Object Interconnections Comparing Alternative Programming Techniques for Multi-threaded Ser
rust_conflicting_implementations_of_trait_概述说明

rust conflicting implementations of trait 概述说明1. 引言1.1 概述本文将讨论Rust 中的trait 冲突实现问题。
Trait 是Rust 的关键特性之一,它允许开发者定义共享行为并在不同类型上实现这些行为。
然而,当多个trait 对同一个类型实现相同的方法时,就会出现冲突。
这种冲突可能导致编译错误,使得代码难以维护和扩展。
1.2 文章结构本文分为五个部分进行叙述。
首先,我们将引言部分提供概述,并介绍文章的结构和目的。
其次,我们将详细探讨冲突的trait 实现问题,并解释产生这种冲突的原因以及所带来的问题和困扰。
接着,我们将阐述解决冲突的方法和技巧,给出一些处理冲突情况的建议。
然后,我们会通过示例代码进行实例分析与讨论,并对比各种解决方案的优缺点。
最后,在结论部分,我们将总结问题和发现,并对解决方案给予评价和建议。
1.3 目的本文旨在帮助读者理解Rust 中trait 冲突实现问题,并提供解决这一问题的方法和技巧。
通过深入分析该问题及相关示例,读者将能够更好地处理自己在编程过程中遇到的类似情况。
同时,本文也旨在促进对Rust trait 特性的理解和应用,提高代码的可维护性和扩展性。
2. 正文本文将围绕Rust中的trait冲突问题展开讨论。
首先,我们将介绍trait和其在Rust语言中的重要性。
然后,我们将详细说明trait冲突的概念以及由此带来的问题和困扰。
最后,我们将探讨解决trait冲突的方法和技巧。
在Rust中,trait是一种定义行为的抽象机制。
它允许我们声明一个或多个方法,并使不同类型之间可以共享这些行为。
这种方式在提供代码复用和抽象能力方面非常有价值。
然而,在某些情况下,当一个类型实现了多个trait且其中存在相同方法名称时,就可能出现trait冲突的问题。
这意味着编译器无法准确地确定哪个实现应该被选择。
具体来说,当两个或多个trait都要求一个类型实现相同函数签名的方法时,就会发生trait冲突。
critical_section和interlockedincrement -回复

critical_section和interlockedincrement -回复什么是critical_section和interlocked_increment?在多线程编程中,critical_section和interlocked_increment是两个常用的同步机制。
critical_section用于保护共享资源,确保同时只有一个线程能够访问临界区。
而interlocked_increment则是一种原子操作,用于对共享变量进行自增操作,并且保证在多线程环境下该操作的原子性。
一、critical_section的作用和使用方式1.1 作用critical_section主要用于保护共享资源,防止多个线程同时访问和修改该资源,从而避免数据竞争和不一致性。
1.2 使用方式步骤1: 需要使用共享资源的线程在访问之前,需要首先获取critical_section。
步骤2: 获取critical_section的线程可以安全地访问和修改共享资源。
步骤3: 当线程访问结束后,需要释放critical_section,以便其他线程能够获取。
1.3 代码示例cpp#include <Windows.h>CRITICAL_SECTION g_cs; 定义一个全局的critical_sectionvoid InitializeCriticalSection(CRITICAL_SECTION* cs) { InitializeCriticalSection(cs);}void DeleteCriticalSection(CRITICAL_SECTION* cs) { DeleteCriticalSection(cs);}void ThreadFunc() {EnterCriticalSection(&g_cs); 线程获取critical_section访问和修改共享资源的代码LeaveCriticalSection(&g_cs); 释放critical_section}int main() {InitializeCriticalSection(&g_cs); 初始化critical_section创建多个线程来执行ThreadFunc...DeleteCriticalSection(&g_cs); 销毁critical_sectionreturn 0;}二、interlocked_increment的作用和使用方式2.1 作用interlocked_increment用于对共享变量进行自增操作,并且保证在多线程环境下该操作的原子性,避免竞争条件导致的错误结果。
collection.intersection 用法 -回复

collection.intersection 用法-回复Collection.intersection方法是在Python中用于获取两个或多个集合的交集的方法。
集合是一种无序且唯一的数据结构,它可以用于存储多个不同的元素。
交集是指对于给定的两个或多个集合,找出它们共同拥有的元素。
在Python中,可以使用set对象来表示集合。
set对象是一种可变的、无序的、不重复的集合数据类型。
使用交集操作可以找出两个或多个集合中相同的元素。
collection.intersection方法就是用来执行这种操作的。
下面,将逐步说明collection.intersection方法的用法。
步骤1: 创建集合首先,我们需要创建两个集合对象,以便进行交集操作。
可以使用set()函数或花括号{}来创建一个集合对象,并向其中添加元素。
下面是一个示例:set1 = set([1, 2, 3, 4, 5])set2 = set([4, 5, 6, 7, 8])在这个例子中,我们创建了两个集合set1和set2,并分别向其中添加了一些元素。
步骤2:使用intersection方法获取交集接下来,我们可以使用collection.intersection方法来获取两个集合的交集。
这个方法接受一个可迭代的对象作为参数,并返回一个新的集合,其中包含所有传入集合中共同拥有的元素。
下面是一个示例:intersection_set = set1.intersection(set2)在这个例子中,我们使用intersection方法获取了集合set1和set2的交集,并将结果赋值给intersection_set变量。
步骤3:打印交集结果最后,我们可以打印交集的结果以查看两个集合之间的共同元素。
可以使用print函数将交集结果输出到控制台。
下面是一个示例:print(intersection_set)在这个例子中,我们打印了交集结果intersection_set。
critical_section和interlockedincrement -回复

critical_section和interlockedincrement -回复什么是critical_section和interlockedincrement?在多线程编程中,当多个线程同时访问共享资源时,可能会引发一些问题,如数据竞争(data race)和竞争条件(race condition)。
为了避免这些问题,需要使用某种机制来实现同步和互斥。
Critical_section和InterlockedIncrement就是其中两种常用的机制。
Critical_section(临界区)是一种同步机制,用于保护共享资源的完整性。
在多个线程中,当一个线程进入临界区时,其他线程会被阻塞,直到该线程退出临界区。
这样可以确保在同一时间只有一个线程可以访问临界区内的代码和数据,避免了数据竞争和竞争条件的问题。
InterlockedIncrement(原子递增)是一种原子操作,用于实现在多线程环境下对变量的安全递增。
在多线程环境中,多个线程同时对一个变量进行递增操作可能会导致计算结果错误。
通过使用InterlockedIncrement,可以保证递增操作是原子的,即在一个线程执行递增操作时,其他线程不能同时对其进行操作。
这样可以避免数据竞争和竞争条件的问题。
如何使用critical_section?使用critical_section时,需要先定义一个临界区对象。
在需要保护共享资源的地方,使用CriticalSection对象进行加锁和解锁操作。
一般情况下,加锁和解锁的代码分别放在共享资源的访问前后。
以下是一个使用critical_section保护共享资源的示例:cpp定义临界区对象CRITICAL_SECTION cs;void AccessSharedResource(){加锁EnterCriticalSection(&cs);访问共享资源...解锁LeaveCriticalSection(&cs);}在上面的示例中,EnterCriticalSection和LeaveCriticalSection函数分别用于加锁和解锁操作。
C++中语法错误中英文对照

Ambiguous operators need parentheses ----------- 不明确的运算需要用括号括起Ambiguous symbol ''xxx'' ---------------- 不明确的符号Argument list syntax error ---------------- 参数表语法错误Array bounds missing ------------------ 丢失数组界限符Array size toolarge ----------------- 数组尺寸太大Bad character in paramenters ------------------ 参数中有不适当的字符Bad file name format in include directive -------------------- 包含命令中文件名格式不正确Bad ifdef directive synatax ------------------------------ 编译预处理ifdef 有语法错Bad undef directive syntax --------------------------- 编译预处理undef 有语法错Bit field too large ---------------- 位字段太长Call of non-function ----------------- 调用未定义的函数Call to function with no prototype --------------- 调用函数时没有函数的说明Cannot modify a const object --------------- 不允许修改常量对象Case outside of switch ---------------- 漏掉了case 语句Case syntax error ------------------ Case 语法错误Code has no effect ----------------- 代码不可述不可能执行到Compound statement missing{ -------------------- 分程序漏掉"{"Conflicting type modifiers ------------------ 不明确的类型说明符Constant expression required ---------------- 要求常量表达式Constant out of range in comparison ----------------- 在比较中常量超出范围Conversion may lose significant digits ----------------- 转换时会丢失意义的数字Conversion of near pointer not allowed ----------------- 不允许转换近指针Could not find file ''xxx'' ----------------------- 找不到XXX 文件Declaration missing ; ---------------- 说明缺少" ;"Declaration syntax error ----------------- 说明中出现语法错误Default outside of switch ------------------ Default 出现在switch 语句之外Define directive needs an identifier ------------------ 定义编译预处理需要标识符Division by zero ------------------ 用零作除数Do statement must have while ------------------ Do-while 语句中缺少while 部分Enum syntax error --------------------- 枚举类型语法错误Enumeration constant syntax error ----------------- 枚举常数语法错误Error directive :xxx ------------------------ 错误的编译预处理命令Error writing output file --------------------- 写输出文件错误Expression syntax error ----------------------- 表达式语法错误Extra parameter in call ------------------------ 调用时出现多余错误File name too long ---------------- 文件名太长Function call missing ----------------- 函数调用缺少右括号Fuction definition out of place ------------------ 函数定义位置错误Fuction should return a value ------------------ 函数必需返回一个值Goto statement missing label ------------------ Goto 语句没有标号Hexadecimal or octal constant too large ------------------16 进制或8 进制常数太大Illegal character ''x'' ------------------ 非法字符xIllegal initialization ------------------ 非法的初始化Illegal octal digit ------------------ 非法的8 进制数字Illegal pointer subtraction ------------------ 非法的指针相减Illegal structure operation ------------------ 非法的结构体操作Illegal use of floating point ----------------- 非法的浮点运算Illegal use of pointer -------------------- 指针使用非法Improper use of a typedefsymbol ---------------- 类型定义符号使用不恰当In-line assembly not allowed ----------------- 不允许使用行间汇编Incompatible storage class ----------------- 存储类别不相容Incompatible type conversion -------------------- 不相容的类型转换Incorrect number format ----------------------- 错误的数据格式Incorrect use of default --------------------- Default 使用不当Invalid indirection --------------------- 无效的间接运算Invalid pointer addition ------------------ 指针相加无效Irreducible expression tree ----------------------- 无法执行的表达式运算Lvalue required --------------------------- 需要逻辑值0 或非0 值Macro argument syntax error ------------------- 宏参数语法错误Macro expansion too long ---------------------- 宏的扩展以后太长Mismatched number of parameters in definition --------------------- 定义中参数个数不匹配Misplaced break --------------------- 此处不应出现break 语句Misplaced continue ------------------------ 此处不应出现continue 语句Misplaced decimal point -------------------- 此处不应出现小数点Misplaced elif directive -------------------- 不应编译预处理elifMisplaced else ---------------------- 此处不应出现elseMisplaced else directive ------------------ 此处不应出现编译预处理elseMisplaced endif directive ------------------- 此处不应出现编译预处理endifMust be addressable ---------------------- 必须是可以编址的Must take address of memory location ------------------ 必须存储定位的地址No declaration for function ''xxx'' ------------------- 没有函数xxx 的说明No stack --------------- 缺少堆栈No type information ------------------ 没有类型信息Non-portable pointer assignment -------------------- 不可移动的指针(地址常数)赋值Non-portable pointer comparison -------------------- 不可移动的指针(地址常数)比较Non-portable pointer conversion ---------------------- 不可移动的指针(地址常数)转换Not a valid expression format type --------------------- 不合法的表达式格式Not an allowed type --------------------- 不允许使用的类型Numeric constant too large ------------------- 数值常太大Out of memory ------------------- 内存不够用Parameter ''xxx'' is never used ------------------ 能数xxx 没有用到Pointer required on left side of -> ----------------------- 符号-> 的左边必须是指针Possible use of ''xxx'' before definition ------------------- 在定义之前就使用了xxx (警告)Possibly incorrect assignment ---------------- 赋值可能不正确Redeclaration of ''xxx'' ------------------- 重复定义了xxxRedefinition of ''xxx'' is not identical ------------------- xxx 的两次定义不一致Register allocation failure ------------------ 寄存器定址失败Repeat cou-nt needs an lvalue ------------------ 重复计数需要逻辑值Size of structure or array not known ------------------ 结构体或数给大小不确定Statement missing ; ------------------ 语句后缺少" ;"Structure or union syntax error -------------- 结构体或联合体语法错误Structure size too large ---------------- 结构体尺寸太大Sub scripting missing ] ---------------- 下标缺少右方括号Superfluous & with function or array ------------------ 函数或数组中有多余的"&" Suspicious pointer conversion --------------------- 可疑的指针转换Symbol limit exceeded --------------- 符号超限Too few parameters in call ----------------- 函数调用时的实参少于函数的参数不Too many default cases ------------------- Default 太多(switch 语句中一个)Too many error or warning messages -------------------- 错误或警告信息太多Too many type in declaration ----------------- 说明中类型太多Too much auto memory in function ----------------- 函数用到的局部存储太多Too much global data defined in file ------------------ 文件中全局数据太多Two consecutive dots ----------------- 两个连续的句点Type mismatch in parameter xxx ---------------- 参数xxx 类型不匹配Type mismatch in redeclaration of ''xxx'' ---------------- xxx 重定义的类型不匹配Unable to create output file ''xxx'' ---------------- 无法建立输出文件xxxUnable to open include file ''xxx'' --------------- 无法打开被包含的文件xxxUnable to open input file ''xxx'' ---------------- 无法打开输入文件xxxUndefined label ''xxx'' ------------------- 没有定义的标号xxxUndefined structure ''xxx'' ----------------- 没有定义的结构xxxUndefined symbol ''xxx'' ----------------- 没有定义的符号xxxUnexpected end of file in comment started on line xxx ---------- 从xxx 行开始的注解尚未结束文件不能结束Unexpected end of file in conditional started on line xxx ---- 从xxx 开始的条件语句尚未结束文件不能结束Unknown assemble instruction ---------------- 未知的汇编结构Unknown option --------------- 未知的操作Unknown preprocessor directive: ''xxx'' ----------------- 不认识的预处理命令xxx Unreachable code ------------------ 无路可达的代码Unterminated string or character constant ----------------- 字符串缺少引号User break ---------------- 用户强行中断了程序V oid functions may not return a value ----------------- V oid 类型的函数不应有返回值Wrong number of arguments ----------------- 调用函数的参数数目错''xxx'' not an argument ----------------- xxx 不是参数''xxx'' not part of structure -------------------- xxx 不是结构体的一部分xxx statement missing ( -------------------- xxx 语句缺少左括号xxx statement missing ) ------------------ xxx 语句缺少右括号xxx statement missing ; -------------------- xxx 缺少分号xxx'' declared but never used ------------------- 说明了xxx 但没有使用xxx'' is assigned a value which is never used ---------------------- 给xxx 赋了值但未用过Zero length structure ------------------ 结构体的长度为零1."c" not an argument in function sum 该标识符不是函数的参数2.array bounds missing ] in function main 缺少数组界限符"]"3.Array size too large in function main 数组规模太大4.bad file name format in include directive 在包含指令中的文件名格式不正确.5.Call of non-function in function main 调用未经过定义的函数.6.cannot modify a const object in function main 对常量不能进行修改.7.character constant too long in function main 字符常量太大.8.constant expression required in funtion main 数组定义的时候,数组大小要求是常数pound statment missing } in function main 复合语句漏掉符号"{"10.declaration syntax error in function main 宣告语法错误11.expression syntax in function main 表达式语法错误12. extra parameter in call to sum in function 调用函数时使用了过多的参数13.illegal use of floating point in function main 浮点数的不合法使用14.illegal pionter subtraction in function main 不合法的指针相减15.invalid pointer addition in function main 无效的指针相加16.out of memory in function main 内存不足17.statement missing ; in function main 语句后面漏掉分号.警告报错18."k" is assigned a value which is never used 定义了一个变量,但程序从来没用过19.possibiy incorrect assignment in function main 这样的赋值可能不正确20.suspicious pointer conversion in function main 可疑的指针转换22.code has no effect in funtion main 代码对程序没效果23.Ambiguous operators need parentheses:不明确的运算需要用括号括起24.Ambiguous symbol 'xxx' :不明确的符号25.Argument list syntax error:参数表语法错误26.Array bounds missing :丢失数组界限符27.Array size toolarge :数组尺寸太大28.Bad character in paramenters :参数中有不适当的字符29.Bad file name format in include directive :包含命令中文件名格式不正确30.Bad ifdef directive synatax :编译预处理ifdef有语法错31.Bad undef directive syntax :编译预处理undef有语法错32.Bit field too large :位字段太长33.Call of non-function :调用未定义的函数34.Call to function with no prototype :调用函数时没有函数的说明35.Cannot modify a const object :不允许修改常量对象36.Case outside of switch :漏掉了case 语句37.Case syntax error :Case 语法错误38.Code has no effect :代码不可述不可能执行到pound statement missing{ :分程序漏掉"{"40.Conflicting type modifiers :不明确的类型说明符41.Constant expression required :要求常量表达式42.Constant out of range in comparison :在比较中常量超出范围43.Conversion may lose significant digits :转换时会丢失意义的数字44.Conversion of near pointer not allowed :不允许转换近指针45.Could not find file 'xxx' :找不到XXX文件46.Declaration missing ; :说明缺少";"47.Declaration syntax error :说明中出现语法错误48.Default outside of switch efault 出现在switch语句之外49.Define directive needs an identifier :定义编译预处理需要标识符50.Division by zero :用零作除数51.Do statement must have while o-while语句中缺少while部分52.Enum syntax error :枚举类型语法错误53.Enumeration constant syntax error :枚举常数语法错误54.Error directive :xxx :错误的编译预处理命令55.Error writing output file :写输出文件错误56.Expression syntax error :表达式语法错误57.Extra parameter in call :调用时出现多余错误58.File name too long :文件名太长59.Function call missing ) :函数调用缺少右括号60.Fuction definition out of place :函数定义位置错误61.Fuction should return a value :函数必需返回一个值62.Goto statement missing label :Goto语句没有标号63.Hexadecimal or octal constant too large :16进制或8进制常数太大64.Illegal character 'x' :非法字符x65.Illegal initialization :非法的初始化66.Illegal octal digit :非法的8进制数字67.Illegal pointer subtraction :非法的指针相减68.Illegal structure operation :非法的结构体操作69.Illegal use of floating point :非法的浮点运算70.Illegal use of pointer :指针使用非法71.Improper use of a typedefsymbol :类型定义符号使用不恰当72.In-line assembly not allowed :不允许使用行间汇编73.Incompatible storage class :存储类别不相容74.Incompatible type conversion :不相容的类型转换75.Incorrect number format :错误的数据格式76.Incorrect use of default efault使用不当77.Invalid indirection 无效的间接运算78.Invalid pointer addition 指针相加无效79.Irreducible expression tree 无法执行的表达式运算80.Lvalue required 需要逻辑值0或非0值81.Macro argument syntax error 宏参数语法错误82.Macro expansion too long 宏的扩展以后太长83.Mismatched number of parameters in definition 定义中参数个数不匹配84.Misplaced break 此处不应出现break语句85.Misplaced continue 此处不应出现continue语句86.Misplaced decimal point 此处不应出现小数点87.Misplaced elif directive 不应编译预处理elif88.Misplaced else 此处不应出现else89.Misplaced else directive 此处不应出现编译预处理else90.Misplaced endif directive 此处不应出现编译预处理endif91.Must be addressable 必须是可以编址的92.Must take address of memory location 必须存储定位的地址93.No declaration for function 'xxx' 没有函数xxx的说明94.No stack 缺少堆栈95.No type information 没有类型信息96.Non-portable pointer assignment 不可移动的指针(地址常数)赋值97.Non-portable pointer comparison 不可移动的指针(地址常数)比较98.Non-portable pointer conversion 不可移动的指针(地址常数)转换99.Not a valid expression format type 不合法的表达式格式100.Not an allowed type 不允许使用的类型101.Numeric constant too large 数值常太大102.Out of memory 内存不够用103.Parameter 'xxx' is never used 能数xxx没有用到104.Pointer required on left side of -> 符号->的左边必须是指针105.Possible use of 'xxx' before definition 在定义之前就使用了xxx(警告)106.Possibly incorrect assignment 赋值可能不正确107.Redeclaration of 'xxx' 重复定义了xxx108.Redefinition of 'xxx' is not identical xx的两次定义不一致109.Register allocation failure 寄存器定址失败110.Repeat count needs an lvalue 重复计数需要逻辑值111.Size of structure or array not known 结构体或数给大小不确定112.Statement missing ; 语句后缺少";"113.Structure or union syntax error X构体或联合体语法错误114.Structure size too large 结构体尺寸太大115.Sub scripting missing ] 下标缺少右方括号116.Superfluous & with function or array 函数或数组中有多余的"&" 117.Suspicious pointer conversion 可疑的指针转换118.Symbol limit exceeded 符号超限119.Too few parameters in call 函数调用时的实参少于函数的参数不120.Too many default cases Default太多(switch语句中一个)121.Too many error or warning messages 错误或警告信息太多122.Too many type in declaration 说明中类型太多123.Too much auto memory in function 函数用到的局部存储太多124.Too much global data defined in file 文件中全局数据太多125.Two consecutive dots 两个连续的句点126.Type mismatch in parameter xxx 数xxx类型不匹配127.Type mismatch in redeclaration of 'xxx' xx重定义的类型不匹配128.Unable to create output file 'xxx' 无法建立输出文件xxx129.Unable to open include file 'xxx' 无法打开被包含的文件xxx130.Unable to open input file 'xxx' 无法打开输入文件xxx131.Undefined label 'xxx' 没有定义的标号xxx132.Undefined structure 'xxx' 没有定义的结构xxx133.Undefined symbol 'xxx' 没有定义的符号xxx134.Unexpected end of file in comment started on line xxx 从xxx行开始的注解尚未结束文件不能结束135.Unexpected end of file in conditional started on line xxx 从xxx 开始的条件语句尚未结束文件不能结束136.Unknown assemble instruction 未知的汇编结构137.Unknown option 未知的操作138.Unknown preprocessor directive: 'xxx' 不认识的预处理命令xxx139.Unreachable code 无路可达的代码140.Unterminated string or character constant 字符串缺少引号er break 用户强行中断了程序142.V oid functions may not return a value V oid类型的函数不应有返回值143.Wrong number of arguments 调用函数的参数数目错144.'xxx' not an argument xxx不是参数145.'xxx' not part of structure xxx不是结构体的一部分146.'xxx' statement missing ( xx语句缺少左括号147.'xxx' statement missing ) xxx语句缺少右括号148.'xxx' statement missing ; xxx缺少分号149.'xxx' declared but never used 说明了xxx但没有使用150.'xxx' is assigned a value which is never used 给xxx赋了值但未用过151.Zero length structure 结构体的长度为零C++课程上机实验常见错误汇集1.在源码中遗失“;”调试器错误信息:syntax error : missing ';'2.缺少命名空间使用定义:即缺少“using namespace std;”调试器错误信息:例:error C2065: 'cout' : undeclared identifier例如cout/cin/endl/<</>>等在命名空间中定义的符号和标示符无法使用。
IBM TRIRIGA 用户体验框架说明书
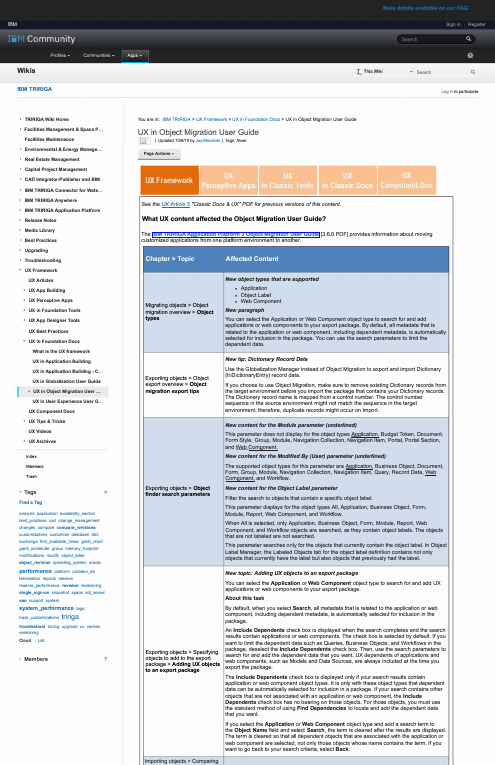
IBMTCM CommunityProfiles -Communities -WikisIBMTRIRIGA► TRIRIGA Wiki Home► Facilities Management & Space P ...Facilities Maintenance► Environmental & Energy Manage ...► Real Estate Management► Capital Project Management► CAD Integrator-Publisher and BIM► IBM TRI R IGA Connector for Wats ...► IBM TRIRIGA Anywhere► IBM TRI R IGA Application Platform► Release Notes► Media Library► Best Practices► Upgrading► Troubleshooting-UX F rameworkUXArticles► UX A pp Building• UX Perceptive Apps• UX in Foundation Tools• UX A pp Designer ToolsUX B est Practices-UX i n Foundation DocsWhat is the UX f rameworkUX i n Application BuildingUX i n Application Building -C ...UX i n Globalization User Guide• UX i n Object Migration User .. .UX i n User Experience User G .. .UX C omponent Docs► UX T ips & TricksUXVideos• UX A rchivesIndexMembersTrash... Tags Find a Tag.,analysis application availability_sectionbest_practices cad change_managementchanges compare compare_revisionscustomizations customize database db2exchange find_available_times gantt_chartgantt_scheduler group memory_footprintmodifications modify object_labelobject_revision operating_system oracleperformance platform problem_determination reports reservereserve_performance revision revisioningsingle_sign-on snapshot space sql_serversso support systemsystem_performance tags:track_ c ustomizations tri r i Q 8troubleshoot tuning upgrade ux versionversioningCloud List► Members ., -I .. This Wiki -Search Sign in Register Q. 0 Q Log in to participate You are in: IBM TRIRIGA > UX Framework > UX in Foundation Docs > UX in Object Migration User Guide UX in Object Migration User Guide §I Updated 10/8/19 by Jay.Manaloto I Tags: None Page Actions -UX F r amewo r k ux Component Doc See the UX A rticle 5 "Classic Docs & UX" PDF for previous versions of this content. What UX content affected the Object Migration User Guide? The IBM T RIRIGAAP-P-lication Platform 3 Object Migration User G uide [3.6.0 PDF] provides information about moving customized applications from one platform environment to another. Migrating objects > Object migration overview> Object types Exporting objects > Object export overview > Object migration export tips Exporting objects > Object finder search parameters Exporting objects > Specifying objects to add to the export package > Adding UX objects to an export package Importing objects > ComparingNew object types that are supported ■Application ■Object Label ■Web Component New paragraph You can select the Application or Web Component object type to search for and add applications or web components to your export package. By default, all metadata that is related to the application or web component, including dependent metadata, is automatically selected for inclusion in the package. You can use the search parameters to limit the dependent data. New tip: Dictionary Record Data Use the Globalization Manager instead of Object Migration to export and import Dictionary (triDictionaryEntry) record data. If you choose to use Object Migration, make sure to remove existing Dictionary records from the target environment before you import the package that contains your Dictionary records. The Dictionary record name is mapped from a control number. The control number sequence in the source environment might not match the sequence in the target environment; therefore, duplicate records might occur on import. New content for the Module parameter (underlined) This parameter does not display for the object types AP-P-lication, Budget Token, Document, Form Style, Group, Module, Navigation Collection, Navigation Item, Portal, Portal Section, and Web ComP-onent. New content for the Modified By (User) parameter (underlined) The supported object types for this parameter are AP-P-lication, Business Object, Document, Form, Group, Module, Navigation Collection, Navigation Item, Query, Record Data, Web ComP-onent, and Workflow. New content for the Object Label parameter Filter the search to objects that contain a specific object label. This parameter displays for the object types All, Application, Business Object, Form, Module, Report, Web Component, and Workflow. When All is selected, only Application, Business Object, Form, Module, Report, Web Component, and Workflow objects are searched, as they contain object labels. The objects that are not labeled are not searched. This parameter searches only for the objects that currently contain the object label. In Object Label Manager, the Labeled Objects tab for the object label definition contains not only objects that currently have the label but also objects that previously had the label. New topic: Adding UX objects to an export package You can select the A pplication or Web Component object type to search for and add UX applications or web components to your export package. About this task By default, when you select Search, all metadata that is related to the application or web component, including dependent metadata, is automatically selected for inclusion in the package. An Include Dependents check box is displayed when the search completes and the search results contain applications or web components. The check box is selected by default. If you want to limit the dependent data such as Queries, Business Objects, and Workflows in the package, deselect the Include Dependents check box. Then, use the search parameters to search for and add the dependent data that you want. UX dependents of applications andweb components, such as Models and Data Sources, are always included at the time you export the package.The Include Dependents check box is displayed only if your search results containapplication or web component object types. It is only with these object types that dependent data can be automatically selected for inclusion in a package. If your search contains other objects that are not associated with an application or web component, the Include Dependents check box has no bearing on those objects. For those objects, you must use the standard method of using Find Dependencies to locate and add the dependent data that you want. If you select the Application or Web Component object type and add a search term to the Object Name field and select Search, the term is cleared after the results are displayed. The term is cleared so that all dependent objects that are associated with the application or web component are selected, not only those objects whose name contains the term. If you want to go back to your search criteria, select Back.。
critical_section和interlockedincrement -回复
critical_section和interlockedincrement -回复Critical sections和InterlockedIncrement是在多线程编程中常用的同步和互斥机制。
它们被广泛地应用于操作系统、数据库管理系统、网络服务器等需要同时运行多个线程的程序中。
首先我们来了解一下什么是多线程编程。
在传统的单线程编程中,程序按照顺序一条一条地执行,而在多线程编程中,程序可以并发地执行多个线程。
每个线程都有自己的执行路径和执行状态,可以独立地执行一段代码。
然而,多线程编程也带来了一些问题。
由于多个线程可以同时访问相同的资源,比如内存、文件或者硬件设备,如果没有正确地进行同步和互斥操作,就可能会导致数据不一致或者其他的错误。
这时候就需要用到同步和互斥机制,其中Critical sections和InterlockedIncrement就是其中两个非常常用的工具。
首先我们来看看Critical sections。
Critical sections是一种同步机制,用于保护共享资源,只允许一个线程在同一时间访问这个资源。
当一个线程进入critical section时,其他线程必须等待该线程退出才能进入。
Critical sections可以通过以下几个步骤来使用:1. 创建一个critical section对象。
这可以通过调用操作系统提供的函数来实现,比如在Windows中可以使用InitializeCriticalSection函数。
2. 在使用共享资源的代码块之前,调用EnterCriticalSection函数来进入critical section。
这样就可以保证只有一个线程在同一时间访问共享资源。
3. 在代码块执行完毕后,调用LeaveCriticalSection函数来离开critical section。
这样其他线程就可以进入该代码块了。
Critical sections的优点是它是轻量级的,而且不需要额外的系统开销。
initialirecriticalsectionex -回复
initialirecriticalsectionex -回复【initialirecriticalsectionex】是一个API函数,常用于多线程编程中的临界区保护。
临界区是指在多线程环境下访问共享资源的代码段,而保护临界区则是为了避免多个线程同时访问导致的数据竞争和不一致性的问题。
在多线程编程中,多个线程同时访问共享资源可能会导致以下问题:竞争条件、死锁和饥饿等。
为了解决这些问题,需要使用临界区保护机制。
临界区保护机制通过对临界区上锁来确保同一时间只有一个线程可以访问。
initialirecriticalsectionex函数就是用来创建和初始化一个临界区对象。
下面我们来一步一步介绍如何使用initialirecriticalsectionex函数。
第一步是包含头文件。
在使用initialirecriticalsectionex函数之前,我们需要包含Windows.h头文件,该头文件包含了定义临界区的相关结构体和函数的声明。
#include <Windows.h>第二步是定义一个临界区对象。
在使用initialirecriticalsectionex函数之前,我们需要先定义一个临界区对象。
临界区对象可以是全局变量,也可以是局部变量,根据具体情况进行选择。
CRITICAL_SECTION g_criticalSection;第三步是使用initialirecriticalsectionex函数初始化临界区对象。
initialirecriticalsectionex函数的原型如下:BOOL WINAPI InitializeCriticalSectionEx(_Out_ LPCRITICAL_SECTION lpCriticalSection,_In_ DWORD dwSpinCount,_In_ DWORD Flags);lpCriticalSection参数是一个指向临界区对象的指针,dwSpinCount参数表示在没有其他线程等待临界区时,尝试获取临界区的次数(自旋次数),Flags参数用于指定初始化的标志。
SNOMED-CT与基本形式性语言的对齐结果说明书
Results•31 terms aligned with BFO •19 top-level terms •8 of their descendants• 4 terms from split of two top-level terms •Destinations•7 equated with existing BFO terms•17 placed as children of BFO or one another •7 terms deprecated•Added two fundamental forces of nature and two ancestor terms for institution for completeness•Overall: 27 terms -> 31 terms -> 35 terms -> 30 aligned with BFO + 5 that cannot be aligned (and thus were deprecated)Methods•Materials•SNOMED-CT , January, 2008•Basic Formal Ontology version 1.1 OWL file •Procedure•Review SNOMED-CT User Guide•Review 19 top-level concepts and their children•Place each of the 19 top-level concepts and ten key children (so far) into BFO •Text definitions for new terms•Assign SNOMED-CT Concept Ids as appropriate•Fill in missing terms in hierarchyBackground•Translational research involves computer processing of large datasets•Datasets will be collected by differentresearchers at different times at different locations •Need to annotate data with controlled,structured vocabularies known as ontologies to enable algorithmic processing•Ontologies used to annotate genotypes must be compatible with ontologies used to annotate phenotypes•Leading candidate phenotype ontology —SNOMED-CT —is not compatible with the Gene Ontology (GO) and other bioinformatics ontologies •GOAL: align top-level of SNOMED-CT with Basic Formal Ontology (BFO), the same top-level ontology with which GO is compatibleConceptPlacementBody structure is_a FiatObjectPartClinical finding DeprecatedDisease is_a DispositionEnvironment or geographical region Environment is_a SiteGeographical region is_a Spatial RegionEventequals Process BoundaryLinkage concept DeprecatedObservable entity equals Specifically DependentContinuantFunction equals Function Process equals Process Organismis_a ObjectPharmaceutical / biologic product Medication is_a Object Physical forceis_a Specifically DependentContinuantElectromagnetism is_a Physical force Gravitation is_a Physical forcePhysical object equals Object Procedure is_a ProcessQualifier value equals Dependent Continuant Record artifact is_a Generically DependentContinuantSituation with explicit context Deprecated Social context DeprecatedCommunity is_a Human social group Family is_a InstitutionInstitution is_a Human social groupSpecial concept DeprecatedSpecimenis_a ObjectStaging and scalesDisease stage is_a QualityClinical measurement scale is_a Generically Dependent ContinuantSubstanceequals ObjectConclusions•Even at the top level, SNOMED-CT has:•Ambiguous terms•Terms that do not refer to any entity •Epistemology•Arbitrary logical combinations •Alignment with BFO:•Identifies and helps remove mistakes •Builds out a logically coherent hierarchy •Harmonizes with top-level of Gene Ontology •Once a concept has been placed into BFO, its children do NOT necessarily follow •Final result is available as OWL fileN a t u r e P r e c e d i n g s : d o i :10.1038/n p r e .2008.2373.1 : P o s t e d 7 O c t 2008。
英语被动句的汉译技巧研究AStudyonChineseTranslationSkillsofE..
Contents
Introduction.................................................................................................................................1 1.Definitions of the Passive .....................................................................................................2
关键词:被动句;被动语态;被动句结构;翻译技巧
Abstract
The passive, a very common yet complex linguistic phenomenon, has never failed to arouse great interest of either linguists or ordinary speakers. A great many grammarians and linguists have attempted to define it and explain its structural characteristics, but these accounts are often different or even conflicting, which are sometimes more confusing and misleading than helpful. And all of English and Chinese have passive structures. However, English is different from the one of the characteristics of Chinese, is widely used in the passive voice, while the Chinese are less use of passive voice. Another, they have different structure. English is the "hypotaxis" language, the passive voice is expressed by changing the verb forms to achieve, and Chinese is "parataxis" language, the passive voice is defined by a pasf the passive words to achieve. Extensive use of passive voice in English, as it goes. When we don‟t know or don‟t willing to take the initiative, or there is no need to say take the initiative, or in order to highlight the passive, or to make a coherent context of convergence, using the passive voice to be more convenient. Moreover, the passive voice explain the issue in the subject of the sentence position, first, to arouse people's attention more; Second, non-emotional, simple and objective. Solving the passive in translation, discussing some skills to settle the problems during the passive Chinese translation of English, can help English learners understand English article fluency and expression better.
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Object InterconnectionsComparing Alternative Programming Techniques for Multi-threaded Servers(Column5) Douglas C.Schmidt Steve Vinoskischmidt@ vinoski@Department of Computer Science Hewlett-Packard Company Washington University,St.Louis,MO63130Chelmsford,MA01824This column will appear in the February1996issue of the SIGS C++Report magazine.1IntroductionThis column examines and evaluates several techniques for developing multi-threaded servers.The server we’re examin-ing mediates access to a stock quote database.Desktop client applications operated by investment brokers interact with our server to query stock prices.As with our previous columns, we’ll compare several ways to program multi-threaded quote servers using C,C++wrappers,and CORBA.1.1BackgroundA process is a collection of resources that enable a program to execute.In modern operating systems like Windows NT, UNIX,and OS/2,process resources include virtual mem-ory,handles to I/O devices,a run-time stack,and access control information.On earlier-generation operating sys-tems(such as BSD UNIX and Windows),processes were single-threaded.However,many applications(particularly networking servers)are hard to develop using single-threaded processes.For example,the single-threaded,iterative stock quote server we presented in our last column cannot block for extended periods of time handling one client request since the quality of service for other clients would suffer.The following are several common ways to avoid blocking in single-threaded servers:Reactive event dispatchers:one approach is to de-velop an event dispatcher(such as the object-oriented Re-actor framework described in[1]).Reactive dispatching is commonly used to manage multiple input devices in single-threaded user-interface frameworks.In these frameworks, the main event dispatcher detects an incoming event,de-multiplexes the event to the appropriate handler object,and dispatches an application-specific callback method to handle the event.The primary drawback with this approach is that long du-ration operations(such as transferring a largefile or per-forming a complex database query)must be developed using non-blocking I/O and explicitfinite state machines.This ap-proach becomes unwieldy as the number of states increase. In addition,since only non-blocking operations are used,it is difficult to improve performance via techniques such as“I/O streaming”or schemes that exploit locality of reference in data and instruction caches.Cooperative tasking:another approach is to use a coop-erative task library.A process can have multiple tasks,each containing a separate run-time stack,instruction pointer,and registers.Therefore,each task is a separate unit of execution, which executes within the context of a process.Cooperative tasking is non-preemptive,which means task context infor-mation will only be stored and retrieved at certain preemption points.1This enables the library to suspend a task’s execution until another task resumes it.The multi-tasking mechanisms on Windows3.1,Mac System7OS,and the original task library bundled with cfront are examples of cooperative task-ing.Cooperative task libraries can be hard to program correctly since developers must modify their programming style to avoid certain OS features(such as asynchronous signals). Another limitation with cooperative tasking is that the OS will block all tasks in a process whenever one task incurs a page fault.Likewise,the failure of a single task(e.g., mistakenly spinning in an infinite loop)will hang the entire process.Multi-processing:another way to alleviate the com-plexity of single-threaded processes is to use coarse-grained multi-processing capabilities provided by system calls like fork on UNIX and CreateProcess on Windows NT. These calls create a separate child process that executes a task concurrently with its parent.Separate processes can collaborate directly(by using mechanisms such as shared memory and memory-mappedfiles)or indirectly(by using pipes or sockets).However,the overhead and inflexibility of creating and using processes may be prohibitively expensive and overly complicated for many applications.For example,process creation overhead can be excessive for short-duration ser-vices(such as resolving the Ethernet number of an IP address,retrieving a disk block from a networkfile server,or setting an attribute in an SNMP MIB).Moreover,it may not be possibleto exertfine-grain control over the scheduling behavior andpriority of processes.In addition,processes that share C++objects in shared memory segments must make non-portableassumptions about the placement of virtual table pointers[2]. Preemptive multi-threading:When used correctly,pre-emptive multi-threading provides a more elegant,and po-tentially more efficient,means to overcome the limitations with the other concurrent processing techniques described above.A thread is a single sequence of execution steps per-formed in the context of a process.In addition to its own instruction pointer,a thread contains other resources such as a run-time stack of function activation records,a set of general-purpose registers,and thread-specific data.A pre-emptive multi-threading operating system(such as Solaris 2.x[3]and Windows NT[4])or library(such as the POSIX pthreads library[5]available with DCE)uses a clock-driven scheduler to ensure that each thread of control executes for a particular period of time.When a thread’s time period has elapsed it is preempted to allow other threads to run. Conventional operating systems(such as variants of UNIX,Windows NT,and OS/2)support the concurrent ex-ecution of multiple processes,each containing one or more threads.A process serves as the unit of protection and re-source allocation within a separate hardware protected ad-dress space.A thread serves as the unit of execution that runs within a process address space that is shared with zero or more threads.The remainder of this column focuses on techniques for programming preemptive multi-threaded servers.1.2Multi-threaded Server Programming Multi-threaded servers are designed to handle multiple client requests simultaneously.The following are common moti-vations for multi-threading a server:Simplify program design:by allowing multiple server tasks to proceed independently using conventional program-ming abstractions(such as synchronous CORBA remote method requests and replies);Improve throughput performance:by using the paral-lel processing capabilities of multi-processor hardware plat-forms and overlapping computation with communication; Improve perceived response time:for interactive client applications(such as user interfaces or network management tools)by associating separate threads with different server tasks so clients don’t block for long.There are a number of different models for designing con-current servers.The following outlines several concurrency models programmers can choose from when multi-threading their servers:Thread-per-request:this model handles each request from a client in a separate thread of control.This model is useful for servers that handle long-duration requests(such as database queries)from multiple clients.It is less useful for short-duration requests due to the overhead of creating a newthread for each request.It can also consume a large number ofOS resources if many clients make requests simultaneously. Thread-per-connection:this model is a variation of thread-per-request that amortizes the cost of spawning thethread across multiple requests.This model handles eachclient that connects with a server in a separate thread for the duration of the conversation.It is useful for servers that carry on long-durations conversations with multiple clients.It is not useful for clients that make only a single request since this is essentially a thread-per-request model.Thread pool:this model is another variation of thread-per-request that also amortizes thread creation costs by pre-spawning a pool of threads.It is useful for servers that want to bound the number of OS resources they consume.Client requests can be executed concurrently until the number of simultaneous requests exceeds the number of threads in the pool.At this point,additional requests must be queued until a thread becomes available.Thread-per-object:this model associates a thread for each logical object(i.e.,service)in the server.It is useful when programmers want to minimize the amount of rework required to multi-thread an existing server.It is less useful if certain objects receive considerably more requests than others since they will become a performance bottleneck.In general,multi-threaded servers require more sophisti-cated synchronization strategies than single-threaded servers.To illustrate how to alleviate unnecessary complexity,wepresent and evaluate a number of strategies and tactics nec-essary to build robust and efficient thread-per-request servers. Wefirst examine a simple solution using C and Solaris threads [3].We then describe how using C++wrappers for threads helps reduce the complexity and improves the portability and robustness of the C solution.Finally,we present a solution that illustrates the thread-per-request concurrency model im-plemented using two multi-threaded versions of CORBA(HP ORB Plus and MT-Orbix[6]).Our next column will show examples of the other concurrency models.A word of caution:the multi-threading techniques wediscuss in this column aren’t standardized throughout the in-dustry.Therefore,some of the code we show is not directlyreusable across all OS platforms.However,the key con-currency techniques and patterns we illustrate are reusable across different platforms.2The Multi-threaded C Server Solu-tion2.1Socket/C CodeThe following code illustrateshow to program the server-side of our stock quote program using sockets,Solaris threads,and C.Our previous column presented a set of utility rou-tines written in C used below to receive stock quote requests from clients(recvstockresponse)./*WIN32already defines this.*/#if defined(unix)typedef int HANDLE;#endif/*unix*//*These implementations were in our last column.*/ HANDLE create_server_endpoint(u_short port);int recv_request(HANDLE h,struct Quote_Request*req); int send_response(HANDLE h,long value);int handle_quote(HANDLE);2.1.1Spawning ThreadsThe main function shown below uses these C utility routinesto create a concurrent quote server.This server uses a thread-per-request concurrency model.The main program sits in an event loop waiting for connection events from clients.Con-nection events are handled directly in the event loop,which spawns off a new thread to perform the handlecreate func-tion.This function spawns a new thread that executes the handle quote function blocks awaiting the connected client to send a stock requeston the socket handle.The handlequote function looks up stock prices in the quote database via a global variable and an accessor function: DETACHED and THR LWP areflags to the Solaristhr quote function willexit silently when it’s complete and(2)a new concurrent execution context should be created,respectively.extern Quote_Database*quote_db;long lookup_stock_price(Quote_Database*,Quote_Request*);The single-threaded implementation of handlequote illustrates a simple way to serialize database access:/*Define a synchronization object thatis initially in the"unlocked"state.*/rwlock_t lock;void handle_quote(HANDLE h){struct Quote_Request req;long value;if(recv_request(h,&req)==0)return0;/*Block until read lock is available*/rw_rdlock(&lock);/*lookup stock in database*/value=lookup_stock_price(quote_db,&req);/*Must release lock or deadlock will result!*/ rw_unlock(&lock);return send_response(h,value);}The rwlockt implements a“readers/writer”lock that serializes thread execution by defining a critical section where multiple threads can read the data concurrently,but only one thread at a time can write to the data.The imple-mentation of rwlock3The solution we’ve shown does not show how stock prices are updated in the database.This is beyond the scope of this column and will be discussed in a future column.current applications at this level of detail has several draw-backs:Lack of portability:The design and implementation of the multi-threaded version of the quote server differs con-siderably from the single-threaded version.It replaces the reactive select-driven event loop with a master dispatcher thread and a set of slave threads that perform database lookups.Unfortunately,the use of Solaris threads is not portable to other platforms(such as Windows NT,OS/2,or other versions of UNIX).Lack of reusability:The use of global variables(like the lock that protects the database from race conditions)intro-duces unnecessary dependencies between different parts of the code.These dependencies make it hard to reuse existing code[7].Lack of robustness:in a large program,instrumenting all the code with mutex locks can be tedious and error-prone. In particular,failing to release a mutex can lead to deadlock or resource failures.The following section describes how we can use C++wrap-pers to alleviate the problems described above.3The Multi-threaded C++Wrappers SolutionUsing C++wrappers is one way to simplify the complexity of programming concurrent network servers.C++wrap-pers encapsulate lower-level OS interfaces such as sockets, multi-threading,and synchronization with type-safe,object-oriented interfaces.The IPCSAP encapsulates standard network programming inter-faces(such as sockets and TLI);the Acceptor implements a reusable design pattern for passively4initializing network services,and the Thread wrapper encapsulates standard OS threading mechanisms(such as Solaris threads,POSIX pthreads,and Windows NT threads).3.1C++Wrapper CodeThis section illustrates how the use of C++wrappers im-proves the reuse,portability,and extensibility of the quote server.Figure1depicts the following components in the quote server architecture:QuoteHandler runs in a separate thread of control.//This method is called by the Quote_Acceptor //to initialize a newly connected Quote_Handler //(which spawns a new thread to handle client).virtual int open (void){Thread::spawn(Quote_Handler<STREAM>::svc,//Entry point.(void *)this,//Entry point arg.THR_DETACHED |THR_NEW_LWP);//Thread flags.}//Static thread entry point method.The thread //exits when this method returns.static int svc (Quote_Handler<STREAM>*client_handle){int result =client_handle->handle_quote ();//Shut down the STREAM to avoid HANDLE leaks.peer_.close ();return result;}//Handles the quote request/response.This can block //since it runs in its own thread.virtual int handle_quote (Quote_Handler *this_ptr){Quote_Request req;int value;int result =0;if (recv_request (req)<=0)return -1;else {//Constructor of m acquires lock_.Read_Guard<RW_Mutex>m (this_ptr->lock_);value =this_ptr->db_.lookup_stock_price (req);//Destructor of m releases lock_.}return send_response (value);}//...private:Quote_Database &db_;//Reference to quote database.RW_Mutex &lock_;//Serialize access to database.};The C++implementation of handlewill be released regardless of whether the methodthrows an exception or returns normally.To ensure this behavior the following ReadGuard class defines a block of code where a lockis acquired when the block is entered and released automat-ically when the block is exited.ReadMutex ,which is a C++wrapper for theSolaris rwlockGuard is parameterized,this class can be usedwith a family of synchronization wrappers that conform to the acquireHandler templateis instantiated with the SOCKSAP class categoryfrom the ACE IPCSAP contains a set of C++classes that shields appli-cations from tedious and error-prone details of programming at the socket level [8].3.1.2The Quote Acceptor class.This class is a factory that implements the strategy for passively initializ-ing a Quote Acceptor supplies concrete template arguments for the following implementa-tion of the Acceptor pattern [9]:template <class SVC_HANDLER,//Service handlerclass PEER_ACCEPTOR>//Passive conn.mech.class Acceptor {public://Initialize a passive-mode connection factory.Acceptor (const PEER_ACCEPTOR::ADDR &addr):peer_acceptor_(addr){}//Implements the strategy to accept connections //from clients,and create and activate//SVC_HANDLERs to exchange data with peers.int handle_input (void){//Create a new SVC_HANDLER.SVC_HANDLER *svc_handler =make_svc_handler ();//Accept connection into the SVC_HANDLER.peer_acceptor_.accept (*svc_handler);//Delegate control to the SVC_HANDLER.svc_handler->open ();}//Virtual Factory Method to make a SVC HANDLER.virtual SVC_HANDLER *make_svc_handler (void)=0;private:PEER_ACCEPTOR peer_acceptor_;//Factory that establishes connections passively.};The QuoteAcceptor orTLIHandler )://Make a specialized version of the Acceptor//factory to handle quote requests from clients.class Quote_Acceptor :public Acceptor <QUOTE_HANDLER,//Quote service.SOCK_Acceptor>//Passive conn.mech.{public:typedef Acceptor <QUOTE_HANDLER,SOCK_Acceptor>inherited;Quote_Acceptor (const SOCK_Acceptor::ADDR &addr,Quote_Database&db):inherited(addr),db_(db){}//Factory method to create a service handler.//This method overrides the base class to//pass pointers to the Quote_Database and//the RW_Mutex lock.virtual QUOTE_HANDLER*make_svc_handler(void){ return new QUOTE_HANDLER(db_,lock_);}private:Quote_Database&db_;//Reference to databaseRW_Mutex lock_;//Serialize access to database. }The main function uses the components defined above to implement the quote server:int main(int argc,char*argv[]){u_short port=argc>1?atoi(argv[1]):10000;//Factory that produces Quote_Handlers.Quote_Acceptor acceptor(port,quote_db);//Single-threaded event loop that dispatches all //events in the Quote_Acceptor::handle_input() //method.for(;;)acceptor.handle_input();/*NOTREACHED*/return0;}After the QuoteHandlers.Each newly-created QuoteGuard idiom automatically acquires and releases mutex locks in critical sections.Improved portability:C++wrappers shield applications from platform-specific details of multi-threaded program-ming interfaces.Encapsulating threads with C++classes (rather than stand-alone C functions)improves application portability.For instance,the server no longer accesses So-laris thread functions directly.Therefore,the implementation shown above can be ported easily to other OS platforms with-out changing the Quote Acceptor classes.Increased reusability and extensibility of components: The Quote Handler compo-nents are not as tightly coupled as the C version shown in Section2.1.This makes it easier to extend the C++solu-tion to include new services,as well as to enhance existing services.For example,to modify or extend the functionality of the quote server(e.g.,to add stock trading functional-ity),only the implementation of the QuoteDatabase is no longer a global variable.It’s now localized within the scope of QuoteAcceptor.Note that the use of C++features like templates and inlin-ing ensures that the improvements described above do not penalize performance.The C++wrapper solution is a significant improvement over the C solution for the reasons we mentioned above. However,it still has all the drawbacks we’ve discussed in pre-vious columns such as not addressing higher-level commu-nication topics like object location,object activation,com-plex marshalling and demarshalling,security,availability and fault tolerance,transactions,and object migration and copying.A distributed object computing(DOC)framework like CORBA or Network OLE is designed to address these issues.DOC frameworks allow application developers to focus on solving their domain problems,rather than worry-ing about network programming details.In the following section we describe several ways to implement thread-per-request servers using CORBA.4The Multi-threaded CORBA Solu-tionThe CORBA2.0specification[14]does not prescribe a con-currency model.Therefore,a CORBA-conformant ORB need not provide multi-threading capabilities.However, commercially-available ORBs are increasingly providing support for multi-threading.The following section out-lines several concurrency mechanisms available in two such ORBs:HP ORB Plus and MT-Orbix.As in previous columns,the server-side CORBA imple-mentation of our stock quote example is based on the follow-ing OMG-IDL specification:module Stock{//Requested stock does not exist.exception Invalid_Stock{};interface Quoter{//Returns the current stock value or//throw an Invalid_Stock exception.long get_quote(in string stock_name)raises(Invalid_Stock);};};In the following section we’ll illustrate how a server program-mer can implement multi-threaded versions of this OMG-IDL interface using HP ORB Plus and MT-Orbix.4.1Overview of Multi-threaded ORBsA multithreaded ORB enables many simultaneous requeststo be serviced by one or more CORBA object implementa-tions.In addition,objects need not be concerned with the duration of each request.Without multiple threads,each re-quest must execute quickly so that incoming requests aren’t starved.Likewise,server applications must somehow ensurethat long-duration requests do not block other requests from being serviced in a timely manner.To understand multi-threaded CORBA implementations, let’sfirst review how a conventional reactive implementationof CORBA is structured.Here’s the main event loop for a typical single-threaded Orbix server:int main(void){//...//Create an object implementation.My_Quoter my_quoter(db);//Listen for requests and dispatch object methods.CORBA::Orbix.impl_is_ready("My_Quoter");//...}Likewise,the main event loop for an equivalent single-threaded HP ORB Plus server might appear as follows:int main(void){//...//Create an object implementation.My_Quoter my_quoter(db);//Generate an object reference for quoter object.Stock::Quoter_var qvar=quoter._this();//Listen for requests and dispatch object methods.//(hpsoa stands for"HP Simplified Object Adapter").hpsoa->run();//...}The impl ready and run methods are public inter-faces to the CORBA event loop.In a single-threaded ORB, these methods typically use the Reactor pattern[1]to waitfor CORBA method requests to arrive from multiple clients.The processing of these requests within the server is drivenby upcalls dispatched by impl ready or run.These upcalls invoke the get Quoter object implementation supplied by the server programmer.The upcall borrows the thread of control from the ORB to execute getisQuoter class for HP ORB Plus is shown below://Implementation class for IDL interface.class My_Quoter//Inherits from an automatically-generated//CORBA skeleton class.:virtual public HPSOA_Stock::Quoter{public:My_Quoter(Quote_Database&db):db_(db){}//Callback invoked by the CORBA skeleton.virtual long get_quote(const char*stock_name,CORBA::Environment&ev){ //assume no exceptionsev.clear();//Constructor of m acquires lock_.MSD_Lock m(lock_);long value=db_.lookup_stock_price(stock_name);if(value==-1)ev.exception(new Stock::Invalid_Stock);return value;//Destructor of m releases the lock_.}private:Quote_Database&db_;//Reference to quote database.MSD_Mutex lock_;//Serialize access to database. };MyStock::Quoter skeleton class. This class is generated automatically from the original IDL Quoter specification.The Quoter interface sup-ports a single operation:getquote relies on an external database object that maintains the current stock price.If the lookup ofthe desired stock price is successful the value of the stockis returned to the caller.If the stock is not found,the database lookup price function returns a valueof 1.This value triggers our implementation to return a Stock::Invalidobject,just like the C and C++solutions presented ear-lier.The code uses the MSD Threads Abstraction Library5 provided by HP ORB Plus.The MSDGuard shown in Section3.1.By using the MSD5MSD stands for“MeasurementSystems Department,”the HP laboratory where the threads abstraction library was developed.CLIENTQuoter implementation class shown below illus-trates how the thread-per-request concurrency model can be implemented in MT-Orbix://Implementation class for IDL interface.class My_Quoter//Inherits from an automatically-generated//CORBA skeleton class.:virtual public Stock::QuoterBOAImpl{public:My_Quoter(Quote_Database&db):db_(db){}//Callback invoked by the CORBA skeleton.virtual long get_quote(const char*stock_name,CORBA::Environment&ev){ //Constructor of m acquires lock.Read_Guard<RW_Mutex>m(lock_);long value=db_.lookup_stock_price(stock_name);if(value==-1)ev.exception(new Stock::Invalid_Stock);return value;//Destructor of m releases lock.}private:Quote_Database&db_;//Reference to quote database.RW_Mutex lock_;//Serialize access to database.};This version of the MyQuoter class inherits from a different skeleton class: Stock::QuoterBOAImpl.This class is generated auto-matically from the original IDL Quoter specification,just like the HP ORB Plus HPSOAquote proxy)to their associated target object(e.g.,myQuoter::getThreadFilter is responsiblefor spawning a thread that dispatches the getCLIENTCLIENTQUOTE SERVER OBJECT ADAPTER: My_QuoterImpl: My_QuoterImpl1: BIND6: HANDLE QUOTE REQUEST2: ACCEPT3: INVOKE FILTER (S )4: SPAWN THREAD 5: UPCALL: TPR Thread FilterFigure 3:MT Orbix Architecture for the Thread-per-Request Stock Quote ServerintTPR_ThreadFilter::inRequestPreMarshal(CORBA::Request &req,//Incoming CORBA Request.CORBA::Environment&){Thread::spawn(continueDispatching,//Entry point.(void *)&req,//Entry point arg.THR_DETACHED |THR_NEW_LWP);//Thread flags.//Tell Orbix we will dispatch request later.return -1;}The continueDispatching function is the entry point where the new thread begins executing:void *continueDispatching (void *vp){CORBA::Request *req =(CORBA::Request *)vp;CORBA::Orbix.continueThreadDispatch (*req);return 0;}The MT-Orbix method continueThreadDispatch will continue processing the request until it sends a reply to the client.At this point,the thread will exit.Our quote server must explicitly create an instance of TPRQuoter object im-plementation class is named Stock::QuoterBOAImpl ,while in the HP ORB Plus code the skeleton base class is named HPSOAthreads wrappers,it allows servers to take advantage of more efficient mechanisms provided by an OS or threads package. For instance,the MT-Orbix implementation in Section4.1.2 uses readers/writer locks.Often,these can be more efficient than the regular mutexes provided by the HP ORB Plus MSD library shown in Section4.1.1.Since CORBA makes no mention of threads,it remains to be seen whether the OMG ORB Task Force will take it upon itself to address this issue as a CORBA portability problem. Clearly,in the short term we could use techniques like the Adapter pattern[12]and reusable C++toolkits like ACE to make our object implementations relatively portable across different OS platforms and different ORBs.Non-C++Exception Handling:Both the HP ORB Plus and MT-Orbix implementations currently use Environment parameters to convey exception informa-tion rather than C++exceptions.Both ORBs will support C++exceptions in the near future.When exception handling is supported the getGuard is essential to protect programs from hazardous side-effects of C++exceptions[15].5Evaluating the Thread-per-Request Concurrency ModelAll the servers shown above were designed using a thread-per-request concurrency model.This is a fairly straightfor-ward model to design and implement.However,it is probably the wrong concurrency model for the task of retrieving stock quotes.There are two primary problems:Thread creation overhead–The time required to lookupa stock quote may be low relative to the time requiredto create the thread.In addition,even if the thread ran for a longer amount of time,the performance of the thread-per-request may not scale.For example,it may lead to unacceptably high resource utilization if there are hundreds or thousands of simultaneously active clients.Connection creation overhead–The thread-per-request model sets up a new connection for each request.There-fore,the overhead of establishing the connection is not amortized if clients send multiple requests to the server.The single-threaded solution we showed in our previous column kept the connection open until it was explicitly shut down by the client.Although our new solutionmight not affect how the client was programmed,the difference in connection strategies would likely show up in performance measurements.The actual performance of a particular concurrency model depends to a large extent on the following factors:The types of requests received from clients–e.g.,short vs.long duration;How threads are implemented–e.g.,in the OS kernel, in a user-space library,or some combination of both;Operating system and networking overhead–e.g.,how much other overhead results from setting up and tearing down connections repeatedly;Higher-level system configuration factors–such as whether replication and/or dynamic load balancing are used,also ultimately affect performance.We’ll discuss these performance issues in future columns. Another drawback with our solution is that the handleDatabase at a very coarse-grained level,i.e.,at the database level.The scope of the mutex ensures that the whole database is locked.This isfine if most operations are lookups and a readers/writer lock is used.However,it may lead to performance bottlenecks if stock prices are frequently updated,or if regular mutexes must be used.A more effi-cient solution would push the locking into the database itself, where record or table locking could be performed.One important conclusion from this evaluation is the im-portance of distinguishingbetween concurrency tactics(such as threading and synchronization mechanisms provided by an OS threads library)and concurrency strategies(such as thread-per-request,thread-per-connection,thread-per-object, etc.).Threading libraries provide low-level mechanisms for creating different concurrency models.However,develop-ers are ultimately responsible for knowing how to use these mechanisms successfully.Design patterns are a particularly effective way to help application developers master subtle differences between different strategies andfirmly under-stand the applicability and consequences of different con-currency models.We’ll explicitly cover key patterns for concurrent distributed object computing in future articles.6Concluding RemarksIn this column,we examined several different programming techniques for developing multi-threaded servers for a dis-tributed stock quote application.Our examples illustrated how object-oriented techniques,C++,and higher-level ab-stractions help to simplify programming and improve exten-sibility.Programming distributed applications without multiple threads is hard,especially for server applications.With-out multi-threading capabilities,the server developer must either ensure that requests can be handled so quickly that。