SAS编程基础

实验2 SAS编程基础
SAS语言和其它计算机语言一样,也有其专有的词汇(即关键字)和语法。关键字、名字、特殊字符和运算符等按照语法规则排列组成SAS语句,一个SAS程序由若干数据步、过程步组合而成,而每一个程序步通常由若干语句构成。SAS程序是在Editor窗口中进行编辑,提交运行后可以在Log窗口中显示有关信息和提示,在Output窗口显示运行的结果。
2.1 实验目的
通过实验了解SAS编程的基本概念,掌握SAS编程的基本方法,掌握SAS数据步对数据集的管理和对数据的预处理。
2.2 实验内容
一、建立逻辑库与数据集,包括逻辑库的建立、直接输入数据建立数据集与读取外部数据文件建立数据集。
二、数据文件的编辑与整理,包括数据集的横向合并与纵向合并、数据集内容的复制、变量的增加与筛选、数据集的拆分和数据的排序。
2.3 实验指导
一、建立逻辑库与数据集
1.建立逻辑库
【实验2-1】编程建立逻辑库。
(1) 首先在D盘创建一个文件夹,如D:\SAS_SHYAN\SAS数据集。
(2) 建立逻辑库mylib,编辑并运行下面程序语句即可。
libname mylib "D:\sas_shiyan\sas数据集";
2.直接输入数据建立数据集
【实验2-2】将表2-1(sy2_2.xls)中的数据直接输入建立数据集sy2_2,并将其存入逻辑库mylib中。
表2-1 职工工资
编号 姓名 性别工作日期 职称 部门基本工资工龄工资奖金扣款 实发工资
1420
0 3003 王以平男1992-8-1 助工生产620300500
3004 林红女1993-8-1 助工供销620280500 200 12003005 吕兴良男1982-1-30 工程师技术1100500500 100 20003006 司马宇男1971-2-17 工人生产520720500 0 17403007 张学武男1967-10-9 工人保卫520800500 200 16203008 冯玉霞女1987-8-1 工程师生产1100400500 250 17503009 赵大强男1968-5-10 工人财务520780500 0 18003010
王萍
女
1987-8-1
工程师
技术
1100
400
500 100 1900
代码如下:
data mylib.sy2_2; length gzrq $ 10;
input bh $ xm $ xb $ gzrq $ zc $ bm $ jbgz glgz jj kk sfgz; label bh='编号' xm='姓名' xb='性别' gzrq='工作日期' zc='职称' bm='部门' jbgz='基本工资' glgz='工龄工资' jj='奖金' kk='扣款' sfgz='实发工资'; cards; 3003 王以平 男 1992-8-1 助工 生产620 300 500 0 1420 3004 林红 女 1993-8-1 助工 供销620 280 500 200 1200 3005 吕兴良 男 1982-1-30 工程师 技术 1100 500 500 100 2000 3006 司马宇 男 1971-2-17 工人 生产520 720 500 0 1740 3007 张学武 男 1967-10-9 工人 保卫520 800 500 200 1620 3008 冯玉霞 女 1987-8-1 工程师 生产1100 400 500 250 1750 3009 赵大强 男 1968-5-10 工人 财务520 780 500 0 1800 3010 王萍
女 1987-8-1 工程师
技术
1100 400 500 100 1900
; RUN;
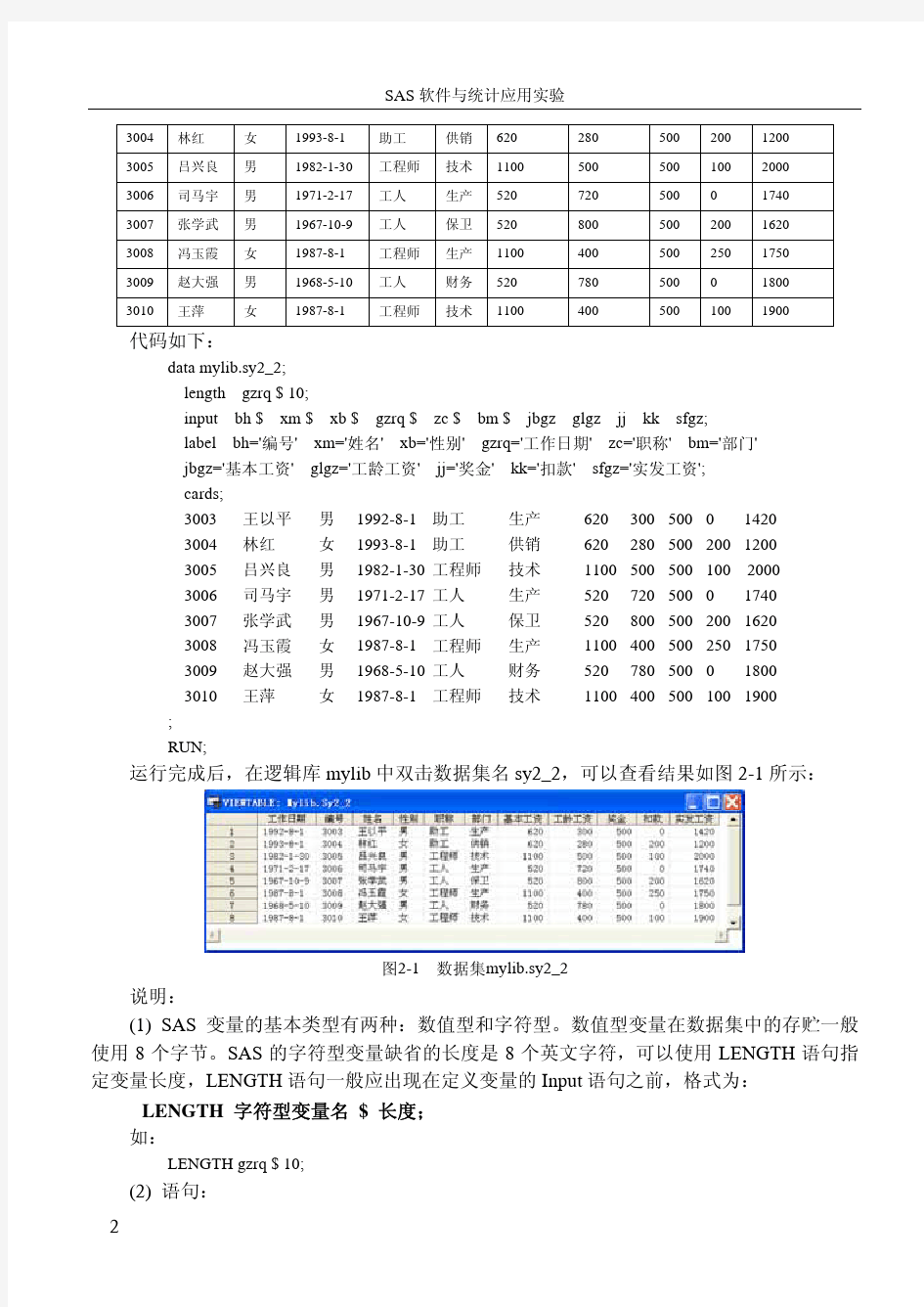
运行完成后,在逻辑库mylib 中双击数据集名sy2_2,可以查看结果如图2-1所示:
图2-1 数据集mylib.sy2_2
说明:
(1) SAS 变量的基本类型有两种:数值型和字符型。数值型变量在数据集中的存贮一般使用8个字节。SAS 的字符型变量缺省的长度是8个英文字符,可以使用LENGTH 语句指定变量长度,LENGTH 语句一般应出现在定义变量的Input 语句之前,格式为:
LENGTH 字符型变量名 $ 长度; 如:
LENGTH gzrq $ 10;
(2) 语句:
label bh = '编号' xm = '姓名' xb = '性别' gzrq = '工作日期' zc = '职称' bm = '部门' jbgz = '基本工资' glgz = '工龄工资' jj = '奖金' kk = '扣款' sfgz = '实发工资';
为每个变量加标签。
(3) 数据块中数据之间可以用空格隔开,也可以使用Tab键。
3.读取外部数据文件建立数据集
【实验2-3】读取文本文件sy2_3.txt(图2-2)建立数据集work.sy2_3。假设文本文件存放在文件夹“D:\SAS_SHYAN\原始数据”中。
图2-2 文本文件sy2_3.txt
代码如下:
data sy2_3;
infile 'd:\sas_shiyan\原始数据\sy2_3.txt';
input bh $ xm $ xb $@@;
length gzrq $ 10;
input gzrq $ zc $ bm $ jbgz glgz jj kk sfgz;
run;
注意:文本文件中数据之间用空格隔开,不能使用Tab键。
运行完成后,在临时库work中双击数据集名sy2_3,可以查看结果如图2-3所示:
图2-3 数据集sy2_3
【实验2-4】读取Excel文件sy2_2.xls(如表2-1所示)建立数据集work.sy2_4。已知Excel 文件sy2_2.xls存放在文件夹“d:\sas_shiyan\原始数据”中。
首先将表2-1修改为如图2-4所示的Excel表sy2_4.xls,并存放在d:\sas_shiyan\原始数据中。
图2-4 Excel表sy2_4.xls
建立数据集work.sy2_4代码如下:
proc import out=sy2_4
datafile = "d:\sas_shiyan\原始数据\sy2_4.xls"
dbms = excel2000 replace;
no; /*如果表中第一行为变量名,则删去此行*/
=
getnames
run;
注意:sy2_4.xls中第3至5列中的多加的“0”是为了保证导入后字符型变量的长度正确。
二、数据文件的编辑与整理
1.数据集的复制与修改
【实验2-5】将mylib.sy2_2中的“工作日期”去掉,基本工资小于600的改为600,生成新的数据集work.sy2_5。
代码如下:
data sy2_5;
set mylib.sy2_2;
drop gzrq;
if jbgz < 600 then jbgz = 600;
run;
2.增加新变量
【实验2-6】在mylib.sy2_2中增加变量yfgz(应发工资=基本工资+工龄工资+奖金)、生成新的数据集work.sy2_6。
代码如下:
data sy2_6;
set mylib.sy2_2;
yfgz = jbgz + glgz + jj;
run;
3.数据集的纵向拆分
【实验2-7】按基本工资是否大于600将mylib.sy2_2拆分成两个新数据集work.sy2_7_1和work.sy2_7_2。
代码如下:
data sy2_7_1 sy2_7_2;
set mylib.sy2_2;
select;
when (jbgz<600) output sy2_7_1;
when (jbgz>=600) output sy2_7_2;
end;
run;
4.数据集的纵向合并
【实验2-8】将上述拆分后的两个数据集纵向合并恢复原样,产生新的数据集work.sy2_8。
代码如下:
data sy2_8;
set sy2_7_1 sy2_7_2;
run;
5.数据集的横向合并
【实验2-9】将mylib.sy2_2中职称为“工人”的观测拆分成一个仅含编号、姓名和基本工资,一个仅含有编号和实发工资的两个新数据集work.sy2_9_1和work.sy2_9_2。然后将work.sy2_9_1和work.sy2_9_2合并成一个新数据集sy2_9。
(1) 提取职称为“工人”的观测:
data sy2_9_0;
set mylib.sy2_2;
if (zc = '工人');
run;
(2) 建立两个数据集:
data sy2_9_1;
set sy2_9_0;
keep bh xm jbgz;
run;
data sy2_9_2;
set sy2_9_0;
keep bh sfgz;
run;
(3) 横向合并:
data sy2_9;
merge sy2_9_1 sy2_9_2;
by bh;
run;
proc print; run; /*列表显示数据集sy2_9*/
6.数据的排序
【实验2-10】将mylib.sy2_2按jbgz升序、sfgz降序排序后生成新的数据集work.sy2_10。
代码如下:
proc sort data= mylib.sy2_2 out = sy2_10;
by jbgz descending sfgz;
run;
proc print data= sy2_10; /*列表显示数据集sy2_10*/
run;
说明:在对两个数据集横向合并时,为了避免因两个数据集观测顺序不同造成混乱,一般应将两个数据集分别按同一个变量(BY变量)排序后再合并,如【实验2-9】中的横向合并可写成:
Proc sort data = sy2_9_1;
by bh;
Proc sort data = sy2_9_2;
by bh;
run;
data sy2_9;
merge sy2_9_1 sy2_9_2;
by bh;
run;
proc print; run;
7.数据的列表显示
【实验2-11】列出数据集mylib.sy2_2中所有男性职工的编号、姓名、部门、基本工资。
代码如下:
Proc print data = mylib.sy2_2 label;
var bh xm bm jbgz ;
label bh = '编号' xm = '姓名' bm = '部门' jigz = '基本工资';
where xb = '男';
run;
2.4 上机演练
【练习2-1】表2-2(lx2_1.xls)为某邮购服务部的部分顾客记录,编程进行如下操作:
表2-2 邮购服务部部分顾客记录
姓名 性别 地区 日期 金额
章文男华东1996-3-201099
王国铭男华东1996-5-1939
童子敏女华北1996-1-5986
刘念新男东北1997-10-13581
李思今女华北1997-4-4659
关昭女东北1996-11-5358
赵霞女东北1998-9-62010
(1) 建立自己的逻辑库(以自己名字的拼音命名);
(2) 用数据步把此数据输入到SAS数据集并存放在自己的逻辑库中;
(3) 列表显示男性顾客购买金额超过1000的那些人;
(4) 按金额降序排序并输出结果;
(5) 把数据拆分为包含姓名、性别、地区的一个数据集和包含姓名、日期、金额的一个数据集;
(6) 用MERGE和BY合并上一步拆开的两个数据集。
【练习2-2】SASHELP.PRDSALE是某国际公司在各地销售记录。变量ACTUAL是实际销售额,PREDICT是预测的销售额,COUNTRY是卖往的国家,REGION是地区,DIVISION 是卖往的部门,PRODTYPE是产品类型,PRODUCT是具体的产品名称,QUARTER,YEAR,MONTH是销售时间的季度、年、月。编程进行如下操作:
(1) 用print过程列出数据集中美国的销售记录,求给各列加上合理的中文标签;
(2) 把数据集按产品类别、年、月排序后按产品类别分类列出年、月、实际销售额,不显示观测序号。
2.5 实验报告
请按练习内容写出包括如下内容的实验报告:
一、实验目的;
二、实验内容、程序及运行结果;
三、实验中存在的问题及解决方法;
四、实验体会(结论、评价、感想与建议等)。