SPSS上机实验报告
实验名称:频数分布
实验目的和要求:绘制频数分布表、频数分布直方图并分析集中趋势指标、差异性指标和分布形状指标
实验内容:绘制频数分布表和频数分布直方图并分析
实验记录、问题处理:
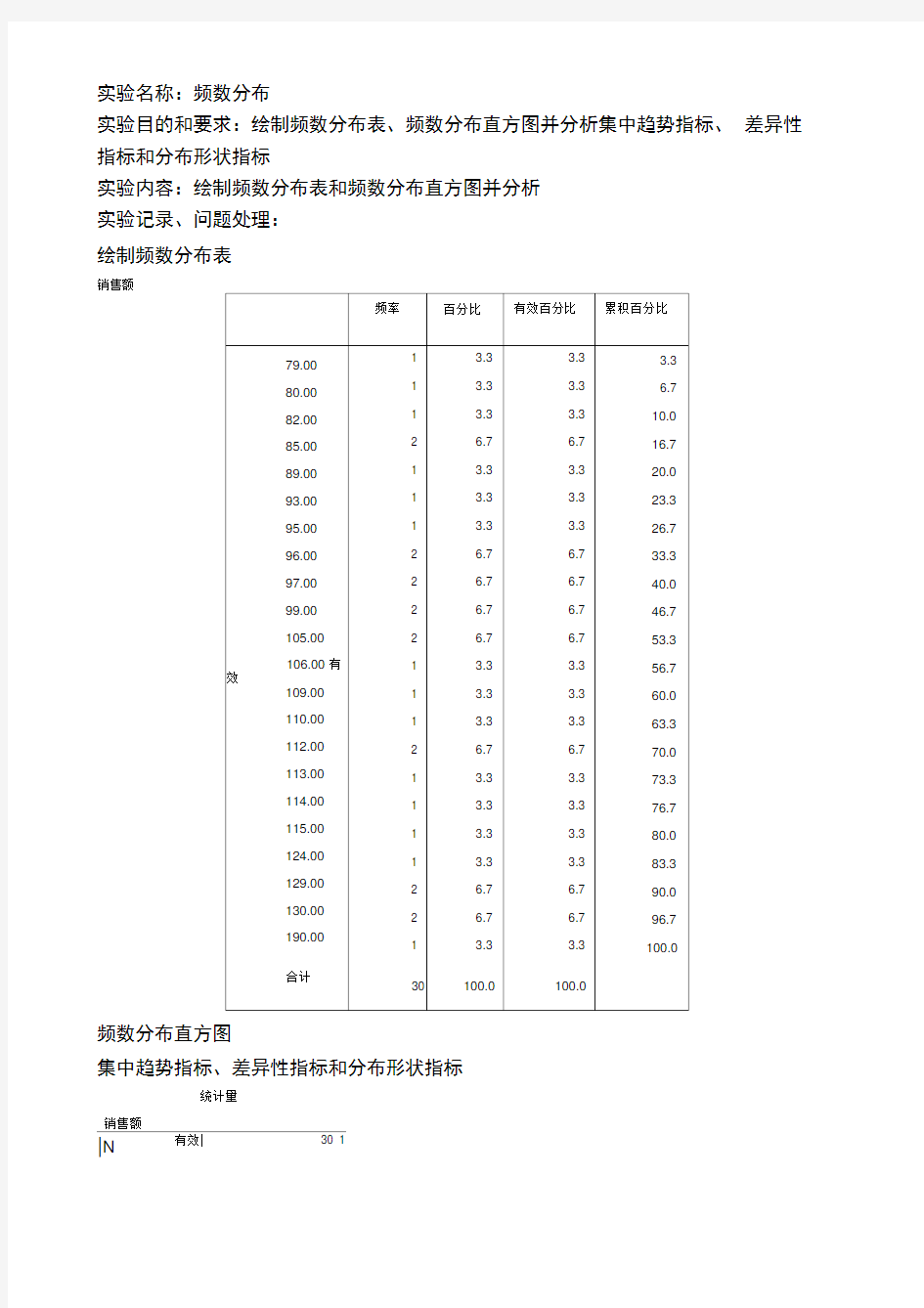
绘制频数分布表
销售额
频率百分比有效百分比累积百分比
79.00
80.00
82.00
85.00
89.00
93.00
95.00
96.00
97.00
99.00
105.00
106.00 有效
109.00
110.00
112.00
113.00
114.00
115.00
124.00
129.00
130.00
190.00
合计1
1
1
2
1
1
1
2
2
2
2
1
1
1
2
1
1
1
1
2
2
1
30
3.3
3.3
3.3
6.7
3.3
3.3
3.3
6.7
6.7
6.7
6.7
3.3
3.3
3.3
6.7
3.3
3.3
3.3
3.3
6.7
6.7
3.3
100.0
3.3
3.3
3.3
6.7
3.3
3.3
3.3
6.7
6.7
6.7
6.7
3.3
3.3
3.3
6.7
3.3
3.3
3.3
3.3
6.7
6.7
3.3
100.0
3.3
6.7
10.0
16.7
20.0
23.3
26.7
33.3
40.0
46.7
53.3
56.7
60.0
63.3
70.0
73.3
76.7
80.0
83.3
90.0
96.7
100.0
频数分布直方图
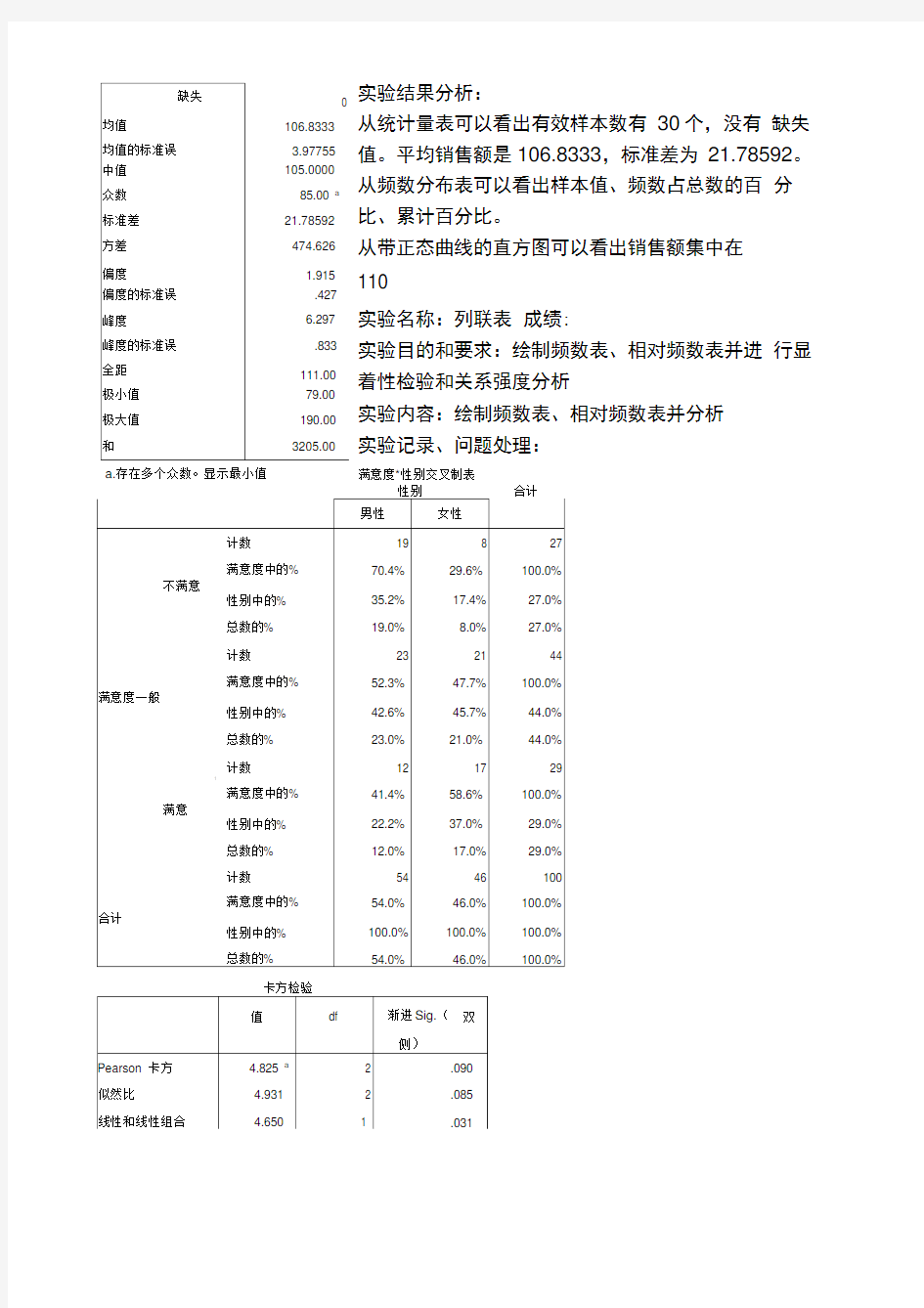
集中趋势指标、差异性指标和分布形状指标销售额
统计量
|N有效|30 1
实验结果分析:
从统计量表可以看出有效样本数有 30个,没有 缺失值。平均销售额是106.8333,标准差为 21.78592。 从频数分布表可以看出样本值、频数占总数的百 分比、累计百分比。
从带正态曲线的直方图可以看出销售额集中在
110
实验名称:列联表 成绩:
实验目的和要求:绘制频数表、相对频数表并进 行显着性检验和关系强度分析
实验内容:绘制频数表、相对频数表并分析 实验记录、问题处理:
满意度*性别交叉制表
a.存在多个众数。显示最小值
b. 使用渐进标准误差假定零假设。
实验结果分析:
从卡方检验看出sig>0.05,不显着。
所以男生女生对满意与否评价没有差异
实验名称:方差分析成绩:
实验目的和要求:单因子方差分析、多因子方差和协方差分析
实验内容:进行单因子方差分析并输出方差分析表、显着性检验及解释结果、多因子方差和协方差分析并输出方差分析表和协方差分析表、显着性检验及解释结果。实验记录、问题处理:
单因子方差分析
分析一一比较均值,单因素一一键入销售额为因变量,键入促销力度为因子两两比较打钩L检验,选项方差齐性检验打钩得:
多因子方差分析
分析一一一般线性模型,单变量一一键入店内促销和赠券状态为固定因子, 销售额为因变量一一两两比较打钩L检验,选项方差齐性检验打钩,得:
协方差分析
分析一一一般线性模型,单变量一一键入店内促销和赠券状态为固定因子,销售额为因变量,键入客源排序为协变量一一两两比较打钩L检验,选项方差齐性检验打钩,得:
实验结果分析:
单因子:组间显着性为0.000,小于0.05,显着影响。
多因子:店内促销和赠券状态显着性分别都为0.000,小于0.05,显着影响
但是店内促销和赠券状态交互作用的显着性为0.206,大于0.05,不显着。
协方差:经协变量客源排序的显着性为0.363,对销售额影响不显着。店内促销的显着性为0.000,小于0.05,对销售额影响显着。赠券状态的显着性为0.000,小于0.05,对销售额影响显着。店内促销和赠券状态的交互作用显着性为0.208,大于0.05,对销售额影响不显着实验名称:相关分析成绩:
实验目的和要求:计算Pearson相关系数和简单相关系数并分析实验内容:计算Pears on相关系数和简单相关系数并分析
实验记录、问题处理:
分析 --- 相关,双变量 --- 添加收、家庭人口、受教育程度、汽车保有量一
默认pears on分析--- 确定,得:
实验结果分析:
1、收入对受教育年数,相关系数为0.327,显着性为0.001,小于0.01,所以收入和受教育年为正向相关,且相关性很强。
2、收入对汽车保有量,相关系数为0.208,显着性为0.038,小于0.05,所以收入对汽车保有量为正向相关。
3、家庭人口对汽车保有量,相关系数为0.576,显着性为0.000,小于0.01,所以收入对汽车保有量为正向相关,且相关性很强。
4、受教育年数对收入,相关系数为0.327,显着性为0.001,小于0.01,所以受教育年数对收入为正想相关,且相关性很强。
实验名称:回归分析成绩:
实验目的和要求:掌握简单回归模型和多元回归分析的SPSS操作方法
实验内容:检验简单回归模型、绘制散点图、输出回归结果并分析、残差分析;检验多元回归分析模型、输出回归结果并分析及残差分析。
实验记录、问题处理:
(一)简单回归
得出
a.预测变量常量),促销水平
a. 因变量月均销售额
b. 预测变量:(常量),促销水平
a.因变量月均销售额
实验结果分析:
R方为0.554,拟合优度一般
P值sig显着
表达式:
销售额=10.667-2.3*促销水平
(二)多元线性回归
得:
模型汇总
a. 预测变量常量),店内促销。
b. 预测变量:(常量),店内促销,赠券状态
a
a. 因变量:销售额
b. 预测变量:(常量),店内促销。
c. 预测变量:(常量),店内促销,赠券状态
a.因变量销售额
实验结果分析:
R方在第二次拟合达到0.856,说明模型的拟合的情况非常好方差分析表显示P值sig<0.05,说明模型非常显着。
表达式:
销售额=14.667-2.3*店内促销-2.667*赠券状态
实验名称:Logistic回归成绩:
实验目的和要求:掌握Logistic回归分析的SPSS操作方法实验内容:估计和检验Logistic回归系数并解释结果。
实验记录、问题处理:
得出:
15
Sig.
.000
a.在步骤1中输入的变量品牌态度产品态度购物态度.
实验结果分析: 结果显示:
品牌忠诚=1.274*品牌态度+0.186*产品态度+0.590*购物态度-8.462 其中品牌态度的
sig 小于0.05,所以品牌态度与品牌购买正向变化显着。 但是因为产品态度和购物态
度的 sig 大于0.05,所以这两个变量与品牌购买 的正向变化不显着 实验名称:因子分析
成绩:
实验目的和要求:掌握因子分析的SPSS 操作方法
实验内容:KMO 和Barlett 氏检验;输出碎石图及旋转前后的因子矩阵;各 因子的特征值和解释的方差比例;解释因子并命名;计算因子得分。 实验记录、问题处理: 步骤处理:
分析 --- 降维 --- 因子分析 将度量变量键入变量框, 选取描述,勾选 KMO 与 bartlett 选取抽取,勾选碎石图
选取旋转,勾选载荷图 选取得分,勾选保存变量和因子得分系数矩阵 如图所示:
取样足够度的Kaiser-Meyer-Olkin 度量 Bartlet 近似卡方
t 的球形度检验
df
球形度检验
KMO 和 Bartlett 的检验
.589 101.749
成份矩阵
提取方法主成分分析法。
a.已提取了2个成份。
实验结果分析:
KM (值为0.589,sig 值为0.000 ,适合作因子分
析
各因子的特征值和解释的方差比例可以在 “解释 的总方差”中看出,其中我们可以知道,特征值
2.569和2.272可以解释方差比例分别是 42.821%和 37.868%。
因为因子1在预防蛀牙、保护牙根有很大载荷, 所以将其命名为保健因子。因子 2在牙齿亮泽、 口气清新、富有魅力有很大载荷,所以将其命名 为社交因子。
计算因子得分,得
保健因子=0.366*预防蛀牙-0.094*牙齿亮泽 +0.362*保护牙龈-0.121* 口气清新-0.315*不预 防坏牙-
0.044*富有魅力
社交因子=0.083*预防蛀牙+0.358*牙齿亮泽
+0.026*保护牙根+0.352* 口气清新-0.170*不预 防
坏牙+0.389*富有魅力 实验名称:聚类分析
成绩:
实验目的和要求:掌握分层聚类和K-means 聚类 的
SPSS 操作方法
实验内容:进行分层聚类和K-means 聚类分析并 输出结果。
实验记录、问题处理: 分层聚类: 步骤处理:
分析 --- 分类 -- 系统聚类
将度量变量键入变量框,勾选统计量中的聚类成员中的方案范围,并且设置 为最小
3最大5.
勾选绘制中的树状图
打开保存选项卡,勾选聚类成员中的方案范围,设置最小 3最大5
结果如图所示:
旋转成份矩阵
提取方法:主成分分析法。
旋转法:具有Kaiser 标准化的正交旋 转法。
a.旋转在3次迭代后收敛。
成份得分系数矩阵
提取方法:主成分分析法。 构成得分。
案例1
2
3
4
5
f
6
7
8
9
10
11
12
13
14 5群集
1
2
1
3
2
1
1
1
2
3
2
1
2
3
4群集
1
2
1
3
2
1
1
1
2
3
2
1
2
3
3群集
1
2
1
3
2
1
1
1
2
3
2
1
2
3
Q *******************
Den drogram using Average Lin kage (Betwee n Groups) Rescaled Dista nee Cluster Combi
ne
C A S E 0 5 10 15 20 25
Label Num + ........... + .......... + ......... + ........................ +……
14 -+
16 - + -+
10 -+ +-+
4 - —+ + ----------- +
19 ---- + + ................................. +
18 ..................... + |
2 . + + + +
13 -+ | | |
5 - -+-+ + ------------------------------- + |
11 -+ +-+ 1 1
9 - —+ + - + |
20 -----+ |
3 + + |
8 - -+ +丨-+ 丨丨
6 - -+-+ +-+ 丨
7 - -+丨丨丨丨
12 -- + -- +丨 +--------------------------------- +
1 - —+ + + 丨
17 --——+丨
15 .............. +
K均值聚类:步骤处理:
分析——分类——K聚类
将变量键入变量框,
勾选保存中的聚类成员
勾选选项中的是统计量下的三个复选框如图所示:
初始聚类中心
聚类
F检验应仅用于描述性目的,因为选中的聚类将被用来最大化不同聚类中的案例间的差别。观测到的显着性水平并未据此进行更正,因此无法将其解释为是对聚类均值相等这一假设的检验。
实验结果分析:
系统聚类:
从聚类表可以知道聚类的具体过程。
从群集成员表中可以知道,当划分为3 5类时,每一样品都分别属于哪一类。从冰柱图可以知道聚合的具体过程。
从树状图可以知道样本逐步合并的过程。
K聚类:
从聚类成员分析可以知道每个案列属于哪一类并且每一案例到最终聚类中心的距离。