DNA测序结果分析

学习
通常一份测序结果图由红、黑、绿和蓝色测序峰组成,代表不同的碱基序列。测序图的两端(本图原图的后半段被剪切掉了)大约50个碱基的测序图部分通常杂质的干扰较大,无法判读,这是正常现象。这也提醒我们在做引物设计时,要避免将所研究的位点离PCR序列的两端太近(通常要大于50个碱基距离),以免测序后难以分析比对。
我的课题是研究基因多态性的,因此下面要介绍的内容也主要以判读测序图中的等位基因突变位点为主。
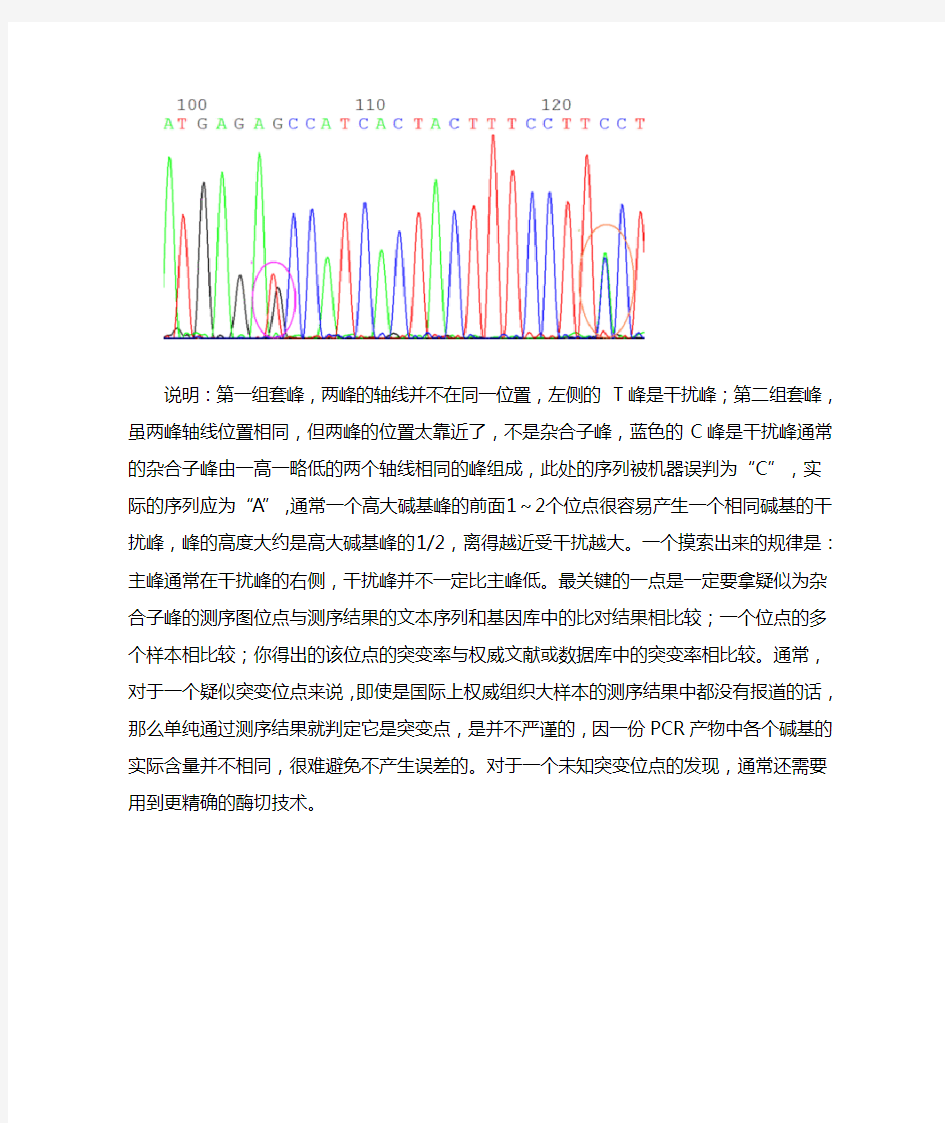
实际上,要在一份测序图中找到真正确实的等位基因多态位点并不是一件容易的事情。由于临床专业的研究生,这些东西是没人带的,只好自己研究。开始时大概的知道等位基因位点在假如在测序图上出现像套叠的两个峰,就是杂合子位点。实际比对了数千份序列后才知道,情况并非那么简单,下面测序图中标出的两
个套峰均不是杂合子位点,如图并说明如下:
说明:第一组套峰,两峰的轴线并不在同一位置,左侧的T峰是干扰峰;第二组套峰,虽两峰轴线位置相同,但两峰的位置太靠近了,不是杂合子峰,蓝色的C峰是干扰峰通常的杂合子峰由一高一略低的两个轴线相同的峰组成,此处的序列被机器误判为“C”,实际的序列应为“A”,通常一个高大碱基峰的前面1~2个位点很容易产生一个相同碱基的干扰峰,峰的高度大约是高大碱基峰的1/2,离得越近受干扰越大。一个摸索出来的规律是:主峰通常在干扰峰的右侧,干扰峰并不一定比主峰低。最关键的一点是一定要拿疑似为杂合子峰的测序图位点与测序结果的文本序列和基因库中的比对结果相比较;一个位点的多个样本相比较;你得出的该位点的突变率与权威文献或数据库中的突变率相比较。通常,对于一个疑似突变位点来说,即使是国际上权威组织大样本的测序结果中都没有报道的话,那么单纯通过测序结果就判定它是突变点,是并不严谨的,因一份PCR产物中各个碱基的实际含量并不相同,很难避免不产生误差的。对于一个未知
突变位点的发现,通常还需要用到更精确的酶切技术。
宏基因组分析和诊断技术在急危重症感染应用的专家共识
宏基因组分析和诊断技术在急危重症感染应用的专家共识 感染是急危重症患者死亡的主要原因之一。近年来,随着新发病原微生物的出现、耐药病原微生物的增多以及免疫抑制宿主的增加,感染的发病率和死亡率仍居高不下,脓毒症(严重感染)患者病死率高达50%[1-3]。最新调查研究发现,中国脓毒症相关性标化死亡率为66.7例/10万人口,全国每年共有脓毒症相关性死亡病例近103万例[3]。重症感染起病急、进展快、病原体复杂,短时间内能否明确致病病原微生物至关重要。 传统的病原微生物检测方法主要包括形态学检测、培养分离、生化检测、免疫学和核酸检测。因操作简单、快速、技术要求不高,同时具有一定的诊断敏感性和特异性,目前仍在临床上广泛使用。但传统的检测方法在敏感性、特异性、时效性、信息量等方面存在局限,而且对于未知或者罕见的病原微生物,无法快速识别。 基于宏基因组新一代测序技术(metagenomics next-generation sequencing,mNGS)不依赖于传统的微生物培养,直接对临床样本中的核酸进行高通量测序,然后与数据库进行比对分析,根据比对到的序列信息来判断样本包含的病原微生物种类,能够快速、客观地检测临床样本中的较多病原微生物(包括病毒、细菌、真菌、寄生虫),且无需特异性扩增[4-8],尤其适用于急危重症和疑难感染的诊断。 为了规范运用mNGS进行病原微生物的诊断、正确解读检测结果和指导治疗,我们组织了急危重病、感染病学和病原微生物学相关领域的专家,制定了本共识。 1 mNGS分析和诊断技术是急危重症感染快速、精准诊疗的发展方向 新一代测序技术是一个开放的分析和诊断系统,目前已经纳入的病原体有8000多种,其中包括3000余种细菌、4000余种病毒、200余种真菌和140种寄生虫,为疑难危重症及罕见病原微生物感染的诊断提供了有效的技术手段。 自2008年成功应用于临床诊断新发病原体感染以来[9-10],目前mNGS技术已经逐步用于临床疑难感染诊断,如华山医院张文宏团队[11]用mNGS协助确诊猪疱疹病毒的跨物种传播,并给予针对性治疗使患者痊愈,深圳市第三人民医院用mNGS确诊了一例罕见阿米巴脑炎[11-12]。 mNGS对脓毒症、免疫抑制宿主并发严重感染、重症肺部感染等疾病具有较高的临床应用价值,能够快速、精准地找到病原体;另外对于抗菌药物治疗方案的制定和治疗效果的评估具有一定的指导作用[9-16]。Long等[17]研究发现血培养联合mNGS诊断细菌或真菌感染,阳性率较单用血培养显著升高。以健康人群为基线,建立每种微生物在正常人群中的分布情况模型,进而计算脓毒症指数来评估检出微生物的核酸数量,Crumaz等[18]发现在脓毒症患者血液标本中病原菌的脓毒症指数绝对值、丰度显著升高,而且其变化与临床治疗效
2_重测序BSA分析项目结题报告
重测序BSA项目结题报告 客户单位:____________________________________ 报告单位:____________ 联系人:____________________________________ 联系电话: ___________________________ 传真:___________________________ 报告日期:____________________________________ 项目负责人:__________ 审核人: __________________ 目录 目录 (1) 1 项目概况 (1) 1.1 合同关键指标 (1)
1.2 项目基本信息 (1) 1.3 项目执行情况 (2) 1.4项目结果概述 (2) 2 项目流程 (3) 2.1 实验流程 (3) 2.2 信息分析流程 (3) 3 生物信息学分析 (5) 3.1 测序数据质控 (5) 3.1.1 原始数据介绍 (5) 3.1.2 碱基测序质量分布 (7) 3.1.3碱基类型分布 (9) 3.1.4 低质量数据过滤 (10) 3.1.5测序数据统计 (10) 3.2 与参考基因组比对统计 (11) 3.2.1 比对结果统计 (11) 3.2.2 插入片段分布统计 (11) 3.2.3 深度分布统计 (12) 3.3 SNP 检测与注释 (14) 331样品与参考基因组间SNP的检测 (14) 332样品之间SNP的检测 (17) 3.3.3 SNP结果注释 (19) 3.4 Small In Del 检测与注释 (22) 3.4.1 样品与参考基因组间Small InDel 的检测 (22) 3.4.2样品之间Small InDel 检测 (22) 343 Small In Del 的注释 (23) 3.5 关联分析 (26) 3.5.1高质量SNP筛选 (26) 3.5.2 SNP-index方法关联结果 (26) 3.5.3 ED方法关联结果 (28)
DNA测序常见问题及分析
DNA测序过程可能遇到的问题及分析 对于一些生物测序公司(如Invitrogen等),我们的菌液或质粒经过PCR和酶切鉴定都没问题,但几天后的测序结果却无法另人满意。 为什么呢? PCR产物直接进行测序,在PCR产物长度以后将无反应信号,机器将产生许多N值。这是由于Taq酶能够在PCR反应的末端非特异性地加上一个A碱基,我们所用的T载体克隆PCR产物就是应用该原理,通常PCR产物结束的位点,PCR产物测序一般末端的一个碱基为A(绿峰),也就是双脱氧核甘酸ddNTP终止反应的位置之前的A,A后的信号会迅速减弱。 N值情况一般是由于有未去除的染料单体造成的干扰峰。该干扰峰和正常序列峰重叠在一起,有时机器377以下的测序仪无法正确判断出为何碱基。有时,在序列的起始端的小片段容易丢失,导致起始区信号过低,机器有时也无法正确判读。在序列的3’端易产生N值。一个测序反应一般可以读出900bp以上的碱基(ABI3730可以达到1200bp),但是,只有一般600bp以前的碱基是可靠的,理想条件下,多至700bp的碱基都是可以用的。一般在650bp以后的序列,由于测序毛细管胶的分辩率问题,会有许多碱基分不开,就会产生N值。测序模板本身含杂合序列,该情况主要发生在PCR产物直接测序,由于PCR产物本身有突变或含等位基因,会造成在某些位置上有重叠峰,产生N值。这种情况很容易判断,那就是整个序列信号都非常好,只有在个别位置有明显的重叠峰,视杂合度不同N值也不同。 测序列是从引物3’末端后第一个碱基开始的,所以就看不到引物序列。有两种方法可以得到引物序列。1.对于较短的PCR产物 (<600bp),可以用另一端的引物进行测序,从另一端测序可以一直测通,可以在序列的末端得到该引物的反向互补序列。对于较长的序列,一个测序反应测不通,就只能将PCR产物片段克隆到载体中,用载体上的通用引物(T7/SP6)进行测序。载体上的通用引物与所插入序列间
DNA测序结果分析
学习 通常一份测序结果图由红、黑、绿和蓝色测序峰组成,代表不同的碱基序列。测序图的两端(本图原图的后半段被剪切掉了)大约50个碱基的测序图部分通常杂质的干扰较大,无法判读,这是正常现象。这也提醒我们在做引物设计时,要避免将所研究的位点离PCR序列的两端太近(通常要大于50个碱基距离),以免测序后难以分析比对。 我的课题是研究基因多态性的,因此下面要介绍的内容也主要以判读测序图中的等位基因突变位点为主。 实际上,要在一份测序图中找到真正确实的等位基因多态位点并不是一件容易的事情。由于临床专业的研究生,这些东西是没人带的,只好自己研究。开始时大概的知道等位基因位点在假如在测序图上出现像套叠的两个峰,就是杂合子位点。实际比对了数千份序列后才知道,情况并非那么简单,下面测序图中标出的两
个套峰均不是杂合子位点,如图并说明如下: 说明:第一组套峰,两峰的轴线并不在同一位置,左侧的T峰是干扰峰;第二组套峰,虽两峰轴线位置相同,但两峰的位置太靠近了,不是杂合子峰,蓝色的C峰是干扰峰通常的杂合子峰由一高一略低的两个轴线相同的峰组成,此处的序列被机器误判为“C”,实际的序列应为“A”,通常一个高大碱基峰的前面1~2个位点很容易产生一个相同碱基的干扰峰,峰的高度大约是高大碱基峰的1/2,离得越近受干扰越大。一个摸索出来的规律是:主峰通常在干扰峰的右侧,干扰峰并不一定比主峰低。最关键的一点是一定要拿疑似为杂合子峰的测序图位点与测序结果的文本序列和基因库中的比对结果相比较;一个位点的多个样本相比较;你得出的该位点的突变率与权威文献或数据库中的突变率相比较。通常,对于一个疑似突变位点来说,即使是国际上权威组织大样本的测序结果中都没有报道的话,那么单纯通过测序结果就判定它是突变点,是并不严谨的,因一份PCR产物中各个碱基的实际含量并不相同,很难避免不产生误差的。对于一个未知
人类基因组重测序分析
6 首页 科技服务 医学检测 科学与技术 市场与支持 加入我们 关于我们提供领先的基因组学解决方案 Providing Advanced Genomic Solutions 诺禾致源 人类疾病基因组重测序分析图3 Circos 图 人类基因组重测序分析6项升级 Novo-Zhonghua Genomes 数据库注释 一些位点的突变可能在千人基因组中或在欧美人群中属于低频突变,但是对于中国人群来说却是常见突变。诺禾致源自建中国人数据库 Novo-Zhonghua Genomes,数据库中的所有样本均来自正常中国人群。已有研究表明,与国际通用的多人种数据库相比,使用单一人种数据库进行疾病研究,可以有效减少假阳性现象。 图2 真核生物基因的结构[6] 复杂疾病变异分类标准 DamLevel Variant Calling Variant Annotation Benign Likely Benign VUS Likely Pathogenic Custom knowledge Clinical Data Pathogenic Family Testing Published + in house data Population frequency Predictions: PolyPhen, SIFT, etc Amino acid conservation Published Disease Information Variant classification Candidate Variants Novo-Zhonghua Genomes 数据库注释 复杂疾病突变位点有害性分类 非编码区(Non-coding region)分析 疾病基因组 CNV/SV 分析 基于基因(Gene-based)的 Burden Analysis (复杂疾病散发样本) 可视化的数据结果展示 基于健康中国人群的千人测序数据,测序深度 > 30× 参考 ACMG 等,推出针对复杂疾病变异位点有害性的分类标准 应用 ENCODE 数据库最新内容,并结合国际通用数据库、自建数 复杂疾病突变位点有害性分类 基于美国医学遗传学会 ACMG[2]与 Duzkale H[3]提出的变异分类标准,诺禾致源疾病基因组信息分析团队推出了一套针对复杂疾病变异位点有害性的分类标准 DamLevel(如下图所示)。DamLevel 将变异位点的有害性分为5个层级:Pathogenic、Likely Pathogenic、VUS(Variant of uncertain significance)、Likely Begnin、Begnin,更好地鉴定个体遗传变异与疾病的相关性。 非编码区(Non-coding region)分析 基因组非编码区变异可以引发多种疾病,包括心脏类疾病、糖尿病、癌症、肥胖症等[4,5],但目前对非编码区突变的筛选和功能描述仍具挑战性。诺禾致源非编码区分析,应用 ENCODE 数据库最新内容对非编码区突变进行注释,通过国际通用数据库和自建的 Novo-Zhonghua Genomes 数据库进行频率筛选以及保守性过滤,精确定位非编码区中低频且保守的突变,筛选到与疾病相关的非编码区突变。 疾病基因组 CNV/SV 分析 CNV/SV 与基因表达、表型、人类疾病发生发展都有着非常密切的关系[7,8],诺禾致源疾病基因组信息分析团队研发了一整套 CNV/SV 筛选方法,包括有害性 CNV/SV 筛选和 de novo CNV/SV 分析(基于成三或成四家系)等。利用 DGV、DECIPHER、CNVD 等数据库对变异检出结果进行标记,从结果中进一步过滤掉良性 CNV/SV,经过一系列筛选后,准确鉴定个体 CNV/SV 遗传变异与疾病的相关性。 图4 CNV 分布图 表1 本次产品升级亮点 图5 Burden 分析结果的热图展示 1 2 3 4 5 Novo-Zhonghua Genomes 数据库注释 Novo-Zhonghua Genomes 数据库是诺禾致源自建针对 中国正常人群的数据库,助 力中国人群基因组信息解析。 复杂疾病突变位点 有害性分类 诺禾致源推出的复杂疾病变 异位点有害性的分类标准 (DamLevel),准确标识复杂 疾病的致病性突变位点。 非编码区 (Non-coding region)分析 应用 ENCODE 数据库最新内 容对非编码区进行注释、筛 选,精确定位非编码区中低 频且保守的突变。 疾病基因组 CNV/SV 分析 完整的有害性 CNV/SV 筛选 和 de novo CNV/SV 分析, 准确鉴定个体 CNV/SV 遗传 变异与疾病的相关性。 基于基因 (Gene-based)的 Burden Analysis 针对复杂疾病的研究,通过 检测疾病状态与基因变异的 相关性,寻找特定疾病(或 性状)的易感基因。 可视化的 数据结果展示 灵活易用的测序数据结果展 示,使大量复杂数据的分析 变得轻松而高效,提高数据 可读性。 ? log 10 ( P ? value ) Mutations of Genes Prioritized by Burden Analysis CIR1 PIGP CTSE PRB2 CYP HDAC1 GRK6 PIGK MYL6B EHD2 0810 246 Mutations 4 3 2 1 基于基因(Gene-based)的 Burden Analysis 关联分析是研究复杂疾病的1个重要方法,其通过检测疾病状态与基因变异的相关性,寻找特定疾病(或性状)的易感基因。通常是在具有不同表型的2组个体(一般为患病者和正常对照者)中,基于遗传位点(或基因、单体型)的频率分布差异,间接反映该遗传位点(或基因)可能与疾病(或性状)存在关联性。 Burden Analysis(Gene-based)基于复杂疾病的 case 和 control 散发样本,通过 Fisher's exact test 以及 SKAT 统计方法分析得到候选基因,针对候选基因可以进行富集分析(KEGG 富集分析和 GO 富集分析)与蛋白网络互作分析。 可视化的结果展示 诺禾致源疾病基因组信息分析团队,会为客户提供不断更新的变异注释、项目特异性分析和灵活易用的“变异-基因-疾病”可视化结果,让科学研究更轻松。 图6 疾病与基因关联性展示图 产品名称升级亮点 引领行 业新 标杆 参考文献 [1] Nagasaki M, Yasuda J, Katsuoka F, et al. Rare variant discovery by deep whole-genome sequencing of 1,070 Japanese individuals.[J]. Nature Communications, 2015, 6. 阅读原文 >> [2] Richards S, Aziz N, Bale S, et al Standards and guidelines for the interpretation of sequence variants: a joint consensus recommendation of the American College of Medical Genetics and Genomics and the Association for Molecular Pathology[J]. Genetics in Medicine, 2015. 阅读原文 >> [3] Duzkale H, Shen J, McLaughlin H, et al. A systematic approach to assessing the clinical significance of genetic variants[J]. Clinical genetics, 2013, 84(5): 453-463. 阅读原文 >> [4] Yoshinari M, Akihiko M, Dongquan S, et al. A functional polymorphism in the 5' UTR of GDF5 is associated with susceptibility to osteoarthritis.[J]. Nature Genetics, 2007, 39(4):529-33. 阅读原文 >> [5] Kjong-Van L, Ting C. Exploring functional variant discovery in non-coding regions with SInBaD.[J]. Nucleic Acids Research, 2012, 41 (1):e7-e7. 阅读原文 >> [6] https://https://www.360docs.net/doc/0015969256.html,/wiki/Regulatory_sequence 阅读原文 >> [7] Sudmant P H, Rausch T, Gardner E J, et al. An integrated map of structural variation in 2,504 human genomes.[J]. Nature, 2015, 526 (7571):75-81. 阅读原文 >> [8] Birney E, Soranzo N. Human genomics: The end of the start for population sequencing.[J]. Nature, 2015, 526(7571):52-3. 阅读原文 >> 免费升级7-9月 新签合同 免费升级数据分析
宏基因组学概述
宏基因组学概述
————————————————————————————————作者: ————————————————————————————————日期: ?
宏基因组学概述 王莹,马伊鸣 (北京交通大学土木建筑工程学院环境1402班) 摘要:随着分子生物学技术的快速发展及其在微生物生态学和环境微生物学研究中的广泛应用,促进了以环境中未培养微生物为研究对象的新兴学科——微生物环境基因组学(又叫宏基因组学、元基因组学,英文名Metagenomics)的产生和快速发展。宏基因组学通过直接从环境样品中提取全部微生物的DNA,构建宏基因组文库,利用基因组学的研究策略研究环境样品所包含的全部微生物的遗传组成及其群落功能.在短短几年内,宏基因组学研究已渗透到各个领域,包括海洋、土壤、热液口、热泉、人体口腔及胃肠道等,并在医药、替代能源、环境修复、生物技术,农业、生物防御及伦理学等各方面显示了重要的价值。本文对宏基因组学的主要研究方法、热点内容及发展趋势进行了综述 关键词:宏基因组宏基因组学环境基因组学基因文库的构建 Macro summary of Metagenomics WangYing,Ma Yi-Ming (BeijingJiaotongUniversity, Institute of civil engineering,)Key words:Metagenome; Metagenomics;The environmental genomics 宏基因组学(Metagenomics)又叫微生物环境基因组学、元基因组学。它通过直接从环境样品中提取全部微生物的DNA,构建宏基因组文库,利用基因组学的研究策略研究环境样品所包含的全部微生物的遗传组成及其群落功能。它是在微生物基因组学的基础上发展起来的一种研究微生物多样性、开发新的生理活性物质(或获得新基因)的新理念和新方法。其主要含义是:对特定环境中全部微生物的总DNA(也称宏基因组,metagenomic)进行克隆,并通过构建宏基因组文库和筛选等手段获得新的生理活性物质;或者根据rDNA数据库设计引物,通过系统学分析获得该环境中微生物的遗传多样性和分子生态学信息。 1.起源 宏基因组学这一概念最早是在1998年由威斯康辛大学植物病理学部门的Jo Handelsman等提出的,是源于将来自环境中基因集可以在某种程度上当成一个单个基因组研究分析的想法,而宏的英文是"meta-",具有更高层组织结构和动态变化的含义。后来伯克利分校的研究人员Kevin Chen和LiorPachter将宏基因组定义为"应用现代基因组学的技术直接研究自然状态下的微生物的有机群落,而不需要在实验室中分离单一的菌株"的科学。 2 研究对象 宏基因组学(Metagenomics)是将环境中全部微生物的遗传信息看作一个整体自上而下地研究微生物与自然环境或生物体之间的关系。宏基因组学不仅克服了微生物难以培养的困难, 而且还可以结合生物信息学的方法, 揭示微生物之间、微生物与环境之间相互作用的规律, 大大拓展了微生物学的研究思路与方法, 为从群落结构水平上全面认识微生物的生态特征和功能开辟了新的途径。目前, 微生物宏基因组学已经成为微生物研究的热点和前沿, 广泛应用于气候变化、水处理工程系统、极端环境、人体肠道、石油污染、生物冶金等领域, 取得了一系列引人瞩目的重要成果。 3 研究方法
高通量测序NGS数据分析中的质控
高通量测序错误总结 一、生信分析部分 1)Q20/Q30 碱基质量分数与错误率是衡量测序质量的重要指标,质量值越高代表碱基被测错的概率越小。Q30代表碱基的正确判别率是99.9%,错误率为0.1%。同时我们也可以理解为1000个碱基里有1个碱基是错误的。Q20代表该位点碱基的正确判别率是99%,错误率为1%。对于整个数据来说,我们可以认为100个碱基里可能有一个是错误的, 在碱基质量模块报告的坐标图中,背景颜色沿y-轴将坐标图分为3个区:最上面的绿色是碱基质量很好的区,Q值在30以上。中间的橘色是碱基质量在一些分析中可以接受的区,Q值在20-30之间。最下面红色的是碱基质量很差的区。在一些生信分析中,比如以检查差异表达为目的的RNA-seq分析,一般要求碱基质量在Q在Q20以上就可以了。但以检查变异为目的的数据分析中,一般要求碱基质量要在Q30以上。 一般来说,测序质量分数的分布有两个特点: 1.测序质量分数会随着测序循环的进行而降低。 2.有时每条序列前几个碱基的位置测序错误率较高,质量值相对较低。 在图中这个例子里,左边的数据碱基质量很好,而右边的数据碱基质量就比较差,需要做剪切(trimming),根据生信分析的目的不同,要将质量低于Q20或者低于Q30的碱基剪切掉。 2)序列的平均质量 这个是碱基序列平均质量报告图。横坐标为序列平均碱基质量值,纵坐标代表序列数量。通过序列的平均质量报告,我们可以查看是否存在整条序列所有的碱基质量都普遍过低的情况。一般来说,当绝大部分碱基序列的平均质量值的峰值大于30,可以判断序列质量较好。如这里左边的图,我们可以判断样品里没有显着数量的低质量序列。但如果曲线如右边的图所示,在质量较低的坐标位置出现另外一个或者多个峰,说明测序数据中有一部分序列质量较差,需要过滤掉。 3)GC含量分布 这个是GC含量分布报告图。GC含量分布检查是检测每一条序列的GC含量。将样品序列的GC 含量和理论的GC含量分布图进行比较,用来检测样品数据是否有污染等问题。理论上,GC含量大致是正态分布,正态分布曲线的峰值对应基因组的GC含量。如果样品的GC含量分布图不是正态分布,如右图出现两个或者多个峰值,表明测序数据里可能有其他来源的DNA序列污染,或者有接头序列的二聚体污染。这种情况下,需要进一步确认这些污染序列的来源,然后将污染清除。 4)序列碱基含量
全基因组重测序数据分析
全基因组重测序数据分析 1. 简介(Introduction) 通过高通量测序识别发现de novo的somatic和germ line 突变,结构变异-SNV,包括重排 突变(deletioin, duplication 以及copy number variation)以及SNP的座位;针对重排突变和SNP的功能性进行综合分析;我们将分析基因功能(包括miRNA),重组率(Recombination)情况,杂合性缺失(LOH)以及进化选择与mutation之间的关系;以及这些关系将怎样使 得在disease(cancer)genome中的mutation产生对应的易感机制和功能。我们将在基因组 学以及比较基因组学,群体遗传学综合层面上深入探索疾病基因组和癌症基因组。 实验设计与样本 (1)Case-Control 对照组设计; (2)家庭成员组设计:父母-子女组(4人、3人组或多人); 初级数据分析 1.数据量产出:总碱基数量、Total Mapping Reads、Uniquely Mapping Reads统计,测序深度分析。 2.一致性序列组装:与参考基因组序列(Reference genome sequence)的比对分析,利用贝叶斯统计模型检测出每个碱基位点的最大可能性基因型,并组装出该个体基因组的一致序列。3.SNP检测及在基因组中的分布:提取全基因组中所有多态性位点,结合质量值、测序深度、重复性等因素作进一步的过滤筛选,最终得到可信度高的SNP数据集。并根据参考基 因组信息对检测到的变异进行注释。 4.InDel检测及在基因组的分布: 在进行mapping的过程中,进行容gap的比对并检测可信的short InDel。在检测过程中,gap的长度为1~5个碱基。对于每个InDel的检测,至少需 要3个Paired-End序列的支持。 5.Structure Variation检测及在基因组中的分布: 能够检测到的结构变异类型主要有:插入、缺失、复制、倒位、易位等。根据测序个体序列与参考基因组序列比对分析结果,检测全基因组水平的结构变异并对检测到的变异进行注释。
一代、二代、三代测序技术
一代、二代、三代测序技术 (2014-01-22 10:42:13) 转载 第一代测序技术-Sanger链终止法 一代测序技术是20世纪70年代中期由Fred Sanger及其同事首先发明。其基本原理是,聚丙烯酰胺凝胶电泳能够把长度只差一个核苷酸的单链DNA分子区分开来。一代测序实验的起始材料是均一的单链DNA分子。第一步是短寡聚核苷酸在每个分子的相同位置上退火,然后该寡聚核苷酸就充当引物来合成与模板互补的新的DNA链。用双脱氧核苷酸作为链终止试剂(双脱氧核苷酸在脱氧核糖上没有聚合酶延伸链所需要的3-OH基团,所以可被用作链终止试剂)通过聚合酶的引物延伸产生一系列大小不同的分子后再进行分离的方法。测序引物与单链DNA模板分子结合后,DNA聚合酶用dNTP延伸引物。延伸反应分四组进行,每一组分别用四种ddNTP(双脱氧核苷酸)中的一种来进行终止,再用PAGE分析四组样品。从得到的PAGE胶上可以读出我们需要的序列。 第二代测序技术-大规模平行测序 大规模平行测序平台(massively parallel DNA sequencing platform)的出现不仅令DNA测序费用降到了以前的百分之一,还让基因组测序这项以前专属于大型测序中心的“特权”能够被众多研究人员分享。新一代DNA测序技术有助于人们以更低廉的价格,更全面、更深入地分析基因组、转录组及蛋白质之间交互作用组的各项数据。市面上出现了很多新一代测序仪产品,例如美国Roche Applied Science公司的454基因组测序仪、美国Illumina公司和英国Solexa technology公司合作开发的Illumina测序仪、美国Applied Biosystems公司的SOLiD测序仪。Illumina/Solexa Genome Analyzer测序的基本原理是边合成边测序。在Sanger等测序方法的基础上,通过技术创新,用不同颜色的荧光标记四种不同的dNTP,当DNA聚合酶合成互补链时,每添加一种dNTP就会释放出不同的荧光,根据捕捉的荧光信号并经过特定的计算机软件处理,从而获得待测DNA的序列信息。以Illumina测序仪说明二代测序的一般流程,(1)文库制备,将DNA用雾化或超声波随机片段化成几百碱基或更短的小片段。用聚合酶和外切核酸酶把DNA片段切成平末端,紧接着磷酸化并增加一个核苷酸黏性末端。然后将Illumina测序接头与片段连接。(2)簇的创建,将模板分子加入芯片用于产生克隆簇和测序循环。芯片有8个纵向泳道的硅基片。每个泳道内芯片表面有无数的被固定的单链接头。上述步骤得到的带接头的DNA 片段变性成单链后与测序通道上的接头引物结合形成桥状结构,以供后续的预扩增使用。通过不断循环获得上百万条成簇分布的双链待测片段。(3)测序,分三步:DNA聚合酶结合荧光可逆终止子,荧光标记簇成像,在下一个循环开
宏基因组测序技术检测方法
宏基因组测序技术检测标准 简介: 宏基因组测序介绍 宏基因组学是以环境样品中的微生物群体基因组为研究对象,通过现代基因组技术手段包括功能基因的筛选和测序分析,对环境中微生物多样性、种群结构、进化关系、功能活性、相互协作关系以及环境之间的关系进行研究的新的微生物研究方法。随着高通量测序技术的发展,为宏基因组学研究提供了新的理想研究方法。高通量测序的方法无需分离环境中各种微生物,也无需构建克隆文库就可以直接对环境中所有微生物进行测序。可以真实客观的反映环境中微生物的多样性、种群结构、进化关系等。目前又可以分为针对16s DNA/18sDNA/ITS测序和针对宏基因组全序列的测序研究。下面就是对这两者的具体介绍。 一、16s DNA/18s DNA/ITS测序 16sDNA是最常用的微生物物种分子鉴定的标签,,通过对样品中16sDNA测序可以鉴定其中微生物物种的丰度和分布情况。目前,普遍使用Roche 454平台来对环境样品进行16s DNA测序。因为16s DNA序列比较相似,读长短的话,难以进行有效的比对,而454平台的平均读长在400bp左右,可以很好的避免此类问题。 二、宏基因组全测序 在这种测序方式中,我们可以假定一个环境中的所有微生物就是一个整体,然后对其中所有的微生物进行测序。这样我们就可以研究样品中的功能基因以及其在环境中所起的作用而不用关心其来自哪个微生物。可以发现新的基因,可以进行基因的预测,甚至有可能得到某个细菌基因组的全序列。此外,该项测序不单可以针对DNA水平,也可以针对全RNA进行基因表达水平的研究。 样品处理:
宏基因组样品收集主要有口腔,下呼吸道痰液,下呼吸道灌洗液,皮肤和粪便。样品采集遵照样品采集规范(人)所规定的操作来进行。尽量留足备份样品。核酸提取: 宏基因组核酸提取主要有两种方法:膜过滤法和直接裂解提取。对于液体样品如痰液,灌洗液两种方法都适用,对于固体样品如粪便宜采用直接裂解的方法。核酸提取后用NanoDrop ND-1000测定,260/280 = , 260/230 = ,电泳检测DNA 应是完整的一条带。 测序Sequencing 1)16S/18S测序: Sanger测序: 用于低通量的16S/18S DNA测序,提取宏基因组后,首先通过PCR将16S/18S 序列扩增出来,再将其连接到克隆载体上,导入感受态细胞,涂平板做蓝白斑筛选,选出阳性克隆提质粒,对质粒进行测序反应,测序反应后纯化后用ABI 3130或ABI 3730进行毛细管电泳测序。 由于其测序准确率比较高,而通量非常低,现通常用做二代测序结果的验证。454 Platform: 454平台主要包括两种测序系统:454 GS FLX+ System和454 GS Junior System。454 GS FLX+ System测序读长可以达到600-1000bp,通量450-700M,GS Junior System测序读长在400bp左右,通量在35M。
宏基因组测序技术检测方法模板
宏基因组测序技术 检测方法
宏基因组测序技术检测标准 简介: 宏基因组测序介绍 宏基因组学是以环境样品中的微生物群体基因组为研究对象,经过现代基因组技术手段包括功能基因的筛选和测序分析,对环境中微生物多样性、种群结构、进化关系、功能活性、相互协作关系以及环境之间的关系进行研究的新的微生物研究方法。随着高通量测序技术的发展,为宏基因组学研究提供了新的理想研究方法。高通量测序的方法无需分离环境中各种微生物,也无需构建克隆文库就能够直接对环境中所有微生物进行测序。能够真实客观的反映环境中微生物的多样性、种群结构、进化关系等。当前又能够分为针对16s DNA/18sDNA/ITS测序和针对宏基因组全序列的测序研究。下面就是对这两者的具体介绍。 一、16s DNA/18s DNA/ITS测序 16sDNA是最常见的微生物物种分子鉴定的标签,,经过对样品中16sDNA测序能够鉴定其中微生物物种的丰度和分布情况。当前,普遍使用Roche 454平台来对环境样品进行16s DNA测序。因为16s DNA序列比较相似,读长短的话,难以进行有效的比对,而454平台的平均读长在400bp左右,能够很好的避免此类问题。 二、宏基因组全测序
在这种测序方式中,我们能够假定一个环境中的所有微生物就是一个整体,然后对其中所有的微生物进行测序。这样我们就能够研究样品中的功能基因以及其在环境中所起的作用而不用关心其来自哪个微生物。能够发现新的基因,能够进行基因的预测,甚至有可能得到某个细菌基因组的全序列。另外,该项测序不单能够针对DNA水平,也能够针对全RNA进行基因表示水平的研究。 样品处理: 宏基因组样品收集主要有口腔,下呼吸道痰液,下呼吸道灌洗液,皮肤和粪便。样品采集遵照样品采集规范(人)所规定的操作来进行。尽量留足备份样品。 核酸提取: 宏基因组核酸提取主要有两种方法:膜过滤法和直接裂解提取。对于液体样品如痰液,灌洗液两种方法都适用,对于固体样品如粪便宜采用直接裂解的方法。核酸提取后用NanoDrop ND-1000测定,260/280 = 1.8-2.0, 260/230 = 1.8-2.0,电泳检测DNA应是完整的一条带。 测序Sequencing 1)16S/18S测序: Sanger测序: 用于低通量的16S/18S DNA测序,提取宏基因组后,首先经过PCR将16S/18S序列扩增出来,再将其连接到克隆载体上,导
高通量测序生物信息学分析(内部极品资料,初学者必看)
基因组测序基础知识 ㈠De Novo测序也叫从头测序,是首次对一个物种的基因组进行测序,用生物信息学的分析方法对测序所得序列进行组装,从而获得该物种的基因组序列图谱。 目前国际上通用的基因组De Novo测序方法有三种: 1. 用Illumina Solexa GA IIx 测序仪直接测序; 2. 用Roche GS FLX Titanium直接完成全基因组测序; 3. 用ABI 3730 或Roche GS FLX Titanium测序,搭建骨架,再用Illumina Solexa GA IIx 进行深度测序,完成基因组拼接。 采用De Novo测序有助于研究者了解未知物种的个体全基因组序列、鉴定新基因组中全部的结构和功能元件,并且将这些信息在基因组水平上进行集成和展示、可以预测新的功能基因及进行比较基因组学研究,为后续的相关研究奠定基础。 实验流程: 公司服务内容 1.基本服务:DNA样品检测;测序文库构建;高通量测序;数据基本分析(Base calling,去接头, 去污染);序列组装达到精细图标准 2.定制服务:基因组注释及功能注释;比较基因组及分子进化分析,数据库搭建;基因组信息展 示平台搭建 1.基因组De Novo测序对DNA样品有什么要求?
(1) 对于细菌真菌,样品来源一定要单一菌落无污染,否则会严重影响测序结果的质量。基因组完整无降解(23 kb以上), OD值在1.8~2.0 之间;样品浓度大于30 ng/μl;每次样品制备需要10 μg样品,如果需要多次制备样品,则需要样品总量=制备样品次数*10 μg。 (2) 对于植物,样品来源要求是黑暗无菌条件下培养的黄化苗或组培样品,最好为纯合或单倍体。基因组完整无降解(23 kb以上),OD值在1.8~2.0 之间;样品浓度大于30 ng/μl;样品总量不小于500 μg,详细要求参见项目合同附件。 (3) 对于动物,样品来源应选用肌肉,血等脂肪含量少的部位,同一个体取样,最好为纯合。基因组完整无降解(23 kb以上),OD值在1.8~2.0 之间;样品浓度大于30 ng/μl;样品总量不小于500 μg,详细要求参见项目合同附件。 (4) 基因组De Novo组装完毕后需要构建BAC或Fosmid文库进行测序验证,用于BAC 或Fosmid文库构建的样品需要保证跟De Novo测序样本同一来源。 2. De Novo有几种测序方式 目前3种测序技术 Roche 454,Solexa和ABI SOLID均有单端测序和双端测序两种方式。在基因组De Novo测序过程中,Roche 454的单端测序读长可以达到400 bp,经常用于基因组骨架的组装,而Solexa和ABI SOLID双端测序可以用于组装scaffolds和填补gap。下面以solexa 为例,对单端测序(Single-read)和双端测序(Paired-end和Mate-pair)进行介绍。Single-read、Paired-end和Mate-pair主要区别在测序文库的构建方法上。 单端测序(Single-read)首先将DNA样本进行片段化处理形成200-500bp的片段,引物序列连接到DNA片段的一端,然后末端加上接头,将片段固定在flow cell上生成DNA簇,上机测序单端读取序列(图1)。 Paired-end方法是指在构建待测DNA文库时在两端的接头上都加上测序引物结合位点,在第一轮测序完成后,去除第一轮测序的模板链,用对读测序模块(Paired-End Module)引导互补链在原位置再生和扩增,以达到第二轮测序所用的模板量,进行第二轮互补链的合成测序(图2)。 图1 Single-read文库构建方法图2 Paired-end文库构建方法
DNA测序结果分析比对(实例)
DNA测序结果分析比对(实例) 关键词:dna测序结果2013-08-22 11:59来源:互联网点击次数:14423 从测序公司得到的一份DNA测序结果通常包含.seq格式的测序结果序列文本和.ab1格式的测序图两个文件,下面是一份测序结果的实例: CYP3A4-E1-1-1(E1B).ab1 CYP3A4-E1-1-1(E1B).seq .seq文件可以用系统自带的记事本程序打开,.ab1文件需要用专门的软件打开。软件名称:Chromas 软件Chromas下载 .seq文件打开后如下图: .ab1文件打开后如下图: 通常一份测序结果图由红、黑、绿和蓝色测序峰组成,代表不同的碱基序列。测序图的两端(下图原图的后半段被剪切掉了)大约50个碱
基的测序图部分通常杂质的干扰较大,无法判读,这是正常现象。这也提醒我们在做引物设计时,要避免将所研究的位点离PCR序列的两端太近(通常要大于50个碱基距离),以免测序后难以分析比对。 我的课题是研究基因多态性的,因此下面要介绍的内容也主要以判读测序图中的等位基因突变位点为主。 实际上,要在一份测序图中找到真正确实的等位基因多态位点并不是一件容易的事情。一般认为等位基因位点假如在测序图上出现像套叠的两个峰,就是杂合子位点。实际比对后才知道,情况并非那么简单,下面测序图中标出的两个套峰均不是杂合子位点,如图并说明如下:
说明: 第一组套峰,两峰的轴线并不在同一位置,左侧的T峰是干扰峰;第二组套峰,虽两峰轴线位置相同,但两峰的位置太靠近了,不是杂合子峰,蓝色的C峰是干扰峰通常的杂合子峰由一高一略低的两个轴线相同的峰组成,此处的序列被机器误判为“C”,实际的序列应为“A”,通常一个高大碱基峰的前面 1~2个位点很容易产生一个相同碱基的干扰峰,峰的高度大约是高大碱基峰的1/2,离得越近受干扰越大。 一个摸索出来的规律是:主峰通常在干扰峰的右侧,干扰峰并不一定比主峰低。最关键的一点是一定要拿疑似为杂合子峰的测序图位点与测序结果的文本序列和基因库中的比对结果相比较;一个位点的多个样本相比较;你得出的该位点的突变率与权威文献或数据库中的突变率相比较。 通常,对于一个疑似突变位点来说,即使是国际上权威组织大样本的测序结果中都没有报道的话,那么单纯通过测序结果就判定它是突变点,是并不严谨的,因一份 PCR产物中各个碱基的实际含量并不相同,很难避免不产生误差的。对于一个未知突变位点的发现,通常还需要用到更精确的酶切技术。 (责任编辑:大汉昆仑王)
宏基因组测序技术检测方法
宏基因组测序技术检测方法
宏基因组测序技术检测标准 简介: 宏基因组测序介绍 宏基因组学是以环境样品中的微生物群体基因组为研究对象,通过现代基因组技术手段包括功能基因的筛选和测序分析,对环境中微生物多样性、种群结构、进化关系、功能活性、相互协作关系以及环境之间的关系进行研究的新的微生物研究方法。随着高通量测序技术的发展,为宏基因组学研究提供了新的理想研究方法。高通量测序的方法无需分离环境中各种微生物,也无需构建克隆文库就可以直接对环境中所有微生物进行测序。可以真实客观的反映环境中微生物的多样性、种群结构、进化关系等。目前又可以分为针对16s DNA/18sDNA/ITS测序和针对宏基因组全序列的测序研究。下面就是对这两者的具体介绍。 一、16s DNA/18s DNA/ITS测序 16sDNA是最常用的微生物物种分子鉴定的标签,,通过对样品中16sDNA 测序可以鉴定其中微生物物种的丰度和分布情况。目前,普遍使用Roche 454平台来对环境样品进行16s DNA测序。因为16s DNA序列比较相似,读长短的话,难以进行有效的比对,而454平台的平均读长在400bp左右,可以很好的避免此类问题。 二、宏基因组全测序 在这种测序方式中,我们可以假定一个环境中的所有微生物就是一个整体,然后对其中所有的微生物进行测序。这样我们就可以研究样品中的功能基因以及其在环境中所起的作用而不用关心其来自哪个微生物。可以发现新的基因,可以进行基因的预测,甚至有可能得到某个细菌基因组的全序列。此外,该项测序不单可以针对DNA水平,也可以针对全RNA进行基因表达水平的研究。 样品处理: 宏基因组样品收集主要有口腔,下呼吸道痰液,下呼吸道灌洗液,皮肤和粪便。样品采集遵照样品采集规范(人)所规定的操作来进行。尽量留足备份样品。
宏基因组测序讲解
宏基因组测序讲解
宏基因组测序 目的 研究藻类物种的分类,研究与特定环境与相关的代谢通路,以及通过不同样品的比较研究微生物内部,微生物与环境,与宿主的关系。技术简介 宏基因组( Metagenome)(也称微生物环境基因组Microbial Environmental Genome, 或元基因组) 。是由 Handelsman 等 1998 年提出的新名词,其定义为"the genomes of the total microbiota found in nature" , 即生境中全部微小生物遗传物质的总和。它包含了可培养的和未可培养的微生物的基因,目前主要指环境样品中的细菌和真菌的基因组总和。而所谓宏基因组学 (或元基因组学, metagenomics) 就是一种以环境样品中的微生物群体基因组为研究对象,以功能基因筛选和/或测序分析为研究手段,以微生物多样性、种群结构、进化关系、功能活性、相互协作关系及与环境之间的关系为研究目的的新的微生物研究方法。一般包括从环境样品中提取基因组 DNA, 进行高通量测序分析,或克隆DNA到合适的载体,导入宿主菌体,筛选目的转化子等工作。 宏基因组( Metagenome)(也称微生物环境基因组Microbial Environmental Genome, 或元基因组) 。是由 Handelsman 等 1998 年提出的新名词,其定义为"the genomes of the total microbiota found in nature" , 即生境中全部微小生物遗传物质的总和。它包含了可培养的和未可培养的微生物的基因,目前主要指环境样品中的细菌和真菌的基因组总和。而所谓宏基因组学 (或元基因组学, metagenomics) 就是一种以环境样品中的微生物群体基因组为研究对象,以功能基因筛选和/或测序分析为研究手段,以微生物多样