数据结构实验指导书

实验一线性表及其应用
实验目的:
1、掌握线性表的顺序存储结构和顺序存储结构中的各种基本操作
2、掌握线性表的链式存储结构和链式存储结构中的各种基本操作
实验内容:
1、建立一个顺序表L={21,23,16,45,65,17,31,9},输出该表中各元素的值,然后在第i=4的位置插入元素68。
2、建立一个带头接点的单链表,各节点的值为{21,34,2,15,21,7,8},要求将用户输入的数据按尾插入法来建立相应的单链表。
实验时数:
4学时(第10周和第11周)
实验地点:逸夫楼3320
实验二栈的基本操作
试验目的:
掌握栈的顺序表示及其基本操作
实验内容:
1、写一函数实现栈的建立。
2、分别写两个函数实现入栈和出栈操作。
3、在主函数中分别调用上面的三个函数实现栈的基本操作。
实验时数:
2学时(第12周)
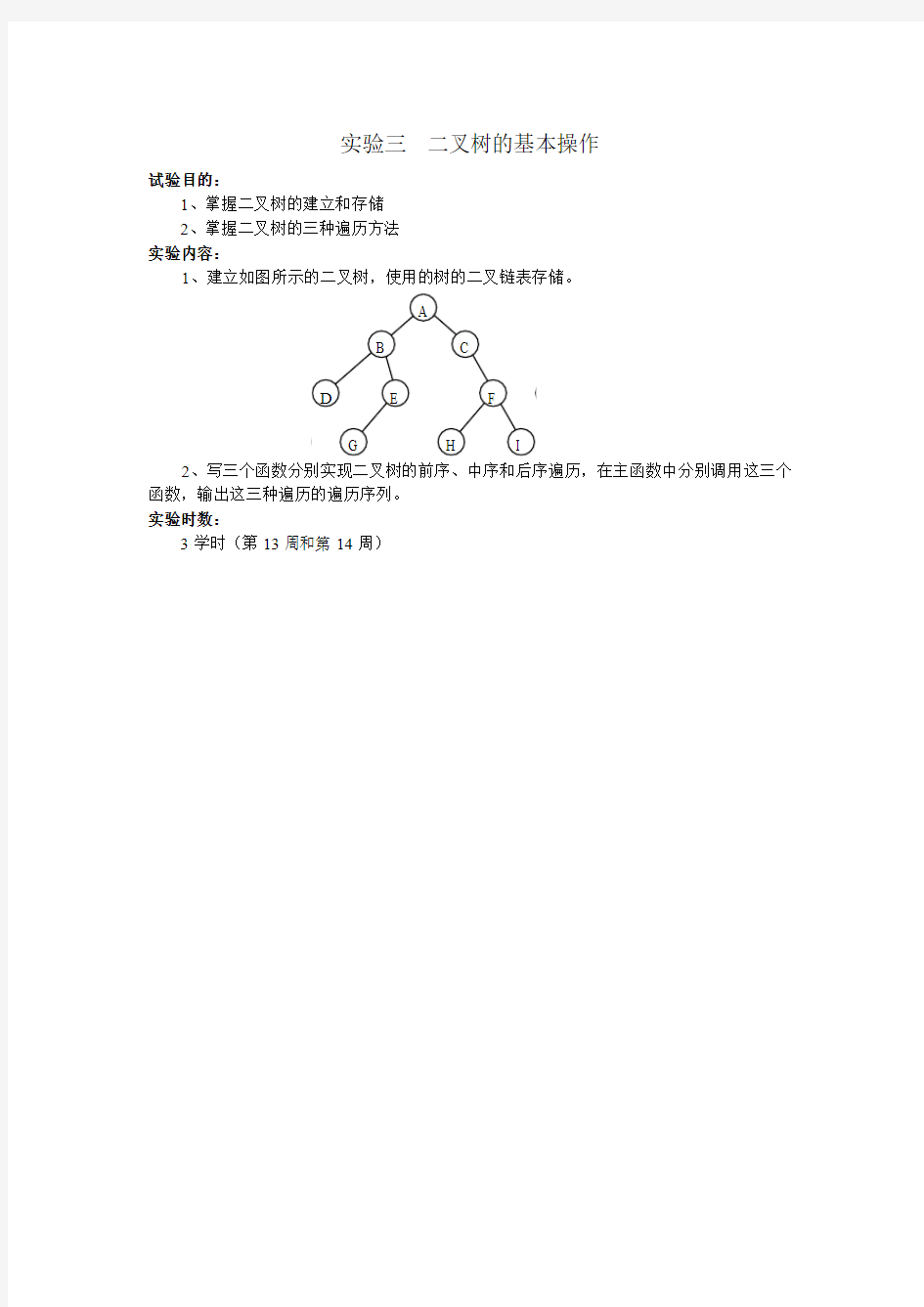
实验三二叉树的基本操作
试验目的:
1、掌握二叉树的建立和存储
2、掌握二叉树的三种遍历方法
实验内容:
1、建立如图所示的二叉树,使用的树的二叉链表存储。
2、写三个函数分别实现二叉树的前序、中序和后序遍历,在主函数中分别调用这三个函数,输出这三种遍历的遍历序列。
实验时数:
3学时(第13周和第14周)
实验四图的广度和深度遍历
试验目的:
1、掌握图的存储方法
2、掌握图的两种遍历方法和图中最短路径算法
实验内容:
假设以一个带权有向图表示某一个区域的公交线路网,图中顶点代表一些区域中的重要场所,弧代表已有的公交线路,弧上的权表示该线路上的票价(或搭乘所需时间),试设计一个交通指南系统,指导前来咨询者以最低的票价或最少的时间从区域中的某一个场所到达另一个场所。
实验时数:
3学时(第14周和第15周)
实验各种排序算法实现
试验目的:
1、掌握各种内部排序算法并能实现
2、了解各种方法的排序过程以及时间复杂度
实验内容:
分别用直接插入排序、冒泡排序、直接选择排序和快速排序对下列序列进行排序{6,46 ,2,5,10,23,18,34,29,55,20},输出排序后的结果。
实验时数:
4学时(第16周和第17周)
数据结构实验十一:图实验
一,实验题目 实验十一:图实验 采用邻接表存储有向图,设计算法判断任意两个顶点间手否存在路径。 二,问题分析 本程序要求采用邻接表存储有向图,设计算法判断任意两个顶点间手否存在路径,完成这些操作需要解决的关键问题是:用邻接表的形式存储有向图并输出该邻接表。用一个函数实现判断任意两点间是否存在路径。 1,数据的输入形式和输入值的范围:输入的图的结点均为整型。 2,结果的输出形式:输出的是两结点间是否存在路径的情况。 3,测试数据:输入的图的结点个数为:4 输入的图的边得个数为:3 边的信息为:1 2,2 3,3 1 三,概要设计 (1)为了实现上述程序的功能,需要: A,用邻接表的方式构建图 B,深度优先遍历该图的结点 C,判断任意两结点间是否存在路径 (2)本程序包含6个函数: a,主函数main() b,用邻接表建立图函数create_adjlistgraph() c,深度优先搜索遍历函数dfs() d,初始化遍历数组并判断有无通路函数dfs_trave() e,输出邻接表函数print() f,释放邻接表结点空间函数freealgraph() 各函数间关系如右图所示: 四,详细设计 (1)邻接表中的结点类型定义:
typedef struct arcnode{ int adjvex; arcnode *nextarc; }arcnode; (2)邻接表中头结点的类型定义: typedef struct{ char vexdata; arcnode *firstarc; }adjlist; (3)邻接表类型定义: typedef struct{ adjlist vextices[max]; int vexnum,arcnum; }algraph; (4)深度优先搜索遍历函数伪代码: int dfs(algraph *alg,int i,int n){ arcnode *p; visited[i]=1; p=alg->vextices[i].firstarc; while(p!=NULL) { if(visited[p->adjvex]==0){ if(p->adjvex==n) {flag=1; } dfs(alg,p->adjvex,n); if(flag==1) return 1; } p=p->nextarc; } return 0; } (5)初始化遍历数组并判断有无通路函数伪代码: void dfs_trave(algraph *alg,int x,int y){ int i; for(i=0;i<=alg->vexnum;i++) visited[i]=0; dfs(alg,x,y); } 五,源代码 #include "stdio.h" #include "stdlib.h" #include "malloc.h" #define max 100 typedef struct arcnode{ //定义邻接表中的结点类型 int adjvex; //定点信息 arcnode *nextarc; //指向下一个结点的指针nextarc }arcnode; typedef struct{ //定义邻接表中头结点的类型 char vexdata; //头结点的序号 arcnode *firstarc; //定义一个arcnode型指针指向头结点所对应的下一个结点}adjlist; typedef struct{ //定义邻接表类型 adjlist vextices[max]; //定义表头结点数组
数据结构实验报告格式
《数据结构课程实验》大纲 一、《数据结构课程实验》的地位与作用 “数据结构”是计算机专业一门重要的专业技术基础课程,是计算机专业的一门核心的关键性课程。本课程较系统地介绍了软件设计中常用的数据结构以及相应的存储结构和实现算法,介绍了常用的多种查找和排序技术,并做了性能分析和比较,内容非常丰富。本课程的学习将为后续课程的学习以及软件设计水平的提高打下良好的基础。 由于以下原因,使得掌握这门课程具有较大的难度: (1)内容丰富,学习量大,给学习带来困难; (2)贯穿全书的动态链表存储结构和递归技术是学习中的重点也是难点; (3)所用到的技术多,而在此之前的各门课程中所介绍的专业性知识又不多,因而加大了学习难度; (4)隐含在各部分的技术和方法丰富,也是学习的重点和难点。 根据《数据结构课程》课程本身的技术特性,设置《数据结构课程实验》实践环节十分重要。通过实验实践内容的训练,突出构造性思维训练的特征, 目的是提高学生组织数据及编写大型程序的能力。实验学时为18。 二、《数据结构课程实验》的目的和要求 不少学生在解答习题尤其是算法设计题时,觉得无从下手,做起来特别费劲。实验中的内容和教科书的内容是密切相关的,解决题目要求所需的各种技术大多可从教科书中找到,只不过其出现的形式呈多样化,因此需要仔细体会,在反复实践的过程中才能掌握。 为了帮助学生更好地学习本课程,理解和掌握算法设计所需的技术,为整个专业学习打好基础,要求运用所学知识,上机解决一些典型问题,通过分析、设计、编码、调试等各环节的训练,使学生深刻理解、牢固掌握所用到的一些技术。数据结构中稍微复杂一些的算法设计中可能同时要用到多种技术和方法,如算法设计的构思方法,动态链表,算法的编码,递归技术,与特定问题相关的技术等,要求重点掌握线性链表、二叉树和树、图结构、数组结构相关算法的设计。在掌握基本算法的基础上,掌握分析、解决实际问题的能力。 三、《数据结构课程实验》内容 课程实验共18学时,要求完成以下六个题目: 实习一约瑟夫环问题(2学时)
《数据结构》实验1实验报告
南京工程学院实验报告 <班级>_<学号>_<实验X>.RAR文件形式交付指导老师。 一、实验目的 1. 掌握查找的不同方法,并能用高级语言实现查找算法; 2. 熟练掌握二叉排序树的构造和查找方法。 3. 了解静态查找表及哈希表查找方法。 二、实验内容 设计一个算法读入一串整数,然后构造二叉排序树,进行查找。 三、实验步骤 1. 从空的二叉树开始,每输入一个结点数据,就建立一个新结点插入到当前已生成的二叉排序树中。 2. 在二叉排序树中查找某一结点。 3.用其它查找算法进行排序。
四、程序主要语句及作用 程序1的主要代码 public class BinarySearchTreeNode //二叉查找树结点 { public int key; public BinarySearchTreeNode left; public BinarySearchTreeNode right; public BinarySearchTreeNode(int nodeValue) { key = nodeValue; left = null; right = null; } public void InsertNode(BinarySearchTreeNode node)//插入结点 { if (node.key > this.key) { if (this.right == null) { this.right = node; return; } else this.right.InsertNode(node); } else { if (this.left == null) { this.left = node; return; } else this.left.InsertNode(node); } } public bool SearchKey(int searchValue) { if (this.key == searchValue) return true; if (searchValue > this.key) { if (this.right == null) return false; else return this.right.SearchKey(searchValue); } else { if (this.left == null) return false; else return this.left.SearchKey(searchValue); }
(完整版)数据结构实验报告全集
数据结构实验报告全集 实验一线性表基本操作和简单程序 1 .实验目的 (1 )掌握使用Visual C++ 6.0 上机调试程序的基本方法; (2 )掌握线性表的基本操作:初始化、插入、删除、取数据元素等运算在顺序存储结构和链表存储结构上的程序设计方法。 2 .实验要求 (1 )认真阅读和掌握和本实验相关的教材内容。 (2 )认真阅读和掌握本章相关内容的程序。 (3 )上机运行程序。 (4 )保存和打印出程序的运行结果,并结合程序进行分析。 (5 )按照你对线性表的操作需要,重新改写主程序并运行,打印出文件清单和运行结果 实验代码: 1)头文件模块 #include iostream.h>// 头文件 #include
nodetype *create()// 建立单链表,由用户输入各结点data 域之值, // 以0 表示输入结束 { elemtype d;// 定义数据元素d nodetype *h=NULL,*s,*t;// 定义结点指针 int i=1; cout<<" 建立一个单链表"<
数据结构实验报告图实验
图实验一,邻接矩阵的实现 1.实验目的 (1)掌握图的逻辑结构 (2)掌握图的邻接矩阵的存储结构 (3)验证图的邻接矩阵存储及其遍历操作的实现 2.实验内容 (1)建立无向图的邻接矩阵存储 (2)进行深度优先遍历 (3)进行广度优先遍历 3.设计与编码 MGraph.h #ifndef MGraph_H #define MGraph_H const int MaxSize = 10;
template
#include
数据结构实验报告
数据结构实验报告 一.题目要求 1)编程实现二叉排序树,包括生成、插入,删除; 2)对二叉排序树进行先根、中根、和后根非递归遍历; 3)每次对树的修改操作和遍历操作的显示结果都需要在屏幕上用树的形状表示出来。 4)分别用二叉排序树和数组去存储一个班(50人以上)的成员信息(至少包括学号、姓名、成绩3项),对比查找效率,并说明在什么情况下二叉排序树效率高,为什么? 二.解决方案 对于前三个题目要求,我们用一个程序实现代码如下 #include 数据结构实验总结报告 一、调试过程中遇到哪些问题? (1)在二叉树的调试中,从广义表生成二叉树的模块花了较多时间调试。 由于一开始设计的广义表的字符串表示没有思考清晰,处理只有一个孩子的节点时发生了混乱。调试之初不以为是设计的问题,从而在代码上花了不少时间调试。 目前的设计是: Tree = Identifier(Node,Node) Node = Identifier | () | Tree Identifier = ASCII Character 例子:a(b((),f),c(d,e)) 这样便消除了歧义,保证只有一个孩子的节点和叶节点的处理中不存在问题。 (2)Huffman树的调试花了较长时间。Huffman编码本身并不难处理,麻烦的是输入输出。①Huffman编码后的文件是按位存储的,因此需要位运算。 ②文件结尾要刷新缓冲区,这里容易引发边界错误。 在实际编程时,首先编写了屏幕输入输出(用0、1表示二进制位)的版本,然后再加入二进制文件的读写模块。主要调试时间在后者。 二、要让演示版压缩程序具有实用性,哪些地方有待改进? (1)压缩文件的最后一字节问题。 压缩文件的最后一字节不一定对齐到字节边界,因此可能有几个多余的0,而这些多余的0可能恰好构成一个Huffman编码。解码程序无法获知这个编码是否属于源文件的一部分。因此有的文件解压后末尾可能出现一个多余的字节。 解决方案: ①在压缩文件头部写入源文件的总长度(字节数)。需要四个字节来存储这个信息(假定文件长度不超过4GB)。 ②增加第257个字符(在一个字节的0~255之外)用于EOF。对于较长的文件, 会造成较大的损耗。 ③在压缩文件头写入源文件的总长度%256的值,需要一个字节。由于最后一个字节存在或不存在会影响文件总长%256的值,因此可以根据这个值判断整个压缩文件的最后一字节末尾的0是否在源文件中存在。 (2)压缩程序的效率问题。 在编写压缩解压程序时 ①编写了屏幕输入输出的版本 ②将输入输出语句用位运算封装成一次一个字节的文件输入输出版本 ③为提高输入输出效率,减少系统调用次数,增加了8KB的输入输出缓存窗口 这样一来,每写一位二进制位,就要在内部进行两次函数调用。如果将这些代码合并起来,再针对位运算进行一些优化,显然不利于代码的可读性,但对程序的执行速度将有一定提高。 (3)程序界面更加人性化。 Huffman Tree Demo (C) 2011-12-16 boj Usage: huffman [-c file] [-u file] output_file -c Compress file. e.g. huffman -c test.txt test.huff -u Uncompress file. e.g. huffman -u test.huff test.txt 目前的程序提示如上所示。如果要求实用性,可以考虑加入其他人性化的功能。 三、调研常用的压缩算法,对这些算法进行比较分析 (一)无损压缩算法 ①RLE RLE又叫Run Length Encoding,是一个针对无损压缩的非常简单的算法。它用重复字节和重复的次数来简单描述来代替重复的字节。尽管简单并且对于通常的压缩非常低效,但它有的时候却非常有用(例如,JPEG就使用它)。 变体1:重复次数+字符 文本字符串:A A A B B B C C C C D D D D,编码后得到:3 A 3 B 4 C 4 D。 邻接矩阵的实现 1. 实验目的 (1)掌握图的逻辑结构 (2)掌握图的邻接矩阵的存储结构 (3)验证图的邻接矩阵存储及其遍历操作的实现2. 实验内容 (1)建立无向图的邻接矩阵存储 (2)进行深度优先遍历 (3)进行广度优先遍历3.设计与编码MGraph.h #ifndef MGraph_H #define MGraph_H const int MaxSize = 10; template int vertexNum, arcNum; }; #endif MGraph.cpp #include 实验1 (C语言补充实验) 有顺序表A和B,其元素值均按从小到大的升序排列,要求将它们合并成一 个顺序表C,且C的元素也是从小到大的升序排列。 #include 求A QB #include 2009级数据结构实验报告 实验名称:约瑟夫问题 学生姓名:李凯 班级:21班 班内序号:06 学号:09210609 日期:2010年11月5日 1.实验要求 1)功能描述:有n个人围城一个圆圈,给任意一个正整数m,从第一个人开始依次报数,数到m时则第m个人出列,重复进行,直到所有人均出列为止。请输出n个人的出列顺序。 2)输入描述:从源文件中读取。 输出描述:依次从显示屏上输出出列顺序。 2. 程序分析 1)存储结构的选择 单循环链表 2)链表的ADT定义 ADT List{ 数据对象:D={a i|a i∈ElemSet,i=1,2,3,…n,n≧0} 数据关系:R={< a i-1, a i>| a i-1 ,a i∈D,i=1,2,3,4….,n} 基本操作: ListInit(&L);//构造一个空的单链表表L ListEmpty(L); //判断单链表L是否是空表,若是,则返回1,否则返回0. ListLength(L); //求单链表L的长度 GetElem(L,i);//返回链表L中第i个数据元素的值; ListSort(LinkList [内容要求] 1、存储结构:顺序表、单链表或其他存储结构,需要画示意图,可参考书上P59 页图2-9 2.2 关键算法分析 结点类: template 班级::学号: 实验一线性表的基本操作 一、实验目的 1、掌握线性表的定义; 2、掌握线性表的基本操作,如建立、查找、插入和删除等。 二、实验容 定义一个包含学生信息(学号,,成绩)的顺序表和链表(二选一),使其具有如下功能: (1) 根据指定学生个数,逐个输入学生信息; (2) 逐个显示学生表中所有学生的相关信息; (3) 根据进行查找,返回此学生的学号和成绩; (4) 根据指定的位置可返回相应的学生信息(学号,,成绩); (5) 给定一个学生信息,插入到表中指定的位置; (6) 删除指定位置的学生记录; (7) 统计表中学生个数。 三、实验环境 Visual C++ 四、程序分析与实验结果 #include typedef int Status; // 定义函数返回值类型 typedef struct { char num[10]; // 学号 char name[20]; // double grade; // 成绩 }student; typedef student ElemType; typedef struct LNode { ElemType data; // 数据域 struct LNode *next; //指针域 }LNode,*LinkList; Status InitList(LinkList &L) // 构造空链表L { L=(struct LNode*)malloc(sizeof(struct LNode)); L->next=NULL; return OK; 数据结构实验报告 实验名称:实验1——线性表 学生姓名: 班级: 班内序号: 学号: 日期: 1.实验要求 1、实验目的:熟悉C++语言的基本编程方法,掌握集成编译环境的调试方法 学习指针、模板类、异常处理的使用 掌握线性表的操作的实现方法 学习使用线性表解决实际问题的能力 2、实验内容: 题目1: 线性表的基本功能: 1、构造:使用头插法、尾插法两种方法 2、插入:要求建立的链表按照关键字从小到大有序 3、删除 4、查找 5、获取链表长度 6、销毁 7、其他:可自行定义 编写测试main()函数测试线性表的正确性。 2. 程序分析 存储结构 带头结点的单链表 关键算法分析 1.头插法 a、伪代码实现:在堆中建立新结点 将x写入到新结点的数据域 修改新结点的指针域 修改头结点的指针域,将新结点加入链表中 b、代码实现: Linklist::Linklist(int a[],int n) 堆中建立新结点 b.将a[i]写入到新结点的数据域 c.将新结点加入到链表中 d.修改修改尾指针 b、代码实现: Linklist::Linklist(int a[],int n,int m)取链表长度函数 a、伪代码实现:判断该链表是否为空链表,如果是,输出长度0 如果不是空链表,新建立一个temp指针,初始化整形数n为0 将temp指针指向头结点 判断temp指针指向的结点的next域是否为空,如果不是,n加一,否 则return n 使temp指针逐个后移,重复d操作,直到temp指针指向的结点的next 域为0,返回n b 、代码实现 void Linklist::Getlength()Linklist(); cout< 《数据结构实验》的实验题目及实验报告模板 实验一客房管理(链表实验) ●实现功能:采用结构化程序设计思想,编程实现客房管理程序的各个功能函数,从而熟练 掌握单链表的创建、输出、查找、修改、插入、删除、排序和复杂综合应用等操作的算法 实现。以带表头结点的单链表为存储结构,实现如下客房管理的设计要求。 ●实验机时:8 ●设计要求: #include 附录A 实验报告 课程:数据结构(c语言)实验名称:图的建立、基本操作以及遍历系别:数字媒体技术实验日期: 12月13号 12月20号 专业班级:媒体161 组别:无 姓名:学号: 实验报告内容 验证性实验 一、预习准备: 实验目的: 1、熟练掌握图的结构特性,熟悉图的各种存储结构的特点及适用范围; 2、熟练掌握几种常见图的遍历方法及遍历算法; 实验环境:Widows操作系统、VC6.0 实验原理: 1.定义: 基本定义和术语 图(Graph)——图G是由两个集合V(G)和E(G)组成的,记为G=(V,E),其中:V(G)是顶点(V ertex)的非空有限集E(G)是边(Edge)的有限集合,边是顶点的无序对(即:无方向的,(v0,v2))或有序对(即:有方向的, 无向图中顶点V i的度TD(V i)是邻接矩阵A中第i行元素之和有向图中, 顶点V i的出度是A中第i行元素之和 顶点V i的入度是A中第i列元素之和 邻接表 实现:为图中每个顶点建立一个单链表,第i个单链表中的结点表示依附于顶点Vi的边(有向图中指以Vi为尾的弧) 特点: 无向图中顶点Vi的度为第i个单链表中的结点数有向图中 顶点Vi的出度为第i个单链表中的结点个数 顶点Vi的入度为整个单链表中邻接点域值是i的结点个数 逆邻接表:有向图中对每个结点建立以Vi为头的弧的单链表。 图的遍历 从图中某个顶点出发访遍图中其余顶点,并且使图中的每个顶点仅被访问一次过程.。遍历图的过程实质上是通过边或弧对每个顶点查找其邻接点的过程,其耗费的时间取决于所采用的存储结构。图的遍历有两条路径:深度优先搜索和广度优先搜索。当用邻接矩阵作图的存储结构时,查找每个顶点的邻接点所需要时间为O(n2),n为图中顶点数;而当以邻接表作图的存储结构时,找邻接点所需时间为O(e),e 为无向图中边的数或有向图中弧的数。 实验内容和要求: 选用任一种图的存储结构,建立如下图所示的带权有向图: 要求:1、建立边的条数为零的图; 数据结构实验报告 (实验名称) 1.实验目标 熟练掌握线性表的顺序存储结构和链式存储结构。 熟练掌握顺序表和链表的有关算法设计。 根据具体问题的需要,设计出合理的表示数据的顺序和链式结构,并设计相关算法。 2.实验内容和要求 内容: <1>在第i个结点前插入值为x的结点。 实验测试数据基本要求: 第一组数据:线性表长度n≥10,x=100, i分别为5,n,n+1,0,1,n+2 第二组数据:线性表长度n=0,x=100,i=5 <2>删除线性表中第i个元素结点。 实验测试数据基本要求: 第一组数据:线性表长度n≥10,i分别为5,n,1,n+1,0 第二组数据:线性表长度n=0, i=5 <3>在一个递增有序的线性表L中插入一个值为x的元素,并保持其递增有 序特性。 实验测试数据基本要求: 线性表元素为(10,20,30,40,50,60,70,80,90,100), x分别为25,85,110和8 <4>求两个递增有序线性表L1和L2中的公共元素,放入新的顺序表L3中。 实验测试数据基本要求: 第一组 第一个线性表元素为(1,3,6,10,15,16,17,18,19,20) 第二个线性表元素为(1,2,3,4,5,6,7,8,9,10,18,20,30)第二组 第一个线性表元素为(1,3,6,10,15,16,17,18,19,20) 第二个线性表元素为(2,4,5,7,8,9,12,22) 第三组 第一个线性表元素为() 第二个线性表元素为(1,2,3,4,5,6,7,8,9,10) 要求:每个题目分别用顺序存储和链式存储实现; 实验程序有较好可读性,各运算和变量的命名直观易懂,符合软件工程要求; 程序有适当的注释。 3.数据结构设计 顺序表结构,链表结构。 4.算法设计 (除书上给出的基本运算(这部分不必给出设计思想),其它实验内容要给出算法设计思想) 按顺序插入:首先插入一个元素,表长加一,用do,while循环整个顺序表,从最后一位开始,比x大的都向后移一位,在第一个小于x的后面停止遍历,吧x插在比x小的第一个数的后面。 寻找两个顺序表中相同的元素:运用嵌套循环,最外层循环遍历第一个表里面的元素为母元素,内部循环遍历第二个表为子元素。在子元素中查找与母元素相同的元素,改变第一个表里面的元素,把相同的放进去,最后删除表一中除了新放进来的元素。 5.运行和测试 顺序表: 1: 2: 数据结构教程 上机实验报告 实验七、图算法上机实现 一、实验目的: 1.了解熟知图的定义和图的基本术语,掌握图的几种存储结构。 2.掌握邻接矩阵和邻接表定义及特点,并通过实例解析掌握邻接矩阵和邻接表的类型定义。 3.掌握图的遍历的定义、复杂性分析及应用,并掌握图的遍历方法及其基本思想。 二、实验内容: 1.建立无向图的邻接矩阵 2.图的xx优先搜索 3.图的xx优先搜索 三、实验步骤及结果: 1.建立无向图的邻接矩阵: 1)源代码: #include "stdio.h" #include "stdlib.h" #define MAXSIZE 30 typedefstruct{charvertex[MAXSIZE];//顶点为字符型且顶点表的长度小于MAXSIZE intedges[MAXSIZE][MAXSIZE];//边为整形且edges为邻近矩阵 }MGraph;//MGraph为采用邻近矩阵存储的图类型 voidCreatMGraph(MGraph *g,inte,int n) {//建立无向图的邻近矩阵g->egdes,n为顶点个数,e为边数inti,j,k; printf("Input data of vertexs(0~n-1): \n"); for(i=0;i 2011~2012第一学期数据结构实验报告 班级:信管一班 学号:201051018 姓名:史孟晨 实验报告题目及要求 一、实验题目 设某班级有M(6)名学生,本学期共开设N(3)门课程,要求实现并修改如下程序(算法)。 1. 输入学生的学号、姓名和 N 门课程的成绩(输入提示和输出显示使用汉字系统), 输出实验结果。(15分) 2. 计算每个学生本学期 N 门课程的总分,输出总分和N门课程成绩排在前 3 名学 生的学号、姓名和成绩。 3. 按学生总分和 N 门课程成绩关键字升序排列名次,总分相同者同名次。 二、实验要求 1.修改算法。将奇偶排序算法升序改为降序。(15分) 2.用选择排序、冒泡排序、插入排序分别替换奇偶排序算法,并将升序算法修改为降序算法;。(45分)) 3.编译、链接以上算法,按要求写出实验报告(25)。 4. 修改后算法的所有语句必须加下划线,没做修改语句保持按原样不动。 5.用A4纸打印输出实验报告。 三、实验报告说明 实验数据可自定义,每种排序算法数据要求均不重复。 (1) 实验题目:《N门课程学生成绩名次排序算法实现》; (2) 实验目的:掌握各种排序算法的基本思想、实验方法和验证算法的准确性; (3) 实验要求:对算法进行上机编译、链接、运行; (4) 实验环境(Windows XP-sp3,Visual c++); (5) 实验算法(给出四种排序算法修改后的全部清单); (6) 实验结果(四种排序算法模拟运行后的实验结果); (7) 实验体会(文字说明本实验成功或不足之处)。 三、实验源程序(算法) Score.c #include "stdio.h" #include "string.h" #define M 6 #define N 3 struct student { char name[10]; int number; int score[N+1]; /*score[N]为总分,score[0]-score[2]为学科成绩*/ }stu[M]; void changesort(struct student a[],int n,int j) {int flag=1,i; struct student temp; while(flag) { flag=0; for(i=1;i数据结构实验总结报告
数据结构实验报告图实验
数据结构实验
数据结构实验报告模板
数据结构实验一 实验报告
数据结构实验一题目一线性表实验报告
《数据结构实验》实验题目及实验报告模板
数据结构实验报告(图)
数据结构实验报告一
数据结构图实验报告
数据结构实验报告及心得体会