植物生理实验报告

缺氮对植物生长的影响
王涛赵为朋
河北农业大学,农学院,植物科学与技术0901班
摘要:已有的实验结果表明,氮、磷、钾肥不同用量配比对于米的产量、效益有较大影响[1]。为研究缺氮对玉米生长发育的影响,以沈玉26 CK玉米为材料,在苗期进行缺氮处理。通过对玉米幼苗生长速度、根冠比、叶片叶绿素含量、地上部和根鲜重等指标进行研究,结果表明:株高在处理后第7天出现明显差异,处理组株高低于对照组2.8cm,仅为对照组的83.33%;对照与处理组间根冠比出现显著差异;对照与处理组间叶绿素含量出现显著差异;地上部和根鲜重出现显著差异。故上述指标可以作为玉米幼苗缺氮对其生长的影响的指标。
关键词:玉米;氮素;生长状况;根冠比;叶绿素含量;地上部和根鲜重比例随着我国人民生活水平的提高和畜牧业的迅速发展, 玉米在饲料中的地位愈来愈重要。我国在大部分玉米供作饲料后, 玉米的生物学产量及其饲用营养品质倍受重视。关于氮素对玉米子粒产量影响
的报道较多[ 2-3 ]。氮素既是植物最重要的结构物质,又是生理代谢中最活跃、无处不在的重要物质——酶的主要成分[ 4]另外作为实验材料玉米幼苗易取得,试验速度快,容易观察。本文以沈玉26CK为实验材料,旨在研究缺氮对玉米幼苗的生长带来的影响和其表现症状。杨丽娟〔5〕、黄鑫〔6〕等分别对玉米进行了缺素症状研究何萍研究了氮肥对春玉米叶片衰老的影响[7 ] ;关义新等研究了光氮互作对玉米幼苗叶片光合碳、氮代谢的影响[8 ] 。结果显示:缺N、P、K、Ca、Mg、Fe 等几种元素.玉米苗地上与地下部分均与对照有显著差异。
1 材料与方法
1.1 材料
供试玉米品种为沈玉26CK,沈玉26CK玉米的种子及其经过培养的幼苗,本实验采用数据取自3号和6号所培养的沈玉26CK玉米幼苗。
其他:蛭石,塑料盆、盘,标签纸,完全营养液,缺氮营养液,95%的乙醇,洗瓶,研钵(一套),25ml棕色容量瓶(两个),玻璃棒,漏斗(两个),50ml 小烧杯(两个),漏斗架,剪刀,直尺,滤纸,托盘,胶头滴管,1ml玻璃比色杯,电子天平,721E型可见分光光度计
1.2 方法
1.2.1 播种
每组选取6个花盆,装满蛭石后,每3盆放入一个塑料盘内,从沈玉26CK 品种的玉米籽粒中选取试验用种子,在每个塑料盆里种6粒,用自来水浸润,保持湿润,放于向阳的阳台上发芽。
1.2.2 选苗,移栽
培养一周后,进行选苗移栽,每组选取6个花盆,装满蛭石后,每3盆放入一个塑料盘内,每组选取生长一致的玉米幼苗,掐去部分根,栽于盆中(1株/盆)在两个塑料盘内分别加入完全营养液和缺氮营养液浸润,贴好标签(营养液类型,姓名,日期,玉米品种)
1.2.3 配营养液及浇灌
1.2.3.1 配制营养液
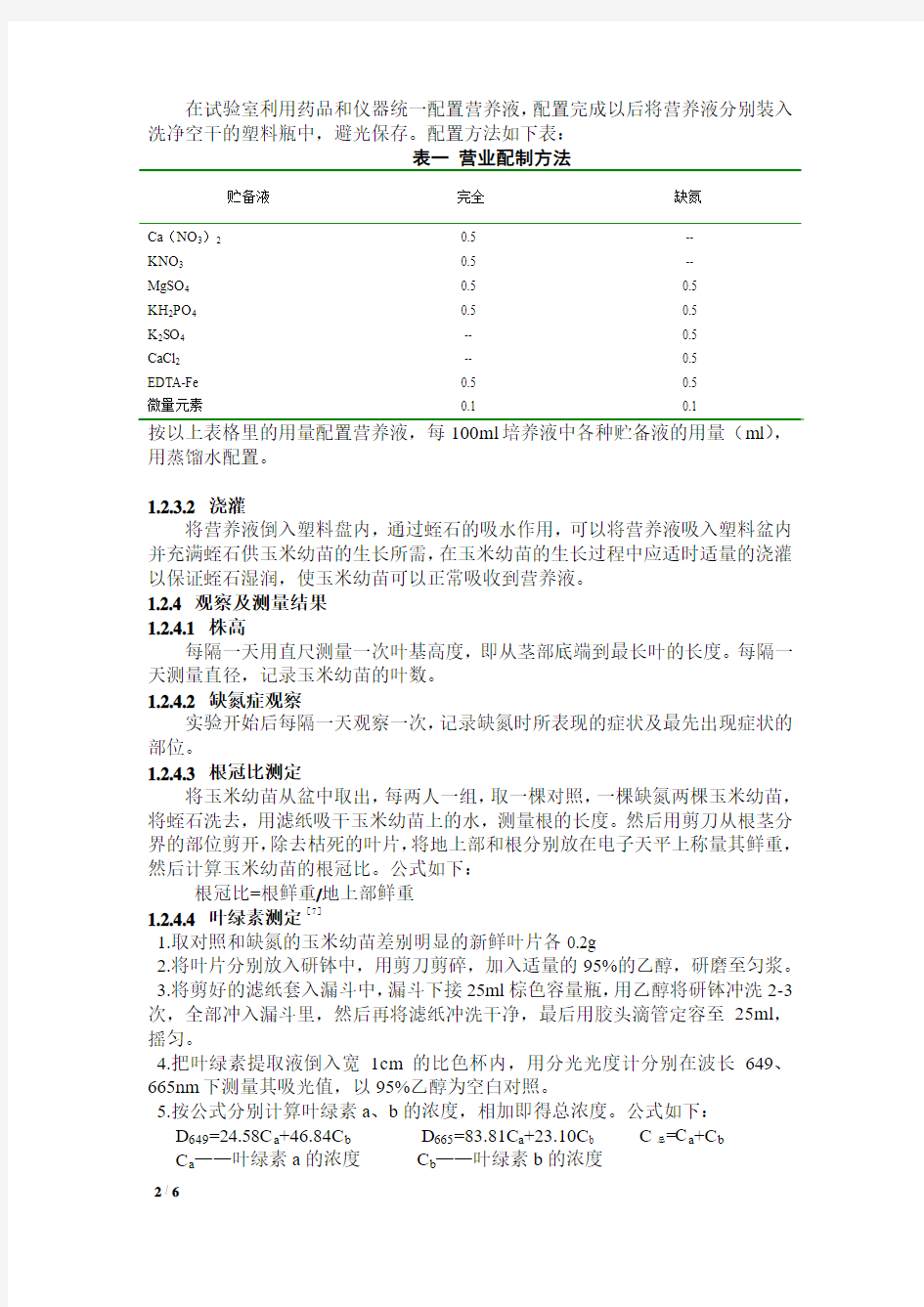
在试验室利用药品和仪器统一配置营养液,配置完成以后将营养液分别装入洗净空干的塑料瓶中,避光保存。配置方法如下表:
表一营业配制方法
贮备液完全缺氮
Ca(NO3)20.5 --
KNO30.5 --
MgSO40.5 0.5
KH2PO40.5 0.5
K2SO4-- 0.5
CaCl2-- 0.5
EDTA-Fe 0.5 0.5
微量元素0.1 0.1
用蒸馏水配置。
1.2.3.2 浇灌
将营养液倒入塑料盘内,通过蛭石的吸水作用,可以将营养液吸入塑料盆内并充满蛭石供玉米幼苗的生长所需,在玉米幼苗的生长过程中应适时适量的浇灌以保证蛭石湿润,使玉米幼苗可以正常吸收到营养液。
1.2.4 观察及测量结果
1.2.4.1 株高
每隔一天用直尺测量一次叶基高度,即从茎部底端到最长叶的长度。每隔一天测量直径,记录玉米幼苗的叶数。
1.2.4.2 缺氮症观察
实验开始后每隔一天观察一次,记录缺氮时所表现的症状及最先出现症状的部位。
1.2.4.3 根冠比测定
将玉米幼苗从盆中取出,每两人一组,取一棵对照,一棵缺氮两棵玉米幼苗,将蛭石洗去,用滤纸吸干玉米幼苗上的水,测量根的长度。然后用剪刀从根茎分界的部位剪开,除去枯死的叶片,将地上部和根分别放在电子天平上称量其鲜重,然后计算玉米幼苗的根冠比。公式如下:
根冠比=根鲜重/地上部鲜重
1.2.4.4 叶绿素测定[7]
1.取对照和缺氮的玉米幼苗差别明显的新鲜叶片各0.2g
2.将叶片分别放入研钵中,用剪刀剪碎,加入适量的95%的乙醇,研磨至匀浆。
3.将剪好的滤纸套入漏斗中,漏斗下接25ml棕色容量瓶,用乙醇将研钵冲洗2-3次,全部冲入漏斗里,然后再将滤纸冲洗干净,最后用胶头滴管定容至25ml,摇匀。
4.把叶绿素提取液倒入宽1cm的比色杯内,用分光光度计分别在波长649、665nm下测量其吸光值,以95%乙醇为空白对照。
5.按公式分别计算叶绿素a、b的浓度,相加即得总浓度。公式如下:
D649=24.58C a+46.84C b D665=83.81C a+23.10C b C总=C a+C b
C a——叶绿素a的浓度C b——叶绿素b的浓度
6.求得叶绿素浓度后再按下式计算叶片的叶绿素含量:
叶绿素含量(鲜重%)=(C 总×1000×25×10-3)/(W ×1000)×100% 1 结果与分析
2.1 缺氮对玉米幼苗症状表现
实验开始第二天处理组幼苗第一片叶子叶尖和基部开始变黄,而对照组叶子无变黄现象,第6天时变黄明显,处理组的第一片叶子完全变黄,对照组仍为绿色,并且处理组幼苗第二片叶子叶尖开始变黄,叶片整体绿色较对照组浅,随着实验进行处理组与对照组叶片差异逐渐明显扩大。处理组整个植株的生长发育状况不如对照组。
2.2 缺氮对株高,生长速度的影响
处理后第3天出现差异,对照组株高大于处理组,处理第7天时差异较为明显,处理组株高低于对照组2.8cm ,仅为对照组的83.33%,第9天开始对照组和处理组株高差异更为显著,并且株高差异扩大趋势明显。
图一 实验过程株高记录
5
10
15
20
25
30
354/295/15/35/55/75/95/11
日期株高
缺氮后玉米生长缓慢,株高增长比不缺氮的玉米幼苗慢。
2.3 缺氮对根冠比的影响
对处理组植株与正常组植株根冠比等指标进行测量结果如下:
表二 玉米植株根冠比与各部分长度
缺N 完全 根重(g )
0.69 0.75 地上部分重量(g )
0.98 1.54 根冠比
0.7 0.49 株高(cm )
19 25.4 根长(cm ) 20.05 17.0
将玉米幼苗的地上部和根分开后用电子天平分别称量其鲜重,对照组的根冠比为0.75g/1.54g=0.49,处理组的根冠比为0.69g/0.98g=0.70.
缺氮后玉米幼苗的根冠鲜重均比不缺氮的玉米幼苗小,根冠比较不缺氮的玉米幼苗大。
2.4 缺氮对叶绿素的影响
在实验室进行叶绿素的提取与测定其含量,结果如下:
表三各样本吸光度值
665nm 649nm
完全0.883 0.432
缺氮0.585 0.280
a b总
表四处理组与正常组叶绿素测定
完全缺氮
C a(g/L)8.6×10-3 6.2×10-3
C b(g/L) 4.7×10-3 2.7×10-3
C总(g/L)0.013 8.9×10-3
叶绿素含量(1.6×10-4)% (1.11×10-4)%
缺氮的玉米幼苗叶绿素含量明显小于不缺氮的玉米幼苗。
3. 讨论
植物除了从土壤中吸收水分外,还要吸收矿质元素以维持正常生命活动。缺乏某种必须元素时会引起生理和形态上的变化。氮素是作物体内叶绿素、蛋白质、核酸和一些激素的重要组成部分[8 ] ,几乎影响了光合作用的各个环节,包括叶片
叶绿素含量、光合速率、暗反应主要酶活性以及光呼吸等,直接或间接影响着光合作用[9]本实验所观测的缺氮后的症状,株高均在3天后才表现出差异,基部第一片叶在第6天后出现明显差异,处理组的根长比对照组的稍长,直径小,根冠比较对照组的要大。在植株缺乏氮素后根系为寻找氮素,主动向下伸长,故处理组根系相对较长。缺氮也会影响叶绿素的合成[10],使植株叶片变黄,发育不良。通过对玉米幼苗的缺氮培养实验可以知道,氮素对玉米生长有着很重要的影响,在农业生产中氮肥的使用一定要跟上玉米的生长需求,否则在玉米生长期中出现缺氮的症状是轻则影响植株的正常生长,重则会减产绝收。
参考文献
[1]范贵国, 张莉, 李天书, 王天书.氮、磷、钾肥料施用量对玉米产量和效益的影响[M]. 贵州农业科学2007, 35( 4) : 79-80
[2]李金洪, 李伯航. 矿质营养对玉米营养品质的影响[ J] .玉米科学, 1995, 3( 3) : 54-58.
[3]武际,郭熙盛,王允青等. 不同土壤养分状况下氮钾配施对弱筋小麦产量和品
质的影响. 麦类作物学报,2007 ,27(5) :841 - 846.
[4] 赵平, 孙谷寿, 彭少林. 植物氮素营养的生理生态学研
究[ J] . 生态科学, 2008, 17( 2) : 36-42.
[5] 杨丽娟,李贵琴,桂明珠,等. 玉米缺素症状的研究[J]. 玉米科
学,2007,8(2):75-79.
[6] 黄鑫,王磊,李成,等. 玉米幼苗缺素症状研究[J]. 东北农业大学
报,2009,35(3):272-275.
[7 ] 何萍,金继运,林葆. 氮肥用量对春玉米叶片衰老的影响及其机理研究[J ] . 中国农业科学,2008 ,31 (3) :66 -71
[8 ] 关义新,林葆,凌碧莹. 光、氮及其互作对玉米幼苗叶片光合碳、氮代谢的影响[J ] . 作物学报,2008 ,26 (6) :806 -812
[9 ] 曹翠玲,李生秀. 氮素对作物生理特性及生长的影响[J ] . 华中农业大学学报,2007 ,23 (5) : 581 -586
[10 ]段巍巍,李慧玲,肖凯,李雁鸣. 氮肥对玉米穗位叶光合作用及其生理生化特性的影响.华北农学报,2007 ,22 ( 1 ) : 26-29
图为培养后的玉米幼苗(左缺氮,右完全)
植物生理学实验课程
《植物生理学实验》课程大纲 一、课程概述 课程名称(中文):植物生理学实验 (英文):Plant Physiology Experiments 课程编号:18241054 课程学分:0.8 课程总学时:24 课程性质:专业基础课 前修课程:植物学、生物化学、植物生理学 二、课程内容简介 植物生理学是农林院校各相关专业的重要学科基础课,是学习相关后续课程的必要前提,也是进行农业科学研究和指导农业生产的重要手段和依据。本实验课程紧密结合理论课学习内容,加深学生对理论知识的理解。掌握植物生理学的实验技术、基本原理以及研究过程对了解植物生理学的基本理论是非常重要的。本大纲体现了植物生理学最实用的技术方法。实验内容上和农业生产实践相结合,加强学生服务三农的能力。实验手段和方法上,注重传统、经典技术理论与现代新兴技术的结合,提高学生对新技术、新知识的理解和应用能力。 三、实验目标与要求 植物生理学实验的基本目标旨在培养各专业、各层次学生有关植物生理学方面的基本研究方法和技能,包括基本操作技能的训练、独立工作能力的培养、实事求是的科学工作态度和严谨的工作作风的建立。开设植物生理学实验课程,不仅可以使学生加深对植物生理学基本原理、基础知识的理解,而且对培养学生分析问题、解决问题的能力和严谨的科学态度以及提高科研能力等都具有十分重要的作用。 要求学生实验前必须预习实验指导和有关理论,明确实验目的、原理、预期结果,操作关键步骤及注意事项;实验时要严肃认真专心操作,注意观察实验过程中出现的现象和结果;及时将实验结果如实记录下来;实验结束后,根据实验结果进行科学分析,完成实验报告。 四、学时分配 植物生理学实验课学时分配 实验项目名称学时实验类别备注 植物组织水势的测定3学时验证性 叶绿体色素的提取及定量测定3学时验证性 植物的溶液培养及缺素症状观察3学时验证性 植物呼吸强度的测定3学时设计性 红外CO2分析仪法测定植物呼吸速率3学时设计性选修 植物生长物质生理效应的测定3学时验证性 植物种子生活力的快速测定3学时验证性
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.360docs.net/doc/1a6309391.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.360docs.net/doc/1a6309391.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
数据分析实验报告
数据分析实验报告 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-
第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 统计量 全国居民 农村居民 城镇居民 N 有效 22 22 22 缺失 均值 1116.82 747.86 2336.41 中值 727.50 530.50 1499.50 方差 1031026.918 399673.838 4536136.444 百分位数 25 304.25 239.75 596.25 50 727.50 530.50 1499.50 75 1893.50 1197.00 4136.75 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】
2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验
结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。 (2 )W 检验 结果:在Shapiro-Wilk 检验结果972.00 w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5 多维正态数据的统计量 数据:
数据挖掘实验报告(一)
数据挖掘实验报告(一) 数据预处理 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1.学习均值平滑,中值平滑,边界值平滑的基本原理 2.掌握链表的使用方法 3.掌握文件读取的方法 二、实验设备 PC一台,dev-c++5.11 三、实验内容 数据平滑 假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70。使用你所熟悉的程序设计语言进行编程,实现如下功能(要求程序具有通用性): (a) 使用按箱平均值平滑法对以上数据进行平滑,箱的深度为3。 (b) 使用按箱中值平滑法对以上数据进行平滑,箱的深度为3。 (c) 使用按箱边界值平滑法对以上数据进行平滑,箱的深度为3。 四、实验原理 使用c语言,对数据文件进行读取,存入带头节点的指针链表中,同时计数,均值求三个数的平均值,中值求中间的一个数的值,边界值将中间的数转换为离边界较近的边界值 五、实验步骤 代码 #include
数据挖掘实验报告资料
大数据理论与技术读书报告 -----K最近邻分类算法 指导老师: 陈莉 学生姓名: 李阳帆 学号: 201531467 专业: 计算机技术 日期 :2016年8月31日
摘要 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地提取出有价值的知识模式,以满足人们不同应用的需要。K 近邻算法(KNN)是基于统计的分类方法,是大数据理论与分析的分类算法中比较常用的一种方法。该算法具有直观、无需先验统计知识、无师学习等特点,目前已经成为数据挖掘技术的理论和应用研究方法之一。本文主要研究了K 近邻分类算法,首先简要地介绍了数据挖掘中的各种分类算法,详细地阐述了K 近邻算法的基本原理和应用领域,最后在matlab环境里仿真实现,并对实验结果进行分析,提出了改进的方法。 关键词:K 近邻,聚类算法,权重,复杂度,准确度
1.引言 (1) 2.研究目的与意义 (1) 3.算法思想 (2) 4.算法实现 (2) 4.1 参数设置 (2) 4.2数据集 (2) 4.3实验步骤 (3) 4.4实验结果与分析 (3) 5.总结与反思 (4) 附件1 (6)
1.引言 随着数据库技术的飞速发展,人工智能领域的一个分支—— 机器学习的研究自 20 世纪 50 年代开始以来也取得了很大进展。用数据库管理系统来存储数据,用机器学习的方法来分析数据,挖掘大量数据背后的知识,这两者的结合促成了数据库中的知识发现(Knowledge Discovery in Databases,简记 KDD)的产生,也称作数据挖掘(Data Ming,简记 DM)。 数据挖掘是信息技术自然演化的结果。信息技术的发展大致可以描述为如下的过程:初期的是简单的数据收集和数据库的构造;后来发展到对数据的管理,包括:数据存储、检索以及数据库事务处理;再后来发展到对数据的分析和理解, 这时候出现了数据仓库技术和数据挖掘技术。数据挖掘是涉及数据库和人工智能等学科的一门当前相当活跃的研究领域。 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地抽取出有价值的知识模式,以满足人们不同应用的需要[1]。目前,数据挖掘已经成为一个具有迫切实现需要的很有前途的热点研究课题。 2.研究目的与意义 近邻方法是在一组历史数据记录中寻找一个或者若干个与当前记录最相似的历史纪录的已知特征值来预测当前记录的未知或遗失特征值[14]。近邻方法是数据挖掘分类算法中比较常用的一种方法。K 近邻算法(简称 KNN)是基于统计的分类方法[15]。KNN 分类算法根据待识样本在特征空间中 K 个最近邻样本中的多数样本的类别来进行分类,因此具有直观、无需先验统计知识、无师学习等特点,从而成为非参数分类的一种重要方法。 大多数分类方法是基于向量空间模型的。当前在分类方法中,对任意两个向量: x= ) ,..., , ( 2 1x x x n和) ,..., , (' ' 2 ' 1 'x x x x n 存在 3 种最通用的距离度量:欧氏距离、余弦距 离[16]和内积[17]。有两种常用的分类策略:一种是计算待分类向量到所有训练集中的向量间的距离:如 K 近邻选择K个距离最小的向量然后进行综合,以决定其类别。另一种是用训练集中的向量构成类别向量,仅计算待分类向量到所有类别向量的距离,选择一个距离最小的类别向量决定类别的归属。很明显,距离计算在分类中起关键作用。由于以上 3 种距离度量不涉及向量的特征之间的关系,这使得距离的计算不精确,从而影响分类的效果。
生理学学生实验报告
昆明理工大学医学院 生理学实验报告 (供临床医学专业使用) 实验一坐骨神经-腓肠肌标本制备 [1] 实验目的 1.学习机能学实验基本的组织分离技术;
2.学习和掌握制备蛙类坐骨神经-腓肠肌标本的方法; 3.了解刺激的种类。 [2] 实验原理 蛙类的一些基本生命活动和生理功能与恒温动物相似,若将蛙的神经-肌肉标本放在任氏液中,其兴奋性在几个小时内可保持不变。若给神经或肌肉一次适宜刺激,可在神经和肌肉上产生一个动作电位,肉眼可看到肌肉收缩和舒张一次,表明神经和肌肉产生了一次兴奋。在机能学实验中常利用蛙的坐骨神经-腓肠肌标本研究神经、肌肉的兴奋、兴奋性,刺激与反应的规律和肌肉收缩的特征等,制备坐骨神经腓肠肌标本是机能学实验的一项基本操作技术。 [3] 实验对象 蛙 [4] 实验药品 任氏液 [5] 仪器与器械 普通剪刀、手术剪、眼科镊(或尖头无齿镊)、金属探针(解剖针)、玻璃分针、蛙板(或玻璃板)、蛙钉、细线、培养皿、滴管、电子刺激器。 [6] 实验方法与步骤 ①破坏脑、脊髓 取蛙一只,用自来水冲洗干净(勿用手搓)。左手握住蛙,使其背部向上,用大拇指或食指使头前俯(以头颅后缘稍稍拱起为宜)。右手持探针由头颅后缘的枕骨大孔处垂直刺入椎管(图3-1-1)。然后将探针改向前刺入颅腔内,左右搅动探针2~3次,捣毁脑组织。如果探针在颅腔内,应有碰及颅底骨的感觉。 再将探针退回至枕骨大孔,使针尖转向尾端,捻动探针使其刺入椎管,捣毁脊髓。此时应注意将脊柱保持平直。针进入椎管的感觉是,进针时有一定的阻力,而且随着进针蛙出现下肢僵直或尿失禁现象。若脑和脊髓破坏完全,蛙下颌呼吸运动消失,四肢完全松软,失去一切反射活动。此时可将探针反向捻动,退出椎管。如蛙仍有反射活动,表示脑和脊髓破坏不彻底,应重新破坏。
花的结构和解剖
(五)花的解剖结构 典型的被子植物的一朵花是由花萼、花冠、雄蕊和雌蕊组成的。 具有上述4部分的花称为完全花,如桃、梅等;缺少其中一部分的花称为不完全花,如桑、榉等。从进化角度来分析,花实际上是一种适应于生殖的变态短枝,而花萼、花冠、雄蕊和雌蕊是变态的叶。 1.花梗和花托 花梗(柄)是花与茎的连接部分,主要起支持和输导作用。花梗的顶端是着生花的花托。花托的形状因植物种类的不同而各式各样,如玉兰的花托呈圆锥形,蔷薇花托呈杯状等等。 2.花被 花被是花萼和花冠的总称。 (1)花萼 位于花的外侧,通常由几个萼片组成。有些植物具有两轮花萼,最外轮的为副萼,如木槿、扶桑等。花萼随花脱落的称为早落萼,如桃、梅等;花萼在果实成熟时仍存留的称为宿存萼,如石榴、柿子等。各萼片完全分离的称离萼,如玉兰、毛茛等;花萼连为一体的称合萼,如石竹等。 (2)花冠 位于花萼内侧,由若干花瓣组成,排列为一轮或数轮,对花蕊有保护作用。由于花瓣中含有色素并能分泌芳香油与蜜汁,所以花冠颜色艳丽,具有芳香,能招引昆虫,起到传粉作用。 花冠的类型 A—十字形花冠;B—蝶形花冠;C—管状花冠;D一舌状花冠; E—唇形花冠;F—有距花冠;G一喇叭状花冠;H—漏斗状花冠 (A、B为离瓣花;C~H为合瓣花) l一柱头;2—花柱;3—花药;4一花冠; 5一花丝;6一冠毛;7—胚珠;8一子房 花冠形态因植物种类的不同而千姿百态,按花瓣离合程度,花冠可分为离瓣花冠与合瓣花冠两类(如上图所示)。①离瓣花冠:花瓣基部彼此完全分离,这种花冠称为离瓣花冠,常见有以下几种: 蔷薇型花冠:由5个(或5的倍数)分离的花瓣排列成,如桃、梨等。 十字型花冠:由4个花瓣十字型排列组成,如二月兰、桂竹香等。 ②合瓣花冠:花瓣全部或基部合生的花冠称为合瓣花冠,常见有以下几种:
数据分析实验报告
《数据分析》实验报告 班级:07信计0班学号:姓名:实验日期2010-3-11 实验地点:实验楼505 实验名称:样本数据的特征分析使用软件名称:MATLAB 实验目的1.熟练掌握利用Matlab软件计算均值、方差、协方差、相关系数、标准差与变异系数、偏度与峰度,中位数、分位数、三均值、四分位极差与极差; 2.熟练掌握jbtest与lillietest关于一元数据的正态性检验; 3.掌握统计作图方法; 4.掌握多元数据的数字特征与相关矩阵的处理方法; 实验内容安徽省1990-2004年万元工业GDP废气排放量、废水排放量、固体废物排放量以及用于污染治理的投入经费比重见表6.1.1,解决以下问题:表6.1.1废气、废水、固体废物排放量及污染治理的投入经费占GDP比重 年份 万元工业GDP 废气排放量 万元工业GDP 固体物排放量 万元工业GDP废 水排放量 环境污染治理投 资占GDP比重 (立方米)(千克)(吨)(%)1990 104254.40 519.48 441.65 0.18 1991 94415.00 476.97 398.19 0.26 1992 89317.41 119.45 332.14 0.23 1993 63012.42 67.93 203.91 0.20 1994 45435.04 7.86 128.20 0.17 1995 46383.42 12.45 113.39 0.22 1996 39874.19 13.24 87.12 0.15 1997 38412.85 37.97 76.98 0.21 1998 35270.79 45.36 59.68 0.11 1999 35200.76 34.93 60.82 0.15 2000 35848.97 1.82 57.35 0.19 2001 40348.43 1.17 53.06 0.11 2002 40392.96 0.16 50.96 0.12 2003 37237.13 0.05 43.94 0.15 2004 34176.27 0.06 36.90 0.13 1.计算各指标的均值、方差、标准差、变异系数以及相关系数矩阵; 2.计算各指标的偏度、峰度、三均值以及极差; 3.做出各指标数据直方图并检验该数据是否服从正态分布?若不服从正态分布,利用boxcox变换以后给出该数据的密度函数; 4.上网查找1990-2004江苏省万元工业GDP废气排放量,安徽省与江苏省是 否服从同样的分布?
数据挖掘实验报告-关联规则挖掘
数据挖掘实验报告(二)关联规则挖掘 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1. 1.掌握关联规则挖掘的Apriori算法; 2.将Apriori算法用具体的编程语言实现。 二、实验设备 PC一台,dev-c++5.11 三、实验内容 根据下列的Apriori算法进行编程:
四、实验步骤 1.编制程序。 2.调试程序。可采用下面的数据库D作为原始数据调试程序,得到的候选1项集、2项集、3项集分别为C1、C2、C3,得到的频繁1项集、2项集、3项集分别为L1、L2、L3。
代码 #include 植物生理综合实验报告植物生长调节剂对植物生长的影响 学院: 专业年级: 姓名: 学号: 指导老师: 完成日期: 烯效唑浸种对小麦幼苗生长的影响 摘要:[目的]研究不同浓度烯效唑浸种对小麦幼苗生长的影响。[方法]以小麦品种川育20号为实验材料,分别用0、15、30、45mg/l烯效唑浸种处理,研究其对小麦幼苗形态指标和生理指标的影响。[结果]与对照相比,烯效唑能影响小麦种子呼吸强度,促进其根系活力,并促进根的发育,此外,烯效唑还能使叶绿素含量增多,丙二醛含量减少,增强幼苗抗性。但是,不同浓度烯效唑对幼苗的影响也有不同。[结论]小麦生产过程中,烯效唑使用浓度以15mg/l为宜,该研究可以进一步拓展烯效唑在大田作物上的开发应用前景提供理论依据。关键词:小麦幼苗;烯效唑;形态指标;生理指标;生长 Abstract: [Objective] the aim was to study the different concentrations of Uniconazole on wheat seedling growth effects. [Methods] in wheat varieties from Sichuan Education No. 20 as the experimental material, were treated with 0,15,30,45mg/l Uniconazole treatment and Research on wheat seedling morphological and physiological indexes of influence. [results] and compared to controls, Uniconazole can affect wheat seed respiration and promote the root vigor, and promote root development. In addition, Uniconazole can enable the content of chlorophyll increased and MDA content decreased, enhance seedling resistance. However, effects of different concentrations of Uniconazole on seedling also different. [Conclusion] the production of Wheat , the use of the concentration of 15mg/l is appropriate, the study can further expand the application prospects of the development and application of the application of the effect of the application of the field in the field of crops to provide a theoretical basis. Key words: wheat seedling; the effect of the form index; the physiological index; the growth of the 前言: 烯效唑(S-3307)又名特效唑、高效唑,化学名(E)-1-对氯苯基-2-(1,2,4-三唑-1-基)-4,4-二甲基-1-戊烯-3-醇,烯效唑作为一种广谱、高效的植物生长 一、实验目的 使用数据挖掘中的分类算法,对数据集进行分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平台的基本功能与使用方法。 二、实验环境 实验采用Weka 平台,数据使用Weka安装目录下data文件夹下的默认数据集iris.arff。 Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 三、数据预处理 Weka平台支持ARFF格式和CSV格式的数据。由于本次使用平台自带的ARFF格式数据,所以不存在格式转换的过程。实验所用的ARFF格式数据集如图1所示 图1 ARFF格式数据集(iris.arff) 对于iris数据集,它包含了150个实例(每个分类包含50个实例),共有sepal length、sepal width、petal length、petal width和class五种属性。期中前四种属性为数值类型,class属性为分类属性,表示实例所对应的的类别。该数据集中的全部实例共可分为三类:Iris Setosa、Iris Versicolour和Iris Virginica。 实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。 实验所需的训练集和测试集均为iris.arff。 四、实验过程及结果 应用iris数据集,分别采用LibSVM、C4.5决策树分类器和朴素贝叶斯分类器进行测试和评价,分别在训练数据上训练出分类模型,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 1、LibSVM分类 Weka 平台内部没有集成libSVM分类器,要使用该分类器,需要下载libsvm.jar并导入到Weka中。 用“Explorer”打开数据集“iris.arff”,并在Explorer中将功能面板切换到“Classify”。点“Choose”按钮选择“functions(weka.classifiers.functions.LibSVM)”,选择LibSVM分类算法。 在Test Options 面板中选择Cross-Validatioin folds=10,即十折交叉验证。然后点击“start”按钮: 首都师范大学生命科学学院实验报告 课程名称植物生理学实验成绩 姓名苗雪鹏班级 1班学号 1080800021 实验题目实验三植物体中N、P、K主要养分的速测 【实验目的】 1.了解植物体内N、P、K测定的意义和方法 2.掌握如何测定植物体中N、P、K的实验技能 【实验原理】 植物体主要由C、H、O、N、P、K、Ca、Mg、S、Fe等十几种元素组成,除 此以外还包括Ca、Zn、Mn、B、Mo,但需要量较少。 在通常条件下,植物利用太阳光能,从空气中获得C,从水中获得氢和氧, 而N、P、K等元素则是来源土壤肥力。在栽培过程中,能够知道植物的需要和 土壤内N、P、K变动的情况,对考虑施肥措施是有帮助的,因此测定土壤及植 物体内的N、P、K是很重要的。 硝态N测定:硝态N是硝酸的阴离子(NO 3 -),它是强氧化剂,所以鉴定N- 离子几乎都用氧化反应,用二苯胺(C 6H 5 ) 2 NH的方法,这个方法的原理是在NO 3 - 存在时二苯胺被硝酸氧化而显蓝色。 有效P和无机P测定:P与钼酸铵反应生成磷钼酸铵,然后以氧化亚锡作为还原剂时,使磷钼酸铵还原为“磷钼兰”(低价钼化合物混合物)溶液呈兰色。此法能测土壤有效P,过磷酸钙中有效P和植物体内的无机磷。 速效K的测定:四苯硼钠〔NaB(C 6H 5 ) 4 〕与钾离子生成白色沉淀为四苯硼酸 钾〔KB(C 6H 5 ) 4 〕 【实验材料和试剂】 在完全培养液、缺乏N、P、K、Fe的营养液中培养四周的玉米苗 硝态氮试剂、磷试剂Ⅰ、磷试剂Ⅱ、K试剂、标准溶液1、5、10、20、40ppm 【实验方法】 1.植物组织浸提液制备 将植物剪成小块,称取1g,迅速倒入已沸腾的蒸馏水(约10ml)烧杯中,用毛细玻璃棒经常搅动,小火煮十分钟,煮液倒入10ml容量瓶中,另加少量蒸馏水,继续小火煮植物材料5分钟,浸提液倒入上述容量瓶内,再以少量蒸馏水洗植物材料,使最后容量为10ml。 植物组织在计算含量时要乘以10,因每克鲜组织稀释了10倍。 2.硝态N测定 在白瓷板的凹内分别滴入1、5、10、20、40ppm的混合标准液1滴,然后将待测液(植物浸提液)分别滴入其他凹内,最后每个凹内各加5滴二苯胺硫酸溶 数据分析实验报告 【最新资料,WORD文档,可编辑修改】 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 方差1031026.918399673.8384536136.444百分位数25304.25239.75596.25 50727.50530.501499.50 751893.501197.004136.75 3画直方图,茎叶图,QQ图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民Stem-and-Leaf Plot Frequency Stem & Leaf 9.00 0 . 122223344 5.00 0 . 56788 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 单样本Kolmogorov-Smirnov 检验 身高N60正态参数a,,b均值139.00 标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z.686 渐近显着性(双侧).735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验 实验一 ID3算法实现 一、实验目的 通过编程实现决策树算法,信息增益的计算、数据子集划分、决策树的构建过程。加深对相关算法的理解过程。 实验类型:验证 计划课间:4学时 二、实验内容 1、分析决策树算法的实现流程; 2、分析信息增益的计算、数据子集划分、决策树的构建过程; 3、根据算法描述编程实现算法,调试运行; 4、对所给数据集进行验算,得到分析结果。 三、实验方法 算法描述: 以代表训练样本的单个结点开始建树; 若样本都在同一个类,则该结点成为树叶,并用该类标记; 否则,算法使用信息增益作为启发信息,选择能够最好地将样本分类的属性; 对测试属性的每个已知值,创建一个分支,并据此划分样本; 算法使用同样的过程,递归形成每个划分上的样本决策树 递归划分步骤,当下列条件之一成立时停止: 给定结点的所有样本属于同一类; 没有剩余属性可以进一步划分样本,在此情况下,采用多数表决进行 四、实验步骤 1、算法实现过程中需要使用的数据结构描述: Struct {int Attrib_Col; // 当前节点对应属性 int Value; // 对应边值 Tree_Node* Left_Node; // 子树 Tree_Node* Right_Node // 同层其他节点 Boolean IsLeaf; // 是否叶子节点 int ClassNo; // 对应分类标号 }Tree_Node; 2、整体算法流程 主程序: InputData(); T=Build_ID3(Data,Record_No, Num_Attrib); OutputRule(T); 释放内存; 3、相关子函数: 3.1、 InputData() { 输入属性集大小Num_Attrib; 输入样本数Num_Record; 分配内存Data[Num_Record][Num_Attrib]; 输入样本数据Data[Num_Record][Num_Attrib]; 获取类别数C(从最后一列中得到); } 3.2、Build_ID3(Data,Record_No, Num_Attrib) { Int Class_Distribute[C]; If (Record_No==0) { return Null } N=new tree_node(); 计算Data中各类的分布情况存入Class_Distribute Temp_Num_Attrib=0; For (i=0;i 实验三 一、实验原理 K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 在数据挖掘中,K-Means算法是一种cluster analysis的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。 算法原理: (1) 随机选取k个中心点; (2) 在第j次迭代中,对于每个样本点,选取最近的中心点,归为该类; (3) 更新中心点为每类的均值; (4) j<-j+1 ,重复(2)(3)迭代更新,直至误差小到某个值或者到达一定的迭代步 数,误差不变. 空间复杂度o(N) 时间复杂度o(I*K*N) 其中N为样本点个数,K为中心点个数,I为迭代次数 二、实验目的: 1、利用R实现数据标准化。 2、利用R实现K-Meams聚类过程。 3、了解K-Means聚类算法在客户价值分析实例中的应用。 三、实验内容 依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。对其进行标准差标准化并保存后,采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。编写R程序,完成客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数 四、实验步骤 1、依据航空公司客户价值分析的LRFMC模型提取客户信息的LRFMC指标。 2、确定要探索分析的变量 3、利用R实现数据标准化。 4、采用k-means算法完成客户的聚类,分析每类的客户特征,从而获得每类客户的价值。 客户的k-means聚类,获得聚类中心与类标号,并统计每个类别的客户数 六、思考与分析 使用不同的预处理对数据进行变化,在使用k-means算法进行聚类,对比聚类的结果。 kmenas算法首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。 这样做的前提是我们已经知道数据集中包含多少个簇. 1.与层次聚类结合 经常会产生较好的聚类结果的一个有趣策略是,首先采用层次凝聚算法决定结果 花的解剖结构 典型的被子植物的一朵花是由花萼、花冠、雄蕊和雌蕊组成的。 具有上述4部分的花称为完全花,如桃、梅等;缺少其中一部分的花称为不完全花,如桑、榉等。从进化角度来分析,花实际上是一种适应于生殖的变态短枝,而花萼、花冠、雄蕊和雌蕊是变态的叶。 1.花梗和花托 花梗(柄)是花与茎的连接部分,主要起支持和输导作用。花梗的顶端是着生花的花托。花托的形状因植物种类的不同而各式各样,如玉兰的花托呈圆锥形,蔷薇花托呈杯状等等。 2.花被 花被是花萼和花冠的总称。 (1)花萼 位于花的外侧,通常由几个萼片组成。有些植物具有两轮花萼,最外轮的为副萼,如木槿、扶桑等。花萼随花脱落的称为早落萼,如桃、梅等;花萼在果实成熟时仍存留的称为宿存萼,如石榴、柿子等。各萼片完全分离的称离萼,如玉兰、毛茛等;花萼连为一体的称合萼,如石竹等。 (2)花冠 位于花萼内侧,由若干花瓣组成,排列为一轮或数轮,对花蕊有保护作用。由于花瓣中含有色素并能分泌芳香油与蜜汁,所以花冠颜色艳丽,具有芳香,能招引昆虫,起到传粉作用。 花冠的类型 A—十字形花冠;B—蝶形花冠;C—管状花冠;D一舌状花冠; E—唇形花冠;F—有距花冠;G一喇叭状花冠;H—漏斗状花冠 (A、B为离瓣花;C~H为合瓣花) l一柱头;2—花柱;3—花药;4一花冠; 5一花丝;6一冠毛;7—胚珠;8一子房 花冠形态因植物种类的不同而千姿百态,按花瓣离合程度,花冠可分为离瓣花冠与合瓣花冠两类(如上图所示)。①离瓣花冠:花瓣基部彼此完全分离,这种花冠称为离瓣花冠,常见有以下几种: 蔷薇型花冠:由5个(或5的倍数)分离的花瓣排列成,如桃、梨等。 十字型花冠:由4个花瓣十字型排列组成,如二月兰、桂竹香等。 ②合瓣花冠:花瓣全部或基部合生的花冠称为合瓣花冠,常见有以下几种: 数据分析与挖掘实验报告 《数据挖掘》实验报告 目录 1.关联规则的基本概念和方法 (1) 1.1数据挖掘 (1) 1.1.1数据挖掘的概念 (1) 1.1.2数据挖掘的方法与技术 (2) 1.2关联规则 (5) 1.2.1关联规则的概念 (5) 1.2.2关联规则的实现——Apriori算法 (7) 2.用Matlab实现关联规则 (12) 2.1Matlab概述 (12) 2.2基于Matlab的Apriori算法 (13) 3.用java实现关联规则 (19) 3.1java界面描述 (19) 3.2java关键代码描述 (23) 4、实验总结 (29) 4.1实验的不足和改进 (29) 4.2实验心得 (30) 1.关联规则的基本概念和方法 1.1数据挖掘 1.1.1数据挖掘的概念 计算机技术和通信技术的迅猛发展将人类社会带入到了信息时代。在最近十几年里,数据库中存储的数据急剧增大。数据挖掘就是信息技术自然进化的结果。数据挖掘可以从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的,人们事先不知道的但又是潜在有用的信息和知识的过程。 许多人将数据挖掘视为另一个流行词汇数据中的知识发现(KDD)的同义词,而另一些人只是把数据挖掘视为知识发现过程的一个基本步骤。知识发现过程如下: ·数据清理(消除噪声和删除不一致的数据)·数据集成(多种数据源可以组合在一起)·数据转换(从数据库中提取和分析任务相关的数据) ·数据变换(从汇总或聚集操作,把数据变换和统一成适合挖掘的形式) ·数据挖掘(基本步骤,使用智能方法提取数 据模式) ·模式评估(根据某种兴趣度度量,识别代表知识的真正有趣的模式) ·知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。 1.1.2数据挖掘的方法与技术 数据挖掘吸纳了诸如数据库和数据仓库技术、统计学、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成等许多应用领域的大量技术。数据挖掘主要包括以下方法。神经网络方法:神经网络由于本身良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性非常适合解决数据挖掘的问题,因此近年来越来越受到人们的关注。典型的神经网络模型主要分3大类:以感知机、bp反向传播模型、函数型网络为代表的,用于分类、预测和模式识别的前馈式神经网络模型;以hopfield 的离散模型和连续模型为代表的,分别用于联想记忆和优化计算的反馈式神经网络模型;以art 模型、koholon模型为代表的,用于聚类的自组 数据预处理 一、实验原理 预处理方法基本方法 1、数据清洗 去掉噪声和无关数据 2、数据集成 将多个数据源中的数据结合起来存放在一个一致的数据存储中 3、数据变换 把原始数据转换成为适合数据挖掘的形式 4、数据归约 主要方法包括:数据立方体聚集,维归约,数据压缩,数值归约,离散化和概念分层等二、实验目的 掌握数据预处理的基本方法。 三、实验内容 1、R语言初步认识(掌握R程序运行环境) 2、实验数据预处理。(掌握R语言中数据预处理的使用) 对给定的测试用例数据集,进行以下操作。 1)、加载程序,熟悉各按钮的功能。 2)、熟悉各函数的功能,运行程序,并对程序进行分析。 对餐饮销量数据进统计量分析,求销量数据均值、中位数、极差、标准差,变异系数和四分位数间距。 对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。 3)数据预处理 缺省值的处理:用均值替换、回归查补和多重查补对缺省值进行处理 对连续属性离散化:用等频、等宽等方法对数据进行离散化处理 四、实验步骤 1、R语言运行环境的安装配置和简单使用 (1)安装R语言 R语言下载安装包,然后进行默认安装,然后安装RStudio 工具(2)R语言控制台的使用 1.2.1查看帮助文档 1.2.2 安装软件包 1.2.3 进行简单的数据操作 (3)RStudio 简单使用 1.3.1 RStudio 中进行简单的数据处理 1.3.2 RStudio 中进行简单的数据处理 2、R语言中数据预处理 (1)加载程序,熟悉各按钮的功能。 (2)熟悉各函数的功能,运行程序,并对程序进行分析 2.2.1 销量中位数、极差、标准差,变异系数和四分位数间距。 , 2.2.2对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。植物生长调节剂对植物生长的影响-植物生理学综合实验报告
大数据挖掘weka大数据分类实验报告材料
植物生理学实验报告
数据分析实验报告
数据挖掘实验报告1
数据挖掘实验报告三
花的解剖结构详解
数据分析与挖掘实验报告
数据挖掘实验报告一