Oracle分析函数与分组关键字的用法

Oracle分析函数与分组关键字的用法
以下是我以前工作中做报表常用的几个函数,在此分享一下,希望对大家有帮助。
(一)分析函数
●row_number
Purpose
ROW_NUMBER is an analytic function. It assigns a unique number to each row to which it is applied (either each row in the partition or each row returned by the query), in the ordered sequence of rows specified in the order_by_clause, beginning with 1.
You cannot use ROW_NUMBER or any other analytic function for expr. That is, you can use other built-in function expressions for expr, but you cannot nest analytic functions.
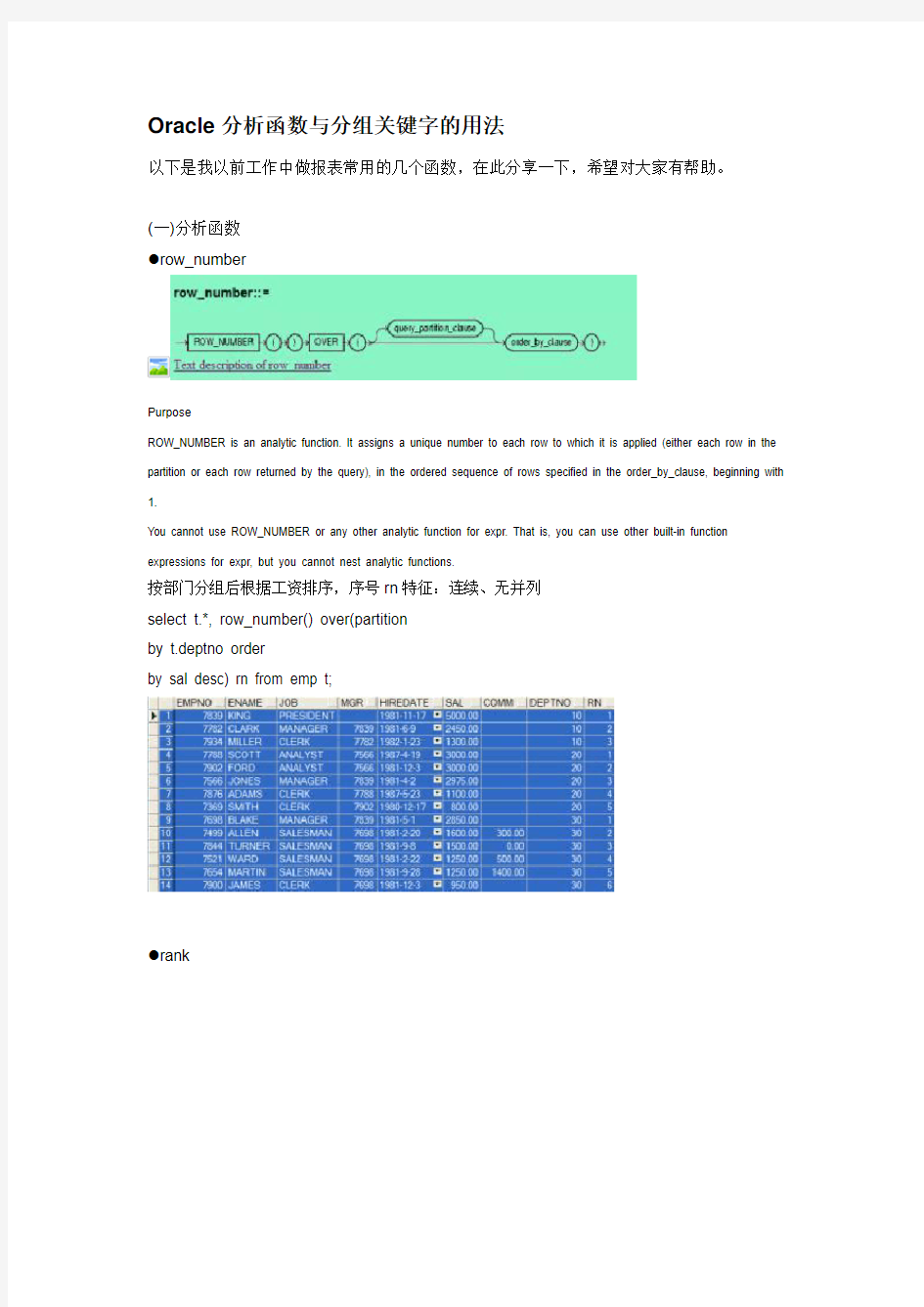
按部门分组后根据工资排序,序号rn特征:连续、无并列
select t.*, row_number() over(partition
by t.deptno order
by sal desc) rn from emp t;
●rank
Purpose
RANK calculates the rank of a value in a group of values. Rows with equal values for the ranking criteria receive the same rank. Oracle then adds the number of tied rows to the tied rank to calculate the next rank. Therefore, the ranks may not be consecutive numbers.
?
As an aggregate function, RANK calculates the rank of a hypothetical row identified by the arguments of the function with respect to a given sort specification. The arguments of the function must all evaluate to constant expressions within each aggregate group, because they identify a single row within each group. The constant argument expressions and the expressions in the ORDER BY clause of the aggregate match by position. Therefore, the number of arguments must be the same and their types must be compatible.
As an analytic function, RANK computes the rank of each row returned from a query with respect to the other rows returned by the query, based on the values of the value_exprs in the order_by_clause.
按部门分组后根据工资排序,序号rn特征:不连续、有并列
select t.*, rank() over(partition
by t.deptno order
by sal desc) rn from emp t;
dense_rank
Purpose
DENSE_RANK computes the rank of a row in an ordered group of rows. The ranks are consecutive integers beginning with 1. The largest rank value is the number of unique values returned by the query. Rank values are not skipped in the event of ties. Rows with equal values for the ranking criteria receive the same rank.
As an aggregate function, DENSE_RANK calculates the dense rank of a hypothetical row identified by the arguments of the function with respect to a given sort specification. The arguments of the function must all evaluate to constant expressions within each aggregate group, because they identify a single row within each group. The constant argument expressions and the expressions in the order_by_clause of the aggregate match by position. Therefore, the number of arguments must be the same and types must be compatible.
As an analytic function, DENSE_RANK computes the rank of each row returned from a query with respect to the other rows, based on the values of the value_exprs in the order_by_clause.
按部门分组后根据工资排序,序号rn特征:连续、有并列
select t.*, dense_rank() over(partition
by t.deptno order
by sal desc) rn from emp t;
(二)分组函数
根据查询结果观察三者的区别,grouping sets用起来更灵活。
友情提示:grouping(expr)函数仅用于分组中,如果expr为null 返回1
●Rollup
select decode(grouping(dept.dname), 1, '总计', dept.dname) dname, decode(grouping(emp.job), 1, '小计', emp.job) job,
sum(sal),
avg(sal)
from emp, dept
where dept.deptno = emp.deptno
group by rollup(dept.dname, emp.job)
order by dname, job;
●Cube
select decode(grouping(dept.dname), 1, '所有部门', dept.dname) dname, nvl(emp.job, '小计') job,
sum(sal),
avg(sal)
from emp, dept
where dept.deptno = emp.deptno
group by cube(dept.dname, emp.job)
order by dname, job;
grouping sets
select dept.dname, emp. job, sum(sal), avg(sal)
from emp, dept
where dept.deptno = emp.deptno
group by grouping sets((dept.dname, emp.job), dept.dname, emp.job) order by dname, job;
Oracle中分析函数用法小结
Oracle中分析函数用法小结 一.分析函数适用场景: ○1需要对同样的数据进行不同级别的聚合操作 ○2需要在表内将多条数据和同一条数据进行多次的比较 ○3需要在排序完的结果集上进行额外的过滤操作 二.分析函数语法: FUNCTION_NAME(
Oracle 分析函数(Analytic Functions) 说明
Oracle 分析函数(Analytic Functions)说明一. Analytic Functions 说明 分析函数是oracle 8中引入的一个概念,为我们分析数据提供了一种简单高效的处理方式. 官方对分析函数的说明如下: Analytic functions compute an aggregate value based on a group of rows. They differ from aggregate functions in that they return multiple rows for each group. The groupof rows is called a window and is defined bythe analytic_clause. For each row, a sliding window of rows is defined.The window determines the range of rows used to perform the calculations forthe current row. Window sizes can be based on either a physical number of rowsor a logical interval such as time. Analytic functions are the last set of operations performed in a query except for thefinal ORDER BY clause. All joins and all WHERE, GROUP BY,and HAVING clauses are completed before the analytic functions areprocessed. Therefore, analytic functions can appear only in the select listor ORDER BY clause. Analytic functions are commonly used to compute cumulative, moving, centered, andreporting aggregates. From:Analytic Functions https://www.360docs.net/doc/3616944713.html,/cd/E11882_01/server.112/e26088/functions004.htm#S QLRF06174 分析函数是对一组查询结果进行运算,然后获得结果,从这个意义上,分析函数非常类似于聚合函数(Aggregate Function)。区别是在调用分析函数时,后面加上了开窗子句over()。 聚合函数是对一个查询结果中的每个分组进行运算,并且对每个分组产生一个运算结果。分析函数也是对一个查询结果中的每个分组进行运算,但每个分组对应的结果可以有多个。产生这个不同的原因是分析函数中有一个窗口的概念,一个窗口对应于一个分组中的若干行,分析函数每次对一个窗口进行运算。运算时窗口在查询结果或分组中从顶到底移动,对每一行数据生成一个窗口。 Oracle 聚合函数(Aggregate Functions)说明 https://www.360docs.net/doc/3616944713.html,/tianlesoftware/article/details/7057249
Oracle练习题讲解
一、填空 1.在多进程Oracle实例系统中,进程分为用户进程、后台进程和服务进程。 2.标准的SQL语言语句类型可以分为:数据定义语句(DDL)、数据操纵语句(DML)和数据控制语句(DCL)。 3.在需要滤除查询结果中重复的行时,必须使用关键字Distinct; 在需要返回查询结果中的所有行时,可以使用关键字ALL。 4.当进行模糊查询时,应使用关键字like和通配符问号(?)或百分号"%"。 5.Where子句可以接收From子句输出的数据,而HA VING子句则可以接收来自WHERE、FROM或GROUP BY子句的输入。 6.在SQL语句中,用于向表中插入数据的语句是Insert。 7.如果需要向表中插入一批已经存在的数据,可以在INSERT语句中使用Select 语句。 8.使用Describe命令可以显示表的结构信息。 9.使用SQL*Plus的Get命令可以将文件检索到缓冲区,并且不执行。 10.使用Save命令可以将缓冲区中的SQL命令保存到一个文件中,并且可以使用Run命令运行该文件。 11.一个模式只能够被一个数据库对象所拥有,其创建的所有模式对象都保存在自己的模式中。 12.根据约束的作用域,约束可以分为表级约束和列级约束两种。列级约束是字段定义的一部分,只能够应用在一个列上;而表级约束的定义独立于列的定义,它可以应用于一个表中的多个列。 13.填写下面的语句,使其可以为Class表的ID列添加一个名为PK_CLASS_ID 的主键约束。 ALTER TABLE Class Add ____________ PK_LASS_ID (Constraint) PRIMARY KEY ________ (ID) 14. 每个Oracle 10g数据库在创建后都有4个默认的数据库用户:system、sys、sysman和DBcnmp
ORACLE排序与分析函数
--已知:两种排名方式(分区和不分区):使用和不使用partition --两种计算方式(连续,不连续),对应函数:dense_rank,rank 语法: rank()over(order by排序字段顺序) rank()over(partition by分组字段order by排序字段顺序) 1.顺序:asc|desc名次与业务相关: 示例:找求优秀学员:成绩:降序迟到次数:升序 2.分区字段:根据什么字段进行分区。 问题:分区与分组有什么区别? ·分区只是将原始数据进行名次排列(记录数不变), ·分组是对原始数据进行聚合统计(记录数变少,每组返回一条),注意:聚合。rank()与dense_rank():非连续排名与连续排名(都是简单排名) ·查询原始数据:学号,姓名,科目名,成绩 select*from t_score; S_ID S_NAME SUB_NAME SCORE 1张三语文80.00 2李四数学80.00 1张三数学0.00 2李四语文50.00 3张三丰语文10.00 3张三丰数学 3张三丰体育120.00 4杨过JAVA90.00 5mike c++80.00 3张三丰Oracle0.00 4杨过Oracle77.00 2李四Oracle77.00 ·查询各学生科目为Oracle排名(简单排名) select sc.s_id,sc.s_name,sub_name,sc.score,rank()over(order by score desc)名次from t_score sc where sub_name='Oracle'; S_ID S_NAME SUB_NAME SCORE名次 4杨过Oracle77.001 2李四Oracle77.001 3张三丰Oracle0.003 ·对比:rank()与dense_rank():非连续排名与连续排名(都是简单排名) S_ID S_NAME SUB_NAME SCORE名次
Oracle分析函数sum over介绍
分析函数sum over() 介绍 报送单位:审核人: 类型:业务应用 关键字:分析函数 1、引言 运维中,常常需要通过SQL语句对单行数据进行查询,同时又需要对结果集进行汇总,通常的方法是通过两个SQL语句分别进行查询汇总,这样效率低下。 2、现象描述 本节介绍一种ORACLE提供的全新的函数sum over(),该类函数称为分析函数,这类函数功能强大,可以通过一个SQL语句对数据进行遍历的同时又进行汇总,而且一张表只进行一次扫描,极大地提高SQL的执行效率。 3、处理过程 语法: FUNCTION_NAME(
执行计划: 下图说明分析函数只对表进行一次扫描 4、举例说明 下面分别举例来说明分析函数的使用,原始数据如下表
示例1:查询单行数据同时对所有数据工资进行汇总求和 示例2:查询所有数据,同时对第各部门工资进行汇总,汇总范围取值为第一行所在部门至当前部门所有数据。
示例3:查询所有数据,并且每一行汇总值按ENAME排序后取第一行至当前行ENAME所在行。 示例4:查询所有数据,并且每一行汇总值按EMPNO排序后取第一行至当前行EMPNO所在行
示例5:查询所有数据,同时每行对各部门分别进行按EMPNO排序后从各组第一行至当前行汇总求和。 示例6:查询所有数据,同时每行对从当前上两行数据范围的工资进行汇总求和。 示例7:查询所有数据,同时每行对从当前向前一行数据向后两行数据范围的工资进行汇总求和。
Oracle分组ROLLUP、GROUP BY、GROUPING、GROUPING SETS区别和作用+++
Oracle分组ROLLUP、GROUP BY、GROUPING、GROUPING SETS区别和作用1.ROLLUP ROLLUP的作用相当于 SQL> set autotrace on SQL> select department_id,job_id,count(*) 2 from employees 3 group by department_id,job_id 4 union 5 select department_id,null,count(*) 6 from employees 7 group by department_id 8 union 9 select null,null,count(*) 10 from employees;
最后面的SA_REP表示此jobid没有部门,为null 这里的union系统默认进行了排序 使用ROLLUP能达到上面GROUP BY的功能,但性能开销更小SQL> ed 已写入file afiedt.buf 1 select department_id,job_id,count(*) 2 from employees 3* group by rollup (department_id,job_id) SQL> /
2.为什么ROLLUP会比GROUP BY性能好 ROLLUP(a,b,c)=a,b,c+a,b+a+All 通过一次全表扫描,得出a,b,c的分组统计信息后;分组统计a,b 相同,c不同的项即可得到a,b;依此类推……,就不用去多次全表扫描 3.ROLLUP的另类用法ROLLUP(a,(b,c)) ROLLUP((a,b)) SQL> ed 已写入file afiedt.buf 1 select department_id,job_id,count(*) 2 from employees 3* group by rollup ((department_id,job_id)) SQL> / 注意面的语句是group by rollup ((department_id,job_id)) 不是group by rollup (department_id,job_id)
Oracle必背选择题
1.( )触发器允许触发操作的语句访问行的列值。(选一项) A、行级 B、语句级 C、模式 D、数据库级 2.( )是oracle在启动期间用来标识物理文件和数据文件的二进制文件。(选一项) A、控制文件 B、参数文件 C、数据文件 D、可执行文件 3.CREATE TABLE 语句用来创建(选一项) A、表 B、视图 C、用户 D、函数 4.imp命令的哪个参数用于确定是否要倒入整个导出文件。(选一项) A、constranints B、tables C、full D、file 5.ORACLE表达式NVL(phone,'0000-0000')的含义是(选一项) A、当phone为字符串0000-0000时显示空值 B、当phone为空值时显示0000-0000 C、判断phone和字符串0000-0000是否相等 D、将phone的全部内容替换为0000-0000 6.ORACLE交集运算符是(选一项) A、intersect B、union C、set D、minus 7.ORACLE使用哪个系统参数设置日期的格式(选一项) A、nls_language B、nls_date C、nls_time_zone D、nls_date_format 8.Oracle数据库中,通过()访问能够以最快的方式访问表中的一行(选一项) A、主键
B、Rowid C、唯一索引 D、整表扫描 9.Oracle数据库中,下面()可以作为有效的列名。(选一项) A、Column B、123_NUM C、NUM_#123 D、#NUM123 10.Oracle数据库中,以下()命令可以删除整个表中的数据,并且无法回滚(选一项) A、drop B、delete C、truncate D、cascade 11.Oracle中, ( )函数将char或varchar数据类型转换为date数据类型。(选一项) A、date B、to_date C、todate D、ctodate 12.ORACLE中,执行语句:SELECT address1||','||address2||','||address2 "Address" FROM employ; 将会返回()列(选一项) A、0 B、1 C、2 D、3 13.Oralce数据库中,以下()函数可以针对任意数据类型进行操作。(选一项) A、TO_CHAR B、LOWER C、MAX D、CEIL 14.partition by list(msn_id)子句的含义是(选一项) A、按msn_id列进行范围分区 B、按msn_id列进行列表分区 C、按msn_id列进行复合分区 D、按msn_id列进行散列分区 15.比较pagesize和linesize两个命令的特点,正确的是(选两项) A、pagesize命令用于设置屏幕上每一页包含的行数 B、linesize命令用于设置屏幕上每一行的字符数
Oracle分析函数
Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是 对于每个组返回多行,而聚合函数对于每个组只返回一行。 一、开窗函数 开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化。 例如: 1)over(order by salary)按照salary排序进行累计,order by是个默认的开窗函数 2)over(partition by department_id)按照部门分区 3)over(order by salary range between 50 preceding and 150 following) 每行对应的数据窗口是之前行幅度值不超过50,之后行幅度值不超过150 4)over(order by salary rows between 50 preceding and 150 following) 每行对应的数据窗口是之前50行,之后150行 5)over(order by salary rows between unbounded preceding and unbounded following) 每行对应的数据窗口是从第一行到最后一行,等效: 6) over(order by salary range between unbounded preceding and unbounded following) 其中: 第一行是unbounded preceding 当前行是current row 最后一行是unbounded following 二、分析函数的概念 分析函数是在整个SQL查询结束后(SQL语句中的ORDER BY的执行比较特殊)再进行的操作, 也就是说 SQL语句中的ORDER BY也会影响分析函数的执行结果。 分析函数中包含三个分析子句:分组(Partition By), 排序(Order By), 窗口(Window) 当省略窗口子句时: 1) 如果存在Order By则默认的窗口是unbounded preceding and current row 2) 如果同时省略Order By则默认的窗口是unbounded preceding and unbounded following 如果省略分组,则把全部记录当成一个组 a) 如果SQL语句中的Order By满足分析函数分析时要求的排序,那么SQL语句中的排序将先执行,分析 函数分析时就不必再排序 b) 如果SQL语句中的Order By不满足分析函数分析时要求的排序,那么SQL语句中的排序将最后在分 析函数分析结束后执行排序 三、分析函数 1)AVG
Oracle自定义聚合函数-分析函数
自定义聚合函数,分析函数 --from GTA Aaron 最近做一数据项目要用到连乘的功能,而Oracle数据库里没有这样的预定义聚合函数,当然利用数据库已有的函数进行数学运算也可以达到这个功能,如: selectexp(sum(ln(field_name))) from table_name; 不过今天的重点不是讲这个数学公式,而是如何自己创建聚合函数,实现自己想要的功能。很幸运Oracle 允许用户自定义聚合函数,提供了相关接口,LZ研究了下,留贴共享。 首先介绍聚合函数接口: 用户可以通过实现Oracle的Extensibility Framework中的ODCIAggregate interface 来创建自定义聚合函数,而且自定义的聚合函数跟内建的聚合函数用法上没有差别。 通过实现ODCIAggregaterountines来创建自定义的聚合函数。可以通过定义一个对象类型(Object Type),然后在这个类型内部实现ODCIAggregate 接口函数(routines),可以用任何一种Oracle支持的语言来实现这些接口函数,比如C/C++, JAVA, PL/SQL等。在这个Object Type定义之后,相应的接口函数也都在该Object Type Body内部实现之后,就可以通过CREATE FUNCTION语句来创建自定义的聚合函数了。 每个自定义的聚合函数需要实现4个ODCIAggregate 接口函数,这些函数定义了任何一个聚合函数内部需要实现的操作: 1. 自定义聚合函数初始化操作,从这儿开始一个聚合函数。初始化的聚合环境(aggregation context)会以对象实例(object type instance)传回给oracle. static function ODCIAggregateInitialize(varIN OUTagg_type ) return number 2. 自定义聚合函数,最主要的步骤,这个函数定义我们的聚合函数具体做什么操作,self 为 当前聚合函数的指针,用来与前面的计算结果进行关联。这个函数用来遍历需要处理的
Oracle 笔试题目带答案
1.( )程序包用于读写操作系统文本文件。(选一项) A、Dbms_output B、Dbms_lob C、Dbms_random D、Utl_file 2.( )触发器允许触发操作的语句访问行的列值。(选一项) A、行级 B、语句级 C、模式 D、数据库级 3.( )是oracle在启动期间用来标识物理文件和数据文件的二进制文件。(选一项) A、控制文件 B、参数文件 C、数据文件 D、可执行文件 4.CREATE TABLE 语句用来创建(选一项) A、表 B、视图 C、用户 D、函数 5.imp命令的哪个参数用于确定是否要倒入整个导出文件。(选一项) A、constranints B、tables C、full D、file 6.ORACLE表达式NVL(phone,'0000-0000')的含义是(选一项) A、当phone为字符串0000-0000时显示空值 B、当phone为空值时显示0000-0000 C、判断phone和字符串0000-0000是否相等 D、将phone的全部内容替换为0000-0000 7.ORACLE交集运算符是(选一项) A、intersect B、union C、set D、minus 8.ORACLE使用哪个系统参数设置日期的格式(选一项) A、nls_language
B、nls_date C、nls_time_zone D、nls_date_format 9.Oracle数据库中,通过()访问能够以最快的方式访问表中的一行(选一项) A、主键 B、Rowid C、唯一索引 D、整表扫描 10.Oracle数据库中,下面()可以作为有效的列名。(选一项) A、Column B、123_NUM C、NUM_#123 D、#NUM123 11.Oracle数据库中,以下()命令可以删除整个表中的数据,并且无法回滚(选一项) A、drop B、delete C、truncate D、cascade 12.Oracle中, ( )函数将char或varchar数据类型转换为date数据类型。(选一项) A、date B、to_date C、todate D、ctodate 13.ORACLE中,执行语句:SELECT address1||','||address2||','||address2 "Address" FROM employ; 将会返回()列(选一项) A、0 B、1 C、2 D、3 14.Oralce数据库中,以下()函数可以针对任意数据类型进行操作。(选一项) A、TO_CHAR B、LOWER C、MAX D、CEIL 15.partition by list(msn_id)子句的含义是(选一项) A、按msn_id列进行范围分区 B、按msn_id列进行列表分区
oracle高级分析函数使用实例
oracle高级分析函数使用实例 2014年11月26日10:26:55 ?标签: ?oracle ?1744 ORACLE的分析函数,发现大家写SQL的时候有些功能写的比较麻烦或者不知道复杂的功能怎么通过SQL实现,ORACLE自带的分析函数有很多相应的功能: 它是Oracle分析函数专门针对类似于"经营总额"、"找出一组中的百分之多少" 或"计算排名前几位"等问题设计的。 分析函数运行效率高,使用方便。 分析函数是基于一组行来计算的。这不同于聚集函数且广泛应用于OLAP环境中。 Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是 对于每个组返回多行,而聚合函数对于每个组只返回一行。 语法:
组。这里的"分区partition"和"组group" 都是同义词。 5 排序子句order-by-clause指定数据是如何存在分区内的。其格式为:order[siblings]by{expr|position|c_alias}[asc|desc][nulls first|nulls last] 其中: (1)asc|desc:指定了排列顺序。 (2)nulls first|nulls last:指定了包含空值的返回行应出现在有序序列中的第一个或最后一个位置。 6窗口子句windowing-clause 给出一个固定的或变化的数据窗口方法,分析函数将对这些数据进行操作。在一组基于任意变化或固定的窗口中, 可用该子句让分析函数计算出它的值。 格式: {rows|range} {between {unbounded preceding|current row |
Oracle高级查询总结
高级查询总结 A.层次查询:start with……connec by prior…….. select lpad(' ',3*level)||ename,job,level from emp start with mgr is null connect by prior empno=mgr; 从根结点向下查,lpad()为左添加,level为第几层,prior为查找的方向;此句若省掉start with….则表示要遍历整个树型结构;若出现level,则后面一定要跟connect by B.交叉报表(case when then end 与decode()) select ename,case when sal>=1500then sal*1.01 else sal*1.1 end工资 from emp; select姓名, max(case课程when'语文'then分数end) 语文, max(case课程when'数学'then分数end) 数学, max(case课程when'历史'then分数end) 历史 from学生group by姓名;------(交叉报表与函数一起使用) select ename,sum(decode(sal,'sal',comm,null)) 奖金from emp group by ename;--可实现分支 decode(条件,(值),(返回值),…………,(默认值)) 部门 select sal,decode(sign(sal-1500),-1,1.1*sal,0,1.1*sal,1,1.05*sal) from emp; C.连接查询 1.等值: select * from emp,dept where emp.deptno(+)=dept.deptno; ‘+’在左则以右表为主,反之亦然 2.非等值:where的运算符不是等号 3.自然连接: select * from emp natural join dept 4.99乘法: select * from emp e full join dept d using (deptno) where deptno=10; --where必须放在using(on)的后面 D集合查询: 1.A Union B:消除重复行,有all则可以重复,默认第一列升序select ename,sal from deptno=20 union select ename,sal from job=’CLERK’; 2.A intersect B:A与B的交集 select ename,sal from deptno=20 intersect select ename,sal from job=’CLERK’; 3.A minus B:在A中减去既属于A又属于B的一部分
Oracle_D3试题
**学院课程考试试卷 课程名称:《Oracle:使用Oracle管理和查询数据》(A)卷 年级:班级: 姓名:_______________ 学号:_________________ 考试(考查) 闭卷 选择题(每题2分,共计100分) 1.以下()内存区不属于SGA(系统全局区 system global area)。见教材P.46 页 A.PGA B.日志缓冲区 C.数据缓冲区 D.共享池 2.将以下结构从数据库开始按层次顺序排列()。 A.数据库段区块表空间 B.数据库段表空间块区 C.数据库表空间段区块 D.数据库表空间块段区 3.()模式存储数据库中数据字典的表和视图。见教材P.23页 A.DBA B.SCOTT C.SYSTEM D.SYS 4.在oracle中创建用户时,若未提及default tablespace 关键字,则oracle就将() 表空间分配给用户作为默认表空间。见教材P.11页 A.HR B.SCOTT C.SYSTEM D.SYS 5.()服务监听并接受来自客户端应用程序的连接请求。 A.OracleHOME_NAMETNSListener B.OracleServerSID C.OracleHOME_NAMEAgent D.OracleHOME_NAMEHTTPServer 6.关于程序全局区PGA的说法正确的是()。[选两项] A.PGA是共享的 B.PGA是非共享的 C.每个服务器进程都有一个私有的PGA D.每个客户端进程都有一个私有的PGA 7.oracle数据库的物理文件不包括()。见教材P.12页 A.数据文件 B.重做日志文件 C.控制文件 D.缓存文件 8.用于在客户端配置网络服务的文件是()。见教材P.26页 A.tnsnames.ora B.listener.ora C.sqlnet.ora D.tnsname(s).ora 9.数据定义语言是用于()的方法。 A.确保数据的准确性 B.定义和修改数据结构 C.查看数据 D.删除和更新数据 10.emp表包含下面这些列,ename varchar2,salary varchar2,hiredate date,管理部门 想要一份在公司工作了5年以上的员工名单,那句sql语可以显示需要的结果()。
Oracle 分析函数
--每一个值占总数的百分比 SELECT x, y, z,round(z/sum(z) over()*100,2)||'%' propn , sum(z) over() sum FROM t1; --每一个值占分组的百分比 SELECT x, y, z,round(z/sum(z) over(partition by x)*100,2)||'%' propn , sum(z) over(partition by x) sum FROM t1; --以x分区,按y排序累计取和 SELECT x, y, z, sum(z) over(partition by x order by y desc) sum FROM t1; --以x分区,按z降序,每个分区取前两个 select * from (select x, y, z, s, dense_rank() over(partition by x order by z desc) r1, rank() over(partition by x order by z desc) r2, count(*) over(partition by x order by z desc, y range unbounded preceding) r3 from (SELECT x, y, z, sum(z) over(partition by x) s FROM t1 order by 4 desc, z desc)) where r3 < 3 order by z desc, x /* 语法: function_name(
Oracle中分组后拼接分组字符串
Oracle中分组后拼接分组字符串 先分组,再把分组后的属于某组的多条记录的某字段进行拼接。 实现方式如下: /* --创建表 test*/ create table test ( NO NUMBER, VALUE VARCHAR2(100), NAME VARCHAR2(100) ); /* ----插入数据*/ insert into test select * from ( select '1','a','测试1' from dual union all select '1','b','测试2' from dual union all select '1','c','测试3' from dual union all select '1','d','测试4' from dual union all select '2','e','测试5' from dual union all select '4','f','测试6' from dual union all select '4','g','测试7' from dual ); /*--Sql语句:*/ select No, ltrim(max(sys_connect_by_path(Value, ';')), ';') as Value, ltrim(max(sys_connect_by_path(Name, ';')), ';') as Name from (select No, Value, Name, rnFirst, lead(rnFirst) over(partition by No order by rnFirst) rnNext from (select a.No, a.Value, https://www.360docs.net/doc/3616944713.html,, row_number() over(order by a.No, a.Value desc) rnFirst from Test a) tmpTable1) tmpTable2 start with rnNext is null connect by rnNext = prior rnFirst group by No; /*--检索结果如下:*/ /*
Oracle分析函数与分组关键字的用法
Oracle分析函数与分组关键字的用法 以下是我以前工作中做报表常用的几个函数,在此分享一下,希望对大家有帮助。 (一)分析函数 ●row_number Purpose ROW_NUMBER is an analytic function. It assigns a unique number to each row to which it is applied (either each row in the partition or each row returned by the query), in the ordered sequence of rows specified in the order_by_clause, beginning with 1. You cannot use ROW_NUMBER or any other analytic function for expr. That is, you can use other built-in function expressions for expr, but you cannot nest analytic functions. 按部门分组后根据工资排序,序号rn特征:连续、无并列 select t.*, row_number() over(partition by t.deptno order by sal desc) rn from emp t; ●rank
Purpose RANK calculates the rank of a value in a group of values. Rows with equal values for the ranking criteria receive the same rank. Oracle then adds the number of tied rows to the tied rank to calculate the next rank. Therefore, the ranks may not be consecutive numbers. ? As an aggregate function, RANK calculates the rank of a hypothetical row identified by the arguments of the function with respect to a given sort specification. The arguments of the function must all evaluate to constant expressions within each aggregate group, because they identify a single row within each group. The constant argument expressions and the expressions in the ORDER BY clause of the aggregate match by position. Therefore, the number of arguments must be the same and their types must be compatible. As an analytic function, RANK computes the rank of each row returned from a query with respect to the other rows returned by the query, based on the values of the value_exprs in the order_by_clause. 按部门分组后根据工资排序,序号rn特征:不连续、有并列 select t.*, rank() over(partition by t.deptno order by sal desc) rn from emp t; dense_rank