根据统计年鉴相关内容填写表中数据

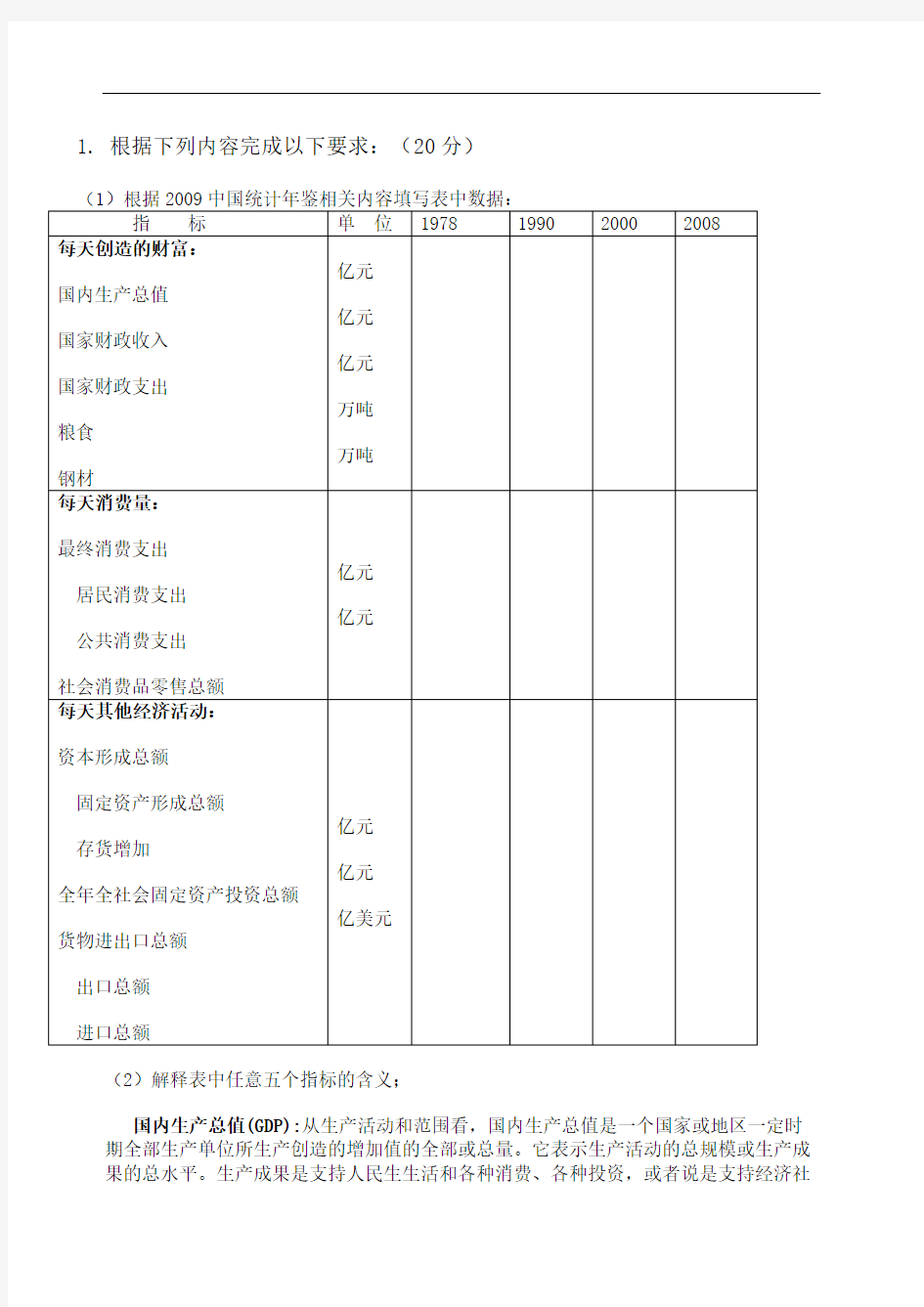
根据统计年鉴相关内容
填写表中数据
Coca-cola standardization office【ZZ5AB-ZZSYT-ZZ2C-ZZ682T-ZZT18】
1. 根据下列内容完成以下要求:(20分)
(2)解释表中任意五个指标的含义;
国内生产总值(GDP):从生产活动和范围看,国内生产总值是一个国家或地区一定时期全部生产单位所生产创造的增加值的全部或总量。它表示生产活动的总规模或生产成果的总水平。生产成果是支持人民生生活和各种消费、各种投资,或者说是支持经济社
会发展的基础,因此它非常重要。国内生产总值有三种表现形态,即:价值形态、收入形态和产品形态;有三种计算方法:即:生产法、收入法和支出法.
财政收入:指国家财政参与社会产品分配所取得的收入,是实现国家职通报财务保证.财政收入主要包括:①各项税收:增值税、营业税、消费税、土地增值税、城市维护建设税、资源税、城市土地使用税、印花税、个人所得税、企业所得税、关税、农牧业税和耕地占用税等;②专项收入:包括征收排污费收入、征收城市水资源费收入、教育费附加收入等;③其他收入:包括基本建设贷款归还收入、基本建设收入、捐赠收入等。
④国有企业计划亏损补贴:这项为负收入,冲减财政收入。
最终消费支出:指常住单位为满足物质、文化和精神生活的需要,从本国经济领土和国外购买的货物和服务的支出。它不包括非常住单位在本国经济领土内的消费支出。最终消费支出分为居民消费支出和政策消费支出资本形成总额:
资本形成总额:指常住单位在一定时期内获得的固定资产减去处置的固定资产和存货的净额,包括固定资本形成总额和存货增加两部分。
全社会固定资产投资:是以货币形式表现的在一定时期内全社会建造和购置固定资产的工作量以及与此有关的费用的总称。该指标是反映固定资产投资规模、结构和发展速度的综合性指标,又是观察工程进度和考核投资效果的重要依据。全社会固定资产投资按登记注册类型可分为国有、集体、个体、联营、股份制、外商、港澳台商、其他等。
(3)以上述任意一项指标2008年的具体数据为依据,说明中国在世界经济实力的排名根据2009年中国统计年鉴表附录二(2—3)2007年国土面积和人口表,附录2-3国内生产总值及其增长率表以及相关数据,2008年世界各国GDP总量排名,中国已经居世界第三位,仅次于美国和日本。中国国内生产总值为44016亿美元,美国和日本分别为142646亿美元、49238亿美元。虽然就GDP与日本GDP总量仅相差5222亿美元,但日本人口仅为中国人口的%,日本人均GDP为美元,而中国人均GDP为亿美元,人均GDP与是日本相差倍,所以目前中国人均GDP仍然排在世界100位以后.
误差及分析数据的统计处理(精)
2 误差及分析数据的统计处理 1.已知分析天平能称准至±0.1 mg ,要使试样的称量误差不大于±0.1 %,则至少要称取试样多少克? 解:两次称量读数最大误差为±0.2mg 3 0.210100%0.1% 0.2g m m -??=?样 样故 4.水中Cl — 含量,经6次测定,求得其平均值为35.2 mg·L -1,s = 0.7 mg·L -1,计算 置信度为90 %时平均值的置信区间。 解:n=6,35.2x =,s=0.7 查t 表,P=90﹪,t 表 =2.015 35.2 2.015μ=±=35.2±0.6 置信区间为(34.6~35.8)mg ?L -1。 8.用两种不同方法测得数据如下: 方法Ⅰ:n 1 = 6 1x = 71.26 % s 1 = 0.13 % 方法Ⅱ:n 2 = 9 2 x = 71.38 % s 2 = 0.11 % 判断两种方法间有无显著性差异? 解:判断两种方法有无显著性差异,可用t 检验法 但首先要求两种方法精密度差别不大,才能进行比较,即通过F 检验法判别之, 2222 (0.13) 1.40(0.11) s F s ===大小 查F 表 f s 大=6–1 f s 小=9–1 F 表=3.69 则F 计 0.118 71.26 1.017 1.90 0.118 1.93 12 s n t +n == ==?=合计 查t 表,f =9+6–2,P=0.95,t 表=2.16 故t 计< t 表,两种方法无显著差异。 12.为了判断测定氯乙酸含量的方法是否可行。今对一质量分数为99.43 %的纯氯乙酸进行测定,测定10次数据如下:97.68,98.10,99.07,99.18,99.41,99.42,99.70,99.70, 99.76,99.82,试对这组数据 (1 ) 进行有无异常值检查; (2) 将所得平均值与已知值进行t 检验,判断方法是否可行; (3) 表示分析结果; (4) 计算该法重复性,以近似表达两次平行测定间的允许差。 解:(1) 用Grubbs 法判断97.68是否该舍弃: n = 10 x = 99.184% 0.732s == =% 199.18497.68 2.050.732x x t s --= ==计 ()9510 2.18 n t %==表 t 计<t 表 故97.68应保留。 如按照Q 值法检验 211010.196 98.1097.68 99.8297.68x x Q x x --= ==--计 ()9010 0.41 n Q %==表 Q 计< Q 表 数据资料的统计处理 ● 对数据的统计分析方法 一、s x -分析法 二、综合达标度 三、次数分布表和次数分布图 四、应答信息分析法 ● 相关关系分析 ● 数量标志的统计检验 ● 品质标志的统计检验 一、s x -分析法 1、平均值x : 描述样本的总体分值集中趋势的量,反映总体分值的一般水平。 n x x i ∑= n :样本的个数 2、标准差S : 描述样本的总体分值中各分值离散程度的量,反映总体中各分值的总体平均值离差(x ;-x ) 的平均水平。 s= n x x i ∑-2 )( 将x 和S 结合起来共同描述样本的整体水平比较科学。 一、分析方法:将x 和S 结合起来,分析整体学习水平 例1:某学科30名学生考试成绩如下表1,试分析30名学生整体学习水平。 表1 n=30 i 1.计算x =83 2. S= n x x i ∑-2 )(=7.73≈7.8 3 图1 x -s 分析图 二、综合达标度 采用综合加权的方法,对达标的程度进行分析 计算方法: 例2、抽取30份物理试卷,分析概念“力”的综合达标度 规定权重b : 知识=1、理解=2、应用=3、分析=4、综合=5、评价=6 总体目标系数K= 6321=++=∑i b 综合加权得分H= ∑i b ·i G =1×0.97+2×0.87+3×0.77=5.02 综合达标度84.06 02.5=== K H T 综合达标分析: 三、数据资料的次数分布表和次数分布图分析法 (一)数据资料的分类 1、计数资料: 指计数事物个数的数值,这个数值称次数 如:在某个分数段所对应得分的学生数 在向卷量表上,同意某种意见的人数。 2、测量资料: 指测量事物时产生的度量值,这个度量值叫量数,如:考试的分数。 (二)特点: 以最简单最直观的形式,最大限度的容纳数据信息。 如,数据的分布情况,集中趋势和离散程度等。 (三)次数分布表的制作方法 次数分布表是用表格的形式,表示数据在某些规定的组别中次数的分布情况,是整理,分析数据的第一步 下面以50名学生物理考试成绩为例,阐述编制次数分布表的方法和步骤。 1、求全距R R=最大数-最小数 =98-51 =47 2、定组数: 一般以10—20组为宜。太多了计算麻烦,太少了可能把很多不同事实归于一类,掩盖了分布特征。 本例分10组 表3 50名学生物理考试成绩次数分布表 1什么是统计学?统计方法可分为哪两大类?统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。方法有描述统计和推断统计两类 2统计数据可分为哪几种类型?不同类型数据各有什么特点?按采取计量尺度,分类、顺序、数值型数据;按统计数据收集方法,观测、实验数据;按被描述对象与时间关系,截面、时间序列数据 统计数据;按所采用的计量尺度不同分; (定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这些类别是有序的。 (定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。 统计数据;按统计数据都收集方法分; 观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。 实验数据:在实验中控制实验对象而收集到的数据。 统计数据;按被描述的现象与实践的关系分; 截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。 3举例说明总体、样本、参数、统计量、变量这几个概念:对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。 4什么是有限总体和无限总体?举例说明 有限总体指总体的范围能够明确确定,而且元素的数目是有限可数的,如若干个企业构成的总体,一批待检查的灯泡。无限总体指总体包括的元素是无限不可数的,如科学实验中每个试验数据可看做是一个总体的一个元素,而试验可无限进行下去,因此由试验数据构成的总体是无限总体 5变量可分为哪几类? 变量可以分为分类变量,顺序变量,数值型变量。 变量也可以分为随机变量和非随机变量。经验变量和理论变量。 1. 概念模式 是数据库中全部数据的整体逻辑结构的描述。它由若干个概念记录类型组成。概念模式不仅要描述概念记录类型,还要描述记录间的联系、操作、数据的完整性、安全性等要求。? 2. X封锁 如果事务T对数据R实现X封锁,那么其他的事务要等T解除X封锁以后,才能对这个数据进行封锁。只有获准X封锁的事务,才能对被封锁的数据进行修改。? 3. 复制透明性 即用户不必关心数据库在网络中各个结点的数据库复制情况,更新操作引起的波及由系统去处理。 4. 主属性 包含在任何一个候选键中的属性。 5. 事务的原子性 一个事务对数据库的操作是一个不可分割的操作系列,事务要么完整地被全部执行,要么全部不执行。 1. DML 数据操纵语言(Data Manipulation Language),由DBMS提供,用于让用户或程序员使用,实现对数据库中数据的操作。DML分成交互型DML和嵌入型DML两类。依据语言的级别,DML 又可分成过程性DML 和非过程性DML两种。 2. S封锁 共享型封锁。如果事务T对某数据R加上S封锁,那么其它事务对数据R的X封锁便不能成功,而对数据R的S封锁请求可以成功。这就保证了其他事务可以读取R但不能修改R,直到事务T释放S封锁。? 3. 分布式DBS 是指数据存放在计算机网络的不同场地的计算机中,每一场地都有自治处理能力并完成局部应用; 而每一场地也参与(至少一种)全局应用程序的执行,全局应用程序可通过网络通信访问系统中的多个场地的数据。 4.事务 数据库系统的一个操作系列,这些操作或者都做,或者都不做,是一个不可分割的工作单位 5. 丢失更新 当两个或以上的事务同时修改同一数据集合时,由于并发处理,使得某些事务对此数据集合的修改被忽视了. 1. 实体完整性规则 这条规则要求关系中元组在组成主键的属性上不能有空值。如果出现空值,那么主键值就起不了唯一标识元组的作用。 1. 域和元组 在关系中,每一个属性都有一个取值范围,称为属性的值域,简称域;记录称为元组。元组对应表中的一行;表示一个实体。? 2. 无损联接 设R是一关系模式,分解成关系模式ρ={R1,R2...,Rk},F是R上的一个函数依赖集。如果对R中满足 F 的每一个关系r都有r=πR1(r)πR2(r)... πRk(r)则称这个分解相对于F 是"无损联接分解"。 3. 事务的原子性? 根据统计年鉴相关内容 填写表中数据 Coca-cola standardization office【ZZ5AB-ZZSYT-ZZ2C-ZZ682T-ZZT18】 1. 根据下列内容完成以下要求:(20分) (2)解释表中任意五个指标的含义; 国内生产总值(GDP):从生产活动和范围看,国内生产总值是一个国家或地区一定时期全部生产单位所生产创造的增加值的全部或总量。它表示生产活动的总规模或生产成果的总水平。生产成果是支持人民生生活和各种消费、各种投资,或者说是支持经济社 会发展的基础,因此它非常重要。国内生产总值有三种表现形态,即:价值形态、收入形态和产品形态;有三种计算方法:即:生产法、收入法和支出法. 财政收入:指国家财政参与社会产品分配所取得的收入,是实现国家职通报财务保证.财政收入主要包括:①各项税收:增值税、营业税、消费税、土地增值税、城市维护建设税、资源税、城市土地使用税、印花税、个人所得税、企业所得税、关税、农牧业税和耕地占用税等;②专项收入:包括征收排污费收入、征收城市水资源费收入、教育费附加收入等;③其他收入:包括基本建设贷款归还收入、基本建设收入、捐赠收入等。 ④国有企业计划亏损补贴:这项为负收入,冲减财政收入。 最终消费支出:指常住单位为满足物质、文化和精神生活的需要,从本国经济领土和国外购买的货物和服务的支出。它不包括非常住单位在本国经济领土内的消费支出。最终消费支出分为居民消费支出和政策消费支出资本形成总额: 资本形成总额:指常住单位在一定时期内获得的固定资产减去处置的固定资产和存货的净额,包括固定资本形成总额和存货增加两部分。 全社会固定资产投资:是以货币形式表现的在一定时期内全社会建造和购置固定资产的工作量以及与此有关的费用的总称。该指标是反映固定资产投资规模、结构和发展速度的综合性指标,又是观察工程进度和考核投资效果的重要依据。全社会固定资产投资按登记注册类型可分为国有、集体、个体、联营、股份制、外商、港澳台商、其他等。 (3)以上述任意一项指标2008年的具体数据为依据,说明中国在世界经济实力的排名根据2009年中国统计年鉴表附录二(2—3)2007年国土面积和人口表,附录2-3国内生产总值及其增长率表以及相关数据,2008年世界各国GDP总量排名,中国已经居世界第三位,仅次于美国和日本。中国国内生产总值为44016亿美元,美国和日本分别为142646亿美元、49238亿美元。虽然就GDP与日本GDP总量仅相差5222亿美元,但日本人口仅为中国人口的%,日本人均GDP为美元,而中国人均GDP为亿美元,人均GDP与是日本相差倍,所以目前中国人均GDP仍然排在世界100位以后. 第一章 1,数据挖掘(Data Mining),就是从存放在数据库,数据仓库或其他信息库中的大量的数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。 2,人工智能(Artificial Intelligence)它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。 3,机器学习(Machine Learning)是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。 4,知识工程(Knowledge Engineering)是人工智能的原理和方法,对那些需要专家知识才能解决的应用难题提供求解的手段。 5,信息检索(Information Retrieval)是指信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术。 6,数据可视化(Data Visualization)是关于数据之视觉表现形式的研究;其中,这种数据的视觉表现形式被定义为一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。 7,联机事务处理系统(OLTP)实时地采集处理与事务相连的数据以及共享数据库和其它文件的地位的变化。在联机事务处理中,事务是被立即执行的,这与批处理相反,一批事务被存储一段时间,然后再被执行。 8, 联机分析处理(OLAP)使分析人员,管理人员或执行人员能够从多角度对信息进行快速 一致,交互地存取,从而获得对数据的更深入了解的一类软件技术。8,决策支持系统(decision support)是辅助决策者通过数据、模型和知识,以人机交互方式进行半结构化或非结构化决策的计算机应用系统。它为决策者提供分析问题、建立模型、模拟决策过程和方案的环境,调用各种信息资源和分析工具,帮助决策者提高决策水平和质量。 10,知识发现(KDD:Knowledge Discovery in Databases)是从数据集中别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。 11,事务数据库(Transaction Database)一个事务数据库由文件构成,每条记录代表一个事务。 典型的事务包含唯一的事务标记,多个项目组成一个事务 12,分布式数据库(Distributed Database)是用计算机网络将物理上分散的多个数据库单元连接起来组成一个逻辑统一的数据库。 第三章 13,并行关联规则挖掘(Parallel Association Rule Mining)是指利用并行处理机,使用挖掘算法或在并行计算的环境下完成数据的高效挖掘工作。 14,数量关联规则挖掘(Quantitive Association Rule Mining)对含有非离散的数值属性的数据进行挖掘的技术 14, 频繁项目集(Frequent Itemsets)对项目集I和事务数据库D,T中所有满足用户指定的最小支持度(Minsupport)的项目集,即大于或等于Minsupport的I的非空子集 15,最大频繁项目集(Maximum Frequent Itemsets)在频繁项目集中挑选出所有不被其他元素包含的频繁项目集 16,闭合项目集(Close Itemset)如果项目的直接超集都不具有和它相同的支持度技术则该项目是闭合的 17,多层次关联规则:具有概念分层的关联规则挖掘产生的规则称为多层关联规则。 18,多维关联规则:在关联规则中的项或属性每个涉及多个维,则它就是多维关联规则。 少量数据的统计处理 Revised by Jack on December 14,2020 少量数据的统计处理 t 分布曲线 正态分布是无限次测量数据的分布规律。当测量数据不多时,其分布服从t 分布规律。对于有限次测量,用s 代替,用t 代替u ,t 的定义是: t 分布图如右。由图可知,t 分布曲线与正态分布曲线相似,纵坐标仍为概率密度,但横 坐标为统计量t 。t 分布曲线随自由度改变f 而改变,当f 趋近∞时,t 分布趋近正态分布。 置信度(P )表示测定值在x tS μ±范围内的概率,当f ,t 即为u 。显着性水平()=1-P :表示测定值在x tS μ±范围之外的概率。 t 值与置信度及自由度有关,一般表示为,f t α。例如:,10 表示置信度为 95%,自由度为 10 时的 t 值。 平均值的置信区间 实际工作中,往往是由样本平均值来估计总体平均值可能存在的区间,根据t 分布可知, x t n μ=± 此式表示在一定的置信度下,以平均值x 为中心,包括总体平均值的范围。此范围称为平均值的置信区间。选定置信度P ,根据P (或)与f 即可查出t ,f 值,从样本的平均值和标准偏差,即可求出相应的置信区间。 例2:分析某尾矿中铁含量得如下结果:x =%,s=%,n=4,求(1)置信度为95%时平均值的置信区间;(2)置信度为99%时平均值的置信区间。 解:置信度为95%,查表得,3=,那么 15.78 3.1815.780.05% 4 x t n μ=±=±? =± 置信度为99%,查表得,3=,那么15.78 5.8415.780.09% 4 x t n μ=±=±? =± 对此例可知,置信度越高,置信区间越大。 例3:下列有关置信区间的定义中,正确的是: a.以真值为中心的某一区间包括测定结果的平均值的几率; b.在一定置信度时,以测量值的平均值为中心的包括总体平均值的范围; c.真值落在某一可靠区间的几率; 数据处理内容 1.标准曲线 作标准曲线时,对于可控性差的实验,可点数应多一些;对于可控性较的实验,取点数可少一些,但不应少于五个点。 r值应根据具体实验的要求,既要满足特定实验的要求,又不能过分人为的提高r值。 标准曲线完成后,检测样品时,测定值应落在标准曲线范围内。 2.有效数字 有效数字的保留应根据实验仪器的有效数字确定。 文字叙述中数字的表达应严谨,比如“精确称取2g样品”是一种典型错误,应表达为“精确称取2.0000g样品”,以表示所用天生秤为万分天秤。 再比如,1mL移液管的读数应为“0.683mL”,而不是“0.68mL”。 3.实验数据处理 实验数据的重复数应根据实验本身的要求决定。 对于可控性较差的实验,实验数据的重复数应增加;对于可控性较好的实验,实验数据的重复数可相应减少,但最少不应少于3个。 实验数据的表示方法应以“平均值(X)±标准差(SD)”表示,数据间应进行显著性分析,并标示出显著性水平和实验的重复数。比如: 表1 多酚对小鼠游泳竭耗实验的影响结果(X±SD) Table 1 Effects of polyphenol on swimming time of mice(X±SD) Group n Swimming time (s) Increase rate(%) 1 10 181.1±58.1 — 2 10 266.2±76.0ac47.0 3 10 354.7±103.9b95.9 4 10 261.7±62.1ac44.5 注:a:P<0.05,b :P<0.001,与1组相比较;c:P<0.05,与3组相比较 Note: a: P<0.05, b: P<0.001, compared with 1 group; c: P<0.05, compared with 3 group 对于表格中数字的描述也应标示其显著性水平。比如“第3组和第1组间有极著性差异”的说法是不完整的,应为“第3组和第1组间有极显著性差异(P<0.001)”。 对于正交实验,应根据极差分析和方差分析的结果综合考虑,以决定最终的结论,而不应只根据极差分析结果就得出结论。 对于论文中的图表应进行适当的说明,不应只把图表放在论文上,而不做任何说明。 名词解释: 第一章 试验设计与数据处理:是以概率论、数理统计及线性代数为理论基础,研究如何有效的安排试验、科学的分析和处理试验结果的一门科学。 试验考察指标(experimental index):依据试验目的而选定的衡量或考察试验效果的特征值. 试验因素;对特征值产生影响的原因或要素. 因素水平:试验实际考虑采用的(某一)因素变化的状态或条件的种类数称为因素水平,简称水平。 局部控制(local control)原则:控制隐藏变量对反应的效应。 重复(replication)原则:重复试验于许多试验单位,以降低结果的机会变异 随机化(randomization)原则:随机化(Randomization)安排试验单位接受指定的处理。实验的目标特性(实验考察指标)目标特性:就是考察和评价实验结果的指标。 定量指标:可以通过实验直接获得,便于计算和进行数据处理。 定性指标:不易确定具体的数值,为便于用数学方法进行分析和处理,必须是将其数字化后进行计算和处理。 因素:凡是能影响实验结果的条件或原因,统称为实验因素(简称为因素)。 水平:因素变化的各种状态和条件称为因素的水平 总体、个体:我们所研究对象的某特性值的全体,叫做总体,又叫母体;其中的每个单元叫做个体。 子样(样本)、样本容量:自总体中随机抽出的一组测量值,称为样本,又叫子样。样本中所含个体(测量值)的数目,叫做样本容量,即样本的大小。 抽样:从总体中随机抽取若干个个体观测其某种数量指标的取值过程称为抽样。 样本空间:就样本而言,一次抽取、观测的结果是n个具体数据x1,x2,…,xn,称为样本(X1,X2,…X n)的一个观测值,而样本观测值所有可能取值的全体称为样本空间。 重复性:由一个分析者,在一个给定的实验室中,用一套给定的仪器,在短时间内,对某物理量进行反复定量测量所得的结果。也称为室内精密度。 再现性;由不同的实验室的不同分析者和仪器,共同对一个物理量进行定量测量的结果。也称室间精密度。 误差:测量值和真值的差数 偏差:测量值和平均值的差数。也叫离差。 偏差平方和:测量值对平均值的偏差的平方的加和,叫偏差平方和。 方差(variance):是测量值在其总体均值周围分布状况的一种量度,方差表征随机变量分布的离散程度。 总体方差的定义是:测量值对总体均值的误差的平方的统计平均 样本方差:只作过有限次测量的样本方差,通常用s2表示。s2是测量值对样本均值的偏差的平方的平均 标准偏差(标准差):方差的平方根的正值,叫标准偏差,或标准差 自由度:是指可以自由取值的数据的个数。 相对标准偏差(变异系数)(relative standard deviation, RSD):是样本标准偏差与平均值的比值,表示偏差值与平均值的相对大小。 第二章 第一章 本课程的主要内容 一、资料的整理及统计分析 平均数 标准差 标准误 二、显著性检验 1. 平均数间差异显著性检验 2. F 检验法 三、相关与回归 四、试验设计 五、Excel 、DPS 统计软件系统 常用术语 1. 总体与样本 总体( polulation )是指根据研究目的确定的、符合指定条件的研究对象的全体。它是由相同性质的(个体)成员所构成的集团。样本( sample )是指从总体中抽取一定数量的个体所组成的集合。 2. 参数与统计量 参数( parameter )是指由总体计算的用来描述总体的特征性数值。它是一个真值,通常用希腊字母表示。如总体 平均数以□表示,总体标准差以b表示。 统计量( statistics )是指由样本计算的用来描述样本的特征性数值。 3. 误差与错误 误差( error )是指试验中由无法控制的非试验因素所引起的差异。它是不可避免的,试验中只能设法减少,而不能 消除。 错误( mistake )是指试验过程中人为的作用所引起的差错,在试验中完全可以避免。 4. 精确性与准确性 精确性( precision )是指试验或调查中同一试验指标或性状的重复观察值彼此的接近程度。 准确性( accuracy )是指试验或调查中某一试验指标或性状的观察值(统计量)与真值(或总体参数)之间的接近程度。 5. 试验指标 在某项试验设计中,用来衡量试验效果的特征量称为试验指标,也称试验结果。试验指标可分为定量指标和定性指标两类。 6. 试验因素试验中对试验指标可能产生影响的原因或要素称为试验因素,也称为因子。 7. 因素水平试验中试验因素所处的各种状态或取值称为因素水平,简称水平。 8. 试验处理试验中各试验因素的水平所形成的一种具体组合方式称为试验处理,简称处理,是在试验单位上的一种具体实现。 9. 试验单位 在试验中能接受不同试验处理的试验载体叫做试验单位。 10. 重复 在一项试验中,将1 个处理在两个或两个以上的试验单位上实施的称为重复。1 个处理所实施的试验单位数称为处理的重复数,或者说某个水平组合重复n 次试验,这个处理的重复数就是n。 试验设计应遵循的基本原则重复随机化局部控制第二章 第一节样品的采集与前处理 一、资料的来源 经常性记录 试验研究记录 调查记录 统计学数据处理的基本思路 数据的整理是数据收集与数据分析之间的中间环节数据整理是对收集来的数据进行加工整理使之符合统计分析的需要。如对数据进行图表显示,以发现数据中的基本规律。数据整理的中心任务就是分组与编制频数分布表。 而数据处理的主要步骤又包括以下几点:数据的预处理,数据的分组,数据的整理与显示,统计表。 数据整理是所以步骤的第一步,也最为重要。统计整理是统计调查的继续,是统计分析的前提和基础,在整个统计工作中,发挥着承上启下的作用。 其中,在数据的预处理中,把混在原始数据中的“异常数据”排除、把真正有用的“信息”提取出来。因此,对异常数据的剔除就显得尤为重要,其中又包含多种方法,主要有1、根据人们对客观事物已有的认识,判别由于外界干扰、人为误差等原因造成实测数据偏离正常结果,在实验过程中随时判断,随时剔除。2、给定一个置信概率,并确定一个置信限,凡超过此限的误差,就认为它不属于随机误差范围,将其视为异常数据剔除。 比如,在对一个班的同学的身高做调查的时候,可以依据常识,在列表中对那些明显不符合的数据做剔除处理,即身高中出现2米多的数据,依常识不可能。 再则,预处理完毕后,则需要对数据进行分组。通过分类发现数据内部的特点。例如,在对全班身高进行整理后得到数据,可以对之进行不同的分组,如分男女生,如分不同高度段等等。通过分组发现数据内部结构的特点。即有所谓的类型分组,分析分组,结构分组等等。 第三,就是数据的整理与显示。包括的重点有:1、频数(落在各类别中的数据个数。)2、频率(某一类别数据的频数占总体单位个数的比重。)3、频数分布(把频数以表格形式全部列出就是~绘制频数分布表的演示操作(调用Excel文件:分类数据的整理)4、比例(各类数据与全部数据之比)5、百分数(把比例基数100化比率:各类数据间的比值)。 这些处理是下一步的前提与基础,为绘图做准备,比如在对全班身高完成分组后,可以依据一定的需要,对其进行整理与显示,如要研究男女身高的差异,可以分别理出男女身高的平均数,频数,频率,频数分布,比例,百分比等等数据。然后根据需要对其进行显示。 最后一步,就是绘图。其中不同的需要目的需要不同的图形予以显示。图形主要有条形图,直方图,饼状图,折线图等等。以条形图为例,长度表示各类频数的多少,而宽度则一般固定。用于显示各数据直观上的绝对多少。其他图形依然。 所以,综上述,基本思路即包括数据的预处理,数据的分组,数据的整理与显示以及绘图。(由于不会word绘图功能,故相关事例绘图滤去) 地理信息系统名词解释大全 地理信息系统Geographic Information System GIS作为信息技术的一种,是在计算机硬、软件的支持下,以地理空间数据库(Geospatial Database)为基础,以具有空间内涵的地理数据为处理对象,运用系统工程和信息科学的理论,采集、存储、显示、处理、分析、输出地理信息的计算机系统,为规划、管理和决策提供信息来源和技术支持。简单地说,GIS就是研究如何利用计算机技术来管理和应用地球表面的空间信息,它是由计算机硬件、软件、地理数据和人员组成的有机体,采用地理模型分析方法,适时提供多种空间的和动态的地理信息,为地理研究和地理决策服务的计算机技术系统。地理信息系统属于空间型信息系统。 地理信息是指表征地理圈或地理环境固有要素或物质的数量、质量、分布特征、联系和规律等的数字、文字、图像和图形等的总称;它属于空间信息,具有空间定位特征、多维结构特征和动态变化特征。 地理信息科学与地理信息系统相比,它更加侧重于将地理信息视作为一门科学,而不仅仅是一个技术实现,主要研究在应用计算机技术对地理信息进行处理、存储、提取以及管理和分析过程中提出的一系列基本问题。地理信息科学在对于地理信息技术研究的同时,还指出了支撑地理信息技术发展的基础理论研究的重要性。 地理数据是以地球表面空间位置为参照,描述自然、社会和人文景观的数据,主要包括数字、文字、图形、图像和表格等。 地理信息流即地理信息从现实世界到概念世界,再到数字世界(GIS),最后到应用领域。 数据是通过数字化或记录下来可以被鉴别的符号,是客观对象的表示,是信息的表达,只有当数据对实体行为产生影响时才成为信息。 信息系统是具有数据采集、管理、分析和表达数据能力的系统,它能够为单一的或有组织的决策过程提供有用的信息。包括计算机硬件、软件、数据和用户四大要素。 四叉树数据结构是将空间区域按照四个象限进行递归分割(2n×2n,且n ≥1),直到子象限的数值单调为止。凡数值(特征码或类型值)呈单调的单元,不论单元大小,均作为最后的存储单元。这样,对同一种空间要素,其区域网格的大小,随该要素分布特征而不同。 不规则三角网模型简称TIN,它根据区域有限个点集将区域划分为相连的三角面网络,区域中任意点落在三角面的顶点、边上或三角形内。如果点不在顶点上,该点的高程值通常通过线性插值的方法得到(在边上用边的两个顶点的高程,在三角形内则用三个顶点的高程)。 拓扑关系拓扑关系是指网结构元素结点、弧段、面域之间的空间关系,主要表现为拓扑邻接、拓扑关联、拓扑包含。根据拓扑关系,不需要利用坐标或距离,可以确定一种地理实体相对于另一种地理实体的位置关系,拓扑数据也有利于空间要素的查询。 拓扑结构为在点、线和多边形之间建立关联,以及彻底解决邻域和岛状信息处理问题而必须建立的数据结构。这种结构应包括以下内容:唯一标识,多边形标识,外包多边形指针,邻接多边形指针,边界链接,范围(最大和最小x、y坐标值)。 游程编码是逐行将相邻同值的网格合并,并记录合并后网格的值及合并网 2利用相关软件对数据作简单的统计处理 §2.利用相关软件对数据作简单的统计处理 1. Excel Excel是美国微软(Microsoft)公司的一种办公系列软件, Excel有友好的用户界面,卓越的数据处理和数据分析能力,它预装的各种函数多达245个,单是统计函数就有80个,用户还可以自行编辑各种公式,或将各个函数组合使用,各种图标化的提示与仅用鼠标就可进行的操作使一般人可以很快掌握基本的操作,无须经过培训。方便的智能型复制功能,极大地减轻了计算工作量,并使大部分结果可以自动生成。 充分利用Excel的统计分析功能,可以对数据作多方面的统计分析处理,包括两个变量之间的相关分析和回归分析。我们相信,关于Excel的数据统计处理功能,读者已经有所了解,此处不拟进行过多的赘述。 2.Matlab 在Matlab中,一整套关于统计分析的运算函数,主要包括 corrcoef(x)——求相关函数; cov(x) ——协方差矩阵; cross(x,y)——向量的向量积; diff(x)——计算元素之间差; dot(x,y)——向量的点积; gradient(z,dx,dy)——近似梯度; histogram(x)——直方图和棒图; max(x), max(x,y)——最大分量; mean(x)——均值或列的平均值; min(x), min(x,y)——最小分量; prod(x)——列元素的积; rand(x)——均匀分布随机数; rands(x)——正态分布随机数; sort(x)——按升序排列; std(x)——列的标准偏差; sum(x)——各列的元素和; subspace(A,B)——两个子空间之间的夹角。 3.SPSS SPSS for Windows是一个功能强大的组合式统计软件包,它集数据整理、分析功能于一身。用户可以根据实际需要和计算机的功能选择模块,以降低对系统硬盘容量的要求,有利于该软件的推广应用。SPSS的基本功能包括数据管理、统计分析、图表分析、输出管理等等。SPSS统计分析过程包括描述性统计、均值比较,以及相关分析、回归分析、方差分析、卡方检验、t检验和非参数检验;也包括近期发展的多元统计技术,如多元回归分析、聚类分析、判别分析、主成分分析和因子分析等方法,并能在屏幕(或打印机)上显示(打印)如正态分布图、直方图、散点图等各种统计图表。 4.例——相关系数计算 数据处理 (从小数据到大数据) 一、小数据 1、信息的度量 在计算机中: 最小数据单位:位(bit) Bit: 0 或1 (由电的状态产生:有电1,无电0)基本数据单位:字节(Byte, B) 1B=8bit 1KB=1024B 1MB=1024KB 1GB=1024MB 1TB=1024GB。 …… 2、不同数制的表示方法 十进制(Decimal notation),如120, (120) 10,120D 二进制(Binary notation) ,如(1010)2 , 1010B 八进制(Octal notation) ,如(175)8 , 175O 十六进制数(Hexdecimal notation) ,如(2BF)16 , 2BF03H 3、不同数制之间的转换方法 (1)任意其他进制(二、八、十六)转换成十进制,可“利用按权展开式展开”。 例如: 10110.101B =1×24+0×23+1×22+1×21+0×20+1×2-1+0×2-2+1×2-3 =22.625D 347.6O =3×82+4×81+7×80+6×8-1 =231.75D D5.6H =D×161+5×160+6×16-1 =213.375D (2)十进制转换成任意其他进制(二、八、十六),整数部分的转换可按“除基取余,倒序排列”的方法,小数部分的转换可按“乘基取整,顺序排列”的方法。(除倒取,乘正取) 例,十进制数59转换为二进制数111011B 例:十进制数0.8125转换为二进制数0.1101B 同理:317 D= 100111101B = 475O = 13DH 0.4375D = 0.0111B = 0.34O = 0.7H (3)八进制数转换成二进制数,可按“逐位转换,一位拆三位”的方法。(8421法) 例如:3107.46O = 3 1 0 7 . 4 6 O =011 001 000 111 . 100 110 B =11001000111.10011B (4)十六进制数转换成二进制数,可按“逐位转换,一位拆四位”的方法。(8421法) 资料的统计处理和结果分析 在采用各种各样的研究学习方法后,学生们获取了各种研究资料和信息。这里的资料不仅包 括研究所需的数量型资料,而且包括大量非数量型的文字背景资料。然而,如果这些资料未经整 理就进行分析,是没有实际的应用价值和科学意义的。 对所获取的数量型资料进行分析,主要是采取统计学上的一些方法。对非数量型资料进行分析,则可以采用概念、判断、推理、归纳、演绎等方式进行分析研究。 统计学(Statistics)是研究统计原理和方法的科学。在对数据进行统计处理时,涉及的内容包括 三部分:描述统计、推断统计和实验设计。 描述统计是指对所搜集的大量数字资料进行整理、概括,寻找数据的分布特征,用以反映研 究对象的内容和实质的统计方法。例如,对原始数据资料用归组、列表、图示等方法加以归纳、 整理,为进一步处理数据资料做好准备工作。计算集中量指标(如算术平均数、中位数)来反映数据 的集中趋势;计算差异量数指标(如标准差、百分位距)来反映数据的离散程度;计算相关量数指标(如相关系数)来反映数据的相关程度。描述统计可使无序而庞杂的数字资料成为有序而清晰的信息 资料。 推断统计是指根据来自样本的数据推断总体的性质,并标明可能发生的误差,以对随机现象 作出估计、推断的统计方法。例如,对总体参数值(如总体平均数,总体标准差)的估计,推断统计 可根据已知材料,去估计、推测未知的可能性大小。 实验设计是指研究者为揭示自变量与因变量的关系,验证假设之前所制定的实验计划。内容 包括研究步骤的制定、抽样、实验变量及实验条件的控制、对结果的统计处理方法等。 对所获取的资料进行定性与定量分析后,得到的结果可以给出结论。但结论必须从事实出发,事实求是,切忌"可能"、"或许"之类不确定性的语句,否则就失去了研究的价值,因为花费了大量 的劳动,最后得到的是一个不确定性的结论,是不会令人满意的,这也就是失败的、不成功的研究。必须注意到,有时根据收集到的资料而得出的结论并不完全符合预先的假设,甚至与假设相反,这是完全正常的,决不能为了验证假设而制造出一个不符合资料分析的、不实事求是的"结论"。结论必须有理论的概括、分析,而不是对资料简单的、表面的、粗浅的描述。 数量型资料的描述统计 (一)图表制作 为了将数据更加直观、清晰地展现出来,并从中得出有关结论,可以采用绘制统计图表的方法,对统计数据进行归类,将研究对象按不同特征进行区分,将有关数据划分到各个类别中,以简洁明了的形式显示出研究对象的数量特征,并由此作进一步分析、综合、比较,从而揭示出事物间的联系及变化规律,得出分析结果。 1.统计图表编制要求 统计图表的绘制,要求格式规范,重点突出,简明易懂。 (1)图表号和标题 图表号指图表的编号,当论文中的统计表或图形不止一个时,应将其分别依次编号,如表1、表2、图1、图2等;当在论文中涉及有关图表的内容时,只需标明"见表×"或"见图×"即可,而不必具体 主要统计指标解释 农林牧渔业总产值指以货币表现的农、林、牧、渔业全部产品和对农林牧渔业生产活动进行的各种支持性服务活动的价值总量,它反映一定时期内农林牧渔业生产总规模和总成果。1957年以前的农林牧渔业总产值中包括了厩肥和农民自给性手工业(如农民自制衣服、鞋、袜,自己从事粮食初步加工等)。1958年及以后,林业中增加了村及村以下竹木采伐产值;牧业中取消了厩肥产值;副业中取消了农民自给性手工业产值,增加了村及村以下办的工业产值;渔业中增加了海洋捕捞水产品产值。1980年及以后,在副业中增加了农民家庭兼营工业商品部分的产值。从1984年起村及村以下工业产值划归工业。从1993年起取消副业,将野生动物的捕猎划入牧业,野生植物采集和农民家庭兼营商品性工业划归农业。从2003年起,执行新的国民经济行业分类标准,农林牧渔业总产值中包括了农林牧渔服务业产值。林业中增加了森林采运业产值。农业中取消了家庭兼营商品性工业产值,将野生林产品的采集划归林业。第一次农业普查以后,由于畜牧业产品年报数据与普查数据之间存在一定的差距,根据农业普查结果,对畜牧业年报数据和畜牧业产值进行了修正。2010年执行《统计用产品分类目录》,对2009年的农业、林业产值做了相应调整。 农林牧渔业总产值的计算方法通常是按农、林、牧、渔业产品及其副产品的产量分别乘以各自单位产品价格求得;少数生产周期较长,当年没有产品或产品产量不易统计的,则采用间接方法匡算其产值;然后将四业产品产值及农林牧渔服务业产值相加即为农林牧渔业总产值。 粮食产量指全社会的产量。包括国有经济经营的、集体统一经营的和农民家庭经营的粮食产量,还包括工矿企业办的农场和其他生产单位的产量。粮食除包括稻谷、小麦、玉米、高粱、谷子及其他杂粮外,还包括薯类和豆类。其产量计算方法,豆类按去豆荚后的干豆计算;薯类(包括甘薯和马铃薯,不包括芋头和木薯)1963年以前按每4公斤鲜薯折1公斤粮食计算,从1964年开始改为按5公斤鲜薯折1公斤粮食计算。城市郊区作为蔬菜的薯类(如马铃薯等)按鲜品计算,并且不作粮食统计。其他粮食一律按脱粒后的原粮计算。1989年以前 第一章导论 1.地理信息系统:是由计算机硬件、软件和不同的方法组成的系统,该系统设计来支持空间数据的采集、管理、处理、分析、建模和现实,以便解决复杂的规划和管理问题。2.GIS与MIS管理信息系统)以及与CAD的异同点? GIS和MIS 相同点:都是以计算机为核心的信息处理系统,都具有数据量大和数据之间关系复杂的特点。区别:GIS主要处理空间数据,如:土地资源、森林资源、交通运输网络、人口分布等数据;MIS主要处理物资、设备、资金、产量、库存、劳动力以及人事档案、生产合同、计划任务等非空间数据。 GIS和CAD 相同点:二者都具有坐标参考系统,都能描述和处理图形数据,也能处理属性数据。 区别:(1)GIS强调空间数据的处理和分析,而CAD更偏向于制图和表达,图形编辑功能较强,具有较强的排版和编辑和制图能力(2)处理的数据量上:GIS处理的是海量的数据,而CAD处理的数据量相对较小(3)数据的地理语义:GIS强,CADD弱(4)属性信息:GIS丰富,CAD较少(5)空间拓扑关系:GIS较强,CAD较弱 3.GIS的基本构成: 系统硬件: (一)数据处理设备:(1)图形工作站(2)个人计算机(3)客户机/服务器系统(Client/Server,简称C/S) (二)数据输入设备(1)图形手扶跟踪数字化仪(2)大幅面图形扫描仪(3)数字测量设备 (三)数据输出设备(1)绘图仪(2)计算机显示器 系统软件: (一)GIS功能软件(1)GIS基础软件平台(2)GIS应用软件 (二)基础支撑软件(1)数据库软件 (三)操作系统软件 空间数据:地理信息系统的操作对象是地理数据,它具体描述地理现象的空间特征、属性特征和时间特征。 (一)空间特征:是指地理现象的空间位置以及相互关系,其数据称为空间数据; (二)属性特征:表示地理现象的名称、类型和数量等,其数据称为属性数据; (三)时间特征:指地理现象随时间而发生的变化,其数据称为时态数据; 应用人员:系统开发人员和GIS技术的最终用户。 应用模型:对于某一应用目的问题的解决,必须通过构建专门的应用模型。 4.GIS的功能: 一、基本功能:(1)数据采集与编辑(2)数据存储与管理(3)数据处理和变换(4)空间分析和统计(5)产品制作与演示(6)二次开发和编程 二、应用功能:(1)资源管理(2)区域规划(3)国土检测(4)辅助决策 5.GIS的发展概况以及发展趋势? 6.GIS中空间数据误差的来源? (1)数据采集:实地测量误差、航测遥感数据分析误差、地图的误差 (2)数据输入:数字化过程中由操作员和设备造成的误差、地理属性没有明显边界引起的误差 (3)数据存储:数字存储有效位不能满足、空间精度不能满足 (4)数据输入:比例尺误差、输出设备误差、介质的变形误差数据资料的统计处理
统计学名词解释汇总情况
数据库期末考试名词解释
根据统计年鉴相关内容填写表中数据
数据挖掘中的名词解释
少量数据的统计处理
数据处理内容.
数据处理名词解释
数据处理总结
统计学数据处理的基本思路
地理信息系统名词解释大全(整理版本)
最新2利用相关软件对数据作简单的统计处理
数据基础知识及数据处理
资料的统计处理和结果分析
主要统计指标解释
专业课名词解释