语言的翻译D、高级语言程序的解释执行11.(A) 是一种典型的解释型语言。
A .BASICB .CC.FORTRAN D.PASCAL12.把汇编语言程序翻译成机器可执行的目标程序的工作是由(B) 完成的。
A. 编译器B. 汇编器C. 解释器D. 预处理器13.用高级语言编写的程序经编译后产生的程序叫(B) A .源程序B .目标程序C.连接程序 D .解释程序14.(C) 不是编译程序的组成部分。
A. 词法分析程序B. 代码生成程序C.设备管理程序D. 语法分析程序15.通常一个编译程序中,不仅包含词法分析,语法分析,语义分析,中间代码生成,代码优目标代码生成等六个部分,还应包括(C)A .模拟执行器B .解释器C.表格处理和出错处理D .符号执行器16.编译程序绝大多数时间花在(D) A .出错处理B.词法分析C.目标代码生成D.表格管理17.源程序是句子的集A. 线性表(B) 可以较好地反映句子的结构。
编译原理复习题目集答案
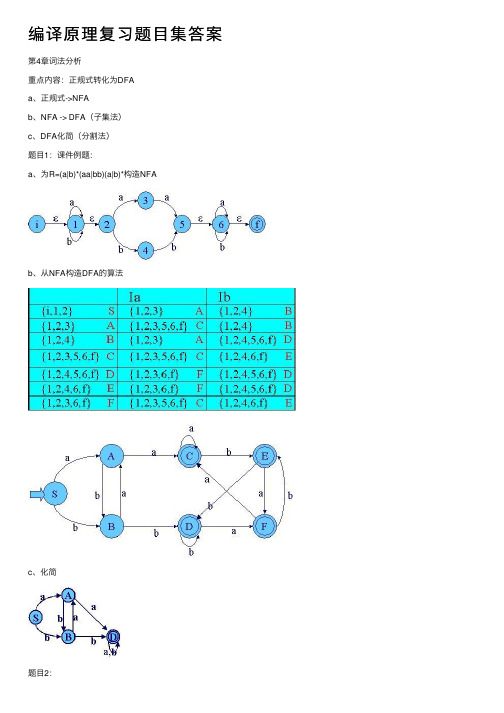
编译原理复习题⽬集答案第4章词法分析重点内容:正规式转化为DFAa、正规式->NFAb、NFA -> DFA(⼦集法)c、DFA化简(分割法)题⽬1:课件例题:a、为R=(a|b)*(aa|bb)(a|b)*构造NFAb、从NFA构造DFA的算法c、化简题⽬2:4.7 例1:构造正规式相应的DFA:1(0|1)*101按照以下三步:(1)由正规表达式构造转换系统(NFA)(2)由转换系统(NFA)构造确定的有穷⾃动机DFA(3)DFA的最⼩化答:(1)构造与1(0|1)*101等价的NFA(2)将NFA转换成DFA:采⽤⼦集法,即DFA的每个状态对应NFA的⼀个状态集合:除X,A外,重新命名其他状态:1、将M 的状态分成⾮终态和终态集{X,A,B,C}和{D}。
2、寻找⼦集中不等价状态{X,A,B,C}=>{X},{A,B}{C}=>{X}{A}{B}{C},⽆需合并。
最后⽣成DFA :题⽬3:⾃习、书本练习4.7,参考答案见《z4 书本练习4.7.doc 》已知⽂法G[S]:S →aA|bQ A →aA|bB|b B →bD|aQ Q →aQ|bD|b E →aB|bF F →bD|aE|b 1、构由于不可到达,去除E 、F 相关的多余产⽣式2、由新的G[S]构造NFA 如下5、使⽤分割法化简以上DFA G:5.1 令G={(0,1,3,4,6),(2,5)}// 分别为⾮终态和终态集5.2 由{0,1,3,4,6}a={1,3},{0,1,3,4,6}b={3,2,5,6,4}将{0,1,3,4,6}划分为 {0,4,6}{1,3},得G={(0,4,6),(1,3),(2,5)}5.3 由{0,4,6}b={3,6,4},将之划分为{0},{4,6},得G={(0),(4,6),(1,3),(2,5)}5.4 观察后,G中状态不可再分,为最⼩化DFA。
6、分别⽤ 0,4,1,2代表各状态,DFA状态转换图如下:造相应的最⼩的DFA第5章⾃顶向下的语法分析重点内容:LL(1)⽂法a、去除左递归b、LL(1)⽂法的判定(first、follow、select集)c、预测分析表d、使⽤栈和预测分析表对输⼊串的分析题⽬1:课件例题:消除左递归+判定+分析算术表达式⽂法GE→E+T│TT→T*F│FF→(E)│Id、分析输⼊串i+i*i#(1)消除G的左递归得到⽂法G‘E→TE 'E'→+TE'│εT→FT 'T'→*FT'│εF→(E)│i(2)求出每个产⽣式的select集,G’是LL(1)⽂法SELECT(E→TE' ) = { (,i }SELECT(E'→+TE' ) = { + } SELECT(E'→ε ) = { ),# }SELECT(T→FT' ) = { (,i } SELECT(T'→*FT' ) = { * }SELECT(T'→ε ) = { +,),# } SELECT(F→(E) ) = { ( }SELECT(F→ i ) = { i }(3)依照选择集合把产⽣式填⼊分析表注:表中空⽩处为出错题⽬2:作业、习题5.1:消除左递归+判定+分析G[S]:S->a|^|(T) T->T,S|Sd、分析输⼊串(a,a)#⽂法G[S]:S->a|^|(T),T->T,S|S(1)给出对(a,(a,a))的最左推导(2)改写⽂法,去除左递归(3)判断新⽂法是否LL1⽂法,如是,给出其预测分析表(4)给出输⼊串(a,a)#的分析过程,判断其是否⽂法G的句⼦。
编译原理考试题及答案

编译原理考试题及答案一、选择题(每题2分,共20分)1. 编译器的主要功能是什么?A. 代码优化B. 代码解释C. 代码翻译D. 代码调试答案:C2. 编译过程中的语法分析阶段主要解决什么问题?A. 词法问题B. 语法问题C. 语义问题D. 代码生成问题答案:B3. 在编译原理中,哪些技术用于处理程序中的递归结构?A. 正则表达式B. 有限自动机C. 上下文无关文法D. 属性文法答案:C4. 编译器的哪个部分负责将中间代码转换为目标代码?A. 词法分析器B. 语法分析器C. 语义分析器D. 代码生成器答案:D5. 编译器中的词法分析器主要使用哪种数据结构来存储输入的源代码?A. 栈B. 队列C. 链表D. 哈希表答案:C6. 在编译原理中,哪个概念用于描述程序语言的语法结构?A. 语法树B. 抽象语法树C. 控制流图D. 数据流图答案:B7. 编译器的哪个阶段负责检查变量是否被正确声明和使用?A. 词法分析B. 语法分析C. 语义分析D. 代码优化答案:C8. 编译器在哪个阶段会进行代码优化?A. 词法分析B. 语法分析C. 语义分析D. 代码生成答案:D9. 在编译原理中,哪些技术用于生成有效的目标代码?A. 语法分析B. 语义分析C. 代码优化D. 目标代码生成答案:D10. 编译器的哪个部分负责将源代码中的注释和空白字符去除?A. 词法分析器B. 语法分析器C. 语义分析器D. 代码生成器答案:A二、填空题(每题2分,共20分)1. 编译器的前端包括词法分析、语法分析和______。
答案:语义分析2. 编译器的后端包括中间代码生成、______和目标代码生成。
答案:代码优化3. 编译原理中的______用于描述词法单元。
答案:词法规则4. 编译原理中的______用于描述程序语言的语法结构。
答案:上下文无关文法5. 编译原理中的______用于描述程序语言的语义。
答案:属性文法6. 编译原理中的______用于描述程序控制流。
编译原理试题汇总+编译原理期末试题(8套含答案+大题集)(完整资料).doc

此文档下载后即可编辑编译原理考试题及答案汇总一、选择1.将编译程序分成若干个“遍”是为了_B__。
A . 提高程序的执行效率B.使程序的结构更加清晰C. 利用有限的机器内存并提高机器的执行效率D.利用有限的机器内存但降低了机器的执行效率2.正规式 MI 和 M2 等价是指__C__。
A . MI 和 M2 的状态数相等和 M2 的有向弧条数相等。
C .M1 和 M2 所识别的语言集相等 D. Ml 和 M2 状态数和有向弧条数相等3.中间代码生成时所依据的是 _C_。
A.语法规则 B.词法规则 C.语义规则 D.等价变换规则4.后缀式 ab+cd+/可用表达式__B_来表示。
A. a+b/c+d B.(a+b)/(c+d) C. a+b/(c+d) D. a+b+c/d6.一个编译程序中,不仅包含词法分析,_A____,中间代码生成,代码优化,目标代码生成等五个部分。
A.( ) 语法分析 B.( )文法分析 C.( )语言分析 D.( )解释分析7.词法分析器用于识别__C___。
A.( ) 字符串 B.( )语句 C.( )单词 D.( )标识符8.语法分析器则可以发现源程序中的___D__。
A.( ) 语义错误 B.( ) 语法和语义错误C.( ) 错误并校正 D.( ) 语法错误9.下面关于解释程序的描述正确的是__B___。
(1) 解释程序的特点是处理程序时不产生目标代码(2) 解释程序适用于 COBOL 和 FORTRAN 语言(3) 解释程序是为打开编译程序技术的僵局而开发的A.( ) (1)(2) B.( ) (1) C.( ) (1)(2)(3) D.( ) (2)(3)10.解释程序处理语言时 , 大多数采用的是__B___方法。
A.( ) 源程序命令被逐个直接解释执行B.( ) 先将源程序转化为中间代码 , 再解释执行C.( ) 先将源程序解释转化为目标程序 , 再执行D.( ) 以上方法都可以11.编译过程中 , 语法分析器的任务就是__B___。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第4章词法分析重点容:正规式转化为DFAa、正规式->NFAb、NFA -> DFA(子集法)c、DFA化简(分割法)题目1:课件例题:a、为R=(a|b)*(aa|bb)(a|b)*构造NFAb、从NFA构造DFA的算法c、化简题目2:4.7 例1:构造正规式相应的DFA :1(0|1)*101 按照以下三步:(1)由正规表达式构造转换系统(NFA )(2)由转换系统(NFA )构造确定的有穷自动机DFA (3)DFA 的最小化 答:(1)构造与1(0|1)*101等价的 NFA(2)将NFA 转换成DFA :采用子集法,即DFA 的每个状态对应NFA 的一个状态集合:0 1 X A A A AB AB AC AB AC A ABY ABYACAB除X ,A 外,重新命名其他状态:0 1 X A AAB(0|1)*111(0|1)*101XYXABCDY1XABCY1110,1B C BC A DD C B2、寻找子集中不等价状态{X,A,B,C}=>{X},{A,B}{C}=>{X}{A}{B}{C},无需合并。
最后生成DFA:题目3:自习、书本练习4.7,参考答案见《z4 书本练习4.7.doc》已知文法G[S]:S→aA|bQ A→aA|bB|b B→bD|aQ Q→aQ|bD|b E→aB|bF F→bD|aE|b1、构由于不可到达,去除E、F相关的多余产生式2、由新的G[S]构造NFA如下3、NFA的转换表:a bS A QA A B,ZB,Z Q DQ Q D,ZD A BD,Z A DB Q D4、子集法重命名状态:(上标0:初态,*:终态)a b00 1 31 1 22* 3 43 3 54 1 65* 1 46 3 4X A B C D1 1 0 1115、使用分割法化简以上DFA G:5.1 令G={(0,1,3,4,6),(2,5)}// 分别为非终态和终态集5.2 由{0,1,3,4,6}a={1,3},{0,1,3,4,6}b={3,2,5,6,4}将{0,1,3,4,6}划分为{0,4,6}{1,3},得G={(0,4,6),(1,3),(2,5)}5.3 由{0,4,6}b={3,6,4},将之划分为{0},{4,6},得G={(0),(4,6),(1,3),(2,5)}5.4 观察后,G中状态不可再分,为最小化DFA。
6、分别用0,4,1,2代表各状态,DFA状态转换图如下:造相应的最小的DFA第5章自顶向下的语法分析重点容:LL(1)文法a、去除左递归b、LL(1)文法的判定(first、follow、select集)c、预测分析表d、使用栈和预测分析表对输入串的分析题目1:课件例题:消除左递归+判定+分析算术表达式文法GE→E+T│TT→T*F│FF→(E)│Id、分析输入串i+i*i#(1)消除G的左递归得到文法G‘E→TE 'E'→+TE'│εT→FT 'T'→*FT'│εF→(E)│i(2)求出每个产生式的select集,G’是LL(1)文法SELECT(E→TE' ) = { (,i } SELECT(E'→+TE' ) = { + } SELECT(E'→ε ) = { ),# } SELECT(T→FT' ) = { (,i } SELECT(T'→*FT' ) = { * } SELECT(T'→ε ) = { +,),# } SELECT(F→(E) ) = { ( } SELECT(F→ i ) = { i }(3)依照选择集合把产生式填入分析表注:表中空白处为出错题目2:作业、习题5.1:消除左递归+判定+分析G[S]:S->a|^|(T) T->T,S|Sd、分析输入串(a,a)#文法G[S]:S->a|^|(T),T->T,S|S(1)给出对(a,(a,a))的最左推导(2)改写文法,去除左递归(3)判断新文法是否LL1文法,如是,给出其预测分析表(4)给出输入串(a,a)#的分析过程,判断其是否文法G的句子。
答:(1)对(a,(a,a))的最左推导为:S=>(T)=>(T,S)=>(S,S)=>(a,S)=>(a,(T))=>(a,(T,S))=>(a,(S,S))=>(a,(a,S))=>(a,(a,a))(2)改写文法为:0) S→a 1) S→ʌ2) S→(T) 3) T→SN 4) N→,SN 5) N→εFIRST (→,S N) = {, }FIRST (→ε) ={ε}FOLLOW (N) ={)}由于SELECT(N→,S N)∩SELECT(N→ε)={, }∩{)}=ᴓ所以文法是LL(1)的。
(3)预测分析表:可由预测分析表中,无多重入口判定文法是LL(1)的。
(4)对输入串(a,a)#的分析过程为:题目3:复习、书本5.6例1:判定+分析G[S]:S→aH,H→aMd|d,M→Ab|ε,A→aM|e d、分析输入串aaabd#(1)判断G[S]是否为LL(1)文法;若是,构造其预测分析表;Select(H→aMd)={a} , Select(H→d)= {d} ;Select(M→Ab)= {a,e}, Select(M→ε)= {d,b};Select(A→aM)= {a} , Select(A→e)= {e}相同左部产生式的select集的交集均为空,所以G[S]是LL(1)文法。
预测分析表:(2)分析aaabd#是否G[S]的句子。
使用栈和预测分析表对输入串的分析:第6章自底向上的语法分析重点容:算符优先文法a、非终结符的firstvt集和lastvt集的计算b、算符优先关系表c、使用栈和算符优先关系表对输入串的归约题目1:课件例题:文法:E→E+T|TT→T×F|FF→(E)|Ic、算符优先归约输入串i+i#(1)求各非终结符的FIRSTVT集与LASTVT集(2)计算算符优先关系表并说明此文法是否算符优先文法(3)给出输入串i+i#的算符优先分析过程非终结符FIRSTVT LASTVTE + × i (+ × ) iT x i (× ) iF i () i+ x ( ) i # + > < < > < > x > > < > < > ( < < < = <) > > > >i > > > ># < < < < = (3)对输入串i+i#的算符优先分析过程为:题目2:作业、习题6.1、复习:文法G[S]:S->a|^|(T) T->T,S|Sc、算符优先归约输入串(a,a)#文法G[S]:S->a|^|(T),T->T,S|S(1)计算G[S]的FIRSTVT、LASTVT(2)改造算符优先关系表并说明G[S]是否算符优先文法(3)给出输入串(a,a)#的算符优先分析过程,判断其是否文法G的句子。
答:文法展开为:S→aS→ʌS→(T)T→T,ST→S(2)算符优先关系表:(3)对输入串(a,a)#的算符优先分析过程为:题目3:自习、书本练习6.4,参考答案见《z6 书本练习6.4.doc》已知文法G[S]:S→S;G S→G G→G(T) G→H H→a H→(S) T→T+S T→Sc、算符优先归约输入串a;(a+a)#(1)构造算符优先关系表FIRSTVT(S)={;}∪FIRSTVT(G) = {; , a , ( }FIRSTVT(G)={ ( }∪FIRSTVT(H) = {a , ( }FIRSTCT(H)={a , ( }FIRSTVT(T) = {+} ∪FIRSTVT(S) = {+ , ; , a , ( }LASTVT(S) = {;} ∪LASTVT(G) = { ; , a , )}LASTVT(G) = { )} ∪LASTVT(H) = { a , )}LASTVT(H) = {a, }}LASTVT(T) = {+ } ∪LASTVT(S) = {+ , ; , a ,} } 即:LASTVT(S)> ;; < FIRSTVT(G)由G→G(T…LASTVT(G)> (( < FIRSTVT(T)由G→…T)LASTVT(T)> )由G→…(T)( = )由T→T+SLASTVT(T)> ++ < FIRSTVT(S)由H→(S)( < FIRSTVT(S)LASTVT(S)> )( = )由S-> #S##< FIRSTVT(S)LASTVT(S)> ## = #(2) 分析a;(a+a) // S→S;G |G G→G(T) |H H→a |(S) T→T+S |S。