印刷体汉字识别及其MATLAB实现

印刷体汉字的识别及其MATLAB实现
0.汉字识别研究的意义
汉字已有数千年的历史,是中华民族文化的重要结晶,闪烁着中国人民智慧的光芒。同时也是世界上使用人数最多和数量最多的文字之一。现如今,汉字印刷材料的数量大大增加,一些专业单位所接触的印刷材料更是浩如烟海,信息量均是爆炸性增长。然而,汉字是非字母化、非拼音化的文字,因此,如何将汉字快速高效地输入计算机,是信息处理的一个关键问题,也是关系到计算机技术能否在我国真正普及的关键问题,更是传播与弘扬中华民族悠久历史文化的关键问题。而且随着劳动力价格的升高,利用人工方法进行汉字输入也将面临经济效益的挑战。因此,对于大量已有的文档资料,汉字自动识别输入就成为了最佳的选择。因此,汉字识别技术也越来越受到人们的重视。汉字识别是一门多学科综合的研究课题,它不仅与人工智能的研究有关,而且与数字信号处理、图像处理、信息论、计算机科学、几何学、统计学、语言学、生物学、模糊数学、决策论等都有着千丝万缕的联系。一方面各学科的发展给它的研究提供了工具;另一方面,它的研究与发展也必将促进各学科的发展。因而有着重要的实用价值和理论意义。
1.印刷体汉字识别的研究
1.1印刷体汉字识别技术的发展历程
计算机技术的快速发展和普及,为文字识别技术应运而生提供了必备条件。加上人们对信息社会发展的要求越来越高,文字识别技术的快速发展可想而知。印刷体文字的识别可以说很早就成为人们的梦想。印刷体汉字的识别最早可以追溯到60年代,但都是西方国家进行的研究。我国对印刷体汉字识别的研究始于70年代末80年代初。同国外相比,我国的印刷体汉字识别研究起步较晚。从80年代开始,汉字ORC的研究开发一直受到国家重视,经过科研人员十多年的辛勤努力,印刷体汉字识别技术的发展和应用,有了长足进步。
1.2印刷体汉字识别的原理分析及算法研究
汉字识别实质是解决文字的分类问题,一般通过特征辨别及特征匹配的方法来实现。目前汉字识别技术按照识别的汉字不同可以分为印刷体汉字识别和手写体汉字识别。印刷体汉字识别从识别字体上可分为单体印刷体汉字识别与多体印刷体汉字识别。
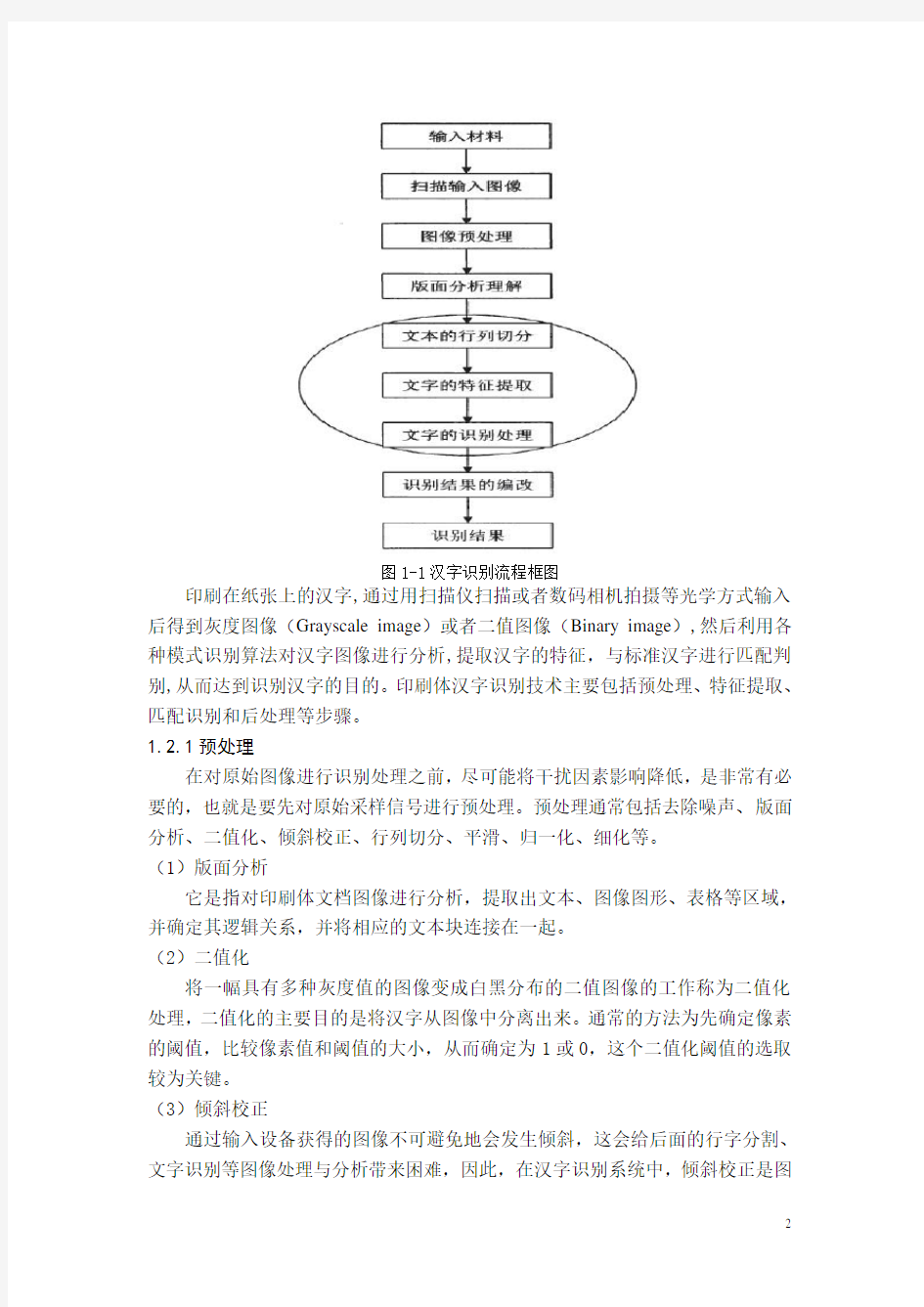
印刷体汉字识别的流程如图1-1所示:
图1-1汉字识别流程框图
印刷在纸张上的汉字,通过用扫描仪扫描或者数码相机拍摄等光学方式输入后得到灰度图像(Grayscale image)或者二值图像(Binary image),然后利用各种模式识别算法对汉字图像进行分析,提取汉字的特征,与标准汉字进行匹配判别,从而达到识别汉字的目的。印刷体汉字识别技术主要包括预处理、特征提取、匹配识别和后处理等步骤。
1.2.1预处理
在对原始图像进行识别处理之前,尽可能将干扰因素影响降低,是非常有必要的,也就是要先对原始采样信号进行预处理。预处理通常包括去除噪声、版面分析、二值化、倾斜校正、行列切分、平滑、归一化、细化等。
(1)版面分析
它是指对印刷体文档图像进行分析,提取出文本、图像图形、表格等区域,并确定其逻辑关系,并将相应的文本块连接在一起。
(2)二值化
将一幅具有多种灰度值的图像变成白黑分布的二值图像的工作称为二值化处理,二值化的主要目的是将汉字从图像中分离出来。通常的方法为先确定像素的阈值,比较像素值和阈值的大小,从而确定为1或0,这个二值化阈值的选取较为关键。
(3)倾斜校正
通过输入设备获得的图像不可避免地会发生倾斜,这会给后面的行字分割、
文字识别等图像处理与分析带来困难,因此,在汉字识别系统中,倾斜校正是图
像预处理的重要部分。倾斜校正的核心在于如何检测出图像的倾斜角。
(4)汉字切分
汉字切分的目的是利用字与字之间、行与行之间的空隙,将单个汉字从整个图像中分离出来。汉字的切分分为行切分和字切分[9]。
(5)归一化
归一化也称规格化,它是把文字尺寸变换成统一大小,纠正文字位置(平移),文字笔画粗细变换等文字图像的规格化处理,并只对文字图像进行投影。
(6)平滑
对数字图像进行平滑,目的是去处孤立的噪声干扰,以平滑笔画边缘。平滑在图像处理中实质是一幅文字图像通过一个低通滤波器,去除高频分量,保留低频分量。
(7)细化
细化处理是将二值化文字点阵逐层剥去轮廓边缘上的点,变成笔画宽度只有一个比特的文字骨架图形。细化处理的目的是搜索图像的骨架,去除图像上多余的像素,从而在不改变图像主要特征的前提下,减少图像的信息量。
1.2.2汉字特征提取
预处理的最终目的是为了更加方便、准确地进行汉字的特征提取,从而提高汉字识别率。对于汉字,其特征大致分为两类,包括结构特征和统计特征,至今总数已经不下百种。
要做到有的放矢,就需要研究已有的获得良好效果的各种汉字特征,分析它们的优点、缺点和适用环境。如下列出常用的一些的汉字结构特征和汉字统计特征。
1.结构特征
(1)抽取笔画法
抽取笔画法是利用汉字由笔画所构成的特点进行识别,它利用汉字的结构信息来进行汉字的联机识别,在印刷体和脱机手写识别中,由于笔画提取的困难,结果不是很理想。
(2)松弛匹配法
松弛匹配法是一种基于全局特征的匹配方法,它对输入汉字作多边近似,抽取边界线段,将这些边界线段组成临近线段表,然后用松弛匹配操作,完成边与边的匹配。这种方法利用弹性吸收汉字的变形,一个字只用一个样本。
(3)非线性匹配法
非线性匹配法是由Tsukumo等提出的,用以解决字形的位移、笔画的变形等现象。此方法试图克服从图形中正确抽取笔画的困难,以提高正确判别的能力。
2.统计特征
(1)笔画复杂性(Complexity Index)
笔画复杂性指数是指文字笔画的线段密度,其定义如下:
x y x L C σ/= (1-1) y x y L C σ/= (1-2)
式(1-1)和(1-2)中
x C 、y C 一横向和纵向的笔画复杂性指数;
x L 、y L 一横向和纵向的文字线段总长度;
x σ、y σ一横向和纵向质心二次矩的平方根;
x C 、y C 分别反应了横向和纵向的笔画复杂性,横多的x C 大,竖多的y C 大。笔画复杂性指数与汉字的位移无关,受字体和字号的影响较小,但易受笔画断裂和粘连的影响,且其分类能力较差,常与另一种粗分类方法“四边码”连用。
(2)四边码(Four-side Code )
四边码是在汉字点阵图的四周各取一条带,计算其中的文字图像素点数,并将它分成四级,构成一个四元组。由于汉字边框不但含有丰富的结构信息,而且边框部分笔画一般较少,不易粘连,抗干扰能力强,但对汉字的位移和旋转比较敏感,与笔画复杂性指数正好形成互补。
(3)特征点
特征点提取算法的主要思想是利用字符点阵中一些有代表性的黑点(笔画)、白点(背景)作为特征来区分不同的字符。特征点包括笔画骨架线的端点、折点、歧点和交点,汉字的背景也含有一定的区别于其它汉字的信息,选择若干背景点作为特征点,有利于提高系统的抗干扰能力。其特点是能够大大压缩特征库的容量,对于内部笔画粘连字符,其识别的适应性较强、直观性好,但不易表示为矢量形式,匹配难度大,不适合作为粗分类的特征。
(4)笔段特征
汉字是由笔画组成的,而笔画又由笔段组成,笔段可近似为一定方向、长度和宽度的矩形段。利用笔段与笔段之间的关系组成特征对汉字进行识别,受字体和字号的影响小,对于多体汉字的识别获得了良好效果。其缺点是笔段的提取会较为困难,匹配的难度大,抗内部笔画断裂或者粘连能力差。 1.2.3汉字识别分类 1.相关匹配
这是一种统计识别方法,它通过在特征空间中计算输入特征向量与各模板向量之间的距离进行分类判决。 (2)文法分析
文法分析的基本思想是将输入的汉字看作是一个语句或符号串,将识别问题转化为判断输入的语句是否属于某种语言,即句子是否符合某种语言的语法约束条件。
(3)松弛匹配
无论是相关匹配还是文法分析,都要求输入特征向量和模板特征向量的各分量之间具有确切的对应关系,然而在结构分析中,往往事先难以确定两者各分量间的对应关系,此时可以采用松弛匹配法。
松
(4)人工神经网络
汉字识别是一个非常活跃的分支,不断有新的方法涌现出来,为汉字识别的研究注入新的活力,其中基于人工神经网络的识别方法是非常引人注目的方向。目前神经网络理论的应用己经渗透到各个领域,并在模式识别、智能控制、计算机视觉、自适应滤波和信号处理、非线性优化、自动目标识别,连续语音识别、声纳信号的处理、知识处理、传感技术与机器人、生物等领域都有广泛地应用。
1.2.4 后处理
后处理就是利用相关算法对识别后的汉字文本或者初级识别结果做进一步的处理,纠正误识的汉字,给出拒识的汉字,确定模棱两可的汉字。汉字识别的后处理方法[12,13]从用户的参与程度来说,可分为三类:手工处理,交互式处理和计算机自动处理。以下对各种常用的后处理方法做简单的介绍。
(1)简单的词匹配
简单的词匹配就是利用文本中字的上下文匹配关系和词的使用频度,给识别后文本中的拒识字提供一个“最佳”的候选字,其关键是建立汉语词条数据库。(2)综合词匹配
综合词匹配方法,就是综合利用初级识别结果和字的上下文关系及词的使用频度,来决定最后的识别结果。这种方法实际上己把识别过程和后处理过程融为一体了。
(3)词法分析
语言是语音和意义的结合体。语素是最小的语言单位。无论是词还是短语,都有其构成规则,利用这些规则,将它们分类。另外,不同的应用背景,也有不同的分类结果。
(4)句法、语义分析
语句无论是从结构上,还是从意思上都有一种人类共同理解、共同接受和共同遵守的语言组合法则。所以利用语义句法的方法,在初级识别结果的基础上,在利用词法分析进行匹配之后或匹配的同时,再进行句法分析和语义分析,从而确定要识别的汉字。
(5)人工神经元网络
利用人工神经元网络的汉字识别后处理可以采取两种方式。一种是把识别过程和后处理过程分开,网络的输入是初级识别结果的短语或者句子,其中包含不
确定的汉字(或拒识的汉字),通过网络的运行,最终确定这些字。另一种方法是把识别过程和后处理过程综合在一起,初级识别给出的结果是每一个待识汉字的前几个候选字和每一候选字与待识字之间的相似度。然后,把这些候选字以及与之相连的相似度输入网络,通过网络的并行作用,找到最符合汉语语法和语义组合关系的词或句子,从而确定出要识别的汉字。
1.3 印刷体汉字识别技术分析
1.3.1结构模式识别方法
汉字的数量巨大,结构复杂,但其特殊的组成结构中蕴藏着相当严的规律[14]。从笔画上讲,汉字有包括横、竖、撇、捺、点、折、勾等七种基本笔画,还有提挑、撇点、横捺等七种变形笔画。从部件上讲,部件是有特殊的笔画组合而成,故部件也是一定的。换而言之,汉字图形具有丰富的有规律可循的结构信息,可以设法提取含有这些信息的结构特征和组字规律,将它们作为汉字识别的依据。这就是结构模式识别。
结构模式识别理论在20 世纪70 年代初形成,是早期汉字识别研究的主要方法。其思想是直接从字符的轮廓或骨架上提取的字符像素分布特征,如笔画、圈、端点、节点、弧、突起、凹陷等多个基元组合,再用结构方法描述基元组合所代表的结构和关系。通常抽取笔段或基本笔画作为基元,由这些基元组合及其相互关系完全可以精确地对汉字加以描述,最后利用形式语言及自动机理论进行文法推断,即识别。结构模式识别方法的主要优点在于对字体变化的适应性强,区分相似字能力强;缺点是抗干扰能力差,从汉字图像中精确的抽取基元、轮廓、特征点比较困难,匹配过程复杂。因此,有人采用汉字轮廓结构信息作为特征,但这一方案需要进行松弛迭代匹配,耗时太长,而且对于笔画较模糊的汉字图像,抽取轮廓会遇到极大困难。也有些学者采用抽取汉字图像中关键特征点来描述汉字,但是特征点的抽取易受噪声点、笔画的粘连与断裂等影响。总之单纯采用结构模式识别方法的脱机手写汉字识别系统,识别率较低。 1.3.2统计模式识别方法
统计模式识别方法是用概率统计模型提取待识别汉字的特征向量,然后根据决策函数进行分类,识别就是判别待识汉字的特征向量属于哪一类。常用的判别准则是距离准则和类似度准则,典型的统计模式识别方法有最小距离分类、最邻近分类等。 1.最小距离分类
最小距离分类器(Minimum - Distance Classifier ) 是以汉字与特征空间模型点之间的距离作为分类准则,它有着图3-2所描述的结构。其中,x 是输入特征向量,他将被分配到C 个类别中的某一个类k ω(C k ,,2,1 =) ,这些类有各自的典型模式mk 表示。
图1-2 最小距离分类器系统图
2. 最邻近分类
最邻近法的思想是对于C 个类别i ω (C i ,,2,1 =) ,每类有标明类别的样本i N 个(C i ,,2,1 =)。规定i ω 的判别函数如式(1-1) 所示。其中k
i x 的角标i 表示i ω类,k 表示i ω类i N 个样本中的第k 个。
k i i
i x x x g -=min )(, i n k ,,2,1 = (1-3)
)(min )(i g x g i i
j =, C i ,,2,1 =, (1-4)
若式(1-2) 成立,则决策j x ω∈ 。即对未知样本x ,比较x 与N 个已知类别的样本之间的欧式距离并决策x 与离它最近的样本同类。
常用的汉字统计模式识别方法包括: (1)模板匹配
(2)利用变换特征的方法 (3)笔画方向特征 (4)外围特征 (5)特征点特征
随着汉字识别技术的发展,已经有越来越多的统计特征出现。但几乎每种特征都不是完美的,都要在特殊条件下施加一些特殊的处理。
2.系统的实现与仿真
2.1系统的实现
印刷品上的汉字输入,经过预处理后,对照标准汉字修补缺损部分,用修补后的汉字进行学习,形成初始的特征库后再进行大量样本的学习,建立实用的特征库。系统在识别过程中可进行自学习。取标准汉字,对每一个汉字计算面积。所有按面积由小到大排列,建立每一汉字与其国标码的指针。对神经网络设置其初始权值,选取大量标准汉字训练网络,反复修改权值,直至与面积序号对应的输出为有效,并建立每一输出与面积特征库之间的连接关系。以后随着学习过程的进行,将建立动态调整面积特征库及其与神经网络之间的对应关系。系统共包括5个子功能模块(见图2-1)。
图2-1 系统模块图
图2-2 系统流程框图
系统的工作流程如图2-2所示,文件首先由文件管理器加载。送人图像处理模块,经二值化转灰度,均值滤波,二值化,行字切分等图像预处理操作后。得到待识文字的点阵,汉字识别模块从点阵中提取识别特征,通过十三点特征提取,精确匹配得出识别结果。
2.2系统的仿真
此次采用MATLAB进行系统仿真(Matlab仿真程序见附录1),其中学习功能使用sim函数实现,特征提取用十三点特征提取法。
y = sim(net, P_test);%用训练出来的神经网络计算数据的第P_test行;其中net是SIMULINK的模型名(神经网络的对象见附录2);P_test是外部输入向量。
十三点特征提取法:
首先把字符平均分成8份,统计每一份内黑色像素点的个数作为8个特征,然后统计水平方向中间两列和竖直方向中间两列的黑色像素点的个数作为4个特征,最后统计所有黑色像素点的个数作为第13个特征。也就是说,画4道线,统计穿过的黑色像素的数目。可以得到4个特征。最后,将字符图像的全部黑色像素的数目的总和作为一个特征。十三点特征提取法有着极好的适应性,但是由于特征点的数目太少所以在样本训练的时候比较难收敛。
系统首先对标准图像(见图2-3)进行识别,识别过程中转灰度(见图2-4),均值滤(见图2-5),二值化(见图2-6),波识别结果见图(2-7)。
图2-3 标准图像
图2-4 标准图像转灰度图像
图2-5 标准图像均值滤波图像
图2-6 标准图像二值化图像
图2-7 标准图像识别结果
通过对标准图像识别学习训练,然后对输入乱序图像(见图2-8)进行识别,过程中转灰度(见图2-9),均值滤波(见图2-10),二值化(见图2-11),识别结果(见图2-12)。
图2-8 乱序图像
图2-9 乱序图像转灰度图像
图2-10 乱序图像均值滤波图像
图2-11 乱序图像二值化图像
图2-12 乱序图像识别结果
由以上实验结果可以看出,当输入标准图像,经过转灰度,均值滤波,二值化,识别输出。然后,输入乱序图像在经过转灰度,均值滤波,二值化,特征提取,匹配识别后,系统能够将乱序图像中的图像识别输出。说明系统基本实现预先设想的功能,能够在学习标准图像识别后建立标准库,并根据标准字库与以后输入的图像进行匹配识别输出。但由于系统比较简单,实现的功能也比较单一,要想实现较完备功能还需进一步完善。
3.附录附录1
%乱序图像识别:
load bp;
G=imread('luanxv.jpg');%读取
I=rgb2gray(G);
%--------转灰度图象
B1=filter2(fspecial('average',3),I)/255; %以[3,3]为模板均值滤波
%--------均值滤波
d=im2bw(B1,0.5);
%--------二值
k1=1;k2=1;s=sum(d');j=2;a=1;c=1 [m, n]=size(d');
while s(j)==m
j=j+1;
end
k1=j;
while s(j)~=m && j<=n-1
j=j+1;
end
k2=j-1;
d=d((k1:k2),:);
%--------行分割
[m,n]=size(d);
k1=1;k2=1;s=sum(d);j=2;a=1;c=1
for a=1:16
while s(j)==m
j=j+1;
end
k1=j;
while s(j)~=m && j<=n-1
j=j+1;
end
k2=j-1;
%--------列分割
if c==1
b1=d(:,(k1:k2));
imwrite(b1,'im1.jpg');
t1=tezhengtiqu(b1);
P_test = [t1'];
y = sim(net,P_test);
%用训练出来的神经网络计算数据的第%P_test行
word=jieguoxianshi(y)
end
%--------第1个字符
if c==2
b2=d(:,(k1:k2));
imwrite(b2,'im2.jpg');
t2=tezhengtiqu(b2);
%用十三点特征提取法提取特征
P_test = [t2];
y = sim(net,P_test');
%用训练出来的神经网络计算数据的
%第P_test行
word=jieguoxianshi(y)
end
%--------第2个字符
if c==3
b3=d(:,(k1:k2));
imwrite(b3,'im3.jpg');
t3=tezhengtiqu(b3);
P_test = [t3];
y = sim(net,P_test');
word=jieguoxianshi(y)
end
%--------第3个字符
if c==4
b4=d(:,(k1:k2));
imwrite(b4,'im4.jpg');
t4=tezhengtiqu(b4);
P_test = [t4];
y = sim(net,P_test');
word=jieguoxianshi(y)
end
%--------第4个字符
if c==5
b5=d(:,(k1:k2));
imwrite(b5,'im5.jpg');
t5=tezhengtiqu(b5);
P_test = [t5];
y = sim(net,P_test');
word=jieguoxianshi(y) end
%--------第5个字符
if c==6
b6=d(:,(k1:k2));
imwrite(b6,'im6.jpg');
t6=tezhengtiqu(b6);
P_test = [t6];
y = sim(net,P_test');
word=jieguoxianshi(y) end
%--------第6个字符
if c==7
b7=d(:,(k1:k2));
imwrite(b7,'im7.jpg');
t7=tezhengtiqu(b7);
P_test = [t7];
y = sim(net,P_test');
word=jieguoxianshi(y) end
%--------第7个字符
if c==8
b8=d(:,(k1:k2));
imwrite(b8,'im8.jpg');
t8=tezhengtiqu(b8);
P_test = [t8];
y = sim(net,P_test');
word=jieguoxianshi(y) end
%--------第8个字符
if c==9
b9=d(:,(k1:k2));
imwrite(b9,'im9.jpg');
t9=tezhengtiqu(b9);
P_test = [t9];
y = sim(net,P_test');
word=jieguoxianshi(y) end
%--------第9个字符
if c==10
b10=d(:,(k1:k2));
imwrite(b10,'im10.jpg');
t10=tezhengtiqu(b10);
P_test = [t10];
y = sim(net,P_test');
word=jieguoxianshi(y) end
%--------第10个字符
if c==11
b11=d(:,(k1:k2));
imwrite(b11,'im11.jpg');
t11=tezhengtiqu(b11);
P_test = [t11];
y = sim(net,P_test');
word=jieguoxianshi(y) end
%--------第11个字符
if c==12
b12=d(:,(k1:k2));
imwrite(b12,'im12.jpg');
t12=tezhengtiqu(b12);
P_test = [t12];
y = sim(net,P_test');
word=jieguoxianshi(y) end
%--------第12个字符
if c==13
b13=d(:,(k1:k2));
imwrite(b13,'im13.jpg');
t13=tezhengtiqu(b13);
P_test = [t13];
y = sim(net,P_test');
word=jieguoxianshi(y) end
%--------第13个字符
if c==14
b14=d(:,(k1:k2));
imwrite(b14,'im14.jpg');
t14=tezhengtiqu(b14);
P_test = [t14];
y = sim(net,P_test');
word=jieguoxianshi(y) end
%--------第14个字符
if c==15
b15=d(:,(k1:k2));
imwrite(b15,'im15.jpg');
t15=tezhengtiqu(b15);
P_test = [t15];
y = sim(net,P_test');
word=jieguoxianshi(y)
end
%--------第15个字符
if c==16
b16=d(:,(k1:k2));
imwrite(b16,'im16.jpg');
t16=tezhengtiqu(b16);
P_test = [t16];
y = sim(net,P_test');
word=jieguoxianshi(y)
end
%--------第16个字符
c=c+1;
end
subplot(2,8,1),imshow('im1.jpg'); subplot(2,8,2),imshow('im2.jpg'); subplot(2,8,3),imshow('im3.jpg'); subplot(2,8,4),imshow('im4.jpg'); subplot(2,8,5),imshow('im5.jpg'); subplot(2,8,6),imshow('im6.jpg'); subplot(2,8,7),imshow('im7.jpg'); subplot(2,8,8),imshow('im8.jpg'); subplot(2,8,9),imshow('im9.jpg'); subplot(2,8,10),imshow('im10.jpg'); subplot(2,8,11),imshow('im11.jpg'); subplot(2,8,12),imshow('im12.jpg'); subplot(2,8,13),imshow('im13.jpg'); subplot(2,8,14),imshow('im14.jpg'); subplot(2,8,15),imshow('im15.jpg'); subplot(2,8,16),imshow('im16.jpg');
%标准图像识别:
load fbp;
G=imread('biaozhun.jpg');%读取
I=rgb2gray(G);
%--------转灰度图象
B1=filter2(fspecial('average',3),I)/255; %--------均值滤波
d=im2bw(B1,0.5);
%--------二值
imshow(d); k1=1;k2=1;s=sum(d');j=2;a=1;c=1 [m,n]=size(d');
while s(j)==m
j=j+1;
end
k1=j;
while s(j)~=m && j<=n-1
j=j+1;
end
k2=j-1;
d=d((k1:k2),:);
%--------行分割
[m,n]=size(d);
k1=1;k2=1;s=sum(d);j=2;a=1;c=1 for a=1:16
while s(j)==m
j=j+1;
end
k1=j;
while s(j)~=m && j<=n-1
j=j+1;
end
k2=j-1;
%--------列分割
if c==1
b1=d(:,(k1:k2));
imwrite(b1,'im1.jpg');
t1=tezhengtiqu(b1);
P_test = [t1'];
y = sim(net,P_test);
word=fbmjieguoxianshi(y) end
%--------第1个字符
if c==2
b2=d(:,(k1:k2));
imwrite(b2,'im2.jpg');
t2=tezhengtiqu(b2);
P_test = [t2];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第2个字符
if c==3
b3=d(:,(k1:k2));
imwrite(b3,'im3.jpg');
t3=tezhengtiqu(b3);
P_test = [t3];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第3个字符
if c==4
b4=d(:,(k1:k2));
imwrite(b4,'im4.jpg');
t4=tezhengtiqu(b4);
P_test = [t4];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第4个字符
if c==5
b5=d(:,(k1:k2));
imwrite(b5,'im5.jpg');
t5=tezhengtiqu(b5);
P_test = [t5];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第5个字符
if c==6
b6=d(:,(k1:k2));
imwrite(b6,'im6.jpg');
t6=tezhengtiqu(b6);
P_test = [t6];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第6个字符
if c==7
b7=d(:,(k1:k2));
imwrite(b7,'im7.jpg');
t7=tezhengtiqu(b7);
P_test = [t7];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第7个字符
if c==8
b8=d(:,(k1:k2));
imwrite(b8,'im8.jpg');
t8=tezhengtiqu(b8);
P_test = [t8];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第8个字符
if c==9
b9=d(:,(k1:k2));
imwrite(b9,'im9.jpg');
t9=tezhengtiqu(b9);
P_test = [t9];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第9个字符
if c==10
b10=d(:,(k1:k2));
imwrite(b10,'im10.jpg');
t10=tezhengtiqu(b10);
P_test = [t10];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第10个字符
if c==11
b11=d(:,(k1:k2));
imwrite(b11,'im11.jpg');
t11=tezhengtiqu(b11);
P_test = [t11];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第11个字符
if c==12
b12=d(:,(k1:k2));
imwrite(b12,'im12.jpg');
t12=tezhengtiqu(b12);
P_test = [t12];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第12个字符
if c==13
b13=d(:,(k1:k2));
imwrite(b13,'im13.jpg');
t13=tezhengtiqu(b13);
P_test = [t13];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第13个字符
if c==14
b14=d(:,(k1:k2));
imwrite(b14,'im14.jpg');
t14=tezhengtiqu(b14);
P_test = [t14];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第14个字符
if c==15
b15=d(:,(k1:k2));
imwrite(b15,'im15.jpg');
t15=tezhengtiqu(b15);
P_test = [t15];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第15个字符
if c==16
b16=d(:,(k1:k2));
imwrite(b16,'im16.jpg');
t16=tezhengtiqu(b16);
P_test = [t16];
y = sim(net,P_test');
word=fbmjieguoxianshi(y) end
%--------第16个字符
c=c+1;
end
subplot(2,8,1),imshow('im1.jpg'); subplot(2,8,2),imshow('im2.jpg'); subplot(2,8,3),imshow('im3.jpg'); subplot(2,8,4),imshow('im4.jpg'); subplot(2,8,5),imshow('im5.jpg'); subplot(2,8,6),imshow('im6.jpg'); subplot(2,8,7),imshow('im7.jpg'); subplot(2,8,8),imshow('im8.jpg'); subplot(2,8,9),imshow('im9.jpg'); subplot(2,8,10),imshow('im10.jpg'); subplot(2,8,11),imshow('im11.jpg'); subplot(2,8,12),imshow('im12.jpg'); subplot(2,8,13),imshow('im13.jpg'); subplot(2,8,14),imshow('im14.jpg'); subplot(2,8,15),imshow('im15.jpg'); subplot(2,8,16),imshow('im16.jpg');
%标准图像识别结果显示:
function word=jieguoxianshi(y)
%显示结果的函数
y=[round(y(1)),round(y(2)),round(y(3)), round(y(4)),round(y(5)),round(y(6)), round(y(7)),round(y(8)),round(y(9)), round(y(10)),round(y(11)),round(y(12)), round(y(13)),round(y(14)),round(y(15)), round(y(16))];
[C,I]=max(y);
if I==16
word='匣';
elseif I==15
word='囡';
elseif I==14
word='图';
elseif I==13
word='国';
elseif I==12
word='盅';
elseif I==11
word='匡';
elseif I==10
word='盏';
elseif I==9
word='固';
elseif I==8
word='监';
elseif I==7
word='盂';
elseif I==6
word='盒';
elseif I==5
word='团';
elseif I==4
word='盈';
elseif I==3
word='団';
elseif I==2
word='盔';
elseif I==1
word='因';
end
%乱序图像识别结果显示
function word=jieguoxianshi(y)
%显示结果的函数
y=[round(y(1)),round(y(2)),round(y(3)), round(y(4))];
if y==[0,0,0,0]
word='匣';
elseif y==[0,0,0,1,]
word='囡';
elseif y==[0,0,1,0]
word='图';
elseif y==[0,0,1,1]
word='国';
elseif y==[0,1,0,0]
word='盅';
elseif y==[0,1,0,1]
word='匡';
elseif y==[0,1,1,0]
word='盏';
elseif y==[0,1,1,1]
word='固';
elseif y==[1,0,0,0]
word='监';
elseif y==[1,0,0,1]
word='盂';
elseif y==[1,0,1,0]
word='盒';
elseif y==[1,0,1,1]
word='团';
elseif y==[1,1,0,0]
word='盈';
elseif y==[1,1,0,1]
word='団'; elseif y==[1,1,1,0]
word='盔';
elseif y==[1,1,1,1]
word='因';
end
%特征提取:
function PN=moshishibie(d)
%特征提取函数
%通过13点特征提取法提取特征%d为已处理图象
[m,n]=size(d);
k1=1;
for i=1:m/4
for j=1:n/2
if d(i,j)==1
k1=k1+1;
end
end
end
k2=1;
for i=1:round(m/4)
for j=round(n/2):round(n)
if d(i,j)==1
k2=k2+1;
end
end
end
k3=1;
for i=round(m/4):m/2
for j=1:n/2
if d(i,j)==1
k3=k3+1;
end
end
end
k4=1;
for i=round(m/4):m/2
for j=round(n/2):n
if d(i,j)==1
k4=k4+1;
end
end
end
k5=1;
for i=round(m/2):round(m*3/4)
for j=1:round(n/2)
if d(i,j)==1
k5=k5+1;
end
end
end
k6=1;
for i=round(m/2):round(m*3/4)
for j=round(n/2):n
if d(i,j)==1
k6=k6+1;
end
end
end
k7=1;
for i=round(m*3/4):m
for j=1:round(n/2)
if d(i,j)==1
k7=k7+1;
end
end
end
k8=1;
for i=round(m*3/4):m
for j=round(n/2):n
if d(i,j)==1
k8=k8+1;
end
end
end
k9=k3+k4;
k10=k5+k6;
k11=k1+k3+k5+k7;
k12=k2+k4+k6+k8;
k13=k11+k12;
k=[k1,k2,k3,k4,k5,k6,k7,k8,k9,k10,k11,k12,13]; [PN,minp,maxp] = premnmx(k); %归一化
附录2
Neural Network object: %神经网络的对象;
architecture: %结构;
numInputs: 1
numLayers: 3
biasConnect: [1; 1; 1]
inputConnect: [1; 0; 0]
layerConnect: [0 0 0; 1 0 0; 0 1 0]
outputConnect: [0 0 1]
targetConnect: [0 0 1]
numOutputs: 1 (read-only)
numTargets: 1 (read-only)
numInputDelays: 0 (read-only)
numLayerDelays: 0 (read-only)
subobject structures: %子对象结构
inputs: {1x1 cell} of inputs
layers: {3x1 cell} of layers
outputs: {1x3 cell} containing 1 output
targets: {1x3 cell} containing 1 target
biases: {3x1 cell} containing 3 biases
inputWeights: {3x1 cell} containing 1 input weight
layerWeights: {3x3 cell} containing 2 layer weights
functions: %功能
adaptFcn: 'trains'
initFcn: 'initlay'
performFcn: 'mse'
trainFcn: 'trainlm'
parameters: %参数
adaptParam: .passes
initParam: (none)
performParam: (none)
trainParam: .epochs, .goal, .max_fail, .mem_reduc,
.min_grad, .mu, .mu_dec, .mu_inc,
.mu_max, .show, .time
weight and bias values: %权重和偏置值
IW: {3x1 cell} containing 1 input weight matrix
LW: {3x3 cell} containing 2 layer weight matrices
b: {3x1 cell} containing 3 bias vectors
other: %其他
userdata: (user stuff)
车牌识别地matlab程序
( 附录 车牌识别程序 clear ; close all; %Step1 获取图像装入待处理彩色图像并显示原始图像 Scolor = imread('');%imread函数读取图像文件 %将彩色图像转换为黑白并显示 Sgray = rgb2gray(Scolor);%rgb2gray转换成灰度图 " figure,imshow(Scolor),title('原始彩色图像');%figure命令同时显示两幅图 figure,imshow(Sgray),title('原始黑白图像'); %Step2 图像预处理对Sgray 原始黑白图像进行开操作得到图像背景s=strel('disk',13);%strel函数 Bgray=imopen(Sgray,s);%打开sgray s图像 figure,imshow(Bgray);title('背景图像');%输出背景图像 %用原始图像与背景图像作减法,增强图像 Egray=imsubtract(Sgray,Bgray);%两幅图相减 ¥ figure,imshow(Egray);title('增强黑白图像');%输出黑白图像 %Step3 取得最佳阈值,将图像二值化 fmax1=double(max(max(Egray)));%egray的最大值并输出双精度型 fmin1=double(min(min(Egray)));%egray的最小值并输出双精度型 level=(fmax1-(fmax1-fmin1)/3)/255;%获得最佳阈值 bw22=im2bw(Egray,level);%转换图像为二进制图像 bw2=double(bw22); %Step4 对得到二值图像作开闭操作进行滤波 、 figure,imshow(bw2);title('图像二值化');%得到二值图像 grd=edge(bw2,'canny')%用canny算子识别强度图像中的边界
利用MATLAB平台实现少量字的语音识别
目录 引言 (4) 1.语音识别简介 (5) 1.1语音识别系统的分类 (5) 1.2语音识别系统的基本构成 (5) 2.语音识别参数 (6) 2.1线性预测系数(LPC) (6) 2.2线性预测倒谱系数(LPCC) (8) 2.3MFCC系数 (8) 2.4参数计算流程 (9) 3.DTW算法 (11) 3.1DTW算法原理 (11) 3.2DTW的高效算法 (14) 4.HMM算法 (16) 4.1HMM的原理 (16) 4.2HMM的前向概率和后向概率 (17) 4.3识别算法——V ITERBI解码 (19) 4.4 BAUM-WELCH算法 (20) 5.实验及总结 (23) 5.1实验准备以及步骤 (23) 5.2实验结果及讨论 (25) 5.3实验结论 (29) 参考文献 (30) 致谢 (31)
引言 自上世纪80年代开始,语音识别技术的研究进入了一个蓬勃发展的时期,一些商用系统也从实验室进入市场。然而,在实际的应用中,由于各种干扰因素导致的测试条件与训练环境的不匹配,系统的性能往往会收到极大的影响。因此提高语音识别系统的性能就成为了语音识别技术真正走向实用化的关键课题。 语音识别是以声音作为研究对象它是语音信号处理的一个重要研究方向,是模式识别的一个分支涉及到生理学、心理学、语言学、计算机科学以及信号处理等诸多领域,甚至还涉及到人的体态语言(如人在说话时的表情、手势等行为动作可帮助对方理解),其最终目标是实现人与机器进行自然语言通信。本文研究了汉语语音识别技术及其实现方法。论文首先分析了语音信号预处理问题。对MFCC倒谱系数在语音识别中的运用做了详细介绍。其次研究了基于DTW的语音识别系统,针对DTW算法中系统识别性能过分依赖于端点检测、动态规划的计算量太大等缺陷,分别提出了快速DTW算法和端点松动的DTW算法,仿真结果比较理想。继而研究了基于HMM的语音识别系统。针对HMM在实际应用中的优化计算问题,包括初始模型选取,定标等进行了深入的分析与探讨。针对传统定标仍能溢出的问题,给出了无溢出的参数重估公式。
语音识别Matlab可视化编程(部分)
附录1:录音函数:audiorecorder.m % 运行平台:Windows 8.1 64bit MATLAB R2014a % 录音2秒钟 clear all;clc;close all; fs = 16000; %2é?ù?μ?ê recorder = audiorecorder; disp('Start speaking.') recordblocking(recorder, 2); disp('End of Recording.'); % 回放录音数据 play(recorder); % 获取录音数据 xx = getaudiodata(recorder,'int16'); %绘制录音数据波形 plot(xx); A6:“录音”按键回调函数 function pushbutton1_Callback(hObject, eventdata, handles) % hObject handle to pushbutton1 (see GCBO) % eventdata reserved - to be defined in a future version of MATLAB % handles structure with handles and user data (see GUIDATA) fs = 16000; recorder = audiorecorder; disp('Start speaking.') recordblocking(recorder, 2); disp('End of Recording.'); % 回放录音数据 % play(recorder); % 获取录音数据 k = getaudiodata(recorder,'int16'); plot(handles.axes1,k); load mfcc.mat; [StartPoint,EndPoint]=vad(k,fs); cc=mfcc(k); cc=cc(StartPoint-2:EndPoint-2,:); test.StartPoint=StartPoint; test.EndPoint=EndPoint;
基于matlab的车牌号码识别程序代码
基于matlab的汽车牌照识别程序 摘要:本次作业的任务是设计一个基于matlab的汽车牌照识别程序,能够实现车牌图像预处理,车牌定位,字符分割,然后通过神经网络对车牌进行字符识别,最终从一幅图像中提取车牌中的字母和数字,给出文本形式的车牌号码。 关键词:车牌识别,matlab,神经网络 1 引言 随着我国交通运输的不断发展,智能交通系统(Intelligent Traffic System,简称ITS)的推广变的越来越重要,而作为ITS的一个重要组成部分,车辆牌照识别系统(vehicle license plate recognition system,简称LPR)对于交通管理、治安处罚等工作的智能化起着十分重要的作用。它可广泛应用于交通流量检测,交通控制于诱导,机场,港口,小区的车辆管理,不停车自动收费,闯红灯等违章车辆监控以及车辆安全防盗等领域,具有广阔的应用前景。由于牌照是机动车辆管理的唯一标识符号,因此,车辆牌照识别系统的研究在机动车管理方面具有十分重要的实际意义。 2 车辆牌照识别系统工作原理 车辆牌照识别系统的基本工作原理为:将摄像头拍摄到的包含车辆牌照的图像通过视频卡输入到计算机中进行预处理,再由检索模块对牌照进行搜索、检测、定位,并分割出包含牌照字符的矩形区域,然后对牌照字符进行二值化并将其分割为单个字符,然后输入JPEG或BMP格式的数字,输出则为车牌号码的数字。 3 车辆牌照识别系统组成 (1)图像预处理:对汽车图像进行图像转换、图像增强和边缘检测等。 (2)车牌定位:从预处理后的汽车图像中分割出车牌图像。即在一幅车辆图像中找到车牌所在的位置。 (3)字符分割:对车牌图像进行几何校正、去噪、二值化以及字符分割以从车牌图像中分离出组成车牌号码的单个字符图像
matlab语音识别系统(源代码)最新版
matlab语音识别系统(源代码)最新版
目录 一、设计任务及要求 (1) 二、语音识别的简单介绍 2.1语者识别的概念 (2) 2.2特征参数的提取 (3) 2.3用矢量量化聚类法生成码本 (3) 2.4VQ的说话人识别 (4) 三、算法程序分析 3.1函数关系 (4) 3.2代码说明 (5) 3.2.1函数mfcc (5) 3.2.2函数disteu (5) 3.2.3函数vqlbg (6) 3.2.4函数test (6) 3.2.5函数testDB (7) 3.2.6 函数train (8) 3.2.7函数melfb (8) 四、演示分析 (9) 五、心得体会 (11) 附:GUI程序代码 (12)
一、设计任务及要求 用MATLAB实现简单的语音识别功能; 具体设计要求如下: 用MATLAB实现简单的数字1~9的语音识别功能。 二、语音识别的简单介绍 基于VQ的说话人识别系统,矢量量化起着双重作用。在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。 语音识别系统结构框图如图1所示。 图1 语音识别系统结构框图 2.1语者识别的概念 语者识别就是根据说话人的语音信号来判别说话人的身份。语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用电话网络还可实现远程客户服务等。因此,近几年来,说话人识别越来越多的受到人们的重视。与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中,是唯一可以用作远程验证的识别技术。因此,说话人识别的应用前景非常广泛:今天,说话人识别技术已经关系到多学科的研究领域,不同领域中的进步都对说话人识别的发展做出了贡献。说话人识别技术是集声学、语言学、计算机、信息处理和人工智能等诸多领域的一项综合技术,应用需求将十分广阔。在吃力语音信号的时候如何提取信号中关键的成分尤为重要。语音信号的特征参数的好坏直接导致了辨别的准确性。
基于MATLAB的语音信号采集与处理
工程设计论文 题目:基于MATLAB的语音信号采集与处理 姓名: 班级: 学号: 指导老师:
一.选题背景 1、实践意义: 语音信号是一种非平稳的时变信号,它携带着各种信息。在语音编码、语音合成、语音识别和语音增强等语音处理中无一例外需要提取语音中包含的各种信息。语音信号分析的目的就在于方便有效地提取并表示语音信号所携带的信息。所以理解并掌握语音信号的时域和频域特性是非常重要的。 通过语音相互传递信息是人类最重要的基本功能之一.语言是人类特有的功能.声音是人类常用工具,是相互传递信息的最重要的手段.虽然,人可以通过多种手段获得外界信息,但最重要,最精细的信息源只有语言,图像和文字三种.与用声音传递信息相比,显然用视觉和文字相互传递信息,其效果要差得多.这是因为语音中除包含实际发音容的话言信息外,还包括发音者是谁及喜怒哀乐等各种信息.所以,语音是人类最重要,最有效,最常用和最方便的交换信息的形式.另一方面,语言和语音与人的智力活动密切相关,与文化和社会的进步紧密相连,它具有最大的信息容量和最高的智能水平。 语音信号处理是研究用数字信号处理技术对语音信号进行处理的一门学科,处理的目的是用于得到某些参数以便高效传输或存储;或者是用于某种应用,如人工合成出语音,辨识出讲话者,识别出讲话容,进行语音增强等. 语音信号处理是一门新兴的学科,同时又是综合性的多学科领域,
是一门涉及面很广的交叉学科.虽然从事达一领域研究的人员主要来自信息处理及计算机等学科.但是它与语音学,语言学,声学,认知科学,生理学,心理学及数理统计等许多学科也有非常密切的联系. 语音信号处理是许多信息领域应用的核心技术之一,是目前发展最为迅速的信息科学研究领域中的一个.语音处理是目前极为活跃和热门的研究领域,其研究涉及一系列前沿科研课题,巳处于迅速发展之中;其研究成果具有重要的学术及应用价值. 数字信号处理是利用计算机或专用处理设备,以数值计算的方法对信号进行采集、抽样、变换、综合、估值与识别等加工处理,借以达到提取信息和便于应用的目的。它在语音、雷达、图像、系统控制、通信、航空航天、生物医学等众多领域都获得了极其广泛的应用。具有灵活、精确、抗干扰强、度快等优点。 数字滤波器, 是数字信号处理中及其重要的一部分。随着信息时代和数字技术的发展,受到人们越来越多的重视。数字滤波器可以通过数值运算实现滤波,所以数字滤波器处理精度高、稳定、体积小、重量轻、灵活不存在阻抗匹配问题,可以实现模拟滤波器无法实现的特殊功能。数字滤波器种类很多,根据其实现的网络结构或者其冲激响应函数的时域特性,可分为两种,即有限冲激响应( FIR,Finite Impulse Response)滤波器和无限冲激响应( IIR,Infinite Impulse Response)滤波器。 FIR滤波器结构上主要是非递归结构,没有输出到输入的反馈,系统函数H (z)在处收敛,极点全部在z = 0处(因果系统),因而只能
matlab车牌识别课程设计报告(附源代码)
Matlab程序设计任务书 目录
一.课程设计目的 (3) 二.设计原理 (3) 三.详细设计步骤 (3) 四. 设计结果及分析 (18) 五. 总结 (19) 六. 设计体会 (20) 七. 参考文献 (21) 一、课程设计目的 车牌定位系统的目的在于正确获取整个图像中车牌的区域,并识别出车牌号。通过
设计实现车牌识别系统,能够提高学生分析问题和解决问题的能力,还能培养一定的科研能力。 二、设计原理: 牌照自动识别是一项利用车辆的动态视频或静态图像进行牌照号码、牌照颜色自动识别的模式识别技术。其硬件基础一般包括触发设备、摄像设备、照明设备、图像采集设备、识别车牌号码的处理机等,其软件核心包括车牌定位算法、车牌字符分割算法和光学字符识别算法等。某些牌照识别系统还具有通过视频图像判断车辆驶入视野的功能称之为视频车辆检测。一个完整的牌照识别系统应包括车辆检测、图像采集、牌照识别等几部分。当车辆检测部分检测到车辆到达时触发图像采集单元,采集当前的视频图像。牌照识别单元对图像进行处理,定位出牌照位置,再将牌照中的字符分割出来进行识别,然后组成牌照号码输出。 三、详细设计步骤: 1. 提出总体设计方案: 牌照号码、颜色识别 为了进行牌照识别,需要以下几个基本的步骤: a.牌照定位,定位图片中的牌照位置; b.牌照字符分割,把牌照中的字符分割出来; c.牌照字符识别,把分割好的字符进行识别,最终组成牌照号码。
牌照识别过程中,牌照颜色的识别依据算法不同,可能在上述不同步骤实现,通常与牌照识别互相配合、互相验证。 (1)牌照定位: 自然环境下,汽车图像背景复杂、光照不均匀,如何在自然背景中准确地确定牌照区域是整个识别过程的关键。首先对采集到的视频图像进行大范围相关搜索,找到符合汽车牌照特征的若干区域作为候选区,然后对这些侯选区域做进一步分析、评判,最后选定一个最佳的区域作为牌照区域,并将其从图象中分割出来。 流程图: 完成牌照区域的定位后,再将牌照区域分割成单个字符,然后进行识别。字符分割一般采用垂直投影法。由于字符在垂直方向上的投影必然在字符间或字符内的间隙处取得局部最小值的附近,并且这个位置应满足牌照的字符书写格式、字符、尺寸限制和一些其他条件。利用垂直投影法对复杂环境下的汽车图像中的字符分割有较好的效果。 字符识别方法目前主要有基于模板匹配算法和基于人工神经网络算法。 基于模板匹配算法首先将分割后的字符二值化,并将其尺寸大小缩放为字符数据库中模板的大小, 然后与所有的模板进行匹配,最后选最佳匹配作为结果。基于人工神经元网络的算法有两种:一种是先对待识别字符进行特征提取,然后用所获得特征来训练神经网络分配器;另一种方法是直接把待处理图像输入网络,由网络自动实现特征提取直至识别出结果。实际应用中,牌照识别系统的识别率与牌照质量和拍摄质量密切相关。牌照质量会受到各种因素的影响,如生锈、污损、油漆剥落、字体褪色、牌照被遮挡、牌照倾斜、高亮反光、多牌照、假牌照等等;实际拍摄过程也会受到环境亮度、拍摄亮度、车辆速度等等因素的影响。这些影响因素不同程度上降低了牌照识别的识别率,也正是牌照识别系统的困难和挑战所在。为了提高识别率,除了不断的完善识别算法,还应该想办法克服各种光照条件,使采集到的图像最利于识别。 clear ; close all;
matlab语音识别系统(源代码)
(威海)《智能仪器》课程设计 题目: MATLAB实现语音识别功能班级: 学号: 姓名: 同组人员: 任课教师: 完成时间:2012/11/3 目录
一、设计任务及要求 (1) 二、语音识别的简单介绍 2.1语者识别的概念 (2) 2.2特征参数的提取 (3) 2.3用矢量量化聚类法生成码本 (3) 2.4VQ的说话人识别 (4) 三、算法程序分析 3.1函数关系 (4) 3.2代码说明 (5) 3.2.1函数mfcc (5) 3.2.2函数disteu (5) 3.2.3函数vqlbg (6) 3.2.4函数test (6) 3.2.5函数testDB (7) 3.2.6 函数train (8) 3.2.7函数melfb (8) 四、演示分析 (9) 五、心得体会 (11) 附:GUI程序代码 (12) 一、设计任务及要求 用MATLAB实现简单的语音识别功能;
具体设计要求如下: 用MATLAB实现简单的数字1~9的语音识别功能。 二、语音识别的简单介绍 基于VQ的说话人识别系统,矢量量化起着双重作用。在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。 语音识别系统结构框图如图1所示。 图1 语音识别系统结构框图 2.1语者识别的概念 语者识别就是根据说话人的语音信号来判别说话人的身份。语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用网络还可实现远程客户服务等。因此,近几年来,说话人识别越来越多的受到人们的重视。与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中,是唯一可以用作远程验证的识别技术。因此,说话人识别的应用前景非常广泛:今天,说话人识别技术已经关系到多学科的研究领域,不同领域中的进步都对说话人识别的发展做出了贡献。说话人识别技术是集声学、语言学、计算机、信息处理和人工智能等诸多领域的一项综合技术,应用需求将十分广阔。在吃力语音信号的时候如何提取信号中关键的成分尤为重要。语音信号的特征参数的好坏直接导致了辨别的准确性。 2.2特征参数的提取 对于特征参数的选取,我们使用mfcc的方法来提取。MFCC参数是基于人的听觉特性利用人听觉的屏蔽效应,在Mel标度频率域提取出来的倒谱特征参数。
基于语音识别的智能小车设计-毕设论文
基于语音识别的智能小车 摘要 随着计算机技术、模式识别和信号处理技术及声学技术等的发展,使得能满足各种需要的语音识别系统的实现成为可能。近二三十年来,语音识别在计算机、信息处理、通信与电子系统、自动控制等领域中有着越来越广泛的应用。本设计是语音识别在控制领域的一个很好实现,它将原本需要手工操作的工作用语音来方便地完成。 语音识别按说话人的讲话方式可分为孤立词(Isolated Word)识别、连接词(Connected Word)识别和连续语音(Continuous Speech)识别。从识别对象的类型来看,语音识别可以分为特定人(Speaker Dependent)语音识别和非特定人(Speaker Independent)语音识别。本设计采用的识别类型是特定人孤立词语音识别。 本系统分上位机和下位机两大方面。上位机利用PC上MATLAB强大的数学计算能力,进行语音输入、端点监测、特征参数提取、匹配、串口控制等工作,根据识别到的不同语音通过PC串口向下位机发送不同的指令。下位机是单片机控制的一个小车,单片机收到上位机传来的指令后,根据不同的指令控制小车完成不同的动作。 该设计对语音识别的现有算法进行了验证和实现,并对端点检测和匹配算法进行了些许改进。本设计达到了预期目标,实现了所期望的功能效果。 关键词:MATLAB,语音识别,端点检测,LPC,单片机,电机控制
SMART CAR GASED SPEECH RECOGNITION ABSTRACT With the development of computer technology,pattern recognition,signal processing technology and acoustic technology etc, the speech recognition system that can meet the various needs of people is more possible to achieve.The past three decades, the voice recognition in the field of computer, information processing, communications and electronic systems, automatic control has increasingly wide range of applications. Speech recognition by the speaker's speech can be divided into isolated word (Isolated Word) identification, conjunctions (Connected Word) and continuous speech recognition (Continuous Speech) identification. Identifying the type of object from the point of view, the voice recognition can be divided into a specific person (Speaker Dependent) speech recognition and non-specific (Speaker Independent) speech recognition. This design uses the identification type is a specific person isolated word speech recognition. This design is of a good implementation of speech recognition in the control field, it does the work that would otherwise require manual operation by the voice of people easily.This system includes two major aspects:the host system and the slave system. The host system use the MATLAB on the computer which has powerful mathematical computing ability to do the work of voice input, endpoint monitoring, feature extraction, matching, identification and serial control,then it send different commands through the PC serial port to slave system according different recognised voice. The slave system is a car controlled by a single-chip micro-controller.It controls the car do different actions according different instructions received.
matlab车牌识别程序代码
% 车牌识别程序主体 clc; close all; clear all; %========================================================== %说明: % % %=========================================================== % ==============测定算法执行的时间,开始计时================= tic %%%%%记录程序运行时间 %=====================读入图片================================ [fn,pn,fi]=uigetfile('*.jpg','选择图片'); I=imread([pn fn]); figure; imshow(I); title('原始图像');%显示原始图像 chepailujing=[pn fn] I_bai=I; [PY2,PY1,PX2,PX1]=caitu_fenge(I); % I=rgb2hsv(I); % [PY2,PY1,PX2,PX1]=caitu_tiqu(I,I_bai);%用HSI模型识别蓝色,用rgb模型识别白色 %================分割车牌区域================================= %===============车牌区域根据面积二次修正====================== [PY2,PY1,PX2,PX1,threshold]=SEC_xiuzheng(PY2,PY1,PX2,PX1); %==============更新图片============================= Plate=I_bai(PY1:PY2,PX1:PX2,:);%使用caitu_tiqu %==============考虑用腐蚀解决蓝色车问题============= bw=Plate;figure,imshow(bw);title('车牌图像');%hsv彩图提取图像 %==============这里要根据图像的倾斜度进行选择这里选择的图片20090425686.jpg bw=rgb2gray(bw);figure,imshow(bw);title('灰度图像'); %================倾斜校正====================== qingxiejiao=rando_bianhuan(bw) bw=imrotate(bw,qingxiejiao,'bilinear','crop');figure,imshow(bw);title('倾斜校正');%取值为负值向右旋转 %============================================== bw=im2bw(bw,graythresh(bw));%figure,imshow(bw); bw=bwmorph(bw,'hbreak',inf);%figure,imshow(bw); bw=bwmorph(bw,'spur',inf);%figure,imshow(bw);title('擦除之前');
车牌识别的matlab程序
附录 车牌识别程序 clear ; close all; %Step1 获取图像装入待处理彩色图像并显示原始图像 Scolor = imread('3.jpg');%imread函数读取图像文件 %将彩色图像转换为黑白并显示 Sgray = rgb2gray(Scolor);%rgb2gray转换成灰度图 figure,imshow(Scolor),title('原始彩色图像');%figure命令同时显示两幅图 figure,imshow(Sgray),title('原始黑白图像'); %Step2 图像预处理对Sgray 原始黑白图像进行开操作得到图像背景s=strel('disk',13);%strel函数 Bgray=imopen(Sgray,s);%打开sgray s图像 figure,imshow(Bgray);title('背景图像');%输出背景图像 %用原始图像与背景图像作减法,增强图像 Egray=imsubtract(Sgray,Bgray);%两幅图相减 figure,imshow(Egray);title('增强黑白图像');%输出黑白图像 %Step3 取得最佳阈值,将图像二值化 fmax1=double(max(max(Egray)));%egray的最大值并输出双精度型 fmin1=double(min(min(Egray)));%egray的最小值并输出双精度型level=(fmax1-(fmax1-fmin1)/3)/255;%获得最佳阈值 bw22=im2bw(Egray,level);%转换图像为二进制图像 bw2=double(bw22); %Step4 对得到二值图像作开闭操作进行滤波 figure,imshow(bw2);title('图像二值化');%得到二值图像 grd=edge(bw2,'canny')%用canny算子识别强度图像中的边界 figure,imshow(grd);title('图像边缘提取');%输出图像边缘 bg1=imclose(grd,strel('rectangle',[5,19]));%取矩形框的闭运算 figure,imshow(bg1);title('图像闭运算[5,19]');%输出闭运算的图像bg3=imopen(bg1,strel('rectangle',[5,19]));%取矩形框的开运算
人脸识别系统设计与仿真 基于matlab的(含matlab源程序)版权不归自己 交流使用
人脸识别系统设计与仿真基于matlab的(含matlab源程序) 交流使用参考后自行那个删除后果自负 目录 第一章绪论 (2) 1.1 研究背景 (2) 1.2 人脸图像识别的应用前景 (3) 1.3 本文研究的问题 (4) 1.4 识别系统构成 (5) 1.5 论文的内容及组织 (7) 第二章图像处理的Matlab实现 (8) 2.1 Matlab简介 (8) 2.2 数字图像处理及过程 (8) 2.2.1图像处理的基本操作 (8) 2.2.2图像类型的转换 (9) 2.2.3图像增强 (9) 2.2.4边缘检测 (10) 2.3图像处理功能的Matlab实现实例 (11) 2.4 本章小结 (15) 第三章人脸图像识别计算机系统 (16) 3.1 引言 (16) 3.2系统基本机构 (17)
3.3 人脸检测定位算法 (18) 3.4 人脸图像的预处理 (25) 3.4.1 仿真系统中实现的人脸图像预处理方法 (26) 第四章基于直方图的人脸识别实现 (29) 4.1识别理论 (29) 4.2 人脸识别的matlab实现 (29) 4.3 本章小结 (30) 第五章总结 (31) 致谢 (32) 参考文献 (33) 附录 (35)
第一章绪论 本章提出了本文的研究背景及应用前景。首先阐述了人脸图像识别意义;然后介绍了人脸图像识别研究中存在的问题;接着介绍了自动人脸识别系统的一般框架构成;最后简要地介绍了本文的主要工作和章节结构。 1.1 研究背景 自70年代以来.随着人工智能技术的兴起.以及人类视觉研究的进展.人们逐渐对人脸图像的机器识别投入很大的热情,并形成了一个人脸图像识别研究领域,.这一领域除了它的重大理论价值外,也极具实用价值。 在进行人工智能的研究中,人们一直想做的事情就是让机器具有像人类一样的思考能力,以及识别事物、处理事物的能力,因此从解剖学、心理学、行为感知学等各个角度来探求人类的思维机制、以及感知事物、处理事物的机制,并努力将这些机制用于实践,如各种智能机器人的研制。人脸图像的机器识别研究就是在这种背景下兴起的,因为人们发现许多对于人类而言可以轻易做到的事情,而让机器来实现却很难,如人脸图像的识别,语音识别,自然语言理解等。如果能够开发出具有像人类一样的机器识别机制,就能够逐步地了解人类是如何存储信息,并进行处理的,从而最终了解人类的思维机制。 同时,进行人脸图像识别研究也具有很大的使用价依。如同人的指纹一样,人脸也具有唯一性,也可用来鉴别一个人的身份。现在己
车牌识别的matlab程序(程序-讲解-模板)
车牌识别的matlab程序(程序-讲解-模板)
clc clear close all I=imread('chepai.jpg'); subplot(3,2,1);imshow(I), title('原始图像'); I_gray=rgb2gray(I); subplot(3,2,2),imshow(I_gray),title('灰度图像'); %====================== 形态学预处理====================== I_edge=edge(I_gray,'sobel'); subplot(3,2,3),imshow(I_edge),title('边缘检测后图像'); se=[1;1;1]; I_erode=imerode(I_edge,se); subplot(3,2,4),imshow(I_erode),title('腐蚀后边缘图像'); se=strel('rectangle',[25,25]); I_close=imclose(I_erode,se); %图像闭合、填充图像 subplot(3,2,5),imshow(I_close),title('填充后图像
for i=1:size(location_of_1,1) %寻找所有白点中,x坐标与y坐标的和最大,最小的两个点的位置 temp=location_of_1(i,1)+location_of_1(i,2); if temp
matlab车牌识别课程设计报告(附源代码)
Matlab程序设计任务书 分院(系)信息科学与工程专业 学生姓名学号 设计题目车牌识别系统设计 内容及要求: 车牌定位系统的目的在于正确获取整个图像中车牌的区域,并识别出车牌号。通过设计实现车牌识别系统,能够提高学生 分析问题和解决问题的能力,还能培养一定的科研能力。 1.牌照识别系统应包括车辆检测、图像采集、牌照识别等几 部分。 2.当车辆检测部分检测到车辆到达时,触发图像采集单元,采 集当前的视频图像。 3.牌照识别单元对图像进行处理,定位出牌照位置,再将牌 照中的字符分割出来进行识别,然后组成牌照号码输出。 进度安排: 19周:Matlab环境熟悉与基础知识学习 19周:课程设计选题与题目分析 20周:程序设计编程实现 20周:课程设计验收与答辩 指导教师(签字): 年月日学院院长(签字): 年月日 目录
一.课程设计目的 (3) 二.设计原理 (3) 三.详细设计步骤 (3) 四. 设计结果及分析 (18) 五. 总结 (19) 六. 设计体会 (20) 七. 参考文献 (21) 一、课程设计目的 车牌定位系统的目的在于正确获取整个图像中车牌的区域,并识别出车牌号。通过
设计实现车牌识别系统,能够提高学生分析问题和解决问题的能力,还能培养一定的科研能力。 二、设计原理: 牌照自动识别是一项利用车辆的动态视频或静态图像进行牌照号码、牌照颜色自动识别的模式识别技术。其硬件基础一般包括触发设备、摄像设备、照明设备、图像采集设备、识别车牌号码的处理机等,其软件核心包括车牌定位算法、车牌字符分割算法和光学字符识别算法等。某些牌照识别系统还具有通过视频图像判断车辆驶入视野的功能称之为视频车辆检测。一个完整的牌照识别系统应包括车辆检测、图像采集、牌照识别等几部分。当车辆检测部分检测到车辆到达时触发图像采集单元,采集当前的视频图像。牌照识别单元对图像进行处理,定位出牌照位置,再将牌照中的字符分割出来进行识别,然后组成牌照号码输出。 三、详细设计步骤: 1. 提出总体设计方案: 牌照号码、颜色识别 为了进行牌照识别,需要以下几个基本的步骤: a.牌照定位,定位图片中的牌照位置;
基于matlab的车牌定位源程序及运行结果 (1)
I=imread('E:\毕业设计\基于matlab的车牌定位的源程\车牌识别程序 \Car1.jpg') [y,x,z]=size(I); myI=double(I); tic Blue_y=zeros(y,1); for i=1:y for j=1:x if((myI(i,j,1)<=30)&&((myI(i,j,2)<=62)&&(myI(i,j,2)>=51))&&((myI(i,j,3) <=142)&&(myI(i,j,3)>=119))) Blue_y(i,1)= Blue_y(i,1)+1; end end end [temp MaxY]=max(Blue_y); PY1=MaxY; while ((Blue_y(PY1,1)>=120)&&(PY1>1)) PY1=PY1-1; end PY2=MaxY; while ((Blue_y(PY2,1)>=40)&&(PY2
matlab语音识别系统(源代码)版
目录 一、设计任务及要求 (1) 二、语音识别的简单介绍 语者识别的概念 (2) 特征参数的提取 (3) 用矢量量化聚类法生成码本 (3) 的说话人识别 (4) 三、算法程序分析 函数关系 (4) 代码说明 (5) 函数mfcc (5) 函数disteu (5) 函数vqlbg (6) 函数test (6) 函数testDB (7) 函数train (8) 函数melfb (8) 四、演示分析 (9) 五、心得体会 (11) 附:GUI程序代码 (12)
一、设计任务及要求 用MATLAB实现简单的语音识别功能; 具体设计要求如下: 用MATLAB实现简单的数字1~9的语音识别功能。 二、语音识别的简单介绍 基于VQ的说话人识别系统,矢量量化起着双重作用。在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。 语音识别系统结构框图如图1所示。
图1 语音识别系统结构框图 语者识别的概念 语者识别就是根据说话人的语音信号来判别说话人的身份。语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用电话网络还可实现远程客户服务等。因此,近几年来,说话人识别越来越多的受到人们的重视。与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中,是唯一可以用作远程验证的识别技术。因此,说话人识别的应用前景非常广泛:今天,说话人识别技术已经关系到多学科的研究领域,不同领域中的进步都对说话人识别的发展做出了贡献。说话人识别技术是集声学、语言学、计算机、信息处理和人工智能等诸多领域的一项综合技术,应用需求将十分广阔。在吃力语音信号的时候如何提取信号中关键的成分尤为重要。语音信号的特征参数的好坏直接导致了辨别的准确性。 特征参数的提取 对于特征参数的选取,我们使用mfcc 的方法来提取。MFCC 参数是基于人的听觉特性利用人听觉的屏蔽效应,在Mel 标度频率域提取出来的倒谱特征参数。 MFCC 参数的提取过程如下: 1. 对输入的语音信号进行分帧、加窗,然后作离散傅立叶变换,获得频谱分布信息。 设语音信号的DFT 为: 10,)()(112-≤≤=∑-=-N k e n x k X N n N nk j a π(1) 其中式中x(n)为输入的语音信号,N 表示傅立叶变换的点数。
基于MATLAB的特定人语音识别算法设计毕业设计
本科毕业设计 基于MATLAB的特定人语音识别算法设计
摘要 语言是人类交换信息最方便、最快捷的一种方式,在高度发达的信息社会中,用数字化的方法进行语音的传送、存储、识别、合成和增强等是整个数字化通信网中最重要、最基本的组成部分之一。而在随着科技技术的发展的今天,除了人与人之间的自然语言通信之外,人与机或机器与机器之间也开始使用语言。也就是因为如此,需要涉及到语音识别技术。为了解决机器能“听懂”人类的语言,在科技如此迅猛发展的今天,语音识别技术一直受到各国科学界的关注,其对计算机发展和社会生活的重要性也日益凸显出来。 在孤立字语音识别中,如语音密码锁,汽车控制等领域,都运用到了特定人语音识别技术,也就是DTW算法,相对于HMM算法,DTW算法具有简单操作。在相同环境下,两者识别效果相差不大,但是HMM算法要复杂得多,主要体现在HMM算法在训练阶段需要提供大量的语音数据,而DTW算法则不需要额外的计算。所以在特定人语音识别当中,DTW算法被广泛使用。 在本次设计中,将运用到MATLAB平台来对语音信号进行处理及识别。相对于C 语言而言,MATLAB平台更能给用户提供一个简单易懂的代码分析窗口。而且在个性化设计中,MATLAB可以为用户提供一个人性化界面--GUI。所以,此次设计,通过MATLAB 平台建立一个GUI界面,接着对一组语音信号的输入进行预处理及端点检测,提取特征参数(MFCC),形成参考模块。然后再对一组相同的语音信号输入进行同样的操作作为测试模块,与参考模块进行DTW算法进行匹配,输出匹配后的识别结果。 关键词:MATLAB GUI 端点检测MFCC DTW