基团贡献方法UNIFAC估算局部组成模型NRTLWILSONUNIQUAC的二元参数
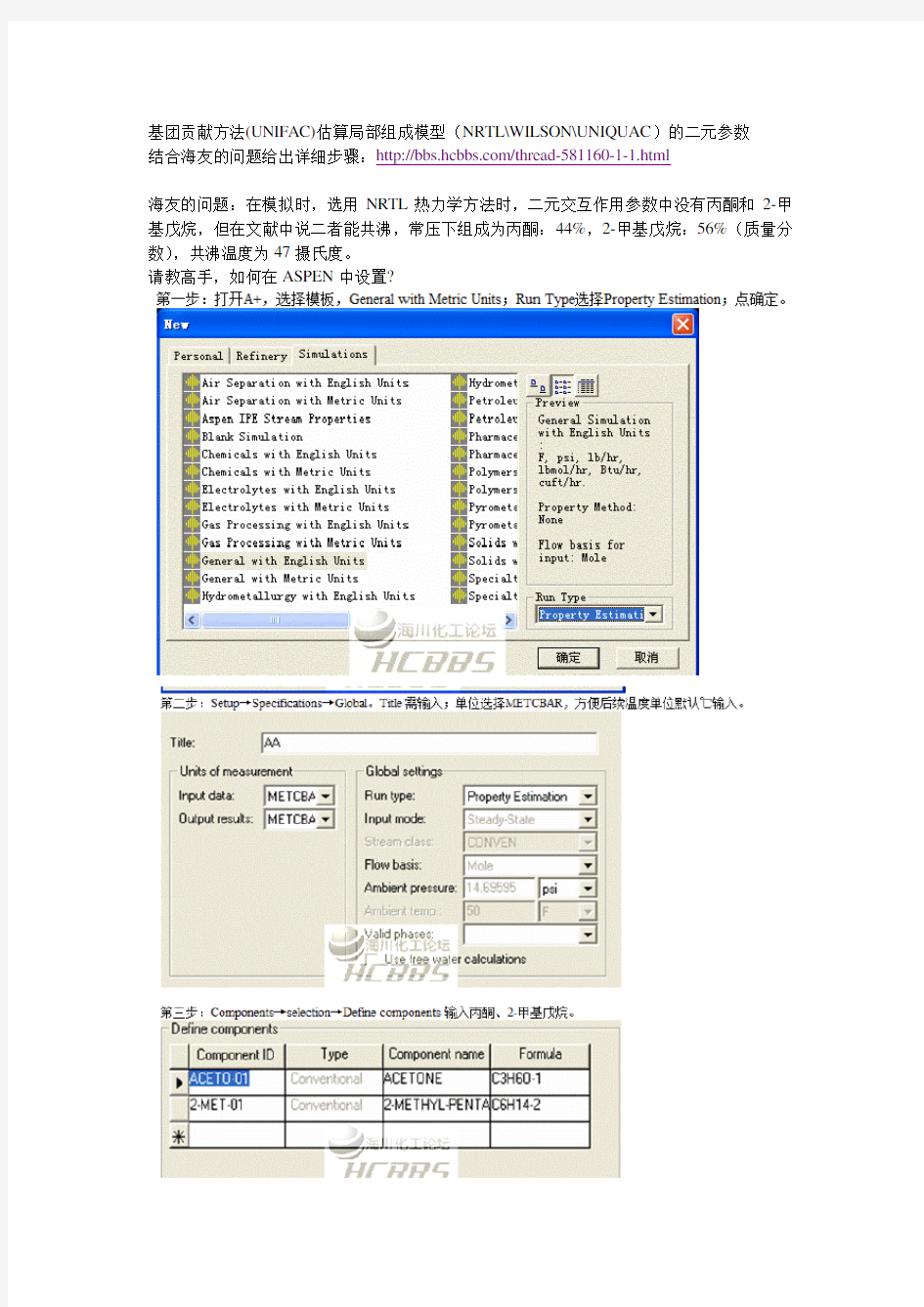

基团贡献方法(UNIFAC)估算局部组成模型(NRTL\WILSON\UNIQUAC)的二元参数
结合海友的问题给出详细步骤:https://www.360docs.net/doc/085134093.html,/thread-581160-1-1.html
海友的问题:在模拟时,选用NRTL热力学方法时,二元交互作用参数中没有丙酮和2-甲基戊烷,但在文献中说二者能共沸,常压下组成为丙酮:44%,2-甲基戊烷:56%(质量分数),共沸温度为47摄氏度。
请教高手,如何在ASPEN中设置?
问题:
1. 在第五步中的Method为什么选Unif-DMD,而没有选其他的方法,比如UNIF-LBY、UNIF-R4等,这些方法有什么本质上的区别吗
UNIFAC-DMD,LBY等没有本质区别,只是修正模型不同而已。你找我发的那个A+10说明书看下,有详细介绍是什么修正。
2. 如果我不想使用Aspen自带的unifac基团交互参数,而是用自己的unifac基团交互参数(基团参数rq仍旧采用软件自带的),来进行楼主帖子中这样的估算,如何操作?
另外,除了上面的问题外,还有一问,那就是如果我自己定义了Aspen中没有的新基团(有时候想把一个物质自己来进行拆分),而且通过别的途径得到了新基团的基团参数RQ以及所需要的相关基团交互参数,那么在这种情况下,在Aspen中怎么样来定义新基团,然后进行楼主帖子中的估算操作呢?
还请楼主解答。
今天研究了一下,你的这两个问题应该都可以解决:
1、当你选择UNIFAC方法的时候,A+默认使用数据库中参数,但也可以修改。你只需要在parameters→unifac group binary→GMUFB-1中输入参数即可。但这前提是你在components中有定义unifac groups,否则gmufb-1是灰色。
2、a+ components的UNIFAC group支持定义新的基团。号码可以自己定义。关键是你能定义官能团(方法有很多,bondi、unifac等等),这一步在分子结构中实现,并可以求的q、r的值。同样你可以在参数中输入。这个时候你不需要在进行回归了。
上面的关键是如何定义官能团(新或者旧)。
能耗计算方法模型说明
能耗计算方法模型说明 1.COP直接计量法 冷量直接计量值与制冷机电耗直接计量值之比。 COP=冷量/制冷机电耗 2.单位空调面积空调末端电耗直接计量法 空调末端(含新风机、空调机组、风机盘管等)电耗直接计量值与总空调面积之比 单位空调面积空调末端电耗=空调末端电耗直接计量值/总空调面积 3.单位空调面积空调系统电耗直接计量法 空调系统(含制冷机、冷冻水泵、冷却水泵、冷却塔、空调末端等)电耗直接计量值与总空调面积之比 单位空调面积空调系统电耗=空调系统电耗直接计量值/总空调面积 4.单位空调面积冷冻泵电耗直接计量法 冷冻水泵电耗直接计量值与总空调面积之比 单位空调面积冷冻泵电耗=冷冻水泵电耗直接计量值/总空调面积 5.单位空调面积冷却泵电耗直接计量法 冷却水泵电耗直接计量值与总空调面积之比 单位空调面积冷却泵电耗=冷却水泵电耗直接计量值/总空调面积 6.单位空调面积冷却塔风机电耗直接计量法 冷却塔风机电耗直接计量值与总空调面积之比 单位空调面积冷却塔风机电耗=冷却塔风机电耗直接计量值/总空调面积7.单位空调面积冷源电耗直接计量法 冷源(含制冷机、冷却塔等)电耗直接计量值与总空调面积之比 单位空调面积冷源电耗=冷源电耗直接计量值/总空调面积 8.单位空调面积制冷机电耗直接计量法 制冷机电耗直接计量值与总空调面积之比 单位空调面积冷源电耗=冷源电耗直接计量值/总空调面积 9.单位面积办公设备电耗间接计量法 办公设备电耗值(根据综合用电的直接计量值按照办公比例等方法计算得
出)与总建筑面积之比。 单位面积办公设备电耗=办公设备电耗值/总建筑面积 10.单位面积办公设备电耗直接计量法 办公设备电耗直接计量值与总建筑面积之比 单位面积办公设备电耗=办公设备电耗值/总建筑面积 11.单位面积常规电耗直接计量法 常规电耗(除特殊电耗外的总能耗值)的直接计量值与总建筑面积之比 单位面积常规电耗=常规电耗/总建筑面积 12.单位面积厨房电耗直接计量法 厨房电耗的直接计量值与总建筑面积之比 单位面积厨房电耗=厨房电耗/总建筑面积 13.单位面积电梯电耗直接计量法 电梯电耗的直接计量值与总建筑面积之比 单位面积电梯电耗=电梯电耗/总建筑面积 14.单位面积空调末端电耗直接计量法 空调末端(含新风机、空调机组、风机盘管等)电耗直接计量值与总建筑面积之比 单位面积空调末端电耗=空调末端电耗直接计量值/总建筑面积 15.单位面积空调系统电耗直接计量法 空调系统(含制冷机、冷冻水泵、冷却水泵、冷却塔、空调末端等)电耗直接计量值与总建筑面积之比 单位面积空调系统电耗=空调系统电耗直接计量值/总建筑面积 16.单位面积冷冻泵电耗直接计量法 冷冻水泵电耗直接计量值与总建筑面积之比 单位空调面积冷冻泵电耗=冷冻水泵电耗直接计量值/总建筑面积 17.单位面积冷量直接计量法 冷量直接计量值与总建筑面积之比 单位面积冷量=冷量直接计量值/总建筑面积 18.单位面积冷却泵电耗直接计量法 冷却水泵电耗直接计量值与总建筑面积之比
基团贡献方法UNIFAC估算局部组成模型NRTLWILSONUNIQUAC的二元参数
基团贡献方法(UNIFAC)估算局部组成模型(NRTL\WILSON\UNIQUAC)的二元参数 结合海友的问题给出详细步骤:https://www.360docs.net/doc/085134093.html,/thread-581160-1-1.html 海友的问题:在模拟时,选用NRTL热力学方法时,二元交互作用参数中没有丙酮和2-甲基戊烷,但在文献中说二者能共沸,常压下组成为丙酮:44%,2-甲基戊烷:56%(质量分数),共沸温度为47摄氏度。 请教高手,如何在ASPEN中设置?
问题: 1. 在第五步中的Method为什么选Unif-DMD,而没有选其他的方法,比如UNIF-LBY、UNIF-R4等,这些方法有什么本质上的区别吗 UNIFAC-DMD,LBY等没有本质区别,只是修正模型不同而已。你找我发的那个A+10说明书看下,有详细介绍是什么修正。 2. 如果我不想使用Aspen自带的unifac基团交互参数,而是用自己的unifac基团交互参数(基团参数rq仍旧采用软件自带的),来进行楼主帖子中这样的估算,如何操作? 另外,除了上面的问题外,还有一问,那就是如果我自己定义了Aspen中没有的新基团(有时候想把一个物质自己来进行拆分),而且通过别的途径得到了新基团的基团参数RQ以及所需要的相关基团交互参数,那么在这种情况下,在Aspen中怎么样来定义新基团,然后进行楼主帖子中的估算操作呢? 还请楼主解答。 今天研究了一下,你的这两个问题应该都可以解决: 1、当你选择UNIFAC方法的时候,A+默认使用数据库中参数,但也可以修改。你只需要在parameters→unifac group binary→GMUFB-1中输入参数即可。但这前提是你在components中有定义unifac groups,否则gmufb-1是灰色。 2、a+ components的UNIFAC group支持定义新的基团。号码可以自己定义。关键是你能定义官能团(方法有很多,bondi、unifac等等),这一步在分子结构中实现,并可以求的q、r的值。同样你可以在参数中输入。这个时候你不需要在进行回归了。 上面的关键是如何定义官能团(新或者旧)。
剖析大数据分析方法论的几种理论模型
剖析大数据分析方法论的几种理论模型 做大数据分析的三大作用,主要是:现状分析、原因分析和预测分析。什么时候开展什么样的数据分析,需要根据我们的需求和目的来确定。 作者:佚名来源:博易股份|2016-12-01 19:10 收藏 分享 做大数据分析的三大作用,主要是:现状分析、原因分析和预测分析。什么时候开展什么样的数据分析,需要根据我们的需求和目的来确定。 利用大数据分析的应用案例更加细化的说明做大数据分析方法中经常用到的几种理论模型。 以营销、管理等理论为指导,结合实际业务情况,搭建分析框架,这是进行大数据分析的首要因素。大数据分析方法论中经常用到的理论模型分为营销方面的理论模型和管理方面的理论模型。 管理方面的理论模型: ?PEST、5W2H、时间管理、生命周期、逻辑树、金字塔、SMART原则等?PEST:主要用于行业分析 ?PEST:政治(Political)、经济(Economic)、社会(Social)和技术(Technological) ?P:构成政治环境的关键指标有,政治体制、经济体制、财政政策、税收政策、产业政策、投资政策、国防开支水平政府补贴水平、民众对政治的参与度等。?E:构成经济环境的关键指标有,GDP及增长率、进出口总额及增长率、利率、汇率、通货膨胀率、消费价格指数、居民可支配收入、失业率、劳动生产率等。?S:构成社会文化环境的关键指标有:人口规模、性别比例、年龄结构、出生率、死亡率、种族结构、妇女生育率、生活方式、购买习惯、教育状况、城市特点、宗教信仰状况等因素。
?T:构成技术环境的关键指标有:新技术的发明和进展、折旧和报废速度、技术更新速度、技术传播速度、技术商品化速度、国家重点支持项目、国家投入的研发费用、专利个数、专利保护情况等因素。 大数据分析的应用案例:吉利收购沃尔沃 大数据分析应用案例 5W2H分析法 何因(Why)、何事(What)、何人(Who)、何时(When)、何地(Where)、如何做(How)、何价(How much) 网游用户的购买行为: 逻辑树:可用于业务问题专题分析
能耗计量系统方案解读
能耗计量系统方案解读 1.1国家政策 随着能耗问题日益突显,如何实现能耗管理和能源成本最小化成为中国的首要任务。为此,在“十二五”开局之年国家相关部门将节能减排指标落实到地区,由各个省、市、地区政府承担相应的节能任务。“政府出面帮助和督促用能单位节能降耗,以行政命令结合扶持政策,鼓励用能单位进行节能改造。” 在我国目前的能耗结构中,建筑所造成的能源消耗,已占我国总的商品能耗的20,,30,。而建筑运行的能耗,包括建筑物照明、采暖、空调和各类建筑内使用电器的能耗,将一直伴随建筑物的使用过程而发生。在建筑的全生命周期中,建筑材料和建造过程所消耗的能源一般只占其总的能源消耗的20,左右,大部分能源消耗发生在建筑物的运行过程中。建筑节能主要是为了降低各类建筑运行过程中消耗的能源。 实际调查数据表明,我国的建筑运行能耗,包括大型公共建筑的能耗都低于同等气候条件的发达国家现状,更远低于美国大多数建筑的目前状况。这是由于对室内环境要求的不同理念和不同标准所致。由于我们的状况与发达国家差异很大,因此不能简单复制国外建筑节能技术与经验。然而目前我国在大型公共建筑的新建和既有改造项目中,一方面建筑设计追求“与国外接轨”,“新、特、奇”,造成大量全玻璃,全密闭的高能耗建筑出现;另一方面又大量采用发达国家的所谓的“节能技术”,如变风量系统(VAV),建筑热电冷联供系统(BCHP),区域供冷,吸收制冷机,等等。但这些技术在大多数情况下并不能真正实现建筑节能。 因此,我国大型公共建筑的节能应该从实际能源消耗数据抓起,建筑实际运行能耗数据是评价和检验建筑节能的唯一标准。建立大型公共建筑分项用能实时监控
运筹学参考文献
参考文献 [1] 胡运权.运筹学教程.北京:高等教育出版社,2005 [2] 胡运权.运筹学基础及应用.哈尔滨:哈尔滨工业大学出版社,1998 [3] 《运筹学》编写组.运筹学.北京:清华大学出版社, 1990 [4] 张莹.运筹学基础.北京:清华大学出版社,2002 [5] 袁亚湘,孙文瑜.最优化理论与方法.北京:科学出版社,1999 [6] 何坚勇.运筹学基础.北京:清华大学出版社, 2000 [7] 马振华等.现代应用数学手册—运筹学与最优化理论卷.北京:清华大学出版社,2000 [8] 牛映武.运筹学.西安:西安交通大学出版社,1993 [9] 梁工谦.运筹学- 典型题解析集自测试题。西安:西北工业大学出版社,2002 [10] 徐永仁.运筹学试题精选与答题技巧.哈尔滨:哈尔滨工业大学出版社,2000 [11] 徐玖平,胡知能,王緌.运筹学(第二版).北京:科学出版社,2004 [12] 刘满风,傅波,聂高辉.运筹学模型与方法教程- 例题分析与题解.北京:清华大学出版社,2001 [13] 胡运权.运筹学习题集.北京:清华大学出版社,2002 [14] 盛昭瀚,朱乔,吴广谋.DEA理论、方法与应用.北京:科学出版社,1996 [15] Frederick ~S.Hillier,Gerald~J.Lieberman.Introduction to Operations Research (6th Ed.).Beijing:China Machine Press/ McGraw - Hill,1999 [16] J.D.Wiest,F.K.Levy.统筹方法管理指南.北京:机械工业出版社,1983 [17] 王元等.华罗庚科普著作选集.上海:上海教育出版社,1984 [18] 江景波等.网络计划技术.北京:冶金工业出版社,1983 [19] David R.Anderson,Dennis J.Sweeney,Thomas A.Williams.数据、模型与决策.北京:机械工业出版社,2003 [20] Frederick S.Hillier,Mark S.Hillier,Jerald J.Lieberman.Introduction to Management Science.Beijing:McGraw - Hill Comanies,Inc.,2001
运筹学实验1预测模型
实验一、需求预测模型 预测是用科学的方法预计、推断事物发展的必要性或可能性的行为,即根据过去和现在预计未来,由已知推断未知的过程。 预测分析的具体方法很多,概括起来主要有两种:定量预测法和定性预测法。定量预测法是在掌握与预测对象有关的各种要素的定量资料的基础上,运用现代数学方法进行数据处理,据以建立能够反映有关变量之间规律性联系的各类预测模型的方法体系。定量预测法又可分为时间系列预测法和因果关系预测法。定性预测法是由有关方面的专业人员根据个人经验和知识,结合预测对象的特点进行综合分析,对事物的未来状况和发展趋势做出推测的预测方法。它一般不需要进行复杂的定量分析,适用于缺乏完备的历史资料或有关变量之间缺乏明显的数量关系等情况下的预测。定性预测法又可分为德尔菲法、各部门主管集体讨论法、销售人员意见汇集法、消费市场调查法等。 定性预测法和定量预测法在实际应用中相互补充、相辅相成。定量分析法虽然较精确,但许多非计量因素无法考虑;定性分析法虽然可以将非计量因素考虑进去,但估计的准确性在很大程度上受预测人员的经验和素质的影响,难免产生预测结论因人而异,带有一定的主观随意性。因此,在实际工作中常常是二者结合,相互取长补短,以提高预测的准确性和预测结论的可信度。 不管何种机构,如果按照以下步骤进行预测,将会使自己的预测结果更加有效:⑴明确定预测目标;⑵将需求规划和预测结合起来;⑶识别影响需求预测的主要因素;⑷理解和识别顾客群;⑸决定采用适当的预测方法;⑹确定预测效果的评估方法和误差的测度方法。 通过上面的介绍,我们知道,需求预测的方法很多,而在本次实验中,我们主要训练学生如何使用Excel来完成定量预测法中时间序列预测法的计算和分析工作。 一、实验目的 1、掌握如何建立时间序列预测模型,并能根据不同的系统需求框架选择合适的预 测方法。 2、掌握如何用Excel完成时间序列预测模型的计算和数据分析工作,包括回归分 析、预测误差的测定。 二、实验内容 1、时间序列预测法的相关知识 任何预测方法的目的都是预测系统需求部分和估计随机需求部分。系统需求部分的数据在一般形式下包含有需求水平、需求趋势和季节性需求。它也可能表现为如下列方程所示的多种形式。 ○复合型:系统需求=需求水平×需求趋势×季节性需求 ○附加型:系统需求=需求水平+需求趋势+季节性需求 ○混合型:系统需求=(需求水平+需求趋势)×季节性需求 运用于既定预测的系统需求部分的具体形式,取决于需求的性质。针对每种形式,企业都可以采用静态法和适应法这两种方法。 下面我们将通过一个实例来阐述时间序列预测法中的静态法和适应法,在预测过程中,我们假定系统需求是混合型,即系统需求=(需求水平+需求趋势)×季节性需求。 2、引例 天然气在线公司利用现有的管道设施供应天然气,同时满足各个分销商的网上紧急订购需求。该公司自2003年第二季度成立以来,需求一直在增长。计划年度将从某给定年度的第二季度开始,并延续到下一年的第一季度。公司正在规划其必备的生产能力及从2006年第
过程能耗分析的方法
过程能耗分析的方法 主要有洽分析法、熵分析法和有效能分析法。其中洽分析法是基于热力学第一定律的能耗分析方法。热力学第一定律规定了能量量的守恒,因此,恰分析法以装置的综合能耗和产品单耗等作为评价准则,其计算准则能表征系统能量在数量上利用状况。然而并不是所有满足能量守恒的过程都可以实现,要使过程能够实现还需同时满足热力学第二定律。因此洽分析方法的缺点是,单纯的以过程消耗能量数值来评价过程能耗优劣忽视了能量在传递过程中的等值折算问题[2】。特别是对于热量传递过程,由于反应过程中能源热力学参数(温度、压力等)的变化必然会导致过程中能量的能级发生变化。因此始分析法具有一定的局限性,导致在节能技术改造中抓不住关键所在,不能真实反映能耗状况。基于热力学第二定律的熵分析法用摘的变化趋势来反应能量能级变化状况,熵增加的幅度越小,说明损失越小,效率越高。然而由于熵值无法反映能量的量变;且熵是反映物质内部混乱和无序状态的一个物理量,不能直接用仪表测量,只能推算出来。因此熵分析法可描述能量质量的变化,但不具有直观性。有效能分析法利用系统与环境参数偏离程度来度量系统可以利用或转化的能量,且把这部分能量称为有效能(础)[3]。以“环境参考态模型”为基础,■的计算可简单表示为[4]: e, =(/1,-/1,+ 其中第一部分表示物质的热洽,第二部分表示物质的熵变,第三部分为其它形式的能量。上式可以看出,棚的计算结合了热力学第一定律和第二定律,因此它能对能的质量、数量变化和差异做统一的描述,从而规定能量的价值,有效能已成为
热力学和能源科学中单独评价能量价值问题的一种物理量。基于■的系统能耗分析方法改变了人们对能的性质、能的损失和能的转换效率等的传统看法,提供了热工分析的科学基础,深刻地揭示了能量转换过程中能量变质退化的本质,因此只有充分和有效发挥灿的作用,尽可能减少那些不必要和不合理的灿损失才是真正的节能。
模型预测控制
云南大学信息学院学生实验报告 课程名称:现代控制理论 实验题目:预测控制 小组成员:李博(12018000748) 金蒋彪(12018000747) 专业:2018级检测技术与自动化专业
1、实验目的 (3) 2、实验原理 (3) 2.1、预测控制特点 (3) 2.2、预测控制模型 (4) 2.3、在线滚动优化 (5) 2.4、反馈校正 (5) 2.5、预测控制分类 (6) 2.6、动态矩阵控制 (7) 3、MATLAB仿真实现 (9) 3.1、对比预测控制与PID控制效果 (9) 3.2、P的变化对控制效果的影响 (12) 3.3、M的变化对控制效果的影响 (13) 3.4、模型失配与未失配时的控制效果对比 (14) 4、总结 (15) 5、附录 (16) 5.1、预测控制与PID控制对比仿真代码 (16) 5.1.1、预测控制代码 (16) 5.1.2、PID控制代码 (17) 5.2、不同P值对比控制效果代码 (19) 5.3、不同M值对比控制效果代码 (20) 5.4、模型失配与未失配对比代码 (20)
1、实验目的 (1)、通过对预测控制原理的学习,掌握预测控制的知识点。 (2)、通过对动态矩阵控制(DMC)的MATLAB仿真,发现其对直接处理具有纯滞后、大惯性的对象,有良好的跟踪性和较强的鲁棒性,输入已 知的控制模型,通过对参数的选择,来获得较好的控制效果。 (3)、了解matlab编程。 2、实验原理 模型预测控制(Model Predictive Control,MPC)是20世纪70年代提出的一种计算机控制算法,最早应用于工业过程控制领域。预测控制的优点是对数学模型要求不高,能直接处理具有纯滞后的过程,具有良好的跟踪性能和较强的抗干扰能力,对模型误差具有较强的鲁棒性。因此,预测控制目前已在多个行业得以应用,如炼油、石化、造纸、冶金、汽车制造、航空和食品加工等,尤其是在复杂工业过程中得到了广泛的应用。在分类上,模型预测控制(MPC)属于先进过程控制,其基本出发点与传统PID控制不同。传统PID控制,是根据过程当前的和过去的输出测量值与设定值之间的偏差来确定当前的控制输入,以达到所要求的性能指标。而预测控制不但利用当前时刻的和过去时刻的偏差值,而且还利用预测模型来预估过程未来的偏差值,以滚动优化确定当前的最优输入策略。因此,从基本思想看,预测控制优于PID控制。 2.1、预测控制特点 首先,对于复杂的工业对象。由于辨识其最小化模型要花费很大的代价,往往给基于传递函数或状态方程的控制算法带来困难,多变量高维度复杂系统难以建立精确的数学模型工业过程的结构、参数以及环境具有不确定性、时变性、非线性、强耦合,最优控制难以实现。而预测控制所需要的模型只强调其预测功能,不苛求其结构形式,从而为系统建模带来了方便。在许多场合下,只需测定对象的阶跃或脉冲响应,便可直接得到预测模型,而不必进一步导出其传递函数或状
数学建模 运筹学模型(一)
运筹学模型(一) 本章重点: 线性规划基础模型、目标规划模型、运输模型及其应用、图论模型、最小树问题、最短路问题 复习要求: 1.进一步理解基本建模过程,掌握类比法、图示法以及问题分析、合理假设的内涵. 2.进一步理解数学模型的作用与特点. 本章复习重点是线性规划基础模型、运输问题模型和目标规划模型.具体说来,要求大家会建立简单的线性规划模型,把实际问题转化为线性规划模型的方法要掌握,当然比较简单.运输问题模型主要要求善于将非线性规划模型转化为运输规化模型,这种转化后求解相当简单.你至少把一个很实际的问题转化为用表格形式写出的模型,至于求解是另外一回事,一般不要求.目标模型一般是比较简单的线性规模模型在提出新的要求之后转化为目标规划模型.另外,关于图论模型的问题涉及到最短路问题,具体说来用双标号法来求解一个最短路模型.这之前恐怕要善于将一个实际问题转化为图论模型.还有一个最小数的问题,该如何把一个网络中的最小数找到.另外在个别场合可能会涉及一笔划问题. 1.营养配餐问题的数学模型 n n x C x C x C Z ++=211m i n ????? ?? ??=≥≥+++≥+++≥+++??) ,,2,1(0, ,, 22112222212111212111n j x b x a x a x a b x a x a x a b x a x a x a t s j m n mn m m n n n n 或更简洁地表为 ∑== n j j j x C Z 1 m i n ??? ??? ?==≥≥??∑=),,2,1,,2,1(01 n j m i x b x a t s j n j i j ij 其中的常数C j 表示第j 种食品的市场价格,a ij 表示第j 种食品含第i 种营养的数量,b i 表示人或动物对第i 种营养的最低需求量. 2.合理配料问题的数学模型 有m 种资源B 1,B 2,…,B m ,可用于生产n 种代号为A 1,A 2,…,A n 的产品.单位产品A j 需用资源B i 的数量为a ij ,获利为C j 单位,第i 种资源可供给总量为b i 个单位.问如何安排生产,使总利润达到最大? 设生产第j 种产品x j 个单位(j =1,2,…,n ),则有 n n x C x C x C Z +++= 2211m a x
空气过滤器的能耗计算模型
空气过滤器的能耗计算模型 摘要:文章介绍了三种计算空气过滤器能耗的模型,用于估算过滤器的耗能情况,并进行了模拟计算。 关键词: 空气过滤器, 压力损失, 能耗 Abstract: The paper introduces three kinds of calculation model of the air filter energy consumption, used to estimate the energy dissipation filter, and by simulation calculation. Key Words: air filter, loss of pressure, energy consumption 引言:在通风系统中,空气过滤器用于过滤空气中的尘粒。普通集中空调系统中,过滤器能耗约占风机总能耗的10%(办公建筑)~30%(制药厂等洁净空调中)[1]。过滤器的能耗与以下几个因素有关:过滤器的数量、类型、气流速度、尘粒的积累程度和过滤器的更换状况等。 River(1996)提出了过滤器压力损失模型,即过滤器总压力损失为空气进出口压力损失和通过过滤器压力损失之和。该模型假定通过过滤器的气流形式为层流,空气进出口压力损失与气流的动压头成比例,通过过滤媒介的压力损失与空气流速成比例[2]。River和Murphy在2000年的研究中又进一步考虑到空气通过过滤媒介被压缩的因素[3]。过滤器的压力损失模型可以利用生产厂家提供的数据建立,当安装日期和气流状况确定后,这个模型理论上可以得到压力损失的精确解。然而在这些模型中都假设气流的温度和压力是恒定的,而许多通风和空调系统的实际运行状况,空气流速是随时间变化的。尽管我们可以根据过滤器寿命期空气的平均流速和平均压力来大致估算过滤器的能耗,但是由于变量之间的非线性关系,得出的结果可能与实际情况相去甚远。 本文介绍了三种计算空气过滤器能耗的方法,这些方法可以克服以前的压力损失模型存在的不足,后两种方法还可用来估算过滤器寿命周期和能耗,进行寿命周期成本分析的研究。 1.压力损失模型 对于一个选定的过滤器,压力损失模型应该反映空气流速和过滤器尘粒积累程度的影响。为了建立压力损失模型,进行以下假定: 对于固定的过滤器尘粒积累度,过滤器的有效面积A,压力损失Δp和空气质量流速m的关系为:
MATLAB模型预测控制工具箱函数
M A T L A B模型预测控制 工具箱函数 TTA standardization office【TTA 5AB- TTAK 08- TTA 2C】
M A T L A B模型预测控制工具箱函数 系统模型建立与转换函数 前面读者论坛了利用系统输入/输出数据进行系统模型辨识的有关函数及使用方法,为时行模型预测控制器的设计,需要对系统模型进行进一步的处理和转换。MATLAB的模型预测控制工具箱中提供了一系列函数完成多种模型转换和复杂系统模型的建立功能。 在模型预测控制工具箱中使用了两种专用的系统模型格式,即MPC状态空间模型和MPC传递函数模型。这两种模型格式分别是状态空间模型和传递函数模型在模型预测控制工具箱中的特殊表达形式。这种模型格式化可以同时支持连续和离散系统模型的表达,在MPC传递函数模型中还增加了对纯时延的支持。表8-2列出了模型预测控制工具箱的模型建立与转换函数。 表8-2 模型建立与转换函数 模型转换 在MATLAB模型预测工具箱中支持多种系统模型格式。这些模型格式包括: ①通用状态空间模型; ②通用传递函数模型; ③MPC阶跃响应模型; ④MPC状态空间模型; ⑤MPC传递函数模型。
在上述5种模型格式中,前两种模型格式是MATLAB通用的模型格式,在其他控制类工具箱中,如控制系统工具箱、鲁棒控制工具等都予以支持;而后三种模型格式化则是模型预测控制工具箱特有的。其中,MPC状态空间模型和MPC传递函数模型是通用的状态空间模型和传递函数模型在模型预测控制工具箱中采用的增广格式。模型预测控制工具箱提供了若干函数,用于完成上述模型格式间的转换功能。下面对这些函数的用法加以介绍。 1.通用状态空间模型与MPC状态空间模型之间的转换 MPC状态空间模型在通用状态空间模型的基础上增加了对系统输入/输出扰动和采样周期的描述信息,函数ss2mod()和mod2ss()用于实现这两种模型格式之间的转换。 1)通用状态空间模型转换为MPC状态空间模型函数ss2mod() 该函数的调用格式为 pmod= ss2mod(A,B,C,D) pmod= ss2mod(A,B,C,D,minfo) pmod= ss2mod(A,B,C,D,minfo,x0,u0,y0,f0) 式中,A, B, C, D为通用状态空间矩阵; minfo为构成MPC状态空间模型的其他描述信息,为7个元素的向量,各元素分别定义为: ◆minfo(1)=dt,系统采样周期,默认值为1; ◆minfo(2)=n,系统阶次,默认值为系统矩阵A的阶次; ◆minfo(3)=nu,受控输入的个数,默认值为系统输入的维数; ◆minfo(4)=nd,测量扰的数目,默认值为0; ◆minfo(5)=nw,未测量扰动的数目,默认值为0; ◆minfo(6)=nym,测量输出的数目,默认值系统输出的维数; ◆minfo(7)=nyu,未测量输出的数目,默认值为0; 注:如果在输入参数中没有指定m i n f o,则取默认值。 x0, u0, y0, f0为线性化条件,默认值均为0; pmod为系统的MPC状态空间模型格式。 例8-5将如下以传递函数表示的系统模型转换为MPC状态空间模型。 解:MATLAB命令如下:
北京化工大学高等化热大作业-基团贡献法
浅谈基团贡献法 引言 不久前,我前往导师XXX的办公室,与他沟通交流学业上的问题。谈话间,王老师提及的一种建立自由基聚合反应过程机理模型的方法──链节分析法[1],引起了我极大的兴趣。这一方法可以对复杂的聚合反应过程进行准确的动态模拟,解决了以往须同时求解无限多个微分方程才能模拟聚合过程的难题。通过这篇文献[1]我得知,对于高分子聚合物体系的热力学性质的处理,一直是建立聚合反应机理模型的难题之一。此法[1]不再把组成和链长不同的无穷多的聚合物大分子作为组分,而是将流程模拟系统的组分中出现的C、E、A·、R·等基本单元,参考其相应的单体物性,从而得到大分子聚合物的各种热力学性质。高分子的绝大部分热力学性质如密度ρ、比热容C p、焓H、摩尔体积V b、各种临界参数都能利用Joback基团贡献法,由基本单元的物性计算得到。联想到化热课堂上与基团贡献法有关的似乎只有UNIFAC模型,因此我想对物性估算法中的基团贡献法展开讨论,描述各种不同的方法并加以简单的评价。这便是本题目的来源。 第1章临界参数估算方法 不论是通过自己对化工热力学的学习,还是通过对文献的查阅,都不难得出这样的结论:对纯物质而言,临界参数是最重要的物性参数之一。其实,在所有的PVT 关系中,无论是对应状态法还是状态方程法都与临界数据有关。对应状态法已成为应用热力学的最基本法则[2],借助于对应状态法,物质的几乎所有的热力学参数和大量的传递参数可被预测,而对应状态法的使用又强烈地依赖于临界数据。此外,涉及到临界现象的高压操作,如超临界萃取和石油钻井[2],也与临界参数密切相关。总而言之,临界数据是化工设计和计算中不可缺少的重要数据。 临界参数如此重要,前人自然少不了花费巨大精力对其进行收集、整理和评定,但据我了解,所收集的临界数据大多局限于稳定物质的临界数据。虽然近几年对不稳定物质临界参数测定方法的研究在开展着,并且也测定了一些不稳定物质的临界参数,但大部分的不稳定物质仍由于测定难度大而缺乏实测的临界数据。因此,人们在致力
新运筹学填空选择简答题题库
基础课程教学资料祝福您及家人身体健康、万事如意、阖家欢乐!祝福同学们快乐成长,能够取得好成绩,为祖国奉献力量 运筹学填空/选择/简答题题库 第一章运筹学概念部分欢迎使用本资料,祝您身体健康、万事如意,阖家欢乐。愿同学们健康快乐的成长。早日为祖国的繁荣昌盛奉献自己的力量 一、填空题 1.运筹学的主要研究对象是各种有组织系统的管理问题,经营活动。欢迎使用本资料,祝您身体健康、万事如意,阖家欢乐。愿同学们健康快乐的成长。早日为祖国的繁荣昌盛奉献自己的力量 2.运筹学的核心主要是运用数学方法研究各种系统的优化途径及方案,为决策者提供科学 决策的依据。欢迎使用本资料,祝您身体健康、万事如意,阖家欢乐。愿同学们健康快乐的成长。早日为祖国的繁荣昌盛奉献自己的力量 3.模型是一件实际事物或现实情况的代表或抽象。 4通常对问题中变量值的限制称为约束条件,它可以表示成一个等式或不等式的集合。5.运筹学研究和解决问题的基础是最优化技术,并强调系统整体优化功能。 6.运筹学用系统的观点研究功能之间的关系。 7.运筹学研究和解决问题的优势是应用各学科交叉的方法,具有典型综合应用特性。8.运筹学的发展趋势是进一步依赖于_计算机的应用和发展。 9.运筹学解决问题时首先要观察待决策问题所处的环境。 10.用运筹学分析与解决问题,是一个科学决策的过程。 11.运筹学的主要目的在于求得一个合理运用人力、物力和财力的最佳方案。 12.运筹学中所使用的模型是数学模型。用运筹学解决问题的核心是建立数学模型,并对模型求解。 13用运筹学解决问题时,要分析,定义待决策的问题。 14.运筹学的系统特征之一是用系统的观点研究功能关系。 15.数学模型中,s.t表示约束(subject to 的缩写)。 16.建立数学模型时,需要回答的问题有性能的客观量度,可控制因素,不可控因素。17.运筹学的主要研究对象是各种有组织系统的管理问题及经营活动。 18. 1940年8月,英国管理部门成立了一个跨学科的11人的运筹学小组,该小组简称为OR。 二、单选题 1.建立数学模型时,考虑可以由决策者控制的因素是( A ) A.销售数量 B.销售价格 C.顾客的需求D.竞争价格 2.我们可以通过(C)来验证模型最优解。 A.观察 B.应用 C.实验 D.调查 3.建立运筹学模型的过程不包括( A )阶段。 A.观察环境 B.数据分析 C.模型设计 D.模型实施 1
《运筹学》期末复习题
《运筹学》期末复习题 第一讲运筹学概念 一、填空题 1.运筹学的主要研究对象就是各种有组织系统的管理问题,经营活动。 2.运筹学的核心主要就是运用数学方法研究各种系统的优化途径及方案,为决策者提供科学决策的依据。 3.模型就是一件实际事物或现实情况的代表或抽象。 4通常对问题中变量值的限制称为约束条件,它可以表示成一个等式或不等式的集合。5.运筹学研究与解决问题的基础就是最优化技术,并强调系统整体优化功能。运筹学研究与解决问题的效果具有连续性。 6.运筹学用系统的观点研究功能之间的关系。 7.运筹学研究与解决问题的优势就是应用各学科交叉的方法,具有典型综合应用特性。 8.运筹学的发展趋势就是进一步依赖于_计算机的应用与发展。 9.运筹学解决问题时首先要观察待决策问题所处的环境。 10.用运筹学分析与解决问题,就是一个科学决策的过程。 11、运筹学的主要目的在于求得一个合理运用人力、物力与财力的最佳方案。 12.运筹学中所使用的模型就是数学模型。用运筹学解决问题的核心就是建立数学模型,并对模型求解。 13用运筹学解决问题时,要分析,定议待决策的问题。 14.运筹学的系统特征之一就是用系统的观点研究功能关系。 15、数学模型中,“s·t”表示约束。 16.建立数学模型时,需要回答的问题有性能的客观量度,可控制因素,不可控因素。 17.运筹学的主要研究对象就是各种有组织系统的管理问题及经营活动。 18、1940年8月,英国管理部门成立了一个跨学科的11人的运筹学小组,该小组简称为OR。 二、单选题 1.建立数学模型时,考虑可以由决策者控制的因素就是( A ) A.销售数量 B.销售价格 C.顾客的需求 D.竞争价格 2.我们可以通过( C )来验证模型最优解。 A.观察 B.应用 C.实验 D.调查 3.建立运筹学模型的过程不包括( A )阶段。 A.观察环境 B.数据分析 C.模型设计 D.模型实施 4、建立模型的一个基本理由就是去揭晓那些重要的或有关的( B ) A数量B变量 C 约束条件 D 目标函数 5、模型中要求变量取值( D ) A可正B可负C非正D非负 6、运筹学研究与解决问题的效果具有( A ) A 连续性 B 整体性 C 阶段性 D 再生性 7、运筹学运用数学方法分析与解决问题,以达到系统的最优目标。可以说这个过程就是一个(C) A解决问题过程B分析问题过程C科学决策过程D前期预策过程8、从趋势上瞧,运筹学的进一步发展依赖于一些外部条件及手段,其中最主要的就是 ( C )
运筹学模型
第5章 运筹学模型 5.2 图论模型 图论是运筹学的一个重要分支,它是建立和处理离散类数学模型的一个重要工具。用图论的方法往往能帮助人们解决一些用其它方法难于解决的问题。图论的发展可以追溯到1736年欧拉所发表的一篇关于解决著名的“哥尼斯堡七桥问题”的论文。由于这种数学模型和方法直观形象,富有启发性和趣味性,深受人们的青睐。到目前为止,已被广泛地应用于系统工程、通讯工程、计算机科学及经济领域。传统的物理、化学、生命科学也越来越广泛地使用了图论模型方法。本章将在介绍图的一些基本概念的基础上,着重介绍最小生成树、最短路、最大流及最小费用最大流问题。 5.2.1 图的基本概念 城市之间的交通关系,家族成员之间的关系,工厂、企业、事业单位内部,部门之间的上下关系,工程中各个工序之间的先后关系等等,用图形来描述往往是很有益的。图论是研究某种特定关系的一门学问。 1.图 图 (graph) 由若干个点 (称作顶点,vertex) 和若干条连接两两顶点的线段(称edge )组成。通常,顶点可用来表示某一事物,边用来表示这些事之间的某种关系。如图5-1中的五个顶点可以代表五个城市。如果两个顶点之间有一条边连接,就表示这两个城市之间有一条铁路。同样,它也可以代表五个人。如果两个人认识,则用一条边把这两个顶点连接 起来。 图5-1 由于图是用来表示某些事物之间的联系,因而在画图时,顶点位置,边的长短、曲直是无关紧要的。只要两个图的顶点可以一一对应,并且 使得对应的顶点之间是否有边相连完全相同,就可以认为是同一个图。例如:图5-1也可以画成图5-2的形式。 图 5-2 设图的顶点集合V ={n v v v ,...,, 21}, 边的集合 E ={m e e e , ... ,,21} 把图记作 ) , (E V G =。这里大括号 { } 内的元素是没有顺序的,而小括号( )内的元素是有顺序 的。如果边e 连接顶点u 和v ,则记作e = {v u ,}。u 和v 称作e 的端点,e 称作u 和v 的关联边。如果u 和v 之间有一条边,即{v u ,}∈E ,则称u 和v 相邻。如果两条边有一个共同的端点,则称这两条边相邻。没有关联边的顶点称作孤立点。两个顶点之间可以有不止一条
能耗计量系统方案汇总-精选.
1.1国家政策 随着能耗问题日益突显,如何实现能耗管理和能源成本最小化成为中国的首要任务。为此,在“十二五”开局之年国家相关部门将节能减排指标落实到地区,由各个省、市、地区政府承担相应的节能任务。“政府出面帮助和督促用能单位节能降耗,以行政命令结合扶持政策,鼓励用能单位进行节能改造。” 在我国目前的能耗结构中,建筑所造成的能源消耗,已占我国总的商品能耗的20%~30%。而建筑运行的能耗,包括建筑物照明、采暖、空调和各类建筑内使用电器的能耗,将一直伴随建筑物的使用过程而发生。在建筑的全生命周期中,建筑材料和建造过程所消耗的能源一般只占其总的能源消耗的20%左右,大部分能源消耗发生在建筑物的运行过程中。建筑节能主要是为了降低各类建筑运行过程中消耗的能源。 实际调查数据表明,我国的建筑运行能耗,包括大型公共建筑的能耗都低于同等气候条件的发达国家现状,更远低于美国大多数建筑的目前状况。这是由于对室内环境要求的不同理念和不同标准所致。由于我们的状况与发达国家差异很大,因此不能简单复制国外建筑节能技术与经验。然而目前我国在大型公共建筑的新建和既有改造项目中,一方面建筑设计追求“与国外接轨”,“新、特、奇”,造成大量全玻璃,全密闭的高能耗建筑出现;另一方面又大量采用发达国家的所谓的“节能技术”,如变风量系统(V A V),建筑热电冷联供系统(BCHP),区域供冷,吸收制冷机,等等。但这些技术在大多数情况下并不能真正实现建筑节能。 因此,我国大型公共建筑的节能应该从实际能源消耗数据抓起,建筑实际运行能耗数据是评价和检验建筑节能的唯一标准。建立大型公共建筑分项用能实时监控管理平台是建筑节能的第一步。这有利于基于能耗数据的节能诊断、改造、运行、管理的服务。
模型预测控制快速求解算法
模型预测控制快速求解算法 模型预测控制(Model Predictive Control,MPC)是一种基于在线计算的控制优化算法,能够统一处理带约束的多参数优化控制问题。当被控对象结构和环境相对复杂时,模型预测控制需选择较大的预测时域和控制时域,因此大大增加了在线求解的计算时间,同时降低了控制效果。从现有的算法来看,模型预测控制通常只适用于采样时间较大、动态过程变化较慢的系统中。因此,研究快速模型预测控制算法具有一定的理论意义和应用价值。 虽然MPC方法为适应当今复杂的工业环境已经发展出各种智能预测控制方法,在工业领域中也得到了一定应用,但是算法的理论分析和实际应用之间仍然存在着一定差距,尤其在多输入多输出系统、非线性特性及参数时变的系统和结果不确定的系统中。预测控制方法发展至今,仍然存在一些问题,具体如下: ①模型难以建立。模型是预测控制方法的基础,因此建立的模型越精确,预测控制效果越好。尽管模型辨识技术已经在预测控制方法的建模过程中得以应用,但是仍无法建立非常精确的系统模型。 ②在线计算过程不够优化。预测控制方法的一大特征是在线优化,即根据系统当前状态、性能指标和约束条件进行在线计算得到当前状态的控制律。在在线优化过程中,当前的优化算法主要有线性规划、二次规划和非线性规划等。在线性系统中,预测控制的在线计算过程大多数采用二次规划方法进行求解,但若被控对象的输入输出个数较多或预测时域较大时,该优化方法的在线计算效率也会无法满足系统快速性需求。而在非线性系统中,在线优化过程通常采用序列二次优化算法,但该方法的在线计算成本相对较高且不能完全保证系统稳定,因此也需要不断改进。 ③误差问题。由于系统建模往往不够精确,且被控系统中往往存在各种干扰,预测控制方法的预测值和实际值之间一定会产生误差。虽然建模误差可以通过补偿进行校正,干扰误差可以通过反馈进行校正,但是当系统更复杂时,上述两种校正结合起来也无法将误差控制在一定范围内。 模型预测控制区别于其它算法的最大特征是处理多变量多约束线性系统的能力,但随着被控对象的输入输出个数的增多,预测控制方法为保证控制输出的精确性,往往会选取较大的预测步长和控制步长,但这样会大大增加在线优化过程的计算量,从而需要更多的计算时间。因此,预测控制方法只能适用于采样周
__运筹学概述
第一讲运筹学概述 一、运筹学是什么 ----------------------晕愁学 其实,这绝对一种误解,事实上运筹学方法及应用早在中小学就比较系统地学过,并且在我们每时每刻的生活过程中都在利用。 北师大版小学语文第六册教材中就有一篇课文《田忌赛马》,在座的各位应该都不陌生。这是战国时期运筹学思想成功应用的典型实例。孙膑同志合理地利用当时的现有资源、条件和比赛规则,只建议田忌调换了赛马的出场顺序,就使得原来屡战屡败的战局得到了彻底的扭转,以获胜而告终。形成了本文主题中“初战失败”、“孙膑献计”、“再赛获胜”的三部分内容。 运筹学思想体现的是,将现有资源的作用得到充分发挥,以获得最优的结果。运筹让生活得更有条理的艺术。 谈起运筹学,是否会想到很通俗的例子——沏茶水。沏茶,看起来是一件日常生活中再小不过的事情,却包含着运筹学的道理。让我们来看一看,沏茶的过程可以分为烧开水、洗茶壶、放茶叶多道“工序”。其中,烧开水所需的时间最长,洗茶壶、放茶叶的时间则较短。善于运筹的人,应该是先将水烧上,在烧水的过程中,从从容容地把茶壶洗净,把茶叶放好。而不善运筹的人,可能会先把茶壶洗净,把茶叶放好,才想起来水还没有烧;或者先把水烧开了,才急急忙忙去洗茶壶、放茶叶,搞得手忙脚乱。 另外还有一个例子我们外地生到上海的路线选择,虽然条条大路都能通到上海,但我们都有一个明确的目标,有些人的目标是准备用最短的时间到达,有些人的目标是用最少费用到达,这样基于不同的目标,就会选择不同的最佳路线。 这两个生活中的运筹学实例说明了运筹学应用的思想并不神秘,而现实的生活中,从沏茶、选择路线这样一件小事,到规模宏大的建设项目,都能运用运筹学的原理。在人生大事的安排上,也同样需要下功夫好好运筹一番。 从技术是,也就是运筹学解决决策问题的工具方面,在初中的数学教材中有一个重要的内容是《线性规划》,其中比较详细地讲述了线性规划的数学表述形式和求解方法。只不过没有详细介绍在实际决策过程中的应用。而线性规划是运筹学的主要决策工具,并且我们
数据中心能耗计算指导方法
数据中心的能耗审计 若想实现数据中心的节能降耗,首先需要确定影响数据中心能耗的基本因素。通过系统化的能耗审计能够提供数据中心能耗的实时概况和模型,明确了解数据中心的总体能耗以及能耗的具体分布状况,同时可以建立基线供未来改造规划之用。 能耗的审计可以通过手动计量,也可以采用先进的自动化设备获取相关数据。在能耗审计过程中,将主要依据以下三类数据开展审计工作: (1) 第一类是电量参数,包括系统和独立设备的工作电流、电压和电流波形等。 (2) 第二类是空气参数,包括温度、湿度、风速和温升等。 (3) 第三类参数,包括水和气的用量等。 数据采集密度越高,精度就越高,审计结果的准确性也越高。为了能够快速准确地进行能耗审计,大中型以上规模的数据中心都装有自动化的数据采集系统和分析系统,可以快速地进行能耗分布情况统计和分析。 通过能耗审计,可以明确知道能源的去向。在能耗较高的方面,能够有针对性地开展节能工作。我们知道,电力消耗是数据中心最主要的消耗,空调制冷等方面的能耗同样是以电力消耗的形式表现出来。 现有的一些研究数据可以让我们比较清楚地看到目前多数数据中心的电能分布情况。虽然这种分布并非理想,却代表了当今的普遍现状。数据中心输入电力分布如图4-1所示。 图4-1数据中心输入电力分布 从图4-1中可以看出,能耗高是目前数据中心普遍存在的现象。当IT设备系统,包括服务器、存储和网络通信等设备产生的能耗约占数据中心机房总能耗的30%时,电能使用效率(PUE)在3左右。其他各系统的具体能耗分布如下: (1) 制冷系统产生的能耗约占数据中心机房总能耗的33%左右。 (2) 空调送风和回风系统产生的能耗约占数据中心机房总能耗的9%左右。 (3) 加湿系统产生的能耗约占数据中心机房总能耗的3%左右。 (4) UPS供电系统的能耗约占数据中心机房总能耗的18%左右。 (5) PDU系统产生的能耗约占数据中心机房总能耗的5%左右。 (6) 照明系统的能耗约占数据中心机房总能耗的1%左右。 (7) 转换开关、线缆及其他系统的能耗约占数据中心机房总能耗的1%左右。 从数据中心电能的流向来看:一是IT设备约占30%;二是空气处理设备约占45%,建筑