实验四 虚拟变量模型

实验四虚拟变量
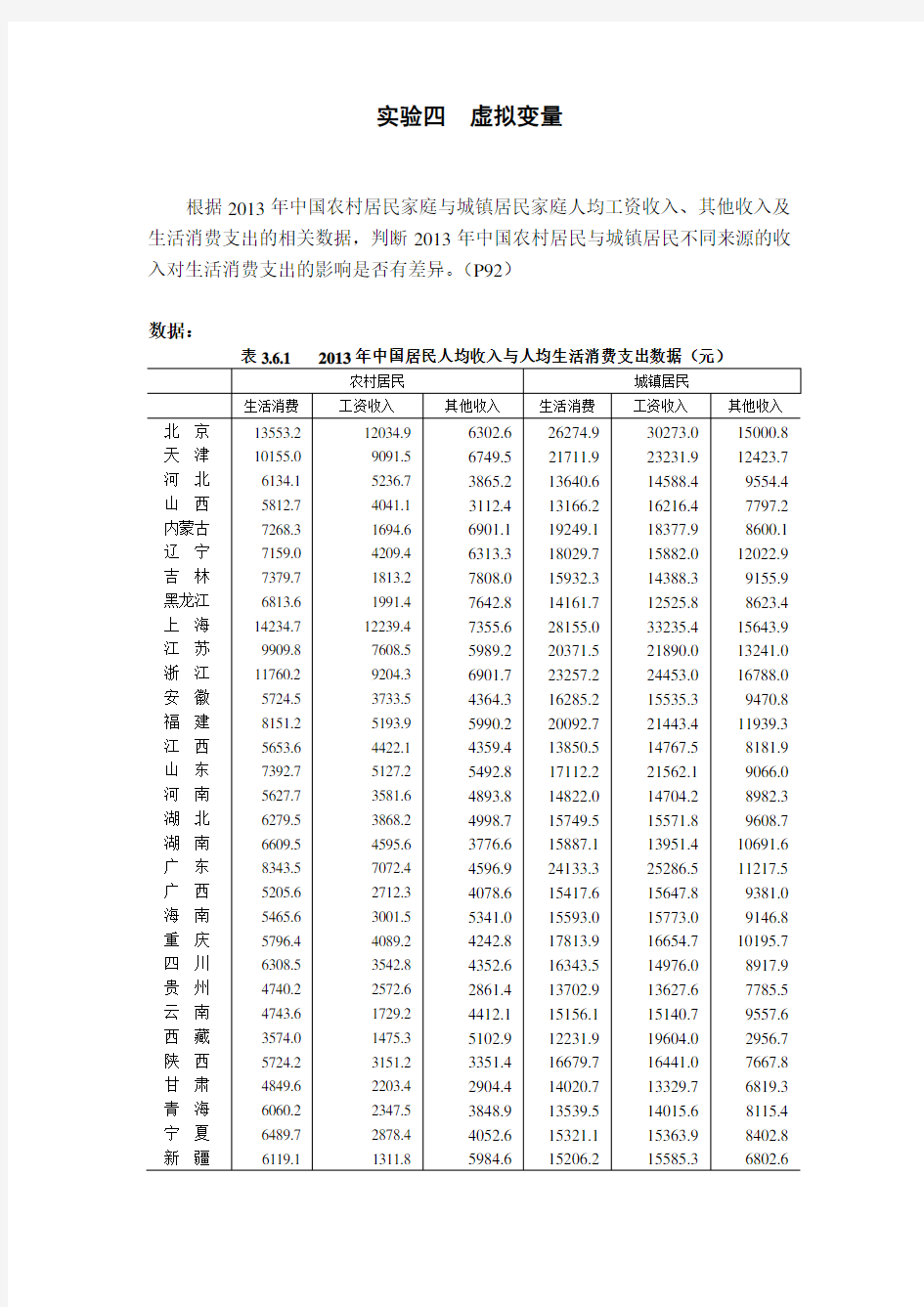
根据2013年中国农村居民家庭与城镇居民家庭人均工资收入、其他收入及生活消费支出的相关数据,判断2013年中国农村居民与城镇居民不同来源的收入对生活消费支出的影响是否有差异。(P92)
数据:
1、 可以通过在收入的系数中引入虚拟变量来考察,设
??
?=城镇居民
,
农村居民,01i D
则全体居民的消费模型可建立如下:
i i i i i X D X Y μβββ++/+=210
其中,Y 、X 分别表示居民家庭人均年消费支出与年可支配收入,虚拟变量D 以与X 相乘的方式引入模型,从而可用来考察边际消费倾向的差异。 2、2013年我国农村与城镇居民人均消费函数可写成:
农村居民:i i i i X X Y 122110μααα+++=(1,...,2,1n i =) 城镇居民:i i i i X X Y 222110μβββ+++=(1,...,2,1n i =) 将1n 和2n 次观察值合并,估计以下回归模型:
i i i i i i i i X D X X D X D Y μδβδβδβ++++++=)()(2222i111100
3、操作
(1)录入数据
打开EViews6,点击“File ”→“New ”→“Workfile ”
在命令行输入:DATA Y X1 X2 D1
将数据复制粘贴到Group 中的表格中,农村居民的D1为1,城镇居民的D1为0:
(2)在命令栏输入命令:
GENR D1X1=D1*X1
GENR D1X2=D1*X2
(3)利用混合样本估计模型,在命令栏输入命令:LE Y C D1 X1 D1X1 X2 D1X2
估计结果如图:
引入虚拟变量的模型为:
2
i 2110059.06017.01896.04865.0895.1573145.2599X D X X D X D Y i i i i i i -+++-=∧
(3.8199)(-1.6856)(10.2724) (2.3977) (7.0190) (-0.0383) 可以看出,2013年中国农村居民的平均消费支出要比城镇居民少1573.90 元。其他条件不变的情况下,农村居民与城镇居民的工资都增加100元时,农村居民要比城镇居民多支出19元用于生活消费;但当其他来源收入方面有相同的增加量时,两者的消费支出没有显著差异。
虚拟变量回归模型
虚拟变量回归模型 以下是为大家整理的虚拟变量回归模型的相关范文,本文关键词为虚拟,变量,回归,模型,内蒙古,科技,大学,课程,计量经济学,您可以从右上方搜索框检索更多相关文章,如果您觉得有用,请继续关注我们并推荐给您的好友,您可以在综合文库中查看更多范文。 内蒙古科技大学
实验报告 课程名:计量经济学实验项目名称:单方程线性回归模型的扩展——虚拟变量回归模型 院(系):专业班级:姓名:学号: 1 内蒙古科技大学 实验地点:经管机房 实验日期:20XX年4月18日 实验目的:掌握虚拟变量回归模型的建立、参数估计和统计检验。实验内容: 1)生成趋势变量2)生成季节虚拟变量3)生成分段虚拟变量4)建立虚拟变量回归模型 5)虚拟变量回归模型的参数估计和统计检验实验方法、步骤和结果: 一、生成趋势变量 1、建立新的工作文件,导入数据并且重命名
2、点击quick,generateseries生成序列,t=@trend(1990:1)+1 2 并填写公式内蒙古科技大学 3、打开gDp,点击View,graph,line生成趋势图。 根据趋势图可以看出近似分段虚拟变量,需剔除季节的影响 3 内蒙古科技大学 二、生成季节虚拟变量 生成虚拟变量,点击quick----generateseries输入公式
D2=@seas(2)D3=@seas(3)D4=@seas(4) 三、生成分段虚拟变量 1、为了研究1997年金融危机对香港经济的影响,以1997年为分界点。设d5=0,将sample改为1990第一季度到1997年第四季度。 4 内蒙古科技大学 2、设d5=1,将sample改为1998年第一季度到20XX年第四季度。 四、建立虚拟变量回归模型 gDp^=?^1+?^2t+?^3d2t+?^4d3t+?^5d4t+?^6d5t+?^7d5t*t 五、虚拟变量回归模型的参数估计和统计检验点击quick,
计量经济学实验教学案例实验9_虚拟变量
实验九虚拟变量 【实验目的】 掌握虚拟变量的设置方法。 【实验内容】 一、试根据表9-1的1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立我国城镇居民彩电需求函数; 资料来源:据《中国统计年鉴1999》整理计算得到 二、试建立我国税收预测模型(数据见实验一); 资料来源:《中国统计年鉴1999》 三、试根据表9-2的资料用混合样本数据建立我国城镇居民消费函数。
资料来源:据《中国统计年鉴》1999-2000整理计算得到 【实验步骤】 一、我国城镇居民彩电需求函数 ⒈相关图分析; 键入命令:SCAT X Y ,则人均收入与彩电拥有量的相关图如9-1所示。 从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下: ?? ?=低收入家庭 中、高收入家庭 1D 图9-1 我国城镇居民人均收入与彩电拥有量相关图 ⒉构造虚拟变量; 方式1:使用DATA 命令直接输入; 方式2:使用SMPL 和GENR 命令直接定义。 DATA D1 GENR XD=X*D1 ⒊估计虚拟变量模型: LS Y C X D1 XD 再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。 按照以上步骤,虚拟变量模型的估计结果如图9-2所示。
图7-2 我国城镇居民彩电需求的估计 我国城镇居民彩电需求函数的估计结果为: i i i i XD D x y 0088.08731.310119.061.57?-++= =t (16.249)(9.028) (8.320) (-6.593) 2R =0.9964 2R =0.9937 F =366.374 S.E =1.066 虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。低收入家庭与中高收入家庭各自的需求函数为: 低收入家庭: i i x y 0119.061.57?+= 中高收入家庭: ()()i i x y 0088.00119.08731.3161.57 ?-++=i x 003.048.89+= 由此可见我国城镇居民家庭现阶段彩电消费需求的特点:对于人均年收入在3300元以下的低收入家庭,需求量随着收入水平的提高而快速上升,人均年收入每增加1000元,百户拥有量将平均增加12台;对于人均年收入在4100元以上的中高收入家庭,虽然需求量随着收入水平的提高也在增加,但增速趋缓,人均年收入每增加1000元,百户拥有量只增加3台。事实上,现阶段我国城镇居民中国收入家庭的彩电普及率已达到百分之百,所以对彩电的消费需求处于更新换代阶段。 二、我国税收预测模型 要求:设置虚拟变量反映1996年税收政策的影响。 方法:取虚拟变量D1=1(1996年以后),D1=0(1996年以前)。 键入命令:GENR XD=X*D1 LS Y C X D1 XD 则模型估计的相关信息如图7-3所示。
Eviews虚拟变量实验报告
实验四虚拟变量 【实验目的】 掌握虚拟变量的基本原理,对虚拟变量的设定和模型的估计与检验,以及相关的Eviews操作方法。 【实验内容】 试根据1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立 【实验步骤】 1、相关图分析 根据表中数据建立人均收入X与彩电拥有量Y的相关图(SCAT X Y)。从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,
因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下: ?? ?=低收入家庭 中、高收入家庭 1D 2、构造虚拟变量 构造虚拟变量 1D (DATA D1),并生成新变量序列: GENR XD=X*D1 3、估计虚拟变量模型 LS Y C X D1 XD 得到估计结果:
我国城镇居民彩电需求函数的估计结果为: XD D X Y 009.0873.31012.0611.571-++=∧ (16.25) (9.03) (8.32) (-6.59) 366,066.1..,9937.02===F e s R 再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。 虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。 低收入家庭与中高收入家庭各自的需求函数为: 低收入家庭: X Y 012.0611.57+=∧ 中高收入家庭: X X Y 003.0484.89)009.0012.0()873.31611.57(+=-++=∧ 由此可见我国城镇居民家庭现阶段彩电消费需求的特点: 对于人均年收入在3300元以下的低收入家庭,需求量随着收入水平的提高而快速上升,人均年收入每增加1000元,百户拥有量将平均增加12台;对于人均年收入在4100元以上的中高收入家庭,虽然需求量随着收入水平的提高也在增加,但增速趋缓,人均年收入每增加1000元,百户拥有量只增加3台。
计量经济学实验报告
计量经济学实验报告——对我国商品房价格的计量经济学研究
摘要:基于我国对住房的庞大的需求,近年来,房地产产业的迅猛发展,全国各地都出现了商品房销售价格持续走高的现象,而由此更是掀起了“购房热”和“炒房热”的浪潮。出于谨慎性原则和解决因房价居高不下而造成的居民“买房难”的困境,国家出台了诸多措施但都收效甚微。无法抑制的上涨的房价,究竟受什么因素在影响,而从哪些方面入手才可以实现对房价的调控呢?本文将从人均可支配收入、房屋造价、土地购置费、地区人均 GDP、政策因素等几个方面展开分析,初步推到出影响商品房销售价格的因素,并对如何实现对房价的调控进行尝试性的讨论。 关键词:房屋销售价格影响因素调控
1引言 自从 1998 年我国实行住房商品化后,随着我国市场化改革的快速推进,房地产业己经成为拉动经济增长的支柱产业。从住房制度改革以来短短几年时间,纵观国内,从沿海开放城市到中西部欠发达地区,中国大地上几乎所有城市商品楼如雨后春笋般拔地而起。 而商品房价格的持续走高也就成为了人们热议的话题。特别是,近年来,中国房价持续走高。尽管国家政策层已经启动了几轮调控,但房价丝毫没有要稳定下来的迹象,房价高涨,一房难求的情况仍在持续。房地产行业已经成为我国国民经济的支柱产业,不仅影响着国民经济的增长,也牵动着千家万户的心。然而,房价到底为何如此之高,其未来走向将会怎样?为了研究这个问题,我们需要建立计量经济学模型。 2理论分析 2.1商品房“房价”问题的思维路程 商品房之所以被称为商品房,原因就在于它同其他商品一样,具有商品的共性。众所周知,商品的价值是由凝结在商品中的无差别的人类劳动所决定的,难么商品房的价格是也是由其价值决定的,其价值既包括所占用土地的价值,包括土地上建筑物的价值。除此之外,与其他商品一样,还受到供求状况、竞争程度、消费者偏好、市场预期、房地产企业经营策略和政府相关政策的影响,其价格围绕价值规律上下波动。但是,与普通商品不同,商品房还具有建设周期长、价
第八章__虚拟解释变量回归.doc
第八章虚拟变量回归 第一节虚拟变量 一、虚拟变量的基本概念 在前面的分析中,被解释变量主要受到一些可以直接度量的变量影响,如收入、产出、 商品需求量、价格、成本、资金、人数等。但现实经济生活中,影响被解释变量变动的因素,除了这些可以直接获得实际观测数据的定量变量外,还包括一些本质上为定性因素(或称属 性因素)的影响,例如性别、种族、肤色、职业、季节、文化程度、战争、自然灾害、政府经济政策的变动等因素。在实际经济分析中,这些定性变量有时具有不可忽视的重要影响。
例如,研究某个企业的销售水平,产业部门(制造业、零售业)、所有制(私营、非私营)、地理位置(东、中、西部)、管理者素质的高低等是值得经常考虑的影响因素,这些因素有共同的特征,即都是表示某种属性的,不能直接用数据精确描述的因素。因此,被解释变量的变动经常是定量因素和属性因素共同作用的结果。在计量经济模型中,应当同时包含定量和属性两种因素对被解释变量的影响作用。 定量因素是指那些可直接测度的数值型因素,如GDP、M2 等。定性因素,或称为属性 因素,是不能直接测度的、说明某种属性或状态存在与否的非数值型因素,如男性或女性、城市居民或非城市居民、气候条件正常或异常、政府经济政策不变与改革等。在计量经济学的建模中应当将定量因素和定性因素同时纳入模型之内。 为了在模型中反映定性因素,可以将定性因素转化为虚拟变量去表现。虚拟变量(或称为属性变量、双值变量、类型变量、定性变量、二元型变量等),是人工构造的取值为0 和1 的作为属性变量代表的变量,一般用字母 D (或DUM ,英文dummy 的缩写)表示。属性 因素通常具有若干类型或水平,通常虚拟变量的取值为0和1,当虚拟变量取值为0,即D=0 时,表示某种属性或状态不出现或不存在,即不是某种类型;当虚拟变量取值为1,即D=1 时,表示某种属性或状态出现或存在,即是某种类型。例如,构造政府经济政策人工变量,当经济政策不变时,虚拟变量取值为0,当经济政策改变时,虚拟变量取值为1。这种做法 实际上是一种变换或映射,将不能精确计量的定性因素的水平或状态变换为用0 和1 来定量描述。 二、虚拟变量的设置规则 在计量经济学模型中引入虚拟变量,可以使我们同时兼顾定量因素和定性因素的影响和作用。但是,在设置虚拟变量时应遵循一定的规则。 1、虚拟变量数量的设置规则 虚拟变量个数的设置规则是:若定性因素有m 个相互排斥的类型(或属性、水平),在有截距项的模型中只能引入m-1 个虚拟变量,否则会陷入所谓“虚拟变量陷阱”,产生完 全的多重共线性。在无截距项的模型中,定性因素有m个相互排斥的类型时,引入m个虚 拟变量不会导致完全多重共线性,不过这时虚拟变量参数的估计结果,实际上是D=1 时的 样本均值。 例如,城镇居民和农村居民住房消费支出的模型可设定为:
实验报告7-虚拟变量
2013-2014学年第 一 学期 实 验 报 告 实验课程名称 虚拟变量模型 专 业 班 级 资产评估1101 学生 学号 31105073 学 生 姓 名 方申慧 实验指导教师 董美双 编号:
实验名称多重共线性检验与修正指导老师董美双成绩 专业资产评估班级 1101 姓名方申慧学号 31105073 一、实验目的 目的:通过实验,理解并掌握虚拟变量模型的意义、建模的方法、虚拟变量引入的原则和技巧等。 要求:熟练掌握虚拟变量引入的加法方式和乘法方式,并正确解读和分析回归结果。 首先做例题8-10,按步骤分析季节性因素的影响;然后利用上证指数的数据分析股市周效应(周1-周5任选),或者自己收集数据按上面的步骤做一遍,把结果输出到word文档中。 步骤: 例题8-10 Dependent Variable: Y Method: Least Squares Date: 11/28/13 Time: 09:12 Sample: 1982:1 1988:4 Included observations: 28 C 2431.198 93.35790 26.04170 0.0000 T 48.95067 4.528524 10.80941 0.0000 D1 1388.091 103.3655 13.42896 0.0000 D2 201.8415 102.8683 1.962136 0.0620 D3 85.00647 102.5688 0.828775 0.4157 R-squared 0.945831 Mean dependent var 3559.718 Adjusted R-squared 0.936411 S.D. dependent var 760.2102 S.E. of regression 191.7016 Akaike info criterion 13.51019 Sum squared resid 845238.2 Schwarz criterion 13.74808
计量实验报告
计量经济学第二次实验报告 (利用所给数据(bothtwins data Excel文件)研究教育的工资回报率问题) 一、实验内容: 1、实验目的: 利用所给数据(bothtwins data Excel文件)研究教育的工资回报率问题。 2、实验要求: 运用Eviews软件进行数据分析,利用已知数据建立回归模型,考虑诸如遗漏变量和测量误差的模型内生性问题。由于数据都是不同家庭的双胞胎数据,分析时请利用这一数据特征 二、实验报告: (1)、问题提出 随着社会的发展,教育的工资回报率问题被提上了日程。对于影响工资回报率的因素我们愈加关注。为了这一问题,我们利用所给数据(bothtwins data Excel文件)研究教育的工资回报率问题。同时考虑诸如遗漏变量和测量误差的模型内生性问题。 (2)、指标选择 根据分析问题的需要,依据指标数据可得性原则,我们选择经济含义明确并具有较好完整性和可比较性的数据(bothtwins data Excel文件)作为数据指标。Age:年龄;age2:年龄平方;Daded:父亲受教育年数;Momed:母亲受教育年数;Hrwage:工资时薪;lwage:时薪工资对数值;female:是否为女性; white:是否为白人;first:是否为家中长子;Educ:受教育年数(自报);Educ_t:双胞胎中另一个受教育年数(自报);Eductt:双胞胎中某个提供的另外一个的受教育年数(互报);Educt_t:此双胞胎的sibling提供的此双胞胎受教育年数(互报)。 (3)、数据来源 数据由老师提供。由于数据量过大,截取部分数据展示如下表1,具体数据参见附表1 表1 数据(bothtwins data Excel文件)(部分数据)
实验四 虚拟变量模型
实验四虚拟变量 根据2013年中国农村居民家庭与城镇居民家庭人均工资收入、其他收入及生活消费支出的相关数据,判断2013年中国农村居民与城镇居民不同来源的收入对生活消费支出的影响是否有差异。(P92) 数据:
1、 可以通过在收入的系数中引入虚拟变量来考察,设 ?? ?=城镇居民 , 农村居民,01i D 则全体居民的消费模型可建立如下: i i i i i X D X Y μβββ++/+=210 其中,Y 、X 分别表示居民家庭人均年消费支出与年可支配收入,虚拟变量D 以与X 相乘的方式引入模型,从而可用来考察边际消费倾向的差异。 2、2013年我国农村与城镇居民人均消费函数可写成: 农村居民:i i i i X X Y 122110μααα+++=(1,...,2,1n i =) 城镇居民:i i i i X X Y 222110μβββ+++=(1,...,2,1n i =) 将1n 和2n 次观察值合并,估计以下回归模型: i i i i i i i i X D X X D X D Y μδβδβδβ++++++=)()(2222i111100 3、操作 (1)录入数据 打开EViews6,点击“File ”→“New ”→“Workfile ” 在命令行输入:DATA Y X1 X2 D1 将数据复制粘贴到Group 中的表格中,农村居民的D1为1,城镇居民的D1为0:
(2)在命令栏输入命令: GENR D1X1=D1*X1 GENR D1X2=D1*X2 (3)利用混合样本估计模型,在命令栏输入命令:LE Y C D1 X1 D1X1 X2 D1X2 估计结果如图: 引入虚拟变量的模型为:
计量经济学实验报告(虚拟变量)
计量经济学实验报告 实验三:虚拟变量模型 姓名:上善若水 班级: 序号: 学号: 中国人均消费影响因素 一、理论基础及数据 1. 研究目的 本文在现代消费理论的基础,分析建立计量模型,通过对 1979—— 2008 年全国城镇居民的人均消费支出做时间序列分析和对2004— 2008年各地区(31 个省市)城镇居民的人均消费支出做面板数据分析,比较分析了人均可支配收入、消费者物价指数和银行一年期存款利率等变量对居民消费的不同影响。
2. 模型理论 西方消费经济学者们认为,收入是影响消费者消费的主要因素,消费是需求的函数。消费经济学有关收入与消费的关系,即消费函数理论有:( 1)凯恩斯的绝对收入理论。他认为消费主要取决于消费者的净收入,边际消费倾向小于平均消费倾向。他假定,人们的现期消费,取决于他们现期收入的绝对量。(2)杜森贝利的相对收入消费理论。他认为消费者会受自己过去的消费习惯以及周围消费水准来决定消费,从而消费是相对的决定的。当期消费主要决定于当期收入和过去的消费支出水平。(3)弗朗科?莫迪利安的生命周期的消费理论。这种理论把人生分为三个阶段:少年、壮年和老年;在少年与老年阶段,消费大于收入;在壮年阶段,收入大于消费,壮年阶段多余的收入用于偿还少年时期的债务或储蓄起来用来防老。( 4)弗里德曼的永久收入消费理论。他认为消费者的消费支出主要不是由他的现期收入来决定,而是由他的永久收入来决定的。这些理论都强调了收入对消费的影响。除此之外,还有其他一些因素也会对消费行为产生影响。(1)利率。传统的看法认为,提高利率会刺激储蓄,从而减少消费。当然现代经济学家也有不同意见,他们认为利率对储蓄的影响要视其对储蓄的替代效应和收入效应而定,具体问题具体分析。( 2)价格指数。价格的变动可以使得实际收入发生变化,从而改变消费。 基于上述这些经济理论,我找到中国 1979-2008 年全国城镇居民人均消费以及城镇居民人均可支配收入、城镇居民消费者物价指数和 2004— 2008年各地区城镇居民人均消费以及城镇居民人均可支配收入、城镇居民消费者物价指数、以及银行一年期存款利率的官方数据。想借此来分析中国消费的影响因素以及它们具体是如何对消费产生影响的。针对这一模型,有以下两个假定。一,自改革开放以来,我国人均消费倾向呈现缓慢的递减趋势,即保持粘性。这一假定符合我国居民的储蓄——消费心理,也与其他一些发展中国家的情况大体一致。二,由储蓄和消费的替代关系,可以假定刺激储蓄的因素,会制约消费。我们知道提高利率会刺激储蓄,因而我把利率也引入模型的分析中。 以下对我所找的数据作一一说明 : 1、城镇居民人均消费水平。借此来代表城镇居民的消费支出情况,这是将要建立计量经济学模型的被解释变量。由下图可以看到消费是逐年增加的,与此同时,人均可支配收入也是逐年增加,隐含着两者可能有很高的线性相关性这层意思。
计量经济学实验7虚拟变量模型
实验七虚拟变量 【实验目的】 掌握虚拟变量的设置方法。 【实验内容】 一、试根据表7-1的1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立我国城镇居民彩电需求函数; 资料来源:据《中国统计年鉴1999》整理计算得到 二、试建立我国税收预测模型(数据见实验一); 三、试根据表7-2的资料用混合样本数据建立我国城镇居民消费函数。
最低收入户 2397.6 2476.75 0 2523.1 2617.8 1 低收入户 2979.27 3303.17 0 3137.34 3492.27 1 中等偏下户 3503.24 4107.26 0 3694.46 4363.78 1 中等收入户 4179.64 5118.99 0 4432.48 5512.12 1 中等偏上户 4980.88 6370.59 0 5347.09 6904.96 1 高收入户 6003.21 7877.69 0 6443.33 8631.94 1 最高收入户 7593.95 10962.16 8262.42 12083.79 1 资料来源:据《中国统计年鉴》1999-2000整理计算得到 【实验步骤】 一、我国城镇居民彩电需求函数 ⒈相关图分析; 键入命令:SCAT X Y ,则人均收入与彩电拥有量的相关图如7-1所示。 从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下: ?? ?=低收入家庭 中、高收入家庭 1D 图7-1 我国城镇居民人均收入与彩电拥有量相关图 ⒉构造虚拟变量; 方式1:使用DATA 命令直接输入;
回归分析报告实验课实验8
实验报告八实验课程:回归分析实验课 专业:统计学 年级: : 学号: 指导教师: 完成时间: 得分:
教师评语: 学生收获与思考:
实验八 含定性变量的回归模型(4学时) 一、实验目的 1.掌握含定性变量的回归模型的建模步骤 3.运用SAS计算含定性变量的各种回归模型的各参数估计及相关检验统计量 二、实验理论与方法 在实际问题的研究中,经常会遇到一些非数量型的变量。如品质变量;性别;战争与和平。我们把这些品质变量也称为定性变量,在建立回归模型的时候我们需要考虑到这些定性变量。定性变量的回归模型分为自变量含定性变量的回归模型和因变量是定性变量的回归模型。 自变量含有定性变量的时候,我们一般引进虚拟变量,将这些定性变量数量化。例如研究粮食产量问题,y为粮食产量,x为施肥量,另外考虑气候问题,分为正常年份和干旱年份两种情况,这个问题数量化方法就是引入一个0-1型变量D,令D i=1 表示正常年份,D i=0表示干旱年份, 粮食产量的回归模型为:y i =β +β 1 x i +β 2 D i +ε i。 因变量是定性变量时,一般用logistic回归模型(分组数据的logistic回归模型,未分组数据的logistic回归模型,多类别的logistic回归模型),probit回归模型等。 三. 实验容 1.用DATA步建立一个永久SAS数据集,数据集名为xt103,数据见表21;对数据集xt103,建立y对公司规模和公司类型的回归,并对所得到的模型进行解释。 2.研制一种新型玻璃,对其做耐冲实验。用一个小球从不同的高度h对玻璃做自由落体撞击,玻璃破碎记为y=1,玻璃未破碎记y=0.数据见表22.是对表中数据建立玻璃耐冲性对高度h的logistic回归,并解释回归方程的含义。 3.某学校对本科毕业生的去向做了一个调查,分析影响毕业去向的相关因素,结果见表23.其中毕业去向“1”=工作,“2”=读研,“3”=出国留学。性别“1”=男生,“0”=女生。用多类别的Logisitic回归分析影响毕业去向的因素。 四.实验仪器 计算机和SAS软件 五.实验步骤和结果分析 1.用DATA步建立一个永久SAS数据集,数据集名为xt103,数据见表21;对数据集xt103,建立y对公司规模和公司类型的回归,并对所得到的模型进行解释。
第五讲 虚拟变量模型
第七讲 经典单方程计量经济学模型:专门问题 虚拟变量模型 学习目标: 教学基本内容 虚拟变量 许多经济变量是可以定量度量,例如:商品需求量、价格、收入、产量等; 但有一些影响经济变量的因素是无法定量度量。 例如:职业、性别对收入的影响, 战争、自然灾害对 GDP 勺影响,季节对某些产品(如冷饮)销售的影响等。 定性变量:把职业、性别这样无法定量度量的变量称为定性变量。 定量变量:把价格、 收入、 销售额这样可以可以定量度量的变量称为定量变 量。 为了能够在模型中能够反映这些因素的影响, 型的功能,需要将它们“量化”。 这种“量化” 来完成的。 根据这些因素的属性类型, 构造只取 称为虚拟变量( dummy variables ) ,记为 D 。 例如:反映性别的虚拟变量 D 1;男 0;女 1; 本科学历 反映文化程度的虚拟变量 D 0;1非;本本科科学学历历 一般地,基础类型和肯定类型取值为 1;比较类型和否定类型取值为 0。 二、 虚拟变量的设置原则 设置原则: 每一定性变量(qualitative variable )所需的虚拟变量个数要比该定性变量的状 态类别数(categories 少1。即如果有m 种状态,只在模型中引入m-1个虚拟变量。 例如,冷饮的销售量会受到季节变化的影响。季节定性变量有春、夏、秋、 冬 4 种状态,只需要设置 3 个虚拟变量: 1. 2. 3. 4. 了解什么是虚拟变量以及什么是虚拟变量模型; 理解虚拟变量的设置原则; 掌握虚拟变量模型的两种基本引入方式(加法方式和乘法方式) 能够自行设计虚拟变量模型,并能够解释其中蕴含的经济意义; 提高模型的精度, 拓展回归模 通常是通过引入“虚拟变量” 0”或“1”的人工变量, 通常 虚拟变量只作为解释变量。
用加法乘法方式引入虚拟变量 阿尔蒙多项式法估计有限分布滞后模型
《计量经济学》上机指导手册三 目录 §3.1 实验介绍 (2) 3.1.1 上机实验名称 (2) 3.1.2 实验目的 (2) 3.1.3 实验要求 (2) 3.1.4 数据资料 (2) §3.2 用加法和乘法加入虚拟变量 (3) 3.2.1 用加法方式引入虚拟变量 (3) 3.2.2 用乘法方式引入虚拟变量 (5) §3.3 阿尔蒙多项式法估计有限分布滞后模型 (7) 3.3.1 参数估计(方法一) (7) 3.3.2 参数估计(方法二) (8) 3.3.3 还原模型 (9) §3.4 Granger因果检验............................................................................. 错误!未定义书签。 3.4.1 序列平稳性检验及调整........................................................... 错误!未定义书签。 3.4.2 Granger因果检验...................................................................... 错误!未定义书签。
§3.1 实验介绍 3.1.1 上机实验名称 用加法和乘法引入虚拟变量 阿尔蒙多项式估计有限分布滞后模型 Granger因果检验 3.1.2 实验目的 通过对用加法和乘法引入虚拟变量、阿尔蒙多项式估计有限分布滞后模型、Granger因果检验的练习,掌握经典单方程模型中一些专门问题的理解及软件操作。 3.1.3 实验要求 根据实验数据,完成实验报告。对于已经完成的工作,请自我测评。将完成要求的标题标成蓝色,未完成的标成红色。例如: 3.1.4 数据资料 (1)《14-15-1 EViews上机数据 3.xls》中《Dummy Variable》 (2)《14-15-1 EViews上机数据 3.xls》中《Almon》 (3)《14-15-1 EViews上机数据 3.xls》中《Granger Test》
计量经济学实验项目与主要内容
《计量经济学》实验项目与主要内容 目录 实验1—— 【实验目的】 了解Eviews软件的基本操作对象,掌握基本操作方法。 【实验内容】 1A-1 Eviews软件的安装与启动 1A-2 工作文件的建立 1A-3数据的输入、编辑与生成 1A-4观察数据的基本特征 1A-5一元回归模型的估计、检验及预测 【实验步骤】 1B-1 观看“”,模仿其中的操作。(点击超链接即可) 1B-2 根据下文示范步骤,完成操作 1B-3 独立完成指定两个实验课题
1B-1 Eviews软件的入门基本操作 观看“”,模仿其中的操作。(点击超链接即可)。 1B-2 根据下文示范步骤,完成操作 例:四川省城市居民1978-1998年家庭人均生活性消费支出Y与人均可支配收入X 的 建立文件: Eviews的操作在工作文件中进行,故首先要有工作文件,然后进行数据输入、分析等等操作。主要有如下几种方法: 【1】操作命令法:create 数据类型样本区间 【2】新建文件:File/New/Workfile,出现对话框“工作文件范围”,选取或填上数据类型、起止时间。OK后,得到一个无名字的工作文件,其中有: 时间范围、当前工作文件样本范围、filter 、默认方程、系数向量C、序列RESID。【3】读已存在文件:File/Open/Workfile。 (1)操作命令法:create a 1978 1998(回车,即完成,见下图所示) (2)菜单操作法:file\new\workfile(单击)\再弹出的对话框中点选“数据类
型”、输入“样本区间”\点击“OK” 输入样本数据 主要有如下几种方法: 【1】从键盘输入:Quick/Empty Group (Edit Series),打开组窗口,产生一个untitled“Group”;按列在表中输入序列名(在OBS)及其数据,每输入一个数 据完,敲一次enter。 【2】从Excel复制数据:先取定Excel中的数据区域,选“复制”;其次,打开Eview,同,建工作文件,使样本区域包含与被复制数据同样多的观察值个数;第三,击 Quick/Empty Group (Edit series);第四,按向上滚动指针,击数据区OBS右边 的单元格,点Edit/Paste,再退出,选No,于是,在工作文件中有被复制的数据 序列的图标。 【3】从Excel复制部分数据到已存在的序列中:取定要复制的数据,复制之;打开包含已存在序列的Group窗口,使之处于Edit模式(开关键是Edit+);将光标指 到目标单元格,点Edit/Paste, (1) 命令操作法:data x y(回车,即完成,见下图所示) 在弹出的对话框中输入各个样本数据有三种方法 ①直接输入: ②若样本数据以表格形式给出,可直接复制——粘贴; ③若样本数据以表格(excel)或文本文件(txt.)格式给出,可直接导入。 ★若样本数据以表格(excel)格式给出, 文件名为sichuan, 保存在“实验”文件夹中,数据导入操作如下: (关闭文件sichuan),点击file\import\read text-lotus\excel
虚拟解释变量回归
虚拟变量回归 第一节虚拟变量 一、虚拟变量的基本概念 在前面的分析中,被解释变量主要受到一些可以直接度量的变量影响,如收入、产出、商品需求量、价格、成本、资金、人数等。但现实经济生活中,影响被解释变量变动的因素,除了这些可以直接获得实际观测数据的定量变量外,还包括一些本质上为定性因素(或称属性因素)的影响,例如性别、种族、肤色、职业、季节、文化程度、战争、自然灾害、政府
经济政策的变动等因素。在实际经济分析中,这些定性变量有时具有不可忽视的重要影响。例如,研究某个企业的销售水平,产业部门(制造业、零售业)、所有制(私营、非私营)、地理位置(东、中、西部)、管理者素质的高低等是值得经常考虑的影响因素,这些因素有共同的特征,即都是表示某种属性的,不能直接用数据精确描述的因素。因此,被解释变量的变动经常是定量因素和属性因素共同作用的结果。在计量经济模型中,应当同时包含定量和属性两种因素对被解释变量的影响作用。 定量因素是指那些可直接测度的数值型因素,如GDP、M2等。定性因素,或称为属性因素,是不能直接测度的、说明某种属性或状态存在与否的非数值型因素,如男性或女性、城市居民或非城市居民、气候条件正常或异常、政府经济政策不变与改革等。在计量经济学的建模中应当将定量因素和定性因素同时纳入模型之内。 为了在模型中反映定性因素,可以将定性因素转化为虚拟变量去表现。虚拟变量(或称为属性变量、双值变量、类型变量、定性变量、二元型变量等),是人工构造的取值为0和1的作为属性变量代表的变量,一般用字母D(或DUM,英文dummy的缩写)表示。属性因素通常具有若干类型或水平,通常虚拟变量的取值为0和1,当虚拟变量取值为0,即D=0时,表示某种属性或状态不出现或不存在,即不是某种类型;当虚拟变量取值为1,即D=1时,表示某种属性或状态出现或存在,即是某种类型。例如,构造政府经济政策人工变量,当经济政策不变时,虚拟变量取值为0,当经济政策改变时,虚拟变量取值为1。这种做法实际上是一种变换或映射,将不能精确计量的定性因素的水平或状态变换为用0 和 1 来定量描述。 二、虚拟变量的设置规则 在计量经济学模型中引入虚拟变量,可以使我们同时兼顾定量因素和定性因素的影响和作用。但是,在设置虚拟变量时应遵循一定的规则。 1、虚拟变量数量的设置规则 虚拟变量个数的设置规则是:若定性因素有m个相互排斥的类型(或属性、水平),在有截距项的模型中只能引入m-1个虚拟变量,否则会陷入所谓“虚拟变量陷阱”,产生完全的多重共线性。在无截距项的模型中,定性因素有m个相互排斥的类型时,引入m个虚拟变量不会导致完全多重共线性,不过这时虚拟变量参数的估计结果,实际上是D=1时的样本均值。 例如,城镇居民和农村居民住房消费支出的模型可设定为:
计量经济学实验报告 虚拟变量
实验三:虚拟变量模型一、研究的目的与要求 根据下表2009年我国城镇居民人均收入与住房方面消费性支出的统计资料建立我国城镇居民住房方面消费性支出函数。 二、模型设立 1、问题描述:2009年我国城镇居民人均收入对住房方面消费性支出的影响。 2、数据: 我国城镇居民家庭抽样调查资料 平均每人全部年 项目住房 D 收入 (元) 困难户60.83 4935.81 0 最低收入户84.73 5950.68 0 低收入户123.92 8956.81 0 中等偏下户178.48 12345.17 0 中等收入户261.37 16858.36 0 中等偏上户526.36 23050.76 1 高收入户659.61 31171.69 1 最高收入户1482.11 51349.57 1 三、相关图分析; 1. 键入命令:SCAT X Y,则人均收入与住房方面消费性支出的相关散点图如下图所示。 从相关图可以看出,前5个样本点(即中低收入家庭)与后3个样本点(中、
高收入)的消费性支出存在较大差异,因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下: 2. 构造虚拟变量。 使用SMPL和GENR命令直接定义。 DATA D1 GENR XD=X*D1 3. 估计虚拟变量模型: 再由t检验值判断虚拟变量的引入方式,并写出各类家庭的消费性支出函数。虚拟变量模型的估计结果如下: Dependent Variable: Y Method: Least Squares Date: 01/03/12 Time: 15:25 Sample: 2001 2008 Included observations: 8 Variable Coefficient Std. Error t-Statistic Prob.?? X 0.016400 0.005743 2.855676 0.0461 D1 -327.1185 118.4766 -2.777039 0.0498 XD 0.018709 0.006356 2.943588 0.0422 C -19.00288 61.67034 -0.308136 0.7734 R-squared 0.992173 ????Mean dependent var 422.1763 Adjusted R-squared 0.986303 ????S.D. dependent var 479.4838 S.E. of regression 56.11683 ????Akaike info criterion 11.19960 Sum squared resid 12596.40 ????Schwarz criterion 11.23932 Log likelihood -40.79841 ????F-statistic 169.0152 Durbin-Watson stat 3.162055 ????Prob(F-statistic) 0.000115 我国城镇居民住房方面消费性支出函数的估计结果为: t (-0.308136) ( 2.855676) (-2.777039) (2.943588) 2 R=0.9921732 R=0.986303 F=169.0152 S.E=56.11683 虚拟变量的回归系数的t检验都是显着的,且模型的拟合优度很高,说明我
(VR虚拟现实)第八章虚拟解释变量回归
(VR虚拟现实)第八章虚拟解释变量回归
第八章虚拟变量回归 引子 男女大学生的消费真的有差异吗? 在校大学生的消费行为越来越受到社会的关注,学生家长也很关心自己的子女上大学究竟要准备多少花费。由共青团中央、全国学联共同发布的《2004中国大学生消费与生活形态研究报告》显示,当代大学生在消费结构方面呈现出多元化趋势。大学生除了日常生活费开支以外,还有人际交往消费、网络通讯消费、书报消费、衣着类消费、化妆品类消费、电脑类消费、旅游类消费、食品类消费、学习用品类消费、各种考证类等消费。大学生时尚化、个性化消费增多已成为趋势与潮流。不同性别大学生的消费结构有所不同,专科生、本科生、研究生的消费结构更有差异。有的记者调查发现,不同年级之间,男女同学之间,消费水平、消费结构、消费方式上都存在着差异。年级越高,消费水平也随之增长,随着阅历的增加,对自己形象的重视,精神享受的追求、学习的投入、配备手机电脑的需求也随之增长。同年级的男生的消费高于女生,虽然女生在化妆品、衣服饰品方面的投入明显高于男生。然而时代在变,对美的追求已不再限于女生,男生对于个人形象、装扮也已慢慢重视起来。此外男生在人际交往方面比女生投入了更多的"本钱"。请客吃饭、朋友聚会、节日送礼已不再罕见。所谓的"人情消费"已从社会向校园中扩张蔓延,而在乎"面子"的男同胞已成为追随这一潮流的"先驱"。高年级女生对于吃饭的投入相对较少,而在化妆品、服饰、零食方面的投入却增长不少。(注:来源于Solie教育网、网易教育频道、新华网等)为了研究男女大学生、不同层次大学生、不同年级大学生的消费结构是否有差异,需要将这些定性的因素引入计量模型,怎样才能在模型中有效地表示这些定性因素的作用呢?
实验七_虚拟变量
实验七虚拟变量 7.1 实验目的 掌握虚拟变量的基本原理,对虚拟变量的设定和模型的估计与检验,以及相关的EViews软件操作方法。 7.2 实验容 建立市场用煤销售量模型 表7.1给出了全国市场用煤销售量(单位:万吨)的季度数据,试建立用时间变量拟合的煤销售量模型。 表7.1 数据来源:《中国统计年鉴》1989年,中国统计 7.3 实验步骤 7.3.1 市场用煤销售量模型 (1)相关图分析 根据表7.1数据建立Y的趋势图,如图7.1。
2500 300035004000450050005500 1982 1983 1984 1985 1986 1987 1988 Y 图 7.1 (2)构造虚拟变量 从图7.1可以看出,从长期趋势看,煤销售量随时间增长而不断增长,且随季节不同呈现明显的周期性变化,由于受到取暖用煤的影响,每年第四季度的销售量大大高于其他季度。鉴于是季节数据可设三个季节变量如下: 1(4 季度) 1(3季度) 1 (2季度) D 1 = D 2 = D 3 = 0(1, 2, 3 季度) 0(1, 2, 4季度) 0(1, 3, 4季度) 模型中要加入时间因素t ,以及虚拟变量D1,D2和D3。 用EViews 生成时间变量及虚拟变量序列,采用的方法为: 在工作文件窗口点击Quick/Generate Series ,在弹出的由方程生成序列的窗口,输入t=trend(1981Q4),如图7.2,即可以生成表7.3中时间变量t 的数据。 生成季度虚拟变量数据,以季节数据D 1为例,在生成序列窗口输入的EViews 命令是D1= seas(4)。用相似的方法生成D2和D3。得到建模数据如表7.3所示。 图7.2
第八章 虚拟变量实验报告
第八章虚拟变量实验报告 一、研究目的 改革开放以来,我国经济保持了长期较快发展,我国对外贸易规模也日益增长。尤其是2002年中国加入WTO之后,我国对外贸易迅速扩张。2012年,我国进出口总值38667.6亿美元,与上年同期相比增长6.2%,我国贸易总额首次超过美国,成为世界贸易规模最大的国家。为了考察我国对外贸贸易与国内生产总值的关系是否发生变化,以国内生产总值代表经济整体发展水平,以对外贸易总额代表对外贸易发展水平,分析我国对外贸易发展受国内生产总值的影响程度。 二、模型设定 为研究我国对外贸易发展规模受我国总体经济发展程度影响,引入国内生产总值为自变量。设定模型为: Y t=β +β1X t+ U t 参数说明: Y t ——对外贸易总额(单位:亿元) X t ——国内生产总值(单位:亿元) U t——随机误差项 收集到数据如下(见表2-1) 表2-1 1985-2011年我国对外贸易总额和国内生产总值单位:亿元 年份对外贸易总额 亿元 国内生产总值 亿元 年份 对外贸易总额 亿元 国内生产总值 亿元 1985 2066.7 9016.03 1999 29896.2 89677.05 1986 2580.4 10275.18 2000 39273.2 99214.55 1987 3084.2 12058.62 2001 42183.6 109655.17 1988 3821.8 15042.82 2002 51378.2 120332.69 1989 4155.9 16992.32 2003 70483.5 135822.76 1990 5560.1 18667.82 2004 95539.1 159878.34 1991 7225.8 21781.5 2005 116921.8 184937.37 1992 9119.6 26923.48 2006 140971.4 216314.43 1993 11271 35333.92 2007 166740.2 265810.31 1994 20381.9 48197.86 2008 179921.5 314045.43 1995 23499.9 60793.73 2009 150648.1 340902.81 1996 24133.8 71176.59 2010 201722.1 401512.8 1997 26967.2 78973.03 2011 236402 472881.56 1998 26693.823 73617.66322