统计学第五次实验-多重共线性实验报告
多重共线性实验报告
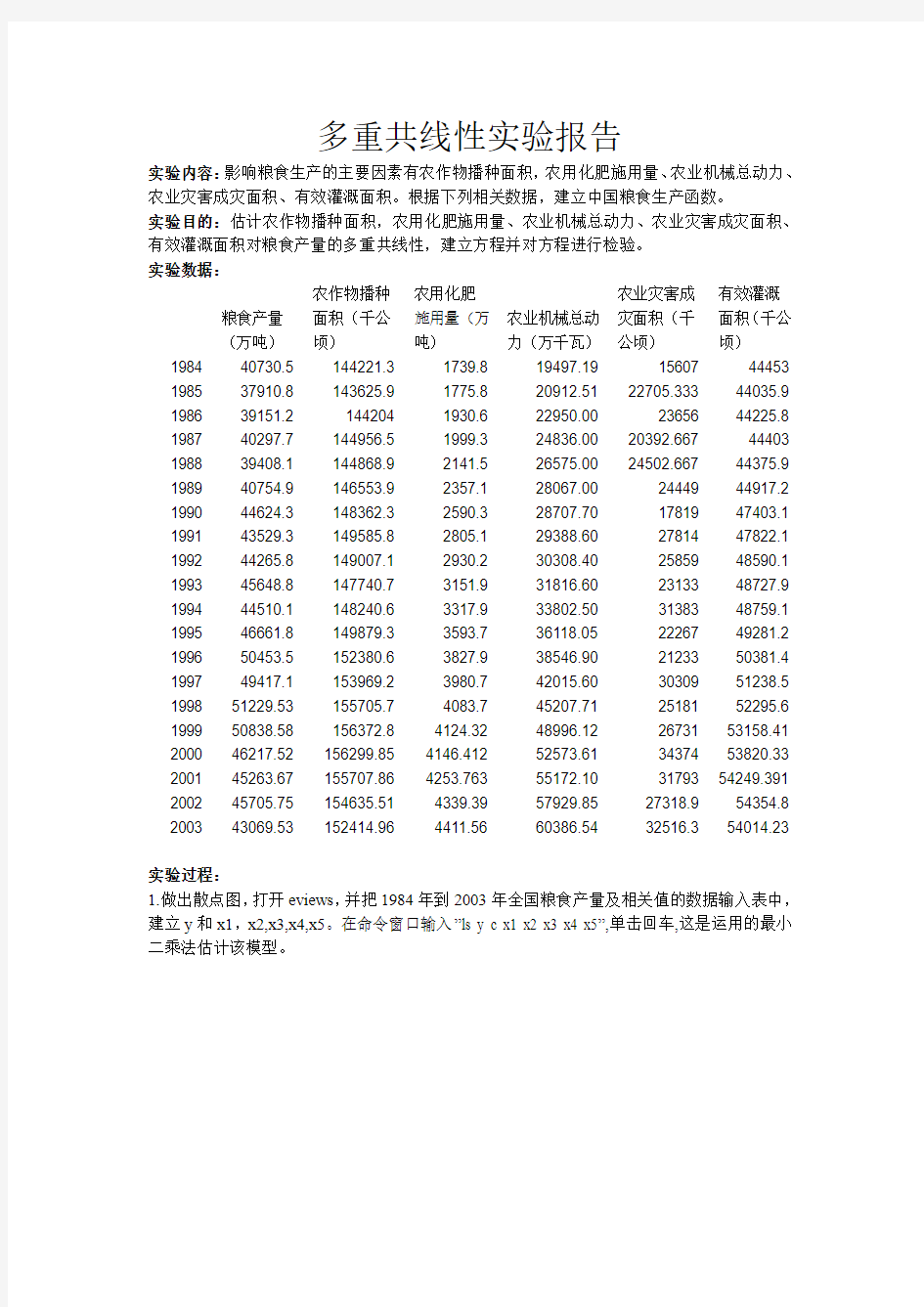
实验内容:影响粮食生产的主要因素有农作物播种面积,农用化肥施用量、农业机械总动力、农业灾害成灾面积、有效灌溉面积。根据下列相关数据,建立中国粮食生产函数。
实验目的:估计农作物播种面积,农用化肥施用量、农业机械总动力、农业灾害成灾面积、有效灌溉面积对粮食产量的多重共线性,建立方程并对方程进行检验。
实验数据:
粮食产量(万吨)农作物播种
面积(千公
顷)
农用化肥
施用量(万
吨)
农业机械总动
力(万千瓦)
农业灾害成
灾面积(千
公顷)
有效灌溉
面积(千公
顷)
1984 40730.5 144221.3 1739.8 19497.19 15607 44453 1985 37910.8 143625.9 1775.8 20912.51 22705.333 44035.9 1986 39151.2 144204 1930.6 22950.00 23656 44225.8 1987 40297.7 144956.5 1999.3 24836.00 20392.667 44403 1988 39408.1 144868.9 2141.5 26575.00 24502.667 44375.9 1989 40754.9 146553.9 2357.1 28067.00 24449 44917.2 1990 44624.3 148362.3 2590.3 28707.70 17819 47403.1 1991 43529.3 149585.8 2805.1 29388.60 27814 47822.1 1992 44265.8 149007.1 2930.2 30308.40 25859 48590.1 1993 45648.8 147740.7 3151.9 31816.60 23133 48727.9 1994 44510.1 148240.6 3317.9 33802.50 31383 48759.1 1995 46661.8 149879.3 3593.7 36118.05 22267 49281.2 1996 50453.5 152380.6 3827.9 38546.90 21233 50381.4 1997 49417.1 153969.2 3980.7 42015.60 30309 51238.5 1998 51229.53 155705.7 4083.7 45207.71 25181 52295.6 1999 50838.58 156372.8 4124.32 48996.12 26731 53158.41 2000 46217.52 156299.85 4146.412 52573.61 34374 53820.33 2001 45263.67 155707.86 4253.763 55172.10 31793 54249.391 2002 45705.75 154635.51 4339.39 57929.85 27318.9 54354.8 2003 43069.53 152414.96 4411.56 60386.54 32516.3 54014.23
实验过程:
1.做出散点图,打开eviews,并把1984年到2003年全国粮食产量及相关值的数据输入表中,建立y和x1,x2,x3,x4,x5。在命令窗口输入”ls y c x1 x2 x3 x4 x5”,单击回车,这是运用的最小二乘法估计该模型。
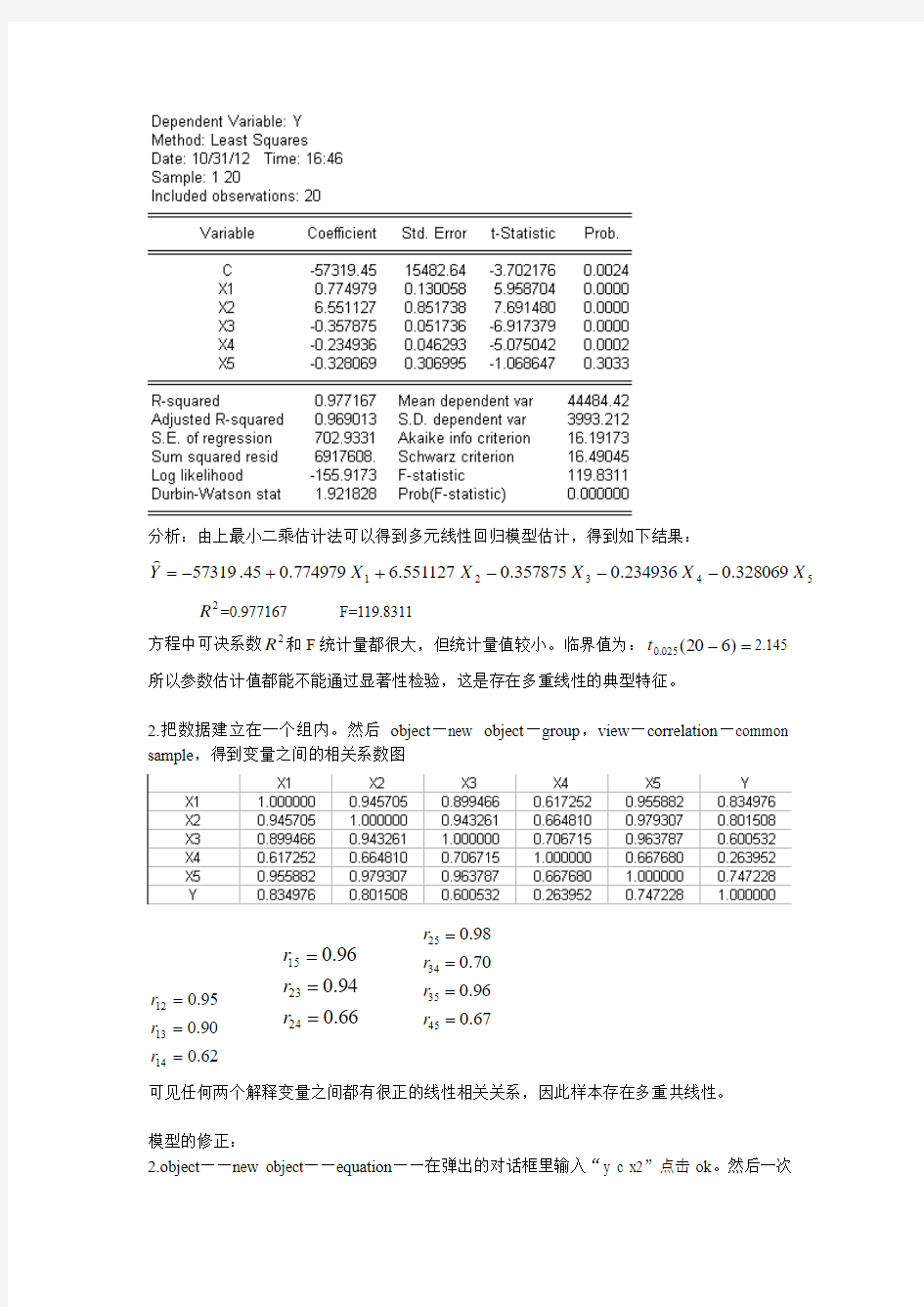
分析:由上最小二乘估计法可以得到多元线性回归模型估计,得到如下结果:
5
4321328069.0234936.0357875.0551127.6774979.045.57319X X X X X Y ---++-=
2R =0.977167 F=119.8311
方程中可决系数2R 和F 统计量都很大,但统计量值较小。临界值为:=-)620(025.0t 2.145 所以参数估计值都能不能通过显著性检验,这是存在多重线性的典型特征。
2.把数据建立在一个组内。然后object —new object —group ,view —correlation —common sample ,得到变量之间的相关系数图
62
.090.095.0141312===r r r 66
.094.096
.0242315===r r r
67.096
.070.098.045353425====r r r r
可见任何两个解释变量之间都有很正的线性相关关系,因此样本存在多重共线性。
模型的修正:
2.object ——new object ——equation ——在弹出的对话框里输入“y c x2”点击ok 。然后一次
输入“y c x3”,"y c x4","y c x5". 出现下面的结果:
方程
t
F
DW
23.362X 33808.53Y += 5.687 0.642 32.338 2453.311 0.701 3188.053.37599X Y +=
3.186 0.361 10.153 3280.470 0.476 4213.06
4.39068X Y += 1.161 0.070 1.348 3957.139 0.659 5790.0684.5770X Y +=
4.770
0.558
0.0001
2726.479 0.517
以上结果显示,除第四个外,任何一个解释变量和被解释变量之间的关系都是显著的。
经济意义检验:
从经济意义的角度看,农作物播种面积和农业化肥施用量应该是主要因素,因此建模时农作物播种面积X1和农业化肥施用量X2应作为基本解释变量予以保留。包含和各种估计式如下:
变量 t
F
DW X1,X2 1.779 0.27416 0.699 19.694 2317.959 0.671 X1 X2 X3 4.213 5.382 -7.589 0.934 76.031 1114.096 2.240 X1 X2 X4 2.078 1.372 -3.296 0.820 24.369 1843.932 0.486 X1 X2 X5
3.275 2.565 -2.993 0.807 22.259 1913.140 1.506 X1 X2 X3 X4 6.263 8.698-9.699
-4.981
0.974 148.101 706.252
1.686
X1 X2 X3 X5 3.728 4.482 -5.451
-0.405
0.935 54.086 1144.379 2.367 X1 X2 X4 X5 3.958 3.757 -3.707
-3.420
0.899
33.426
1427.377 0.903
由以上各估计式可以看出,具有保留了X1,和X2的估计式通过了显著性检验,而且经济意义明显,是一个相当好的样本回归方程。尽管两者之间还存在多重共线性,但是由于模型的整体显著,每个估计值也显著,因此可以不考虑他们之间的共线性问题。
21471.0653.019.54910X X Y ++-=
(1.779) (0.274)
统计学实验报告汇总
本科生实验报告 实验课程统计学 学院名称商学院 专业名称会计学 学生姓名苑蕊 学生学号0113 指导教师刘后平 实验地点成都理工大学南校区 实验成绩 二〇一五年十月二〇一五年十月
依据上述资料编制组距变量数列,并用次数分布表列出各组的频数和频率,以及向上、向下累计的频数和频率, 并绘制直方图、折线图。 学生 实验 心得
2.已知2001-2012年我国的国内生产总值数据如表2-16所示。 学生 实验 心得 要求:(1)依据2001-2012年的国内生产总值数据,利用Excel软件绘制线图和条形图。
(2)依据2012年的国内生产总值及其构成数据,绘制环形图和圆形图。 学生 实验 心得 3.计算以下数据的指标数据 1100 1200 1200 1400 1500 1500 1700 1700 1700 1800 1800 1900 1900 2100 2100 2200 2200 2200 2300 2300 2300 2300 2400 2400 2500 2500 2500 2500 2600 2600 2600 2700 2700 2800 2800 2800 2900 2900 2900 3100 3100 3100 3100 3200 3200 3300 3300 3400 3400 3400 3500 3500 3500 3600 3600 3600 3800 3800 3800 4200
4.一家食品公司,每天大约生产袋装食品若干,按规定每袋的重量应为100g。为对产品质量进行检测,该企业质检部门采用抽样技术,每天抽取一定数量的食品,以分析每袋重量是否符合质量要求。现从某一天生产的一批食品8000袋中随机抽取了25袋(不重复抽样),测得它们的重量分别为: 学生实验心得 101 103 102 95 100 102 105 已知产品重量服从正态分布,且总体方差为100g。试估计该批产品平均重量的置信区间,置信水平为95%.
多重共线性的解决之法
第七章 多重共线性 教学目的及要求: 1、重点理解多重共线性在经济现象中的表现及产生的原因和后果 2、掌握检验和处理多重共线性问题的方法 3、学会灵活运用Eviews 软件解决多重共线性的实际问题。 第一节 多重共线性的产生及后果 一、多重共线性的含义 1、含义 在多元线性回归模型经典假设中,其重要假定之一是回归模型的解释变量之间不存在线性关系,也就是说,解释变量X 1,X 2,……,X k 中的任何一个都不能是其他解释变量的线性组合。如果违背这一假定,即线性回归模型中某一个解释变量与其他解释变量间存在线性关系,就称线性回归模型中存在多重共线性。多重共线性违背了解释变量间不相关的古典假设,将给普通最小二乘法带来严重后果。 2、类型 多重共线性包含完全多重共线性和不完全多重共线性两种类型。 (1)完全多重共线性 完全多重共线性是指线性回归模型中至少有一个解释变量可以被其他解释变量线性表示,存在严格的线性关系。 如对于多元线性回归模型 i ki k i i i X X X Y μββββ+++++= 22110 (7-1) 存在不全为零的数k λλλ,,,21 ,使得下式成立: X X X 2211=+++ki k i i λλλ (7-2) 则可以说解释变量k X ,,X ,X 21 之间存在完全的线性相关关系,即存在完全多重共线性。 从矩阵形式来看,就是0' =X X , 即1)(- (2)不完全多重共线性 不完全多重共线性是指线性回归模型中解释变量间存在不严格的线性关系,即近似线性关系。 如对于多元线性回归模型(7-1)存在不全为零的数k λλλ,,,21 ,使得下式成立: X X X 2211=++++i ki k i i u λλλ (7-3) 其中i u 为随机误差项,则可以说解释变量k X ,,X ,X 21 之间存在不完全多重共线性。随机误差项表明上述线性关系是一种近似的关系式,大体上反映了解释变量间的相关程度。 完全多重共线性与完全非线性都是极端情况,一般说来,统计数据中多个解释变量之间多少都存在一定程度的相关性,对多重共线性程度强弱的判断和解决方法是本章讨论的重点。 二、多重共线性产生的原因 多重共线性在经济现象中具有普遍性,其产生的原因很多,一般较常见的有以下几种情况。 (一)经济变量间具有相同方向的变化趋势 在同一经济发展阶段,一些因素的变化往往同时影响若干经济变量向相同方向变化,从而引起多重共线性。如在经济上升时期,投资、收入、消费、储蓄等经济指标都趋向增长,这些经济变量在引入同一线性回归模型并作为解释变量时,往往存在较严重的多重共线性。 (二)经济变量间存在较密切关系 由于组成经济系统的各要素之间是相互影响相互制约的,因而在数量关系上也会存在一定联系。如耕地面积与施肥量都会对粮食总产量有一定影响,同时,二者本身存在密切关系。 (三)采用滞后变量作为解释变量较易产生多重共线性 一般滞后变量与当期变量在经济意义上关联度比较密切,往往会产生多重共线性。如在研究消费规律时,解释变量因素不但要考虑当期收入,还要考虑以往各期收入,而当期收入与滞后收入间存在多重共线性的可能很大。 (四)数据收集范围过窄,有时会造成变量间存在多重共线性问题。 三、多重共线性产生的后果 由前述可知,多重共线性分完全多重共线性和不完全多重共线性两种情况,两种情况都会对模 第6章 多重共线性 本章专门讨论古典假设中无多重共线性假定被违反的情况,主要内容包括多重共线性的概念、产生的原因和表现、产生的后果、多重共线性的检验方法及无多重共线性假定违反后的解决方法。 6.1多重共线性的概念 在第三章的多元线性回归模型的建立中,强调了无多重共线性,即假定各解释变量之间不存在线性关系,或者各解释变量的观测值之间线性无关。计量经济学中的多重共线性是指模型中各解释变量的线性关系,它不仅包括解释变量之间精确的线性关系,还包括解释变量之间近似的线性关系,因此多重共线性也就表现为完全多重共线性和近似多重共线性。 6.1.1完全多重共线性 从数学意义上去说明多重共线性,就是对于解释变量k X 、、X X 32,如果存在不全为0的数k λλλ,2,1 ,能使得 n ,2, ,1i 033221 ==++++ki k i i X X X λλλλ ( 6.1.1 ) 则称解释变量k X X X ,,,32 之间存在着完全的多重共线性 用矩阵表示,解释变量的数据矩阵为: X=?? ??? ???????kn n n k k X X X X X X X X X 322 32 22 1 31211 11 (6.1.2) 当矩阵X 的秩小于k 时,表明其中至少有一个列向量可以用其余的列向量线性表示,则说明存在完全多重共线性。 6.1.2不完全的多重共线性 在实际经济问题中,完全的多重共线性并不多见。比较常见的是解释变量 k X X X ,,,32 之间存在不完全的多重共线性。所谓不完全的多重共线性,是指对于解释变 量k X 、、X X 32,存在不全为0的数k λλλ,2,1 ,使得 n ,2, ,1i 033221 ==+++++i ki k i i u X X X λλλλ (6.1.3) 其中,i u 为随机变量。这表明解释变量k X 、、X X 32存在一种近似的线性关系。 如果k 个解释变量之间不存在完全或不完全的线性关系,则称无多重共线性①。若用矩阵表示,这时X 为满秩矩阵,即Rank(X)=k 。 总之,回归模型中解释变量的关系用相关系数表示出来有三种情形: ①0=j x i x r ,解释变量间不存在线性关系,变量间相互正交。这时不需要作多元回归,可以通过Y 对X j 的多个一元回归来估计每个参数值βj 。 ②1=j x i x r ,解释变量间存在完全共线性。此时模型参数将无法估计。当两变量按同一方式 ① 解释变量之间不存在线性关系,并非不存在非线性关系,当解释变量存在非线性关系时,并不违反无多 重共线性假定。 实验报告 实验题目:多重共线性的研究指导老师: 学生一: 学生二: 实验时间:2011年10月 多重线性回归分析及其实验报告 实验目的:为了更好地了解财政收入构成,需要定量地分析影响财政收入的因素 模型设定及其估计:经分析,影响财政收入的主要因素,农业增加值X1,工业增加值X2,建筑业增加值X3,总人口X4,受灾面积X5.为此设定了如下形式的计量经济模型: Y=β 1+β 2 X1+β 3 X2+β 4 X3+β 5 X4+β 6 X5+u0 其中,Y为财政收入(元),X1农业增加值(元),X2为工业增加值(元),X3为建筑业增加值(元),X4为总人口(万人),X5为受灾面积(千公顷) 为估计模型参数,收集1978~2007年财政收入及其影响因素数据,如图: 1978~2007年财政收入及其影响因素数据 年份 财政收入CS/亿 元 农业增加值 NZ/亿元 工业增加值 GZ/亿元 建筑业增加 值JZZ/亿元 总人口 TPOP/万 人 受灾面积 SZM/千公顷1978 1132.3 1027.5 1607 138.2 96259 50790 1979 1146.6 1270.2 1769.7 143.8 97542 39370 1980 1159.9 1371.4 1996.5 195.5 98705 44526 1981 1175.8 1559.5 2048.5 207.1 100072 39790 1982 1212.3 1777.4 2162.3 220.7 101654 33130 1983 1367 1978.5 2375.8 270.6 103008 34710 1984 1642.5 2316.1 2789 316.7 104357 31890 1985 2004.6 2564.3 3448.5 417.9 105851 44365 1986 2122 2788.7 3987.5 525.7 107507 47170 1987 2199.4 3233 4565.9 665.8 109300 42090 1988 2357.6 3865.4 5062 810 111026 50870 1989 2664.5 5062 8087.3 794 112704 46991 1990 2937.4 5342.3 10284.5 859.4 114333 38474 华东理工大学2016–2017学年第二学期 《多元统计学》实验报告 实验名 称实验1数据整理与描述统计分析 教师批阅:实验成绩: 教师签名: 日期: 实验报告正文: 实验数据整理 (一)对“employee”进行数据整理 1.观察量排序 ( based on current salary) 2.变量值排序(based on current salary : rsalary) 3.计算新的变量(incremental salary=current salary - beginning salary) 4.拆分数据文件(based on gender) 结论:There are 215 female employees and 259 male employees. 5.分类汇总 (break variable: gender ; function: mean ) 结论:The average current salary of female is . The average current salary of male is . (二)分别给出三种工作类别的薪水的描述统计量 实验描述统计分析 1)样本均值矩阵 结论:总共分析六组变量,每组含有十个样本。 每股收益(X1)的均值为;净资产收益率(X2)的均值为;总资产报酬率(X3)的均值为;销售净 利率(X4)的均值为;主营业务增长率(X5)的均值为;净利润增长率(X6)的均值为. 2)协方差阵 结论:矩阵共六行六列,显示了每股收益(X1)、净资产收益率(X2)、总资产报酬率(X3)、销售净利率(X4)、主营业务增长率(X5)和净利润增长率(X6)的协方差。 3)相关系数 结论:矩阵共六行六列,显示了每股收益 (X1)、净资产收益率(X2)、总资产报酬 率(X3)、销售净利率(X4)、主营业务增 长率(X5)和净利润增长率(X6)之间的 相关系数。 每格中三行分别显示了相关系数、显著性 检验与样本个数。 4)矩阵散点图 计量经济学E v i e w s多重共线性实验报告 Company Document number:WUUT-WUUY-WBBGB-BWYTT-1982GT 实验报告课程名称计量经济学 实验项目名称多重共线性 班级与班级代码 专业 任课教师 学号: 姓名: 实验日期: 2014 年 05 月 11日 广东商学院教务处制 姓名实验报告成绩 评语: 指导教师(签名) 年月日 说明:指导教师评分后,实验报告交院(系)办公室保存。 计量经济学实验报告 一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。 三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。 四、预备知识:最小二乘法估计的原理、t检验、F检验、2R值。 五、实验步骤 1、选择数据 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费标准煤总量、国民总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。主要数据如下: 1985~2007年统计数据 资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。 为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图: 能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98至02年开始缓慢回升,02年到06年开始快速增长。 国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。 工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。 2、设定并估计多元线性回归模型 t t t t t t t u X X X X X Y ++++++=66554433221ββββββ () 录入数据,得到图。 2.2.1)采用OLS 估计参数 在主界面命令框栏中输入 ls y c x1 x2 x3 x4 x5 x6 x7回车,即可得到参数的估计结果。 由此可见,该模型的可决系数为,修正的可决系数为,模型拟和很好,F 统计量为,回归方程整体上显着。 可是其中的lnX3、lnX4、lnX6对lnY 影响不显着,不仅如此,lnX2、lnX5的参数为负值,在经济意义上不合理。所以这样的回归结果并不理想。 3、多重共线性模型的识别 计量经济学多元线性回归、多重共线性、异方差实验报告记录 ————————————————————————————————作者:————————————————————————————————日期: 计量经济学实验报告 多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到亿人次,同比增长%,国内旅游收入万亿元,同比增长%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β 1 X 1 +β 2 X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元 *****大学 应用统计学课程实验(上机)报告 专业班级: 学号: 学生姓名: 指导老师: 实验地点: 学期: 实验(上机)日期:第一次 实验(上机)主题:统计软件的运用 实验(上机)类别:验证性 完成方式:独立 实验(上机)目的与要求: 1、掌握启动和退出统计软件 2、掌握数据库的建立 3、搜集一些数据并建立数据库 4、进行统计计算(函数、描述性统计) 5、制作统计图 6、计算各种统计指标 实验(上机)内容及方法(学生填写) 第1步:打开Excel输入需要分析的数据,然后点击公式选项,选择其中需要的函数进行计算分析。 第2步:在A1:A20区域选取从-3到3,间距为0.058的数据序列作为X序列。在B1单元格中输入公式 “=NORMDIST(A1,0,1,FALSE)”,然后将公式复制到B1:B20区域,在B1:B20区域形成相对A1:A20区间点的正态分布概率密度函数序列。 第3步:选取自由度为2,在A1:A20区域填充从0—12的等差数列,步长为0.1.在B1单元格输入公式“=(A1×EXP(-A1/2) /2)”即可得A1在自由度为2时的卡方分布概率值,然后将B1单元格的公式复制到B1:B20区域,同样选择图标向导和折线图,经过编辑和修饰得到卡方分布概率密度函数图。 实验(上机)过程与结果(学生如实记载上机操作内容、步骤及结果) 本专业男生身高数值(单位:cm): 165、167、168、172、175、173、168、170、180、178、175、181、172、170、169、177、173、168、170、171 1.计算统计指标:在菜单栏中选择工具,然后单击数据分析,再选择描述统计输入数据。 2.点击图表向导,选择折线图第一个样式。 第六章多重共线性 前面两章所讲的异方差性和自相关性都是表现在随机误差项中的,我们下面所讲的多重共线性讨论的是模型中的解释变量违背基本假设的问题。 回忆以下我们在讲多元线性回归模型时,基本假定与简单线性回归模型不同的是哪一点?——就是无多重共线性假定:即假定各解释变量之间不存在线性关系,或者说各解释变量的观测值之间线性无关。 这一章我们讨论的多重共线性就是当解释变量违背了这一条基本假定的情形。 第一节多重共线性概念 先看一个实例:我们研究某个地区家庭消费及其影响因素。我们除了引入收入X1以外,还引入了消费者的家庭财产X2作为第2个解释变量。根据抽样数据回归得到以下结果: Y^=24.7747+0.9415X1-0.0424X2 t=(3.6690) (1.1442) (-0.5261) R2=0.9635 R2——=0.9531 F=92.4020 这一回归结果说明什么? 1、可决系数和修正可决系数都很理想 2、F统计量高度显著,说明X1、X2联合对Y的影响显著 3、各变量参数的t检验都不显著,不能否定等于零的假设 4、财产变量的系数竟然与预期的符号相反。 为什么会出现这样的结果呢? 再看一个例子:分析某地区汽车保养费用支出与汽车的行程数以及汽车拥有的时间建立模型,通过样本数据估计得:Y^=7.29+27.58X1-151.15X2 t= (0.06) (0.958) (-7.06) R2——=0.946 F=52.53 这个结果修正可决系数理想,F检验也显著,但X的T检验不显著,X2的T检验虽然显著,但系数符号与经济意义不符。为什么也出现这种结果? 一、多重共线性的概念: 如果某两个或多个解释变量之间出现了相关性,则称为多重共线性。 完全共线性与不完全共线性表示的是一种线性相关程度。比如我们在第一个例子中,发现可支配收入与家庭财富之间有明显的共线性关系,他们的相关系数高达0.9989,第二个例子中汽车的行程数与拥有汽车的时间的相关系数也为0.9960,表明两个变量之间存在一种不完全的线性相关关系,我们可以认为他们之间有程度很高的多重共线性. 不存在多重共线性只说明解释变量之间没有线性关系,而不排除他们之间存在某种非线性关系。 二、产生多重共线性的原因 1、许多经济变量在随时间的变化过程中往往存在共同的变动趋势。这就使得它们之间 容易产生多重共线性。例如在经济繁荣时期,收入、消费、储蓄、投资、就业都趋 向于增长;在经济衰退时期,都趋向于下降。如果将这些变量作为解释变量同时引 入模型,则它们之间极有可能存在很强的相关性。时间序列中的这种增长因素和趋 向因素是造成多重共线性的主要根源 2、用截面数据建立回归模型时,根据研究的具体问题选择的解释变量常常从经济意义 上存在着密切的关联度。比如P69以某一行业的企业为样本建立企业生产函数模型,以产出量为解释变量,选择资本、劳动、技术等投入要素为解释变量。而这些投入 要素的数量往往与产出量呈正比,产出量高的企业,投入的各种要素都比较多,这 就使得投入要素之间出现线性相关性。 3、在模型中大量采用滞后变量也容易产生多重共线性。因为滞后变量从经济性质来看 与原来的变量无区别,只是时间上有所不同,从经济意义上这些变量之间的关联度 比较紧密。P69 一般来讲,解释变量之间存在多重共线性是难以避免的,所以在多元线性回归模型中,我们关心的并不是多重共线性的有无,而是多重共线性的程度。当多重共线性程度过高时,给最小二乘估计量带来严重的后果。因此,我们追求的也是使多重共线性的程度尽可能地减弱。 实验报告 课程名称计量经济学 实验项目名称多重共线性 班级与班级代码 专业 任课教师 学号: 姓名: 实验日期: 2014 年 05 月 11日 广东商学院教务处制姓名实验报告成绩 评语: 指导教师(签名) 年月日 说明:指导教师评分后,实验报告交院(系)办公室保存。 计量经济学实验报告 一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。 三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。 R值。 四、预备知识:最小二乘法估计的原理、t检验、F检验、2 五、实验步骤 1、选择数据 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费标准煤总量、国民总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。主要数据如下: 1985~2007年统计数据 资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。 为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图: 能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98 至02年开始缓慢回升,02年到06年开始快速增长。 国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。 工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。 2、设定并估计多元线性回归模型 t t t t t t t u X X X X X Y ++++++=66554433221ββββββ (2.1) 2.1录入数据,得到图。 河南工业大学管理学院 课程设计(实验)报告书题目统计学实验 专业电子商务 班级1204班 学生姓名伍琴 学号201217050430 指导教师任明利 时间:2012 年 4 月 6 日 实验一:数据整理 一、项目名称:数据整理 二、实验目的 (1)掌握Excel中基本的数据处理方法; (2)学会使用Excel进行统计分组,能以此方式独立完成相关作业。 三、实验要求 1、已学习教材相关内容,理解数据整理中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。 2、准备好一个统计分组问题及相应数据(可用本实验导引所提供问题与数据)。 3、以Excel文件形式提交实验报告(包括实验过程记录、疑难问题发现与解决记录)。 四、实验内容和操作步骤 (一)问题与数据 某百货公司连续40天的商品销售额如下(单位:万元): 41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42 36 37 37 49 39 42 32 36 35 根据上面的数据进行适当分组,编制频数分布表,并绘制直方图. (二)操作步骤: 1、在单元区域A1:E9中输入原始数据,如图: 2、并计算原始数据的最大值(在单元格B10中)与最小值(在单元格D10中)。 3、根据经验公式计算经验组距和经验组数。 4、根据步骤3的计算结果,计算并确定各组上限、下限(在单元区域F1:G6),如图所示: 5、绘制频数分布表框架,如图所示: 6、计算各组频数: (1)选定B19:B23作为存放计算结果的区域。 (2)从“公式”菜单中选择“插入函数”项。 (3)在弹出的“插入函数”对话框中选择“统计”函数FREQUENCY. 统计学实验报告1 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII 实验报告 二、打开文件“数据 3.XLS”中“城市住房状况评价”工作表,完成以下操作。 1)通过函数,计算出各频率以及向上累计次数和向下累计次数;2)根据两城市频数分布数据,绘制出两城市满意度评价的环形图三、打开文件“数据 3.XLS”中“期末统计成绩”工作表,完成以下操作。 1)要求根据数据绘制出雷达图,比较两个班考试成绩的相似情况。 实验过程: 实验任务一: 1)利用函数frequency制作一张频数分布表 步骤1:打开文件“数据 3. XLS”中“某公司4个月电脑销售情况”工作表 步骤 2.在“频率(%)”的右侧加入一列“分组上限”,因统计分组采用“上限不在内”,故每组数据的上限都比真正的上限值小0.1,例如:“140-150”该组的上限实际值应为“150”,但我们为了计算接下来的频数取“149.9”. 步骤3.选定C20:C29,再选择“插入函数”按钮 3 步骤 4.选择类别“统计”—选择函数“FREQUENCY” 步骤5.在“data_array”对话框中输入“A2:I13”,在“bins_array”对话框中输入“E20:E29 该函数的第一个参数指定用于编制分布数列的原始数据,第二个参数指定每一组的上限. 步骤6.选定C20:C30区域,再按“自动求和” 按钮,即可得到频数的合计 步骤7.在D20中输入“=(C20/$C$30)*1OO” 步骤8:再将该公式复制到D21:D29中,并按“自动求和”按钮计算得出所有频率的合计。 第七章 多重共线性及其处理 第一部分 学习辅导 一、本章学习目的与要求 1.理解多重共线性的概念; 2.掌握多重共线性存在的主要原因; 3.理解多重共线性可能造成的后果; 4.掌握多重共线性的检验与修正的方法。 二、本章内容提要 本章主要介绍计量经济模型的计量经济检验。即多重共线性问题。 多重共线性是多元回归模型可能存在的一类现象,分为完全共线与近似共线两类。模型的多个解释变量间出现完全共线性时,模型的参数无法估计。更多的情况则是近似共线性,这时,由于并不违背所有的基本假定,模型参数的估计仍是无偏、一致且有效的,但估计的参数的标准差往往较大,从而使得t 统计值减小,参数的显著性下降,导致某些本应存在于模型中的变量被排除,甚至出现参数正负号方面的一些混乱。显然,近似多重共线性使得模型偏回归系数的特征不再明显,从而很难对单个系数的经济含义进行解释。多重共线性的检验包括检验多重共线性是否存在以及估计多重共线性的范围两层递进的检验。而解决多重共线性的办法通常有逐步回归法、差分法以及使用额外信息、增大样本容量等方法。 (一)多重共线性及其产生的原因 当我们利用统计数据进行分析时,解释变量之间经常会出现高度多重共线性的情况。 1.多重共线性的基本概念 多重共线性(Multicollinearity )一词由弗里希(Frish )于1934年在其撰写的《借助于完全回归系统的统计合流分析》中首次提出。它的原义是指一个回归模型中的一些或全部解释变量之间存在有一种“完全”或准确的线性关系。 如果在经典回归模型Y X βε=+中,经典假定(5)遭到破坏,则有()1R X k <+,此时称解释变量k X X X ,,,21ΛΛ间存在完全多重共线性。解释变量的完全多重共线性,也就是解释变量之间存在严格的线性关系,即数据矩阵X 的列向量线性相关。因此,必有一个列向量可由其余列向量线性表示。 同时还有另外一种情况,即解释变量之间虽然不存在严格的线性关系,但是却有近似的线性关系,即解释变量之间高度相关。 2.多重共线性产生的原因 多元线性回归模型产生多重共线性的原因很多,主要有: (1)经济变量的内在联系 这是产生多重共线性的根本原因。 (2)解释变量中含有滞后变量 (3)经济变量变化趋势的“共向性” 必须指出,多重共线性基本上是一种样本现象。因为人们在设定模型时,总是尽量避免将理论上具有严格线性关系的变量作为解释变量收集在一起,因此,实际问题中的多重共线性并不是解释变量之间存在理论上或实际上的线性关系造成的,而是由所收集的数据(解释变量观察值)之间存在近似的线性关系所致。 (二)多重共线性的影响 多重共线性会产生以下问题: (1)增大了OLS 估计量的方差 (2)难以区分每个解释变量的单独影响 (3)回归模型缺乏稳定性 (4)t 检验的可靠性降低 (三)多重共线性的判别 在应用多元回归模型中,人们总结了许多检验多重共线性的方法。 1.系数判定法 计量经济学实验报告 多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到30.0亿人次,同比增长13.6%,国内旅游收入2.3万亿元,同比增长19.1%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β1X 1 +β2X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元 统计实验报告 的方法来决定圆周率π。上个世纪40年代电子计算机的出现,特别是近年来高速电子计算机的出现,使得用数学方法在计算机上大量、快速地模拟这样的试验成为可能。 此外,模拟任何一个实际过程,Monte Carlo方法都需要用到大量的随机数,计算量很大、人工计算是不可能的,只能在计算机上实现。 实验目的 用统计科学方法求2,3的近似值并得以推广。 实验原理与统计模型 来源乌拉姆和·诺伊曼核试验模拟,几何概率 实验所用软件及版本 R version 2.14.1 主要容(要点) 、 (1)构造问题的概率模型 对随机性的问题,如中子碰撞、粒子扩散运动等,主要是描述和模拟运动,概率过程,建立概率模型或判别式。 对确定性的问题,如确定π值,计算定积分,则需将问题转化为随机性的问题,例如图2.2(a)计算连续函数g(x)在区间[a,b] 的 定积分,则是c(b-a)的有界区域产生若干随机焦,并计数满足不等式()j j x g y≤的点数,从而构成了问题的概率模型。 (2)从己知概率分布抽样 实验过程况录(含基本步骤、主要程序清单及异常情况记录等)一.求2 考虑 1 2 dx x x = ? 然后等概率地产生n个随机点(xi,yi),i=1,2,…,n,即xi是(1,2)上均匀分布的随机数,yi 是(0,1)上均匀分布的随机数。设n个点中有k个点落在下图阴影区域,即有k个点(xi,yi)满足yi*2*(xi)^0.5<1。则当∞ → n,有如下关系 P=k/n=阴影部分面积/1=2-1 因此2的估计值=k/n+1 下面编写的模拟程序(程序名:MC1.R)> MC1<-function(n){ + k<-0;x<- runif(n,1,2);y<-runif(n) + for (i in 1:n){ + if (2*x[i]^0.5*y[i]<1) + k<- k+1 + } + k/n+1 + } > MC1(100000) [1] 1.41463 3 二.求 多重共线性的解决之 法 第七章多重共线性 教学目的及要求: 1、重点理解多重共线性在经济现象中的表现及产生的原因和后果 2、掌握检验和处理多重共线性问题的方法 3、学会灵活运用Eviews软件解决多重共线性的实际问题。 第一节多重共线性的产生及后果 一、多重共线性的含义 1、含义 在多元线性回归模型经典假设中,其重要假定之一是回归模型的解释变量之间不存在线性关系,也就是说,解释变量X1,X2,……,X k中的任何一个都不能是其他解释变量的线性组合。如果违背这一假定,即线性回归模型中某一个解释变量与其他解释变量间存在线性关系,就称线性回归模型中存在多重共线性。多重共线性违背了解释变量间不相关的古典假设,将给普通最小二乘法带来严重后果。 2、类型 多重共线性包含完全多重共线性和不完全多重共线性两种类型。 (1)完全多重共线性 完全多重共线性是指线性回归模型中至少有一个解释变量可以被其他解释变量线性表示,存在严格的线性关系。 如对于多元线性回归模型 i ki k i i i X X X Y μββββ+++++= 22110 (7- 1) 存在不全为零的数k λλλ,,,21 ,使得下式成立: 0X X X 2211=+++ki k i i λλλ (7-2) 则可以说解释变量k X ,,X ,X 21 之间存在完全的线性相关关系,即存在完全多重共 线性。 从矩阵形式来看,就是0'=X X , 即1)(- 第六章 6.6 (1)判断多重共线性 做y 与x1,x2,x3,x4x5,x6的线性回归方程,得到 由表中的VIF 值可知x1,x2,x3,x4,x5的方差膨胀因子远大于10,这几个变量之间存在很高的线性相关性,说明回归方程存在多重共线性。 (2)逐步回归法 得到回归方程:215^ 353.0611.0637.06.874x x x y --+= 方程通过了三大检验。 其中,x1为农业,x2为工业,x5为社会消费总额,由方程表明农业每增加一亿元,财政收入减少0.611亿元;工业每增加一亿元,财政收入减少0.353亿元;社会消费总额每增加一亿元,财政收入增加0.637亿元。结合实际可看出该回归方程不合理。 由表中的VIF 值可知三个自变量的方差膨胀因子远大于10,说明逐步回归法得到的回归方程仍然存在多重共线性。 (3)VIF 后退法 由(1)判断得知原方程存在严重的多重共线性,要消除多重共线性利用VIF 后退法。 首先剔除VIF 值最大的自变量x2,得到 由表中的VIF 值可知除x6外其他自变量的方差膨胀因子仍然大于10 ,方程仍存在多重共线性。 再剔除VIF 值最大的自变量x5,得到 由表中的VIF 值可知除x6外其他自变量的方差膨胀因子仍然大于10,方程仍存在多重共线性。 再剔除VIF 值最大的自变量x1,得到 由表中的VIF 值可知剩余自变量的方差膨胀因子都小于10,说明方程的多重共线性已消除。 所以得到回归方程:643^ 004.0.031.0359.1332.2296 x x x y +++-= 方程通过了R 检验和F 检验,但是x6没有通过t 检验,说明不显著,所以剔除x6,得到 《多重共线性案例分析》实验报告 表2 由此可见,该模型,可决系数很高,F 检验值 173.3525,明显显著。但是当时,不仅、 系数的t 检验不显著,而且系数的符号与预期的相反,这表明很可能存在严重的多重共线性。 9954.02=R 9897.02 =R 05.0=α776 .2)610()(025.02=-=-t k n t α2X 6X 6X ②.计算各解释变量的相关系数,选择X2、X3、X4、X5、X6数据,点”view/correlations ”得相关系数矩阵 表3 由关系数矩阵可以看出:各解释变量相互之间的相关系数较高,证实确实存在严重多重共线性相。 4.消除多重共线性 ①采用逐步回归的办法,去检验和解决多重共线性问题。 分别作Y 对X2、X3、X4、X5、X6的一元回归 如下图所示 变量 X2 X3 X4 X5 X6 参数估计值 0.0842 9.0523 11.6673 34.3324 2014.146 t 统计量 8.6659 13.1598 5.1967 6.4675 8.7487 0.9037 0.9558 0.7715 0.8394 0.9054 表4 按的大小排序为:X3、X6、X2、X5、X4。 以X3为基础,顺次加入其他变量逐步回归。首先加入X6回归结果为: t=(2.9086) (0.46214) 2R 2 R 6 31784.285850632.7639.4109?X X Y t ++-=957152.02 =R 1995 1375.7 62900 464.0 61.5 115.70 5.97 1996 1638.4 63900 534.1 70.5 118.58 6.49 1997 2112.7 64400 599.8 145.7 122.64 6.60 1998 2391.2 69450 607.0 197.0 127.85 6.64 1999 2831.9 71900 614.8 249.5 135.17 6.74 2000 3175.5 74400 678.6 226.6 140.27 6.87 2001 3522.4 78400 708.3 212.7 169.80 7.01 2002 3878.4 87800 739.7 209.1 176.52 7.19 2003 3442.3 87000 684.9 200.0 180.98 7.30 表1:1994年—2003年中国游旅收入及相关数据 实验1:数据整理 一、实验目的 1)掌握Excel中基本的数据处理方法; 2)学会使用Excel进行统计分组,能以此方式独立完成相关作业 二、实验时间及地点 试验时间:2014年9月23日实验地点:计算机房 三、实验内容和操作步骤 (一)问题与数据 某百货公司连续40天的商品销售额如下(单位:万元): 41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42 36 37 37 49 39 42 32 36 35 根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。 (二)实验内容:使用FREQUENCY函数绘制频数分布表(图) (三)实验步骤: 1.在A1输入:某百货公司连续40天的商品销售额如下。选中A1:D1选 择合并单元格。 2.在单元区域A2:D11中输入原始数据。 3.并计算原始数据的最大值(在单元格B12中)与最小值(在单元格D12 中)。 4.根据Sturges经验公式计算经验组距(在单元格B13)和(经验数据D13 中)。 5.根据步骤3的计算结果,计算并确定各组上限、下限(在单元区域E2: F7). 步骤1~5如图所示: 6.绘制频数分布表框架,如图所示: 7.计算各组频数: 1)选定i7:i12作为存放计算结果的区域。 2)从“插入”菜单中选择“函数”项。 3)在弹出的“插入函数”对话框中选择“统计”函数FREQUENCY。 步骤(1)~(3)如图所示: 4)单击“插入函数”对话框中的“确定”按钮,弹出 “FREQUENCY”对话框。 5)确定FREQUENCY函数的两个参数的值。其中: Data-array:原始数据或其所在单元格区域(A2:D11) Bins-array:分组各组的上限值或其所在的单元格区域 (F2:F7). 步骤(4)~(5)如图所示: 6)按Shift+Ctrl+Enter组合键,如图所示 7)用公式:频数密度=频数/组距选定G7输入=i7:i12/4按 Shift+Ctrl+Enter组合键 频率=频数/总数 如图所示:第6章 多重共线性
多重共线性回归分析及其实验报告
多元统计学SPSS实验报告一
计量经济学Eviews多重共线性实验报告
计量经济学多元线性回归、多重共线性、异方差实验报告记录
使用统计学实验报告
第六章 多重共线性
计量经济学Eviews多重共线性实验报告
统计学实验报告
统计学实验报告1
第七章 多共线性及其处理
计量经济学多元线性回归、多重共线性、异方差实验报告概要
统计学实验报告
最新多重共线性的解决之法
多重共线性
多重共线性案例分析实验报告
统计学实验报告