聚类分析:原始数据

聚类分析:原始数据
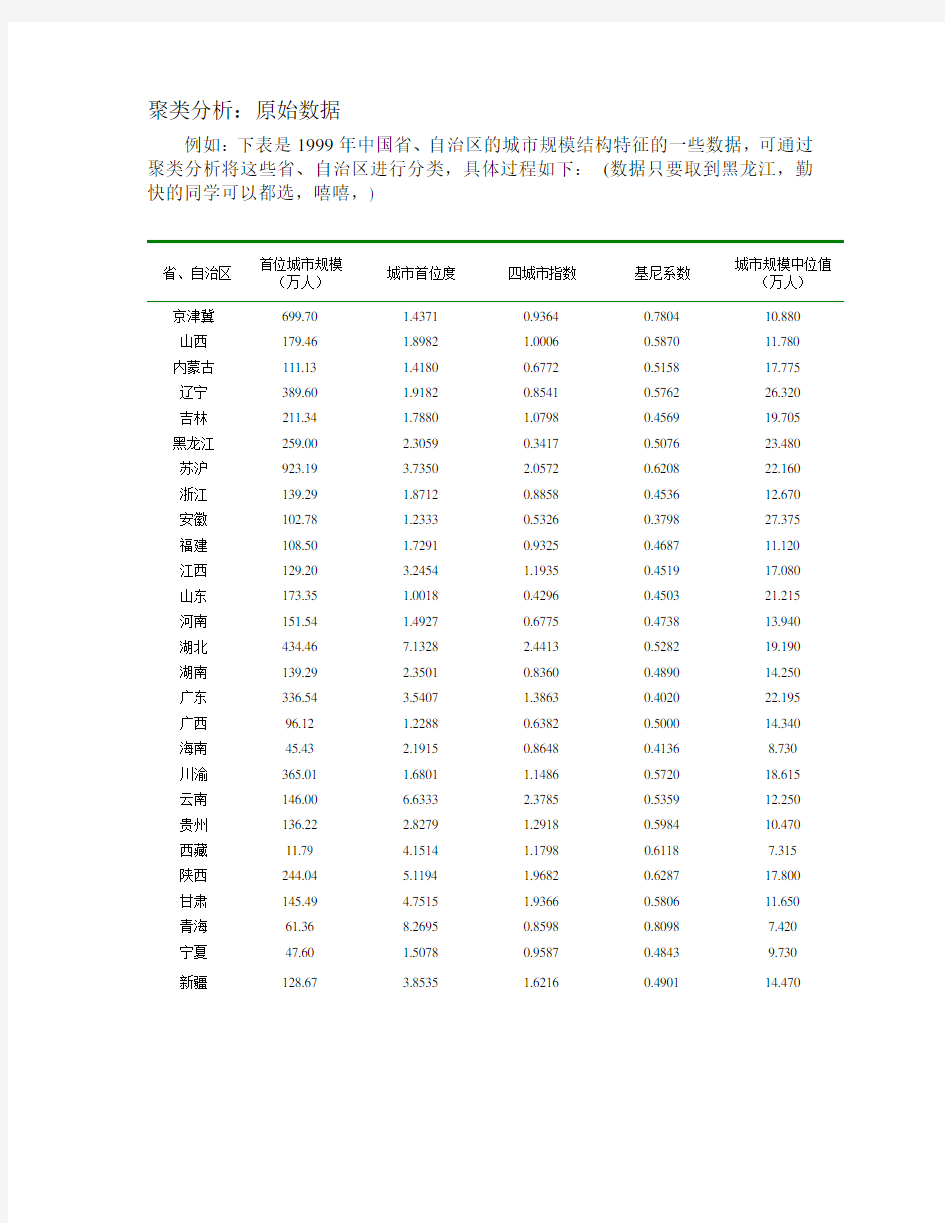
例如:下表是1999年中国省、自治区的城市规模结构特征的一些数据,可通过聚类分析将这些省、自治区进行分类,具体过程如下:(数据只要取到黑龙江,勤快的同学可以都选,嘻嘻,)
省、自治区首位城市规模
(万人)
城市首位度四城市指数基尼系数
城市规模中位值
(万人)
京津冀699.70 1.4371 0.9364 0.7804 10.880 山西179.46 1.8982 1.0006 0.5870 11.780 内蒙古111.13 1.4180 0.6772 0.5158 17.775 辽宁389.60 1.9182 0.8541 0.5762 26.320 吉林211.34 1.7880 1.0798 0.4569 19.705 黑龙江259.00 2.3059 0.3417 0.5076 23.480 苏沪923.19 3.7350 2.0572 0.6208 22.160 浙江139.29 1.8712 0.8858 0.4536 12.670 安徽102.78 1.2333 0.5326 0.3798 27.375 福建108.50 1.7291 0.9325 0.4687 11.120 江西129.20 3.2454 1.1935 0.4519 17.080 山东173.35 1.0018 0.4296 0.4503 21.215 河南151.54 1.4927 0.6775 0.4738 13.940 湖北434.46 7.1328 2.4413 0.5282 19.190 湖南139.29 2.3501 0.8360 0.4890 14.250 广东336.54 3.5407 1.3863 0.4020 22.195 广西96.12 1.2288 0.6382 0.5000 14.340 海南45.43 2.1915 0.8648 0.4136 8.730 川渝365.01 1.6801 1.1486 0.5720 18.615 云南146.00 6.6333 2.3785 0.5359 12.250 贵州136.22 2.8279 1.2918 0.5984 10.470 西藏11.79 4.1514 1.1798 0.6118 7.315 陕西244.04 5.1194 1.9682 0.6287 17.800 甘肃145.49 4.7515 1.9366 0.5806 11.650 青海61.36 8.2695 0.8598 0.8098 7.420 宁夏47.60 1.5078 0.9587 0.4843 9.730 新疆128.67 3.8535 1.6216 0.4901 14.470
物联网大数据聚类分析方法和技术探讨
物联网大数据聚类分析方法和技术探讨 发表时间:2019-09-11T15:11:03.983Z 来源:《基层建设》2019年第16期作者:吴政[导读] 摘要:文章先分析了物联网关键技术以及数据发现等相关技术,随后介绍了聚类分析方法,包括关键算法和技术流程,希望能给相关人士提供有效参考。 广州市汇源通信建设监理有限公司广东省广州市 510220 摘要:文章先分析了物联网关键技术以及数据发现等相关技术,随后介绍了聚类分析方法,包括关键算法和技术流程,希望能给相关人士提供有效参考。 关键词:物联网;大数据;聚类分析 引言:物联网感知层中的无线射频技术是无线通信技术,具有准确识别目标物的功能。在RFID技术不断发展的背景下,其在制造业和电商行业中发挥了巨大的作用,随着数据复杂度的提高,和数据量的扩大,需要对数据存储和数据处理技术进行创新研究,促进大数据技术架构优化设计。 一、物联网关键技术分析 物联网其实是指通过信息传感相关红外感应器、定位系统和激光扫描器,在射频识别条件下将待测物体和网络之间进行有效连接,从而实现全方位物体识别、定位、跟踪管理和全过程监控等功能。物联网的诞生进一步改变了原有的识别技术,对现代化信息改革具有重要的促进作用。随着时代的发展,社会中的多个领域也逐渐将注意力转移到物联网领域当中。物联网相关技术包括以下三种:第一是数据处理和现代通信。现代通信是物联网基础支持,其中具有代表性的是无线智能网络。结合宽带通信的帮助,大部分领域都开始创建多媒体通信,同时相关技术也呈现出不断发展的趋势。第二是智能终端,这部分是物联网整个网络中的核心内容,其中包括智能电话和智能型PDA,可以利用传感器精确采集信息,全面识别判断各种图像。第三是信息安全。将物联网有效应用到各个领域当中,需要进一步确保信息安全,为此需要合理使用相应的加密方法对各种实时访问进行全面监控,进行系统化的安全管理和访问。对于当下的物联网而言,只有的网络状态下才能对各种物体进行准确识别。 二、数据发现 模式识别即利用逻辑关系、文字、数值等内容表征事物现象的信息,实施识别、分析和处理的过程。模式识别也可以称作模式分类,具体包括无监督和监督模式识别,两种模式之间的差异时样本类型已知状态。其中的监督模式是在已知样本类型的基础上进行识别,而无监督则是在不知道样本类型的基础上进行识别。通过计算机识别的目标可以是抽象的也可以是具体的,具体的包括图像、声音、文字等内容,而抽象的包括程度和状态等内容,模式信息即把识别对象和数字信息清除区分开来,这种技术涉及范围较广,包括人工智能、数据库、统计学等内容,是各种技术的综合。在数据挖掘中,模式发现是其中的核心内容,数据挖掘相关任务包括分类、关联、聚类等形式。数据库相关知识模式发现流程如图1所示: 在处理RFID相关事件时,应该先详细解析事件定义,随后根据事件流中各种事件的定义关系,对已形成的模式关系实施定义分析,随后按照事件之间的对应关系实施量化,在量化后距离基础上实施聚类分析。该部分定义中,先对事件进行解析,将其转化为原子事件,随后对其定义,在已经完成定义的原子实践基础上,再对现实事件中的各种关系进行定义,同时分析交易事件中的属性量化指标。原子事件即将事件定义成一个,包括事件标识符ID,也是唯一的标记;DOMAIN是交易事件中问题域实际位置;ALIAS是事件名称,和命名事件相关的一种名称;TYPE是事件种类,和问题域具有一定联系,可以是相关研发人员进行自定义操作,同时也可以是系统自带;TIME是事件出现时间;STIMULATION是激发事件的基础条件,比如快递运输中的某一物品被RFID读取后,证明该物品处于被签收状态,其中的激发因素便是被签收,如果没有被RFID识别器解读,证明该物品尚未发出,也不会出现任何事情。LAOCATION是指事件出现的位置,和事件相关性具有一定联系。 三、聚类分析技术方法 (一)关键算法 第一是平均算法,这种算法从本质上来看是以聚类划分为基础的,在近几年平均算法逐渐广泛应用开来。利用这种算法可以对相关对象进行合理划分,将其分成各种类型的簇。也因此对象组之间也呈现出一种相似性特点。如果是针对特定类型的数据分析工作,则关注点需要放在数据集和数据簇总数上,并从中挑选出可分析数据集。对各组别数据对象进行分配,便能规划处具有较强相似性的簇平均值。第二是分解奇异值算法,这种算法是以特定矩阵为基础,其中包含实数或复数的矩阵,如果该种类型的矩阵存在,便可以直接实施分解奇异值的操作。从整个矩阵范围内分析,涉及到M×M矩阵,这种矩阵类型是一种半正定和对角矩阵。分解奇异值还会涉及到共轭矩阵,并把其看做奇异值分解。从当下的实际发展状况分析,通常可以利用特定类型仿真软件分解相关数值,随后通过归纳得到函数式[1]。 第三是主成分分析算法,这种算法也可以叫做PCA分析办法,正常情况下,如果是多种算法变量,可以利用线性变换方法促进全过程实现简化变换的目标,或利用多元统计方式进行算法分析。从信息分析和数据分析两种视角入手,分析主成分其核心价值是创建对应的数据集,但不能遗漏全方位简化运算。在分析主成分的基础上,降低数据集维度,可以适当保留一些低阶的主成分,忽略高阶成分。第四是决策树学习,其属于一种概率分析图解方法,这种方法需要以事件概率为基础前提,针对不同类型的事件进行系统解析。决策树重点针对特殊期望值,保证其最终结果大于零。同时决策树还涉及到可行性判断和决策分析等方面。
16种常用的大数据分析报告方法汇总情况
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似;
C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、在信度;每个量表是否测量到单一的概念,同时组成两表的在体项一致性如何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。
聚类分析:原始数据
聚类分析:原始数据 例如:下表是1999年中国省、自治区的城市规模结构特征的一些数据,可通过聚类分析将这些省、自治区进行分类,具体过程如下:(数据只要取到黑龙江,勤快的同学可以都选,嘻嘻,) 省、自治区首位城市规模 (万人) 城市首位度四城市指数基尼系数 城市规模中位值 (万人) 京津冀699.70 1.4371 0.9364 0.7804 10.880 山西179.46 1.8982 1.0006 0.5870 11.780 内蒙古111.13 1.4180 0.6772 0.5158 17.775 辽宁389.60 1.9182 0.8541 0.5762 26.320 吉林211.34 1.7880 1.0798 0.4569 19.705 黑龙江259.00 2.3059 0.3417 0.5076 23.480 苏沪923.19 3.7350 2.0572 0.6208 22.160 浙江139.29 1.8712 0.8858 0.4536 12.670 安徽102.78 1.2333 0.5326 0.3798 27.375 福建108.50 1.7291 0.9325 0.4687 11.120 江西129.20 3.2454 1.1935 0.4519 17.080 山东173.35 1.0018 0.4296 0.4503 21.215 河南151.54 1.4927 0.6775 0.4738 13.940 湖北434.46 7.1328 2.4413 0.5282 19.190 湖南139.29 2.3501 0.8360 0.4890 14.250 广东336.54 3.5407 1.3863 0.4020 22.195 广西96.12 1.2288 0.6382 0.5000 14.340 海南45.43 2.1915 0.8648 0.4136 8.730 川渝365.01 1.6801 1.1486 0.5720 18.615 云南146.00 6.6333 2.3785 0.5359 12.250 贵州136.22 2.8279 1.2918 0.5984 10.470 西藏11.79 4.1514 1.1798 0.6118 7.315 陕西244.04 5.1194 1.9682 0.6287 17.800 甘肃145.49 4.7515 1.9366 0.5806 11.650 青海61.36 8.2695 0.8598 0.8098 7.420 宁夏47.60 1.5078 0.9587 0.4843 9.730 新疆128.67 3.8535 1.6216 0.4901 14.470
数据挖掘中的聚类分析方法
计算机工程应用技术本栏目责任编辑:贾薇薇 数据挖掘中的聚类分析方法 黄利文 (泉州师范学院理工学院,福建泉州362000) 摘要:聚类分析是多元统计分析的重要方法之一,该方法在许多领域都有广泛的应用。本文首先对聚类的分类做简要的介绍,然后给出了常用的聚类分析方法的基本思想和优缺点,并对常用的聚类方法作比较分析,以便人们根据实际的问题选择合适的聚类方法。 关键词:聚类分析;数据挖掘 中图分类号:TP311文献标识码:A文章编号:1009-3044(2008)12-20564-02 ClusterAnlaysisMethodsofDataMining HUANGLi-wen (SchoolofScience,QuanzhouNormalUniversity,Quanzhou362000,China) Abstract:Clusteranalysisisoneoftheimportantmethodsofmultivariatestatisticalanalysis,andthismethodhasawiderangeofapplica-tionsinmanyfields.Inthispaper,theclassificationoftheclusterisintroducedbriefly,andthengivessomecommonmethodsofclusteranalysisandtheadvantagesanddisadvantagesofthesemethods,andtheseclusteringmethodwerecomparedandanslyzedsothatpeoplecanchosesuitableclusteringmethodsaccordingtotheactualissues. Keywords:ClusterAnalysis;DataMining 1引言 聚类分析是数据挖掘中的重要方法之一,它把一个没有类别标记的样本集按某种准则划分成若干个子类,使相似的样品尽可能归为一类,而不相似的样品尽量划分到不同的类中。目前,该方法已经被广泛地应用于生物、气候学、经济学和遥感等许多领域,其目的在于区别不同事物并认识事物间的相似性。因此,聚类分析的研究具有重要的意义。 本文主要介绍常用的一些聚类方法,并从聚类的可伸缩性、类的形状识别、抗“噪声”能力、处理高维能力和算法效率五个方面对其进行比较分析,以便人们根据实际的问题选择合适的聚类方法。 2聚类的分类 聚类分析给人们提供了丰富多彩的分类方法,这些方法大致可归纳为以下几种[1,2,3,4]:划分方法、层次方法、基于密度的聚类方法、基于网格的聚类方法和基于模型的聚类方法。 2.1划分法(partitiongingmethods) 给定一个含有n个对象(或元组)的数据库,采用一个划分方法构建数据的k个划分,每个划分表示一个聚簇,且k≤n。在聚类的过程中,需预先给定划分的数目k,并初始化k个划分,然后采用迭代的方法进行改进划分,使得在同一类中的对象之间尽可能地相似,而不同类的中的对象之间尽可能地相异。这种聚类方法适用于中小数据集,对大规模的数据集进行聚类时需要作进一步的改进。 2.2层次法(hietarchicalmethods) 层次法对给定数据对象集合按层次进行分解,分解的结果形成一颗以数据子集为节点的聚类树,它表明类与类之间的相互关系。根据层次分解是自低向上还是自顶向下,可分为凝聚聚类法和分解聚类法:凝聚聚类法的主要思想是将每个对象作为一个单独的一个类,然后相继地合并相近的对象和类,直到所有的类合并为一个,或者符合预先给定的终止条件;分裂聚类法的主要思想是将所有的对象置于一个簇中,在迭代的每一步中,一个簇被分裂为更小的簇,直到最终每个对象在单独的一个簇中,或者符合预先给定的终止条件。在层次聚类法中,当数据对象集很大,且划分的类别数较少时,其速度较快,但是,该方法常常有这样的缺点:一个步骤(合并或分裂)完成,它就不能被取消,也就是说,开始错分的对象,以后无法再改变,从而使错分的对象不断增加,影响聚类的精度,此外,其抗“噪声”的能力也较弱,但是若把层次聚类和其他的聚类技术集成,形成多阶段聚类,聚类的效果有很大的提高。2.3基于密度的方法(density-basedmethods) 该方法的主要思想是只要临近区域的密度(对象或数据点的数目)超过某个阈值,就继续聚类。也就是说,对于给定的每个数据点,在一个给定范围的区域中必须至少包含某个数目的点。这样的方法就可以用来滤处"噪声"孤立点数据,发现任意形状的簇。2.4基于网格的方法(grid-basedmethods) 这种方法是把对象空间量化为有限数目的单元,形成一个网格结构。所有的聚类操作都在这个网格结构上进行。用这种方法进行聚类处理速度很快,其处理时间独立于数据对象的数目,只与量化空间中每一维的单元数目有关。 2.5基于模型的方法(model-basedmethod) 基于模型的方法为每个簇假定一个模型,寻找数据对给定模型的最佳拟合。该方法经常基于这样的假设:数据是根据潜在的概 收稿日期:2008-02-17 作者简介:黄利文(1979-),男,助教。
大数据成功案例
1.1 成功案例1-汤姆森路透(Thomson Reuters) 利用Oracle 大 数据解决方案实现互联网资讯和社交媒体分析 Oracle Customer: Thomson Reuters Location: USA Industry: Media and Entertainment/Newspapers and Periodicals 汤姆森路透(Thomson Reuters)成立于2008年4月17 日,是由加拿大汤姆森 公司(The Thomson Corporation)与英国路透集团(Reuters Group PLC)合并组成的商务和专 业智能信息提供商,总部位于纽约,全球拥有6万多名员工,分布在超过100 个国家和地区。 汤姆森路透是世界一流的企业及专业情报信息提供商,其将行业专门知识与创新技术相结合,在全世界最可靠的新闻机构支持下,为专业企业、金融机构和消费者提供专业财经信息服务,以及为金融、法律、税务、会计、科技和媒体市场的领先决策者提供智能信息及解决方案。 在金融市场中,投资者的心理活动和认知偏差会影响其对未来市场的观念和情绪,并由情绪最终影响市场表现。随着互联网和社交媒体的迅速发展,人们可以方便快捷的获知政治、经济和社会资讯,通过社交媒体表达自己的观点和感受,并通过网络传播形成对市场情绪的强大影响。汤姆森路透原有市场心理指数和新闻分析产品仅对路透社新闻和全球专业资讯进行处理分析,已不能涵盖市场情绪的构成因素,时效性也不能满足专业金融机构日趋实时和高频交易的需求。 因此汤姆森路透采用Oracle的大数据解决方案,使用Big Data Appliance 大 数据机、Exadata 数据库云服务器和Exalytics 商业智能云服务器搭建了互联网资讯 和社交媒体大数据分析平台,实时采集5 万个新闻网站和400 万社交媒体渠道的资 讯,汇总路透社新闻和其他专业新闻,进行自然语义处理,通过基于行为金融学模型多维度的度量标准,全面评估分析市场情绪,形成可操作的分析结论,支持其专业金融机
对数据进行聚类分析实验报告
对数据进行聚类分析实验报告 1.方法背景 聚类分析又称群分析,是多元统计分析中研究样本或指标的一种主要的分类方法,在古老的分类学中,人们主要靠经验和专业知识,很少利用数学方法。随着生产技术和科学的发展,分类越来越细,以致有时仅凭经验和专业知识还不能进行确切分类,于是数学这个有用的工具逐渐被引进到分类学中,形成了数值分类学。近些年来,数理统计的多元分析方法有了迅速的发展,多元分析的技术自然被引用到分类学中,于是从数值分类学中逐渐的分离出聚类分析这个新的分支。结合了更为强大的数学工具的聚类分析方法已经越来越多应用到经济分析和社会工作分析中。在经济领域中,主要是根据影响国家、地区及至单个企业的经济效益、发展水平的各项指标进行聚类分析,然后很据分析结果进行综合评价,以便得出科学的结论。 2.基本要求 用FAMALE.TXT、MALE.TXT和/或test2.txt的数据作为本次实验使用的样本集,利用C均值和分级聚类方法对样本集进行聚类分析,对结果进行分析,从而加深对所学内容的理解和感性认识。 3.实验要求 (1)把FAMALE.TXT和MALE.TXT两个文件合并成一个,同时采用身高和体重数据作为特征,设类别数为2,利用C均值聚类方法对数据进行聚类,并将聚类结果表示在二维平面上。尝试不同初始值对此数据集是否会造成不同的结果。 (2)对1中的数据利用C均值聚类方法分别进行两类、三类、四类、五类聚类,画出聚类指标与类别数之间的关系曲线,探讨是否可以确定出合理的类别数目。 (3)对1中的数据利用分级聚类方法进行聚类,分析聚类结果,体会分级聚类方法。。(4)利用test2.txt数据或者把test2.txt的数据与上述1中的数据合并在一起,重复上述实验,考察结果是否有变化,对观察到的现象进行分析,写出体会 4.实验步骤及流程图 根据以上实验要求,本次试验我们将分为两组:一、首先对FEMALE 与MALE中数据组成的样本按照上面要求用C均值法进行聚类分析,然后对FEMALE、MALE、test2中数据组成的样本集用C均值法进行聚类分析,比较二者结果。二、将上述两个样本用分即聚类方法进行聚类,观察聚类结果。并将两种聚类结果进行比较。 (1)、C均值算法思想
大数据成功案例电子教案
1.1成功案例1-汤姆森路透(Thomson Reuters)利用Oracle大 数据解决方案实现互联网资讯和社交媒体分析 ?Oracle Customer: Thomson Reuters ?Location: USA ?Industry: Media and Entertainment/Newspapers and Periodicals 汤姆森路透(Thomson Reuters)成立于2008年4月17日,是由加拿大汤姆森公司(The Thomson Corporation)与英国路透集团(Reuters Group PLC)合并组成的商务和专业智能 信息提供商,总部位于纽约,全球拥有6万多名员工,分布在超过100个国家和地区。 汤姆森路透是世界一流的企业及专业情报信息提供商,其将行业专门知识与创新技术相结合,在全世界最可靠的新闻机构支持下,为专业企业、金融机构和消费者提供专业财经信息服务,以及为金融、法律、税务、会计、科技和媒体市场的领先决策者提供智能信息及解决方案。 在金融市场中,投资者的心理活动和认知偏差会影响其对未来市场的观念和情绪,并由情绪最终影响市场表现。随着互联网和社交媒体的迅速发展,人们可以方便快捷的获知政治、经济和社会资讯,通过社交媒体表达自己的观点和感受,并通过网络传播形成对市场情绪的强大影响。汤姆森路透原有市场心理指数和新闻分析产品仅对路透社新闻和全球专业资讯进行处理分析,已不能涵盖市场情绪的构成因素,时效性也不能满足专业金融机构日趋实时和高频交易的需求。 因此汤姆森路透采用Oracle的大数据解决方案,使用Big Data Appliance大数据机、Exadata数据库云服务器和Exalytics商业智能云服务器搭建了互联网资讯和社交媒体大数据分析平台,实时采集5万个新闻网站和400万社交媒体渠道的资讯,汇总路透社新闻和其他专业新闻,进行自然语义处理,通过基于行为金融学模型多维度的度量标准,全面评估分析市场情绪,形成可操作的分析结论,支持其专业金融机构客户的交易、投资和风险管理。
聚类分析中的数据类型
聚类分析中的数据类型 1. Interval-scaled variables:区间标度变量 1.1 什么是区间标度变量? 区间标度变量是一个线性标度的连续变量。典型的例子包括重量和高度,经度和纬度坐标,以及大气温度。 1.2 怎样将一个变量的数据标准化? 为了避免对度量单位选择的依赖,数据应当标准化。 为了实现度量值的标准化,一种方法是将原来的度量值转换为无单位的值。 1.3 度量值变换 给定一个变量f 的度量值,可以进行如下的变换: 1)计算平均的绝对偏差(mean absolute deviation )sf : nf f f f nf f f f f n f f f f f x x x n m f mf n f x x x m x m x m x n s 2121211,,1 的平均值,即是个度量值,的是这里的 2)计算标准化的度量值,z-score : f f f i if s m x z - 1.4 举例 Age: 18; 22; 25; 42; 28; 43; 33; 35;56; 28 6 .08 .833286 .28.83356,2.08.83335,08.833331 .18.83343,6.08.83328,0.18.833429 .08.83325,25.18.83322,7.18.833188.83328335633353333334333283342332533223318101332856353343284225221810 1 10987654321 z z z z z z z z z z s m age age 2. Binary variables:二进制变量 2.1 二进制数据的列联表
大数据聚类算法研究(汽车类的)
大数据聚类算法研究(汽车类的) 摘要:本文分析了汽车行业基于不同思想的各类大数据聚类算法,用户应该根 据实际应用中的具体问题具体分析,选择恰当的聚类算法。聚类算法具有非常广 泛的应用,改进聚类算法或者开发新的聚类算法是一件非常有意义工作,相信在 不久的将来,聚类算法将随着新技术的出现和应用的需求而在汽车行业得到蓬勃 的发展。 关键词:汽车;大数据;聚类算法;划分 就精确系数不算太严格的情况而言,汽车行业内对各种大型数据集,通过对 比各种聚类算法,提出了一种部分优先聚类算法。然后在此基础之上分析研究聚 类成员的产生过程与聚类融合方式,通过设计共识函数并利用加权方式确定类中心,在部分优先聚类算法的基础上进行聚类融合,从而使算法的计算准度加以提升。通过不断的实验,我们可以感受到优化之后算法的显著优势,这不仅体现在 其可靠性,同时在其稳定性以及扩展性、鲁棒性等方面都得到了很好的展现。 一、汽车行业在大数据时代有三个鲜明的特征 1、数据全面数字化,第一人的行为数字化,包括所有驾驶操作、每天所有的行为习惯,甚至是座椅的习惯等等都将形成相应的数字化。以车为中心物理事件 的数字化,车况、维修保养、交通、地理、信息等等都会形成数字化,全面数字 化就会形成庞大的汽车产业链,汽车的大数据生态圈。这是第一个特点。 由于大数据拥有分析和总结的核心优势,越来越多的品牌厂商和广告营销机 构都在大力发展以数据为基础的网络营销模式,这些变化也在不断地向传统的汽 车营销领域发起进攻。从前品牌做营销仅能凭主观想法和经验去预估,而现在大 数据的出现则可以帮助客户进行精准的客户群定位。 2、第二个特点是数据互联资源化。有一个领导人讲过:未来大数据会成为石油一样的资源。这说明大数据可以创造巨大的价值,甚至可能成为石油之外,更 为强大的自然资源。 大数据首先改变了传统调研的方式。通过观察Cookie等方式,广告从业者可 以通过直观的数据了解客观的需求。之前的汽车市场调研抽样的样本有限,而且 在问题设计和角度选取过程中,人为因素总是或多或少地介入,这就可能会影响 到市场调研的客观性。大数据分析不只会分析互联网行为,也会关注人生活的更 多纬度。数据可以更加丰富,比如了解到消费者的习惯和周期、兴趣爱好、对人 的理解会更加深刻。这些因素综合在一起就会形成一笔无形且珍贵的数据资源。 有了大数据的支持,便可以实现曾经很多只能“纸上谈兵”的理论。 3、第三个特点则是产生虚拟的汽车,人和汽车可以对话,更具有智慧的新兴产业。这个就是未来在大数据时代,汽车行业会呈现的特点。 在这个情况下,我们以人、车、社会形成汽车产业大数据的生态圈,现实生 活中每个有车一族所产生的数据都对整个生态圈有积极的影响。车辆上传的每一 组数据都带有位置信息和时间,并且很容易形成海量数据。如果说大数据的特征 是完整和混杂,那么车联网与车有关的大数据特征则是完整和精准。如某些与车 辆本身有关的数据,都有明确的一个用户,根据不同用户可以关联到相应的车主 信息,并且这些信息都是极其精准的,这样形成的数据才是有价值的数据。 二、汽车行业大数据下聚类算法的含义 汽车行业大数据是指以多元形式,由许多来源搜集而组成的庞大数据组。电 子商务网站、社交网站以及网页浏览记录等都可以成为大数据的数据来源。同时,
大数据数据分析方法、数据处理流程实战案例
数据分析方法、数据处理流程实战案例 大数据时代,我们人人都逐渐开始用数据的眼光来看待每一个事情、事物。确实,数据的直观明了传达出来的信息让人一下子就能领略且毫无疑点,不过前提是数据本身的真实性和准确度要有保证。今天就来和大家分享一下关于数据分析方法、数据处理流程的实战案例,让大家对于数据分析师这个岗位的工作内容有更多的理解和认识,让可以趁机了解了解咱们平时看似轻松便捷的数据可视化的背后都是有多专业的流程在支撑着。 一、大数据思维 在2011年、2012年大数据概念火了之后,可以说这几年许多传统企业也好,互联网企业也好,都把自己的业务给大数据靠一靠,并且提的比较多的大数据思维。
那么大数据思维是怎么回事我们来看两个例子: 案例1:输入法 首先,我们来看一下输入法的例子。 我2001年上大学,那时用的输入法比较多的是智能ABC,还有微软拼音,还有五笔。那时候的输入法比现在来说要慢的很多,许多时候输一个词都要选好几次,去选词还是调整才能把这个字打出来,效率是非常低的。
到了2002年,2003年出了一种新的输出法——紫光拼音,感觉真的很快,键盘没有按下去字就已经跳出来了。但是,后来很快发现紫光拼音输入法也有它的问题,比如当时互联网发展已经比较快了,
会经常出现一些新的词汇,这些词汇在它的词库里没有的话,就很难敲出来这个词。 在2006年左右,搜狗输入法出现了。搜狗输入法基于搜狗本身是一个搜索,它积累了一些用户输入的检索词这些数据,用户用输入法时候产生的这些词的信息,将它们进行统计分析,把一些新的词汇逐步添加到词库里去,通过云的方式进行管理。 比如,去年流行一个词叫“然并卵”,这样的一个词如果用传统的方式,因为它是一个重新构造的词,在输入法是没办法通过拼音“ran bing luan”直接把它找出来的。然而,在大数据思维下那就不一样了,换句话说,我们先不知道有这么一个词汇,但是我们发现有许多人在输入了这个词汇,于是,我们可以通过统计发现最近新出现的一个高频词汇,把它加到司库里面并更新给所有人,大家在使用的时候可以直接找到这个词了。 案例2:地图
2020年大数据应用分析案例分析(实用)
大数据应用分析案例分析大数据应用与案例分析当下,”大数据"几乎是每个IT人都在谈论的一个词汇,不单单是时代发展的趋势,也是革命技术的创新.大数据对于行业的用户也越来越重要。掌握了核心数据,不单单可以进行智能化的决策,还可以在竞争激烈的行业当中脱颖而出,所以对于大数据的战略布局让越来越多的企业引起了重视,并重新定义了自己的在行业的核心竞争。 在当前的互联网领域,大数据的应用已十分广泛,尤其以企业为主,企业成为大数据应用的主体.大数据真能改变企业的运作方式吗?答案毋庸置疑是肯定的。随着企业开始利用大数据,我们每天都会看到大数据新的奇妙的应用,帮助人们真正从中获益.大数据的应用已广泛深入我们生活的方方面面,涵盖医疗、交通、金融、教育、体育、零售等各行各业。...感谢聆听... 大数据应用的关键,也是其必要条件,就在于"IT”与”经营"的融合,当然,这里的经营的内涵可以非常广泛,小至一个零售门店的经营,大至一个城市的经营。以下是关于各行各业,不同的组织机构在大数据方面的应用的案例,并在此基础上作简单的梳理和分类。
一、大数据应用案例之:医疗行业 SetonHealthcare是采用IBM最新沃森技术医疗保健内容分析预测的首个客户。该技术允许企业找到大量病人相关的临床医疗信息,通过大数据处理,更好地分析病人的信息。在加拿大多伦多的一家医院,针对早产婴儿,每秒钟有超过3000次的数据读取。通过这些数据分析,医院能够提前知道哪些早产儿出现问题并且有针对性地采取措施,避免早产婴儿夭折. ...感谢聆听... 它让更多的创业者更方便地开发产品,比如通过社交网络来收集数据的健康类App。也许未来数年后,它们搜集的数据能让医生给你的诊断变得更为精确,比方说不是通用的成人每日三次一次一片,而是检测到你的血液中药剂已经代谢完成会自动提醒你再次服药. 二、大数据应用案例之:能源行业 智能电网现在欧洲已经做到了终端,也就是所谓的智能电表。在德国,为了鼓励利用太阳能,会在家庭安装太阳能,除了卖电给你,当你的太阳能有多余电的时候还可以买回来.通过电网收集每隔五分钟或十分钟收集一次数据,收集来的这些数据可以用来预测客户的用电习惯等,从而推断出在未来2~3个月时间里,整个电网大概需要多少电。有了这个预测后,就可以向发电或者供电企业购买一定数量的电.因为电有点像期货一样,如果提前买就会比较便
聚类分析基础知识总结
聚类分析cluster analysis 聚类分析方法是按样品(或变量)的数据特征,把相似的样品(或变量)倾向于分在同一类中,把不相似的样品(或变量)倾向于分在不同类中。 聚类分析根据分类对象不同分为Q型和R型聚类分析 在聚类分析过程中类的个数如何来确定才合适呢?这是一个十分困难的问题,人们至今仍未找到令人满意的方法。但是这个问题又是不可回避的。下面我们介绍几种方法。 1、给定阈值——通过观测聚类图,给出一个合适的阈值T。要求类与类之间的距离不要超过T值。例如我们给定T=0.35,当聚类时,类间的距离已经超过了0.35,则聚类结束。 聚类分析的出发点是研究对象之间可能存在的相似性和亲疏关系。 样品间亲疏程度的测度 研究样品或变量的亲疏程度的数量指标有两种,一种叫相似系数,性质越接近的变量或样品,它们的相似系数越接近于1或一l,而彼此无关的变量或样品它们的相似系数则越接近于0,相似的为一类,不相似的为不同类;另一种叫距离,它是将每一个样品看作p维空间的一个点,并用某种度量测量点与点之间的距离,距离较近的归为一类,距离较远的点应属于不同的类。 变量之间的聚类即R型聚类分析,常用相似系数来测度变量之间的亲疏程度。而样品之间的聚类即Q型聚类分析,则常用距离来测度样品之间的亲疏程度。 定义:在聚类分析中反映样品或变量间关系亲疏程度的统计量称为聚类统计量,常用的聚类统计量分为距离和相似系数两种。 距离:用于对样品的聚类。常用欧氏距离,在求距离前,需把指标进行标准化。 相似系数:常用于对变量的聚类。一般采用相关系数。 相似性度量:距离和相似系数。 距离常用来度量样品之间的相似性,相似系数常用来度量变量之间的相似性。 样品之间的距离和相似系数有着各种不同的定义,而这些定义与变量的类型有着非常密切的关系。 距离和相似系数这两个概念反映了样品(或变量)之间的相似程度。相似程度越高,一般两个样品(或变量)间的距离就越小或相似系数的绝对值就越大;反之,相似程度越低,一般两个样品(或变量)间的距离就越大或相似系数的绝对值就越小。 一、变量测量尺度的类型 为了将样本进行分类,就需要研究样品之间的关系;而为了将变量进行分类,就需要研究变量之间的关系。但无论是样品之间的关系,还是变量之间的关系,都是用变量来描述的,变量的类型不同,描述方法也就不同。通常,变量按照测量它们的尺度不同,可以分为三类。 (1)间隔尺度。指标度量时用数量来表示,其数值由测量或计数、统计得到,如长度、重量、收入、支出等。一般来说,计数得到的数量是离散数量,测量得到的数量是连续数量。在间隔尺度中如果存在绝对零点,又称比例尺度。
大数据分析报告与可视化
数据分析与可视化 1.什么是数据分析? 数据分析是基于商业目的,有目的的进行收集、整理、加工和分析数据,提炼有价信息的一个过程。其过程概括起来主要包括:明确分析目的与框架、数据收集、数据处理、数据分析、数据展现和撰写报告等6个阶段。 1、明确分析目的与框架 一个分析项目,你的数据对象是谁?商业目的是什么?要解决什么业务问题?数据分析师对这些都要了然于心。基于商业的理解,整理分析框架和分析思路。例如,减少新客户的流失、优化活动效果、提高客户响应率等等。不同的项目对数据的要求,使用的分析手段也是不一样的。 2、数据收集 数据收集是按照确定的数据分析和框架内容,有目的的收集、整合相关数据的一个过程,它是数据分析的一个基础。 3、数据处理 数据处理是指对收集到的数据进行加工、整理,以便开展数据分析,它是数据分析前必不可少的阶段。这个过程是数据分析整个过程中最占据时间的,也在一定程度上取决于数据仓库的搭建和数据质量的保证。 数据处理主要包括数据清洗、数据转化等处理方法。 4、数据分析 数据分析是指通过分析手段、方法和技巧对准备好的数据进行探索、分析,从中发现因果关系、内部联系和业务规律,为商业目提供决策参考。 到了这个阶段,要能驾驭数据、开展数据分析,就要涉及到工具和方法的使用。其一要熟悉常规数据分析方法,最基本的要了解例如方差、回归、因子、聚类、分类、时间序列等多元和数据分析方法的原理、使用范围、优缺点和结果的解释;其二是熟悉1+1种数据分析工具,Excel是最常见,一般的数据分析我们可以通过Excel完成,后而要熟悉一个专业的分析软件,如数据分析工具SPSS/SAS/R/Matlab等,便于进行一些专业的统计分析、数据建模等。
聚类分析原理及步骤.doc
聚类分析原理及步骤——将未知数据按相似程度分类到不同的类或簇的过程 1》传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS等。 典型应用 1》动植物分类和对基因进行分类 2》在网上进行文档归类来修复信息 3》帮助电子商务的用户了解自己的客户,向客户提供更合适的服务 主要步骤 1》数据预处理——选择数量,类型和特征的标度((依据特征选择和抽取)特征选择选择重要的特征,特征抽取把输入的特征转化 为一个新的显著特征,它们经常被用来获取一个合适的特征集来为避免“维数 灾”进行聚类)和将孤立点移出数据(孤立点是不依附于一般数 据行为或模型的数据) 2》为衡量数据点间的相似度定义一个距离函数——既然相类似性是定义一个类的基础,那么不同数据之间在同一个特 征空间相似度的衡量对于聚类步骤是很重要的,由于特征类型和特 征标度的多样性,距离度量必须谨慎,它经常依赖于应用,例如, 通常通过定义在特征空间的距离度量来评估不同对象的相异性,很 多距离度都应用在一些不同的领域一个简单的距离度量,如 Euclidean距离,经常被用作反映不同数据间的相异性,一些有关相
似性的度量,例如PMC和SMC,能够被用来特征化不同数据的概 念相似性,在图像聚类上,子图图像的误差更正能够被用来衡量两 个图形的相似性 3》聚类或分组——将数据对象分到不同的类中【划分方法 (划分方法一般从初始划分和最优化一个聚类标准开始,Cris p Clustering和Fuzzy Clusterin是划分方法的两个主要技术,Crisp Clustering,它的每一个数据都属于单独的类;Fuzzy Clustering,它的 每个数据可能在任何一个类中)和层次方法(基于某个标准产生一 个嵌套的划分系列,它可以度量不同类之间的相似性或一个类的可分 离性用来合并和分裂类)是聚类分析的两个主要方法,另外还有基于 密度的聚类,基于模型的聚类,基于网格的聚类】 4》评估输出——评估聚类结果的质量(它是通过一个类有效索引来 评价,,一般来说,几何性质,包括类间的分离和类内部的耦合,一般 都用来评价聚类结果的质量,类有效索引在决定类的数目时经常扮演 了一个重要角色,类有效索引的最佳值被期望从真实的类数目中获取, 一个通常的决定类数目的方法是选择一个特定的类有效索引的最佳 值,这个索引能否真实的得出类的数目是判断该索引是否有效的标准, 很多已经存在的标准对于相互分离的类数据集合都能得出很好的结 果,但是对于复杂的数据集,却通常行不通,例如,对于交叠类的集 合。) 聚类分析的主要计算方法原理及步骤划分法 1》将数据集分割成K个组(每个组至少包 含一个数据且每一个数据纪录属于且 仅属于一个分组),每个组成为一类2》通过反复迭代的方法改变分组,使得每 一次改进之后的分组方案都较前一次 好(标准就是:同一分组中的记录越近 越好,而不同分组中的纪录越远越好, 使用这个基本思想的算法有:
大数据经典使用十大案例
如有人问你什么是大数据?不妨说说这10个典型的大数据案例(-from 互联网) 在听Gartner的分析师Doug Laney用55分钟讲述55个大数据应用案例之前,你可能对于大数据是否落地还心存疑虑。Laney的演讲如同莎士比亚的全集一样,不过可能“缺乏娱乐性而更具信息量”(也许对于技术人员来说是这样的)。这个演讲是对大数据3v 特性的全面阐释:variety(类型)、velocity(产生速度)和volume(规模)。术语的发明者就是用这种方式来描述大数据的–可以追溯到2001年。 这55个例子不是用来虚张声势,Laney的意图是说明大数据的实际应用前景,听众们应该思考如何在自己公司里让大数据落地并促进业务的发展。“也许有些例子并非来自于你当前所处的行业,但是你需要考虑如何做到他山之石可以攻玉。”Laney表示。 下面是其中的10个典型案例: 1. 梅西百货的实时定价机制。根据需求和库存的情况,该公司基于SAS的系统对多达7300万种货品进行实时调价。 2. Tipp24 AG针对欧洲博彩业构建的下注和预测平台。该公司用KXEN软件来分析数十亿计的交易以及客户的特性,然后通过预测模型对特定用户进行动态的营销活动。这项举措减少了90%的预测模型构建时间。SAP公司正在试图收购KXEN。“SAP想通过这次收购来扭转其长久以来在预测分析方面的劣势。”Laney分析到。 3. 沃尔玛的搜索。这家零售业寡头为其网站https://www.360docs.net/doc/0f9898289.html,自行设计了最新的搜索引擎Polaris,利用语义数据进行文本分析、机器学习和同义词挖掘等。根据沃尔玛的说法,语义搜索技术的运用使得在线购物的完成率提升了10%到15%。“对沃尔玛来说,这就意味着数十亿美元的金额。”Laney说。 4. 快餐业的视频分析(Laney没有说出这家公司的名字)。该公司通过视频分析等候队列的长度,然后自动变化电子菜单显示的内容。如果队列较长,则显示可以快速供给的食物;如果队列较短,则显示那些利润较高但准备时间相对长的食品。 5. Morton牛排店的品牌认知。当一位顾客开玩笑地通过推特向这家位于芝加哥的牛排连锁店订餐送到纽约Newark机场(他将在一天工作之后抵达该处)时,Morton就开始了自己的社交秀。首先,分析推特数据,发现该顾客是本店的常客,也是推特的常用者。根据客户以往的订单,推测出其所乘的航班,然后派出一位身着燕尾服的侍者为客户提
聚类分析原理及步骤
聚类分析原理及步骤 聚类分析原理及步骤——将未知数据按相似程度分类到不同的 类或簇的过程 1》传统的统计聚类分析方法包括系统聚类法、分解法、加入法、 动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。采用 k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名 的统计分析软件包中,如SPSS、SAS等。 典型应用 1》动植物分类和对基因进行分类 2》在网上进行文档归类来修复信息 3》帮助电子商务的用户了解自己的客户,向客户提供更合适 的服务 主要步骤 1》数据预处理——选择数量,类型和特征的标度((依 据特征选择和抽取)特征选择选择重要的特征,特征抽取把输入的特征转化 为一个新的显著特征,它们经常被用来获取一个合适的特征集来为避免“维数灾”进行聚类)和将孤立点移出数据(孤立点是不依附于一般数 据行为或模型的数据) 2》为衡量数据点间的相似度定义一个距离函数—— 既然相类似性是定义一个类的基础,那么不同数据之间在同一个特 征空间相似度的衡量对于聚类步骤是很重要的,由于特征类型和特 征标度的多样性,距离度量必须谨慎,它经常依赖于应用,例如, 通常通过定义在特征空间的距离度量来评估不同对象的相异性,很
多距离度都应用在一些不同的领域一个简单的距离度量,如 Euclidean距离,经常被用作反映不同数据间的相异性,一些有关相 似性的度量,例如PMC和SMC,能够被用来特征化不同数据的概 念相似性,在图像聚类上,子图图像的误差更正能够被用来衡量两 个图形的相似性 3》聚类或分组——将数据对象分到不同的类中【划分方法 (划分方法一般从初始划分和最优化一个聚类标准开始,Crisp Clustering和Fuzzy Clusterin是划分方法的两个主要技术,Crisp Clustering,它的每一个数据都属于单独的类;Fuzzy Clustering,它的每个数据可能在任何一个类中)和层次方法(基于某个标准产生一 个嵌套的划分系列,它可以度量不同类之间的相似性或一个类的可分 离性用来合并和分裂类)是聚类分析的两个主要方法,另外还有基于 密度的聚类,基于模型的聚类,基于网格的聚类】 4》评估输出——评估聚类结果的质量(它是通过一个类有效索引来 评价,,一般来说,几何性质,包括类间的分离和类内部的耦合,一般都用来评价聚类结果的质量,类有效索引在决定类的数目时经常扮演 了一个重要角色,类有效索引的最佳值被期望从真实的类数目中获取,一个通常的决定类数目的方法是选择一个特定的类有效索引的最佳 值,这个索引能否真实的得出类的数目是判断该索引是否有效的标准,很多已经存在的标准对于相互分离的类数据集合都能得出很好的结 果,但是对于复杂的数据集,却通常行不通,例如,对于交叠类的集合。) 聚类分析的主要计算方法原理及步骤划分法 1》将数据集分割成K个组(每个组至少包