标准差与估计标准差

2-3 變異的計算及解析
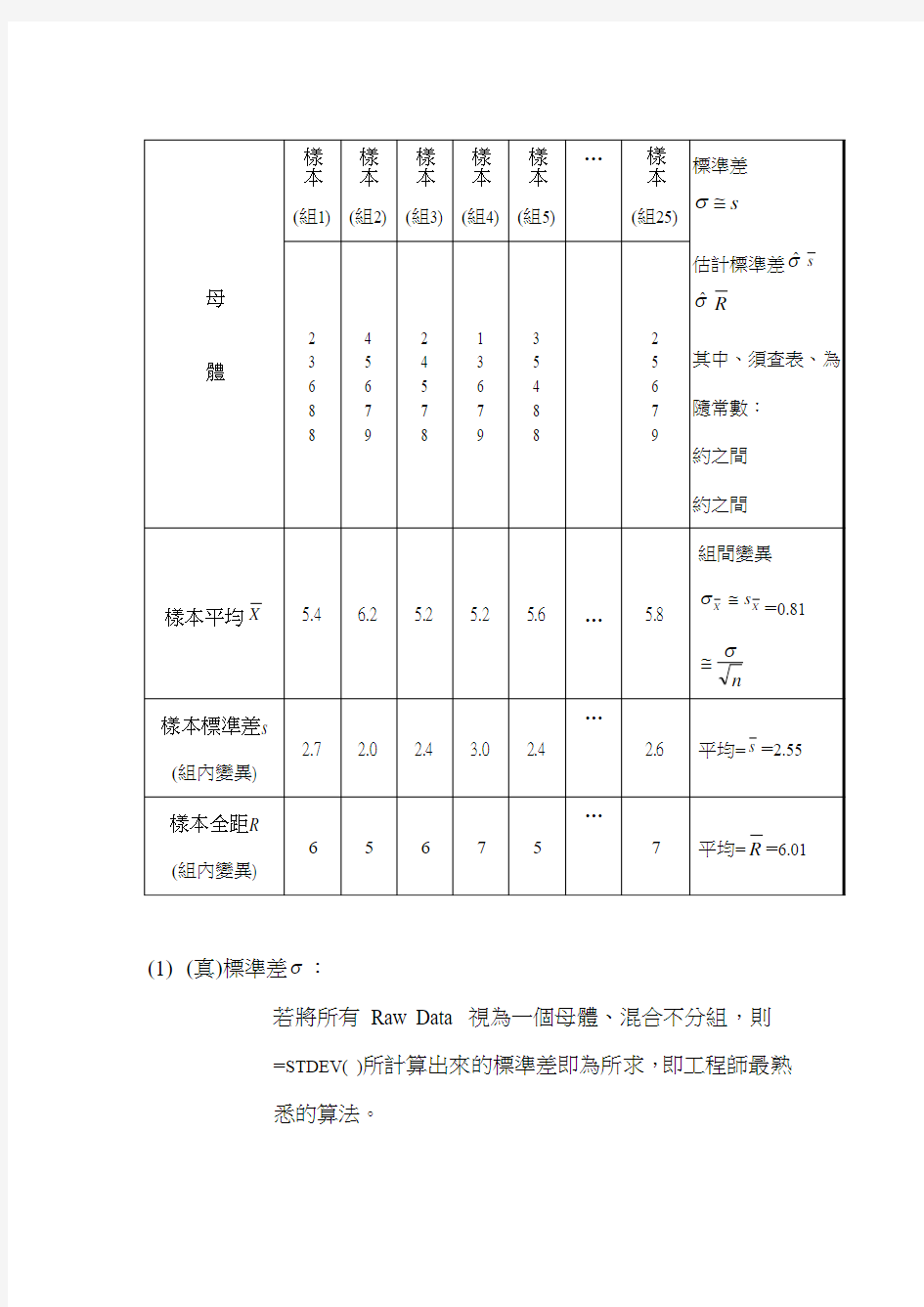
由基礎課程裡我們可以知道:表示變異的方法有很多,其最常使用的是“標準差”;關於標準差的計算又分兩個觀念:(真)標準差σ與估計標準差σ?。
為了解釋這兩個觀念的差異,我們先看下例數據:
下例數據有經過分組,每組抽測5個數據(即S/S 或n = 5的意思)。分組的原因不外乎量產、或長期研究等, 需要分批量測而形成母體與樣本的關係。
(1)(真)標準差σ:
若將所有Raw Data 視為一個母體、混合不分組,則
=STDEV( )所計算出來的標準差即為所求,即工程師最熟
悉的算法。
--------------------------------------------------------------
使用時機:a.) 想了解母體真正的變異的時候;b.) 想敏銳地抓出上圖/組間變異的異常的時候。
---------------------------------
目的:了解整個母體的總變異。
優點:可以充分反映整個母體的異常(含上圖/組間變異、及下圖/組內變異的異常…尤其是組間變異的異
常)。
缺點:數據量要夠大(避免誤差過大)、且上圖不能有異常(避免組間變異顯著),否則計算出來的 不具代
表性。
(2) 估計標準差σ?:
大部分的工程師沒聽說過估計標準差。Raw Data 若經過分組(分組與抽樣皆要隨機),我們可以利用樣本的變異、去估算整個母體的變異;但是要特別注意組間變
σ)已經被假設成常態分配;以白話來說:想像管制異(X
圖-上圖的每個組平均X是一顆綠豆,當這些綠豆被一把撒到管制圖-上圖的時候,這些綠豆皆自動定位到常態分配該有的位置上,因此整個上圖的假設都是常態分配,若真有異常、也早已被視而不見。
故以估計標準差σ?來看問題,祇能解析下圖/組內變異的
異常(即管理面的異常:如某單一人/機抽樣技術不穩定的問題、某單一作業機台不穩定的問題、某個別材料品質不穩定的問題等 一般因 …主要還是抽樣技術不穩定的問題)。
此時的計算,都是由下圖/組內變異的平均來倒推,以估算整個母體變異的期望值:σ?=s/c4 =R/d2 (註),其中c4、d2是查表值( 附表),隨著n (即S/S)而變,n愈大估計值就會愈接近母體。
註:樣本s、R、MR與母體σ之間的關係,令母體與樣本均為常態分配,不需執行冗繁的計算,可以直接以查表方式整理如下:
E(s)= c4σ,D(s)= c3σ,其中c4、c3是查表值(
附表)
E(R)= d2σ,D(R)= d3σ,其中d2、d3是查表值( 附表)
--------------------------------------------------------------------------------------------
使用時機:當組間變異過於顯著,無法正確評估製程之實力時。(註)
註:理想上σ?=σ;實務上通常σ?<σ:
σ?代表著統計經驗對一特性在常態分配時的理想預
測;也許是因為製程真的較差、也許是因為管制圖
的管理分組做得並不好,造成上圖/組間變異變得比
常態分配預期的還要大。
-----------------------------------------------------------------
目的:估算整個母體的總變異的期望值。
優點:因為計算的是期望值,當數據量不大時、較(真)標準差具代表性。
缺點:只能反映下圖/組內變異的異常,而組內變異的異常通常只能反映管理問題,所以較適合量產使用。
t检验是对各回归系数的显著性所进行的检验,(--这个太不全面了,这是指在多元回归分析中,检验回归系数是否为0的时候,先用F检验,考虑整体回归系数,再对每个系数是否为零进行t检验。t检验还可以用来检验样本为来自一元正态分布的总体的期望,即均值;和检验样本为来自二元正态分布的总体的期望是否相等)目的:比较样本均数所代表的未知总体均数μ和已知总体均数μ0。
计算公式:
t统计量:
自由度:v=n - 1
适用条件:
(1) 已知一个总体均数;
(2) 可得到一个样本均数及该样本标准误;
(3) 样本来自正态或近似正态总体。
例1 难产儿出生体重n=35, =3.42, S =0.40,
一般婴儿出生体重μ0=3.30(大规模调查获得),问相同否?
解:1.建立假设、确定检验水准α
H0:μ = μ0 (无效假设,null hypothesis)
H1:(备择假设,alternative hypothesis,)
双侧检验,检验水准:α=0.05
2.计算检验统计量
,v=n-1=35-1=34
3.查相应界值表,确定P值,下结论
查附表1,t0.05 / 2.34 = 2.032,t < t0.05 / 2.34,P >0.05,按α=0.05水准,不拒绝H0,两者的差别无统计学意义
什么是T检验
T检验,亦称student t检验(Student's t test),主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布资料。
T检验是用于小样本(样本容量小于30)的两个平均值差异程度的检验方法。它是用T分布理论来推断差异发生的概率,从而判定两个平均数的差异是否显著。
T检验是戈斯特为了观测酿酒质量而发明的。戈斯特在位于都柏林的健力士酿酒厂担任统计学家,基于Claude Guinness聘用从牛津大学和剑桥大学出来的最好的毕业生以将生物化学及统计学应用到健力士工业程序的创新政策。戈特特于1908年在Biometrika上公布T检验,但因其老板认为其为商业机密而被迫使用笔名(学生)。实际上,戈斯特的真实身份不只是其它统计学家不知道,连其老板也不知道。
T检验的适用条件:正态分布资料
单个样本的t检验
目的:比较样本均数所代表的未知总体均数μ和已知总体均数μ0。
计算公式:
t统计量:
自由度:v=n - 1
适用条件:
(1) 已知一个总体均数;
(2) 可得到一个样本均数及该样本标准误;
(3) 样本来自正态或近似正态总体。
例1 难产儿出生体重n=35, =3.42, S =0.40,
一般婴儿出生体重μ0=3.30(大规模调查获得),问相同否?
解:1.建立假设、确定检验水准α
H0:μ = μ0(无效假设,null hypothesis)
H1:(备择假设,alternative hypothesis,)
双侧检验,检验水准:α=0.05
2.计算检验统计量
,v=n-1=35-1=34
3.查相应界值表,确定P值,下结论
查附表1,t0.05 / 2.34= 2.032,t< t0.05 / 2.34,P >0.05,按α=0.05水准,不拒绝H0,两者的差别无统计学意义
配对样本t检验
配对设计:将受试对象的某些重要特征按相近的原则配成对子,目的是消除混杂因素的影响,一对观察对象之间除了处理因素/研究因素之外,其它因素基本齐同,每对中的两个个体随机给予两种处理。
?两种同质对象分别接受两种不同的处理,如性别、年龄、体重、病情程度相同配成对。
?同一受试对象或同一样本的两个部分,分别接受两种不同的处理
?自身对比。即同一受试对象处理前后的结果进行比较。
目的:判断不同的处理是否有差别
计算公式及意义:
t 统计量:
自由度:v=对子数-1
适用条件:配对资料
T检验的步骤
1、建立虚无假设H0:μ1= μ2,即先假定两个总体平均数之间没有显著差异;
2、计算统计量T值,对于不同类型的问题选用不同的统计量计算方法;
1)如果要评断一个总体中的小样本平均数与总体平均值之间的差异程度,其统计量T值的计算公式为:
2)如果要评断两组样本平均数之间的差异程度,其统计量T值的计算公式为:
3、根据自由度df=n-1,查T值表,找出规定的T理论值并进行比较。理论值差异的显著水平为0.01级或0.05级。不同自由度的显著水平理论值记为T(d f)0.01和T(df)0.05
4、比较计算得到的t值和理论T值,推断发生的概率,依据下表给出的T 值与差异显著性关系表作出判断。
T值与差异显著性关系表
T P值差异显著程度
差异非常显著
差异显著
T< T(df)0.05 P> 0.05 差异不显著
5、根据是以上分析,结合具体情况,作出结论。
T检验举例说明
例如,T检验可用于比较药物治疗组与安慰剂治疗组病人的测量差别。理论上,即使样本量很小时,也可以进行T检验。(如样本量为10,一些学者声称甚至更小的样本也行),只要每组中变量呈正态分布,两组方差不会明显不同。如上所述,可以通过观察数据的分布或进行正态性检验估计数据的正态假设。方差齐性的假设可进行F检验,或进行更有效的Levene's检验。如果不满足这些条件,只好使用非参数检验代替T检验进行两组间均值的比较。
T检验中的P值是接受两均值存在差异这个假设可能犯错的概率。在统计学上,当两组观察对象总体中的确不存在差别时,这个概率与我们拒绝了该假设有关。一些学者认为如果差异具有特定的方向性,我们只要考虑单侧概率分布,将所得到t-检验的P值分为两半。另一些学者则认为无论何种情况下都要报告标准的双侧T检验概率。
1、数据的排列
为了进行独立样本T检验,需要一个自(分组)变量(如性别:男女)与一个因变量(如测量值)。根据自变量的特定值,比较各组中因变量的均值。用T检验比较下列男、女儿童身高的均值。
性别身高
对象1 对象2 对象3 对象4 对象5 男性
男性
男性
女性
女性
111
110
109
102
104 男性身高均数= 110
女性身高均数= 103
2、T检验图
在T检验中用箱式图可以直观地看出均值与方差的比较,见下图:
这些图示能够很快地估计并且直观地表现出分组变量与因变量关联的强度。
3、多组间的比较
科研实践中,经常需要进行两组以上比较,或含有多个自变量并控制各个自变量单独效应后的各组间的比较,(如性别、药物类型与剂量),此时,需要用方差分析进行数据分析,方差分析被认为是T检验的推广。在较为复杂的设计时,方差分析具有许多t-检验所不具备的优点。(进行多次的T检验进行比较设计中不同格子均值时)。
T检验注意事项
?要有严密的抽样设计随机、均衡、可比
?选用的检验方法必须符合其适用条件(注意:t检验的前提是资料服从正态分布)
?单侧检验和双侧检验
单侧检验的界值小于双侧检验的界值,因此更容易拒绝,犯第Ⅰ错误的可能性大。
?假设检验的结论不能绝对化
?不能拒绝H0,有可能是样本数量不够拒绝H0,有可能犯第Ⅰ类错误
?正确理解P值与差别有无统计学意义
P越小,不是说明实际差别越大,而是说越有理由拒绝H0 ,越有理由说明两者有差异,差别有无统计学意义和有无专业上的实际意义并不完全相同
?假设检验和可信区间的关系
?结论具有一致性
?差异:提供的信息不同
区间估计给出总体均值可能取值范围,但不给出确切的概率值,假设检验可以给出H0成立与否的概率
学习教育统计中,对自由度的概念不甚了解,故求助于baidu。
https://www.360docs.net/doc/2d981240.html,/blogger/post_show.asp?BlogID=468742&PostID=6594917
自由度,很多统计量的计算公式中都有自由度的概念,可为什么同样是计算标准差,总体标准差的自由度是n,而样本标准差的自由度就是n-1?为什么其它公式中的自由度还有n-2、n-3呢?它到底是什么含意?
翻看了以前的教材以及到网上查阅了大量相关资料,原来,不仅仅是统计学里有自由度的概念呀!下面把有关自由度的问题点简要归纳一下。
理论力学:确定物体的位置所需要的独立坐标数称作物体的自由度,当物体受到某些限制时——自由度减少。一个质点在空间自由运动,它的位置由三个独立坐标就可以确定,所以质点的运动有三个自由度。假如将质点限制在一个平面或一个曲面上运动,它有两个自由度。假如将质点限制在一条直线或一条曲线上运动,它只有一个自由度。刚体在空间的运动既有平动也有转动,其自由度有六个,即三个平动自由度x、y、z和三个转动自由度a、b、q。如果刚体运动存在某些限制条件,自由度会相应减少。
热力学中:分子运动自由度就是决定一个分子在空间的位置所需要的独立坐标数目。
统计学中:在统计模型中,自由度指样本中可以自由变动的变量的个数,当有约束条件时,自由度减少自由度计算公式:自由度=样本个数-样本数据受约束条件的个数,即df = n - k(df自由度,n样本个数,k约束条件个数)
我们当然最关心的还是统计学里面的自由度的概念。这里自由度的概念是怎么来的呢?
据说:
一般总体方差(sigma^2),其实它是衡量所有数据对于中心位置(总体平均)平均差异的概念,所以也称为离散程度,通常表示为sum(Xi-Xbar)^1/2/N ,(有多少个数据就除多少)而样本方差(S^2),则是利用样本数据所计算出来估计总体变异用的(样本统计量的基本目的:少量资料估计总体).一般习惯上,总体怎么算,样本就怎么算,可是在统计上估计量(或叫样本统计量)必须符合一个特性--无偏性,也就是估计量的数学期望值要等于被估计
的总体参数=> E(S^2)=sigma^2(无偏估计)。很不幸的,样本变异数E(S^2)并不会等于s igma^2所以必须做修正,而修正后即为sum(Xi-Xbar)^2/(N-1).才会继续带出后来的自由度概念。(自由度是由修正样本统计量得来的吗?)
网上一些文献的说法也是林林总总。
金志成实验设计书中的定义:能独立变化的数据数目。只要有n-1个数确定,第n个值就确定了,它不能自由变化。所以自由度就是n-1。自由度表示的是一组数据可以自由表化的数量的多少。
通俗点说,一个班上有50个人,我们知道他们语文成绩平均分为80,现在只需要知道49个人的成绩就能推断出剩下那个人的成绩。你可以随便报出49个人的成绩,但是最后一个人的你不能瞎说,因为平均分已经固定下来了,自由度少一个了。
自由度的设定是出于这样一个理由:在总体平均数未知时,用样本平均数去计算离差(常用小s)会受到一个限制————要计算标准差(小s)就必须先知道样本平均数,而样本平均数和n都知道的情况下,数据的总和就是一个常数了。所以,“最后一个”样本数据就不可以变了,因为它要是变,总和就变了,而这是不允许的。至于有的自由度是n-2什么的,都是同样道理。
n-1是通常的计算方法,更准确的讲应该是n-k,n表示“处理”的数量,k表示实际需要计算的参数的数量。如需要计算2个参数,则数据里只有n-2个数据可以自由变化。例如,一组数据,平均数一定,则这组数据有n-1个数据可以自由变化;如一组数据平均数一定,标准差也一定,则有n-2个数据可以自由变化。df=n-k的得出是需要大量的数理统计的证明的。太复杂的情况,我们就不讨论了。
另https://www.360docs.net/doc/2d981240.html,/bbs/simple/index.php?t1907.html
对卡方分布,t分布而言,从其统计量的来源看,卡方分布自由度n理解为来自n个服从正态分布的样本,而且他们之间并没有什么约束关系,也就是说n个样本都是可以自由变化的。
而对于我们在统计检验中构造的那些统计量而言,也可以这样理解,一般自由度并不为n,是因为这n个样本之间有约束关系,约束方程的个数为a,则自由度为n-a,因为一般约束方程的个数等于未知参数的个数,也就是说自由度是n -未知参数的个数,但是这种解释在有些场合不容易理解,也没有说到本质上,严格的解释应该还是从统计量对应的二次型的秩的角度来理解。
参见南开大学王兆军数理统计讲义 2006
或几篇论文:
1、刘丽君,数理统计中的“自由度”及教材中一处证明的订正,温州师范学院学报(自然科学版),vol24,5,2003。
2、张宏广,自由度的求法,承德民族师专学报,第26 卷第2 期,2006。
3、曲卫彬,浅谈“自由度”,高校教育。
标准差公式
标准差(Standard Deviation ) ,也称均方差(mean square error ),是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用S (σ)表示。标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的,标准差未必相同。 标准差也被称为标准偏差,或者实验标准差,公式如下两式: ()1 n x x S n 1 i 2 i --= ∑= 或 1 n n x x S 2 n 1i i n 1 i 2i -??? ??- =∑∑ == 即: () 1 n x x 1 n n x x S n 1 i 2 i 2 n 1i i n 1 i 2i --= -??? ??- = ∑∑∑ === 如是总体,标准差公式根号内除以n 如是样本,标准差公式根号内除以(n-1) 因为我们大量接触的是样本,所以普遍使用根号内除以(n-1) 公式意义 所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一),再把所得值开根号,所得之数就是这组数据的标准差。 标准差越高,表示实验数据越离散,也就是说越不精确;反之,标准
差越低,代表实验的数据越精确 简单来说,标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。 例如,两组数的集合{0, 5, 9, 14} 和{5, 6, 8, 9} 其平均值都是7 ,但第二个集合具有较小的标准差。 标准差可以当作不确定性的一种测量。例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。 标准差应用于投资上,可作为量度回报稳定性的指标。标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。相反,标准差数值越细,代表回报较为稳定,风险亦较小。 例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。这两组的平均数都是70,但A组的标准差为17.07分,B组的标准差为2.37分(此数据时在R统计软件中运行获得),说明A组学生之间的差距要比B组学生之间的差距大得多。
标准差σ的4种计算公式
标准差σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和Minitab中 标准差σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和Minitab中的Pooled standard deviation(合并标准差) 做数据分析,经常会碰到提到标准差σ这个概念,关于标准差σ的计算方式,目前,本人知道有4种标准差σ的计算方法,如下: 一,简易标准差σ的计算方式 上面是计算整体的标准差,如果是计算样本的标准差,这里的N, 应该为N-1. 一般情况下,都是计算样本的标准差。关于这个标准的详细运算公式和案例分析,可以参考附件,里面有比较详细的解释。 标准差的简易计算公式和案例分析.rar(28.19 KB, 下载次数: 1262) 二,XBAR-R管制图分析( X-R Control Chart)图中的Rbar/d2 算法 XBAR-R管制图分析( X-R Control Chart):由平均数管制图与全距管制图组成。 ●品质数据可以合理分组时,可以使用X管制图分析或管制制程平均;使用R管制图分析制程变异。 ●工业界最常使用的计量值管制图。
关于上面公式中用到的A2、A3、D2、D3、D4等常数请参考帖子下面的表格三,XBAR-s管制图分析( X-sControl Chart)中的Sbar/C4算法 XBAR-S 管制图分析( X-S Control Chart):由平均数管制图与标准差管制图组成。 ●与X-R管制图相同,惟s管制图检出力较R管制图大,但计算麻烦。 ●一般样本大小n小于等于8可以使用R管制图,n大于8则使用S管制图。 ●有电脑软件辅助时,使用S管制图当然较好。
标准差
标准差 次数分布中的数据不仅有集中趋势,而且还有离中趋势。所谓离中趋势指的是数据具有偏离中心位置的趋势,它反映了一组数据本身的离散程度和差异性程度。标准差能综合反映一组数据的离散程度或个别差异程度。 例如,甲、乙两班学生各50人,其语文平均成绩都是80分,但甲班最高成绩98分,最低42分,而乙班最高成绩86分,最低60分。初步看出,两班语文成绩是不一样的,甲班学生的语文成绩个别差异程度大、水平参差不齐;而乙班学生的语文成绩差异程度小,语文水平整齐度大些。怎样用标准差这个特征量数来刻画一组数据的差异程度呢?下面介绍标准差的概念及计算。 一、标准差概念与计算 1.标准差定义与计算公式 一组数据的标准差,指的是这组数据的离差平方和除以数据个数所得商的算术平方根。若用S 代表标准差,则标准差的计算公式为: 标准差的平方,称为方差,用S2表示方差。 计算标准差时,首先要计算数据的平均数,接着要计算各数据与平均数之间的离差 平方,即()2,最后由公式(2-5)计算标准差S。 例如,4名儿童的身高分别是110厘米,100厘米,120厘米和150厘米,若求4名儿童身高数据的标准差时,其基本步骤如下: ①求平均数:(厘米) ②求离差平方和: )2=(110―120)2+(100―120)2+(120―120)2+(150―120)2 =100+400+0+900=1400(平方厘米) ③求标准差S:S= (厘米)
这样,我们大体可认为,这4名儿童身高差异程度,从平均角度来看,约相差18.71厘米。 2.标准差的计算中心方法 计算标准差的方法有三种,一是按公式逐步分析计算,如上述所示;二是以列表计算的方式;三是利用计算器或计算机进行计算。下面再举一例说明采用列表方式计算标准差S。 [例7] 已知8 位同学在某图形辨认测验中的成绩数据(见表2-2),计算这组数据的标准差。 [分析解答] 采用列表计算方式,应用公式(2-5)确定数据的标准差,详见表2-2。 表2-2 计算标准差S的示例 - () (1) = (2) () = 标准差在实际中有广泛的用途,同时对深化研究数据也具有重要的作用。如不同班级考试成绩的平均数和标准差,不同年度或不同学科测验分数的平均数和标准差,以及其他体能测试或心理测验数据的平均数和标准差,就是一些具体的应用。后续各章内容的学习,将经常用到平均数、标准差和方差这些概念。 由于标准差计算公式结构适合于代数处理,因此,许多具有统计功能的计算器,都有计算方差和标准差的相应功能。学习者只要花少量时间学习与掌握有关计算器的使用,即可以轻松自如地处理大量数据,求取平均数和标准差。 在利用公式(2-5)手工求标准差时,如表2-2所示,由于平均数有小数,这使计算离差平方的数据更加复杂,小数点的位数加倍增加,同时四舍五入的计算误差以及出错的可能性都有所增加。为克服这个弊病,我们可从公式(2-5)出发,通过代数演算,推导出另一个与公式(2-5)等价的新公式,即公式(2-6)。这一新公式对计算标准差来讲,不用通过计 算平均数以及离差平方和,用原始数据直接计算标准差,因而在许多情况下,具有更简便、准确的特点。其计算公式:
标准差σ的4种计算公式
标准差σ的4种计算公式
标准差σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和Minitab中标准差σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和Minitab中的Pooled standard deviation(合并标准差) 做数据分析,经常会碰到提到标准差σ这个概念,关于标准差σ的计算方式,目前,本人知道有4种标准差σ的计算方法,如下: 一,简易标准差σ的计算方式 上面是计算整体的标准差,如果是计算样本的标准差,这里的N, 应该为N-1. 一般情况下,都是计算样本的标准差。关于这个
关于上面公式中用到的A2、A3、D2、D3、D4等常数请参考https://www.360docs.net/doc/2d981240.html,/thread-476-1-1.html帖子下面的表格 三,XBAR-s管制图分析( X-sControl Chart)中的Sbar/C4算法 XBAR-S 管制图分析( X-S Control Chart):由平均数管制图与标准差管制图组成。
●与X-R管制图相同,惟s管制图检出力较R 管制图大,但计算麻烦。 ●一般样本大小n小于等于8可以使用R管制图,n大于8则使用S管制图。 ●有电脑软件辅助时,使用S管制图当然较好。 关于上面公式中用到的A2、A3、D2、D3、D4等常数请参考https://www.360docs.net/doc/2d981240.html,/thread-476-1-1.html帖子下面的表格 四,Minitab中所使用的Pooled standard
deviation(合并标准差) Minitab中所使用的Pooled standard deviation,这个标准差的计算和一般的不一样,这个是Minitab默认的,相关的计算公式可以参考《Minitab: Pooled standard deviation》https://www.360docs.net/doc/2d981240.html,/thread-288-1-1.html Minitab: Pooled standard deviation(合并标准差), Rbar, Sbar Pooled standard deviation(合并标准差) is a way to find a better estimate of the true standard deviation given several different samples taken in different circumstances where the mean may vary between samples but the true standard deviation (precision) is assumed to remain the same. It is calculated by where sp is the pooled standard deviation,
标准差和标准偏差
标准差和标准偏差 1)首先给出计算公式 标准差:σ=(1) 标准偏差:s =(2)方差就是标准偏差的平方 这下大家就困惑了,这两个公式分别表示什么意义?他们分别在什么情况下用?这两个公式是怎么来的? 2)公式由来 标准差又叫均方差、标准方差,这个大家都不陌生,它是各数据偏离平均数的距离的平均数,是距离均差平方和平均后的方根,用σ表示。。说白了就是表示数据分本离散度的一个值。计算公式也很好理解,从一开始接触我们用的看的都是这个公式。 那么第二个公式,怎么来的呢?其实标准偏差从样本估计中来的。比如我们有一批数据,共10000个点,他们服从正太分布,很容易计算出它的均值和标准差。在这里我们叫做样本均值和样本标准差。表示如下: 样本均值:1 1n i i X X n ==∑ 样本方差:2211()n n i i s X X n ==-∑ 这两个公式就是大家常用的公式。那么现在我们认为,我们想用采集到的这10000个样本估计数据的真实分布,想要求出其均值μ和方差2σ。 对于均值μ,我们容易通过期望获得:
但是对于方差,我们知道 2 1 2 () n i i X X σ = - ∑ 是服从卡分分布2 1 n χ - 的(这一点请查阅卡分分布的 定义)。因此有下面的公式: 这个公式的第一个等号后面是利用期望的性质,试图构造卡分分布来求解。第二个等号后面是利用卡分分布的均值计算出来的。请自行查阅卡方分布的定义和性质。 这么一来,我们就能看出,X是μ的无偏估计,而2 n s则不是2σ的无偏估计。但是我们 可以通过对样本方差进行重新构造,从而是2 n s就是2σ的无偏估计。我们定义:这样我们重新来求解方差的期望: 这样一来,2s就是2σ的无偏估计,这也就是这个公式的由来。 3)这两个公式的应用。 在实际中,公式(2)用的更多。因为当样本容量比较小的时候,公式(1)会过小的估计实际标准差;如果样本容量较大,公式(1)和公式(2)很接近。这时候公式(1)叫做渐近无偏估计,当然还是比不上公式(2)的无偏估计喽。 看了上面这段话,你可能还不知道该用哪个。其实是这样的:如果我们想求一批数据的标准差,那么自然就用公式(1)。如果我们是利用现在的样本估计真实的分布,那么就用公式(2)。 4)在EXCEL中,方差是VAR(),标准偏差是STDEV(),函数里解释是基于样本,分母是除的N-1,其实就是公式(2)。还有个VARP()和STDEVP(),基于样本总体,分母是N,也就是说你关注的就是这批数据。 在Excel透视表中 标准偏差为=STDEVA()
强度标准差计算公式
直接转的:看看对你有帮助没有。 Sfcu=[(∑ fcu?i2-n?mfcu2)/(n-1)]1/2 公式表述显示不明,用语言表述下,即公式中的2和1/2都应为上角表,分别表示平方和根号(开平方)。 语言表述如下:fcu.i的平方求和再减去n 乘以fcu平均值的平方,用他们的差再除以(n-1)这样得出的除数开方;也可以是fcu.i-fcu平均值差的平方求和得出的数再除以(n-1)这样得出的除数开方。当Sfcu<0.06fcu,k时,取Sfcu=0.06fcu,k 具体参数表述如下: fcu,k一混凝土立方体抗压强度标准值 fcu为设计强度标准值 mfcu为平均值 n为试块组数 Sfcu为n组试块的强度值标准差 fcu.i : 第i组试块的立方体抗压强度值
在线规范网https://www.360docs.net/doc/2d981240.html, 协助网站:给排水On Line 5.4 混凝土强度换算及推定 5.4.1 混凝土强度换算值可采用以下三类测强曲线计算: 1 统一测强曲线:由全国有代表性的材料、成型养护工艺配制的混凝土试件,通过试验所建立的曲线。其允许的强度平均相对误差(δ)应为±15.0%,相对标准差(er)不应大于18.0%。 2 地区测强曲线:由本地区常用的材料、成型养护工艺配制的混凝土试件,通过试验所建立的曲线。其允许的强度平均相对误差(δ)应为±14.0%,相对标准差(er)不应大于17.0%。 3 专用测强曲线:由与结构或构件混凝土相同的材料、成型养护工艺配制的混凝土试件,通过试验所建立的曲线。其允许的强度平均相对误差(δ)应为±12.0%,相对标准差(er)不应大于14.0%。 4 平均相对误差(δ)和相对标准差(er)的计算应符合本规程附录F的规定。 5 各检测单位应按专用测强曲线、地区测强曲线、统一测强曲线的次序选用测强曲线。 5.4.2 地区和专用测强曲线应与制定该类测强曲线条件相同的混凝土相适应,不得超出该类测强曲线的适用范围。应经常抽取一定数量的同条件试件进行校核,当发现有显著差异时,应及时查找原因,并不得继续使用。 5.4.3 符合下列条件的混凝土应采用本规程附录G进行测区混凝土强度换算: 1 混凝土采用的材料、拌和用水符合国家现行的有关标准; 2 不掺引气型外加剂; 3 采用普通成型工艺; 4 采用符合现行的《铁路混凝土与砌体工程施工质量验收标准》(TB10424)规定的模板; 5 自然养护或蒸汽养护出池后经自然养护7d以上,且混凝土表层为干燥状态; 6 龄期为14~1000d; 7 抗压强度为10~60MPa。 5.4.4 当有下列情况之一时,测区混凝土强度值不得按本规程附录G换算,但可制定专用测强曲线或通过试验进行修正,专用测强曲线的制定方法宜符合本规程附录F的有关规定:
计算全距平均差方差和标准差
计算全距、平均差、方差和标准差 一、全距 R(range) 全距是一组数据中的最大值(maximum)与该组数据中最小值(minimum)之差,又称极差。 R=Xmax-Xmin 一般用于研究的预备阶段,用它检查数据的分布范围,以便确定如何进行统计分析 原始数据计算公式 三、四分位差(Quartile) 四分位差是第一个四分位数与第三个四分位数之差计算公式为 Q=Q 3-Q 1 四、方差与标准差 方差:又称为变异数、均方,是每个数据与该组数据平均数之差乘方后的均值,是表示一组数据离散程度的统计指标。 样本的方差用表示,总体的方差用表示。 标准差是方差的算术平方根。一般样本的标准差用 S 表示,总体的标准差用表示。 标准差和方差是描述数据离散程度的最常用的差异量。 分组数据方差与标准差的计算公式 方差与标准差的性质 ?方差是对一组数据中各种变异的总和的测量,具有可加性和可分解性特点。 ?标准差是一组数据方差的算术平方根,它不可以进行代数计算,但有以下特性: 总体方差、标准差或者方差、标准才差的合成 ?方差具有可加性的特点。当已知几个小组数据的方差或标准差时,可
以计算几个小组联合在一起的总的方差或标准差。 ?需要注意的是,只有在应用同一种观测手段,测量的是同一种特质,只是样本不同的数据时,才能计算合成方差或标准差。 方差和标准差的优点: 方差与标准差是表示一组数据离散程度的最好指标,其值越大,离散程度越大。 应用方差和标准差表示一组数据的离散程度,须注意必须是同一类数据(即同一种测量工具的测量结果),而且被比较样本的水平比较接近。 优点: ?反应灵敏。每个数据发生变化,方差与标准差也随之变化 ?有一定计算公式的严密确定 ?容易计算 ?受抽样变动的影响小 ?简单明了 ?方差具有可加性(区分变异源,组间/组内) 五、差异系数(coefficient of variation) 差异系数指标准差与其算术平均数的百分比,它是没有单位的相对数。用CV表示。 何种情况下运用差异系数: ?两个或两个以上样本所测特质不同,即所使用的观测工具不同,如何比较两者的离散程度? ?即使使用同一种观测量具,但样本水平相差较大,如何比较其离散程度? 差异系数的作用 ?比较不同单位资料的差异程度 ?比较单位相同而平均数相差较大的两组资料的差异程度 ?可判断特殊差异情况
方差 — 标准差
方差(Variance) [编辑] 什么是方差 方差和标准差是测度数据变异程度的最重要、最常用的指标。 方差是各个数据与其算术平均数的离差平方和的平均数,通常以σ2表示。方差的计量单位和量纲不便于从经济意义上进行解释,所以实际统计工作中多用方差的算术平方根——标准差来测度统计数据的差异程度。 标准差又称均方差,一般用σ表示。方差和标准差的计算也分为简单平均法和加权平均法,另外,对于总体数据和样本数据,公式略有不同。 [编辑] 方差的计算公式 设总体方差为σ2,对于未经分组整理的原始数据,方差的计算公式为: 对于分组数据,方差的计算公式为: 方差的平方根即为标准差,其相应的计算公式为: 未分组数据: 分组数据: [编辑]
样本方差和标准差 样本方差与总体方差在计算上的区别是:总体方差是用数据个数或总频数去除离差平方和,而样本方差则是用样本数据个数或总频数减1去除离差平方和,其中样本数据个数减1即n-1 称为自由度。设样本方差为,根据未分组数据和分组数据计算样本方差的公式分别为: 未分组数据: 分组数据: 未分组数据: 分组数据: 例:考察一台机器的生产能力,利用抽样程序来检验生产出来的产品质量,假设搜集的数据如下: 根据该行业通用法则:如果一个样本中的14个数据项的方差大于0.005,则该机器必须关闭待修。问此时的机器是否必须关闭? 解:根据已知数据,计算
因此,该机器工作正常。 方差和标准差也是根据全部数据计算的,它反映了每个数据与其均值相比平均相差的数值,因此它能准确地反映出数据的离散程度。方差和标准差是实际中应用最广泛的离散程度测度值。 ?函数VAR假设其参数是样本总体中的一个样本。如果数据为整个样本总体,则应使用函数VARP来计算方差。 ?参数可以是数字或者是包含数字的名称、数组或引用。 ?逻辑值和直接键入到参数列表中代表数字的文本被计算在内。 ?如果参数是一个数组或引用,则只计算其中的数字。数组或引用中的空白单元格、逻辑值、文本或错误值将被忽略。 ?如果参数为错误值或为不能转换为数字的文本,将会导致错误。 ?如果要使计算包含引用中的逻辑值和代表数字的文本,请使用VARA 函数。 ?函数VAR 的计算公式如下: 其中x 为样本平均值AVERAGE(number1,number2,…),n 为样本大小。 示例 假设有10 件工具在制造过程中是由同一台机器制造出来的,并取样为随机样本进行抗断强度检验。 如果将示例复制到一个空白工作表中,可能会更容易理解该示例。 STDEV(number1,number2,...) Number1,number2,...为对应于总体样本的 1 到255 个参数。也可以不使用这种用逗号分隔参数的形式,而用单个数组或对数组的引用。 注解 ?函数STDEV 假设其参数是总体中的样本。如果数据代表全部样本总体,则应该使用函数STDEVP来计算标准偏差。 ?此处标准偏差的计算使用“n-1”方法。
标准差的有关介绍及标准差计算公式标准差标准差
标准差的有关介绍及标准差计算公式标准差标准差标准差的有关介绍及标准差计算公式标准差标准差(Standard Deviation) 也称均方差(mean square error) 各数据偏离平均数的距离(离均差)的平均数,它是离均差平方和平均后的方根。用& sigma;表示。因此标准差是方差的算术平方根。 例如:如果有n个数据X1 ,X2 ,X3……Xn ,数据的平均数为X,标准差c : 标准差能反映一个数据集的离散程度。平均数相同的,标准差未必相同。 例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B 72、71、69、68、67。这两组的平均数都是70,但A组的标准差为18.71分, B组组的分数为73、 的标准差为2.37分(此数据时在R统计软件中运行获得),说明A组学生之间的差距要比B组学生之间的差距大得多。 标准差也被称为标准偏差,或者实验标准差。 关于这个函数在EXCEL中的STDEV函数有详细描述,EXCEL中文版里面就是用的“标准偏差”字样。但我国的中文教材等通常还是使用的是“标准差”。 在EXCEL中STDEV函数就是下面评论所说的另外一种标准差,也就是总体标准差。在繁体中文的一些地方可能叫做“母体标准差” 在R统计软件中标准差的程序为:sum((x-mean(x)F2)/(length(x)-1) 因为有两个定义,用在不同的场合: 如是总体,标准差公式根号内除以n, 如是样本,标准差公式根号内除以(n-1),
因为我们大量接触的是样本,所以普遍使用根号内除以(n-1), 外汇术语: 标准差指统计上用于衡量一组数值中某一数值与其平均值差异程度的指标。标准差被用来评估价格可能的变化或波动程度。标准差越大,价格波动的范围就越广,股票等金融工具表现的波动就越大。 阐述及应用 简单来说,标准差是一组数值自平均值分散开来的程度的一种测量观念。一个较大的标准差,代表大部分的数值和其平均值之间差异较大; 一个较小的标准差,代表这些数值较接近平均值。 例如,两组数的集合{0, 5, 9, 14} 和{5, 6, 8, 9} 其平均值都是7 ,但 第二个集合具有较小的标准差。 标准差可以当作不确定性的一种测量。例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色: 如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。 标准差应用于投资上,可作为量度回报稳定性的指标。标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。相反,标准差数值越细,代表回报较为稳定,风险亦较小。 样本标准差 在真实世界中,除非在某些特殊情况下,不然找到一个总体的真实的标准差是不现实的。大多数情况下,总体标准差是通过随机抽取一定量的样本并计算样本标准差估计的。 标准差的简易计算公式
标准差的计算公式实例
通常,计算标准偏差有四个步骤:计算平均值,计算方差,计算平均方差和计算标准差。例如,对于一组六个数字2、3、4、5、6、8,可以通过以下步骤计算标准偏差: 计算平均值: (2 + 3 + 4 + 5+ 6 + 8)/ 6 = 30/6 = 5 计算方差 (2 – 5)^ 2 =(-3)^ 2 = 9 (3 – 5)^ 2 =(-2)^ 2 = 4 (4 – 5)^ 2 =(-1)^ 2 = 0 (5 – 5)^ 2 = 0 ^ 2 = 0 (6 – 5)^ 2 = 1 ^ 2 = 1 (8 – 5)^ 2 = 3 ^ 2 = 9 计算出平均方差 (9 + 4 + 0 + 0 + 1 + 9)/ 6 = 24/6 = 4 计算标准偏差: √4= 2 标准差是概率统计中最常用的统计离散度度量。标准偏差定义为方差的算术平方根,它反映组中个体之间的分散程度。原则上,按分布程度测量的结果具有两个属性:总量或随机变量的标准偏差以及子集中样本数量的标准偏差。公式如下。标准偏差的概念由卡尔·皮尔森(Karl Pearson)引入统计学中。 洋葱备注:
所有数字减去其平均值的平方和,然后将结果除以数字组的数量(或数字减去1,即变数),然后打开获得的值的根和获得的数字是这组数据的标准差 方差=(x1-x)^ 2 +(x2-x)^ 2 +(x3-x)^ 2 + ... +(xn-x)^ 2 = X1 ^ 2 + X2 ^ 2 + X3 ^ 2 + ...... + Xn ^ 2-2x(X1 + X2 + X3 +…+ Xn)+ n X ^ 2 (其中x 1,X2,X3,xn是每个项目的编号,X是平均值)(n)根的标准偏差
标准差σ的种计算公式
标准差σ的种计算公式文档编制序号:[KK8UY-LL9IO69-TTO6M3-MTOL89-FTT688]
标准差σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和Minitab中 σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和中的Pooled standard deviation(合并标准差) 做数据分析,经常会碰到提到标准差σ这个概念,关于标准差σ的计算方式,目前,本人知道有4种标准差σ的计算方法,如下: 一,简易标准差σ的计算方式 上面是计算整体的标准差,如果是计算样本的标准差,这里的N, 应该为N-1. 一般情况下,都是计算样本的标准差。关于这个标准的详细运算公式和案例分析,可以参考附件,里面有比较详细的解释。 KB, 下载次数: 1262)
二,XBAR-R管制图分析( X-R Control Chart)图中的 Rbar/d2 算法 XBAR-R管制图分析( X-R Control Chart):由平均数管制图与全距管制图组成。 ●品质数据可以合理分组时,可以使用X管制图分析或管制制程平均;使用R管制图分析制程变异。 ●工业界最常使用的值管制图。 关于上面公式中用到的 A2、A3、D2、D3、D4等常数请参考帖子下面的表格
三,XBAR-s管制图分析( X-s Control Chart)中的Sbar/C4算法 XBAR-S 管制图分析( X-S Control Chart):由平均数管制图与标准差管制图组成。 ●与X-R管制图相同,惟s管制图检出力较R管制图大,但计算麻烦。 ●一般样本大小n小于等于8可以使用R管制图,n大于8则使用S管制图。 ●有电脑软件辅助时,使用S管制图当然较好。 关于上面公式中用到的 A2、A3、D2、D3、D4等常数请参考帖子下面的表格四,Minitab中所使用的Pooled standard deviation(合并标准差)
标准差σ的4种计算公式
标准差/的4种计算公式 标准差c的4种计算公式:简易标准差,Rbar/d2 , Sbar/C4 和Minitab中 标准差c的4种计算公式:简易标准差,Rbar/d2 , Sbar/C4 和Minitab 中的Pooled standard deviation(合并标准差) 做数据分析,经常会碰到提到标准差c这个概念,关于标准差c的计算方式,目前,本人知道 有4种标准差c的计算方法,如下: —,简易标准差c的计算方式 上面是计算整体的标准差,如果是计算样本的标 准差,这里的N,应该为N-1.
=\占討硼 亠般情况下,都是计算样本的标准差。关于这个
标准的详细运算公式和案例分析,可以参考附件,里面有比较详细的解释。 魏标准差的简易计算公式和案例分析(28.19 KB,下载次数:1262) 二,XBAR—R 管制图分析(X-R Control Chart) 图中的Rbar/d2算法 XBAR-R 管制图分析(X-R Control Chart):由平均数管制图与全距管制图组成。 ?品质数据可以合理分组时,可以使用X管制图分析或管制制程平均;使用R管制图分析制程变异。?工业界最常使用的计量值管制图o
制程平均矗标建差己知耒知. ML灵=Px * 30-7=p + 3o■/ C n) 2*x bar + A2 R CL元二 LCLx 二P A—加天=p _ 3cr# ( n ) '2 X仙-幻R 中 *3C R-d2仃十3d2口曲口厲 UCL R= G - UCL R=二 d 2 J" R LCL R二口R —M R=d er- 5d3 3R p卜于零时不计) A =:Z =冥b跡i A =頁卅d ?, (7 上 1^2 - 3 n —id;* 3()小# a n * D 2~ f d 2-3dal z J D斗 品质协会vw.PinZlxi, erg 有问题'来查下wv. ChaKia. coin 关于上面公式中用到的A2、A3、D2、D3、D4 等常数请参考http://www.pi https://www.360docs.net/doc/2d981240.html,/thread-476-1- 1.html 帖子下面的表格 三,XBAR —s管制图分析(X —s Con trol Chart)中的Sbar/C4 算法 XBAR —S 管制图分析(X —S Control Chart): 由平均数管制图与标准差管制图组成。
标准差的计算公式的推导及理解
方差s^2=[(x1-x)^2+(x2-x)^2+......(xn-x)^2]/n 标准差=方差的算术平方根 标准差计算公式的来源 标准差是反应一组数据离散程度最常用的一种量化形式,是表示精密确的最要指标。 虽然样本的真实值是不能知道,但是每个样本总是会有一个真实值的,不管它究竟是多少。可以想象,一个好的检测方法,基检测值应该很紧密的分散在真实值周围。如不紧密,那距真实值的就会大,准确性当然也就不好了,不可能想象离散度大的方法,会测出准确的结果。因此,离散度是评价方法的好坏的最重要也是最基本的指标。 一组数据怎样去评价与量化它的离散度?有很多种方法: 1.极差 最直接也是最简单的方法,即最大值-最小值(也就是极差)来评价一组数据的离散度。这一方法最为常见,比如比赛中去掉最高最低分就是极差的具体应用。 2.离均差的平方和 由于误差的不可控性,因此只由两个数据来评判一组数据是不科学的。所以人们在要求更高的领域不使用极差来评判。其实,离散度就是数据偏离平均值的程度。因此将数据与均值之差(我们叫它离均差)加起来就能反映出一个准确的离散程度,越大离散度也就越大。 但是由于偶然误差是成正态分布的,离均差有正有负,对于大样本离均差的代数相加为零的。为了避免正负问题,在数学有上有两种方法:一种是取绝对值,也就是常说的离均差绝对值相加。而为了避免符号问题,数学上最常用的是另一种方法--平方,这样就都成了非负数。因此,离均差的平方累加成了评价离散度一个指标。 3.方差(S2) 由于离均差的平方累加值与样本个数有关,只能反应相同样本的离散度,而实际工作中做比较很难做到相同的样本,因此为了消除样本个数的影响,增加可比性,将标准差求平均值,这就是我们所说的方差成了评价离散度的较好指标。 我们知道,样本量越大越能反映真实的情况,而算数均值却完全忽略了这个问题,对此统计学上早有考虑,在统计学中样本的均差多是除以自由度(n-1),它是意思是样本能自由选择的程度。当选到只剩一个时,它不可能再有自由了,所以自由度是n-1。 4.标准差(SD) 由于方差是数据的平方,与检测值本身相差太大,人们难以直观的衡量,所以常用方差开根号换算回来这就是我们要说的标准差。
混凝土标准差计算公式
混凝土标准差计算公式 估算样本的标准偏差。标准偏差反映相对于平均值(mean) 的离散程度。 STDEV(number1,number2,...) 为对应于总体样本的 1 到30 个参数。也可以不使用这种用逗号分隔参数的形式,而用单个数组或对数组的引用。 说明 函数STDEV 假设其参数是总体中的样本。如果数据代表全部样本总体,则应该使用函数STDEVP 来计算标准偏差。 此处标准偏差的计算使用“无偏差”或“n-1”方法。 函数STDEV 的计算公式如下: `````_______________ ````/`````````` ```2 ```/`n∑X 2-(∑X) ``/_______________ \/```````n(n-1) 忽略逻辑值(TRUE 或FALSE)和文本。如果不能忽略逻辑值和文本,请使用STDEVA 工作表函数。
示例: 假设有10 件工具在制造过程中是由同一台机器制造出来的,并取样为随机样本进行抗断强度检验。 列题 A 1 强度 2 1345 3 1301 4 1368 5 1322 6 1310 7 1370 8 1318 9 1350 10 1303 11 1299 公式说明(结果) =STDEV(A2:A11) 抗断强度的标准偏差(27.46391572)
混凝土抗压强度标准差的计算公式 Sfcu=[(∑ fcu?i2-n?mfcu2)/(n-1)]1/2 公式表述显示不明,用语言表述下,即公式中的2和1/2都应为上角表,分别表示平方和根号(开平方)。 语言表述如下:fcu.i的平方求和再减去n 乘以fcu平均值的平方,用他们的差再除以(n-1)这样得出的除数开方;也可以是fcu.i-fcu 平均值差的平方求和得出的数再除以(n-1)这样得出的除数开方。当Sfcu<0.06fcu,k时,取Sfcu=0.06fcu,k 具体参数表述如下:fcu,k一混凝土立方体抗压强度标准值 fcu为设计强度标准值 mfcu为平均值 n为试块组数 Sfcu为n组试块的强度值标准差 fcu.i : 第i组试块的立方体抗压强度值
标准差σ的种计算公式
标准差σ的种计算公式Prepared on 21 November 2021
标准差σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和Minitab中 σ的4种计算公式: 简易标准差,Rbar/d2,Sbar/C4和中的Pooled standard deviation(合并标准差) 做数据分析,经常会碰到提到标准差σ这个概念,关于标准差σ的计算方式,目前,本人知道有4种标准差σ的计算方法,如下: 一,简易标准差σ的计算方式 上面是计算整体的标准差,如果是计算样本的标准差,这里的N, 应该为N-1. 一般情况下,都是计算样本的标准差。关于这个标准的详细运算公式和案例分析,可以参考附件,里面有比较详细的解释。 KB, 下载次数: 1262) 二,XBAR-R管制图分析( X-R Control Chart)图中的 Rbar/d2 算法 XBAR-R管制图分析( X-R Control Chart):由平均数管制图与全距管制图组成。 ●品质数据可以合理分组时,可以使用X管制图分析或管制制程平均;使用R管制图分析制程变异。
●工业界最常使用的值管制图。 关于上面公式中用到的 A2、A3、D2、D3、D4等常数请参考帖子下面的表格 三,XBAR-s管制图分析( X-s Control Chart)中的Sbar/C4算法XBAR-S 管制图分析( X-S Control Chart):由平均数管制图与标准差管制图组成。●与X-R管制图相同,惟s管制图检出力较R管制图大,但计算麻烦。●一般样本大小n小于等于8可以使用R管制图,n大于8则使用S管制图。●有电脑软件辅助时,使用S管制图当然较好。
标准差计算公式]
9. 標準差計算公式:用以衡量報酬率之波動程度,以公式表示如下: 計算一年度標準差時, n 以12代入 ( 亦即以過去12個月報酬率計算標準差 ),計算兩年度標準差,則n以24代入 :月標準差 : 季化標準差: 年化標準差 Ri : i 月之月報酬率: n 個月報酬率之平均值 10. 夏普指標(SHARPE):用以衡量每單位總風險(以月化標準差衡量)所得之超額報酬,所謂超額報酬為基金過去一年及兩年平均月報酬率超過平均一個月定存利率之部分。 以公式表示如下:為月標準差 為無風險報酬率 11. β係數:用以衡量基金之市場風險(或稱系統性風險)。其計算方式為以過去十二個月或二十四個月之基金月報酬率對同期市場月報酬率做迴歸,估計斜率係數而得。亦即 t(一年)=-11,-10,....,0 t(兩年)=-23,-22,....,0 所估得之bi值即為b係數。6.自 89年10月起基金績效評比增列新欄位,欄位名稱為「經理未滿一年」,係列出基金經理人經理該基金未滿一年者。 7. 股票型基金中,除店頭基金之市場報酬率以 OTC 指數為準,其餘皆以加權股價指數為準。 8.原基金分類中之封閉型基金,因基金個數少於5支,故不再另成一類,而將其併入特殊類基金中。 3. 由於個別基金成立日期不同,基金自成立日起迄今之報酬率不予排名。 4. 基金存在期間若小於評估期間,則該評估期間不計算報酬率,以“ - "表示。 5. ★代表資料不足, ☆代表為封閉型之店頭基金, 代表新成立之基金, 代表在一個月內基金之經理人有更動者, ? 代表迴歸式解釋能力過低, β值不具參考性, @ 代表下市之封閉型基金。 《 說明 》 1. 基金在各評估期間之報酬率係基金在該期間之淨值累計報酬率。例如遠東大聯科技基金過去一個月(92年08月01日至 92年08月29日)之 淨值累計報酬率為10.08%; 過去三個月(92年06月01日至92年08月29日)之值累計報酬率為37.41%。 2. 基金排列順序依各類型基金過去一個月之報酬率順序,由高而低排列。跨國投資類因各基金投資之市場歧異甚大,只列示各基金報酬率,不予以排名。 ()R R R R i t f t i i m t f t i t ,,,,,?=+?+αβεR f σi σ月σ年σ季
标准差的计算公式实例
标准差系数: 标准差系数,又称为均方差系数,离散系数。它是从相对角度观察的差异和离散程度,在比较相关事物的差异程度时较之直接比较标准差要好些。 标准差: 标准差,是离均差平方的算术平均数的算术平方根,用σ表示。标准差也被称为标准偏差,或者实验标准差,在概率统计中最常使用作为统计分布程度上的测量依据。 标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的两组数据,标准差未必相同。 标准差的性质和应用: 标准差,在概率统计中最常使用作为统计分布程度上的测量。标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。它反映组内个体间的离散程度。测量到分布程度的结果,原则上具有两种性质: 为非负数值,与测量资料具有相同单位。一个总量的标准差或一个随机变量的标准差,及一个子集合样品数的标准差之间,有所差别。 简单来说,标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。 例如,两组数的集合{0,5,9,14}和{5,6,8,9}其平均值都是7,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量。例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。 标准差应用于投资上,可作为量度回报稳定性的指标。标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。相反,标准差数值越小,代表回报较为稳定,风险亦较小。 例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。这两组的平均数都是70,但A组的标准差约为17.08分,B组的标准差约为2.16分,说明A组学生之间的差距要比B组学生之间的差距大得多。 如是总体(即估算总体方差),根号内除以n(对应excel函数:STDEVP); 如是抽样(即估算样本方差),根号内除以(n-1)(对应excel 函数:STDEV); 因为我们大量接触的是样本,所以普遍使用根号内除以(n-1)。
样本的标准差
样本的标准差 样本的标准差 计算公式 标准差(Standard Deviation),在概率统计中最常使用作为统计分布程度(statistical dispersion)上的测量。标准差定义是总体各单位标准值与其平均数离差 平方的算术平均数的平方根。它反映组内个体间的离散程度。测量到分布程度的结果,原 则上具有两种性质:为非负数值,与测量资料具有相同单位。一个总量的标准差或一个 随机变量的标准差,及一个子集合样品数的标准差之间,有所差别。 标准计算公式: 假设有一组数值X1,X2,X3,......XN(皆为实数),其平均值(算术平均值)为μ, 公式如图1。 标准差也被称为标准偏差,或者实验标准差,公式为。简单来说,标准差是一组数 据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异 较大;一个较小的标准差,代表这些数值较接近平均值。例如,两组数的集合 {0,5,9,14} 和 {5,6,8,9} 其平均值都是 7 ,但第二个集合具有较小的标准差。 标准差可以当作不确定性的一种测量。例如在物理科学中,做重复性测量时,测量数 值集合的标准差代表这些测量的精确度。当要决定测量值是否符合预测值,测量值的标准 差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认 为测量值与预测值互相矛盾。这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。 标准差应用于投资上,可作为量度回报稳定性的指标。标准差数值越大,代表回报远 离过去平均数值,回报较不稳定故风险越高。相反,标准差数值越小,代表回报较为稳定,风险亦较小。 例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。这两组的平均数都是70,但A组的标准差约为17.08分,B组的标准差约为2.16分,说明A组学生之间的差距要比B组学生之间的差距大得多。 如是总体(即估算总体方差),根号内除以n(对应excel函数:STDEVP); 如是抽样(即估算样本方差),根号内除以(n-1)(对应excel函数:STDEV); 因为我们大量接触的是样本,所以普遍使用根号内除以(n-1)。