方差分析显著性检验实例分析-推荐下载
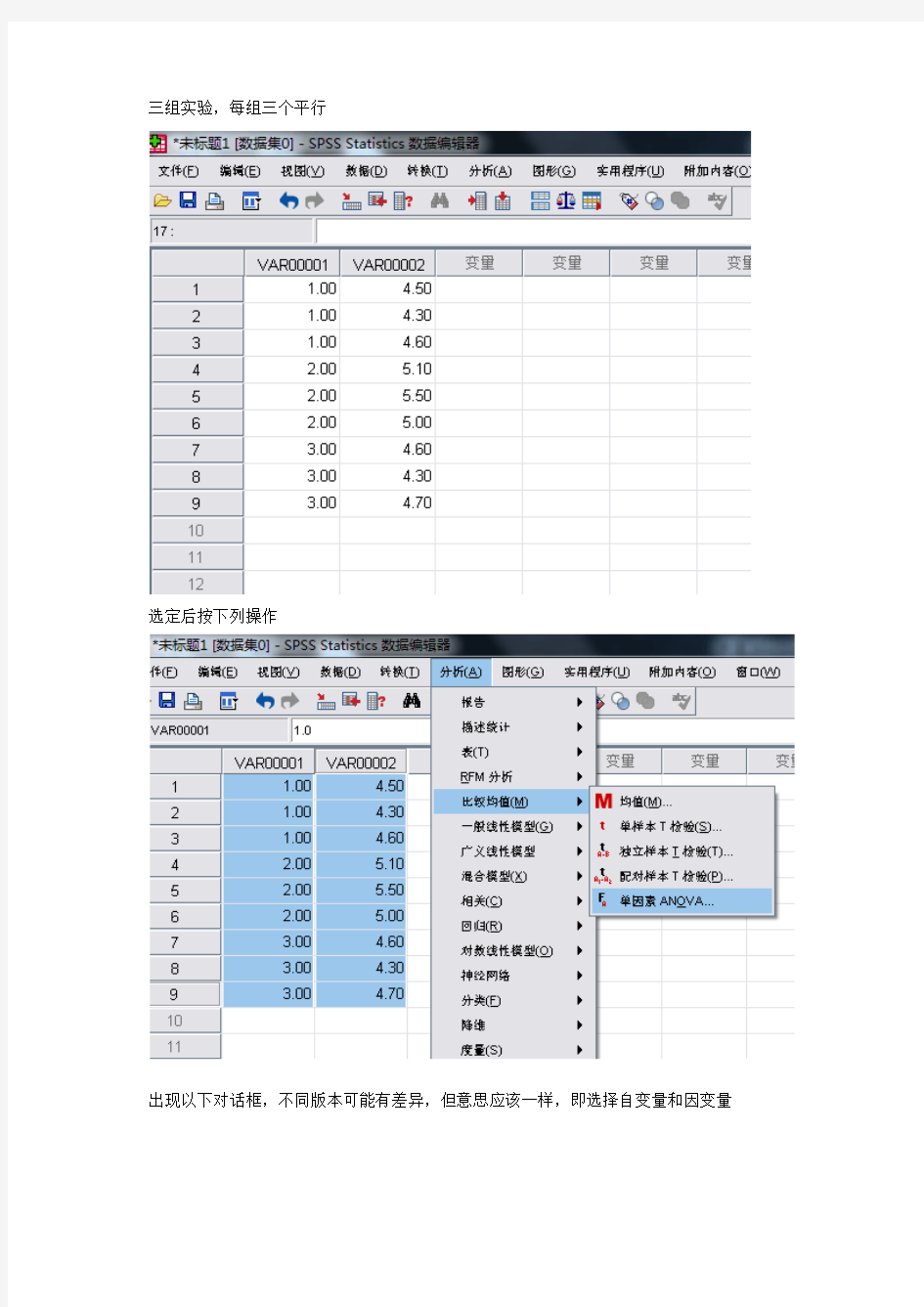
三组实验,每组三个平行
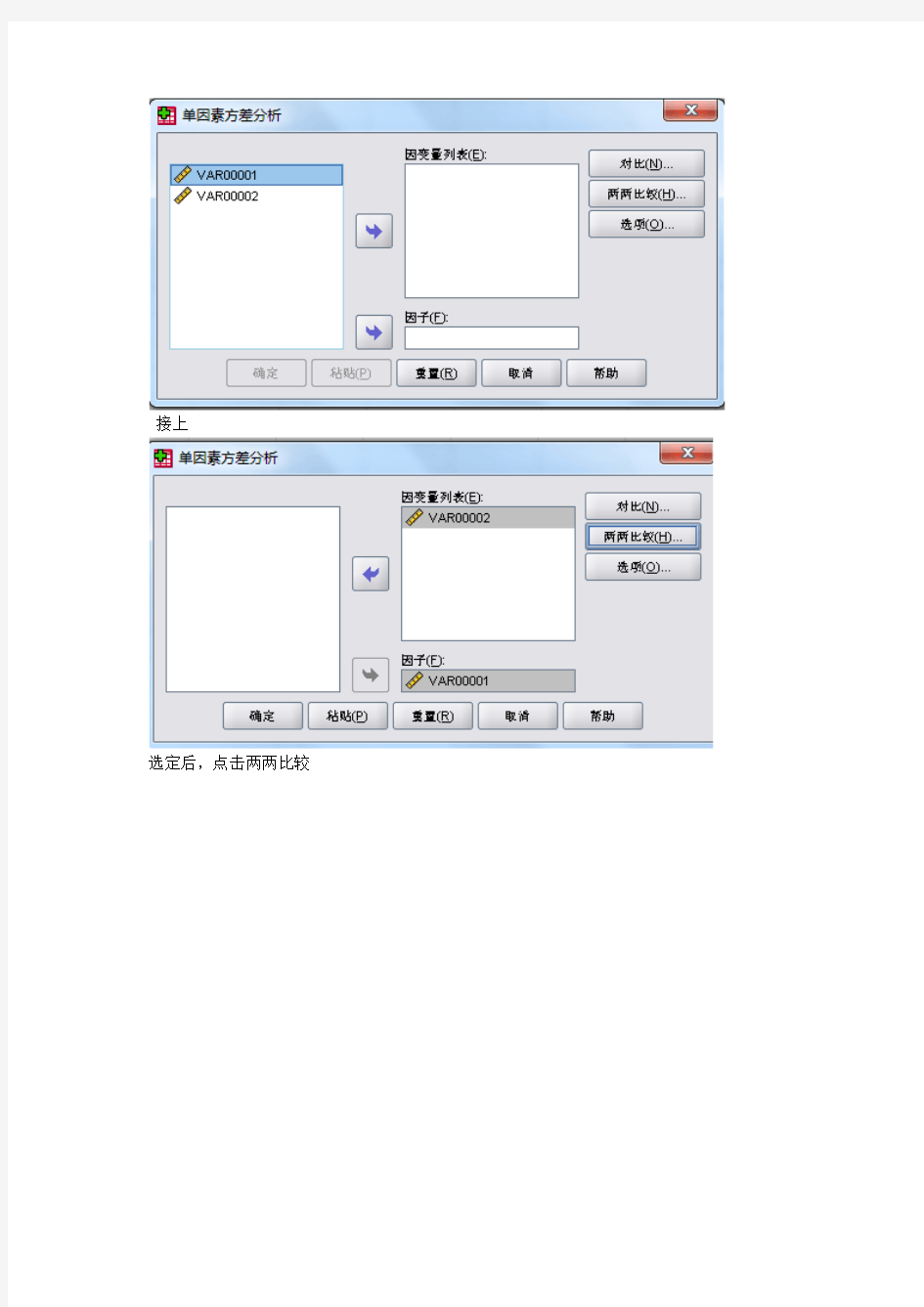
选定后按下列操作
出现以下对话框,不同版本可能有差异,但意思应该一样,即选择自变量和因变量
接上
选定后,点击两两比较
一般选择LSD检验即可下面可以选择显著性水平。点继续后回到之前对话框,点击确定即可出来数据分析。
已经显示出两两比较结果,一般都大到小标注字母。
第五章:异方差性(作业)教学文案
第五章:异方差性(作 业)
5.3 为了研究中国出口商品总额EXPORT对国内生产总值GDP的影响,搜集了1990~2015年相关的指标数据,如表5.3所示。 表3 中国出口商品总额与国内生产总值(单位:亿元) 资料来源:《国家统计局网站》 (1) 根据以上数据,建立适当线性回归模型。 (2) 试分别用White检验法与ARCH检验法检验模型是否存在异方差? (3) 如果存在异方差,用适当方法加以修正。 解:(1) 仅供学习与交流,如有侵权请联系网站删除谢谢2
仅供学习与交流,如有侵权请联系网站删除 谢谢3 100,000 200,000300,000400,000500,000600,000700,000 X Y Dependent Variable: Y Method: Least Squares Date: 04/18/20 Time: 15:38 Sample: 1991 2015 Included observations: 25 Variable Coefficient Std. Error t-Statistic Prob. C -673.0863 15354.24 -0.043837 0.9654 X 4.061131 0.201677 20.13684 0.0000 R-squared 0.946323 Mean dependent var 234690.8 Adjusted R-squared 0.943990 S.D. dependent var 210356.7 S.E. of regression 49784.06 Akaike info criterion 24.54540 Sum squared resid 5.70E+10 Schwarz criterion 24.64291 Log likelihood -304.8174 Hannan-Quinn criter. 24.57244 F-statistic 405.4924 Durbin-Watson stat 0.366228 Prob(F-statistic) 0.000000 模型回归的结果: ^ 673.0863 4.0611i X i Y =-+ ()(0.043820.1368)t =- 20.9463,25R n == (2)white: 该模型存在异方差 Heteroskedasticity Test: White F-statistic 4.493068 Prob. F(2,22) 0.0231
异方差性的white检验及处理方法
实验二异方差模型的white检验与处理 【实验目的】 掌握异方差性的white检验及处理方法 【实验原理】 1. 定性分析异方差 (1) 经济变量规模差别很大时容易出现异方差。如个人收入与支出关系,投入与产出 关系。 (2) 利用散点图做初步判断。 (3) 利用残差图做初步判断。 2、异方差表现与来源异方差通常有三种表现形式 (1)递增型 (2)递减型 (3)条件自回归型。 3、White检验 (1)不需要对观测值排序,也不依赖于随机误差项服从正态分布,它是通过一个辅助回归式构造 2 统计量进行异方差检验。White检验的零假设和备择假设是 H0: (4-1)式中的ut不存在异方差, H1: (4-2)式中的ut存在异方差。 (2)在不存在异方差假设条件下,统计量 T R 2 2(5) 其中T表示样本容量,R2是辅助回归式(4-3)的OLS估计式的可决系数。自由度5表示辅助回归式(4-3)中解释变量项数(注意,不计算常数项)。T R 2属于LM统计量。 (3)判别规则是 若T R 2 2 (5), 接受H0(ut 具有同方差) 若T R 2 > 2 (5), 拒绝H0(ut 具有异方差) 【实验软件】 Eview6 【实验要求】 熟练掌握异方差white检验方法 【实验内容】 建立并检验我国部分城市国民收入y和对外直接投资FDI异方差模型 【实验方案设计】 下表列出了我国各地区农村居民家庭人均纯收入与家庭人均生活消费支出的数据,并利用统计软件Eviews建立异方差模型
表1 各地区农村居民家庭人均纯收入与家庭人均生活消费支出的数据(单位:元) 【实验过程】 1、启动Eviews6软件,建立新的workfile. 在主菜单中选择【File 】--【New 】--【Workfile 】,弹出 Workfile Create 对话框,在Workfile structure typ 中选择unstructured/undted.然后在observations 中输入31.在WF 中输入Work1,点击OK 按钮。如图: 2、数据导入且将要分析的数据复制黏贴. 在主菜单的空白处输入data x y 按下enter 。将家庭人均纯收入X 和家庭生活消 地区 家庭人均 纯收入 家庭生活消费支出 地区 家庭人均 纯收入 家庭生活消费支出 北京 湖北 3090 天津 湖南 河北 广东 山西 广西 内蒙古 海南 辽宁 重庆 吉林 四川 黑龙江 贵州 上海 云南 江苏 西藏 浙江 陕西 安徽 甘肃 福建 青海 江西 宁夏 山东 新疆 河南
异方差性检验
金融122班 23号钟萌 异方差性检验 引入滞后变量X-1、X-2、Y-1 。可建立如下中国居民消费函数: Y=β0+β1X+β2X(-1)+β3X(-2)+β4Y(-1) 用OLS法进行估计,结果如下: 对应的表达式为 Y=429.3512+0.143X-0.104X(-1)+0.063X(-2)+0.838Y(-1) 2.18 2.09 -0.73 0.63 7.66 R2=0.9988 F=4503.94 估计结果显示,在5%的显著性水平下,自由度为25的临界值为2.060,若存在异方差性,则可能是由X、Y(-1)引起的。
做OLS回归得到的残差平方项分别与X、Y(-1)的散点图
从散点图可以看出,两者存在异方差性。下面进行统计检验。 采用White异方差检验: 所以辅助回归结果为: e2=-194156.4-249.491X+0.003X2+265.306X(-1)-0.004X(-1)2+4.187X(-2)- 0.001X(-2)2 +51.377Y(-1)+0.001Y(-1)2 -1.566 -4.604 2.863 2.648 -1.604 0.055 -0.301 0.579 0.410 X与X的平方项的参数的t检验是显著的,且White统计量为
16.999>5%显著性水平下,自由度为8的卡方分布值15.51,(从nR2 统计量的对应值的伴随概率值容易看出)所以在5%的显著性水平下,拒绝同方差性这一原假设,方程确实存在异方差性。 用加权最小二乘法对异方差性进行修正,重新进行回归估计, 得到加权后消除异方差性的估计结果: 回归表达式为: Y=275.0278-0.0192X+0.1617X(-1)-0.0732X(-2)+0.9165Y(-1) 3.5753 -0.3139 1.3190 -1.0469 16.5504
t检验、u检验、卡方检验、F检验、方差分析
统计中经常会用到各种检验,如何知道何时用什么检验呢,根据结合自己的工作来说一说: t检验有单样本t检验,配对t检验和两样本t检验。 单样本t检验:是用样本均数代表的未知总体均数和已知总体均数进行比较,来观察此组样本与总体的差异性。 配对t检验:是采用配对设计方法观察以下几种情形,1,两个同质受试对象分别接受两种不同的处理;2,同一受试对象接受两种不同的处理;3,同一受试对象处理前后。 u检验:t检验和就是统计量为t,u的假设检验,两者均是常见的假设检验方法。当样本含量n较大时,样本均数符合正态分布,故可用u检验进行分析。当样本含量n小时,若观察值x符合正态分布,则用t检验(因此时样本均数符合t 分布),当x为未知分布时应采用秩和检验。 F检验又叫方差齐性检验。在两样本t检验中要用到F检验。 从两研究总体中随机抽取样本,要对这两个样本进行比较的时候,首先要判断两总体方差是否相同,即方差齐性。若两总体方差相等,则直接用t检验,若不等,可采用t'检验或变量变换或秩和检验等方法。 其中要判断两总体方差是否相等,就可以用F检验。 简单的说就是检验两个样本的方差是否有显著性差异这是选择何种T检验(等方差双样本检验,异方差双样本检验)的前提条件。 在t检验中,如果是比较大于小于之类的就用单侧检验,等于之类的问题就用双侧检验。 卡方检验 是对两个或两个以上率(构成比)进行比较的统计方法,在临床和医学实验中应用十分广泛,特别是临床科研中许多资料是记数资料,就需要用到卡方检验。方差分析 用方差分析比较多个样本均数,可有效地控制第一类错误。方差分析(analysis of variance,ANOVA)由英国统计学家R.A.Fisher首先提出,以F命名其统计量,故方差分析又称F检验。 其目的是推断两组或多组资料的总体均数是否相同,检验两个或多个样本均数的差异是否有统计学意义。我们要学习的主要内容包括 单因素方差分析即完全随机设计或成组设计的方差分析(one-way ANOVA):用途:用于完全随机设计的多个样本均数间的比较,其统计推断是推断各样本所代表的各总体均数是否相等。完全随机设计(completely random design)不考虑个体差异的影响,仅涉及一个处理因素,但可以有两个或多个水平,所以亦称单因素实验设计。在实验研究中按随机化原则将受试对象随机分配到一个处理因
统计学例题-方差分析、相关分析、卡方检验和交互分析
第一章 方差分析 例1、1977年,美国的某项调查从三种受过不同教育类型的妇女中各分别抽取了50位全日制工作的妇女 样本,她们的年收入(单位:千美元)数据整理后归纳如下: 完成的学历年数 收入平均值X () 2 )(∑-X X 初中(8年)X1 高中(12年)X2 大学(16年)X3 7.8 9.7 14.0 1835 2442 4707 解:: = :三组收入均值有显著差异 F = ,即组间均方/组内均方 其中,组间自由度 =3-1=2,组内自由度 =(50-1)╳3=147 由于样本均值=(7.8+9.7+14.0)/3=10.5 所以组间偏差平方和=50=50*( + + )=1009 组内偏差平方和= =1835+2442+4707=8984 所以,F = ≈ 8.2548419 > (2,147)=3.07 拒绝原假设;认为不同学历的妇女收入存在差异。 例2、月收入数据: 男:2500,2550,2050,2300,1900 女:2200,2300,1900,2000,1800 如果用Y 表示收入,哑变量X 表示性别(X =1为女性),计算Y 对X 的回归方程,并在5%的水平下检验收入是否与性别无关(先求回归系数的置信区间)。 解:令Y=+X+ 根据最小二乘法,可知= (1) VAR()= (2) = (3) 计算如下: :收入与性别无关 收入与性别不完全无关
Y 2500255020502300190022002300190020001800 X 0 0 0 0 0 1 1 1 1 1 240 290 -210 40 -360 160 260 -140 -40 -240 =2150=0.5 根据公式1,得=-220;,即Y=-220X+ 根据公式2、3,得VAR()=≈156.3549577 n=10.,n-2=8;当df=8时,=2.306 的0.05置信区间求解方法如下: -2.036<=<=2.306,得140.57769. 由于原假设=0落入了这个置信区间,所以接受原假设,认为系数不显著,收入与性别无关。 第二章相关分析 例1、10对夫妇的一个随机样本给出了如下的结婚年龄数据 结婚时丈夫的年龄y 24 22 26 20 23 21 24 25 22 23 结婚时妻子的年龄x 24 18 25 22 20 23 19 24 23 22 2) 求总体相关系数 的95%置信区间; 3) 以5%的水平,检验“夫妻的结婚年龄之间没有什么线性联系”这一原假设。 解:(1) = 由于=22,=23;=≈0.3426 (2)由于se()=,n=10,df=8=2.306,所以: se()=0.332 -2.036<=<=2.306 得 1.062072
计量经济学课后答案第五章 异方差性汇总
第五章课后答案 5.1 (1)因为22()i i f X X =,所以取221i i W X =,用2i W 乘给定模型两端,得 31232222 1i i i i i i i Y X u X X X X βββ=+++ 上述模型的随机误差项的方差为一固定常数,即 2 2221 ()()i i i i u Var Var u X X σ== (2)根据加权最小二乘法,可得修正异方差后的参数估计式为 ***12233???Y X X βββ=-- ()()()() ()()() ***2*** *22232322 322*2*2** 2223223?i i i i i i i i i i i i i i i i i i W y x W x W y x W x x W x W x W x x β-= -∑∑∑∑∑∑∑ ()()( )()()( )( )** *2 ** ** 232222223 3 2 *2 *2** 2223223?i i i i i i i i i i i i i i i i i i W y x W x W y x W x x W x W x W x x β-= -∑∑ ∑ ∑ ∑∑∑ 其中 2223 2***23222, , i i i i i i i i i W X W X W Y X X Y W W W = = = ∑∑∑∑∑∑ ***** *222333 i i i i i x X X x X X y Y Y =-=-=- 5.2 (1) 22222 11111 ln()ln()ln(1)1 u ln()1 Y X Y X Y u u X X X u ββββββββββ--==+≈=-∴=+ [ln()]0 ()[ln()1][ln()]11 E u E E u E u μ=∴=+=+=又 (2) [ln()]ln ln 0 1 ()11 i i i i P P i i i i P P i i E P E μμμμμμμ===?====∑∏∏∑∏∏不能推导出 所以E 1μ()=时,不一定有E 0μ(ln )= (3) 对方程进行差分得: 1)i i βμμ--i i-12i i-1lnY -lnY =(lnX -X )+(ln ln 则有:1)]0i i μμ--=E[(ln ln
异方差性的检验及处理方法
实验四异方差性 【实验目的】 掌握异方差性的检验及处理方法 【实验内容】 建立并检验我国制造业利润函数模型 【实验步骤】 【例1】表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型。 一、检验异方差性 ⒈图形分析检验 ⑴观察销售利润(Y)与销售收入(X)的相关图(图1):SCAT X Y 图1 我国制造工业销售利润与销售收入相关图 从图中可以看出,随着销售收入的增加,销售利润的平均水平不断提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。
⑵残差分析 首先将数据排序(命令格式为:SORT 解释变量),然后建立回归方程。在方程窗口中点击Resids按钮就可以得到模型的残差分布图(或建立方程后在Eviews工作文件窗口中点击resid对象来观察)。 图2 我国制造业销售利润回归模型残差分布 图2显示回归方程的残差分布有明显的扩大趋势,即表明存在异方差性。 ⒉Goldfeld-Quant检验 ⑴将样本按解释变量排序(SORT X)并分成两部分(分别有1到10共11个样本合19到28共10个样本) ⑵利用样本1建立回归模型1(回归结果如图3),其残差平方和为2579.587。 SMPL 1 10 LS Y C X 图3 样本1回归结果 ⑶利用样本2建立回归模型2(回归结果如图4),其残差平方和为63769.67。 SMPL 19 28 LS Y C X
图4 样本2回归结果 ⑷计算F 统计量:12/RSS RSS F ==63769.67/2579.59=24.72,21RSS RSS 和分别是模型1和模型2的残差平方和。 取 05 .0=α时,查F 分布表得 44.3)1110,1110(05.0=----F ,而 44.372.2405.0=>=F F ,所以存在异方差性 ⒊White 检验 ⑴建立回归模型:LS Y C X ,回归结果如图5。 图5 我国制造业销售利润回归模型 ⑵在方程窗口上点击View\Residual\Test\White Heteroskedastcity,检验结果如图6。 图6 White 检验结果
在EXCEL中实现多总体方差的Bartlett齐性检验
在EXCEL中实现多总体方差的Bartlet t齐性检验 在体育教学和运动训练等的科学实验中,对影响体育教学成绩及运动竞赛的成绩的原因的探究,一直是当代体育科研中研究的主线。例如,在运动训练中,为更加有效地提高运动成绩,通常需要考察不同的运动强度、不同的运动量和不同的运动持续时间等因素对不同的专项运动成绩的影响,目的是为了找出适合不同专项的运动强度、运动量、运动持续时间的较佳组合。又如,我们从运动系体操专业的学生中随机抽取条件相似的20 名学生随机分成4组,每组5人,由 4 位教师施以不同的教学方法,教20 个具有相当难度的体操动作,并规定每个动作的计分标准,试教一学期后举行测试,测得各组得分,见下表。现假定每组的得分服从正态分布,则这 4 种教学方法的效果间是否有显著性差异的问题就是我们迫切需要了解的。 如果仅仅从上例每组的总分上看,显然四种不同的教法带来了四种不同的学生得分,分值上肯定有差异,但这种差异主要是由随机误差引起的,还是主要是由于教学方法的不同而引起的,即是否有显著性差异的统计结论,还须经统计检验后才能得出。若用两个样本间均数差异的显著性检验方法来处理本类问题的话,需要做6次检验。若这样的试验安排共有N组,则需要做N (N-1)/2 次两两比较,这一方面,显然太麻烦了,另一方面,
当设定两两比较时,犯第一类错误的概率 a =0.05,则N个独立 样本两两比较时,每次比较不犯第一类错误的概率为0.95N(N-1) /2,相应犯第一类错误的概率为1-0.95N(N-1) /2,远远大于 事先设定的0.05。因此,多个均数比较时不宜采用我们熟知的t 检验作两两比较,应采用一种新的统计处理方法来实现。 解决这一类问题的方法是方差分析。它最早由英国统计学家费舍( R.A.Fisher )在1923 年提出,最初用于生物学和农业试验方面,后于1946年由斯内德克(G.W.Snedecor)进一步加以完善。为纪念费舍的杰出贡献,又把它称为 F 检验。现在它在体育领域中也得到了广泛的应用。 方差分析是在总体服从正态分布且方差齐性的假设下展开的,在满足总体正态性但方差不齐时,此法不可用,而只能改用方差不齐时两均数差异的显著性检验的方法来进行两两均数间的比较。因此,这里很有必要来考虑方差的齐性检验的问题。本文主要介绍在EXCEL中如何来实现多总体方差的Bartlett 齐性检验的自动计算。 1 Bartlett 方差齐性检验的方法 Bartlett 法是一种可在各水平重复测定次数不等时用来检验方差齐性的方法,虽然,当各水平重复测定次数相等时,可用Cochran 提供的检验方法,但Bartlett 法同样适用。 2在EXCEL中进行Bartlett 方差齐性检验的方法 2.1工作表的安排 在用Bartlett 法进行方差齐性检验时,为使计算相对自动化,
第五章:异方差性(作业)
5.3 为了研究中国出口商品总额EXPORT 对国内生产总值GDP 的影响,搜集了1990~2015年相关的指标数据,如表5.3所示。 资料来源:《国家统计局网站》 (1) 根据以上数据,建立适当线性回归模型。 (2) 试分别用White 检验法与ARCH 检验法检验模型是否存在异方差? (3) 如果存在异方差,用适当方法加以修正。 解:(1) 100,000 200,000300,000400,000500,000600,000700,000X Y Dependent Variable: Y Method: Least Squares Date: 04/18/20 Time: 15:38
Sample: 1991 2015 Included observations: 25 Variable Coefficient Std. Error t-Statistic Prob. C -673.0863 15354.24 -0.043837 0.9654 X 4.061131 0.201677 20.13684 0.0000 R-squared 0.946323 Mean dependent var 234690.8 Adjusted R-squared 0.943990 S.D. dependent var 210356.7 S.E. of regression 49784.06 Akaike info criterion 24.54540 Sum squared resid 5.70E+10 Schwarz criterion 24.64291 Log likelihood -304.8174 Hannan-Quinn criter. 24.57244 F-statistic 405.4924 Durbin-Watson stat 0.366228 Prob(F-statistic) 0.000000 模型回归的结果: ^ 673.0863 4.0611i X i Y =-+ ()(0.043820.1368)t =- 20.9463,25R n == (2)white: 该模型存在异方差 Heteroskedasticity Test: White F-statistic 4.493068 Prob. F(2,22) 0.0231 Obs*R-squared 7.250127 Prob. Chi-Square(2) 0.0266 Scaled explained SS 8.361541 Prob. Chi-Square(2) 0.0153 Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 04/18/20 Time: 17:45 Sample: 1991 2015 Included observations: 25 Variable Coefficient Std. Error t-Statistic Prob. C -1.00E+09 1.43E+09 -0.700378 0.4910 X^2 -0.455420 0.420966 -1.081847 0.2910 X 102226.2 60664.19 1.685117 0.1061 R-squared 0.290005 Mean dependent var 2.28E+09
异方差检验
七、 异方差与自相关 一、背景 我们讨论如果古典假定中的同方差和无自相关假定不能得到满足,会引起什么样的估计问题呢?另一方面,如何发现问题,也就是发现和检验异方差以及自相关的存在性也是一个重要的方面,这个部分就是就这个问题进行讨论。 二、知识要点 1、引起异方差的原因及其对参数估计的影响 2、异方差的检验(发现异方差) 3、异方差问题的解决办法 4、引起自相关的原因及其对参数估计的影响 5、自相关的检验(发现自相关) 6、自相关问题的解决办法 (时间序列部分讲解) 三、要点细纲 1、引起异方差的原因及其对参数估计的影响 原因:引起异方差的众多原因中,我们讨论两个主要的原因,一是模型的设定偏误,主要指的是遗漏变量的影响。这样,遗漏的变量就进入了模型的残差项中。当省略的变量与回归方程中的变量有相关关系的时候,不仅会引起内生性问题,还会引起异方差。二是截面数据中总体各单位的差异。 后果:异方差对参数估计的影响主要是对参数估计有效性的影响。在存在异方差的情况下,OLS 方法得到的参数估计仍然是无偏的,但是已经不具备最小方差性质。一般而言,异方差会引起真实方差的低估,从而夸大参数估计的显著性,即是参数估计的t 统计量偏大,使得本应该被接受的原假设被错误的拒绝。 2、异方差的检验 (1)图示检验法 由于异方差通常被认为是由于残差的大小随自变量的大小而变化,因此,可以通过散点图的方式来简单的判断是否存在异方差。具体的做法是,以回归的残差的平方2i e 为纵坐标,回归式中的某个解释变量i x 为横坐标,画散点图。如果散点图表现出一定的趋势,则可以判断存在异方差。 (2)Goldfeld-Quandt 检验
第五章:异方差性(作业)
为了研究中国出口商品总额EXPORT 对国内生产总值GDP 的影响,搜集了1990~2015年相关的指标数据,如表所示。 资料来源:《国家统计局网站》 (1) 根据以上数据,建立适当线性回归模型。 (2) 试分别用White 检验法与ARCH 检验法检验模型是否存在异方差 (3) 如果存在异方差,用适当方法加以修正。 解:(1) 100,000 200,000300,000400,000500,000600,000700,000X Y Dependent Variable: Y Method: Least Squares Date: 04/18/20 Time: 15:38
Sample: 1991 2015 Included observations: 25 Variable Coefficient Std. Error t-Statistic Prob. C X R-squared Mean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid +10 Schwarz criterion Log likelihood Hannan-Quinn criter. F-statistic Durbin-Watson stat Prob(F-statistic) 模型回归的结果: ^ 673.0863 4.0611i X i Y =-+ ()(0.043820.1368)t =- 20.9463,25R n == (2)white: 该模型存在异方差 Heteroskedasticity Test: White F-statistic Prob. F(2,22) Obs*R-squared Prob. Chi-Square(2) Scaled explained SS Prob. Chi-Square(2) Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 04/18/20 Time: 17:45 Sample: 1991 2015 Included observations: 25 Variable Coefficient Std. Error t-Statistic Prob. C +09 +09 X^2
方差齐性检验的原理
统计学搜索整理汇总——方差齐性检验的原理 LXK的结论:齐性检验时F越小(p越大),就证明没有差异,就说明齐,比如F=1.27,p>0.05则齐,这与方差分析均数时F越大约好相反。 LXK注:方差(MS或s2)=离均差平方和/自由度(即离均差平方和的均数) 标准差=方差的平方根(s) F=MS组间/MS误差=(处理因素的影响+个体差异带来的误差)/个体差异带来的误差 ================= F检验为什么要求各比较组的方差齐性? ——之所以需要这些前提条件,是因为必须在这样的前提下所计算出的t统计量才服从t分布,而t检验正是以t分布作为其理论依据的检验方法。 在方差分析的F检验中,是以各个实验组内总体方差齐性为前提的,因此,按理应该在方差分析之前,要对各个实验组内的总体方差先进行齐性检验。如果各个实验组内总体方差为齐性,而且经过F检验所得多个样本所属总体平均数差异显著,这时才可以将多个样本所属总体平均数的差异归因于各种实验处理的不同所致;如果各个总体方差不齐,那么经过F 检验所得多个样本所属总体平均数差异显著的结果,可能有一部分归因于各个实验组内总体方差不同所致。 简单地说就是在进行两组或多组数据进行比较时,先要使各组数据符合正态分布,另外就是要使各组数据的方差相等(齐性)。 ----------------- 在SPSS中,如果进行方差齐性检验呢?命令是什么? 方差分析(Anaylsis of Variance, ANOVA)要求各组方差整齐,不过一般认为,如果各组人数相若,就算未能通过方差整齐检验,问题也不大。 One-Way ANOVA对话方块中,点击Options…(选项…)按扭, 勾Homogeneity-of-variance即可。它会产生Levene、Cochran C、Bartlett-Box F等检验值及其显著性水平P值,若P值<于0.05,便拒绝方差整齐的假设。 顺带一提,Cochran和Bartlett检定对非正态性相当敏感, 若出现「拒绝方差整齐」的检测结果,或因这原因而做成。 --------------- 用spss处理完数据的显示结果中,F值,t值及其显著性(sig)都分别是解释什么的? 答案 一般而言,为了确定从样本(sample)统计结果推论至总体时所犯错的概率,我们会利用统计学家所开发的一些统计方法,进行统计检定。 通过把所得到的统计检定值,与统计学家建立了一些随机变量的概率分布(probability distribution)进行比较,我们可以知道在多少%的机会下会得到目前的结果。倘若经比较后发现,出现这结果的机率很少,亦即是说,是在机会很少、很罕有的情况下才出现;那我们便可以有信心的说,这不是巧合,是具有统计学上的意义的(用统计学的话讲,就是能够拒绝
第五章 异方差性参考答案
第五章 异方差性课后题参考答案 5.1 (1)因为22()i i f X X =,所以取221i i W X =,用2i W 乘给定模型两端,得 31232222 1i i i i i i i Y X u X X X X βββ=+++ 上述模型的随机误差项的方差为一固定常数,即 2 2221 ()()i i i i u Var Var u X X σ== (2)根据加权最小二乘法,可得修正异方差后的参数估计式为 ***12233???Y X X βββ=-- ()()()() ()()() ***2*** *22232322 322*2*2** 2223223?i i i i i i i i i i i i i i i i i i W y x W x W y x W x x W x W x W x x β-= -∑∑∑∑∑∑∑ ()()( )()()( )()***2 ** * *232222 22 33 2 *2*2** 2223223?i i i i i i i i i i i i i i i i i i W y x W x W y x W x x W x W x W x x β-= -∑∑ ∑ ∑∑∑∑ 其中 2223 2***23222, , i i i i i i i i i W X W X W Y X X Y W W W = = = ∑∑∑∑∑∑ ***** *222333 i i i i i x X X x X X y Y Y =-=-=- 5.2 (1) 22222 11111 ln()ln()ln(1)1 u ln()1 Y X Y X Y u u X X X u ββββββββββ--==+≈=-∴=+ [ln()]0 ()[ln()1][ln()]11 E u E E u E u μ=∴=+=+= 又 (2) [ln()]ln ln 0 1 ()11 i i i i P P i i i i P P i i E P E μμμμμμμ===?====∑∏∏∑∏∏不能推导出 所以E 1μ()=时,不一定有E 0μ(ln )= (3)对方程进行差分得: 1)i i βμμ--i i-12i i-1lnY -lnY =(lnX -X )+(ln ln
Eviews 进行异方差性检验及估计模型
异方差性检验及存在异方差模型估计 检验使用方法:(1)G-Q检验(2)White 检验 模型估计方法:加权最小二乘法(WLS) 下表为2000年中国部分省市城镇居民每个家庭平均年可支配收入(X)与消费性支出(Y)的统计数据: 1
一、利用Eviews求出线性模型 可得模型: ?272.2250.755 i i Y X =+ 2
(1.705) (32.394) R2=0.9832 二、异方差检验 (1)G-Q检验:首先将可支配收入X升序进行排列,然后去掉中间4个样本,将余下的样本分为容量各为8的两个子样本,并分别进行回归。 大样本小样本 3
样本取值较小的Eviews输出结果如下 残差平方和:RSS1=126528.3 4
样本取值较大的Eviews输出结果如下: 残差平方和:RSS2=615073.7 因此统计量为:2 14.8611 RSS F RSS == 在5%的显著性水平下,0.05(6,6) 4.28 F=,4.86>4.28,因此拒绝原假设,存在异方差性。 5
(2)White检验:在原模型的最小二乘估计窗口上选择“View\Residual Tests\Heteroskedasticity Tests\White”得到如下结果: x ,因此12.6478>5.99,因而拒绝原假设,检验统计量值为12.64768,查询20.05(2) 5.99 模型存在异方差。 三、估计存在异方差的经济模型 利用加权最小二乘法(WLS)进行估计:首先在对原模型进行估计后,保存残差,步骤如下:①Quick\Generate Series 再输入“e1=resid”,得到e1 ②Quick\Estimte Equation 再输入“Y C X” ③选择Options,在“Weighted LS/TLS”输入“1/abs(e1)”(备注:abs表示绝对值) 得到如下结果; 6
方差齐性检验
一、方差齐性检验 1、 data abc; do a=1 to 4; do i=1 to 4; Input x @@; Output; end; end; t=_n_; /*自动生成序号变量t*/ cards; 19 23 21 13 21 24 27 20 20 18 19 15 22 25 27 22 ; Proc gplot data=a; /*绘图—按文件a作散点图*/ Plot x*t; /*纵坐标为x,横坐标为t*/ proc print a; proc anova; class a; model x=a; means a/hovtest; run; 2、 data d0; Input x @@; t=_n_; cards; 58 86 92 95 93 97 90 72 67 39 51 63 77 57 57 59 45 45 80 38 36 39 85 94 ; proc print; var t x; proc gplot data=d0; plot x*t; symbol c=red i=join v=star; run; data d1; do a=1 to 4; do i=1 to 6; Input y @@; output; end; end; cards; 58 86 92 95 93 97 90 72 67 39 51 63 77 57 57 59 45 45 80 38 36 39 85 94 ; proc anova; class a; model y=a; means a/hovtest; proc print; var a y; run; data d0; Input y @@; t=_n_; do a=1 to 4; do i=1 to 6; Input x @@; output; end; end; cards; 58 86 92 95 93 97 90 72 67 39 51 63 77 57 57 59 45 45 80 38 36 39 85 94 ; proc print; var t x; proc gplot data=d0; plot x*t; symbol c=red i=join v=star; run; proc anova; class a; model x=a; means a/hovtest; run;
第五章-异方差性-答案说课讲解
第五章-异方差性-答 案
第五章 异方差性 一、判断题 1. 在异方差的情况下,通常预测失效。( T ) 2. 当模型存在异方差时,普通最小二乘法是有偏的。( F ) 3. 存在异方差时,可以用广义差分法进行补救。(F ) 4. 存在异方差时,普通最小二乘法会低估参数估计量的方差。(F ) 5. 如果回归模型遗漏一个重要变量,则OLS 残差必定表现出明显的趋势。 ( T ) 二、单项选择题 1.Goldfeld-Quandt 方法用于检验( A ) A.异方差性 B.自相关性 C.随机解释变量 D.多重共线性 2.在异方差性情况下,常用的估计方法是( D ) A.一阶差分法 B.广义差分法 C.工具变量法 D.加权最小二乘法 3.White 检验方法主要用于检验( A ) A.异方差性 B.自相关性 C.随机解释变量 D.多重共线性 4.下列哪种方法不是检验异方差的方法( D ) A.戈德菲尔特——匡特检验 B.怀特检验 C.戈里瑟检验 D.方差膨胀因子检验 5.加权最小二乘法克服异方差的主要原理是通过赋予不同观测点以不同的权数,从而提高估计精度,即( B ) A.重视大误差的作用,轻视小误差的作用 B.重视小误差的作用,轻视大误差的作用 C.重视小误差和大误差的作用 D.轻视小误差和大误差的作用 6.如果戈里瑟检验表明,普通最小二乘估计结果的残差与有显著的形式的相关关系(满足线性模型的全部经典假设),则用加权最小二乘法估计模型参数时,权数应为( B ) A. B. C. D. 7.设回归模型为,其中()2i 2i x u Var σ=,则b 的最有效估计量为 ( D ) i e i x i i i v x e +=28715.0i v i x 21i x i x 1i x 1i i i u bx y +=
异方差性及其检验
异方差性及其检验 I 概念 对于多元线性回归模型 同方差性假设为 如果出现 即对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,不具有等同的分散程度,则认为出现了异方差(Heteroskedasticity ) II 类型 同方差性假定是指,回归模型中不可观察的随机误差项i u 以解释变量X 为条件的方差是一个常数,因此每个i u 的条件方差不随X 的变化而变化,即有 2()i i f X σ=≠常数 在异方差的情况下,总体中的随机误差项i u 的方差 2 i σ不再是常数, 通常它随解释变量值的变化而变化,即 异方差一般可归结为三种类型: 01122 1,2, ,i i i k ki i Y X X X i n ββββμ=+++ ++=2(), 1,2,...,i Var i n μσ==2(), 1,2,...,i i Var i n μσ==2() i i f X σ=
异方差类型图: III来源 (1)截面数据(不同样本点除解释变量外其他影响差异大) (2)时间序列(规模差异) (3)分组数据、异常值等 (4)模型函数形式设置不正确和数据变形不正确 (5)边错边改学习模型 IV影响 计量经济学模型一旦出现异方差,如果仍然用普通最小二乘法估计模型参数,会产生一系列不良后果。 (1)参数估计量非有效 (2)OLS估计的随机干扰项的方差不再是无偏的
(3)基于OLS估计的各种统计检验非有效 (4)模型的预测失效 V检验 异方差性,即相对于不同的样本点,也就是相对于不同的解释变量观测值,随机干扰项具有不同的方差,那么检验异方差性,也就是检验随机干扰项的方差与解释变量观测值之间的相关性。 一般检验方法如下: (1)图示检验法 (2)帕克(Park)检验与戈里瑟(Gleiser)检验 (3)G-Q(Goldfeld-Quandt)检验 (4)F检验 (5)拉格朗日乘子检验 (6)怀特检验 (具体步骤随后介绍) VI修正方法 加权最小二乘法 定义:加权最小二乘法是对原模型加权,使之变成一个新的不存在异方差性的模型,然后采用OLS法估计其参数。 基本思想:在采用OLS方法时,对较小的残差平方2? e赋予较大的权 i 重,对较大的2? e赋予较小的权重,以对残差提供的信息的重要程度 i 作一番修正,提高参数估计的精确程度。 不同形式的异方差要求用不同的加权方法来处理:
异方差性习题与答案
第五章 异方差性习题与答案 1、产生异方差的后果是什么? 2、下列哪种情况是异方差性造成的结果? (1)OLS 估计量是有偏的 (2)通常的t 检验不再服从t 分布。 (3)OLS 估计量不再具有最佳线性无偏性。 3、已知模型:i i i i u X X Y +++=22110βββ 式中,i Y 为某公司在第i 个地区的销售额;i X 1为该地区的总收入;i X 2为该公司在该地区投入的广告费用(i=0,1,2……,50)。 (1)由于不同地区人口规模i P 可能影响着该公司在该地区的销售,因此有理由怀疑随机误差项u i 是异方差的。假设i σ依赖于总体i P 的容量,逐步描述你如何对此进行检验。需说明:A 、零假设和备择假设;B 、要进行的回归;C 、要计算的检验统计值及它的分布(包括自由度);D 、接受或拒绝零假设的标准。 (2)假设i i P σσ=。逐步描述如何求得BLUE 并给出理论依据。 4、下表数据给出按学位和年龄划分的经济学家的中位数工薪: 表1 经济学家的工资表 年 龄 中位数工薪(以千美元计算) 硕士 博士 25-29 8.0 8.8 30-34 9.2 9.6 35-39 11.0 11.0 40-44 12.8 12.5 45-49 14.2 13.6 50-54 14.7 14.3 55-59 14.5 15.0 60-64 13.5 15.0 65-69 12.0 15.0 (1)有硕士学位和有博士学位经济学家的中位数工薪的方差相等么? (2)如果相等,你会怎样检验两组平均中位数工薪相等的假设? (3)在年龄35至5岁之间的经济学家,有硕士学位的比有博士学位的赚更多的钱,那么你会怎样解释这一发现? 5、为了解美国工作妇女是否受到歧视,可以用美国统计局的“当前人口调查”中的截面数据,研究男女工资有没有差别。这项多元回归分析研究所用到的变量有: W —雇员的工资率(美元/小时) 1表示雇员为女性, 0表示女性意外的雇员。ED :受教育的年数。AGE :年龄