第三版计量经济学第五章习题作业

第五章习题2
根据经济理论建立计量经济模型
i i 10i X Y μββ++=
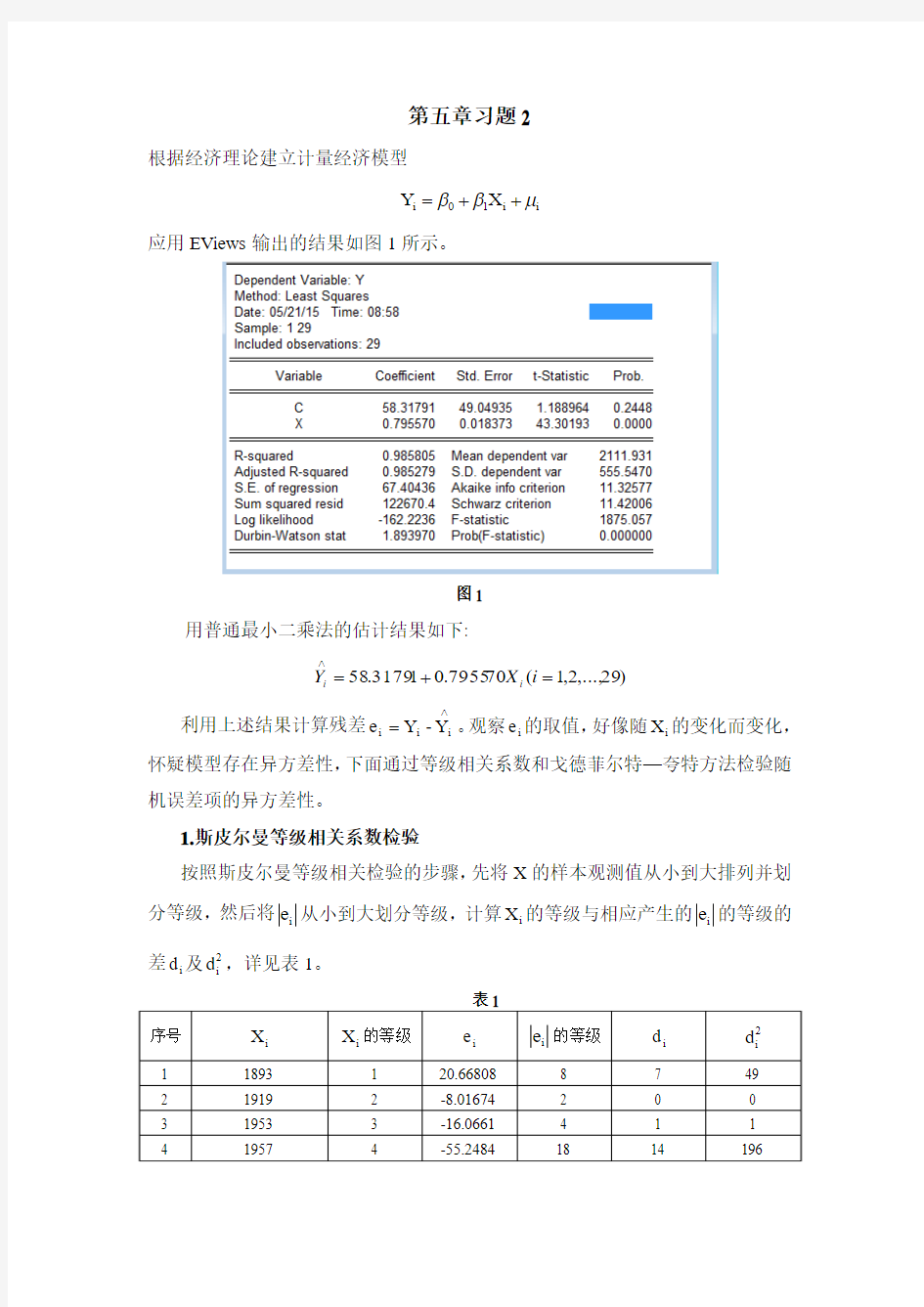
应用EViews 输出的结果如图1所示。
图1
用普通最小二乘法的估计结果如下:
)29,...,2,1(707955.013179.58=+=∧
i X Y i i
利用上述结果计算残差∧
=i i i Y -Y e 。观察i e 的取值,好像随i X 的变化而变化,怀疑模型存在异方差性,下面通过等级相关系数和戈德菲尔特—夸特方法检验随机误差项的异方差性。
1.斯皮尔曼等级相关系数检验
按照斯皮尔曼等级相关检验的步骤,先将X 的样本观测值从小到大排列并划分等级,然后将i e 从小到大划分等级,计算i X 的等级与相应产生的i e 的等级的差i d 及2i d ,详见表1。
表1
计算等级相关系数
2334d
1
i 2i
=∑=
0.42512329
-292334
6-
1N
-N d 6-
1r 3
3
1i 2i =?==∑= 对等级相关系数进行检验,提出原假设与备择假设
)
,(),(::28
1
0N 1-N 10N ~r 0
H 0H 10=≠=ρρ
构造Z 统计量
2.2495428*0.4251231
-N 1r
Z ===
给定显著水平0.05=α,查正态分布表,得 1.96Z 2
=α因为 1.962.24954Z >=,
所以应拒绝原假设,接收备择假设,即等级相关系数显著,说明其随机误差项存在异方差性。
2. 戈德菲尔特—夸特方法检验
将X 的样本观测值按升序排列,Y 的样本观测值按原来与X 样本观测值的对应关系进行排列,略去中心7个数据,将剩下的22个样本观测值分成容量相等的两个子样本,每个子样本的样本观测值个数均为11。排列结果见表2。
用第一个子样本估计模型,得到的结果如图2所示:
图2
用第一个子样本估计模型,得0.974751X -287.1872Y +=∧
残差平方和21688.89
e 2
i1=∑ 用第二个子样本估计模型,得到的结果如图3所示:
图3
用第一个子样本估计模型,得0.820337X -27.68345Y +=∧
残差平方和43702.65
e 2i2=∑ 提出原假设 2
2922210......H σσσ===: 备择假设 229
22211......H σσσ:互不相同。 构造F 统计量
2.0121688.89
43702.65
e
e F 2i1
2i2==
=
∑∑
给定显著性水平0.05=α,差F 分布表,v 92-1121===νν, 3.1899F 0.05=),(,因为F=2.01<3.18,所以应接受原假设,即该模型误差项不存在异方差性。
3. 用加权最小二乘法克服异方差
用EViews 进行加权最小二乘估计, 估计结果如图4所示。
图4
在该对话框中,点击VIEW ,选择RESIDUAL TESTS/WHITE Heteroske dasticity (no cross terms ),即得到图5。即对图5的残差做white 检验可知
0.6)2(1.189TR 2
05.02=<=χ,已经克服了异方差性。
图5
4.用加权最小二乘估计式预测
根据上述步骤,得到加权最小二乘估计结果为:
i X 783976.087.47796Y i +=∧
将2423X 29=带入上式,得:
1887.05182423783976.087.47796Y i =?+=∧
预测误差是3.2%。
计量经济学作业HW1
Homework1for Econometrics (due March27,2013) Spring2013 Instructor:Jihai Yu TA:Kunyuan Qiao 1.Suppose that you are asked to conduct a study to determine whether smaller class sizes lead to improved student performance of fourth graders. (i)If you could conduct any experiment you want,what would you do?Be speci…c. (ii)More realistically,suppose you can collect observational data on several thousand fourth graders in a given state.You can obtain the size of their fourth-grade class and a standardized test score taken at the end of fourth grade.Why might you expect a negative correlation between class size and test score? (iii)Would a negative correlation necessarily show that smaller class sizes cause better performance? Explain. 2.The data set BWGHT.DTA contains data on births to women in the United States.Two variables of interest are the dependent variable,infant birth weight in ounces(bwght),and an explanatory variable, average number of cigarettes the mother smoked per day during pregnancy(cigs).The following simple regression was estimated using data on n=1,388births: \ bwght=119:77 0:514cigs (i)What is the predicted birth weight when cigs0?What about when cigs20(one pack per day)? Comment on the di¤erence. (ii)Does this simple regression necessarily capture a causal relationship between the child’s birth weight and the mother’s smoking habits?Explain. (iii)To predict a birth weight of125ounces,what would cigs have to be?Comment. (iv)The proportion of women in the sample who do not smoke while pregnant is about0.85.Does this help reconcile your…nding from part(iii)? https://www.360docs.net/doc/2d2942228.html,ing data from1988for houses sold in Andover,Massachusetts,from Kiel and McClain(1995),the following equation relates housing price(price)to the distance from a recently built garbage incinerator
庞皓计量经济学课后答案第三章
统计学2班 第二次作业 1、?i =-151.0263 + 0.1179X 1i + 1.5452X 2i T= (-3.066806) (6.652983) (3.378064) R 2=0.934331 R 2=0.92964 F=191.1894 n=31 ⑴模型估计结果说明,各省市旅游外汇收入Y 受旅行社职工人数X 1,国际旅游人数X 2的影响。由所估计出的参数可知,在假定其他变量不变的情况下,当旅行社职工人数每增加1人,各省市旅游外汇收入增加0.1179百万美元。在嘉定其他变量不变的情况下。当国际旅游人数每增加1万人,各省市旅游外汇收入增加1.5452百万美元。 ⑵由题已知,估计的回归系数β1的T 值为:t (β1)=6.652983。 β2的T 值分为: t (β2)=3.378064。 α=0.05.查得自由度为n-2=22-2=29的临界值t 0.025(29)=2.045229 因为t (β1)=6.652983≥t 0.025(29)=2.045229.所以拒绝原假设H 0:β1=0。 表明在显著性水平α=0.05下,当其他解释变量不变的情况下,旅行社职工人数X 1对各省市旅游外汇收入Y 有显著性影响。 因为 t (β2)=3.378064≥t 0.025(29)=2.045229,所以拒绝原假设H 0:β2=0 表明在显著性水平α=0.05下,当其他解释变量不变的情况下,和国际旅游人数X 2对各省市旅游外汇收入Y 有显著性影响。 ⑶正对H O :β1=β2=0,给定显著水性水平α=0.05,自由度为k-1=2,n-k=28的临界值 F 0.05(2,28)=3.34038。由题已知F=191.1894>F 0.05(2,28)=3.34038,应拒绝原假设 H O :β1=β2=0,说明回归方程显著,即旅行社职工人数和旅游人数变量联合起来对各省市旅游外汇收入有显著影响。 2、⑴样本容量n=15 残差平方和RSS=66042-65965=77 回归平方和ESS 的自由度为K-1=2 残差平方和RSS 的自由度为n-k=13 ⑵可决系数R 2=TSS ESS =6604265965 =0.99883 调整的可决系数R 2=1-(1-R 2)k n n --1=1-(1-0.99883)1214=0.99863 ⑶利用可决系数R 2=0.99883,调整的可决系数R 2=0.99863,说明模型对样本的拟合很好。不能确定两个解释变量X 2和X 3个字对Y 都有显著影响。
计量经济学第三版庞浩第三章习题
第三章习题 3.1 (1)2011年各地区的百户拥有家用汽车量及影响因素数据图形 可以看出,2011年各地区的百户拥有家用汽车量及影响因素的差异明显,其变动的方向基本相同,相互间可能具有一定的相关性,因而将其模型设定为线性回归模型形式: Y=β1+β2X2+β3X3+β4X4
估计参数 Y=246.854+5.996865X 2-0.524027X 3-2.26568X 4 模型检验 ① R 2是0.666062,修正的R 2为0.628957,说明模型对样本拟合较好 ② F 检验,分别针对H0:βj=0(j=1,2,3,4),给定显著性水平α=0.05,在F 分布表中查出自由度为k-1=3,n-k=27的临界值F α(3,27)=3.65,由表可知,F=17.95108>F α(3,27)=3.65,应拒绝原假设,回归方程显著。 ③ t 检验,分别针对H0:βj=0(j=1,2,3,4),给定显著性水平α=0.05,查t 分布表得自由度为n-k=27临界值t 2 05.0(n-k )=2.0518。对应的t 统计量分 别为 4.749476,4.265020,-2.922950,-4.366842,其绝对值均大于t (27) =2.0518,所以这些系数都是显著的。 (2)人均GDP增加1万元,百户拥有家用汽车增加5.996865辆, 城镇人口比重增加1个百分点,百户拥有家用汽车减少0.524027辆, 交通工具消费价格指数每上升1,百户拥有家用汽车减少2.265680辆。 (3)将其模型设定为 Y=β1+β2X 2+β3LnX 3+β4LnX 4
计量经济学第三次作业
下表列出了某年中国部分省市城镇居民每个家庭平均全年可支配收入X与消费性支出Y 的统计数据。 地区可支配收入 (X)消费性支出 (Y) 地区可支配收入 (X) 消费性支出 (Y) 北京10349.69 8493.49 浙江9279.16 7020.22 天津8140.50 6121.04 山东6489.97 5022.00 河北5661.16 4348.47 河南4766.26 3830.71 山西4724.11 3941.87 湖北5524.54 4644.5 内蒙古5129.05 3927.75 湖南6218.73 5218.79 辽宁5357.79 4356.06 广东9761.57 8016.91 吉林4810.00 4020.87 陕西5124.24 4276.67 黑龙江4912.88 3824.44 甘肃4916.25 4126.47 上海11718.01 8868.19 青海5169.96 4185.73 江苏6800.23 5323.18 新疆5644.86 4422.93 (1)试用普通最小二乘法建立居民人均消费支出与可支配收入的线性模型; (2)检验模型是否存在异方差性; (3)如果存在异方差性,试采用适当的方法估计模型参数。 解: (1)a.建立对象,录入可支配收入X与消费性支出Y,如下图: b. 设定一元线性回归模型为: 点击主界面菜单Quick\Estimate Equation,在弹出的对话框中输入Y、C、X,操作
(2)a.生成残差序列。在工作文件中点击Object\Generate Series…,在弹出的窗口中,在主窗口键入命令如下“e1=resid^2”得到残差平方和序列e1。如下图: (3)a. 设定一元线性回归模型为:
庞皓计量经济学 第三章练习题及参考解答 (第3版)
第三章练习题及参考解答 3.1 第三章的“引子”中分析了,经济增长、公共服务、市场价格、交通状况、社会环境、政策因素,都会影响中国汽车拥有量。为了研究一些主要因素与家用汽车拥有量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”、“城镇人口比重”、“交通工具消费价格指数”等变量,2011年全国各省市区的有关数据如下: 表3.6 2011年各地区的百户拥有家用汽车量等数据 资料来源:中国统计年鉴2012.中国统计出版社
1)建立百户拥有家用汽车量计量经济模型,估计参数并对模型加以检验,检验结论 的依据是什么?。 2)分析模型参数估计结果的经济意义,你如何解读模型估计检验的结果? 3) 你认为模型还可以如何改进? 【练习题3.1参考解答】: 1)建立线性回归模型: 1223344t t t t t Y X X X u ββββ=++++ 回归结果如下: 由F 统计量为17.87881, P 值为0.000001,可判断模型整体上显著, “人均地区生产总值”、“城镇人口比重”、“交通工具消费价格指数”等变量联合起来对百户拥有家用汽车量有显著影响。解释变量参数的t 统计量的绝对值均大于临界值0.025(27) 2.052t =,或P 值均明显小于0.05α=,表明在其他变量不变的情况下,“人均地区生产总值”、“城镇人口比重”、“交通工具消费价格指数”分别对百户拥有家用汽车量都有显著影响。 2)X2的参数估计值为5.9911,表明随着经济的增长,人均地区生产总值每增加1万元,平均说来百户拥有家用汽车量将增加近6辆。由于城镇公共交通的大力发展,有减少家用汽车的必要性,X3的参数估计值为-0.5231,表明随着城镇化的推进,“城镇人口比重”每增加1%,平均说来百户拥有家用汽车量将减少0.5231辆。汽车价格和使用费用的提高将抑制家用汽车的使用, X4的参数估计值为-2.2677,表明随着家用汽车使用成本的提高, “交通工具消费价格指数”每增加1个百分点,平均说来百户拥有家用汽车量将减少2.2677辆。 3)模型的可决系数为0.6652,说明模型中解释变量变解释了百户拥有家用汽车量变动的66.52%,还有33.48%未被解释。影响百户拥有家用汽车量的因素可能还有交通状况、社会环境、政策因素等,还可以考虑纳入一些解释变量。但是使用更多解释变量或许会面临某些基本假定的违反,需要采取一些其他措施。
计量经济学第三章练习题与参考全部解答
第三章练习题及参考解答 3.1为研究中国各地区入境旅游状况,建立了各省市旅游外汇收入(Y ,百万美元)、旅行社职工人数(X1,人)、国际旅游人数(X2,万人次)的模型,用某年31个省市的截面数据估计结果如下: i i i X X Y 215452.11179.00263.151?++-= t=(-3.066806) (6.652983) (3.378064) R 2=0.934331 92964.02 =R F=191.1894 n=31 1)从经济意义上考察估计模型的合理性。 2)在5%显著性水平上,分别检验参数21,ββ的显著性。 3)在5%显著性水平上,检验模型的整体显著性。 练习题3.1参考解答: (1)由模型估计结果可看出:从经济意义上说明,旅行社职工人数和国际旅游人数均与旅游外汇收入正相关。平均说来,旅行社职工人数增加1人,旅游外汇收入将增加0.1179百万美元;国际旅游人数增加1万人次,旅游外汇收入增加1.5452百万美元。这与经济理论及经验符合,是合理的。 (2)取05.0=α ,查表得048.2)331(025.0=-t 因为3个参数t 统计量的绝对值均大于048.2)331(025.0=-t ,说明经t 检验3个参数均显著不为0,即旅行社职工人数和国 际旅游人数分别对旅游外汇收入都有显著影响。 (3)取05.0=α ,查表得34.3)28,2(05.0=F ,由于34.3)28,2(1894.19905.0=>=F F ,说明旅行社职工人数和 国际旅游人数联合起来对旅游外汇收入有显著影响,线性回归方程显著成立。 3.2 表3.6给出了有两个解释变量 2X 和.3X 的回归模型方差分析的部分结果: 表3.6 方差分析表 1)回归模型估计结果的样本容量n 、残差平方和RSS 、回归平方和ESS 与残差平方和RSS 的自由度各为多少? 2)此模型的可决系数和调整的可决系数为多少? 3)利用此结果能对模型的检验得出什么结论?能否确定两个解释变量 2X 和.3X 各自对Y 都有显著影响? 练习题3.2参考解答: (1) 因为总变差的自由度为14=n-1,所以样本容量:n=14+1=15 因为 TSS=RSS+ESS 残差平方和RSS=TSS-ESS=66042-65965=77 回归平方和的自由度为:k-1=3-1=2 残差平方和RSS 的自由度为:n-k=15-3=12 (2)可决系数为:2 65965 0.99883466042 ES R TSS S = == 修正的可决系数:2 2 2115177 110.998615366042 i i e n R n k y --=- =-?=--∑∑ (3)这说明两个解释变量2X 和.3X 联合起来对被解释变量有很显著的影响,但是还不能确定两个解释变量2X 和.3X 各 自对Y 都有显著影响。
CCER 计量经济学 第三次作业和答案
Intermediate Econometrics Class 1 Problem Set 3 with Answers Handout Date: Dec. 4th, 2011 Due Date: Dec. 9th, 2011 (Hand in BEFORE class) 1.An estimated equation is with , and SSR = 1.5 Use F-statistic to test the following (1). (2). (3). (Hint: The tests involve only the sub-matrix in the lower-right corner of . Refer to TA materials for the formula of inverses of partitioned matrices.) (1). equals the single element at the lower right-hand corner of ,which is 2.5. Then the F-statistic is calculated as It falls well short of any usually critical value for . So we cannot reject . (2). only involves the elements in the sub-matrix in the lower right-hand corner of The F-statistic equals From the tables of F distribution, , so we cannot reject the null at 5% significance level.
计量经济学第三章课后习题详解
第三章习题 3.1 2011年各地区的百户拥有家用汽车量等数据 北京37.71 8.05 86.20 95.92 天津20.62 8.34 80.50 103.57 河北23.32 3.39 45.60 99.03 山西18.60 3.13 49.68 98.96 19.62 5.79 56.62 99.11 内蒙 古 辽宁11.15 5.07 64.05 100.12 吉林11.24 3.84 53.40 97.15 黑龙 5.29 3.28 5 6.50 100.54 江 上海18.15 8.18 89.30 101.58 江苏23.92 6.22 61.90 98.95 浙江33.85 5.92 62.30 96.69 安徽9.20 2.56 44.80 100.25 福建17.83 4.72 58.10 100.75 江西8.88 2.61 45.70 100.91 山东28.12 4.71 50.95 98.50 河南14.06 2.87 40.57 100.59 湖北9.69 3.41 51.83 101.15 湖南12.82 2.98 45.10 100.02 广东30.71 5.07 66.50 97.55 广西17.24 2.52 41.80 102.28 海南15.82 2.88 50.50 102.06 重庆10.44 3.43 55.02 99.12 四川12.25 2.61 41.83 99.76 贵州10.48 1.64 34.96 100.71 云南23.32 1.92 36.80 96.25 西藏25.30 2.00 22.71 99.95 陕西12.22 3.34 47.30 101.59 甘肃7.33 1.96 37.15 100.54 青海 6.08 2.94 46.22 100.46 宁夏12.40 3.29 49.82 100.99 新疆12.32 2.99 43.54 100.97 一、研究的目的和要求 经济增长,公共服务、市场价格、交通状况,社会环境、政策因素都会影响中国汽车拥有量。为了研究一些主要因素与家用汽车拥有量的数量关系,选择“人均地区生产总值”、“城镇人口比重”、“交通工具消费价格指数”等变量来进行研究和分析。 为了研究影响2011年各地区的百户拥有家用汽车量差异的主要原因,分析2011年各地区的百户拥有家用汽车量增长的数量规律,预测各地区的百户拥有家用汽车量的增长趋势,需要建立计量经济模型。 二、模型设定 为了探究影响2011年各地区的百户拥有家用汽车量差异的主要原因,选择百户拥有家用汽车量为被解释变量,人均GDP、城镇人口比重、交通工具消费价格指数为解释变量。
计量经济学习题第三章
第三章、经典单方程计量经济学模型:多元线性回归模型 一、内容提要 本章将一元回归模型拓展到了多元回归模型,其基本的建模思想与建模方法与一元的情形相同。主要内容仍然包括模型的基本假定、模型的估计、模型的检验以及模型在预测方面的应用等方面。只不过为了多元建模的需要,在基本假设方面以及检验方面有所扩充。 本章仍重点介绍了多元线性回归模型的基本假设、估计方法以及检验程序。与一元回归分析相比,多元回归分析的基本假设中引入了多个解释变量间不存在(完全)多重共线性这一假设;在检验部分,一方面引入了修正的可决系数,另一方面引入了对多个解释变量是否对被解释变量有显著线性影响关系的联合性F检验,并讨论了F检验与拟合优度检验的内在联系。 本章的另一个重点是将线性回归模型拓展到非线性回归模型,主要学习非线性模型如何转化为线性回归模型的常见类型与方法。这里需要注意各回归参数的具体经济含义。 本章第三个学习重点是关于模型的约束性检验问题,包括参数的线性约束与非线性约束检验。参数的线性约束检验包括对参数线性约束的检验、对模型增加或减少解释变量的检验以及参数的稳定性检验三方面的内容,其中参数稳定性检验又包括邹氏参数稳定性检验与邹氏预测检验两种类型的检验。检验都是以F检验为主要检验工具,以受约束模型与无约束模型是否有显著差异为检验基点。参数的非线性约束检验主要包括最大似然比检验、沃尔德检验与拉格朗日乘数检验。它们仍以估计无约束模型与受约束模型为基础,但以最大似然 χ分布为检验统计原理进行估计,且都适用于大样本情形,都以约束条件个数为自由度的2 量的分布特征。非线性约束检验中的拉格朗日乘数检验在后面的章节中多次使用。 二、典型例题分析 例1.某地区通过一个样本容量为722的调查数据得到劳动力受教育的一个回归方程为36 .0 . + = - 10+ 094 medu fedu .0 sibs edu210 131 .0 R2=0.214 式中,edu为劳动力受教育年数,sibs为该劳动力家庭中兄弟姐妹的个数,medu与fedu分别为母亲与父亲受到教育的年数。问
计量经济学习题第10章 联立方程模型
第10章联立方程模型 一、单选 1、如果联立方程中某个结构方程包含了所有的变量,则这个方程为() A、恰好识别 B、过度识别 C、不可识别 D、可以识别 2、下面关于简化式模型的概念,不正确的是() A、简化式方程的解释变量都是前定变量 B、简化式参数反映解释变量对被解释的变量的总影响 C、简化式参数是结构式参数的线性函数 D、简化式模型的经济含义不明确 3、对联立方程模型进行参数估计的方法可以分两类,即:( ) A、间接最小二乘法和系统估计法 B、单方程估计法和系统估计法 C、单方程估计法和二阶段最小二乘法 D、工具变量法和间接最小二乘法 4、在结构式模型中,其解释变量( ) A、都是前定变量 B、都是内生变量 C、可以内生变量也可以是前定变量 D、都是外生变量 5、如果某个结构式方程是过度识别的,则估计该方程参数的方法可用() A、二阶段最小二乘法 B、间接最小二乘法 C、广义差分法 D、加权最小二乘法 6、当模型中第i个方程是不可识别的,则该模型是( ) A、可识别的 B、不可识别的 C、过度识别 D、恰好识别 7、结构式模型中的每一个方程都称为结构式方程,在结构方程中,解释变量可以是前定变量,也可以是( ) A、外生变量 B、滞后变量 C、内生变量 D、外生变量和内生变量 8. 在完备的结构式模型 A、Y t B.Y t – 1 C.I t D.G t 9. 在完备的结构式模型 A.方程1 B.方程2 C.方程3 D.方程1和2 10.联立方程模型中不属于随机方程的是() A.行为方程 B.技术方程 C.制度方程 D.恒等式 11.结构式方程中的系数称为() A.短期影响乘数 B.长期影响乘数 C.结构式参数 D.简化式参数 12.简化式参数反映对应的解释变量对被解释变量的 A.直接影响 B.间接影响 C.前两者之和 D.前两者之差 13.对于恰好识别方程,在简化式方程满足线性模型的基本假定的条件下,间接最小二乘估 计量具备() A.精确性 B.无偏性 C.真实性 D.一致性 二、多选 1、当结构方程为恰好识别时,可选择的估计方法是() A、最小二乘法 B、广义差分法 C、间接最小二乘法 D、二阶段最小二乘法 E、有限信息极大似然估计法 2、对联立方程模型参数的单方程估计法包括( ) A、工具变量法 B、间接最小二乘法 C、完全信息极大似然估计法 D、二阶段最小二乘法 E、三阶段最小二乘法
计量经济学第三次作业
点击主界面菜单Quick\Estimate Equation,在弹出的对话框中输入Y、C、X,操作如下图:
(2) a.生成残差序列。在工作文件中点击Object'Generate Series ,在 弹出的窗口中,在主窗口键入命令如下“e1=resid A2 ”得到残差平方和序 列e10如下图: b.绘制el与x的散点图。按住Ctrl键,同时选择变量X与e2以组对象方式打幵,进入数据列表,再点击View\Graph\Scatter\Simple Scatter , 可得散点图。如上图: (3)a.设定一元线性回归模型为: 点击主界面菜单Quick'Estimate Equatio n ,在弹出的对话框中输入Iog(e1)、C X,得出结果如下图: b.在工作文件中点击Object'Generate Series ,在弹出的窗口中,在主窗口键入命令如下”w=1/sqr(exp+*x)) ”得出权数W. c.点击主界面菜单Quick'Estimate Equation,在弹出的Specification 对话框中输入Y、C、X,在Options中的Weight series中填入权数w.如下图: (1)结果 Depe ndent Variable: Y Method: Least Squares Date: 12/5/16 Time: 19:57 Sample: 1 20 In cluded observatio ns: 20 Coeffici Std. t-Statist Variable ent Error ic Prob.
F= 估计结果显示,即使在10%的显着性水平下,都不拒绝常数项为零的假设。 (2) 由b 的图可知,残差平方e1与x 大致存在递增关系,即存在单调增型 异方差。 (3) 通过加权得出的方程结果如下: Method: Least Squares Date: 12/5/16 Time: 20:01 Sample: 1 20 X R-squared Adjusted R-squared .of regressi on Sum squared resid Log likelihood F-statistic Prob(F-statisti c) 得到模型的估计结果为: Mean depe ndent var .dependent var Akaike info criterio n Schwarz criteri on Hannan-Qu inn criter. Durb in-Wats on stat
第十章练习题参考解答
第十章练习题参考解答 练习题 10.1下表是某国的宏观经济数据(GDP——国内生产总值,单位:10亿美元;PDI——个人可支配收入,单位:10亿美元;PCE——个人消费支出,单位:10亿美元;利润——公司税后利润,单位:10亿美元;红利——公司净红利支出,单位:10亿美元)。 某国1980年到2001年宏观经济季度数据
(1)画出利润和红利的散点图,并直观地考察这两个时间序列是否是平稳的。 (2) 应用单位根检验分别检验两个时间序列是否是平稳的。 10.2下表数据是1970-1991年美国制造业固定厂房设备投资Y和销售量X,以10亿美元计价,且经过季节调整,根据该数据,判断厂房开支和销售量序列是否平稳? 10.3 根据习题10.1的数据,回答如下问题: (1) 如果利润和红利时间序列并不是平稳的,而如果你以利润来回归红利,那么回归 的结果会是虚假的吗?为什么?你是如何判定的,说明必要的计算。 (2) 取利润和红利两个时间序列的一阶差分,确定一阶差分时间序列是否是平稳的。 10.4 从《中国统计年鉴》中取得1978年-2005年全国全社会固定资产投资额的时间序
列数据,检验其是否平稳,并确定其单整阶数。 10.5 下表是1978-2003年中国财政收入Y和税收X的数据(单位:亿元),判断lnY 和lnX的平稳性,如果是同阶单整的,检验它们之间是否存在协整关系,如果协整,则建立相应的协整模型。 (1)10.6下表是某地区消费模型建立所需的数据,对实际人均年消费支出C和人均年收人Y(单位:元)
分别取对数,得到lc ly 和: (2) 对lc ly 和进行平稳性检验。 (3) 用EG 两步检验法对lc ly 和进行协整性检验并建立误差修正模型。 分析该模型的经济意义。 练习题参考解答 练习题10.1参考解答 利润和红利的散点图如下: 从图中看出,利润和红利序列存在趋势,均值和方差不稳定,因此可能非平稳。下面用ADF 检验是否平稳。选择带截距和时间趋势的模型进行估计,结果如下:
计量经济学作业
计量经济学报告 一、背景介绍 为了了解宏观经济模型,找到显著影响国内生产总值的解释变量,例如个人可支配收入, 个人消费支出,公司税后利润,公司净红利支出。 为此找到1990-2001年间的季度数据数据来源于统计年鉴。以国内生产总值为被解释变 量,以个人可支配收入,个人消费支出,公司税后利润,公司净红利支出四个变量为解释变 量进行建模,其中共有观测值48个。在下面建模时设定y为国内生产总值, x1 为个人可支 配收入,x2为个人消费支出,x3为公司税后利润,x4为公司净红利支出。 二、模型设定 模型初步拟合 (1)估计参数 (156.3372) (0.1581641) (0.1557289) (0.1747617) (0.8398794) t= (1.27) (2.90) (5.54) (-7.93) (-0.35) F=2343.75 n=48 (2)经济意义检验 当其他不变,x1即个人可支配收入每增加一个单位,平均来说,y增加0.4588558个单 位。x2即个人消费支出每增加一个单位,平均来说,y增加0. 8628708个单位。x3即公司 税后利润每增加一个单位,平均来说,y增加1.38581个单位.。x4即公司净红利支出每增加 一个单位,平均来说,y减少0..2937867个单位。
(3)拟合优度和统计检验 模型检验:模型整体的R^2 为2343.75,P值小于0.01,通过显著性检验,可以看出模型整体拟合很好。但是可以看出前三个解释变量通过了显著性检验,即对GDP的影响是显著的,但是x4没有通过显著性检验。因此我们怀疑模型中可能存在多种共线性,下面进行多重共线的检验。 三、多重共线性检验 检验方差膨胀因子 从方差膨胀因子来看,除了x3外,其他解释变量的VIF都大于10,因此存在多重共线性。 检验自变量间的相关系数 可以看出x1,x2,x4三者相互之间的相关系数都很大,超过0.8,说明他们之间的相关性很强,需要对模型进行修正。 四、模型修正 1、对各变量取对数 取对数
计量经济学第三章课后习题
(1)估计回归方程的参数及随机干扰项的方差∧2σ,计算2R及2R。(2)对方程进行F检验,对参数进行t检验,并构造参数95%的置信区间。 (3)如果商品单价变为35元,则某一月收入为20000元的家庭消费支出估计是多少?构造该估计值的95%的置信区间。(个值与均值)R代码与输出结果: x1=c(23.56,24.44,32.07,32.46,31.15,34.14,35.3,38.7,39.63,46.68) x2=c(7620,9120,10670,11160,11900,12920,14340,15960,18000,19300) y=c(591.9,654.5,623.6,647,674,644.4,680,724,757.1,706.8) nx1=length(x1) nx2=length(x2) ny=length(y) nx1;nx2;ny lm.1=lm(y~x1+x2) summary(lm.1) Call: lm(formula = y ~ x1 + x2) Residuals: Min 1Q Median 3Q Max -22.014 -14.084 4.591 10.502 19.640
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 626.509285 40.130100 15.612 1.07e-06 *** x1 -9.790570 3.197843 -3.062 0.01828 * x2 0.028618 0.005838 4.902 0.00175 ** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘’1 Residual standard error: 17.39 on 7 degrees of freedom Multiple R-squared: 0.9022, Adjusted R-squared: 0.8743 F-statistic: 32.29 on 2 and 7 DF, p-value: 0.0002923 由输出结果显示,两个解释变量的估计值为-9.79057、0.028618。对方程进行F检验,其中F统计量的值为32.29,P值为0.0002923小于0.05,拒绝原假设,即认为该方程显著;对参数进行t检验,其P 值分别为0.01828、0.00175,均小于0.05,则拒绝原假设,即该回归参数显著。 anova(lm.1)#方差分析表 Analysis of Variance Table Response: y Df Sum Sq Mean Sq F value Pr(>F) x1 1 12265.1 12265.1 40.558 0.0003785 ***
计量经济学部分习题答案解析
第三章 一元线性回归模型 P56. 3.3 从某公司分布在11个地区的销售点的销售量()Y 和销售价格()X 观测值得出以下结果: 519.8X = 217.82Y = 23134543i X =∑ 1296836i i X Y =∑ 2539512i Y =∑ (1)、估计截距0β和斜率系数1β及其标准误,并进行t 检验; (2)、销售的总离差平方和中,样本回归直线未解释的比例是多少? (3)、对0β和1β分别建立95%的置信区间。 解:(1)、设01i i Y X ββ=+,根据OLS 估计量有: μ()() () 1 1 1 11 1 2 2 2 22211 112 =129683611519.8217.820.32313454311519.8 N N N N N i i i i i i i i i i i i i N N N N i i i i i i i i N Y X Y X N Y X N X NY Y X N X Y N X N X X N X N X X β=========---= = ??--- ? ?? -??==-?∑∑∑∑∑∑∑∑∑ μμ01 217.820.32519.851.48Y X ββ=-=-?= 残差平方和: $ ( )μ( ) μμμ() μμμμ() μμμμ2 2 2 1 12 2 222 201111111 22222222010101011111111=225395121N N i i i i i N N N N N N i i i i i i i i i i i i N N N N N i i i i i i i i i i i u RSS TSS ESS Y Y Y Y Y Y Y Y Y X N N Y X X Y N X X ββββββββββ===============-=---????--+=-+ ? ???????=-++=-++ ??? =-∑∑∑∑∑∑∑∑∑∑∑∑∑∑()22151.480.32313454320.3251.4811519.8997.20224 ?+?+????=另解:对$( )μ( )2 2 2 11 N N i i i i i u RSS TSS ESS Y Y Y Y ====-=---∑∑∑,根据OLS 估计μμ01Y X ββ=-知μμ01 +Y X ββ=,因此有
计量经济学第十章
一:绘制时间序列图 根据1970-1991年的美国制造业固定厂房设备投资Y和销售量X的数据在Eviews中录入数据得到固定厂房设备投资Y时间序列图如下 由上图我们可以看出该时间序列可能存在趋势和截距项所以我们选择ADF检验的模型对其检验是否为平稳序列。 二:ADF检验结果
从检验的结果可以看出,在1%、5%、10%三个显着水平下,单位根检验的Mackinnon的临界值分别为、、,t检验统计量为远远大于相应的临界值,从而不能拒绝原假设,即可以说明固定厂房设备投资Y存在单位根,是非平稳数列。 三:根据1970-1991年的美国制造业固定厂房设备投资Y和销售量X的数据在Eviews 中录入数得到销售量X的时间序列图如下 由上图我们可以看出该时间序列可能存在趋势和截距项所以我们选择ADF检验的模型对其检验是否为平稳序列。 四ADF检验结果
从检验的结果可以看出,在1%、5%、10%三个显着水平下,单位根检验的Mackinnon的临界值分别为、、,t检验统计量为远大于相应的临界值,从而不能拒绝原假设,即可以说明销售量X存在单位根,是非平稳数列。 五:单整阶数检验
从检验的结果可以看出,在1%、5%、10%三个显着水平下,单位根检验的Mackinnon的临界值分别为、、,t检验统计量为,小于于相应的临界值,从而能拒绝原假设,即可以说明销售量X已经不存在单位根,是平稳数列。即是二阶单整。
从 检 验 的 结 果 可 以 看 出, 在 1%、 5%、 10% 三 个 显 着 水 平 下, 单 位 根 检 验 的 Mac kin non 的 临 界 值分别为、、,t检验统计量质为.小于相应的临界值,从而能拒绝原假设,即可以说明固定厂房设备投资Y已经存在单位根,是平稳数列。即是二阶单整。
以往《计量经济学》作业答案汇编
以往计量经济学作业答案 第一次作业: 1-2. 计量经济学的研究的对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征? 答:计量经济学的研究对象是经济现象,是研究经济现象中的具体数量规律(或者说,计量经济学是利用数学方法,根据统计测定的经济数据,对反映经济现象本质的经济数量关系进行研究)。计量经济学的内容大致包括两个方面:一是方法论,即计量经济学方法或理论计量经济学;二是应用,即应用计量经济学;无论是理论计量经济学还是应用计量经济学,都包括理论、方法和数据三种要素。 计量经济学模型研究的经济关系有两个基本特征:一是随机关系;二是因果关系。 1-4.建立与应用计量经济学模型的主要步骤有哪些? 答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和一致性;(3)估计模型参数;(4)模型检验,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。 1-6.模型的检验包括几个方面?其具体含义是什么? 答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型预测检验。在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 第二次作业: 2-1 答:P27 6条 2-3 线性回归模型有哪些基本假设?违背基本假设的计量经济学模
计量经济学第十章习题最新版本
第10章模型设定与实践 问题 10.1 模型设定误差有哪些类型?如何诊断? 答:模型设定误差主要有以下四种类型: 1.漏掉一个相关变量; 2.包含一个无关的变量; 3.错误的函数形式; 4.对误差项的错误假定。 诊断的方法有:1.侦察是否含有无关变量;2.残差分析,拉姆齐(Ramsey)的RESET检验法,DM(Davidsion-MacKinnon:戴维森麦-克金龙)检验;3.拟合优度、校正拟合优度、系数显著性、系数符合的合理性。 10.2 模型遗漏相关变量的后果是什么? 答:模型遗漏相关变量的后果是:所有回归系数的估计量是有偏的,除非这个被去除的变量与每一个放入的变量都不相关。常数估计量通常也是有偏的,从而预测值是有偏的。由于放入变量的回归系数估计量是有偏的,所以假设检验是无效的。系数估计量的方差估计量是有偏的。 10.3 模型包含不相关变量的后果是什么? 答:模型包含不相关变量的后果是:系数估计量的方差变大,从而估计量的精度下降。10.4 什么是嵌套模型?什么是非嵌套模型? 答:如果两个模型不能被互相包容,即任何一个都不是另一个的特殊情形,便称这两个模型是非嵌套的。如果两个模型能互相包容,即其中一个是另一个的特殊情形,便称这两个模型是嵌套的。 10.5 非嵌套模型之间的比较有哪些方法? 答:非嵌套模型之间的比较方法有:拟合优度或校正拟合优度、AIC(Akaike’s information criterion)准则、SIC(Schwarz’s information criterion)准则和HQ(Hannnan-Qinn criterion)准则。拉姆齐(Ramsey)的RESET检验法,DM(Davidsion-MacKinnon:戴维森麦-克金龙)检验。 习题 10.6 对数线性模型在人力资源文献中有比较广泛的应用,其理论建议把工资或收入的对数
计量经济学各章作业习题后附答案
《计量经济学》 习 题 集
第一章绪论 一、单项选择题 1、变量之间的关系可以分为两大类,它们是【】 A 函数关系和相关关系 B 线性相关关系和非线性相关关系 C 正相关关系和负相关关系 D 简单相关关系和复杂相关关系 2、相关关系是指【】 A 变量间的依存关系 B 变量间的因果关系 C 变量间的函数关系 D 变量间表现出来的随机数学关系 3、进行相关分析时,假定相关的两个变量【】 A 都是随机变量 B 都不是随机变量 C 一个是随机变量,一个不是随机变量 D 随机或非随机都可以 4、计量经济研究中的数据主要有两类:一类是时间序列数据,另一类是【】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 5、下面属于截面数据的是【】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 6、同一统计指标按时间顺序记录的数据列称为【】 A 横截面数据 B 时间序列数据 C 修匀数据D原始数据 7、经济计量分析的基本步骤是【】 A 设定理论模型→收集样本资料→估计模型参数→检验模型 B 设定模型→估计参数→检验模型→应用模型 C 个体设计→总体设计→估计模型→应用模型 D 确定模型导向→确定变量及方程式→估计模型→应用模型 8、计量经济模型的基本应用领域有【】 A 结构分析、经济预测、政策评价 B 弹性分析、乘数分析、政策模拟 C 消费需求分析、生产技术分析、市场均衡分析 D 季度分析、年度分析、中长期分析 9、计量经济模型是指【】