Loadrunner对ORACLE进行参数化
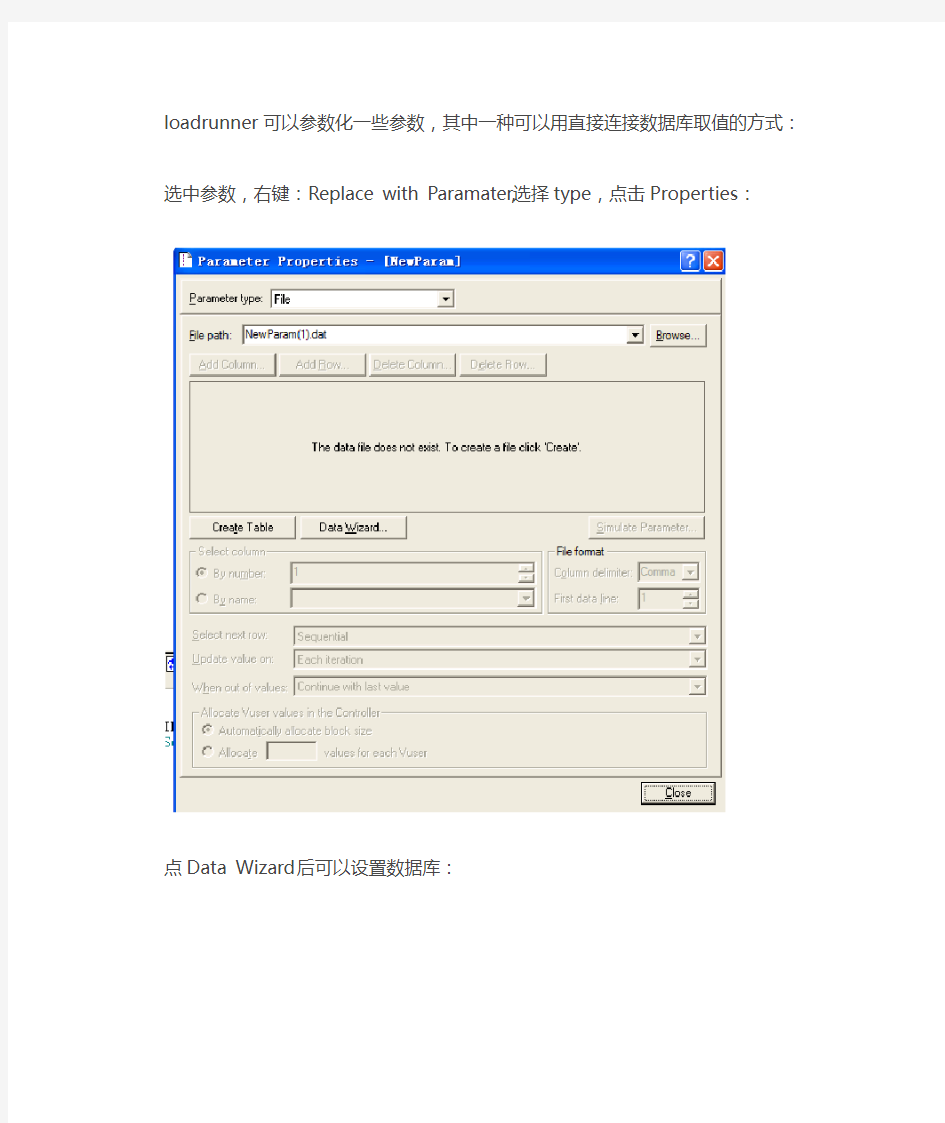

loadrunner可以参数化一些参数,其中一种可以用直接连接数据库取值的方式:选中参数,右键:Replace with Paramater,选择type,点击Properties:
点Data Wizard后可以设置数据库:
下一步后,点Create-->机器数据源-->新建-->系统数据源-->下一步:
1、postgres数据库:
选择你需要的数据源(如:PostgresSQL ODBC Driver(UNICODE))-->下一步-->完成:
这时可以点击Test查看你的数据库配置是否正确
这些做完后,输入sql语句,Finish即可:
2、oralce数据库:
先安装oracle客户端,其间有建立Net服务名
(前面跟postgres数据库一样,然后)选择你安装的oracle:
-->下一步-->完成
-->Data Source Name:the name used to identify the data source to ODBC. For example, "odbc-pc". You must enter a Data Source Name.
Description - a description or comment about the data in the data source. For example, "Hire date, salary history, and current review of all employees." The Description field is optional.
TNS Service Name - the location of the Oracle database from which the ODBC driver will retrieve data. This is the same name entered in configuring network database services using the Oracle Net Manager. For more information, see the Oracle Net Services documentation and Using the Oracle ODBC Driver for the First Time. The TNS Service Name can be selected from a pulldown list of available TNS names. For example, "ODBC-PC". You must enter a TNS Service Name.
User ID - the user name of the account on the server used to access the data. For example, "scott". The User ID field is optional.
-->点击:Test Connection看是否可以连接
-->输入用户名密码-->OK-->OK
-->选择你的数据库源名称,然后确定-->输入用户名密码
在SQL statement框里输入你要查询的sql语句:Finish就OK了
LoadRunner教程(附图)
LoadRunner生成脚本的方式有两种,一种是自己编写手动添加或嵌入源代码;一种是通过LoadRunner提供的录制功能,运行程序自动录制生成脚本。这两种方式各有利弊,但首选还是录制生成脚本,因为它简单且智能化,对于测试初学者来说更加容易操作。但是仅靠着自动录制脚本,可能无法满足用户的复杂要求,这就需要手工添加函数,进行必要的手动关联或在函数中进行参数化来配合,增强脚本的实用性。手写添加增强脚本的独特之处在于: 1.可读性好,流程清晰,检查点截取含义明确。业务级的代码读起来总比协议级代码更容易让人理解,也更容易维护,而且必要时可建立一个脚本库。而录制生成的代码大多没有维护的价值,现炒现卖。 2.手写脚本比录制的脚本更能真实地模拟应用运行。因为录制的脚本是截获了网络包,生成的协议级的代码,而略掉了客户端的处理逻辑。 3.手写脚本比录制脚本更能提高测试人员的技术水平。LoadRunner提供了Java user、VB user、C user等语言类型的脚本,允许用户根据不同的测试要求自定义开发各种语言类型的测试脚本。 增强脚本的好坏关系到这个脚本是否能在实际运行环境中更真实地进行模 拟操作。 至于具体使用哪种方式来生成脚本,还应该以脚本模拟程序的真实有效为准。例如,有些程序只需要执行迭代多次操作,没有特殊要求,选择自动生成的脚本就可以了;有些程序需要加入参数化方可满足用户的要求,此时应该使用增强的手工脚本。再就是结合项目进度、开发难易程度等因素综合考虑。 3.1 插入检查点 在进行Web应用的压力测试时,经常会有页面间数据传递的操作,如果做性能测试时传递次数逐渐增多,页面间就会发生传递混乱的情况,或者客户端与服务端数据传输中断或不正确的现象。为了解决这些问题,LoadRunner提供了在脚本中插入检查点的方法,就是检查Web服务器返回的网页是否正确。在每次脚本运行到此检查点时,自动检查该处的网页是否正确,省去执行结束后人工检查的步骤和时间,进而加快了测试进度。 插入检查点的方法,在工作原理上说就是在VuGen中插入“Text/Image”检查点。这些检查点验证网页上是否存在指定的Text或者Image,还可以测试在比较大的压力测试环境中,被测的网站功能是否保持正确。VuGen在进行Web测试时,有“Tree View”和“Script View”两种视图方式。前面我们见到的一直都是“Script View”,但在插入“Text/Image”检查点时,使用“Tree View”(树视图)视图方式会比较方便。这种视图之间切换,可以通过菜单或者工具栏的方式进行,如图3-1所示。
解析Oracle数据库中配置文件
Oracle主要配置文件: Profile文件,oratab文件, 数据库实例初始化文件initSID.ora, listener.ora文件, sqlnet.ora文件, tnsnames.ora文件 Oracle主要配置文件介绍 一、/etc/profile 文件 系统级的环境变量一般在/etc/profile 文件中定义在 CAMS系统与数据库,相关的环境变量就定义在/etc/profile 文件中如下所示: export ORACLE_BASE=/u01/app/oracle export ORACLE_HOME=$ORACLE_BASE/product/8.1.7 export PATH=$PATH:$ORACLE_HOME/bin export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib export ORACLE_SID=cams export ORACLE_TERM=vt100 export ORA_NLS33=$ORACLE_HOME/ocommon/nls/admin/data export NLS_LANG=AMERICAN.ZHS16CGB231280 说明: 1、配置上述环境变量要注意定义的先后顺序如: 定义 ORACLE_HOME时用到了ORACLE_BASE,那么ORACLE_HOME的定义应该在ORACLE_BASE之后 2、使用中文版 CAMS 环境变量 NLS_LANG 的值应该设置为AMERICAN.ZHS16CGB231280 如上所示在使用英文版 CAMS时可以不设置NLS_LANG 即去掉export NLS_LANG=... ... 那一行,也可以设置NLS_LANG 的值为AMERICAN_https://www.360docs.net/doc/0d17752444.html,7ASCII 二、/etc/oratab 文件 /etc/oratab 文件描述目前系统中创建的数据库实例以及是否通过 dbstart 和dbshut 来控制该实例的启动与关闭如下所示忽略以#开头的注释部分 : cams:/u01/app/oracle/product/ 其中 cams 为实例 ID /u01/app/oracle/product/ ORACLE_HOME目录 Y表示允许使用 dbstart和 dbshut 启动和关闭该实例数据库如果设置为 N 表示不通过 dbstart 和 dbshut 启动和关闭实例数据库 CAMS 系统要求在安装完 ORACLE 后要求将该参数修改为 Y 以保证 ORACLE 数据库自启动和关闭 三、数据库实例初始化文件 initSID.ora
产品级参数化设计
第三章产品级参数化设计 本章所研究的是关于产品级的参数化设计问题,为此,拟订“产品模块化、模块参数化”的技术思路来对小型热风微波耦合干燥设备模块化设计进行研究。 3.1参数化设计概述 传统的CAD设计主要针对零件级别的建模,对产品设计本身缺乏有效的支撑,只有最后的结果,不注重整个设计过程,有输入数据量大,操作难度大,无参数设计功能,不能自动更新现有模型,设计周期长,效率低,工作量重复等缺点。 参数化设计过程中,Revit Building是一中重要思想,它在保证参数化模型约束不变的的条件下,通过修改模型的基本尺寸参数来驱动参数化模型,完成模型更新从而获得新模型的现代化设计方法。模型的设计不是一蹴而就的,往往经过一个复杂的过程,在设计初期,设计人员对产品的认识较浅,不能完全确定设计其边界条件,并不能一次性设计出满足产品要求的所有条件。随着时间的推移,研究的深入,设计人员通过不断的修改模型的尺寸和造型,摸索研究之后,一步一步设计出满足所有条件的产品。由此可知,设计是一个不断修改,不断更新数据并且不断满足模型约束条件的过程,这种精益求精,追求完美的过程促进了CAD系统中参数化设计的产生华和发展。参数化设计大大提高了设计的效率,缩短了设计周期的同时大大减少了设计人员的工作强度和工作压力。 目前,参数化设计已经实际运用并且不断的发展壮大,已经成为现代设计与制造,机械设计系统等方向的研究热点,与之相关的各种CAD软件系统也不断的设计完善自己的参数化设计系统和功能,满足未来设计发展的需要。另外,对于标准化,系列化产品,参数化设计尤为重要,对于此次热风微波耦合干燥系列产品,采用参数化设计技术是非常好的选择。 3.1.1 参数化设计定义 参数化设计是机械CAD系统的一项非常关键技术,从最初的概念设计到详细设计,到最后形成产品,它贯穿产品设计的全过程。参数化设计是将参数化的产品模型用数学中一一对应关系来表示,而不是确定其数值,当某些参数变化时,与之相关的其他参数也将随之改变,达到几何更改控制几何形状的目的。这种快速反应的尺寸驱动,高效的图形修改功能,为产品设计、产品造型、产品更新修改,产品系列化设计等提供了有效的手段。其核心是通过产品约束的表达方式,使用设计好的一组尺寸参数和约束来描述产品模型的几个图形,能够充分满足相同或者相近几何拓扑关系的设计需求,充分体现设计者的设计思想。 根据参数化设计对象不同,可以将参数化设计分成两种:零件级参数化设计和产品级参数化设计。目前,广泛应用于实践的是零件级参数化设计方法,主要是指在单个零部件的内部通过尺寸参数和约束控制零件的参数化模型,当尺寸参数和约束发生变化时,参数化零件模型自动更新。相对于零件级参数化设计,产品级参数化设计是一种更加高级的参数化设计方法,它更加注重零部件之间的相互关联关系,当某一个零件的参数修改后,与该零件相关的其他零部件也将完成同步更新,这种更新包括形状的更新和尺寸的更新。由此可知,产品
LoadRunner性能测试实战教程
LoadRunner性能测试实战讲解 内容介绍: 很多使用LoadRunner的测试人员经常面临两个难题:脚本开发与性能测试分析。本书就是基于帮助测试人员解决这两个问题而编写,致力于使读者学精LoadRunnner这一强大的性能测试工具。 全书共分为四部分:入门篇、基础篇、探索篇、实战篇。第一篇入门篇的内容包括第1章和第2章,着重于讲解性能测试与LoadRunner的基础理论知识。第二篇基础篇的内容包括第3章至第5章,是LoadRunner 的基本使用部分,着重讲解Virtual User Generator、Controller、Analysis的使用方法。第三篇探索篇的... 第1部分入门篇.. (1) 第1章性能测试基础知识.. 3 1.1 性能测试基本概念 (4) 1.1.1 什么是性能测试 (4) 1.1.2 性能测试应用领域 (6) 1.1.3 性能测试常见术语 (8) 1.2 全面性能测试模型 (11) 1.2.1 性能测试策略模型 (14) 1.2.2 性能测试用例模型 (17) 1.2.3 模型的使用方法 (20) 1.3 性能测试调整基础 (21) 1.4 如何做好性能测试 (24) 1.5 本章小结 (28) 第2章LoadRunner基础知识.. 29 2.1 LoadRunner简介 (29) 2.1.1 LoadRunner主要特点 (29) 2.1.2 LoadRunner常用术语 (31) 2.2 LoadRunner工作原理 (32) 2.3 LoadRunner测试流程 (33) 2.4 LoadRunner的部署与安装 (35) 2.5 本章小结 (41) 第2部分基础篇 (43) 第3章脚本的录制与开发.. 45 3.1 Virtual User Generator简介 (45)
loadrunner中十六进制报文参数化方法
loadrunner中十六进制报文参数化方法 2012年7月5日 10:10 熊瑞 在做tuxedo和socket脚本的过程中,经常会碰到发送的报文是十六进制字符串。而 往往我们又需要针对十六进制报文中的某些数据进行参数化。当然,直接针对十六进制报文,选中后右键参数化是不会被识别的。需要经过相应的转化后才能参数化成功。 首先,针对一串发送报文,需要了解报文体的结构,具体要了解的是:发送报文长度 多少、十六进制报文对应的可通俗识别的十进制或者字符串显示、每一个可识别字符串在 报文中的偏移位置。当然熟悉报文体中字段的内容是需要参考接口文档。 具体例子如下,下面是一段原始报文: 0: 00 D1 35 44 41 31 46 35 35 36 43 33 42 32 44 30 __________*?DA1F556C3B2D0 10: 33 39 30 30 30 30 30 30 30 30 30 30 30 30 30 30 __________3900000000000000 20: 31 31 31 31 31 31 31 31 30 31 31 30 30 30 30 63 __________111111*********c 30: 6F 70 00 00 00 00 00 00 30 00 00 30 00 00 00 00 __________op******0**0**** 40: 31 31 30 00 00 00 00 00 00 00 00 00 00 00 00 00 __________110************* 50: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 __________**************** 60: 00 00 00 00 00 00 00 00 00 00 00 31 30 30 31 37 __________***********10017 70: 00 00 00 00 37 37 39 31 37 32 35 36 39 32 00 00 __________****7791725692** 80: 39 37 37 34 00 00 00 00 00 00 00 00 00 00 00 00 __________9774************ 90: 00 00 00 00 00 00 00 00 00 00 00 00 00 32 30 31 __________*************201 a0: 32 30 36 32 30 00 00 00 00 00 00 00 00 00 00 00 __________20620*********** b0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 __________**************** c0: 10 31 30 32 39 36 66 30 00 32 30 31 30 30 34 30 __________*10296f0*2010040 d0: 32 __________2 如上所示,十六进制报文一般是每16位是一行,最左边的用黄色标注的0: 10:其实就是16的累加,也可以理解是一个偏移量,当然,和我们具体要参数化的报文中的字段的偏移量是不同的,那个是需要自己进行计算;用绿色标注的__________只是开发人员在log输出中为了标识而打印出来的,可不用关注。用红色标注的地方,如*?DA1F556C3B2D0,这是我们看到的第一行十六进制串对应的字符串,这一段也是开发人员在log输出中伴随 打印出来,也就是我们要了解的地方,还有一点需要说明的是,中间这段十六进制码是右 边红色标记的字符串的ASC码的十六进制。(这段只是对上述报文做一个详述,各位看官 在自己实际开发的报文的过程中,可能与此不同,具体问题具体对待) 当然,我们在实际报文发送的过程中,仅仅只是需要16进制串而已,即一下一段: 00 D1 35 44 41 31 46 35 35 36 43 33 42 32 44 30 33 39 30 30 30 30 30 30 30 30 30 30 30 30 30 30 31 31 31 31 31 31 31 31 30 31 31 30 30 30 30 63 6F 70 00 00 00 00 00 00 30 00 00 30 00 00 00 00 31 31 30 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 31 30 30 31 37 00 00 00 00 37 37 39 31 37 32 35 36 39 32 00 00 39 37 37 34 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 32 30 31 32 30 36 32 30 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 10 31 30 32 39 36 66 30 00 32 30 31 30 30 34 30 32 针对这一段报文,我们需要使用编辑工具进行相应处理,因为loadrunner中使用相 关函数时,都是在处理字符串,所以,我们需要把这段报文转化成十六进制串,转换后如下: \x00\xD1\x35\x44\x41\x31\x46\x35\x35\x36\x43\x33\x42\x32\x44\x30
1模块化机械设计
1模块化机械设计 1.1模块及模块化的概念 模块是一组具有同一功能和结合要素(指联接部位的形状、 尺寸、连接件间的配合或啮合等),但性能、规格或结构不同却能 互换的单元。模块化则是指在对产品进行市场预测、功能分析的基础上划分并设计出一系列通用的功能模块,然后根据用户的 要求,对模块进行选择和组合,以构成不同功能或功能相同但性 能不同、规格不同的产品。 1.2模块化机械设计相关性 模块化设计所依赖的是模块的组合,即结合面,又称为接 口。为了保证不同功能模块的组合和相同功能模块的互换,模块 应具有可组合性和可互换性两个特征。这两个特征主要体现在 接口上,必须提高模块标准化、通用化、规格化的程度。对于模块化机械设计,可见其关键是怎样划分模块,这里主要通过综合考 虑零部件在功能、几何、物理上存在的相关性来划分模块。 (1)功能相关性零部件之间的功能相关性是指在模块划分 时,将那些为实现同一功能的零部件聚在一起构成模块,这有助 于提高模块的功能独立性。 (2)几何相关性零部件之间的几何相关性是指零部件之间 的空间、几何关系上的物理联接、紧固、尺寸、垂直度、平等度和同轴度等几何关系。 (3)物理相关性零部件之间的物理相关性是指零部件之间 存在着能量流、信息流或物料流的传递物理关系。 1.3模块化机械设计的优点 模块化机械设计在技术上和经济上都具有明显的优点,经 理论分析和实践证明,其优越性主要体现在下述几方面: (1)可使现在机械工业得到振兴,并向高科技产业发展; (2)减轻机械产品设计、制造及装配专业技术人员的劳动强 度; (3)模块化机械产品质量高、成本低,并且妥善解决了多品 种小批量加工所带来的制造方面的问题; (4)有利于企业根据市场变化,采用先进技术改造产品、开 发新产品; (5)缩短机械产品的设计、制造和供货期限,以赢得用户; (6)模块化机械产品互换性强,便于维修。 2模块化机械设计在UG中的实现 2.1总体构思 在用UG进行机械设计时,为了将常用件模块化,首先要把 常用件的三维模型表达出来。对于系列产品,可按照成组技术的 原理进行分类,一组相似的常用件建立一个三维模型,即所谓的 三维模型样板。根据UG参数化设计思想,一个三维模型样板可 认为是一组尺寸不同、结构相似的系列化零部件的基本模型。把
参数化设计相关理论
《基于参数化的风景园林设计行业发展》 数字化(digital)“是将许多复杂多变的信息转变为可以度量的数字、数据,再将这些数字、数据转变为一系列二进制代码,引入计算机内部,进行统一处理后建立数字化模型。数字计算机的一切运算和功能都是用数字来完成的”[1],在设计领域中应用时,数字化设计(digital design)“包含的范围非常广泛,只要在设计的任何一个环节以任何方式使用了计算机,都可以说是数字化设计”[1]。[1] 匡纬. 风景园林“参数化”规划设计发展现状概述与思考[J]. 风景园林,2013(1):58-64.他们认为在范畴上,数字化设计包含参数化设计。 参数化设计发展简史 其实参数化设计思想介入前期方案生成在欧美发达国家早已有之,在20 世纪50~60 年代,美国经历了大萧条之后的第一次建设高峰,而欧洲则忙于处理二次世界大战后满目疮痍的景象。在经历了为解决居住问题和就业问题而快速发展短暂狂热之后,针对已经空前成熟的资本主义价值观本身,欧美人显然发现本国本地区文化遗产的延续和自然生态保护的重要性。 70 年代后期,计算机技术开始萌芽并以惊人的速度发展,随着晶体管技术的发明和推广,以IBM 为代表的企业纷纷走向计算机技术之路,在这个国际大背景下,在众多的设计公司中,SOM 建筑师事务所是最早意识到计算机能够给建筑行业带来一场前所未有革命的公司,早在20 世纪70~80 年代就提出了BIM(Building information modeling)即“一体化设计”的概念。伊恩·麦克哈格(Ian Lennox McHarg)是最早将参数化思想运用到生态园林景观设计的设计师之一,《设计结合自然》(Design With Nature,1969)中所介绍的矢量叠合绘制专题图的分析方法在现在看来已经无甚新奇,但在当时的社会环境背景下可谓巨大突破[3] [3]伊恩?伦诺克斯?麦克哈格. 设计结合自然[M]. 芮经纬译. 天津:天津大学出版社,2006.10. 实质上,参数化设计并不仅仅是建筑表皮的生成和建筑造型的“酷炫”这么简单,正因建筑本身的非自足性,一系列制约因素必须考虑其中,包括方案阶段的日照、供电、采暖、能源利用、环保、材料,建设过程中的结构实施难度、施工工艺、结构安全性和建成后的各种检验(包括LEED 检验),牵一发而动全身,在这种客观环境要求下,BIM 一体化设计模式就有了意义,其所追求的目标是建筑单体从内而外、自始至终整个生命周期的合理性、科学性和节约性,而现今我们所看到的在中国发生的种种建筑实践,大部分都与此毫无关联。 随着参数化设计在建筑领域的不断发展渗透,一种新的思潮“参数化主义”也随之涌现。“参数化主义”(parametricism)是由英国皇家建筑师学会建筑师、扎哈·哈迪德(Zaha Hadid)建筑事务所合伙人帕特里克·舒马赫(Patrik Schumacher)最早提出的(如图6),尽管这个称谓仍有争议,但已在一定范围(哲学领域)内开始运用。 线性景观是可以用简单的数量和逻辑关系概括的、直接性的、静态的景观,以欧洲古典园林为代表的规则对称式园林是最好的例证——一切均以数学上的几何比例为基础扩展开去,甚至将人的尺度也纳入到这一庞大的比例美学系统中来,其从形式到功能布局均是简单的二元关系(从点到点),是可以用x、y、z 三轴向量概括的;而非线性景观则融合了复杂的多元关系,单纯靠几何比例已无法解释其微妙之处,其特征是神秘而和谐,并带有混沌中意外的突变,且其中蕴含着各种逻辑上的关系,甚至哲学和心理学上的某种相互关联,并不单单是美学关联那么简单了。中国古典园林所蕴含的哲学原理和审美特质,使其体现出朴素的非线性特征来——看似随意而为的外在布局形式,实质上是追随“画意”和中国人眼中的自然主义的结果,而使其被赋予了一种内在的“禅意” 在现阶段的中国,面对一个数据充实、分析到位、系统完善而可能平面上不那么好看的科学设计,与一个平面表现十分花哨,却漏洞百出、难以自圆其说的艺术设计,很多决策者可能
ORACLE参数优化设置
ORACLE的参数优化配置说明 目录 ---------------------------------------------------------------------------------------------------- 硬件配置在2CPU,2G内存,32位数据库应用 硬件配置在4CPU,4G内存,32位数据库应用 硬件配置在4CPU,4G内存,64位数据库应用 硬件配置在8CPU,8G内存,64位数据库应用 关于创建和配置oracle数据库的几点补充说明 ---------------------------------------------------------------------------------------------------- ----------------------------------------------------------------------------------------------------●硬件配置在2CPU,2G内存设置情况 系统大约支持用户并发数:30左右 ----------------------------------------------------------------------------------------------------oracle9i版本(32bit) db_cache_size=629145600(600M) shared_pool_size=209715200(200M) large_pool_size=614400 java_pool_size=20971520 processes=80(根据具体情况调大此值,比如测试环境可以调制500) sessions=80(根据具体情况调大此值,比如测试环境可以调制500) log_buffer=5242880 db_writer_processes=2 open_cursors=2000 workarea_size_policy=auto pga_aggregate_target=250M pre_page_sga=true(win2000下参数) lock_sga=true(unix下参数,不包含solaris) optimizer_index_cost_adj=40 optimizer_dynamic_sampling=4 dml_locks=100000 enqueue_resources=10000 oracle10g版本(32bit) db_cache_size=629145600(600M) shared_pool_size=209715200(200M) large_pool_size=614400 java_pool_size=20971520 processes=80(根据具体情况调大此值,比如测试环境可以调制500) sessions=80(根据具体情况调大此值,比如测试环境可以调制500) log_buffer=5242880
Loadrunner对ORACLE进行参数化
loadrunner可以参数化一些参数,其中一种可以用直接连接数据库取值的方式:选中参数,右键:Replace with Paramater,选择type,点击Properties: 点Data Wizard后可以设置数据库:
下一步后,点Create-->机器数据源-->新建-->系统数据源-->下一步: 1、postgres数据库: 选择你需要的数据源(如:PostgresSQL ODBC Driver(UNICODE))-->下一步-->完成: 这时可以点击Test查看你的数据库配置是否正确 这些做完后,输入sql语句,Finish即可:
2、oralce数据库: 先安装oracle客户端,其间有建立Net服务名 (前面跟postgres数据库一样,然后)选择你安装的oracle:
-->下一步-->完成 -->Data Source Name:the name used to identify the data source to ODBC. For example, "odbc-pc". You must enter a Data Source Name. Description - a description or comment about the data in the data source. For example, "Hire date, salary history, and current review of all employees." The Description field is optional. TNS Service Name - the location of the Oracle database from which the ODBC driver will retrieve data. This is the same name entered in configuring network database services using the Oracle Net Manager. For more information, see the Oracle Net Services documentation and Using the Oracle ODBC Driver for the First Time. The TNS Service Name can be selected from a pulldown list of available TNS names. For example, "ODBC-PC". You must enter a TNS Service Name.
Oracle参数文件学习
Oracle参数文件 --======================== -->Oracle 参数文件 --======================== /* 参数文件(10g中的参数文件) 主要用来记录数据库的配置文件,在数据库启动时,Oracle读取参数文件,并根据参数文件中的参数设置来配置数据库。 如内存池的分配,允许打开的进程数和会话数等。 两类参数文件: pfile:文本文件的参数文件,可以使用vi,vim等编辑器修改,文件名通常为init
实训 LoadRunner测试脚本的参数化模板
实训LoadRunner测试脚本的参数化 1.1实训目标 能够使用参数化数据解决系统压力问题 能够使用数据池中数据对参数变量实施参数化 能够使用数据库中数据对参数变量实施参数化 具备使用不同数据对系统施加预期压力的能力 1.2问题引出: 观察以下示例代码 web_url("MercuryWebTours", "URL=http://localhost/MercuryWebTours/", "Resource=0", "RecContentType=text/html", "Referer=", "Snapshot=t2.inf", "Mode=HTML", LAST); lr_think_time(5); web_submit_form("login.pl", "Snapshot=t3.inf", ITEMDATA, "Name=username", "Value=jojo", ENDITEM, "Name=password", "Value=bean", ENDITEM, "Name=login.x", "Value=53", ENDITEM, "Name=login.y", "Value=18", ENDITEM, LAST); 代码分析: 在这段代码中,用灰色背景黑色字体标识的是用户输入的用户名和口令,如果直接使用这段脚本对应用进行测试,则所有VU都会使用同一个用户名和口令登录系统。如果要模拟更加真实的应用场景(例如,不同权限的用户执行同一个操作),就有必要将用户名和口令用变量代替,为变量的取值准备一个“数据池”并设定变量的取值规则,这样每个VU在执行的时候就能根据要求取不同的值。 当然,要进行参数化的场合远远不止用户名和口令的处理。设想这样一种情况,需要模拟多个用户同时操作一个页面,该页面要求用户输入一条信息记录,且规定记录内容不能重复。对于这种情况,如果不采用参数化的方式,则必须为每个可能的VU使用一个不同的脚本。采用参数化方式时,只需要将输入的内容设置为参数,在参数池中给出大于VU 的数据即可。
Oracle显示和设置初始化参数文件
Oracle显示和设置初始化参数文件 为了在SQL*Plus中显示初始化参数,可以使用SHOW PARAMETER命令。该命令会显示初始化参数的名称、类型和参数值。 为了显示所有初始化参数的位置,可以直接执行SHOW PARAMETER命令。例如:SQL>show parameter NAME TYPE V ALUE ------------------------------------ ----------- ------------------------------ db_writer_processes integer 1 dbwr_io_slaves integer 0 ddl_lock_timeout integer 0 dg_broker_config_file1 string D:\APP\MANAGER\PRODUCT\11.1.0\ DB_1\DATABASE\DR1ORCL.DAT dg_broker_config_file2 string D:\APP\MANAGER\PRODUCT\11.1.0\ DB_1\DATABASE\DR2ORCL.DAT dg_broker_start boolean FALSE …. SHOW PARAMETER命令也可以显示特定初始化参数。为了显示特定初始化参数的名称、类型和参数值,可以在SHOW PARAMETER命令后指定参数名。示例如下:SQL> show parameter db_block_size NAME TYPE V ALUE ------------------------------------ ----------- ----------- db_block_size integer 8192 当使用SHOW PARAMETER命令显示初始化参数信息时,只能显示参数名、类型和参数值,为了取得初始化参数的详细信息,应该查询动态性能视图V$PARAMETER。例如:SQL> select isses_modifiable,issys_modifiable,ismodified 2 from v$parameter where name='sort_area_size'; ISSES ISSYS_MOD ISMODIFIED ----- --------- ---------- TRUE DEFERRED FALSE ISSES_MODIFIABLE用于标识初始化参数是否可以使用ALTER SESSION命令进行修改,当取值为TRUE时表示可以修改;取值为FALSE则表示不可以修改。ISSYS_MODIFIABLE用于标识初始化参数是否可以使用ALTER SYSTEM命令进行修改,取值IMMEDIATE时表示可以直接修改;取值为DEFERRED表示需要使用带有DEFERRED 的选项进行修改;取值为FALSE表示不能进行修改。ISMODIFIED用于标识该初始化参数是否已经被修改,取值为MODIFIED表示使用ALTER SESSION进行了修改;SYSTEM_MOD表示使用ALTER SYSTEM命令进行修改;FALSE表示未进行修改。 静态参数是指只能通过修改参数文件而改变的初始化参数:动态参数是指在数据库运行时可以使用ALTER SESSION或ALTER SYSTEM命令动态改变的初始化参数。下面的命令将显示系统的静态参数:
性能测试与LoadRunner基础笔试题
性能测试与LoadRunner基础笔试题 笔试:45分钟满分100分 选择:(共6分,3分一题) 1. To control the time between iterations in a Vuser, you will need to configure which run-time(2分) feature? A. Run Logic B. Pacing C. Think Time D. Network Speed 2. You are about to run a Debug scenario with a small number of Vusers. What type of log setting will you select to help identify and check errors in the Vuser scripts?(2分) A. Only when errors occur B. Standard log C. Extended log 判断:(共20分,2分一题) 1.集合点可以贯穿整个事务,加了集合点,整个事务都是同步运行的 2.集合点可以加在vuser_int中 3.LR可以录制单机程序 4.一个脚本中可以有多个action 5.10M的网络环境中,不能模拟20M的带宽 6.HTTPS安全协议,可以使用‘HTML-based script’模式录制 7.vuser_end中内容是不可以迭代运行的 8.file类型参数化,最多只能参数化100个 9.手动关联,查找需要关联的数据,要在Sending request中查找 10.调试lr脚本可以run step by step
LR参数化用户名密码
loadrunner参数化用户名密码方式 技术文档---测试2010-04-13 13:13:36 阅读244 评论0 字号:大中小订阅 参数化 参数化:可以理解为开发语言中的变量的意思。在脚本中,如果不使用参数,那么所有的测试数据是跟脚本绑定在一起的,如果需要测试不同的数据,需要运行一次,改一下,再运行。如果使用了参数化,可以把多个测试数据保存起来,测试时脚本自动选择测试数据运行。 以上面录制的脚本为例,介绍参数化的使用方法,实现10个用户分别登陆51testing。 1、打开脚本,找到登陆动作对应的代码。 2、我们看到,录制时的用户名是“测试”,密码是“111111”(此处的用户名和密码都是虚构)。 3、首先对用户名进行参数化:选中用户名,点击鼠标右键,在出现的快捷菜单中选择“Replace with a parameter”,如下图。 4、在弹出的对话框中输入参数名和参数类型,参数名是自己起的,参数类型选择“File”,点击OK。
5、对密码进行同样的操作。 6、参数化完成后,我们需要给增加一些测试数据。点击工具栏上的Param List按钮打开参数设置页面。选择UserName,点击“Add Row”按钮增加行,然后在行中输入其他可以登陆的用户名。完成后的效果如下图: 7、对密码参数做同样的操作,按顺序输入和用户名对应的密码,完成后的效果如下图:
8、设置脚本取参数的顺序。假设我们想让脚本在运行时以顺序方式取这5个用户登陆,那么对用户名的设置:Select next row:Sequential;Update value on:Each iteration。意思是每一次迭代时按顺序取下一个参数。 9、对密码的设置,因为密码和用户名是一一对应的。所以对密码的设置是“Same line as UserName”。意思是和用户名称取相同的行的数据。这样就可以保证一一对应了。 10、因为我们有5个用户,所以需要让脚本跑5遍。打开“Run-time Setting”对话框,设置脚本运行5次。
Oracle 官方安装文档
rpm -q grep binutils-2.* \ elfutils-libelf-0.* \ glibc-2.* \ glibc-common-2.* \ libaio-0.* \ libgcc-4.* \ libstdc++-4.* \ make-3.* \ compat-libstdc++-33 \ elfutils-libelf-devel-0.* \ glibc-devel-2.* \ gcc-4.* \ gcc-c++-4.* \ libaio-devel-0.* \ libstdc++-devel-4.* \ unixODBC-2.* \ unixODBC-devel-2.* \ sysstat-7.* 2.如缺少相应的补丁包,可以到系统安装盘安装相关的补丁包 cd /media/Enterprise\ Linux\ dvd\ 20090127/Server/ rpm -Uvh grep binutils-2.* rpm -Uvh elfutils-libelf-0.* rpm -Uvh glibc-2.* rpm -Uvh glibc-common-2.* rpm -Uvh libaio-0.* rpm -Uvh libgcc-4.* rpm -Uvh libstdc++-4.* rpm -Uvh make-3.* rpm -Uvh compat-libstdc++-33 rpm -Uvh elfutils-libelf-devel-0.* rpm -Uvh glibc-devel-2.* rpm -Uvh gcc-4.* rpm -Uvh gcc-c++-4.* rpm -Uvh libaio-devel-0.* rpm -Uvh libstdc++-devel-4.* rpm -Uvh unixODBC-2.* rpm -Uvh unixODBC-devel-2.* rpm -Uvh sysstat-7.*
LoadRunner性能测试软件的基本使用步骤
LoadRunner性能测试软件的基本使用步骤 一. 1、测试脚本录制 1.1录制前准备工作 在录制脚本前需检查压测环境的整体功能是否正确,待测部分的功能是否正确,只有确定功能正确后才可进行压测。 1.2录制及调试脚本 在准备工作OK后,进行脚本的录制,具体过程如下: 打开“开始>程序>MercuryLoadRunner>MercuryLoadRunner”测试脚本录制; 2、点击“Create/EdirScripts”,也可在“File”下选择New 新建。 3、选择Web(HTTP/HTML)协议,我们测试的是B/S模式,采用的是Web协议,选择后点【OK】按钮。 4、点击界面中的录制按钮,这个表示开始录制脚本点。 录制前,如果已经打开待测页面的话,建议关闭该页面。点【OK】后,同时会出现这表示现在已经开始录制。 5、所有操作完成后,点击中停止按钮,停止录制,页面将自动关闭,返回到loadrunner录制界面,将在界面中显示录制脚本代码,保存录制的脚本。 6、调试代码并进行参数化 录制后的代码需要进行调试才可用于压测,调试的办法就是进行
回放操作,如果回放过程无错误,运行结果也正确的话,则可用于压测。 二.设计测试场景 在脚本录制完成,调试通过后,可以进行测试场景的设计。 1.打开“开始>程序>MercuryLoadRunner >MercuryLoadRunner” 2.点击的RunLoadTests;在新建场景的窗口,选择一种场景类型。 3.选择要进行场景设计的脚本,若没有出现需要对应的脚本,可点击Browse查找后添加进来,选择好脚本后,点add则可加入到右边的窗口中然后点【OK】。 4.显示的是脚本的路径与并发数个数,根据测试方案中的并发 数可更改此处的并发数。 Eg:假如我们设计的场景是每15秒增加2个,所有并发数增加完后持续运行5分钟,5分钟运行结束后,每30秒减少5个并发。 5.再点击页面右下角的“Run-timeSettings” 。 6.一切设置OK后,点击运行测试场景。 三.测试结果分析 1.场景执行结束后可以,使用loadrunner自带的分析工具进行结果分析。 2.在菜单栏中选择打开,找到要分析的场景执行结果,点【打开】即可,还可以直接在场景运行结束后,点击Controller菜单栏