Sqlserver2008数据库复制及问题解决
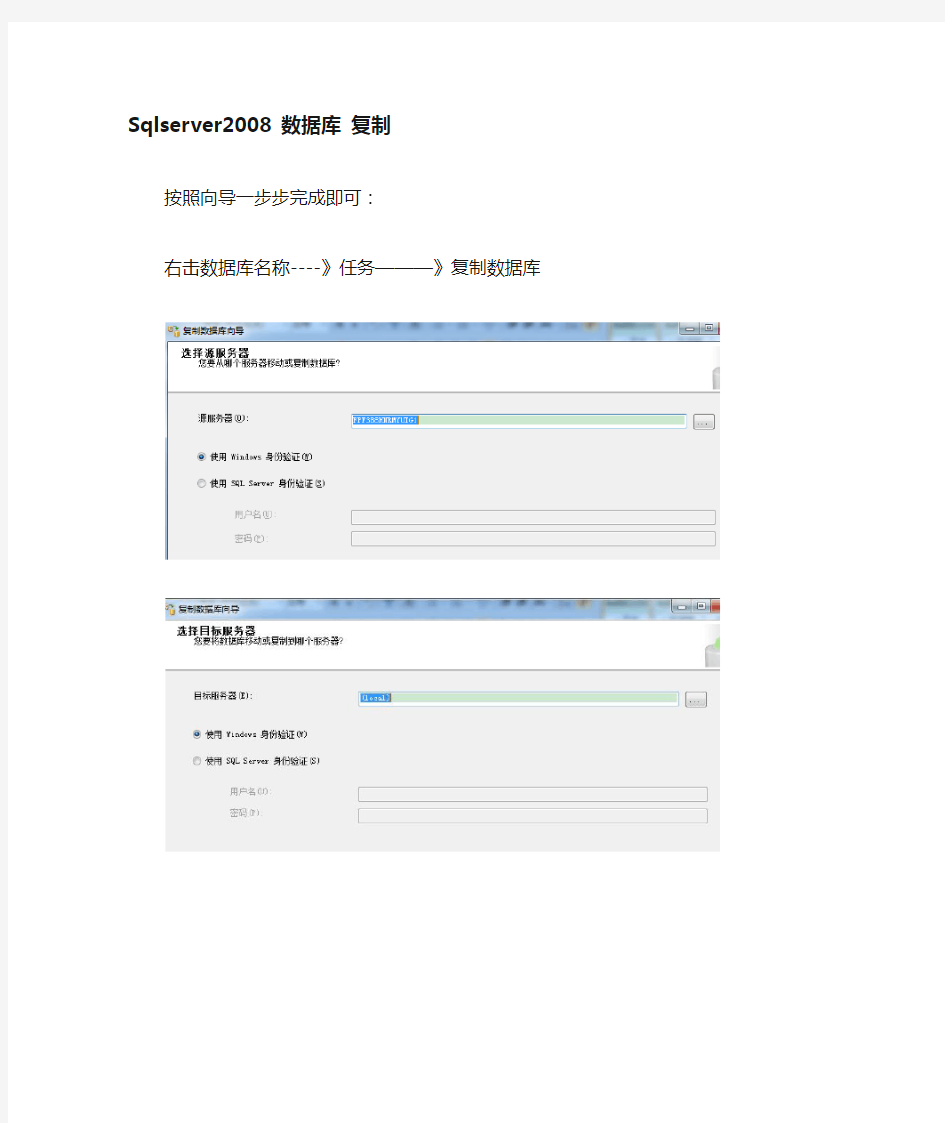
Sqlserver2008 数据库复制
按照向导一步步完成即可:
右击数据库名称----》任务———》复制数据库
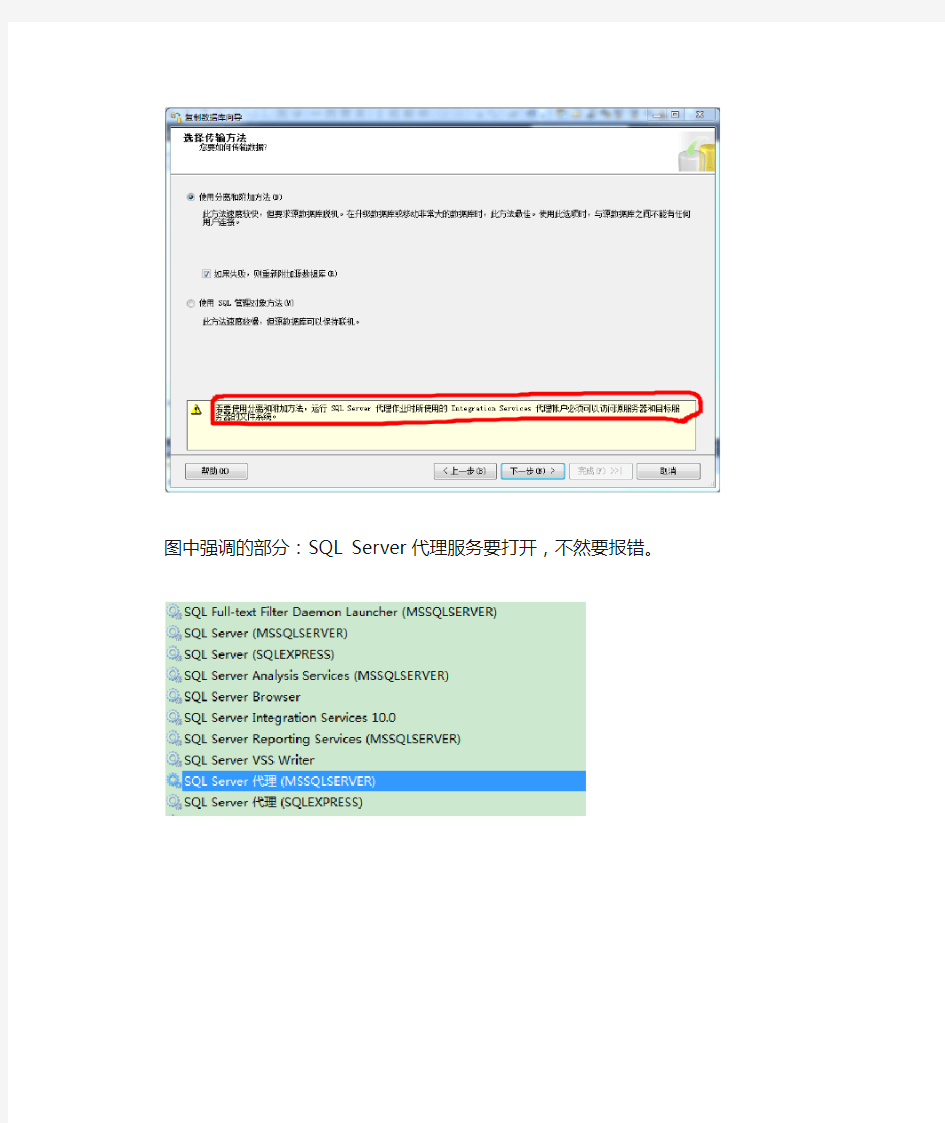
图中强调的部分:SQL Server 代理服务要打开,不然要报错。
SQL SERVER 的数据库复制
SQL SERVER 的数据库复制数据库的复制是分布式数据库应用程序中常用的一种数据拷贝技术,它将一个数据库中的数据拷贝到通过局域网(LAN)、广域网(WAN)或Internet网络连接的不同站点或同一个服务器中的不同数据库中,并能够自动保持这些数据的同步,使各个拷贝具有相同的数据。 一、SQL SERVER复制技术 (一)、复制结构 SQL SERVR 数据复制基于“出版—订阅”模型,它由出版者、分发者和订阅者三种服务器构成。出版服务器标识其数据库中的哪些数据用于复制,并检测这些数据的变化和维护该站点中的所有出版信息。 分发服务器中建立一个或多个分发数据库,用来保存出版服务器的出版物,并向订阅者传递它们所订阅的复制数据。 订阅服务器用于存储复制数据和接收对复制数据的更改,SQL SERVE 7.0还允许修改订阅服务器所接收到的出版物。 出版服务器所出版数据的最小单位为条目,出版条目可以是数据库中的表或存储过程。SQL SERVER允许对所出版表添加纵向或横向过滤器,从而使出版条目中只包含表中的某些列或其中的某些数据行,一组出版条目的集合构成一个出版物。 订阅服务器对出版物的订阅方式有推式订阅和拉式订阅两种,SQL SERVER中的每个出版物均支持推式订阅和拉式订阅这两种订阅方式。所谓推式订阅是指当出版物内容被修改时,由出版服务器通知订阅服务器,而不需要订阅服务器进行查询。推式订阅的优点是订阅服务器能够及时了解出版数据的改变情况,但它相应加重了出版服务器的负载。所以,推式订阅适合于需要近乎实时要求的数据复制。 拉式订阅是指由订阅服务器定期轮询出版服务器中出版物的内容是否改变,之后决定是否需要再次进行复制。拉式订阅能够减轻出版服务器的负担,所以常用于拥有大量订阅者的数据复制领域。此外,拉订阅也适合于移动用户,因为移动用户与出版服务器间没有永久固定的通信连接,他们采用订阅方式,只是在需要时才查询出版物内容的变化情况。 (二)复制代理 SQL Server 复制部件采用模块化设计,各种复制操作通过不同的复制代理实现。SQL Server 中的复制代理包括: 快照代理:快照代理运行在SQL Server 代理服务环境下。其功能是:为复制准备表结构、初始化出版表和存储过程的数据文件、将出版物快照存储到分发服务器的分发数据库中、并记录分发数据库的同步状态信息。每个出版物在分发服务器上均运行着自己的快照代理,并通过快照代理与出版服务器连接。 日志阅读代理:将用于复制的事务从出版服务器的事务日志中拷贝到分发数据库。每一个使用事务复制出版的数据库在分发服务器上均运行着自己的日志阅读代理,并通过该代理与出版服务器连接: 分发代理:将保存在分发数据库中的事务或出版物快照传递到订阅者。分发代理运行在SQL Server 代理服务环境下,可以直接使用SQL 企业管理进行管理。对于快照复制和事务复制,如果在配置推订阅时采用立即同步(所谓同步是指维护出版服务器上
mysql数据库复制
mysql数据库复制技巧集锦 最近在学习关于mysql的数据库复制方面的东东,搜集了一些资料,整理如下: 1:mysql手动复制数据库技巧 2:MYSQL 复制范例详解 3:MYSQL数据同步备份复制电脑网络 4:MySql数据库同步复制;mysql数据复制方案 5:MySQL异步复制备忘 6:mysql的root口令忘记了怎么办? 7:【翻译】MYSQL数据库复制 mysql数据库复制技巧集锦 1:mysql手动复制数据库技巧 引用源博文网址:https://www.360docs.net/doc/303696999.html,/blog/ccid/do_showone/tid_49707.html 我工作的环境中,有一个开发的MYSQL数据库,一个处于生产环境的MYSQL数据库。我不定期的从生产环境复制数据到我哦大开发环境。以前,我都是导出到脚本,然后再导入。其实,利用?mysqldump‘命令以及管道操作符,还有?mysql‘可以一步完成。 命令是: mysqldump wap --opt | mysql wap -h 221.218.9.41 我下面对这个命令的几个部分说明一下。mysqldump wap --opt,是把名为wap的这个数据库导出到标准输出。并且使用--opt选项。--opt 等效于--add-drop-table, --add-locks, --create-options, --quick, --extended-insert, --lock-tables, --set-charset, 和--disable-keys。这在完全导出然后完全导入数据的时候,非常有用。在这里,我没有指定登陆帐号和密码,因为我的配置文件https://www.360docs.net/doc/303696999.html,f已经指定了。 然后是一个管道操作符。它的作用是把第二个的输出转为第二个命令的输出。在这里,我没有指定登陆帐号和密码,因为我的配置文件https://www.360docs.net/doc/303696999.html,f已经指定了。 第三个命令,则是我们常用的mysql命令行客户端,-h选项指定了目标机器。 希望我写的这个小技巧,能够对你有用。不过,你前晚得小心了——别弄反了导入和导出的方向。
数据库同步更新
数据库同步更新 一、两类方法实现数据库实时更新 1、简单表更新可通过创建触发器实现时时更新,如果数据量大的话,不建议此类。x 2、数据量大的话,可通过数据库复制技术实现。 二,方法概述: 复制是将数据或数据库对象从一个数据库复制和分发到另外一个数据库,并进行数据同步,从而使源数据库和目标数据库保持一致。使用复制,可以在局域网和广域网、拨号连接、无线连接和 Internet 上将数据分发到不同位置以及分发给远程或移动用户。 一组SQL SERVER2005复制有发布服务器、分发服务器、订阅服务器(图1 复制服务器之间的关系图)组成,他们之间的关系类似于书报行业的报社或出版社、邮局或书店、读者之间的关系。以报纸发行为例说明,发布服务器类似于报社,报社提供报刊的内容并印刷,是数据源;分发服务器相当于邮局,他将各报社的报刊送(分发)到订户手中;订阅服务器相当于订户,从邮局那里收到报刊。在实际的复制中,发布服务器是一种数据库实例,它通过复制向其他位置提供数据,分发服务器也是一种数据库实例,它起着存储区的作用,用于复制与一个或多个发布服务器相关联的特定数据。每个发布服务器都与分发服务器上的单个数据库(称作分发数据库)相关联。分发数据库存储复制状态数据和有关发布的元数据,并且在某些情况下为从发布服务器向订阅服务器移动的数据起着排队的作用。在很多情况下,一个数据库服务器实例充当发布服务器和分发服务器两个角色。这称为“本地分发服务器”。订阅服务器是接收复制数据的数据库实例。一个订阅服务器可以从多个发布服务器和发布接收 数据。 (图1) 复制有三种类:事务复制、快照复制、合并复制。
事务复制是将复制启用后的所有发布服务器上发布的内容在修改时传给订阅服务器,数据更改将按照其在发布服务器上发生的顺序和事务边界,应用于订阅服务器,在发布内部可以保证事务的一致性。快照复制将数据以特定时刻的瞬时状态分发,而不监视对数据的更新。发生同步时,将生成完整的快照并将其发送到订阅服务器。合并复制通常是从发布数据库对象和数据的快照开始,并且用触发器跟踪在发布服务器和订阅服务器上所做的后续数据更改和架构修改。订阅服务器在连接到网络时将与发布服务器进行同步,并交换自上次同步以来发布服务器和订阅服务器之间发生更改的所有行。 1、复制实例 这里以配置一个事务复制来说明复制配置过程。 试验在同一台机器的二个实例间进行,实例名分别是SERVER01、SERVER02 。将SERVER01配置发布服务器和分发服务器(也就是前面提到的“本地分发服务器”),SERVER02配置为 订阅服务器。在本例中将SERVER01中一个DBCoper库中person表作为发布的数据,在发布前请确保person表有主键、SQL SERVER 代理自动启动、发布数据库是日志是完整模式。第一步:完全备份SERVER01 DBCopy数据库,在SERVER02上恢复DBCopy数据库(复制前的同步,使用发布的源和目标数据一致) 第二步:在SERVER01上设置发布和分发A 在SERVER01的复制节点—>本地发布右键选择新建订阅(图2) ()(图2) B B 在新建发布向导中首先要求选择分发服务器,本例选择本机作为分发服务器,选择默认值。(图3)
数据镜像复制技术
数据镜像复制技术 大型的业务系统中,数据库中的各类数据,如市场数据,客户数据,交易历史数据,财务管理数据、社会综合数据、生产研发数据等,都是公司至关重要的资产,它不仅关系着整个业务系统的稳定和正常运行,还可能关系着巨大的经济利益。数据系统中,存储设备的安全和高可用性与数据库软件系统一样,都至关重要的一旦数据丢失,就有可能面临着百万、千万元的经济损失。 正因为如此,一个大型数据库系统要具有高安全、高可用性,就必须具有以下几个方面的特点: 高可用性HA(High Availability) l有遭受失败的能力 l有单独的服务和资源管理的能力 l通过一种类型的Cluster进行操作 l关键概念是失败转移(takeover) l与容错不同(容错失败是不可见的) 持续可用性CA( Continuous Availability) l一对或Cluster系统,支持100%联机运行 l高度分布式系统 l设计有多层冗余 l设计有客户端自动失败转移 l为非单点失败而设计 l为非计划停机事件而设计 在数据库系统设计中,常用到的系统结构图如: (图2) 如图所示中,数据库软件、主机、HBA卡和网络交换机一般都采用双机方式,通过多台设备间的Active-Active工作方式来保障系统中的高可用性。不过从上图我们也可以看到,整个系统中,只有存储是单台设备。虽然存储设备内部可通过双控制器、双电源和RAID组来实现内部的冗余,但从存储设备整体而言,仍然存在许多单点故障,比如控制器的背板,
磁盘扩展柜等;这与主机和网络层的高可用工作方式是不匹配的。一旦存储设备发生整体故障,将会直接引起整个系统瘫痪,甚至造成数据丢失,给使用者带来具大的损失。 1.1 卷镜像复制和RAID镜像卷 为了提供存储设备的高可用性,保障数据的安全性,常用的一种解决方案是再增加一台备用存储设备,由两台存储设备负责数据库系统的数据存储服务,保障数据库的安全和数据存储服务器稳定。根据两个存储设备之间工作方式的不同,数据同步和复制机制的不同,可分为两种方式,第一种是卷镜像复制方式,第二种是RAID镜像卷方式。 卷镜像复制工作方式的系统结构图如下: (图3) 左侧存储为主存储设备设备,右侧为备用存储设备,再通过卷镜像复制软件、数据备份软件、网络层的存储虚拟化设备、存储设备自带的卷镜像复制功能等多种方式来实现主、备两个存储之间的卷镜像复制,以此来保障数据的安全性,同时备份存储设备也可以作为数据库系统中的数据存储服务功能的一种后备方式,一旦主存储设备发生故障,就需要自动或手动的切换到备份存储设备上,这种切换实际上是主存储设备生产卷到备份存储设备的镜像卷的切换,经常会导致数据库不一致,数据库重起,切换时间过长等问题。。 RAID镜像卷工作方式的系统结构图下:
SQL SERVER 2008数据库同步复制
SQL Server 2008数据库复制实现数据库同步备份 SQL Server 2008数据库复制是通过发布/订阅的机制进行多台服务器之间的数据同步,我们把它用于数据库的同步备份。这里的同步备份指的是备份服务器与主服务器进行实时数据同步,正常情况下只使用主数据库服务器,备份服务器只在主服务器出现故障时投入使用。它是一种优于文件备份的数据库备份解决方案。 在选择数据库同步备份解决方案时,我们评估了两种方式:SQL Server 2008的数据库镜像和SQL Server 2008数据库复制。数据库镜像的优点是系统能自动发现主服务器故障,并且自动切换至镜像服务器。但缺点是配置复杂,镜像数据库中的数据不可见(在SQL Server Management Studio中,只能看到镜像数据库处于镜像状态,无法进行任何数据库操作,最简单的查询也不行。想眼见为实,看看镜像数据库中的数据是否正确都不行。只有将镜像数据库切换主数据库才可见)。如果你要使用数据库镜像,强烈推荐killkill写的SQL Server 2005 镜像构建手册,我们就是按照这篇文章完成了数据库镜像部署测试。 最终,我们选择了SQL Server 2008数据库复制。 下面通过一个示例和大家一起学习一下如何部署SQL Server 2008数据库复制。 测试环境:Windows Server 2008 R2 + SQL Server 2008 R2(英文版),两台服务器,一台主数据库服务器CNBlogsDB1,一台备份数据库服务器CNBlogsDB2。 复制原理:我们采用的是基于快照的事务复制。主数据库服务器生成快照,备份库服务器读取并加载该快照,然后不停地从主数据库服务器复制事务日志。见下图:
数据库容灾、复制解决方案全分析(绝对精品)要点
数据库容灾、复制解决方案全分析(绝对精品) 目前,针对oracle数据库的远程复制、容灾主要有以下几种技术或解决方案: (1)基于存储层的容灾复制方案 这种技术的复制机制是通过基于SAN的存储局域网进行复制,复制针对每个IO进行,复制的数据量比较大;系统可以实现数据的同步或异步两种方式的复制.对大数据量的系统来说有很大的优势(每天日志量在60G以上),但是对主机、操作系统、数据库版本等要求一致,且对络环境的要求比较高。 目标系统不需要有主机,只要有存储设备就可以,如果需要目标系统可读,需要额外的配置和设备,比较麻烦。 (2)基于逻辑卷的容灾复制方案 这种技术的机制是通过基于TCP/IP的网络环境进行复制,由操作系统进程捕捉逻辑卷的变化进行复制。其特点与基于存储设备的复制方案比较类似,也可以选择同步或异步两种方式,对主机的软、硬件环境的一致性要求也比较高,对大数据量的应用比较有优势。其目标系统如果要实现可读,需要创建第三方镜像。个人认为这种技术和上面提到的基于存储的复制技术比较适合于超大数据量的系统,或者是应用系统的容灾复制。 我一直有一个困惑,存储级的复制,假如是同步的,能保证数据库所有文件一致吗?或者说是保证在异常发生的那一刻有足够的缓冲来保障? 也就是说,复制的时候起文件写入顺序和oracle的顺序一致吗?如果不一致就可能有问题,那么是通过什么机制来实现的呢? 上次一个存储厂商来讲产品,我问技术工程师这个问题,没有能给出答案 我对存储级的复制没有深入的研究过,主要是我自己的一些理解,你们帮我看一下吧…… 我觉得基于存储的复制应该是捕捉原系统存储上的每一个变化,而不是每隔一段时间去复制一下原系统存储上文件内容的改变结果,所以在任意时刻,如果原系统的文件是一致的,那么目标端也应该是一致的,如果原系统没有一致,那目标端也会一样的。形象一点说它的原理可能有点像raid 0,就是说它的写入顺序应该和原系统是一样的。不知道我的理解对不对。另外,在发生故障的那一刻,如果是类似断电的情况,那么肯定会有缓存中数据的损失,也不能100%保证数据文件的一致。一般来说是用这种方式做oracle的容灾备份,在发生灾难以后目标系统的数据库一般是只有2/3的机会是可以正常启动的(这是我接触过的很多这方面的技术人员的一种说法,我没有实际测试过)。我在一个移动运营商那里看到过实际的情况,他们的数据库没有归档,虽然使用了存储级的备份,但是白天却是不做同步的,只有在晚上再将存储同步,到第二天早上,再把存储的同步断掉,然后由另外一台主机来启动目标端存储上的数据库,而且基本上是有1/3的机会目标端数据库是起不来的,需要重新同步。 所以我觉得如果不是数据量大的惊人,其他方式没办法做到同步,或者要同时对数据库和应用进行容灾,存储级的方案是没有什么优势的,尤其是它对网络的环境要求是非常高的,在异地环境中几乎不可能实现。
SQLServer2008数据库复制
通过SQLServer 2008数据库复制实现数据库同步备份 SQL Server 2008数据库复制是通过发布/订阅的机制进行多台服务器之间的数据同步,我们把它用于数据库的同步备份。这里的同步备份指的是备份服务器与主服务器进行实时数据 同步,正常情况下只使用主数据库服务器,备份服务器只在主服务器出现故障时投入使用。它是一种优于文件备份的数据库备份解决方案。 在选择数据库同步备份解决方案时,我们评估了两种方式:SQL Server 2008的数据库镜像 和SQL Server 2008 数据库复制。数据库镜像的优点是系统能自动发现主服务器故障,并且自动切换至镜像服务器。但缺点是配置复杂,镜像数据库中的数据不可见(在SQL Server Man ageme nt Studio 中,只能看到镜像数据库处于镜像状态,无法进行任何数据库操作, 最简单的查询也不行。想眼见为实,看看镜像数据库中的数据是否正确都不行。只有将镜像数据库切换主数据库才可见)。如果你要使用数据库镜像,强烈推荐killkill写的SQL Server 2005镜像构建手册,我们就是按照这篇文章完成了数据库镜像部署测试。 最终,我们选择了SQL Server 2008 数据库复制。 下面通过一个示例和大家一起学习一下如何部署SQL Server 2008 数据库复制。 测试环境:Win dows Server 2008 R2 + SQL Server 2008R2 (英文版),两台服务器,一 台主数据库服务器CNBIogsDB1,—台备份数据库服务器CNBIogsDB2 。 复制原理:我们采用的是基于快照的事务复制。主数据库服务器生成快照,备份库服务器读取并加载该快照,然后不停地从主数据库服务器复制事务日志。见下图:
SQL server 数据库的导入导出与复制
第13章数据库的导入导出与复制 本章内容 13.1 数据库的导入导出 13.2 数据库复制技术 13.1 数据库的导入导出 13.1.1 导入导出概述 13.1.2 导入数据 13.1.3 导出数据 13.1.1 导入导出概述 ?数据导入导出操作(为SQL的数据转换服务)主要解决异构数据源之间相互转换。 ?目的是提高数据库管理系统的适应性,是数据库管理系统的一个核心技术和组件。 数据导入导出实现不同格式的数据在应用程序之间交换 dBase Microsoft Access Microsoft Data Link Microsoft Excel Microsoft Visual FoxPro 其他ODBC数据源 其他OLE DB数据源 Paradox 文本文件 表13-1 数据导入导出方法和工具 13.1.2 导入数据 导入数据的操作步骤: 步骤1: ?在企业管理器中,从“工具”菜单中选择“向导…” ?在“向导”对话框中选择数据转换服务中的DTS导入向导 步骤2 ?打开“数据转换服务导入/导出向导”界面,单击“下一步”按钮 步骤3 ?选择导入数据源。选择文本文件为数据源,在“文件名”编辑框中输入C:\SUPPLIER.TXT 文本文件,将其导入Sales数据库的Supplier表 步骤4 ?单击“下一步”按钮,显示“选择文件格式”对话框 步骤5 ?单击“下一步”按钮,显示“指定列分隔符”对话框。“预览”列表框显示数据文件的数据。 步骤6 ?单击“下一步”按钮,显示“选择目的”对话框。 步骤7 ?单击“下一步”按钮,显示选择源表和视图对话框。选择导入数据的supplier表 步骤8 ?单击“下一步”按钮,显示“保存、调度和复制包”对话框。 步骤9 ?单击“下一步”按钮,在“正在完成DTS导入/导出向导”界面中单击“完成”按钮,运行数据导入工作。最后显示用户操作成功。 13.1.3 导出数据 导出数据的操作步骤:
数据库流复制软件方案(优.选)
1项目背景 随着行业的信息化建设,各行业对集中交易系统的安全性、可靠性和业务连续性等方面提出了越来越高的要求。交易系统的可能运行涉及数以百亿元计的资金和大量客户的实时交易行为,因此系统的安全与稳定尤为重要。 根据业务系统信息量大、结构复杂、数据在线、可靠性要求高的特点,在数据高可用方面的需求具体归纳如下: 1) 可靠性要求非常高,强调持续化服务能力,业务运行不允许中断;行业的信息化程度越来越高,导致了业务的开展对信息系统的依赖程度的加深。客户要求务系统必须提供不间断的高可用性服务。 2) 强调数据的准确性,不允许数据丢失或出错;客户的交易数据等信息,事关客户的财产安全,容不得半点疏漏和丢失。 3) 需要可靠的备份恢复方案,保证数据的安全及提供快速的恢复和应急能力;对于客户而言,时间就是金钱,在信息系统故障发生时,信息系统的故障恢复体系应该可以提供快速的系统切换。为此需建立一套实时的、可用的备用系统,减少主系统的单个故障点,从而保障业务系统的持续服务能力。 我们针对具体需求、特定环境,着重考虑合理地设计和建设一体化数据库高可用的数据保护系统,同时优化数据中心的应用结构,设计出一套解决方案,供级领导及技术人员参考。
2项目目标 跨硬件级操作系统平台为业务系统实时的建立一个独立的于生产系统完全一致的数据库,若生产系统数据库异常,可及时进行应急切换,保证业务系统数据访问的稳定性和安全性。 由于客户将来查询业务将快速的增长,现有系统的硬件资源将无法满足系统未来的查询需求。在不影响生产系统性能的同时,提供了一个与生产系统实时同步的数据源,分担主库的查询工作。
3方案设计 3.1 数据库流复制软件工作原理 1.在备份主机上创建一个空的数据库。 2.通过软件将生产数据库在发起复制以前的数据(简称为历史数据)复制到备份主机的数据库中。 3.软件通过数据库SCN号的变化,监控生产数据库的数据变化,实时抓取生产数据库的在线重做日志的变化(简称为增量数据)。 4.软件将抓取的在线日志的变化内容筛选过滤合成为交易文件。 5.软件将交易文件发送至备份主机上。 6.软件将备份主机上的交易文件按顺序,通过OCI接口,装载至备份主机的数据库中。7.反复通过3~6步备份主机数据库与生产主机数据库实时保持数据的一致性。 下图为数据库流软件复制工作原理图:
sql2000数据库数据同步复制技术资料
SQL2000数据库数据同步复制技术详解 SqlServer数据库数据同步是项目中常用到的环节,若一个项目中的数据同时存在于不同的数据库服务器中,而这些数据库需要被多个不同的网域调用时,配置SqlServer数据库数据同步是个比较好的解决方案。SqlServer数据库数据同步的配置比较烦锁,下面对其配置详细步骤进行介绍: 一、数据复制前提条件 1. 数据库故障还原模型必需为完全还原模型。 2. 所有被同步的数据表都必须要用主键。 3. 发布服务器、分发服务器和订阅服务器必须使用计算机名称来进行SQLSERVER服务器的注册。 4. SQLSERVER必需启动代理服务,且代理服务必需以本地计算机的帐号运行。 二、解决前提条件实施步骤 1. 将数据库故障还原模型调整为完全还原模型。具体步骤如下: 打开SQLSERVER企业管理器à选择对应的数据库à单击右键选择属性à选择”选项”à 故障还原模型选择完全还原模型。 2. 所有被同步的数据表都必须要用主键。(主要指事务复制)如果没有主键的数据表,增加一个字段名称为id,类型为int 型,标识为自增1的字段。 3. 发布服务器、分发服务器和订阅服务器必须使用计算机名称来进行SQLSERVER服务器的注册。 在企业管理器里面注册的服务器,如果需要用作发布服务器、分发服务器和订阅服务器,都必需以服务器名称进行注册。不得使用IP地址以及别名进行注册,比如LOCAL, “.”以及LOCALHOST等。 如果非同一网段或者远程服务器,需要将其对应关系加到本地系统网络配置文件中。文件的具体位置 在%systemroot%\system32\drivers\etc\hosts 配置方式: 用记事本打开hosts文件,在文件的最下方添加IP地址和主机名的对应关系。如图:
在SQL_Server_2000里设置和使用数据库复制订阅
在SQL Server 2000里设置和使用数据库复制订阅 在SQL Server 2000里设置和使用数据库复制之前,应先检查相关的几台SQL Server服务器下面几点是否满足: 1、MSSQLserver和Sqlserveragent服务是否是以域用户身份启动并运行的(.\administrator用户也 是可以的) 如果登录用的是本地系统帐户local,将不具备网络功能,会产生以下错误: 进程未能连接到Distributor '@Server name' (如果您的服务器已经用了SQL Server全文检索服务, 请不要修改MSSQLserver和Sqlserveragent 服务的local启动。 会照成全文检索服务不能用。请换另外一台机器来做SQL Server 2000里复制中的分发服务器。) 修改服务启动的登录用户,需要重新启动MSSQLserver和Sqlserveragent服务才能生效。 2、检查相关的几台SQL Server服务器是否改过名称(需要srvid=0的本地机器上srvname和datasource 一样) 在查询分析器里执行: use master select srvid,srvname,datasource from sysservers 如果没有srvid=0或者srvid=0(也就是本机器)但srvname和datasource不一样, 需要按如下方
法修改: USE master GO -- 设置两个变量 DECLARE @serverproperty_servername varchar(100), @servername varchar(100) -- 取得Windows NT 服务器和与指定的 SQL Server 实例关联的实例信息 SELECT @serverproperty_servername = CONVERT(varchar(100), SERVERPROPERTY('ServerName')) -- 返回运行 Microsoft SQL Server 的本地服务器名称 SELECT @servername = CONVERT(varchar(100), @@SERVERNAME) -- 显示获取的这两个参数 select @serverproperty_servername,@servername --如果@serverproperty_servername和@servername不同(因为你改过计算机名字),再运行下面的 --删除错误的服务器名 EXEC sp_dropserver @server=@servername --添加正确的服务器名 EXEC sp_addserver @server=@serverproperty_servername, @local='local' 修改这项参数,需要重新启动MSSQLserver和Sqlserveragent服务才能生效。 这样一来就不会在创建复制的过程中出现18482、18483错误了。 3、检查SQL Server企业管理器里面相关的几台SQL Server注册名是否和上面第二点里介绍的srvname 一样 不能用IP地址的注册名。 (我们可以删掉IP地址的注册,新建以SQL Server管理员级别的用户注册的服务器名)
浅谈四种容灾复制技术
浅谈四种容灾复制技术 数据复制是构建容灾的基石,利用复制软件实时地将数据从一个主机(或磁盘)复制到另一个主机(磁盘),生成一个数据副本。 数据复制有多种分类方法,依据复制启动点的不同,可分为同步复制、异步复制。同步复制,数据复制是在向主机返回写请求确认信号之前实时进行的;对于异步复制,数据复制是在向主机返回写请求确认信号之后实时进行的。 一、四种容灾复制技术说明 根据操作系统的I/O(读写操作)路径以及复制对象划分为四大种类:基于应用层事务复制、基于文件层复制、基于逻辑卷层复制、基于磁盘阵列复制。当然,目前出现了基于SAN交换机的复制,但是相对技术不太成熟,应用很少。 按照数据复制软件或硬件安装的位置又可划分为主机型复制和非主机型复制。应用层、文件层、逻辑卷层的都属于主机型复制,主机型复制软件需安装在主机上,需要消耗一定的主机资源。存储层属于非主机型复制,复制直接由磁盘阵列的内部组件完成,理论上无需消耗应用所在主机的资源。 一般而言,容灾要保护的数据是结构化数据,即存储在数据库的数据。以下都用复制数据库来说明。 1.基于应用层事务复制 基于应用层事务的复制,一般采用采用异步复制机制,复制对象为应用事务,其过程为:捕获应用系统的事务,例如SQLServer或Oracle数据库的事务,经由传输组件传输到目标服务器,然后目标装载进程按照数据库的关系原理排序事务,将事务保存到目标数据库。 这层的复制完全能保障数据库的一致性,且目标数据库处于在线运行状态。当生产数据库发生故障时,直接使用目标数据库即可恢复业务,容灾的RTO指标趋于零。但是支持的应用有限,一般为SQLServer、Oracle、Sybase、DB2、MySQL等等数据库。另外复制速度较慢,因为数据要通过数据库的装载接口才能写入数据库。 应用层代表厂商:浪擎、DSG、Goldengate、Quest、Oracle、微软等。 2.基于磁盘阵列复制 基于磁盘阵列层的复制,磁盘阵列厂商的复制技术,其原理与逻辑卷层的相似,属于非主机型的复制。但与硬件绑定,成本高昂,实施复杂。 基于磁盘阵列层的复制不能完全保障数据库一致性,目标数据库处于脱机状态。当生产数据库发生故障时,需要启动数据库才能恢复业务,正是由于不能保障数据库一致性,很可能数据库不能正常启动。尽管存在这样的缺陷,但这一层的复制对主机的影响极其轻微,所以还是可应用在一些非常大型、繁忙的数据库容灾,作为一种补充保护手段。 磁盘阵列层代表厂商:IBM、HP、EMC、HDS等。 3.基于逻辑卷层复制 基于逻辑卷层的复制,一般采用采用同步复制机制,复制对象为逻辑卷层的变化Block,其过程为:捕获
拷贝数据库方法
注意:关于数据库的练习操作,一定不要在服务器上进行,防止损坏服务器数据库文件。 拷贝数据库文件方法 1.依次单击“开始”—“所有程序”—“Microsoft SQL Server” —“企业管理器”,启动“企业管理器”,进入“图1”所示的界面: 图1 2.依次展开“控制台根目录”中的树形目录,如“图2”所示:
图2 3. 在如“图2”所示的界面中点击“数据库”展开“数据库”的目录,在其中找到要进行拷贝的数据库,如“mqdy”数据库,如“图3”: 图3 4. 选中“mqdy”数据库,在其上单击鼠标的右键,在弹出的快捷菜单中选择“属性”选项,进入“图4”所示的界面:
图4 5. 在“图4”单击所示的界面中单击“数据文件”选项卡,进入“图5”所示的界面,在其中可以查看“mqdy”数据库文件的位置 图5 6. 单击桌面右下角的SQL Server图标,弹出“服务管理器”的界面,如“图6”所示:
图6 7. 单击“图6”中的红色方框中的下拉按钮,弹出“图7”所示的界面: 图7 8. 在其中点击“SQL Server”选项,弹出“图8”所示的界面,在其中点击“停止”按钮,等待下面的“正在运行”文字变为“已停止”时,“SQL Server”已经关闭;
图8 9. 用同样的方法选中“图7”中的“SQL Server Agent”,并使其停止运行; 10. 完成上面的操作后,进入到“图5”找到的“mqdy”数据库所在的位置,找到含有格式为“.mdf”和“.ldf”的文件夹,把这个文件夹复制出来,即可完成此数据库的拷贝,拷贝出的文件夹上要注明拷贝的地点、时间,方便以后的使用; 11.拷贝完数据库后,要重新打开“服务管理器”,选中“SQL Server”项,并点击“开始/继续”按钮,使“已停止”状态恢复到“正在运行”状态,如“图9”所示:
ORACLE 数据库在不同计算机上的迁移(克隆数据库)
ORACLE 数据库在不同计算机上的迁移(克隆数据库) 描述:一台联想台式机上安装了oracle11g,建立了自己的数据库,现在想在宿舍DELL笔记本电脑上克隆这个数据库。 1 在目标机器上安装数据库,密码一致数据库名字一致。 2 登陆sys as sysdba 这时数据库自动启动 3 shutdown immediate 关闭数据库,startup nomount,这时系统释放掉控制文件和数据文件,就是在这时完成替换。 4 复制数据文件和redo文件到目标机相应目录下原先的文件全部删除(数据目录下) 我的是在C:\app\Administrator\oradata\orcl\目录下 5 重建控制文件,主要就是让数据库系统知道有哪些数据文件,文件路径(指定的文件都应该有存在,否则会报错,这就是4在前的原因) 如果不重建,会报控制文件太旧的错误,所以重建控制文件时必须的; 6 set linesize 400; col file# for 99; col name for a100; col status for a20; select file#,name,status from v$datafile; /////// SQL> set linesize 400; SQL> col file# for 99; SQL> col name for a100; SQL> col status for a20; SQL> select file#,name,status from v$datafile; FILE# NAME STATUS ----- ---------------------------------------------------------------------------------------------------- ------------- 1 D:\APP\ADMINISTRATOR\ORADATA\ORCL\SYSTEM01.DBF SYSTEM 2 D:\APP\ADMINISTRATOR\ORADATA\ORCL\SYSAUX01.DBF RECOVER 3 D:\APP\ADMINISTRATOR\ORADATA\ORCL\UNDOTBS01.DBF RECOVER 4 D:\APP\ADMINISTRATOR\ORADATA\ORCL\USERS01.DBF RECOVER 5 D:\APP\ADMINISTRATOR\ORADATA\ORCL\MILKWAY_TBS_01 RECOVER 6 D:\APP\ADMINISTRATOR\ORADATA\ORCL\MILKWAY_TBS_02 RECOVER 找到文件编号 7 SQL> recover datafile 1;
SQL Server 2000数据库复制实战操作
(接SQL Server 2000数据库复制实战(一)) 4必需的存储过程 在数据库复制中,发布服务器与分发服务器需要具有一定安全威胁的存储过程,如果因安全原因将为些存储过程删除了,则要进行恢复,恢复的代码如下: sp_addextendedproc 'xp_regenumvalues',@dllname ='xpstar.dll' go sp_addextendedproc 'xp_regdeletevalue',@dllname ='xpstar.dll' go sp_addextendedproc 'xp_regdeletekey',@dllname ='xpstar.dll' go sp_addextendedproc xp_cmdshell ,@dllname ='xplog70.dll' 5相关服务器的注册 在发布服务器与分发服务器的SQL Server企业管理器里注册相关服务器,服务器名称不能使用IP地址、local等,必须使用第2点中使用的@servername 名称。注册的方法如下: 如果本机使用的是local注册名,则删除重新注册。启动SQL Server客户端网络实用工具:
网络库为:TCP/IP,服务器名称为服务器的实际IP地址,服务器别名为第2步中的@servername名称。将所有相关服务器按以上方法追加。 在发布服务器的SQL Server企业管理器里将相关服务器都注册上,如下图所示: 说明: 服务器XSBNOTE是作为发布服务器、分发服务器,其中数据库CopyTest用于复制。 服务器SX-VEOAI73LUMAW是作为订阅服务器。即要将数据库服务器XSBNOTE的数据库CopyTest复制到数据库SX-VEOAI73LUMAW中。 如果采用请求订阅,则在订阅服务器上要执行以上操作,将分发服务器进行注册。 以下的所有操作均是遵从以上说明。
不同数据库之间复制表的数据的方法
不同数据库之间复制表的数据的方法 当表目标表存在时: insert into 目的数据库..表select * from 源数据库..表 当目标表不存在时: select * into 目的数据库..表from 源数据库..表 --如果在不同的SQL之间: insert into openrowset('sqloledb','目的服务器名';'sa';'',目的数据库.dbo.表) select * from 源数据库..表 --或用链接服务器: ----------------------------------------创建链接服务器------------------------------------ exec sp_addlinkedserver 'srv_lnk','','SQLOLEDB','远程服务器名' exec sp_addlinkedsrvlogin 'srv_lnk','false',null,'sa','密码' exec sp_serveroption 'srv_lnk','rpc out','true' --这个允许调用链接服务器上的存储过程 go --查询示例 select * from srv_lnk.数据库名.dbo.表名 --导入示例 select * into 表from srv_lnk.数据库名.dbo.表名 go --后删除链接服务器 exec sp_dropserver 'srv_lnk','droplogins' --如果是将一个数据库中的数据全部复制到另一个数据库,而且两个库结构完全一样的话,就用备份/恢复的方式: /*--将一个数据库完整复制成另一个数据库--*/ /*--调用示例