IP数据报分片
分片报文详解

分片报文详解分片报文是网络通信中用于处理大数据传输的一种技术。
当IP数据报的总长度大于链路层所能传输的最大数据长度时,需要对IP数据报进行分片。
下面将对分片报文进行详细解释:1. 分片的原因:IP数据报(IP头+DATA)被封装在链路层数据报中,因此链路层的MTU(最大传输单元)严格限制了IP数据报的长度。
在IP数据报的源与目的地路径上的各段链路可能使用不同的链路层协议,有不同的MTU。
例如,以太网的MTU为1500字节,而许多广域网的MTU不超过576字节。
当IP数据报的总长度大于链路MTU时,就需要将IP数据报中的数据分装在两个或更多个较小的IP数据报中,这些较小的数据报叫做片。
2. 分片的过程:分片由IPv4头部中的标识(Identification)、分片偏移(Fragment offset)和更多分片(More Fragments, MF)字段控制。
分片的标识(Identification)都是同样的,而且分片偏移(Fragment offset)是以8字节为单位的偏移。
先对数据进行分片,然后每一部分再加上报头。
3. 分片的组装:这就需要用到IP报头中的三个字段:16位分片标识、3位标志、13位片偏移。
其中,13位片偏移用于确定分片以后,各个部分在原始报文的哪个位置,即在原始报文中的偏移量;16位分片标识用于判断一个报文是否分片,如果一个报文不分片,不同报文之间的16位标识符是不同的;如果一个报文分片了,分片报文的16位标识符是一样的,说明这些分片报文原本属于一个完整的报文。
4. 分片的判断:根据片偏移判断是否为普通报文或分片报文的最后一部分。
如果片偏移为0,说明是普通报文,结束判断,直接向上层交付;如果片偏移不为0,说明是分片报文,需要加入到具有相同16位标识符的集合中。
然后判断所有的报文是否收全。
以上信息仅供参考,如需了解更多信息,建议咨询专业人士或查阅相关书籍文献。
深入理解IP包分片原理

深入理解IP包分片原理原理, 分片一、关键术语MTU MRU PMTU MSS包分片ip 分片和tcp分片差异1.IP分片产生的原因是网络层的MTU;TCP分段产生原因是MSS.2.IP分片由网络层完成,也在网络层进行重组;TCP分段是在传输层完成,并在传输层进行重组. //透明性3.对于以太网,MSS为1460字节,而MUT往往会大于MSS.故采用TCP协议进行数据传输,是不会造成IP分片的。
若数据过大,只会在传输层进行数据分段,到了IP层就不用分片。
而我们常提到的IP分片是由于UDP传输协议造成的,因为UDP传输协议并未限定传输数据报的大小。
为什么会有IP分片?直接原因是上层协议企图发送一段数据,其长度超过了M TU (Maxitum Transmi ssionUnit)。
什么情况,或者说什么协议会尝试发送这么长的数据?常见的有UDP和ICMP,需要特别注意的是,TCP一般不会。
为什么TCP不会造成IP分片呢?原因是TCP自身支持分段:当TCP要传输长度超过MS S(Maxitum Segment Size)的数据时,会先对数据进行分段,正常情况下,MSS小于MT U,因此,TCP一般不会造成IP分片。
而UDP和IC MP就不支持这种分段功能了,UDP和ICM P认为网络层可以传输无限长(实际上有65535的限制)的数据,当这两种协议发送数据时,它们不考虑数据长度,仅在其头部添加UDP或IC MP首部,然后直接交给网络层就万事大吉了。
接着网络层IP协议对这种“身长头短”的数据进行分片,不要指望IP能很“智能”地识别传给它的数据上层头部在哪里,载荷又在哪里,它会直接将整个的数据切成N个分片,这样做的结果是,只有第一个分片具有UDP或者ICMP首部,而其它分片则没有。
ip分片重组流程

ip分片重组流程1. 啥是IP分片呀。
你想啊,网络世界就像一个超级大的交通网络,数据就是那些在网络里跑来跑去的小汽车。
而IP数据包就是装载这些数据的“大货车”。
有时候呢,这个“大货车”太大了,没办法一下子通过网络里一些比较窄的“路”,这时候就得把这个大的IP数据包拆分成一个个小的片段,就像把大货车上的货物分装到几个小车上一样,这就是IP分片啦。
比如说,一个很大的文件要从一个地方传到另一个地方,网络条件不太允许一次性传过去,那就得分成好几块来传咯。
2. 为啥要进行IP分片呢。
这就好比你要搬家,有个超级大的沙发,电梯太小装不下,那你是不是得把沙发拆成几块,一块一块地搬上去呀?IP分片也是这个道理。
网络里有些设备或者链路对数据包的大小是有限制的,要是数据包太大,就过不去啦。
通过分片,就能让数据顺利地在网络里“旅行”,最后再把它们重新组合起来,就像把拆了的沙发在新家里再装起来一样。
这样就能保证数据完整地到达目的地咯。
3. 分片的过程是咋样的呢。
当要发送一个比较大的IP数据包的时候,发送端就会开始干活啦。
它会根据网络的情况,比如说链路的最大传输单元(MTU)大小,来决定把这个大数据包分成几个小片段。
每个小片段都有自己的“身份证”哦,里面包含了一些重要的信息,像原来大数据包的标识、这个小片段在整个数据包里的位置序号等等。
就好像把大沙发拆成几块后,给每一块都编个号,这样到时候就知道怎么组装啦。
4. 重组又是咋回事呢。
等这些小片段在网络里“跋山涉水”,终于都到达目的地啦,接收端就开始忙活重组的事儿。
它会根据小片段里的“身份证”信息,也就是那些标识和序号,把它们按照原来的顺序排好队。
就像你把拆了的沙发零件按照编号一个一个摆好,然后再把它们组装起来,这样就得到了原来完整的大数据包啦。
接收端会检查是不是所有的小片段都到齐了,如果有哪个调皮的小片段丢了,它还会想办法去处理呢,可能会请求重新发送丢失的那部分。
5. 遇到问题咋办呀。
IP数据报分片、组装和MAC帧报文结构

IP数据报分片、组装和MAC帧报文结构1 IP数据报分片、组装一、术语:a、MTU:当两台远程PC互联的时候,它们的数据需要穿过很多的路由器和各种各样的网络媒介才能到达对端,网络中不同媒介的MTU各不相同,就好比一长段的水管,由不同粗细的水管组成(MTU不同)通过这段水管最大水量就要由中间最细的水管决定。
网络层IP协议会检查每个从上层协议下来的数据包的大小,并根据本机MTU的大小决定是否作“分片”处理。
b、DF:DF(Donot Fragment)。
这是一个标志位,指明了不能进行IP数据包的分片。
当这个IP数据包的DF设定为1,在一大段网络(水管里面)传输的时候,如果遇到MTU小于IP数据包的情况,转发设备就会根据要求丢弃这个数据包。
然后返回一个错误信息给发送者。
c、MSS:MSS就是TCP数据包每次能够传输的最大数据分段。
为了达到最佳的传输效能TCP协议在建立连接的时候通常要协商双方的MSS值,这个值TCP协议在实现的时候往往用MTU值代替(需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes)所以往往MSS为1460。
通讯双方会根据双方提供的MSS值得最小值确定为这次连接的最大MSS值。
二、分片:IP报文在传输过程中,有些时候“水管”会越来越窄,也就是MTU会越来越小。
IP报文也会一分再分。
每个IP分片的报头基本相同,只是片偏移不一样。
把一个数据报为了适合网络传输而分成多个数据报的过程称为分片,被分片后的各个IP数据报可能经过不同的路径到达目标主机。
一个IP数据报在传输过程中可能被分片,也可能不被分片。
如果被分片,分片后的IP数据报和原来没有分片的IP数据报结构是相同的,即也是由IP头部和IP数据区两个部分组成:分片后的IP数据报,数据区是原IP数据报数据区的一个连续部分,头部是原IP数据报头部的复制,但与原来未分片的IP数据报头部有两点主要不同:标志和片偏移:(1) 标志:在IP数据报头部有一个叫“标志”的字段,用3位二进制数表示:不分片DF(Do not Fragment)标志如果被置1,则数据报在传输过程中不能被分片,如网络连通性测试命令ping就可以用-F参数设置为在数据传输时不分片,但这样当数据不能通过MTU较小的网络时,将产生数据不可达的错误。
IP分片

1、分片ICMP ECHO请求发送与响应1.1、IP报头中的分片处理[RFC 791]:The fields which may be affected by fragmentation include:(1) options field(2) more fragments flag(3) fragment offset(4) internet header length field(5) total length field(6) header checksum如果假设各个分片都没有选项字段那么与数据报的分片与重组有关的字段是:数据报总长度、数据报标识(每个分片该字段值都一样)、分段标志、分片偏移、16位首部校验和。
数据报总长度:该字段是报头长度和数据字节的总和,以字节为单位。
最大长度为65535字节。
从IP报头开始算。
数据报标识:这个唯一的16位标识符由产生它的主机指定给数据报。
发送主机为它送出的每个数据报产生一个单独ID,但数据报在传输的过程中可能会分段,并经过不同的网络而到达目的地。
分段后的数据报都共享同一个数据报ID,这将帮助接收主机对分段进行重装。
分段标志:3位分段标志位中的第一位未用,其他两位用于控制数据报的分段方式。
如果“不能分段(DF)”位设为1,意味着数据报在选路到目的地的过程中不会分段传输。
如果数据报不分段就无法选路,试图分段的路由器将丢掉该数据报并向源主机发送错误报文。
如果“更多段(MF)”位设为1,意味着该数据报是某两个或多个分段中的一个,但不是最后一段。
如果MF位设为0,意味着后面没有其他分段或者是该数据报本来就没有分段。
接收主机把标志位和分段偏移一起使用,以重组被分段的数据报。
所以第一个包DF=0,MF=1;第二个包DF=0,MF=0分段偏移值:这个字段包含13位,它表示以8字节为单位,当前数据报相对于初始数据报的开头的位置。
换句话说,数据报的第一个分段的偏移值为0;如果第二个分段中的数据从初始数据报开头的第800字节开始,该偏移值将是100。
IP协议 (通俗易懂),IP协议的主要功能及实现原理,IP地址分类,IP数据包分片,IP数据报格式。

IP协议(通俗易懂),IP协议的主要功能及实现原理,IP地址分类,IP数据包分片,IP数据报格式。
「主页」:士别三日wyx「简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创「专栏简介」:此文章已录入专栏《计算机网络零基础快速入门》本章重点1.IP协议的作用是什么?2.IP地址分类有哪些?3.IP数据包为什么分片?怎么分片?IP是一种「不可靠」的「端到端」的数据包「传输服务」,主要实现两个功能:数据传输和数据分片。
一、IP地址IP协议根据「IP地址」将数据传输到指定的目标主机,就像你寄快递的时候需要提供一个收货地址一样。
IP地址是全世界唯一的 32 位「二进制」数,通常用4位点分十进制来表示。
在 cmd 中执行 ipconfig 命令,查看本机的IP地址:为了便于寻址以及层次化构造网络,每个IP地址分为「网络号码」和「主机号码」两个部分,同一个物理网络上的所有主机都使用同一个网络号码。
1)IP地址分类IP地址分为A、B、C、D、E五类。
A类地址第一段是网络号码,剩下三段是主机号码;B类地址前两段是网络号码,剩下两段是主机号码;C类地址前三段是网络号码,最后一段是主机号码;类别IP范围子网掩码描述A类(1~126)1.0.0.1 ~127.255.255.254255.0.0.0共有126个网络,每个网络有1600万台主机,适合大规模的网络。
B类(128~191)128.0.0.1 ~191.255.255.254255.255.0.0共有16384个网络,每个网络有6万台主机,适合中等规模的网络。
C类(192~223)192.0.0.1 ~233.255.255.254255.255.255.0共有209万个网络,每个网络有254台主机,适合小型网络。
D类224.0.0.0 ~ 组播地址类别IP范围子网掩码描述(224~239)239.255.255.255E类(240~255)240.0.0.0 ~255.255.255.254保留地址2)私有IP地址A、B、C类地址中,分为公有IP和私有IP。
IP数据报的分片和重组
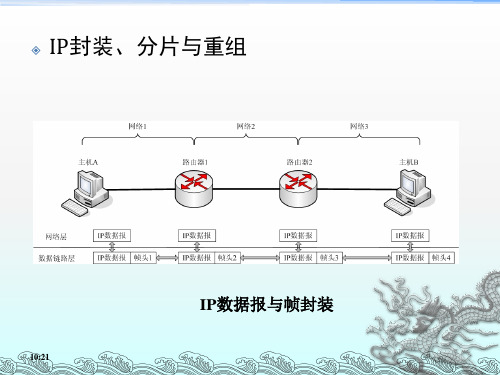
数据1(600字节) 数据2(600字节) 数据(160节) 数据2(600字节)
数据3 (200字节)
首部 首部 首部
数据1:偏移量=0,MF=1
数据2:偏移量=75(600) MF=1
数据3: 偏移量=150(1200) MF=0
00:03
问题:分片首部如何设置?
00:03
问题?
IP数据报的分片发生在哪里? 源点主机会对IP分组进行分片吗?
00:03
数据报的分片控制
数据报的封装 (以太网帧类型0800H) 数据报首部 帧头 数据报数据区 帧数据区
问题:每种网络有固定的MTU,若IP报文长度大于 MTU,怎么办?
数据分片(如何分片?)
00:03
首部长度:若无选项,和原数据报相同,否则重新计算。 ID、标志域和片偏移量:如前所述。 总长度:分片首部的长度+分片数据部分的长度。 校验和:必须重新计算。(为什么?) 选项:EOL和NOP不可复制,LSR、SSR复制到所有分片 中,记录路由和时间戳选项只能复制到第一个分片中。
00:03
00:03
MF (More Fragment):片未 完位 MF=0,是最后一片 MF=1,不是最后一片 解决了:分片的结束
如何组装?
组装时,需要重新设置首部的某些字段 (1)修改分片标志和片偏移量字段 (2)首部其它字段复制原来数据报首部的相应字段 标识符
DF MF
片偏移量
00:03
首部 首部 首部 首部
(2)如何标识同一个数据报分片的顺序?
(3)如何标识同一个数据报分片的结束?
00:03
标识
DF MF 片偏移量
ip数据报中与分片有关的3个字段。

ip数据报中与分片有关的3个字段。
IP数据报中与分片有关的三个字段是总长度(Total Length)、标识(Identification)和片偏移(Fragment Offset)。
总长度字段指示了整个IP数据报的长度,它包括IP头部和数据负载部分的总和。
这个字段是16位的,可以表示最大长度为65535字节的数据报。
当传输的数据超过了网络链路的最大传输单元(MTU),就需要进行分片来适应不同的网络链路。
数据报的总长度字段的值就是在分片过程中根据MTU大小将原始数据分割后,每个片段的长度之和。
标识字段是唯一地识别数据报的一个值,用于在接收端重新组装和识别来自同一个源IP地址的片段。
当一个数据报被分成多个片段时,每个片段的标识字段都会有相同的值。
这使得接收端能够正确地将这些片段重新组装成原始的数据报。
标识字段是一个16位的值,范围从0到65535。
片偏移字段指示了每个片段在原始数据报中的相对位置。
它的单位是8个字节,因此片偏移字段的值是以8个字节为单位的偏移量。
接收端使用片偏移字段来确定每个片段在重组时的正确顺序,以及片段的相对位置以重新组装原始数据报。
IP数据报中的这三个字段在分片过程中发挥着重要的作用。
它们确保了在不同的网络链路上传输的数据能够正确地被重新组装成原始的数据报。
这种分片机制使得不同网络链路的设备能够适应不同的MTU 大小,从而实现了跨网络的数据传输。
在实际应用中,了解这些与分片有关的字段是非常重要的。
在网络设计和配置中需要考虑数据报的总长度、标识和片偏移,以确保数据能够在网络中正确传输和重新组装。
此外,了解分片机制还可以帮助网络管理员优化网络性能和解决网络中的分包问题。
总而言之,掌握IP数据报中与分片有关的字段对于理解和优化网络传输是非常有指导意义的。