网页小说采集方法

https://www.360docs.net/doc/12778139.html,
网页小说采集方法
很多朋友有对网页小说进行收集整理的需要,如何改变过去的人工采集模式,运用软件一键收集海量数据呢。下面给大家介绍一种运用八爪鱼采集器采集网页小说的方法。
本文介绍使用八爪鱼采集器采集小说(以起点小说为例)方法。
采集网站:https://https://www.360docs.net/doc/12778139.html,/info/53269
使用功能点:
分页列表及详细信息提取
https://www.360docs.net/doc/12778139.html,/tutorial/fylbxq7.aspx?t=1
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
https://www.360docs.net/doc/12778139.html,
网页小说采集方法步骤1
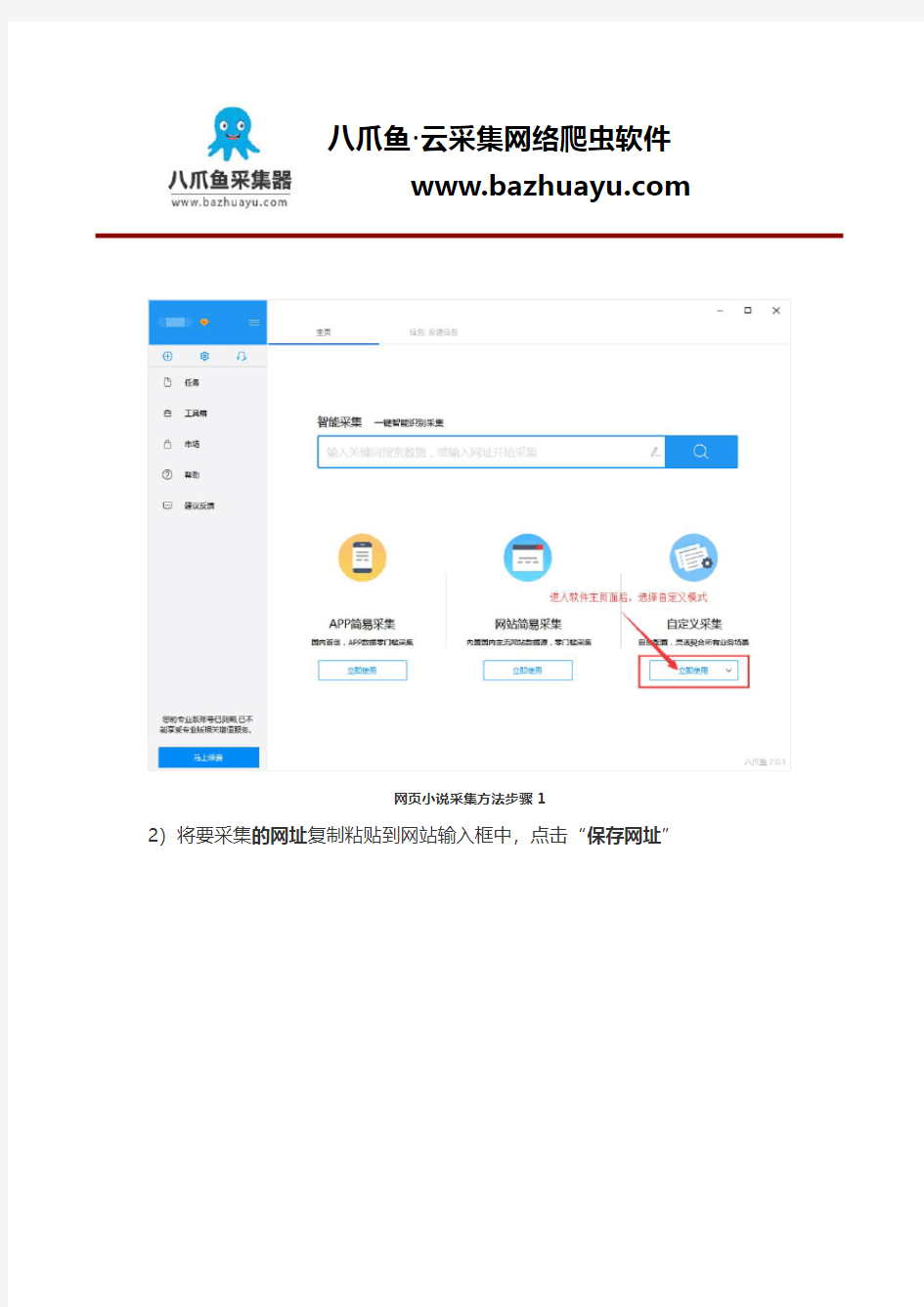
2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/12778139.html,
网页小说采集方法步骤2
步骤2:创建列表循环
1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。选中页面里的第一条链接,系统会自动识别页面内的同类链接,选择“选中全部”
https://www.360docs.net/doc/12778139.html,
网页小说采集方法步骤3
2)选择“循环点击每个链接”
https://www.360docs.net/doc/12778139.html,
网页小说采集方法步骤4
步骤3:采集小说内容
1)选中页面内要采集的小说内容(被选中的内容会变成绿色),选择“采集该元素的文本”
https://www.360docs.net/doc/12778139.html,
网页小说采集方法步骤5
2)修改字段名称
https://www.360docs.net/doc/12778139.html,
网页小说采集方法步骤6
3)选择“启动本地采集”
https://www.360docs.net/doc/12778139.html,
网页小说采集方法步骤7
步骤4:数据采集及导出
1)采集完成后,会跳出提示,选择“导出数据。选择“合适的导出方式”,将采集好的评论信息数据导出
https://www.360docs.net/doc/12778139.html,
网页小说采集方法步骤8
2)这里我们选择excel作为导出为格式,数据导出后如下图,这个时候小说就完全的采集下来了。
https://www.360docs.net/doc/12778139.html,
网页小说采集方法步骤9
相关采集教程:
起点中文网小说采集方法以及详细步骤
欢乐书客小说采集
八爪鱼采集原理以及实现功能
https://www.360docs.net/doc/12778139.html,
八爪鱼采集URL循环使用教程(7.0版本),以豆瓣电影为例
八爪鱼采集器7.0简介
八爪鱼采集原理
八爪鱼采集器URL循环-视频教程
https://www.360docs.net/doc/12778139.html,
教你如何提取网页中的视频、音乐歌曲、
教你如何提取网页中的视频、音乐歌曲、flash、图片等多媒体文件(很实用) 打开网页后,发现里面有好看的视频、好听的音乐、好看的图片、很炫的flash,是不是想把它们弄到自己电脑上或手机、mp4上?但很多时候视频无法下载,音乐只能试听,或者好听的背景音乐根本就不知道什么名字,更别说怎么下了;至于图片直接右键另存为即可,不过如果网页突然关掉了,但又想把看过的图片弄下来,而忘了图片网页地址或者不想再通过历史记录打开,这时又该怎么办? 其实这些问题都能很好的解决,并且很简单,只要用一个软件 来替你从电脑的缓存中搜索一下就OK了,因为网页中显示的内容基本 上全部都在缓存中,如果自己手动搜索,那将是很累人滴,又不好找,东西太多,又没分类。 无意中发现一个小软件很强(对此感兴趣,本人玩过无数小软件),我一直在用,也是用它帮了很多网友的忙,为了让更多的网友解决问题,于是拿来和亲们分享一下。不废话了,下面进入主题: 这款免费小软件就是YuanBox(元宝箱)v1.6,百度一搜就能下载。 下面是我自己整理的使用步骤,供亲们参考(其实不用看就行,软件简单,不用学就会),我只是用的时间长了,很熟练罢了: 软件下好后,解压,打开里面的YuanBox.exe即可,不用安装;打开此软件前,先打开你要提取东西的网页(之后再关掉也行),这是为了保证电脑缓存中有你要的东西。 运行软件,初始界面如下图:
之后直接是flv格式视频搜索结果的界面,原因就是此软件的全称是 元宝箱FLV视频下载专家,不想要视频的话,点击最上面的设置或者最下面的高级设置,即可进行搜索范围设定
下面是搜索条件设定界面 以swf格式flash为例,进行搜索,选择类型中的第二项 点击确定,开始搜索,结果如下:
淘宝图片抓取工具使用方法
https://www.360docs.net/doc/12778139.html, 淘宝图片抓取工具使用方法 对于电商设计师来说,抓取竞品的宝贝的图片和店铺装修图片,来分析设计自己店铺的风格并做出差异化,是非常有用的方法哦。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【淘宝图片】为例,教大家如何使用八爪鱼采集软件采集淘宝图片的方法。 本文介绍使用八爪鱼7.0采集淘宝商品图片的方法:首先将淘宝商品搜索结果网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的淘宝商品图片URL,下载并保存到本地电脑中。 采集网址:淘宝商品搜索页面 比如T恤(可更换其他关键词对淘宝商品图片进行采集): https://https://www.360docs.net/doc/12778139.html,/search?q=T%E6%81%A4&imgfile=&commend=all &search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taob ao-item.1&ie=utf8&initiative_id=tbindexz_20170306 采集数据内容:淘宝商品图片地址
https://www.360docs.net/doc/12778139.html, 使用功能点: ●翻页设置 ●图片链接采集 步骤1:创建淘宝商品图片采集任务1)进入八爪鱼采集器主界面,选择自定义模式 淘宝商品图片采集步骤1
https://www.360docs.net/doc/12778139.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 淘宝商品图片采集步骤2 3)如下图红色框中的淘宝商品图片即为本次要采集的内容。
https://www.360docs.net/doc/12778139.html, 淘宝商品图片采集步骤3 步骤2:创建翻页循环 ●找到翻页按钮,设置翻页循环 ●设置ajax翻页时间 ●设置滚动页面 1)将淘宝商品搜索结果页页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”这个选项。
网站内容采集方法
https://www.360docs.net/doc/12778139.html, 网站内容采集方法 作为内容编辑者,每天都需要采编大量网络上的内容,尽可能收集更多可用的文字素材或者话题素材,以备不时之需。面对每天海量的内容,这时就需要一个款高效、好用的工具帮忙了。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集】,以【腾讯新闻】为例,教大家如何使用八爪鱼采集软件简易模式采集腾讯新闻标题与内容的方法。 需要采集腾讯网的相关内容的,在网页简易模式界面里点击腾讯网进去之后可以看到关于腾讯的三个规则信息,我们直接使用就可以的。 腾讯新闻标题与内容采集软件使用步骤1
https://www.360docs.net/doc/12778139.html, 采集腾讯新闻中心的内容(下图所示)即打开腾讯网主页点击中间的新闻中心-滚动新闻点击进去进行设定,采集需要的新闻内容。 1、找到新闻中心-滚动新闻规则然后点击立即使用 腾讯新闻标题与内容采集软件使用步骤2 2、下图显示的即为简易模式里面的新闻中心-滚动新闻规则 ①查看详情:点开可以看到示例网址 ②任务名:自定义任务名,默认为新闻中心-滚动新闻 ③任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 ④翻页次数:设置要采集的页数 ⑤采集数目:设置你每页要采集的新闻数 ⑥示例数据:这个规则采集的所有字段信息
https://www.360docs.net/doc/12778139.html, 腾讯新闻标题与内容采集软件使用步骤3 3、规则制作示例 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行 翻页次数:2 采集数目:20 设置好之后点击保存,保存之后会出现开始采集的按钮 保存之后会出现开始采集的按钮
网页数据采集器如何使用
https://www.360docs.net/doc/12778139.html, 网页数据采集器如何使用 新浪微博是目前国内比较火的一个社交互动平台,明星、各大品牌都有注册官方微博,有什么活动也都会在微博上宣传造势,和粉丝评论互动。普通人平常也喜欢将生活中的点滴分享到微博,所以微博聚集了大批的用户。本文就以使用八爪鱼采集器的简易模式采集新浪微博数据为例子,为大家介绍网页数据采集器的使用方法。 需要采集微博内容的,在网页简易采集界面里点击微博网页进去之后可以看到所有关于微博的规则信息,我们直接使用就可以的。 新浪微博数据采集器的使用步骤1 采集微博主页面或主页中不同版块的信息(下图所示)即打开微博主页后采集该页面的内容。 1、找到微博主页面信息采集规则然后点击立即使用
https://www.360docs.net/doc/12778139.html, 新浪微博数据采集器的使用步骤2 2、下图显示的即为简易模式里面微博主页面信息采集的规则 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为微博主页面信息采集 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 网址:设置要采集的网址,如果有多个网址用回车(Enter)分隔开,一行一个。支持输入微博首页网址和首页各个子版本的网址,如 https://www.360docs.net/doc/12778139.html,/?category=1760 示例数据:这个规则采集的所有字段信息
https://www.360docs.net/doc/12778139.html, 新浪微博数据采集器的使用步骤3 3、规则制作示例 例如采集微博主页面和社会版块的信息。设置如下图所示: 任务名:自定义任务名,也可以不设置按照默认的就行 任务组:自定义任务组,也可以不设置按照默认的就行 网址:从浏览器中将要采集网址复制黏贴到输入框中,本示例为https://www.360docs.net/doc/12778139.html,/ https://www.360docs.net/doc/12778139.html,/?category=7 设置好之后点击保存
网页图片提取方法
https://www.360docs.net/doc/12778139.html, 网页图片提取方法 对于新媒体运营来说,平日一定要注意积累图片素材,这样到写文案用的时候,才不会临时来照图片,耗费大量的时间。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【图片采集】为例,教大家如何使用八爪鱼采集软件采集网络图片的方法。 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.360docs.net/doc/12778139.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.360docs.net/doc/12778139.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置:
https://www.360docs.net/doc/12778139.html, ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔; ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集 采集示例:百度网图片采集教程https://www.360docs.net/doc/12778139.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.360docs.net/doc/12778139.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.360docs.net/doc/12778139.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
大数据采集工具如何使用
https://www.360docs.net/doc/12778139.html, 大数据采集工具如何使用 在商业活动,大数据已然成为必不可少的参考依据,通过对大数据的挖掘分析处理能为商业决策、战略部署、企业发展提供准确的指导。特别是电子商务,即时采集商品的价格、销量、评价等大量信息进行处理分析,形成反馈结果应用到实际中,能为商业活动带来巨大的经济价值。因而,掌握大数据采集工具如何使用是必须的。 对于某些用户来说,直接自定义规则可能有难度,所以在这种情况下,我们提供了网页简易模式,网页简易模式下存放了国内一些主流网站爬虫采集规则,在你需要采集相关网站时可以直接调用,节省了制作规则的时间以及精力。 天猫商品数据采集下来有很多作用,比如可以分析天猫商品价格变化趋势情况,评价数量,竞品销量和价格,竞争店铺分析等,快速掌握市场行情,帮助企业决策。 所以本次介绍八爪鱼简易采集模式下“天猫数据抓取”的使用教程以及注意要点。步骤一、下载八爪鱼软件并登陆 1、打开https://www.360docs.net/doc/12778139.html,/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
https://www.360docs.net/doc/12778139.html, 2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆。
https://www.360docs.net/doc/12778139.html, 步骤二、设置天猫商品列表抓取规则 1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
https://www.360docs.net/doc/12778139.html, 2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集京东内容的,这里选择天猫即可。
https://www.360docs.net/doc/12778139.html, 3、找到天猫商品列表采集这条爬虫规则,点击即可使用。
侵略者_网页数据采集系统_介绍
侵略者WEB数据采集系统V3.0.1 介绍 Copyright ? 2005-2010 All Rights Reserved 侵略者软件 https://www.360docs.net/doc/12778139.html,
目录 目录 (2) 一.开发背景 (3) 二.功能介绍 (3) 三.模块组成 (3) 1.网页下载配置 (3) 2.网页下载进程 (4) 3.网页解析配置 (4) 4.网页解析进程 (4) 5.采集任务配置 (4) 6.采集任务测试和分配 (4) 7.角色管理 (4) 8.采集服务器的管理,监控,统计,分析等 (5) 9.数据的导入,导出,备份等 (5) 10.插件管理发布 (5) 11.服务进程 (5) 四.运行部署 (5) 五.维护管理监控 (6) 六.软硬件要求 (7) 七.性能分析 (7) 八.名词解释 (7)
一.开发背景 随着用户对信息获取速度的要求,很多公司开始做面向各行各业的垂直搜索引擎,垂直搜索引擎最核心的就是准确及时的获取数据源。 本系统的设计目标就是为了满足这个需求。给垂直搜索引擎提供准确及时是数据采集服务。 二.功能介绍 本系统提供对互联网数据进行采集的服务。 根据用户事先配置好的规则(网页下载规则,数据块解析规则等),进行数据采集。 当对方网站数据进行了更新,或者添加新数据时,系统自动会进行检测,并进行采集,然后更新到自己的数据库(或者别的存储方式),这个过程不再需要人工干涉。 本系统采用分布式处理,可以通过采集管理平台把采集任务发布到不同的服务器,能够进行对大量数据源网站进行高频率的并行监控采集。 对服务器群管理方便快捷,通过采集管理平台进行统一管理,监控,统计,分析。 本系统主要适合于对数据量要求大的行业垂直搜索引擎和情报分析系统的数据采集,也适合于一些对数据量要求不高的信息发布网站。 本系统采用插件方式,对采集来的数据可以进行修正。对输出方式可以通过插件自由定制。可扩展性高。 三.模块组成 1. 网页下载配置 负责制定网页下载规则,登录设置,下载策略设置。主要供网页下载进程使用。
网站图片抓取方法
https://www.360docs.net/doc/12778139.html, 网站图片抓取方法 你是否有过想将网站上看到的图片抓取保存到本地电脑?图片少量时,还可以手动一张张下载,但是图片量巨大时,这个时候手动下载既耗费时间精力,效率又极其低下。遇到这种情况怎么办呢?让八爪鱼来帮你把~只需要在八爪鱼软件中配置相应的流程,图片下载到电脑就是so easy~下面就为大家介绍最全的网站图片抓取方法。 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.360docs.net/doc/12778139.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.360docs.net/doc/12778139.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置: ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔;
https://www.360docs.net/doc/12778139.html, ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集 采集示例:百度网图片采集教程https://www.360docs.net/doc/12778139.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.360docs.net/doc/12778139.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.360docs.net/doc/12778139.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
网页链接提取方法
https://www.360docs.net/doc/12778139.html, 网页链接提取方法 网页链接的提取是数据采集中非常重要的部分,当我们要采集列表页的数据时,除了列表标题的链接还有页码的链接,数据采集只采集一页是不够,还要从首页遍历到末页直到把所有的列表标题链接采集完,然后再用这些链接采集详情页的信息。若仅仅靠手工打开网页源代码一个一个链接复制粘贴出来,太麻烦了。掌握网页链接提取方法能让我们的工作事半功倍。在进行数据采集的时候,我们可能有提取网页链接的需求。网页链接提取一般有两种情况:提取页面内的链接;提取当前页地址栏的链接。针对这两种情况,八爪鱼采集器均有相关功能实现。下面介绍一个网页链接提取方法。 一、八爪鱼提取页面内的超链接 在网页里点击需要提取的链接,选择“采集以下链接地址”
https://www.360docs.net/doc/12778139.html, 网页链接提取方法1 二、八爪鱼提取当前地址栏的超链接 从左边栏拖出一个提取数据的步骤出来(如果当前页已经有其他的提取字段,这一步可省略)点击“添加特殊字段”,选择“添加当前页面网址”。可以看到,当前地址栏的超链接被抓取下来
https://www.360docs.net/doc/12778139.html, 网页链接提取方法2 而批量提取网页链接的需求,一般是指批量提取页面内的超链接。以下是一个使用八爪鱼批量提取页面内超链接的完整示例。 采集网站: https://https://www.360docs.net/doc/12778139.html,/search?initiative_id=tbindexz_20170918&ie=utf8&spm=a21 bo.50862.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=sugg est
WEB数据采集系统
WEB数据采集系统 一.概述 面对互联网海量的信息,政府机关、企事业单位和研究机构都迫切希望获取与自身工作相关的有价值信息,如何方便快捷地获取这些信息就变得至关重要了。如果采用原始的手工收集方式,费时费力且毫无效率,面对越来越多的信息资源,劳动强度和难度可想而知。因此,现代的政府和企业都迫切需要一种能够提供高质量和高效运作的信息采集解决方案。 本系统针对不同行业用户的应用需求,以抓取互联网为目的,实现在用户自定义规则下,从互联网中抓取指定信息。抓取的信息可存入数据库或直接入库发送至指定栏目,实现网站信息及时更新和数据量提升,从而使得搜索引擎收录量提升,扩大企业信息宣传推广力度。 二.典型应用 1. 政府机关 ●实时跟踪、采集与业务工作相关的信息来源。 ●全面满足内部工作人员对互联网信息的全局观测需求。 ●及时解决政务外网、政务内网的信息源问题,实现动态发布。 ●快速解决政府主网站对各地级子网站的信息获取需求。 ●全面整合信息,实现政府内部跨地区、跨部门的信息资源共享与有效 沟通。 ●节约信息采集的人力、物力、时间,提高办公效率。
2. 企业 ●实时准确地监控、追踪竞争对手动态,是企业获取竞争情报的利器。 ●及时获取竞争对手的公开信息以便研究同行业的发展与市场需求。 ●为企业决策部门和管理层提供便捷、多途径的企业战略决策工具。 ●大幅度地提高企业获取、利用情报的效率,节省情报信息收集、存 储、挖掘的相关费用,是提高企业核心竞争力的关键。 ●提高企业整体分析研究能力、市场快速反应能力,建立起以知识管 ,是提高企业核心竞争力的神经中枢。 理为核心的“竞争情报数据仓库” 3. 新闻媒体 ●快速准确地自动采集数信息。 ●支持每天对数万条新闻进行有效抓取。 ●支持对所需内容的智能提取、审核。 ●实现互联网信息内容采集、浏览、编辑、管理、发布的一体化。三. 系统构架 工作过程描述 采集的目的就是把对方网站上网页中的某块文字或者图片等资源下载到自己的站网上,这个过程需要做如下配置工作:下载网页配置,解析网页配置,修正结果配置,数据输出配置。如果数据符合自己要求,修正结果这步可省略。配置完毕后,把配置形成任务(任务以XML格式描述),采集系统
美团商家数据采集器以及采集方法
https://www.360docs.net/doc/12778139.html, 7.0采集美团商家数据的方法 本文介绍使用八爪鱼 采集网站: 使用功能点: ●Ajax滚动加载设置 ●分页列表内容提取 相关采集教程: 淘宝评论采集 天猫店铺采集 大众点评评价采集 步骤1:创建采集任务 1)进入主界面选择,选择自定义模式
https://www.360docs.net/doc/12778139.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 美团商家数据采集方法图2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容
https://www.360docs.net/doc/12778139.html, 美团商家数据采集方法图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间 1)在页面打开后,当下拉页面时,会发现页面有新的数据在进行加载(具体参考八爪鱼7.0教程——AJAX滚动教程)
https://www.360docs.net/doc/12778139.html, 美团商家数据采集方法图4 所以需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 美团商家数据采集方法图5
https://www.360docs.net/doc/12778139.html, 2)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页” 美团商家数据采集方法图6 由于页面使用了ajax加载技术,当采集时候,网站总需要重新加载,所以对翻页步骤需进行上面打开网页步骤中的设置
国内主要信息抓取软件盘点
国内主要信息抓取软件盘点 近年来,随着国内大数据战略越来越清晰,数据抓取和信息采集系列产品迎来了巨大的发展 机遇,采集产品数量也出现迅猛增长。然而与产品种类快速增长相反的是,信息采集技术相 对薄弱、市场竞争激烈、质量良莠不齐。在此,本文列出当前信息采集和数据抓取市场最具 影响力的六大品牌,供各大数据和情报中心建设单位采购时参考: TOP.1 乐思网络信息采集系统 乐思网络信息采系统的主要目标就是解决网络信息采集和网络数据抓取问题。是根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 主要用于:大数据基础建设,舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。 TOP.2 火车采集器 火车采集器是一款专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从网页上抓取结构化的文本、图片、文件等资源信息,可编辑筛选处理后选择发布到网站后台,各类文件或其他数据库系统中。被广泛应用于数据采集挖掘、垂直搜索、信息汇聚和门户、企业网信息汇聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各类对数据有采集挖掘需求的群体。 TOP.3 熊猫采集软件 熊猫采集软件利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。 TOP.4 狂人采集器 狂人采集器是一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,通过相关配置,能轻松的采集80%的网站内容为己所用。根据各建站程序
教你如何提取网页中的视频(主要flv),音乐,flash,图片等多媒体文件
教你如何提取网页中的视频(主要flv),音乐,flash,图片 等多媒体文件 打开网页后,发现里面有好看的视频、好听的音乐、好看的图片、很炫的flash,是不是想把它们弄到自己电脑上或手机、mp4上?但很多时候视频无法下载,音乐只能试听,或者好听的背景音乐根本就不知道什么名字,更别说怎么下了;至于图片直接右键另存为即可,不过如果网页突然关掉了,但又想把看过的图片弄下来,而忘了图片网页地址或者不想再通过历史记录打开,这时又该怎么办? 其实这些问题都能很好的解决,并且很简单,只要用一个软件来替你从电脑的缓存中搜索一下就OK了,因为网页中显示的内容基本上全部都在缓存中,如果自己手动搜索,那将是很累人滴,又不好找,东西太多,又没分类。 无意中发现一个小软件很强(对此感兴趣,本人玩过无数小软件),我一直在用,也是用它帮了很多网友的忙,为了让更多的网友解决问题,于是拿来和亲们分享一下。 工具/原料 这款免费小软件就是YuanBox(元宝箱)v1.6,全称:元宝箱FLV视频下载专家,百度一搜就能下载。 下面是我自己整理的使用步骤,供亲们参考(其实不用看就行,软件简单,不用学就会),我只是用的时间长了,很熟练罢了: 软件下好后,解压,打开里面的YuanBox.exe即可,不用安装;打开此软件前,先打开你要提取东西的网页(之后再关掉也行),这是为了保证电脑缓存中有你要的东西。 步骤/方法 ○11运行软件,初始界面如下图:
○22之后直接是flv格式视频搜索结果的界面,原因就是此软件的全称是 元宝箱FLV视频下载专家,不想要视频的话,点击最上面的设置或者最下面的高级设置,即可进行搜索范围设定 ○33下面是搜索条件设定界面
图片爬虫如何使用
https://www.360docs.net/doc/12778139.html, 图片爬虫如何使用 目标网站上有许多我们喜欢的图片,想用到自己的工作或生活中去,但苦于工作量太大,图片一张张保存太过耗时耗力,因此总是力不从心。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【ebay】为例,教大家如何使用八爪鱼采集软件采集ebay网站的方法。 可以将网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。 采集网站: https://https://www.360docs.net/doc/12778139.html,/sch/i.html?_from=R40&_trksid=p2050601.m570.l1313.TR0.TRC0.H0.Xnik e.TRS0&_nkw=nike&_sacat=0 使用功能点: ●分页列表信息采集 ●执行前等待 ●图片URL转换
https://www.360docs.net/doc/12778139.html, 步骤1:创建采集任务 1)进入主界面,选择“自定义采集” ebay爬虫采集步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/12778139.html, ebay爬虫采集步骤2 3)系统自动打开网页,红色方框中的图片是这次演示要采集的内容
https://www.360docs.net/doc/12778139.html, ebay爬虫采集步骤3 步骤二:创建翻页循环 1)点击右上角的“流程”,即可以看到配置流程图。将页面下拉到底部,找到下一页的大于号标志按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接” ebay爬虫采集步骤4 由于该网页每次翻页网址随之变化,所以不是ajax页面,不需要设置ajax。如果有网站每次翻页,网址不变,则需要在高级选项设置ajax加载。
网站爬虫如何爬取数据
https://www.360docs.net/doc/12778139.html, 网站爬虫如何爬取数据 大数据时代,用数据做出理性分析显然更为有力。做数据分析前,能够找到合适的的数据源是一件非常重要的事情,获取数据的方式有很多种,最简便的方法就是使用爬虫工具抓取。今天我们用八爪鱼采集器来演示如何去爬取网站数据,以今日头条网站为例。 采集网站: https://https://www.360docs.net/doc/12778139.html,/ch/news_hot/ 步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式” 网站爬虫如何爬取数据图1
https://www.360docs.net/doc/12778139.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 网站爬虫如何爬取数据图2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容
https://www.360docs.net/doc/12778139.html, 网站爬虫如何爬取数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定
https://www.360docs.net/doc/12778139.html, 网站爬虫如何爬取数据图4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量
https://www.360docs.net/doc/12778139.html, 网站爬虫如何爬取数据图5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 然后点击“选中子元素”
基于Web的远程监控与数据采集系统
第32卷第4期电子科技大学学报V ol.32 No.4 2003年8月 Journal of UEST of China Aug. 2003 基于Web的远程监控与数据采集系统 陈 新* (郑州轻工业学院信息与控制工程系郑州 450002) 【摘要】分析了监控系统的发展趋势,提出了一种基于Web技术的远程监控与数据采集系统的设计方案。Web 数据库采用ASP技术实现,远程智能终端采用单片机系统实现,用户可以通过浏览器实现对现场设备状态的监控。 该设计方案在实现铁路供水监控系统中取得了成功,通过控制网和Internet的结合,实现了集控制、管理、信息、 网络于一体的企业综合自动化。 关键词监控系统; Web数据库; 服务器; ASP技术 中图分类号TP277 文献标识码 A Application of Long Distance Supervisory Control and Data Acquisition System Based on Web Chen Xin (Dept. of Information and Controlling Eng., Zhengzhou Inst. of Light Ind., Zhengzhou 450002) Abstract In this paper, the development trend and the general significance of the supervisory control system is analyzed, and also a design project of water supply’s supervisory control and data acquisition system based on Web is introduced. The Web database adopts ASP technology to realize, and the long distance intelligent terminal uses MCU system. The user can supervise and control the water supply’s equipments though the browser. The design has met with success in the system of railway water supply’s supervisory control. Though the combination between control network and Internet, the corporation can achieve its automation with control, management, information and network together. Key words supervisory control system; Web database; service; ASP technology 监控系统是集计算机技术、控制技术、网络技术为一体的高新技术产品,具有控制功能强、操作简便和可靠性高等特点,可以方便地用于工业装置的生产控制和经营管理。监控技术经过了单机监控系统、集中式监控系统和网络范围内的远程监控三个发展阶段。远程监控是指本地计算机通过网络系统对远端的控制系统进行监测和控制[1],其中基于Web的远程监控与数据采集(Supervisory Control and Data Acquisition, SCADA)模式成为当前监控系统的发展趋势[2]。同时,随着社会的发展,人们对水利供应、电力供应、环境监测、城市燃气供应、集中供热以及银行防盗等系统的正常运行提出了更高的要求。以上系统的特点是站点分布较为分散,而站点的正常运行又极为重要。以铁路沿线供水为例,其供水站点的分布很广,传统的人工现场监控浪费人力物力,效率低下,所以研制开发低成本、高可靠性、配置灵活,适用范围广的远程监控系统具有普遍的意义和实用价值。本文结合某铁路局沿线供水监控项目,开发了基于Web的远程监控与数据采集的系统方案。 1 系统整体说明 基于Web的远程监控系统可分为现场监控(智能终端)、监控中心(包括通信模块、数据库服务器、Web服 2002年11月12日收稿 * 男 43岁硕士副教授主要从事过程控制方面的研究
最全的网页图片采集方法
https://www.360docs.net/doc/12778139.html, 最全的网页图片采集方法 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.360docs.net/doc/12778139.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.360docs.net/doc/12778139.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置: ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔; ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集
https://www.360docs.net/doc/12778139.html, 采集示例:百度网图片采集教程https://www.360docs.net/doc/12778139.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.360docs.net/doc/12778139.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.360docs.net/doc/12778139.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
如何对整个网页页面进行截图
一、在键盘右上侧有一个键print screen sys rq键(打印屏幕),可以用它将显示屏显示的画面抓下来,复制到“剪贴板”中,然后再把图片粘贴到“画图”、“Photoshop”之类的图像处理软件中,进行编辑处理后保存成图片文件,或粘贴到“Word”、“Powerpoint”、“Wps”等支持图文编辑的应用软件里直接使用。 1、截获屏幕图像 ①将所要截取的画面窗口处于windows窗口的最前方(当前编辑窗口); ②按键盘上的“Print Screen”键,系统将会截取全屏幕画面并保存到“剪贴板”中; ③打开图片处理软件(如“画图”),点击该软件工具栏上的“粘贴”按钮或编辑菜单中的“粘贴”命令,图片被粘贴到该软件编辑窗口中(画布上),编辑图片,保存文件。 或打开(切换到)图文编辑软件(如“Word”、“Powerpoint”等),点击该软件工具栏上的“粘贴”按钮或编辑菜单中的“粘贴”命令,图片被粘贴到编辑窗口中,也可以使用该类软件的图片工具进行编辑。 注意,当粘贴到“画图”中时,可能会弹出一个“剪贴板中的图像比位图大,是否扩大位图?”对话框,此时点击“是”即可。 2、抓取当前活动窗口 我们经常不需要整个屏幕,而只要屏幕中的一个窗口,比如我们要“Word”窗口的图片。按下Alt键,同时按Print Screen即可。 ①将所要截取的窗口处于windows窗口的最前方(即当前编辑窗口); ②同时按下Alt键和“Print Screen”键,系统将会截取当前窗口画面并保存到“剪贴板”中; ③粘贴到图像处理软件中或图文编辑软件中。 二、直接点击Ctrl+Alt+A键,然后可见鼠标的箭头变成彩色的,按住左键移动鼠标选择截图范围,然后在截图内右键鼠标另存为即可,可方便了. 三、用第三方软件如QQ截图:点击聊天框截图---显示彩色鼠标---用其圈定所选目标(右键取消)----双击(单击左键为重新选择)---进入QQ聊天框--右键另存为---到达所到地址 如果想上传则:右键点击图片---编辑---另存为---把保存类型改为JPEG格式即可。 方法1.1 屏幕截图 登陆QQ—→按下“Ctrl+Alt+A”组合键—→按下鼠标左键不放选择截取范围—→用鼠标左键调整截取范围的大小和位置—→截取范围内双击鼠标左键。所截图像保存在系统剪贴板。
国内主要数据采集和抓取工具
国内6大网络信息采集和页面数据抓取工具 近年来,随着国内大数据战略越来越清晰,数据抓取和信息采集系列产品迎来了巨大的发展机遇,采集产品数量也出现迅猛增长。然而与产品种类快速增长相反的是,信息采集技术相对薄弱、市场竞争激烈、质量良莠不齐。在此,本文列出当前信息采集和数据抓取市场最具影响力的六大品牌,供各大数据和情报中心建设单位采购时参考: TOP.1 乐思网络信息采集系统(https://www.360docs.net/doc/12778139.html,) 乐思网络信息采系统的主要目标就是解决网络信息采集和网络数据抓取问题。是根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 该系统主要用于:大数据基础建设,舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。 TOP.2 火车采集器(https://www.360docs.net/doc/12778139.html,) 火车采集器是一款专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从网页上抓取结构化的文本、图片、文件等资源信息,可编辑筛选处理后选择发布到网站后台,各类文件或其他数据库系统中。被广泛应用于数据采集挖掘、垂直搜索、信息汇聚和门户、企业网信息汇聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各类对数据有采集挖掘需求的群体。 TOP.3 熊猫采集软件(https://www.360docs.net/doc/12778139.html,) 熊猫采集软件利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。 TOP.4 狂人采集器(https://www.360docs.net/doc/12778139.html,) 狂人采集器是一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,通过相关配置,能轻松的采集80%的网站内容为己所用。根据各建站程序的区别,狂人采集器分论坛采集器、CMS采集器和博客采集器三类,总计支持近40种主流建站程序的上百个版本的数据采集和发布任务,支持图片本地化,支持网站登陆采集,分页抓取,全面模拟人工登陆发布,软件运行快速安全稳定!论坛采集器还支持论坛会员无限注册,自动增加帖子查看人数,自动顶贴等。 TOP.5 网络神采(https://www.360docs.net/doc/12778139.html,) 网络神采是一款专业的网络信息采集系统,通过灵活的规则可以从任何类型的网站采集信息,
常用网页数据采集软件对比
近年来,随着国内大数据战略越来越清晰,数据抓取和信息采集系列产品迎来了巨大的发展机遇,采集产品数量也出现迅猛增长。然而与产品种类快速增长相反的是,信息采集技术相对薄弱、市场竞争激烈、质量良莠不齐。在此,本文列出当前信息采集和数据抓取市场最具影响力的六大品牌,供各大数据和情报中心建设单位采购时参考: TOP.1 乐思网络信息采集系统 乐思网络信息采系统的主要目标就是解决网络信息采集和网络数据抓取问题。是根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 该系统主要用于:大数据基础建设,舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。 TOP.2 火车采集器 火车采集器是一款专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从网页上抓取结构化的文本、图片、文
件等资源信息,可编辑筛选处理后选择发布到网站后台,各类文件或其他数据库系统中。被广泛应用于数据采集挖掘、垂直搜索、信息汇聚和门户、企业网信息汇聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各类对数据有采集挖掘需求的群体。 TOP.3 熊猫采集软件 熊猫采集软件利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。 TOP.4 狂人采集器 狂人采集器是一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,通过相关配置,能轻松的采集80%的网站内容为己所用。根据各建站程序的区别,狂人采集器分论坛采集器、CMS采集器和博客采集器三类,总计支持近40种主流建站程序的上百个版本的数据采集和发布任务,支持图片本地化,支持网站登陆采集,分页抓取,全面模拟人工登陆发布,软件运行快速安
提取PPT中背景图片的三种方法
提取PPT中漂亮背景图片的三种方法 自己制作PPT课件过程中,经常需要用到一些比较好的背景图片,作为教师有必要随时储备一些精美的图片素材备用。网络中的图片虽然很多,但是要找到适合做课件背景的却不容易,一种可行的办法就是从现成课件里提取背景,那么如何提取呢?下面介绍三种可行的方法,与大家共享。 第一种: 最简单省事,就是直接提取人家PPT课件中的背景。 1.启动PowerPoint,打开相应的演示文稿文档。 2.在非文本框和组合内容外的空白处,单击右键选择“保存背景”,选择适当保存位置和对应背景图片名称,即完成背景图片的保存。 说明:此方法对有些PPT文件是不适用的,在非文本框和组合内容外的空白处,单击右键时不出现“保存背景”命令。 第二种: 制作者需要将某个PowerPoint演示文稿中的图片单独提取出来,只要将其另存为网页格式即可。
1.启动PowerPoint,打开相应的演示文稿文档。 2.执行“文件→另存为网页”命令,打开“另存为网页”对话框。 3.将“保存类型”设置为“网页(*.htm*.html)” ,然后取名(如123)保存返回。 4.我们在上述网页文件保存的文件夹中,会找到一个名为“123.files”的文件夹,PPT文件所用的所有图片都是单独保存了文件夹中,包括背景图片。 第三种: 1.先打开课件,找到你喜欢那张背景的幻灯片,然后把它上面的所有文本框等删去,再按幻灯片放映,放到那张背景时,按CTRL+PRINT SCREEN(全屏截取)。 2.找开“画图”(开始---附件)或者其它图片处理程序,按CTRL+V(粘贴)调出截图,另存为JPEG或GIF文件(记住位置)。 3.打开新的幻灯片,右键单击空白处---背景---填充效果---图片---选择图片(找到刚刚保存的那张图片)---确定---应用。