数据分析验证性实验报告

数据分析验证性实验报告
一、题目
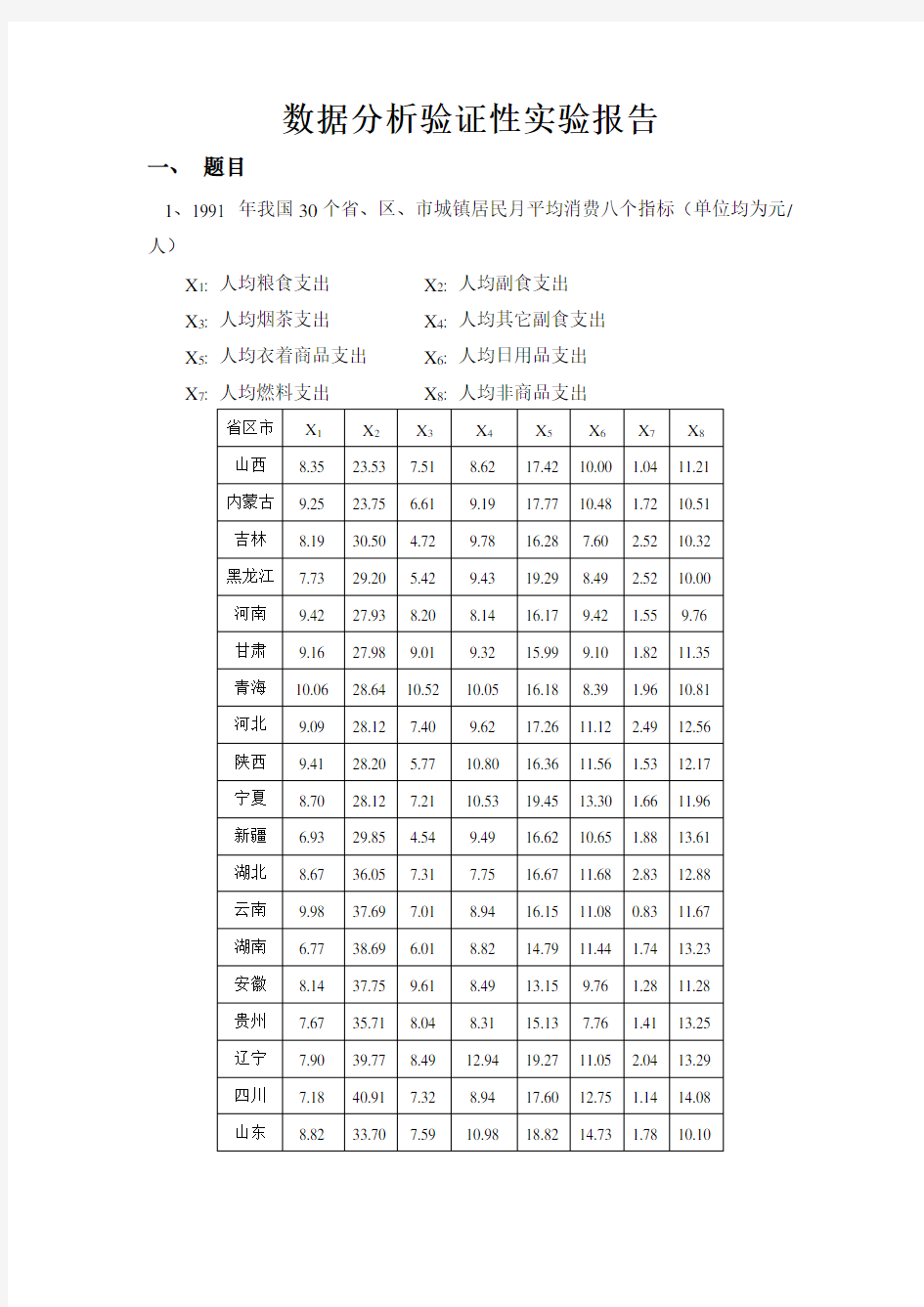
1、1991 年我国30个省、区、市城镇居民月平均消费八个指标(单位均为元/人)
X1: 人均粮食支出X2: 人均副食支出
X3: 人均烟茶支出X4: 人均其它副食支出
X5: 人均衣着商品支出X6: 人均日用品支出
X7: 人均燃料支出X8: 人均非商品支出
省区市X1X2X3X4X5X6X7X8
山西8.35 23.53 7.51 8.62 17.42 10.00 1.04 11.21
内蒙古9.25 23.75 6.61 9.19 17.77 10.48 1.72 10.51
吉林8.19 30.50 4.72 9.78 16.28 7.60 2.52 10.32
黑龙江7.73 29.20 5.42 9.43 19.29 8.49 2.52 10.00
河南9.42 27.93 8.20 8.14 16.17 9.42 1.55 9.76
甘肃9.16 27.98 9.01 9.32 15.99 9.10 1.82 11.35
青海10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.81
河北9.09 28.12 7.40 9.62 17.26 11.12 2.49 12.56
陕西9.41 28.20 5.77 10.80 16.36 11.56 1.53 12.17
宁夏8.70 28.12 7.21 10.53 19.45 13.30 1.66 11.96
新疆 6.93 29.85 4.54 9.49 16.62 10.65 1.88 13.61
湖北8.67 36.05 7.31 7.75 16.67 11.68 2.83 12.88
云南9.98 37.69 7.01 8.94 16.15 11.08 0.83 11.67
湖南 6.77 38.69 6.01 8.82 14.79 11.44 1.74 13.23
安徽8.14 37.75 9.61 8.49 13.15 9.76 1.28 11.28
贵州7.67 35.71 8.04 8.31 15.13 7.76 1.41 13.25
辽宁7.90 39.77 8.49 12.94 19.27 11.05 2.04 13.29
四川7.18 40.91 7.32 8.94 17.60 12.75 1.14 14.08
山东8.82 33.70 7.59 10.98 18.82 14.73 1.78 10.10
江西 6.25 35.02 4.72 6.28 10.03 7.15 1.93 10.39
福建10.60 52.41 7.70 9.98 12.53 11.70 2.31 14.69
广西7.27 52.65 3.84 9.16 13.03 15.26 1.98 14.57
海南13.445 55.85 5.50 7.45 9.55 9.52 2.21 16.30
天津10.85 44.68 7.32 14.51 17.13 12.08 1.26 11.57
江苏7.21 45.79 7.66 10.36 16.56 12.86 2.25 11.69
浙江7.68 50.37 11.35 13.30 19.25 14.59 2.75 14.87
北京7.78 48.44 8.00 20.51 22.12 15.73 1.15 16.61
西藏7.94 39.65 20.97 20.82 22.52 12.41 1.75 7.90
上海8.28 64.34 8.00 22.22 20.06 15.12 0.72 22.89
广东12.47 76.39 5.52 11.24 14.52 22.00 5.46 25.50 设前20个省份为第1类G1,21-27号省份(即福建,…,北京)为第2类
G2,最后三个省份(西藏、上海、广东)待判。
试判别西藏、上海、广东各属哪一类,并计算判别率的回代估计。80
二、程序
1.录入数据
2. 按“Analyze → Classify → Discriminant ”顺序,打开Discriminant Analysis主对话框,选择“类别”为Grouping Variable(分组变量),定义“类别”的区域,选择x1、x2、x3、x4、x5、x6、x7、x8为Indepent Variable(解释变量)。
3. 点击Statistics按钮,进入Statistics对话框,在Descriptives栏选择Mean(对各组的各个变量作均值和标准差的描述;②在Function Coefficients栏(判别函数的系数)选择Fisher’s(Fisher线性判别函数)和Unstandardized(判别方程的非标准化系数)非标准化函数;③在Matrices栏选Within-groups correlation(组
内相关矩阵),Within-groups covariance(组内协方差矩阵),Separate-groups covariance(组间协方差矩阵) ,Total covariance(总
协方差矩阵)。
4.点击Classification按钮,进入Classification对话框。在Prior Probabilities栏选择All groups equal;②在display栏选择casewise
results(每个个体的结果),Summerry table(综合表)
5. 点击Save按钮,保存选项中可以选择预测的分类、判别得分
以及所属类别的概率。
三、运行结果
表1
协方差矩阵a
类别x1 x2 x3 x4 x5 x6 x7 x8
1 x1 1.14
2 -2.486 .886 .432 .809 .328 -.049 -.512
x2 -2.486 28.166 .604 -.289 -2.989 1.861 -.353 3.573 x3 .886 .604 2.639 .407 .339 .204 -.208 -.027 x4 .432 -.289 .407 1.908 2.167 1.204 .069 .277 x5 .809 -2.989 .339 2.167 4.862 2.371 .167 .260 x6 .328 1.861 .204 1.204 2.371 3.920 -.176 .894 x7 -.049 -.353 -.208 .069 .167 -.176 .275 -.073 x8 -.512 3.573 -.027 .277 .260 .894 -.073 1.820 2 x1 5.788 4.060 -1.377 -3.903 -6.551 -4.759 -.047 .843
x2 4.060 15.941 -3.326 -9.715 -11.772 -2.618 1.069 5.911 x3 -1.377 -3.326 5.397 4.640 6.373 1.030 .389 -.242 x4 -3.903 -9.715 4.640 19.286 17.225 5.855 -1.672 1.189 x5 -6.551 -11.772 6.373 17.225 18.599 6.866 -.976 -.593 x6 -4.759 -2.618 1.030 5.855 6.866 4.946 -.275 .535 x7 -.047 1.069 .389 -1.672 -.976 -.275 .339 .062 x8 .843 5.911 -.242 1.189 -.593 .535 .062 4.024 合计x1 2.324 2.272 .362 -.083 -1.058 -.380 -.011 .277
x2 2.272 88.673 .348 7.799 -7.701 10.541 .719 13.319 x3 .362 .348 3.181 1.475 1.689 .489 -.055 .022 x4 -.083 7.799 1.475 7.476 5.113 3.789 -.219 1.964 x5 -1.058 -7.701 1.689 5.113 7.967 2.892 -.135 -.353 x6 -.380 10.541 .489 3.789 2.892 5.493 -.082 2.196 x7 -.011 .719 -.055 -.219 -.135 -.082 .287 .067 x8 .277 13.319 .022 1.964 -.353 2.196 .067 3.614 a. 总的协方差矩阵的自由度为 26。
该表给出各类的协方差矩阵和总协方差矩阵。
表2:有关典型判别函数的输出表
特征值
函数特征值方差的 % 累积 % 正则相关性
1 4.937a100.0 100.0 .912
a. 分析中使用了前 1 个典型判别式函数。
Wilks 的 Lambda
函数检验Wilks 的
Lambda 卡方df Sig.
1 .168 37.404 8 .000
标准化的典型判别式函
数系数
函数
1
x1 .376
x2 .891
x3 -.118
x4 1.006
x5 -.644
x6 .393
x7 .372
x8 -.310
结构矩阵
函数
1
x2 .733 x8 .349 x6 .274 x4 .238 x1 .120 x7 .078 x5 -.056 x3 .021 判别变量和标准化典型判别式函数之间的汇聚组间相关性
按函数内相关性的绝对大小排序的变量。
组质心处的函数
类别函数1
1 -1.265
2 3.614
在组均值处评估的非标
准化典型判别式函数
分类处理摘要
已处理的27 已排除的缺失或越界组代码0 至少一个缺失判别变量0 用于输出中27
组的先验概率
类别先验
用于分析的案例
未加权的已加权的
1 .500 20 20.000
2 .500 7 7.000 合计 1.000 27 27.000
解:由上可得:
分类函数系数
类别
1 2
x1 6.830 8.051
x2 2.132 2.997
x3 -.395 -.710
x4 -2.117 -.126
x5 5.923 4.822
x6 -.236 .703
x7 7.089 10.460
x8 2.280 1.294
(常量) -119.594 -171.802
Fisher 的线性判别式函数
(1)、判别函数表达式为:
F2=8.051x1+2.997x2-0.710x3-0.126x4+4.822x5+0.703x6+10.466x7+
1.294x8-171.802
F1=6.836x1+2.132x2-0.395x3-2.117x4+5.923x5-0.236x6+7.089x7+2.2
80x8-119.594
协方差S1矩阵为:
1 x1 1.14
2 -2.486 .886 .432 .809 .328 -.049 -.512
x2 -2.486 28.166 .604 -.289 -2.989 1.861 -.353 3.573
x3 .886 .604 2.639 .407 .339 .204 -.208 -.027
x4 .432 -.289 .407 1.908 2.167 1.204 .069 .277
x5 .809 -2.989 .339 2.167 4.862 2.371 .167 .260
x6 .328 1.861 .204 1.204 2.371 3.920 -.176 .894
x7 -.049 -.353 -.208 .069 .167 -.176 .275 -.073
x8 -.512 3.573 -.027 .277 .260 .894 -.073 1.820 协方差S2矩阵为
协方差矩阵s2a
类别 x1 x2 x3 x4 x5 x6 x7 x8 2
x1 5.788 4.060 -1.377 -3.903 -6.551 -4.759 -.047 .843 x2 4.060 15.941 -3.326 -9.715 -11.772 -2.618 1.069 5.911 x3 -1.377 -3.326 5.397 4.640 6.373 1.030 .389 -.242 x4 -3.903 -9.715 4.640 19.286 17.225 5.855 -1.672 1.189 x5 -6.551 -11.772 6.373 17.225 18.599 6.866 -.976 -.593 x6 -4.759 -2.618 1.030 5.855 6.866 4.946 -.275 .535 x7 -.047 1.069 .389 -1.672 -.976 -.275 .339 .062 x8
.843
5.911
-.242
1.189
-.593
.535
.062
4.024
])1()1[(2
1
?221121S n S n n n S -+--+===∑
(2)判别准则:
若F1>F2,则1G x ∈; 若F1 样品号 原类号 判归类别 1 1 1 2 1 1 3 1 1 4 1 1 5 1 1 6 1 1 7 1 1 8 1 1 9 1 1 10 1 1 11 1 1 12 1 1 13 1 1 14 1 1 15 1 1 16 1 1 17 1 1 18 1 1 19 1 1 20 1 1 21 2 2 22 2 2 23 2 2 24 2 2 25 2 2 26 2 2 27 2 2 分类结果a 类别 预测组成员 合计1 2 初始计数 1 20 0 20 2 0 7 7 % 1 100.0 .0 100.0 2 .0 100.0 100.0 a. 已对初始分组案例中的 100.0% 个进行了正确分类。 由此可知,初始分组案例分组100%正确,故无误判,即误判估计为零。 (4) 对待判样品判别归类结果 省市区判别函数F2的值判别函数F1的值判归类别 西藏121.86195 127.70307 1 上海202.54867 196.54101 2 广东297.00534 280.24294 2 质性研究方法 一、质性研究方法的定义及特点 “质性研究”这个词在台湾、港、澳地区用得比较多,在大陆有的称其为“质的研究”、“质化研究”;还有的为将其与定性研究、定量研究相比较,称为“定质研究”。 1.质性研究的定义 所谓质性研究,就是“以研究者本人为研究工具、在自然情境下采用多种资料收集方法对社会现象进行整体性探究、使用归纳法分析资料和形成理论、通过与研究对象互动对其行为和意义建构获得解释性理解的一种活动”。 2.质性研究的特点: 1)自然主义的探究传统 质性研究是在自然情境下,研究者与被研究者直接接触,通过面对面的交往,实地考察被研究者的日常生活状态和过程,了解被研究者所处的环境以及环境对他们产生的影响。自然探究的传统要求研究者注重社会现象的整体性和关系性。在对一个事件进行考察时,不仅要了解事件本身,而且要了解事件发生和变化时的社会文化背景以及对该实践与其他事件之间的联系。 2)对意义的“解释性理解” 质性研究的主要目的是对被研究者的个人经验和意义建构作“解释性理解”,从他们的角度理解他们的行为及其意义解释。由于理解是双方互动的结果,研究者需要对自己的“前设”和“偏见”进行反省,了解自己与对方达到理解的机制和过程。 3)研究是一个演化的过程 随着实际情况的变化,研究者要不断调整自己的研究设计,收集和分析资料的方法,建构理论的方式。因此对研究的过程必须加以细致的反省和报道。 4)使用归纳法,自下而上分析资料 质性研究中的资料分析主要采纳归纳的方法,自下而上在资料的基础上建立分析类别和理论假设,然后通过相关检验得到充实和系统化。因此,“质性研究”的结果只适用于特定的情境和条件,不能推广到样本之外。 5)重视研究关系 由于注重解释性理解,质性研究对研究者与被研究者之间的关系非常重视,特别是伦理道德问题。研究者必须事先征求被研究者的同意,对他们所提供的信息严格保密,与他们保持良好的关系,并合理回报他们所给予的帮助。 “质性研究”就是一种“情境中”的研究。质性研究的特点决定了这是一种非常适合教育领域的研究。 3.质性研究与量的研究的区别:(只说黑体字) 验证性实验——触发器功能测试及其应用实验报告纸模版 3、 D触发器在CP的前沿发生翻转,触发器的次态取决于CP脉冲上升沿来到之前D端广州大学学生实验报告 n+1的状态,即Q = D。因此,它具有置“0”和“1”两种功能。由于在CP=1期间电 路具有阻塞作用,在CP=1期间,D端数据结构变化,不会影响触发器的输出状态。开课学院及实验室:电子楼410 2012年月日 和分别是置“0”端和置“1”端,不需要强迫置“0”和置“1”时,都应是高机电学院年级、专学院电气102 姓名夏方舟学号 1007300069 业、班电平。74LS74(CC4013),74LS74(CC4042)均为上升沿触发器。以下为74LS74 实验课程名称成绩数字电子技术实验的引脚图和逻辑图。 指导实验项目名称王晓刚验证性实验——触发器功能测试及其应用老师 一、实验目的 二、实验原理 三、使用仪器、材料 四、实验步骤 五、实验过程原始记录(数据、图表、计算等) 六、实验结果及分析 一、实验目的 三、使用仪器、材料 1、熟悉基本RS触发器,JK,D,T触发器的功能测试及其使用方法; 1、数字电路实验箱; 2、能进行触发器之间的相互转换; 2、数字双综示波器; 3、学习触发器的一些应用。 3、指示灯; 4、 74LS00、74LS74。 四、实验步骤二、实验原理 1、触发器是一个具有记忆功能的二进制信息存储器件,是构成多种时序电路的最五、实验过程原始记录,数据、图表、计算等~ 基本逻辑单元,也是数字逻辑电路中一种重要的单元电路。在数字系统和计算机中 有着广泛的应用。触发器具有两个稳定状态,即“0”和“1”,在一定的外界信号作 用下,可以从一个稳定状态翻转到另一个稳定状态。触发器有集成触发器和门电路 (主要是“与非门”)组成的触发器。按其功能可分为有RS触发器、JK触发器、D 触发器、T功能等触发器。触发方式有电平触发和边沿触发两种。 数据分析实验报告 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58- 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 统计量 全国居民 农村居民 城镇居民 N 有效 22 22 22 缺失 均值 1116.82 747.86 2336.41 中值 727.50 530.50 1499.50 方差 1031026.918 399673.838 4536136.444 百分位数 25 304.25 239.75 596.25 50 727.50 530.50 1499.50 75 1893.50 1197.00 4136.75 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。 (2 )W 检验 结果:在Shapiro-Wilk 检验结果972.00 w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5 多维正态数据的统计量 数据: 南京天田设备有限公司 质量信息和数据分析管理规定 编制: 审核: 批准: 2007-06-01 发布 2007-07-01 实施 1 范围 本规定规定了质量信息和数据分析的职责和工作程序。 本规定适用于本公司实施质量信息和数据分析的管理和控制。 2 引用文件 GJB9001A-2001 质量管理体系要求 GB/T19001-2000 质量管理体系要求 CT-ZLSC-02-2007 质量手册 3 术语和定义 无条文。 4 职责 4.1 质量部 a) 负责公司质量信息的归口管理; b) 负责产品符合性质量信息和数据的收集、分析和处理,并对各部门的质量信息管理进行检查和考核评价。 4.2 市场部 a) 负责与顾客沟通过程和市场调研有关质量信息及数据的收集、传递; b) 负责合同完成及顾客满意等有关质量信息和数据的收集、传递。 c) 负责产品售后服务有关质量信息收集、传递。 4.3 技术部 负责产品设计、调试、测试的过程有关质量信息和数据的收集、传递。 4.4 生产部 a) 负责产品装配、调试、搬运、包装等过程有关质量信息和数据的收集、传递。 b) 负责基础设施、工作环境等有关质量信息和数据的收集、传递; c) 负责采购过程有关质量信息和数据的收集、传递; d) 负责生产计划等有关质量信息和数据的收集、传递; 4.5 总经办 负责与财务有关的产品质量成本、内外部质量损失等有关信息和数据的收集、传递。 5 工作程序 5.1 质量信息管理 5.1.1 信息收集 相关部门应识别、收集、传递有关的信息(包括量化的信息,即数据),并对信息进行分类、记录。 5.1.2 信息和数据的来源、内容 信息和数据主要来自监视和测量活动以及其他有关方面能客观地反映事实的资料,如市场分析、相关的科技发展动态、研制和生产计划报表、质量和财务报表、销售报表、售后服务报告、过程监视和测量记录、审核和评审结果、顾客的期望等。 5.1.2.1 质量部 收集的渠道: a) 对产品的检验验收和试验; c) 对产品质量问题的处理及不合格品的审理; d) 产品质量分析会; e) 内、外审和管理评审。 f) 监视和测量装置的校准和检定; 收集的信息和数据内容: a) 采购产品的合格率; b) 产品一次交验合格率、军验一次交验合格率; c) 质量目标完成情况考核; d) 内、外部审核和管理评审记录。 e) 计量器具送检率、合格率; 5.1.2.2 技术部 《数据分析》实验报告 班级:07信计0班学号:姓名:实验日期2010-3-11 实验地点:实验楼505 实验名称:样本数据的特征分析使用软件名称:MATLAB 实验目的1.熟练掌握利用Matlab软件计算均值、方差、协方差、相关系数、标准差与变异系数、偏度与峰度,中位数、分位数、三均值、四分位极差与极差; 2.熟练掌握jbtest与lillietest关于一元数据的正态性检验; 3.掌握统计作图方法; 4.掌握多元数据的数字特征与相关矩阵的处理方法; 实验内容安徽省1990-2004年万元工业GDP废气排放量、废水排放量、固体废物排放量以及用于污染治理的投入经费比重见表6.1.1,解决以下问题:表6.1.1废气、废水、固体废物排放量及污染治理的投入经费占GDP比重 年份 万元工业GDP 废气排放量 万元工业GDP 固体物排放量 万元工业GDP废 水排放量 环境污染治理投 资占GDP比重 (立方米)(千克)(吨)(%)1990 104254.40 519.48 441.65 0.18 1991 94415.00 476.97 398.19 0.26 1992 89317.41 119.45 332.14 0.23 1993 63012.42 67.93 203.91 0.20 1994 45435.04 7.86 128.20 0.17 1995 46383.42 12.45 113.39 0.22 1996 39874.19 13.24 87.12 0.15 1997 38412.85 37.97 76.98 0.21 1998 35270.79 45.36 59.68 0.11 1999 35200.76 34.93 60.82 0.15 2000 35848.97 1.82 57.35 0.19 2001 40348.43 1.17 53.06 0.11 2002 40392.96 0.16 50.96 0.12 2003 37237.13 0.05 43.94 0.15 2004 34176.27 0.06 36.90 0.13 1.计算各指标的均值、方差、标准差、变异系数以及相关系数矩阵; 2.计算各指标的偏度、峰度、三均值以及极差; 3.做出各指标数据直方图并检验该数据是否服从正态分布?若不服从正态分布,利用boxcox变换以后给出该数据的密度函数; 4.上网查找1990-2004江苏省万元工业GDP废气排放量,安徽省与江苏省是 否服从同样的分布? 《数据分析》实验报告 班级: 07信计0班 学号: 姓名: 实验日期 2010-3-11 实验地点: 实 验楼505 实验名称: 样本数据的特征分析 使用软件名称:MATLAB 1. 熟练掌握利用Matlab 软件计算均值、方差、协方差、相关系数、标准差 与变异系数、偏度与峰度,中位数、分位数、三均值、四分位极差与极差; 2. 熟练掌握jbtest 与lillietest 关于一元数据的正态性检验; 3. 掌握统计作图方法; 4. 掌握多元数据的数字特征与相关矩阵的处理方法; 安徽省1990-2004年万元工业GDP 废气排放量、废水排放量、固体废物排放 量以及用于污染治理的投入经费比重见表 6.1.1,解决以下问题: 表6.1.1 实 验 目 的 1. 计算各指标的均值、方差、标准差、变异系数以及相关系数矩阵; 2. 计算各指标的偏度、峰度、三均值以及极差; 3?做出各指标数据直方图并检验该数据是否服从正态分布?若不服从正态分布,利用boxcox变换以后给出该数据的密度函数; 4.上网查找1990-2004江苏省万元工业GDR废气排放量,安徽省与江苏省是否 服从同样的分布? 程序如下: clear;clc format ba nk %保留两位小数 %%%%%%%%%%%安徽省%数据%%%%%%%%%%%%%%%%%% A=[104254.40 519.48 441.65 0.18 94415.00 476.97 398.19 0.26 89317.41 119.45 332.14 0.23 63012.42 67.93 203.91 0.20 45435.04 7.86 128.20 0.17 46383.42 12.45 113.39 0.22 39874.19 13.24 87.12 0.15 38412.85 37.97 76.98 0.21 35270.79 45.36 59.68 0.11 35200.76 34.93 60.82 0.15 35848.97 1.82 57.35 0.19 40348.43 1.17 53.06 0.11 40392.96 0.16 50.96 0.12 37237.13 0.05 43.94 0.15 34176.27 0.06 36.90 0.13]; %计算各指标的均值、方差、标准差、变异系数、偏度、峰度以及极差 A1=[mea n(A);var(A);std(A);std(A)./mea n(A);skew ness(A,0);kurtosis(A,0)-3;ra nge( A)] %E均值 A2=[1/4 1/2 1/4]*prctile(A,[25 50 75]) % 十算各指标的相关系数矩阵 A3=corrcoef(A) %做岀各指标数据直方图 subplot(221),histfit(A(:,1),8) subplot(222),histfit(A(:,2),8) subplot(223),histfit(A(:,3),8) subplot(224),histfit(A(:,4),7) %检验该数据是否服从正态分布 for i=1:4 [h(i),p(i),lstat(i),cv(i)]=lillietest(A(:,i),0.05); end h,p %十算岀前二列不服从正态分布,利用boxcox变换以后给岀该数据的密度函数[t1,l1]=boxcox(A(:,1)) [t2,l2]=boxcox(A(:,2)) [t3,I3]=boxcox(A(:,3)) 质性研究:意义编码 《质性研究访谈》试读:意义编码 在社会科学中,编码和归类早已是文本分析的方法。编码是以一个或多个关键词与文本片段形成关联,以便随后对一种观点加以确认,而归类是对某种观点进行更系统的概念化,以便于量化。不过这两个术语通常是可以互换的。编码可以采用不同的形式进行,它是访谈文本的扎根理论、内容分析以及计算机辅助分析的关键部分(参见Gibbs, 2007)。 在1967年由Glaser和Strauss进行的质性研究中,编码在扎根理论方法中发挥了重要的作用。这里开放编码(open coding)的意思是指“数据分解、检测、比较、观念化和归类过程”(Strauss& Corbin,1990,p.61)。与内容分析相比,编码在扎根理论方法中不必被量化,但要对编码之间的关系以及编码与情境和行为结果的关系进行质性分析。对于访谈的计算机辅助分析程序来说,编码也已经成为新程序的关键特征(参见第十一章)。 Glaser和Strauss最初的构想非常重要,它使质性研究者能够在编码研究过程中通过呈现明确的策略来提供访谈这一方法的合理化证据。扎根理论的目的并非是检测现存的理论,而是归纳性地发展理论。具体地说,采用扎根理论意味着对材料进行全面的编码,而且正如 Charmaz(2005)所说,编码是及时的、简短的,是对受访者所描述的体验或行动的界定。目的是为了进行归类,以获得所要研究的体验和行动的全面资料。数据实例要不断地进行相似性和差异性的比较,这就会产生新的数据样本和理论上的内部备忘录。如果进一步的编码后没有出现新的见解或解释时,就要进行更集中的编码,分析也逐渐从描述性的层面转换为更加理论化的层面。 正如Gibbs(2007)明确指出的那样,编码需要采用“编码备忘录”,研究者可以记录不同编码的名称,由谁承担哪一部分材料的编码,编码完成之后的数据资料,编码所使用的定义,以及记录研究者对于编码的一些想法(p.41)。编码可以由概念驱动,也可由数据驱动,以概念驱动的编码所采用的是由研究者事先编好的那些编码,这些编码可能是通过查找相关材料或是查阅该领域的现有文献而获得的,而以数据驱动的编码是指研究人员在开始时并没有编码,是通过阅读材料进行编码的(例如扎根理论)。原则上,任何事情都可以被编码——Gibbs提出了如下例子:特定的行为、事件、活动、策略、情况、意义、标准、符号、参与水平、关系、条件或限制、结果、环境,也可以是一些反应性的编码,即记录研究人员在这个过程中的角色(pp. 47-48)。 内容分析(content analysis)是一种对大量的交 《数据分析》 实验报告册 20 15 - 20 16 学年第一学期 班级: 学号: 姓名: 授课教师:实验教师: 目录 实验一网上书店的数据库创建及其查询 实验1-1 “响当当”网上书店的数据库创建 实验1-2 “响当当”网上书店库存、图书和会员信息查询 实验1-3 “响当当”网上书店会员分布和图书销售查询 实验二企业销售数据的分类汇总分析 实验2-1 Northwind公司客户特征分析 实验2-2 “北风”贸易公司销售业绩观测板 实验三餐饮公司经营数据时间序列预测 实验3-1 “美食佳”公司半成品年销售量预测 实验3-2 “美食佳”公司月管理费预测 实验3-3 “美食佳”华东分公司销售额趋势预测 实验3-4 “美食佳”公司会员卡发行量趋势预测 实验3-5 “美食佳”火锅连锁店原料年度采购成本预测 实验四住房建筑许可证数量的回归分析 实验4-1 “家家有房”公司建筑许可证一元线性回归分析实验4-2 “家家有房”公司建筑许可证一元非线性回归分析实验4-3 “家家有房”公司建筑许可证多元线性回归分析实验4-4 “家家有房”公司建筑许可证多元非线性回归分析 实验五手机用户消费习惯聚类分析 实验六新产品价格敏感度测试模型分析 实验一网上书店的数据库创建及其查询实验1-1 “响当当”网上书店的数据库创建 实验类型:验证性实验学时:2 实验目的: ?理解数据库的概念; ?理解关系(二维表)的概念以及关系数据库中数据的组织方式; ?了解数据库创建方法。 实验步骤: 这个实验我们没有直接做,只是了解了一下数据库的概念。 实验1-2 “响当当”网上书店库存、图书和会员信息查询 实验目的 ?理解odbc的概念; ?掌握利用microsoft query进行数据查询的方法。 实验步骤: 1..建立odbc数据源:启动microsoft office query应用程序,在microsoft office query应用程序窗口中,执行“文件/新建”命令,出现“选择数据源”对话框,单击“确定”按钮,出现“创建新数据源”对话框,按照要求做相应的操作。 选择数据源对话框创建新数据源窗口 做图上所示的选择odbc microsoft access安装对话框 数据分析实验报告 【最新资料,WORD文档,可编辑修改】 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 方差1031026.918399673.8384536136.444百分位数25304.25239.75596.25 50727.50530.501499.50 751893.501197.004136.75 3画直方图,茎叶图,QQ图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民Stem-and-Leaf Plot Frequency Stem & Leaf 9.00 0 . 122223344 5.00 0 . 56788 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 单样本Kolmogorov-Smirnov 检验 身高N60正态参数a,,b均值139.00 标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z.686 渐近显着性(双侧).735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验 北京大学教育学院张冉 2 ?第一时间补全笔记 ?完成转录稿 ?给数据文件编号 ?为什么要编码和做数据分析笔记? ?收完数据后,为什么不可以“拍拍脑袋”就开始 ?数据很多的时候毫无头绪而言,编码可以帮助从数据中发 现线索 ?“拍拍脑袋”就写作 ?编码可以反复调整,数据分析笔记可以不断扩充和修改,它们就像数据分析的 角度进行整合,这样可以: ?--〉提高效度,增加产出!?数据的“标签”: 对数据的总结、概括和提炼 ?编码有低层次(初级或者初始)编码和高层次(高级)编码 ?初级编码:直接来源于数据,多是对数据的简单总结, Carspecken:以*或者**甚至***来标注高级编码及其高 级的“程度” ?总的原则是?同时也是可以写数据分析笔记的地方 ?把数据拆分为不同的部分和属性 ?可以将不同部分或者不同人的数据进行间呼应之处与差异之处 ?注意数据中的“漏洞 ?把不同的要点组织起来?建议大家由逐行、逐句、或者逐段阅读分析开始,不断积累,反复修改和调整,在初级编码的基础上再进行提升。 ?类似三级编码过程( 介绍) ?表格框架式:如三级编码表格 ?凯西·卡麦兹(2009). 南. 重庆, 重庆大学出版社 ?也可以将不同级别的编码整合在一个表格中,翰·洛夫兰德, 戴维 Glaser的理论编码?层级式笔记: ?Carspecken, P. F. (2005). 论与实务指南. 上海 ?按编码的层级进行安排 ?将原文的相关部分拷过来或者以页码和行号予以标注 ?叙述的形式?符号或者数字的代码 ?剪刀+档案袋形式 ?陈向明老师书中的介绍 ?在一个大桌子上进行工作,可以灵活地挪来挪去,比较直 观 ?以档案卡、页边评注来辅助 16 ?分析笔记体现的是一个思考的过程,帮助你探索到你的发现并使其清晰化 ?有时可以帮助你实现从聚焦编码到轴心编码、理论编码、或者概念类属的跳跃?编码备忘录 ?理论备忘录:theorizing write-ups ?操作性/程序性备忘录 数据分析与挖掘实验报告 《数据挖掘》实验报告 目录 1.关联规则的基本概念和方法 (1) 1.1数据挖掘 (1) 1.1.1数据挖掘的概念 (1) 1.1.2数据挖掘的方法与技术 (2) 1.2关联规则 (5) 1.2.1关联规则的概念 (5) 1.2.2关联规则的实现——Apriori算法 (7) 2.用Matlab实现关联规则 (12) 2.1Matlab概述 (12) 2.2基于Matlab的Apriori算法 (13) 3.用java实现关联规则 (19) 3.1java界面描述 (19) 3.2java关键代码描述 (23) 4、实验总结 (29) 4.1实验的不足和改进 (29) 4.2实验心得 (30) 1.关联规则的基本概念和方法 1.1数据挖掘 1.1.1数据挖掘的概念 计算机技术和通信技术的迅猛发展将人类社会带入到了信息时代。在最近十几年里,数据库中存储的数据急剧增大。数据挖掘就是信息技术自然进化的结果。数据挖掘可以从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的,人们事先不知道的但又是潜在有用的信息和知识的过程。 许多人将数据挖掘视为另一个流行词汇数据中的知识发现(KDD)的同义词,而另一些人只是把数据挖掘视为知识发现过程的一个基本步骤。知识发现过程如下: ·数据清理(消除噪声和删除不一致的数据)·数据集成(多种数据源可以组合在一起)·数据转换(从数据库中提取和分析任务相关的数据) ·数据变换(从汇总或聚集操作,把数据变换和统一成适合挖掘的形式) ·数据挖掘(基本步骤,使用智能方法提取数 据模式) ·模式评估(根据某种兴趣度度量,识别代表知识的真正有趣的模式) ·知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。 1.1.2数据挖掘的方法与技术 数据挖掘吸纳了诸如数据库和数据仓库技术、统计学、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成等许多应用领域的大量技术。数据挖掘主要包括以下方法。神经网络方法:神经网络由于本身良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性非常适合解决数据挖掘的问题,因此近年来越来越受到人们的关注。典型的神经网络模型主要分3大类:以感知机、bp反向传播模型、函数型网络为代表的,用于分类、预测和模式识别的前馈式神经网络模型;以hopfield 的离散模型和连续模型为代表的,分别用于联想记忆和优化计算的反馈式神经网络模型;以art 模型、koholon模型为代表的,用于聚类的自组 可靠性数据分析的计算方法 PROCEEDINGS,Annual RELIABILITY and MAINTAINABILITY Symposium(1996) 可靠性数据分析的计算方法 Gordon Johnston, SAS Institute Inc., Cary 关键词:寿命数据分析加速试验修复数据分析软件工具 摘要&结论 许多从事组件和系统可靠度研究的专业人员并没有意识到,通过廉价的台式电脑的普及使用,很多用于可靠度分析的功能强大的统计工具已经用于实践中。软件的计算功能还可以将复杂的计算统计和图形技术应用于可靠度分析问题。这大大的便利了工业统计学家和可靠性工程师,他们可以将这些灵活精确的方法应用于在可靠度分析时所遇到的许多不同类型的数据。 在本文中,我们在SAS@系统中将一些最有用的统计数据和图形技术应用到例子的当中,这些例子主要包涵了寿命数据,加速试验数据,以及可修复系统中的数据。随着越来越多的人意识到创新性软件在可靠性数据分析中解决问题的需要,毫无疑问,计算密集型技术在可靠性数据分析中的应用的趋势将会继续扩大。 1.介绍 本文探讨了人们在可靠性数据分析普遍遇到的三个方面: 寿命数据分析 试验加速数据分析 可修复系统数据的分析 在上述各领域,图形和分析的统计方法已被开发用于探索性数据分析,可靠性预测,并用于比较不同的设计系统,供应商等的可靠性性能。 为了体现将现代统计方法用于结合使用高分辨率图形的使用价值,在下面的章节中图形和统计方法将被应用于含有上述三个方面的可靠性数据的例子中。2.寿命数据分析 概率统计图的寿命数据分析中使用的最常见的图形工具之一。Weibull 图是最常见的使用可靠性的概率图的类型,但是当Weibull概率分布并不符合实际数据的时候,类似于对数正态分布和指数分布这一类的概率图在寿命数据分析中也能够起到帮助。 在许多情况下,可用的数据不仅包含故障时间,但也包含在分析时没有发生故障的单位的运行时间。在某些情况下,只能够知道两次故障发生之间的时间间隔。例如,在测试大量的电子元件时,如果记录每一个发生故障的元件的故障时间,那么这可能不经济。相反,在固定的时间间隔内 表1-1:不同频率下的遏止电压表 λ(nm)365 404.7 435.8 546.1 577 v(10^14)8.219 7.413 6.884 5.493 5.199 |Ua|(v) 1.727 1.357 1.129 0.544 0.418 表1-2:λ=365(nm)时不同电压下对应的电流值 U/(v)-1.927 -1.827 -1.727 -1.627 -1.527 -1.427 -1.327 I/(10^-11)A-0.4 -0.2 0 0.9 3.9 8.2 14 -1.227 -1.127 -1.027 -0.927 -0.827 -0.727 -0.718 24.2 38.1 52 66 80 97.2 100 表1-3:λ=404.7(nm)时不同电压下对应的电流值 U/(v) -1.477 -1.417 -1.357 -1.297 -1.237 -1.177 -1.117 I/(10^-11)A -1 -0.4 0 1.8 4.1 10 16.2 -1.057 -0.997 -0.937 -0.877 -0.817 -0.757 -0.737 24.2 36.2 49.8 63.9 80 93.9 100 表1-4:λ=435.8(nm)时不同电压下对应的电流值 U/(v)-1.229 -1.179 -1.129 -1.079 -1.029 -0.979 -0.929 I/(10^-11)A-1.8 -0.4 0 2 4.2 10.2 17.9 -0.879 -0.829 -0.779 -0.729 -0.679 -0.629 -0.579 -0.575 24.8 36 47 59 71.6 83.8 98 100 表1-5:λ=546.1(nm)时不同电压下对应的电流值 U/(v)-0.604 -0.574 -0.544 -0.514 -0.484 -0.454 -0.424 I/(10^-11)A-4 -2 0 3.8 10 16.2 24 -0.394 -0.364 -0.334 -0.304 -0.274 -0.244 -0.242 34 46 56.2 72 84.2 98.2 100 表1-6:λ=577(nm)时不同电压下对应的电流值 U/(v)-0.478 -0.448 -0.418 -0.388 -0.358 -0.328 -0.298 I/(10^-11)A-3.1 -1.8 0 2 6 10.2 16.1 -0.268 -0.238 -0.208 -0.178 -0.148 -0.118 -0.088 -0.058 22.1 31.8 39.8 49 58 68.2 79.8 90.1 -0.04 100 实验名称:Lagrange插值(实验一) 实验目的: 掌握Lagrange插值数值算法,能够根据给定的函数值表达求出插值多项式和函数在某一点的近似值。实验准备: 1.在开始本实验之前,请回顾教科书的相关内容; 2.需要一台准备安装Windows XP Professional操作系统和装有数学软件的计算机。 实验内容及要求 已知数据如下: 要求: 试用Lagrange插值多项式求0.5626,0.5635,0.5645 x 时的函数近似值. 实验过程: 编写Matlab函数M文件Lagrange如下: function yy=lagrange(x,y,xi) m=length(x); n=length(y); if m~=n,error('向量x与y的长度必须一致');end for k=1:length(xi) s=0; for i=1:m z=1; for j=1:n if j~=i z=z*(xi(k)-x(j))/(x(i)-x(j)); end end s=s+z*y(i); end yy=s end 在命令窗口调用函数M文件lagrange,输出结果如下: >>x=[0.56160, 0.56280, 0.56401, 0.56521]; >>y=[0.82741, 0.82659, 0.82577, 0.82495]; >>xi=[0.5626, 0.5635, 0.5645]; >>yi= lagrange (x,y,xi) yi= 0.8628 0.8261 0.8254 实验总结(由学生填写): 教师对本次实验的评价(下面的表格由教师填写): 实验名称:曲线拟合的最小二乘方法(实验二) 实验目的: 掌握最小二乘方法,并能根据给定数据求其最小二乘一次或二次多项式,然后进行曲线拟合。实验准备: 1.在开始本实验之前,请回顾教科书的相关内容; 实验五相关分析实验报关费 一、实验目的: 学习利用spss对数据进行相关分析(积差相关、肯德尔等级相关)、偏相关分析。利用交叉表进行相关分析。 二、实验内容: 某班学生成绩表1如实验图表所示。 1.对该班物理成绩与数学成绩之间进行积差相关分析和肯德尔等级相关 分析。 2.在控制物理成绩不变的条件下,做数学成绩与英语成绩的相关分析(这 种情况下的相关分析称为偏相关分析)。 3.对该班物理成绩与数学成绩制作交叉表及进行其中的相关分析。 三、实验步骤: 1.选择分析→相关→双变量,弹出窗口,在对话框的变量列表中选变量 “数学成绩”、“物理成绩”,在相关系数列进行选择,本次实验选择 皮尔逊相关(积差相关)和肯德尔等级相关。单击选项,对描述统计 量进行选择,选择标准差和均值。单击确定,得出输出结果,对结果 进行分析解释。 2.选择分析→相关→偏相关,弹出窗口,在对话框的变量列表选变量“数 学成绩”、“英语成绩”,在控制列表选择要控制的变量“物理成绩” 以在控制物理成绩的影响下对变量数学成绩与英语成绩进行偏相关分 析;在“显著性检验”框中选双侧检验,单击确定,得出输出结果, 对结果进行分析解释。 3.选择分析→描述统计→交叉表,弹出窗口,对交叉表的行和列进行选 择,行选择为数学成绩,列选择为物理成绩。然后对统计量进行设置, 选择相关性,点击继续→确定,得出输出结果,对结果进行分析解释。 四、实验结果与分析: 表1 五、实验结果及其分析: 分析一:由实验结果可观察出,数学成绩与物理成绩的积差相关系数r=,肯德尔等级相关系数r=可知该班物理成绩和数学成绩之间存在显著相关。 统计分析综合实验报告 学院: 专业: 姓名: 学号: 统计分析综合实验考题 一.样本数据特征分析: 要求收集国家统计局2011年全国人口普查与2000年全国人口普查相关数据,进行二者的比较,然后写出有说明解释的数据统计分析报告,具体要求如下: 1.报告必须包含所收集的公开数据表,至少包括总人口,流动人口,城乡、性别、年龄、民族构成,教育程度,家庭户人口八大指标; 2.报告中必须有针对某些指标的条形图,饼图,直方图,茎叶图以及累计频率条形图;(注:不同图形针对不同的指标)3.采用适当方式检验二次调查得到的人口年龄比例以及教育程度这两个指标是否有显著不同,写明检验过程及结论。 4.报告文字通顺,通过数据说明问题,重点突出。 二.线性回归模型分析: 自选某个实际问题通过建立线性回归模型进行研究,要求: 1.自行搜集问题所需的相关数据并且建立线性回归模型; 2.通过SPSS软件进行回归系数的计算和模型检验; 3.如果回归模型通过检验,对回归系数以及模型的意义进行 解释并且作出散点图 一、样本数据特征分析 2010年全国人口普查与2000年全国人口普查相关数据分析报告 2011年第六次全国人口普查数据显示,总人口数为1370536875,比2000年的第五次人口普查的1265825048人次,总人口数增加73899804人,增长5.84%,平均年增长率为0.57%。 做茎叶图分析: 描述 年份统计量标准误 人口数量2000年均值40084265.35 4698126.750 均值的 95% 置信区间 下限30489410.50 上限49679120.21 5% 修整均值39305445.50 中值35365072.00 方差 68424424372574 4.400 标准差26158062.691 极小值2616329 质性研究及Atlas.ti技巧与应用 与量化数据的分析相比,质性资料的分析有什么独特性?质性分析的一般过程中,需要使用哪些材料,最终又能获得怎样的结果?我们又可以使用哪些工具,来获得更深入、更准确的结论? 基于这些问题,本篇以网易某产品app中一个页面的可用性测试为例,介绍用研中Atlas.ti这款质性研究工具的使用技巧和业务用途,让大家了解如何通过工具的使用来更有效地发现产品中的痛点和潜在的用户需求。 1质性分析概览 我们日常中接触到的信息资料,大多以质性资料(亦即定性资料)的形式存储,诸如文本、多媒体材料等举不胜数。可以说,质性资料中包含着丰富的信息,也蕴含着极高的价值。 以用户研究来说,质性资料的获得的形式、获取渠道丰富而可观,我们可以从可用性测试中获得文本记录、录音资料甚至摄屏录像,我们也可以从客服后台、应用商店、贴吧微博等处获取用户评论数据,我们还可以通过开放式问卷有针对性地获取用户资料。得到这些资料并完成预处理后,我们就会开始质性分析的分析过程,狭义上的质性研究也是从这里开始的。 一般来说,对质性资料的处理要经过开放式编码、轴心式编码、选择式编码这样一个循序渐进的过程,从最初简单的编码到编码簇与编码关联的建立,再到核心编码的确认。通过逐步深入、逐步凝练的过程,我们就可以从最初的原始资料中获得质性结论,最后则是结论的报表或可视化展现。 然而长久以来,质性研究的热度似乎始终低于量化研究,即使是在学术领域,质性研究也只得到了一小部分学者的青睐。究其原因,我们认为或许是因为这些: 首先,我们接触到的最初始的质性资料往往是一个庞杂的信息库,而业务需要又要求我们从中挖掘出有价值的信息和结论;其次,质性研究依赖于操作者的主观经验,而这一点恰恰是质性研究结论的客观性为人所诟病的原因所在; 再者,质性研究从研究方案制定、执行、资料获取、预处理、分析和最后的结论产出有着一套严谨而繁琐的流程,但这又与互联网行业敏捷开发的宗旨相冲突;最后, 1 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 2.00 1 . 03 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验 数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下: (1)K—S检验 单样本 Kolmogorov-Smirnov 检验 身高 N 60 正态参数a,,b均值139.00 标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z .686 渐近显着性(双侧) .735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验 正态性检验 结果:在Shapiro-Wilk 检验结果972.00=w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5多维正态数据的统计量 均值向量为:)767.33,505.4,836.27,219.18(=- X . 信息工程学院资源环境学院《GIS原理》实验报告 实验名称矢量及栅格数据分析 实验时间2015.4.22 实验地点资环楼229 姓名 学号 班级遥感科学与技术131 《GIS原理》实验报告 一、实验目的及要求 1)掌握矢量数据插值分析、栅格数据重分类、叠加分析的基本原理; 2)熟悉ArcGis 中离散点数据插值分析的基本方法; 3)熟悉ArcGis 中栅格数据重分类、栅格计算器的基本操作; 4)熟悉ArcGis 中栅格数据分区统计的基本方法; 5)了解ArcGis 中缓冲区分析、按掩膜提取的基本方法。 二、实验设备及软件平台 ArcCatalog 10、ArcMap 10.2 三、实验原理 1)数据插值分析 2)栅格数据重分类原理 3)叠加分析的基本原理 四、实验容与步骤 1 空间插值分析 1)打开ArcMap中,将数据框更名为“任务1”,加入省边界图层。 2)将2011 年02 月27 日08 时观测资料.xls、2011 年02 月27日14 时.xls 通过Add Xy Data 功能,生成点图层。导出数据,分别命名为Obs2708.shp 和Obs2714.shp。 3)对Obs2708.shp 中的属性“温度”在四川围进行插值分析。可以通过“Arctoolbox->Spatial Analyst(空间分析)工具中的Interpolate to Raster(插值)工具选择。(本实验采用反距离权重法IDW),点插值成栅格表面。 4)通过属性中的符号系统,修改显示样式。 2 多栅格局域运算 1)启动ArcMap,添加数据框,并更名为“任务2”,将温度栅格数据IDW2708、IDW2714 加入。 2)确认是否选择扩展模块的许可。“自定义菜单(Customize)”中的“扩展模块Extensions”功能对话框中的Spatial Analyst 均已打钩。 质性研究方法 ——JonesYo 一、质性研究方法的定义及特点 “质性研究”这个词在台湾、港、澳地区用得比较多,在大陆有的称其为“质的研究”、“质化研究”;还有的为将其与定性研究、定量研究相比较,称为“定质研究”。 1.质性研究的定义 所谓质性研究,就是“以研究者本人为研究工具、在自然情境下采用多种资料收集方法对社会现象进行整体性探究、使用归纳法分析资料和形成理论、通过与研究对象互动对其行为和意义建构获得解释性理解的一种活动”。 2.质性研究的特点: 1) 自然主义的探究传统 质性研究是在自然情境下,研究者与被研究者直接接触,通过面对面的交往,实地考察被研究者的日常生活状态和过程,了解被研究者所处的环境以及环境对他们产生的影响。自然探究的传统要求研究者注重社会现象的整体性和关系性。在对一个事件进行考察时,不仅要了解事件本身,而且要了解事件发生和变化时的社会文化背景以及对该实践与其他事件之间的联系。 2) 对意义的“解释性理解” 质性研究的主要目的是对被研究者的个人经验和意义建构作“解释性理解”,从他们的角度理解他们的行为及其意义解释。由于理解是双方互动的结果,研究者需要对自己的“前设”和“偏见”进行反省,了解自己与对方达到理解的机制和过程。 3) 研究是一个演化的过程 随着实际情况的变化,研究者要不断调整自己的研究设计,收集和分析资料的方法,建构理论的方式。因此对研究的过程必须加以细致的反省和报道。 4)使用归纳法,自下而上分析资料 质性研究中的资料分析主要采纳归纳的方法,自下而上在资料的基础上建立分析类别和理论假设,然后通过相关检验得到充实和系统化。因此,“质性研究”的结果只适用于特定的情境和条件,不能推广到样本之外。 5)重视研究关系 由于注重解释性理解,质性研究对研究者与被研究者之间的关系非常重视,特别是伦理道德问题。研究者必须事先征求被研究者的同意,对他们所提供的信息严格保密,与他们保持良好的关系,并合理回报他们所给予的帮助。 “质性研究”就是一种“情境中”的研究。质性研究的特点决定了这是一种非常适合教育领域的研究。 3质性研究方法(1)
验证性实验——触发器功能测试及其应用 实验报告纸模版
数据分析实验报告
质量信息和数据分析管理规定
数据分析实验报告
数据分析实验报告
质性研究意义编码
数据分析实验报告册
数据分析实验报告
Nvivo课程核心资料!!!质的研究数据分析基础:编码和备忘录详细版 (1)
数据分析与挖掘实验报告
可靠性数据分析的计算方法
光电效应实验报告数据处理 误差分析
数值分析实验报告册
spss相关分析实验报告
统计分析实验报告
质性研究及Atlas ti技巧与应用探讨
数据分析实验报告p
矢量及栅格数据分析实验报告
质性分析小论文