mp3解码算法原理详解

MPEG1 Layer3 (MP3)解码算法原理详解
本文介绍了符合ISO/IEC 11172-3(MPEG 1 Audio codec Layer I, Layer II and Layer III audio specifications) 或 ISO/IEC 13818-3(BC Audio Codec)的音频编码原理。通过madlib解码库进行实现。
1、程序系统结构
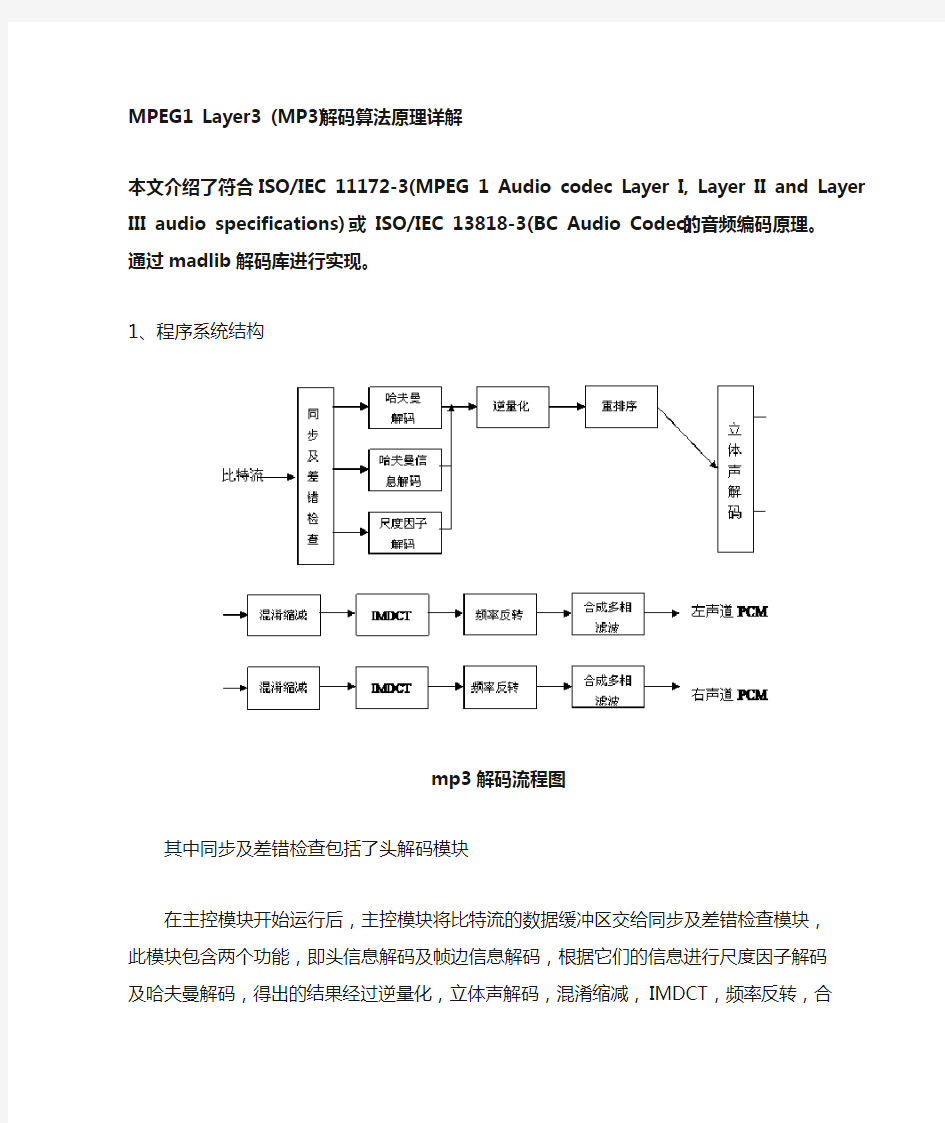
mp3解码流程图
其中同步及差错检查包括了头解码模块
在主控模块开始运行后,主控模块将比特流的数据缓冲区交给同步及差错检查模块,此模块包含两个功能,即头信息解码及帧边信息解码,根据它们的信息进行尺度因子解码及哈夫曼解码,得出的结果经过逆量化,立体声解码,混淆缩减,IMDCT,频率反转,合成多相滤波这几个模块之后,得出左右声道的PCM码流,再由主控模块将其放入输出缓冲区输出到声音播放设备。
2、主控模块
主控模块的主要任务是操作输入输出缓冲区,调用其它各模块协同工作。
其中,输入输出缓冲区均由DSP控制模块提供接口。
输入缓冲区中放的数据为原始mp3压缩数据流,DSP控制模块每次给出大于最大可能帧长度的一块缓冲区,这块缓冲区与上次解帧完后的数据(必然小于一帧)连接在一起,构成新的缓冲区。
输出缓冲区中将存放的数据为解码出来的PCM数据,代表了声音的振幅。它由一块固定长度的缓冲区构成,通过调用DSP控制模块的接口函数,得到头指针,在完成输出缓冲区的填充后,调用中断处理输出至I2S接口所连接的音频ADC芯片(立体声音频DAC和DirectDrive耳机放大器)输出模拟声音。
3、同步及差错检测
同步及差错检测模块主要用于找出数据帧在比特流中的位置,并对以此位置开始的帧头、CRC校验码及帧边信息进行解码,这些解码的结果用于后继的尺度因子解码模块和哈夫曼解码模块。Mpeg1 layer 3的流的主数据格式见下图:
主数据的组织结构图
其中granule0和granule1表示在一帧里面的粒度组1和粒度组2,channel0
和channel1表示在一个粒度组里面的两个通道,scalefactor为尺度因子quantized value为量化后的哈夫曼编码值,它分为big values大值区和count1 1值区
CRC校验:表达式为X16+X15+X2+1
3.1 帧同步
帧同步目的在于找出帧头在比特流中的位置,ISO 1172-3规定,MPEG1 的帧头为12比特的“1111 1111 1111”,且相邻的两个帧头隔有等间距的字节数,这个字节数可由下式算出:
N= 144 * 比特率 / 采样率
如果这个式子的结果不是整数,那么就需要用到一个叫填充位的参数,表示间距为N +1。
3.2 头信息解码
头信息解码目的是找出这一帧的特征信息,如采样率,是否受保护,是否有填充
位等。头信息见下图:
帧头信息结构图
其长度为4 字节,数据结构如下:
typedef struct tagHeader {
unsigned int sync : 11 ; / / 同步信息
unsigned int version : 2 ; / / 版本
unsigned int layer : 2 ; / / 层
unsigned int error2protection : 1 ; / / CRC校正
unsigned int bit2rate2index : 4 ; / / 位率索引
unsigned int sample2rate2index : 2 ; / / 采样率索引
unsigned int padding : 1 ; / / 空白字
unsigned int extension : 1 ; / / 私有标志
unsigned int channel2mode : 2 ; / / 立体声模式
unsigned int mode extension : 2 ; / / 保留
unsigned int copyright : 1 ; / / 版权标志
unsigned int original : 1 ; / / 原始媒体
unsigned int emphasis : 2 ; / / 强调方式
} HEADER
3.3 帧边信息解码
帧边信息解码的主要目的在于找出解这帧的各个参数,包括主数据开始位置,尺
度因子长度等。帧边信息如下图所示:
帧边信息(side_infomation)表
3.4 main_data_begin
main_data_begin(主数据开始)是一个偏移值,指出主数据是在同步字之前多少个字节开始。需要注意的是,1.帧头不一定是一帧的开始,帧头CRC校验字和帧边信息在帧数据中是滑动的。2.这个数值忽略帧头和帧边信息的存在,如果main_data_begin = 0, 则主数据从帧边信息的下一个字节开始。参见下图:
同步示意图
3.5 block_type
block_type指出如下三种块类型:
block_type = 0 长块
block_type = 1 开始块
block_type = 3 结束块
block_type = 2 短块
在编码过程中进行IMDCT 变换时,针对不同信号为同时得到较好的时域和频域分辨率定义了两种不同的块长:长块的块长为18个样本,短块的块长为6个样本。这使得长块对于平稳的声音信号可以得到更高的频率分辨率,而短块对跳变信号可以得到更高的时域分辨率。由于在短块模式下,3 个短块代替1个长块,而短块的大小恰好是一个长块的1/3,所以IMDCT的样本数不受块长的影响。对于给定的一帧声音信号,IMDCT 可以全部使用长块或全部使用短块,也可以长短块混合使用。因为低频区的频域分辨率对音质有重大影响,所以在混合块模式下,IMDCT对最低频的2个子带使用长块,而对其余的30个子带使用短块。这样,既能保证低频区的频域分辨率,又不会牺牲高频区的时域分辨率。长块和短块之间的切换有一个过程,一般用一个带特殊长转短(即,起始块block_type = 1)或短转长(即终止块,block_type = 3)数据窗口的长块来完成这个长短块之间的切换。因此长块也就是包括正常窗,起始块和终止块数据窗口的数据块;短块也包含18个数据,但是是由6个数据独立加窗后在经过连接计算得到的。
3.6 big_values, count1
每一个粒度组的频谱都是用不同的哈夫曼表来进行编码的。编码时,把整个从0 到奈奎斯特频率的频率范围(共576个频率线)分成几个区域,然后再用不同的表编码。划分过程是根据最大的量化值来完成的,它假设较高频率的值有较低的幅度或者根本不需要编码。从高频开始,一对一对的计算量化值等于“0”的数目,此数目记为“rzero”。然后4个一组地计算绝对值不超过“1”的量化值(也就是说,其中只可能有-1,0 和+1共3 个可能的量化级别)的数目,记为
“count1”,在此区域只应用了4 个哈夫曼编码表。最后,剩下的偶数个值的对数记为“big values”,在此区域只应用了32 个哈夫曼编码表。在此范围里的最大绝对值限制为8191。此后,为增强哈夫曼编码性能,进一步划分了频谱。也就是说,对big values的区域(姑且称为大值区)再细化,目的是为了得到更好的错误顽健性和更好的编码效率。在不同的区域内应用了不同的哈夫曼编码表。具体使用哪一个表由table_select给出。从帧边信息表中可以看到:当window_switch_flag == 0时,只将大值区在细分为2个区,此时
region1_count无意义,此时的region0_count的值是标准默认的;但当window_switch_flag == 1时再将大值区细分为3 个区。但是由于region0_count 和region1_count是根据从576个频率线划分的,因此有可能超出了
big_values *2的范围,此时以big_values *2 为准. region0_count 和region1_count表示的只是一个索引值,具体频带要根据标准中的缩放因子频带表来查得.
参见下图:
缩放因子、大值区、1值区和零值区分布图
3.7 处理流程
4、缩放因子(scale factor)解码
缩放因子用于对哈夫曼解码数据进行逆量化的样点重构。根据帧边信息中的scalefactor_compress 和标准中的对应表格来确定的slen1和slen2 对缩放因子进行解码,即直接从主数据块中读取缩放因子信息并存入表
scalefac_l[gr][ch][sfb]和scalefac_s[gr][ch][sfb]中。对第2 粒度组解码时,若为长块,则必须考虑尺度因子选择信息。
4.1 尺度因子带(scalefactor-band)
在mpeg layer 3中576条频率线根据人耳的听觉特性被分成多个组,每个组对应若干个尺度因子,这些组就叫做尺度因子带,每个长窗有21个尺度因子带而每个短窗有12个尺度因子带。
4.2 scfsi
scfsi(尺度因子选择信息)用于指出是否将粒度组1的尺度因子用于粒度组2。如果为0表示不用,则在比特流中需读取粒度组2的尺度因子。
4.3 处理流程
缩放因子解码流程图
5、哈夫曼解码
哈夫曼编码是一种变长编码,在mp3哈夫曼编码中,高频的一串零值不编码,不超过1的下一个区域使用四维哈夫曼编码,其余的大值区域采用二维哈夫曼编码,而且可选择地分为三个亚区,每个有独立选择的哈夫曼码表。通过每个亚区单独的自适应码表,增强编码效率,而且同时降低了对传输误码的敏感度。
在程序实现上,哈夫曼表逻辑存储采用了广义表结构,物理存储上使用数组结构。查表时,先读入4bit数据,以这4bit数据作为索引,其指向的元素有两种类型,一种是值结构,另一种是链表指针式结构,在链表指针式结构中给出了还需要读取的bit数,及一个偏移值。如果索引指向的是一个值结构,则这个值结构就包含了要查找的数据。如果索引指向的是一个链表指针式结构,则还需再读取其中
指定的比特数,再把读取出的比特数同偏移值相加,递归的找下去,直到找到值结构为止。
5.1 处理流程
6、逆量化
6.1 逆量化公式
逆量化由下面公式算出:
短窗模式:
长窗模式:
其中:
is[i] :由huffman编码构造的频率线
sbg :subblock_gain
scalefac_multiplier := (scalefac_scale + 1) / 2
其它值均可在帧边信息中找到。
7、联合立体声转换
7.1 强度立体声转换
在强度立体声模式中,左声道传的是幅值,右声道的scalefactor传的是立体声的位置is_pos。需要转换的频率线有一个低边界,这个低边界是由右声道的zero_part决定的,并且使用右声道的尺度因子来作为is_pos。
强度立体声比
左声道:右声道:
7.2 M_S立体声转换
在M_S立体声模式中,传送的是规格化的中间/旁边声道的信息
左声道右声道
其中Mi是channel[0]的值,Si是channel[1]的值
7.3 处理流程
强度立体声模式:
MS_STEREO因公式单一,较易理解,故流程图略去。
8、重排序
重排序的目的在于把哈夫曼解码之后的短块的每个尺度因子带3个窗,每个窗sfbwidth(尺度因子带宽度)个采样的顺序整理成为每个子带三个窗,每个窗六个采样xr[sb][window][freq_line]的顺序。
8.1 处理流程
重排序处理流程图
混淆缩减
对于长块,在进入IMDCT之前应当先进行混淆缩减。其算法思想是用蝶形算法进行相邻块相邻频率线的调整。如图:
混淆缩减算法图
其计算公式如下:
其中ci可由ISO 1172.3 table B.9查得
计算流程如下(pascal 描述):
For sb = 1 to 32 do
For i = 0 to 7 do
Xar[18sb- i -1] = xr[18sb – i - 1]cs[i] – xr[18sb + i]ca[i] Xar[18sb+i] = xr[18sb +i]cs[i] + xr[18sb -i- 1]ca[i]
End for
End for
10、IMDCT覆盖叠加
MDCT的目的在于进行时域到频域的转换,减少信号的相关性,使得信号的压缩可以更加高效地完成,而它的反变换IMDCT的目的在于将信号还原为没有变换之前的数值,使频域值向时域值过渡。
其公式如下:
在进行了IMDCT变换之后,需对频率信号进行加窗、覆盖、叠加。
10.1 加窗:
长块:
开始块:
结束块:
短块的每个窗口分别计算:
10.2 叠加:
将每一块变换出来的值的前半部分与前一块的后半部分相加,并把后半部分保留来和下一块的前半部分相加。如下公式:
resulti = zi + si for i = 0 to 17
si = zi+18 for i = 0 to 17
10.3 Szu-Wei Lee的快速算法
Szu-Wei Lee的IMDCT快速算法是针对非2的n次幂个点的IMDCT快速算法。他的主要步骤如下:
1.将N点MDCT化为N/2点DCT-IV
2.将N/2点DCT-IV化为N/2点SDCT-II
3.将N/2点SDCT-II化为2个相同的N/4点SDCT-II
4.计算SDCT-II(9点)
在本程序中,因为对短块使用这个快速算法并没有带来较大的速度改善,故只对长块使用此快速算法,相较于直接运算的648次乘和612次加来,它只用43次乘和115次加。
11、频率反转
在IMDCT之后,进入合成多相滤波之前必须进行频率反转补偿以校正多相滤波器组的频率反转。方法是将奇数号子带的奇数个采样值乘以-1.
12、合成多相滤波
合成多相滤波的目的是将频域信号转化为时域信号。其原理流程如下:
合成多相滤波算法图
上图流程可简述如下:
1.将从32个子带抽来的32个sample值通过一个矩阵运算算
出64个中间值
2.将这64个中间值放入一个长度为1024的FIFO缓冲区(这个
缓冲区初始化为0)。
3.从这个缓冲区中每连续的128个值中取头尾各32个值,合
为64个值。完成后组成512值的向量U
4.加窗,即将Ui与窗口系数Di相乘,得到另一512值向量W
5.最后将这512值向量W每连续的32个值中顺次取一个值,
一次共取得512/32 = 16个值相加。完成后一共取得32个
最终的时域信号值。
Byeong Gi Lee的dct快速算法
Byeong Gi Lee的DCT快速算法是用于2的n次幂个点的dct快速算法。它用于
N点的DCT时仅需(N/2) * log2N次乘法和小于3·*(N/2)*log2 N ) 次加法。其基本思想是,将N个点的DCT转化为两个N/2个点的DCT的和。进一步分解,即重复这个过程,减少乘法数量。
由于向量Vi的运算是一个类似于DCT的变换,故使用了此快速算法。32点运算共使用了80次乘法和80次加法119次减法。
术语说明
MPEG:Motion Picture Expert Group
IMDCT:反离散余弦变换
gr:granule粒度组
ch:channel 通道
参考文献
1.ISO/IEC 11172_3
2.赖鸿志:MPEG-1 LAYER 3 音訊解碼器於DSP晶片之即時軟體實現
3.An Introduction to Digital Audio John Watkinson
4.Madlib源程序
5.Szu-Wei Lee : Improved Algorithm for Efficient Computation fo the
Forward and Backward MDCT in MPEG Audio Coder
6.BYEONG GI LEE :A New Algorithm to Compute the Discrete Cosine
Transform
音频的编解码
音频编码解码基本概念介绍 对数字音频信息的压缩主要是依据音频信息自身的相关性以及人耳对音频信息的听觉冗余度。音频信息在编码技术中通常分成两类来处理,分别是语音和音乐,各自采用的技术有差异。 语音编码技术又分为三类:波形编码、参数编码以及混合编码。 波形编码:波形编码是在时域上进行处理,力图使重建的语音波形保持原始语音信号的形状,它将语音信号作为一般的波形信号来处理,具有适应能力强、话音质量好等优点,缺点是压缩比偏低。该类编码的技术主要有非线性量化技术、时域自适应差分编码和量化技术。非线性量化技术利用语音信号小幅度出现的概率大而大幅度出现的概率小的特点,通过为小信号分配小的量化阶,为大信号分配大的量阶来减少总量化误差。我们最常用的G.711标准用的就是这个技术。自适应差分编码是利用过去的语音来预测当前的语音,只对它们的差进行编码,从而大大减少了编码数据的动态范围,节省了码率。自适应量化技术是根据量化数据的动态范围来动态调整量阶,使得量阶与量化数据相匹配。G.726标准中应用了这两项技术,G.722标准把语音分成高低两个子带,然后在每个子带中分别应用这两项技术。 参数编码:广泛应用于军事领域。利用语音信息产生的数学模型,提取语音信号的特征参量,并按照模型参数重构音频信号。它只能收敛到模型约束的最好质量上,力图使重建语音信号具有尽可能高的可懂性,而重建信号的波形与原始语音信号的波形相比可能会有相当大的差别。这种编码技术的优点是压缩比高,但重建音频信号的质量较差,自然度低,适用于窄带信道的语音通讯,如军事通讯、航空通讯等。美国的军方标准LPC-10,就是从语音信号中提取出来反射系数、增益、基音周期、清/浊音标志等参数进行编码的。MPEG-4标准中的HVXC声码器用的也是参数编码技术,当它在无声信号片段时,激励信号与在CELP时相似,都是通过一个码本索引和通过幅度信息描述;在发声信号片段时则应用了谐波综合,它是将基音和谐音的正弦振荡按照传输的基频进行综合。 混合编码:将上述两种编码方法结合起来,采用混合编码的方法,可以在较低的数码率上得到较高的音质。它的特点是它工作在非常低的比特率(4~16 kbps)。混合编码器采用合成分析技术。
AAC解码算法原理详解
AAC解码算法原理详解 原作者:龙帅 (loppp138@https://www.360docs.net/doc/0216727518.html,) 此文章为便携式多媒体技术中心提供,未经站长授权,严禁转载,但欢迎链接到此地址。 本文详细介绍了符合ISO/IEC 13818-7(MPEG2 AAC audio codec) , ISO/IEC 14496-3(MPEG4 Audio Codec AAC Low Complexity)进行压缩的的AAC音频的解码算法。 1、程序系统结构 下面是AAC解码流程图: AAC解码流程图 在主控模块开始运行后,主控模块将AAC比特流的一部分放入输入缓冲区,通过查找同步字得到一帧的起始,找到后,根据ISO/IEC 13818-7所述的语法开始进行Noisless Decoding(无噪解码),无噪解码实际上就是哈夫曼解码,通过反量化(Dequantize)、联合立体声(Joint Stereo),知觉噪声替换(PNS),瞬时噪声整形(TNS),反离散余弦变换(IMDCT),频段复制(SBR)这几个模块之后,得出左右声道的PCM码流,再由主控模块将其放入输出缓冲区输出到声音播放设备。
2. 主控模块 主控模块的主要任务是操作输入输出缓冲区,调用其它各模块协同工作。其中,输入输出缓冲区均由DSP控制模块提供接口。输出缓冲区中将存放的数据为解码出来的PCM数据,代表了声音的振幅。它由一块固定长度的缓冲区构成,通过调用DSP控制模块的接口函数,得到头指针,在完成输出缓冲区的填充后,调用中断处理输出至I2S接口所连接的音频ADC芯片(立体声音频DAC和DirectDrive 耳机放大器)输出模拟声音。 3. 同步及元素解码 同步及元素解码模块主要用于找出格式信息,并进行头信息解码,以及对元素信息进行解码。这些解码的结果用于后续的无噪解码和尺度因子解码模块。 AAC的音频文件格式有以下两种: ADIF:Audio Data Interchange Format 音频数据交换格式。这种格式的特征是可以确定的找到这个音频数据的开始,不需进行在音频数据流中间开始的解码,即它的解码必须在明确定义的开始处进行。故这种格式常用在磁盘文件中。 ADTS:Audio Data Transport Stream 音频数据传输流。这种格式的特征是它是一个有同步字的比特流,解码可以在这个流中任何位置开始。它的特征类似于mp3数据流格式。 AAC的ADIF格式见下图: 3.1 ADIF的组织结构 AAC的ADTS的一般格式见下图: 3.2 ADTS的组织结构 图中表示出了ADTS一帧的简明结构,其两边的空白矩形表示一帧前后的数据。ADIF和ADTS的header是不同的。它们分别如下所示:
mp3解码算法原理详解
MPEG1 Layer3 (MP3)解码算法原理详解 本文介绍了符合ISO/IEC 11172-3(MPEG 1 Audio codec Layer I, Layer II and Layer III audio specifications) 或 ISO/IEC 13818-3(BC Audio Codec)的音频编码原理。通过madlib解码库进行实现。 1、程序系统结构 mp3解码流程图 其中同步及差错检查包括了头解码模块 在主控模块开始运行后,主控模块将比特流的数据缓冲区交给同步及差错检查模块,此模块包含两个功能,即头信息解码及帧边信息解码,根据它们的信息进行尺度因子解码及哈夫曼解码,得出的结果经过逆量化,立体声解码,混淆缩减,IMDCT,频率反转,合成多相滤波这几个模块之后,得出左右声道的PCM码流,再由主控模块将其放入输出缓冲区输出到声音播放设备。 2、主控模块
主控模块的主要任务是操作输入输出缓冲区,调用其它各模块协同工作。 其中,输入输出缓冲区均由DSP控制模块提供接口。 输入缓冲区中放的数据为原始mp3压缩数据流,DSP控制模块每次给出大于最大可能帧长度的一块缓冲区,这块缓冲区与上次解帧完后的数据(必然小于一帧)连接在一起,构成新的缓冲区。 输出缓冲区中将存放的数据为解码出来的PCM数据,代表了声音的振幅。它由一块固定长度的缓冲区构成,通过调用DSP控制模块的接口函数,得到头指针,在完成输出缓冲区的填充后,调用中断处理输出至I2S接口所连接的音频ADC芯片(立体声音频DAC和DirectDrive耳机放大器)输出模拟声音。 3、同步及差错检测 同步及差错检测模块主要用于找出数据帧在比特流中的位置,并对以此位置开始的帧头、CRC校验码及帧边信息进行解码,这些解码的结果用于后继的尺度因子解码模块和哈夫曼解码模块。Mpeg1 layer 3的流的主数据格式见下图: 主数据的组织结构图 其中granule0和granule1表示在一帧里面的粒度组1和粒度组2,channel0 和channel1表示在一个粒度组里面的两个通道,scalefactor为尺度因子quantized value为量化后的哈夫曼编码值,它分为big values大值区和count1 1值区 CRC校验:表达式为X16+X15+X2+1 3.1 帧同步 帧同步目的在于找出帧头在比特流中的位置,ISO 1172-3规定,MPEG1 的帧头为12比特的“1111 1111 1111”,且相邻的两个帧头隔有等间距的字节数,这个字节数可由下式算出: N= 144 * 比特率 / 采样率 如果这个式子的结果不是整数,那么就需要用到一个叫填充位的参数,表示间距为N +1。
AAC解码算法原理详解
A A C解码算法原理详解原作者:龙帅 此文章为提供,未经站长授权,严禁转载,但欢迎链接到此地址。 本文详细介绍了符合 ISO/IEC13818-7(MPEG2AACaudiocodec),ISO/IEC144 96-3(MPEG4AudioCodecAACLowComplexity)进行压缩的的AAC音频的解码算法。 1、程序系统结构 下面是AAC解码流程图: AAC解码流程图 ?在主控模块开始运行后,主控模块将AAC比特流的一部分放入输入缓冲区,通过查找同步字得到一帧的起始,找到后,根据ISO/IEC13818-7所述的语法开始进行NoislessDecoding(无噪解码),无噪解码实际上就是哈夫曼解码,通过反量化(Dequantize)、联合立体声(JointStereo),知觉噪声替换(PNS),瞬时噪声整形(TNS),反离散余弦变换(IMDCT),频段复制(SBR)这几个模块之后,得出左右声道的PCM码流,再由主控模块将其放入输出缓冲区输出到声音播放设备。 2.主控模块 主控模块的主要任务是操作输入输出缓冲区,调用其它各模块协同工作。其中,输入输出缓冲区均由DSP控制模块提供接口。输出缓冲区中将存放的数据为解码出来的PCM数据,代表了声音的振幅。它由一块固定长度的缓冲区构成,通过调用DSP控制模块的接口函数,得到头指针,在完成输出缓冲区的填充后,调用中断处理输出至I2S接口所连接的音频ADC芯片(立体声音频DAC和DirectDrive 耳机放大器)输出模拟声音。 3.同步及元素解码 同步及元素解码模块主要用于找出格式信息,并进行头信息解码,以及对元素信
AAC的ADTS格式及解码算法详解
AAC的ADTS格式及解码算法详解 本文详细介绍了符合ISO/IEC 13818-7(MPEG2 AAC audio codec) , ISO/IEC 14496-3(MPEG4 Audio Codec AAC Low Complexity)进行压缩的的AAC音频的解码算法。 1、程序系统结构 下面是AAC解码流程图: AAC解码流程图 在主控模块开始运行后,主控模块将AAC比特流的一部分放入输入缓冲区,通过查找同步字得到一帧的起始,找到后,根据ISO/IEC 13818-7所述的语法开始进行Noisless Decoding(无噪解码),无噪解码实际上就是哈夫曼解码,通过反量化(Dequantize)、联合立体声(Joint Stereo),知觉噪声替换(PNS),瞬时噪声整形(TNS),反离散余弦变换(IMDCT),频段复制(SBR)这几个模块之后,得出左右声道的PCM码流,再由主控模块将其放入输出缓冲区输出到声音播放设备。 2. 主控模块 主控模块的主要任务是操作输入输出缓冲区,调用其它各模块协同工作。其中,输入输出缓冲区均由DSP控制模块提供接口。输出缓冲区中将存放的数据为解码出来的PCM数据,代表了声音的振幅。它由一块固定长度的缓冲区构成,通过调用DSP控制模块的接口函数,得到头指针,在完成输出缓冲区的填充后,调用中断处理输出至I2S接口所连接的音频ADC 芯片(立体声音频DAC和DirectDrive耳机放大器)输出模拟声音。 3. 同步及元素解码 同步及元素解码模块主要用于找出格式信息,并进行头信息解码,以及对元素信息进行解码。这些解码的结果用于后续的无噪解码和尺度因子解码模块。 AAC的音频文件格式有以下两种: ADIF:Audio Data Interchange Format 音频数据交换格式。这种格式的特征是可以确定的找到这个音频数据的开始,不需进行在音频数据流中间开始的解码,即它的解码必须在明确定义的开始处进行。故这种格式常用在磁盘文件中。 ADTS:Audio Data Transport Stream 音频数据传输流。这种格式的特征是它是一个有同步字的比特流,解码可以在这个流中任何位置开始。它的特征类似于mp3数据流格式。 AAC的ADIF格式见下图: 3.1 ADIF的组织结构 AAC的ADTS的一般格式见下图:
各种音视频编解码学习详解 h264
各种音视频编解码学习详解h264 ,mpeg4 ,aac 等所有音视频格式 编解码学习笔记(一):基本概念 媒体业务是网络的主要业务之间。尤其移动互联网业务的兴起,在运营商和应用开发商中,媒体业务份量极重,其中媒体的编解码服务涉及需求分析、应用开发、释放license收费等等。最近因为项目的关系,需要理清媒体的codec,比较搞的是,在豆丁网上看运营商的规范标准,同一运营商同样的业务在不同文档中不同的要求,而且有些要求就我看来应当是历史的延续,也就是现在已经很少采用了。所以豆丁上看不出所以然,从wiki上查。中文的wiki信息量有限,很短,而wiki的英文内容内多,删减版也减肥得太过。我在网上还看到一个山寨的中文wiki,长得很像,红色的,叫―天下维客‖。wiki的中文还是很不错的,但是阅读后建议再阅读英文。 我对媒体codec做了一些整理和总结,资料来源于wiki,小部分来源于网络博客的收集。网友资料我们将给出来源。如果资料已经转手几趟就没办法,雁过留声,我们只能给出某个轨迹。 基本概念 编解码 编解码器(codec)指的是一个能够对一个信号或者一个数据流进行变换的设备或者程序。这里指的变换既包括将信号或者数据流进行编码(通常是为了传输、存储或者加密)或者提取得到一个编码流的操作,也包括为了观察或者处理从这个编码流中恢复适合观察或操作的形式的操作。编解码器经常用在视频会议和流媒体等应用中。 容器 很多多媒体数据流需要同时包含音频数据和视频数据,这时通常会加入一些用于音频和视频数据同步的元数据,例如字幕。这三种数据流可能会被不同的程序,进程或者硬件处理,但是当它们传输或者存储的时候,这三种数据通常是被封装在一起的。通常这种封装是通过视频文件格式来实现的,例如常见的*.mpg, *.avi, *.mov, *.mp4, *.rm, *.ogg or *.tta. 这些格式中有些只能使用某些编解码器,而更多可以以容器的方式使用各种编解码器。 FourCC全称Four-Character Codes,是由4个字符(4 bytes)组成,是一种独立标示视频数据流格式的四字节,在wav、a vi档案之中会有一段FourCC来描述这个AVI档案,是利用何种codec来编码的。因此wav、avi大量存在等于―IDP3‖的FourCC。 视频是现在电脑中多媒体系统中的重要一环。为了适应储存视频的需要,人们设定了不同的视频文件格式来把视频和音频放在一个文件中,以方便同时回放。视频档实际上都是一个容器里面包裹着不同的轨道,使用的容器的格式关系到视频档的可扩展性。 参数介绍 采样率 采样率(也称为采样速度或者采样频率)定义了每秒从连续信号中提取并组成离散信号的采样个数,它用赫兹(Hz)来表示。采样频率的倒数叫作采样周期或采样时间,它是采样之间的时间间隔。注意不要将采样率与比特率(bit rate,亦称―位速率‖)相混淆。
(完整)流媒体传输协议及音视频编解码技术
1.1音视频编解码技术 1.1.1 MPEG4 MPEG全称是Moving Pictures Experts Group,它是“动态图象专家组”的英文缩写,该专家组成立于1988年,致力于运动图像及其伴音的压缩编码标准化工作,原先他们打算开发MPEG1、MPEG2、MPEG3和MPEG4四个版本,以适用于不同带宽和数字影像质量的要求。 目前,MPEG1技术被广泛的应用于VCD,而MPEG2标准则用于广播电视和DVD等。MPEG3最初是为HDTV开发的编码和压缩标准,但由于MPEG2的出色性能表现,MPEG3只能是死于襁褓了。MPEG4于1999年初正式成为国际标准。它是一个适用于低传输速率应用的方案。与MPEG1和MPEG2相比,MPEG4更加注重多媒体系统的交互性和灵活性MPEG1、MPEG2技术当初制定时,它们定位的标准均为高层媒体表示与结构,但随着计算机软件及网络技术的快速发展,MPEG1、MPEG2技术的弊端就显示出来了:交互性及灵活性较低,压缩的多媒体文件体积过于庞大,难以实现网络的实时传播。而MPEG4技术的标准是对运动图像中的内容进行编码,其具体的编码对象就是图像中的音频和视频,术语称为“AV对象”,而连续的AV对象组合在一起又可以形成AV场景。因此,MPEG4标准就是围绕着AV对象的编码、存储、传输和组合而制定的,高效率地编码、组织、存储、传输AV 对象是MPEG4标准的基本内容。 在视频编码方面,MPEG4支持对自然和合成的视觉对象的编码。(合成的视觉对象包括2D、3D动画和人面部表情动画等)。在音频编码上,MPEG4可以在一组编码工具支持下,对语音、音乐等自然声音对象和具有回响、空间方位感的合成声音对象进行音频编码。 由于MPEG4只处理图像帧与帧之间有差异的元素,而舍弃相同的元素,因此大大减少了合成多媒体文件的体积。应用MPEG4技术的影音文件最显著特点就是压缩率高且成像清晰,一般来说,一小时的影像可以被压缩为350M左右的数据,而一部高清晰度的DVD电影, 可以压缩成两张甚至一张650M CD光碟来存储。对广大的“平民”计算机用户来说,这就意味着, 您不需要购置DVD-ROM就可以欣赏近似DVD质量的高品质影像。而且采用MPEG4编码技术的影片,对机器硬件配置的要求非常之低,300MHZ 以上CPU,64M的内存和一个8M显存的显卡就可以流畅的播放。在播放软件方面,它要求也非常宽松,你只需要安装一个500K左右的MPEG4 编码驱动后,用WINDOWS 自带的媒体播放器就可以流畅的播放了 AV对象(AVO,Audio Visual Object)是MPEG-4为支持基于内容编码而提出的重要概念。对象是指在一个场景中能够访问和操纵的实体,对象的划分可根据其独特的纹理、运动、形状、模型和高层语义为依据。在MPEG-4中所见的音视频已不再是过去MPEG-1、MPEG-2中图像帧的概念,而是一个个视听场景(AV场景),这些不同的AV场景由不同的AV对象组成。AV对象是听觉、视觉、或者视听内容的表示单元,其基本单位是原始AV对象,它可以是自然的或合成的声音、图像。原始AV对象具有高效编码、高效存储与传输以及可交互性的特性,它又可进一步组成复合AV对象。因此MPEG-4标准的基本内容就是对AV对象进行高效编码、组织、存储与传输。AV对象的提出,使多媒体通信具有高度交互及高效编码的能力,AV对象编码就是MPEG-4的核心编码技术。 MPEG-4不仅可提供高压缩率,同时也可实现更好的多媒体内容互动性及全方位的存取性,它采用开放的编码系统,可随时加入新的编码算法模块,同时也可根据不同应用需求现场配置解码器,以支持多种多媒体应用 1.1.2 H264 H.264是由ITU-T的VCEG(视频编码专家组)和ISO/IEC的MPEG(活动图像编码专家组)联合组建的联合视频组(JVT:joint video team)提出的一个新的数字视频编码标准,
音频编解码介绍
音频编解码原理介绍 一.为什么要进行音频编解码 二.音频编解码原理 三.几种基本音频编解码介绍 一、为什么要进行音频编解码 随着人们对多媒体图像和声音的要求越来越高,在高清晰数字电视(HDTV)和数字电影中不仅应有高质量的图像,也应当具有CD质量的立体声。因为用数字方法记录声音比用模拟方法记录声音具有更强的优势,例如传输时抗噪声能力强、增加音频动态范围、多次翻录没有信号衰减等。但是数字声音最大的缺陷是记录的数据量大,表现在两个方面:其一是在传输过程中,传输数字声音需要占用很宽的传输带宽;其二是在存储过程中,需要占用大量的存储空间。所以在数字音频中需要采用数字音频压缩技术,对音频数据进行压缩。 二、音频编解码原理 每张CD光盘重放双声道立体声信号可达74分钟。VCD视盘机要同时重放声音和图像,图像信号数据需要压缩,其伴音信号数据也要压缩,否则伴音信号难于存储到VCD光盘中。 一、伴音压缩编码原理 伴音信号的结构较图像信号简单一些。伴音信号的压缩方法与图像信号压缩技术有相似性,也要从伴音信号中剔除冗余信息。人耳朵对音频信号的听觉灵敏度有规律性,对于不同频段或不同声压级的伴音有其特殊的敏感特性。在伴音数据压缩过程中,主要应用了听觉阈值及掩蔽效应等听觉心理特性。 1、阈值和掩蔽效应 (1) 阈值特性 人耳朵对不同频率的声音具有不同的听觉灵敏度,对低频段(例如100Hz以下)和超高频段(例如16KHZ以上)的听觉灵敏度较低,而在1K-5KHZ的中音频段时,听觉灵敏度明显提高。通常,将这种现象称为人耳的阈值特性。若将这种听觉特性用曲线表示出来,就称为人耳的阈值特性曲线,阈值特性曲线反映该特性的数值界限。将曲线界限以下的声音舍弃掉,对人耳的实际听音效果没有影响,这些声音属于冗余信息。 在伴音压缩编码过程中,应当将阈值曲线以上的可听频段的声音信号保留住,它是可听频段的主要成分,而那些听觉不灵敏的频段信号不易被察觉。应当保留强大的信号,忽略舍弃弱小的信号。经过这样处理的声音,人耳在听觉上几乎察觉不到其失真。在实际伴音压缩编码过程中,也要对不同频段的声音数据进行量化处理。可对人耳不敏感频段采用较粗的量化步长进行量化,可舍弃一些次要信息;而对人耳敏感频段则采用较细小的量化步长,使用较多的码位来传送。 (2)掩蔽效应 掩蔽效应是人耳的另一个重要生理特征。如果在一段较窄的频段上存在两种声音信号,当一个强度大于另一个时,则人耳的听觉阈值将提高,人耳朵可以听到大音量的声音信号,而其附近频率小音量的声音信号却听不到,好像是小音量信号被大音量信号掩蔽掉了。由于其它声音信号存在而听不到本声音存在的现象,称为掩蔽效应。 根据人耳的掩蔽特性,可将大音量附近的小音量信号舍弃掉,对实际听音效果不会发生影响。既使保留这些小音量信号,人耳也听不到它们的存在,它属于伴音信号中的冗余信息。舍弃掉这些信号,可以进一步压缩伴音数据总量。
数字音视频编解码技术标准工作组
数字音视频编解码技术标准工作组 A VS Mxxxx: 201X年XX月 来源: 包括作者、单位名称等与创作者相关的信息 标题: 状态: 描述文件的版本或其他需要说明的信息,例如视频提案、DRM信息等 ___________________________________________________ 正文 中国数字音视频编解码技术标准工作组 会员提案专利披露与许可承诺表 根据《中国数字音视频编解码技术标准工作组知识产权政策》第十四、十五、十六条等相关规定,A VS会员在向工作组各专题组提交技术提案时应填写本《会员提案专利披露与许可承诺表》,作为该提案的必要组成部分同时提交。 专题组名称:音频□视频□系统□DRM□ 提案A VS文档编号:_ 提案日期:________ 提案标题: 提案会员名称:_ 提案代表姓名(印刷体):Email: 提案代表通讯地址:邮编 电话:______ __ 传真:__ ______________________ 提案会员应当通过选中表A或者通过选中并填写表B相关部分完成此表。表C可以自愿填写。下列表格均可根据实际需要增加表格行。 表A: 提案会员在其实际知晓的范围内已获知本提案不涉及提案会员和他人的专利、专利申请和专利计划。□ 表B-1: 在中华人民共和国已获得授权的专利和/或已公开的专利申请□ 如果本提案中包含提案会员或其关联者在中华人民共和国已获得授权的专利和/或已公开的专利申请,提案会员应当填写下表: 表B-2: 在中华人民共和国未公开的专利申请□ 如果提案会员的缺省许可义务不是RAND-RF或者POOL,当提案会员或其关联者有与此提案相关的未公
音频编解码技术的延时问题
SBC编解码器在A2DP协议里是必不可少的。由于是将信号以帧的形式填充到蓝牙数据包中,其整体延迟时间比较高,主要归于以下几个因素: 1.编解码器延迟:每个音频编解码器在将数据进行编码、解码并发出去之前会造成一定的内部延迟。传统的编解码器已检测到高达50ms的编解码器延迟。 2.传输延迟:A2DP传输层采用数据包结构。工程师在使用基于SBC或感知的帧填充数据包时,有两个方案选择:其一是将一个帧放入大型蓝牙数据包中(图1);其二是将一个帧分解成两个蓝牙数据包(图2)。采用第一个方案会降低数据传输的稳健性,而在第二个方案中,解码器只有在接收到两个蓝牙数据包以后才能对分解帧进行解码,因此将大大增加传输延迟时间。 图1
图2 apt-X是CSR 公司专有的一种编码格式,压缩率4:1(约352 kbit/s),号称可以达到CD 音质。由于是专有格式,必须要求播放设备与接受设备均采用CSR的蓝牙模块才行。 特点:无缓冲,低延迟,如果出现数据包损失的话,几乎无需重传数据。apt-X不同于SBC,它采用无框架结构。解码过程中,aptX编解码器无需等待便可高效地对蓝牙数据包进行填充,也就是说,一旦它接收到数据包便即刻启动解码过程,无需等待(图3)。此外,aptX采用固定压缩率算法,可在传输过程中始终提供相同的比特率,从而保证每个配备aptX的产品输出相同的音质。 aptX具备的一系列独特特性在提供专业的音频性能及稳健性的同时,还可保证40ms的编解码延迟。 图3 关于解码方式的一个比喻: 我们可以想象一个四车道的高速公路经过一座只有单车道的桥。使用aptX技术相当于桥头上的收费站将四车道上的车流处理(或编码)成单车道队列,使其能够穿桥而过。然后,在桥尾有另一个收费站将单车道车流又处理(或解码)回四车道。 SBC、AAC 和MP3技术的这些收费站,会限制通过车辆所允许携带的汽油量,这样每辆车都必须将超出限量的汽油放掉。当他们通过桥另一端的收费站后,虽然汽油也许不会全部用完,但肯定比来时要少很多。此外,一旦您过了桥,之前放掉的汽油不会再还给您。换句话说,您永远失去了这些汽油。对重现音频这一事件来说,相当于上述几种解码方法使用更具破坏性的压缩技术来处理音频数据,使其能通过蓝牙传输,这意味着它们将扔掉自认为不重要的音频元素,仅重现有限的音频带宽。 SBC与aptX差别: 与SBC(Sub-Band Codec子带编解码)技术相比,aptX的优势比较明显: 在频率响应方面,aptX可以在整个频率范围内真实还原音频,SBC则会随着频率的增高,信号渐弱,从而导致失真显著。
(完整版)音频基础知识及编码原理
一、基本概念 1 比特率:表示经过编码(压缩)后的音频数据每秒钟需要用多少个比特来表示,单位常为kbps。 2 响度和强度:声音的主观属性响度表示的是一个声音听来有多响的程度。响度主要随声音的强度而变化,但也受频率的影响。总的说,中频纯音听来比低频和高频纯音响一些。 3 采样和采样率:采样是把连续的时间信号,变成离散的数字信号。采样率是指每秒钟采集多少个样本。 Nyquist采样定律:采样率大于或等于连续信号最高频率分量的2倍时,采样信号可以用来完美重构原始连续信号。 二、常见音频格式 1. WAV格式,是微软公司开发的一种声音文件格式,也叫波形声音文件,是最早的数字音频格式,被Windows平台及其应用程序广泛支持,压缩率低。 2. MIDI是Musical Instrument Digital Interface的缩写,又称作乐器数字接口,是数字音乐/电子合成乐器的统一国际标准。它定义了计算机音乐程序、数字合成器及其它电子设备交换音乐信号的方式,规定了不同厂家的电子乐器与计算机连接的电缆和硬件及设备间数据传
输的协议,可以模拟多种乐器的声音。MIDI文件就是MIDI格式的文件,在MIDI文件中存储的是一些指令。把这些指令发送给声卡,由声卡按照指令将声音合成出来。 3. MP3全称是MPEG-1 Audio Layer 3,它在1992年合并至MPEG规范中。MP3能够以高音质、低采样率对数字音频文件进行压缩。应用最普遍。 4. MP3Pro是由瑞典Coding科技公司开发的,其中包含了两大技术:一是来自于Coding 科技公司所特有的解码技术,二是由MP3的专利持有者法国汤姆森多媒体公司和德国Fraunhofer集成电路协会共同研究的一项译码技术。MP3Pro可以在基本不改变文件大小的情况下改善原先的MP3音乐音质。它能够在用较低的比特率压缩音频文件的情况下,最大程度地保持压缩前的音质。 5. MP3Pro是由瑞典Coding科技公司开发的,其中包含了两大技术:一是来自于Coding 科技公司所特有的解码技术,二是由MP3的专利持有者法国汤姆森多媒体公司和德国Fraunhofer集成电路协会共同研究的一项译码技术。MP3Pro可以在基本不改变文件大小的情况下改善原先的MP3音乐音质。它能够在用较低的比特率压缩音频文件的情况下,最大程度地保持压缩前的音质。 6. WMA (Windows Media Audio)是微软在互联网音频、视频领域的力作。WMA格式是以减少数据流量但保持音质的方法来达到更高的压缩率目的,其压缩率一般可以达到1:18。此外,WMA还可以通过DRM(Digital Rights Management)保护版权。 7. RealAudio是由Real Networks公司推出的一种文件格式,最大的特点就是可以实时传输音频信息,尤其是在网速较慢的情况下,仍然可以较为流畅地传送数据,因此RealAudio 主要适用于网络上的在线播放。现在的RealAudio文件格式主要有RA(RealAudio)、RM (RealMedia,RealAudio G2)、RMX(RealAudio Secured)等三种,这些文件的共同性在于随着网络带宽的不同而改变声音的质量,在保证大多数人听到流畅声音的前提下,令带宽较宽敞的听众获得较好的音质。 8. Audible拥有四种不同的格式:Audible1、2、3、4。https://www.360docs.net/doc/0216727518.html,网站主要是在互联网上贩卖有声书籍,并对它们所销售商品、文件通过四种https://www.360docs.net/doc/0216727518.html, 专用音频格式中的一种提供保护。每一种格式主要考虑音频源以及所使用的收听的设备。格式1、2和3采用不同级别的语音压缩,而格式4采用更低的采样率和MP3相同的解码方式,所得到语音吐辞更清楚,而且可以更有效地从网上进行下载。Audible 所采用的是他们自己的桌面播放工具,这就是Audible Manager,使用这种播放器就可以播放存放在PC或者是传输到便携式播放器上的Audible格式文件
各种音视频编解码学习详解
各种音视频编解码学习详解 编解码学习笔记(一):基本概念 媒体业务是网络的主要业务之间。尤其移动互联网业务的兴起,在运营商和应用开发商中,媒体业务份量极重,其中媒体的编解码服务涉及需求分析、应用开发、释放license收费等等。最近因为项目的关系,需要理清媒体的codec,比较搞的是,在豆丁网上看运营商的规范标准,同一运营商同样的业务在不同文档中不同的要求,而且有些要求就我看来应当是历史的延续,也就是现在已经很少采用了。所以豆丁上看不出所以然,从wiki上查。中文的wiki信息量有限,很短,而wiki的英文内容内多,删减版也减肥得太过。我在网上还看到一个山寨的中文wiki,长得很像,红色的,叫―天下维客‖。wiki的中文还是很不错的,但是阅读后建议再阅读英文。 我对媒体codec做了一些整理和总结,资料来源于wiki,小部分来源于网络博客的收集。网友资料我们将给出来源。如果资料已经转手几趟就没办法,雁过留声,我们只能给出某个轨迹。 基本概念 编解码 编解码器(codec)指的是一个能够对一个信号或者一个数据流进行变换的设备或者程序。这里指的变换既包括将信号或者数据流进行编码(通常是为了传输、存储或者加密)或者提取得到一个编码流的操作,也包括为了观察或者处理从这个编码流中恢复适合观察或操作的形式的操作。编解码器经常用在视频会议和流媒体等应用中。 容器 很多多媒体数据流需要同时包含音频数据和视频数据,这时通常会加入一些用于音频和视频数据同步的元数据,例如字幕。这三种数据流可能会被不同的程序,进程或者硬件处理,但是当它们传输或者存储的时候,这三种数据通常是被封装在一起的。通常这种封装是通过视频文件格式来实现的,例如常见的*.mpg, *.avi, *.mov, *.mp4, *.rm, *.ogg or *.tta. 这些格式中有些只能使用某些编解码器,而更多可以以容器的方式使用各种编解码器。 FourCC全称Four-Character Codes,是由4个字符(4 bytes)组成,是一种独立标示视频数据流格式的四字节,在wav、avi档案之中会有一段FourCC来描述这个AVI档案,是利用何种codec来编码的。因此wav、avi大量存在等于―IDP3‖的FourCC。 视频是现在电脑中多媒体系统中的重要一环。为了适应储存视频的需要,人们设定了不同的视频文件格式来把视频和音频放在一个文件中,以方便同时回放。视频档实际上都是一个容器里面包裹着不同的轨道,使用的容器的格式关系到视频档的可扩展性。 参数介绍 采样率 采样率(也称为采样速度或者采样频率)定义了每秒从连续信号中提取并组成离散信号的采样个数,它用赫兹(Hz)来表示。采样频率的倒数叫作采样周期或采样时间,它是采样之间的时间间隔。注意不要将采样率与比特率(bit rate,亦称―位速率‖)相混淆。 采样定理表明采样频率必须大于被采样信号带宽的两倍,另外一种等同的说法是奈奎斯特频率必须大于被采样信号的带宽。如果信号的带宽是100Hz,那么为了避免混叠现象采样频率必须大于200Hz。换句话说就是采样频率必须至少是信号中最大频率分量频率的两倍,否则就不能从信号采样中恢复原始信号。 对于语音采样: ?8,000 Hz - 电话所用采样率, 对于人的说话已经足够 ?11,025 Hz ?22,050 Hz - 无线电广播所用采样率 ?32,000 Hz - miniDV 数码视频camcorder、DAT (LP mode)所用采样率 ?44,100 Hz - 音频CD, 也常用于MPEG-1 音频(VCD, SVCD, MP3)所用采样率
音频编码及常用格式
音频编码及常用格式 音频编码标准发展现状 国际电信联盟(ITU)主要负责研究和制定与通信相关的标准,作为主要通信业务的电话通信业务中使用的语音编码标准均是由ITU负责完成的。其中用于固定网络电话业务使用的语音编码标准如ITU-T G.711等主要在ITU-T SG 15完成,并广泛应用于全球的电话通信系统之中。目前,随着Internet网络及其应用的快速发展,在2005到2008研究期内,ITU-T将研究和制定变速率语音编码标准的工作转移到主要负责研究和制定多媒体通信系统、终端标准的SG16中进行。 在欧洲、北美、中国和日本的电话网络中通用的语音编码器是8位对数量化器(相应于64Kb/s的比特率)。该量化器所采用的技术在1972年由CCITT (ITU-T的前身)标准化为G.711。在1983年,CCIT规定了32Kb/s的语音编码标准G.721,其目标是在通用电话网络上的应用(标准修正后称为G.726)。这个编码器价格虽低但却提供了高质量的语音。至于数字蜂窝电话的语音编码标准,在欧洲,TCH-HS是欧洲电信标准研究所(ETSI)的一部分,由他们负责制定数字蜂窝标准。在北美,这项工作是由电信工业联盟(TIA)负责执行。在日本,由无线系统开发和研究中心(称为RCR)组织这些标准化的工作。此外,国际海事卫星协会(Inmarsat)是管理地球上同步通信卫星的组织,也已经制定了一系列的卫星电话应用标准。 音频编码标准发展现状 音频编码标准主要由ISO的MPEG组来完成。MPEG1是世界上第一个高保真音频数据压缩标准。MPEG1是针对最多两声道的音频而开发的。但随着技术的不断进步和生活水准的不断提高,有的立体声形式已经不能满足听众对声音节目的欣赏要求,具有更强定位能力和空间效果的三维声音技术得到蓬勃发展。而在三维声音技术中最具代表性的就是多声道环绕声技术。目前有两种主要的多声道编码方案:MUSICAM环绕声和杜比AC-3。MPEG2音频编码标准采用的就是MUSICAM环绕声方案,它是MPEG2音频编码的核心,是基于人耳听觉感知特性的子带编码算法。而美国的HDTV伴音则采用的是杜比AC-3方案。MPEG2规定了两种音频压缩编码算法,一种称为MPEG2后向兼容多声道音频编码标准,简称MPEG2BC;另一种是称为高级音频编码标准,简称MPEG2AAC,因为它与MPEG1不兼容,也称MPEG NBC。MPEG4的目标是提供未来的交互多媒体应用,它具有高度的灵活性和可扩展性。与以前的音频标准相比,MPEG4增加了许多新的关于合成内容及场景描述等领域的工作。MPEG4将以前发展良好但相互独立的高质量音频编码、计算机音乐及合成语音等第一次合并在一起,并在诸多领域内给予高度的灵活性。
MP3编码原理概述
音频压缩由编码和解码两个部分组成。把波形文件里的数字音频数据转换为高度压缩的形式(称为比特流)即为编码;要解码则把比特流重建为波形文件。 音频压缩可以分为无损(lossless)压缩和有损压缩。无损压缩就是尽量降低音频数据的冗余度,以减小其体积。音频信号经过编码和解码之后,必须要和原来的信号一致。无损压缩的压缩率是比较有限的,不过现在比较出色的APE能做到50%的压缩率(本人用Monkey's Audio 3.97,Extra High压缩模式下压缩WAV,压缩率最低能达到52%);有损压缩就是用尽一切手段,包括无损压缩用到的方法,丢掉一切能丢掉的数据,以减小体积。而音频压缩后解码听起来起码是要跟原来差不多的,有损压缩的压缩比能大幅提高,MP3就是属于有损压缩,压缩比是12:1(128kbps)。 MP3文件是由帧(frame)构成的,帧是MP3文件最小的组成单位。什么是帧?还记得最初的动画是怎么做的吗?不同的连续画面切换以达到动态效果,每幅画面就是一个“帧”,不同的是MP3里面的帧记录的是音频数据而不是图形数据。MP3的帧速度大概是30帧/秒。 每个帧又由帧头和帧数据组成,帧头记录着该帧的基本信息,包括位率索引和采样率索引(这对理解ABR和VBR编码方式很重要)。帧数据,顾名思义就是记录着主体音频数据。 上面说的都是MP3编码的基础,但事实上,早期的编码器都非常不完善,压缩算法近于粗暴,音质很不理想。MP3的音质达到现在的水平有两次飞跃:人体听觉心理学模型(Perceptual Model)的导入和VBR技术的应用。 ◆人体听觉心理学模型 下面将简要介绍一下几个重要原理: 1) 最小听觉门槛判定(The minimal audition threshold) 人耳的听力范围是20Hz-20k Hz的频率范围,但是人耳对不同的频率声音的灵敏度是不同的,不同频率的声音要达到能被人耳听到的水平所需要的强度是不一样。那么通过计算,可以把音乐文件中存在但不能被人耳听到的声音去掉。通过这原理,我们还可以建立模型,把大部分数据空间分配到人耳最灵敏的2kHz 到5kHz范围,其余频率分配比较少的空间; 2) 人耳的遮蔽效应(The Masking effect) 蔽效应表现在强信号会遮蔽邻近频率的弱信号。用生活经验来说,在安静的房间中,一根针掉到地上都能听见,可到了大街上,就算手机音量调到最大,来电时也未必能听见,而手机的声音确确实实是存在的,原因就是被周围更大的声音遮蔽了。有了对遮蔽效应的研究成果,编码器就能根据已建立的数学模型,计算强信号对附近弱信号的遮蔽,把能引起人们注意的声音才保留。
音频编解码原理讲解和分析
音频编码原理讲解和分析 作者:谢湘勇,算法部,xie.chris@https://www.360docs.net/doc/0216727518.html, 2007-10-13 简述 (2) 音频基本知识 (2) 采样(ADC) (3) 心理声学模型原理和分析 (3) 滤波器组和window原理和分析 (6) Window (6) TDAC:时域混叠抵消,time domain aliasing cancellation (7) Long and short window、block switch (7) FFT、MDCT (8) Setero and couple原理和分析 (8) 量化原理和分析 (9) mp3、AAC量化编码的过程 (9) ogg量化编码的过程 (11) AC3量化编码的过程 (11) Huffman编码原理和分析 (12) mp3、ogg、AC3的编码策略 (12) 其他技术原理简介 (13) 比特池技术 (13) TNS (13) SBR (13) 预测模型 (14) 增益控制 (14) OGG编码原理和过程详细分析 (14) Ogg V orbis的引入 (14) Ogg V orbis的编码过程 (14) ogg心理声学模型 (15) ogg量化编码的过程 (16) ogg的huffman编码策略 (17) 主要音频格式编码对比分析 (19) Mp3 (19) Ogg (20) AAC (21) AC3 (22) DRA(A VS内的中国音频标准多声道数字音频编码) (23) BSAC,TwinVQ (24) RA (24) 音频编码格式的对比分析 (25) 主要格式对比表格如下 (26) 语音编码算法简介 (26) 后处理技术原理和简介 (28) EQ (28)
常见的音频编码标准
常见的音频编码标准 在自然界中人类能够听到的所有声音都称之为音频,它可能包括噪音、声音被录制下来以后,无论是说话声、歌声、乐器都可以通过数字音乐软件处理。把它制作成CD,这时候所有的声音没有改变,因为CD本来就是音频文件的一种类型。而音频只是储存在计算机里的声音。演讲和音乐,如果有计算机加上相应的音频卡,我们可以把所有的声音录制下来,声音的声学特性,音的高低都可以用计算机硬盘文件的方式储存下来。反过来,我们也可以把储存下来的音频文件通过一定的音频程序播放,还原以前录下的声音。自然界中的声音非常复杂,波形极其复杂,通常我们采用的是脉冲代码调制编码,即PCM编码。PCM通过抽样、量化、编码三个步骤将连续变化的模拟信号转换为数字编码。然而,3G网络带来了移动多媒体业务的蓬勃发展,视频、音频编解码标准是多媒体应用的基础性标准,但其种类较多,有繁花渐欲迷人眼之感。那么常见的编码技术就是我们必须知道的,下面我们介绍一下最常见的编码技术。 1.PCM PCM 脉冲编码调制是Pulse Code Modulation的缩写。PCM编码的最大的优点就是音质好,最大的缺点就是体积大。我们常见的Audio CD就采用了PCM编码,一张光盘的容量只能容纳72分钟的音乐信息。 2.W A V WA V是Microsoft Windows本身提供的音频格式,由于Windows本身的影响力,这个格式已经成为了事实上的通用音频格式。实际上是Apple电脑的AIFF格式的克隆。通常我们使用W A V格式都是用来保存一些没有压缩的音频,但实际上W A V格式的设计是非常灵活(非常复杂)的,该格式本身与任何媒体数据都不冲突,换句话说,只要有软件支持,你甚至可以在W A V格式里面存放图像。之所以能这样,是因为W A V文件里面存放的每一块数据都有自己独立的标识,通过这些标识可以告诉用户究竟这是什么数据。在WINDOWS 平台上通过ACM(Audio Compression Manager)结构及相应的驱动程序(通常称为CODEC,编码/解码器),可以在W A V文件中存放超过20种的压缩格式,比如ADPCM、GSM、CCITT G.711、G.723等等,当然也包括MP3格式。 虽然W A V文件可以存放压缩音频甚至MP3,但由于它本身的结构注定了它的用途是存放音频数据并用作进一步的处理,而不是像MP3那样用于聆听。目前所有的音频播放软件和编辑软件都支持这一格式,并将该格式作为默认文件保存格式之一。这些软件包括:Sound Forge, Cool Edit Pro, 等等。 3.MP3 MP3它的全称是MPEG(MPEG:Moving Picture Experts Group) Audio Layer-3,1993年由德国夫朗和费研究院和法国汤姆生公司合作发展成功。刚出现时它的编码技术并不完善,它更像一个编码标准框架,留待人们去完善。这个比喻相信大家都会同意。MP3是Fraunhofer-IIS研究的研究成果。MP3是第一个实用的有损音频压缩编码。在MP3出现之前,一般的音频编码即使以有损方式进行压缩能达到4:1的压缩比例已经非常不错了。但是,MP3可以实现12:1的压缩比例,这使得MP3迅速地流行起来。MP3之所以能够达到如此高的压缩比例同时又能保持相当不错的音质是因为利用了知觉音频编码技术,也就是利用了人耳的特性,削减音乐中人耳听不到的成分,同时尝试尽可能地维持原来的声音质量。 由于MP3是世界上第一个有损压缩的编码方案,所以可以说所有的播放软件都支持它,否则就根本没有生命力。在制作方面,也曾经产生了许多第三方的编码工具。不过随着后来Fraunhofer-IIS宣布对编码器征收版税之后很多都消失了。目前属于开放源代码并且免费的