《标准差与标准误》word版

标准差
标准差(Standard Deviation),也称均方差(mean square error),是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用σ表示。标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的,标准差未必相同。
标准差(Standard Deviation),在概率统计中最常使用作为统计分布程度(statistical dispersion)上的测量。标准差定义为方差的算术平方根,反映组内个体间的离散程度。测量到分布程度的结果,原则上具有两种性质:
为非负数值,与测量资料具有相同单位。一个总量的标准差或一个随机变量的标准差,及一个子集合样品数的标准差之间,有所差别。
标准计算公式
假设有一组数值X1,X2,X3,......Xn(皆为实数),其平均值为μ,公式如图1.
图1
标准差也被称为标准偏差,或者实验标准差,公式如图2。
图2
简单来说,标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合 {0, 5, 9, 14} 和 {5, 6, 8, 9} 其平均值都是7,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量。例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差应用于投资上,可作为量度回报稳定性的指标。标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。相反,标准差数值越细,代表回报较为稳定,风险亦较小。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。这两组的平均数都是70,但A组的标准差为17.078分,B组的标准差为2.16分(此数据是在R统计软件中运行获得),说明A组学生之间的差距要比B组学生之间的差距大得多。
如是总体,标准差公式根号内N=n,如是样本,标准差公式根号内N=(n-1),因为我们大量接触的是样本,所以普遍使用根号内除以(n-1)。
公式意义
所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一,即变异数),再把所得值开根号,所得之数就是这组数据的标准差。
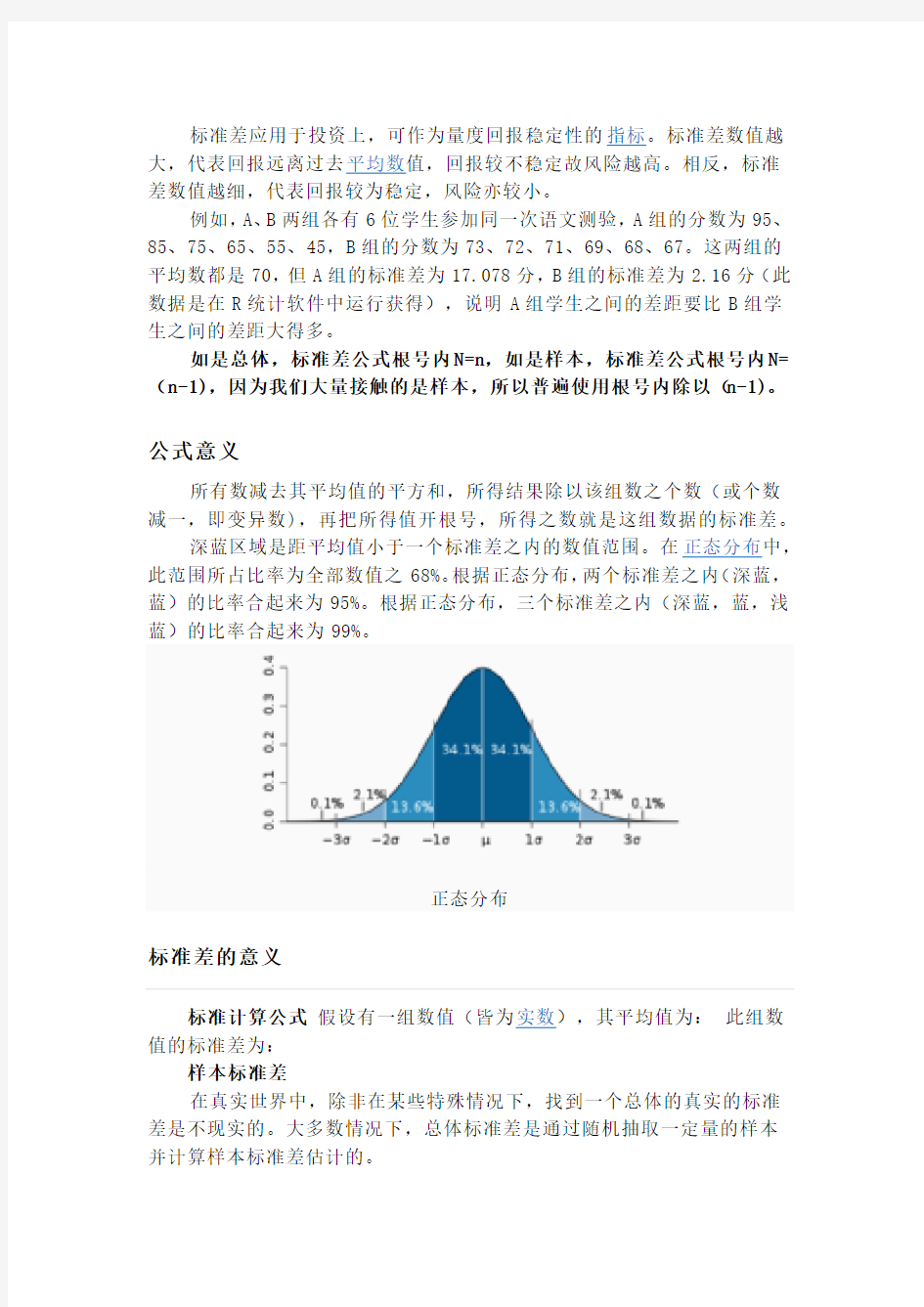
深蓝区域是距平均值小于一个标准差之内的数值范围。在正态分布中,此范围所占比率为全部数值之68%。根据正态分布,两个标准差之内(深蓝,蓝)的比率合起来为95%。根据正态分布,三个标准差之内(深蓝,蓝,浅蓝)的比率合起来为99%。
正态分布
标准计算公式假设有一组数值(皆为实数),其平均值为:此组数值的标准差为:
样本标准差
在真实世界中,除非在某些特殊情况下,找到一个总体的真实的标准差是不现实的。大多数情况下,总体标准差是通过随机抽取一定量的样本并计算样本标准差估计的。
从一大组数值当中取出一样本数值组合,常定义其样本标准差:
样本方差s是对总体方差σ的无偏估计。s中分母为n- 1 是因为样本的自由度为n-1 ,这是由于存在约束条件。
这里示范如何计算一组数的标准差。例如一群儿童年龄的数值为 { 5, 6, 8, 9 } :
第一步,计算平均值
第二步,计算标准差
2]
σ=√1/4[(x1?u)2+(x2?u)2+(x3?u)2+(x4?u)2
2
σ=√1/4[(5?7)2+(6?7)2+(8?7)2+(9?7)2]
2
σ=√1/4[4+1+1+4]
σ=√2此为标准差
标准差是反应一组数据离散程度最常用的一种量化形式,是表示精确度的重要指标。说起标准差首先得搞清楚它出现的目的。我们使用方法去检测它,但检测方法总是有误差的,所以检测值并不是其真实值。检测值与真实值之间的差距就是评价检测方法最有决定性的指标。但是真实值是多少,不得而知。因此怎样量化检测方法的准确性就成了难题。这也是临床工作质控的目的:保证每批实验结果的准确可靠。
虽然样本的真实值是不可能知道的,但是每个样本总是会有一个真实值的,不管它究竟是多少。可以想象,一个好的检测方法,其检测值应该很紧密的分散在真实值周围。如果不紧密,与真实值的距离就会大,准确性当然也就不好了,不可能想象离散度大的方法,会测出准确的结果。因此,离散度是评价方法的好坏的最重要也是最基本的指标。
一组数据怎样去评价和量化它的离散度呢?人们使用了很多种方法:
1.极差
最直接也是最简单的方法,即最大值-最小值(也就是极差)来评价一组数据的离散度。这一方法在日常生活中最为常见,比如比赛中去掉最高最低分就是极差的具体应用。
2.离均差的平方和
由于误差的不可控性,因此只由两个数据来评判一组数据是不科学的。所以人们在要求更高的领域不使用极差来评判。其实,离散度就是数据偏离平均值的程度。因此将数据与均值之差(我们叫它离均差)加起来就能反映出一个准确的离散程度。和越大离散度也就越大。
但是由于偶然误差是成正态分布的,离均差有正有负,对于大样本离均差的代数和为零的。为了避免正负问题,在数学有上有两种方法:一种是取绝对值,也就是常说的离均差绝对值之和。而为了避免符号问题,数学上最常用的是另一种方法——平方,这样就都成了非负数。因此,离均差的平方和成了评价离散度一个指标。
3.方差(S2)
由于离均差的平方和与样本个数有关,只能反应相同样本的离散度,而实际工作中做比较很难做到相同的样本,因此为了消除样本个数的影响,增加可比性,将标准差求平均值,这就是我们所说的方差成了评价离散度的较好指标。
样本量越大越能反映真实的情况,而算数均值却完全忽略了这个问题,对此统计学上早有考虑,在统计学中样本的均差多是除以自由度(n-1),它的意思是样本能自由选择的程度。当选到只剩一个时,它不可能再有自由了,所以自由度是n-1。
4.标准差(SD)
由于方差是数据的平方,与检测值本身相差太大,人们难以直观的衡量,所以常用方差开根号换算回来这就是我们要说的标准差。
在统计学中样本的均差多是除以自由度(n-1),它是意思是样本能自由选择的程度。当选到只剩一个时,它不可能再有自由了,所以自由度是
n-1。
5.变异系数(CV)
标准差能很客观准确的反映一组数据的离散程度,但是对于不同的检目,或同一项目不同的样本,标准差就缺乏可比性了,因此对于方法学评价来说又引入了变异系数CV。
一组数据的平均值及标准差常常同时做为参考的依据。在直觉上,如果数值的中心以平均值来考虑,则标准差为统计分布之一“自然”的测量。
定义公式:其中N应为n-1,即自由度
标准差与平均值定义公式
1、方差s^2=[(x1-x)^2+(x2-x)^2+......(xn-x)^2]/(n) (x为平均数)
2、标准差=方差的算术平方根
error bar。在实验中单次测量总是难免会产生误差,为此我们经常测量多次,然后用测量值的平均值表示测量的量,并用误差条来表征数据的分布,其中误差条的高度为±标准误。这里即标准差standard deviation和标准误standard error 的计算公式分别为
标准差
标准误
从几何学的角度出发,标准差可以理解为一个从n维空间的一个点到
一条直线的距离的函数。举一个简单的例子,一组数据中有3个值,X1,X2,X3。它们可以在3维空间中确定一个点 P = (X1,X2,X3)。想像一条通过原点的直线。如果这组数据中的3个值都相等,则点 P 就是直线 L 上的一个点,
P 到 L 的距离为0, 所以标准差也为0。若这3个值不都相等,过点 P 作垂线 PR 垂直于 L,PR 交 L 于点 R,则 R 的坐标为这3个值的平均数:
(公式)
运用一些代数知识,不难发现点P与点R之间的距离(也就是点 P 到
直线 L 的距离)是。在 n 维空间中,这个规律同样适用,把3换成 n 就
可以了。
标准差与标准误的区别
标准差与标准误都是心理统计学的内容,两者不但在字面上比较相近,而
且两者都是表示距离某一个标准值或中间值的离散程度,即都表示变异程度,但是两者是有着较大的区别的。
首先要从统计抽样的方面说起。现实生活或者调查研究中,我们常常
无法对某类欲进行调查的目标群体的所有成员都加以施测,而只能够在所
有成员(即样本)中抽取一些成员出来进行调查,然后利用统计原理和方
法对所得数据进行分析,分析出来的数据结果就是样本的结果,然后用样
本结果推断总体的情况。一个总体可以抽取出多个样本,所抽取的样本越多,其样本均值就越接近总体数据的平均值。
表示的就是样本数据的离散程度。标准差就是样本平均数方差的开平方,标准差通常是相对于样本数据的平均值而定的,通常用M±SD来表示,表示样本某个数据观察值相距平均值有多远。从这里可以看到,标准差受
到极值的影响。标准差越小,表明数据越聚集;标准差越大,表明数据越
离散。标准差的大小因测验而定,如果一个测验是学术测验,标准差大,
表示学生分数的离散程度大,更能够测量出学生的学业水平;如果一个测
验测量的是某种心理品质,标准差小,表明所编写的题目是同质的,这时
候的标准差小的更好。标准差与正态分布有密切联系:在正态分布中,1个标准差等于正态分布下曲线的68.26%的面积,1.96个标准差等于95%的面积。这在测验分数等值上有重要作用。
标准误
表示的是抽样的误差。因为从一个总体中可以抽取出无数多种样本,
每一个样本的数据都是对总体的数据的估计。标准误代表的就是当前的样
本对总体数据的估计,标准误代表的就是样本均数与总体均数的相对误差。标准误是由样本的标准差除以样本容量的开平方来计算的
。从这里可以看到,标准误更大的是受到样本容量的影响。样本容量越大,标准误越小,那么抽样误差就越小,就表明所抽取的样本能够较好地代表总体。
Excel函数
Excel中有STDEV、STDEVP、STDEVA、STDEVPA四个函数,分别表示样本标准差、总体标准差;包含逻辑值运算的样本标准差、包含逻辑值运算的总体标准差(excel用的是“标准偏差”字样)。
在计算方法上的差异是:样本标准差=(样本方差/(数据个数-1))^2;总体标准差=(总体方差/(数据个数))^2。
函数的excel分解:
(1)stdev()函数可以分解为(假设样本数据为A1:E10这样一个矩阵): stdev(A1:E10)=sqrt(DEVSQ(A1:E10)/(COUNT(A1:E10)-1)) (2)stdevp()函数可以分解为(假设总体数据为A1:E10这样一个矩阵):
stdev(A1:E10)=sqrt(DEVSQ(A1:E10)/(COUNT(A1:E10))) 同样的道理stdeva()与stdevpa()也有同样的分解方法。
(注:素材和资料部分来自网络,供参考。请预览后才下载,期待你的好评与关注!)