聚类算法总结
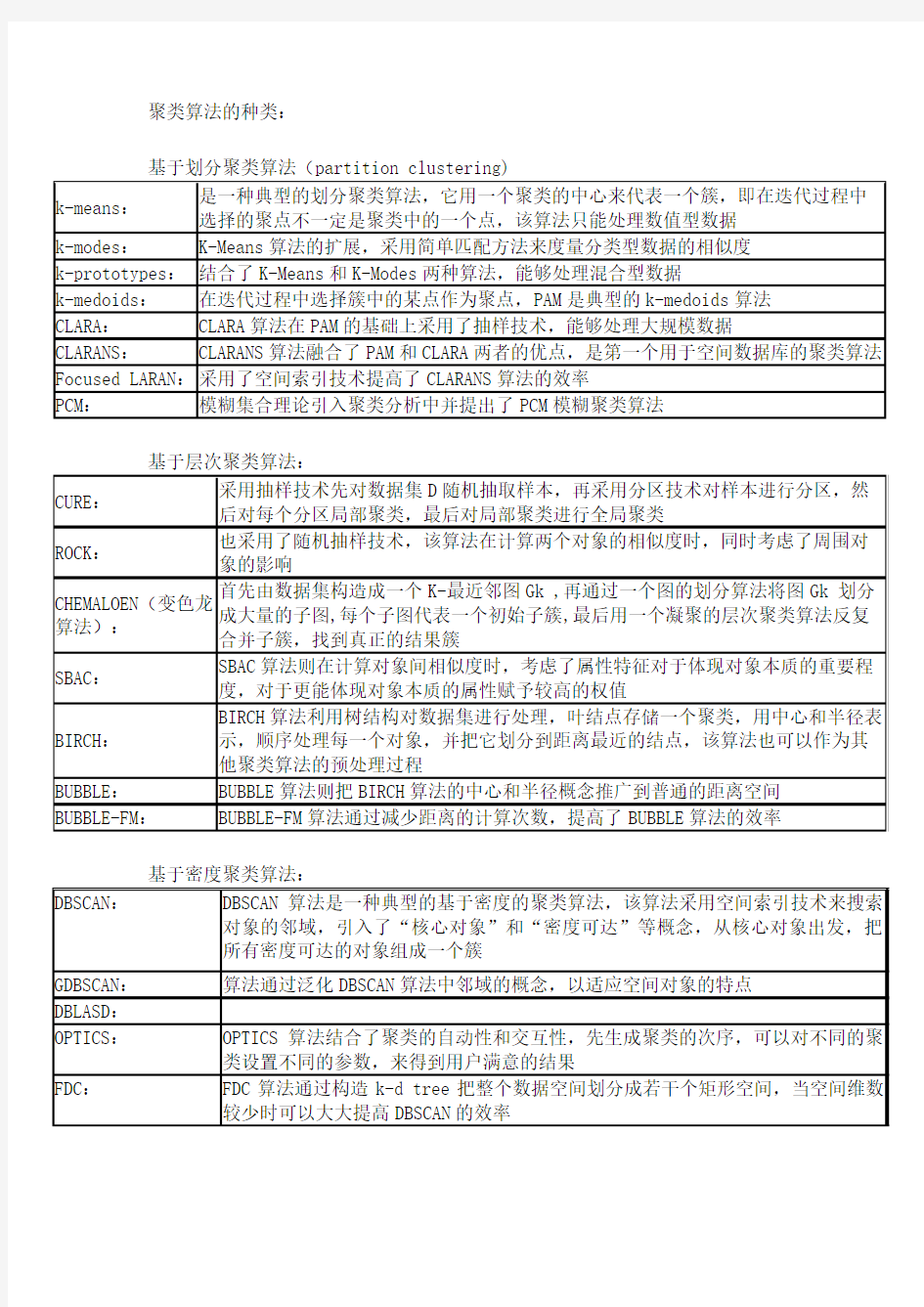
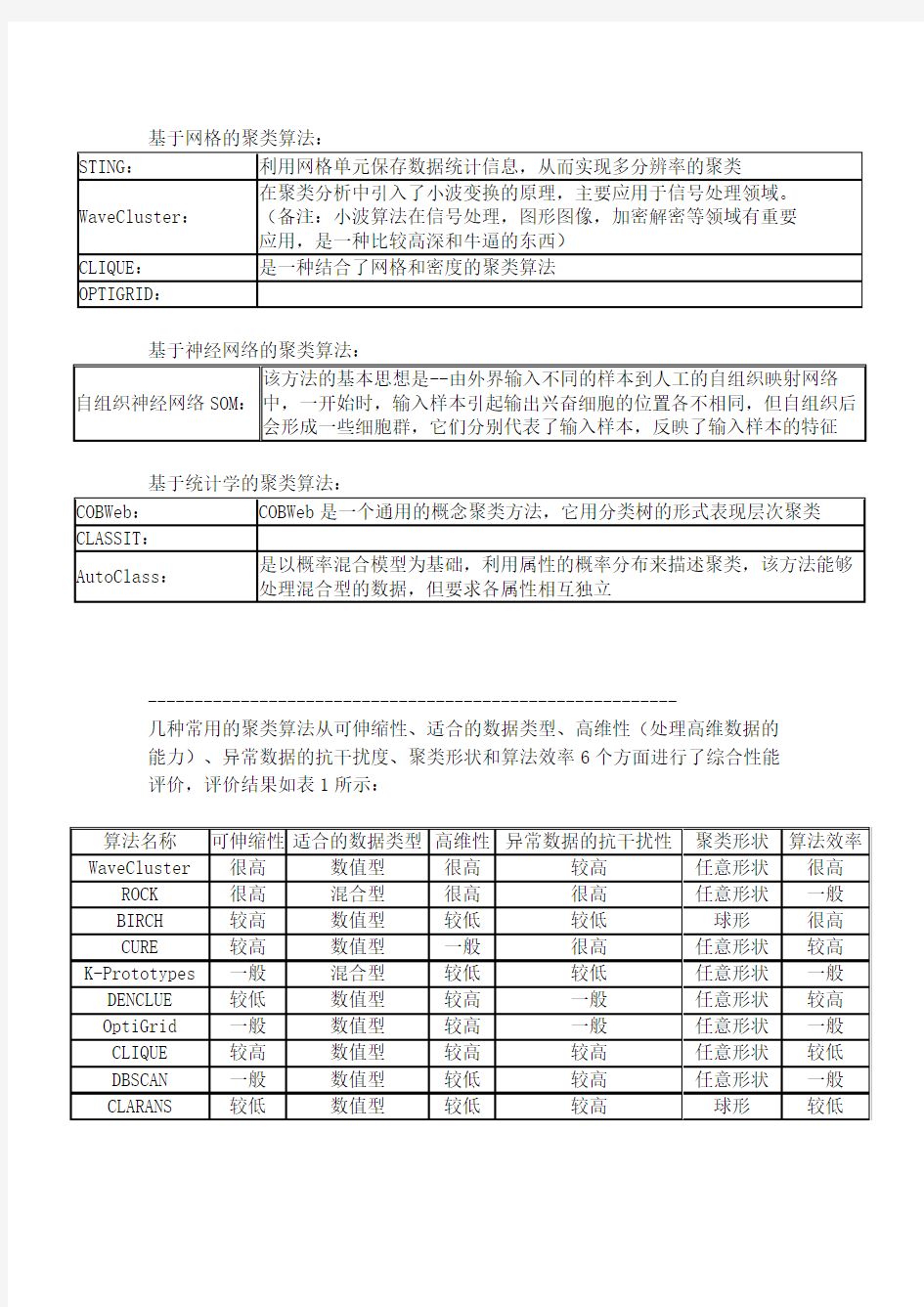
聚类算法的种类:
---------------------------------------------------------
几种常用的聚类算法从可伸缩性、适合的数据类型、高维性(处理高维数据的能力)、异常数据的抗干扰度、聚类形状和算法效率6个方面进行了综合性能评价,评价结果如表1所示:
---------------------------------------------------------
目前聚类分析研究的主要内容:
对聚类进行研究是数据挖掘中的一个热门方向,由于以上所介绍的聚类方法都
存在着某些缺点,因此近些年对于聚类分析的研究很多都专注于改进现有的聚
类方法或者是提出一种新的聚类方法。以下将对传统聚类方法中存在的问题以
及人们在这些问题上所做的努力做一个简单的总结:
1 从以上对传统的聚类分析方法所做的总结来看,不管是k-means方法,还是CURE方法,在进行聚类之前都需要用户事先确定要得到的聚类的数目。然而在
现实数据中,聚类的数目是未知的,通常要经过不断的实验来获得合适的聚类
数目,得到较好的聚类结果。
2 传统的聚类方法一般都是适合于某种情况的聚类,没有一种方法能够满足各
种情况下的聚类,比如BIRCH方法对于球状簇有很好的聚类性能,但是对于不
规则的聚类,则不能很好的工作;K-medoids方法不太受孤立点的影响,但是
其计算代价又很大。因此如何解决这个问题成为当前的一个研究热点,有学者
提出将不同的聚类思想进行融合以形成新的聚类算法,从而综合利用不同聚类
算法的优点,在一次聚类过程中综合利用多种聚类方法,能够有效的缓解这个
问题。
3 随着信息时代的到来,对大量的数据进行分析处理是一个很庞大的工作,这
就关系到一个计算效率的问题。有文献提出了一种基于最小生成树的聚类算法,该算法通过逐渐丢弃最长的边来实现聚类结果,当某条边的长度超过了某个阈值,那么更长边就不需要计算而直接丢弃,这样就极大地提高了计算效率,降
低了计算成本。
4 处理大规模数据和高维数据的能力有待于提高。目前许多聚类方法处理小规
模数据和低维数据时性能比较好,但是当数据规模增大,维度升高时,性能就
会急剧下降,比如k-medoids方法处理小规模数据时性能很好,但是随着数据
量增多,效率就逐渐下降,而现实生活中的数据大部分又都属于规模比较大、
维度比较高的数据集。有文献提出了一种在高维空间挖掘映射聚类的方法PCKA (Projected Clustering based on the K-Means Algorithm),它从多个维度中选择属性相关的维度,去除不相关的维度,沿着相关维度进行聚类,以此对
高维数据进行聚类。
5 目前的许多算法都只是理论上的,经常处于某种假设之下,比如聚类能很好
的被分离,没有突出的孤立点等,但是现实数据通常是很复杂的,噪声很大,
因此如何有效的消除噪声的影响,提高处理现实数据的能力还有待进一步的提高。
K - M e a n s 聚 类 算 法
基于K-means聚类算法的入侵检测系统的设计 基于K-means聚类算法的入侵检测系统的设计 今天给大家讲述的是K-means聚类算法在入侵检测系统中的应用首先,介绍一下 聚类算法 将认识对象进行分类是人类认识世界的一种重要方法,比如有关世界的时间进程的研究,就形成了历史学,有关世界空间地域的研究,则形成了地理学。 又如在生物学中,为了研究生物的演变,需要对生物进行分类,生物学家根据各种生物的特征,将它们归属于不同的界、门、纲、目、科、属、种之中。 事实上,分门别类地对事物进行研究,要远比在一个混杂多变的集合中更清晰、明了和细致,这是因为同一类事物会具有更多的近似特性。 通常,人们可以凭经验和专业知识来实现分类。而聚类分析(cluster analysis)作为一种定量方法,将从数据分析的角度,给出一个更准确、细致的分类工具。 (聚类分析我们说得朴实一点叫做多元统计分析,说得时髦一点叫做数据挖掘算法,因为这个算法可以在一堆数据中获取很有用的信息,这就不就是数据挖掘吗,所以大家平时也不要被那些高大上的名词给吓到了,它背后的核心原理大多数我们都是可以略懂一二的,再
比如说现在AI这么火,如果大家还有印象的话,以前我们在大二上学习概率论的时候,我也和大家分享过自然语言处理的数学原理,就是如何让机器人理解我们人类的自然语言,比如说,苹果手机上的Siri系统,当时还让杨帆同学帮我在黑板上写了三句话,其实就是贝叶斯公式+隐含马尔可夫链。估计大家不记得了,扯得有点远了接下来还是回归我们的正题,今天要讨论的聚类算法。) K-Means是常用的聚类算法,与其他聚类算法相比,其时间复杂度低,结果稳定,聚类的效果也还不错, 相异度计算 在正式讨论聚类前,我们要先弄清楚一个问题:如何定量计算两个可比较元素间的相异度。用通俗的话说,相异度就是两个东西差别有多大,例如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能我们直观感受到的。但是,计算机没有这种直观感受能力,我们必须对相异度在数学上进行定量定义。 要用数量化的方法对事物进行分类,就必须用数量化的方法描述事物之间的相似程度。一个事物常常需要用多个特征变量来刻画,就比如说我们举一个例证,就有一项比较神奇的技术叫面部识别技术,其实听起来很高大上,它是如何做到的,提取一个人的面部特征,比如说嘴巴的长度,鼻梁的高度,眼睛中心到鼻子的距离,鼻子到嘴巴的距离,这些指标对应得数值可以组成一个向量作为每一个个体的一个标度变量(),或者说叫做每一个人的一个特征向量。 如果对于一群有待分类的样本点需用p 个特征变量值描述,则每
MATLAB实现FCM 聚类算法
本文在阐述聚类分析方法的基础上重点研究FCM 聚类算法。FCM 算法是一种基于划分的聚类算法,它的思想是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小。最后基于MATLAB实现了对图像信息的聚类。 第 1 章概述 聚类分析是数据挖掘的一项重要功能,而聚类算法是目前研究的核心,聚类分析就是使用聚类算法来发现有意义的聚类,即“物以类聚” 。虽然聚类也可起到分类的作用,但和大多数分类或预测不同。大多数分类方法都是演绎的,即人们事先确定某种事物分类的准则或各类别的标准,分类的过程就是比较分类的要素与各类别标准,然后将各要素划归于各类别中。确定事物的分类准则或各类别的标准或多或少带有主观色彩。 为获得基于划分聚类分析的全局最优结果,则需要穷举所有可能的对象划分,为此大多数应用采用的常用启发方法包括:k-均值算法,算法中的每一个聚类均用相应聚类中对象的均值来表示;k-medoid 算法,算法中的每一个聚类均用相应聚类中离聚类中心最近的对象来表示。这些启发聚类方法在分析中小规模数据集以发现圆形或球状聚类时工作得很好,但当分析处理大规模数据集或复杂数据类型时效果较差,需要对其进行扩展。 而模糊C均值(Fuzzy C-means, FCM)聚类方法,属于基于目标函数的模糊聚类算法的范畴。模糊C均值聚类方法是基于目标函数的模糊聚类算法理论中最为完善、应用最为广泛的一种算法。模糊c均值算法最早从硬聚类目标函数的优化中导出的。为了借助目标函数法求解聚类问题,人们利用均方逼近理论构造了带约束的非线性规划函数,以此来求解聚类问题,从此类内平方误差和WGSS(Within-Groups Sum of Squared Error)成为聚类目标函数的普遍形式。随着模糊划分概念的提出,Dunn [10] 首先将其推广到加权WGSS 函数,后来由Bezdek 扩展到加权WGSS 的无限族,形成了FCM 聚类算法的通用聚类准则。从此这类模糊聚类蓬勃发展起来,目前已经形成庞大的体系。 第 2 章聚类分析方法 2-1 聚类分析 聚类分析就是根据对象的相似性将其分群,聚类是一种无监督学习方法,它不需要先验的分类知识就能发现数据下的隐藏结构。它的目标是要对一个给定的数据集进行划分,这种划分应满足以下两个特性:①类内相似性:属于同一类的数据应尽可能相似。②类间相异性:属于不同类的数据应尽可能相异。图2.1是一个简单聚类分析的例子。
PAM聚类算法的分析与实现
毕业论文(设计)论文(设计)题目:PAM聚类算法的分析与实现 系别: 专业: 学号: 姓名: 指导教师: 时间:
毕业论文(设计)开题报告 系别:计算机与信息科学系专业:网络工程 学号姓名高华荣 论文(设计)题目PAM聚类算法的分析与实现 命题来源□√教师命题□学生自主命题□教师课题 选题意义(不少于300字): 随着计算机技术、网络技术的迅猛发展与广泛应用,人们面临着日益增多的业务数据,这些数据中往往隐含了大量的不易被人们察觉的宝贵信息,为了得到这些信息,人们想尽了一切办法。数据挖掘技术就是在这种状况下应运而生了。而聚类知识发现是数据挖掘中的一项重要的内容。 在日常生活、生产和科研工作中,经常要对被研究的对象经行分类。而聚类分析就是研究和处理给定对象的分类常用的数学方法。聚类就是将数据对象分组成多个簇,同一个簇中的对象之间具有较高的相似性,而不同簇中的对象具有较大的差异性。 在目前的许多聚类算法中,PAM算法的优势在于:PAM算法比较健壮,对“噪声”和孤立点数据不敏感;由它发现的族与测试数据的输入顺序无关;能够处理不同类型的数据点。 研究综述(前人的研究现状及进展情况,不少于600字): PAM(Partitioning Around Medoid,围绕中心点的划分)算法是是划分算法中一种很重要的算法,有时也称为k-中心点算法,是指用中心点来代表一个簇。PAM算法最早由Kaufman和Rousseevw提出,Medoid的意思就是位于中心位置的对象。PAM算法的目的是对n个数据对象给出k个划分。PAM算法的基本思想:PAM算法的目的是对成员集合D中的N个数据对象给出k个划分,形成k个簇,在每个簇中随机选取1个成员设置为中心点,然后在每一步中,对输入数据集中目前还不是中心点的成员根据其与中心点的相异度或者距离进行逐个比较,看是否可能成为中心点。用簇中的非中心点到簇的中心点的所有距离之和来度量聚类效果,其中成员总是被分配到离自身最近的簇中,以此来提高聚类的质量。 由于PAM算法对小数据集非常有效,但对大的数据集合没有良好的可伸缩性,就出现了结合PAM的CLARA(Cluster LARger Application)算法。CLARA是基于k-中心点类型的算法,能处理更大的数据集合。CLARA先抽取数据集合的多个样本,然后用PAM方法在抽取的样本中寻找最佳的k个中心点,返回最好的聚类结果作为输出。后来又出现了CLARNS(Cluster Larger Application based upon RANdomized
CLOPE-快速有效的聚类算法
CLOPE:针对交易的数据快速有效聚类算法 摘要 本文研究分类数据的聚类问题,特别针对多维和大型的交易数据。从增加聚簇直方图的高宽比的方法得到启发,我们开发了一种新的算法---CLOPE,这是一种非常快速、可伸缩,同时又非常有效的算法。我们展示了算法对两个现实数据集聚类的性能,并将CLOPE与现有的聚类算法进行了比较。 关键词 数据挖掘,聚类,分类数据,可伸缩性 1.简介 聚类是一种非常重要的数据挖掘技术,它的目的是将相似的交易[12, 14, 4, 1]分组在一起。最近,越来越多的注意力已经放到了分类数据[10,8,6,5,7,13]的聚类上,分类数据是由非数值项构成的数据。交易数据,例如购物篮数据和网络日志数据,可以被认为是一种特殊的拥有布尔型值的分类数据,它们将所有可能的项作为项。快速而精确地对交易数据进行聚类的技术在零售行业,电子商务智能化等方面有着很大的应用潜力。 但是,快速而有效聚类交易数据是非常困难的,因为这类的数据通常有着高维,稀疏和大容量的特征。基于距离的算法例如k-means[11]和CLARANS[12]都是对低维的数值型数据有效。但是对于高维分类数据的处理效果却通常不那么令人满意[7]。像ROCK这类的分层聚类算法在分类数据聚类中表现的非常有效,但是他们在处理大型数据库时表现出先天的无效。 LargeItem[13]算法通过迭代优化一个全局评估函数对分类数据进行聚类。这个评估函数是基于大项概念的,大项是在一个聚簇内出现概率比一个用户自定义的参数——最小支持度大的项。计算全局评估函数要远比计算局部评估函数快得多,局部评估函数是根据成对相似性定义的。这种全局方法使得LargeItem算法非常适合于聚类大型的分类数据库。 在这篇文章中,我们提出了一种新的全局评估函数,它试图通过增加聚簇直方图的高度与宽度之比来增加交易项在聚簇内的重叠性。此外,我们通过引用一个参数来控制聚簇紧密性的方法来泛化我们的想法,通过修改这个参数可以得到
(完整word版)各种聚类算法介绍及对比
一、层次聚类 1、层次聚类的原理及分类 1)层次法(Hierarchical methods)先计算样本之间的距离。每次将距离最近的点合并到同一个类。然后,再计算类与类之间的距离,将距离最近的类合并为一个大类。不停的合并,直到合成了一个类。其中类与类的距离的计算方法有:最短距离法,最长距离法,中间距离法,类平均法等。比如最短距离法,将类与类的距离定义为类与类之间样本的最短距离。 层次聚类算法根据层次分解的顺序分为:自下底向上和自上向下,即凝聚的层次聚类算法和分裂的层次聚类算法(agglomerative和divisive),也可以理解为自下而上法(bottom-up)和自上而下法(top-down)。自下而上法就是一开始每个个体(object)都是一个 类,然后根据linkage寻找同类,最后形成一个“类”。自上而下法就是反过来,一开始所有个体都属于一个“类”,然后根据linkage排除异己,最后每个个体都成为一个“类”。这两种路方法没有孰优孰劣之分,只是在实际应用的时候要根据数据特点以及你想要的“类”的个数,来考虑是自上而下更快还是自下而上更快。至于根据Linkage判断“类” 的方法就是最短距离法、最长距离法、中间距离法、类平均法等等(其中类平均法往往被认为是最常用也最好用的方法,一方面因为其良好的单调性,另一方面因为其空间扩张/浓缩的程度适中)。为弥补分解与合并的不足,层次合并经常要与其它聚类方法相结合,如循环定位。 2)Hierarchical methods中比较新的算法有BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies利用层次方法的平衡迭代规约和聚类)主要是在数据量很大的时候使用,而且数据类型是numerical。首先利用树的结构对对象集进行划分,然后再利用其它聚类方法对这些聚类进行优化;ROCK(A Hierarchical Clustering Algorithm for Categorical Attributes)主要用在categorical的数据类型上;Chameleon(A Hierarchical Clustering Algorithm Using Dynamic Modeling)里用到的linkage是kNN(k-nearest-neighbor)算法,并以此构建一个graph,Chameleon的聚类效果被认为非常强大,比BIRCH好用,但运算复杂度很高,O(n^2)。 2、层次聚类的流程 凝聚型层次聚类的策略是先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有对象都在一个簇中,或者某个终结条件被满足。绝大多数层次聚类属于凝聚型层次聚类,它们只是在簇间相似度的定义上有所不同。这里给出采用最小距离的凝聚层次聚类算法流程: (1) 将每个对象看作一类,计算两两之间的最小距离; (2) 将距离最小的两个类合并成一个新类; (3) 重新计算新类与所有类之间的距离; (4) 重复(2)、(3),直到所有类最后合并成一类。
KMeans聚类算法模式识别
K-Means聚类算法 1.算法原理 k-means是划分方法中较经典的聚类算法之一。由于该算法的效率高,所以在对大规模数据进行聚类时被广泛应用。目前,许多算法均围绕着该算法进行扩展和改进。 k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。k-means算法的处理过程如下:首先,随机地选择k个对象,每个对象初始地代表了一个簇的平均值或中心;对剩余的每个对象,根据其与各簇中心的距离,将它赋给最近的簇;然后重新计算每个簇的平均值。这个过程不断重复,直到准则函数收敛。通常,采用平方误差准则,其定义如下: 这里E是数据库中所有对象的平方误差的总和,p是空间中的点,mi 是簇Ci的平均值。该目标函数使生成的簇尽可能紧凑独立,使用的距离度量是欧几里得距离,当然也可以用其他距离度量。k-means聚类算法的算法流程如下: 输入:包含n个对象的数据库和簇的数目k; 输出:k个簇,使平方误差准则最小。 步骤: (1) 任意选择k个对象作为初始的簇中心; (2) repeat; (3) 根据簇中对象的平均值,将每个对象(重新)赋予最类似的簇; (4) 更新簇的平均值,即计算每个簇中对象的平均值;
(5) 直到不再发生变化。 2.主要代码 主程序: clc; clear; close all; %% 聚类算法测试 nSample = [500, 500, 500]; % 3维情况 dim = 3; coeff = { [-2 0.8; -1 0.9; 2 0.7;], .... [1 0.9; -2 0.7; -2 0.8; ], ... [-2 0.7; 2 0.8; -1 0.9; ], }; data = createSample(nSample, dim , coeff); %% 得到训练数据 nClass = length(nSample); tlabel = []; tdata = []; for i = 1 : nClass
(完整版)聚类算法总结
1.聚类定义 “聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有一些相似的属性”——wikipedia “聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。它是一种重要的人类行为。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。”——百度百科 说白了,聚类(clustering)是完全可以按字面意思来理解的——将相同、相似、相近、相关的对象实例聚成一类的过程。简单理解,如果一个数据集合包含N个实例,根据某种准则可以将这N 个实例划分为m个类别,每个类别中的实例都是相关的,而不同类别之间是区别的也就是不相关的,这个过程就叫聚类了。 2.聚类过程: 1) 数据准备:包括特征标准化和降维. 2) 特征选择:从最初的特征中选择最有效的特征,并将其存储于向量中. 3) 特征提取:通过对所选择的特征进行转换形成新的突出特征.
4) 聚类(或分组):首先选择合适特征类型的某种距离函数(或构造新的距离函数)进行接近程度的度量;而后执行聚类或分组. 5) 聚类结果评估:是指对聚类结果进行评估.评估主要有3 种:外部有效性评估、内部有效性评估和相关性测试评估. 3聚类算法的类别 没有任何一种聚类技术(聚类算法)可以普遍适用于揭示各种多维数据集所呈现出来的多种多样的结构,根据数据在聚类中的积聚规则以及应用这些规则的方法,有多种聚类算法.聚类算法有多种分类方法将聚类算法大致分成层次化聚类算法、划分式聚类算法、基于密度和网格的聚类算法和其他聚类算法,如图1 所示 的4 个类别.
机器学习聚类算法实现
《人工智能与机器学习》 实验报告 年级__ xxxx班____________ 专业___________xxxxx____ _____ 学号____________6315070301XX___________ 姓名_____________gllh________________ 日期___________2018-5-12 __
实验五聚类算法实现 一、实验目的 1、了解常用聚类算法及其优缺点 2、掌握k-means聚类算法对数据进行聚类分析的基本原理和划分方法 3、利用k-means聚类算法对已知数据集进行聚类分析 实验类型:验证性 计划课间:4学时 二、实验内容 1、利用python的sklearn库函数对给定的数据集进行聚类分析 2、分析k-means算法的实现流程 3、根据算法描述编程实现,调试运行 4、对所给数据集进行验证,得到分析结果 三、实验步骤 1、k-means算法原理 2、k-means算法流程 3、k-means算法实现 4、对已知数据集进行分析 四、实验结果分析 1.利用python的sklearn库函数对给定的数据集进行聚类分析: 其中数据集选取iris鸢尾花数据集 import numpy as np from sklearn.datasets import load_iris iris = load_iris() def dist(x,y):
return sum(x*y)/(sum(x**2)*sum(y**2))**0.5 def K_means(data=iris.data,k=3,ping=0,maxiter=100): n, m = data.shape centers = data[:k,:] while ping < maxiter: dis = np.zeros([n,k+1]) for i in range(n): for j in range(k): dis[i,j] = dist(data[i,:],centers[j,:]) dis[i,k] = dis[i,:k].argmax() centers_new = np.zeros([k,m]) for i in range(k): index = dis[:,k]==i centers_new[i,:] = np.mean(data[index,:],axis=0) if np.all(centers==centers_new): break centers = centers_new ping += 1 return dis if __name__ == '__main__': res = K_means() print(res) (1)、首先求出样本之间的余弦相似度: sum(x*y)/(sum(x**2)*sum(y**2))**0.5 (2)、设置k类别数为3,最大迭代次数为100 K_means(data=iris.data,k=3,ping=0,maxiter=100):
实验三K均值聚类算法实验报告
实验三 K-Means聚类算法 一、实验目的 1) 加深对非监督学习的理解和认识 2) 掌握动态聚类方法K-Means 算法的设计方法 二、实验环境 1) 具有相关编程软件的PC机 三、实验原理 1) 非监督学习的理论基础 2) 动态聚类分析的思想和理论依据 3) 聚类算法的评价指标 四、算法思想 K-均值算法的主要思想是先在需要分类的数据中寻找K组数据作为初始聚类中心,然后计算其他数据距离这三个聚类中心的距离,将数据归入与其距离最近的聚类中心,之后再对这K个聚类的数据计算均值,作为新的聚类中心,继续以上步骤,直到新的聚类中心与上一次的聚类中心值相等时结束算法。 实验代码 function km(k,A)%函数名里不要出现“-” warning off [n,p]=size(A);%输入数据有n个样本,p个属性 cid=ones(k,p+1);%聚类中心组成k行p列的矩阵,k表示第几类,p是属性 %A(:,p+1)=100; A(:,p+1)=0; for i=1:k %cid(i,:)=A(i,:); %直接取前三个元祖作为聚类中心 m=i*floor(n/k)-floor(rand(1,1)*(n/k)) cid(i,:)=A(m,:); cid; end Asum=0; Csum2=NaN; flags=1; times=1; while flags flags=0; times=times+1; %计算每个向量到聚类中心的欧氏距离 for i=1:n
for j=1:k dist(i,j)=sqrt(sum((A(i,:)-cid(j,:)).^2));%欧氏距离 end %A(i,p+1)=min(dist(i,:));%与中心的最小距离 [x,y]=find(dist(i,:)==min(dist(i,:))); [c,d]=size(find(y==A(i,p+1))); if c==0 %说明聚类中心变了 flags=flags+1; A(i,p+1)=y(1,1); else continue; end end i flags for j=1:k Asum=0; [r,c]=find(A(:,p+1)==j); cid(j,:)=mean(A(r,:),1); for m=1:length(r) Asum=Asum+sqrt(sum((A(r(m),:)-cid(j,:)).^2)); end Csum(1,j)=Asum; end sum(Csum(1,:)) %if sum(Csum(1,:))>Csum2 % break; %end Csum2=sum(Csum(1,:)); Csum; cid; %得到新的聚类中心 end times display('A矩阵,最后一列是所属类别'); A for j=1:k [a,b]=size(find(A(:,p+1)==j)); numK(j)=a; end numK times xlswrite('data.xls',A);
K 均值聚类算法(原理加程序代码)
K-均值聚类算法 1.初始化:选择c 个代表点,...,,321c p p p p 2.建立c 个空间聚类表:C K K K ...,21 3.按照最小距离法则逐个对样本X 进行分类: ),(),,(min arg J i i K x add p x j ?= 4.计算J 及用各聚类列表计算聚类均值,并用来作为各聚类新的代表点(更新代表点) 5.若J 不变或代表点未发生变化,则停止。否则转2. 6.),(1∑∑=∈=c i K x i i p x J δ 具体代码如下: clear all clc x=[0 1 0 1 2 1 2 3 6 7 8 6 7 8 9 7 8 9 8 9;0 0 1 1 1 2 2 2 6 6 6 7 7 7 7 8 8 8 9 9]; figure(1) plot(x(1,:),x(2,:),'r*') %%第一步选取聚类中心,即令K=2 Z1=[x(1,1);x(2,1)]; Z2=[x(1,2);x(2,2)]; R1=[]; R2=[]; t=1; K=1;%记录迭代的次数 dif1=inf; dif2=inf; %%第二步计算各点与聚类中心的距离 while (dif1>eps&dif2>eps) for i=1:20 dist1=sqrt((x(1,i)-Z1(1)).^2+(x(2,i)-Z1(2)).^2); dist2=sqrt((x(1,i)-Z2(1)).^2+(x(2,i)-Z2(2)).^2); temp=[x(1,i),x(2,i)]'; if dist1 第37卷第11期 2000年11月计算机研究与发展JOU RNAL O F COM PU T ER R ESEA RCH &D EV ELO PM EN T V o l 137,N o 111N ov .2000 原稿收到日期:1999209220;修改稿收到日期:1999212209.本课题得到国家自然科学基金项目(项目编号69743001)和国家教委博士点教育基金的资助.周水庚,男,1966年生,博士研究生,高级工程师,主要从事数据库、数据仓库和数据挖掘以及信息检索等的研究.周傲英,男,1965年生,教授,博士生导师,主要从事数据库、数据挖掘和W eb 信息管理等研究.曹晶,女,1976年生,硕士研究生,主要从事数据库、数据挖掘等研究.胡运发,男,1940年生,教授,博士生导师,主要从事知识工程、数字图书馆、信息检索等研究. 一种基于密度的快速聚类算法 周水庚 周傲英 曹 晶 胡运发 (复旦大学计算机科学系 上海 200433) 摘 要 聚类是数据挖掘领域中的一个重要研究方向.聚类技术在统计数据分析、模式识别、图像处理等领域有广泛应用.迄今为止人们提出了许多用于大规模数据库的聚类算法.基于密度的聚类算法DBSCAN 就是一个典型代表.以DBSCAN 为基础,提出了一种基于密度的快速聚类算法.新算法以核心对象邻域中所有对象的代表对象为种子对象来扩展类,从而减少区域查询次数,降低I O 开销,实现快速聚类.对二维空间数据测试表明:快速算法能够有效地对大规模数据库进行聚类,速度上数倍于已有DBSCAN 算法. 关键词 空间数据库,数据挖掘,聚类,密度,快速算法,代表对象 中图法分类号 T P 311.13;T P 391 A FAST D ENSIT Y -BASED CL USTER ING AL G OR ITH M ZHOU Shu i 2Geng ,ZHOU A o 2Y ing ,CAO J ing ,and HU Yun 2Fa (D ep a rt m en t of Co mp u ter S cience ,F ud an U n iversity ,S hang ha i 200433) Abstract C lu stering is a p rom ising app licati on area fo r m any fields including data m in ing ,statistical data analysis ,p attern recogn iti on ,i m age p rocessing ,etc .In th is paper ,a fast den sity 2based clu stering algo rithm is developed ,w h ich con siderab ly speeds up the o riginal DB SCAN algo rithm .U n like DB SCAN ,the new DB SCAN u ses on ly a s m all num ber of rep resen tative ob jects in a co re ob ject’s neighbo rhood as seeds to exp and the clu ster so that the execu ti on frequency of regi on query can be decreased ,and con sequen tly the I O co st is reduced .Experi m en tal resu lts show that the new algo rithm is effective and efficien t in clu stering large 2scale databases ,and it is faster than the o riginal DB SCAN by several ti m es . Key words spatial database ,data m in ing ,clu stering ,den sity ,fast algo rithm ,rep resen tative ob jects 1 概 述 近10多年来,数据挖掘逐渐成为数据库研究领域的一个热点[1].其中,聚类分析就是广为研究的问题之一.所谓聚类,就是将数据库中的数据进行分组,使得每一组内的数据尽可能相似而不同组内的数据尽可能不同.聚类技术在统计数据分析、模式识别、图像处理等领域都有广泛的应用前景.迄今为止,人们已经提出了许多聚类算法[2~7].所有这些算法都试图解决大规模数据的聚类问题.以基于密度的聚类算法DB SCAN [4]为基础,本文提出一种基于密度的快速聚类算法.通过选用核心对象附近区域包含的所有对象的代表对象作为种子对象来扩展类,快速算法减少了区域查询的次数,从而减低了聚类时间和I O 开销 .本文内容安排如下:首先在第2节中介绍基于密度的聚类算法DB SCAN 的基本思想,并分析它的局限 文献阅读报告 课程名称:《模式识别》课程编号:题目: 基于划分的聚类算法 研究生姓名: 学号: 论文评语: 成绩: 任课教师: 评阅日期: 基于划分的聚类算法 2016-11-20 摘要: 聚类分析是数据挖掘的一个重要研究分支,已经提出了许多聚类算法,划分方法是其中之一。基于划分的聚类算法就是用统计分析的方法研究分类问题。本文介绍了聚类的定义以及聚类算法的种类,详细阐述了K 均值聚类算法和K中心点聚类算法的基本原理并对他们的性能进行分析,对近年来各学者对基于划分的聚类算法的研究现状进行梳理,对其具体应用实例作简要介绍。 关键字:数据挖掘;聚类;K 均值聚类算法;K 中心点聚类算法;K众数算法;k多层次聚类算法 Partitional clustering algorithms Abstract:Clustering analysis is an important branch of data mining, many clustering algorithms have been proposed, the dividing method is one of them. Based on the clustering algorithm is divided into classification problems using the method of statistical analysis. In this paper,we introduces the definition of clustering and type of clustering algorithm,the basic principle of k-means clustering algorithm and K-center clustering algorithm are expounded in detail,we also analyze their performance,the scholars in recent years the study of the clustering algorithm based on partitioning present situation has carried on the comb,make a brief introduction to its specific application instance. Key words:Data mining;clustering;k-means clustering algorithms;k-medoids clustering algorithms;k-modes clustering algorithms ;k-prototype clustering algorithms 1.引言 把单个的数据对象的集合划分为相类似的样本组成的多个簇或多个类的过程,这就叫聚类[1]。在无监督的情况下,具有独立的学习能力,这就是聚类。将数据空间中的所有数据点分别划分到不同的类中,相近距离的划分到相同类,较远距离的划分到不同类,这就是聚类的目的.聚类分析常作为一种数据的预处理过程被用于许多应用当中,它是更深一步分析数据、处理数据的基础。人们通过聚类分析这一最有效的手段来认识事物、探索事物之间的内在联系,而且,关联规则等分析算法的预处理步骤也可以用它。现在,在气象分析中,在图像处理时,在模式识别领域,在食品检验过程中,都有用到它。随着现代科技水平的不断提高、网络的迅猛发展、计算机技术的不断改革和创新,大批量的数据不断涌现。怎样从这些数据中提取有意义的信息成为人们关注的问题。这对聚类分析技术来说无疑是个巨大的挑战。只有具有处理高维的数据的能力的聚类算法才能解决该问题. 研究者们开始设计各种聚类算法,于是,基于划分的聚类算法便应运而生,而且,取得了很好的效果。 2.正文 1 聚类概述 各种聚类算法的比较 聚类的目标是使同一类对象的相似度尽可能地小;不同类对象之间的相似度尽可能地大。目前聚类的方法很多,根据基本思想的不同,大致可以将聚类算法分为五大类:层次聚类算法、分割聚类算法、基于约束的聚类算法、机器学习中的聚类算法和用于高维度的聚类算法。摘自数据挖掘中的聚类分析研究综述这篇论文。 1、层次聚类算法 1.1聚合聚类 1.1.1相似度依据距离不同:Single-Link:最近距离、Complete-Link:最远距离、Average-Link:平均距离 1.1.2最具代表性算法 1)CURE算法 特点:固定数目有代表性的点共同代表类 优点:识别形状复杂,大小不一的聚类,过滤孤立点 2)ROCK算法 特点:对CURE算法的改进 优点:同上,并适用于类别属性的数据 3)CHAMELEON算法 特点:利用了动态建模技术 1.2分解聚类 1.3优缺点 优点:适用于任意形状和任意属性的数据集;灵活控制不同层次的聚类粒度,强聚类能力 缺点:大大延长了算法的执行时间,不能回溯处理 2、分割聚类算法 2.1基于密度的聚类 2.1.1特点 将密度足够大的相邻区域连接,能有效处理异常数据,主要用于对空间数据的聚类 1)DBSCAN:不断生长足够高密度的区域 2)DENCLUE:根据数据点在属性空间中的密度进行聚类,密度和网格与处理的结合 3)OPTICS、DBCLASD、CURD:均针对数据在空间中呈现的不同密度分不对DBSCAN作了改进 2.2基于网格的聚类 2.2.1特点 利用属性空间的多维网格数据结构,将空间划分为有限数目的单元以构成网格结构; 1)优点:处理时间与数据对象的数目无关,与数据的输入顺序无关,可以处理任意类型的数据 2)缺点:处理时间与每维空间所划分的单元数相关,一定程度上降低了聚类的质量和准确性 2.2.2典型算法 1)STING:基于网格多分辨率,将空间划分为方形单元,对应不同分辨率2)STING+:改进STING,用于处理动态进化的空间数据 3)CLIQUE:结合网格和密度聚类的思想,能处理大规模高维度数据4)WaveCluster:以信号处理思想为基础 2.3基于图论的聚类 2.3.1特点 转换为组合优化问题,并利用图论和相关启发式算法来解决,构造数据集的最小生成数,再逐步删除最长边 1)优点:不需要进行相似度的计算 2.3.2两个主要的应用形式 1)基于超图的划分 2)基于光谱的图划分 2.4基于平方误差的迭代重分配聚类 2.4.1思想 逐步对聚类结果进行优化、不断将目标数据集向各个聚类中心进行重新分配以获最优解 内容摘要本文在分析和实现经典k-means算法的基础上,针对初始类中心选择问题,结合已有的工作,基于对象距离和密度对算法进行了改进。在算法实现部分使用vc6.0作为开发环境、sql sever2005作为后台数据库对算法进行了验证,实验表明,改进后的算法可以提高算法稳定性,并减少迭代次数。 关键字 k-means;随机聚类;优化聚类;记录的密度 1 引言 1.1聚类相关知识介绍 聚类分析是直接比较各事物之间性质,将性质相近的归为一类,将性质不同的归为一类,在医学实践中也经常需要做一些分类工作。如根据病人一系列症状、体征和生化检查的结果,将其划分成某几种方法适合用于甲类病的检查,另几种方法适合用于乙类病的检查,等等。聚类分析被广泛研究了许多年。基于聚类分析的工具已经被加入到许多统计分析软件或系统中,入s-plus,spss,以及sas。 大体上,聚类算法可以划分为如下几类: 1) 划分方法。 2) 层次方法。 3) 基于密度的算法。 4) 基于网格的方法。 5) 基于模型的方法。 1.2 研究聚类算法的意义 在很多情况下,研究的目标之间很难找到直接的联系,很难用理论的途径去解决。在各目标之间找不到明显的关联,所能得到的只是些模糊的认识,由长期的经验所形成的感知和由测量所积累的数据。因此,若能用计算机技术对以往的经验、观察、数据进行总结,寻找个目标间的各种联系或目标的优化区域、优化方向,则是对实际问题的解决具有指导意义和应用价值的。在无监督情况下,我们可以尝试多种方式描述问题,其中之一是将问题陈述为对数分组或聚类的处理。尽管得到的聚类算法没有明显的理论性,但它确实是模式识别研究中非常有用的一类技术。聚类是一个将数据集划分为若干聚类的过程,是同一聚类具有较高相似性,不同聚类不具相似性,相似或不相似根据数据的属性值来度量,通常使用基于距离的方法。通过聚类,可以发现数据密集和稀疏的区域,从而发现数据整体的分布模式,以及数据属性间有意义的关联。 2 k-means算法简介 2.1 k-means算法描述 k-means 算法接受输入量k,然后将n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高,而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”来进行计算的。k-means 算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数。 k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。 2.2 k-means算法实现步骤 在原始的k-means算法中,由于数据对象的分类被不断地调整,因此平均误差准则函数在每次迭代过程中的值必定在不断减小。当没有数据对象被调整时,e(e指每个对象到该类中心的距离平方之和)的值不再变化,说明算法运行结果已经达到最优,同时算法运行结束。 ISSN 1000-9825, CODEN RUXUEW E-mail: jos@https://www.360docs.net/doc/1116201334.html, Journal of Software, Vol.19, No.7, July 2008, pp.1683?1692 https://www.360docs.net/doc/1116201334.html, DOI: 10.3724/SP.J.1001.2008.01683 Tel/Fax: +86-10-62562563 ? 2008 by Journal of Software. All rights reserved. ? 一种基于K-Means局部最优性的高效聚类算法 雷小锋1,2+, 谢昆青1, 林帆1, 夏征义3 1(北京大学信息科学技术学院智能科学系/视觉与听觉国家重点实验室,北京 100871) 2(中国矿业大学计算机学院,江苏徐州 221116) 3(中国人民解放军总后勤部后勤科学研究所,北京 100071) An Efficient Clustering Algorithm Based on Local Optimality of K-Means LEI Xiao-Feng1,2+, XIE Kun-Qing1, LIN Fan1, XIA Zheng-Yi3 1(Department of Intelligence Science/National Laboratory on Machine Perception, Peking University, Beijing 100871, China) 2(School of Computer Science and Technology, China University of Mining and Technology, Xuzhou 221116, China) 3(Logistics Science and Technology Institute, P.L.A. Chief Logistics Department, Beijing 100071, China) + Corresponding author: E-mail: leiyunhui@https://www.360docs.net/doc/1116201334.html, Lei XF, Xie KQ, Lin F, Xia ZY. An efficient clustering algorithm based on local optimality of K-Means. Journal of Software, 2008,19(7):1683?1692. https://www.360docs.net/doc/1116201334.html,/1000-9825/19/1683.htm Abstract: K-Means is the most popular clustering algorithm with the convergence to one of numerous local minima, which results in much sensitivity to initial representatives. Many researches are made to overcome the sensitivity of K-Means algorithm. However, this paper proposes a novel clustering algorithm called K-MeanSCAN by means of the local optimality and sensitivity of K-Means. The core idea is to build the connectivity between sub-clusters based on the multiple clustering results of K-Means, where these clustering results are distinct because of local optimality and sensitivity of K-Means. Then a weighted connected graph of the sub-clusters is constructed using the connectivity, and the sub-clusters are merged by the graph search algorithm. Theoretic analysis and experimental demonstrations show that K-MeanSCAN outperforms existing algorithms in clustering quality and efficiency. Key words: K-MeanSCAN; density-based; K-Means; clustering; connectivity 摘要: K-Means聚类算法只能保证收敛到局部最优,从而导致聚类结果对初始代表点的选择非常敏感.许多研究 工作都着力于降低这种敏感性.然而,K-Means的局部最优和结果敏感性却构成了K-MeanSCAN聚类算法的基 础.K-MeanSCAN算法对数据集进行多次采样和K-Means预聚类以产生多组不同的聚类结果,来自不同聚类结果的 子簇之间必然会存在交集.算法的核心思想是,利用这些交集构造出关于子簇的加权连通图,并根据连通性合并子 簇.理论和实验证明,K-MeanScan算法可以在很大程度上提高聚类结果的质量和算法的效率. 关键词: K-MeanSCAN;基于密度;K-Means;聚类;连通性 中图法分类号: TP18文献标识码: A ? Supported by the National High-Tech Research and Development Plan of China under Grant No.2006AA12Z217 (国家高技术研究发 展计划(863)); the Foundation of China University of Mining and Technology under Grant No.OD080313 (中国矿业大学科技基金) Received 2006-10-09; Accepted 2007-07-17一种基于密度的快速聚类算法
基于划分的聚类算法
各种聚类算法的比较
K-MEANS聚类算法的实现及应用
一种基于K-Means局部最优性的高效聚类算法