网页数据采集器如何使用

https://www.360docs.net/doc/087403444.html,
网页数据采集器如何使用
新浪微博是目前国内比较火的一个社交互动平台,明星、各大品牌都有注册官方微博,有什么活动也都会在微博上宣传造势,和粉丝评论互动。普通人平常也喜欢将生活中的点滴分享到微博,所以微博聚集了大批的用户。本文就以使用八爪鱼采集器的简易模式采集新浪微博数据为例子,为大家介绍网页数据采集器的使用方法。
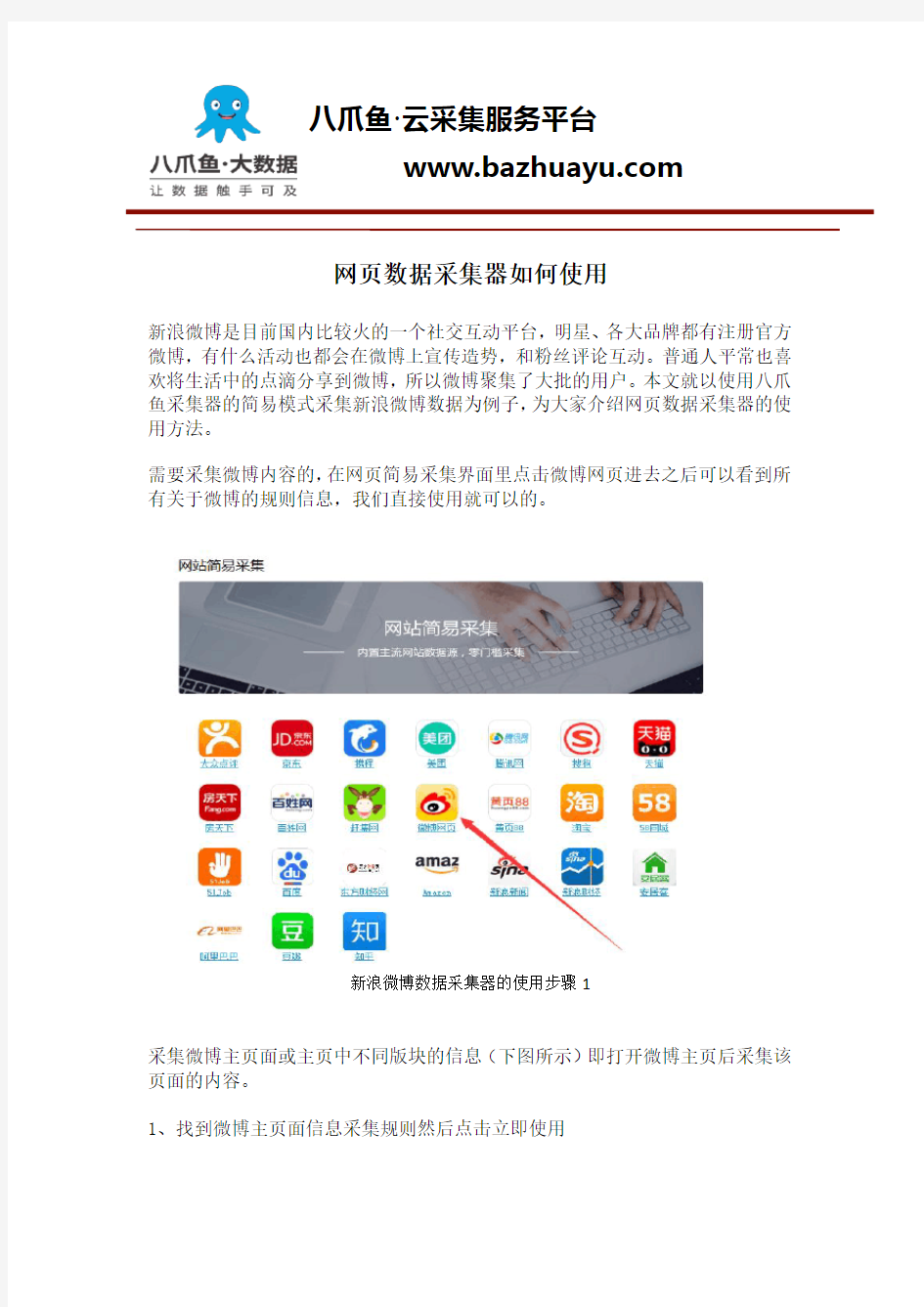
需要采集微博内容的,在网页简易采集界面里点击微博网页进去之后可以看到所有关于微博的规则信息,我们直接使用就可以的。
新浪微博数据采集器的使用步骤1
采集微博主页面或主页中不同版块的信息(下图所示)即打开微博主页后采集该页面的内容。
1、找到微博主页面信息采集规则然后点击立即使用
https://www.360docs.net/doc/087403444.html,
新浪微博数据采集器的使用步骤2
2、下图显示的即为简易模式里面微博主页面信息采集的规则
查看详情:点开可以看到示例网址
任务名:自定义任务名,默认为微博主页面信息采集
任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组
网址:设置要采集的网址,如果有多个网址用回车(Enter)分隔开,一行一个。支持输入微博首页网址和首页各个子版本的网址,如
https://www.360docs.net/doc/087403444.html,/?category=1760
示例数据:这个规则采集的所有字段信息
https://www.360docs.net/doc/087403444.html,
新浪微博数据采集器的使用步骤3
3、规则制作示例
例如采集微博主页面和社会版块的信息。设置如下图所示:
任务名:自定义任务名,也可以不设置按照默认的就行
任务组:自定义任务组,也可以不设置按照默认的就行
网址:从浏览器中将要采集网址复制黏贴到输入框中,本示例为https://www.360docs.net/doc/087403444.html,/
https://www.360docs.net/doc/087403444.html,/?category=7
设置好之后点击保存
https://www.360docs.net/doc/087403444.html,
新浪微博数据采集器的使用步骤3
保存之后会出现开始采集的按钮
https://www.360docs.net/doc/087403444.html,
新浪微博数据采集器的使用步骤4
4、选择开始采集之后系统将会弹出运行任务的界面
可以选择启动本地采集(本地执行采集流程)或者启动云采集(由云服务器执行采集流程),这里以启动本地采集为例,我们选择启动本地采集按钮
https://www.360docs.net/doc/087403444.html,
新浪微博数据采集器的使用步骤5
5、选择本地采集按钮之后,系统将会在本地执行这个采集流程来采集数据,下图为本地采集的效果
新浪微博数据采集器的使用步骤6
6、采集完毕之后选择导出数据按钮即可,这里以导出excel 2007为例,选择这个选项之后点击确定
https://www.360docs.net/doc/087403444.html,
新浪微博数据采集器的使用步骤7
7、然后选择文件存放在电脑上的路径,路径选择好之后选择保存
新浪微博数据采集器的使用步骤8
8、这样数据就被完整的导出到自己的电脑上来了哦
https://www.360docs.net/doc/087403444.html,
新浪微博数据采集器的使用步骤9
注:采集过程中如出现提示是否补采,请先选择“是”,程序即进行补采,注意观察页面数据量变化情况,如无增加,则再提示补采时请选择“否”。有则继续补采,云上会自动补采。
新浪微博数据采集器的使用步骤10
相关采集教程:
淘宝数据采集:
https://www.360docs.net/doc/087403444.html,/tutorial/hottutorial/dianshang/taobao
https://www.360docs.net/doc/087403444.html,
京东爬虫:
https://www.360docs.net/doc/087403444.html,/tutorial/hottutorial/dianshang/jd
天猫爬虫:
https://www.360docs.net/doc/087403444.html,/tutorial/hottutorial/dianshang/tmall
阿里巴巴数据采集:
https://www.360docs.net/doc/087403444.html,/tutorial/hottutorial/dianshang/alibaba
亚马逊爬虫:
https://www.360docs.net/doc/087403444.html,/tutorial/hottutorial/dianshang/amazon
今日头条采集:
https://www.360docs.net/doc/087403444.html,/tutorial/hottutorial/xwmt/toutiao
腾讯新闻采集:
https://www.360docs.net/doc/087403444.html,/tutorial/hottutorial/xwmt/tenxunnews
天眼查爬虫:
https://www.360docs.net/doc/087403444.html,/tutorial/hottutorial/qyxx/tianyancha
顺企网企业信息采集:
https://www.360docs.net/doc/087403444.html,/tutorial/hottutorial/qyxx/shunqiwang
链家爬虫:
https://www.360docs.net/doc/087403444.html,/tutorial/hottutorial/fangyuan/lianjia
八爪鱼——100万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。配置好采集任务后可关机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
https://www.360docs.net/doc/087403444.html,
34970A数据采集器中文说明书
Agilent34970A 数据采集仪基本操作实验 一、实验目的 1.了解Agilent34970A数据采集仪的基本结构和功能。 2.了解Agilent34901A测量模块的基本功能和工作原理。 3.学习Agilent34970A数据采集仪使用面板进行数据采集的方法。 二、实验要求 1.根据Agilent34970A数据采集仪用户手册,掌握各开关、按钮的功能与作用。 2.通过Agilent34901A测量模块,分别对J型热电偶、Pt100、502AT热敏电组、直流电压、直流电流进行测量。 三、实验内容与步骤 1.实验准备 Agilent34970A数据采集仪的基本功能与性能。Agilent 34970A数据采集仪是一种精度为6位半的带通讯接口和程序控制的多功能数据采集装置,外形结构如图1、图2所示:
其性能指标和功能如下: 1.仪器支持热电偶、热电阻和热敏电阻的直接测量,具体包括如下类型: 热电偶:B、E、J、K、N、R|T型,并可进行外部或固定参考温度冷端补偿。 热电阻:R0=49?至?,α=(NID/IEC751)或α=的所有热电阻。 热敏电阻:k?、5 k?、10 k?型。
2.仪器支持直流电压、直流电流、交流电压、交流电流、二线电阻、四线电阻、频率、周期等11种信号的测量。 3.可对测量信号进行增益和偏移(Mx+B)的设置。 4.具有数字量输入/输出、定时和计数功能。 5.能进行度量单位、量程、分辨率和积分周期的自由设置。 6.具有报警设置和输出功能。 7.热电偶测量基本准确度:℃,温度系数:℃。 8.热电阻测量基本准确度:℃,温度系数:℃。 9.热敏电阻测量基本准确度:℃,温度系数:℃。 10.直流电压测量基本准确度:+(读数的℅+量程的℅)。 11.直流电流测量基本准确度:+(读数的℅+量程的℅)。 12.电阻测量基本准确度:+(读数的℅+量程的℅)。 13.交流电压测量基本准确度:+(读数的℅+量程的℅)(10Hz~20kHz 时)。 14.交流电流测量基本准确度:+(读数的℅+量程的℅)(10Hz~5kHz 时)。 15.频率、周期测量基本准确度:(读数的℅)(40Hz~300kHz时)。16.具有系统状态、校准设置和数据存储等功能。 Agilent34970A 数据采集仪的面板按钮功能与作用。 1. 在所显示的通道上配置测量参数:
网页数据采集器如何使用
https://www.360docs.net/doc/087403444.html, 网页数据采集器如何使用 新浪微博是目前国内比较火的一个社交互动平台,明星、各大品牌都有注册官方微博,有什么活动也都会在微博上宣传造势,和粉丝评论互动。普通人平常也喜欢将生活中的点滴分享到微博,所以微博聚集了大批的用户。本文就以使用八爪鱼采集器的简易模式采集新浪微博数据为例子,为大家介绍网页数据采集器的使用方法。 需要采集微博内容的,在网页简易采集界面里点击微博网页进去之后可以看到所有关于微博的规则信息,我们直接使用就可以的。 新浪微博数据采集器的使用步骤1 采集微博主页面或主页中不同版块的信息(下图所示)即打开微博主页后采集该页面的内容。 1、找到微博主页面信息采集规则然后点击立即使用
https://www.360docs.net/doc/087403444.html, 新浪微博数据采集器的使用步骤2 2、下图显示的即为简易模式里面微博主页面信息采集的规则 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为微博主页面信息采集 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 网址:设置要采集的网址,如果有多个网址用回车(Enter)分隔开,一行一个。支持输入微博首页网址和首页各个子版本的网址,如 https://www.360docs.net/doc/087403444.html,/?category=1760 示例数据:这个规则采集的所有字段信息
https://www.360docs.net/doc/087403444.html, 新浪微博数据采集器的使用步骤3 3、规则制作示例 例如采集微博主页面和社会版块的信息。设置如下图所示: 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行 网址:从浏览器中将要采集网址复制黏贴到输入框中,本示例为https://www.360docs.net/doc/087403444.html,/ https://www.360docs.net/doc/087403444.html,/?category=7 设置好之后点击保存
淘宝图片抓取工具使用方法
https://www.360docs.net/doc/087403444.html, 淘宝图片抓取工具使用方法 对于电商设计师来说,抓取竞品的宝贝的图片和店铺装修图片,来分析设计自己店铺的风格并做出差异化,是非常有用的方法哦。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【淘宝图片】为例,教大家如何使用八爪鱼采集软件采集淘宝图片的方法。 本文介绍使用八爪鱼7.0采集淘宝商品图片的方法:首先将淘宝商品搜索结果网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的淘宝商品图片URL,下载并保存到本地电脑中。 采集网址:淘宝商品搜索页面 比如T恤(可更换其他关键词对淘宝商品图片进行采集): https://https://www.360docs.net/doc/087403444.html,/search?q=T%E6%81%A4&imgfile=&commend=all &search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taob ao-item.1&ie=utf8&initiative_id=tbindexz_20170306 采集数据内容:淘宝商品图片地址
https://www.360docs.net/doc/087403444.html, 使用功能点: ●翻页设置 ●图片链接采集 步骤1:创建淘宝商品图片采集任务1)进入八爪鱼采集器主界面,选择自定义模式 淘宝商品图片采集步骤1
https://www.360docs.net/doc/087403444.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 淘宝商品图片采集步骤2 3)如下图红色框中的淘宝商品图片即为本次要采集的内容。
https://www.360docs.net/doc/087403444.html, 淘宝商品图片采集步骤3 步骤2:创建翻页循环 ●找到翻页按钮,设置翻页循环 ●设置ajax翻页时间 ●设置滚动页面 1)将淘宝商品搜索结果页页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”这个选项。
网站爬虫如何爬取数据
https://www.360docs.net/doc/087403444.html, 网站爬虫如何爬取数据 大数据时代,用数据做出理性分析显然更为有力。做数据分析前,能够找到合适的的数据源是一件非常重要的事情,获取数据的方式有很多种,最简便的方法就是使用爬虫工具抓取。今天我们用八爪鱼采集器来演示如何去爬取网站数据,以今日头条网站为例。 采集网站: https://https://www.360docs.net/doc/087403444.html,/ch/news_hot/ 步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式” 网站爬虫如何爬取数据图1
https://www.360docs.net/doc/087403444.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 网站爬虫如何爬取数据图2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容
https://www.360docs.net/doc/087403444.html, 网站爬虫如何爬取数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定
https://www.360docs.net/doc/087403444.html, 网站爬虫如何爬取数据图4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量
https://www.360docs.net/doc/087403444.html, 网站爬虫如何爬取数据图5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 然后点击“选中子元素”
数据采集器采集各种设备和仪表的配置说明 V1.8
绿色建筑能源与环境监控主机 配置及操作说明V1.8 (内部使用,未完待续) 重庆德易安科技发展有限公司Chongqing EHS Technology Development Co.,Ltd.
目录 界面概述 (4) 1.沈阳航发热能表 (6) 1.1.航发超声波表配置 (6) 1.2.航发机械表配置 (7) 2.德易安温控器 (11) 3.江阴众和电表(645-2007) (13) 4.埃美柯水表 (14) 5.TTD温度传感器 (15) 6.深圳北电电表(645-1997) (17) 7.长沙索拓温控器 (18) 8.宁波甬港热能表 (20) 9.宁波冷水表 (22) 9.1.M-BUS接口 (22) 9.2.RS485接口 (23) 10.重庆伟岸热量表 (24) 11.合肥艾通单相电表 (27) 12.山东力创三相电表(DTSD106) (28) 13.上海德易特热能表 (30) 13.1.德易特超声波表配置 (30) 13.2.连利水表 (32) 14. PZ系列直流电参量检测仪表 (33) 15. 柏诚(SX96) (35) 16.山东力创DDSD-113-Ⅱ单相电子式电能表 (39) 17.浙江立新DDS238-4单相电子式电能表 (40) 18.浙江立新DDS238-7三相电子式电能表 (41) 19.深圳北电电表三相四线电子式有功电能表(645-1997) (42) 20.浙江立新DTS238-7 ZN/S型三相四线电子式电能表 (43)
界面概述 A: 根据采集器下连接的设备选择相应的协议和参数,选择好后单击“下载采集器端口配置”都配好需要保存配置时,单击上方的“保存配置”。 B: 输入相应的IP地址连接其采集器。也可以对采集器的IP地址进行更改,输入新的IP地址和其他等相关参数后单击“下载LAN端口配置”“保存配置”并“重启采集器”,新的IP地址即可生效。IP设置正确后单击“连接”在D中显示“连接到”即连接成功。(忘记ip时可以复位采集器,复位后采集器的默认IP为192.168.0.222)。 C: 将数据需要上传到哪个主机上就配置为相应的主机ip和相对应的端口,一般将服务器1配置为本地的配置软件上,端口取默认值9032。服务器2配置为能耗服务器或者计费软件。 单击“下载远程服务器设置”,其设置生效。“保存配置”对设置进行保存。 D:对连接状态和相关操作的显示 读取配置:当连接到采集器后单击“读取配置”即读取以前保存的数据。 本地保存:将配置保存到电脑上方便以后调用。 本地读取:将以前保存出来的配置调用出来,分别下载后并保存到采集其中。 打开服务器:(以服务器1为例,其它同理)
数据采集软件使用说明
数据采集软件使用说明 一.软件安装 点击数据采集系统的安装文件,按照指示安装 二.驱动程序安装 如果是购买的数据线是USB接口的,请先安装驱动程序,在“USB驱动程序”目录下,点击“CH341SER”文件,安装指示安装 三.界面说明 四.操作说明 1.连接 打开软件后,点击【打开设备】按钮,软件自动搜寻设备,当前值窗口将有数据显示,【打开设备】按键变为【关闭设备】。 如果弹出 则表示设备连接失败,请按照说明书所附的故障处理来检查原因。 2.参数设定 在设备连接和断开的状态下都可以设置系统参数,点击【参数设置】按钮,参数设置窗口数据变成绿色(见下图),表示可以修改,数据修改完成后,再点击此按钮,参数保存,窗口恢复原样。
参数说明 1)标准尺寸 表示零件的名义尺寸 2)上公差 允许与标准尺寸的上偏差值 3)下公差 允许与标准尺寸的下偏差值 4)采集间隔 数据自动采集保存的间隔时间 5)测量单位 采集数据的单位由用户自己定义,可以是毫米、英寸和度 6)提示音 在数据保存时选择是否需要提示音 7)工件名称 工件名称用户可自己命名 8)操作员 操作员名称用户可自己命名 3.数据保存 数据保存可以是手动保存和自动保存,点击【手动采集】按钮,数据可以保存一条记录,点击【自动采集】按钮,可以按照参数设定中自动采集的时间来自动记录数据,记录过程中再点击该按钮可以停止采集。 点击【清除记录】按钮,可清除当前记录的数据 点击【保存导出】按钮,可把数据保存成EXCEL格式文件,做进一步处理。 五.故障处理 如果点击【打开设备】,显示找不到可用串口,请按下面的提示检测问题 1)检测设备是否打开 2)检测数据线是否连接正常 3)检测数据线是否被电脑识别 a.如果是USB数据接口请检测驱动程序是否安装,并在WINDOW的设备管理器中 找到已安装的设备 b.设备管理器的检测方式: 选择“我的电脑”,点击鼠标右键,在菜单中点击“属性”,弹出下面窗口 然后再点击“硬件”这一栏
阿里巴巴数据采集器使用方法
https://www.360docs.net/doc/087403444.html, 阿里巴巴数据采集器使用方法 阿里巴巴集团经过十几年的快速发展,在全球范围都有它的身影,众多的业务和关联公司形成了一个多样性的生态系统,旗下的业务有:淘宝,天猫,1688,速卖通,闲鱼,蚂蚁金服,阿里云等。如此多的关联业务,其中的数据也是很有参考价值的。学习阿里巴巴数据采集器的使用方法让获取数据的来源更广阔。本文介绍使用八爪鱼采集器采集阿里巴巴数据(以保温杯厂商为例)的方法。 采集网站: https://https://www.360docs.net/doc/087403444.html,/selloffer/offer_search.htm?keywords=%B1%A3%CE%C2%B1%AD&n=y&spm= a260k.635.3262836.d102 本文仅以保温杯厂商搜索结果页URL作为采集示例,大家需要采集其他产品厂商可以更换链接进行采集。 采集的内容:阿里巴巴商品标题,阿里巴巴厂家名称,阿里巴巴厂家电话(其他阿里相关的数据如果要采集的话也是可以添加的) 使用功能点: ●创建循环翻页 ●商品URL采集提取
https://www.360docs.net/doc/087403444.html, ●创建URL循环采集任务 ●修改Xpath 步骤1:创建阿里巴巴数据采集任务 1)进入主界面,选择“自定义采集”
https://www.360docs.net/doc/087403444.html, 2)将要采集的阿里巴巴列表或搜索结果页URL复制粘贴到输入框中,点击“保存网址” 3)打开网页的时候页面需要向下滚动才会出现所有的数据,所以可以在这一步设置一个高级选项,在滚动页面这里设置页面加载完成向下滚动,滚动次数设置3秒,每次间隔3秒,滚动方式选择“直接滚动到底部”。
https://www.360docs.net/doc/087403444.html, 4)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的商品url是这次演示采集的信息
网页抓取工具如何进行http模拟请求
网页抓取工具如何进行http模拟请求 在使用网页抓取工具采集网页是,进行http模拟请求可以通过浏览器自动获取登录cookie、返回头信息,查看源码等。具体如何操作呢?这里分享给大家网页抓取工具火车采集器V9中的http模拟请求。许多请求工具都是仿照火车采集器中的请求工具所写,因此大家可以此为例学习一下。 http模拟请求可以设置如何发起一个http请求,包括设置请求信息,返回头信息等。并具有自动提交的功能。工具主要包含两大部分:一个MDI父窗体和请求配置窗体。 1.1请求地址:正确填写请求的链接。 1.2请求信息:常规设置和更高级设置两部分。 (1)常规设置: ①来源页:正确填写请求页来源页地址。 ②发送方式:get和post,当选择post时,请在发送数据文本框正确填写发布数据。 ③客户端:选择或粘贴浏览器类型至此处。 ④cookie值:读取本地登录信息和自定义两种选择。 高级设置:包含如图所示系列设置,当不需要以上高级设置时,点击关闭按钮即可。 ①网页压缩:选择压缩方式,可全选,对应请求头信息的Accept-Encoding。 ②网页编码:自动识别和自定义两种选择,若选中自定义,自定义后面会出现编
码选择框,在选择框选择请求的编码。 ③Keep-Alive:决定当前请求是否与internet资源建立持久性链接。 ④自动跳转:决定当前请求是否应跟随重定向响应。 ⑤基于Windows身份验证类型的表单:正确填写用户名,密码,域即可,无身份认证时不必填写。 ⑥更多发送头信息:显示发送的头信息,以列表形式显示更清晰直观的了解到请求的头信息。此处的头信息供用户选填的,若要将某一名称的头信息进行请求,勾选Header名对应的复选框即可,Header名和Header值都是可以进行编辑的。 1.3返回头信息:将详细罗列请求成功之后返回的头信息,如下图。 1.4源码:待请求完毕后,工具会自动跳转到源码选项,在此可查看请求成功之后所返回的页面源码信息。 1.5预览:可在此预览请求成功之后返回的页面。 1.6自动操作选项:可设置自动刷新/提交的时间间隔和运行次数,启用此操作后,工具会自动的按一定的时间间隔和运行次数向服务器自动请求,若想取消此操作,点击后面的停止按钮即可。 配置好上述信息后,点击“开始查看”按钮即可查看请求信息,返回头信息等,为避免填写请求信息,可以点击“粘贴外部监视HTTP请求数据”按钮粘贴请求的头信息,然后点击开始查看按钮即可。这种捷径是在粘贴的头信息格式正确的前提下,否则会弹出错误提示框。 更多有关网页抓取工具或网页采集的教程都可以从火车采集器的系列教程中学习借鉴。
python抓取网页数据的常见方法
https://www.360docs.net/doc/087403444.html, python抓取网页数据的常见方法 很多时候爬虫去抓取数据,其实更多是模拟的人操作,只不过面向网页,我们看到的是html在CSS样式辅助下呈现的样子,但爬虫面对的是带着各类标签的html。下面介绍python抓取网页数据的常见方法。 一、Urllib抓取网页数据 Urllib是python内置的HTTP请求库 包括以下模块:urllib.request 请求模块、urllib.error 异常处理模块、urllib.parse url解析模块、urllib.robotparser robots.txt解析模块urlopen 关于urllib.request.urlopen参数的介绍: urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) url参数的使用 先写一个简单的例子:
https://www.360docs.net/doc/087403444.html, import urllib.request response = urllib.request.urlopen(' print(response.read().decode('utf-8')) urlopen一般常用的有三个参数,它的参数如下: urllib.requeset.urlopen(url,data,timeout) response.read()可以获取到网页的内容,如果没有read(),将返回如下内容 data参数的使用 上述的例子是通过请求百度的get请求获得百度,下面使用urllib的post请求 这里通过https://www.360docs.net/doc/087403444.html,/post网站演示(该网站可以作为练习使用urllib的一个站点使用,可以 模拟各种请求操作)。 import urllib.parse import urllib.request data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
便携式红外通信数据采集器使用说明5页word
便携式红外通信数据采集器使用说明1)数据采集器简介 便携式红外通信数据采集器以下简称数据采集器,是采用微电脑芯片工作的红外遥控取数装置,主要用于不能有线传输的 野外偏远工作区,可以同时为12台监测仪提供服务,存储容量为 256K,可以存储10000组数据,掉电数据不丢失,LCD点阵式液晶 显示器,轻触式键盘操作,全日立实时显示,红外数据通讯功能,2400bps传输速率。具体使用如下: 仪器图示: 数据采集器面板 2)功能键操作说明 按下“ON”键开机LCD显示提示菜单如下: 0:FJ 1:QS 2:TX 0: FJ表示按键“0”设定监测仪编号和测量时间间隔 1:QS表示按键“1”从监测仪取数 2:TX表示按键“2”与计算机通信 3:QD表示按键“3”启动监测仪并校正监测仪时钟 4:SJ表示按键“4”显示内存数据 5:QC表示按键“5”清除数据采集器内存数据 6:SZ表示按键“6”显示或调整时钟 7: JD表示设定压力基点(范围) a)设定监测仪号、测量时间间隔
将数据采集器挂到监测仪上,在开机初始状态下按下数字“0”键,屏幕显示 FJH No.00 此时仪器进入监测仪号设定和定时间隔设定状态,上面一行为监测仪 号设定,设定范围为00~12;下面一行为测量时间间隔设定,设定范围为00:01~23:59, b) 取数 将数据采集器挂到监测仪上,在开机初始状态下按下数字“1”键,屏幕显示 GET DATA 仪器进入从监测仪读取数据状态,此时再按下压力监测仪的“启动”键,数据采集器开始从监测仪读取数据,此时数据采集器依次显示“GET DATE BEGIN”; “GET DATA No(监测仪号)”;“GET DATE END” GET DATA 以上状态表示取数成功,三秒钟后自动将监测仪内数据清除并校正监测仪时钟,此时数据采集器依次显示“START BEGIN”;“START END”(注意:采集数据前必须清除内存数据) 如果读取不到数据,屏幕一直处于上述状态,按下ESC键,屏幕显示 GET DATA 再次按下ESC键,仪器返回开机初始状态。 c) 通信 将数据采集器面板朝上平放到红外数据计算机通信适配器左上方,在
数据采集器用户手册
数据采集器用户手册 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-MG129]
支持环境监测数据的接入、存储、分析和业务流程,服务于各级环保主管机构和监测中心、监测站,提高环保监测、执法效率和效能; 2.发展方向 随着社会经济的高速发展,重视人类生存环境逐渐成为人们意识、行动的重要的指导思想。根据国家环保总局的要求,要逐步在一些大中城市建立区域性的环境质量和污染源监测的自动化网络系统。 全国重点工业污染源企业分期逐步实施全天候污染源自动监测系统.主要针对企业治污设施的运行状况和排污口水质、流量进行持续全自动监测,将整个运行数据记录下来,以便随时抽调,为各级环保部门的监督管理提供准确依据。 在环境监测、环境信息方面,要开展区域环境质量地面自动监测、预报与预警技术研究。研究常规环境质量自动监测网络技术,研制基于激光遥感技术的区域空气质量监测、预报、预警及决策支持的技术体系,开展重点流域地表水监测预警系统技术研究和重点生态区与海洋环境预警监视系统建立的研究,研究农村源污染控制地面监测技术。 研究环境信息应用和综合决策技术方法,提高我国环境管理的统一规划与综合决策能力。开展环境信息数据库技术研究,研制环境信息传输系统,研究基于地理信息系统的环境信息查询、服务及基于因特网的环境信息技术,建立环境综合决策模型。 三、分类 1.JLWZ-YX-300-II数据采集器提供两种工作方式: 单机运行方式:作为本地的排污单位的监测仪器单独使用。
组网运行方式:采集器根据本地或中心站远程设置的采集周期采集 各通道数据、存储,通过GPRS上传给中心站。从而构成环境污染在 线监测系统。设备地址设置为1-14个ASCII字符,由中心站统一分 配。 2.JLWZ-YX-300-II数据采集器按数据链路不同,可以分为: ●GPRS方式(以下针对GPRS方式进行说明); ●PSTN方式; ●ADSL方式; ●SMS方式。 四、组网方式 环境污染在线监测系统组网方式如图1所示: 图1 环境污染在线监测系统组网方式 五、功能简介 1.JLWZ-YX-300-II数据采集器主要由8个子模块组成: 模拟量采集子模块 数字量采集子模块 开关量检测子模块 反控子模块 微处理器子模块 远程通讯子模块 人机界面子模块
网络文字抓取工具使用方法
https://www.360docs.net/doc/087403444.html, 网络文字抓取工具使用方法 网页文字是网页中常见的一种内容,有些朋友在浏览网页的时候,可能会有批量采集网页内容的需求,比如你在浏览今日头条文章的时候,看到了某个栏目有很多高质量的文章,想批量采集下来,下面本文以采集今日头条为例,介绍网络文字抓取工具的使用方法。 采集网站: 使用功能点: ●Ajax滚动加载设置 ●列表内容提取 步骤1:创建采集任务
https://www.360docs.net/doc/087403444.html, 1)进入主界面选择,选择“自定义模式” 今日头条网络文字抓取工具使用步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/087403444.html, 今日头条网络文字抓取工具使用步骤2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
https://www.360docs.net/doc/087403444.html, 今日头条网络文字抓取工具使用步骤3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间
https://www.360docs.net/doc/087403444.html, 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 今日头条网络文字抓取工具使用步骤4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
https://www.360docs.net/doc/087403444.html, 今日头条网络文字抓取工具使用步骤5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色
如何利用爬虫爬取马蜂窝千万+数据
https://www.360docs.net/doc/087403444.html, 如何利用爬虫爬取马蜂窝千万+数据 最近有人爬了马蜂窝的1800万数据就刷爆了网络,惊动了互联网界和投资界,背后的数据团队也因此爆红。 你一定会想像这个团队像是电影里演的非常牛掰黑客一样的人物吧? 你以为爬数据一定要懂爬虫写代码、懂Python才能爬取网络数据是吧? 小八告诉你,过去可能是,但现在真的不!是!
https://www.360docs.net/doc/087403444.html, 爬这样千万级数据的工作,我们绝大部分人即使不懂写代码,都可以实现。 如何实现? 就是利用「数据爬虫工具」。 目前的爬虫工具已经趋向于简易、智能、可视化了,即使不懂代码和爬虫的小白用户都可以用。 比如在全球坐拥百万用户粉丝的八爪鱼数据采集器。 简单来说,用八爪鱼 爬取马蜂窝数据只要4个步骤。这里我们以爬取【马蜂窝景点点评数据】举例。
https://www.360docs.net/doc/087403444.html, ★ 第一步 打开马蜂窝,选择某城市的景点页面,(本文以采集成都景点点评为例) 第二步 用八爪鱼爬取马蜂窝的成都的top30景点页面超链接url地址
https://www.360docs.net/doc/087403444.html, 八爪鱼采集成都top30 景点网址url
https://www.360docs.net/doc/087403444.html, 第三步 用八爪鱼简易模板「蚂蜂窝国内景点点评爬虫」 第四步 导出数据到EXCEL。
https://www.360docs.net/doc/087403444.html, 小八只花了15分钟的时间就采集到成都TOP热门30景点的842条点评数据。如果同时运行多个客户端并使用使用云采集,将会更快。 (由于只是示例,每个景点小八只采集了842条评,如果有需要可以采集更多,这个可自己设置) 爬取结果
微信文章抓取工具详细使用方法
https://www.360docs.net/doc/087403444.html, 微信文章抓取工具详细使用方法 如今越来越多的优质内容发布在微信公众号中,面对这些内容,有些朋友就有采集下来的需求,下面为大家介绍使用八爪鱼抓取工具去抓取采集微信文章信息。 抓取的内容包括:微信文章标题、微信文章关键词、微信文章部分内容展示、微信所属公众号、微信文章发布时间、微信文章URL等字段数据。 采集网站:https://www.360docs.net/doc/087403444.html,/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
https://www.360docs.net/doc/087403444.html, 微信文章抓取工具详细使用步骤1 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/087403444.html, 微信文章抓取工具详细使用步骤2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”
https://www.360docs.net/doc/087403444.html, 微信文章抓取工具详细使用步骤3 2)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮 微信文章抓取工具详细使用步骤4
https://www.360docs.net/doc/087403444.html, 3)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮” 微信文章抓取工具详细使用步骤5 4)页面中出现了 “八爪鱼大数据”的文章搜索结果。将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”
https://www.360docs.net/doc/087403444.html, 微信文章抓取工具详细使用步骤6 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里第一篇文章的区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
K37环保数据采集器使用说明书
K37环保数据采集器 使用说明书 博控自动化技术有限公司2010年2月
前言 感谢您购买本公司的产品!感谢您对环保事业做出的贡献! 本手册是关于设备的功能、设置、安装、接线方法、操作方法、故障时的处理方法等的说明书。在操作之前请仔细阅读本手册,正确使用。 请将本手册妥善保存,以便随时翻阅和操作时参考。 注意事项 本手册容如因功能升级而有修改时,恕不另行通知。 如果您在使用过程中对我们的产品或者服务有任何建议或意见,请与我们联系。 说明书版本 2010年2月,版本号:1.2。
请安全使用本设备 为了您能安全使用本设备,操作时请务必遵守下述安全注意事项。如果不按照本手册的说明操作,有导致设备不能正常使用的可能,甚至有导致损坏设备的危险,如因此导致设备故障,我公司不承担责任。 警告 ●只有受过培训的专职人员才能进行设备安装调试和操作。 ●接通电源之前请确认设备的电源电压是否与供电电压一致。 ●电源需要有接地端。 ●必须在设备断电的情况下进行接线。 ●必须在设备断电的情况下插拔SIM卡。 ●未经过培训的人员,不得打开设备外壳。
第一章.概述 (6) 1-1.产品的通信方式说明 (6) 1-2.产品的数据采集原理 (7) 1-3.产品特点 (8) 第二章. 产品技术参数 (10) 2-1.外形图 (10) 2-2.技术参数 (11) 2-3.使用条件 (12) 第三章.安装与维护 (13) 3-1.接线前的准备 (13) 3-2.接线说明 (14) 3-3.跳线说明 (15) 3-4.安装注意事项 (16) 3-5.设备的维护与保养 (17) 3-6.设备的保修 (17) 3-7.设备安装尺寸 (18) 第四章.显示和键盘操作 (19) 4-1.主菜单 (19) 4-2.采集量显示 (20) 4-3.显示符号说明 (22) 4-4.LED指示灯说明 (23) 4-5.键盘 (24) 4-6.系统设置 (27)
数据采集器配置、驱动软件设置说明
MODEL UT-5526 :32通道高速数字电压表 产品使用说明书 深圳市宇泰科技有限公司 UTEK TECHNOLOGY SHENZHEN CO.,LTD. ()
1.11.2 2.12.2LED 2.3UT-5526 3.13.2IP 3.4DDNS 4.UT-55264.14.24.34.5PING 5.5.15.2Vir-COM 5.3Vir-COM 6.一、了解二、硬件安装与初始设定 三、系统设定 串UT-5526 UT-5526介绍 主要功能 硬件定义 状态说明 初始设定值 行端口操作模式 设定 (动态域名系统) 系统管理设定 系统管理者设定 系统状态 备份与还原 虚拟串口应用程序 虚拟串口应用程序 虚拟串口驱动和运行环境 使用方法 故障排除说明【目录】
一、了解、介绍 UT-5526 1UT-55263232通道数字电压表是一种多通道电压表,有通道电压独立输入,采用多种通信方式,可和计算机方便连接,构成实验室、产品质量检测等各种领域的远程电压采集系统,也可构成工业生产过程监控系统。
UT-5526 HUB Straight-Through Cable RJ45Jack Connector Tx+Tx-Rx+Rx-RJ45Jack Connector Tx+ Tx- Rx+ Rx-RJ45plug pin1CableWiring 123 61236 图1三、电源供应: 转换器可使用已配的的电源适配器供电,也可从其它直流电源或设备供电、供电电压、UT-5526TCP/IP12V9-48VDC6W UT-5526NET---TXD---RXD---PWR---面板指示灯含义如下: 指示以太网连接是否建立,红灯亮表示建立,不亮反之。 绿灯闪亮表示正在发送数据。 黄灯闪亮表示正在接收数据。 电源指示,接通电源时为红色。
数据采集软件必备使用手册
数据采集软件使用手册 第一章操作说明 一、采集软件的特点 (一)简便性 数据采集软件是一套免安装的应用软件,在使用该软件的时候可以直接在光盘上运行,为我们的使用提供了很大方便。同时,由于该软件不需要安装,因此不会对企业的计算机造成任何的影响。 (二)智能化 无需用户提供企业所用财务软件的版本、应用数据库类型,能实现自动搜索财务软件类型、财务软件应用数据库、自动破解数据库密码(仅限服务器端)、自动搜索财务软件帐套。 附表:在服务器端或客户端及非财务软件计算机上采集的区别 (三)通用性 提供高级采集工具,通过数据库连接的建立,实现万能采集。(仅限Windows系列操作系统) (四)安全性 数据采集软件仅用于将企业的涉税电子数据转换成标准的电子文档,供“涉税鉴证软件”使用。其采集的文档经过加密计算的处理,其他任何程序无法读取其数据,为企业信息的安全提供了保障。
二、代替符号的说明 为了使本说明书更加简洁、明了,我们在编写本书的过程中使用了一些简单的符号代替部分图形和文字描述: 第二章采集软件的操作 一、采集软件运行与退出 (一)采集软件的运行
将涉税鉴证业务软件光盘放入到企业的装有财务软件的计算机中,双击桌面上的〖我的电脑〗,选择光盘上的〖数据转换系统〗下的“数据采集软件”并双击打开,这时系统将自动运行数据采集软件,运行的界面如下图所示: 数据采集软件根据企业所使用的财务软件的性质大致分为三大类:〖国内软件〗、〖地方软件〗、〖国外软件〗和〖其它软件〗。 〖国内软件〗按软件的种类分成九小类;〖其它软件〗涵盖了铁路通信、电力等行业软件;〖国外软件〗和〖地方软件〗则根据我们所接触到的加以补充。在使用的过程中,我们可根据企业实际采用的财务软件种类和版本加以区别选择。 (二)采集软件的退出 在上面显示的运行主界面中,单击〖退出〗,即可退出数据采集软件。 二、采集软件的示范说明 (一)金蝶软件 金蝶软件为深圳金蝶软件科技有限公司产品,目前主要分金蝶2000财务软件、k3企业管理软件及KIS三个系列。金蝶2000主要包括总帐报表版、标准版、工业版、商业版和行政事业版,采用Access数据库,其操作方式基本相同;K3主要包括工业版和商业版,采用SQL Server数据库;KIS系列中的标准版、迷你版采用Access数据库(数据转换操作同金蝶2000系列),KIS专业版采用SQL Server数据库(数据转换操作同金蝶2000系列)。以下分别针对有代表性的K3系列及2000系列介绍数据转换操作:
淘宝商品抓取工具使用教程
https://www.360docs.net/doc/087403444.html, 淘宝商品抓取工具使用教程 现在从事电商、微商的人越来越多,竞争越来越激烈,如何才能脱颖而出,无非是做到知己知彼,百战百胜。如何了解你的竞争对手,这里将教您使用一款非常好用的电子商品采集数据工具。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【淘宝网】为例,教大家如何使用八爪鱼采集软件采集淘宝网商品信息的方法。 采集网站: https://https://www.360docs.net/doc/087403444.html,/search?q=%E6%89%8B%E8%A1%A8 使用功能点: ●商品Url采集提取 ●创建url循环采集任务 ●商品信息采集 步骤1:创建采集任务 1)进入主界面,选择自定义模式
https://www.360docs.net/doc/087403444.html, 淘宝商品抓取步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/087403444.html, 淘宝商品抓取步骤2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的商品url 是这次演示采集的信息 淘 宝商品抓取步骤3 步骤2:创建翻页循环 找到翻页按钮,设置翻页循环 1)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”
https://www.360docs.net/doc/087403444.html, 步骤3:商品url采集 ●选中需要采集的字段信息,创建采集列表 ●编辑采集字段名称 1)如图,移动鼠标选中列表中商品的名称,右键点击,需采集的内容会变成绿色,然后点击“选中全部”
https://www.360docs.net/doc/087403444.html, 淘宝商品抓取步骤5 2)选择“采集以下链接地址” 淘宝商品抓取步骤6
网站数据爬取方法
https://www.360docs.net/doc/087403444.html, 网站数据爬取方法 网站数据主要是指网页上的文字,图像,声音,视频这几类,在告诉的信息化时代,如何去爬取这些网站数据显得至关重要。对于程序员或开发人员来说,拥有编程能力使得他们能轻松构建一个网页数据抓取程序,但是对于大多数没有任何编程知识的用户来说,一些好用的网络爬虫软件则显得非常的重要了。以下是一些使用八爪鱼采集器抓取网页数据的几种解决方案: 1、从动态网页中提取内容。 网页可以是静态的也可以是动态的。通常情况下,您想要提取的网页内容会随着访问网站的时间而改变。通常,这个网站是一个动态网站,它使用AJAX技术或其他技术来使网页内容能够及时更新。AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
https://www.360docs.net/doc/087403444.html, 表现特征为点击网页中某个选项时,大部分网站的网址不会改变;网页不是完全加载,只是局部进行了数据加载,有所变化。这个时候你可以在八爪鱼的元素“高级选项”的“Ajax加载”中可以设置,就能抓取Ajax加载的网页数据了。 八爪鱼中的AJAX加载设置
https://www.360docs.net/doc/087403444.html, 2.从网页中抓取隐藏的内容。 你有没有想过从网站上获取特定的数据,但是当你触发链接或鼠标悬停在某处时,内容会出现?例如,下图中的网站需要鼠标移动到选择彩票上才能显示出分类,这对这种可以设置“鼠标移动到该链接上”的功能,就能抓取网页中隐藏的内容了。 鼠标移动到该链接上的内容采集方法
https://www.360docs.net/doc/087403444.html, 在滚动到网页底部之后,有些网站只会出现一部分你要提取的数据。例如今日头条首页,您需要不停地滚动到网页的底部以此加载更多文章内容,无限滚动的网站通常会使用AJAX或JavaScript来从网站请求额外的内容。在这种情况下,您可以设置AJAX超时设置并选择滚动方法和滚动时间以从网页中提取内容。
数据采集器采集各种设备和仪表的配置说明
DED-BA-E7101数据采集器 设备和仪表配置说明 (内部使用,未完待续) 重庆德易安科技发展有限公司Chongqing EHS Technology Development Co.,Ltd.
目录 界面概述6 1.沈阳航发热能表8 1.1.航发超声波表配置8 1.2.航发机械表配置10 2.德易安温控器13 3.江阴众和电表(645-2007)15 4.埃美柯水表16 5.TTD温度传感器18 6.深圳北电电表(645-1997)19 7.长沙索拓温控器21 8.宁波甬港热能表22 9.宁波冷水表24 9.1.M-BUS接口24 9.2.RS485接口25 10.重庆伟岸热量表26 11.合肥艾通单相电表29 12.山东力创三相电表(DTSD106)30 13.上海德易特热能表32 13.1.德易特超声波表配置32 13.2.连利水表34 14.PZ系列直流电参量检测仪表35 14.1 采集端口配置:35 14.2 配置温控器地址:35 14.3 采集数据配置:36 14.4 采集数据显示:36 15.柏诚(SX96)37 15.1.采集端口配置37 15.2.配置表地址:37 15.3.采集数据配置:37 15.4.采集数据显示:38 16.山东力创DDSD-113-Ⅱ单相电子式电能表41 16.1.采集端口配置:41 16.2.配置温控器地址:41 16.3.采集数据配置:41 16.4.采集数据显示:41 16.5.解读:42 17.浙江立新DDS238-4单相电子式电能表42 17.1.采集端口配置:42 17.2.配置温控器地址:42 17.3.采集数据配置:42 17.4.采集数据显示:43 17.5.解读:43
Amazon数据抓取工具推荐
https://www.360docs.net/doc/087403444.html, Amazon数据抓取工具推荐 本文介绍使用八爪鱼简易模式采集Amazon数据(以采集详情页信息为例)的方法。 需要采集Amazon里商品的详细内容,在网页简易模式界面里点击Amazon,进去之后可以看到关于Amazon的三个规则信息,我们依次直接使用就可以的。 Amazon数据抓取工具使用步骤1 一、要采集Amazon详情页信息(下图所示)即打开Amazon主页点击第二个(Amazon详情页信息采集)采集网页上的内容。 1、找到Amazon详情页信息采集规则然后点击立即使用
https://www.360docs.net/doc/087403444.html, Amazon数据抓取工具使用步骤2 2、下图显示的即为简易模式里面Amazon详情页信息采集的规则 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为Amazon详情页信息采集 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 循环网址:放入要采集的Amazon网页链接(这些链接的页面格式都要是一样的)示例数据:这个规则采集的所有字段信息
https://www.360docs.net/doc/087403444.html, Amazon数据抓取工具使用步骤3 3、规则制作示例 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行 循环网址: https://https://www.360docs.net/doc/087403444.html,/dp/B00J0C3DTE?psc=1 https://https://www.360docs.net/doc/087403444.html,/dp/B003Z9W3IK?psc=1 https://https://www.360docs.net/doc/087403444.html,/dp/B002RZCZ90?psc=1 我们这边示例放三个网址,设置好之后点击保存,保存之后会出现开始采集的按钮