决策树算法介绍

3.1分类与决策树概述
3.1.1分类与预测
分类是一种应用非常广泛的数据挖掘技术,应用的例子也很多。例如,根据信用卡支付历史记录,来判断具备哪些特征的用户往往具有良好的信用;根据某种病
症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。这些过程的一个共同特点是:根据数据的某些属性,来估计一个特定属性的值。例如在信用分析案例中,根据用户的“年龄”、“性别”、“收入水平”、“职业”等属性的值,来估计该用户“信用度”属性的值应该取“好”还是“差”,在这个例子中,所研究的属性“信用度”是E—个离散属性,它的取值是一个类别值,这种问题在数
据挖掘中被称为分类。
还有一种问题,例如根据股市交易的历史数据估计下一个交易日的大盘指数,这
里所研究的属性“大盘指数”是一个连续属性,它的取值是一个实数。那么这种
问题在数据挖掘中被称为预测。
总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。
3.1.2决策树的基本原理
1. 构建决策树
通过一个实际的例子,来了解一些与决策树有关的基本概念。
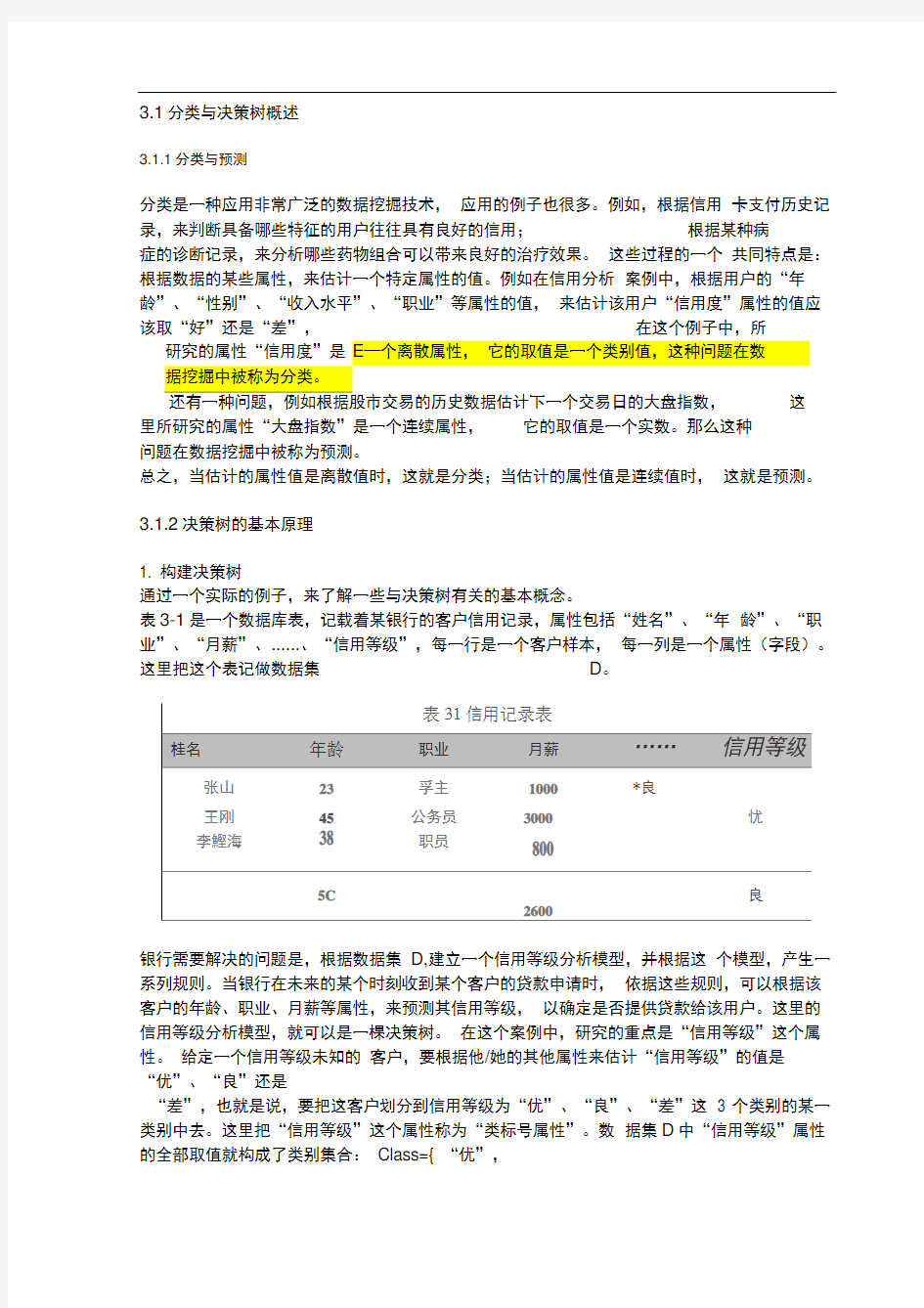
表3-1是一个数据库表,记载着某银行的客户信用记录,属性包括“姓名”、“年龄”、“职业”、“月薪”、......、“信用等级”,每一行是一个客户样本,每一列是一个属性(字段)。这里把这个表记做数据集D。
银行需要解决的问题是,根据数据集D,建立一个信用等级分析模型,并根据这个模型,产生一系列规则。当银行在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、月薪等属性,来预测其信用等级,以确定是否提供贷款给该用户。这里的信用等级分析模型,就可以是一棵决策树。在这个案例中,研究的重点是“信用等级”这个属性。给定一个信用等级未知的客户,要根据他/她的其他属性来估计“信用等级”的值是“优”、“良”还是
“差”,也就是说,要把这客户划分到信用等级为“优”、“良”、“差”这3 个类别的某一类别中去。这里把“信用等级”这个属性称为“类标号属性”。数据集D中“信用等级”属性的全部取值就构成了类别集合:Class={ “优”,
良,差}。
在决策树方法中,有两个基本的步骤。其一是构建决策树,其二是将决策树应用于数据库。大多数研究都集中在如何有效地构建决策树,而应用则相对比较简单。构建决策树算法比较多,在Clementine中提供了4种算法,包括C&RT CHAID QUEST和C5.0。采用其中的某种算法,输入训练数据集,就可以构造出一棵类似于图3.1所示的决策树。
一棵决策树是一棵有向无环树,它由若干个节点、分支、分裂谓词以及类别组成。节点是一棵决策树的主体。其中,没有父亲节点的节点称为根节点,如图3.1
中的节点1;没有子节点的节点称为叶子节点,如图3.1中的节点4、5、6、7、 &一个节点按照某个属性分裂时,这个属性称为分裂属性,如节点1按照“年龄”被分裂,这里“年龄”就是分裂属性,同理,“职业”、“月薪”也是分裂属性。每一个分支都会被标记一个分裂谓词,这个分裂谓词就是分裂父节点的具体依据,例如在将节点1分裂时,产生两个分支,对应的分裂谓词分别是“年龄<40”和“年龄>=40'。另外,每一个叶子节点都被确定一个类标号,这里是
“优”、“良”或者“差”。
基于以上描述,下面给出决策树的定义:
给定一个数据集D出息…其中曲血』>是D中的第i个样本(內2,???卫),数据集模式包含的属性集为{AiA,…血},用是第i个样本的第j个属姓均的值(j时2」人同时给
定类标号集合C={G怎…金}。对于数据集D,决策树是指具有下列2个性质的树,令毎个非叶子节点都被标记一个分裂風性和,
令毎个分支都被标记一个分裂谒词,这个分製谓诃是分裂戈节点的具体依据*
P 每个叶子节点都夜标记一个类标号CjtC.
由此可以看出,构建一棵决策树,关键问题就在于,如何选择一个合适的分裂属性来进行一次分裂,以及如何制定合适的分裂谓词来产生相应的分支。各种决策树算法的主要区别也正在于此。
2. 修剪决策树
利用决策树算法构建一个初始的树之后,为了有效地分类,还要对其进行剪枝。
这是因为,由于数据表示不当、有噪音等原因,会造成生成的决策树过大或过度拟合。因此为了简化决策树,寻找一颗最优的决策树,剪枝是一个必不可少的过程。
通常,决策树越小,就越容易理解,其存储与传输的代价也就越小,但决策树过小会导致错误率较大。反之,决策树越复杂,节点越多,每个节点包含的训练样本个数越少,则支持每个节点样本数量也越少,可能导致决策树在测试集上的分类错误率越大。因此,剪枝的基本原则就是,在保证一定的决策精度的前提下,使树的叶子节点最少,叶子节点的深度最小。要在树的大小和正确率之间寻找平衡点。
不同的算法,其剪枝的方法也不尽相同。常有的剪枝方法有预剪枝和后剪枝两种。例如CHAID和C5.0采用预剪枝,CART则采用后剪枝。
预剪枝,是指在构建决策树之前,先制定好生长停止准则(例如指定某个评估参数的阈值),在树的生长过程中,一旦某个分支满足了停止准则,则停止该分支的生长,这样就可以限制树的过度生长。采用预剪枝的算法有可能过早地停止决策树的构建过程,但由于不必生成完整的决策树,算法的效率很高,适合应用于大规模问题。
后剪枝,是指待决策树完全生长结束后,再根据一定的准则,剪去决策树中那些不具一般代表性的叶子节点或者分支。这时,可以将数据集划分为两个部分,一个是训练数据集,一个是测试数据集。训练数据集用来生成决策树,而测试数据集用来对生成的决策树进行测试,并在测试的过程中通过剪枝来对决策树进行优化。
3. 生成原则
在生成一棵最优的决策树之后,就可以根据这棵决策树来生成一系列规则。这些规则采用“ If... ,Then... ”的形式。从根节点到叶子节点的每一条路径,都可以生成一条规则。这条路径上的分裂属性和分裂谓词形成规则的前件(If部分),叶子节点的类标号形成规则的后件(Then部分)。
例如,图3.1的决策树可以形成以下5条规则:
If (年龄<40)and (职业=“学生” or职业=“教师”)Then信用等级=“优” If (年龄<40) a nd(职业!= “学生” and职业!= “教师”)The n信用等级=“良”
If (年龄>=40)and (月薪<1000)Then信用等级=“差”
If (年龄>=40)and (月薪>=1000 and 月薪<=3000)Then 信用等级=“良”
If (年龄>=40)and (月薪>3000)Then信用等级=“优”
这些规则即可应用到对未来观测样本的分类中了。
ID3算法是最有影响力的决策树算法之一,由Quinlan提出。ID3算法的某些弱
点被改善之后得到了C4.5算法;C5.0则进一步改进了C4.5算法,使其综合性能大幅度提高。但由于C5.0是C4.5的商业版本,其算法细节属于商业机密,因此没有被公开,不过在许多数据挖掘软件包中都嵌入了C5.0算法,包括Clementine。
3.2.1 ID3
1?信息增益
任何一个决策树算法,其核心步骤都是为每一次分裂确定一个分裂属性,即究竟
按照哪一个属性来把当前数据集划分为若干个子集,从而形成若干个“树枝”。
ID3算法采用“信息增益”为度量来选择分裂属性的。哪个属性在分裂中产生的信息增益最大,就选择该属性作为分裂属性。那么什么是信息增益呢?这需要首先了解“熵”这个概念。熵,是数据集中的不确定性、突发性或随机性的程度的度量。当一个数据集中的记录全部都属于同一类的时候,则没有不确定性,这种情况下的熵为0。
决策树分类的基本原则是,数据集被分裂为若干个子集后,要使每个子集中的数据尽可能的“纯”,也就是说子集中的记录要尽可能属于同一个类别。如果套用熵的概念,即要使分裂后各子集的熵尽可能的小。
例如在一次分裂中,数据集D被按照分裂属性“年龄”分裂为两个子集D1和D2, 如图3.2所示。
m l
■
其中,H(D)、H(Di)x H(D)分别是数据集D 、Di 、6的新那么,按照“年龄”将数据臬D 分裂为D|和D :所得到的信息增益为:
Gag 年龄)=H(D)?[P(DJ X H(DJ+P(DJ X H(DJ]
其亡,P(D)是D 中的样本祓划分到D 】中射槪率,P(D?)是D 中的样本被划分到D2中的槪 率,P(Di)xH(D)+ P(D 2)X H(D 2)^ H(D)和 H(D)的“加权和冷
显然,如果D [和0中的数据越“纯”,H(D0和H(DQ 的越小,信息増益就越大,或者说 爛下降得越多。
按照这个方法,测试每一个属性的信息缙益.选择增益值最大的属性作为分裂属性,下更绐 出倍息增益的计第方法。
设S 是日§个样本组成的数据崖:若S 的类标号属性具有m 个不同的取值.即定义了 m 个 不同的类C 1(i=l J 2;...J m)e 设属于类G 的样本的个数为$,那么数据集S 的埼为:
pxlb —
5丿」
其中,R 是任意样本禺于类别Cj 的槪率,用S/S 来估计。
设S 的某个属性A 具有v 个不同值⑵內,?…a 、.},先根据舄性A 将数据集S 划分为V 个不同 的子集{SbS :?...?SJ,子集Sj 中所有样本的厲性A 的值都等于丐(H 二…?、)。 于是.在分裂为v 个子集Z 后,任意一个子集*的箱为:
H(D)
H(D 2)
其中,聊=12是子集殆中厲于类别C的样本数量,卩旷対不是勺申的样本属于类别G的概率,询是子集*中的样本数量“
阮以,S按照屬性A划分出的零个子集的爛的加权和为;
E(SM)二£卜沁厂丹5如切…%)]
J-iL S」
其中切小:"钿是子集勺的权重.蒔于子集£中的样本敖量?除以E中的样本忌数
所以,按聽属性A把数据集s分裂.所得的信息増益就等于Sc?Ms的烤减去各子集的埔的加权和:
Gain(S. A ) = l{%*,…,鶴)
ID3算法计算每一个属性的信息增益.并选择增益最大的JB性作为分裂属性.然后月该属性的每一个不同的值创縫一个分支,从而梅数据翼划分为若干个子冀’
2.ID3算法的流程
ID3算法是一个从上到下、分而治之的归纳过程。
ID3算法的核心是:在决策树各级节点上选择分裂属性时,通过计算信息增益来选择属性,以使得在每一个非叶节点进行测试时,能获得关于被测试样本最大的类别信息。其具体方法是:检测所有的属性,选择信息增益最大的属性产生决策树节点,由该属性的不同取值建立分支,再对各分支的子集递归调用该方法建立决策树节点的分支,直到所有子集仅包括同一类别的数据为止。最后得到一棵决策树,它可以用来对新的样本进行分类。
1D3算法思想捲述如下;
(1)初始化决策树T为只含一个树很〔&Q).其中X是全体样本集,Q为全体属性集.
(2)IRT中所有叶节点(X:Q)都满足X属于同一类或Q*为空)thm算法停止;
(3)else
{任取一个不具有(2)中所述狀态的叶节点PCQW
(4)for each Q'中的属性Ado计算告息増益Gain(A_Q');
(5)选释具有最高信息增益的属性B作为节点(X:QJ的分裂属性;
(6)for亡arh E的取值b do
{从该节点(RQ)}伸出分支,代表分裂输出求得X中B值等于血的子集X,并
生成相应的叶节点(X/, Q\ {B});}
⑺转(2);}
下面通过一个实例来了解一下决策树的构建过程。
表3-2是一个假想的银行贷款客户历史信息(略去了客户姓名),包含14个样本。现要求以这14个样本为训练数据集,以“提供贷款”为类标号属性,用ID3 算法构造决策树。
表3 2训绦数据麋D
No.年龄收入术平有固定收入MP类别’提供贷款
1<30高否木a否
1
■M<30高是否
3[305Q]高否否是4中否否是
5>50低否是
6>50低是星否7[30.50]低是是是8<30牛否
9<30低是否是10>50是否量11<30丰是是是12[3050]中否星是B[30^50]二是14>50中口是口