完整word版,SPSS信效度难度区分度分析举例

SPSS信度分析
一、分半信度
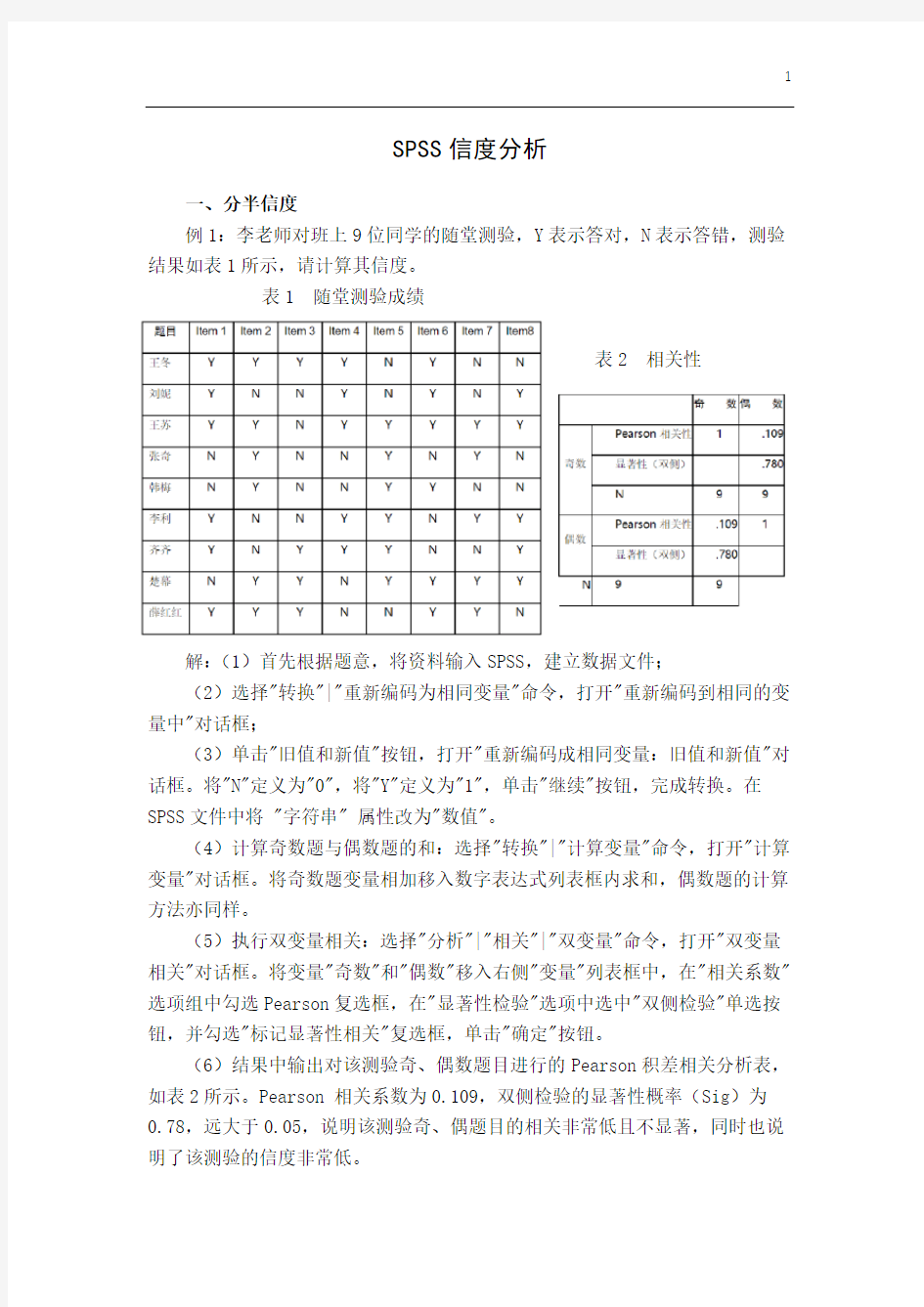
例1:李老师对班上9位同学的随堂测验,Y表示答对,N表示答错,测验结果如表1所示,请计算其信度。
表1 随堂测验成绩
表2 相关性
解:(1)首先根据题意,将资料输入SPSS,建立数据文件;
(2)选择"转换"|"重新编码为相同变量"命令,打开"重新编码到相同的变量中"对话框;
(3)单击"旧值和新值"按钮,打开"重新编码成相同变量:旧值和新值"对话框。将"N"定义为"0",将"Y"定义为"1",单击"继续"按钮,完成转换。在SPSS文件中将 "字符串" 属性改为"数值"。
(4)计算奇数题与偶数题的和:选择"转换"|"计算变量"命令,打开"计算变量"对话框。将奇数题变量相加移入数字表达式列表框内求和,偶数题的计算方法亦同样。
(5)执行双变量相关:选择"分析"|"相关"|"双变量"命令,打开"双变量相关"对话框。将变量"奇数"和"偶数"移入右侧"变量"列表框中,在"相关系数"选项组中勾选Pearson复选框,在"显著性检验"选项中选中"双侧检验"单选按钮,并勾选"标记显著性相关"复选框,单击"确定"按钮。
(6)结果中输出对该测验奇、偶数题目进行的Pearson积差相关分析表,如表2所示。Pearson 相关系数为0.109,双侧检验的显著性概率(Sig)为0.78,远大于0.05,说明该测验奇、偶题目的相关非常低且不显著,同时也说明了该测验的信度非常低。
分半信度也可直接使用"可靠性分析"命令来完成,简要步骤如下。
(1)建立数据文件。
(2)将资料转为数字(同上)。
(3)选择模型:选择"分析"|"度量"|"可靠性分析"命令,弹出"可靠性分析"对话框。将左边列表框中的题目依所需次序前后分半选入右边的"项目"列表框中,在左下角的"模型"下拉列表框中选取"半分"选项。
(4)选择统计量,单击"统计量"按钮,打开"统计量"对话框并完成相应的设置。最后单击"确定"按钮,输出统计结果。
二、同质性信度
(1)点击分析-度量-可靠性分析。
(2)将要检验的问卷或者维度放入变量框中。
(3)点击确定,生成结果。信度指标就是Cronbach's Alpha。
三、重测、复本信度
(1)打开或建立数据文件。
(2)选择"分析"︱"相关"︱"双变量相关"命令,打开"双变量相关"对话框,如下图所示。
(3)选择变量:选择要进行分析的变量并将其移入右侧的"变量"列表框中。当变量多于两个时,结果中会计算所有选入"变量"列表框中变量两两之间的相关系数。
(4)选择相关系数:"相关系数"选项组包含Pearson、Kendall的tau-b 和Spearman 3个复选框,研究中根据数据类型可以通过勾选对应的复选框来选择相关系数的计算方法。
(5)选择显著性检验类型:通过选中"显著性检验"选项组下相应的单选按钮,选择显著性检验使用"双侧检验"还是"单侧检验"。
(6)标记显著性相关:勾选"标记显著性相关"复选框,在统计结果中将用"*"号标记有显著相关的相关系数,系统默认选中。当P<0.05时,相关系数旁会标识"*",表明两变量在0.05水平上达到显著相关;当P<0.01时,相关系数旁会标识"**",表明两变量在0.01水平上达到显著相关。
(7)选项设置:单击"选项"按钮,打开"双变量
相关性:选项"对话框,对"统计量"和"缺失值"完成
相应的设置。
(8)单击"确定"按钮,执行操作,输出结果。
四、评分者信度(肯德尔和谐系数)
例2:某校举办校园歌手大赛,6人进入决赛,请5位评委老师为这6名选手评定等级。结果如下。如何衡量5位老师评定结果的一致性程度?
表1 5位老师为6名选手评定的等级
评分教师(k=5)
选手编号(n=6)
A1 A2 A3 A4 A5 A6
A 3 1 6 4 5 2
B 2 1 5 6 3 4
C 2 1 5 6 4 3
D 1 2 6 5 3 4
E 1 2 6 5 4 3
R
i
9 7 28 26 19 16
解:(1)数据录入。计算肯德尔和谐系数的数据编排与通常的不同:一个被评对象为一列数据(相当于变量),一个评分者为一行数据(相当于样品)。数据编排同表1.
(2)单击“分析|非参数检验|旧对话框|K个相关样本检验”,在对话框中,将A1—A6全部选定,单击肯德尔和谐系数,确认即可。
(3)在结果分析中,肯德尔和谐系数W=0.845,渐近显著性概率为
0.001,小于0.01,故而,相关非常显著。
(4)值得注意的是,如果数据是按照通常的编排输入的,即一位选手得到的等级为一行,一个评分者的评分为一列,那么可以使用“数据”菜单下的“转置”(transpose)功能,将原数据行列互换。
SPSS效度分析
一、结构效度
结构效度是测验对理论上的构想或特质的测量程度。结构效度所采用的方法是因子分析。有学者认为,效度分析最理想的方法是利用因子分析测量量表或者整个问卷的结构效度。因子分析的步骤如下:
(1)选择分析中的“降维”→“因子分析”;
(2)将所有的变量都选到因子分析变量中。
(3)描述选项卡,勾选,原始数据分析和KMO和Bartlett球形度检验。
(4)抽取选择主成分分析方法,其他默认即可。
(5)旋转选项卡,方法选择最大方差法。
(6)点击确定即可得出spss分析出的结果。KMO的值在0.9以上,表明非常适合做因子分析;0.8--0.9:很适合;0.7--0.8适合;0.6-0.7尚可;
0.5--0.6表示很差;0.45以下:应该放弃。
二、效标关联效度
确定效标关联效度最常用的方法是,计算测验分数与效标测量的相关。如以学生平时成绩为效标,计算问卷的效标效度,计算平时成绩和问卷得分的相关即可。
然后点击“分析——相关——双相关”,将“问卷”和“平时成绩”选中点箭头,然后点击确定。得到下表的结果
表中r是Pearson 相关性=0.997;p是显著性(双侧),该指等于
0.000,小于0.001,说明二者存在显著的正相关关系。
SPSS难度分析
一、难度计算公式
1.某题的难度=通过人数/总人数。
2.某题的难度=(高分组+低分组通过率)/2.
3.某题的难度=平均分/满分
4.选择题难度矫正,吉尔福特公式。CP=(KP-1)/(K-1)
二、SPSS操作步骤
例3:本试卷(满分100分)有两个部分组成:客观性与主观性试题,其中客观性试题共40分,占40%,主观性试题共60分,占60%。具体情况见下表。
注:q1是填空、q2是选择、q3是判断、q4是简答、q5是问答、q6论述。
解:(1)数据录入,将47份试卷按照各部分得分情况和他们的总成绩、平
时成绩输入到相应的表格中。
(2)基本描述性统计分析
主要包括参加考试的学生总数、缺考人数、每个部分的最高分、最低分、
极差、平均分、标准偏差(方差)等。
在试卷质量分析数据中,运行菜单:分析|描述统计|描述,把除平时成绩外
的所有变量加入到“变量”中,点击“选项”对话框,选中Mean、Minimum、
Maximum、Range、Std. deviation、Variance。再点击OK。得到如下结果。
(3)难度分析
对于选择题,先计算得出难度系数P,然后再根据公式cp=(kp-1)/(k-1)(k
为选项个数)算出矫正难度系数cp。试题难度系数与试题实际难易程度正好相
反,越大表示试题越容易,而越小则试题越难。一般认为,难度适中更能客观
地反映出学生的学习效果情况,多数试题应分布在0.3~0.7之间,选拔性测试
为0.5左右为宜,通常期末考试为目标参照性考试,可适当偏高,全卷平均难
度以0.7左右为宜,0.6~0.8为正常。
(4)区分度分析
对于客观题来说,使用等级相关分析,在此使用斯皮尔曼(Spearman)等级相关分析。对于主观题来说,样本数为47,大于30,可以看成非等间距测度的连续变量,在此采用皮尔逊(Pearson)相关分析对试题进行分析。
具体操作如下:Analyze→Correlate→Bivariate。在弹出对话框中选择各个客观题题号变量和总成绩进入Variables,然后在Correlation Coefficients 中单击Spearman,完成后即可得到客观题的区分度。主观题的区分度分析方法同上,只需选择主观题和总成绩进入,然后选择Pearson即可。得到每个部分的区分度,见下图:
SPSS区分度分析
一、区分度计算公式
1.鉴别指数法,区分度=高分组通过率-低分组通过率。
2.相关法,以某一项目分数与测验总分的相关,作为该题区分度的指标。
2.1点二列相关,一个二分变量(双峰分布),一个连续变量。选择题(答对得2分,答错0分)与总分。
2.2二列相关,一个连续变量(人为被分成二分变量),一个连续变量。论述题(满分10分,超过6分即合格)与总分。
2.3φ相关,两个变量均为二分变量。总分区分为高分组和低分组,项目得分为通过和未通过。
二、SPSS操作步骤
1.鉴别指数法
(1)数据录入与整理。将总分按照从高到低排列。
(2)分别计算出高分组通过率和低分组通过率。
(3)两者差值即为区分度。
2.相关法
(1)排序。先将所有人的总成绩由高到低(或者由低到高)进行排序,然后去取前27%和后27%的临界点上的学生成绩作为高低分组的临界点。
(2)转换。然后在spss菜单中选择转换——编码为不同变量,将总成绩选入右边的输入输出框,然后给输出变量命个名,写高低分组就可以,然后点击更改按钮。
(3)赋值。接着点击旧值和新值按钮,将从最低到后27%的临界值编码为新值1,将从前27%的临界值到最高编码为新值2,然后确定,从而形成一个新的变量“高低分组”。
(4)接着在菜单中选择分析——比较均值——独立样本T检验,将高低分组选入分组变量框,按1,2编码,然后将要求区分度的各项目得分选入检验变量框,然后确定就可以看到差异检验的结果了,sig<0.05,即是高低分组差异显著。
SPSS主成分分析操作步骤,详细的很啊^_^==
SPSS主成分分析操作步骤,详细的很啊^_^ SPSS在调用Factor Analyze过程进行分析时,SPSS会自动对原始数据进行标准化处理,所以在得到计算结果后指的变量都是指经过标准化处理后的变量,但SPSS不会直接给出标准化后的数据,如需要得到标准化数据,则需调用Descriptives过程进行计算。 图表 3 相关系数矩阵
图表 4 方差分解主成分提取分析表 主成分分析在SPSS中的操作应用(3) 图表 5 初始因子载荷矩阵
从图表3可知GDP与工业增加值,第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、地方财政收入这几个指标存在着极其显著的关系,与海关出口总额存在着显著关系。可见许多变量之间直接的相关性比较强,证明他们存在信息上的重叠。 主成分个数提取原则为主成分对应的特征值大于1的前m个主成分。注:特征值在某种程度上可以被看成是表示主成分影响力度大小的指标,如果特征值小于1,说明该主成分的解释力度还不如直接引入一个原变量的平均解释力度大,因此一般可以用特征值大于1作为纳入标准。通过图表4(方差分解主成分提取分析)可知,提取2个主成分,即m=2,从图表5(初始因子载荷矩阵)可知GDP、工业增加值、第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、海关出口总额、地方财政收入在第一主成分上有较高载荷,说明第一主成分基本反映了这些指标的信息;人均GDP和农业增加值指标在第二主成分上有较高载荷,说明第二主成分基本反映了人均GDP和农业增加值两个指标的信息。所以提取两个主成分是可以基本反映全部指标的信息,所以决定用两个新变量来代替原来的十个变量。但这两个新变量的表达还不能从输出窗口中直接得到,因为“Component Matrix”是指初始因子载荷矩阵,每一个载荷量表示主成分与对应变量的相关系数。用图表5(主成分载荷矩阵)中的数据除以主成分相对应的特征值开平方根便得到两个主成分中每个指标所对应的系数[2]。将初始因子载荷矩阵中的两列数据输入(可用复制粘贴的方法)到数据编辑窗口(为变量B1、B2),然后利用“TransformàCompute Variable”,在Compute Variable对话框中输入“A1=B1/SQR(7.22)” [注:第二主成分SQR后的括号中填1.235],即可得到特征向量A1(见图表6)。同理,可得到特征向量A2。将得到的特征向量与标准化后的数据相乘,然后就可以得出主成分表达式[注:因本例只是为了说明如何在SPSS进行主成分分析,故在此不对提取的主成分进行命名,有兴趣的读者可自行命名]: F 1=0.353ZX 1 +0.042ZX 2 -0.041ZX 3 +0.364ZX 4 +0.367ZX 5 +0.366ZX 6 +0.352ZX 7 +0.364ZX 8+0.298ZX 9 +0.355ZX 10
spss统计分析报告期末考精彩试题
《统计分析软件》试(题)卷 班级xxx班xxx 学号xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel 数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。
spss统计分析期末考试题
《统计分析软件》试(题)卷 班级 xxx班姓名 xxx 学号 xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: 描述统计量 性别N极小值极大值均值标准差 男数学477.0085.0082.2500 3.77492有效的 N (列表状态)4 女数学1667.0090.0078.50007.09930有效的 N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
SPSS操作方法:判别分析例题
为研究1991年中国城镇居民月平均收入状况,按标准化欧氏平方距离、离差平方和聚类方法将30个省、市、自治区.分为三种类型。试建立判别函数,判定广东、西藏分别属于哪个收入类型。判别指标及原始数据见表9-4。 1991年30个省、市、自治区城镇居民月平均收人数据表 单位:元/人 x1:人均生活费收入 x6:人均各种奖金、超额工资(国有+集体) x2:人均国有经济单位职工工资 x7:人均各种津贴(国有+集体) x3:人均来源于国有经济单位标准工资 x8:人均从工作单位得到的其他收入 x4:人均集体所有制工资收入 x9:个体劳动者收入 5
贝叶斯判别的SPSS操作方法: 1. 建立数据文件 2.单击Analyze→ Classify→ Discriminant,打开Discriminant Analysis 判别分析对话框如图1所示: 图1 Discriminant Analysis判别分析对话框 3.从对话框左侧的变量列表中选中进行判别分析的有关变量x1~x9进入Independents 框,作为判别分析的基础数据变量。 从对话框左侧的变量列表中选分组变量Group进入Grouping Variable 框,并点击Define Range...钮,在打开的Discriminant Analysis: Define Range对话框中,定义判别原始数据的类别数,由于原始数据分为3类,则在Minimum(最小值)处输入1,在Maximum(最大值)处输入3(见图2)。。 选择后点击Continue按钮返回Discriminant Analysis主对话框。 图2 Define Range对话框 4、选择分析方法 Enter independent together 所有变量全部参与判别分析(系统默 认)。本例选择此项。 Use stepwise method 采用逐步判别法自动筛选变量。
spss 期末题库
课程名称:《SPSS分析方法与应用》 课程号: 2007422 一、单项选择题(共112小题) 1、试题编号:1000110,答案:RetEncryption(D)。 SPSS的安装类型有() A. 典型安装 B.压缩安装 C.用户自定义安装 D.以上都是 2、试题编号:1000310,答案:RetEncryption(D)。 数据编辑窗口的主要功能有() A.定义SPSS数据的结构 B.录入编辑和管理待分析的数据 C.结果输出 和B 3、试题编号:1000410,答案:RetEncryption(A)。 ()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。 4、试题编号:1000510,答案:RetEncryption(D)。 ()是SPSS为用户提供的基本运行方式。 A.完全窗口菜单方式 B.程序运行方式 C.混合运行方式 D.以上都是 5、试题编号:1000810,答案:RetEncryption(D)。 ()是SPSS中有可用的基本数据类型 A.数值型 B.字符型 C.日期型 D.以上都是 6、试题编号:1000910,答案:RetEncryption(D)。 spss数据文件的扩展名是( ) A..htm B..xls C..dat D..sav 7、试题编号:1001010,答案:RetEncryption(B)。 数据编辑窗口中的一行称为一个() A.变量 B.个案 C.属性 D.元组 8、试题编号:1001110,答案:RetEncryption(C)。
变量的起名规则一般:变量名的字符个数不多于() A. 6 B. 7 C. 8 D. 9 9、试题编号:1001210,答案:RetEncryption(A)。 统计学依据数据的计量尺度将数据划分为三大类,它不包括() A. 定值型数据 B.定距型数据 C.定序型数据 D.定类型数据 10、试题编号:1001310,答案:RetEncryption(A)。 在横向合并数据文件时,两个数据文件都必须事先按关键变量值() A.升序排序 B.降序排序 C.不排序 D.可升可降 11、试题编号:1001810,答案:RetEncryption(A)。 SPSS算术表达式中,字符型()应该用引号引起来。 A 常量 B变量 C算术运算符 D函数 12、试题编号:1001910,答案:RetEncryption(A)。 复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。 B AND C OR D都不是 13、试题编号:1002010,答案:RetEncryption(A)。 数据选取的方法中,()是按符合条件的数据进行选取。 A 按指定条件选取 B 随即选取 C选取某一区域内样本 D过滤变量选取 14、试题编号:1002110,答案:RetEncryption(B)。 通过()可以达到将数据编辑窗口中的技术数据还原为原始数据的目的。 A 数据转置 B 加权处理 C 数据才分 D以上都是 15、试题编号:1002210,答案:RetEncryption(A)。 SPSS的()就是将数据编辑窗口中数据的行列互换 A 数据转置 B 加权处理 C 数据才分 D以上不都是 16、试题编号:1002310,答案:RetEncryption(B)。 SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。 A、哈佛大学 B、斯坦福大学 C、波士顿大学 D、剑桥大学 17、试题编号:1002710,答案:RetEncryption(D)。 SPSS中进行参数检验应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 18、试题编号:1002810,答案:RetEncryption(A)。 SPSS中进行输出结果的保存应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 19、试题编号:1002910,答案:RetEncryption(C)。 SPSS中进行数据的排序应选择()主窗口菜单。 A、视图 B、编辑 C、数据 D、分析
spss期末大数据分析报告
SPSS在教育研究中的应用某大学学生对本校的满意度调查 学院:教育学院 专业:课程与教学论 学号:201411000156 姓名:李平 2014年12月13日
目录 一、研究问题的提出 (3) 二、研究内容与方法 (3) (一) 研究内容 (3) (二) 研究方法 (3) 三、调查对象及人数 (4) 四、问卷分析 (5) (一)回收情况 (5) (二)信度分析 (5) 五、数据统计与分析 (6) (一)数据输入 (6) (二)数据分析 (7) 1.描述统计 (7) (1)多选题描述统计 (7) (2)单选题描述统计 (9) 2.推断统计 (12) (1)独立样本T检验 (12) (2)单一样本T检验 (15) (3)单因素方差分析 (17) (4) X2检验 (21) 3.相关分析 (22) (1)变量间相关分析 (22) (2)维度间相关分析 (23) 六、结论 (27) 七、附录 (28)
一、研究问题的提出 学生的学校生活和成长密切相关。我们通过对他们的大学生活满意度的调查结果向有关部门提出建议,并希望能引起学校对这一系列问题的关注,最终希望大学生对其大学的满意度有所提升,大学生是一个庞大的群体,特别是近几年,随着高校的扩招,我国越来越多人能够上大学。上大学是很多人的梦想,他们都憧憬着大学校园的生活,然而当他们进了大学后才发现大学生活并非所想的美好,取而代之的却是对校园生活的不满,大学生是十分宝贵的人才资源,他们对校园生活的体验和感受,与他们的更好的学习。 二、研究内容与方法 (一)研究内容 了解学生对于学校的师资水平、环境、日常管理等各方面的满意度。 (二)研究方法 1.问卷编制 本研究采用自编问卷,问卷共由两部分组成:基本情况部分包括被调查者的性别、年级等,问卷主体部分包括师资水平、学校环境、日常管理三大维度,细分为12个三级指标(见表2-1),问卷采用五点制计分法,即“非常满意”、“满意”、“一般”、“不满意”、“非常不满意”,分别赋值5分、4分、3分、2分、1分。 表2-1 某大学学生对本校的满意度测评指标体系 一 级指标 二级指标(潜在变量)三级指标(观测变量) 对自己师资水平对教师教学方法、对教师工作态 度、对教师人品修养、对师资配备 学校的意学校环境对学习环境、对就餐环境、对居住 环境、对校园绿化环境 满度指数日常管理对专业课时安排、对收费标准、对 奖、助学金制度、对学校治安
SPSS期末考试整理
●一。变量的赋值 1.乘方(**),例如二的三次方:2**3 2.不同规则的赋值:转换→计算变量(如果),每一个规则的赋值都要重新进行此步骤(但注意每一遍的变量名都不变,并且他都会问你要不要替换成新的变量,你选是就行了) 3.不同规则的赋值:(1)转换→重新编码为不同变量:输入变量,输出变量,要点击“变化量”才可保存输出变量→新值和旧值:值(直接选取取值)、范围(最大到最小的范围,包含端点值),点击“添加”成功保存新值和旧值→所有不同取值规则都完成后点击继续、确定,则在变量视图多出一个新变量(2)若不想包含端点值,可以采取小数的方式变换,eg. 899.9(小数位比该变量属性的小数位多一位就行了) (3)这种要先把BMI按照男女分开,然后再分组的,可以在对话框中点击“如果”选项进行设置,并且要分别对男女进行上述操作(一共做两遍)。 二。离散化 1可视离散化:转换→可视分箱,分割点:所以想生成几组,就定义几个分割点;填写第一个分割点的时候就必须填写最小值;一定要选中上端点排除。 三。排序 1.转换→自动重新编码:不分组,从头到尾排序 2.转换→个案排秩(1)多层次数据:基于A变量对B变量进行排序。(例如,基于职称对收入进行排序,就是不同职称各自组内排工资的高低)(2)设置秩1;绑定值 四。时间序列:转换→变动值 五。查找与计数:转换→对个案内的值计数(查找“基本工资800-900女职工”,生成新变量,满足这个条件的标为1,不符合这个标准的标为0,男职工标为缺失。范围:包含上限下限) ●六。数据→个案排序:把变量顺序完全按照你想要的标准排序,所有的变量顺序都会改变 七。拆分文件:要分男女进行数据统计:数据→拆分文件→比较组/按组输出,分组依据。不分男女进行数据统计:数据→拆分文件→分析所有个案 八。选择个案(例如只选择三年级的变量进行分析):数据→选择个案→如果条件满足:如果;随机个案样本;基于时间或个案范围;使用过滤变量(例如要把身高为缺失值和值为0的剔除)→输出:过滤(不符合条件的数据会画上“/”,原始数据并未删除);将选定个案复制到新数据集(形成一个新的SPSS数据文件,原始数据并未删除);删除未选定的个案(删除原始数据,不建议使用)→之后在分析的时候就只会分析三年级的变量。不想只分析三年及,记得重新做这一步。 九。加权个案:数据→加权个案(例。100分的有5人)。不想加权了,记得重新做这一步。 十。分类汇总(1)例如算不同年级的人的身高的均值、方差…(只能计算函数)(2)数据→汇总,分界变量(分类标准变量),变量摘要(计算变量),函数:选择计算变量函数,变量名称与标签:定义新生成变量的名称与标签 ●十一。长宽数据的转换 1.长数据变宽数据:索引变量消失变成score的尾缀 (1)数据→重组(重构)→个案重组为变量,标识变量,索引变量,电脑会自动帮你选出是xx xx要重构(不同疗程值不同的变量)。选完上述这些之后就一直点下一步&完成&立即重构&确定即可 (2)注意:当有多个变量需要重构时要自己决定“新变量组的顺序”。(A1A2B1B2;A1B1A2B2) 2.宽数据变长数据:score的尾缀消失变成索引变量 (1)数据→重组(重构)→变量重组为个案,个案组标识:使用选定变量,固定变量(手动选择,电脑不会自动帮你选出了),要转置的变量即值不固定的要重构的变量(手动选择,电脑不会自动帮你选出了)。选完上述这些之后就一直点击下一步&完成&立即重构数据&确定就行了 (2)当有多个变量需要重构时,这块的操作要特别注意:○1首先在“变量组数目”中选择“多个”○2然后在“选择变量”里要对于不同的“目标变量”分别定义“要转置的变量”(在本题中,即对于kidid目标变量定义一遍要转置的变量;对于age目标变量在定义一遍要转置的变量。其中,这两个要转置的变量必须是完全不同的)。但只需要定义一次“个案组标识”&“固定变量”(固定变量是相对于kidid & age都固定的那些变量;而不是说在对kidid进行转置的时候,age就是固定变量了;因此,固定变量只用定义一次且固定变量可以为空)。并且,你要特别注意,“个案组标识”里选择的变量& n个“要转置的变量”里选择的变量&“固定变量”里选择的变量都必须是完全不相同的。
SPSS操作方法:判别分析例题
实验指导之二 判别分析的SPSS软件的基本操作 [实验例题]为研究1991年中国城镇居民月平均收入状况,按标准化欧氏平方距离、离差平方和聚类方法将30个省、市、自治区.分为三种类型。试建立判别函数,判定广东、西藏分别属于哪个收入类型。判别指标及原始数据见表9-4。 1991年30个省、市、自治区城镇居民月平均收人数据表 单位:元/人 x1:人均生活费收入 x6:人均各种奖金、超额工资(国有+集体) x2:人均国有经济单位职工工资 x7:人均各种津贴(国有+集体) x3:人均来源于国有经济单位标准工资 x8:人均从工作单位得到的其他收入 x4:人均集体所有制工资收入 x9:个体劳动者收入 x5:人均集体所有制职工标准工资
贝叶斯判别的SPSS操作方法: 1. 建立数据文件 2.单击Analyze→Classify→Discriminant,打开Discriminant Analysis判别分析对话框如图1所示: 图1 Discriminant Analysis判别分析对话框 3.从对话框左侧的变量列表中选中进行判别分析的有关变量x1~x9进入Independents 框,作为判别分析的基础数据变量。 从对话框左侧的变量列表中选分组变量Group进入Grouping Variable 框,并点击Define Range...钮,在打开的Discriminant Analysis: Define Range 对话框中,定义判别原始数据的类别数,由于原始数据分为3类,则在Minimum(最小值)处输入1,在Maximum(最大值)处输入3(见图2)。。 选择后点击Continue按钮返回Discriminant Analysis主对话框。 图2 Define Range对话框 4、选择分析方法
spss统计分析期末考试题
《统计分析软件》试(题)卷 班级xxx班姓名xxx 学号xxx 题号一二三四五六总成绩成绩 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
SPSS调查报告 - 期末作业
---------------------------------------------装--------------------------------- --------- 订 -----------------------------------------线---------------------------------------- 班级 姓名 学号 - 广 东 财 经 大 学 答 题 纸(格式二) 课程 数据处理技术与SPSS 20 15 -20 16 学年第 1 学期 成绩 评阅人 评语: ========================================== (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课”现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面,帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷,回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。
多元统计分析--判别分析SPSS实验报告
实验课程名称: __多元统计分析--判别分析___
准则判别归类,则可写成: ?? ? ??=>∈<∈) ,(),( ,),(),(,),(),(,21212211G X D G X D G X D G X D G X G X D G X D G X 当待判当当 题目:表11.5的数据包含三种鸢尾的X2=萼片宽度与X4=花瓣的宽度的观测值。对每种鸢尾有n1=n2=n3=50个观测值。 部分数据:
第二部分:实验过程记录(可加页)(包括实验原始数据记录,实验现象记录,实验过程发现的问题等) 散点图:图形→旧对话框→散点图,打开简单散点图子对话框;将想X2选入X轴变量,X4选入Y轴变量,将总体选入设置标记框中,点击确定。 判别分析: 步骤: 1、选择分析→分类→判别,打开判别分析子对话框。 2、选择变量“总体”,单击→,将其加入到分组变量栏中。 3、打开定义范围子对话框,最小值输入1,最大值输入3。 4、将变量“X2萼片宽度”、“X4花瓣的宽度”选入自变量栏中。选择“一起输入自 变量”的方法。 5、打开统计变量子对话框,选择均值、单变量ANOVA、Box’M、未标准化、组内协 方差、分组协方差及总体协方差,单击继续。 6、打开分类子对话框,选择不考虑该个案时的分类,其余为默认值。 7、打开保存,选择所有的变量。
相关系数矩阵a 总体萼片宽度X2 花瓣宽度X4 合计萼片宽度X2 .190 -.122 花瓣宽度X4 -.122 .581 对数行列式 总体秩对数行列式 1 2 -6.496 2 2 -6.141 3 2 -5.189 汇聚的组内 2 -5.583 检验结果 箱的M 52.832 F 近似。8.632 df1 6 df2 538562.769 Sig. .000 Wilks 的Lambda 函数检 验Wilks 的Lambda 卡方df Sig. 1 到 2 .038 477.868 4 .000 2 .809 31.075 1 .000 典型判别式函数系数 函数 1 2 萼片宽度X2 -1.987 2.680 花瓣宽度X4 5.477 .817 (常量) -.494 -9.174 非标准化系数
SPSS期末大作业-完整版
第1题:基本统计分析1 分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。 1、基本思路: (1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。分组后进行频数分析并绘制带正态曲线的直方图。 (2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。 操作步骤: (1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。 存取款金额1 频率百分比有效百分比累积百分比 有效1.00 82 34.6 34.6 34.6 2.00 76 32.1 32.1 66.7 3.00 10 4.2 4.2 70.9 4.00 22 9.3 9.3 80.2 5.00 47 19.8 19.8 100.0 合计237 100.0 100.0 (2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,确定。
(3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。 统计量 存(取)款金额 20岁以下 N 有效 1 缺失 0 百分位数 25 50.00 50 50.00 75 50.00 20~35岁 N 有效 131 缺失 0 百分位数 25 500.00 50 1000.00 75 5000.00 35~50岁 N 有效 73 缺失 0 百分位数 25 500.00 50 1000.00 75 4500.00 50岁以上 N 有效 32 缺失 0 百分位数 25 525.00 50 1000.00 75 2000.00 结果及结果描述: 频数分布表表明,有一半以上的人的一次存取款金额少于2000元,且有34.6%的人的存取款金额少于500元,19.8%的人的存取款金额多于5000元,下图为相应的带正态曲线的直方图。
spss进行判别分析步骤
spss进行判别分析步骤1.Discriminant Analysis判别分析主对话框 图1-1 Discriminant Analysis 主对话框
(1)选择分类变量及其范围 在主对话框中左面的矩形框中选择表明已知的观测量所属类别的变量(一定是离散变量), 按上面的一个向右的箭头按钮,使该变量名移到右面的Grouping Variable 框中。 此时矩形框下面的Define Range 按钮加亮,按该按钮屏幕显示一个小对话框如图1-2 所示,供指定该分类变量的数值范围。 图1-2 Define Range 对话框 在Minimum 框中输入该分类变量的最小值在Maximum 框中输入该分类变量的最大值。按Continue 按钮返回主对话框。 (2)指定判别分析的自变量 图1-3 展开Selection Variable 对话框的主对话框 在主对话框的左面的变量表中选择表明观测量特征的变量,按下面箭头按钮。
把选中的变量移到Independents 矩形框中,作为参与判别分析的变量。(3)选择观测量 图1-4 Set Value 子对话框 如果希望使用一部分观测量进行判别函数的推导而且有一个变量的某个值可以作为这些观测量的标识, 则用Select 功能进行选择,操作方法是单击Select 按钮展开Selection Variable。选择框如图1-3 所示。 并从变量列表框中选择变量移入该框中再单击Selection Variable 选择框右侧的Value按钮, 展开Set Value(子对话框)对话框,如图1-4 所示,键入标识参与分析的观测量所具有的该变量值, 一般均使用数据文件中的所有合法观测量此步骤可以省略。 (4)选择分析方法
spss统计软件期末课程考试题
《SPSS统计软件》课程作业 要求:数据计算题要求注明选用的统计分析模块和输出结果;并解释结果的意义。完成后将作业电子稿发送至 1. 某单位对100名女生测定血清总蛋白含量,数据如下: 计算样本均值、中位数、方差、标准差、最大值、最小值、极差、偏度和峰度,并给出均值的置信水平为95%的置信区间。 解: 描述 统计量标准误 血清总蛋白含量均值.39389 均值的 95% 置信区间下限 上限
5% 修整均值 中值 方差 标准差 极小值 极大值 范围 四分位距 偏度.054.241 峰度.037.478 样本均值为:;中位数为:;方差为:;标准差为:;最大值为:;最小值为:;极差为:;偏度为:;峰度为:;均值的置信水平为95%的置信区间为:【,】。 2. 绘出习题1所给数据的直方图、盒形图和QQ图,并判断该数据是否服从正态分布。解:
正态性检验 Kolmogorov-Smirnov a Shapiro-Wilk 统计量 df Sig. 统计量 df Sig. 血清总蛋白含量 .073 100 .200* .990 100 .671 a. Lilliefors 显著水平修正 *. 这是真实显著水平的下限。 表中显示了正态性检验结果,包括统计量、自由度及显著性水平,以K-S 方法的自由度sig.=,明显大于,故应接受原假设,认为数据服从正态分布。 3. 正常男子血小板计数均值为9 22510/L , 今测得20名男性油漆工作者的血小板计数值(单位:9 10/L )如下: 220 188 162 230 145 160 238 188 247 113
SPSS数据分析报告
SPSS期末报告 关于员工受教育程度对其工资水平的影响 统计分析报告 课程名称:SPSS统计分析方法 姓名:汤重阳 学号:1402030108 所在专业:人力资源管理 所在班级:三班
目录 一、数据样本描述 (1) 二、要解决的问题描述 (1) 1 数据管理与软件入门部分 (1) 1.1 分类汇总 (1) 1.2 个案排秩 (1) 1.3 连续变量变分组变量 (1) 2 统计描述与统计图表部分 (1) 2.1 频数分析 (1) 2.2 描述统计分析 (1) 3 假设检验方法部分 (1) 3.1 分布类型检验 (2) 3.1.1 正态分布 (2) 3.1.2 二项分布 (2) 3.1.3 游程检验 (2) 3.2 单因素方差分析 (2) 3.3 卡方检验 (2) 3.4 相关与线性回归的分析方法 (2) 3.4.1 相关分析(双变量相关分析&偏相关分析) (2) 3.4.2 线性回归模型 (2) 4 高级阶段方法部分 (2) 三、具体步骤描述 (3) 1 数据管理与软件入门部分 (3) 1.1 分类汇总 (3) 1.2 个案排秩 (4) 1.3 连续变量变分组变量 (4) 2 统计描述与统计图表部分 (5) 2.1 频数分析 (5) 2.2 描述统计分析 (7) 3 假设检验方法部分 (8) 3.1 分布类型检验 (8) 3.1.1 正态分布 (8) 3.1.2 二项分布 (10) 3.1.3 游程检验 (10) 3.2 单因素方差分析 (12) 3.3 卡方检验 (13) 3.4 相关与线性回归的分析方法 (14) 3.4.1 相关分析 (14) 3.4.2 线性回归模型 (15) 4 高级阶段方法部分 (17) 4.1 信度 (18) 4.2 效度 (18)
SPSS期末数据分析
1.为研究某合作游戏对幼儿合作意愿的影响,将18名幼儿随机分到甲、乙、丙3个组,每组6人,分别参加不同的合作游戏,12周后测量他们的合作意愿,数据见表,问不同合作游戏是否对幼儿的合作意愿产生显著影响? 单因素分析单因素方差分析:因变量—合作意愿得分;自变量—不同合作游戏(3种不同的水平) 显著性水平为0.541,大于0.05,说明这三组数据总体方差相等,适合方差齐性检验 从上表可以看出组间离差平方和为2.528,组内离差平方和为4.035,组间方差检验F=4.698,对应的显著性水平0.026,小于显著性水平0.05,说明3组中至少有一组与另外一组存在显著性差异。
由上表可以看出甲组与乙组的显著性为0.184 大于0.05,说明这两组的合作意愿得分没有显著差异,,但是甲组和乙组的相伴概率为0.008,说明这两组的合作意愿得分有显著性差异。
2.现有10名男生进行观察能力的训练,训练前后各进行一次测验,结果如下表所示。 解答:两配对样本T检验 从上表可以看出样本有10个,训练前10个男生的观察能力的样本均值是71,标准差是10.477,训练后观察能力的均值是79.50,标准差是9.823 由上表可以得出训练前后的相伴概率为0.028小于显著性水平0.05,说明训练前后能力的相关性较高 由上表可以得出t统计量为-3.341,相伴概率为0.009,小于0.05,说明训练能够是10个男生的观察能力有显著性的变化 3.某教师为考察复习方法对学生记忆单词效果的影响,将20名学生随机分成4组,每组5人采用一种复习方法,学生学完一定数量单词之后,在规定时间内进行复习,然后进行测试。结果见表。问各种方法的效果是否有差异?并将各种复习方法按效果好坏排序
统计分析与SPSS应用_期末作业
统计分析与SPSS的应用 摘要:为对统计分析与spss应用分析所学知识进行巩固和检验,特运用所学知识进行简单的统计分析应用,下文以某校学生学期成绩进行模拟分析。 一:原始数据:10级市场营销2班成绩 分析一:综测成绩四分位数 上表表明:综测成绩的最小值为68.61分,最大值为89.15分。其中25%的学生综测成绩为74.4100分,50%的学生综测成绩为80.3740分,75%的学生综测成绩为85.2200分。四分位数差从侧面证实了学生综测成绩呈一定左偏分布。
分析二:综测成绩直方图 上图表明:该班学生的综测成绩均分为80.07分,标准差为5.62。从图中可以看出,综测成绩呈左偏性分布,在85分左右的学生人数最多,70分左右的学生人数最少。 分析三:综测成绩的基本统计量分析 上表表明:综测成绩的极差为20.55分,意味着数据相对较分散。另外,综测成绩的最小值和最大值分别为68.61分和89.15分,平均分为80.0734分,标准差为5.61963。从偏度系数可以看出,系数小于0,偏度标准误差为0.421,因而该班综测成绩呈左偏分布,。从峰度系数可以看出,峰度值小于0,峰度标准误差为0.821,因而数据的分布比标准正态分布更加平缓,称
为平峰分布。 分析四:各科成绩的统计量分析比较 各科成绩统计量结果分析表 由上表可知:宏观经济学的全距最大,而生产与运作管理的全距最小,表明宏观经济学的成绩离散程度最高,而生产与运作管理的成绩离散程度最低;同时,对于标准差而言,也是宏观经济学的标准差最大而生产与运作管理的标准差最小。各科成绩平均分最高的为体育成绩,平均分最低的为英语成绩。各科成绩中只有人力资源管理的成绩是呈右偏分布,其他各科成绩均呈左偏分布。另外,各科成绩中,只有宏观经济学的成绩呈尖峰分布,其他各科呈平峰分布。
spss统计分析方法应用期末作业
1.作业1(基本统计+参数检验+方差分析1) 利用城际出行行为数据,从中随机选取90%的样本,实现以下分析目标: (1)分析出行时间的分布,需做直方图。 (2)分析不同性别的出行方式是否一致。 (3)检验老年人(≥60)与其他人的出行时间是否有显著差异。 (4)检验是否老年人和出行目的两因素对其它时间的影响(考虑交互作用)。 1.1 分析出行时间的分布,需做直方图 1.1.1 解题思路 首先,根据题目要求在城际出行行为数据中随机选择90%的样本;由于出行时间分布数据是定距变量,且出行时间数据数量较多,不宜使用频数进行分析。因此在分析之前先对出行时间进行分组,再进行频数分布。根据公式(1- (1-1)中n为数据个数,对结果四舍五入取整后为理论分组数目。 原样本数为235,随机选择之后剩余样本是n为213个,根据公式(1-1)计算得到分组数目为9。选中的数据中出行时间的最大值为150,出行时间的最 1.1.2操作步骤 数据选择:【数据→选择个案】,选择【随机个案样本】→【样本】→在【大约】中填入“90%”→选择【删除未选定的个案】,点击确认。剩下的即为随机选择之后的数据。 数据分组:【转换】→【重新编码为不同变量】→将“出行时间”加入到有边框中,输出变量名称改为“城市出行时间分组”,点击【更改】,在点击【旧值和新值】,按照60-70、70-80、80-90、90-100、100-110、110-120、120-130、
130-140、140-150,分别对应1,2,3,4,5,6,7,8,9。点击【完成】。 频数分析:【分析】→【描述统计】→【频率】,将“城市出行时间分组”加入到【变量】中。点击【图表】→【直方图】→选中【在直方图上显示正态曲线】→【确定】。 1.1.3输出结果与分析 总计213 100.0 100.0 图1-1城市出行时间分布直方图 从表1-1中可以看出,出行时间分布中,出行时间在60-70分钟的比较少,占比为4.7%,出行时间在120-130分钟、130-140分钟和140-150分钟的都比较少,三组总和占比仅为6.1%。出行时间在70-120分钟之间的人数最多,